Embed Size (px)
Citation preview

Techniques for Obtaining High Performance in Java Programs
IFFAT H. KAZI, HOWARD H. CHEN, BERDENIA STANLEY, AND DAVID J. LILJA
Minnesota Supercomputing Institute, University of Minnesota
This survey describes research directions in techniques to improve the performance ofprograms written in the Java programming language. The standard technique for Javaexecution is interpretation, which provides for extensive portability of programs. A Javainterpreter dynamically executes Java bytecodes, which comprise the instruction set ofthe Java Virtual Machine (JVM). Execution time performance of Java programs can beimproved through compilation, possibly at the expense of portability. Various types ofJava compilers have been proposed, including Just-In-Time (JIT) compilers thatcompile bytecodes into native processor instructions on the fly; direct compilers thatdirectly translate the Java source code into the target processor’s native language; andbytecode-to-source translators that generate either native code or an intermediatelanguage, such as C, from the bytecodes. Additional techniques, including bytecodeoptimization, dynamic compilation, and executing Java programs in parallel, attempt toimprove Java run-time performance while maintaining Java’s portability. Anotheralternative for executing Java programs is a Java processor that implements the JVMdirectly in hardware. In this survey, we discuss the basic features, and the advantagesand disadvantages, of the various Java execution techniques. We also discuss thevarious Java benchmarks that are being used by the Java community for performanceevaluation of the different techniques. Finally, we conclude with a comparison of theperformance of the alternative Java execution techniques based on reported results.
Categories and Subject Descriptors: A.1 [General Literature]: Introductory andSurvey; C.4 [Computer Systems Organization]: Performance of Systems; D.3[Software]: Programming Languages
General Terms: Languages, Performance
Additional Key Words and Phrases: Java, Java virtual machine, interpreters,just-in-time compilers, direct compilers, bytecode-to-source translators, dynamiccompilation
1. INTRODUCTION
The Java programming language thatevolved out of a research project startedby Sun Microsystems in 1990 [Arnold andGosling 1996; Gosling et al. 1996] is oneof the most exciting technical develop-ments in recent years. Java combines sev-
Authors’ addresses: I. H. Kazi, Dept. of Electrical and Computer Engineering, Minnesota SupercomputingInst., Univ. of Minnesota, 200 Union St., SE, Minneapolis, MN 55455; H. Chen, Dept. of Computer Scienceand Engineering; B. Stanley, Dept. of Electrical and Computer Engineering; D. J. Lilja, Dept. of Electricaland Computer Engineering.
Permission to make digital/hard copy of part or all of this work for personal or classroom use is grantedwithout fee provided that the copies are not made or distributed for profit or commercial advantage, thecopyright notice, the title of the publication, and its date appear, and notice is given that copying is bypermission of the ACM, Inc. To copy otherwise, to republish, to post on servers, or to redistribute to lists,requires prior specific permission and/or a fee.c©2001 ACM 0360-0300/01/0900-0213 $5.00
eral features found in different program-ming paradigms into one language. Fea-tures such as platform independence forportability, an object-orientation model,support for multithreading, support fordistributed programming, and automaticgarbage collection, make Java very ap-pealing to program developers. Java’s
ACM Computing Surveys, Vol. 32, No. 3, September 2000, pp. 213–240.

214 I. H. Kazi et al.
“write-once, run anywhere” philosophycaptures much of what developers havebeen looking for in a programming lan-guage in terms of application portabil-ity, robustness, and security. The cost ofJava’s flexibility, however, is its slow per-formance due to the high degree of hard-ware abstraction it offers.
To support portability, Java source codeis translated into architecture neutralbytecodes that can be executed on anyplatform that supports an implementa-tion of the Java Virtual Machine (JVM).Most JVM implementations execute Javabytecodes through either interpretationor Just-In-Time (JIT) compilation. Sinceboth interpretation and JIT compilationrequire runtime translation of bytecodes,they both result in relatively slow ex-ecution times for an application pro-gram. While advances with JIT compilersare making progress towards improvingJava performance, existing Java execu-tion techniques do not yet match the per-formance attained by conventional com-piled languages. Of course, performanceimproves when Java is compiled directlyto native machine code, but at the expenseof diminished portability.
This survey describes the different exe-cution techniques that are currently beingused with the Java programming lan-guage. Section 2 describes the basic con-cepts behind the JVM. Section 3 discussesthe different Java execution techniques,including interpreters, JIT and static com-pilers, and Java processors. In Section 4,we describe several optimization tech-niques for improving Java performance,including dynamic compilation, bytecodeoptimization, and parallel and distributedtechniques. Section 5 reviews the exist-ing benchmarks available to evaluate theperformance of the various Java executiontechniques with a summary of their per-formance presented in Section 6. Conclu-sions are presented in Section 7.
2. BASIC JAVA EXECUTION
Basic execution of an application writtenin the Java programming language beginswith the Java source code. The Java source
code files (.java files) are translated by aJava compiler into Java bytecodes, whichare then placed into .class files. The byte-codes define the instruction set for theJVM which actually executes the user’sapplication program.
