Embed Size (px)
Citation preview

Text Processing of Social Media I Saarland University (8/7/2014)
Text Processing of Social Media IOverview, Language Content Analysis, Language
Identification
Timothy Baldwin

Text Processing of Social Media I Saarland University (8/7/2014)
Talk Outline1 Overview2 Social Media 101
IntroductionThe Appeals/Challenges of Social Media for NLP
3 Cross-comparison of the Language Content ofSocial Media Sources
BackgroundCorporaIntra-Corpus AnalysisInter-Corpus AnalysisConcluding Remarks
4 Language Identification over Social MediaBackgroundDatasetsEvaluation

Text Processing of Social Media I Saarland University (8/7/2014)
Structure of the Lecture Series
� Three lectures on social media and NLP, which attempts toprovide a cross-section of current research:
� Part 1: overview of social media and NLP; cross-sitecomparison of language content; language identificationover social media
� Part 2: lexical normalisation; user geolocation; TwitterPOS tagging
� Part 3: semantic and discourse analysis of social media;user profiling; social media applications; restrictions andethics of social media usage
� “Unashamedly” egocentric view of social media and NLP

Text Processing of Social Media I Saarland University (8/7/2014)
Talk Outline1 Overview2 Social Media 101
IntroductionThe Appeals/Challenges of Social Media for NLP
3 Cross-comparison of the Language Content ofSocial Media Sources
BackgroundCorporaIntra-Corpus AnalysisInter-Corpus AnalysisConcluding Remarks
4 Language Identification over Social MediaBackgroundDatasetsEvaluation

Text Processing of Social Media I Saarland University (8/7/2014)
What is Social Media?
� According to Wikipedia (7/7/2014):Social media is the social interaction among people in which theycreate, share or exchange information and ideas in virtual commu-nities and networks. Andreas Kaplan and Michael Haenlein definesocial media as “a group of Internet-based applications that buildon the ideological and technological foundations of Web 2.0, andthat allow the creation and exchange of user-generated content.”
WarningThe examples and perspective in this article deal primarily withthe United States and do not represent a worldwide view of thesubject.

Text Processing of Social Media I Saarland University (8/7/2014)
What is Social Media?
� According to Wikipedia (7/7/2014):Social media is the social interaction among people in which theycreate, share or exchange information and ideas in virtual commu-nities and networks. Andreas Kaplan and Michael Haenlein definesocial media as “a group of Internet-based applications that buildon the ideological and technological foundations of Web 2.0, andthat allow the creation and exchange of user-generated content.”
WarningThe examples and perspective in this article deal primarily withthe United States and do not represent a worldwide view of thesubject.
Text Processing of Social Media I Saarland University (8/7/2014)
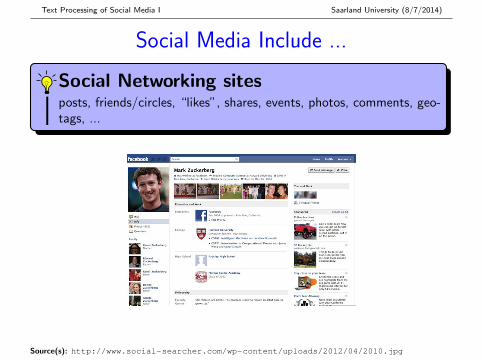
Social Media Include ...
Social Networking sitesposts, friends/circles, “likes”, shares, events, photos, comments, geo-tags, ...
Source(s): http://www.social-searcher.com/wp-content/uploads/2012/04/2010.jpg
Text Processing of Social Media I Saarland University (8/7/2014)
Social Media Include ...
Micro-blogsposts, followers/followees, shares, hashtagging, geotags, ...
Source(s): http://itunes.apple.com/us/app/twitter/
Text Processing of Social Media I Saarland University (8/7/2014)
Social Media Include ...
Web user forumsposts, threading, followers/followees, ...
Source(s): http://forums.cnet.com/7723-6617_102-570394/ubuntu-running-minecraft/
Text Processing of Social Media I Saarland University (8/7/2014)
Social Media Include ...
Wikisposts, versioning, linking, tagging, ...
Source(s): http://en.wikipedia.org/wiki/Social_media

Text Processing of Social Media I Saarland University (8/7/2014)
Source(s): http://xkcd.com/802/

Text Processing of Social Media I Saarland University (8/7/2014)
Source(s): http://www.domo.com/learn/data-never-sleeps-2

Text Processing of Social Media I Saarland University (8/7/2014)
Common Features of Social Media
� Posts
� Social network (explicit or implicit)
� Cross-post/user linking
� Social tagging
� Comments
� Likes/favourites/starring/...
� Author information, and linking to user profile features
� Aggregation/ease of access

Text Processing of Social Media I Saarland University (8/7/2014)
Common Features of Social Media
� Posts
� Social network (explicit or implicit)
� Cross-post/user linking
� Social tagging
� Comments
� Likes/favourites/starring/...
� Author information, and linking to user profile features
� Aggregation/ease of access

Text Processing of Social Media I Saarland University (8/7/2014)
Research on Social Media Data
� Social network analysis
� Friendship prediction/recommendation
� Search over social media data
� Social influence/dynamics
� Information dispersion
� Text mining/language technology variously ...

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Edited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!
Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
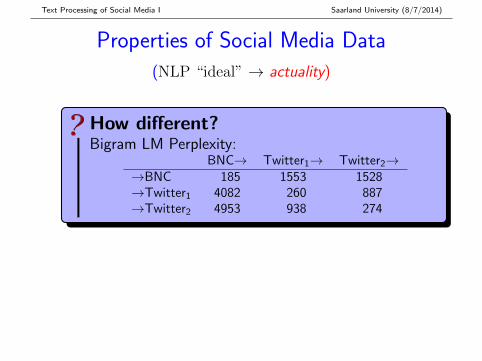
How different?Bigram LM Perplexity:
BNC→ Twitter1→ Twitter2→→BNC 185 1553 1528→Twitter1 4082 260 887→Twitter2 4953 938 274
� Streamed data� Short documents; very little context� Little language, potentially lots of other context� All over the place� What’s a sentence?� Yer what?� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Static data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text� Streamed data
Challenges of Streaming Datathroughput guaranteesbatch vs. streamed processing of data (e.g. for topicmodelling)potential need for “incremental” models (with abilityto “forget” bursty old data)
� Short documents; very little context� Little language, potentially lots of other context� All over the place� What’s a sentence?� Yer what?� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Long(ish) documents; plenty of context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
Document ContextHard to adjust document-level priors when little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� All context is language context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text� Streamed data� Short documents; very little context� Little language, potentially lots of other context
Priors, priors everywhereuser priorsuser-declared metadata priorslocation priorssocial network-based priorshashtag priorstimezone priorsimplicit social networks (retweets, user mentions, ...)
...
� All over the place� What’s a sentence?� Yer what?� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� Well-defined domain/genre
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� Sentence tokenisation
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Grammaticality
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Most of what glitters is English (and if your method canhandle one language, it can handle ’em all)

Text Processing of Social Media I Saarland University (8/7/2014)
Properties of Social Media Data
(NLP “ideal” → actuality)
� Unedited text
� Streamed data
� Short documents; very little context
� Little language, potentially lots of other context
� All over the place
� What’s a sentence?
� Yer what?
� Anything goes — lots of languages, multilingual documents,ad hoc spelling, mix of language and markup ... languageanarchy!

