Embed Size (px)
Citation preview

The Baker’s Dozen Business Intelligence
13 Tips for the SQL Server Columnstore Index
Kevin S. GoffMicrosoft SQL Server MVP

Intro to Power BI for Office 365 2
Kevin S. Goff – Brief BIO
• Developer/architect since 1987 / Microsoft SQL Server MVP• Columnist for CoDe Magazine since 2004,
“The Baker’s Dozen” Productivity Series”, 13 tips on a SQL/BI topic• Wrote a book, collaborated on a 2nd book• Frequent speaker for SQL Server community events and SQL Live!360
Conferences• Email: [email protected] • My site/blog: www.KevinSGoff.Net (includes SQL/BI webcasts)• Releasing some SQL/BI video courseware in 2015
Columnstore Index - Introduction
• Today: 13 topics for the Columnstore index• New index in SQL Server 2012, enhanced in SQL 2014• More than just an index, an in-memory compressed
structure• A real game-changer, one of the biggest features in the SQL
database engine of all time• Some companies upgraded to SQL 2012 just because of this
feature• Represents another example where MS is devoting serious
attention to the underlying database engine– Earlier versions of SQL Server (2005) focused largely on language and developer
enhancements– SQL 2008 and 2012 have seen underlying database management/engine changes (Change
Data Capture and Columnstore Index)

Columnstore Index - Introduction
• In SQL 2012, not everyone benefits from this• Built for more Data warehouse/data mart environments , and
even then, only certain ones (in 2012 it’s a READONLY index, but that changes in 2014)
• For Data Warehousing environments, the columnstore index is one more reason why Data Warehouses/Data Marts should shape data in star-schema Fact/Dimension Models with surrogate integer keys

1. Quick demonstration 2. Overview to the Columnstore Index3. Characteristics of the Columnstore Index4. Who benefits from this?5. Columnstore indexes vs Rowstore Index6. Execution plan using the Columnstore index7. Batch Mode Processing – new processing mode for the Columnstore
index8. Where the Columnstore index can’t directly be used9. Selective vs non-Selective queries – where Columnstore index isn’t used10.General Usage rules11.Restriction rules on the Columnstore index12.Overall Performance Benchmarks13.New features in SQL Server 2014
Columnstore Index - Topics

1 – Quick Demonstration
Demo code…

• New relational, xVelocity memory-optimized database index in SQL Server 2012, “baked in” to the database engine
• xVelocity used to be called VertiPaq, found in PowerPivot going back to 2010• More and more functionality in DB engine (xVelocity, CDC)• Potentially Significant performance enhancements for data warehousing
and data mart scenarios – a real game changer– (not really for OLTP databases, we’ll see why later)
• Best for queries that scan/aggregate large sets of data• My opinion? One of the coolest things ever in SQL Server• In a regular index, indexed data from each row kept together on single page
– and the data in each column spread across all pages of index • In a columnstore index, data from each column is kept together (pages
stored adjacently) so each data page contains data only from a single column (compressed, more fits in memory, more efficient IO)
2 – Introduction to Columnstore Index

• Highly compressed - Exploits similarity of data within column– Typical in data warehouse Fact Table foreign keys
• IO Statistics - dramatically reduces # of logical reads!!!• Not stored in standard buffer pools, but rather in a new
optimized buffer pool cache and a new memory broker• Smart IO and caching using aggressive read-ahead read strategy• Part of Microsoft’s xVelocity technology – compression is factor
of 8 (and twice as efficient as page compression)• Once posted, only READONLY (this changes in SQL 2014)• Best for data warehouse/mart queries that scan/aggregate large
amounts of data–might lower need for OLAP aggregation• Some queries might run at least 10x faster (or more)
3 – Characteristics of Columnstore Index

• Queries and reports against Data Warehouses/Data Marts (works best with Fact/Dimension tables modeled in a star schema)
• Load from Data Warehouses/Marts into OLAP Cubes (more so in SQL 2014)
• SSAS OLAP Databases that use the ROLAP methodology or pass-through mode “might” benefit (more so in SQL 2014)
• New Analysis Services Tabular Model uses xVelocity engine• Some companies took the release candidate and put into production,
simply for this feature (some case studies show queries that went from 17 minutes to 3 seconds!)
• If you want to see Memory Usage, good blog entry from Joe D’Antoni (website is SQL Herald, http://joeydantoni.com/). He and other developers wrote procedure to return amount of memory used by columnstore object pool– http
://joeydantoni.com/2014/04/23/how-do-i-show-memory-usage-from-a-columnstore-index-in-sql-server/
4 – Who Benefits?

