Embed Size (px)
Citation preview

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
The Effect of HPC Cluster
Architecture on the Scalability
Performance of CAE Simulations
Pak Lui
HPC Advisory Council
June 7, 2016
1

Agenda
• Introduction to HPC Advisory Council
• Benchmark Configuration
• Performance Benchmark Testing/Results
• Summary
• Q&A / For More Information

Mission Statement
The HPC Advisory Council
• World-wide HPC non-profit organization (429+ members)
• Bridges the gap between HPC usage and its potential
• Provides best practices and a support/development center
• Explores future technologies and future developments
• Leading edge solutions and technology demonstrations

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
HPC Advisory Council Members

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
HPC Advisory Council Cluster CenterDell™ PowerEdge™ R730
32-node cluster
HP Cluster Platform 3000SL
16-node clusterHP Proliant XL230a
Gen9 10-node cluster
Dell™ PowerEdge™ R815
11-node cluster
Dell™ PowerEdge™ C6145
6-node cluster
Dell™ PowerEdge™ M610
38-node cluster
Dell™ PowerEdge™ C6100
4-node cluster
White-box InfiniBand-based Storage (Lustre)
Dell™ PowerEdge™
R720xd/R720 32-node cluster
Dell PowerVault MD3420
Dell PowerVault MD3460
InfiniBand
Storage
(Lustre)

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
HPC Training
• HPC Training Center– CPUs
– GPUs
– Interconnects
– Clustering
– Storage
– Cables
– Programming
– Applications
• Network of Experts– Ask the experts

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Special Interest Subgroups
• HPC|Scale Subgroup
– Explore usage of commodity HPC as a
replacement for multi-million dollar
mainframes and proprietary based
supercomputers
• HPC|Cloud Subgroup
– Explore usage of HPC components as
part of the creation of
external/public/internal/private cloud
computing environments.
• HPC|Works Subgroup
– Provide best practices for building
balanced and scalable HPC systems,
performance tuning and application
guidelines.
• HPC|Storage Subgroup
– Demonstrate how to build high-
performance storage solutions and
their affect on application
performance and productivity
• HPC|GPU Subgroup
– Explore usage models of GPU
components as part of next generation
compute environments and potential
optimizations for GPU based computing
• HPC|Music
– To enable HPC in music production and
to develop HPC cluster solutions that
further enable the future of music
production

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
University Award Program
• University award program– Universities / individuals are encouraged to submit proposals for advanced research
• Selected proposal will be provided with:– Exclusive computation time on the HPC Advisory Council’s Compute Center
– Invitation to present in one of the HPC Advisory Council’s worldwide workshops
– Publication of the research results on the HPC Advisory Council website
• 2010 award winner is Dr. Xiangqian Hu, Duke University– Topic: “Massively Parallel Quantum Mechanical Simulations for Liquid Water”
• 2011 award winner is Dr. Marco Aldinucci, University of Torino– Topic: “Effective Streaming on Multi-core by Way of the FastFlow Framework’
• 2012 award winner is Jacob Nelson, University of Washington– “Runtime Support for Sparse Graph Applications”
• 2013 award winner is Antonis Karalis– Topic: “Music Production using HPC”
• 2014 award winner is Antonis Karalis– Topic: “Music Production using HPC”
• 2015 award winner is Christian Kniep– Topic: Dockers
• To submit a proposal – please check the HPC Advisory Council web site
Exploring All Platforms
X86, Power, GPU, FPGA and ARM based Platforms
x86 Power FPGA ARMGPU

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
• LS-DYNA
• miniFE
• MILC
• MSC Nastran
• MR Bayes
• MM5
• MPQC
• NAMD
• Nekbone
• NEMO
• NWChem
• Octopus
• OpenAtom
• OpenFOAM
• MILC
• OpenMX
• PARATEC
• PFA
• PFLOTRAN
• Quantum
ESPRESSO
• RADIOSS
• SPECFEM3D
• WRF
158+ Applications Best Practices Published
• Abaqus
• AcuSolve
• Amber
• AMG
• AMR
• ABySS
• ANSYS CFX
• ANSYS FLUENT
• ANSYS Mechanics
• BQCD
• CCSM
• CESM
• COSMO
• CP2K
• CPMD
• Dacapo
• Desmond
• DL-POLY
• Eclipse
• FLOW-3D
• GADGET-2
• GROMACS
• Himeno
• HOOMD-blue
• HYCOM
• ICON
• Lattice QCD
• LAMMPS
For more information, visit: http://www.hpcadvisorycouncil.com/best_practices.php

