Embed Size (px)
Citation preview

Mike Wang | Solutions Architect
NVIDIA | Australia & NZ
TESLA ACCELERATED COMPUTING

2
THE WORLD LEADER IN VISUAL COMPUTING
PC DATA CENTER MOBILE
ENTERPRISE VIRTUALIZATION
AUTONOMOUS MACHINES
HPC & CLOUD SERVICE PROVIDERSGAMING DESIGN

3
Founded in 1993
Jen-Hsun Huang is co-founder and CEO
Listed with NASDAQ under the symbol NVDA in 1999
Invented the GPU in 1999 and has shipped more than 1 billion to date
FY15: $4.7 billion in revenue
9,100 employees worldwide
7,300 patents
Headquartered in Santa Clara, Calif.

4
CPUOptimized for Serial Tasks
GPU AcceleratorOptimized for Parallel Tasks
ACCELERATED COMPUTING10X PERFORMANCE & 5X ENERGY EFFICIENCY

5
Vision: Mainstream Parallel Programming
Enable more programmers to write parallel software
Give programmers the choice of language to use
Embrace and evolve standards in key languages
C

6
HOW GPU ACCELERATION WORKS
Application Code
+
GPU CPU5% of Code
Compute-Intensive Functions
Rest of SequentialCPU Code
7
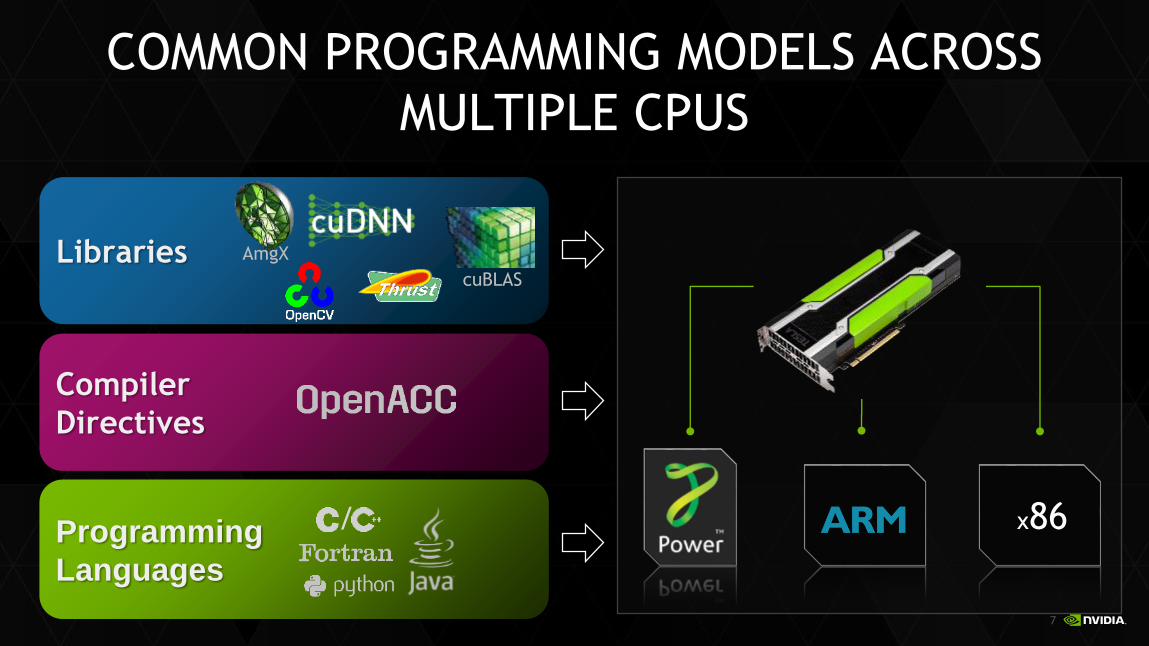
COMMON PROGRAMMING MODELS ACROSS
MULTIPLE CPUS
x86
Libraries
Programming
Languages
Compiler
Directives
AmgX
cuBLAS
/

