Embed Size (px)
Citation preview

THE IEEE
Intelligent Informatics BULLETIN
IEEE Computer Society Technical Committee
August 2017 Vol. 18 No. 1 (ISSN 1727-5997) on Intelligent Informatics
——————————————————————————————————————Communications. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Vijay Raghavan 1
——————————————————————————————————————Conference Report
AI as a 30+ Year Florida Statewide Strategic Initiative. . . . . . . . . . . . . . . . Pierre Larochelle, Marius Silaghi and Vasile Rus 2
——————————————————————————————————————R&D Profile
Intelligent Informatics and the United Nations: A Window of Opportunity. . . . . . . . . . . . . . . . . . . . . . . . .Karen Judd Smith 5
——————————————————————————————————————
Short Feature Articles
A Consultant Framework for Natural Language Processing in Integrated Robot Architectures . . . . . . . . . . . Tom Williams 10
Process Mining for Trauma Resuscitation
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . Sen Yang, Jingyuan Li, Xiaoyi Tang, Shuhong Chen, Ivan Marsic and Randall S. Burd 15
——————————————————————————————————————Selected PhD Thesis Abstracts. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . Xin Li 20
——————————————————————————————————————Book Review
Cognitive Computing: Theory and Applications. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Weiyi Meng 34
——————————————————————————————————————
On-line version: http://www.comp.hkbu.edu.hk/~iib (ISSN 1727-6004)

IEEE Computer Society Technical
Committee on Intelligent
Informatics (TCII)
Executive Committee of the TCII: Chair: Chengqi Zhang
University of Technology, Sydney,
Australia
Email: [email protected] Vice Chair: Yiu-ming Cheung
(membership, etc.)
Hong Kong Baptist University, HK
Email: [email protected] Jeffrey M. Bradshaw
(early-career faculty/student mentoring)
Institute for Human and Machine
Cognition, USA
Email: [email protected] Dominik Slezak
(conference sponsorship)
University of Warsaw, Poland.
Email: [email protected] Gabriella Pasi
(curriculum/training development)
University of Milano Bicocca, Milan, Italy
Email: [email protected] Takayuki Ito
(university/industrial relations)
Nagoya Institute of Technology, Japan
Email: [email protected] Vijay Raghavan
(TCII Bulletin)
University of Louisiana- Lafayette, USA
Email: [email protected] Past Chair: Jiming Liu
Hong Kong Baptist University, HK
Email: [email protected] The Technical Committee on Intelligent
Informatics (TCII) of the IEEE Computer
Society deals with tools and systems using
biologically and linguistically motivated
computational paradigms such as artificial
neural networks, fuzzy logic, evolutionary
optimization, rough sets, data mining, Web
intelligence, intelligent agent technology,
parallel and distributed information
processing, and virtual reality. If you are a
member of the IEEE Computer Society,
you may join the TCII without cost at
http://computer.org/tcsignup/.
The IEEE Intelligent Informatics
Bulletin
Aims and Scope
The IEEE Intelligent Informatics Bulletin
is the official publication of the Technical
Committee on Intelligent Informatics
(TCII) of the IEEE Computer Society,
which is published twice a year in both
hardcopies and electronic copies. The
contents of the Bulletin include (but may
not be limited to):
1) Letters and Communications of
the TCII Executive Committee
2) Feature Articles
3) R&D Profiles (R&D organizations,
interview profile on individuals,
and projects etc.)
4) Selected PhD Thesis Abstracts
5) Book Reviews
6) News, Reports, and Announcements
(TCII sponsored or important/related
activities)
Materials suitable for publication at the
IEEE Intelligent Informatics Bulletin
should be sent directly to the Associate
Editors of respective sections.
Technical or survey articles are subject to
peer reviews, and their scope may include
the theories, methods, tools, techniques,
systems, and experiences for/in developing
and applying biologically and
linguistically motivated computational
paradigms, such as artificial neural
networks, fuzzy logic, evolutionary
optimization, rough sets, and
self-organization in the research and
application domains, such as data mining,
Web intelligence, intelligent agent
technology, parallel and distributed
information processing, and virtual reality.
Editorial Board Editor-in-Chief:
Vijay Raghavan
University of Louisiana- Lafayette, USA
Email: [email protected]
Managing Editor:
William K. Cheung
Hong Kong Baptist University, HK
Email: [email protected]
Assistant Managing Editor:
Xin Li
Beijing Institute of Technology, China
Email: [email protected]
Associate Editors:
Mike Howard (R & D Profiles)
Information Sciences Laboratory
HRL Laboratories, USA
Email: [email protected] Marius C. Silaghi
(News & Reports on Activities)
Florida Institute of Technology, USA
Email: [email protected] Ruili Wang (Book Reviews)
Inst. of Info. Sciences and Technology
Massey University, New Zealand
Email: [email protected] Sanjay Chawla (Feature Articles)
Sydney University, NSW, Australia
Email: [email protected] Ian Davidson (Feature Articles)
University at Albany, SUNY, USA
Email: [email protected] Michel Desmarais (Feature Articles)
Ecole Polytechnique de Montreal, Canada
Email: [email protected] Yuefeng Li (Feature Articles)
Queensland University of Technology,
Australia
Email: [email protected] Pang-Ning Tan (Feature Articles)
Dept of Computer Science & Engineering
Michigan State University, USA
Email: [email protected] Shichao Zhang (Feature Articles)
Guangxi Normal University, China
Email: [email protected]
Xun Wang (Feature Articles)
Zhejiang Gongshang University, China
Email: [email protected]
Publisher: The IEEE Computer Society Technical Committee on Intelligent Informatics
Address: Department of Computer Science, Hong Kong Baptist University, Kowloon Tong, Hong Kong (Attention: Dr. William K. Cheung;
Email:[email protected])
ISSN Number: 1727-5997(printed)1727-6004(on-line)
Abstracting and Indexing: All the published articles will be submitted to the following on-line search engines and bibliographies databases
for indexing—Google(www.google.com), The ResearchIndex(citeseer.nj.nec.com), The Collection of Computer Science Bibliographies
(liinwww.ira.uka.de/bibliography/index.html), and DBLP Computer Science Bibliography (www.informatik.uni-trier.de/~ley/db/index.html).
© 2017 IEEE. Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional
purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this
work in other works must be obtained from the IEEE.

Communications
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1
1
The IEEE Intelligent Informatics Bulletin (IIB) is the official publication of the Technical Committee on
Intelligent Informatics ( TCII ) of the IEEE Computer Society. It aims at promoting the excellent research on
the wide spectrum of intelligent informatics, as well as displaying the news/reports on TCII related
conferences and other activities. This issue- the first of its kind- of the IEEE Intelligent Informatics Bulletin
makes a novel attempt publishing a carefully selected collection of Ph.D. thesis abstracts. Only theses
defended during the period of January 2016 to July 2017 are targeted considering timeliness. This issue also
includes, a Report edited by Marius Silaghi, a profile by Karen J. Smith (edited by Mike Howard), two short
feature articles, respectively by Tom Williams and Sen Yang, and a book review by Weiyi Meng (edited by
Ruili Wang).
This new attempt of the Intelligent Informatics Bulletin intends to offer an opportunity for young talented
scholars at the beginning of their career to introduce their previous and ongoing research work to potentially
interested scholars in similar intelligent informatics subdomains. To achieve this goal, it is required that a
URL to Ph.D. theses' soft copy should be included with the submitted abstract, and this URL should be
accessible and properly maintained continuously.
In total, 43 abstracts of the Ph.D. thesis were successfully submitted. 55 authors come from 21 different
countries located in Asia, North America, Europe and Africa. Each submitted abstract was reviewed by at
least 2 editorial board members of the bulletin. According to the ranking of reviewing scores, only the top 24
submissions were selected to publish in this Ph.D. thesis abstracts section. The selected submissions cover
numerous research and applications under intelligent informatics such as robotics, cyber-physical systems,
social intelligence, intelligent agent technology, recommender systems, complex rough sets, multi-view
learning, text mining, general-purpose learning systems, Bayesian modeling, knowledge graphs, genetic
programming and dynamic adversarial mining.
The key issues of this Ph.D. thesis abstracts section are summarized above. The organizers wish that this
special issue can bridge different subdomains of intelligent informatics and encourage further
communications and cooperation within the whole scholar community. Special thanks are due to Prof. Xin Li
for spearheading this effort.
In addition, we are pleased to announce that the publication of selected PhD abstracts will be continued in
future years. Thus, we plan to have two issues of IIB published each year, one in summer and one in winter.
We welcome your feedback on this special issue, as well as future issues of IIB.
Vijay Raghavan
(University of Louisiana- Lafayette, USA)
Editor-in-Chief
The IEEE Intelligent Informatics Bulletin
Message from the Editor-in-Chief

Editor: Marius C. Silagh
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin
2
I. A STATE OF FLORIDA INITIATIVE
Approximately 30 year ago, in 1987, an
effort of the state of Florida was
channeled toward the exploitation of the
local intellectual and technical
infrastructure for the advancement of
local research, in particular through the
support and organization of conferences.
Groups of scientists from the main
Florida universities and representing
various key research fields were invited
to Tallahassee and encouraged to discuss
ways of organizing events, such as local
conferences, that would support their
technical or scientific activities.
Among these groups, two focused on
research directions that are currently
converging into topics related to
intelligent informatics. These were the
group specialized on artificial
intelligence (AI) and the group
specialized on robotics. Each of the two
groups ended up giving rise to a
corresponding successful conference,
while each of them followed a very
different approach towards a distinct
vision. The artificial intelligence group
decided to create a research society and
an international conference, FLAIRS
(Florida Artificial Intelligence Research
Society), that would bring together
researchers from all over the world,
exploiting not only the local research
base but also the available rich local
attractions. The robotics group decided
to construct an intimate conference,
FCRAR (Florida Conference on Recent
Advances in Robotics), coaching local
graduate students on research. FLAIRS
became a top scientific conference with
indexed proceedings while FCRAR is a
vibrant conference with free registration
and “lightly” reviewed online
proceedings.
II. FCRAR 30: THE 30TH
FLORIDA
CONFERENCE ON RECENT ADVANCES IN
ROBOTICS
The FCRAR 2017 conference was
organized during May 11-12 at the
Florida Atlantic University (FAU) by Dr.
Oren Masory and Dr. Zvi Roth. The
conference is a traditional venue for
presenting ongoing robotic research in a
formal environment. It has originally
focused on the mechanical part of
robotics but artificial intelligence proved
to be inseparable from its topic and is
now addressed by a significant part of
the presentations.
As with previous editions, the 2017
FCRAR did span over two days. In most
years FCRAR is a single track
conference. However, two parallel
sessions were needed this year for the 49
regular articles accepted. Still, the
whole attendance met for the first
session and welcome message, as well
as for the three valuable invited talks:
A. The first invited talk, by Dr.
Andrew Goldenberg, Professor Emeritus
from the University of Toronto,
provided insights from his rich
experience with transferring technology
from academia to industry, as well as
to the market size and trends for various
types of robots. A glimpse was offered
into the extent to which robotics is
planned to quickly replace significantly
more service jobs in the fast food
industry. His advice to students
stressed the fact that challenges
remain mainly with the artificial
intelligence component, which persists
as an important constraint and
bottleneck of the democratization of the
robot. Challenges posed by the
development of robots for prostate
surgery under MRI, as well as
exploitation of IP in academia made the
subject of most questions after the
talk.
B. The invited talk of Dr. Deborah
Nagle focused on her experience as a
robotic surgeon and researcher with
surgery robotics. A detailed account was
given of the stages of evolution in
robotic surgery, as well as of difficulties
faced by surgeons in using the
equipment. The emphasis was put on the
desire of surgeons to get more help
in terms of machine learning
techniques, to help them during medical
procedures. While the surgery robotics
market is hard to penetrate, the speaker
explained challenges by newcomer
Google to the established DaVinci
manufacturer.
C. The third invited speaker was
University of Florida’s Dr. Gloria Wiens,
Director of FloridaMakes BRIDG, who
described governmental efforts for
supporting local innovation with current
projects in domains such as smart
kitchens and smart agriculture. Most
questions from attendees concerned the
history of results earned by similar
centers.
The conference also contained a
robotic expo session where, under the
leadership of Dr. Erik Engeberg,
participants were shown the robotic
jellyfish manufactured at the FAU, as
well as their large collection of robotic
arms and sensors. Visitors experimented
with the control of industrial robots
30 YEARS ANNIVERSARY OF FCRAR AND FLAIRS
AI as a 30+ Year Florida Statewide
Strategic Initiative
FCRAR Robotic Jellyfish Demo
FLAIRS: Plenary Session
FAU Robotic Lab Expo.

Conference Report: AI as a 30+ Year Florida Statewide Strategic Initiative
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1
3
using gloves, thought, or other
techniques to simply capture and
replicate human motion or desires.
In regular sessions, presenters
addressed various robotic prototypes as
well as machine learning techniques to
learn patterns and interpret images. New
machine learning techniques for
detecting seizures in EKG and
recognizing fish sounds using Slantlet
transforms were described by
Ibrahim. Search heuristics described
by Medina were part of AI techniques to
explore space in NASA Swarmathon.
ID3-like entropy reducing decision tree
building heuristics were described by
Ballard for eye in arm robots exploring
workspaces. Heuristics for graph
traversal used in remote laser-based
soldering of cracks detected visually
were described by Findling, while Drada
discussed regular soldering systems. A
family of path-planning techniques for
inspection of nuclear waste tanks were
described by Sebastian Zanlongo,
extending A* and Disjktra's algorithms
with heuristics modeling details
concerning travel difficulties and tether
cables. Other addressed robotics
applications include intelligent robots to
carry luggage, the BudeE robot for
surveillance of children, vertical farming,
construction robots, autonomous buoys.
AI related problems addressed span
strategy planning, path-planning
algorithms, component failure
prediction, user trust, and frustration
management.
III. FLAIRS 30: THE 30TH
FLORIDA
ARTIFICIAL INTELLIGENCE RESEARCH
SOCIETY CONFERENCE
The 2017 FLAIRS conference was
organized by Dr. Ingrid Russell during
May 22-24 at the Marco Island Hilton
Hotel. As in previous editions, a set of
special tracks was integrated with the
main conference, each special track
having its own topic and program
committee. Acceptance criteria were
unified by the program committee
consisting of Vasile Rus, Zdravko
Markov, and Keith Brawner. This
edition accommodated 17 special tracks
and 192 participants. The conference
program was organized in sets of 4
parallel sessions for the 103 accepted
full papers. A poster session was held
during the first afternoon session on the
first conference day. There were 61
posters, 25 of them having an abstract
published in the proceedings that has
undergone a separate reviewing process,
while the rest corresponding to accepted
short papers. Six papers were nominated
for the best paper and best student paper
awards.
Recent FLAIRS editions include
lunches and dinners in the registration
package, reducing noon breaks and
helping participants to interact and
discuss collaborations, one of the
appreciated strengths of the conference.
There were four special track invited
talks, presented in parallel sessions and
three main conference invited talks
presented in plenary sessions:
A. The first invited talk was offered
by Thomas Dietterich, on “Robust
Artificial Intelligence: Why and How”.
It was suggested to address lack of
robustness by modeling randomness as
an attacker, using minimax. General AI
can take inspiration from the field of
Automatic Speech Recognition (ASR)
where noisy bands are detected based
on unlikely repetition of phonemes. Four
ideas emerge:
1) Employ anomaly detectors
2) Use dynamic model extensions
3) Use causal directions, as they
work better than diagnostic models
4) Combine techniques
Citing Minsky: “You understand only if
you understand in multiple ways”.
Public questions addressed: evolution,
impact of small errors and wrong
datasets, advantage of ensemble
methods (portfolios) over thinking too
much, and difference between building
incomplete models versus building
causal models. Science studies causal
relations while engineering is satisfied
with incomplete models. While ASR
was improved with more data, that may
not work for adversarial situations.
Accordingly DARPA has a project on
“Explainable AI”.
B. The second plenary invited talk
was delivered by Prof. Jiawei Han on
“Mining Structures from Massive Text
Data: A Data-Driven Approach”. The
speaker presented his research in using
large text data sets to create relatively
structured networks, usable as
knowledge. Questions raised the
challenge of approximate knowledge
needed to answer queries such as: “Who
is the President of England?” and
representation of nested concepts such
as “President of [United States]”.
C. The third plenary invited speech
was given by Dr. James Allen on
broad-coverage deep language
understanding. The challenge question
was for a definition of deep
understanding. It was suggested that
solutions include: no word left behind,
preservation of details, preservation of
ambiguity, and preservation of
compositional structure. The TRIPS
word organization capturing common
sense semantics, proposed by the
speaker, was contrasted with WordNet.
Comprehensive dictionaries are now
parsed to build ontologies. It was
stressed that words are used for
arguments rather than relations.
Disambiguation is achieved by filtering
semantics based on annotations and
temporal constraints. However,
construction & composition require
invention of new semantics as in “The
dog barked the cat up the tree”. The
questions addressed: parsing of
emoticons, dots, templates of allowable
constructions, different semantics,
complex world in long novels,
non-English text.
The “Radical-Based Hierarchical
Embeddings for Chinese Sentiment
Analysis at Sentence Level” by Peng
et.al. won the best paper award. Natural
language processing is one of the main
strength of the FLAIRS community, but
most other AI branches are represented.
31th FLAIRS and 31th FCRAR
will take place during May
2018.
FLAIRS Awards Ceremony

Editor: Marius C. Silagh
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin
4
Contact Information
Pierre Larochelle
South Dakota School of Mines and
Technology
Marius Silaghi
Florida Institute of Technology
Vasile Rus
University of Memphis

R&D Profile: Intelligent Informatics and the United Nations: A Window of Opportunity
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1
5
Abstract —“Every one of us is
responsible for the future of all of us.” Dr.
Gro Harlem Burndtland, Former Prime
Minister of Norway and former head of
the World Health Organization.
K.A. Judd Smith, Co-Chair of the
Alliance of NGOs on Crime Prevention
and Criminal Justice
(www.CPCJAlliance.org) and consultant
to the United Nations Office of
Information and Communications
Technology, outlines the way the flood of
new technologies has led to types of
criminal activity that are cheaper, more
anonymous, and with global reach. She
challenges the tech sector to build
protections of social good into their
technologies, and to uncover novel ways to
infuse compassion and empathy into the
machinery and so make it safer and
human friendly by integrating
comprehensive perspectives of how we
function socially as human beings.
Index Terms—computational and
artificial intelligence, intelligent
transportation systems, industry
applications, systems, decision support
systems, policy, ethics.
I. A STATE OF FLORIDA INITIATIVE
Ten years into the smart phone and
mobile device phase of our digital
revolution, transnational organized
criminals have consistently been agile
adopters and adapters of new
technologies. Even the once-stable
societies are being unsettled by this
surge of change, the white noise of
abundant information, and a rise in
disinformation and “fake news.”
This triple play of an unprecedented
pace of technological development, the
human ability to integrate tools into our
daily lives, and the inbuilt resistance to
change of our major social institutions,
is creating an ethical Gray Zone where
the collective “we” strain toward
anomie. Our increasing number of
available sets of norms, none of which
are clearly binding, blurs the clarity once
afforded by social institutions in slower
times. With each day, evolving
technologies multiply their impact on
society leaving our twentieth century
governing institutions unable to dampen
the turbulence. Even the relative
constancy of the most stable societies is
being disrupted with dissent and
family-dividing ideological differences.
Fast-paced change is the new norm.
Fig. 1. The Gray Zone: This indicates the areas of
social life increasingly unregulated by traditional
mechanisms.
Both legitimate and criminal
innovations outstrip the ability of our
national and international institutions to
create and implement timely and needed
responses. Our key social institutions are
caught in old ways of functioning that
are in dire need of innovation.
It has now been seventeen years since
the 2000 adoption of the United Nations
Convention against Transnational
Organized Crime (UNTOC). True, these
years have seen an increasing number of
UN member states that are party to the
Convention, but little significant
headway has been made.
This problem of transnational
organized crime is not some distant,
faceless issue. Rather, it affects the daily
lives of men, women and children in all
our cities as well as rural locations
worldwide. Those on both sides of this
dark economy are our neighbors. The
anonymous agents streaming the rape of
children to clients willing to pay with
cryptocurrencies often have well known
faces in our communities. Drug sales are
shifting from the street to the Dark Web.
Zero-day exploits and sophisticated
hacking tools can be bought easily in this
masked economy.
Few of these types of criminal
activities are totally new. What is
different, however, are the increasing
access, decreasing costs and increased
anonymity. In short, we have an
explosion of the Dark Web economy.
This new territory, including social
media and the Internet of Things (IoT),
also brings with it, a significant decline
in ethical and moral clarity. The
twentieth-century forms of regulation
and self-regulation still in place are
unable to keep up with this increasing
onslaught of changing variables.
Privacy issues blended with security
concerns are also less and less easy to
determine. The values associated with
hacking are also complex. Thus, the
democratization of information and
access to evolving technologies have
brought with them a plethora of
opportunities both for the greater good
and to the detriment of many. Few could
have predicted what we face less than
thirty years after the open sourcing of the
World Wide Web back in 1989 by the
British scientist at the Conseil Européen
pour la Recherche Nucléaire (CERN),
Tim Berners-Lee.
In addition to the freedoms, benefits,
convenience, and remarkable progress
resulting from this tidal surge of
technological development, there are
those on the dark side who use these
technology tools without regard to
human rights or the rule of law. Human
trafficking, sexual exploitation, money
laundering, hacking-as-a-service, drug
and weapons sales, the ability to
disseminate radical causes with
destructive intent, etc. now fuel violent
extremism and contribute to the
destabilization of whole regions. Yet no
KAREN JUDD SMITH
Intelligent Informatics and the United
Nations: A Window of Opportunity