Student Cluster CompetitionHPCAC - ISC’16
• University-based teams to compete and demonstrate the incredible capabilities of state-of- the-art HPC systems and applications on the International Super Computing HPC (ISC HPC) show-floor
• The Student Cluster Challenge is designed to introduce the next generation of students to the high performance computing world and community

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
ISC'15 – Student Cluster Competition Award
Ceremony

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
ISC'16 – Student Cluster Competition Teams

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Getting Ready to 2016 Student Cluster Competition

Conferences
HPCAC Conferences 2015

Introduction
2016 HPC Advisory Council Conferences
• HPC Advisory Council (HPCAC)
– 429+ members, http://www.hpcadvisorycouncil.com/
– Application best practices, case studies
– Benchmarking center with remote access for users
– World-wide workshops
– Value add for your customers to stay up to date andin tune to HPC market
• 2016 Conferences
– USA (Stanford University) – February 24-26
– Switzerland (CSCS) – March 21-23
– Mexico – TBD
– Spain (BSC) – September 21
– China (HPC China) – October 26
• For more information
– www.hpcadvisorycouncil.com

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS by Altair
• Altair RADIOSS
– Structural analysis solver for highly non-linear problems under dynamic loadings
– Consists of features for:
• multiphysics simulation and advanced materials such as composites
– Highly differentiated for Scalability, Quality and Robustness
• RADIOSS is used across all industry worldwide
– Improves crashworthiness, safety, and manufacturability of structural designs
• RADIOSS has established itself as an industry standard
– for automotive crash and impact analysis for over 20 years

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
• Dell™ PowerEdge™ R730 32-node (896-core) “Thor” cluster– Dual-Socket 14-core Intel E5-2697v3 @ 2.60 GHz CPUs (Turbo on, Max Perf set in BIOS)
– OS: RHEL 6.5, OFED MLNX_OFED_LINUX-2.4-1.0.5 InfiniBand SW stack
– Memory: 64GB memory, DDR3 2133 MHz
– Hard Drives: 1TB 7.2 RPM SATA 2.5”
• Mellanox ConnectX-4 EDR 100Gb/s InfiniBand VPI adapters
• Mellanox Switch-IB SB7700 100Gb/s InfiniBand VPI switch
• Mellanox ConnectX-3 40/56Gb/s QDR/FDR InfiniBand VPI adapters
• Mellanox SwitchX SX6036 56Gb/s FDR InfiniBand VPI switch
• MPI: Intel MPI 5.0.2, Mellanox HPC-X v1.2.0
• Application: Altair RADIOSS 13.0
• Benchmark datasets:– Neon benchmarks: 1 million elements (8ms, Double Precision),
– unless otherwise stated
Test Cluster Configuration

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
PowerEdge R730
Massive flexibility for data intensive
operations• Performance and efficiency
– Intelligent hardware-driven systems managementwith extensive power management features
– Innovative tools including automation for parts replacement and lifecycle manageability
– Broad choice of networking technologies from GbE to IB
– Built in redundancy with hot plug and swappable PSU, HDDs and fans
• Benefits– Designed for performance workloads
• from big data analytics, distributed storage or distributed computing where local storage is key to classic HPC and large scale hosting environments
• High performance scale-out compute and low cost dense storage in one package
• Hardware Capabilities– Flexible compute platform with dense storage capacity
• 2S/2U server, 7 PCIe slots
– Large memory footprint (Up to 1.5TB / 24 DIMMs)
– High I/O performance and optional storage configurations • HDD: SAS, SATA, nearline SAS; SSD: SAS, SATA
• 16 x 2.5” – up to 29TB via 1.8TB hot-plug SAS hard drives
• 8 x 3.5” – up to 64TB via 8TB hot-plug nearline SAS hard drives