2.1. Java Virtual Machine
The Java Virtual Machine (JVM) executesthe Java program’s bytecodes [Lindholmand Yellin 1997; Meyer and Downing1997]. The JVM is said to be virtual since,in general, it is implemented in softwareon an existing hardware platform. TheJVM must be implemented on the tar-get platform before any compiled Javaprograms can be executed on that plat-form. The ability to implement the JVMon various platforms is what makes Javaportable. The JVM provides the interfacebetween compiled Java programs and anytarget hardware platform.
Traditionally, the JVM executes theJava bytecodes by interpreting a streamof bytecodes as a sequence of instructions.One stream of bytecodes exists for eachmethod1 in the class. They are interpretedand executed when a method is invokedduring the execution of the program. Eachof the JVM’s stack-based instructions con-sists of a one-byte opcode immediately fol-lowed by zero or more operands. The in-structions operate on byte, short, integer,long, float, double, char, object, and returnaddress data types. The JVM’s instructionset defines 200 standard opcodes, 25 quickvariations of some opcodes (to support ef-ficient dynamic binding), and three re-served opcodes. The opcodes dictate to theJVM what action to perform. Operandsprovide additional information, if needed,for the JVM to execute the action. Sincebytecode instructions operate primarily ona stack, all operands must be pushed onthe stack before they can be used.
The JVM can be divided into the five ba-sic components shown in Figure 1. Eachof the registers, stack, garbage-collectedheap, methods area, and execution engine
1 A method roughly corresponds to a function call ina procedural language.
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 215
Fig. 1 . Basic components of the Java Virtual Machine.
components must be implemented in someform in every JVM. The registers compo-nent includes a program counter and threeother registers used to manage the stack.Since most of the bytecode instructions op-erate on the stack, only a few registers areneeded. The bytecodes are stored in themethods area. The program counter pointsto the next byte in the methods area to beexecuted by the JVM. Parameters for byte-code instructions, as well as results fromthe execution of bytecode instructions,are stored in the stack. The stack passesparameters and return values to and fromthe methods. It is also used to maintainthe state of each method invocation, whichis referred to as the stack frame. The op-top, frame, and vars registers manage thestack frame.
Since the JVM is a stack-based machine,all operations on data must occur throughthe stack. Data is pushed onto the stackfrom constant pools stored in the methodsarea and from the local variables sectionof the stack. The stack frame is dividedinto three sections. The first is the localvariables section which contains all of thelocal variables being utilized by the cur-rent method invocation. The vars registerpoints to this section of the stack frame.The second section of the stack frame is theexecution environment, which maintainsthe stack operations. The frame registerpoints to this section. The final section is
the operand stack. This section is utilizedby the bytecode instructions for storing pa-rameters and temporary data for expres-sion evaluations.
The optop register points to the top ofthe operand stack. It should be noted thatthe operand stack is always the topmoststack section. Therefore, the optop registeralways points to the top of the entire stack.While instructions obtain their operandsfrom the top of the stack, the JVM requiresrandom access into the stack to supportinstructions like iload, which loads an in-teger from the local variables section ontothe operand stack, or istore, which pops aninteger from the top of the operand stackand stores it in the local variables section.
Memory is dynamically allocated toexecuting programs from the garbage-collected heap using the new operator. TheJVM specification requires that any spaceallocated for a new object be preinitializedto zeroes. Java does not permit the user toexplicitly free allocated memory. Instead,the garbage collection process monitorsexisting objects on the heap and periodi-cally marks those that are no longer beingused by the currently executing Java pro-gram. Marked objects are then returned tothe pool of available memory. Implementa-tion details of the garbage collection mech-anism are discussed further in Section 2.2.
The core of the JVM is the execu-tion engine, which is a “virtual” processor
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

216 I. H. Kazi et al.
that executes the bytecodes of the Javamethods. This “virtual” processor can beimplemented as an interpreter, a compiler,or a Java-specific processor. Interpretersand compilers are software implementa-tions of the JVM while Java processorsimplement the JVM directly in hardware.The execution engine interacts with themethods area to retrieve the bytecodesfor execution. Various implementations ofthe Java execution engine are described insubsequent sections.
2.2. Garbage Collection
In Java, objects are never explicitlydeleted. Instead, Java relies on some formof garbage collection to free memory whenobjects are no longer in use. The JVMspecification [Lindholm and Yellin 1997]requires that every Java runtime imple-mentation should have some form of au-tomatic garbage collection. The specificdetails of the mechanism are left upto the implementors. A large variety ofgarbage collection algorithms have beendeveloped, including reference counting,mark-sweep, mark-compact, copying, andnoncopying implicit collection [Wilson1992]. While these techniques typicallyhalt processing of the application pro-gram when garbage collection is needed,incremental garbage collection techniqueshave been developed that allow garbagecollection to be interleaved with normalprogram execution. Another class of tech-niques known as generational garbage col-lection improve efficiency and memory lo-cality by working on a smaller area ofmemory. These techniques exploit the ob-servation that recently allocated objectsare most likely to become garbage withina short period of time.