8
GPU ACCELERATED LIBRARIES
“Drop-in” Acceleration for Your Applications
Linear AlgebraFFT, BLAS,
SPARSE, Matrix
Numerical & MathRAND, Statistics
Data Struct. & AISort, Scan, Zero Sum
Visual ProcessingImage & Video
NVIDIA
cuFFT,
cuBLAS,
cuSPARSE
NVIDIA
Math Lib NVIDIA cuRAND
NVIDIA
NPP
NVIDIA
Video
Encode
GPU AI –
Board
Games
GPU AI –
Path Finding
9
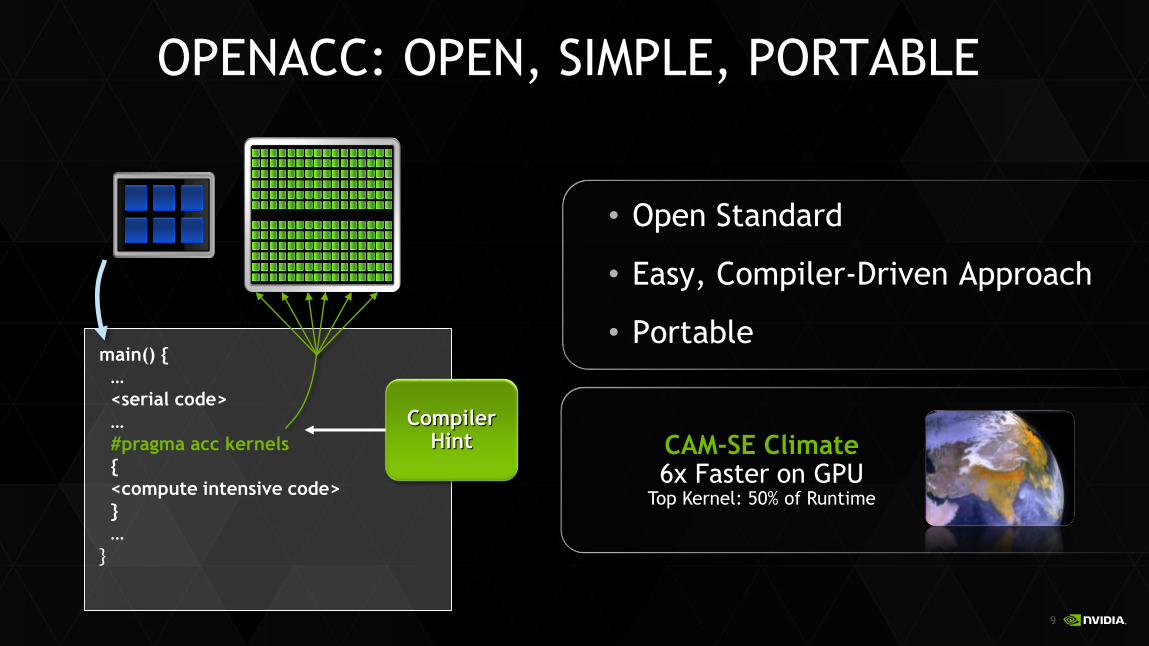
OPENACC: OPEN, SIMPLE, PORTABLE
• Open Standard
• Easy, Compiler-Driven Approach
• Portablemain() {
…
<serial code>
…
#pragma acc kernels
{
<compute intensive code>
}
…
}
CompilerHint CAM-SE Climate
6x Faster on GPUTop Kernel: 50% of Runtime
10
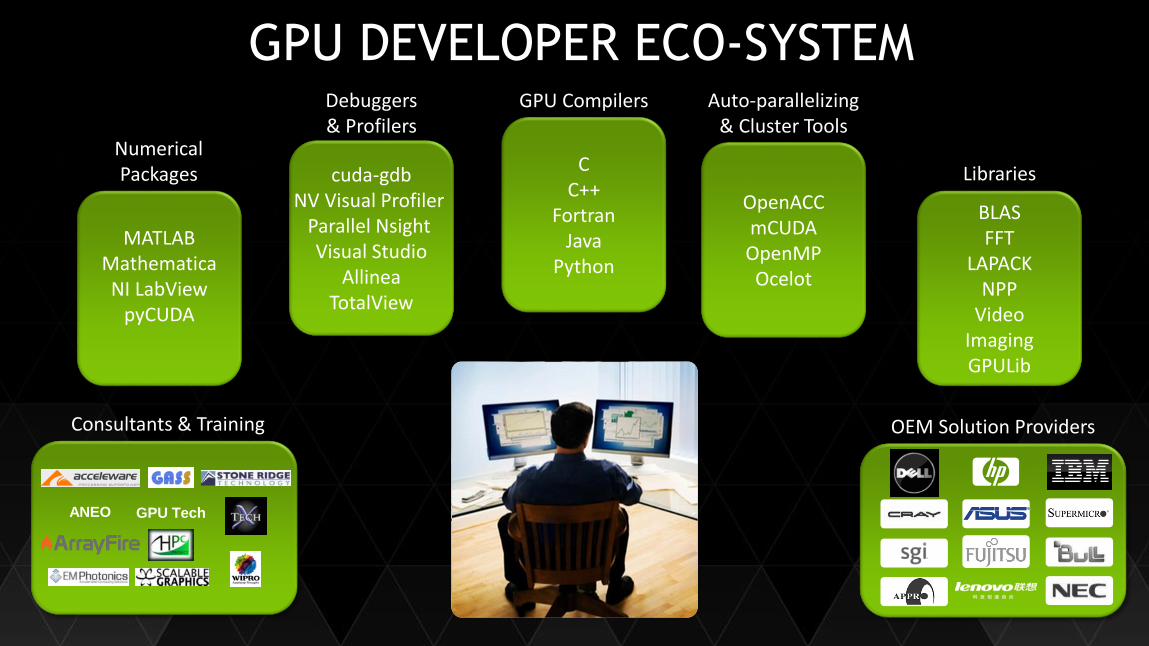
GPU DEVELOPER ECO-SYSTEMDebuggers& Profilers
cuda-gdbNV Visual Profiler
Parallel NsightVisual Studio
AllineaTotalView
MATLABMathematicaNI LabView
pyCUDA
Numerical Packages
OpenACCmCUDAOpenMP
Ocelot
Auto-parallelizing& Cluster Tools
BLASFFT
LAPACKNPP
VideoImagingGPULib
Libraries
OEM Solution ProvidersConsultants & Training
ANEO GPU Tech
CC++
FortranJava
Python
GPU Compilers

