Embed Size (px)
Citation preview

P.Bakowski 1
The Architecture of The Architecture of Graphic Processor Unit – GPUGraphic Processor Unit – GPU
and CUDA programmingand CUDA programming
P. BakowskiP. Bakowski

P.Bakowski 2
Evolution of parallel architecturesEvolution of parallel architectures
..We can distinguish 3 generations of We can distinguish 3 generations of massively parallelmassively parallel architectures (scientific calculation):architectures (scientific calculation):
((19761976) The super-computers with special processors ) The super-computers with special processors for vector calculation (for vector calculation (SSingle ingle IInstruction nstruction MMultiple ultiple DData)ata)
The Cray-1 contained 200,000 integrated circuits and The Cray-1 contained 200,000 integrated circuits and could perform 100 million floating point operations per could perform 100 million floating point operations per second (second (100 MFLOPS100 MFLOPS).).
price: price: $5 - $8.8M$5 - $8.8M
Number of units sold: Number of units sold: 8585

P.Bakowski 3
Evolution of parallel architecturesEvolution of parallel architectures
((20102010) The super-computers with standard ) The super-computers with standard microprocessors adapted for microprocessors adapted for massive multiprocessingmassive multiprocessing operating as operating as MMultiple ultiple IInstruction nstruction MMultiple ultiple DData computers.ata computers.
IBMIBM RoadrunnerRoadrunner: PowerXCell 8i : PowerXCell 8i CPUs, 6480 dual cores - AMD CPUs, 6480 dual cores - AMD Opteron, Opteron, LinuxLinux
Consumption: Consumption: 2,35 MW2,35 MWSurface: 296 racks, 560 mSurface: 296 racks, 560 m22 Memory: 103,6 TiBMemory: 103,6 TiBPerformance: 1,042 petaflopsPerformance: 1,042 petaflopsPrice:Price: USD USD $125M$125M

P.Bakowski 4
Evolution of GPU architectures Evolution of GPU architectures
((20122012) ) GGeneral eneral PProcessing on rocessing on GGraphic raphic PProcessing rocessing UUnits (GPGPU) technology based on the circuits nits (GPGPU) technology based on the circuits integrated into graphic cards.integrated into graphic cards.
