Embed Size (px)
Citation preview

Thema 2
Digtale Logik und wie der Computer rechnet
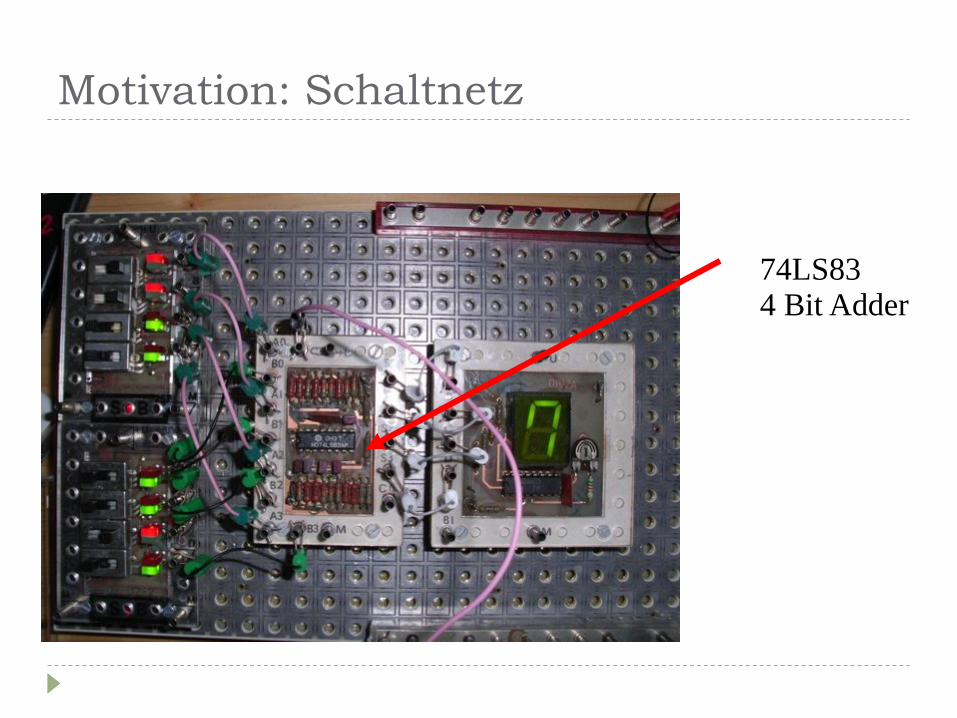
Motivation: Schaltnetz
74LS83 4 Bit Adder
für Interessenten: die Anzeigen sind TIL-311
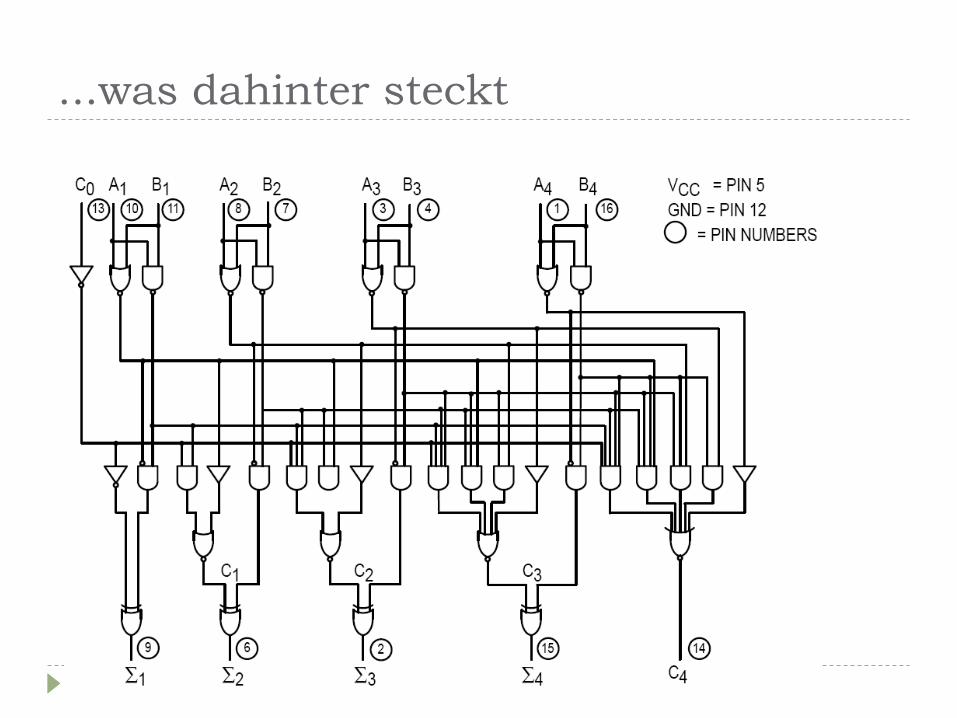
...was dahinter steckt

Grundlagen der Schaltalgebra
Schaltalgebra ist spezielle Boolesche Algebra (siehe /1/)
(M;,+,’) --> einstellige Operation 1-a , zweistellige Operation Min(a,b), Max(a,b)
Ziel: Analyse von Verknüpfungsschaltungen
Synthese von Schaltungen für Verknüpfungen aus Schaltungen für elementare Operationen
Wir werden unterscheiden: Kombinatorische Schaltungen (Schaltnetze)
Sequentielle Schaltungen (Schaltwerke)

Definitionen:
Eine Variable, die genau zwei Werte annehmen kann (also
aB , heißt
binäre Schaltvariable.
Eine Abbildung BnB heißt
binäre Schaltfunktion.
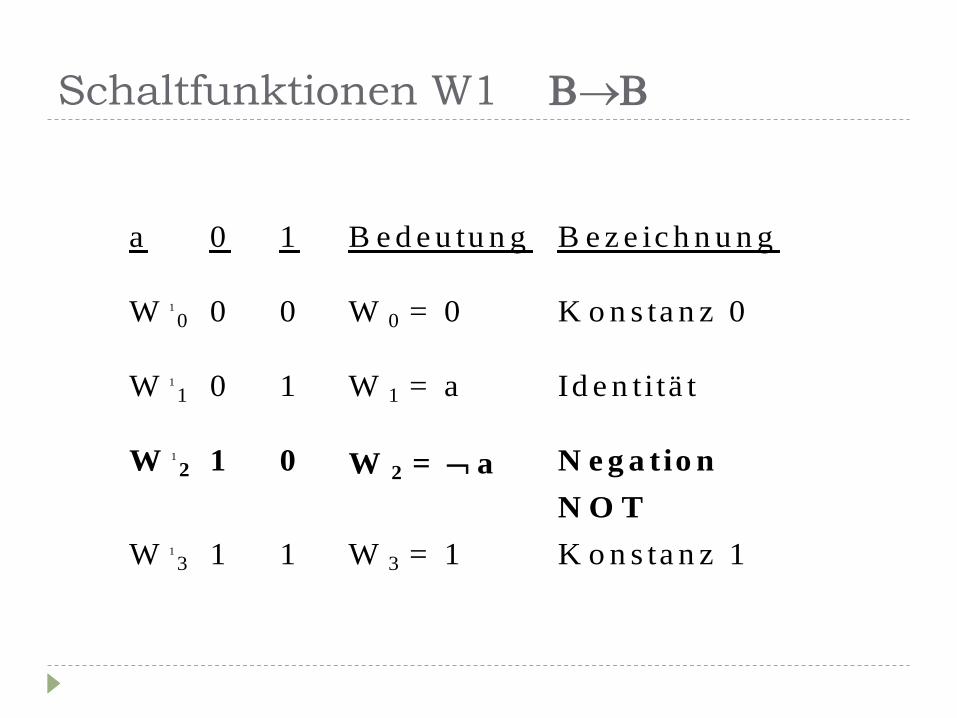
Schaltfunktionen W1
a 0 1 B e d e u tu n g B e z e ic h n u n g
W 1
0 0 0 W 0 = 0 K o n s ta n z 0
W 1
1 0 1 W 1 = a Id e n ti tä t
W 1
2 1 0 W 2 = a N e g a tio n
N O T
W 1
3 1 1 W 3 = 1 K o n s ta n z 1
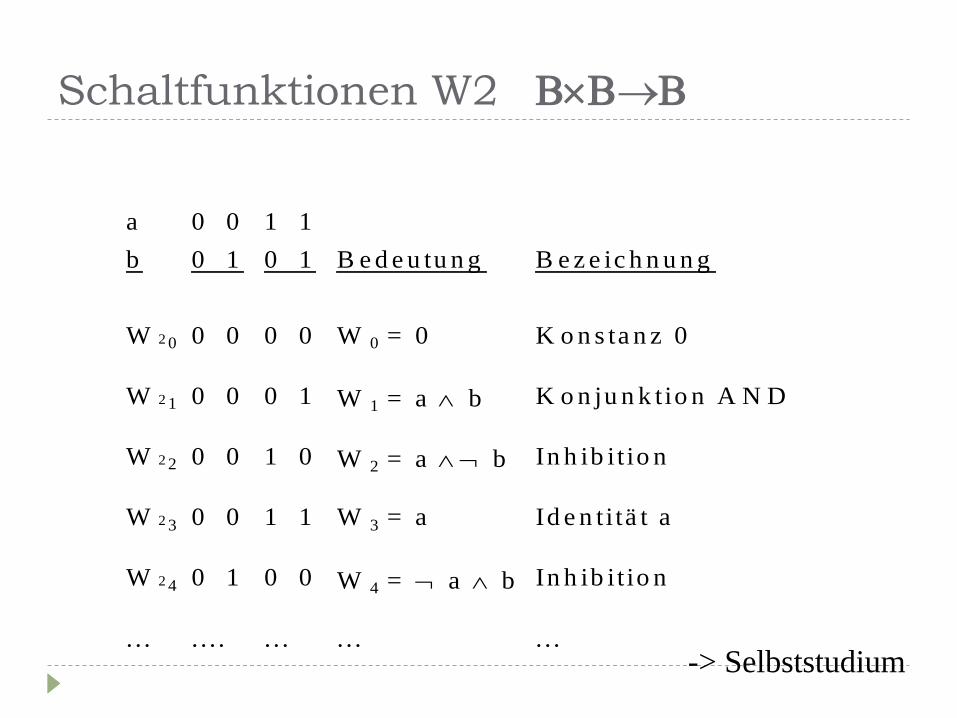
Schaltfunktionen W2
a
b
0 0
0 1
1 1
0 1
B e d e u tu n g
B e z e ic h n u n g
W 2 0 0 0 0 0 W 0 = 0 K o n s ta n z 0
W 2 1 0 0 0 1 W 1 = a b K o n ju n k tio n A N D
W 2 2 0 0 1 0 W 2 = a b In h ib it io n
W 2 3 0 0 1 1 W 3 = a Id e n ti tä t a
W 2 4 0 1 0 0 W 4 = a b In h ib it io n
. . . . . . . . . . . . . . . .
-> Selbststudium
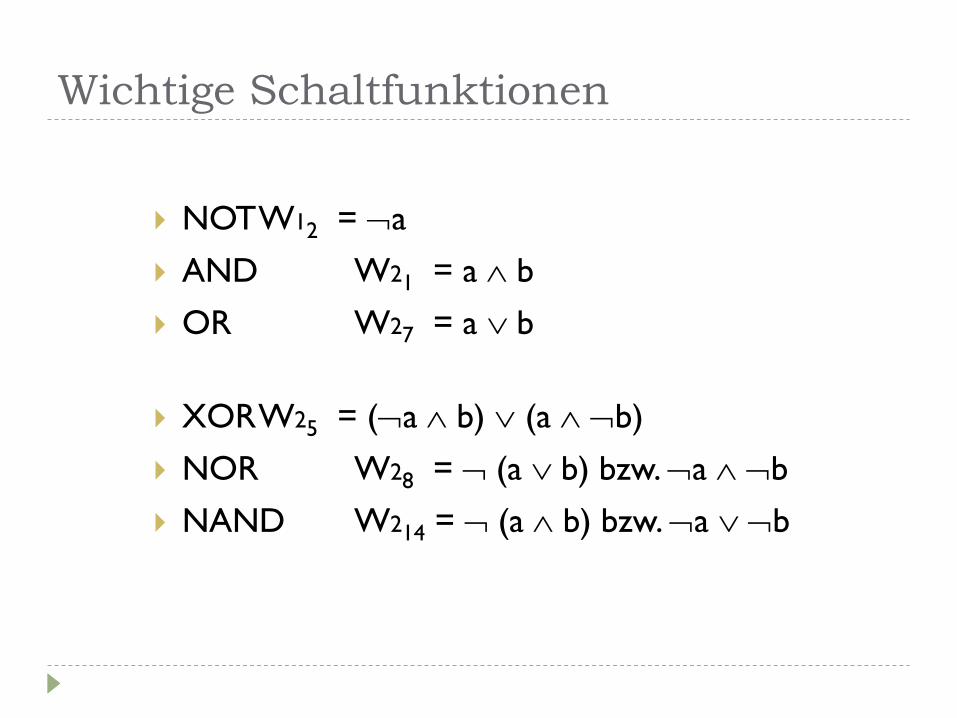
Wichtige Schaltfunktionen
NOT W12 = a
AND W21 = a b
OR W27 = a b
XOR W25 = (a b) (a b)
NOR W28 = (a b) bzw. a b
NAND W214 = (a b) bzw. a b