Text Processing of Social Media I Saarland University (8/7/2014)
Observation/Questions
� Much of the work that is currently being carried out oversocial media data doesn’t make use of NLP
� Are NLP methods not suited to social media analysis?� Is social media data too challenging for modern-day NLP?� Are simple term search-based methods sufficient for social
media analysis, i.e. is NLP overkill for social media?

Text Processing of Social Media I Saarland University (8/7/2014)
Observation/Questions
� Much of the work that is currently being carried out oversocial media data doesn’t make use of NLP
� Are NLP methods not suited to social media analysis?
� Is social media data too challenging for modern-day NLP?� Are simple term search-based methods sufficient for social
media analysis, i.e. is NLP overkill for social media?

Text Processing of Social Media I Saarland University (8/7/2014)
Observation/Questions
� Much of the work that is currently being carried out oversocial media data doesn’t make use of NLP
� Are NLP methods not suited to social media analysis?� Is social media data too challenging for modern-day NLP?
� Are simple term search-based methods sufficient for socialmedia analysis, i.e. is NLP overkill for social media?

Text Processing of Social Media I Saarland University (8/7/2014)
Observation/Questions
� Much of the work that is currently being carried out oversocial media data doesn’t make use of NLP
� Are NLP methods not suited to social media analysis?� Is social media data too challenging for modern-day NLP?� Are simple term search-based methods sufficient for social
media analysis, i.e. is NLP overkill for social media?

Text Processing of Social Media I Saarland University (8/7/2014)
Possible Ways Forward
� Assuming that the issue is the accuracy of NLP tools oversocial media data, there are two ways to proceed:
� “adapt” the data to the NLP tools through preprocessingof various forms
� “adapt” the NLP tools to the data through “domain”(de-)adaptation

Text Processing of Social Media I Saarland University (8/7/2014)
Possible Ways Forward
� Assuming that the issue is the accuracy of NLP tools oversocial media data, there are two ways to proceed:
� “adapt” the data to the NLP tools through preprocessingof various forms
� “adapt” the NLP tools to the data through “domain”(de-)adaptation

Text Processing of Social Media I Saarland University (8/7/2014)
Possible Ways Forward
� Assuming that the issue is the accuracy of NLP tools oversocial media data, there are two ways to proceed:
� “adapt” the data to the NLP tools through preprocessingof various forms
� “adapt” the NLP tools to the data through “domain”(de-)adaptation

Text Processing of Social Media I Saarland University (8/7/2014)
Talk Outline1 Overview2 Social Media 101
IntroductionThe Appeals/Challenges of Social Media for NLP
3 Cross-comparison of the Language Content ofSocial Media Sources
BackgroundCorporaIntra-Corpus AnalysisInter-Corpus AnalysisConcluding Remarks
4 Language Identification over Social MediaBackgroundDatasetsEvaluation
Text Processing of Social Media I Saarland University (8/7/2014)
Background
� Various claims made about social media text being“noisy”
... how “noisy” are we talking, and in what ways?
... are different social media sources equally “noisy”?
... ultimately, are the differences between social mediasources all that great?
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Background
� Various claims made about social media text being“noisy”... but
... how “noisy” are we talking, and in what ways?
... are different social media sources equally “noisy”?
... ultimately, are the differences between social mediasources all that great?
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Background
� Various claims made about social media text being“noisy”... but
... how “noisy” are we talking, and in what ways?
... are different social media sources equally “noisy”?
... ultimately, are the differences between social mediasources all that great?
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Background
� Various claims made about social media text being“noisy”... but
... how “noisy” are we talking, and in what ways?
... are different social media sources equally “noisy”?
... ultimately, are the differences between social mediasources all that great?
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Outline of Approach
1 Assemble corpora across a spectrum of social media sources+ BNC
2 Apply a range of analyses to each individual social mediasource
3 Perform comparative analysis between different corpuspairings
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Outline of Approach
1 Assemble corpora across a spectrum of social media sources+ BNC
2 Apply a range of analyses to each individual social mediasource
3 Perform comparative analysis between different corpuspairings
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Outline of Approach
1 Assemble corpora across a spectrum of social media sources+ BNC
2 Apply a range of analyses to each individual social mediasource
3 Perform comparative analysis between different corpuspairings
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Corpora
� Social media sources targeted in this research:
1 Twitter: micro-blog posts from Twitter2 Comments: comments from YouTube3 Blogs: blog posts from Spinn3r dataset4 Forums: forum posts from popular forums5 Wikipedia: documents from English Wikipedia
� As a balanced, non-social media counterpoint corpus:
6 BNC: written portion of British National Corpus
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
� 1M posts from garden hose feed of Twitter, in the form oftwo sub-corpora collected at different times:
A Twitter-1 = 22 September 2011B Twitter-2 = 22 February 2012
� Max document length = 140 characters; single author perdocument; no post-editing
Corpus DocumentsAverage wordsper document
Twitter-1 1,000,000 11.8±8.3Twitter-2 1,000,000 11.6±8.1

Text Processing of Social Media I Saarland University (8/7/2014)
Comments
� All comments associate with YouTube videos in dataset ofO’Callaghan et al. [2012]
� Max document length = 500 characters; single author perdocument; no post-editing
Corpus DocumentsAverage wordsper document
Comments 874,772 15.8±18.6

Text Processing of Social Media I Saarland University (8/7/2014)
Forums
� 1M randomly-selected posts from top-1000 vBulletin-basedforums in the Big Boards forum ranking
� Max document length = site variable; single author perdocument; option for post-editing
Corpus DocumentsAverage wordsper document
Forums 1,000,000 23.2±29.3

Text Processing of Social Media I Saarland University (8/7/2014)
Blogs
� 1M randomly-selected documents from Spinn3r dataset(ICWSM-2011 tier-one)
� Max document length = none; single author per document;post-editing possible
Corpus DocumentsAverage wordsper document
Blogs 1,000,000 147.7±339.3

Text Processing of Social Media I Saarland University (8/7/2014)
Wikipedia
� 200K randomly-selected documents (≥ 500 bytes) fromEnglish Wikipedia
� Mediawiki markup removed with wikidump
� Max document length = none; multiple authors perdocument; post-editing possible
Corpus DocumentsAverage wordsper document
Wikipedia 200,000 281.2±363.8