The garbage collection process imposesa time penalty on the user program. Con-sequently, it is important that the garbagecollector is efficient and interferes withprogram execution as little as possible.From the implementor’s point of view,the programming effort required to imple-ment the garbage collector is another con-sideration. However, easy-to-implementtechniques may not be the most execution-
time efficient. For example, conservativegarbage collectors treat every register andword of allocated memory as a potentialpointer and thus do not require any addi-tional type information for allocated mem-ory blocks to be maintained. The draw-back, however, is slower execution time.Thus, there are trade-offs between ease ofimplementation and execution-time per-formance to be made when selecting agarbage collection technique for the JVMimplementation.
3. ALTERNATIVE EXECUTION TECHNIQUESFOR JAVA PROGRAMS
In addition to the standard interpretedJVM implementation, a variety of execu-tion techniques have been proposed to re-duce the execution time of Java programs.In this section, we discuss the alterna-tive execution techniques summarized inFigure 2.
As shown in this figure, there are nu-merous alternatives for executing Javaprograms compared to the execution ofprograms written in a typical program-ming language such as C. The standardmechanism for executing Java programs isthrough interpretation, which is discussedin Section 3.1. Compilation is another al-ternative for executing Java programs anda variety of Java compilers are availablethat operate on either Java source code orJava bytecodes. We describe several differ-ent Java compilers in Section 3.2. Finally,Java processors, which are hardware im-plementations of the JVM, are discussedin Section 3.3.
3.1. Java Interpreters
Java interpreters are the original methodfor executing Java bytecodes. An inter-preter emulates the operation of a pro-cessor by executing a program, in thiscase, the JVM, on a target processor.In other words, the running JVM pro-gram reads and executes each of thebytecodes of the user’s application pro-gram in order. An interpreter has severaladvantages over a traditional compiledexecution. Interpretation is very simple,
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 217
Fig. 2 . Alternatives for executing Java compared to a typical C programming language compilationprocess.
and it does not require a large mem-ory to store the compiled program. Fur-thermore, interpreters are relatively easyto implement. However, the primary dis-advantage of an interpreter is its slowperformance.
There are several existing Java inter-preters. The Sun Java Developers Kit(JDK) [Sun Microsystems] is used todevelop Java applications and applets thatwill run in all Java-enabled web browsers.The JDK contains all of the necessaryclasses, source files, applet viewer, debug-ger, compiler, and interpreter. Versions ex-ist that execute on the SPARC Solaris, x86Solaris, Windows NT, Windows 95, andMacintosh platforms. The Sun JVM is it-self implemented in the C programminglanguage. The Microsoft Software Devel-opment Kit (SDK) also provides the toolsto compile, execute, and test Java appletsand applications [Microsoft SDK Tools].The SDK contains the Microsoft Win32Virtual Machine for Java (Microsoft VM),
classes, APIs, and so forth for the x86 andALPHA platforms.
3.2. Java Compilers
Another technique to execute Java pro-grams is with a compiler that translatesthe Java bytecodes into native machinecode. Like traditional high-level languagecompilers, a direct Java compiler startswith an application’s Java source code (or,alternatively, with its bytecode) and trans-lates it directly into the machine languageof the target processor. The JIT compil-ers, on the other hand, are dynamically-invoked compilers that compile the Javabytecode during runtime. These compil-ers can apply different optimizations tospeed up the execution of the generatednative code. We discuss some commonJava-specific compiler optimizations inSection 3.2.1. The subsequent sections de-scribe the various Java compilers andtheir specific features.
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

218 I. H. Kazi et al.
3.2.1. Java Compiler Optimizations
Due to the unique features of the JVM,such as the stack architecture, dynamicloading, and exception handling, Java na-tive code compilers need to apply differenttypes of optimizations than those used intraditional compilers. Some commonly im-plemented optimizations include mappingstack variables to machine registers, mov-ing constant stack variables into native in-structions, increasing the efficiency of ex-ception handling, and inlining of methods.
Mapping variables to machine regis-ters increases native code performancesince registers are much faster to ac-cess than memory. Registers can also beused to reduce the amount of stack du-plication in Java. Specifically, each Javabytecode instruction consumes stack vari-ables. Therefore, if a bytecode operand isused by multiple bytecode instructions,it must be duplicated on the stack. Reg-ister operands can be used over mul-tiple instructions, however, eliminatingthe stack duplication overhead for thoseinstructions.
Stack activity also can be reduced bymoving constants on the stack into nativeinstructions as immediate operands.Java bytecode instructions must receiveconstant operands from the stack. Sincemost architectures support instructionswith immediate operands, this optimiza-tion eliminates the overhead of loadingthe constant into a register or memorylocation.
Exception overhead can be reduced byeliminating unnecessary exception checksand increasing the efficiency of the excep-tion checking mechanism. For example,arrays are often used in iterative loops.If an array index value remains boundedinside of a loop, array bounds checks canbe eliminated inside of the loop, whichcan produce significant performance ad-vantages for large arrays.
Inlining of static methods is useful forspeeding up the execution of method calls.However, the Java to bytecode compilercan only inline static methods withinthe class because static methods in otherclasses may be changed before actual ex-
ecution. The implementation of any sin-gle class instantiation is stable at runtimeand can therefore be inlined. The JIT com-pilers described in Section 3.2.2 can makeuse of this fact to inline small static meth-ods to thereby reduce the overall numberof static method calls. Dynamic methodscan be converted to static methods given aset of classes using class hierarchy analy-sis [Dean et al. 1995]. If a virtual methodhas not been overloaded in the class hier-archy, dynamic calls to that method can bereplaced by static calls. However, class hi-erarchy analysis may be invalidated if anew class is dynamically loaded into theprogram.