Regeln:
Vorrangregel ““vor ““ vor ““
Kommutativgesetz a b = b a a b = b a
Assoziativgesetz (a b) c = a (b c) (a b) c = a (b c)
Distributivgesetz a(bc) = (ab) (ac) a(bc) = ab ac
Komplementgesetz a a = 0 a a = 1
Idempotenzgesetz a a = a a a = a
Absorptionsgesetz a (a b) = a a (a b) = a
„0“ und „1“ Gesetz a = 0, a = 1 a 0 = a, a 1 = 1
de Morgan (a b) = a b (a b) = a b
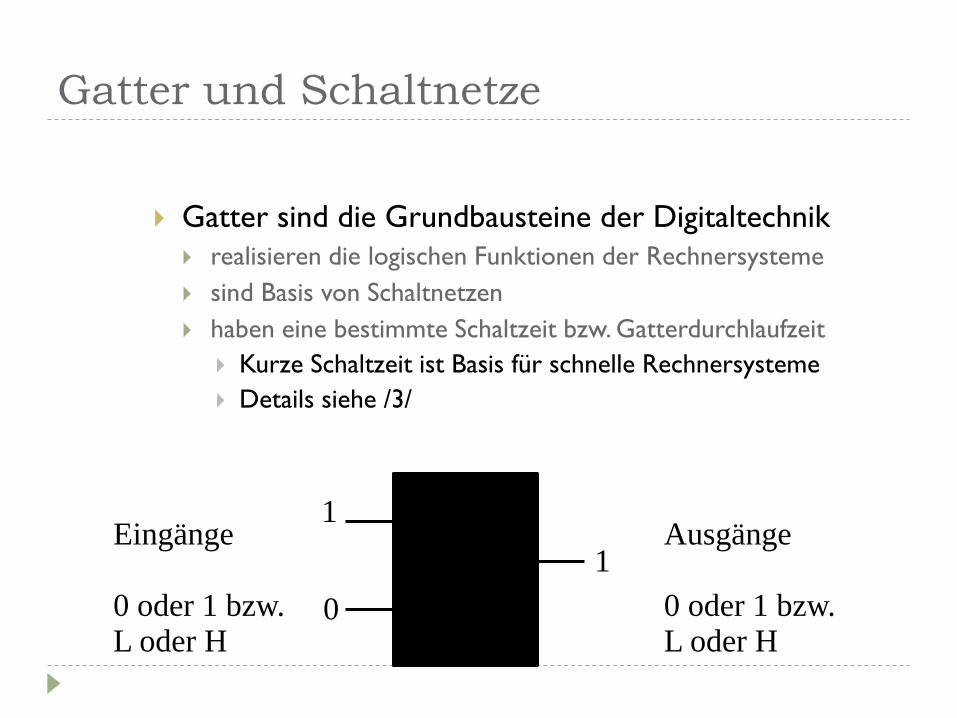
Gatter und Schaltnetze
Gatter sind die Grundbausteine der Digitaltechnik
realisieren die logischen Funktionen der Rechnersysteme
sind Basis von Schaltnetzen
haben eine bestimmte Schaltzeit bzw. Gatterdurchlaufzeit
Kurze Schaltzeit ist Basis für schnelle Rechnersysteme
Details siehe /3/
? Eingänge 0 oder 1 bzw. L oder H
Ausgänge 0 oder 1 bzw. L oder H
1
0
1
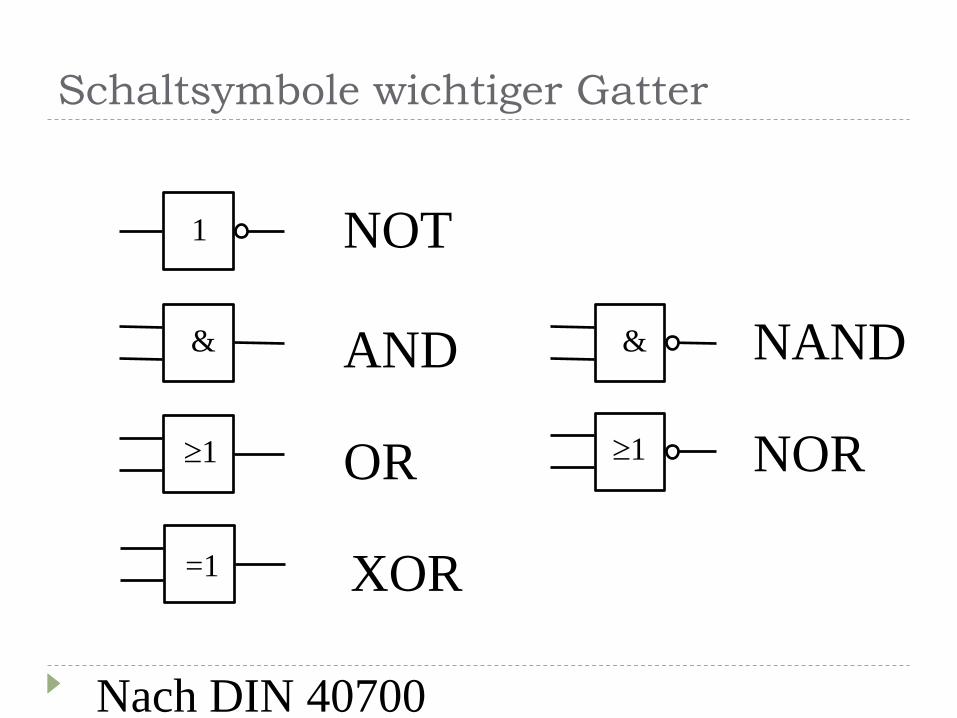
Schaltsymbole wichtiger Gatter
1 NOT
AND
OR
NAND
NOR
XOR
& &
Nach DIN 40700
1
=1
1
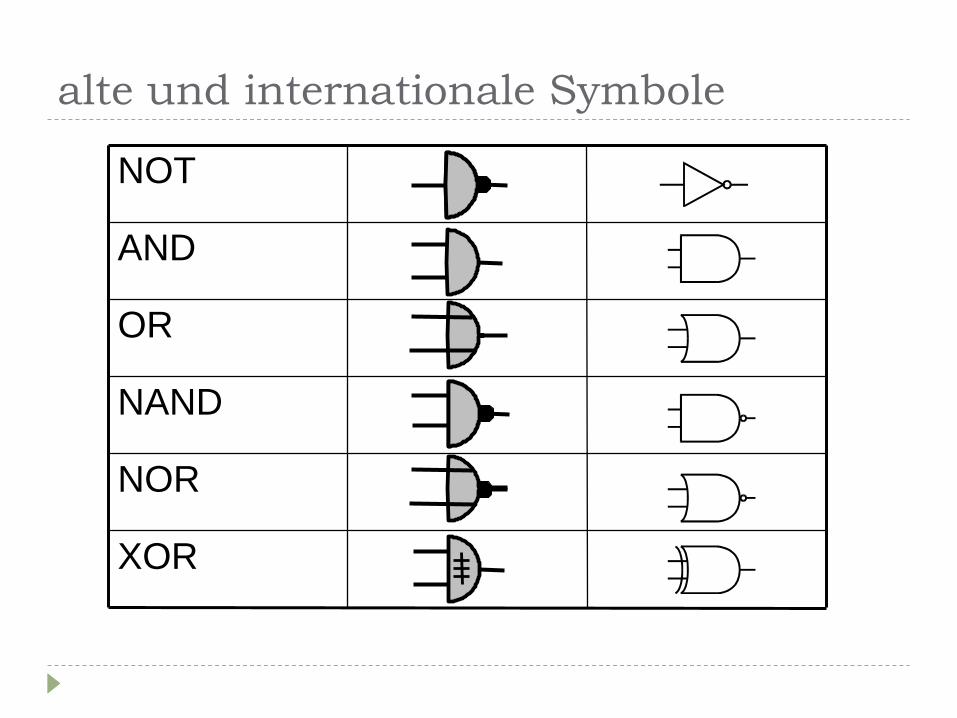
alte und internationale Symbole
XOR
NOR
NAND
OR
AND
NOT

Vereinfachungen
Zur Vereinfachung können aufeinander folgende
Schaltglieder unmittelbar ohne Abstand hintereinander
gezeichnet werden.
Schaltglieder, die zwei Eingänge besitzen, können
prinzipiell auch mehr als zwei Eingänge besitzen.

Axiome
Jede beliebige Schaltung kann unter alleiniger Verwendung
von NOT, AND und OR
aufgebaut werden.
Jede beliebige Schaltung kann unter alleiniger Verwendung
von NAND oder NOR
aufgebaut werden.

Experimente mit Gattern
1. Elektronik-Bastelei:
Breadboard, Netzteil, LEDs, TTL Schaltkreise,...
Literatur : /3/
vgl. einführendes Beispiel
2. Simulatoren für Digitalfunktionen
viele Systeme im Internet, hier empfohlen Yenka
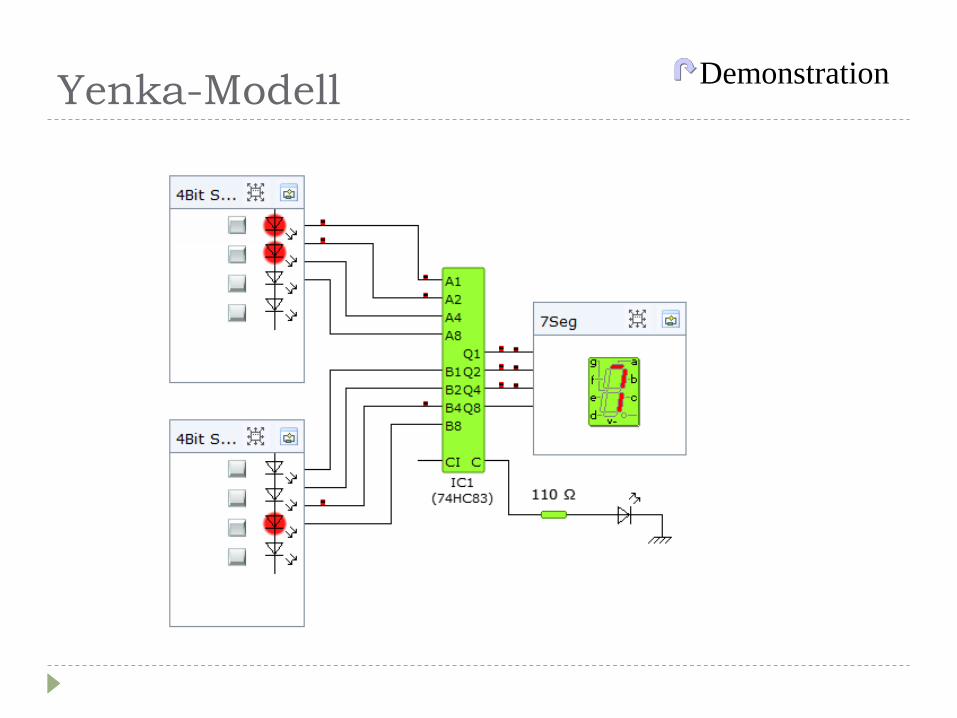
Yenka-Modell Demonstration
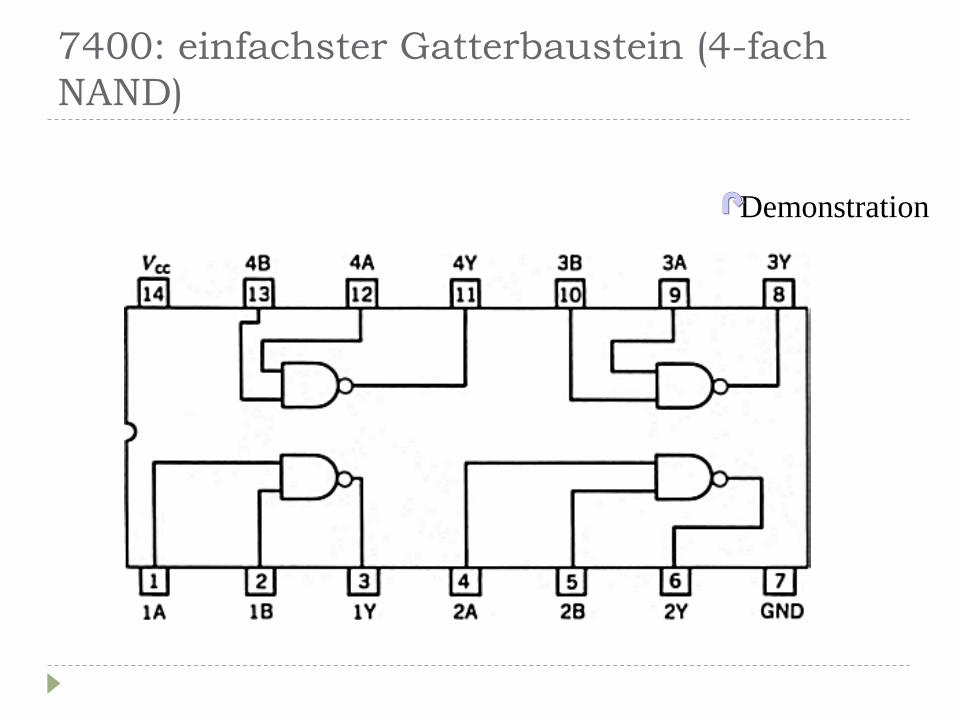
7400: einfachster Gatterbaustein (4-fach
NAND)
Demonstration
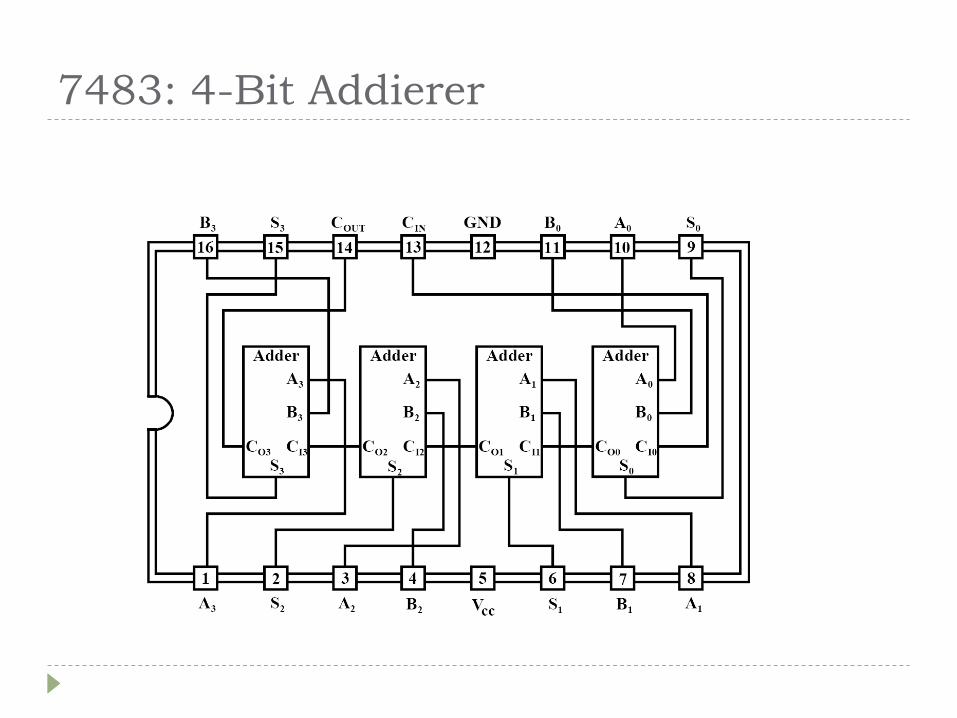
7483: 4-Bit Addierer