Text Processing of Social Media I Saarland University (8/7/2014)
BNC
� All documents in written portion of the British NationalCorpus
� Max document length = none; mostly single-authordocuments; post-editing possible
Corpus DocumentsAverage wordsper document
BNC 3141 31609.0±30424.3

Text Processing of Social Media I Saarland University (8/7/2014)
Corpus Preprocessing
� We apply the following preprocessing to all corpora:
1 language identification with langid.py; non-Englishdocuments filtered from corpus
2 sentence-tokenise with tokenizer, based on findings ofRead et al. [2012]
3 tokenise and POS tag with TweetNLP 0.34 remove all “non-linguistic” tokens, on basis of TweetNLP
@helloworld Swinging with the #besties! #awesome⇓
@helloworld Swinging with the #besties! #awesome
� Extract a random sub-sample of 4K sentences
Source(s): http://www.cis.uni-muenchen.de/˜wastl/misc/; Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
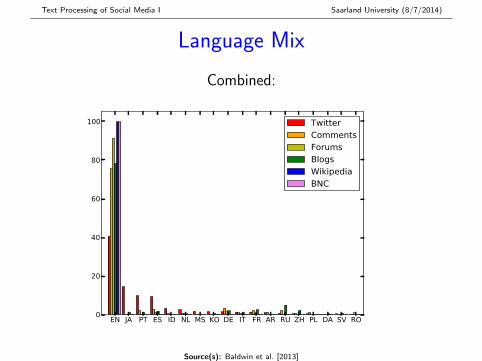
Language Mix
Combined:
EN JA PT ES ID NL MS KO DE IT FR AR RU ZH PL DA SV RO0
20
40
60
80
100 TwitterCommentsForumsBlogsWikipediaBNC
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
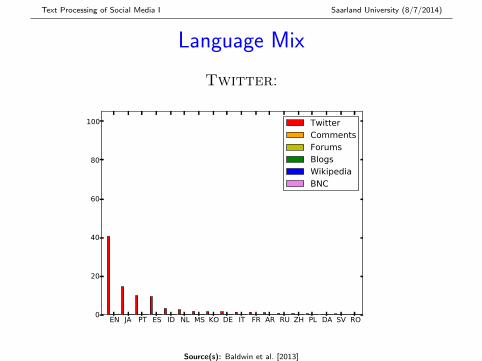
Language Mix
Twitter:
EN JA PT ES ID NL MS KO DE IT FR AR RU ZH PL DA SV RO0
20
40
60
80
100 TwitterCommentsForumsBlogsWikipediaBNC
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
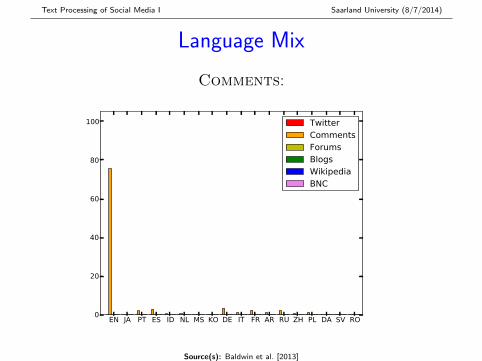
Language Mix
Comments:
EN JA PT ES ID NL MS KO DE IT FR AR RU ZH PL DA SV RO0
20
40
60
80
100 TwitterCommentsForumsBlogsWikipediaBNC
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
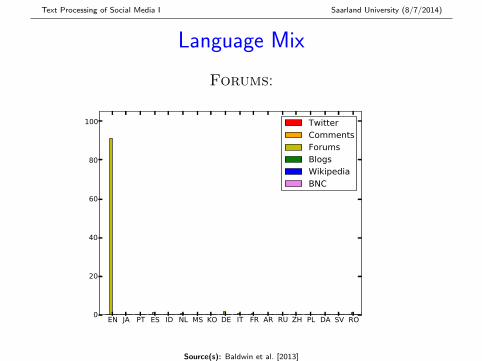
Language Mix
Forums:
EN JA PT ES ID NL MS KO DE IT FR AR RU ZH PL DA SV RO0
20
40
60
80
100 TwitterCommentsForumsBlogsWikipediaBNC
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
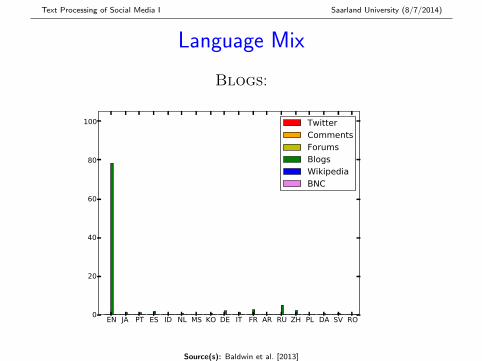
Language Mix
Blogs:
EN JA PT ES ID NL MS KO DE IT FR AR RU ZH PL DA SV RO0
20
40
60
80
100 TwitterCommentsForumsBlogsWikipediaBNC
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
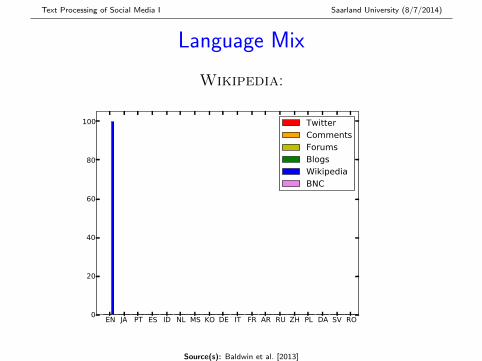
Language Mix
Wikipedia:
EN JA PT ES ID NL MS KO DE IT FR AR RU ZH PL DA SV RO0
20
40
60
80
100 TwitterCommentsForumsBlogsWikipediaBNC
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
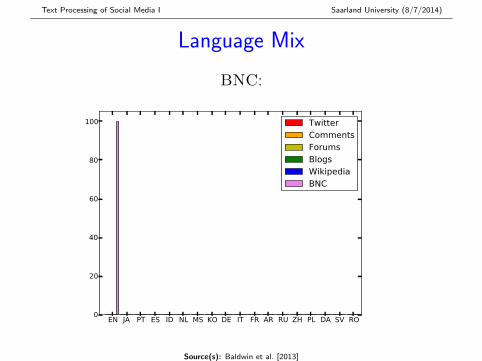
Language Mix
BNC:
EN JA PT ES ID NL MS KO DE IT FR AR RU ZH PL DA SV RO0
20
40
60
80
100 TwitterCommentsForumsBlogsWikipediaBNC
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Language Mix: Overall Findings
� Twitter most multilingual (> 50% non-EN), followed byComments, Blogs and Forums
� All 97 languages modelled by langid.py found inTwitter and Comments
... from here on, all analyses are based on the 4K ENsentence subset for each corpus
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Language Mix: Overall Findings
� Twitter most multilingual (> 50% non-EN), followed byComments, Blogs and Forums
� All 97 languages modelled by langid.py found inTwitter and Comments
... from here on, all analyses are based on the 4K ENsentence subset for each corpus
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
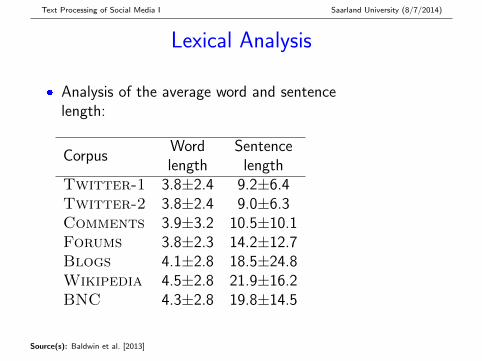
Lexical Analysis
� Analysis of the average word and sentencelength:
CorpusWord Sentencelength length
Twitter-1 3.8±2.4 9.2±6.4Twitter-2 3.8±2.4 9.0±6.3Comments 3.9±3.2 10.5±10.1Forums 3.8±2.3 14.2±12.7Blogs 4.1±2.8 18.5±24.8Wikipedia 4.5±2.8 21.9±16.2BNC 4.3±2.8 19.8±14.5
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
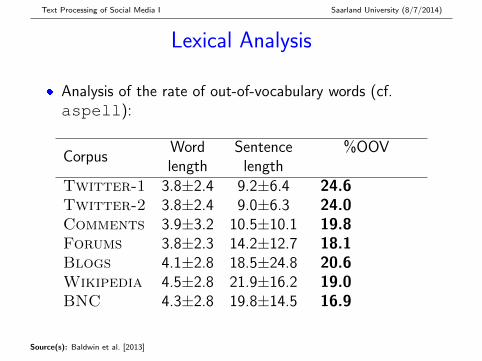
Lexical Analysis
� Analysis of the rate of out-of-vocabulary words (cf.aspell):
CorpusWord Sentence %OOVlength length
Twitter-1 3.8±2.4 9.2±6.4 24.6Twitter-2 3.8±2.4 9.0±6.3 24.0Comments 3.9±3.2 10.5±10.1 19.8Forums 3.8±2.3 14.2±12.7 18.1Blogs 4.1±2.8 18.5±24.8 20.6Wikipedia 4.5±2.8 21.9±16.2 19.0BNC 4.3±2.8 19.8±14.5 16.9
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
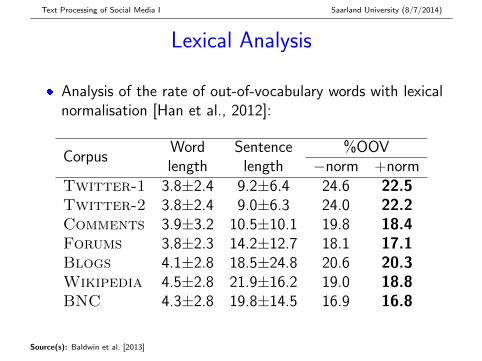
Lexical Analysis
� Analysis of the rate of out-of-vocabulary words with lexicalnormalisation [Han et al., 2012]:
CorpusWord Sentence %OOVlength length −norm +norm
Twitter-1 3.8±2.4 9.2±6.4 24.6 22.5Twitter-2 3.8±2.4 9.0±6.3 24.0 22.2Comments 3.9±3.2 10.5±10.1 19.8 18.4Forums 3.8±2.3 14.2±12.7 18.1 17.1Blogs 4.1±2.8 18.5±24.8 20.6 20.3Wikipedia 4.5±2.8 21.9±16.2 19.0 18.8BNC 4.3±2.8 19.8±14.5 16.9 16.8