~$16000~$16000

P.Bakowski 5
GPGPU on embedded GPU architecturesGPGPU on embedded GPU architectures
(2014) Embedded (2014) Embedded GPGPU is based on advanced SoCsGPGPU is based on advanced SoCs
Nvidia Tegra K1:Nvidia Tegra K1:
– ARM Cortex-15 (4) + Kepler GPUARM Cortex-15 (4) + Kepler GPU
Exynos 5422:Exynos 5422:
– ARM Cortex-15 (4) + Mali-T6xx, T7xx, T8xx GPUsARM Cortex-15 (4) + Mali-T6xx, T7xx, T8xx GPUs
$200 $200 ~16W~16W
$100$100~8W~8W

P.Bakowski 6
GPU based processingGPU based processing
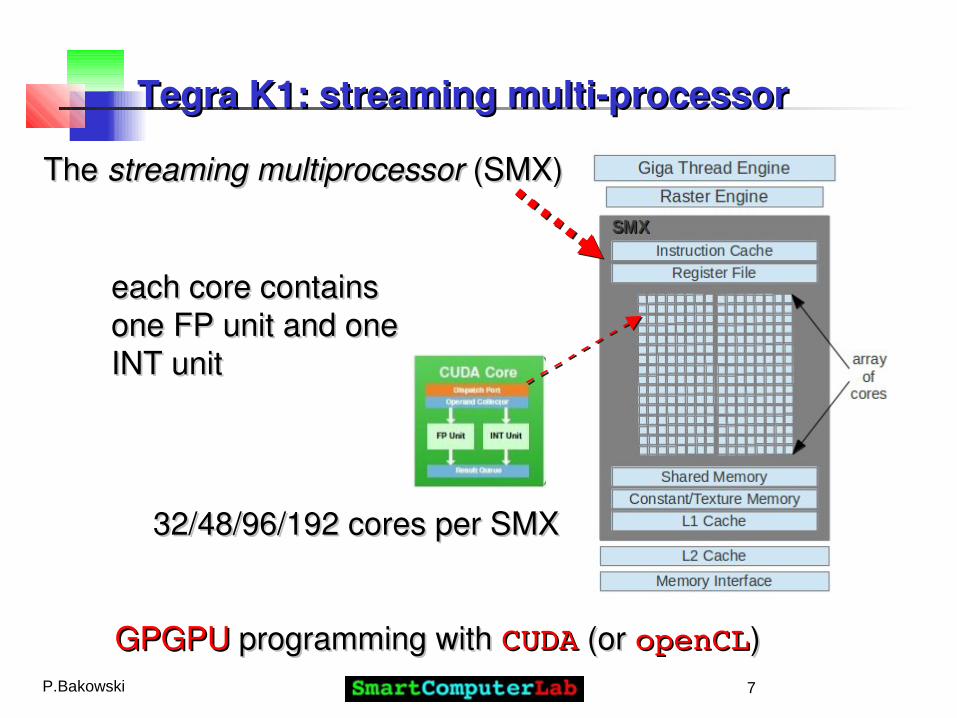
..Tegra K1Tegra K1: a Kepler class GPU unit with : a Kepler class GPU unit with 192192 processing processing cores, 2 signal processors, video processing units for cores, 2 signal processors, video processing units for high definition (2K) video encoding and decoding, audio high definition (2K) video encoding and decoding, audio processing unit, and a set of data, video, and audio processing unit, and a set of data, video, and audio interfaces.interfaces.
P.Bakowski 7
Tegra K1: streaming multi-processorTegra K1: streaming multi-processor
..The The streamingstreaming multiprocessormultiprocessor (SMX) (SMX)
32/48/96/19232/48/96/192 cores per SMX cores per SMX
each core contains each core contains one FP unit and one one FP unit and one INT unitINT unit
GPGPUGPGPU programming with programming with CUDACUDA (or (or openCLopenCL))
P.Bakowski 8
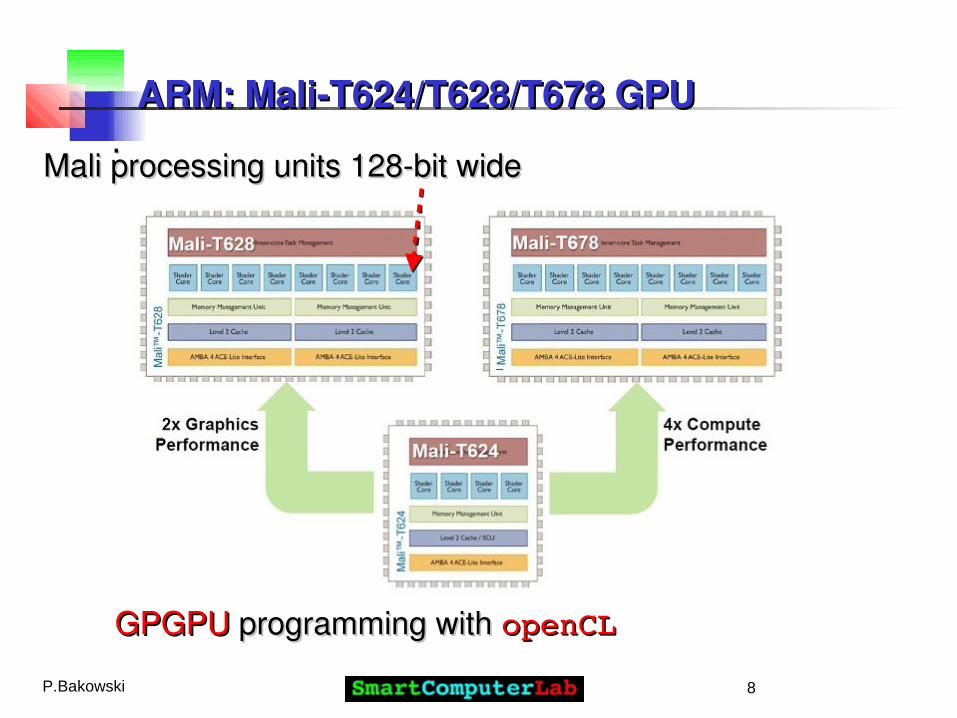
ARM: Mali-T624/T628/T678 GPUARM: Mali-T624/T628/T678 GPU..
Mali processing units 128-bit wide Mali processing units 128-bit wide
GPGPUGPGPU programming with programming with openCLopenCL
P.Bakowski 9
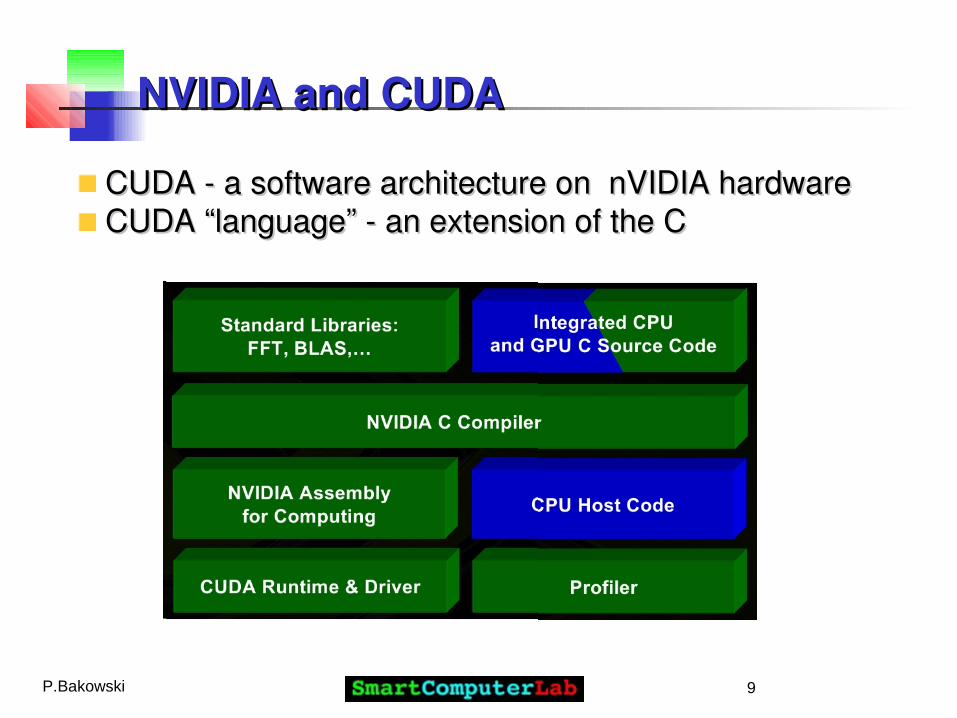
NVIDIA and CUDANVIDIA and CUDA
CUDA - a software architecture on nVIDIA hardware CUDA - a software architecture on nVIDIA hardware CUDA “language” - an extension of the CCUDA “language” - an extension of the C