Kombinatorische Schaltungen
auch Schaltnetze genannt
Ausgangsgrößen sind nur vom momentanen Wert der Eingangsgrößen abhängig
Einige Beispiele: 2bit Ampelansteuerung (4 Zustände)
Kodewandler dezimal --> binär (BCD)
binär (BCD) --> dezimal
binär (BCD) --> 7 Segment
Paritätsgeneratoren, Paritätstester
Halb- und Volladder
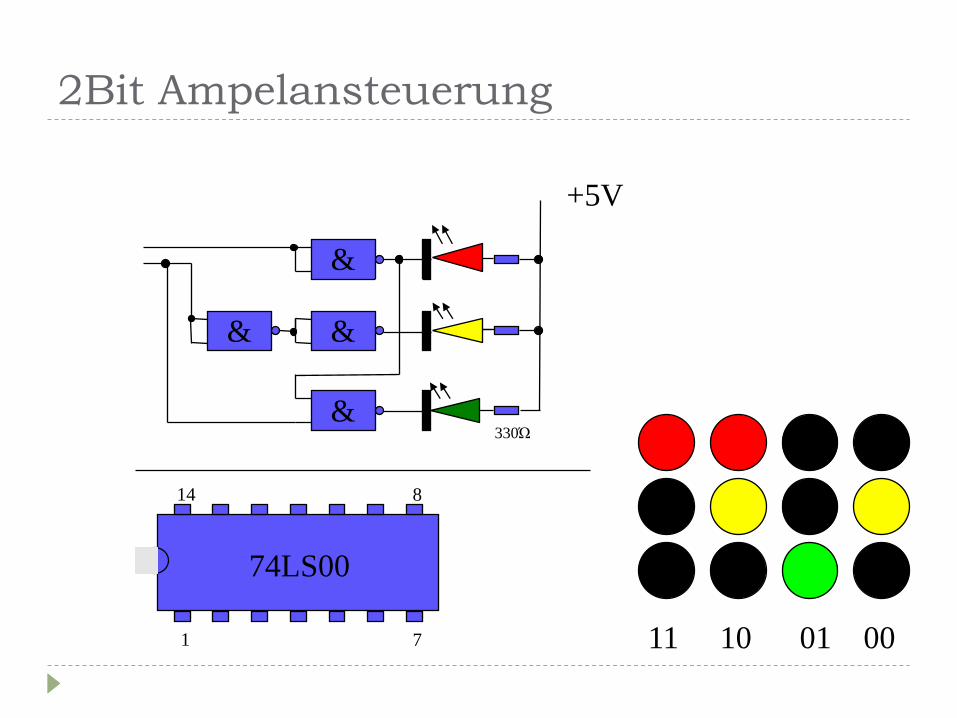
2Bit Ampelansteuerung
11 10 01 00
14 8
1 7
74LS00
&
&
& &
+5V
330Ώ
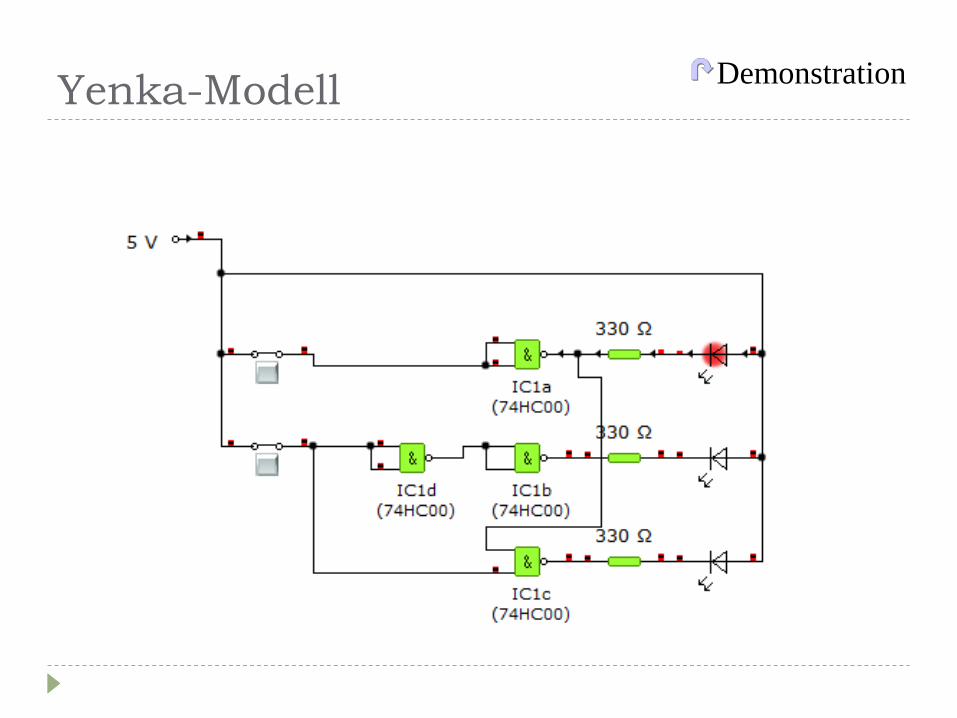
Yenka-Modell Demonstration

2Bit Ampelansteuerung
Aufgabenstellung: Die Ampelphasen
„ROT“
„ROT-GELB“
„GRÜN“
„GELB“
sollen mit zwei Bit gesteuert werden
Gn Ge Rot E2 E1
1 1 0 1 1
1 0 0 0 1
0 1 1 1 0
1 0 1 0 0
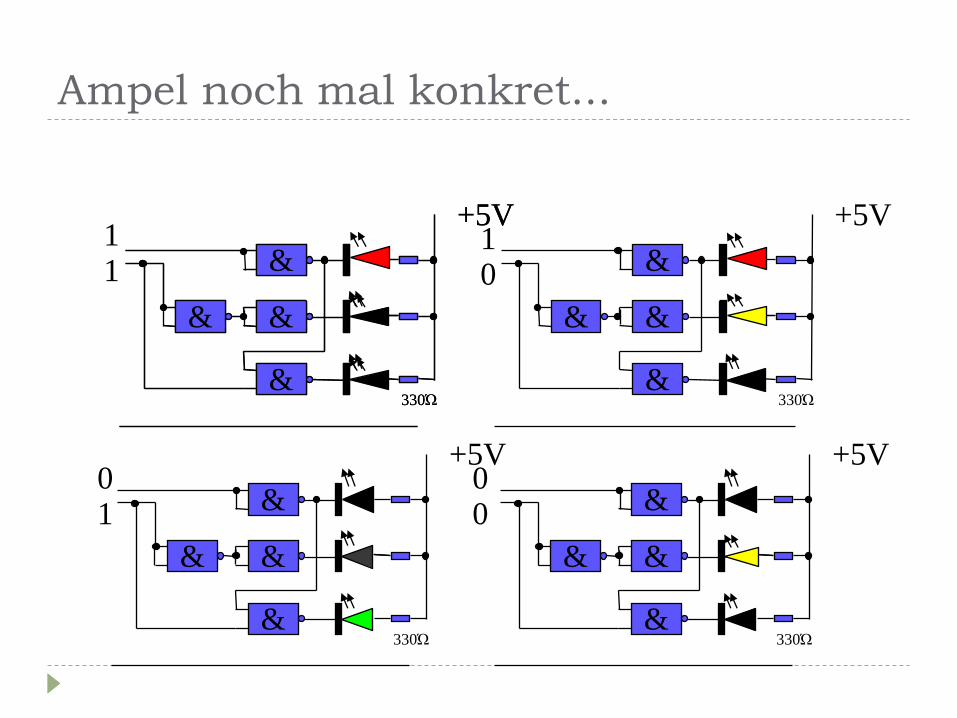
Ampel noch mal konkret...
&
&
& &
+5V
330Ώ
&
&
& &
+5V
330Ώ
&
&
& &
+5V
330Ώ
&
&
& &
+5V
330Ώ
1 1 &
&
& &
+5V
330Ώ
1 0
0 1
0 0
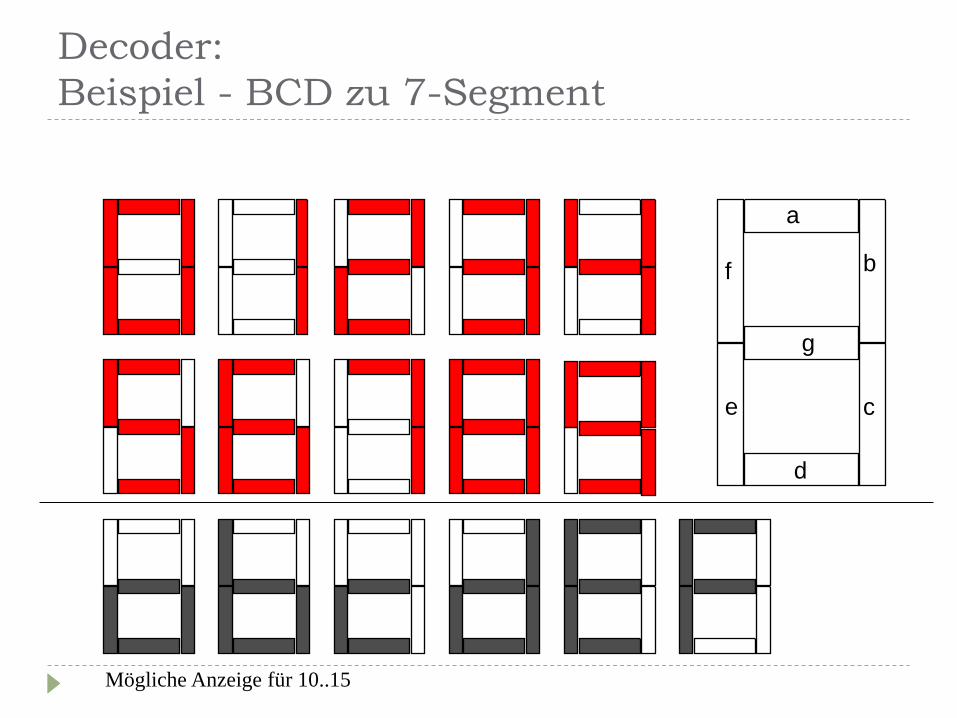
Decoder:
Beispiel - BCD zu 7-Segment
a
b
c
d
e
f
g
Mögliche Anzeige für 10..15

Tabelle...
23
22
21
20
a b c d e f g
0 0 0 0 1 1 1 1 1 1 0
0 0 0 1 0 1 1 0 0 0 0
0 0 1 0 1 1 0 1 1 0 1
0 0 1 1 1 1 1 1 0 0 1
0 1 0 0 0 1 1 0 0 1 1
0 1 0 1 1 0 1 1 0 1 1
0 1 1 0 1 0 1 1 1 1 1
0 1 1 1 1 1 1 0 0 0 0
1 0 0 0 1 1 1 1 1 1 1
1 0 0 1 1 1 1 1 0 1 1
...Synthese ?
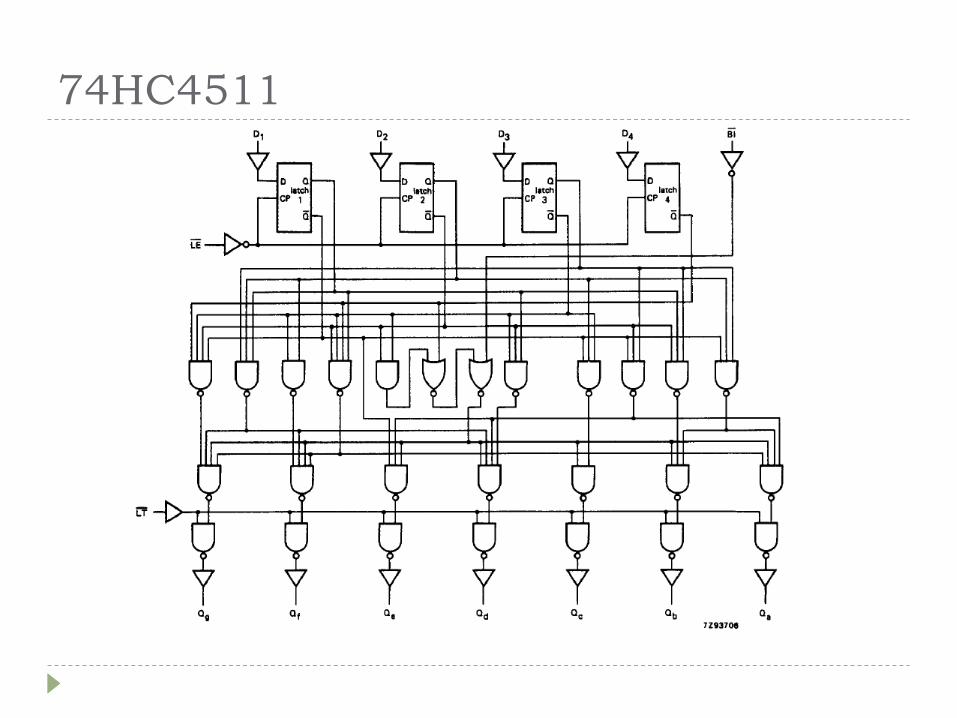
74HC4511