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Lexical Analysis: Overall Findings
� Slight difference in average word length; much largerdifference in average sentence length:{Wikipedia,BNC,Blogs } > Forums >{Comments,Twitter }
� With OOV%, Twitter-1/2 is the obvious outlier,although we found around half of this effect to beameliorated through lexical normalisation
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Grammaticality
� Analyse the grammaticality of sentences in the differentcorpora using the English Resource Grammar (ERG), judgedas:
1 strict (e.g. Saarbrucken is great.) vs. informal (e.g.saarbrucken is great)
2 full sentence (e.g. I am loving Saarbrucken) vs. fragment(e.g. Loving Saarbrucken)
� Modified the unknown word handling in the ERG to acceptPOS tags from TweetNLP 0.3, and also modified theTweetNLP tokenisation slightly
� NB results not representative of “full-strength” ERG for agiven data source
Source(s): Baldwin et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
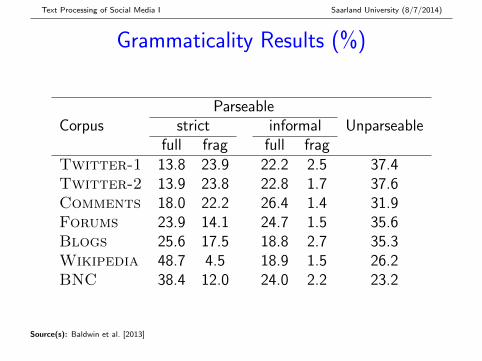
Grammaticality Results (%)
CorpusParseable
Unparseablestrict informalfull frag full frag
Twitter-1 13.8 23.9 22.2 2.5 37.4Twitter-2 13.9 23.8 22.8 1.7 37.6Comments 18.0 22.2 26.4 1.4 31.9Forums 23.9 14.1 24.7 1.5 35.6Blogs 25.6 17.5 18.8 2.7 35.3Wikipedia 48.7 4.5 18.9 1.5 26.2BNC 38.4 12.0 24.0 2.2 23.2
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Grammaticality Findings
� Wikipedia and BNC more grammatical than othersources; Comments > {Blogs, Forums } > Twitter
� More fragments in Twitter, Comments
� Ungrammaticality underestimated, esp. for Blogs,Wikipedia and BNC
� Preprocessing is a common cause of parser failure, withsentence tokenisation being the primary contributor
� Overall, syntactic “noise” in social media relatively minor;relative constant level of syntactic “noise” in Twitter,Comments and Forums
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Corpus Similarity
� Next, we compare the (original) corpora with one anotherby:
1 χ2-based corpus homogeneity [Kilgarriff, 2001]2 trigram language model-based perplexity
Source(s): Baldwin et al. [2013]
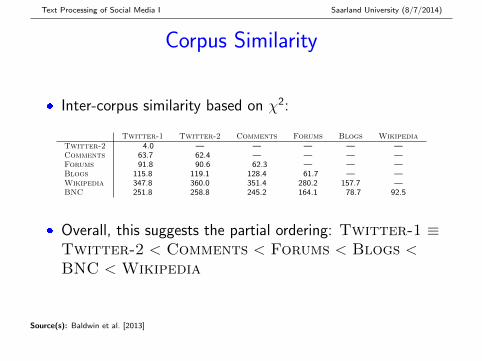
Text Processing of Social Media I Saarland University (8/7/2014)
Corpus Similarity
� Inter-corpus similarity based on χ2:
Twitter-1 Twitter-2 Comments Forums Blogs WikipediaTwitter-2 4.0 — — — — —Comments 63.7 62.4 — — — —Forums 91.8 90.6 62.3 — — —Blogs 115.8 119.1 128.4 61.7 — —Wikipedia 347.8 360.0 351.4 280.2 157.7 —BNC 251.8 258.8 245.2 164.1 78.7 92.5
� Overall, this suggests the partial ordering: Twitter-1 ≡Twitter-2 < Comments < Forums < Blogs <BNC < Wikipedia
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Corpus Homogeneity
� Corpus-level homogeneity based on χ2:
Corpus HomogeneityTwitter-1 549Twitter-2 553Comments 613Forums 570Blogs 716Wikipedia 575BNC 542
� Blogs are much more diverse in (lexical) content thanother sources
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Language Model-based Similarity
BNCWikipedia
BlogsForums
CommentsTwitter-2Twitter-1
Forums
BNCWikipedia
BlogsForums
CommentsTwitter-2Twitter-1
Comments
BNCWikipedia
BlogsForums
CommentsTwitter-2Twitter-1
Twitter-2
BNCWikipedia
BlogsForums
CommentsTwitter-2Twitter-1
Twitter-1
Perplexity
BNCWikipedia
BlogsForums
CommentsTwitter-2Twitter-1
500 1000 1500
BNC
BNCWikipedia
BlogsForums
CommentsTwitter-2Twitter-1
Wikipedia
BNCWikipedia
BlogsForums
CommentsTwitter-2Twitter-1
Blogs
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Corpus Similarity Findings
� Overall, there appears to be a partial ordering in corpussimilarity: Twitter-1/2 ≡ Comments < Forums <Blogs < BNC < Wikipedia
� Internal homogeneity is broadly similar across social mediasources, with Blogs as an outlier
� The “median” social media source (in terms of relativesimilarity to other sources) is Forums
� There is an observable difference in content betweenTwitter over different time periods, although it isrelatively modest
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Summary of Overall Findings I
� Large-scale analysis of a range of social media sources (+BNC), in terms of language distribution, lexical analysis,grammaticality, and two measures of corpus similarity
� How “noisy” are social media sources, and in what ways?
� vastly differing levels of multilingual “noise”� some lexical noise (esp. Twitter), but POS tagging +