11
334 GPU-Accelerated Applicationswww.nvidia.com/appscatalog
12
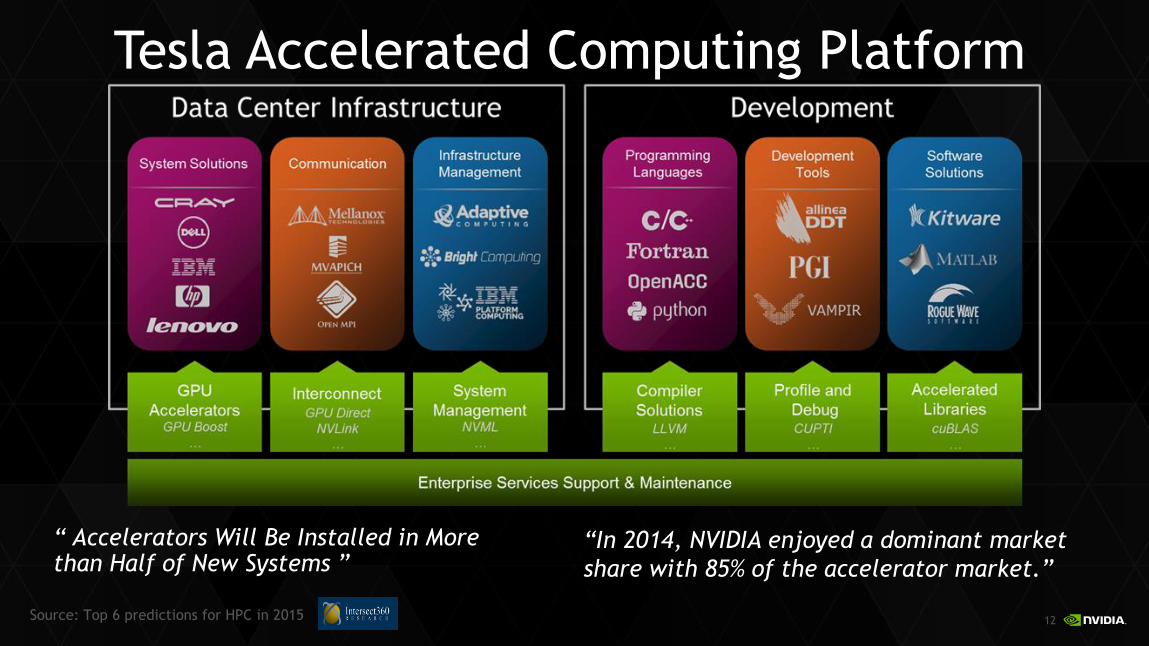
“ Accelerators Will Be Installed in More than Half of New Systems ”
Source: Top 6 predictions for HPC in 2015
“In 2014, NVIDIA enjoyed a dominant market
share with 85% of the accelerator market.”
Tesla Accelerated Computing Platform