3.2.2. Just-In-Time Compilers
A Just-In-Time (JIT) compiler translatesJava bytecodes into equivalent native ma-chine instructions as shown in Figure 2.This translation is performed at runtimeimmediately after a method is invoked. In-stead of interpreting the code for an in-voked method, the JIT compiler translatesa method’s bytecodes into a sequence ofnative machine instructions. These nativeinstructions are executed in place of thebytecodes. Translated bytecodes are thencached to eliminate redundant translationof bytecodes.
In most cases, executing JIT compilergenerated native code is more efficientthan interpreting the equivalent byte-codes since an interpreter identifies andinterprets a bytecode every time it is en-countered during execution. JIT compi-lation, on the other hand, identifies andtranslates each instruction only once—thefirst time a method is invoked. In pro-grams with large loops or recursive meth-ods, the combination of the JIT compila-tion and native code execution times canbe drastically reduced compared to an in-terpreter. Additionally, a JIT compiler canspeed up native code execution by optimiz-ing the code it generates, as described inSection 3.2.1.
Since the total execution time of a Javaprogram is a combination of compilationtime and execution time, a JIT compilerneeds to balance the time spent optimizing
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 219
generated code against the time it saves bythe optimization. Code optimization is fur-ther limited by the scope of compilation.Since compilation occurs on demand forone class or one method at a time, it is diffi-cult for a JIT compiler to perform nonlocaloptimizations. Due to the time and scoperestrictions of JIT compilation, JIT opti-mizations are generally simple ones thatare expected to yield reasonably large per-formance gains compared to the optimiza-tion time.
Although JIT compilers are generallymore efficient than interpreters, thereare still advantages to using an inter-preter. One advantage is that interpretersare better suited to debugging programs.Another advantage is that JIT compila-tion compiles an entire method at once,while interpretation translates only theinstructions that actually are executed.If only a small percentage of the byte-codes in a method are ever executed andthe method is rarely executed, the timespent on JIT compilation may never berecouped by the reduction in executiontime.
Current JIT compilers offer a varietyof target platforms and features. TheSymantec Cafe JIT is included in theJava 2 runtime environment for Win-dows 95/NT and Netscape Navigator[Symantec]. Microsoft includes a JIT withInternet Explorer for Windows 95/NTand Macintosh [Just-In-Time Compila-tion]. No published information is avail-able about the implementation details ofthese JIT compilers.
IBM includes an optimizing JITcompiler in its IBM Developer Kit forWindows [Ishizaki et al. 1999; Suganumaet al. 2000]. This JIT compiler performs avariety of optimizations including methodinlining, exception check elimination,common subexpression elimination, loopversioning, and code scheduling. The com-piler begins by performing flow analysisto identify basic blocks and loop struc-ture information for later optimizations.The bytecodes are transformed into aninternal representation, called extendedbytecodes, on which the optimizations areperformed.
The optimizations begin with methodinlining. Empty method calls originatingfrom object constructors or small accessmethods are always inlined. To avoid codeexpansion (and thus, the resulting cacheinefficiency) other method calls are inlinedonly if they are in program hotspots suchas loops. Virtual method calls are handledby adding an explicit check to make surethat the inlined method is still valid. Ifthe check fails, standard virtual methodinvocation is performed. If the referencedmethod changes frequently, the additionalcheck and inlined code space adds addi-tional overhead to the invocation. How-ever, the referenced method is likely toremain the same in most instances, elimi-nating the cost of a virtual method lookupand invocation.
Following inlining, the IBM JIT com-piler performs general exception checkelimination and common subexpressionelimination based on program flow infor-mation. The number of array bound excep-tion checks is further reduced using loopversioning. Loop versioning creates twoversions of a target loop—a safe versionwith exception checking and an unsafeversion without exception checking. De-pending on the loop index range test at theentry point of the loop, either the safe orthe unsafe version of the loop is executed.
At this point, the IBM JIT compilergenerates native x86 machine code basedon the extended bytecode representation.Certain stack manipulation semantics aredetected in the bytecode by matching byte-code sequences known to represent spe-cific stack operations. Register allocationis applied by assigning registers to stackvariables first and then to local variablesbased on usage counts. Register allocationand code generation are performed in thesame pass to reduce compilation time.Finally, the generated native code is sched-uled within the basic block level to fit therequirements of the underlying machine.
Intel includes a JIT compiler with theVTune optimization package for Java thatinterfaces with the Microsoft JVM [Adl-Tabatabai et al. 1998]. The Intel JITcompiler performs optimizations and gen-erates code in a single pass without
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

220 I. H. Kazi et al.
generating a complete internal represen-tation of the program. This approachspeeds up native code generation whilelimiting the scope of the optimizations toextended basic blocks only. The Intel JITcompiler applies common subexpressionelimination (CSE) within basic blocks, lo-cal and global register allocation, and lim-ited exception optimizations.