P.Bakowski 10
NVIDIA and NVIDIA and CUDACUDA
The CUDA The CUDA ToolkitToolkit contains:contains:
compiler: compiler: nvccnvcc libraries libraries FFTFFT and and BLASBLAS profilerprofiler debugger debugger gdbgdb for GPU for GPU runtimeruntime driver for CUDA included in nVIDIA drivers driver for CUDA included in nVIDIA drivers guide of programmingguide of programming SDK for SDK for CUDACUDA developers developers source codes (examples) and documentationsource codes (examples) and documentation
P.Bakowski 11
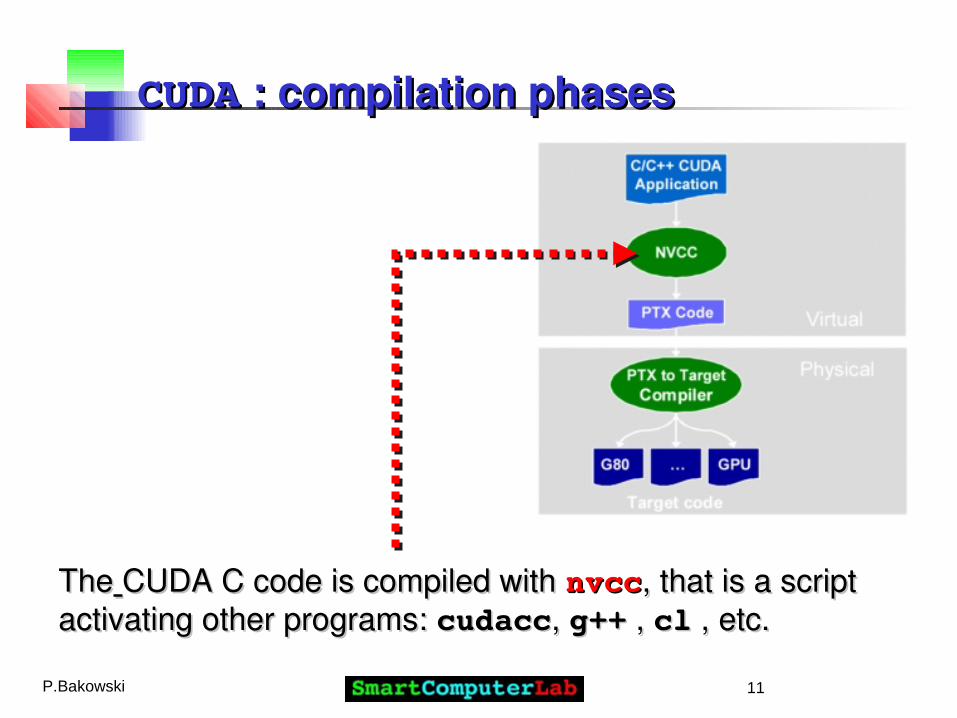
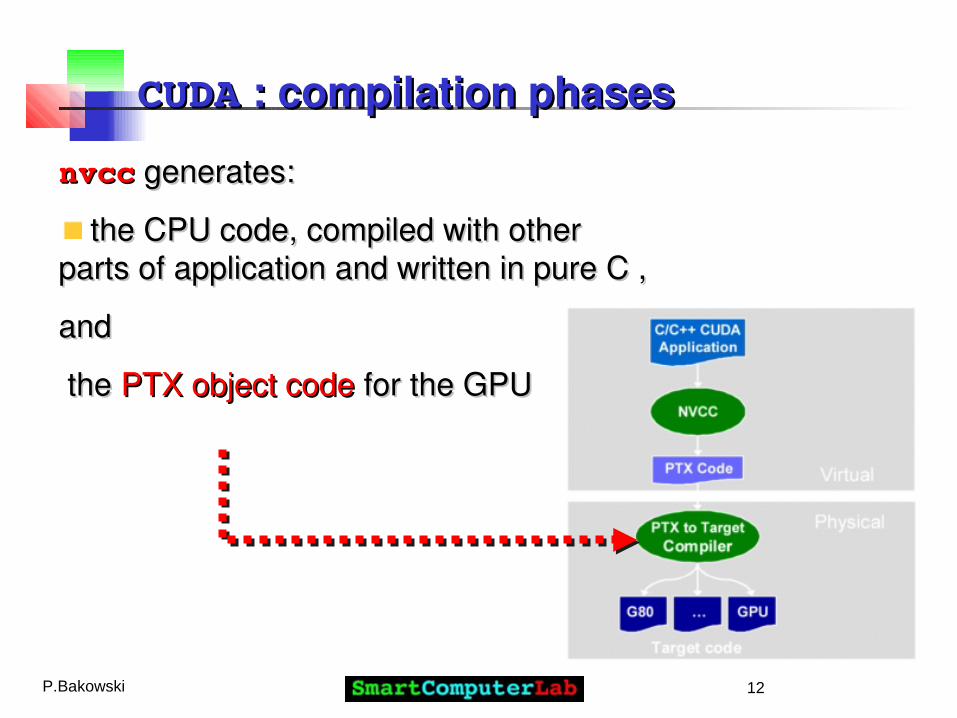
CUDACUDA : compilation phases : compilation phases
TheThe CUDA C code is compiled with CUDA C code is compiled with nvccnvcc, that is a script , that is a script activating other programs: activating other programs: cudacccudacc, , g++g++ , , clcl , etc. , etc.
P.Bakowski 12
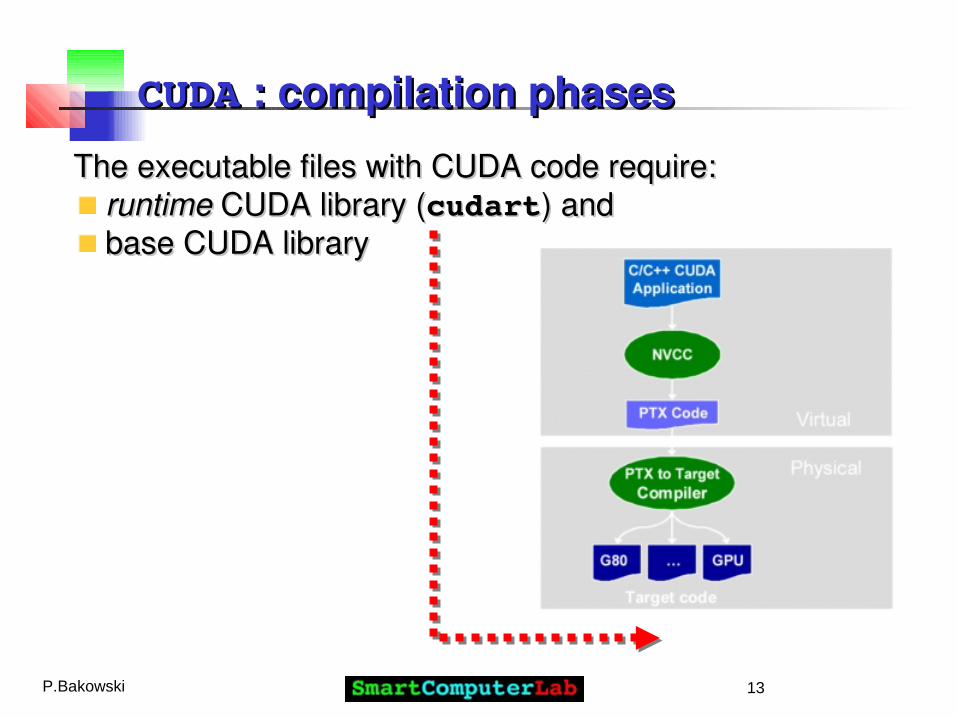
CUDACUDA : compilation phases : compilation phases
nvccnvcc generates: generates:
the CPU code, compiled with other the CPU code, compiled with other parts of application and written in pure C , parts of application and written in pure C ,
and and
the the PTX object codePTX object code for the GPU for the GPU
P.Bakowski 13
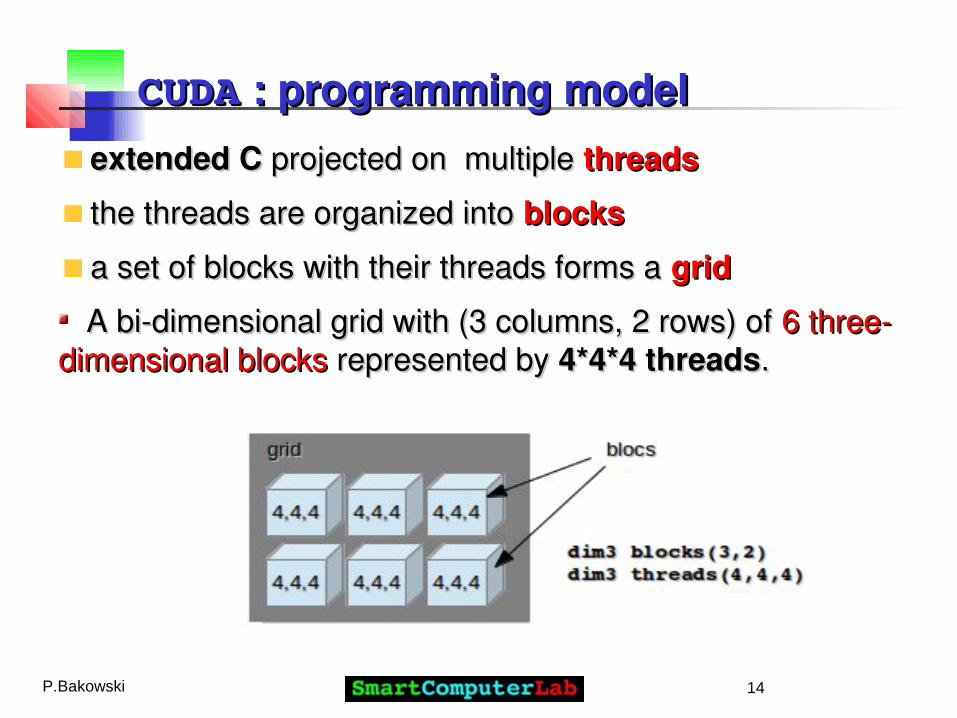
CUDACUDA : compilation phases : compilation phases
The executable files with CUDA code require:The executable files with CUDA code require: runtimeruntime CUDA library ( CUDA library (cudartcudart) and ) and base CUDA librarybase CUDA library
P.Bakowski 14
CUDACUDA : programming model : programming model extended Cextended C projected on multiple projected on multiple threadsthreads
the threads are organized into the threads are organized into blocksblocks
a set of blocks with their threads forms a a set of blocks with their threads forms a gridgrid
A bi-dimensional grid with (3 columns, 2 rows) of A bi-dimensional grid with (3 columns, 2 rows) of 6 three-6 three-dimensional blocksdimensional blocks represented by represented by 4*4*4 threads4*4*4 threads. .