…drei EINFACHE Beispiele
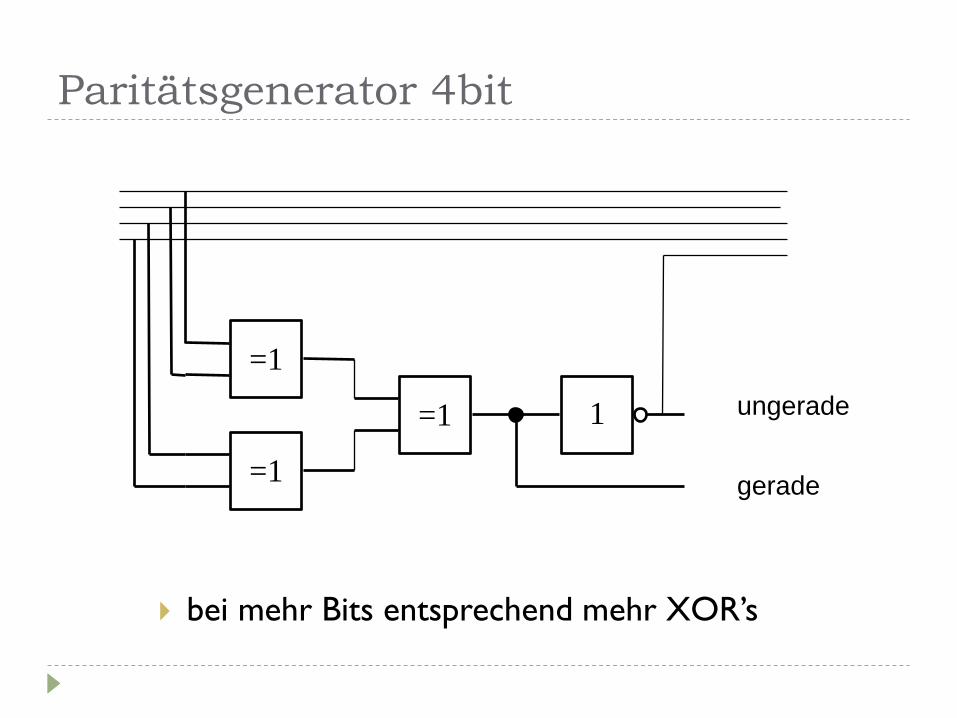
Paritätsgenerator 4bit
bei mehr Bits entsprechend mehr XOR’s
=1
=1
=1 1 ungerade
gerade
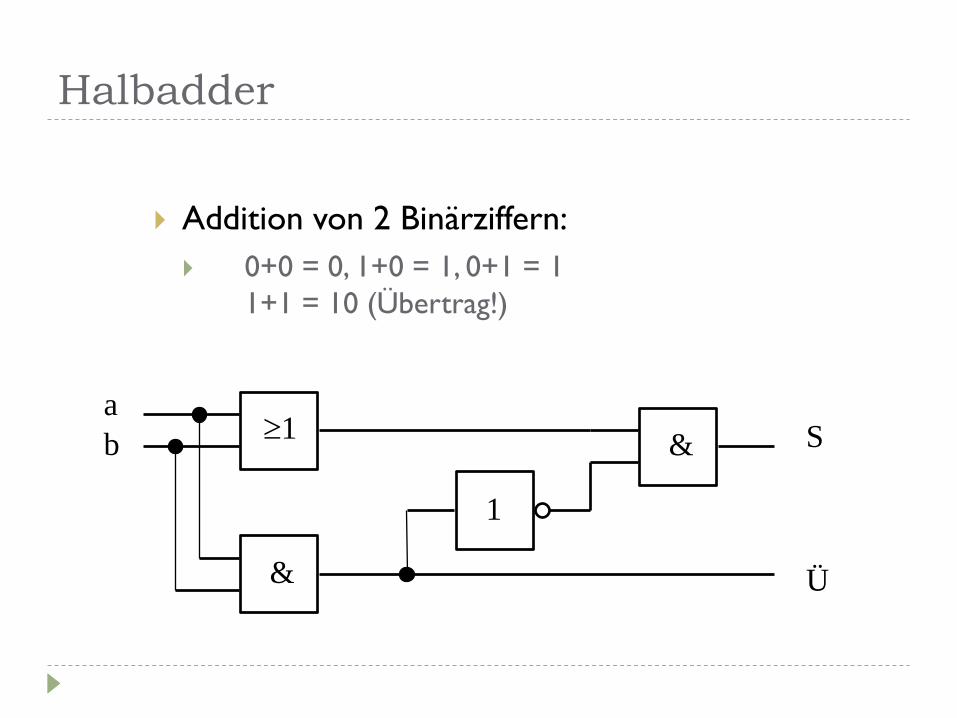
Halbadder
Addition von 2 Binärziffern:
0+0 = 0, 1+0 = 1, 0+1 = 1
1+1 = 10 (Übertrag!)
1
&
1 &
a
b S
Ü
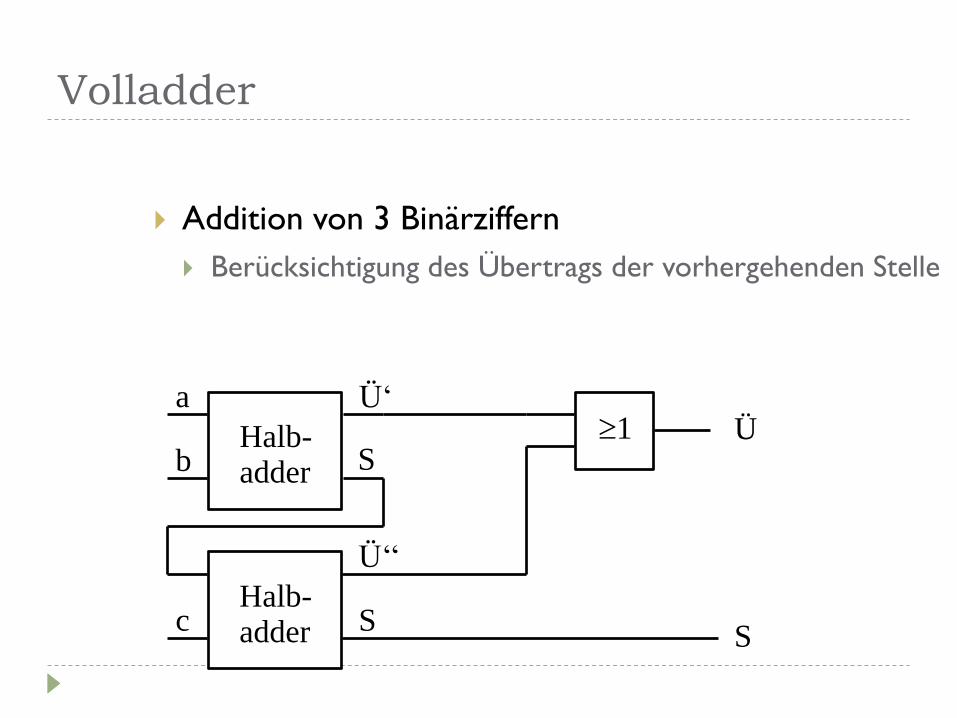
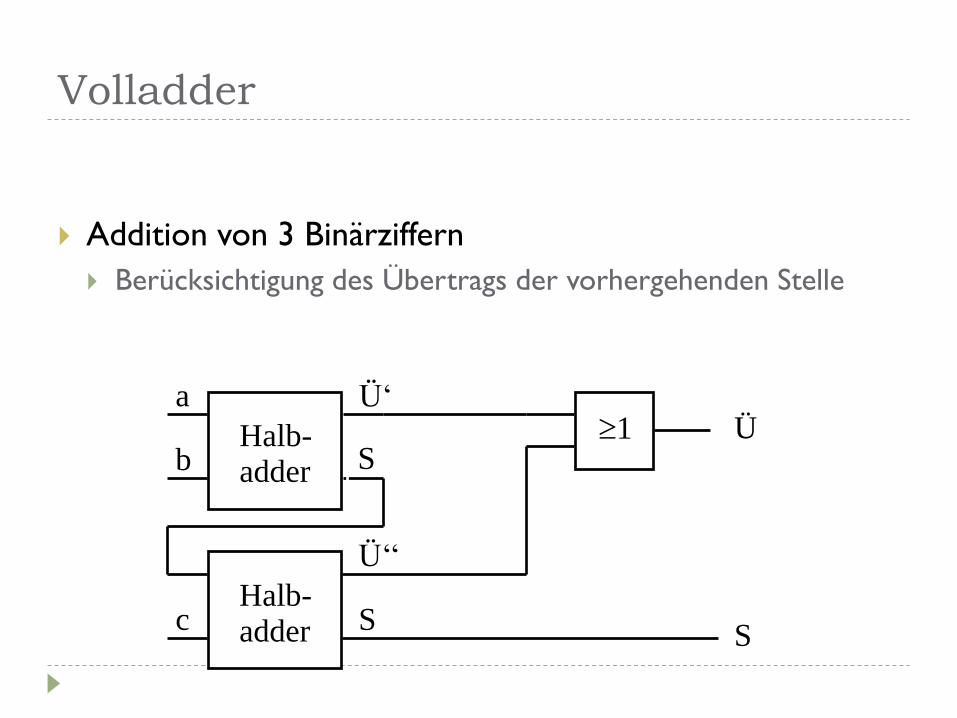
Volladder
Addition von 3 Binärziffern
Berücksichtigung des Übertrags der vorhergehenden Stelle
a
b
Ü‘
S Halb- adder
c
Ü‘‘
S Halb- adder
1 Ü
S

Vereinfachungen von Schaltnetzen
Warum ?
Kostenoptimierung für die Herstellung
Wie
Durch Vereinfachung der Boole‘schen Ausdrücke
Zur einfacheren Schreibweise nehmen wir a b -> ab, a b -> a+b, a -> a
Mit Karnaugh-Veitch Plänen
Mit Computerprogrammen