Editor: Mike Howard
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin
6
amount of sophisticated socio-political
handwringing will ever be able to put
this technological genie back into the
bottle.
What we can do, however, is to look
for opportunities to leverage
institutional innovation from within this
growing Gray Zone. To emphasize, we
can and should determine to fight this
technological fire with an at least equally
dedicated technological counter-fire.
Technological advancement now
enables us to pursue the social good in
ways never before possible. Artificial
intelligence (AI), machine language, the
emergent fields of material engineering,
bio-tech, and the use of biologically and
linguistically motivated computational
paradigms, place in our hands new ways
to contribute to the global social good.
As new challenges are banging hard
on our doors, there are reasons to believe
we may be on the cusp of significant
institutional-level innovation, if we put
emerging intelligent technologies to
work more strategically in our
multicultural, multireligious,
multinational, multi-disciplinary, and
multipurposed endeavors.
Before turning our attention to one of
today’s underutilized and strategic
opportunities for engagement, we will
briefly consider the “Transilience
Framework” which highlights key forces
at play in any social good endeavor.
These provide additional insight for the
work at hand whether planning a project,
assessing impact, or developing a
strategy. This framework is not a
strategic planning methodology with
milestones and waypoints, but rather a
way to assess the sea-conditions within
which the endeavor takes place. As a
decision-matrix of sorts, it factors in
social, rational and neurological forces
to our journey in today’s Gray Zone.
Finally, we will conclude with the
recommendation to pursue a new, if
challenging partnership that could open
up new levels of thinking, insight, and
strategic impact. The timing is right. Just
as mobile devices in Africa enabled the
continent to bypass the need for building
an extensive and expensive wired
communications infrastructure, this
confluence of new resources and needs
may well enable our global community
to leap-frog over some of our most
intransigent issues.
II.THE TRANSILIENCE FRAMEWORK
The definition of transilient as
“passing quickly from one thing to
another” comes from the Latin
“transilīre—to jump over.” In the
context of social change, this framework
calls attention to our innate human
capacity for inventiveness and ways to
leverage this potent human capacity.
Transilience pays particular attention to
the transformative resilience of human
beings, the factors affecting it and its
role in the midst of turbulence, change,
and uncertainty.
The three sets of factors this
framework considers are Difference,
Drivers, and Domain, each being part of
a social good compass of sorts. The
concept of True North here indicates
pursuits that best serve our
metahumanity, an holistic description
that includes all aspects of optimal living
for human beings as individuals, as
social animals with a strong propensity
for accounting, and as a species still
reliant upon the health of our planet for
our own health and well-being.
A. Difference
Difference recognizes the varying forces
involved with change. The greater the
degree of change sought or needed in a
shorter space of time, will require
different kinds of effort and leadership
than circumstances that value stability,
strict adherence to standards and
system-wide trustworthiness. The
former calls for bold, adaptive
leadership to ensure that the culture,
talent, and structures operate well in less
familiar, riskier environments. The
latter, management-oriented leadership
focuses on managing the variables in a
more closed system to ensure a quality of
service output for all stakeholders. Each
kind of leadership has its own place and
they are not mutually exclusive. Capable
leaders or project designers recognize
the differing emphasis needed due to the
nature of the work at hand.
Difference also takes into
consideration psychological time, that is,
whether we are forward-looking or
backward-looking. In reality, we cannot
go back in time, but we can and do delve
into our memories and our efforts.
Mindset and vision tend to have an
orientation that is forward and
exploratory or backward and focused on
sustaining a status quo.
In either case, whether the differences
are larger or smaller, forward-looking or
backward-looking the pathways being
chosen by leaders or designers need to
be adapted appropriately for the
stakeholders and the forces they will
encounter.
Fig. 2 Difference: This reminds us of the forces in
play when endeavoring to make a difference.
Resistance increases with as greater changes are
sought. It also indicates that psychologically, we
may be forward or backward looking in our focus.
As can be seen in Fig. 2, the greater
the distance from the status quo sought,
whether forward or backward, efforts are
met with increasingly powerful forces or
resistance to change. This resistance is
compounded by the Drivers, as will be
explained in the next section.
The forces at play here can be seen in
the slow development of laws on
cybercrime or the lack of global
initiatives, for example, to globally
change router security standards. So it
remains possible to hack into a bank or a
power plant and leave no trace because
there is no extra layer of identification
required. This is just one instance where
legislators neither adequately
understand technology nor include
technologists in legislative
decision-making in a timely manner.
B. Drivers
Drivers are both the rational and
pre-rational dimensions of social

R&D Profile: Intelligent Informatics and the United Nations: A Window of Opportunity
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1
7
engagement. These are at play in all
human interactions. Curiously, while it is
known that humans tend to make
decisions emotionally (or
pre-rationally), our rational sense of self
often overlooks this. Paying attention to
these Drivers is an effort to acknowledge
and factor in the full complexity of
human interaction that is being
described here as the ongoing interaction
of our (evolutionarily speaking) “three
brains” and the impact of each of these
on our moment-to-moment
decision-making.
This is an essential consideration to
note because all too often the more
analytical, rational actors (such as
researchers and engineers) overlook
these pre-rational considerations during
development. This reverence for
rationality can lead to the filtering out of
the non-rational as irrelevant. This is
especially true when intuitive responses
stand in direct opposition of what makes
rational, long-term sense. We then end
up surprised by voting results, the
eruption of violence, and unexpected
aspects of social relationships.
Fig. 3. The Drivers: This figure identifies in a
symbolic manner, the pre-rational and rational
dimensions of human decision-making: our
reptilian complex, paleomammalian complex and
neomammalian complex. [1] Paying attention to
any one alone or ignoring any of these, can lead to
poor judgment and misreading of social dynamics.
When we factor in both the logical
complexity of changes being sought and
the pre-rational drivers that are
stimulated by those changes, we can
make greater sense out of some of the
political dynamics today. Nationalist
surges are showing up in many countries
in part as a reaction to underlying
uncertainties—politically, socially and
economically—as technologies hasten
the pace of change. The body-language
of today’s changing times stimulates our
reptilian complex and our limbic
systems which, when unmediated by our
more logical neocortex, naturally stirs up
the desire to retreat to something more
familiar and safe. We see this playing
out in the Brexit vote and in the US
response to “making America great
again,” to mention just two of many
phenomena.
The Transilience Framework,
therefore, encourages consideration be
given to the impact new tech may have
on the pre-rational, lizard and limbic
aspects of ourselves in addition to the
tasks they are being designed to fulfill.
We cannot change these hard-wired
dimensions of our brains. But by being
more fully aware of how much they
impact our behavior, we can work to put
each to better use. Then perhaps during
the next US election, pollsters will find
novel ways to measure the temperature
all three areas of human concern:
survival issues, social concerns and
preferred political strategies.
C. Domain or Scope
The final component woven into our
social good strategies as indicated by the
Transilience Framework addresses the
scope of work. Projects and services can
target an individual or larger groupings
and social institutions. The latter can
range from family units, through to
national and international structures. As
for most systems, moving from the inner
individual levels to the outer larger
institutions means a shift to significantly
more complex structures. Identifying the
scope of work facilitates establishing
time frames, methodologies, resources,
the clarification of which benefits the
management expectations.
How does this help identify strategic
actions for today’s evolving intelligence
informatics community? First, since the
focus here is on developing potential
partnerships with some aspect of the
United Nations, it will help to clarify
some notions of the UN. There is a
tendency for people to view the UN as an
entity that is responsible for peace and
security at the global level. This is
however, false. While it may be the most
global oriented entity we have, it does
not have global level authority. It is not
structured as an entity with a mandate to
secure world peace. It can advise nations
about peace and security and facilitate
governmental negotiations on the issues,
but the UN itself was never globally
purposed. There was, and remains, an
aversion to a single “global state” and its
accompanying notion of a common
political authority for all of humanity.
Fig. 4 Domain: This identifies the scope of work
at hand ranges from the individual level to that of
metahumanity. The degree of complexity of
implementing solutions increases exponentially
making global issues enormously more complex.
This suggests the most critical and perhaps
strategic space for the augmentation of human
efforts by intelligence informatics is at the global
or metahumanity level.
Though the UN is the agreed meeting
place where governmental
representatives negotiate according to
their national agendas and interests. In
this relatively transparent environment,
Member States often do operate from
enlightened self-interest. However there
is nothing stopping them from putting
national interests above the interests of
other nations and peoples. The UN’s
Charter makes this clear, that it pursues
peace between nations; neighborly
relations among its members; and
respect for each other’s national
sovereignty.
The Charter does encourage the use of
“international machinery for the
promotion of the economic and social
advancement of all people,” [2] but this
too is an endeavor of nations. Then there
is the 1948 Universal Declaration of
Human Rights that has enlightened and
strengthened the work of those seeking
peaceful solutions. But this universal
instrument does not change the fact that

Editor: Mike Howard
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin
8
the UN does not have global authority.
When someone asks, “What did the
UN do about the UN Convention on
Transnational Organized Crime
(UNTOC)?” for example, the more
telling rephrasing of that question would
be something like this series of
questions: “What did each nation agree
to in that meeting?” “What are they now
doing to implement their
commitments?” “How do we know?”
While the UN may be the one social
institution endowed with the moral
authority to act for the greater good, it is
not structured to do so. Hence the phrase
often heard, “UN resolutions have no
teeth.” But none of these and other
factors stop people from questing for the
betterment of humanity as a whole with
or without a global authority established
to facilitate this.
As the ubiquity of the Internet and its
attendant web-based intelligence,
communications and finances evolve, it
becomes clearer that significant
trans-national organizational issues
remain to be addressed. The UN remains
the most obvious, yet still limited entity
for this work. What is also needed are
self-organizing efforts to step up to the
plate. That is how the UN International
Criminal Court (ICC) and the 1997
Convention on the Prohibition of the
Use, Stockpiling, Production and
Transfer of Anti-Personnel Mines came
into existence. Those with vision,
expertise and drive step up and make
something happen.
III.GLOBAL GOVERNANCE AND
INTELLIGENT INFORMATICS
Many of our global social challenges
are already incorporated into the UN’s
2030 Sustainable Development Goals
(SDGs) [3], into the work of the United
Nations Office of Drugs and Crime, the
Security Council, and taken up by its
multiple businesses and agencies such as
UNICEF, UNESCO, WHO, and dozens
of others. With focused effort, the right
kinds of leadership in appropriate places
and technical savvy, much of this good
work could be upgraded and improved
further.
The UN already has innovation labs in
field offices around the world bringing
together technologists with local social
activists in pursuit of the UN’s
development mandates. The UN also has
significant efforts underway to optimize
its technical infrastructure, though there
is much more that can be done there too.
The more complex work of innovative
uses of existing data and domain experts
to provide intelligence for governance in
a complex system such as the UN is still
missing. But now that the
multidisciplinary intelligence and
security informatics communities are
maturing, and the UN is creating digital
platforms to better enable innovative
partnerships and engagement with
technically oriented civil society and the
private sector, these crossing paths
provide an unusual opportunity to leap
forward and benefit the greater global
community.
Bringing the diverse mindsets of
technologists and global legislators to
work together on some of the stickiest
global issues has the potential to be a
powerful difference engine fueling
needed innovations.
There is yet another gain that could be
made. If teams from the think tanks and
institutes currently funded by the likes of
Steven Hawking, Elon Musk, and Peter
Thiel (to name just a few concerned for
AI’s existential threats to the future of
humanity), would forge partnerships
with the UN’s Digital Blue Helmets for
example, these small, targeted
cross-disciplinary partnerships could
work in situ. They would have easier
access to the data and resources of the
UN’s 50-plus agencies and
organizations and their domain experts
otherwise unavailable to AI
technologists. There may be no better
work place available for infusing human
friendly compassion and empathy into
intelligence systems than that alongside
those striving to fulfill the UN’s
challenging mandates.
The Digital Blue Helmet platform has
already been established by
forward-looking technologists at the UN
for “rapid information exchange and
better coordination of protective and
defensive measures against information
technology security incidents for the
United Nations, its agencies, funds, and
programmes.” [4] What is needed now is
for those in civil society, the private and
philanthropic sectors to step up to these
global challenges and infuse the UN’s
work with additional innovative
energies. Now that Google’s AI has
challenged and beaten the
world-champion Go player, Ke Jie, it is
time to put AI, machine learning,
robotics, bioinformatics, big data and the
best of the best to work on something
even more complex and challenging:
world peace.
By bringing web intelligence
resources to the challenges such as those
the Digital Blue Helmets are contending
with: transnational organized crime,
cybersecurity, crisis intervention, and
the multitude of uses of today’s
technologies for the global good, we can
all benefit. Of course there are risks and
concerns at which those in the C-Suites
of the UN, the private sector and
academia will need to look. But in
principle, it is wise for us all to keep an
eye on the clock, and assess the risks
both of action and inaction.
Governance intelligence may neither
have the same dramatic optics of a moon
landing nor the feel of the latest piece of
shiny tech; however, bold steps with
metahumanity in mind need to be taken
today. The urgency of this can be
measured in the numbers of people
going to the streets in protest, the
escalating threats of violence and war,
the need for faster, better response to
natural and man-made crises, the
millions of displaced persons looking for
refuge, the economic challenges of
rapidly changing job markets, and more.
A window of opportunity is opening
right now—what better time for the odd
couple of technologists and global
legislators working for the social good
decide to self-organize and step up to
tackle the complex problems that affect
us all?
IV.REFERENCES
[1] MacLean, Paul D., and Vojtech A. Kral. A
Triune Concept of the Brain and Behaviour.:
Including Psychology of Memory [U.a.] :

R&D Profile: Intelligent Informatics and the United Nations: A Window of Opportunity
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1
9
Papers Presented at Queen's University,
Kingston, Ontario, February 1969 / by V.A.
Kral. Toronto [u.a.]: Univ. of Toronto Pr,
1973. The triune brain is a model of the
evolution of the vertebrate forebrain and
behavior. [2] United Nations: Department Of Public
Information. Charter of the United Nations
and Statute of the International Court of
Justice. [Place of publication not identified]:
United Nations, 2015. [3] UN’s 2030 Sustainable Development Goals,
http://www.undp.org/content/undp/en/home
/sustainable-development-goals.html.
[4] The UN’ s Digital Blue Helmets,
https://unite.un.org/digitalbluehelmets/
Contact Information
Dr. Karen Judd Smith
Co-Chair, Alliance of NGOs on Crime
Prevention and Criminal Justice
Consultant, United Nations Office of
Information and Communications
Technology
Email: [email protected]