13
TESLA K80
WORLD’S FASTEST ACCELERATOR
FOR DATA ANALYTICS AND
SCIENTIFIC COMPUTING
Caffe Benchmark: AlexNet training throughput based on 20 iterations, CPU: E5-2697v2 @ 2.70GHz. 64GB System Memory, CentOS 6.2
Maximum PerformanceDynamically Maximize Perf for
Every Application
Double the MemoryDesigned for Big Data Apps
24GB
Oil & Gas
Data Analytics
HPC Viz
K4012GB
2x Faster2.9 TF| 4992 Cores | 480 GB/s
0x
5x
10x
15x
20x
25x
CPU Tesla K40 Tesla K80
Deep Learning: Caffe
Dual-GPU Accelerator for
Max Throughput
14
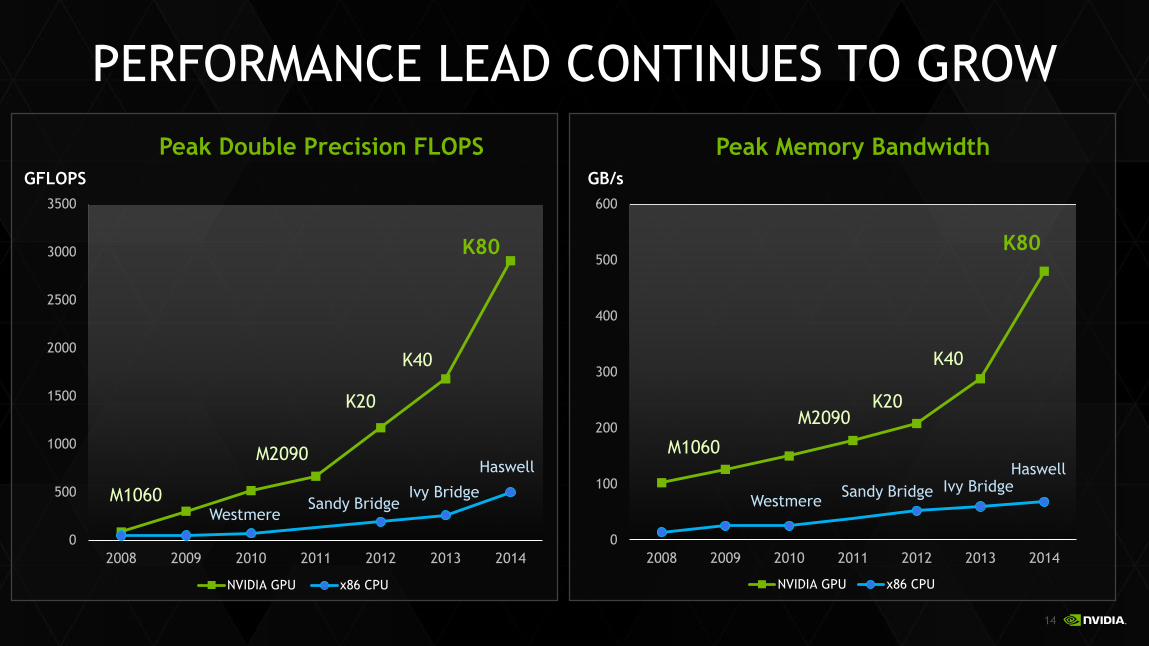
PERFORMANCE LEAD CONTINUES TO GROW
0
500
1000
1500
2000
2500
3000
3500
2008 2009 2010 2011 2012 2013 2014
Peak Double Precision FLOPS
NVIDIA GPU x86 CPU
M2090
M1060
K20
K80
WestmereSandy Bridge
Haswell
GFLOPS
0
100
200
300
400
500
600
2008 2009 2010 2011 2012 2013 2014
Peak Memory Bandwidth
NVIDIA GPU x86 CPU
GB/s
K20
K80
WestmereSandy Bridge
Haswell
Ivy Bridge
K40
Ivy Bridge
K40
M2090
M1060
15
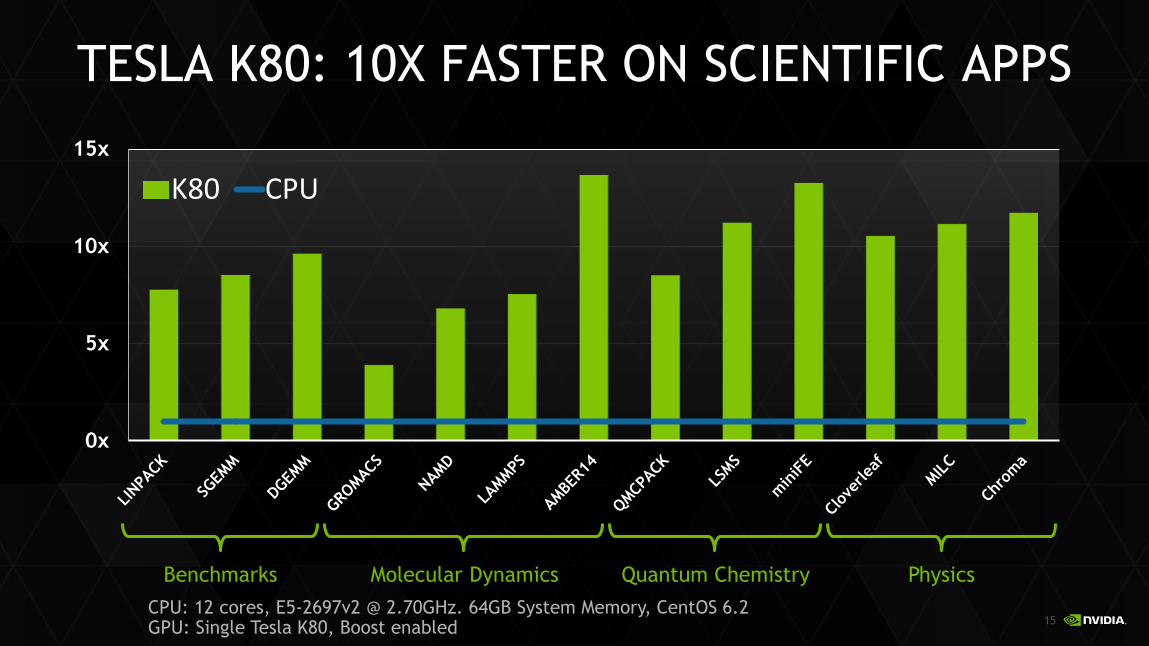
0x
5x
10x
15x
K80 CPU
TESLA K80: 10X FASTER ON SCIENTIFIC APPS
CPU: 12 cores, E5-2697v2 @ 2.70GHz. 64GB System Memory, CentOS 6.2GPU: Single Tesla K80, Boost enabled
Quantum ChemistryMolecular Dynamics PhysicsBenchmarks

