Embed Size (px)
Citation preview

The Future of MPI
William GroppArgonne National Laboratory
www.mcs.anl.gov/~gropp

University of Chicago Department of Energy
The Success of MPI
• Applications Most recent Gordon Bell prize winners use MPI
• Libraries Growing collection of powerful software components
• Tools Performance tracing (Vampir, Jumpshot, etc.) Debugging (Totalview, etc.)
• Results Papers: http://www.mcs.anl.gov/mpi/papers
• Clusters Ubiquitous parallel computing

University of Chicago Department of Energy
Why Was MPI Successful?
• It address all of the following issues: Portability Performance Simplicity and Symmetry Modularity Composability Completeness

University of Chicago Department of Energy
Portability and Performance
• Portability does not require a “lowest common denominator” approach Good design allows the use of special,
performance enhancing features without requiring hardware support
MPI’s nonblocking message-passing semantics allows but does not require “zero-copy” data transfers
• BTW, it is “Greatest Common Denominator”

University of Chicago Department of Energy
Simplicity and Symmetry
• MPI is organized around a small number of concepts The number of routines is not a good
measure of complexity Fortran
• Large number of intrinsic functions C and Java runtimes are large Development Frameworks
• Hundreds to thousands of methods This doesn’t bother millions of programmers

University of Chicago Department of Energy
Measuring Complexity
• Complexity should be measured in the number of concepts, not functions or size of the manual
• MPI is organized around a few powerful concepts Point-to-point message passing Datatypes Blocking and nonblocking buffer handling Communication contexts and process
groups

University of Chicago Department of Energy
Elegance of Design
• MPI often uses one concept to solve multiple problems
• Example: Datatypes Describe noncontiguous data transfers,
necessary for performance Describe data formats, necessary for
heterogeneous systems
• “Proof” of elegance: Datatypes exactly what is needed for high-
performance I/O, added in MPI-2.

University of Chicago Department of Energy
Parallel I/O
• Collective model provides high I/O performance Matches applications most general view:
objects, distributed among processes
• MPI Datatypes extend I/O model to noncontiguous data in both memory and file Unix readv/writev only applies to memory
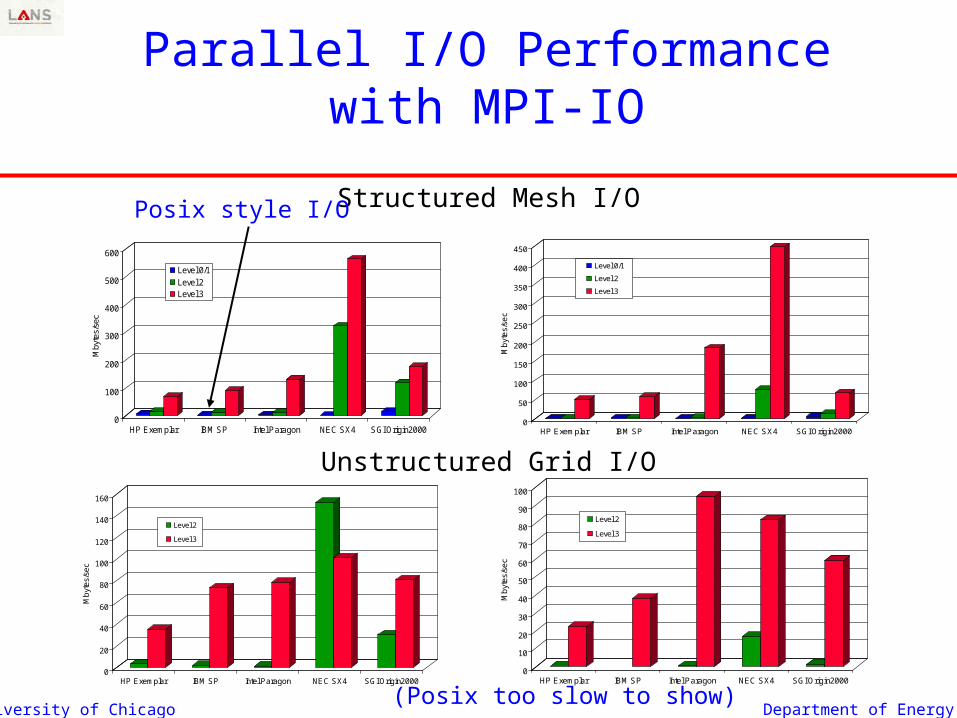
University of Chicago Department of Energy
Parallel I/O Performance with MPI-IO
0
100
200
300
400
500
600
Mby
tes/
sec
HP Exemplar IBM SP Intel Paragon NEC SX4 SGI Origin2000
Level 0/1Level 2Level 3
0
50
100
150
200
250
300
350
400
450
Mb
yte
s/se
c
HP Exemplar IBM SP Intel Paragon NEC SX4 SGI Origin2000
Level 0/1
Level 2
Level 3
0
20
40
60
80
100
120
140
160
Mb
yte
s/se
c
HP Exemplar IBM SP Intel Paragon NEC SX4 SGI Origin2000
Level 2
Level 3
0
10
20
30
40
50
60
70
80
90
100
Mb
yte
s/se
c
HP Exemplar IBM SP Intel Paragon NEC SX4 SGI Origin2000
Level 2
Level 3
Structured Mesh I/O
Unstructured Grid I/O
Posix style I/O
(Posix too slow to show)