Sequentielle Schaltungen
bisher: Wert der Ausgabevariablen nur
vom Zustand der Eingabevariablen
abhängig (Schaltnetz)
y = f(x)
neu: Wert der Ausgabevariablen zusätzlich auch vom Zustand der Schaltung abhängig (Schaltwerk) y = f(x,z); z‘=g(x,z)
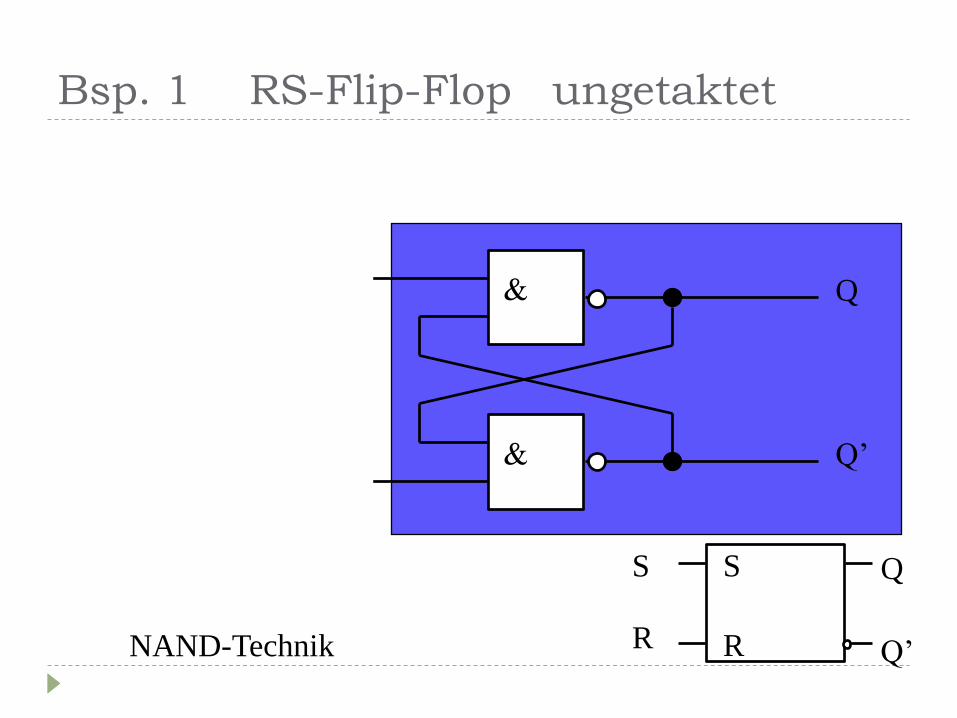
Bsp. 1 RS-Flip-Flop ungetaktet
S
R
Q
Q’
S
R
Q
Q’ NAND-Technik
S
R
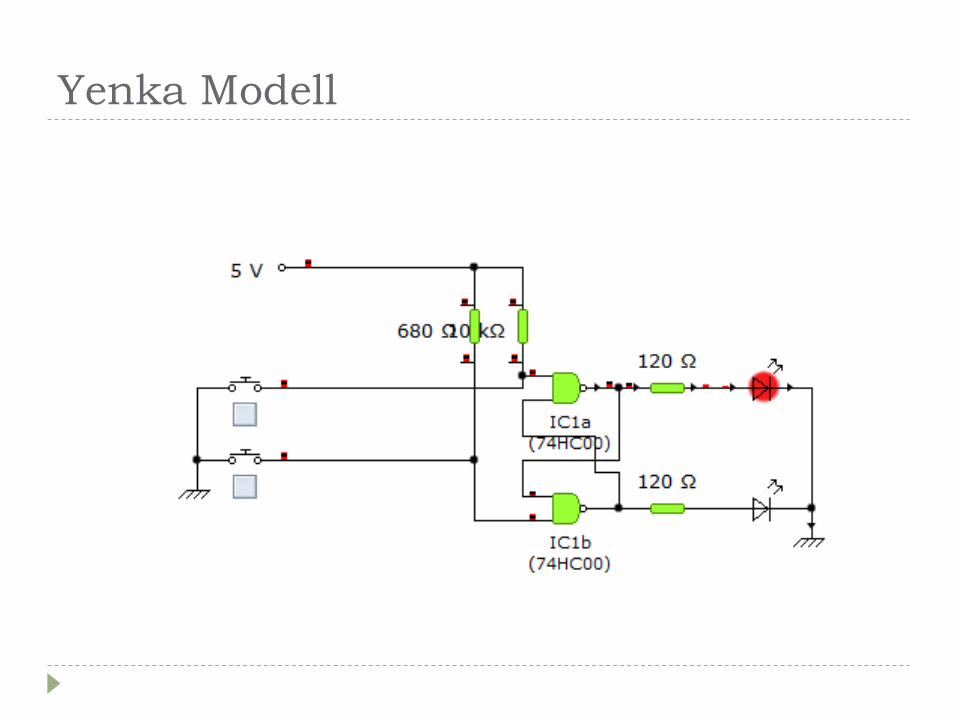
Yenka Modell
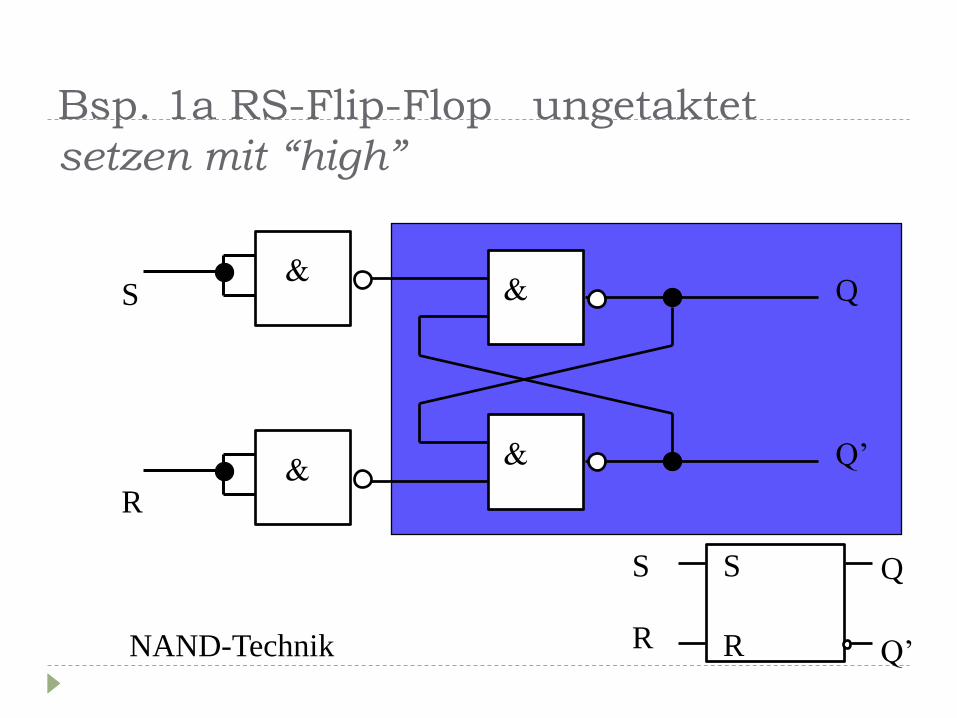
Bsp. 1a RS-Flip-Flop ungetaktet
setzen mit “high”
S
R
Q
Q’
S
R
Q
Q’ NAND-Technik
S
R
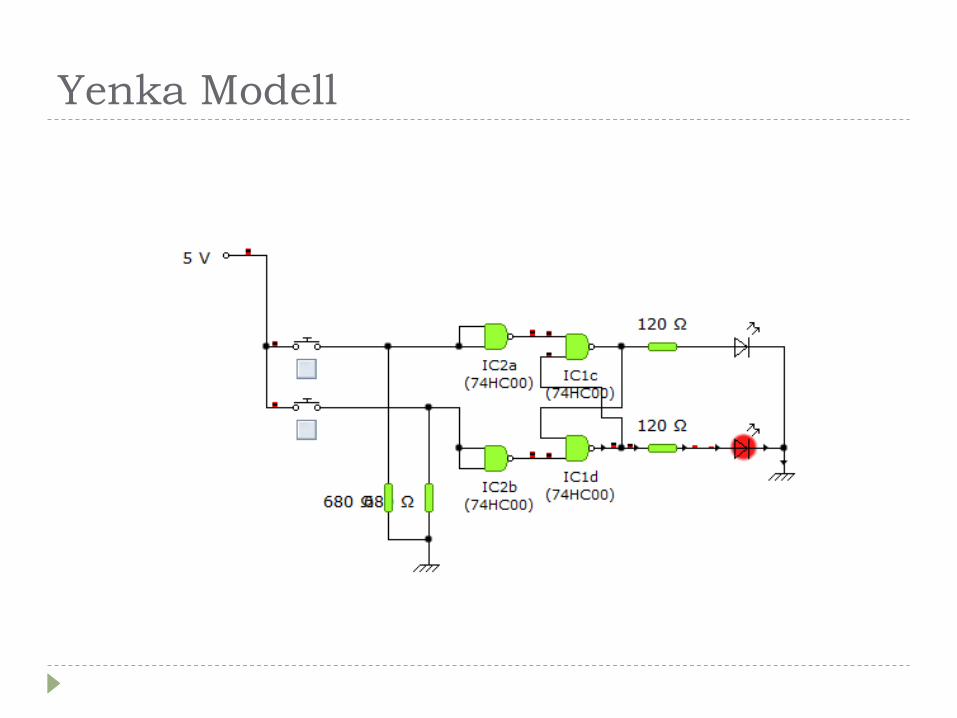
Yenka Modell
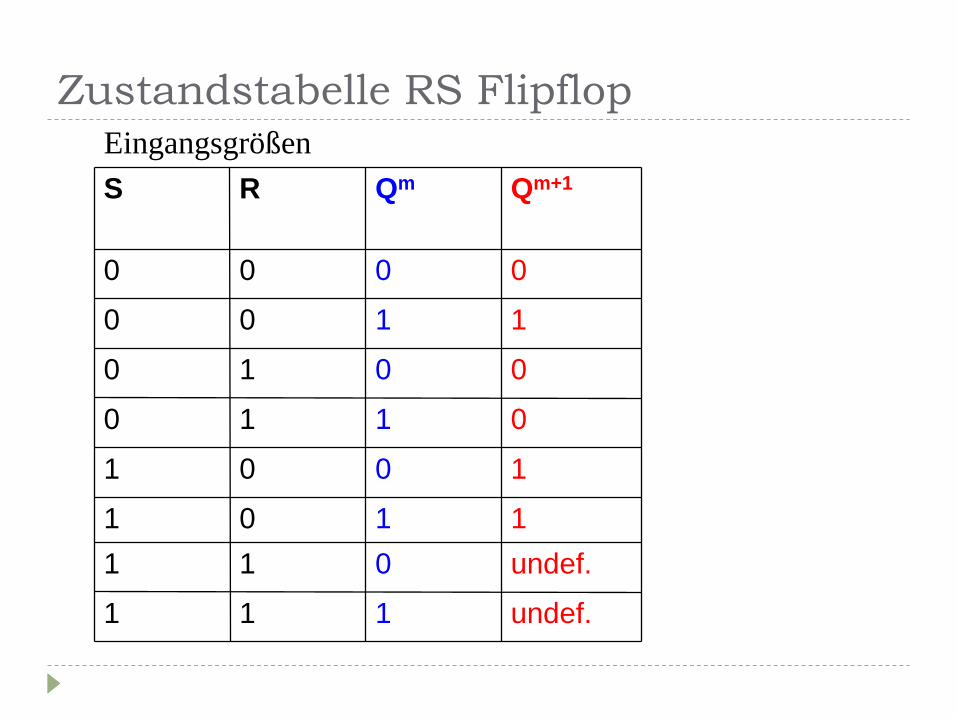
Zustandstabelle RS Flipflop
1 0 0 1
0 1 1 0
1 1 0 1
undef. 0 1 1
undef.
0
1
0
Qm+1
1
0
1
0
Qm
0 0
1 1
1 0
0 0
R S
Eingangsgrößen
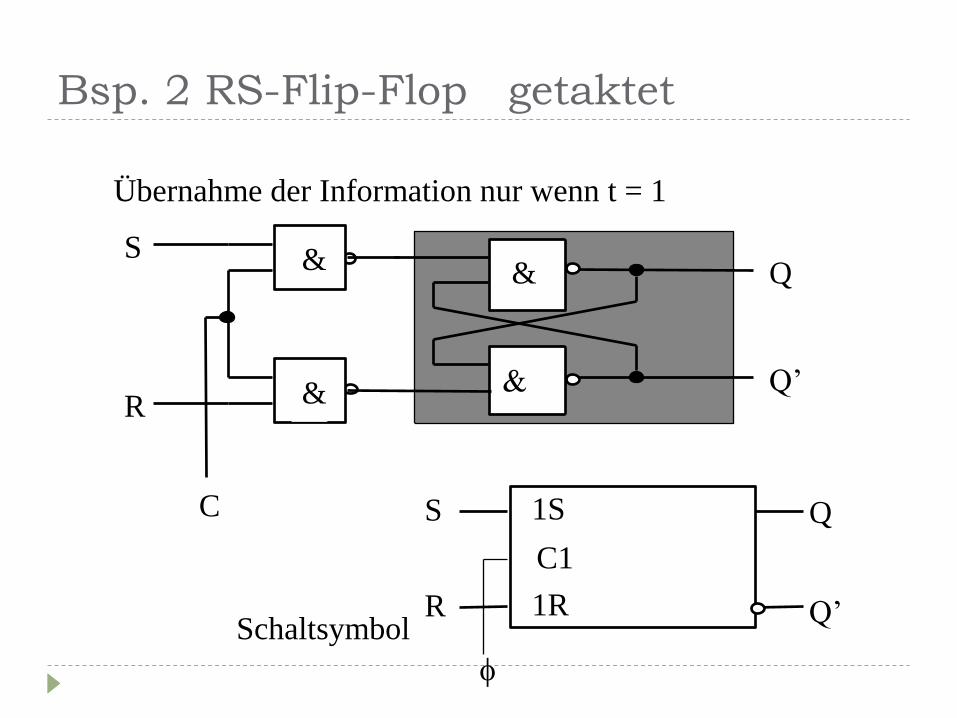
Bsp. 2 RS-Flip-Flop getaktet
& S
R
Q
Q’
&
&
C
Schaltsymbol
Übernahme der Information nur wenn t = 1
1S
1R
Q
Q’
C1
S
R
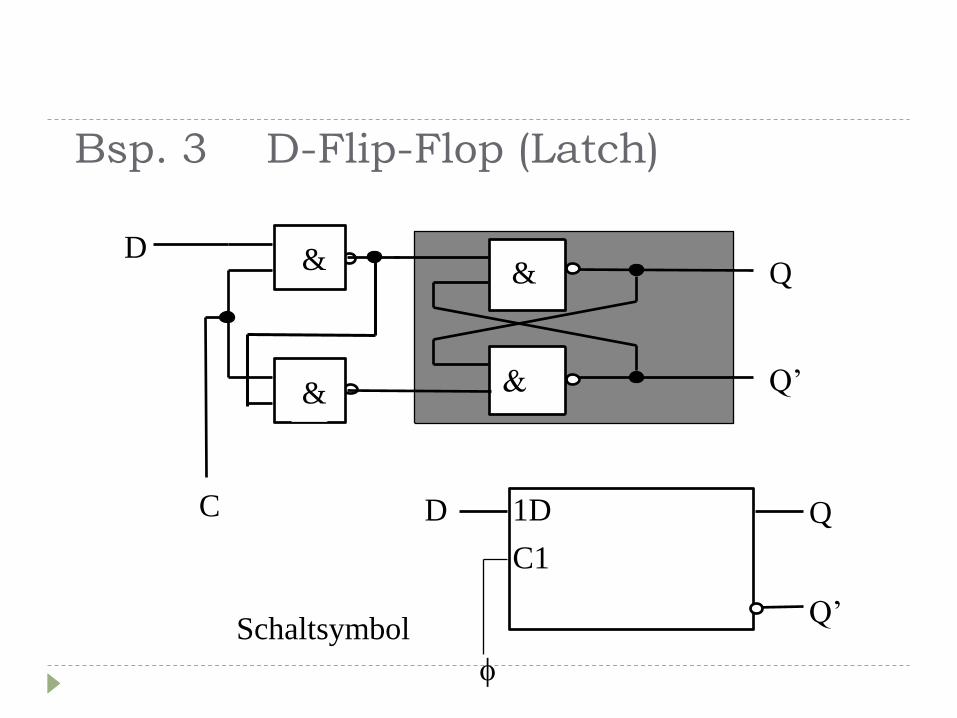
Bsp. 3 D-Flip-Flop (Latch)
& D
Q
Q’
&
&
C 1D Q
Q’ Schaltsymbol
C1
D
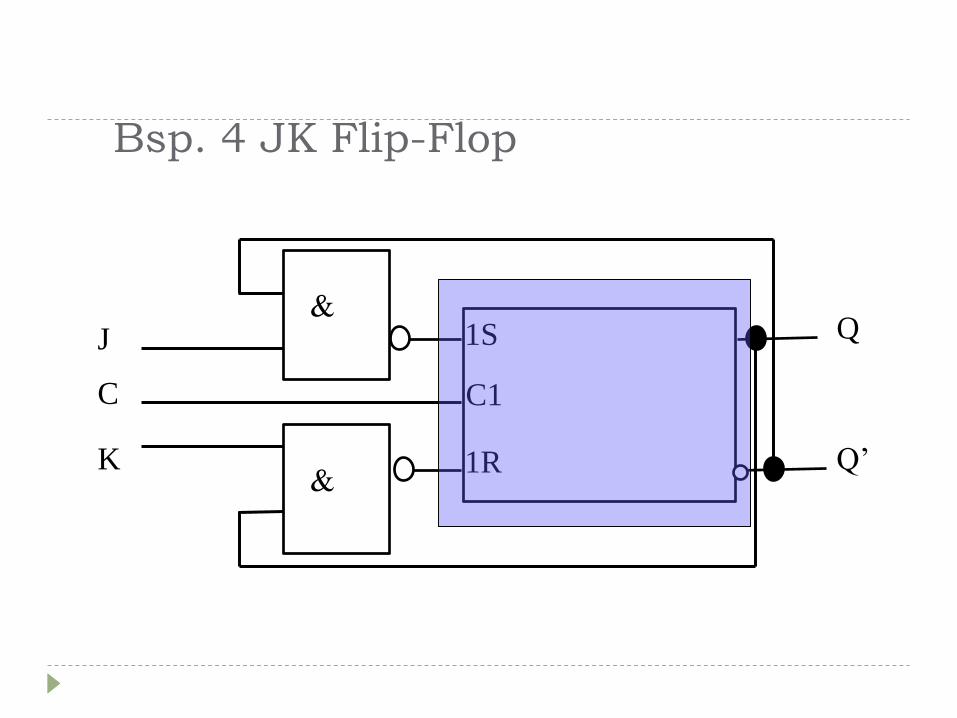
Bsp. 4 JK Flip-Flop
1S
1R
Q
Q’
C1
J
K
C
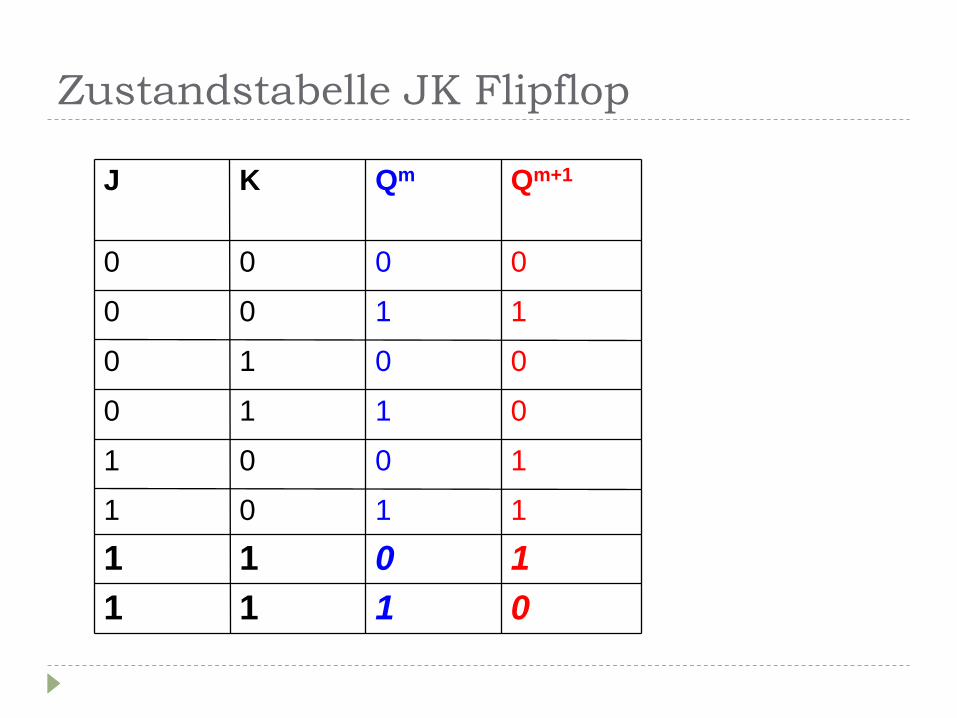
Zustandstabelle JK Flipflop
1 0 0 1
0 1 1 0
1 1 0 1
1 0 1 1
0
0
1
0
Qm+1
1
0
1
0
Qm
0 0
1 1
1 0
0 0
K J
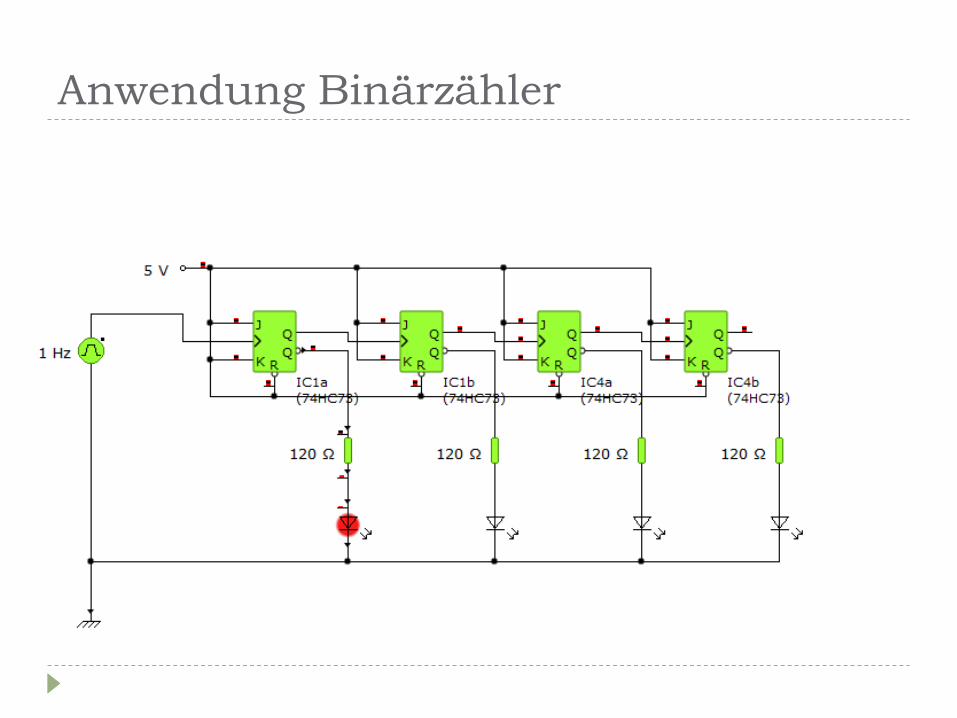
Anwendung Binärzähler
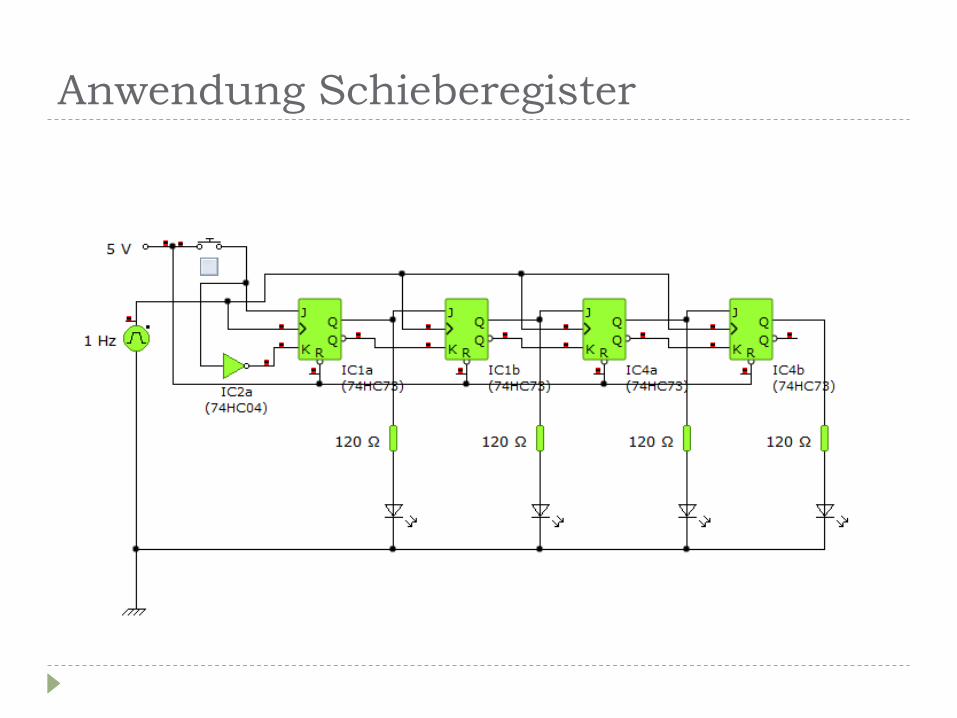
Anwendung Schieberegister