• Columnstore index stores each column in separate set of pages (vs. storing multiple data rows per page using b-trees, key values)
• Only columns needed are fetched• Easier to compress redundant column data• Uses xVelocity found in PowerPivot• Improved IO scan/buffer hit rates• Segment elimination: each partition is broken
into million row segments with metadata for min/max values – segment is not read if query scope does not include min/max values
• Query will only fetch necessary columns• In reality, not “really” an index – more like a
compressed “cube”
5 – Columnstore vs Rowstore Index

• Because a Fact table might contain millions of rows for a single CustomerFK or ProductFK, SQL Server can compress all the repeated surrogate keys to a single value
• Under the hood, SQL Server is not storing the values of 2, 3, etc….it is storing a special vector - an offset value with respect to the prior value (for efficiency)
• SQL Server also uses segment elimination for rows not needed – so any query for year of 2011 can eliminate the segments for 2010 and 2012
• Bottom line: ALL SORTS of efficiency baked into the engine – but there’s even more!
• This is one more reason to shape data warehouses/marts into star-schema, Fact-Dimension models with surrogate keys
5 – Columnstore vs Rowstore Index
CustomerFK
1
1
1
2
2
2
ProductFK
1001
1001
1001
1002
1002
1002
DateFK
20100101
20100102
20110102
20110102
20120101
20120101
Stored as a vector (value
that determines position of one point in space
relative to another)

• Go back to Execution Plan• Columnstore index was 5% of the
batch• Clustered index was 65% of the
batch• Covering index (which would have
been the best approach prior to SQL Server 2012) was 35% of the batch
• Time Statistics, 12x faster than covering index, 20x faster than clustered index
6 – Execution Plan with Columnstore

• Go back to Execution Plan• New Processing Model in
SQL 2012• Certain execution plan
operators (Hash Join and Hash Aggregation in particular) use new Batch execution mode
• Reads rows in blocks of 1,000 in parallel, minimizes instructions per row
• Data moves in batches through query plan operators
• Big performance benefit over row-based execution
7 – Batch Mode Processing
Packets of about 1,000 rows are passed between operators, with column data represented as a vector
“Vector-oriented processing”
Huge reduction in CPU Usage, at least by a factor of 10 or more
Batch mode takes advantage of advanced hardware architectures, processor cache, and RAM , improves parallelism
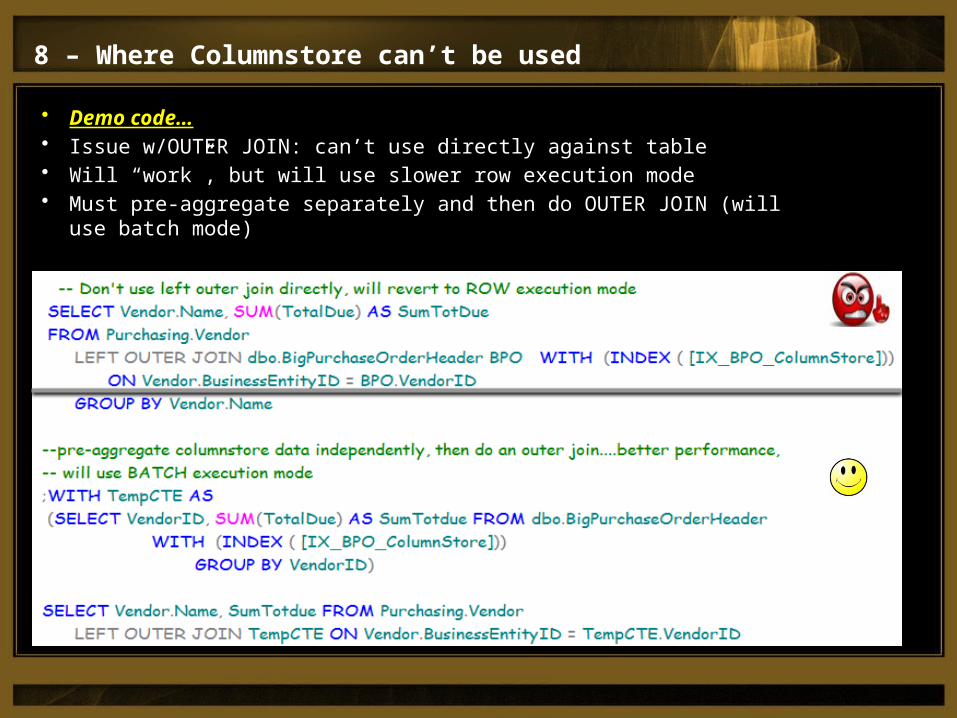
• Demo code…• Issue w/OUTER JOIN: can’t use directly against table• Will “work”, but will use slower row execution mode • Must pre-aggregate separately and then do OUTER JOIN (will use batch mode)
8 – Where Columnstore can’t be used