lexical normalisation significantly reduces it� certainly grammatical “noise” (esp. Twitter-1/2), but
under preprocessing, the relative differences aren’t thatgreat
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Summary of Overall Findings I
� Large-scale analysis of a range of social media sources (+BNC), in terms of language distribution, lexical analysis,grammaticality, and two measures of corpus similarity
� How “noisy” are social media sources, and in what ways?
� vastly differing levels of multilingual “noise”� some lexical noise (esp. Twitter), but POS tagging +
lexical normalisation significantly reduces it� certainly grammatical “noise” (esp. Twitter-1/2), but
under preprocessing, the relative differences aren’t thatgreat
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Summary of Overall Findings I
� Large-scale analysis of a range of social media sources (+BNC), in terms of language distribution, lexical analysis,grammaticality, and two measures of corpus similarity
� How “noisy” are social media sources, and in what ways?� vastly differing levels of multilingual “noise”
� some lexical noise (esp. Twitter), but POS tagging +lexical normalisation significantly reduces it
� certainly grammatical “noise” (esp. Twitter-1/2), butunder preprocessing, the relative differences aren’t thatgreat
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Summary of Overall Findings I
� Large-scale analysis of a range of social media sources (+BNC), in terms of language distribution, lexical analysis,grammaticality, and two measures of corpus similarity
� How “noisy” are social media sources, and in what ways?� vastly differing levels of multilingual “noise”� some lexical noise (esp. Twitter), but POS tagging +
lexical normalisation significantly reduces it
� certainly grammatical “noise” (esp. Twitter-1/2), butunder preprocessing, the relative differences aren’t thatgreat
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Summary of Overall Findings I
� Large-scale analysis of a range of social media sources (+BNC), in terms of language distribution, lexical analysis,grammaticality, and two measures of corpus similarity
� How “noisy” are social media sources, and in what ways?� vastly differing levels of multilingual “noise”� some lexical noise (esp. Twitter), but POS tagging +
lexical normalisation significantly reduces it� certainly grammatical “noise” (esp. Twitter-1/2), but
under preprocessing, the relative differences aren’t thatgreat
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Summary of Overall Findings II
� Are different social media sources equally “noisy”?
� no; Twitter definitely on the noisy end of the spectrum,and Wikipedia “cleaner” than BNC, but the spread isless than you might think
� Ultimately, are the differences between social media sourcesall that great?
� social media spans a broad continuum from pristine tosomewhat noisy, but the span is perhaps less broad thanconventionally thought
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Summary of Overall Findings II
� Are different social media sources equally “noisy”?� no; Twitter definitely on the noisy end of the spectrum,
and Wikipedia “cleaner” than BNC, but the spread isless than you might think
� Ultimately, are the differences between social media sourcesall that great?
� social media spans a broad continuum from pristine tosomewhat noisy, but the span is perhaps less broad thanconventionally thought
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Summary of Overall Findings II
� Are different social media sources equally “noisy”?� no; Twitter definitely on the noisy end of the spectrum,
and Wikipedia “cleaner” than BNC, but the spread isless than you might think
� Ultimately, are the differences between social media sourcesall that great?
� social media spans a broad continuum from pristine tosomewhat noisy, but the span is perhaps less broad thanconventionally thought
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Summary of Overall Findings II
� Are different social media sources equally “noisy”?� no; Twitter definitely on the noisy end of the spectrum,
and Wikipedia “cleaner” than BNC, but the spread isless than you might think
� Ultimately, are the differences between social media sourcesall that great?
� social media spans a broad continuum from pristine tosomewhat noisy, but the span is perhaps less broad thanconventionally thought
Source(s): Baldwin et al. [2013]