weitere Beispiele
n-Bit Latch z.B. Ports im E/A Adressraum
n-Bit Speicher --> Statische RAMs da teuer, Anwendung hauptsächlich als Cache (der
Arbeitsspeicher ist dynamischer RAM!)
Arithmetische Schaltungen z.B. Serienaddierwerk
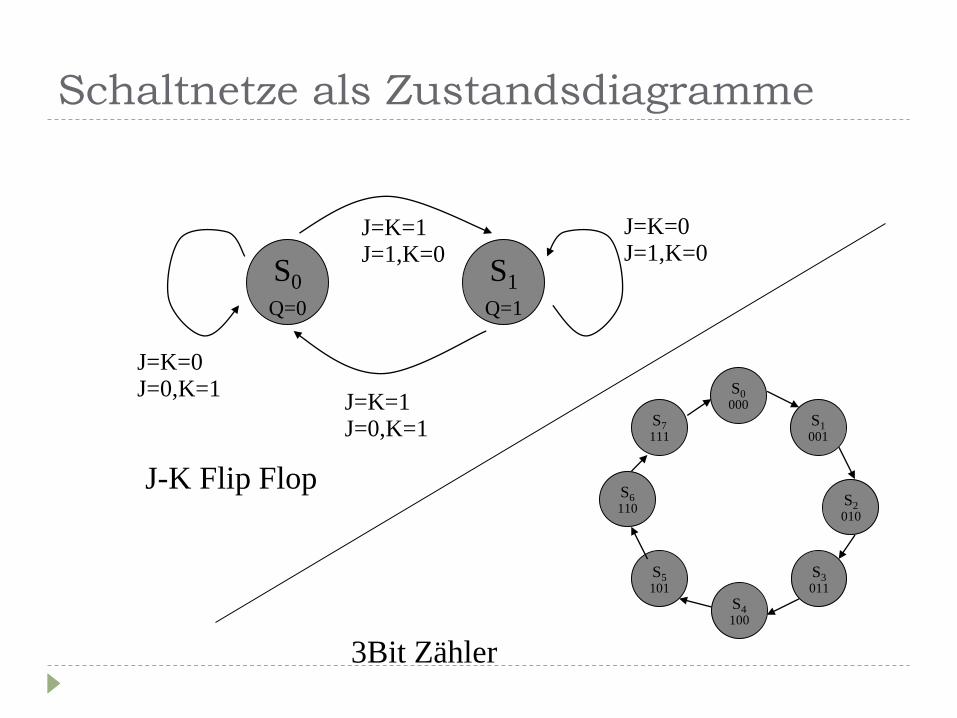
Schaltnetze als Zustandsdiagramme
S0
Q=0
S1
Q=1
J=K=0 J=0,K=1
J=K=0 J=1,K=0
J=K=1 J=0,K=1
J=K=1 J=1,K=0
S0 000
S4 100
S2 010
S6 110
S7 111
S1 001
S3 011
S5 101
J-K Flip Flop
3Bit Zähler

…wie der Computer rechnet
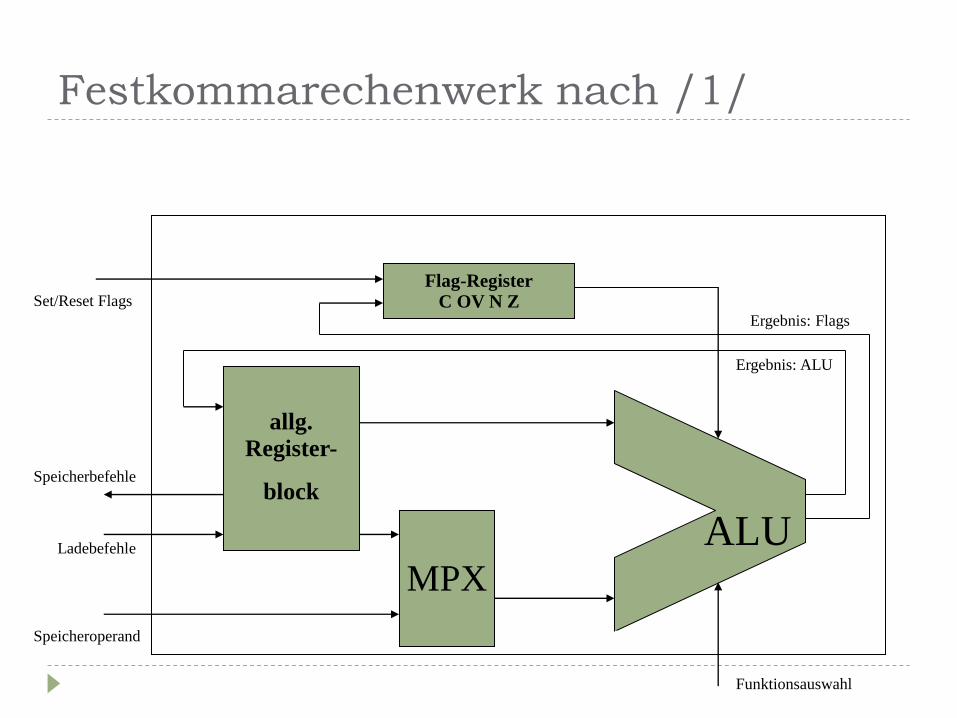
Festkommarechenwerk nach /1/
MPX
allg.
Register-
block
Flag-Register C OV N Z
ALU
Ergebnis: Flags
Ergebnis: ALU
Set/Reset Flags
Speicherbefehle
Ladebefehle
Speicheroperand
Funktionsauswahl

eine ALU (74181)
Aufgaben der ALU arithmetische Operationen
z.B. Addition, Subtraktion, Komplement, Inkrement, Dekrement, ...
logische Operationen AND, OR, XOR, NOT, ...
vgl. Dokumentation ALU 74F181.pdf
Demonstration