P.Bakowski 15
CUDACUDA : memory model : memory modelGlobalGlobal memory - all SMX and CPU memory - all SMX and CPU
SharedShared memories - the threads running in the same block memories - the threads running in the same block
ConstantConstant memory and memory and TextureTexture memory - all threads memory - all threads globally in globally in read-onlyread-only mode mode
Each thread - Each thread - LocalLocal memory and set of memory and set of registersregisters

P.Bakowski 16
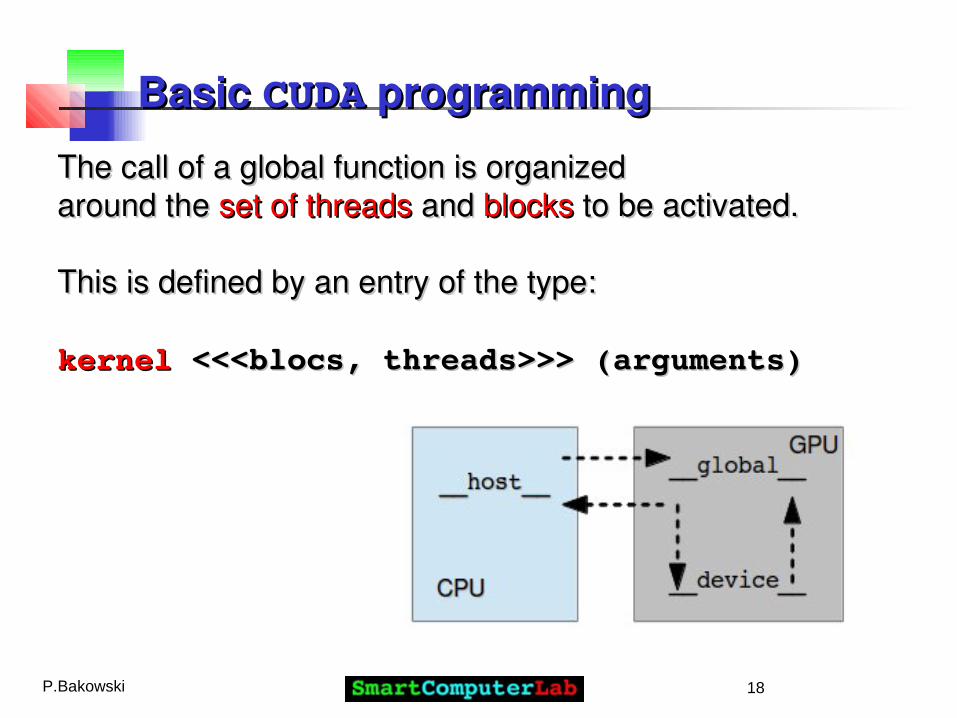
Basic Basic CUDACUDA programming programming
The CUDA programs:The CUDA programs:- - pure Cpure C code for the execution on code for the execution on CPUCPU and and - - extended Cextended C code for the execution on code for the execution on GPUGPU
In this context In this context three typesthree types of functions are defined: of functions are defined:
____hosthost____ running only on the CPU (optional)running only on the CPU (optional)____globalglobal____ running on the GPU, called by the CPUrunning on the GPU, called by the CPU____devicedevice__ __ running on the GPU, called by the GPUrunning on the GPU, called by the GPU

P.Bakowski 17
Basic Basic CUDACUDA programming programming
____hosthost____ runningrunning only on the only on the CPUCPU (optional) (optional)____globalglobal____ runningrunning on the on the GPUGPU, called by the , called by the CPUCPU____devicedevice__ __ runningrunning on the on the GPUGPU, called by the , called by the GPUGPU
The function marked by the prefix The function marked by the prefix ____globalglobal____ is also called is also called kernelkernel..
P.Bakowski 18
Basic Basic CUDACUDA programming programming
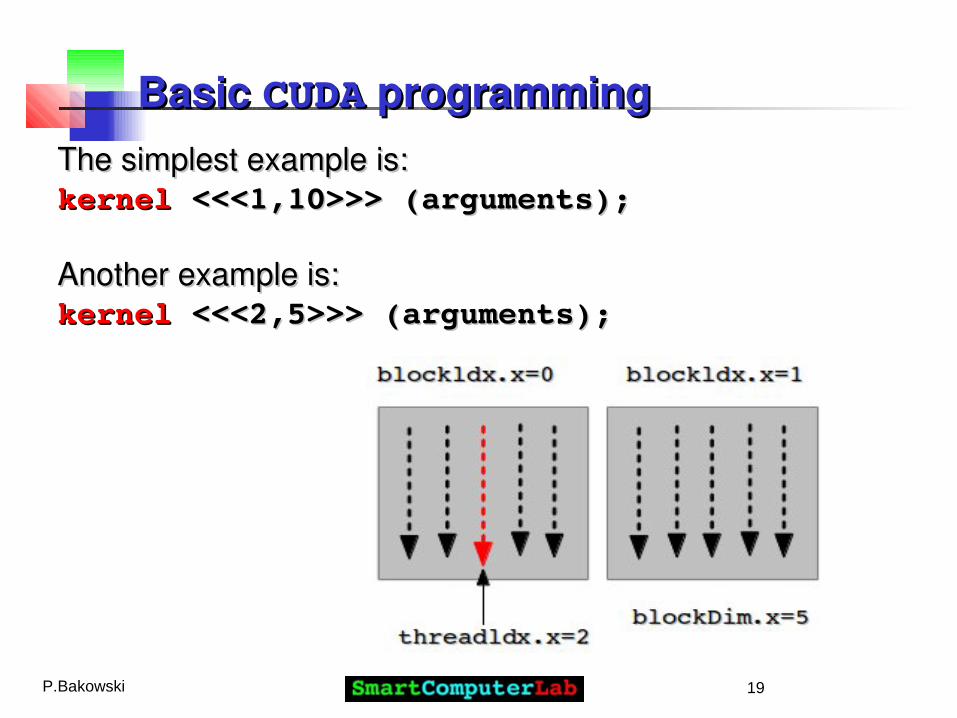
The call of a global function is organized The call of a global function is organized around the around the set of threadsset of threads and and blocksblocks to be activated. to be activated.
This is defined by an entry of the type:This is defined by an entry of the type:
kernelkernel <<<blocs, threads>>> (arguments) <<<blocs, threads>>> (arguments)
P.Bakowski 19
Basic Basic CUDACUDA programming programmingThe simplest example is:The simplest example is:kernelkernel <<<1,10>>> (arguments); <<<1,10>>> (arguments);
Another example is:Another example is:kernelkernel <<<2,5>>> (arguments); <<<2,5>>> (arguments);