Text Processing of Social Media I Saarland University (8/7/2014)
Talk Outline1 Overview2 Social Media 101
IntroductionThe Appeals/Challenges of Social Media for NLP
3 Cross-comparison of the Language Content ofSocial Media Sources
BackgroundCorporaIntra-Corpus AnalysisInter-Corpus AnalysisConcluding Remarks
4 Language Identification over Social MediaBackgroundDatasetsEvaluation

Text Processing of Social Media I Saarland University (8/7/2014)
What is Language Identification (LangID)?
自然語言處理是人工智慧和語言學領域的分支學科。在這此領域中探討如何處理及運用自然語言;自然語言認知則是指讓電腦「懂」人類的語言。自然語言生成系統把計算機數據轉化為自然語言。自然語言理解系統把自然語言轉化為計算機程序更易于處理的形式。
Natural Language processing (NLP) is a field of computer science and linguistics concerned with the interactions between computers and human (natural) languages. In theory, natural-language processing is a very attractive method of human-computer interaction.
L'Elaborazione del linguaggio naturale, detta anche NLP (dall'inglese Natural Language Processing), è il processo di estrazione di informazioni semantiche da espressioni del linguaggio umano o naturale, scritte o parlate, tramite l'elaborazione di un calcolatore elettronico.
自然⾔語処理は、⼈間が⽇常的に使って
いる自然⾔語をコンピュータに処理させ
る⼀連の技術であり、⼈⼯知能と⾔語学
の⼀分野である。計算⾔語学も同じ意味
であるが、前者は⼯学的な視点からの⾔
語処理をさすのに対して、後者は⾔語学
的視点を重視する⼿法をさす事が多い。
データベース内の情報を自然⾔語に変換
したり、自然⾔語の⽂章をより形式的な
(コンピュータが理解しやすい)表現に
変換するといった処理が含まれる。

Text Processing of Social Media I Saarland University (8/7/2014)
What is Language Identification (LangID)?
@Luii_S2_KiSeop 哈哈哈 四次元这名号很match他xDDDDD 姐不是official kissme
么??要怎样才能成为官方km??
RT @ThotsOnTees: Its not rocket science.....Man was designed to fail.So to those that av their trust in Man,goodluck...mine is on GOD!
#Campiglio stellata, freddo, neve dura, ma sufficiente. Rossi, Alo e Massa ok, Hayden spalla ancora immobile e dolorante.Domani #StudioSport
実行はいつなされるんですか? RT
“@a_X_o: 制服プレイのメールの返事きてさ「いやらしすぎる」だけ帰ってきたんだけどもうなんか嫌だ”

Text Processing of Social Media I Saarland University (8/7/2014)
Why do we need LangID for Twitter?
� Twitter is highly multilingual� 65 Languages in 10M message sample [Bergsma et al.,
2012]� Indigenous Tweets: 157 low-density languages (Feb 2014)
� NLP often monolingual
� Keyword-based approaches have shortcomings� poor recall� cognates/false friends
� Twitter added language predictions in March 2013� spoiler: it is not perfect!� older crawls?
Source(s): Lui and Baldwin [2014]

Text Processing of Social Media I Saarland University (8/7/2014)
Challenges in LangID on Social Media
� Short message length: individual documents are generallyshort
� Variety of registers, domains, ...: there is a lot of varietyin the content of documents
� Lexical variation: there is a lot of fluidity in how a givenword is spelled
� Linguistic diversity: a rich mix of languages can be foundon social media sites, often with different distributions, andwith no “closed-world” guarantee
� Limited labelled corpora: language-labelled corpora ofsocial media data are few and far between
Source(s): Lui and Baldwin [2014]

Text Processing of Social Media I Saarland University (8/7/2014)
Challenges in LangID on Social Media
� Short message length: individual documents are generallyshort
� Variety of registers, domains, ...: there is a lot of varietyin the content of documents
� Lexical variation: there is a lot of fluidity in how a givenword is spelled
� Linguistic diversity: a rich mix of languages can be foundon social media sites, often with different distributions, andwith no “closed-world” guarantee
� Limited labelled corpora: language-labelled corpora ofsocial media data are few and far between
Source(s): Lui and Baldwin [2014]

Text Processing of Social Media I Saarland University (8/7/2014)
Challenges in LangID on Social Media
� Short message length: individual documents are generallyshort
� Variety of registers, domains, ...: there is a lot of varietyin the content of documents
� Lexical variation: there is a lot of fluidity in how a givenword is spelled
� Linguistic diversity: a rich mix of languages can be foundon social media sites, often with different distributions, andwith no “closed-world” guarantee
� Limited labelled corpora: language-labelled corpora ofsocial media data are few and far between
Source(s): Lui and Baldwin [2014]

Text Processing of Social Media I Saarland University (8/7/2014)
Challenges in LangID on Social Media
� Short message length: individual documents are generallyshort
� Variety of registers, domains, ...: there is a lot of varietyin the content of documents
� Lexical variation: there is a lot of fluidity in how a givenword is spelled
� Linguistic diversity: a rich mix of languages can be foundon social media sites, often with different distributions, andwith no “closed-world” guarantee
� Limited labelled corpora: language-labelled corpora ofsocial media data are few and far between
Source(s): Lui and Baldwin [2014]

Text Processing of Social Media I Saarland University (8/7/2014)
Challenges in LangID on Social Media
� Short message length: individual documents are generallyshort
� Variety of registers, domains, ...: there is a lot of varietyin the content of documents
� Lexical variation: there is a lot of fluidity in how a givenword is spelled
� Linguistic diversity: a rich mix of languages can be foundon social media sites, often with different distributions, andwith no “closed-world” guarantee
� Limited labelled corpora: language-labelled corpora ofsocial media data are few and far between
Source(s): Lui and Baldwin [2014]

Text Processing of Social Media I Saarland University (8/7/2014)
Another Complication I
Source Domain Target Domain
⇒
Supervised Learning
⇒
Inductive Transfer Learning
⇒
Transductive Transfer Learning

Text Processing of Social Media I Saarland University (8/7/2014)
Another Complication II
� LangID Accuracy drops considerably when moving from a supervisedto an inductive transfer learning setting
Source(s): Lui and Baldwin [2012]

Text Processing of Social Media I Saarland University (8/7/2014)
Selecting Features with Cross-domain Utility I
� Observation: per-domain vs. per-language informationgain of byte n-grams (1 ≤ n ≤ 4):
0.05 0.10 0.15 0.20 0.25 0.30 0.35IG Language
0.1
0.2
0.3
0.4
0.5
0.6
IG D
omai
n
0.0
0.8
1.6
2.4
3.2
4.0
4.8
5.6
log1
0(N)

Text Processing of Social Media I Saarland University (8/7/2014)
Selecting Features with Cross-domain Utility II� Solution:
� pre-filter the feature set according to DF (the number ofdocuments containing a given feature), based on theobservation that low DF → low IG
5000 10000 15000 20000 25000 30000 35000 40000Document Frequency
�0.4
�0.3
�0.2
�0.1
0.0
0.1
0.2
0.3
Lang
Dom
ain
scor
e
0.0
0.8
1.6
2.4
3.2
4.0
4.8
5.6
log1
0(N)
� calculate the information gain for each of the top-Nfeatures t relative to a given language l , using a simplesubtractive method to compensate for domain effects:
LDbin(t|l) = IGbinlanguage(t|l)− IGdomain(t)
Source(s): Lui and Baldwin [2011]