Festkommaaddition
Erinnerung: Volladder
Addition von Maschinenworten
serieller Addierer (sequentieller Addierer)
parallele Addierer
vollständiges Schaltnetz
RCA (Ripple Carry Adder)
CLAA (Carry Look Ahead Adder)
Volladder
Addition von 3 Binärziffern
Berücksichtigung des Übertrags der vorhergehenden Stelle
a
b
Ü‘
S Halb- adder
c
Ü‘‘
S Halb- adder
1 Ü
S
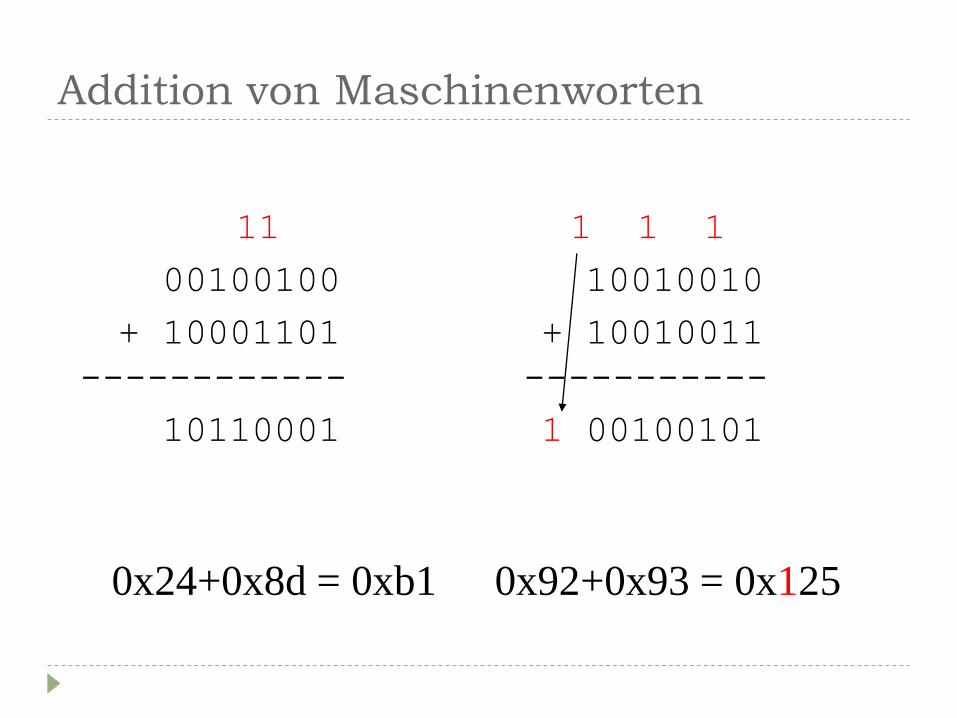
Addition von Maschinenworten
11 1 1 1
00100100 10010010
+ 10001101 + 10010011
------------ -----------
10110001 1 00100101
0x24+0x8d = 0xb1 0x92+0x93 = 0x125
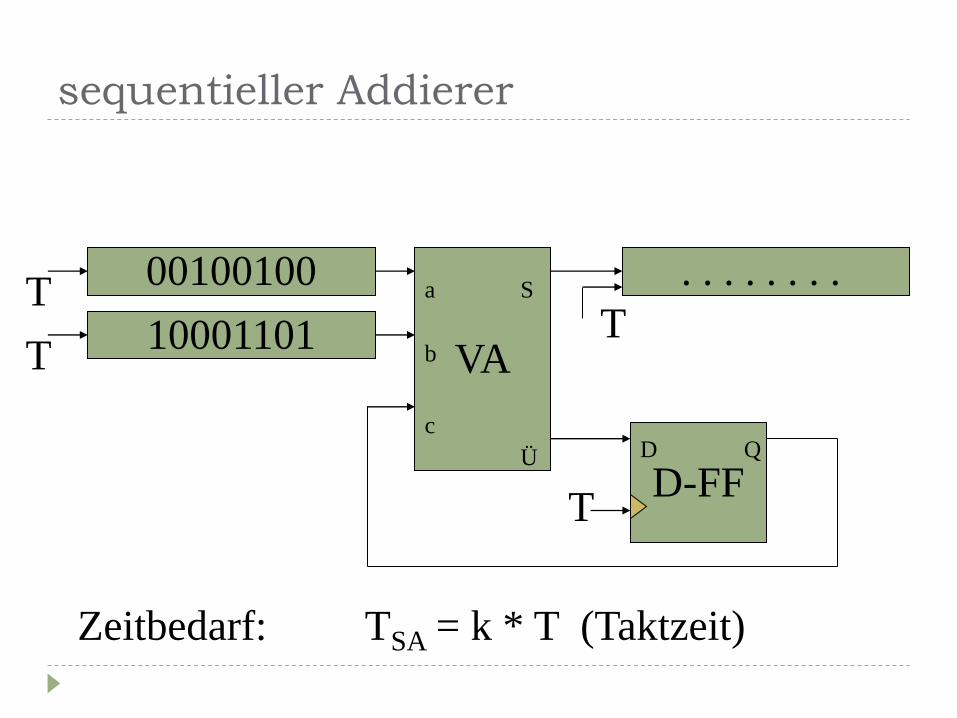
sequentieller Addierer
10001101 VA
D-FF
00100100 . . . . . . . .
D Q
T
T
T
T a
b
c
S
Ü
Zeitbedarf: TSA = k * T (Taktzeit)
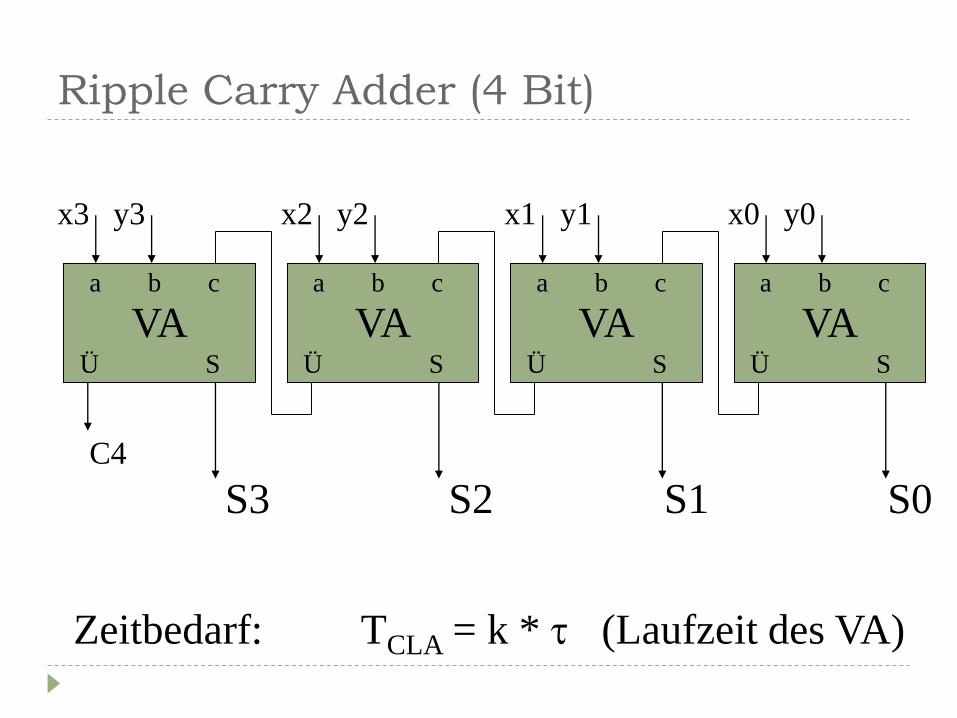
Ripple Carry Adder (4 Bit)
VA a b c
Ü S
VA a b c
Ü S
VA a b c
Ü S
VA a b c
Ü S
Zeitbedarf: TCLA = k * (Laufzeit des VA)
x3 y3 x2 y2 x1 y1 x0 y0
S3 S2 S1 S0
C4

Carry Look Ahead Adder
Ausgangspunkt:
maximale Beschleunigung der Addition
wäre mit vollständiger Parallelisierung möglich (Schaltnetz für alle
möglichen Varianten)
hoher Ressourcenverbrauch
(nach /1/ DNFs mit 4*3k-1 Konjunktionen je Summenbit k)
Kompromiss: CLAA
Kombination aus Volladdern und einem CLA-Generator
Laufzeit : TCLAA = 1 + 2 (Laufzeit eines VA + CLAG)
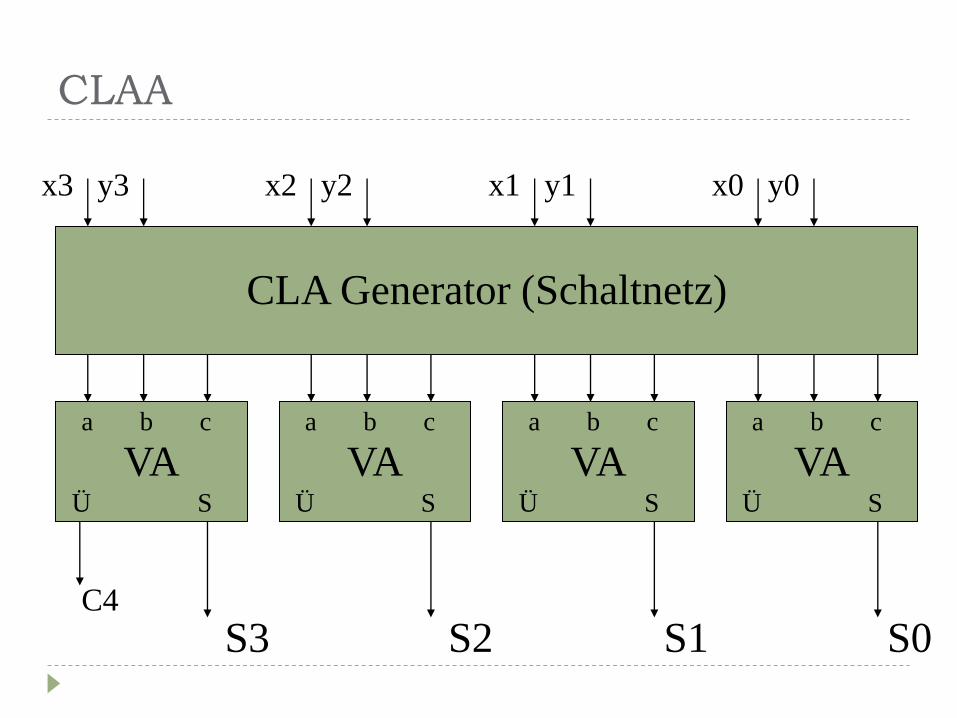
CLAA
VA a b c
Ü S
VA a b c
Ü S
VA a b c
Ü S
VA a b c
Ü S
CLA Generator (Schaltnetz)
x3 y3 x2 y2 x1 y1 x0 y0
S3 S2 S1 S0 C4
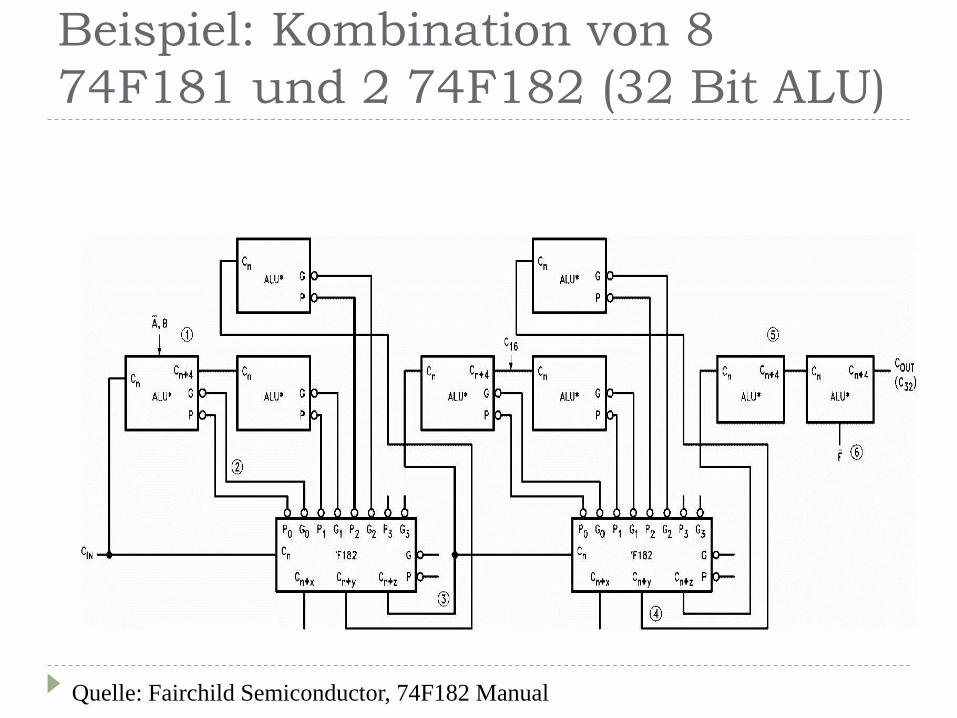
Beispiel: Kombination von 8
74F181 und 2 74F182 (32 Bit ALU)
Quelle: Fairchild Semiconductor, 74F182 Manual

einige Bemerkungen zur Subtraktion
eigenständige Subtraktionsschaltungen wären möglich
aus dem Zusammenhang mit der Darstellung negativer Zahlen
als Zweierkomplement ergibt sich die
-> Rückführung der Subtraktion auf die Addition der entsprechend
Zahl im Zweierkomplement
Beispiel (8 Bit):
68 - 43 = 68 + (43)zk = 68 + 213 = 25
(eigentlich 281 = 0x119 (da 8 Bit, bleibt nur 0x19 = 25 übrig,
die 1 setzt das Carry Flag)

Multiplikation
gefunden in /2/:
Multiplication is vexation, Division is as bad;
The rule of three doth puzzle me, And practice drives me mad.
Anonymous, Elizabethan manuscript, 1570
offensichtlich ist die Multiplikation von zwei Zahlen im Stellenwertsystem mit größeren
Schwierigkeiten verbunden als die Addition!
Befehle zur Multiplikation sind erst spät in die ISA einer CPU integriert worden:
der Z80-Prozessor hat keinen Multiplikations- oder Divisionsbefehl, aktuelle PIC Mikrocontroller
ebenfalls nicht!
Im Allgemeinen wird für die Multiplikation von Maschinenworten kein Schaltnetz erstellt (sehr
aufwendig für akzeptable Wortbreite) .
>Multiplikation wird algorithmisch behandelt (Mikrocode).

Algorithmen zur Multiplikation von
Festkommazahlen
Beachte vorher: Multiplikation mit 2 kann durch "links schieben" erreicht werden.
für positive Zahlen (Vorzeichenproblematik kann man extra behandeln)
Multiplikation durch wiederholte Addition langsamste Form des Multiplikationsalgorithmus
Multiplikation durch Kombination von Additionen und Verschiebungen
für auch vorzeichenbehaftete Zahlen (Zweierkomplement) der Algorithmus von Booth

Vorbemerkungen
für die Addition von n-Bit-Maschinenworten genügt ein n-Bit Ergebnisregister (+ Carry-Flag).
für die Multiplikation von zwei n-Bit-Maschinenworten ist ein größeres Ergebnisregister (2*n-Bit) notwendig! in einer realen ISA wird das Ergebnis einer Multiplikation
meist in zwei (aufeinanderfolgenden) allgemeinen Registern abgelegt.

...wiederholte Addition
sicher trivial, wird hier nicht weiter betrachtet!