P.Bakowski 20
CUDACUDA : kernel structure : kernel structure
The automatic variables are: The automatic variables are: threadIdxthreadIdx, , blockIdxblockIdx, , blockDimblockDim, , gridDimgridDim..For one dimensional organization: For one dimensional organization: threadIdx.xthreadIdx.x,, blockIdx.x blockIdx.x, , blockDim.xblockDim.x, and , and gridDim.xgridDim.x
// GPU kernel for AddVect.Float.cu // GPU kernel for AddVect.Float.cu ____globalglobal__ __ void addVect(float* in1, float* in2, float* out) void addVect(float* in1, float* in2, float* out) { { int i = threadIdx.x + blockIdx.x*blockDim.x; int i = threadIdx.x + blockIdx.x*blockDim.x; out[i] = in1[i] + in2[i]; out[i] = in1[i] + in2[i]; }}

P.Bakowski 21
CUDACUDA : example – CPU side : example – CPU side
int main() int main() { int i=0; { int i=0; float v1[]={1,2,3,4,5,6,7,8,9,10}; float v1[]={1,2,3,4,5,6,7,8,9,10}; float v2[]={1.0,1.1,1.2,1.3,1.4,1.5,1.6,1.7,1.8,1.9}; float v2[]={1.0,1.1,1.2,1.3,1.4,1.5,1.6,1.7,1.8,1.9}; int memsize = sizeof(v1); int memsize = sizeof(v1); int vsize = memsize/sizeof(float); int vsize = memsize/sizeof(float); float res[vsize]; float res[vsize]; float* Cv1; cudaMalloc((void **)&Cv1,memsize); float* Cv1; cudaMalloc((void **)&Cv1,memsize); float* Cv2; cudaMalloc((void **)&Cv2,memsize); float* Cv2; cudaMalloc((void **)&Cv2,memsize); float* Cres; cudaMalloc((void **)&Cres,memsize); float* Cres; cudaMalloc((void **)&Cres,memsize); cudaMemcpy(Cv1,v1,memsize,cudaMemcpy(Cv1,v1,memsize,cudaMemcpyHostToDevicecudaMemcpyHostToDevice); ); cudaMemcpy(Cv2,v2,memsize,cudaMemcpy(Cv2,v2,memsize,cudaMemcpyHostToDevicecudaMemcpyHostToDevice); ); ....

P.Bakowski 22
CUDACUDA : example – CPU side : example – CPU side
.. .. cudaMemcpy(Cv1,v1,memsize,cudaMemcpy(Cv1,v1,memsize,cudaMemcpyHostToDevicecudaMemcpyHostToDevice); ); cudaMemcpy(Cv2,v2,memsize,cudaMemcpy(Cv2,v2,memsize,cudaMemcpyHostToDevicecudaMemcpyHostToDevice); ); addVect<<<addVect<<<22,,vsize/2vsize/2>>>(Cv1,Cv2,Cres); // 2 blocks >>>(Cv1,Cv2,Cres); // 2 blocks cudaMemcpy(res,Cres,memsize,cudaMemcpy(res,Cres,memsize,cudaMemcpyDeviceToHostcudaMemcpyDeviceToHost); ); printf("res= { "); printf("res= { "); for(i=0;i<vsize;i++){printf("%2.2f ",res[i]);} for(i=0;i<vsize;i++){printf("%2.2f ",res[i]);} printf("}\n"); printf("}\n"); }}

P.Bakowski 23
CUDACUDA : Tegra K1 – : Tegra K1 – Zero CopyZero Copy
// Set flag to enable zero copy access// Set flag to enable zero copy accesscudaSetDeviceFlags(cudaSetDeviceFlags(cudaDeviceMapHostcudaDeviceMapHost););// Host Arrays// Host Arraysfloat* float* h_inh_in = NULL; = NULL;float* float* h_outh_out = NULL; = NULL;// Allocate host memory using CUDA allocation calls// Allocate host memory using CUDA allocation callscudaHostAlloc((void **)&cudaHostAlloc((void **)&h_inh_in, sizeIn, , sizeIn, cudaHostAllocMappedcudaHostAllocMapped););cudaHostAlloc((void **)&cudaHostAlloc((void **)&h_outh_out,sizeOut,,sizeOut,cudaHostAllocMappedcudaHostAllocMapped););// Device arrays// Device arraysfloat *float *d_outd_out, *, *d_ind_in;;// Get device pointer from host memory. No allocation or memcpy// Get device pointer from host memory. No allocation or memcpycudaHostGetDevicePointer((void **)&cudaHostGetDevicePointer((void **)&d_ind_in, (void *), (void *)h_inh_in , 0); , 0);cudaHostGetDevicePointer((void **)&cudaHostGetDevicePointer((void **)&d_outd_out, (void *), (void *)h_outh_out, 0);, 0);// Launch the GPU kernel// Launch the GPU kernelkernel<<<blocks, threads>>>(d_out, d_in);kernel<<<blocks, threads>>>(d_out, d_in);// No need to copy d_out back// No need to copy d_out back// Continue processing on host using h_out}// Continue processing on host using h_out}