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Performance –
Interconnect (MPP)
• EDR InfiniBand provides higher scalability than Ethernet
– 70 times better performance than 1GbE at 16 nodes / 448 cores
– 4.8x better performance than 10GbE at 16 nodes / cores
– Ethernet solutions does not scale beyond 4 nodes with pure MPI
28 Processes/Node
4.8x
Intel MPI
Higher is better
70x

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Profiling –
% Time Spent on MPI
• RADIOSS utilizes point-to-point communications in most data transfers
• The most time MPI consuming calls is MPI_Waitany() and MPI_Wait()
– MPI_Recv(55%), MPI_Waitany(23%), MPI_Allreduce(13%)
28 Processes/NodeMPP Mode

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Performance – Interconnect
(MPP)
• EDR InfiniBand provides better scalability performance
– EDR IB improves over QDR IB by 28% at 16 nodes / 448 cores
– EDR InfiniBand outperforms FDR InfiniBand by 25% at 16 nodes
28 Processes/Node
25%28%
Higher is better

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Performance – CPU Cores
• Running more cores per node generally improves overall performance
– Seen improvement of 18% from 20 to 28 cores per node at 8 nodes
– Improvement seems not as consistent at higher node counts
• Guideline: Most optimal workload distribution is 4000 elements/process
– For test case of 1 million elements, most optimal core sizes is ~256 cores
– 4000 elements per process should provides sufficient workload for each process
– Hybrid MPP (HMPP) provides way to achieve additional scalability on more CPUs
6%
Intel MPIHigher is better
18%

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Performance – IMPI Tuning (MPP)
• Tuning Intel MPI collective algorithm can improve performance
– MPI profile shows about 20% of runtime spent on MPI_Allreduce
communications
– Default algorithm in Intel MPI is Recursive Doubling
– The default algorithm is the best among all tested for MPP
Intel MPI
Higher is better 28 Processes/Node

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Performance – Hybrid MPP
version
• Enabling Hybrid MPP mode unlocks the RADIOSS scalability
– At larger scale, productivity improves as more threads involves
– As more threads involved, amount of communications by processes are reduced
– At 32 nodes/896 cores, best configuration is 1 process per socket to spawn 14 threads each
– 28 threads/1 PPN is not advised due to breach of data locality across different CPU socket
• The following environment setting and tuned flags are used for Intel MPI:
– I_MPI_PIN_DOMAIN auto
– I_MPI_ADJUST_ALLREDUCE 5
– I_MPI_ADJUST_BCAST 1
– KMP_AFFINITY compact
– KMP_STACKSIZE 400m
– ulimit -s unlimited
EDR InfiniBand
Intel MPI
3.7x
32% 70%