Text Processing of Social Media I Saarland University (8/7/2014)
Benchmarking LangID over Twitter
langid.py Lui and Baldwin [2012]
ChromeCLD McCandless [2010]
LangDetect Nakatani [2010]
LDIG Nakatani [2012]
whatlang Brown [2013]
YALI Majlis [2012]
TextCat Scheelen [2003]
MSR-LID Goldszmidt et al. [2013]
Text Processing of Social Media I Saarland University (8/7/2014)
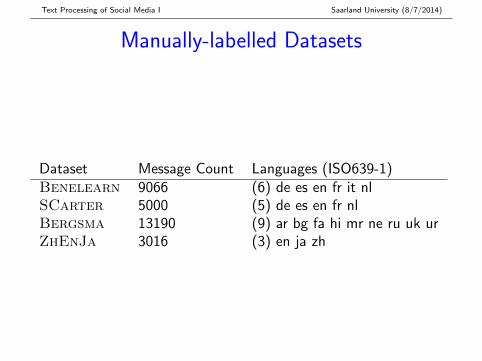
Manually-labelled Datasets
Dataset Message Count Languages (ISO639-1)Benelearn 9066 (6) de es en fr it nlSCarter 5000 (5) de es en fr nlBergsma 13190 (9) ar bg fa hi mr ne ru uk urZhEnJa 3016 (3) en ja zh
Text Processing of Social Media I Saarland University (8/7/2014)
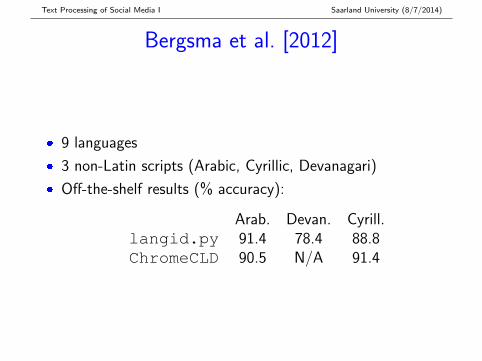
Bergsma et al. [2012]
� 9 languages
� 3 non-Latin scripts (Arabic, Cyrillic, Devanagari)
� Off-the-shelf results (% accuracy):
Arab. Devan. Cyrill.langid.py 91.4 78.4 88.8ChromeCLD 90.5 N/A 91.4

Text Processing of Social Media I Saarland University (8/7/2014)
ZhEnJa dataset
� Randomly sampled 5000 messages from a 24h period
� Each message annotated by speakers of:� Mandarin Chinese (zh)� English (en)� Japanese (ja)
� Each message annotated by 3 speakers of each language
� Total 3016 messages labeled:� zh: 16 (0.3%)� en: 1953 (39.1%)� ja: 1047 (20.9%)
Source(s): Lui and Baldwin [2014]
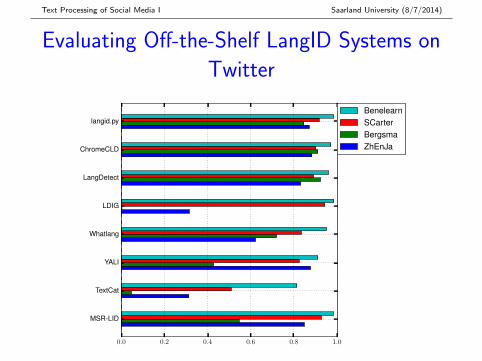
Text Processing of Social Media I Saarland University (8/7/2014)
Evaluating Off-the-Shelf LangID Systems on
0.0 0.2 0.4 0.6 0.8 1.0
MSR-LID
TextCat
YALI
Whatlang
LDIG
LangDetect
ChromeCLD
langid.pyBenelearnSCarterBergsmaZhEnJa

Text Processing of Social Media I Saarland University (8/7/2014)
Which LangID System to Use?
� Used the 4 existing datasets to evaluate all 8 systems
� Evaluated 3-system, 5-system and 7-system majority vote
� Voting compensates for individual systems’ weakness onBergsma and ZhEnJa
� 3-system vote between langid.py, ChromeCLD andLangDetect is a good choice

Text Processing of Social Media I Saarland University (8/7/2014)
TwitUser Dataset
� Active: 5 msgs/day on 7 different days (31 days of data)
� 65 languages
� Top: en (50.6%) ja (14.1%) pt (13.0%)
� Randomly selected up to 100 users per language
� Pool of 26011 msgs from 2914 users
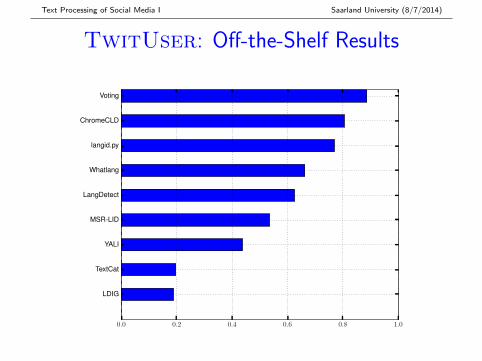
Text Processing of Social Media I Saarland University (8/7/2014)
TwitUser: Off-the-Shelf Results
0.0 0.2 0.4 0.6 0.8 1.0
LDIG
TextCat
YALI
MSR-LID
LangDetect
Whatlang
langid.py
ChromeCLD
Voting
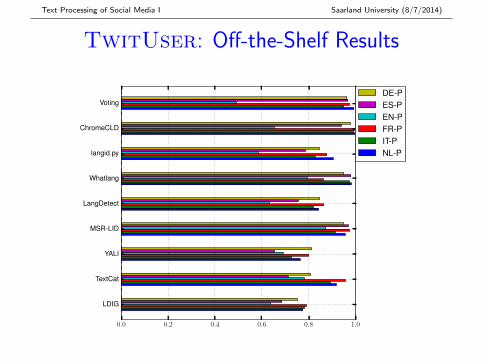
Text Processing of Social Media I Saarland University (8/7/2014)
TwitUser: Off-the-Shelf Results
0.0 0.2 0.4 0.6 0.8 1.0
LDIG
TextCat
YALI
MSR-LID
LangDetect
Whatlang
langid.py
ChromeCLD
VotingDE-PES-PEN-PFR-PIT-PNL-P

Text Processing of Social Media I Saarland University (8/7/2014)
Custom Tweaks for Social Media Processing I
� Tweak: “clean” the text to pre-remove URLs, usermentions, hashtags and smilies [Tromp and Pechenizkiy,2011]
� Motivation: “metadata” in the tweet is often in ASCII andmisleading in terms of language content
� Practicum:
� very easy to implement� no difference on Twitter-specific systems (MSR-LID,LDIG)
� small improvement on other systems (< 2%)