The compiler first performs a linear scanof the bytecodes to record stack and vari-able information for use in later stages.This is followed by a global register al-location, code generation, code emission,and code patching pass. The compiler usestwo alternative schemes for global registerallocation. The first scheme allocates the4 callee-saved registers to the variableswith the highest static reference countsfor the duration of the method. The sec-ond scheme iterates through all of thevariables in order of decreasing static ref-erence counts, allocating a register to avariable if the register is available in allof the basic blocks that the variable is ref-erenced.
CSE is implemented by matchingnonoverlapping subsequences in ex-pressions. Basic blocks are representedas a string of bytes where commonsubexpressions are detected as duplicatesubstrings in the string. Any two matchedsubstrings of less than sixteen bytecodesis considered as a candidate for elimina-tion. If the value calculated during thefirst expression instance is still availableduring the second instance of the expres-sion, the previous value is reused andthe duplicate expression is eliminated. Inthis scheme, transitivity of expressions isnot considered. Therefore, the expression“x+ y” would not match with “ y + x.”
Unnecessary array bounds checks aredetected by keeping track of the maxi-mum constant array index that is boundschecked and eliminating index boundchecks for constant values less than themaximum constant array index check. Forexample, if array location 10 is accessedbefore location 5, the bounds check for ar-ray location 5 is eliminated. This optimiza-tion is useful during array initializationsince the array creation size is considered
a successful bounds check of the highestarray index. This eliminates bound checksfor any initialization of array values us-ing constant array indices. However, elim-ination of bounds checks does not applyto variables nor does it extend beyond thescope of a basic block.
Code for handling thrown exceptions ismoved to the end of the generated code fora method. By placing exception handlingcode at the end of the method, the staticbranch predictor on Pentium processorswill predict the branches to be not takenand the exception handling code is lesslikely to be loaded into a cache line. Sinceexceptions do not occur frequently, this iswell-suited for the common case execution.
The OpenJIT project [Matsuoka et al.1998] is a reflective JIT compiler writ-ten in Java. The compiler is reflective inthe sense that it contains a set of self-descriptive modules that allow a user pro-gram to examine the internal state ofthe compiler’s compilation and modify thestate through a compiler-supplied inter-face. This interface allows user programsto perform program-specific optimizationsby defining program-specific semantics.For instance, defining properties of com-mutivity and transitivity for a user objectprovides the compiler with more informa-tion to perform useful optimizations.
The open-source Kaffe project providesa JIT compiler for the Kaffe JVM thatsupports various operating systems onthe x86, Sparc, M68k, MIPS, Alpha, andPARisc architectures [Wilkinson, Kaffev0.10.0]. The Kaffe JIT compiler uses amachine-independent front-end that con-verts bytecodes to an intermediate repre-sentation called the KaffeIR. The KaffeIRis then translated using a set of macroswhich define how KaffeIR instructionsmap to native code.
The AJIT compilation system generatesannotations in bytecode files to aid theJIT compilation [Azevedo et al. 1999].A Java to bytecode compiler generatesannotations that are stored as additionalcode attributes in generated class filesto maintain compatibility with existingJVMs. These annotations carry compileroptimization-related information that
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 221
allow the JIT compiler to generate op-timized native code without extensiveruntime analysis. An example of a gen-erated attribute in the AJIT system isthe mapping of variables to an infinitevirtual register set. This virtual registerallocation (VRA) annotation is used by anannotation-reading JIT compiler to speedup register allocation and to identify un-necessary duplication of stack variables.
CACAO is a stand-alone JIT compilerfor the DEC ALPHA architecture [Kralland Grafl 1997]. The CACAO compilertranslates bytecodes to an intermedi-ate representation, performs register al-location, and replaces constant operandson the stack with immediate instructionoperands.
Fajita [FAJITA] is a variation of a JITcompiler that runs as a Java compila-tion server on a network, independent ofthe Java runtime. The server compilesJava bytecode as a pass-through proxyserver, allowing class compilation to becached and shared among different pro-grams and machines. Since the lifetime ofcompiled code in this environment is gen-erally much longer than a standard JIT,this compiler has more time to performadvanced optimizations.
3.2.3. Direct Compilers
A direct compiler translates either Javasource code or bytecodes into machine in-structions that are directly executable onthe designated target processor (refer toFigure 2). The main difference betweena direct compiler and a JIT compiler isthat the compiled code generated by a di-rect compiler is available for future exe-cutions of the Java program. In JIT com-pilation, since the translation is done atrun-time, compilation speed requirementslimit the type and range of code optimiza-tions that can be applied. Direct compi-lation is done statically, however, and socan apply traditional time-consuming op-timization techniques, such as data-flowanalysis, interprocedural analysis, and soon [Aho et al. 1986], to improve the per-formance of the compiled code. However,because they provide static compilation,
direct compilers cannot support dynamicclass loading. Direct compilation also re-sults in a loss of portability since the gen-erated code can be executed only on thespecific target processor. It should be notedthat the portability is not completely lostif the original bytecodes or source code arestill available, however.