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Profiling – Number of MPI Calls
• For MPP utilizes most non-blocking calls for communications
– MPI_Recv, MPI_Waitany, MPI_Allreduce are used most of the time
• For HMPP, communication behavior has changed
– Higher time percentage in MPI_Waitany, MPI_Allreduce, and MPI_Recv
• MPI Communication behavior changed from previous RADIOSS version
– Most likely due to more CPU cores available on the current cluster
HMPP, 2PPN / 14 ThreadsMPP, 28PPN
June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
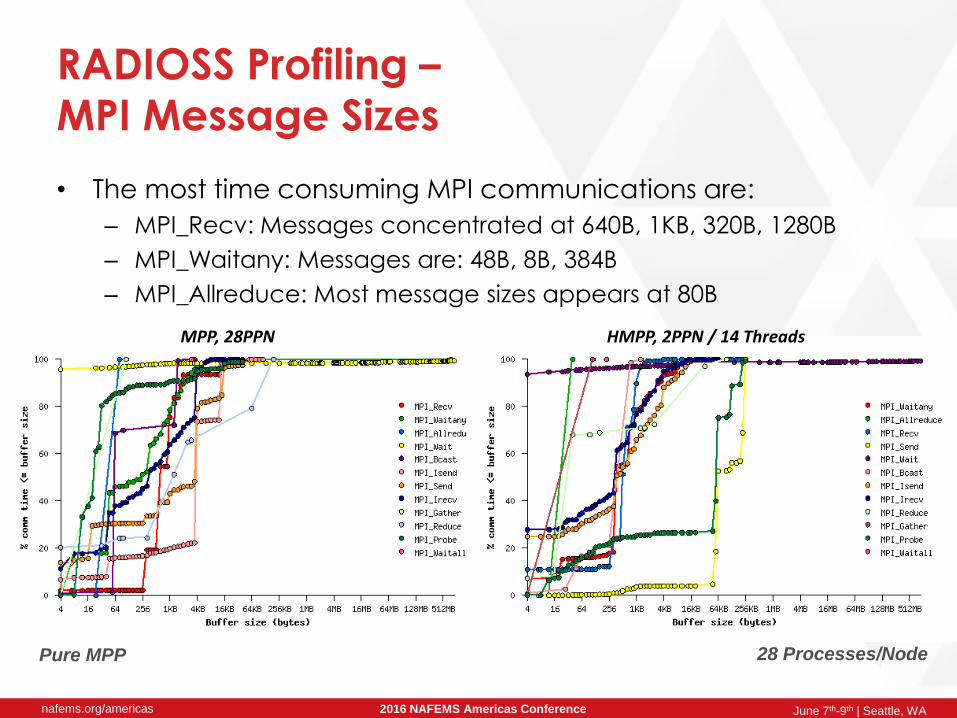
RADIOSS Profiling –
MPI Message Sizes
• The most time consuming MPI communications are:
– MPI_Recv: Messages concentrated at 640B, 1KB, 320B, 1280B
– MPI_Waitany: Messages are: 48B, 8B, 384B
– MPI_Allreduce: Most message sizes appears at 80B
28 Processes/NodePure MPP
HMPP, 2PPN / 14 ThreadsMPP, 28PPN

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Performance –
Intel MPI Tuning (DP)
• For Hybrid MPP DP, tuning MPI_Allreduce shows more gain than MPP
– For DAPL provider, Binomial gather+scatter #5 improved perf by 27% over default
– For OFA provider, tuned MPI_Allreduce algorithm improves by 44% over default
– Both OFA and DAPL improved by tuning I_MPI_ADJUST_ALLREDUCE=5
– Flags for OFA: I_MPI_OFA_USE_XRC 1. For DAPL: ofa-v2-mlx5_0-1u provider
27%
Intel MPI
Higher is better 2 PPN / 14 OpenMP
44%

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Performance –
Interconnect (HMPP)
• EDR InfiniBand provides better scalability performance than Ethernet
– 214% better performance than 1GbE at 16 nodes
– 104% better performance than 10GbE at 16 nodes
– InfiniBand typically outperforms other interconnect in collective
operations
214%
104%
2 PPN / 14 OpenMP
Intel MPI
Higher is better

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Performance –
Interconnect (HMPP)
• EDR InfiniBand provides better scalability performance than FDR IB
– EDR IB outperforms FDR IB by 27% at 32 nodes
– Improvement for EDR InfiniBand occurs at high node count
27%
2 PPN / 14 OpenMP
Intel MPI
Higher is better

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS Performance –
System Generations
• Intel E5-2680v3 (Haswell) cluster outperforms prior generations
– Performs faster by 100% vs Jupiter, by 238% vs Janus at 16 nodes
• System components used:
– Thor: 2-socket Intel [email protected], 2133MHz DIMMs, EDR IB, v13.0
– Jupiter: 2-socket Intel [email protected], 1600MHz DIMMs, FDR IB, v12.0
– Janus: 2-socket Intel [email protected], 1333MHz DIMMs, QDR IB, v12.0
Single Precision
100%
238%

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
RADIOSS – Summary
• RADIOSS is designed to perform at scale in HPC environment– Shows excellent scalability over 896 cores/32 nodes and beyond
with Hybrid MPP
– Hybrid MPP version enhanced RADIOSS scalability• 2 MPI processes per node (or 1 MPI process per socket), 14 threads each
– Additional CPU cores generally accelerating time to solution performance
• Network and MPI Tuning– EDR IB outperforms other Ethernet in scalability
– EDR IB delivers higher scalability performance than FDR/QDR IB
– Tuning environment/parameters to maximize performance
– Tuning MPI collective ops helps RADIOSS to achieve even better scalability