Text Processing of Social Media I Saarland University (8/7/2014)
Custom Tweaks for Social Media Processing II
� Tweak: bootstrapping, i.e. train the classifier onautomatically-labelled tweets [Goldszmidt et al., 2013]
� Motivation: data is cheap but labels are expensive; largevolumes of slightly noisy training data > smaller volumes ofpristine training data
� Practicum:
� requires re-training classifier� tested with LangDetect, TextCat, langid.py� used 2 methods to construct bootstrap collection (direct
LangID, user prior)� not consistently better than off-the-shelf

Text Processing of Social Media I Saarland University (8/7/2014)
Custom Tweaks for Social Media Processing III
� Tweak: learn LangID priors of different types (user, link,mention, hashtag, thread), and incorporate these into theclassifier [Carter et al., 2013, Bontcheva et al., 2013]
� Motivation: individual users will tend to use only a smallset of languages; these are strong predictors of whatlanguages they are likely to tweet in in the future
� Practicum:
� requires processing a massive background collection, andstoring a large set of user priors
� Carter et al. [2013] and Bontcheva et al. [2013] reportpositive results

Text Processing of Social Media I Saarland University (8/7/2014)
Twitter API predictions
� While it is against Twitters Terms of Service to benchmarkagainst the Twitter LangID predictions, we can make someobservations:
� 25% of tweets in TwitUser are not LangID tagged
� Some obvious language gaps, e.g. all Romanian messagesare identified as Italian
� Twitter’s predictions are:� not perfect� not substantially better than off-the-shelf

Text Processing of Social Media I Saarland University (8/7/2014)
Conclusion
� Importance of “domain deadaptation” in LangID, becauseof: (a) lack of large-scale training corpora; and (b)susceptibility of LangID systems to negative transfer
� LangID over Twitter far from perfect (state-of-the-art =0.89 F-Score), and Twitter API certainly not perfect
� Scope for improvement in accuracy through use of priors ofvarious types (going beyond the individual message)
� Further research needed to broaden scope and increaseaccuracy

Text Processing of Social Media I Saarland University (8/7/2014)
References I
Timothy Baldwin, Paul Cook, Marco Lui, Andrew MacKinlay, and Li Wang. How noisysocial media text, how diffrnt social media sources? In Proceedings of the 6thInternational Joint Conference on Natural Language Processing (IJCNLP 2013), pages356–364, Nagoya, Japan, 2013.
Shane Bergsma, Paul McNamee, Mossaab Bagdouri, Clayton Fink, and Theresa Wilson.Language identification for creating language-specific Twitter collections. InProceedings of the Second Workshop on Language in Social Media, pages 65–74,Montreal, Canada, 2012. URLhttp://www.aclweb.org/anthology/W12-2108.
Kalina Bontcheva, Leon Derczynski, Adam Funk, Mark A. Greenwood, Diana Maynard,and Niraj Aswani. TwitIE: An open-source information extraction pipeline formicroblog text. In Proceedings of Recent Advances in Natural Language Processing(RANLP 2013), Hissar, Buglaria, 2013.
Ralf Brown. Selecting and weighting n-grams to identify 1100 languages. In Proceedingsof the 16th international conference on text, speech and dialogue (TSD 2013), Plzen,Czech Republic, 2013.
Simon Carter, Wouter Weerkamp, and Manos Tsagkias. Microblog languageidentification: Overcoming the limitations of short, unedited and idiomatic text.Language Resources and Evaluation, pages 1–21, 2013.

Text Processing of Social Media I Saarland University (8/7/2014)
References II
Moises Goldszmidt, Marc Najork, and Stelios Paparizos. Boot-strapping languageidentifiers for short colloquial postings. In Proceedings of the European Conference onMachine Learning and Principles and Practice of Knowledge Discovery in Databases(ECMLPKDD 2013), Prague, Czech Republic, 2013.
Bo Han, Paul Cook, and Timothy Baldwin. Automatically constructing a normalisationdictionary for microblogs. In Proceedings of the Joint Conference on EmpiricalMethods in Natural Language Processing and Computational Natural LanguageLearning 2012 (EMNLP-CoNLL 2012), pages 421–432, Jeju, Korea, 2012.
Adam Kilgarriff. Comparing corpora. International Journal of Corpus Linguistics, 6(1):97–133, 2001.
Marco Lui and Timothy Baldwin. Cross-domain feature selection for languageidentification. In Proceedings of the 5th International Joint Conference on NaturalLanguage Processing (IJCNLP 2011), pages 553–561, Chiang Mai, Thailand, 2011.
Marco Lui and Timothy Baldwin. langid.py: An off-the-shelf language identification tool.In Proceedings of the 50th Annual Meeting of the Association for ComputationalLinguistics (ACL 2012) Demo Session, pages 25–30, Jeju, Republic of Korea, 2012.
Marco Lui and Timothy Baldwin. Accurate language identification of twitter messages. InProceedings of the 5th Workshop on Language Analysis for Social Media (LASM),pages 17–25, Gothenburg, Sweden, 2014. URLhttp://www.aclweb.org/anthology/W14-1303.
Text Processing of Social Media I Saarland University (8/7/2014)
References IIIMartin Majlis. Yet another language identifier. In Proceedings of the Student Research
Workshop at the 13th Conference of the European Chapter of the Association forComputational Linguistics, pages 46–54, Avignon, France, 2012.
Michael McCandless. Accuracy and performance of google’s compact language detector.blog post. available at http://blog.mikemccandless.com/2011/10/accuracy-and-performance-of-googles.html, 2010.
Shuyo Nakatani. Language detection library (slides). http://www.slideshare.net/shuyo/language-detection-library-for-java, 2010. Retrieved on21/06/2013.
Shuyo Nakatani. Short text language detection with infinity-gram. blog post. available athttp://shuyo.wordpress.com/2012/05/17/short-text-language-detection-with-infinity-gram/, 2012.
Derek O’Callaghan, Martin Harrigan, Joe Carthy, and Padraig Cunningham. Networkanalysis of recurring YouTube spam campaigns. In Proceedings of the 6thInternational Conference on Weblogs and Social Media (ICWSM 2012), pages531–534, Dublin, Ireland, 2012.
Jonathon Read, Rebecca Dridan, Stephan Oepen, and Lars Jørgen Solberg. Sentenceboundary detection: A long solved problem? In Proceedings of COLING 2012:Posters, pages 985–994, Mumbai, India, 2012. URLhttp://www.aclweb.org/anthology/C12-2096.
Frank Scheelen. libtextcat, 2003. Software available athttp://software.wise-guys.nl/libtextcat/.

Text Processing of Social Media I Saarland University (8/7/2014)
References IV
Erik Tromp and Mykola Pechenizkiy. Graph-based n-gram language identification on shorttexts. In Proceedings of Benelearn 2011, pages 27–35, The Hague, Netherlands, 2011.





