P.Bakowski 24
CUDACUDA : analysis of a device : analysis of a device { // { // struct struct cudaDevicePropcudaDevicePropchar name [256];char name [256];totalGlobalMem size_t // possible value 2 GBtotalGlobalMem size_t // possible value 2 GBsharedMemPerBlock size_t // possible value 128 KBsharedMemPerBlock size_t // possible value 128 KBregsPerBlock int // possible value 64regsPerBlock int // possible value 64warpSize int //possible value 32warpSize int //possible value 32memPitch size_t;memPitch size_t;maxThreadsPerBlock int // possible value 1024maxThreadsPerBlock int // possible value 1024maxThreadsDim int [3];maxThreadsDim int [3];maxGridSize int [3];maxGridSize int [3];totalConstMem size_t;totalConstMem size_t;int major; // possible value – 1, 2 or int major; // possible value – 1, 2 or 33int minor; // possible value 1,int minor; // possible value 1,22,3,3int clockrate / / possible value 1.2 GHzint clockrate / / possible value 1.2 GHztextureAlignment size_t;textureAlignment size_t;deviceOverlap int;deviceOverlap int;int multiProcessorCount – int multiProcessorCount – 11,2,4,2,4kernelExecTimeoutEnabled int;kernelExecTimeoutEnabled int;}}
P.Bakowski 25
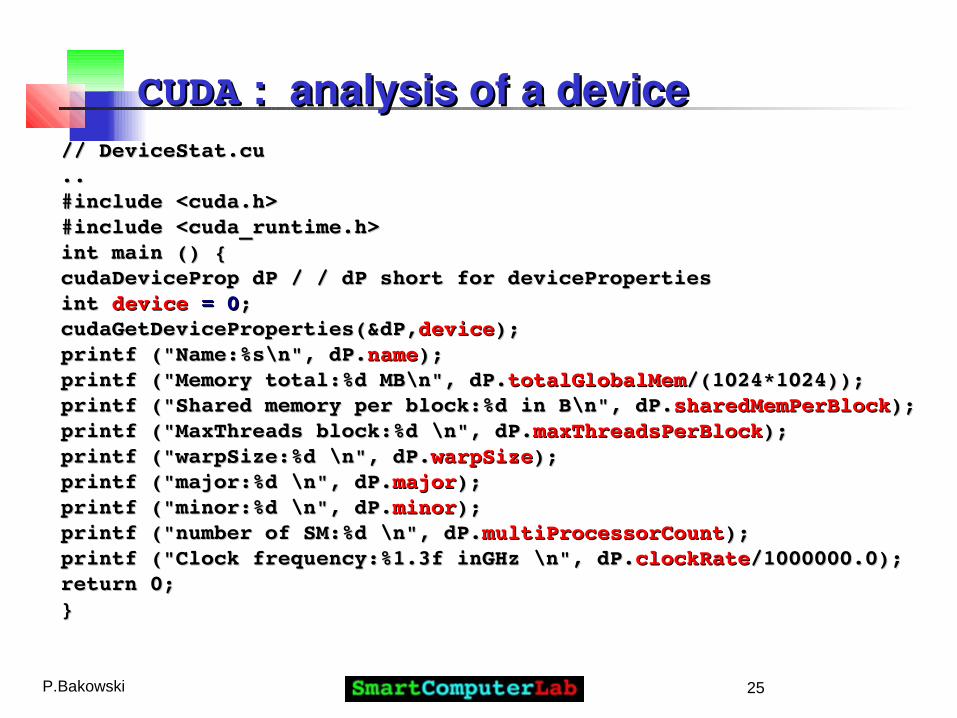
CUDACUDA : analysis of a device : analysis of a device // DeviceStat.cu// DeviceStat.cu.. .. #include <cuda.h> #include <cuda.h> #include <cuda_runtime.h>#include <cuda_runtime.h>int main () {int main () {cudaDeviceProp dP / / dP short for devicePropertiescudaDeviceProp dP / / dP short for devicePropertiesint int devicedevice = 0 = 0;;cudaGetDeviceProperties(&dP,cudaGetDeviceProperties(&dP,devicedevice););printf ("Name:%s\n", dP.printf ("Name:%s\n", dP.namename););printf ("Memory total:%d MB\n", dP.printf ("Memory total:%d MB\n", dP.totalGlobalMemtotalGlobalMem/(1024*1024));/(1024*1024));printf ("Shared memory per block:%d in B\n", dP.printf ("Shared memory per block:%d in B\n", dP.sharedMemPerBlocksharedMemPerBlock););printf ("MaxThreads block:%d \n", dP.printf ("MaxThreads block:%d \n", dP.maxThreadsPerBlockmaxThreadsPerBlock););printf ("warpSize:%d \n", dP.printf ("warpSize:%d \n", dP.warpSizewarpSize););printf ("major:%d \n", dP.printf ("major:%d \n", dP.majormajor););printf ("minor:%d \n", dP.printf ("minor:%d \n", dP.minorminor););printf ("number of SM:%d \n", dP.printf ("number of SM:%d \n", dP.multiProcessorCountmultiProcessorCount););printf ("Clock frequency:%1.3f inGHz \n", dP.printf ("Clock frequency:%1.3f inGHz \n", dP.clockRateclockRate/1000000.0);/1000000.0);return 0;return 0;}}

P.Bakowski 26
CUDACUDA : analysis of a device : analysis of a device
For For Tegra K1Tegra K1 we obtain: we obtain:ubuntu@tegraubuntu:~/cuda$./devicestat ubuntu@tegraubuntu:~/cuda$./devicestat name: name: GK20AGK20A totalGlobalMem: totalGlobalMem: 17461746 in MB in MB shared memory per block: shared memory per block: 4848 in KBytes in KBytes max threads per block: max threads per block: 10241024 warpSize: warpSize: 3232 major: major: 33 minor: minor: 22 multi processor count: multi processor count: 11 clock rate: clock rate: 0.8520.852 in GHz in GHz

P.Bakowski 27
CUDACUDA : matrix multiplication : matrix multiplication
void CPU_matrix_mul(float* a, float* b, float* c) void CPU_matrix_mul(float* a, float* b, float* c) { { for(int i=0;i<DIM;i++) for(int i=0;i<DIM;i++) for(int j=0;j<DIM;j++) for(int j=0;j<DIM;j++) for(int k=0;k<DIM;k++) for(int k=0;k<DIM;k++) c[j+i*DIM] += a[k+j*DIM]*b[j+k*DIM]; c[j+i*DIM] += a[k+j*DIM]*b[j+k*DIM]; }}

P.Bakowski 28
CUDACUDA : matrix multiplication : matrix multiplication#define Width 512 // corresponds to DIM #define Width 512 // corresponds to DIM __global__ void __global__ void matrix_mul(float* dev_A,float* dev_B,float* dev_C,int Width) matrix_mul(float* dev_A,float* dev_B,float* dev_C,int Width) { { // 2D thread ID // 2D thread ID int tx = threadIdx.x; int tx = threadIdx.x; int ty = threadIdx.y; int ty = threadIdx.y; float Pvalue =0; float Pvalue =0; for(int k=0;k<Width;++k) for(int k=0;k<Width;++k) { { float Ael=dev_A[ty*Width + k]; float Ael=dev_A[ty*Width + k]; float Bel=dev_B[k*Width +tx]; float Bel=dev_B[k*Width +tx]; Pvalue += Ael*Bel; Pvalue += Ael*Bel; } } dev_C[ty*Width+tx]=Pvalue; dev_C[ty*Width+tx]=Pvalue; } }
Each product (512*512) is Each product (512*512) is calculated by a separate calculated by a separate thread that adds the products thread that adds the products in 512 steps in 512 steps