10 Short Feature Article: A Consultant Framework for Natural Language Processing in Integrated Robot Architectures
A Consultant Framework for Natural LanguageProcessing in Integrated Robot Architectures
Tom Williams
Abstract—One of the goals of the field of human-robot inter-action is to enable robots to interact through natural language.This is a particularly challenging problem due to the uncertainand open nature of most application domains. In this paper,we summarize our recent work in developing natural languageunderstanding and generation algorithms. These algorithms arespecifically designed to handle the uncertain and open-worldsin which interactive robots must operate, and use a ConsultantFramework specifically designed to account for the realities ofintegrated robot architectures.
Index Terms—human-robot interaction; natural language un-derstanding; natural language generation; natural languagepragmatics; integrated robot architectures
I. INTRODUCTION
ENGAGING in task-based natural language interactionsin realistic situated environments is incredibly challeng-
ing [1]. This is especially true for robotic agents for threereasons. First, their knowledge is woefully incomplete, bothphysically (only having knowledge of a small number of ob-jects, people, locations, and so forth) and socially (only havingknowledge of a small number of social norms). Second, theirknowledge is highly uncertain due perceptual and cognitivelimitations. Finally, natural language is highly ambiguous. Assuch, language-enabled robotic architectures must be designedto handle uncertainty, ignorance, and ambiguity at each stageof the natural language pipeline.
In this article, we will summarize research performed inthe Human-Robot Interaction laboratory at Tufts Universityin service of this goal1. Specifically, we will discuss researchintending to account for uncertainty, ignorance, and ambiguityin the referential and pragmatic components of our robotarchitecture, DIARC [3], as implemented in the Agent Devel-opment Environment (ADE) [4]2. We will begin by describingour mnemonic architecture: a Consultant Framework designedto facilitate domain independent memory retrieval in uncertain,open and ambiguous worlds. We will then describe our linguis-tic architecture: the language-processing components of ourrobot architecture which benefit from those mnemonic designchoices.
Tom Williams was with the Department of Computer Science at TuftsUniversity, Medford MA 02145 USA. E-mail: [email protected] (Seealso: http://inside.mines.edu/~twilliams).
1Specifically, we summarize work that contributed to the author’s doctoraldissertation [2]
2While our laboratory has also examined these topics at other stages of thenatural language pipeline [5], that work is beyond the scope of this review.
II. MNEMONIC ARCHITECTURE
A. Distributed Heterogeneous Knowledge Bases
In integrated robot architectures (e.g., [3], [6]), infor-mation may be distributed across a variety of architecturalcomponents. Information about objects may be stored in onelocation, information about locations in another, and infor-mation about people and social relationships in yet another.Furthermore, each of these stores of knowledge may use a verydifferent representational framework. The set of architecturalcomponents capable of providing information about entitiesthat may be referenced in dialogue can thus be viewed asa set of distributed, heterogeneous knowledge bases [7]. Ourmnemonic architecture makes the following assumptions [2]about such DHKBs: (1) Each DHKB has knowledge of someset of entities; (2) A subset of knowledge regarding each entitycan be accessed through introspection and described usingpositive arity predicate symbols; (3) Any knowledge that canbe accessed in this way can also be assessed as to strength ofbelief; and (4) Each sort of knowledge that can be accessed,assessed, and described can also be imagined to hold for agiven entity.
B. Consultants
These assumptions are exploited using a set of Consultants.Each architectural Consultant provides domain-independentaccess to a particular DHKB, allowing other componentsto access, assess, and imagine entities without needing toknow anything about how such entities are represented (seealso Fig. 1). To facilitate this, each Consultant provides fourcapabilities: (1) providing a set of atomic entities assessablethrough introspection; (2) advertising a list of predicates thatcan be assessed with respect to such entities, listed accordingto a descending preference ordering; (3) assessing the extent towhich it is believed such properties apply to such entities; and(4) imagining new entities and asserting knowledge regardingthem.
III. LINGUISTIC ARCHITECTURE
Now that we have described DIARC’s mnemonic architec-ture, we are ready to describe the linguistic architecture thatleverages it (see also Fig. 2). We will begin by discussingnatural language understanding components (reference resolu-tion and pragmatic understanding), and then discuss naturallanguage generation components (pragmatic generation andreferring expression generation).
Throughout this section, we will use the example utterance“I need the medkit that is on the shelf in the breakroom”, and a
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Short Feature Article: Tom Williams 11
mnemonic architecture using three DKHBs (Mapping, Vision,Social) and three associated consultants (locs,objs,ppl).
A. Reference Resolution
The first architectural component we will discuss isour Reference Resolution Component, whose job is toascertain the identities of any entities referenced throughnatural language. For example, upon receiving the semanticrepresentation for “I need the medkit that is on the shelf inthe breakroom” (Statement(speaker, self, need(self,X),{on(X,Y ),medkit(X), shelf(Y ), breakroom(Z), in(Y,Z)}),it is up to the Reference Resolution Component to determinewhat entities should be associated with variables X , Y and Z.This problem can be broken down into three levels: closed-world reference resolution, open-world reference resolution,and anaphora resolution. In the following subsections wewill discuss algorithms for solving each of these increasinglylarger problems.
1) Closed-World Reference Resolution: Closed-World Ref-erence Resolution is the basic problem of finding the op-timal mapping from references to known entities. Undera simplifying assumption of inter-constraint independence,Closed-World Reference Resolution can be modeled usingthe following equation, where Λ = {λ0, . . . λn} is a set ofsemantic constraints, Γ = {Γ0, . . . ,Γn} is the set of possiblebindings to the variables contained in those constraints, andΦ = φ0, . . . , φn is a set of satisfaction variables for whicheach φi is True iff formula λi holds under a given binding:
Γ? = argmaxΓ∈Γ
|Λ|∏i=0
P (φi | Γ, λi)
That is, the optimal set of bindings Γ? is that which maximizesthe joint probability of a set of satisfaction variables Φ beingsatisfied under that binding and the set of provided semanticconstraints Λ (under a simplifying assumption of independencebetween constraints). This model is algorithmically realizedusing the DIST-CoWER algorithm [2], [7], [8], which searchesthrough the space of possible variable-entity assignments,pruning branches whose incrementally computed probabilityfalls below a given threshold. For the example sentence, ifthe robot knows of a medkit on a shelf in a breakroom, itmight return a set of bindings such as {X → objs4, Y →objs6, Z → locs9}, along with an associated probability value.
2) Open-World Reference Resolution: DIST-CoWER facil-itates reference resolution under uncertainty, but presumesthat all entities that could be referenced are known a priori:an assumption which is unwarranted in realistic human-robotinteraction scenarios. To continue the previous example, if arobot knows of a breakroom but does not know of a shelf inthat breakroom, DIST-CoWER will fail to return any bindingsfor “the medkit that is on the shelf in the breakroom”. Ideally,however, the robot would be able to both resolve the portionsof the utterance that it does know of a priori, and learn in oneshot about other, previously unknown entities referenced in theutterance. We model this problem, which we call Open-WorldReference Resolution, using the following equation, where Λ is
a set of constraints, ΛV is an ordering of the variables involvedin those constraints, Γi? is the optimal solution provided byDIST-CoWER given the constraints involving only the last|ΛV | −i variables in ΛV , Γi?P is the probability associatedwith this solution, and complete is a function which createsnew representation to associate with any variables appearingin ΛV but not in optimal open-world solution Γi?:
Γ? = complete
(argmax
Γi?∈{Γ0?,...,Γ|ΛV |?}
{i, if Γi?P > τ
0, otherwise
).
That is, the optimal set of bindings Γ? is the first sufficientlyprobable set of bindings returned from a series of callsto DIST-CoWER made using different subsets of the fullpredicate set Λ. This model is algorithmically realized usingthe DIST-POWER algorithm [2], [7], [8], which (1) finds avariable ordering over the variables used in predicate list Λbased on linguistic factors such as prepositional attachmen-t; (2) successively removing variables from this list untilcalling DIST-CoWER on only the predicates involving theremaining variables returns a sufficiently probable solution;(3) for each variable removed in this way, instructing theappropriate consultant to create a mental representation fora new entity; (4) instructing the appropriate Consultants tomake any representations created in this way to be consistentwith all related predicates in Λ; (5) returning a unified set ofbindings from the set of variables used in Λ to known and/ornewly created entity representations.
For example, if in the example sentence the robot does notknow of a shelf in a breakroom, it might return the set of bind-ings {X → objs44, Y → objs45, Z → locs9}, where objs44
and objs45 are references to newly created representations forhypothesized entities, and locs9 is a reference to a previouslyexisting representation for a (grounded or hypothetical) entity.
3) Anaphora Resolution: The algorithms discussed in theprevious sections allow our robots to resolve references inuncertain and open worlds using definite noun phrases (i.e.,“the-N” phrases). Humans, however, have a tendency to usea much wider variety of referring forms, (e.g., “a-N”, “this”,“it”). In order to handle this multitude of forms, we embedDIST-POWER within a larger algorithm called GH-POWER [9]for its use of the Givenness Hierarchy theory of reference.The Givenness Hierarchy divides referential forms into sixgroups, each of which is associated with a different tier ofa hierarchy of six nested cognitive statuses. For example,when one uses “it”, the Givenness Hierarchy suggests that thespeaker believes their target referent to be at least in focus forthe listener; when one uses “this”, the Givenness Hierarchysuggests the speaker believes their target referent to be atleast activated, that is, in short-term memory for the listener(and possibly also in focus because of the nested nature of thesix tiers); and so forth. Using this theory, when a particularreferential form is used, we infer the set of possible statusesthe speaker may believe their target referent to have, and fromthis infer a sequence of mnemonic actions to take: creating anew representation of a referent or searching for an existingone in a particular data structure. For example, when a definitenoun phrase is used, GH-POWER will search through the set
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1

12 Short Feature Article: A Consultant Framework for Natural Language Processing in Integrated Robot Architectures
Fig. 1. Memory Model: TheFocus of Attention, Short Ter-m Memory, Discourse Con-text are hierarchically nested,and contain references to en-tities stored in the Distribut-ed, Heterogeneous KnowledgeBases which comprise long-term memory (Mapping, Vision,Social), access to which is en-abled and controlled using a setof Consultants (locs, objs, ppl).
Fig. 2. ArchitecturalDiagram: Informationflows through the followingcomponents: Automatic SpeechRecognition (ASR), NaturalLanguage Processing (NLP),Reference Resolution (RR),Pragmatic Understanding(PUND), the DialogueBelief and Goal Manager(DBGM), Pragmatic Generation(PGEN), Referring ExpressionGeneration (REG), NaturalLanguage Generation (NLG),Text to Speech (TTS). Utilizedby these components are theconsultant framework andassociated Memory Model(MM) and the Pragmatic RuleSet (PRS)
of activated entities, the focus of attention, the set of familiarentities, and, if none of these steps are successful, will useDIST-POWER to search through all of the robot’s long termmemory, and hypothesizing a new representation if that searchfails. Fig. 1 shows the set of Givenness Hierarchy-theoretic da-ta structures we use (Focus of Attention, Short Term Memory,Discourse Context), their hierarchical relationship with eachother, and how the representations within each other can beviewed as references to entities stored in the DHKBs whichcomprise long-term memory (Mapping, Vision, Social), accessto which is enabled and controlled using a set of Consultants(locs, objs, ppl).
For example, in the example sentence, all three entitiesare described using “the”; as such, GH-POWER will use thesequence of mnemonic actions Search STM, Search FoA,Search DC, Search LTM, Hypothesize, where these last twosteps are achieved (if necessary) by performing a DIST-POWER query. If sufficiently probable candidate referents canbe found in the upper level GH-theoretic data structures, thismay not be necessary.
4) Discussion: To summarize thus far, given the unboundsemantic interpretation of an incoming utterance, our refer-ential components will first identify sequences of mnemonicactions to take to resolve the references found in that utterance;those sequences will then be used to initiate searches throughvarious data structures for entities that, according to theappropriate Consultants, are likely to satisfy the predicatesthat comprise the semantic interpretation; in the worst casethis will require the use of DIST-POWER to search all oflong-term memory. Once the reference resolution process is
completed, the end result is a set of hypotheses, each ofwhich associate the variables found in the incoming semanticinterpretation with a different set of entities, and each ofwhich has a particular likelihood. As described in [10], thesehypotheses are then used to create a set of bound utterances,which are combined into a single Dempster-Shafer theoreticbody of evidence which is passed to our pragmatic reasoningcomponent.
Our approach significantly differs from most other recentlanguage understanding work in robotics. Most other work hasfocused on tackling the full language grounding problem ofmapping from natural language to continuous perceptual repre-sentations [11]–[20]. In contrast, we separate this problem intotwo halves: reference resolution, in which natural languageis mapped to discrete symbols representing unique entities,and symbol grounding, in which those symbols are associatedwith continuous perceptual representations, and focus on thedevelopment of reference resolution algorithms. This divisionhas allowed us to develop a framework for resolving referencesboth to grounded, observed entities, as well as to heretoforeunknown or even hypothetical and imaginary entities, thus pro-viding us the means to tackle open-world reference resolution.
B. Pragmatic Reasoning
In this section we will discuss the Pragmatic Reasoningcomponents of our architecture: Pragmatic Understanding andits counterpart, Pragmatic Generation.
1) Pragmatic Understanding: The pragmatic reasoningcomponent’s primary purpose is to infer the intentions behindincoming utterances. Specifically, this component attempts toinfer the intentions behind conventionally indirect utteranceforms, also known as Indirect Speech Acts, which recentwork has shown to be prevalent throughout human-robotdialogue [21]. Provided with the Dempster-Shafer theoreticset of candidate utterances Θu produced by GH-POWER, aDempster-Shafer theoretic set of contextual information Θc
and a set of Dempster-Shafer theoretic rules of the formu ∧ c ⇒ i, the pragmatic reasoning component produces aDempster-Shafer theoretic set of intentions Θi by computingmi(·) = ((mu ⊗mc)�muc→i) (·), where ⊗ is a Dempster-Shafer theoretic And operator, and � is a Dempster-Shafertheoretic Modus Ponens operator [22].
For example, when processing the example sentence, arobot might have a pragmatic rule that says (with someprobability between, say, 0.7 and 0.8) that when someonesays to someone they believe to be their subordinate that theyneed something, they likely want their subordinate to bringthem that something:
Stmt(A,B, need(A,C)) ∧ bel(A, subordinate(B,A))
[0.7,0.8]=====⇒ want(A, goal(B, bring(B,C,A))).
Because the example utterance matches this rule’s utteranceform, the uncertainty interval reflecting the confidence thatthat utterance was what was actually said is combined withthe uncertainty interval reflecting the robot’s confidence thatthe speaker believes the robot to be their subordinate, as wellas with the uncertainty interval associated with the rule itself,
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Short Feature Article: Tom Williams 13
producing an uncertainty interval reflecting how confident therobot is that the speaker wants it to bring them the describedobject.
Each candidate intention I inferred in this way is thusaugmented with a Dempster-Shafer theoretic interval [α, β]within which the probability that I is true can be said to lie.If an interval is determined to reflect sufficient uncertainty byNunez’ uncertainty measure [23]
λ = 1 +β
1 + β − αlog2β
1 + β − α +1− α
1 + β − αlog21− α
1 + β − α,
the robot generates it’s own intention – an intention toknow whether or not it should actually infer that candidateintention. This allows the robot to identify sources of bothpragmatic and referential uncertainty and ignorance. If suchan intention is generated, it will satisfied by generating aclarification request [10]. This highlights the other capabilityof the pragmatic reasoning component: to perform pragmaticgeneration.
2) Pragmatic Generation: Due to our use of a Dempster-Shafer-theoretic approach, the same rules used to infer theintentions behind utterances (pragmatic understanding) canalso be used to abduce utterances that can be used to commu-nicate intentions (pragmatic generation). Pragmatic generationis performed using the same set of Dempster-Shafer theoreticrules and logical operators used during pragmatic understand-ing [22], with the addition of one pre-processing step and onepost-processing step.
Before pragmatic generation is performed, it is determinedwhether the robot is generating a clarification request, andif so, whether there are more than two choices must bearbitrated between [10]. If so (e.g., if, in the example,the robot determines it knows of two medkits on a shelfin a breakroom), those choices are unified into a singlepredicate which will allow a generic WH-question (e.g.,“Which medkit would you like?”) rather than a many-item YN-question (e.g., “Would you like the red medkitor the blue medkit or the white medkit or the greenmedkit?”), which are only when there are two or feweroptions. Note, however, that at this stage of processing,only the bare utterance form has been generated (e.g., Ques-tionYN(self,speaker, or(would(speaker,like(speaker,obj1)),would(speaker,like(speaker,obj2))))), and not the propertiesused to describe each referenced entity.
After pragmatic generation has yielded a set of utteranceforms which could be communicated, each is passed forwardsthrough the pragmatic reasoning module, in order to simulatethe utterance understanding process. This creates a set ofintentions the robot may believe its interlocutor will infer if itchooses to use that particular utterance form. This allows therobot to detect unintended side-effects of different candidateutterance forms so that it can choose the best possible utteranceto communicate its intentions. The best candidate utteranceform is then selected and sent to our Referring ExpressionGeneration module.
3) Discussion: Our work on pragmatic understanding di-rectly builds off of previous work from Briggs et al. [24].Like that work, our own understands utterances based on itsbeliefs about the speaker’s beliefs; but we improve on that
work by handling uncertainty (and ignorance) and allowingfor adaptation: capabilities also largely lacking from previouscomputational approaches to ISA understanding (e.g., [25]–[27]).
Our techniques for generating clarification requests comparefavorably to previous work due to our accounting for humanpreferences (cf. [28], [29]) and our ability to handle uncertain-ty (cf. [12]). Similarly, while there has been some previouswork on generating indirect language (e.g., [24], [30]), webelieve that our work is the first to enable robots’ generationof conventionalized indirect speech acts under uncertainty.
C. Referring Expression GenerationOnce a robot has chosen an utterance form to communicate,
it must decide what properties to use to describe the thingsit wishes to communicate about. This is a problem knownas Referring Expression Generation. To solve this problem,we use DIST-PIA [31], a version of the classic IncrementalAlgorithm [32], modified to use our consultant framework.When crafting a referring expression for a given entity, ouralgorithm proceeds through the ordered list of propertiesprovided by the consultant responsible for that entity: eachproperty is added to the list of properties to be used inthe description if it is sufficiently probable that it applies tothe target referent, and if it is not sufficiently probable thatit applies to one or more distractors, thus allowing thosedistractors to be ruled out. This algorithm improves on theclassic Incremental Algorithm in its use of our MnemonicArchitecture (to enable use in integrated robot architectures)and in its ability to operate under uncertainty.
For example, suppose the objs consultant advertisesthat it can handle the following properties: {shelf(X −objs),medkit(X − objs), green(X − objs), red(X −objs), on(X − objs, Y − objs), in(X − objs, Y − locs)}, andthat the DIST-PIA algorithm is used to generate a descriptionof objs4. Suppose objs4 is not likely to be a shelf – thatproperty will be ignored. Suppose objs4 is likely to be amedkit, as are two other objects – medkit(objs4) will beadded to the set of properties to use. Suppose objs4 is notlikely to be green – that property will be ignored. Supposeobjs4 is likely to be red, and that neither of the two distractormedkits are likely to be so – red(objs4) will be added to theset of properties to be used, and since all distractors havebeen eliminated, the set {medkit(objs4), red(objs4)} willbe returned, allowing a description such as “the red medkit”to be generated.
Of equal contribution in the work that presented this algo-rithm [31] is our development of a novel evaluation frameworkthat solicits certainty estimates from humans in order to craftprobability distributions that can then be used by uncertainty-handling REG algorithms. This allows such algorithms to beevaluated with respect to both other algorithms and humanbeings, without committing to any particular set of visualclassifiers (cf. [33]–[35]).
IV. CONCLUSION
In this article, we have described a natural language under-standing and generation pipeline designed specifically for use
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1