Caffeine [Hsieh et al. 1996] is a Javabytecode-to-native code compiler that gen-erates optimized machine code for theX86 architecture. The compilation pro-cess involves several translation steps.First, it translates the bytecodes into aninternal language representation, calledJava IR, that is organized into functionsand basic blocks. The Java IR is thenconverted to a machine-independent IR,called Lcode, using stack analysis, stack-to-register mapping, and class hierarchyanalysis. The IMPACT compiler [Changet al. 1991] is then used to generatean optimized machine-independent IR byapplying optimizations such as inlining,data-dependence and interclass analysisto improve instruction-level parallelism(ILP). Further, machine-specific optimiza-tions, including peephole optimization, in-struction scheduling, speculation, and reg-ister allocation, are applied to generatethe optimized machine-specific IR. Finally,optimized machine code is generated fromthis machine-specific IR. Caffeine usesan enhanced memory model to reducethe overhead due to additional indirec-tions specified in the standard Java mem-ory model. It combines the Java class in-stance data block and the method tableinto one object block and thus requiresonly one level of indirection. Caffeine sup-ports exception handling only through ar-ray bounds checking. It does not supportgarbage collection, threads, and the use ofgraphics libraries.
The Native Executable Translation(NET) compiler [Hsieh et al. 1997] extendsthe Caffeine prototype by supportinggarbage collection. It uses a mark-and-sweep garbage collector which is invokedonly when memory is full or reaches apredefined limit. Thus, NET eliminatesthe overhead due to garbage collection insmaller application programs that have
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

222 I. H. Kazi et al.
low memory requirements. NET also sup-ports threads and graphic libraries.
The IBM High Performance Compilerfor Java (HPCJ) [Seshadri 1997] is an-other optimizing native code compiler tar-geted for the AIX, OS/2, Windows95, andWindowsNT platforms. HPCJ takes bothJava source code and bytecodes as itsinput. If the Java source code is usedas an input, it invokes the AIX JDK’sJava source-to-bytecode compiler (javac)to produce the bytecodes. Java bytecodesare translated to an internal compiler in-termediate language (IL) representation.The common back-end from IBM’s XL fam-ily of compilers for the RS/6000 is used totranslate the IL code into an object mod-ule (.o file). The object module is thenlinked to other object modules from theJava application program and libraries toproduce the executable machine code. Thelibraries in HPCJ implement garbage col-lection, Java APIs, and various runtimesystem routines to support object creation,threads, and exception handling.
A common back-end for the native codegeneration allows HPCJ to apply vari-ous language-independent optimizations,such as instruction scheduling, commonsubexpression elimination, intramodularinlining, constant propagation, global reg-ister allocation, and so on. The bytecode-to-IL translator reduces the overhead forJava run-time checking by performing asimple bytecode simulation during basicblock compilation to determine whethersuch checks can be eliminated. HPCJ re-duces the overhead due to method indirec-tion by emitting direct calls for instancemethods that are known to be final orthat are known to belong to a final class.It uses a conservative garbage collec-tor since the common back-end does notprovide any special support for garbagecollection.
3.2.4. Bytecode-to-Source Translators
Bytecode-to-source translators are staticcompilers that generate an intermediatehigh-level language, such as C, from theJava bytecodes (see Figure 2). A standardcompiler for the intermediate language is
then used to generate executable machinecode. Choosing a high-level language suchas C as an intermediate language allowsthe use of existing compiler technology,which is useful since many compilers thatincorporate extensive optimization tech-niques are available for almost all plat-forms.
Toba [Proebsting et al. 1997] is abytecode-to-source translator for Irix, So-laris, and Linux platforms that convertsJava class files directly into C code. Thegenerated C code can then be compiledinto machine code. Toba describes itselfas a Way-Ahead-of-Time compiler since itcompiles bytecodes before program execu-tion in contrast to JIT compilers whichcompile the bytecodes immediately beforeexecution. All versions of Toba providesupport for garbage collection, exceptions,threads, and the BISS-AWT, an alterna-tive to the Sun AWT (Abstract WindowToolkit). In addition, the Linux versionof Toba also supports dynamic loading ofclasses using a JIT compiler. The Toba Ccode generator naively converts each byte-code directly into equivalent C statementswithout a complex intermediate represen-tation, relying on the C compiler to even-tually optimize the code.
Harissa [Muller et al. 1997, Welcome toHarissa] is a Java environment that in-cludes both a bytecode translator and aninterpreter for SunOS, Solaris, Linux, andDEC Alpha platforms. The Harissa com-piler reads in Java source code and con-verts it into an intermediate representa-tion (IR). It then analyzes and optimizesthe structure of the Java code and out-puts optimized C files. Since existing Ccompilers can be used to perform moregeneralized optimizations, Harissa’s com-piler focuses on IR optimizations such asstatic evaluation to eliminate the stack,elimination of redundant bounds checks,elimination of bounds checks on array in-dices that can be statically determined,and transforming virtual method callsinto simple procedure calls using class hi-erarchy analysis. A complete interpret-ing JVM has been integrated into theruntime library to allow code to be dy-namically loaded into previously compiled
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 223
applications. Since data structures arecompatible between the compiled code andthe interpreter, Harissa provides an envi-ronment that cleanly allows the mixing ofbytecodes and compiled code.