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
STAR-CCM+
• STAR-CCM+
– An engineering process-oriented CFD tool
– Client-server architecture, object-oriented programming
– Delivers the entire CFD process in a single integrated software
environment
• Developed by CD-adapco

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Test Cluster Configuration
• Dell PowerEdge R730 32-node (896-core) “Thor” cluster
– Dual-Socket 14-Core Intel E5-2697v3 @ 2.60 GHz CPUs
– BIOS: Maximum Performance, Home Snoop
– Memory: 64GB memory, DDR4 2133 MHz (Snoop Mode: Home Snoop)
– OS: RHEL 6.5, MLNX_OFED_LINUX-3.0-1.0.1 InfiniBand SW stack
– Hard Drives: 2x 1TB 7.2 RPM SATA 2.5” on RAID 1
• Mellanox ConnectX-4 EDR 100Gb/s InfiniBand Adapters
• Mellanox Switch-IB SB7700 36-port EDR 100Gb/s InfiniBand Switch
• Mellanox ConnectX-3 FDR VPI InfiniBand and 40Gb/s Ethernet Adapters
• Mellanox SwitchX-2 SX6036 36-port 56Gb/s FDR InfiniBand / VPI Ethernet Switch
• Dell InfiniBand-Based Lustre Storage
– based on Dell PowerVault MD3460 and Dell PowerVault MD3420
• MPI: Platform MPI 9.1.2
• Application: STAR-CCM+ 10.02.012
• Benchmarks:
– lemans_poly_17m
– civil_trim_20m
– reactor_9m, LeMans_100M.amg

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
STAR-CCM+ Performance – Network
Interconnects
• EDR InfiniBand delivers superior scalability in application performance
– IB delivers 66% higher performance than 40GbE, 88% higher than 10GbE at 32 nodes
– Scalability stops beyond 4 nodes for 1GbE; scalability is limited for 10/40GbE
– Input data: Lemans_poly_17m: A race car model with 17 million cells
28 MPI Processes / Node Higher is better
66%88%
748%

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
STAR-CCM+ Performance – Network
Interconnects
• EDR InfiniBand delivers superior scalability in application
performance
– EDR IB provides 177 higher performance than 40GbE, 194% than
40GbE at 32 nodes
– InfiniBand demonstrates continuous performance gain at scale
– Input data: reactor_9m: A reactor model with 9 million cells
177%194%
28 MPI Processes / Node Higher is better

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
STAR-CCM+ Profiling – % of MPI Calls
• For the most time consuming MPI calls:
– Lemans_17m: 55% MPI_Allreduce, 23% MPI_Waitany, 7% MPI_Bcast, 7% MPI_Recv
– Reactor_9m: 59% MPI_Allreduce, 21% MPI_Waitany, 7% MPI_Recv, 4% MPI_Bcast
• MPI as a percentage in wall clock times:
– Lemans_17m: 12% MPI_Allreduce, 5% MPI_Waitany, 2% MPI_Bcast, 2% MPI_Recv
– Reactor_9m: 15% MPI_Allreduce, 5% MPI_Waitany, 2% MPI_Recv, 1% MPI_Bcast
reactor_9m – 32 Nodes / 896 Processeslemans_17m – 32 nodes / 896 Processes