14 Short Feature Article: A Consultant Framework for Natural Language Processing in Integrated Robot Architectures
in integrated robot architectures and for operation in uncertainand open worlds. It is our hope that the general frameworkspresented in this work will allow researchers to more easilyintegrate together disparate approaches – and that this workwill draw researchers’ attention to the under-studied area ofopen-world language processing. For a complete treatment ofthe work described in this paper, we direct the interested readerto the authors’ recent dissertation, which describes the workcited herein in much more detail [2].
ACKNOWLEDGMENT
This work was funded in part by ONR grants #N00014-11-1-0289, #N00014-11- 1-0493, #N00014-10-1-0140 #N00014-14-1-0144, #N00014-14-1-0149, #N00014-14-1-0751, andNSF grants #1111323, #1038257.
REFERENCES
[1] N. Mavridis, “A review of verbal and non-verbal human–robot interac-tive communication,” Robotics and Autonomous Systems, vol. 63, pp.22–35, 2015.
[2] T. Williams, “Situated natural language interaction in uncertain and openworlds,” Ph.D. dissertation, Tufts University, 2017.
[3] P. W. Schermerhorn, J. F. Kramer, C. Middendorff, and M. Scheutz,“DIARC: A testbed for natural human-robot interaction.” in Proceedingsof the AAAI Conference on Artificial Intelligence, 2006, pp. 1972–1973.
[4] M. Scheutz, G. Briggs, R. Cantrell, E. Krause, T. Williams, and R. Veale,“Novel mechanisms for natural human-robot interactions in the diarcarchitecture,” in Proceedings of AAAI Workshop on Intelligent RoboticSystems, 2013.
[5] M. Scheutz, E. Krause, B. Oosterveld, T. Frasca, and R. Platt, “Spokeninstruction-based one-shot object and action learning in a cognitiverobotic architecture,” in Proceedings of the Sixteenth InternationalConference on Autonomous Agents and Multiagent Systems (AAMAS),2017.
[6] M. Quigley, J. Faust, T. Foote, and J. Leibs, “ROS: an open-source robotoperating system,” in ICRA Workshop on Open Source Software, 2009.
[7] T. Williams and M. Scheutz, “A framework for resolving open-worldreferential expressions in distributed heterogeneous knowledge bases,” inProceedings of the Thirtieth AAAI Conference on Artificial Intelligence,2016.
[8] ——, “POWER: A domain-independent algorithm for probabilistic,open-world entity resolution,” in IEEE/RSJ International Conference onIntelligent Robots and Systems (IROS), 2015.
[9] T. Williams, S. Acharya, S. Schreitter, and M. Scheutz, “Situated openworld reference resolution for human-robot dialogue,” in Proceedingsof the Eleventh ACM/IEEE International Conference on Human-RobotInteraction (HRI), 2016.
[10] T. Williams and M. Scheutz, “Resolution of referential ambiguity inhuman-robot dialogue using dempster-shafer theoretic pragmatics,” inProceedings of Robotics: Science and Systems (RSS), 2017.
[11] P. Gorniak and D. Roy, “Grounded semantic composition for visualscenes,” Journal of Artificial Intelligence Research, vol. 21, pp. 429–470, 2004.
[12] G.-J. M. Kruijff, P. Lison, T. Benjamin, H. Jacobsson, and N. Hawes,“Incremental, multi-level processing for comprehending situated dia-logue in human-robot interaction,” in Symposium on Language andRobots, 2007.
[13] S. Lemaignan, R. Ros, R. Alami, and M. Beetz, “What are you talkingabout? grounding dialogue in a perspective-aware robotic architecture,”in The Eighteenth IEEE International Symposium on Robot and HumanInteractive Communication (RO-MAN), 2011, pp. 107–112.
[14] F. Meyer, “Grounding words to objects: A joint model for co-referenceand entity resolution using markov logic for robot instruction process-ing,” Ph.D. dissertation, TUHH.
[15] J. Y. Chai, L. She, R. Fang, S. Ottarson, C. Littley, C. Liu, andK. Hanson, “Collaborative effort towards common ground in situatedhuman-robot dialogue,” in Proceedings of the ACM/IEEE InternationalConference on Human-robot Interaction (HRI), 2014, pp. 33–40.
[16] J. Fasola and M. J. Mataric, “Interpreting instruction sequences inspatial language discourse with pragmatics towards natural human-robotinteraction,” in Proceedings of the IEEE International Conference onRobotics and Automation (ICRA), 2014, pp. 2720–2727.
[17] C. Kennington and D. Schlangen, “A simple generative model of incre-mental reference resolution for situated dialogue,” Computer Speech &Language, vol. 41, pp. 43–67, 2017.
[18] S. Tellex, T. Kollar, S. Dickerson, M. R. Walter, A. G. Banerjee,S. Teller, and N. Roy, “Approaching the symbol grounding problemwith probabilistic graphical models,” AI Magazine, 2011.
[19] I. Chung, O. Propp, M. R. Walter, and T. M. Howard, “On the per-formance of hierarchical distributed correspondence graphs for efficientsymbol grounding of robot instructions,” in Proceedings of the IEEE/RSJInternational Conference on Intelligent Robots and Systems (IROS),2015, pp. 5247–5252.
[20] C. Matuszek, E. Herbst, L. Zettlemoyer, and D. Fox, “Learning to parsenatural language commands to a robot control system,” in Proceedingsof the Thirteenth International Symposium on Experimental Robotics(ISER), 2012.
[21] G. Briggs, T. Williams, and M. Scheutz, “Enabling robots to understandindirect speech acts in task-based interactions,” Journal of Human-RobotInteraction, 2017.
[22] T. Williams, G. Briggs, B. Oosterveld, and M. Scheutz, “Going be-yond command-based instructions: Extending robotic natural languageinteraction capabilities,” in Proceedings of 29th AAAI Conference onArtificial Intelligence, 2015.
[23] R. C. Nunez, R. Dabarera, M. Scheutz, G. Briggs, O. Bueno, K. Pre-maratne, and M. N. Murthi, “DS-Based Uncertain Implication Rules forInference and Fusion Applications,” in Sixteenth International Confer-ence on Information Fusion, July 2013.
[24] G. Briggs and M. Scheutz, “A hybrid architectural approach to under-standing and appropriately generating indirect speech acts,” in Proceed-ings of the Twenty-Seventh AAAI Conference on Artificial Intelligence,2013.
[25] D. J. Litman and J. F. Allen, “A plan recognition model for subdialoguesin conversations,” Cognitive science, vol. 11, no. 2, pp. 163–200, 1987.
[26] E. A. Hinkelman and J. F. Allen, “Two constraints on speech actambiguity,” in Proceedings of the Twenty-Seventh annual meeting of theAssociation for Computational Linguistics (ACL), 1989, pp. 212–219.
[27] S. Wilske and G.-J. Kruijff, “Service robots dealing with indirect speechacts,” in Proceedings of the IEEE/RSJ International Conference onIntelligent Robots and Systems (IROS), 2006, pp. 4698–4703.
[28] R. Deits, S. Tellex, T. Kollar, and N. Roy, “Clarifying commands withinformation-theoretic human-robot dialog,” Journal of Human-RobotInteraction, 2013.
[29] S. Hemachandra, M. R. Walter, S. Tellex, and S. Teller, “Learningspatial-semantic representations from natural language descriptions andscene classifications,” in International Conference on Robotics andAutomation (ICRA), 2014.
[30] R. A. Knepper, C. I. Mavrogiannis, J. Proft, and C. Liang, “Implicitcommunication in a joint action,” in Proceedings of the ACM/IEEEInternational Conference on Human-Robot Interaction (HRI). ACM,2017, pp. 283–292.
[31] T. Williams and M. Scheutz, “Referring expression generation underuncertainty: Algorithm and evaluation framework,” in Proceedings ofthe Tenth International Conference on Natural Language Generation(INLG), 2017.
[32] R. Dale and E. Reiter, “Computational interpretations of the griceanmaxims in the generation of referring expressions,” Cognitive science,vol. 19, no. 2, pp. 233–263, 1995.
[33] H. Horacek, “Generating referential descriptions under conditions ofuncertainty,” in Proceedings of the Tenth European Workshop on NaturalLanguage Generation (ENLG), 2005, pp. 58–67.
[34] A. Sadovnik, A. Gallagher, and T. Chen, “Not everybody’s special:Using neighbors in referring expressions with uncertain attributes,” inProceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops, 2013, pp. 269–276.
[35] R. Fang, C. Liu, L. She, and J. Y. Chai, “Towards situated dia-logue: Revisiting referring expression generation.” in Proceedings ofthe Conference on Empirical Methods for Natural Language Processing(EMNLP), 2013, pp. 392–402.
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Feature Article: Sen Yang, Jingyuan Li, Xiaoyi Tang, Shuhong Chen, Ivan Marsic, Randall S. Burd 15
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1
Abstract—We present our process mining system for analyzing
the trauma resuscitation process to improve medical team perfor-
mance and patient outcomes. Our system has four main parts:
trauma resuscitation process model discovery, process model en-
hancement (or repair), process deviation analysis, and process
recommendation. We developed novel algorithms to address the
technical challenges for each problem. We validated our system
on real-world trauma resuscitation data from the Children’s
National Medical Center (CNMC), a level 1 trauma center. Our
results show our system’s capability of supporting complex
medical processes. Our approaches were also implemented in an
interactive visual analytic tool.
Index Terms—Process Mining, Trauma Resuscitation, Medical
Process Diagnosis
I. INTRODUCTION
RAUMA is the leading cause of death and acquired
disability among children and young adults. Because early
trauma evaluation and management strongly impact the
injury’s outcome, it is critical that severely injured patients
receive efficient and error-free treatment in the first several
hours of injury. During the trauma resuscitation,
multidisciplinary teams rapidly identify and treat potential
life-threatening injuries, then develop and execute a short-term
management plan. The Advanced Trauma Life Support (ATLS)
[1] protocol has been widely adopted as the initial evaluation
and management strategy for injured patients worldwide.
Although its implementation has been associated with
improved outcomes, the application of this protocol has been
shown to vary considerably, even with experienced teams.
Many deviations from the ATLS protocol, e.g. the omission or
delaying of steps, may have minimal impact on the outcome,
but have been shown to increase the likelihood of a major
uncorrected error that may lead to an adverse outcome.
The objective of this project is to develop a computerized
decision support system that can automatically identify devia-
tions during trauma resuscitations and provide real-time alerts
of risk conditions to the medical team. We are approaching this
goal using four process mining techniques [2] (Figure 1). (1)
Process model discovery, extracting workflow models from
data. (2) Process model enhancement, repairing the workflow
model to mitigate the divergence between data-driven work-
flow models and expert hand-made models. (3) Process devia-
tion analysis, discovering and analyzing the medical team er-
rors. (4) Process recommendation, building a recommender
system that can give treatment suggestions to medical teams.
Key challenges for this study include limited data size, per-
missible deviations, variable patients, and concurrent team-
work. (1) Limited data: the trauma resuscitation workflow data
needs to be coded manually in a labor-intensive way. To our
best knowledge, there is no reliable system that can automati-
cally capture trauma resuscitation workflow data. (2)
Permissible deviations: it is necessary to distinguish the
acceptable deviations (false alarms) from unexpected
deviations (true alarms). (3) Variable patients: patients come to
the trauma bay with different injuries that need different
treatment plans. (4) Concurrent teamwork: trauma
resuscitations need concurrent collaborative work within a
medical team comprised of examining providers (surveying
physicians), bedside nurses (left nurse, right nurse and charge
nurse), and other team roles (e.g., surgical coordinator,
anesthetist).
In this study, we contributed a comprehensive process
mining framework with related techniques. We showed what
problem each process mining technique solved and how these
techniques worked together to achieve our project goals. We
evaluated our process mining framework and techniques on a
complex real-world medical case, the trauma resuscitation
process. Our results showed the effectiveness of our techniques
over existing process mining methods. Note that this paper is an
overview of our previous work. The technical techniques can
be found in our previous work.
II. RELATED WORK
Many medical processes are performed based on domain
knowledge and standard protocols. For trauma resuscitations,
the ATLS [1] protocol suggests a medical examination flow
based on treatment priorities: Airway Breathing Circula-
tion Neurological Disability. Despite the use of standardized
evaluation and management protocols, deviations are observed
in up to 85% of trauma resuscitations [3]. Although most devia-
tions are variations that result from the flexibility or
adaptability needed for managing patients with different
injuries, other deviations represent “errors” that can contribute
to significant adverse patient outcomes, including death [4][5].
To discover and analyze the process errors, previous research
used two different approaches: data-driven and
expert-model-based. Data-driven methods rely on process
models or patterns discovered from historic data, while
expert-model methods rely on process models or rules designed
by domain experts. Data-driven methods work by comparing
individual process enactments to the discovered average
process representation, such as the average process trace [6],
Process Mining for Trauma Resuscitation
T
Sen Yang, Jingyuan Li, Xiaoyi Tang, Shuhong Chen, Ivan Marsic, Randall S. Burd
Sen Yang, Jingyuan Li, Xiaoyi Tang, Shuhong Chen and Ivan Marsic are with the Department of Electrical and Computer Engineering at Rutgers
University, NJ, USA. Emails: [email protected], [email protected],
[email protected], [email protected], [email protected] Randall S. Burd is with Children’s National Medical Center, Washington
DC, USA. Email: [email protected]

16 Feature Article: Process Mining for Trauma Resuscitation
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin
the data-driven model [7], or frequently occurring patterns [8].
Expert-model-based approaches locate the deviations by
checking the conformance between particular enactments to the
expert model [9], or constraints or rules specified by medical
experts [10]. In our study, we combined both methods. First, we
discovered the data-driven model and designed the expert
model based on medical domain knowledge. Then, we
compared the data-driven and expert-model to uncover the
discrepancies between practice and expectation. The
discrepancies were evaluated by medical experts to determine
if model enhancement is needed. Lastly, we used the enhanced
expert model to discover and analyze more process deviations.
To reduce process errors, Clarke et al. [11] and Fitzgerald et
al. [5] developed computer-aided decision support systems that
recommend treatment steps. These systems, however, rely on
hand-made rules specified by medical experts, lack generaliza-
bility, and are subject to human bias. We developed an auto-
matic, data-driven, label-free framework for process analysis
and recommendation.
III. DATA DESCRIPTION AND DEFINITIONS
Ninety-five resuscitations were coded by medical experts
from video recordings collected at trauma bay of CNMC be-
tween August 2014 and October 2016. Collection and use of the
data was approved by the Institutional Review Board.
The coded trauma resuscitation cases 𝒄 = [𝑐(1), … , 𝑐(𝑙)]𝑇
is a vector of elements 𝑐(𝑖) . Each 𝑐(𝑖) = {𝑖𝑑(𝑖), 𝒙(𝑖), 𝑻(𝑖)} de-
notes a resuscitation case (TABLE II), which is indexed with a
unique case id, contains the resuscitation trace 𝑻(𝑖), and has a
vector 𝒙(𝑖) of context attributes. A resuscitation trace
𝑻(𝑖) = [𝑎1(𝑖), … , 𝑎𝑘
(𝑖)]𝑇 includes k activities that are ordered
based on activity occurrence time. Context attributes
𝒙(𝑖) = [𝑥1(𝑖), … , 𝑥𝑔
(𝑖)]𝑇 is a vector of 𝑔 recorded patient
attributes (e.g., patient age, injury type) and hospital factors
(e.g., day vs. night shift, prehospital triage of injury severity).
IV. PROCESS MINING METHODS AND RESULTS
Process model discovery, process model enhancement, and
process deviation analysis are descriptive analytics, aiming to
extract insights and knowledge from historic data. Process
recommendation is predictive or prescriptive analytics, aiming
to determine the best treatment procedure given observed con-
text attributes (e.g., patient demographics). For each subsec-
tion, we discuss the methods first, followed by our achieved
results.
A. Process Discovery of Resuscitation Workflow
Existing workflow discovery algorithms (e.g., heuristic
miner, genetic miner, alpha miner [2]) have problems in han-
dling duplicate activities. For example, during trauma
resuscitation, the medical team checks patient’s eyes twice for
different reasons. First, during the primary survey, they assess
the patient’s pupillary response for neurological disability.
Second, during the secondary survey, they examine patient’s
eyes in more detail, looking for injuries to the cornea, sclera and
eyelids. An accurate workflow model should be able to
distinguish the first eye check from the second one, despite
their identical labels. Existing workflow mining algorithms
TABLE II
SAMPLE TRAUMA RESUSCITATION DATA
Case ID Activity Start Time End Time
xx1 Pt arrival 0:00:00 0:00:01
xx1 Visual assessment-AA 0:00:45 0:00:52
xx1 Chest Auscultation-BA 0:00:55 0:00:58
xx1 R DP/PT-PC 0:01:04 0:01:05
xx1 Total Verbalized-GCS 0:01:29 0:01:30
xx1 Total Verbalized-GCS 0:01:50 0:01:51
xx1 Right pupil-PU 0:02:12 0:02:18
xx1 Left pupil-PU 0:02:19 0:02:24
xx1 Right pupil-PU 0:02:24 0:02:25
xx1 Visual inspection-H 0:02:33 0:02:34
xx1 Palpation-H 0:02:33 0:02:37
Case ID xxx1 xxx2
Age category 24-96 24-96
Sex Male Female
Night Shift 0 1
Weekend 0 0
Pre-arrivalNotification 1 0
Trauma Activation Level Transfer Attending
Intubation 0 0
Glasgow Coma Score >13 1 0
Injury Type Blunt Penetrating
Injury Severity Score 5 12
Neck Injury Severity Score 3 5
(a) Trauma resuscitation trace (b) Context attributes
𝑖𝑑(1)
…
𝑥1(1),… , 𝑥𝑔
(1)
ID Ext. Attributes Resus. Traces
𝑖𝑑( )
𝑖𝑑( )
𝑥1( ),… , 𝑥𝑔
( )
𝑥1( ), … , 𝑥𝑔
( )
…
𝑎1(1), … , 𝑎𝑘
(1)
𝑎1( ), … , 𝑎𝑘
( )
𝑎1( ), … , 𝑎𝑘
( )
…
(d) Data formalization
Properties Stats
Num. Cases (or Patients) 95
Num. Total Activities 10851
Num. Activity Types 132
Num. External Attributes 17
Time Period 2014.08 – 2016.12
Size of Medical Team [7, 12]
Longest Trace (Num. Acts.) 196
Shortest Trace (Num. Acts.) 60
Avg. Num. Acts. in Traces 114.2
(c) Data statistics
Figure 1. Process mining framework with related techniques we used in trauma
resuscitation process analysis.
Conformance Checking
Intention Mining
HMM
LSTM
Process Trace Similarity
Process Trace Clustering
Process Prototype Extraction
Context Mining
Data Sequencing
Trace Alignment
State-splitting HMM Inference
Model Repair
Expert Model Design
Process Model Simplification
Significance Test
Conformance Checking
Trace Alignment
Model Confidence
Model Fidelity
Data-driven Model vs. Expert Model
Deviation Detection
Deviation Classification
Coding Improvement
Algorithm Improvement
Prescriptive Analytics
Seq2Seq
Hypothesis Test
Manual Deviation Labeling
Deviation vs. Major Errors
Deviation Prediction
Deviation vs. Context Attributes
Markov Chain
Deep Mining
Logistic Regression
TABLE I
COMPARISON OF AGSS WITH EXISTING STATE-SPLITTING ALGORITHMS ON
PRIMARY SURVEY AND SECONDARY SURVEY IN TRAUMA RESUSCITATION
PROCESSES. MODEL FIDELITY (𝑀𝑓 ) AND MODEL CONFIDENCE (𝑀𝑐 ) ARE
SCALED BY THE NUMBER OF PROCESS TRACES IN EACH PROCESS.
Primary Survey Secondary Survey
𝑴𝒇 𝑴𝒄 𝑴𝒇 𝑴𝒄
Markov Chain -10.00 -10.38 -47.59 -44.09
AGSS -9.98 -10.16 -45.22 -44.13
ML-SSS (0.01) -9.05 -10.66 -48.79 -60.52
Heuristic -8.50 -10.95 -47.59 -44.10
MDL -12.37 -12.97 -64.44 -65.37
STACT -9.32 -10.19 -49.22 -58.08

Feature Article: Sen Yang, Jingyuan Li, Xiaoyi Tang, Shuhong Chen, Ivan Marsic, Randall S. Burd 17
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1
assume that duplicate activities in a process trace are
equivalent. We solved this problem using Hidden Markov
Models (HMM) to represent the workflow. To induce an
HMM, we proposed a novel inference algorithm guided by
trace alignment (AGSS) [12]. AGSS (Figure 2 and Problem 1)
first initializes a general Markov chain 𝜆0. After initialization,
AGSS determines two factors: which states to split and when to
stop splitting. AGSS determines the splitting candidates from
the alignment matrix and orders them by column frequency.
After calculating the splitting candidates, AGSS performs
iterative splitting.
We tested AGSS on trauma resuscitation workflow data and
compared it to existing state-splitting HMM inference algo-
rithms (e.g., ML-SSS, STACT) [12]. The performance was
measured based on (1) model’s quality and (2) the algorithm’s
computational efficiency. The model quality is measured by
model fidelity and model confidence. Model fidelity (or accu-
racy) measures the agreement between a given workflow model
and the observed process traces (i.e., the log likelihood of
generating the observed traces using the given model). Model
confidence measures how well a workflow model represents
the underlying process that generates the observed process
traces. High model confidence means the model describes not
only the observed traces, but also the unobserved realizations of
the underlying process. Our results show that AGSS is not only
more computationally efficient (by a factor of 𝒪(𝑛), where 𝑛
is the number of hidden states), but also produces HMMs of
higher model fidelity (𝑀𝑓) and model confidence (𝑀𝑐) (TABLE
I). Our results also show the workflow model discovered by
AGSS is more readable and more representative than models
discovered by existing HMM inference and process mining
algorithms [12].
B. Process Model Enhancement of Resuscitation Workflow
As required for process deviation analysis, an initial expert
model was developed by medical experts. The initial model
underwent several revisions until the domain experts reached a
consensus about which medical activities to include and in
which order. We used two different approaches to enhance the
expert model. First, we compared expert model to the
data-driven model discovered using our AGSS algorithm. The
model induced by AGSS helped discover three discrepancies
between the initial expert model and actual practice. These
discrepancies were analyzed for repairing the expert model
[12]. Afterwards, we performed a more detailed and
comprehensive model diagnosis using conformance checking
[15] with twenty-four trauma resuscitation cases (Problem 2).
We discovered more discrepancies between the model and
practice, and came to the conclusion that our initial model could
not fully represent the resuscitation process. In our preliminary
analysis, we identified 57.3% (630 out of 1099) activities as
deviations based on the initial expert model, of which only
24.6% (155 out of 630) were true deviations (i.e., process
errors), while the remaining 75.4% deviations were false
alarms due to process model incompleteness, coding errors, or
inadequate algorithms. We then applied different strategies to
address the false alarms, e.g., repairing the expert model,
improving the coding procedure, and updating the algorithm.
We tested the repaired model on ten unseen resuscitations,
achieving 93.1% deviation discovery accuracy.
Problem 1: AGSS Medical Process Model Discovery:
Given: A set of resuscitation traces 𝑻 = [𝑻(1), … , 𝑻( )]. Objective: Successively splitting state 𝑠𝑗 ∈ 𝑺 to find an
HMM topology 𝜆𝒔 that maximizes probability 𝑃(𝑻|𝜆):
𝜆𝒔(𝑻) = argmax𝜆
𝑃(𝑻|𝜆) = argmax𝜆
∏ 𝑃(𝑻(𝑖)|𝜆)
𝑖
(1)
where 𝑃(𝑻(𝑖)|𝜆) is observation sequence probability, solved
with the Forward algorithm [13]. 𝑺, the set of states to be split,
is calculated using the trace alignment algorithm [14].
Problem 2: Process Enhancement:
Given: Historic resuscitation traces 𝑻 = [𝑻(1), … , 𝑻( )] and a hand-made expert model 𝜆𝑒.
Objective #1: Discover process deviations 𝜺 from 𝑻:
𝜺 = 𝒞(𝑻, 𝜆𝑒) (2)
where 𝒞(𝑻, 𝜆𝑒) is the conformance checking algorithm
[15], taking process traces and expert model as input and
outputting the process deviations.
Objective #2: Classify 𝜺 as true alarms (i.e., process
errors) and acceptable variations (i.e., false alarms 𝜺′). Repair the expert model 𝜆𝑒 to eliminate 𝜺′.
Figure 2. Our Alignment-guided State-splitting algorithm for discovering a more representative data-driven workflow model [12]. (a) Trace alignment
algorithm to find splitting candidates. (b)(c)(d) State-splitting HMM inference.
B C EDA
B EAB EDA B
B EDCB E
D
A
A B D E
AD D
B
BB
B
A
AA
AA
A
1 1 0.2 0.4 1 10.2 0.6 1
0.11
A
B
10.5
S1
S2
S0
C D E
0.5
0.4
0.330.22
0.17
0.83
0.6
0.33
1S3 S4 S5 S6
0.11
B
11
S1
S2
S0
C D E
0.33
0.40.22
0.17
0.83
0.6
0.33
1S3 S4 S5 S6
A1 A2S7
1
0.17
11
S1
S2
S0
C D E0.33
0.17
0.83
0.5
1S3 S4 S5 S6
A1 A2S7
1B2
B1
10.6
0.4
S8
(a)
(b)
(c)
(d)
Filtered ConsensusSequence ( ’) Here =
Column Frequency
Trace Alignment
A B B C D ED B A Consensus Sequence ( )
Split S1
Split S2
State-Splitting
Splitting Candidates (𝑺 )