P.Bakowski 29
CUDACUDA : performance evaluation : performance evaluationfloat eT; // short for elapsedTimefloat eT; // short for elapsedTimecudaEventcudaEvent_t start, stop;_t start, stop;cudaEventCreate(&start);cudaEventCreate(&start);cudaEventCreate(&stop);cudaEventCreate(&stop);cudaEventRecord(start, 0);cudaEventRecord(start, 0);
// here we call the GPU kernel (or CPU function)// here we call the GPU kernel (or CPU function)
cudaEventRecord(stop,0);cudaEventRecord(stop,0);cudaEventSynchronize(stop);cudaEventSynchronize(stop);cudaEventElapsedTime(&eT,start,stop);cudaEventElapsedTime(&eT,start,stop);
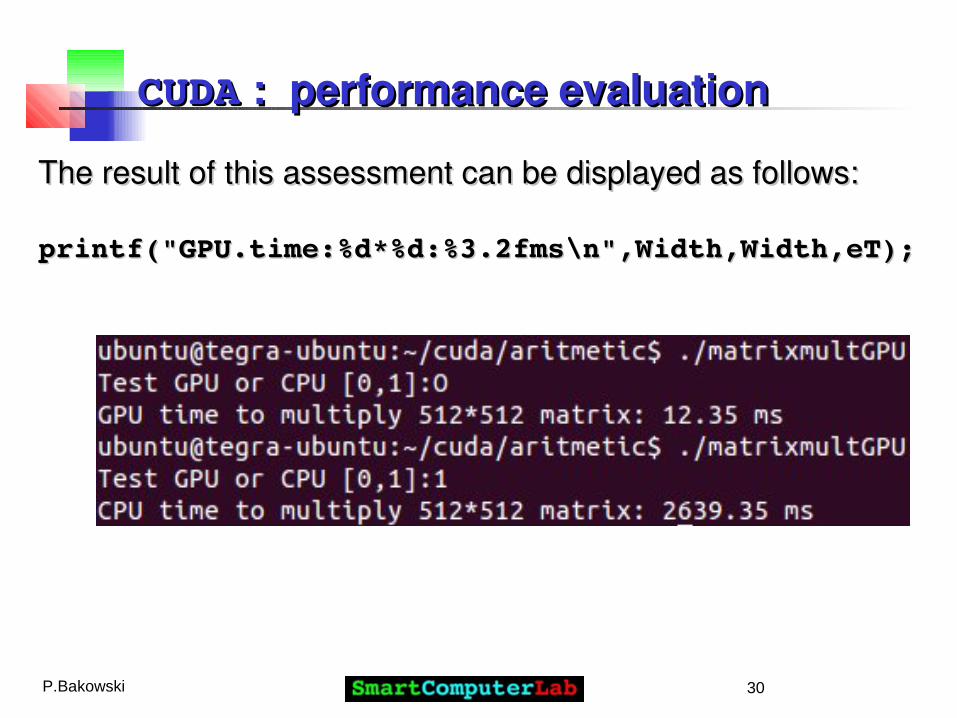
The result of this assessment can be displayed as follows:The result of this assessment can be displayed as follows:
printf("GPU.time:%d*%d:%3.2fms\n",Width,Width,eT);printf("GPU.time:%d*%d:%3.2fms\n",Width,Width,eT);
P.Bakowski 30
CUDACUDA : performance evaluation : performance evaluation
The result of this assessment can be displayed as follows:The result of this assessment can be displayed as follows:
printf("GPU.time:%d*%d:%3.2fms\n",Width,Width,eT);printf("GPU.time:%d*%d:%3.2fms\n",Width,Width,eT);

P.Bakowski 31
CUDACUDA : shared memory & synchronization : shared memory & synchronization
Shared memoryShared memory - threads running in - threads running in the same blockthe same block. . A A scalar product of two vectors: scalar product of two vectors: consecutive elements of consecutive elements of these vectors are multiplied and added to an amount that these vectors are multiplied and added to an amount that ultimately represents the scalar product called ultimately represents the scalar product called dot productdot product..

P.Bakowski 32
CUDACUDA : shared memory & synchronization : shared memory & synchronization
__global__ void dot(float *a, float *b, float *c)__global__ void dot(float *a, float *b, float *c){{____sharedshared__ float cache[threadsPerBlock];__ float cache[threadsPerBlock];int int tidtid = threadIdx.x + blockIdx.x *blockDim.x; = threadIdx.x + blockIdx.x *blockDim.x;int int cIdxcIdx = threadIdx.x ; // = threadIdx.x ; // cIdxcIdx short for cacheIndex short for cacheIndexfloat temp = 0;float temp = 0;// addition of products in blocks of threads// addition of products in blocks of threadswhile(tid) {while(tid) {temp += a[tid] * b[tid];temp += a[tid] * b[tid];// addition of the threads in a block// addition of the threads in a blocktid += blockDim.x*gridDim.x;tid += blockDim.x*gridDim.x;}}cache[cIdx] = temp;cache[cIdx] = temp;____syncthreadssyncthreads();();
// reduction// reduction

P.Bakowski 33
CUDACUDA : shared memory & synchronization : shared memory & synchronization
int i = blockDim.x/2; // vector reduction int i = blockDim.x/2; // vector reduction while (i! = 0)while (i! = 0){{if(cIdx <i) cache[cIdx]+= cache[cIdx+i];if(cIdx <i) cache[cIdx]+= cache[cIdx+i];____syncthreadssyncthreads();();i/=2; i/=2; }}if (cIdx == 0) if (cIdx == 0) c[blockIdx.x] = cache[0]; c[blockIdx.x] = cache[0]; // final product// final product}}
reduction in several stepsreduction in several steps

P.Bakowski 34
CUDACUDA and graphic APIs and graphic APIs
CUDACUDA programs may exploit the graphic functions programs may exploit the graphic functions provided by graphic APIs (provided by graphic APIs (openCVopenCV, , openGLopenGL))
These functions provide necessary image processing These functions provide necessary image processing and generation operations for and generation operations for rasteringrastering and and shadingshading – – rendering of the images on the screen. rendering of the images on the screen.
We use only some We use only some openCVopenCV and and openGLopenGL operations to operations to read/write images from/to files (read/write images from/to files (openCVopenCV) and to display the ) and to display the images directly from GPU memory (images directly from GPU memory (openGLopenGL).).