Additionen und Verschiebungen
(Vorwärtsalgorithmus)
angelehnt an das Verfahren der schriftlichen Multiplikation: 1234 x 2345
-----------
6170 0 + 6170 = 6710
4936 6710 + 49360 = 55530
3702 55530 + 370200 = 425730
2468 425730 + 2468000 = 2893730
-----------
2893730
0100 x 0011
-----------
0100 00000000 + 0100 = 00000100
0100 00000100 + 01000 = 00001100
0000 00001100 + 000000 = 00001100
0000 00001100 + 0000000 = 00001100
-----------
0001100
-> Aufbereitung für Implementation

Implementaion (Vorwärtsalgorithmus)
0100 x 0011
-----------
0100 0011: 0000|0000 + 0100L = 0100|0000
0100 0001: 0010|0000 + 0100L = 0110|0000
0000 0000: 0011|0000 + 0000L = 0011|0000
0000 0000: 0001|1000 + 0000L = 0001|1000
----------- 0000|1100
0001100
jeweils Addition in der linken Hälfte des
Ergebnisregisters, dann nach rechts schieben
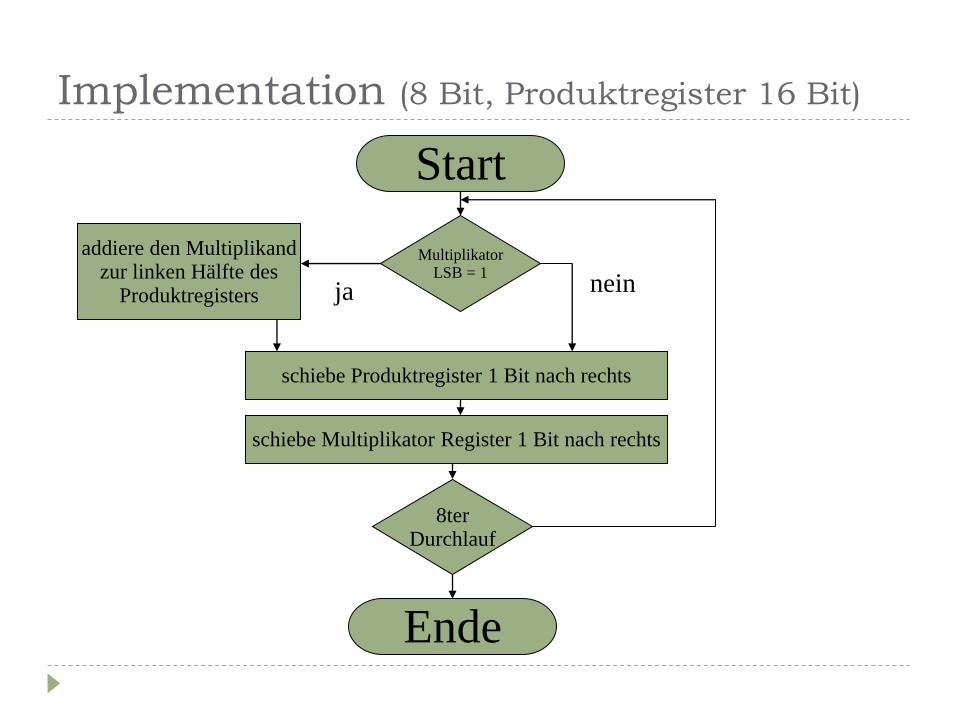
Implementation (8 Bit, Produktregister 16 Bit)
Multiplikator LSB = 1
Start
Ende
schiebe Produktregister 1 Bit nach rechts
8ter Durchlauf
schiebe Multiplikator Register 1 Bit nach rechts
addiere den Multiplikand zur linken Hälfte des
Produktregisters ja nein
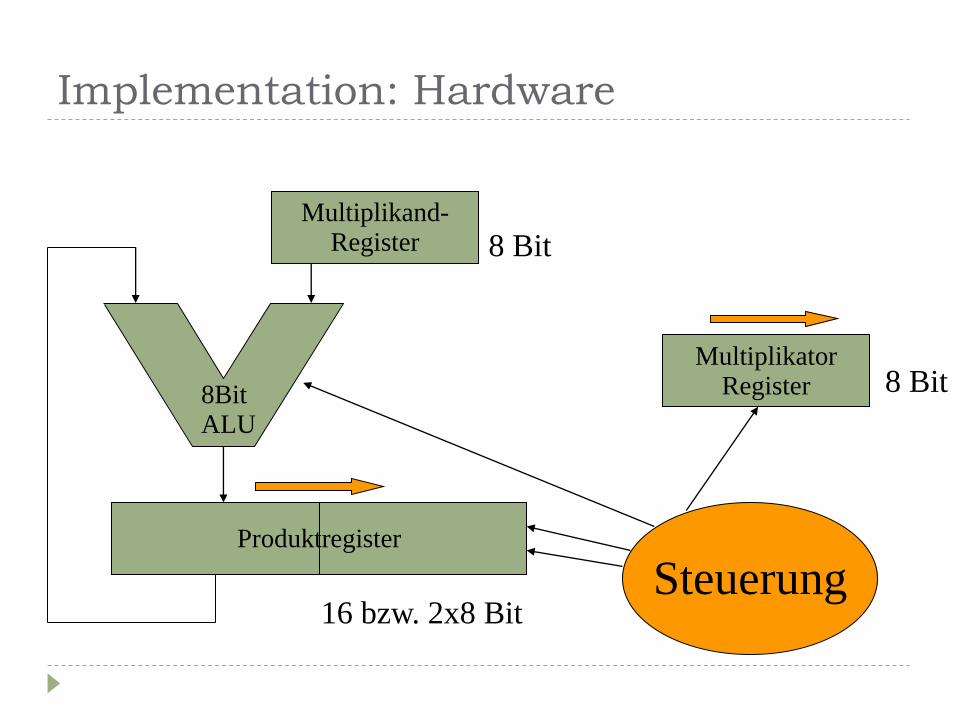
Implementation: Hardware
Produktregister
Multiplikand- Register
Multiplikator Register 8Bit
ALU
Steuerung
8 Bit
8 Bit
16 bzw. 2x8 Bit
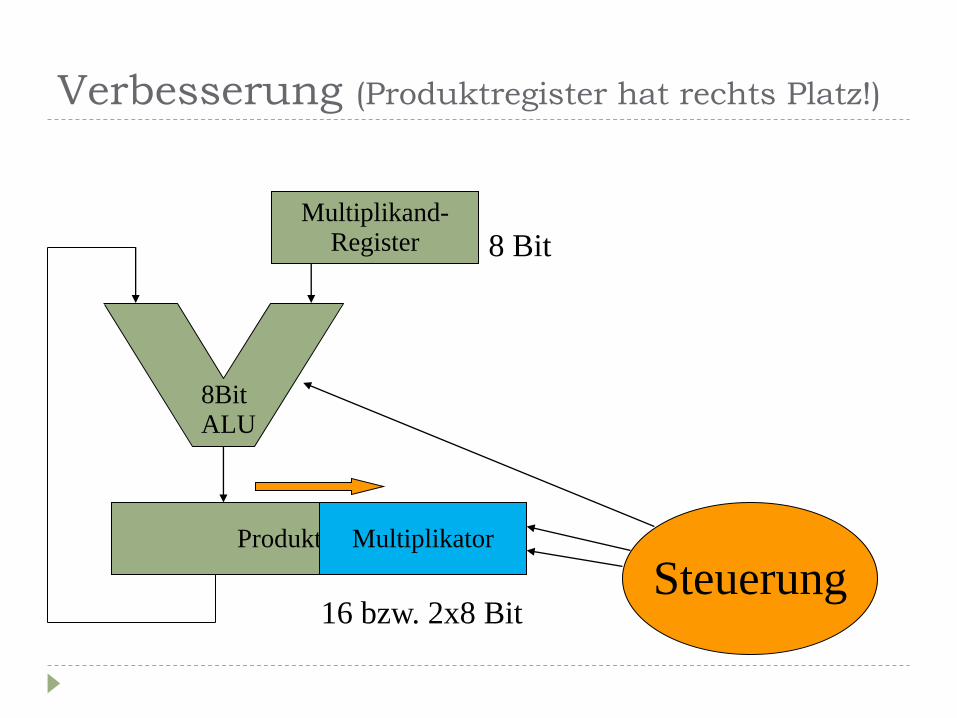
Verbesserung (Produktregister hat rechts Platz!)
Produktregister
Multiplikand- Register
Multiplikator
8Bit ALU
Steuerung
8 Bit
16 bzw. 2x8 Bit
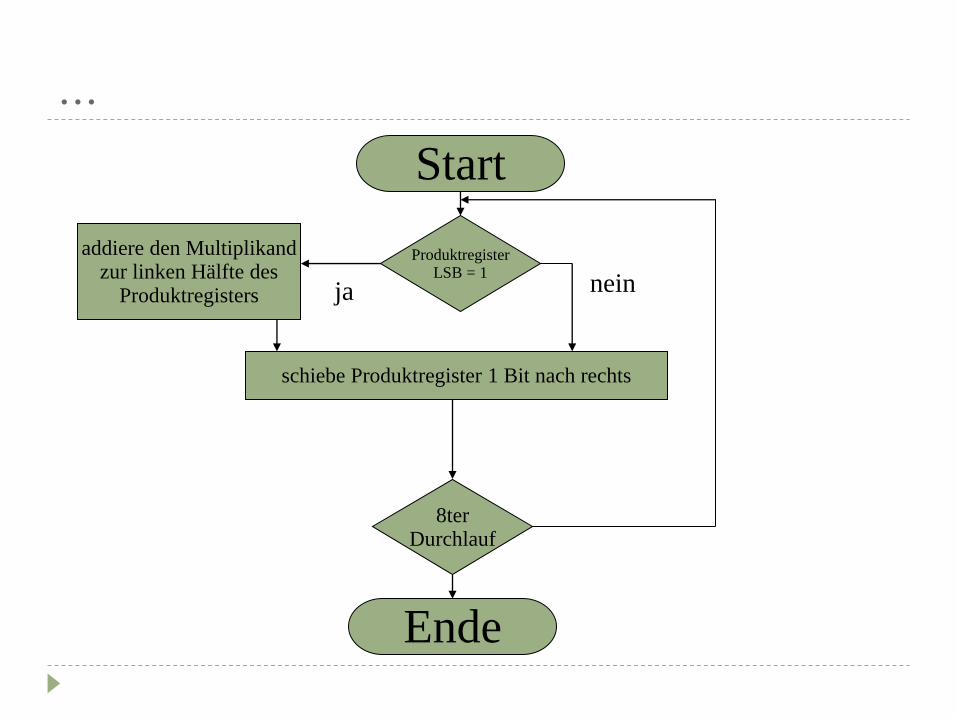
...
Produktregister LSB = 1
Start
Ende
schiebe Produktregister 1 Bit nach rechts
8ter Durchlauf
addiere den Multiplikand zur linken Hälfte des
Produktregisters ja nein

Ausblick I: Der Algorithmus von Booth
bisher: Multiplikation nur für positive Zahlen, negative1)
Zahlen müssen extra behandelt werden Vorzeichenbestimmung des Ergebnisses
+a * -b = -c, -a * +b = -c, -a * -b = c
Umwandlung negativer Zahlen in positive
Durchführung der positiven Multiplikation
Rückwandlung in negative Zahlen, wenn notwendig
Algorithmus von Booth behandelt auch negative Zahlen
automatisch
1) Zweierkomplementdarstellung

Algorithmus von Booth
arbeitet ähnlich dem vorgestellten Algorithmus mit
folgenden Ergänzungen: dem Produktregister wird rechts ein weites Bit angefügt (Anfangswert =0)
in Abhängigkeit von den jetzt zwei rechten Bits des Produktregisters wird nun
vor dem (arithmetischen!) schieben
bei 00 und 11 nichts getan
bei 01 der Multiplikand addiert
bei 10 der Multiplikand subtrahiert (Zweierkomplement addiert)

Beispiel: 2 x 6
2 x 6 = 0010 x 0110 (Zk von 0010 = 1110)
Initial: PR = 00000110 0
Schritt 1: (00) PR = 0000|0110 0 -> 00000011 0
Schritt 2: (10) PR = 1110|0011 0 -> 11110001 1
Schritt 3: (11) PR = 1111|0001 1 -> 11111000 1
Schritt 4: (01) PR = 0001|1000 1 -> 00001100 0
12

Beispiel: 2 x -6
2 x -6 = 0010 x 1010 (Zk von 0010 = 1110)
Initial: PR = 00001010 0
Schritt 1: (00) PR = 0000|1010 0 -> 00000101 0
Schritt 2: (10) PR = 1110|0101 0 -> 11110010 1
Schritt 3: (01) PR = 0001|0010 1 -> 00001001 0
Schritt 4: (10) PR = 1110|1001 0 -> 11110100 1
-12

Beispiel: -2 x 6
-2 x 6 = 1110 x 0110 (Zk von 1110 = 0010)
Initial: PR = 00000110 0
Schritt 1: (00) PR = 0000|0110 0 -> 00000011 0
Schritt 2: (10) PR = 0010|0011 0 -> 00010001 1
Schritt 3: (11) PR = 0001|0001 0 -> 00001000 1
Schritt 4: (01) PR = 1110|1000 1 -> 11110100 0
-12

Beispiel: -2 x -6
-2 x -6 = 1110 x 1010 (Zk von 1110 = 0010)
Initial: PR = 00001010 0
Schritt 1: (00) PR = 0000|1010 0 -> 00000101 0
Schritt 2: (10) PR = 0010|0101 0 -> 00010010 1
Schritt 3: (01) PR = 1111|0010 1 -> 11111001 0
Schritt 4: (10) PR = 0001|1001 0 -> 00001100 1
12

Division
ähnliche Algorithmen können für die Division von
Festkommazahlen erstellt werden.
Division durch 2 kann durch "rechts schieben"
erreicht werden!
Die entsprechenden Divisionsalgorithmen werden
hier nicht behandelt.
Für das Selbststudium sei die Literatur empfohlen!

Ausblick II:
Gleitkommarechenwerke
Gleitkommazahlen werden im Maschinenwort in der Form 1.m-1m-2...m-k * 2
BIAS-n dargestellt.
Das Rechenwerk muss entsprechend den Regeln für die Arbeit mit Gleitkommazahlen in Exponentialdarstellung getrennte Operationen für Mantissenteil und Exponenten-teil des Maschinenworts realisieren. Dabei sind zusätzlich die Vorzeichen zu beachten. Addition, Subtraktion:
gleiche Exponenten erzeugen, Mantissen addieren/subtrahieren
Multiplikation
Mantissen multiplizieren/dividieren, Exponenten addieren/subtrahieren

IA32 Floating Point Unit
bei 386er als Koprozessor, seit 80486 Bestandteil der CPU
Realisiert die Arbeit mit IEEE 754 konformen Gleitkommazahlen 32 und 64 Bit
Was kann die IA32-FPU ? intern wird mit 80 Bit "temporary real" gerechnet
laden, speichern
vier Grundrechenarten (auch ganze Zahlen)
Vergleiche
Betragsbildung, Vorzeichenumkehr, Reste, Runden
Quadratwurzel, dualer Logarithmus, 2x
SIN, COS, partieller TAN und ARCTAN



