18 Feature Article: Process Mining for Trauma Resuscitation
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin
C. Process Deviation Analysis of Resuscitation Workflow
The main goal of process deviation analysis is to test our
hypotheses, proving the adverse effects of accumulated devia-
tions on trauma patient outcomes and team’s ability to
compensate for major errors. The goal can be achieved in two
steps. First, identify the process deviations (manually or based
on conformance checking). Second, contact statistical analysis
to test the association between the process deviations and
patient outcomes (or patient attributes).
Our previous deviation analyses were performed both
manually by medical experts and automatically based on the
conformance checking algorithms. For manual deviation
analysis, we analyzed thirty-nine resuscitations and discovered
the number of errors and the number of high-risk errors per
resuscitation increased with the number of non-error process
deviations per resuscitation (correlation-coefficient = 0.42, p =
0.01 and correlation-coefficient = 0.62, p < 0.001,
respectively) [18]. For automated deviation analysis, we
performed conformance checking on the enhanced process
model using ninety-five trauma resuscitations. We detected
1,059 process deviations in 5,659 activities of 42 commonly
performed assessment activity types (11.1 deviations per case).
Our results also show that the resuscitations of patients with no
pre-arrival notification (p = 0.037) and blunt injury (blunt vs.
non-blunt p = 0.013) were significantly correlated with more
deviations.
D. Process Recommendation of Resuscitation Workflow
To help reduce medical team errors, we developed a process
recommender system [16][17] (Figure 3 and Problem 3) that
provides data-driven step-by-step treatment recommendations.
Our system was built based on the associations between similar
historic process performances and contextual information (e.g.,
patient demographics). We introduced a novel similarity metric
(named TwS-TP [16]) that incorporates temporal information
about activity performance, and handles concurrent activities.
Our recommender system selects the appropriate prototype
performance of the process based on user-provided context
attributes. Our approach for determining the prototypes
discovers the commonly performed activities and their
temporal relationships.
We implemented our recommender system with several
different similarity metrics: edit distance (ED), sequential
pattern based (SP) and TwS-TP, and different clustering algo-
rithms: hierarchical clustering (HC), density peak clustering
(DPC) and affinity propagation clustering (APC). We clustered
the process traces using different combinations of similarity
Problem 3: Process Recommendation:
Given: A new patient with context attributes 𝒙′. Objective: Recommend a treatment plan 𝑻𝒙′ = [𝑎1, … , 𝑎𝑘]
𝑇
to the medical team that maximizes:
𝑻𝒙′ = argmax𝑻
𝑆(𝑻, 𝑻𝑔) (3)
where 𝑻𝑔 is the ground-truth treatment procedure and
𝑆(𝑻𝑥 , 𝑻𝑦) is the similarity measure of two process traces [16].
Figure 3. Medical process recommender framework [16]. Treatment procedures were clustered based on similarity (horizontal axis of the matrices represents time and vertical axis represents activity type). A logistic regression model is trained between context attributes and cluster membership. Treatment prototypes were
calculated from each cluster. When a new patient comes to the trauma bay (bottom box), trained regression model takes context attributes as input and outputs the
cluster membership (e.g., C1). A treatment prototype is recommended based on the cluster membership (e.g., Prototype of C1).
00.20.40.60.8
1
Agecategory
Male
Night Shift
Weekend
Pre-arrivalNotification
TransferIntubation
GlasgowComa Score
>13
InjuryType_Blunt
InjuryType_Penet
rating
InjurySeverity
Score
Prototype of C1 Prototype of C2 Overlapped Act.
Cluster 1
Cluster 2
Train
Logistic
Regression
00.20.40.60.8
1
Agecategory
Male
Night Shift
Weekend
Pre-arrivalNotification
TransferIntubation
GlasgowComa Score
>13
InjuryType_Blunt
InjuryType_Penet
rating
InjurySeverity
Score
00.20.40.60.8
1
Agecategory
Male
Night Shift
Weekend
Pre-arrivalNotification
TransferIntubation
GlasgowComa Score
>13
InjuryType_Blunt
InjuryType_Penet
rating
InjurySeverity
Score
00.20.40.60.8
1Age…
Male
Night Shift
Weekend
Pre-arrival…
TransferIntubation
Glasgow…
Injury…
Injury…
Injury…
Old Patients & Context Attributes Treatment Procedure Clustering
Treatment Prototypes for Two Clusters
Trained Regression
Model
New Patient
Predicted Cluster
Membership: C1
Recommended
Treatment Procedure:
Prototype of C1
00.20.40.60.8
1
Agecategory
Male
Night Shift
Weekend
Pre-arrivalNotification
TransferIntubation
GlasgowComa Score
>13
InjuryType_Blunt
InjuryType_Penet
rating
InjurySeverity
Score
x y
Prototype
Extraction
00.20.40.60.8
1
Agecategory
Male
Night Shift
Weekend
Pre-arrivalNotification
TransferIntubation
GlasgowComa Score
>13
InjuryType_Blunt
InjuryType_Penet
rating
InjurySeverity
Score
Treatment Prototypes
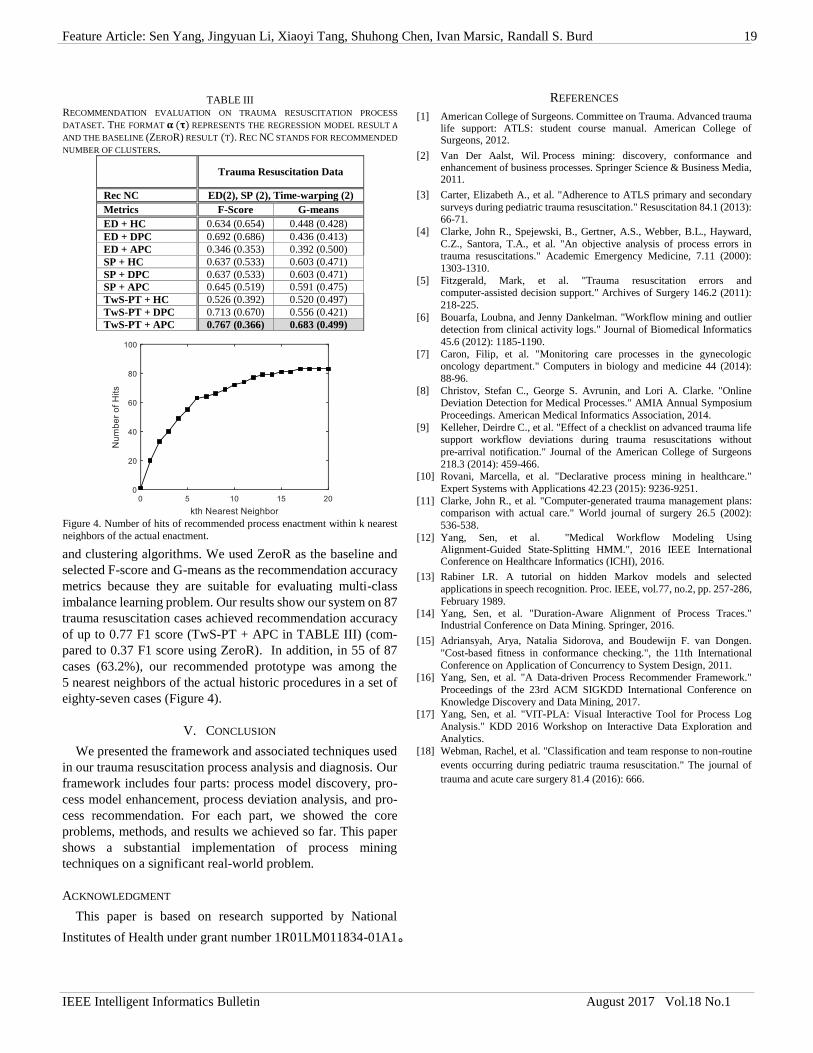
Feature Article: Sen Yang, Jingyuan Li, Xiaoyi Tang, Shuhong Chen, Ivan Marsic, Randall S. Burd 19
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1
and clustering algorithms. We used ZeroR as the baseline and
selected F-score and G-means as the recommendation accuracy
metrics because they are suitable for evaluating multi-class
imbalance learning problem. Our results show our system on 87
trauma resuscitation cases achieved recommendation accuracy
of up to 0.77 F1 score (TwS-PT + APC in TABLE III) (com-
pared to 0.37 F1 score using ZeroR). In addition, in 55 of 87
cases (63.2%), our recommended prototype was among the
5 nearest neighbors of the actual historic procedures in a set of
eighty-seven cases (Figure 4).
V. CONCLUSION
We presented the framework and associated techniques used
in our trauma resuscitation process analysis and diagnosis. Our
framework includes four parts: process model discovery, pro-
cess model enhancement, process deviation analysis, and pro-
cess recommendation. For each part, we showed the core
problems, methods, and results we achieved so far. This paper
shows a substantial implementation of process mining
techniques on a significant real-world problem.
ACKNOWLEDGMENT
This paper is based on research supported by National
Institutes of Health under grant number 1R01LM011834-01A1。
REFERENCES
[1] American College of Surgeons. Committee on Trauma. Advanced trauma life support: ATLS: student course manual. American College of Surgeons, 2012.
[2] Van Der Aalst, Wil. Process mining: discovery, conformance and enhancement of business processes. Springer Science & Business Media, 2011.
[3] Carter, Elizabeth A., et al. "Adherence to ATLS primary and secondary
surveys during pediatric trauma resuscitation." Resuscitation 84.1 (2013): 66-71.
[4] Clarke, John R., Spejewski, B., Gertner, A.S., Webber, B.L., Hayward,
C.Z., Santora, T.A., et al. "An objective analysis of process errors in trauma resuscitations." Academic Emergency Medicine, 7.11 (2000):
1303-1310.
[5] Fitzgerald, Mark, et al. "Trauma resuscitation errors and computer-assisted decision support." Archives of Surgery 146.2 (2011):
218-225.
[6] Bouarfa, Loubna, and Jenny Dankelman. "Workflow mining and outlier detection from clinical activity logs." Journal of Biomedical Informatics
45.6 (2012): 1185-1190.
[7] Caron, Filip, et al. "Monitoring care processes in the gynecologic oncology department." Computers in biology and medicine 44 (2014):
88-96.
[8] Christov, Stefan C., George S. Avrunin, and Lori A. Clarke. "Online Deviation Detection for Medical Processes." AMIA Annual Symposium
Proceedings. American Medical Informatics Association, 2014.
[9] Kelleher, Deirdre C., et al. "Effect of a checklist on advanced trauma life support workflow deviations during trauma resuscitations without
pre-arrival notification." Journal of the American College of Surgeons
218.3 (2014): 459-466. [10] Rovani, Marcella, et al. "Declarative process mining in healthcare."
Expert Systems with Applications 42.23 (2015): 9236-9251.
[11] Clarke, John R., et al. "Computer-generated trauma management plans: comparison with actual care." World journal of surgery 26.5 (2002):
536-538.
[12] Yang, Sen, et al. "Medical Workflow Modeling Using Alignment-Guided State-Splitting HMM.", 2016 IEEE International Conference on Healthcare Informatics (ICHI), 2016.
[13] Rabiner LR. A tutorial on hidden Markov models and selected
applications in speech recognition. Proc. IEEE, vol.77, no.2, pp. 257-286,
February 1989. [14] Yang, Sen, et al. "Duration-Aware Alignment of Process Traces."
Industrial Conference on Data Mining. Springer, 2016.
[15] Adriansyah, Arya, Natalia Sidorova, and Boudewijn F. van Dongen.
"Cost-based fitness in conformance checking.", the 11th International
Conference on Application of Concurrency to System Design, 2011. [16] Yang, Sen, et al. "A Data-driven Process Recommender Framework."
Proceedings of the 23rd ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining, 2017. [17] Yang, Sen, et al. "VIT-PLA: Visual Interactive Tool for Process Log
Analysis." KDD 2016 Workshop on Interactive Data Exploration and
Analytics.
[18] Webman, Rachel, et al. "Classification and team response to non-routine
events occurring during pediatric trauma resuscitation." The journal of
trauma and acute care surgery 81.4 (2016): 666.
TABLE III
RECOMMENDATION EVALUATION ON TRAUMA RESUSCITATION PROCESS
DATASET. THE FORMAT 𝛂 (𝛕) REPRESENTS THE REGRESSION MODEL RESULT Α
AND THE BASELINE (ZEROR) RESULT (Τ). REC NC STANDS FOR RECOMMENDED
NUMBER OF CLUSTERS.
Trauma Resuscitation Data
Rec NC ED(2), SP (2), Time-warping (2)
Metrics F-Score G-means
ED + HC 0.634 (0.654) 0.448 (0.428)
ED + DPC 0.692 (0.686) 0.436 (0.413)
ED + APC 0.346 (0.353) 0.392 (0.500)
SP + HC 0.637 (0.533) 0.603 (0.471)
SP + DPC 0.637 (0.533) 0.603 (0.471)
SP + APC 0.645 (0.519) 0.591 (0.475)
TwS-PT + HC 0.526 (0.392) 0.520 (0.497)
TwS-PT + DPC 0.713 (0.670) 0.556 (0.421)
TwS-PT + APC 0.767 (0.366) 0.683 (0.499)
Figure 4. Number of hits of recommended process enactment within k nearest
neighbors of the actual enactment.

20 Editor: Xin Li
Selected Ph.D. Thesis Abstracts
This Ph.D. thesis abstracts section presents abstracts of 24theses defended during the period of January 2016 to July2017. These abstracts were selected out of 43 submissionscovering numerous research and applications under intelligentinformatics such as robotics, cyber-physical systems, socialintelligence, intelligent agent technology, recommender sys-tems, complex rough sets, multi-view learning, text mining,general-purpose learning systems, bayesian modeling, knowl-edge graphs, genetic programming and dynamic adversarialmining. These thesis abstracts are organized by the alphabeti-cal order of the author’s family name. Fig. 1 presents a wordcloud of the submitted abstracts.
Fig. 1. Word Cloud of the Ph.D Abstracts
INFERRING DIFFUSION MODELS WITH STRUCTURALAND BEHAVIORAL DEPENDENCY IN SOCIAL NETWORKS
Qing [email protected]
Hong Kong Baptist University, Hong Kong
ONLINE social and information networks, like Facebookand Twitter, exploit the in- fluence of neighbors to
achieve effective information sharing and spreading. The pro-cess that information is spread via the connected nodes in so-cial and information networks is referred to as diffusion. In theliterature, a number of diffusion models have been proposedfor different applications like influential user identification andpersonalized recommendation. However, comprehensive stud-ies to discover the hidden diffusion mechanisms governing theinformation diffusion using the datadriven paradigm are stilllacking. This thesis research aims to design novel diffusionmodels with the structural and behaviorable dependency ofneighboring nodes for representing social networks, and todevelop computational algorithms to infer the diffusion modelsas well as the underlying diffusion mechanisms based oninformation cascades observed in real social networks.
By incorporating structural dependency and diversity ofnode neighborhood into a widely used diffusion modelcalled Independent Cascade (IC) Model, we first proposea component-based diffusion model where the influence ofparent nodes is exerted via connected components. Instead ofestimating the node-based diffusion probabilities as in the ICModel, component-based diffusion probabilities are estimatedusing an expectation maximization (EM) algorithm derivedunder a Bayesian framework. Also, a newly derived structuraldiversity measure namely dynamic effective size is proposedfor quantifying the dynamic information redundancy withineach parent component.
The component-based diffusion model suggests that nodeconnectivity is a good proxy to quantify how a nodes activationbehavior is affected by its node neighborhood. To modeldirectly the behavioral dependency of node neighborhood, wethen propose a co-activation pattern based diffusion modelby integrating the latent class model into the IC Modelwhere the co-activation patterns of parent nodes form thelatent classes for each node. Both the co-activation patternsand the corresponding pattern-based diffusion probabilities areinferred using a two-level EM algorithm. As compared to thecomponent-based diffusion model, the inferred co-activationpatterns can be interpreted as the soft parent components,providing insights on how each node is influenced by itsneighbors as reflected by the observed cascade data.
With the motivation to discover a common set of the over-represented temporal activation patterns (motifs) character-izing the overall diffusion in a social network, we furtherpropose a motif-based diffusion model. By considering thetemporal ordering of the parent activations and the social rolesestimated for each node, each temporal activation motif isrepresented using a Markov chain with the social roles beingits states. Again, a two-level EM algorithm is proposed toinfer both the temporal activation motifs and the correspondingdiffusion network simultaneously. The inferred activation mo-tifs can be interpreted as the underlying diffusion mechanismscharacterizing the diffusion happening in the social network.
Extensive experiments have been carried out to evaluate theperformance of all the proposed diffusion models using bothsynthetic and real data. The results obtained and presentedin the thesis demonstrate the effectiveness of the proposedmodels. In addition, we discuss in detail how to interpret theinferred co-activation patterns and interaction motifs as thediffusion mechanisms under the context of different real socialnetwork data sets (http://repository.hkbu.edu.hk/etd oa/305/).
BAYESIAN MODELING FOR OPTIMIZATION ANDCONTROL IN ROBOTICS
Roberto [email protected]
UC Berkeley, USA.
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Selected PhD Thesis Abstracts 21
ROBOTICS has the potential to be one of the mostrevolutionary technologies in human history. The impact
of cheap and potentially limitless manpower could have aprofound influence on our everyday life and overall onto oursociety. As envisioned by Iain M. Banks, Asimov and manyother science fictions writers, the effects of robotics on oursociety might lead to the disappearance of physical labor anda generalized increase of the quality of life. However, thelarge-scale deployment of robots in our society is still farfrom reality, except perhaps in a few niche markets suchas manufacturing. One reason for this limited deploymentof robots is that, despite the tremendous advances in thecapabilities of the robotic hardware, a similar advance on thecontrol software is still lacking. The use of robots in oureveryday life is still hindered by the necessary complexityto manually design and tune the controllers used to executetasks. As a result, the deployment of robots often requireslengthy and extensive validations based on human expertknowledge, which limit their adaptation capabilities and theirwidespread diffusion. In the future, in order to truly achieve anubiquitous robotization of our society, it is necessary to reducethe complexity of deploying new robots in new environmentsand tasks.
The goal of this dissertation is to provide automatic toolsbased on Machine Learning techniques to simplify and stream-line the design of controllers for new tasks. In particular, wehere argue that Bayesian modeling is an important tool forautomatically learning models from raw data and properlycapture the uncertainty of the such models. Automaticallylearning models however requires the definition of appropriatefeatures used as input for the model. Hence, we presentan approach that extend traditional Gaussian process modelsby jointly learning an appropriate feature representation andthe subsequent model. By doing so, we can strongly guidethe features representation to be useful for the subsequentprediction task.
A first robotics application where the use of Bayesianmodeling is beneficial is the accurate learning of complexdynamics models. For highly non-linear robotic systems, suchas in presence of contacts, the use of analytical system iden-tification techniques can be challenging and time-consuming,or even intractable. We introduce a new approach for learninginverse dynamics models exploiting artificial tactile sensors.This approach allows to recognize and compensate for thepresence of unknown contacts, without requiring a spatialcalibration of the tactile sensors. We demonstrate on thehumanoid robot iCub that our approach outperforms state-of-the-art analytical models, and when employed in control taskssignificantly improves the tracking accuracy.
A second robotics application of Bayesian modeling isautomatic black-box optimization of the parameters of acontroller. When the dynamics of a system cannot be modeled(either out of complexity or due to the lack of a full staterepresentation), it is still possible to solve a task by adaptingan existing controller. The approach used in this thesis isBayesian optimization, which allows to automatically optimizethe parameters of the controller for a specific task. We evaluateand compare the performance of Bayesian optimization on a
gait optimization task on the dynamic bipedal walker Fox. Ourexperiments highlight the benefit of this approach by reducingthe parameters tuning time from weeks to a single day.
In many robotic application, it is however not possible toalways define a single straightforward desired objective. Moreoften, multiple conflicting objectives are desirable at the sametime, and thus the designer needs to take a decision about thedesired trade-off between such objectives (e.g., velocity vs.energy consumption). One framework that is useful to assistin this decision making is the multi-objective optimizationframework, and in particular the definition of Pareto optimal-ity. We propose a novel framework that leverages the use ofBayesian modeling to improve the quality of traditional multi-objective optimization approaches, even in low-data regimes.By removing the misleading effects of stochastic noise, thedesigner is presented with an accurate and continuous Paretofront from which to choose the desired trade-off. Additionally,our framework allows the seamless introduction of multiplerobustness metrics which can be considered during the designphase. These contributions allow an unprecedented support tothe design process of complex robotic systems in presence ofmultiple objective, and in particular with regards to robustness.
The overall work in this thesis successfully demonstrateson real robots that the complexity of deploying robots tosolve new tasks can be greatly reduced trough automaticlearning techniques. We believe this is a first step towardsa future where robots can be used outside of closely su-pervised environments, and where a newly deployed robotcould quickly and automatically adapt to accomplish the de-sired tasks (http://tuprints.ulb.tu-darmstadt.de/5878/13/thesisroberto calandra.pdf).
APPLICATION OF AGENT TECHNOLOGY FOR FAULTDIAGNOSIS OF TELECOMMUNICATION NETWORKS
Alvaro [email protected]
Universidad Politecnica de Madrid, Spain
THIS PhD thesis contributes to the problem of auto-nomic fault diagnosis of telecommunication networks.
Nowadays, in telecommunication networks, operators performmanual diagnosis tasks. Those operations must be carriedout by high skilled network engineers which have increasingdifficulties to properly manage the growing of those networks,both in size, complexity and heterogeneity. Moreover, theadvent of the Future Internet makes the demand of solutionswhich simplifies and automates the telecommunication net-work management has been increased in recent years. To col-lect the domain knowledge required to developed the proposedsolutions and to simplify its adoption by the operators, an agiletesting methodology is defined for multi-agent systems. Thismethodology is focused on the communication gap betweenthe different work groups involved in any software devel-opment project, stakeholders and developers. To contributeto overcoming the problem of autonomic fault diagnosis, anagent architecture for fault diagnosis of telecommunicationnetworks is defined. That architecture extends the Belief-Desire-Intention (BDI) agent model with different diagnostic
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1