P.Bakowski 35
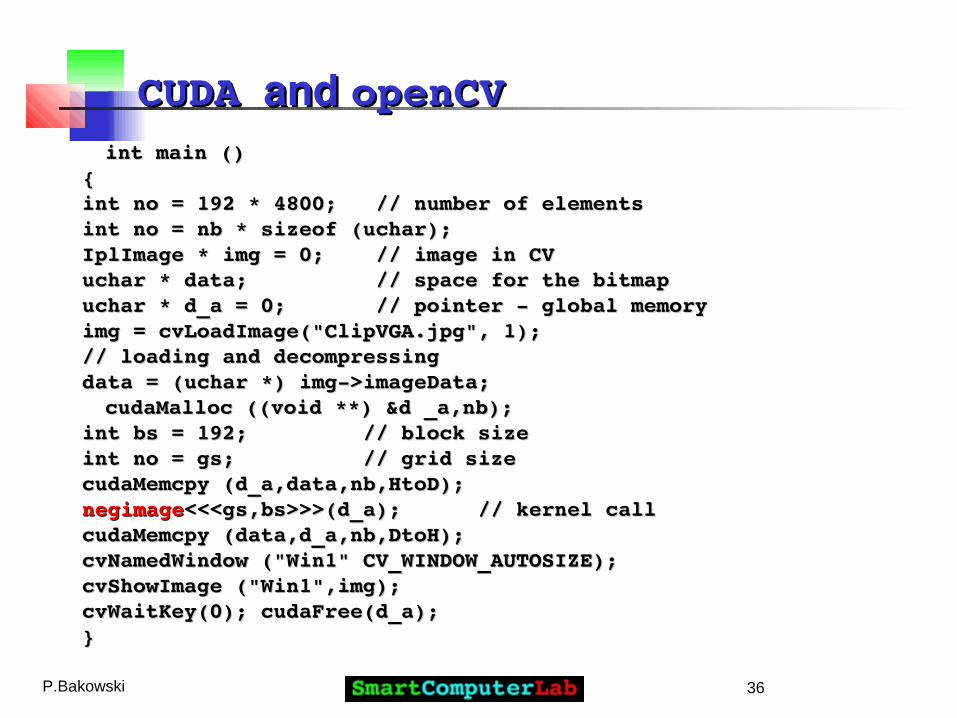
CUDACUDA and and openCVopenCV// NegImage.CV.cu// NegImage.CV.cu
#include <opencv/highgui.h>#include <opencv/highgui.h>#define uchar unsigned char#define uchar unsigned char#define DtoH cudaMemcpyDeviceToHost#define DtoH cudaMemcpyDeviceToHost#define HtoD cudaMemcpyHostToDevice#define HtoD cudaMemcpyHostToDevice
__global__ void negimage (uchar * array)__global__ void negimage (uchar * array){{int i = int i = threadIdx.xthreadIdx.x + blockIdx.x*blockDim.x; + blockIdx.x*blockDim.x;array[i] = 255 array[i]; // byte complementarray[i] = 255 array[i]; // byte complement}}
P.Bakowski 36
CUDACUDA and and openCVopenCVint main ()int main ()
{{int no = 192 * 4800; // number of elementsint no = 192 * 4800; // number of elementsint no = nb * sizeof (uchar);int no = nb * sizeof (uchar);IplImage * img = 0; // image in CVIplImage * img = 0; // image in CVuchar * data; // space for the bitmapuchar * data; // space for the bitmapuchar * d_a = 0; // pointer global memoryuchar * d_a = 0; // pointer global memoryimg = cvLoadImage("ClipVGA.jpg", 1);img = cvLoadImage("ClipVGA.jpg", 1);// loading and decompressing// loading and decompressingdata = (uchar *) img>imageData; data = (uchar *) img>imageData; cudaMalloc ((void **) &d _a,nb);cudaMalloc ((void **) &d _a,nb);
int bs = 192; // block size int bs = 192; // block size int no = gs; // grid sizeint no = gs; // grid sizecudaMemcpy (d_a,data,nb,HtoD);cudaMemcpy (d_a,data,nb,HtoD);negimagenegimage<<<gs,bs>>>(d_a); // kernel call<<<gs,bs>>>(d_a); // kernel callcudaMemcpy (data,d_a,nb,DtoH);cudaMemcpy (data,d_a,nb,DtoH);cvNamedWindow ("Win1" CV_WINDOW_AUTOSIZE);cvNamedWindow ("Win1" CV_WINDOW_AUTOSIZE);cvShowImage ("Win1",img);cvShowImage ("Win1",img);cvWaitKey(0); cudaFree(d_a);cvWaitKey(0); cudaFree(d_a);}}
P.Bakowski 37
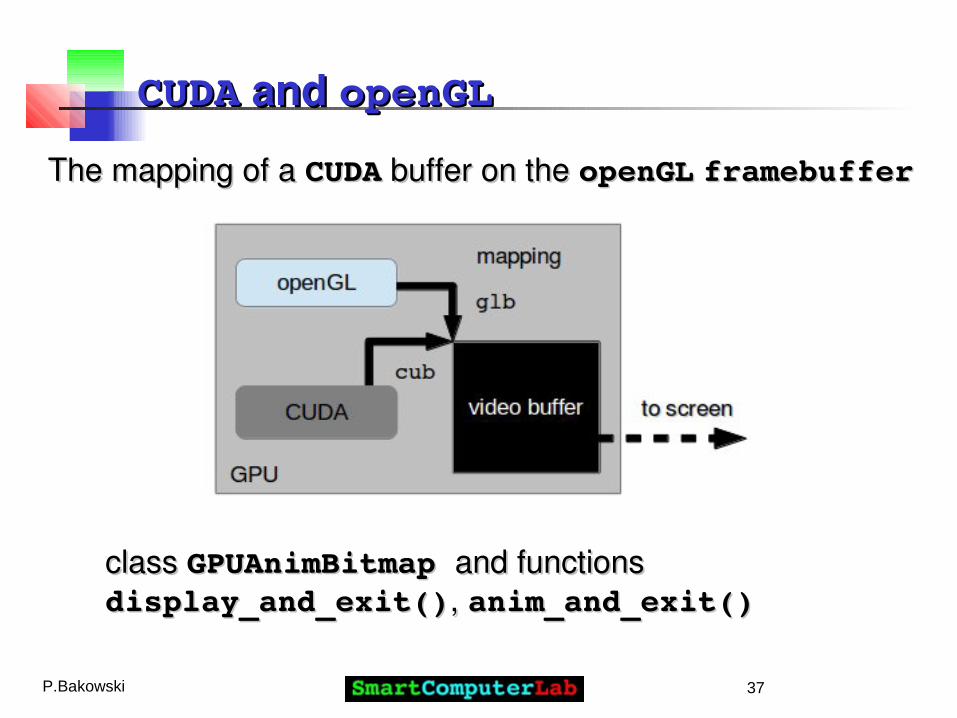
CUDACUDA and and openGLopenGL
The mapping of a The mapping of a CUDACUDA buffer on the buffer on the openGLopenGL framebufferframebuffer
classclass GPUAnimBitmap GPUAnimBitmap and functionsand functions display_and_exit()display_and_exit(),, anim_and_exit()anim_and_exit()

P.Bakowski 38
CUDACUDA and and openGLopenGL
int main( int argc, char **argv ) { int main( int argc, char **argv ) { GPUAnimBitmap bitmap( DIMX, DIMY, NULL ); GPUAnimBitmap bitmap( DIMX, DIMY, NULL ); bitmap.bitmap.displaydisplay_and_exit_and_exit( ( (void(*(uchar4*,void*))(void(*(uchar4*,void*))generate_framegenerate_frame,NULL); ,NULL); }}
int main( void ) { int main( void ) { GPUAnimBitmap bitmap(DIMX,DIMY,NULL ); GPUAnimBitmap bitmap(DIMX,DIMY,NULL ); bitmap.bitmap.animanim_and_exit_and_exit((void(*)((void(*)(uchar4*,void*,(uchar4*,void*,intint))generate_frame,NULL); ))generate_frame,NULL); } }
clock tickclock tick

P.Bakowski 39
SummarySummary
Evolution of massive multiprocessing (multi-core)Evolution of massive multiprocessing (multi-core)
GPUs – independent and integrated (embedded)GPUs – independent and integrated (embedded)
NVIDIA Tegra K1 architectureNVIDIA Tegra K1 architecture
NVIDIA and NVIDIA and CUDACUDA
CUDACUDA processing and memory model processing and memory model
a few simple examplesa few simple examples
CUDACUDA - - openCVopenCV and and openGLopenGL





