16
LIFE & MATERIAL SCIENCES
MD: All key codes are GPU-accelerated
ACEMD*, AMBER (PMEMD)*, BAND, CHARMM, DESMOND, ESPResso, Folding@Home, GPUgrid.net, GROMACS, HALMD, HOOMD-Blue*, LAMMPS, Lattice Microbes, mdcore, NAMD, OpenMM, SOP-GPU
Great multi-GPU performance!
Focus: on dense (up to 16) GPU nodes & large # of GPU nodes
QC: All key codes are ported or optimizing:
GPU-accelerated and available today:
ABINIT, ACES III, ADF, BigDFT, CP2K, GAMESS, Quantum Espresso/PWscf, MOLCAS, MOPAC2012, NWChem, QUICK, Q-Chem, TeraChem*
Active GPU acceleration projects:
CASTEP, CPMD, GAMESS, Gaussian, NWChem, ONETEP, Quantum Supercharger Library, VASP & more
Focus: on using GPU-accelerated math libraries, OpenACC directives
Overview of Accelerated Applications
green* = application where all the workload is on GPU
17
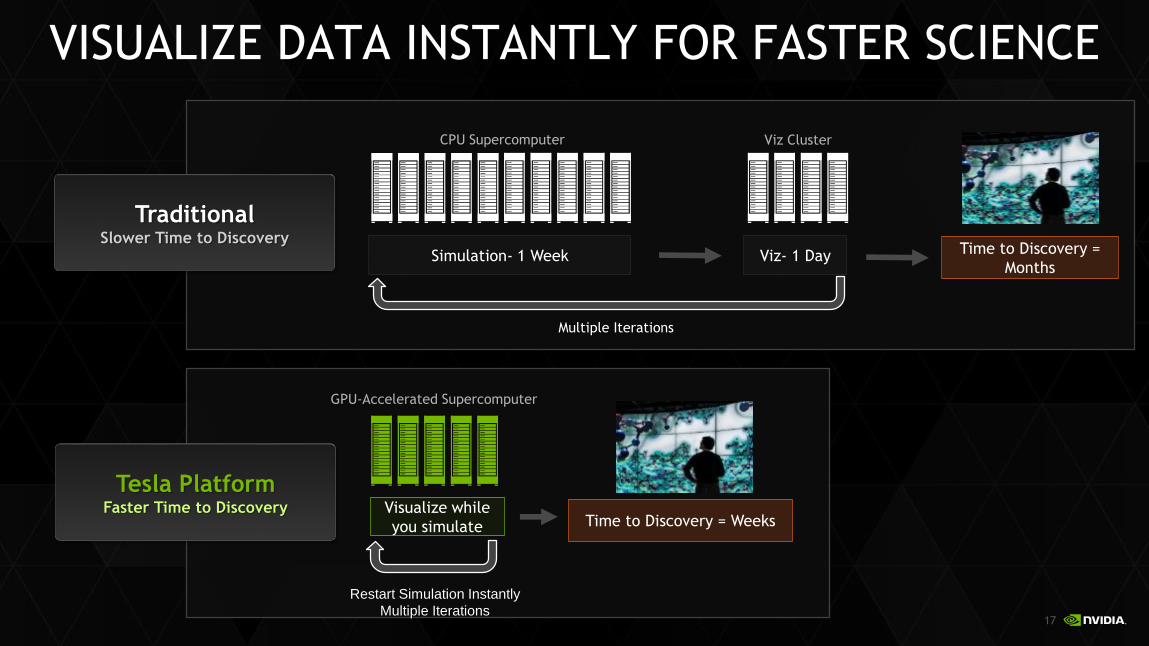
VISUALIZE DATA INSTANTLY FOR FASTER SCIENCE
TraditionalSlower Time to Discovery
CPU Supercomputer Viz Cluster
Simulation- 1 Week Viz- 1 Day
Multiple Iterations
Time to Discovery =
Months
Tesla PlatformFaster Time to Discovery
GPU-Accelerated Supercomputer
Visualize while
you simulate
Restart Simulation Instantly
Multiple Iterations
Time to Discovery = Weeks
18
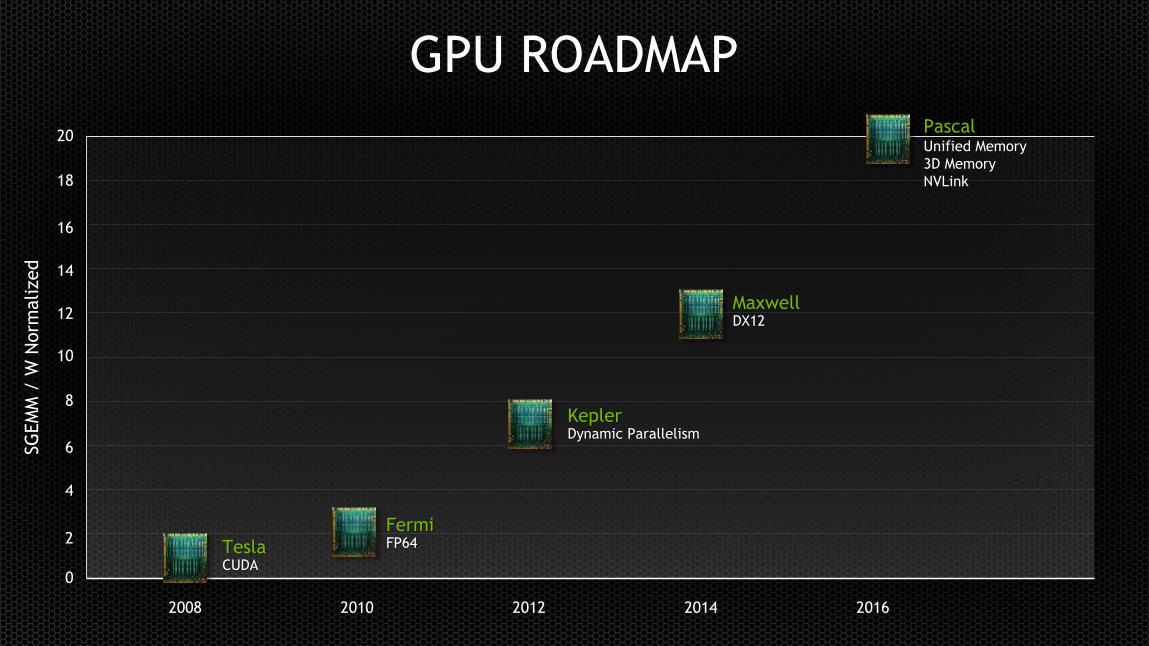
GPU ROADMAPSG
EM
M /
W N
orm
alized
2012 20142008 2010 2016
TeslaCUDA
FermiFP64
KeplerDynamic Parallelism
MaxwellDX12
PascalUnified Memory
3D Memory
NVLink
20
16
12
8
6
2
0
4
10
14
18