22 Editor: Xin Li
models which handle the different subtasks of the process.The proposed architecture combines different reasoning tech-niques to achieve its objective using a structural model of thenetwork, which uses ontology-based reasoning, and a causalmodel, which uses Bayesian reasoning to properly handle theuncertainty of the diagnosis process. To ensure the suitabilityof the proposed architecture in complex and heterogeneousenvironments, an argumentation framework is defined. Thisframework allows agents to perform fault diagnosis in fed-erated domains. To apply this framework in a multi-agentsystem, a coordination protocol is defined. This protocol isused by agents to dialogue until a reliable conclusion fora specific diagnosis case is reached. Future work comprisesthe further extension of the agent architecture to approachother managements problems, such as self-discovery or self-optimisation; the application of reputation techniques in theargumentation framework to improve the extensibility of thediagnostic system in federated domains; and the applicationof the proposed agent architecture in emergent networkingarchitectures, such as SDN, which offers new capabilities ofcontrol for the network (http://oa.upm.es/39170/).
MULTI-AGENT SYSTEM FOR COORDINATION OFDISTRIBUTED ENERGY RESOURCES IN VIRTUAL POWER
PLANTS
Anders [email protected]
Centre for Smart Energy Solution, University of SouthernDenmark, Denmark
THE electricity grid is facing challenges as a result of anincrease in the share of renewable energy in electricity
production. In this context, Demand Response (DR) is consid-ered an inexpensive and CO2-friendly approach to handle theresulting fluctuations in the electricity production. The conceptof DR refers to changes in consumption patterns of DistributedEnergy Resources (DER), in response to incentive paymentsor changes in the price of electricity over time. ExistingDR programs have capacity requirements, which individualDER entities are often unable to meet. As a consequence,the concept of a Virtual Power Plant (VPP) has emerged. AVPP aggregates multiple DER, and exposes them as a single,controllable entity.
The contribution of this thesis is a general method forintegrating DER in VPPs. The approach constitutes a meta-model for VPPs, which describes DER and VPPs as entities.Each entity is constituted by a group of software agents.The meta-model describes the interaction between groups andcontains two negotiation models: the intradomain- and theinterdomain negotiation models. The intradomain negotiationmodel describes agent decision logic and communicationbetween agents in a group. The model contains a mediator-based negotiation protocol, where agents negotiate over a setof issues, allowing each entity to pursue several objectives anddecide upon several issues.
The interdomain negotiation model describes negotiationbetween groups of agents. In practice this means that theinterdomain negotiation model ties instances of intradomain
negotiation together. A key aspect of the interdomain negoti-ation model is that it ensures group autonomy.
Both negotiation models have been implemented in Con-troleum, a framework for multi-objective optimization. In thiscontext, Controleum has been refactored to allow for theabstractions of the negotiation models to be implemented inthe framework. Furthermore, a Domain Specific Language(DSL) has been developed and implemented to allow for easyconfiguration of negotiations.
Experiments with simulations of different VPP scenarioshave been conducted. These experiments indicate that theproposed approach is capable of integrating complex andheterogeneous DER in VPPs, while preserving the autonomousnature of the DER. Experiments are also conducted on in-stances of the 0/1 Knapsack problem. These experiments serveto illustrate the general applicability of the proposed solu-tion.Future experiments will test the solution in real scenarios(http://aclausen.dk/documents/thesis.pdf).
EFFICIENT KNOWLEDGE MANAGEMENT FORNAMED ENTITIES FROM TEXT
Sourav [email protected]
Saarland University, Germany
THE evolution of search from keywords to entities hasnecessitated the efficient harvesting and management of
entity-centric information for constructing knowledge basescatering to various applications such as semantic search, ques-tion answering, and information retrieval. The vast amounts ofnatural language texts available across diverse domains on theWeb provide rich sources for discovering facts about namedentities such as people, places, and organizations.
A key challenge, in this regard, entails the need for preciseidentification and disambiguation of entities across documentsfor extraction of attributes/relations and their proper represen-tation in knowledge bases. Additionally, the applicability ofsuch repositories not only involves the quality and accuracyof the stored information, but also storage management andquery processing efficiency. This dissertation aims to tackle theabove problems by presenting efficient approaches for entity-centric knowledge acquisition from texts and its representationin knowledge repositories.
This dissertation presents a robust approach for identifyingtext phrases pertaining to the same named entity across hugecorpora, and their disambiguation to canonical entities presentin a knowledge base, by using enriched semantic contexts andlink validation encapsulated in a hierarchical clustering frame-work. This work further presents language and consistencyfeatures for classification models to compute the credibilityof obtained textual facts, ensuring quality of the extractedinformation. Finally, an encoding algorithm, using frequentterm detection and improved data locality, to represent entitiesfor enhanced knowledge base storage and query performanceis presented (http://scidok.sulb.uni-saarland.de/volltexte/2017/6792/).
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Selected PhD Thesis Abstracts 23
BAYESIAN MODELS OF CATEGORY ACQUISITION ANDMEANING DEVELOPMENT
University of Edinburgh, UK.
THE ability to organize concepts (e.g., dog, chair) into effi-cient mental representations, i.e., categories (e.g., animal,
furniture) is a fundamental mechanism which allows humansto perceive, organize, and adapt to their world. Much researchhas been dedicated to the questions of how categories emergeand how they are represented. Experimental evidence suggeststhat (i) concepts and categories are represented through setsof features (e.g., dogs bark, chairs are made of wood) whichare structured into different types (e.g, behavior, material); (ii)categories and their featural representations are learnt jointlyand incrementally; and (iii) categories are dynamic and theirrepresentations adapt to changing environments.
This thesis investigates the mechanisms underlying theincremental and dynamic formation of categories and their fea-tural representations through cognitively motivated Bayesiancomputational models. Models of category acquisition havebeen extensively studied in cognitive science and primarilytested on perceptual abstractions or artificial stimuli. In thisthesis, we focus on categories acquired from natural languagestimuli, using nouns as a stand-in for their reference concepts,and their linguistic contexts as a representation of the conceptsfeatures. The use of text corpora allows us to (i) develop large-scale unsupervised models thus simulating human learning,and (ii) model child category acquisition, leveraging the lin-guistic input available to children in the form of transcribedchild-directed language.
In the first part of this thesis we investigate the incrementalprocess of category acquisition. We present a Bayesian modeland an incremental learning algorithm which sequentiallyintegrates newly observed data. We evaluate our model outputagainst gold standard categories (elicited experimentally fromhuman participants), and show that high-quality categories arelearnt both from child-directed data and from large, thematical-ly unrestricted text corpora. We find that the model performswell even under constrained memory resources, resemblinghuman cognitive limitations. While lists of representative fea-tures for categories emerge from this model, they are neitherstructured nor jointly optimized with the categories.
We address these shortcomings in the second part of thethesis, and present a Bayesian model which jointly learnscategories and structured featural representations. We presentboth batch and incremental learning algorithms, and demon-strate the models effectiveness on both encyclopedic andchild-directed data. We show that high-quality categories andfeatures emerge in the joint learning process, and that thestructured features are intuitively interpretable through humanplausibility judgment evaluation.
In the third part of the thesis we turn to the dynamicnature of meaning: categories and their featural representationschange over time, e.g., children distinguish some types offeatures (such as size and shade) less clearly than adults, andword meanings adapt to our ever changing environment and its
structure. We present a dynamic Bayesian model of meaningchange, which infers time-specific concept representations asa set of feature types and their prevalence, and captures theirdevelopment as a smooth process. We analyze the develop-ment of concept representations in their complexity over timefrom child-directed data, and show that our model capturesestablished patterns of child concept learning. We also applyour model to diachronic change of word meaning, modelinghow word senses change internally and in prevalence overcenturies.
The contributions of this thesis are threefold. Firstly, weshow that a variety of experimental results on the acquisitionand representation of categories can be captured with compu-tational models within the framework of Bayesian modeling.Secondly, we show that natural language text is an appropri-ate source of information for modeling categorization-relatedphenomena suggesting that the environmental structure thatdrives category formation is encoded in this data. Thirdly,we show that the experimental findings hold on a largerscale. Our models are trained and tested on a larger setof concepts and categories than is common in behavioralexperiments and the categories and featural representationsthey can learn from linguistic text are in principle unrestricted(http://frermann.de/dataFiles/phd thesis leafrermann.pdf).
LATENT FACTOR MODELS FORCOLLABORATIVE FILTERING
Anupriya [email protected]
Indraprastha Institute of Information Technology - Delhi,India
THE enormous growth in online availability of informa-tion content has made Recommender Systems (RS) an
integral part of most online portals and e-commerce sites.Most websites and service portals, be it movie rental services,online shopping or travel package providers, offer some formof recommendations to users. These recommendations providethe users more clarity, that too expeditiously and accuratelyin limiting (shortlisting) the items/information they need tosearch through, thereby improving the customer’s experience.The direct link between customer’s satisfaction and revenue ofe-commerce sites induce widespread interest of both, academiaand industry, in the design of efficient recommender systems.
The current de-facto approach for RS design is Collabora-tive Filtering (CF). CF techniques use the ratings provided byusers, to a subset of the items in the repository, to make futurerecommendations. However, the rating information is hard toacquire; often a user has rated less than 5% of the items.Thus, the biggest challenge in recommender system design isto infer users preference from this extremely limited predilec-tion information. The lack of adequate (explicit) preferenceinformation has motivated several works to augment the ratingdata with auxiliary information such as users demographics,trust networks, and item tags. Further, the scale of the problem,i.e. the amount of the data to be processed (selecting fewitems out of hundreds and thousands of items for an equallylarge number of users) adds another dimension to the concerns
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1

24 Editor: Xin Li
surrounding the design of a good RS. There have been severaldevelopments in the field of RS design over the past decades.However, the difficulty in achieving the desired accuracy andeffectiveness in recommendations leaves considerable scopefor improvement.
In this work, we model effective recommendation strategies,using optimization centric frameworks, by exploiting reliableand readily available information, to address several pertinentissues concerning RS design. Our proposed recommendationstrategies are built on the principals of latent factor models(LFM). LFM are constructed on the belief that a users choicefor an item is governed by a handful of factors C the latentfactors. For example, in the case of movies, these factors maybe genre, director, language while for hotels it can be priceand location.
Our first contribution targets improvement in predictionaccuracy as well the speed of processing by suggesting mod-ifications to the standard LFM frameworks. We develop amore intuitive model, supported by effective algorithm design,which better captures the underlying structure of the ratingdatabase while ensuring a reduction in run time compared tostandard CF techniques. In the next step, we build upon theseproposed frameworks to address the problem of lack of collab-orative data, especially for cold start (new) users and items, bymaking use of readily available user and item metadata - itemcategory and user demographics. Our suggested frameworksmake use of available metadata to add additional constraintsin the standard models; thereby presenting a comprehensivestrategy to improve prediction accuracy in both warm (existingusers/items for which rating data is available) and cold startscenario.
Although, high recommendation accuracy is the hallmarkof a good RS, over-emphasis on accuracy compromises onvariety and leads to monotony. Our next set of models aimsto address this concern and promote diversity and noveltyin recommendations. Most existing works, targeting diversity,build ad-hoc exploratory models relying heavily on heuristicformulations. In the proposed work, we modify the latentfactor model to formulate a joint optimization strategy toestablish accuracy-diversity balance; our models yield superiorresults than existing works.
The last contribution of this work is to explore the use ofanother representation learning tool for collaborative filteringC Autoencoder (AE). Conventional AE based designs, useonly the rating information; lack of adequate data hampersthe performance of these structures, thus, they do not performas well as conventional LFM based designs. In this work,we propose a modification of the standard autoencoder C theSupervised Autoencoder C which can jointly accommodateinformation from multiple sources resulting in better perfor-mance than existing architectures (https://repository.iiitd.edu.in/xmlui/handle/123456789/501).
MACHINE LEARNING THROUGH EXPLORATION FORPERCEPTION-DRIVEN ROBOTICS
Herke van [email protected]
McGill University, Canada
THE ability of robots to perform tasks in human envi-ronments, such as our homes, has largely been limited
to rather simple tasks, such as lawn mowing and vacuumcleaning. One reason for this limitation is that every homehas a different layout with different objects and furniture.Thus, it is impossible for a human designer to anticipate allchallenges a robot might face, and equip the robot a prioriwith all necessary perceptual and manipulation skills.
Instead, robots could use machine learning techniques toadapt to new environments. Many current learning techniques,however, rely on human supervisors to provide data in theform of annotations, demonstrations, and parameter settings.As such, making a robot perform a task in a novel environmentcan still require a significant time investment. In this thesis,instead, multiple techniques are studied to let robots collecttheir own training data through autonomous exploration.
The first study concerns an unsupervised robot that learnsfrom sensory feedback obtained though interactive explorationof its environment. In a novel bottom-up, probabilistic ap-proach, the robot tries to segment the objects in its environ-ment through clustering with minimal prior knowledge. Thisclustering is based on cues elicited through the robots actions.Evaluations on a real robot system show that the proposedmethod handles noisy inputs better than previous methods.Furthermore, a proposed scheme for action selection criterionaccording to the expected information gain criterion is shownto increase the learning speed.
Often, however, the goal of a robot is not just to learn thestructure of the environment, but to learn how to perform atask encoded by a reward signal. In a second study, a novelrobot reinforcement learning algorithm is proposed that useslearned non-parametric models, value functions, and policiesthat can deal with high-dimensional sensory representations.To avoid that the robot converges prematurely to a sub-optimalsolution, the information loss of policy updates is limited. Theexperiments show that the proposed algorithm performs wellrelative to prior methods. Furthermore, the method is validatedon a real-robot setup with high-dimensional camera imageinputs.
One problem with typical exploration strategies is thatthe behavior is perturbed independently in each time step.The resulting incoherent exploration behavior can result ininefficient random walk behavior and wear and tear on therobot. Perturbing policy parameters for an entire episode yieldscoherent exploration, but tends to increase the number ofepisodes needed. In a third study, a strategy is introduced thatmakes a balanced trade-off between these two approaches. Theexperiments show that such trade-offs are beneficial acrossdifferent tasks and learning algorithms.
This thesis thus addresses how robots can learn au-tonomously by exploring the world. Throughout the thesis,new approaches and algorithms are introduced: a probabilisticinteractive segmentation approach, the non-parametric rela-tive entropy policy search algorithm, and a framework forgeneralized exploration. These approaches and algorithmscontribute towards the capability of robots to autonomously
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Selected PhD Thesis Abstracts 25
learn useful skills in human environments in a practical manner(http://tuprints.ulb.tu-darmstadt.de/5749/).
A SERVICE-ORIENTED FRAMEWORK FOR THESPECIFICATION, DEPLOYMENT, EXECUTION,
BENCHMARKING, AND PREDICTION OF PERFORMANCEOF SCALABLE PRIVACY-PRESERVING RECORD
LINKAGE TECHNIQUES
Dimitrios [email protected]
Hellenic Open University, Greece
AT the dawn of a new era of computing and the growth ofbig data, information integration is more important than
ever before. Large organizations, such as corporations, healthproviders, public sector agencies, or research institutes, inte-grate their data in order to generate insightful data analytics.This data integration and analysis enables these organizationsto make certain decisions toward deriving better businessoutcomes.
Record linkage, also known as entity resolution or datamatching, is the process of resolving whether two records thatbelong to disparate data sets, refer to the same real- worldentity. The lack of common identifiers, as well as typos andinconsistencies in the data, render the process of record linkagevery challenging and mandatory for organizations which needto integrate their records. When data is deemed as private, thenspecialized techniques are employed that perform Privacy-Preserving Record Linkage (PPRL) in a secure manner, byrespecting the privacy of the individuals who are representedby those records. For instance, in the public sector, thereare databases which contain records that refer to the samecitizen holding outdated information. Although, there is anurgent need of integration, the lack of common identifiersposes significant impediments in the linkage process.
Due to the large volumes of records contained in the datasets, core component of PPRL is the blocking phase, in whichrecords are inserted into overlapping blocks and, then, arecompared with one another. The purpose of the blockingphase is to formulate as many as possible matching recordpairs. The blocking methods proposed thus far in the literatureapply empirical techniques, which, given the particularities andtechnical characteristics of the data sets at hand, produce arbi-trary results. This dissertation is the first to provide theoreticalguarantees of completeness in the generated result set of thePPRL process, by introducing a randomized framework thatallows for easy tuning of its configuration. Its flexibility liesin the fact that one can specify the level of its performance,with respect to the completeness of the results, taking intoaccount multiple factors, such as: the urgency of the problembeing solved, the desired response time, or the criticalness ofthe results completeness. Additionally, we enhance its mainfunctionality, by providing certain extensions, and illustrate itsapplicability to both offline and online settings. The frameworkhas been materialized by a prototype that is freely availableso that it can be used by practitioners and researchers in theirtasks.
This dissertation is divided into several chapters; we firstintroduce the core of our framework and its capabilities,and, then, we present its several extensions, such as theintegration with the map/reduce paradigm for scaling up largevolumes of records, or the add-on for performing PPRL usingnumeric values. In each of these chapters, we report onan extensive evaluation of the application of the constituentmethods with real data sets, which illustrates that they out-perform existing approaches (https://drive.google.com/file/d/0B2tBkOmLy8WZc0Z4OU0zQ2dOMVE/view?usp=sharing).
LEARNING WITH MULTIPLE VIEWS OF DATA: SOMETHEORETICAL AND PRACTICAL CONTRIBUTIONS
Chao [email protected]
University of Kansas, USA.
IN machine learning applications, instances are oftendescribable by multiple feature sets, each somewhat
interpretable and sufficient for the learning task. In this case,each feature set is called a view, the instances are calledmulti-view data, and the study of learning with multi-viewdata is called multi-view learning. In this dissertation, weinvestigated several issues of multi-view learning in twosettings: one is called statistical setting, where one aims tolearn predictive models based on random multi-view sample;the other one is called matrix setting, where one aims torecover missing values in the feature matrices of multipleviews. In statistical setting, we first theoretically investigatedthe possibility of training an accurate predictive model usingas few unlabeled multi-view data as possible, and concludedsuch possibility by improving the state-of-the-art unlabeledsample complexity of semi-supervised multi-view learningby a logarithm factor. We then investigated the applicationof multi-view clustering methods in social circle detectionon ego social networks. We finally proposed a simplemulti-view multi-class learning algorithm that consistentlyoutperforms the state-of-the-art algorithm. In matrix setting,we focused on the negative transfer problem in CollectiveMatrix Factorization (CMF), which is a popular method torecover missing values in multi-view feature matrices. Wefirst theoretically characterized negative transfer in a CMFestimator, as the decrease of its ideal minimax learning rateby a root function. We then showed our presented ideal rateis tight (up to a constant factor), by employing the statisticalPAC theory to derive a matching upper bound for it; ouremployment of the PAC theory improved the state-of-the-artone, by relaxing its strong i.i.d. assumption of matrix recoveryerrors. We finally proposed a simple variant of CMF thatoutperforms a current variant in small sample case. Atthe conceptual level, we have been bridging gaps betweenresearch in statistical setting and matrix setting. Specifically,we employed statistical PAC theory to analyze matrixrecovery error in both active and passive learning settings;we employed statistical multi-view learning framework todevelop a variant of CMF for matrix recovery; we employedstatistical mini-max theory to analyze CMF performance.Finally, our research in multi-view learning has motivated two
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1