University of Chicago Department of Energy
Modularity
• Modern algorithms are hierarchical Do not assume that all operations involve all
or only one process Provide tools that don’t limit the user
• Modern software is built from components MPI designed to support libraries Many applications have no explicit MPI calls;
all MPI contained within well-designed libraries

University of Chicago Department of Energy
Composability
• Environments are built from components Compilers, libraries, runtime systems MPI designed to “play well with others”
• MPI exploits newest advancements in compilers … without ever talking to compiler writers OpenMP is an example

University of Chicago Department of Energy
Completeness
• MPI provides a complete parallel programming model and avoids simplifications that limit the model Contrast: Models that require that
synchronization only occurs collectively for all processes or tasks
• Make sure that the functionality is there when the user needs it Don’t force the user to start over with a new
programming model when a new feature is needed

University of Chicago Department of Energy
Is Ease of Use the Overriding Goal?
• MPI often described as “the assembly language of parallel programming”
• C and Fortran have been described as “portable assembly languages”
• Ease of use is important. But completeness is more important. Don’t force users to switch to a different
approach as their application evolves

University of Chicago Department of Energy
Lessons From MPI
• A general programming model for high-performance technical computing must address many issues to succeed
• Even that is not enough. Also needs: Good design Buy-in by the community Effective implementations
• MPI achieved these through an Open Standards Process

University of Chicago Department of Energy
An Open and Balanced Process
• Balanced representation from Users
• What users want and need Including correctness
Implementers (Vendors)• What can be provided
Many MPI features determined by implementation needs
Researchers• Directions and Futures
MPI planned for interoperation with OpenMP before OpenMP conceived
Support for libraries strongly influenced by research

University of Chicago Department of Energy
Where Next?
• Improving MPI Simplifying and enhancing the expression of MPI
programs
• Improving MPI Implementations Performance Performance Performance
• New Directions What can displace (or complement) MPI?
(Yesterday’s panel presentation on programming models project and tomorrow’s panel on the future of supercomputing)

University of Chicago Department of Energy
Improving MPI
• Simpler interfaces Use compiler or precompiler techniques to support simpler, integrated
syntax Fortran 95 arrays, datatypes in C/C++
• Eliminate function calls Use program analysis and transformation to inline operations
• More tools for correctness and performance debugging MPI profiling interface is a good start Debugger interface used by Totalview is an example of tool
development Effort to provide a common interface to internal performance data,
such as idle time waiting for a message• Changes to MPI
E.g., MPI-2 RMA lacks a read-modify-write But don’t hold your breath
• These require research and experimentation before they are ready for a standardization process

University of Chicago Department of Energy
Improving MPI Implementations
• Faster Point-to-point Some current implementations make unnecessary copies
• Collective operations Better algorithms exist
• SMP optimizations• Scatter-gather broadcast, reduce, etc.
• Optimizing for new hardware RDMA networks NIC-enabled remote atomic operations
• Wide area networks Optimizations for high latency Speculative sends Quality of service extensions (through MPI attributes)
• Massive scaling Many implementations optimize internal buffers for modest numbers of
processes Some MPI routines (e.g., MPI_Graph_create) do not have scalable definitions

University of Chicago Department of Energy
More Improvements for MPI Implementations
• Reduce latency Automatic techniques to compress code paths Closer match to hardware capabilities
• Improve RMA Many current implementations at best functional
• Parallel I/O, particularly for clusters Communication aggregation Reliability in the presence of faults
• Fault tolerance Exploit MPI Intercommunicators to generalize the two-party model
• Thread safe and efficient implementations Lock-free design Software engineering for common MPI implementation source tree
• Many groups working on improved MPI implementations MPICH-2 is an all-new and efficient implementation
• Includes many of these ideas• Designed, as MPICH was, to encourage others to experiment and extend MPI