19
PASCAL GPU FEATURESNVLINK AND STACKED MEMORY
NVLINKGPU high speed interconnect
80-200 GB/s
3D Stacked Memory4x Higher Bandwidth (~1 TB/s)
3x Larger Capacity
4x More Energy Efficient per bit
20
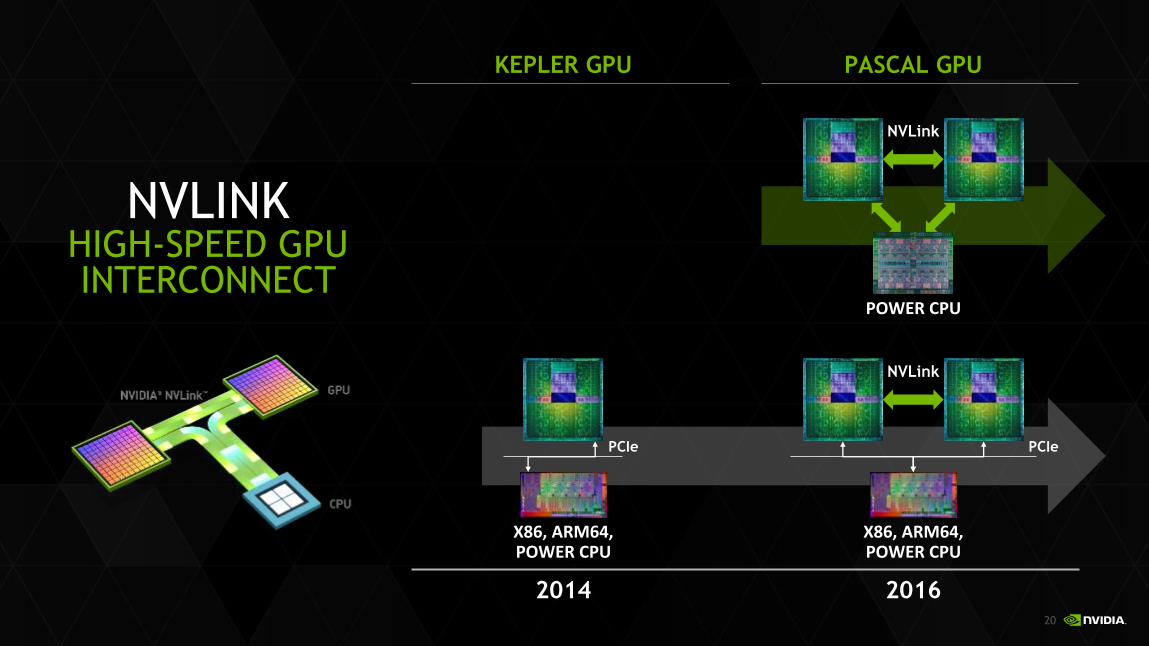
NVLINKHIGH-SPEED GPU INTERCONNECT
NVLink
NVLink
POWER CPU
X86, ARM64, POWER CPU
X86, ARM64, POWER CPU
PASCAL GPUKEPLER GPU
20162014
PCIe PCIe
21 21
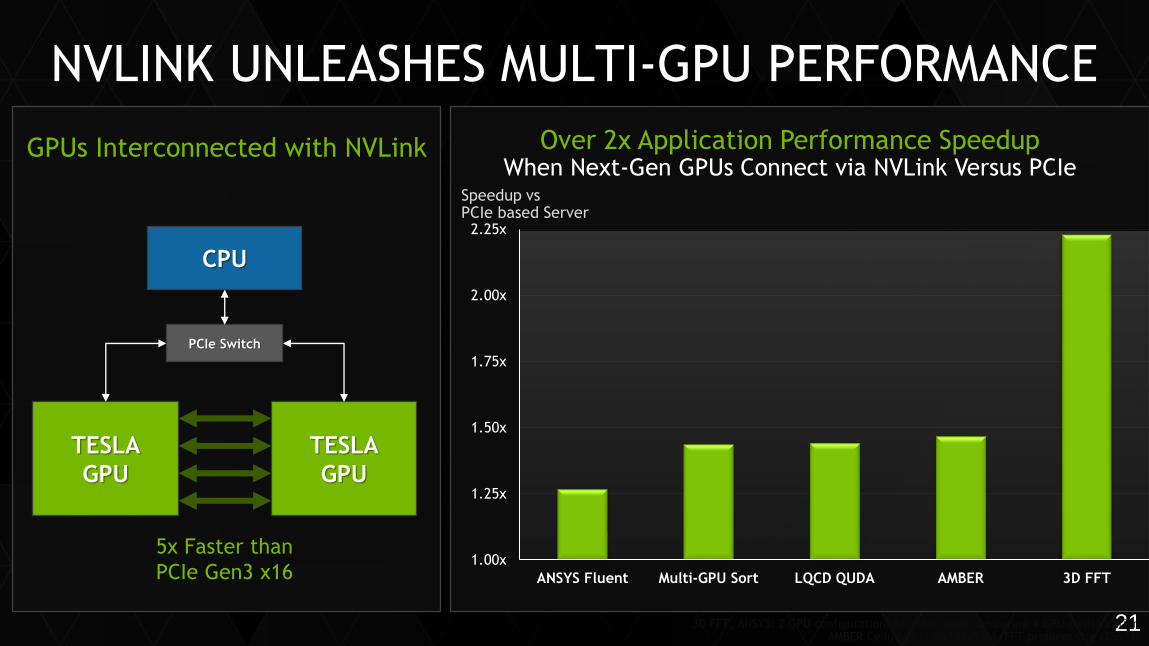
NVLINK UNLEASHES MULTI-GPU PERFORMANCE
3D FFT, ANSYS: 2 GPU configuration, All other apps comparing 4 GPU configuration AMBER Cellulose (256x128x128), FFT problem size (256^3)