26 Editor: Xin Li
other studies. One study challenged a common assumption incheminformatics that unreported substance-compound bindingprofiles are all negative. The other study proposed a firstactive matrix recovery method with PAC guarantee.(https://www.dropbox.com/s/1zf3qksqoc8oqnr/dissertation.pdf?dl=0)
TRANSFORMATION-BASED COMMUNITYDETECTIONFROM SOCIAL NETWORKS
Sungsu [email protected]
Korea Advanced Institute of Science and Technology, Korea
IN recent decades social network analysis has becomeone of the most attractive issues in data mining. In par-
ticular, community detection is a fundamental problem insocial network analysis. Many theories, models, and methodshave been developed for this purpose. However, owing to awide variety of network structures, there remain challengesto determining community structures from social networks.Among them, we focus on solving four important problemsfor community detection with different underlying structures.These are identifying the community structure of a graph whenit consists of (i) overlapping community structure, (ii) highlymixed community structure, (iii) complex sub-structure, and(iv) highly mixed overlapping community structure.
We address these problems by developing transformationtechniques. Our key motivation is that the transformationof a given network can provide us an improved structureto identify the community structure of an original network,as a kernel trick does. We propose a transformation-basedalgorithm that converts an original graph to a transformedgraph that reflects the structure of the original network andhas a superior structure for each problem. We identify thecommunity structure using the transformed graph and thenthe membership on the transformed graph is translated backto that of the original graph.
For the first problem, we present a notion of the linkspacetransformation that enables us to combine the advantages ofboth the original graph and the line graph, thereby convenient-ly achieving overlapping communities. Based on this notion,we develop an overlapping community detection algorithmLinkSCAN∗ [1]. The experimental results demonstrate that theproposed algorithm outperforms existing algorithms, especial-ly for networks with many highly overlapping nodes.
For the second problem, we propose a community detectionalgorithm BlackHole [2]. The proposed graph embeddingmodel attempts to place the vertices of the same communityat a single position, similar to how a black hole attractseverything nearby. Then, these positions are easily grouped bya conventional clustering algorithm. The proposed algorithmis proven to achieve extremely high performance regardless ofthe difficulty of community detection in terms of the mixingand the clustering coefficient.
For the third problem, we propose a motif-based embed-ding method for graph clustering by modeling higher-orderrelationships among vertices in a graph [3]. The proposedmethod considers motif-based attractive forces to enhance the
clustering tendency of points in the output space of graphembedding. We prove the relationship with graph clusteringand verify the performance and applicability.
For the fourth problem, we develop an algorithm to addressthe highly mixed overlapping community detection problem.The transformation of the proposed algorithm LinkBlackHoleconsists of a sequence of two different transformations. By firstapplying the link-space transformation and then the BlackHoletransformation, we can detect highly mixed link communities.
The strength of this dissertation is based on a wide varietyof community detection problems from social networks. Webelieve that this work will enhance the quality of communitydiscovery for social network analysis (http://library.kaist.ac.kr/thesis02/2016/2016D020115245 S1.pdf).
INCREMENTAL AND DEVELOPMENTAL PERSPECTIVESFOR GENERAL-PURPOSE LEARNING SYSTEMS
Fernando Martł[email protected]
Universitat Politcnica de Valencia, Spain
THE stupefying success of Artificial Intelligence (AI)for specific problems, from recommender systems to
self-driving cars, has not yet been matched with a similarprogress in general AI systems, coping with a variety of(different) problems. This dissertation deals with the long-standing problem of creating more general AI systems, throughthe analysis of their development and the evaluation of theircognitive abilities.
Firstly, this thesis contributes with a general-purpose declar-ative learning system gErl [2],[3] that meets several desirablecharacteristics in terms of expressiveness, comprehensibilityand versatility. The system works with approaches that areinherently general: inductive programming and reinforcementlearning. The system does not rely on a fixed library of learn-ing operators, but can be endowed with new ones, so beingable to operate in a wide variety of contexts. This flexibility,jointly with its declarative character, makes it possible to usethe system as an instrument for better understanding the role(and difficulty) of the constructs that each task requires.
Secondly, the learning process is also overhauled witha new developmental and lifelong approach for knowledgeacquisition, consolidation and forgetting, which is necessarywhen bounded resources (memory and time) are considered. Inthis sense we present a parametrisable (hierarchical) approach[4] for structuring knowledge (based on coverage) which isable to check whether the new learnt knowledge can beconsidered redundant, irrelevant or inconsistent with the oldone, and whether it may be built upon previously acquiredknowledge.
Thirdly, this thesis analyses whether the use of more ability-oriented evaluation techniques for AI (such as intelligencetests) is a much better alternative to most task-oriented eval-uation approaches in AI. Accordingly, we make a review ofwhat has been done when AI systems have been confrontedagainst tasks taken from intelligence tests [5]. In this regard,we scrutinise what intelligence tests measure in machines,whether they are useful to evaluate AI systems, whether they
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Selected PhD Thesis Abstracts 27
are really challenging problems, and whether they are useful tounderstand (human) intelligence. Our aim here is to contributeto a more widespread realisation that more general classes ofproblems are needed when constructing benchmarks for AIevaluation.
As a final contribution, we show that intelligence testscan also be useful to examine concept dependencies (men-tal operational constructs) in the cognitive development ofartificial systems, therefore supporting the assumption that,even for fluid intelligence tests, the difficult items require amore advanced cognitive development than the simpler ones.In this sense, in [3] we show how several fluid intelligencetest problems are addressed by our general-purpose learningsystem gErl, which, although it is not particularly designed onpurpose to solve intelligence tests, is able to perform relativelywell for this kind of tests. gErl makes it explicitly howcomplex each pattern is and what operators are used for eachproblem, thus providing useful insight into the characteristicsand usefulness of these tests when assessing the abilities andcognitive development of AI systems.
Summing up, this dissertation represents one step forward inthe hard and long pursuit of making more general AI systemsand fostering less customary (and challenging) ability-orientedevaluation approach.
NOVEL METHODS OF MEASURING THE SIMILARITYAND DISTANCE BETWEEN COMPLEX FUZZY SETS
Josie [email protected]
University of Nottingham, UK.
THIS thesis develops measures that enable comparisons ofsubjective information that is represented through fuzzy
sets. Many applications rely on information that is subjectiveand imprecise due to varying contexts and so fuzzy setswere developed as a method of modelling uncertain data.However, making relative comparisons between data-drivenfuzzy sets can be challenging. For example, when data sets areambiguous or contradictory, then the fuzzy set models oftenbecome non-normal or non-convex, making them difficult tocompare.
This thesis presents methods of comparing data that maybe represented by such (complex) non-normal or non-convexfuzzy sets. The developed approaches for calculating relativecomparisons also enable fusing methods of measuring sim-ilarity and distance between fuzzy sets. By using multiplemethods, more meaningful comparisons of fuzzy sets arepossible. Whereas if only a single type of measure is used,ambiguous results are more likely to occur.
This thesis provides a series of advances around the mea-suring of similarity and distance. Based on them, novelapplications are possible, such as personalised and crowd-driven product recommendations. To demonstrate the val-ue of the proposed methods, a recommendation system isdeveloped that enables a person to describe their desiredproduct in relation to one or more other known products.Relative comparisons are then used to find and recommendsomething that matches a persons subjective preferences.
Demonstrations illustrate that the proposed method is usefulfor comparing complex, nonnormal and non-convex fuzzysets. In addition, the recommendation system is effective atusing this approach to find products that match a given query(http://eprints.nottingham.ac.uk/id/eprint/33401).
MULTI-DOCUMENT SUMMARIZATION BASED ONPATTERNS WITH WILDCARDS AND PROBABILISTIC
TOPIC MODELING
Jipeng [email protected]
Yangzhou University, China
W ITH the rapid development of information technology,a huge amount of electronic documents are available
online, such as Web news, scientific literature, digital books,email, microblogging, and etc. How to effectively organize andmanage such vast amount of text data, and make the systemfacilitate and show the information to users, have becomechallenges in the field of intelligent information processing.Therefore, now more than ever, users need access to robusttext summarization systems, which can effectively condenseinformation found in a large amount of documents into ashort, readable synopsis, or summary. In recent years, withthe rapid development of e-commerce and social networks,we can obtain a large amout of short texts, e.g., book reviews,movie reviews, online chatting, and product introductions. Ashort text probably contains a lot of useful information thatcan help to learn hidden topics among texts. Meanwhile, onlyvery limited word co-occurrence information is available inshort texts compared with long texts, so traditional multi-document summarization algorithms cannot work very well onthese texts. Thus, how to generate a summary from multipledocuments has important research and practical values.
In this thesis, we study multi-document summarization(MDS) on long texts and multi-document summarization onshort texts, and propose several multi-document summariza-tion algorithms based on patterns with wildcards and proba-bility topic modeling. Our main contributions are as follows.
(1) A novel pattern-based model for generic multi-documentsummarization is proposed. There are two main categoriesof multi-document summarization: term-based and ontology-based meth- ods. A term-based method cannot deal withthe problems of polysemy and synonymy. An ontology-basedapproach addresses such problems by taking into accountof the semantic information of document con- tent, but theconstruction of ontology requires lots of manpower. To over-come these open problems, this paper presents a pattern-basedmodel for generic multi-document summarization, which ex-ploits closed patterns to extract the most salient sentencesfrom a document collection and reduce redundancy in thesummary. Our method calculates the weight of each sentenceof a document collection by accumulating the weights ofits covering closed patterns with respect to this sentence,and iteratively selects one sentence that owns the highestweight and less similarity to the previously selected sentences,un- til reaching the length limitation. Our method combinesthe advantages of the term-based and ontology-based models
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1

28 Editor: Xin Li
while avoiding their weaknesses. Empirical studies on thebenchmark DUC2004 datasets demonstrate that our pattern-based method significantly outperforms the state-of-the-artmethods.
(2) A new MDS paradigm called user-aware multi-document summarization is proposed. The aim of MDS meetsthe demands of users, and the comments contain implicitinformation of their care. Therefore, the generated summariesfrom the reports for an event should be salient accordingto not only the reports but also the comments. Recently,Bayesian models have successfully been applied to multi-document summarization showing state-of-the-art results insummarization competitions. News articles are often long.Tweets and news comments can be short texts. In this thesis,the corpus includes both short texts and long texts, referredto as heterogeneous text. Long text topic modeling viewstexts as a mixture of probabilistic topics, and short text topicmodeling adopts simple assumption that each text is sampledfrom only one latent topic. For heterogeneous texts, in this caseneither method developed for only long texts nor methods foronly short texts can generate satisfying results. In this thesis,we present an innovative method to discover latent topicsfrom a heterogeneous corpus including both long and shorttexts. Then, we apply the learned topics to the generation ofsummarizations. Experiments on real-world datasets validatethe effectiveness of the proposed model in comparison withother state-of-the-art models.
(3) A new short text topic model based on word embed-dings is proposed. Existing methods such as probabilisticlatent semantic analysis (PLSA) and latent Dirichlet alloca-tion (LDA) cannot solve this problem very well since onlyvery limited word co-occurrence information is available inshort texts. Based on recent results in word embeddingsthat learn semantical representations for words from a largecorpus, we introduce a novel method, Embedding-based TopicModeling (ETM), to learn latent topics from short texts.ETM not only solves the problem of very limited word co-occurrence information by aggregating short texts into longpseudo-texts, but also utilizes a Markov Random Field reg-ularized model that gives correlated words a better chanceto be put into the same topic. Experiments on real-worlddatasets validate the effectiveness of our model comparingwith the state-of-the-art models (https://drive.google.com/file/d/0B3BkztuizBiyeTltMmFlci10dUU/view?usp=sharing).
PROBABILISTIC MODELS FOR LEARNING FROMCROWDSOURCED DATA
Filipe [email protected]
Denmark Technical University, Denmark
THIS thesis leverages the general framework of probabilis-tic graphical models to develop probabilistic approaches
for learning from crowdsourced data. This type of data israpidly changing the way we approach many machine learningproblems in different areas such as natural language process-ing, computer vision and music. By exploiting the wisdomof crowds, machine learning researchers and practitioners
are able to develop approaches to perform complex tasks ina much more scalable manner. For instance, crowdsourcingplatforms like Amazon mechanical turk provide users with aninexpensive and accessible resource for labeling large datasetsefficiently. However, the different biases and levels of exper-tise that are commonly found among different annotators inthese platforms deem the development of targeted approachesnecessary.
With the issue of annotator heterogeneity in mind, we startby introducing a class of latent expertise models which are ableto discern reliable annotators from random ones without accessto the ground truth, while jointly learning a logistic regressionclassifier or a conditional random field. Then, a generalizationof Gaussian process classifiers to multiple-annotator settingsis developed, which makes it possible to learn non-lineardecision boundaries between classes and to develop an activelearning methodology that is able to increase the efficiency ofcrowdsourcing while reducing its cost. Lastly, since the ma-jority of the tasks for which crowdsourced data is commonlyused involves complex high-dimensional data such as imagesor text, two supervised topic models are also proposed, onefor classification and another for regression problems. Usingreal crowdsourced data from Mechanical Turk, we empiricallydemonstrate the superiority of the aforementioned models overstate-ofthe-art approaches in many different tasks such asclassifying posts, news stories, images and music, or evenpredicting the sentiment of a text, the number of stars of areview or the rating of movie.
But the concept of crowdsourcing is not limited to dedicatedplatforms such as Mechanical Turk. For example, if we consid-er the social aspects of the modern Web, we begin to perceivethe true ubiquitous nature of crowdsourcing. This opened upan exciting new world of possibilities in artificial intelligence.For instance, from the perspective of intelligent transportationsystems, the information shared online by crowds providesthe context that allows us to better understand how peoplemove in urban environments. In the second part of this thesis,we explore the use of data generated by crowds as additionalinputs in order to improve machine learning models. Namely,the problem of understanding public transport demand in thepresence of special events such as concerts, sports gamesor festivals, is considered. First, a probabilistic model isdeveloped for explaining non-habitual overcrowding usingcrowd-generated information mined from the Web. Then, aBayesian additive model with Gaussian process componentsis proposed. Using real data from Singapores transport systemand crowd-generated data regarding special events, this modelis empirically shown to be able to outperform state-of-the-artapproaches for predicting public transport demand. Further-more, due to its additive formulation, the proposed model isable to breakdown an observed time-series of transport demandinto a routine component corresponding to commuting and thecontributions of individual special events.
Overall, the models proposed in this thesis for learning fromcrowdsourced data are of wide applicability and can be ofgreat value to a broad range of research communities (http://www.fprodrigues.com/thesis phd fmpr.pdf).
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Selected PhD Thesis Abstracts 29
EXPLORING MIXED REALITY IN DISTRIBUTEDCOLLABORATIVE LEARNING ENVIRONMENTS
Anasol Pena [email protected]
University of Essex, UK.
SOCIETY is moving rapidly towards a world, where tech-nology enables people to exist in a blend of physical and
virtual realities. In education, this vision involves technologiesranging from smart classrooms to e-learning, creating greateropportunities for distance learners, bringing the potential tochange the fundamental nature of universities. However, todate, most online educational platforms have focused onconveying information rather than supporting collaborativephysical activities which are common in university scienceand engineering laboratories. Moreover, even when onlinelaboratory support is considered, such systems tend to beconfined to the use of simulations or pre-recorded videos. Thelack of support for online collaborative physical laboratoryactivities, is a serious shortcoming for distance learners and asignificant challenge to educators and researchers.
In working towards a solution to this challenge, this thesispresents an innovative mixed reality framework (computationalmodel, conceptual architecture and proof-of-concept imple-mentation) that enables geographically dispersed learners toperform co-creative teamwork using a computer-based proto-type comprising hardware and software components.
Contributions from this work include a novel distributedcomputational model for synchronising physical objects andtheir 3D virtual representations, expanding the dual-realityparadigm from single linked pairs to complex groupings,addressing the challenge of interconnecting geographicallydispersed environments; and the creation of a computationalparadigm that blends a model of distributed learning objectswith a constructionist pedagogical model, to produce a solutionfor distributed mixed reality laboratories.
By way of evidence to support the research findings, thisthesis reports on evaluations performed with students fromeight different universities in six countries, namely China,Malaysia, Mexico, UAE, USA and UK; providing an im-portant insight to the role of social interactions in distancelearning, and demonstrating that the inclusion of a physicalcomponent made a positive difference to students learningexperience, supporting the use of mixed reality objects ineducational activities (http://repository.essex.ac.uk/16172/).
DYNAMIC ADVERSARIAL MINING - EFFECTIVELYAPPLYING MACHINE LEARNING IN ADVERSARIAL
NON-STATIONARY ENVIRONMENTS
Tegjyot Singh [email protected]
University of Louisville, USA.
WHILE understanding of machine learning and datamining is still in its budding stages, the engineering
applications of the same has found immense acceptance andsuccess. Cybersecurity applications such as intrusion detectionsystems, spam filtering, and CAPTCHA authentication, have
all begun adopting machine learning as a viable technique todeal with large scale adversarial activity. However, the naiveusage of machine learning in an adversarial setting is proneto reverse engineering and evasion attacks, as most of thesetechniques were designed primarily for a static setting. Thesecurity domain is a dynamic landscape, with an ongoingnever ending arms race between the system designer and theattackers. Any solution designed for such a domain needs totake into account an active adversary and needs to evolveover time, in the face of emerging threats. We term this asthe Dynamic Adversarial Mining problem, and the presentedwork provides the foundation for this new interdisciplinaryarea of research, at the crossroads of Machine Learning,Cybersecurity, and Streaming Data Mining.
We start with a white hat analysis of the vulnerabili-ties of classification systems to exploratory attack. The pro-posed Seed-Explore-Exploit framework provides characteriza-tion and modeling of attacks, ranging from simple randomevasion attacks to sophisticated reverse engineering. It isobserved that, even systems having prediction accuracy closeto 100%, can be easily evaded with more than 90% precision.This evasion can be performed without any information aboutthe underlying classifier, training dataset, or the domain ofapplication.
Attacks on machine learning systems cause the data toexhibit non stationarity (i.e., the training and the testing datahave different distributions). It is necessary to detect thesechanges in distribution, called concept drift, as they couldcause the prediction performance of the model to degrade overtime. However, the detection cannot overly rely on labeleddata to compute performance explicitly and monitor a drop,as labeling is expensive and time consuming, and at times maynot be a possibility altogether. As such, we propose the MarginDensity Drift Detection (MD3) algorithm, which can reliablydetect concept drift from unlabeled data only. MD3 provideshigh detection accuracy with a low false alarm rate, making itsuitable for cybersecurity applications; where excessive falsealarms are expensive and can lead to loss of trust in thewarning system. Additionally, MD3 is designed as a classifierindependent and streaming algorithm for usage in a variety ofcontinuous never-ending learning systems.
We then propose a Dynamic Adversarial Mining basedlearning framework, for learning in non stationary and ad-versarial environments, which provides security by design.The proposed Predict-Detect classifier framework, aims toprovide: robustness against attacks, ease of attack detectionusing unlabeled data, and swift recovery from attacks. Ideasof feature hiding and obfuscation of feature importance areproposed as strategies to enhance the learning frameworkssecurity. Metrics for evaluating the dynamic security of asystem and recover-ability after an attack are introduced toprovide a practical way of measuring efficacy of dynamicsecurity strategies. The framework is developed as a streamingdata methodology, capable of continually functioning withlimited supervision and effectively responding to adversarialdynamics.
The developed ideas, methodology, algorithms, and experi-mental analysis, aim to provide a foundation for future work
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1