TurboJ is a Java bytecode-to-sourcetranslator [TurboJ Java to Native Com-piler] that also uses C as an intermediaterepresentation. The generated code re-tains all of the Java run-time checks, al-though redundant checks are eliminated.TurboJ is not a stand-alone Java runtimesystem. Instead it operates in conjunctionwith a Java runtime system and uses thenative JDK on a given platform for mem-ory allocation, garbage collection, and ac-cess to the standard thread package.
Vortex is an optimizing compiler thatsupports general object-oriented lan-guages [UW Cecil/Vortex Project, Deanet al. 1996]. The Java, C++, Cecil, andModula-3 languages are all translatedinto a common IL. If the Java source codeis not available, this system can use amodified version of the javap bytecodedisassembler to translate the bytecodesinto the Vortex IL. The IL representationof the program is then optimized usingsuch techniques as intraprocedural classanalysis, class hierarchy analysis, re-ceiver class prediction, and inlining. Anenhanced CSE technique is also provided.Once optimization is complete, either Ccode or assembly code can be generated.
3.3. Java Processors
To run Java applications on general-purpose processors, the compiled byte-codes need to be executed through aninterpreter or through some sort of com-pilation, as described in the previoussections. While a JIT compiler can pro-vide significant speedups over an inter-preter, it introduces additional compila-tion time and can require a large amountof memory. If the bytecodes can be di-rectly executed on a processor, the mem-ory advantage of the interpreter and theperformance speedup of the JIT compilercan be combined. Such a processor mustsupport the architectural features spec-ified for the JVM. A Java processor is
an execution model that implements theJVM in silicon to directly execute Javabytecodes. Java processors can be tailoredspecifically to the Java environment byproviding hardware support for such fea-tures as stack processing, multithreading,and garbage collection. Thus, a Java pro-cessor can potentially deliver much bet-ter performance for Java applications thana general-purpose processor. Java proces-sors appear to be particularly well-suitedfor cost-sensitive embedded computingapplications.
Some of the design goals behind theJVM definition were to provide portabil-ity, security, and small code size for theexecutable programs. In addition, it wasdesigned to simplify the task of writing aninterpreter or a JIT compiler for a spe-cific target processor and operating sys-tem. However, these design goals resultin architectural features for the JVM thatpose significant challenges in developingan effective implementation of a Java pro-cessor [O’Connor and Tremblay 1997]. Inparticular, there are certain common char-acteristics of Java programs that are dif-ferent from traditional procedural pro-gramming languages. For instance, Javaprocessors are stack-based and must sup-port the multithreading and unique mem-ory management features of the JVM.These unique characteristics suggest thatthe architects of a Java processor musttake into consideration the dynamic fre-quency counts of the various instructionstypes to achieve high performance.
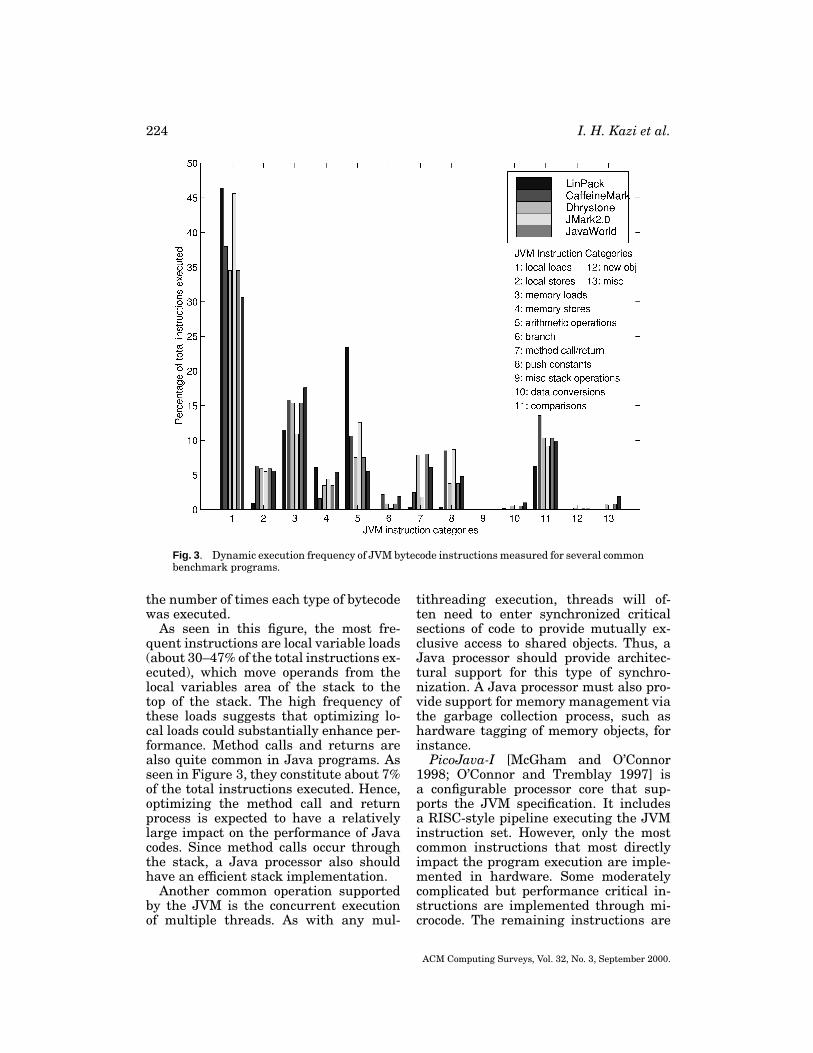
The JVM instructions fall into sev-eral categories, namely, local-variableloads and stores, memory loads andstores, integer and floating-point compu-tations, branches, method calls and re-turns, stack operations, and new objectcreation. Figure 3 shows the dynamic fre-quencies of the various JVM instruc-tion categories measured in the Javabenchmark programs LinPack, Caffeine-Mark, Dhrystone, Symantec, JMark2.0,and JavaWorld (benchmark programdetails are provided in Section 5). Thesedynamic instruction frequencies were ob-tained by instrumenting the source codeof the Sun 1.1.5 JVM interpreter to count
ACM Computing Surveys, Vol. 32, No. 3, September 2000.