TESLA
GPU
TESLA
GPU
CPU
5x Faster than
PCIe Gen3 x16
PCIe Switch
GPUs Interconnected with NVLink
1.00x
1.25x
1.50x
1.75x
2.00x
2.25x
ANSYS Fluent Multi-GPU Sort LQCD QUDA AMBER 3D FFT
Over 2x Application Performance SpeedupWhen Next-Gen GPUs Connect via NVLink Versus PCIe
Speedup vs PCIe based Server
22
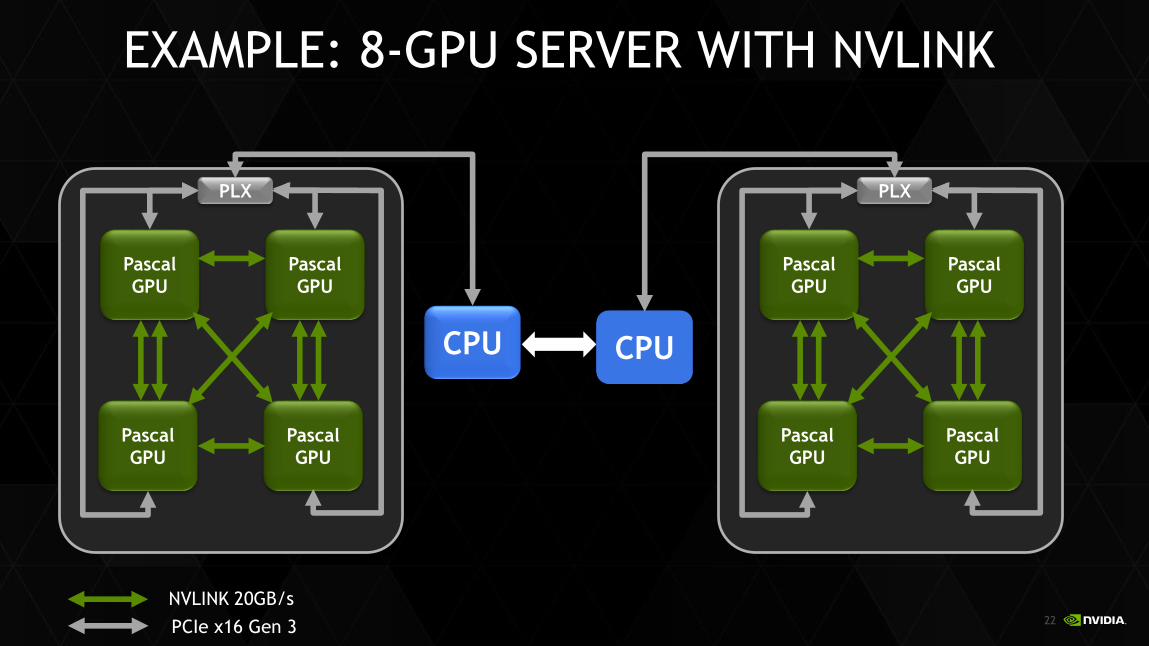
EXAMPLE: 8-GPU SERVER WITH NVLINK
NVLINK 20GB/s
PCIe x16 Gen 3
CPU
Pascal
GPU
Pascal
GPU
Pascal
GPU
Pascal
GPU
PLX
CPU
Pascal
GPU
Pascal
GPU
Pascal
GPU
Pascal
GPU
PLX