30 Editor: Xin Li
in the area of Dynamic Adversarial Mining, wherein a holisticapproach to machine learning based security is motivated.
LEVERAGING MULTIMODAL INFORMATION INSEMANTICS AND SENTICS ANALYSIS OF
USER-GENERATED CONTENT
Rajiv [email protected]
Singapore Management University, Singapore
THE amount of user-generated multimedia content (UGC)has increased rapidly in recent years due to the ubiquitous
availability of smartphones, digital cameras, and affordablenetwork infrastructures. To benefit people from an automaticsemantics and sentics understanding of UGC, this thesis1,2focuses on developing effective algorithms for several sig-nificant multimedia analytics problems. Sentics are commonaffective patterns associated with natural language conceptsexploited for tasks such as emotion recognition from tex-t/speech or sentiment analysis. Knowledge structures derivedfrom UGC are beneficial in an efficient multimedia search,retrieval, and recommendation. However, real-world UGC iscomplex, and extracting the semantics and sentics from onlymultimedia content is very difficult because suitable conceptsmay be exhibited in different representations. Advancementsin technology enable users to collect a significant amount ofcontextual information (e.g., spatial, temporal, and preferen-tial information). Thus, it necessitates analyzing UGC frommultiple modalities to facilitate problems such as multimediasummarization, tag ranking and recommendation, preference-aware multimedia recommendation, and multimedia-based e-learning.
We focus on the semantics and sentics understanding ofUGC leveraging both content and contextual information.First, for a better semantics understanding of an event from alarge collection of photos, we present the EventBuilder system[2]. It enables people to automatically generate a summaryfor the event in real-time by visualizing different social me-dia such as Wikipedia and Flickr. In particular, we exploitWikipedia as the event background knowledge to obtain morecontextual information about the event. This information isvery useful in effective event detection. Next, we solve anoptimization problem to produce text summaries for the event.Subsequently, we present the EventSensor system [6] that aimsto address sentics understanding and produces a multimediasummary for a given mood. It extracts concepts and mood tagsfrom the visual content and textual metadata of photos and ex-ploits them in a sentics-based multimedia summary. Moreover,we focus on computing tag relevance for UGIs. Specifically,we leverage personal and social contexts of UGIs and followa neighbor voting scheme to predict and rank tags [1, 5].Furthermore, we focus on semantics and sentics understandingfrom videos (http://dl.acm.org/citation.cfm?id=2912032).
BIG DATA FOR SOCIAL SCIENCES: MEASURINGPATTERNS OF HUMAN BEHAVIOR THROUGH
LARGE-SCALE MOBILE PHONE DATA
Pal Sundsoy
[email protected] of OSLO, Norway
ANALYSIS of large amounts of data, so called Big Data,is changing the way we think about science and society.
One of the most promising rich Big Data sources is mobilephone data, which has the potential to deliver near real-time information of human behaviour on an individual andsocietal scale. Several challenges in society can be tackledin a more efficient way if such information is applied in auseful manner. Through seven publications this dissertationshows how anonymized mobile phone data can contribute tothe social good and provide insights into human behaviour ona largescale.
The size of the datasets analysed ranges from 500 millionto 300 billion phone records, covering millions of people. Thekey contributions are two-fold: Big Data for Social Good:Through prediction algorithms the results show how mobilephone data can be useful to predict important socio-economicindicators, such as income, illiteracy and poverty in developingcountries. Such knowledge can be used to identify where vul-nerable groups in society are, improve allocation of resourcesfor poverty alleviation programs, reduce economic shocks, andis a critical component for monitoring poverty rates over time.Further, the dissertation demonstrates how mobile phone datacan be used to better understand human behaviour during largeshocks and disasters in society, exemplified by an analysisof data from the terror attack 22nd July 2011 in Norwayand a natural disaster on the south-coast in Bangladesh. Thiswork leads to an increased understanding of how informationspreads, and how millions of people move around. The inten-tion is to identify displaced people faster, cheaper and moreaccurately than existing survey-based methods.
Big Data for efficient marketing: Finally, the dissertationoffers an insight into how anonymised mobile phone datacan be used to map out large social networks, coveringmillions of people, to understand how products spread insidethese networks. Results show that by including social patternsand machine learning techniques in a large-scale marketingexperiment in Asia, the adoption rate is increased by 13 timescompared to the approach used by experienced marketers. Adata-driven and scientific approach to marketing, through moretailored campaigns, contributes to less irrelevant offers forthe customers, and better cost efficiency for the companies(https://www.duo.uio.no/handle/10852/55139).
TOWARD INTELLIGENT CYBER-PHYSICALSYSTEMS: ALGORITHMS, ARCHITECTURES,
AND APPLICATIONS
University of Rhode Island, USA.
CYBER-physical systems (CPS) are the new generationof engineered systems integrated with computation and
physical processes. The integration of computation, commu-nication and control adds new capabilities to the systemsbeing able to interact with physical world. The uncertainty in
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Selected PhD Thesis Abstracts 31
physical environment makes future CPS to be more reliant onmachine learning algorithms which can learn and accumulateknowledge from historical data to support intelligent decisionmaking. Such CPS with the incorporation of intelligence orsmartness are termed as intelligent CPS which are safer, morereliable and more efficient.
This thesis studies fundamental machine learning algorithmsin supervised and unsupervised manners and examines newcomputing architecture for the development of next generationCPS. Two important applications of CPS, including smartpipeline and smart grid, are also studied in this thesis. Par-ticularly, regarding supervised machine learning algorithms,several generative learning and discriminative learning meth-ods are proposed to improve learning performance. For thegenerative learning, we build novel classification methodsbased on exponentially embedded families (EEF), a new prob-ability density function (PDF) estimation method, when someof the sufficient statistics are known. For the discriminativelearning, we develop an extended nearest neighbor (ENN)method to predict patterns according to the maximum gainof intra-class coherence. The new method makes a predictionin a “two-way communication” style: it considers not onlywho are the nearest neighbors of the test sample, but alsowho consider the test sample as their nearest neighbors.By exploiting the generalized class-wise statistics from alltraining data, the proposed ENN is able to learn from theglobal distribution, therefore improving pattern recognitionperformance and providing a powerful technique for a widerange of data analysis applications. Based on the concept ofENN, an anomaly detection method is also developed in anunsupervised manner.
CPS usually have high-dimensional data, such as text, video,and other multi-modal sensor data. It is necessary to reducefeature dimensions to facilitate the learning. We propose anoptimal feature selection framework which aims to selectfeature subsets with maximum discrimination capacity. Tofurther address the information loss issue in feature reduction,we develop a novel learning method, termed generalized PDFprojection theorem (GPPT), to reconstruct the distribution inhigh-dimensional raw data space from the low-dimensionalfeature subspace.
To support the distributed computations throughout theCPS, it needs a novel computing architecture to offer high-performance computing over multiple spatial and temporalscales and to support Internet of Things for machine-to-machine communications. We develop a hierarchical distribut-ed Fog computing architecture for the next generation CPS. Aprototype of such architecture for smart pipeline monitoring isimplemented to verify its feasibility in real world applications.
Regarding the applications, we examine false data injectiondetection in smart grid. False data injection is a type of mali-cious attack which can threaten the security of energy systems.We examine the observability of false data injection and devel-op statistical models to estimate underlying system states anddetect false data injection attacks under different scenarios toenhance the security of power systems (http://digitalcommons.uri.edu/cgi/viewcontent.cgi?article=1508&context=oa diss).
GENETIC PROGRAMMING TECHNIQUES FOR REGULAREXPRESSION INFERENCE FROM EXAMPLES
Fabiano [email protected]
Department of Engineering and Architecture, University ofTrieste, Italy
MACHINE Learning (ML) techniques have proven theireffectiveness for obtaining solutions to a given problem
automatically, from observations of problem instances andfrom examples of the desired solution behaviour. In this thesiswe describe the work carried out at the Machine LearningLab at University of Trieste on several real world problems ofpractical interest.
The main contribution is the design and implementation ofa tool, based on Genetic Programming (GP), capable of con-structing regular expressions for text extraction automatically,based only on examples of the text to be extracted as well as ofthe text not to be extracted. Regular expressions are used in anumber of different application domains but writing a regularexpression for solving a specific task is usually quite difficult,requiring significant technical skills and creativity. The resultsdemonstrate that our tool not only generates text extractorswith much higher effectiveness on more difficult tasks thanpreviously proposed algorithms, it is also human-competitivein terms of both accuracy of the regular expressions andtime required for their construction. We base this claim ona large-scale experiment involving more than 1700 users on10 text extraction tasks of realistic complexity. Thanks tothese achievements, our proposal has been awarded the SilverMedal at the 13th Annual ”Humies” Award, an internationalcompetition that establishes the state of the art in genetic andevolutionary computation.
Moreover, in this thesis we consider two variants of theproposed regular expressions generator, tailored to differentapplication domains(i) an automatic Regex Golf game player,i.e., a tool for constructing a regular expression that matchesa given list of strings and that does not match another givenlist of strings; and, (ii) the identification of Genic Interactionsin sentences extracted from scientific papers.
This thesis also encompasses contributions beyond thefield of Genetic Programming, including: a methodology forpredicting the accuracy of text extractors; a novel learn-ing algorithm able to generate a string similarity functiontailored to problems of syntax-based entity extraction fromunstructured text; a system for continuous reauthenticationof web users based on the observed mouse dynamics; amethod for the authentication of an unknown document,given a set of verified documents from the same author; amethod for user profiling based on a set of his/her tweet-s; automatic text generators capable of generating fake re-views for a given scientific paper and fake consumer re-views for a restaurant. The proposed algorithms employseveral ML techniques ranging from Grammatical Evolu-tion to Support Vector Machines, from Random Forests toRecurrent Neural Networks (https://drive.google.com/file/d/0B67gF86BZtPLdmNyYzZUNF8wTDg/view?usp=sharing).
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1

32 Editor: Xin Li
DATA-DRIVEN STUDY ON TWO DYNAMIC EVOLUTIONPHENOMENA OF SOCIAL NETWORKS: RUMOR
DIFFUSION IN ONLINE SOCIAL MEDIA ANDBANKRUPTCY EVOLUTION AMONG FIRMS
Shihan [email protected]
Tokyo Institute of Technology, Japan
THE fast growth of computational technologies and un-precedented volume of data have revolutionized the way
we understand our society. While the social network structureis commonly used to conceptualize and describe individualsand collectives in the highly connected world, social networkanalysis becomes an important means of exploring insightsbehind this social structure. Social networks usually keepevolving slowly over time. This evolution can become verydramatic when facing external influences, which raised newchallenges for scholars in understanding the complex socialphenomenon.
In the thesis, we concentrate on the dynamic evolutionphenomena of social networks caused by external factorsfrom both interpersonal and inter-organizational perspectives:rumor diffusion in online social media (i.e. interpersonalnetwork) and bankruptcy evolution among the firms (i.e. inter-organizational network). Driven by real big data resources,we applied various computational technologies to explore thebehavioral patterns in dynamic social networks and provideimplications for solving these social problems.
From the individual perspective, we explore the rumordiffusion phenomenon in online social media (i.e. Twitterin particular). With the extremely fast and wide spread ofinformation, online trending rumors cause devastating so-cioeconomic damage before being effectively identified andcorrected. To fix the gap in real-time situation, we propose anearly detection mechanism to monitor and identify rumors inthe online streaming social media as early as possible. Therumor-related patterns (combining features of users attitudeand network structure in information propagation) are firstdefined, as well as a pattern matching algorithm for trackingthe patterns in streaming data. Then, we analyze the snapshotsof data stream and alarm matched patterns automatically basedon the sliding window mechanism. The experiments in twodifferent real Twitter datasets show that our approach capturesearly signal patterns of trending rumors and have a goodpotential to be used in real-time rumor discovery.
From the organizational perspective, we understand thedynamic evolution phenomenon of inter-firm network emerg-ing from bankruptcy. When the bankruptcy transfers as achain among trade partners (i.e. firms), it causes serioussocioeconomic concerns. Beyond previous studies in statisticalanalysis and propagation modeling, we focus on one under-lying humanrelated factor, the social network among seniorexecutives of firms, and investigate its effects on this socialphenomenon. Based on empirical analysis of real Japanesefirms data in ten years, an agent-based model is particularlyproposed to understand the role of this human factor in twoperspectives: the number of social partners and the localinteraction mechanism among firms (i.e. triangle structure in
inter-firm social network). Using real and artificial datasets,the beneficial effects of a number of social partners are wellexamined and validated in various simulated scenarios fromboth micro and macro levels. Our results also indicate theinfluential strategies to keep firms resilience when facing thebankrupt emergency.
Besides the contributions we made in each researchfield respectively, our study in this thesis enhances theunderstanding of dynamic independent and interactivebehaviors in complex social phenomena, and provides a goodperspective to seek solutions in other computational socialproblems.(https://drive.google.com/file/d/0BX4oFwLeg7udDhCempyN3JFbEk/view?usp=sharing)
EXPLORING THE KNOWLEDGE CURATION PROCESS OFONLINE HEALTH COMMUNITIES
Wanli [email protected]
Texas Tech University, USA.
MORE and more people turn to online health com-munities for social support to satisfy their health-
related needs. Previous studies on social support and onlinehealth communities in general have focused on the contentof social support and the relationship of social support withother entities using traditional social science methods. Littleis known about how social support facilitates the knowledgecuration process in an online health community. Moreover,the presence of misinformation in online health communitiesalso calls for research into the knowledge curation processin order to reduce the risk of misinformation. This studyuses data mining technologies to analyze around one millionposts across 23 online health communities along with 900 postinformation accuracy data. It aims to reveal how information,through social support, flows between the community usersworking as a whole to dynamically curate knowledge andfurther interacts with information accuracy.
Text mining methods was used to analyze the 1 million postsdata to characterize information flow among the three userpositional roles from a quantitative perspective. The resultsshowed that (i) xperiphery users instead of core users domi-nate the quantitative information flow to request and receiveinformational support for knowledge curation in online healthcommunities and (iii) the xpeirphery users showed the bestpotential for generating new information. Granger causalitywas then employed to analyze the data mining results tocharacterize information flow between the three user positionalroles from content perspective The results demonstrated that(i) it was the xperihpery users who played a central role indirecting the content information flow and development; (ii)however, the xperiphery users were still the least active usergroup in responding to other user positional roles.
Information flow was further quantified from temporalperspective using Directed Acyclic Graphs. K-meansclustering and negative binomial regression were furtheremployed to identify three distinct information flow patternsfor users to curate knowledge in online health communities
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin

Selected PhD Thesis Abstracts 33
and each with distinct characteristics. Further logisticregression models were built to examine the interactionbetween the identified information flow patterns withinformation accuracy. The results showed that (i) informationpatterns and time had a statistically significant influenceon information accuracy, and (ii) information accuracy alsoshowed distinct variation trends between information flowpatterns. These findings not only have important implicationsfor social support use, delivery and social support researchmethodologies but also can inform future online healthplatform design.(https://www.researchgate.net/publication/317224472 EXPLORING THE COLLECTIVE KNOWLEDGE CURATION PROCESS OF ONLINE HEALTH COMMUNITIES)
SEMANTIC SIMILARITY ANALYSIS AND APPLICATION INKNOWLEDGE GRAPHS
Ganggao [email protected]
Universidad Politecnica de Madrid, Spain
THE advanced information extraction techniques and in-creasing availability of linked data have given birth to
the notion of large-scale Knowledge Graph (KG). With theincreasing popularity of KGs containing millions of conceptsand entities, the research of fundamental tools studying se-mantic features of KGs is critical for the development of KG-based applications, apart from the study of KG populationtechniques. With such focus, this thesis exploits semantic sim-ilarity in KGs taking into consideration of concept taxonomy,concept distribution, entity descriptions, and categories. Se-mantic similarity captures the closeness of meanings. Throughstudying the semantic network of concepts and entities withmeaningful relations in KGs, we proposed a novel WPathsemantic similarity metric and new graph-based InformationContent (IC) computation method. With the WPath and graph-based IC, semantic similarity of concepts can be comput-ed directly and only based on the structural and statisticalknowledge contained in KG. The word similarity experimentshave shown that the improvement of the proposed methodsis statistical significant comparing to conventional methods.Moreover, observing that concepts are usually collocated withtextual descriptions, we propose a novel embedding approachto train concept and word embedding jointly. The sharedvector space of concepts and words has provided convenientsimilarity computation between concepts and words throughvector similarity. Furthermore, the applications of knowledge-based, corpus-based and embedding-based similarity methodsare shown and compared to the task of semantic disambigua-tion and classification, in order to demonstrate the capabilityand suitability of different similarity methods in the specificapplication. Finally, semantic entity search is used as anillustrative showcase to demonstrate the higher level of theapplication consisting of text matching, disambiguation andquery expansion. To implement the complete demonstrationof entity-centric information querying, we also propose arule-based approach for constructing and executing SPAR-QL queries automatically. In summary, the thesis exploits
various similarity methods and illustrates their correspondingapplications for KGs. The proposed similarity methods andpresented similarity based applications would help in facili-tating the research and development of applications in KGs(http://oa.upm.es/47031/).
IEEE Intelligent Informatics Bulletin August 2017 Vol.18 No.1

Book Review: Cognitive Computing: Theory and Applications
August 2017 Vol.18 No.1 IEEE Intelligent Informatics Bulletin
34
REVIEWED BY WEIYI MENG
This is a timely book about an
emergent discipline – cognitive
computing. It actually belongs to an
interdisciplinary domain
encompassing cognitive science,
neuroscience, data science, and high
performance computing. The book
provides an excellent coverage of
two primary lines of research in this
discipline. One is cognitive science
which is a discipline that studies
human mind and human cognition.
This line of research covers
neuroscience, psychology,
linguistics, among others. The other
line is largely based on computer
science, especially the following
subdisciplines: high-performance
and cloud computing, machine
learning, NLP, computer vision,
information retrieval, data
management and data science.
The book is comprised of 11
chapters written by 20 leading
researchers in various relevant areas
of cognitive computing. The first
two chapters provide an excellent
introduction to cognitive computing
and set the stage for reading the rest
of the book. They introduce key
concepts, architectures and systems,
principles and theorems, as well as
recent advances in cognitive
computing. The next five chapters
present various concrete methods
that can be applied to tackling
cognitive computing problems.
These methods include graph-based
visual analytics, machine learning
algorithms for cognitive analytics,
random forest model based big data
classification, and Bayesian additive
regression tree. The final four
chapters present in-depth case
studies of four application areas that
can benefit from research in
cognitive computing:
food-water-energy, education and
learning, spoken language
processing, and Internet of Things
(IoT). The book strikes a good
balance in breadth and depth in
introducing the state-of-the-art of
cognitive computing to the readers.
The chapters I read are all very well
written – rich in content, informative
and up-to-date, and clear in writing.
This book can be easily adopted as a
textbook for an advanced
undergraduate or graduate course on
cognitive computing. It will also be
an excellent reference book for a
number of computer science courses
in the areas of data science, big data
analytics, and machine learning.
Researchers and practitioners who
are interested in these areas can also
benefit greatly from reading this
book. I personally learned a lot from
reading this book and I strongly
recommend it.
THE BOOK:
GUDIVADA,V.N.,
RAGHAVAN,V.V., GOVINDARAJU,
V., RAO, C.R. (EDS) (2016),
COGNITIVE COMPUTING:
THEORY AND APPLICATIONS, 404
P.
ELSEVIER
PRINT BOOK ISBN : 9780444637444
ABOUT THE REVIEWER:
WEIYI MENG
Chair and Professor, Department of
Computer Science, Binghamton
University, Binghamton, NY 13902
Contact him at: [email protected]
Cognitive Computing: Theory and Applications BY V. N. GUDIVADA, V.V. RAGHAVAN, V. GOVINDARAJU, C.R. RAO (EDITORS) - ISBN: 978-0-4446-3744-4

IEEE Computer Society 1730 Massachusetts Ave, NW Washington, D.C. 20036-1903
Non-profit Org. U.S. Postage
PAID Silver Spring, MD
Permit 1398





