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
STAR-CCM+ Profiling –
MPI Message Size Distribution
• For the most time consuming MPI calls
– Lemans_17m: MPI_Allreduce 4B (30%), 16B (19%), 8B (6%),
MPI_Bcast 4B (4%)
– Reactor_9m: MPI_Allreduce 16B (35%), 4B (15%), 8B (8%),
MPI_Bcast 1B (4%)
reactor_9m – 32 Nodes / 896 Processeslemans_17m – 32 nodes / 896 Processes
June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
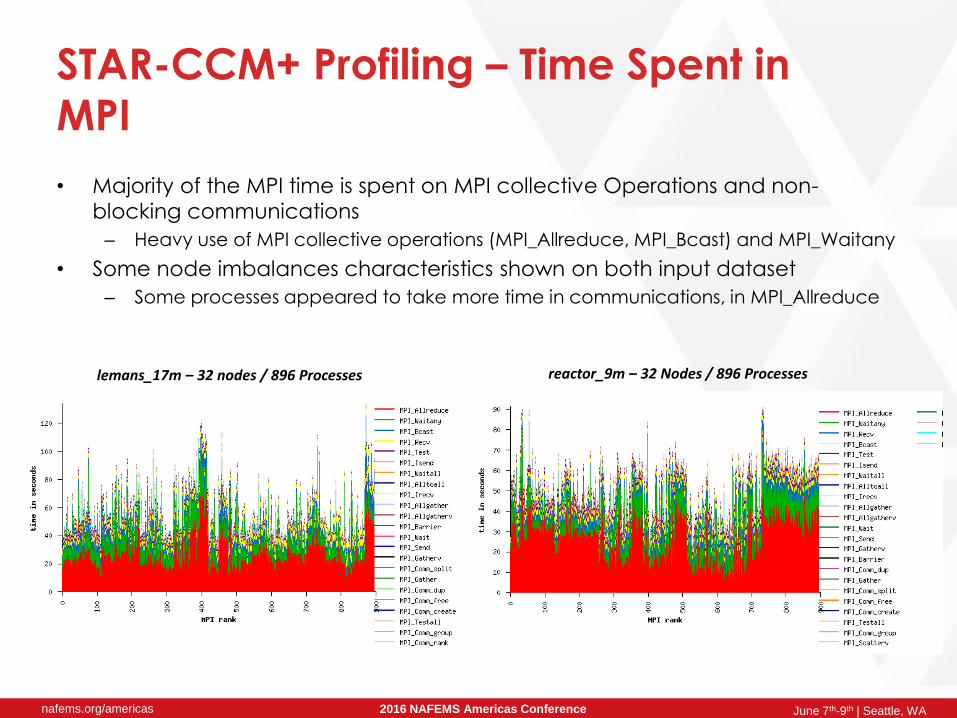
STAR-CCM+ Profiling – Time Spent in
MPI
• Majority of the MPI time is spent on MPI collective Operations and non-
blocking communications
– Heavy use of MPI collective operations (MPI_Allreduce, MPI_Bcast) and MPI_Waitany
• Some node imbalances characteristics shown on both input dataset
– Some processes appeared to take more time in communications, in MPI_Allreduce
reactor_9m – 32 Nodes / 896 Processeslemans_17m – 32 nodes / 896 Processes

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
STAR-CCM+ Performance –
Scalability Speedup
• EDR InfiniBand demonstrates linear scaling for STAR-CCM+
– STAR-CCM+ is able to achieve linear scaling with EDR InfiniBand
– Other interconnects only provided limited scalability• As demonstrated in previous slides
28 MPI Processes / Node Higher is better

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
STAR-CCM+ Performance –
System Generations
• Current system generations of HW & SW configuration outperform prior generations
– Current Haswell systems outperformed Ivy Bridge by 38%, Sandy Bridge by 149%, Westmere by 409%
– Dramatic performance benefit due to better system architecture in compute and network scalability
• System components used:
– Haswell: 2-socket 14-core [email protected], DDR4 2133MHz DIMMs, ConnectX-4 EDR InfiniBand, v10.02.012
– Ivy Bridge: 2-socket 10-core [email protected], DDR3 1600MHz DIMMs, Connect-IB FDR InfiniBand, v9.02.005
– Sandy Bridge: 2-socket 8-core [email protected], DDR3 1600MHz DIMMs, ConnectX-3 FDR InfiniBand, v7.02.008
– Westmere: 2-socket 6-core [email protected], DDR3 1333MHz DIMMs, ConnectX-2 QDR InfiniBand, v5.04.006
409%
38%149%
Higher is better