2015
Simon See
Director, Solutions Architecture & Engineering
NVIDIA APJ
NVIDIA APJ TECHNOLOGY CENTER
PROJECT OVERVIEW

24
GOALS OF CENTER
Developed New Application or Solutions
Engage in R/D with Key institutions and Universities
Develop APJ GPU Ecosystem
Developed capabilities (e.g Training)
Facilitate collaboration between RI and Industry
Engage New Lighthouse Accounts in Asia Pacific (e.g Asia, ANZ and India)
Enable Local Partners

25
TECHNOLOGY CENTER PRIORITIESWELL ALIGNED WITH NVIDIA ENTERPRISE PLATFORMS
Deep Learning
Defense, Smart Nation, BATQ research collaborations, IVA, SMART, Automotive/ADAS
Accelerated Computing
A*Star supercomputing center, university R&D, commercial life sciences
Smart Sensor, IVA, Smart Mobility
Enterprise graphics virtualization and advanced visualization
Virtual Singapore Smart Nation Initiatives
VDI for increased productivity of core sectors – AEC/Engineering

26
COORDINATION POINT FOR EXISTING APAC CCOE & JOINT LABS
CCOEs
SJTU, Tsinghua, NTHU Taiwan
OEM/Commercial joint labs
Huawei, Inspur, Baidu, Tencent, Alibaba, BGI
NTU joint labs
Institute for Media Innovation (IMI), ROSE Lab (Inspur, Tencent), Multi-platform Game Innovation Center (MAGIC)
Other university/research joint labs
KISTI MPCC (Korea), MIMOS & UPN (Malaysia)
27
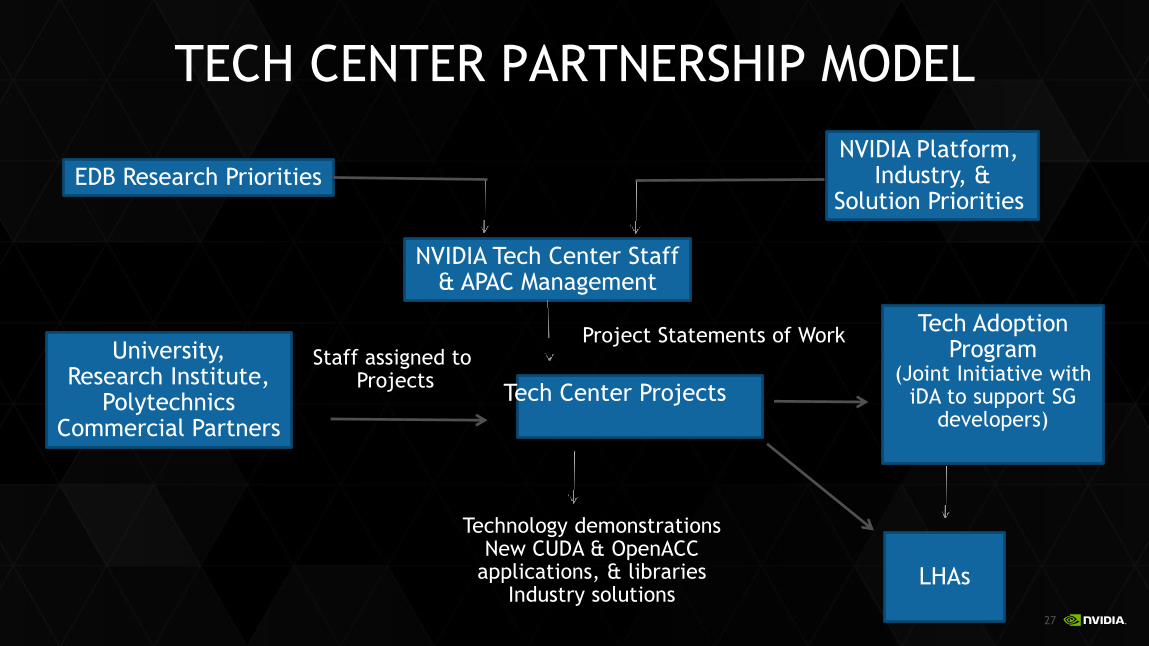
TECH CENTER PARTNERSHIP MODEL
EDB Research Priorities
NVIDIA Tech Center Staff& APAC Management
NVIDIA Platform, Industry, &
Solution Priorities
Tech Center Projects
Project Statements of WorkUniversity,
Research Institute,Polytechnics
Commercial Partners
Staff assigned to Projects
Technology demonstrationsNew CUDA & OpenACC
applications, & librariesIndustry solutions
Tech Adoption Program
(Joint Initiative with iDA to support SG
developers)
LHAs
28
HOSTED BY NANYANG TECHNOLOGY UNIV.





