University of Chicago Department of Energy
What’s New in MPICH2
• Beta-test version available for groups that expect to perform research on MPI implementations with MPICH2 Version 0.92 released last Friday
• Contains All of MPI-1, MPI-I/O, service functions from MPI-2, active-
target RMA C, C++, Fortran 77 bindings Example devices for TCP, Infiniband, shared memory Documentation
• Passes extensive correctness tests Intel test suite (as corrected); good unit test suite MPICH test suite; adequate system test suite Notre Dame C++ tests, based on IBM C test suite Passes more tests than MPICH1

University of Chicago Department of Energy
MPICH2 Research
• All new implementation is our vehicle for research in Thread safety and efficiency (e.g., avoid thread locks) Optimized MPI datatypes Optimized Remote Memory Access (RMA) High Scalability (64K MPI processes and more) Exploiting Remote Direct Memory Access (RDMA) capable
networks All of MPI-2, including dynamic process management, parallel
I/O, RMA Usability and Robustness
• Software engineering techniques that automate and simplify creating and maintaining a solid, user-friendly implementation
• Allow extensive runtime error checking but do not require it• Integrated performance debugging
Clean interfaces to other system components such as scalable process managers

University of Chicago Department of Energy
Some Target Platforms
• Clusters (TCP, UDP, Infiniband, Myrinet, Proprietary Interconnects, …)
• Clusters of SMPs• Grids (UDP, TCP, Globus I/O, …)• Cray Red Storm• BlueGene/x
64K processors; 64K address spaces ANL/IBM developing MPI for BG/L
• QCDoC• Cray X1 (at least I/O)• Other systems
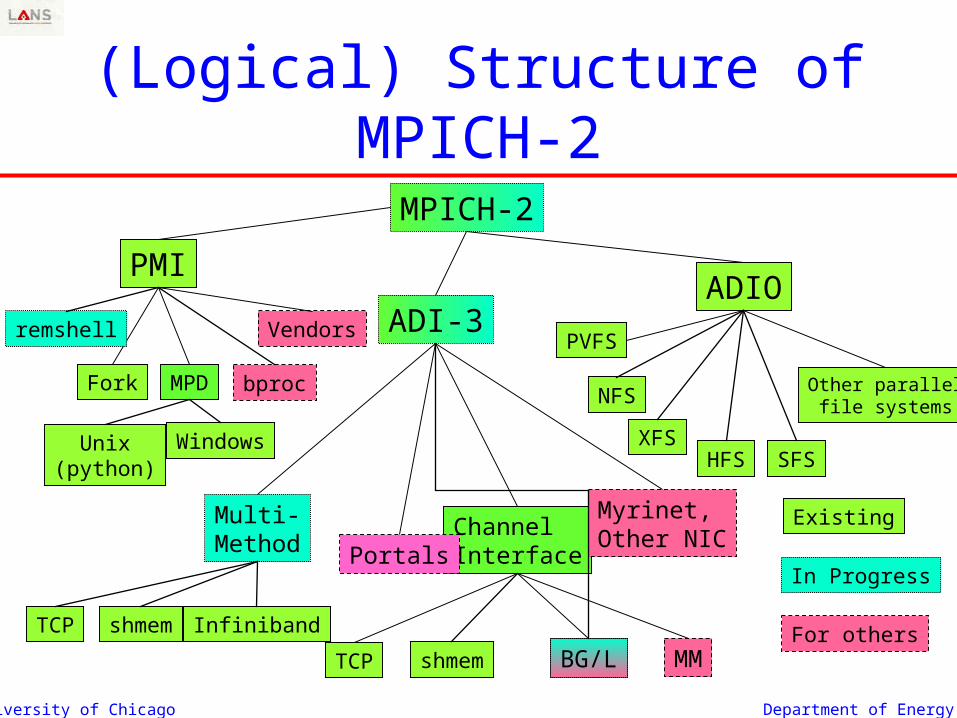
University of Chicago Department of Energy
(Logical) Structure of MPICH-2
ADI-3ADIO
MPICH-2
Other parallel file systems
PMI
MPD
Vendors
ChannelInterface
Myrinet,Other NIC
Multi-Method
BG/L
Portals
MM
Existing
In Progress
For others
Fork
PVFS
TCP
Unix(python)
Windows
shmem
TCP shmem Infiniband
remshell
XFS
NFS
HFS SFS
bproc

University of Chicago Department of Energy
Conclusions
• The Future of MPI is Bright! Higher-performance implementations More libraries and applications Better tools for developing and tuning MPI
programs Leverage of complementary technologies
• Full MPI-2 implementations will become common Several already exist; many ES apps use
MPI RMA





