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
STAR-CCM+ Summary
Compute: cluster of the current generation outperforms system architecture of previous generations
– Outperformed Ivy Bridge by 38%, Sandy Bridge by 149%, Westmere by 409%
– Dramatic performance benefit due to better system architecture in compute and network scalability
Network: EDR InfiniBand demonstrates superior scalability in STAR-CCM+ performance
– EDR IB provides higher performance by over 4-5 times vs 1GbE, 10GbE and 40GbE, 15% vs FDR IB at 32 nodes
– Lemans_17m: Scalability stops beyond 4 nodes for 1GbE; scalability is limited for 10/40 GbE
– Reactor_9m: EDR IB provides 177 higher performance than 40GbE, 194% than 40GbE at 32 nodes
– EDR InfiniBand demonstrates linear scalability in STAR-CCM+ performance on the test cases

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
ANSYS Fluent
• Computational Fluid Dynamics (CFD) is a computational technology
– Enables the study of the dynamics of things that flow
– Enable better understanding of qualitative and quantitative physical
phenomena in the flow which is used to improve engineering design
• CFD brings together a number of different disciplines
– Fluid dynamics, mathematical theory of partial differential systems,
computational geometry, numerical analysis, Computer science
• ANSYS FLUENT is a leading CFD application from ANSYS
– Widely used in almost every industry sector and manufactured product

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Test Cluster Configuration
• Dell PowerEdge R730 32-node (896-core) “Thor” cluster– Dual-Socket 14-Core Intel E5-2697v3 @ 2.60 GHz CPUs
– Turbo enabled (Power Management: Maximum Performance)
– Memory: 64GB memory, DDR4 2133 MHz (Memory Snoop: Home Snoop)
– OS: RHEL 6.5, MLNX_OFED_LINUX-3.0-1.0.1 InfiniBand SW stack
– Hard Drives: 2x 1TB 7.2 RPM SATA 2.5” on RAID 1
• Mellanox Switch-IB SB7700 36-port 100Gb/s EDR InfiniBand Switch
• Mellanox ConnectX-4 EDR 100Gbps EDR InfiniBand Adapters
• Mellanox SwitchX-2 SX6036 36-port 56Gb/s FDR InfiniBand / VPI Ethernet Switch
• Mellanox ConnectX-3 FDR InfiniBand, 10/40GbE Ethernet VPI Adapters
• MPI: Mellanox HPC-X v1.2.0-326, Platform MPI 9.1
• Application: ANSYS Fluent 16.1
• Benchmark datasets:– eddy_417k
– truck_111m

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Fluent Performance –
Network Interconnects
• InfiniBand delivers superior scalability performance
– EDR InfiniBand provides higher performance than Ethernet
– InfiniBand delivers ~20 to 44 times higher performance and
continuous scalability
– Ethernet performance stays flat (or stops scaling) beyond 2 nodes
20x20x44x
28 MPI Processes / Node Higher is better