9 – Selective vs Non-Selective queries
Demo code…

• Syntax is simple: use new COLUMNSTORE keyword• 1 Columnstore index per table: cannot be clustered (in 2014 can be clustered)• Order of columns does not matter • Include all columns from table• No INCLUDE statement, No ASC/DESC• General MS recommendation: if queries will frequently use a certainly column on
the predicate, create a clustered index on that column and then create the columnstore index. – Even though column store index isn’t “ordered” itself, you’ll get better segment elimination
CREATE NONCLUSTERED COLUMNSTORE INDEX [IX_BPO_ColumnStore] ON [BigPurchaseOrderHeader] (PurchaseOrderID, VendorID, OrderDate, ShipMethodID, Freight, TotalDue)
10 – General Usage Syntax and Rules
• Include all columns• Order doesn’t
matter• No key columns
• Cannot be clustered, cannot be created against a view• Cannot act as a PK or FK, cannot include sparse columns• Can’t work on tables with Change Data Capture/Change Tracking or
FileStream, can’t participate in replication, nor when page/row compression exists
• Cannot be used with certain data types, such as binary, text/image, rowversion/timestamp, CLR data types (hierarchyID/spatial), nor with data types created with MAX keyword…e.g. varchar(max)
• Cannot be used with UniqueIdentifier• Cannot be used with decimal > 18 • Cannot be modified with ALTER – must be dropped and recreated• It’s a read-only index - cannot insert rows and expect columnstore
index to be maintained (changes in SQL 2014)
11 – Restrictions and Rules
• Note: range partitioning is supported….(use partitioning to load a table, index it with a columnstore index, and switch it in as newest partition.) – Partition by day, split the last partition– Load data into staging table and then create columnstore index– Switch it in (URL reference at end of slides for an example)– SQL Server 2012 permits 15,000 partitions per table
• Not optimized for certain statements (OUTER JOIN, UNION, NOT IN <subquery>)
• Not optimized for certain scenarios (high selectivity, queries lacking any aggregations)
• Not optimized for a JOIN statement on a composite set of columns (truthfully, a join between a fact table and a dimension table should only be on one integer key)
• Best practice – always use integer keys for FKs
11 – Restrictions and Rules (continued)

Index CPU time (ms)
Total Time (ms)
Logical Reads Read-aheadReads
Clustered index 4,337 3,899 27,631 0
Non-clustered covering index 2,246 2,393 21,334 8
Column Store index 140 199 4,180 12,652
Total Time (ms) Logical Reads0
5000
10000
15000
20000
25000
30000
Clustered Index
Non-clustered covering index
Column Store Index
12 – General Benchmarks
• New Clustered Columnstore Index (CCI)• CREATE CLUSTERED COLUMNSTORE INDEX [IndexName] on [TableName]• No columns specified - The CCI “is” the data
– It’s Updateable, No longer a read-only index– Cannot have any non-clustered indexes– Cannot have key constraints
• So you have one of two options:– A non-clustered read-only columnstore index, index plus as many non-clustered
indexes for FK values as you need (2012 model)– A clustered read-write columnstore index, but no non-clustered indexes for specific FK
values (2014 model)• 2014 CCI Index might perform better against highly selective queries than 2012
columnstore indexes did on highly selective queries• Support for more data types• Basically all data types except CLR, varchar(max) and varbinary(max), XML, and spatial data
types• Additional Archive compression on top of regular columnstore compression• Some ask – what is difference between this and Hekaton in-memory optimized tables?
13 – Enhancements in SQL 2014

• A great video on Columnstore Index from Tech-Ed 2013:– http://channel9.msdn.com/Events/TechEd/NorthAmerica/2013/DBI-B322#fbid=cse0UEXBRpZ
• Adding data to a table using Partition Switching– http://social.technet.microsoft.com/wiki/contents/articles/5069.add-data-to-a-table-with-a-columnsto
re-index-using-partition-switching.aspx
• Last year I did a 13-part series on new features in SQL 2012 for TechNet:– http://blogs.technet.com/b/jweston/archive/2012/03/28/sql-2012-free-training-one-blog-post-13-web
cast-recordings-mvp-kevin-goff.aspx
• I’ve written some articles in CoDe Magazine on SQL 2012– 2 part series on Columnstore index, T-SQL Features, and SSIS Features
• http://code-magazine.com/articleprint.aspx?quickid=1203051&printmode=true• http://code-magazine.com/articleprint.aspx?quickid=1206021&printmode=true
Recommended Links