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Fluent Performance –
EDR vs FDR InfiniBand
• EDR InfiniBand delivers superior scalability in application performance
– As the number of nodes scales, performance gap of EDR IB becomes
widen
• Performance advantage of EDR InfiniBand increases for larger core
counts
– EDR InfiniBand provides 111% versus FDR InfiniBand at 16 nodes (448 cores)
111%
28 MPI Processes / Node Higher is better
June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
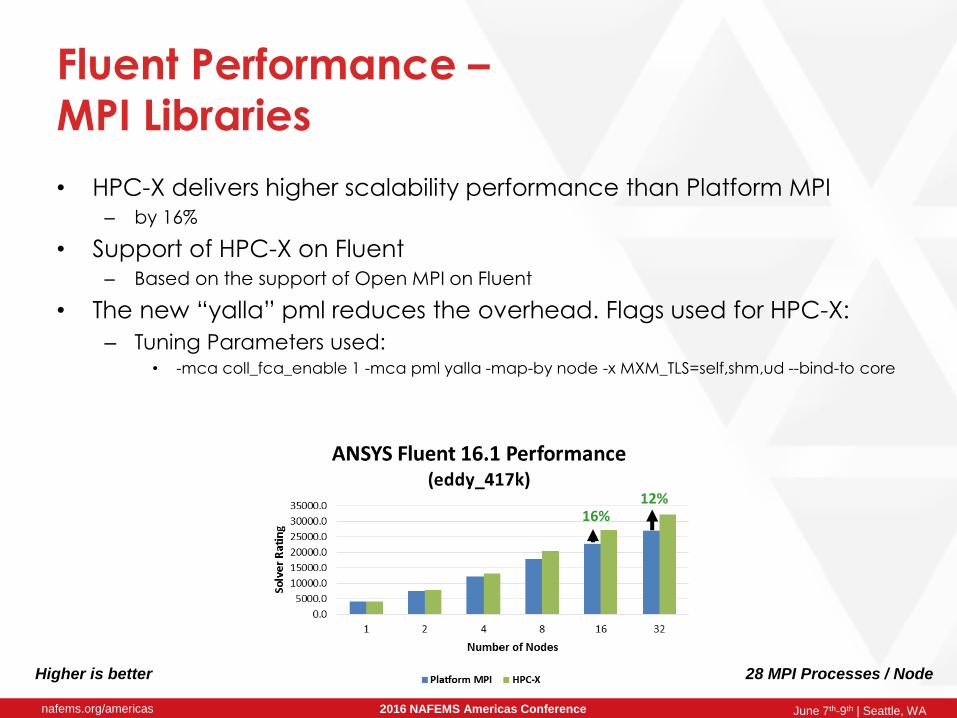
Fluent Performance –
MPI Libraries
• HPC-X delivers higher scalability performance than Platform MPI – by 16%
• Support of HPC-X on Fluent– Based on the support of Open MPI on Fluent
• The new “yalla” pml reduces the overhead. Flags used for HPC-X:
– Tuning Parameters used:• -mca coll_fca_enable 1 -mca pml yalla -map-by node -x MXM_TLS=self,shm,ud --bind-to core
12%16%
28 MPI Processes / Node Higher is better

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Fluent Profiling –
Time Spent by MPI Calls
• Different communication patterns seen depending on data
– Eddy_417k: • Most time spent in MPI_Recv, MPI_Allreduce, MPI_Waitall
– Truck_111m: • Most time spent in MPI_Bcast, MPI_Recv, MPI_Allreduce
truck_111meddy_417k

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Fluent Profiling –
Time Spent by MPI Calls
• Different communication patterns seen with
different input data
– Eddy_417k: Most time spent in MPI_Recv, MPI_Allreduce,
MPI_Waitall
– Truck_111m: Most time spent in MPI_Bcast, MPI_Recv,
MPI_Allreduce
truck_111meddy_417k

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Fluent Profiling –
MPI Message Sizes
• The most time consuming transfers are from small messages:
– Eddy_417k : MPI_Recv@16B (28%wall), MPI_Allreduce@4B (14%
wall), MPI_Bcast @4B (6%wall)
– Truck_111m: MPI_Bcast @24B (22%wall), MPI_Recv @16B (19%wall),
MPI_Bcast @4B (13%wall)
32 Nodes
truck_111meddy_417k

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Fluent Summary
• Performance– Compute: Intel Haswell cluster outperforms system
architecture of previous generations• Haswell cluster outperforms Ivy Bridge cluster by 26%-49%
at 32 node (896 cores) depending on workload
– Network: EDR InfiniBand delivers superior scalability in application performance
• EDR InfiniBand provides 20 to 44 times higher performance and more scalable compared to 1GbE/10GbE/40GbE
• Performance for Ethernet (1GbE/10GbE/40GbE) stays flat (or stops scaling) beyond 2 nodes
• EDR InfiniBand provides 111% versus FDR InfiniBand at 16nodes / 448 cores
– MPI: HPC-X delivers higher scalability performance than Platform MPI by 16%

June 7th-9th | Seattle, WA2016 NAFEMS Americas Conferencenafems.org/americas
Thank You!
52All trademarks are property of their respective owners. All information is provided “As-Is” without any kind of warranty. The HPC Advisory Council makes no representation to the accuracy and
completeness of the information contained herein. HPC Advisory Council undertakes no duty and assumes no obligation to update or correct any information presented herein





