224 I. H. Kazi et al.
Fig. 3 . Dynamic execution frequency of JVM bytecode instructions measured for several commonbenchmark programs.
the number of times each type of bytecodewas executed.
As seen in this figure, the most fre-quent instructions are local variable loads(about 30–47% of the total instructions ex-ecuted), which move operands from thelocal variables area of the stack to thetop of the stack. The high frequency ofthese loads suggests that optimizing lo-cal loads could substantially enhance per-formance. Method calls and returns arealso quite common in Java programs. Asseen in Figure 3, they constitute about 7%of the total instructions executed. Hence,optimizing the method call and returnprocess is expected to have a relativelylarge impact on the performance of Javacodes. Since method calls occur throughthe stack, a Java processor also shouldhave an efficient stack implementation.
Another common operation supportedby the JVM is the concurrent executionof multiple threads. As with any mul-
tithreading execution, threads will of-ten need to enter synchronized criticalsections of code to provide mutually ex-clusive access to shared objects. Thus, aJava processor should provide architec-tural support for this type of synchro-nization. A Java processor must also pro-vide support for memory management viathe garbage collection process, such ashardware tagging of memory objects, forinstance.
PicoJava-I [McGham and O’Connor1998; O’Connor and Tremblay 1997] isa configurable processor core that sup-ports the JVM specification. It includesa RISC-style pipeline executing the JVMinstruction set. However, only the mostcommon instructions that most directlyimpact the program execution are imple-mented in hardware. Some moderatelycomplicated but performance critical in-structions are implemented through mi-crocode. The remaining instructions are
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 225
trapped and emulated in software bythe processor core. The hardware de-sign is thus simplified since the complex,but infrequently executed, instructions donot need to be directly implemented inhardware.
In the Java bytecodes, it is common foran instruction that copies data from a lo-cal variable to the top of the stack to pre-cede an instruction that uses it. The pico-Java core folds these two instructions intoone by accessing the local variable directlyand using it in the operation. This foldingoperation accelerates Java bytecode exe-cution by taking advantage of the single-cycle random access to the stack cache.Hardware support for synchronization isprovided to the operating system by usingthe low-order 2-bits in shared objects asflags to control access to the object.
The picoJava-2 core [Turley 1997],which is the successor to the picoJava-I processor, augments the bytecode in-struction set with a number of extendedinstructions to manipulate the caches,control registers, and absolute memory ad-dresses. These extended instructions areintended to be useful for non-Java applica-tion programs that are run on this Java ex-ecution core. All programs, however, stillneed to be compiled to Java bytecodes first,since these bytecodes are the processor’snative instruction set. The pipeline is ex-tended to 6 stages compared to the 4 stagesin the picoJava-I pipeline. Finally, the fold-ing operation is extended to include twolocal variable accesses, instead of just one.
Another Java processor is the SunmicroJava 701 microprocessor [SunMicrosystems. MicroJava-701 Proces-sor]. It is based on the picoJava-2 coreand is supported by a complete set ofsoftware and hardware developmenttools. The Patriot PSC1000 microproces-sor [Patriot Scientific Corporation] is ageneral-purpose 32-bit, stack-orientedarchitecture. Since its instruction set isvery similar to the JVM bytecodes, thePSC1000 can efficiently execute Javaprograms.
Another proposed Java processor[Vijaykrishnan et al. 1998] providesarchitectural support for direct object ma-
nipulation, stack processing, and methodinvocations to enhance the execution ofJava bytecodes. This architecture uses avirtual address object cache for efficientmanipulation and relocation of objects.Three cache-based schemes—the hybridcache, the hybrid polymorphic cache,and the two-level hybrid cache—havebeen proposed to efficiently implementvirtual method invocations. The processoruses extended folding operations similarto those in the picoJava-2 core. Also,simple, frequently executed instructionsare directly implemented in the hard-ware, while more complex but infrequentinstructions are executed via a traphandler.
The Java ILP processor [Ebcioglu etal. 1997] executes Java applications onan ILP machine with a Java JIT com-piler hidden within the chip architecture.The first time a fragment of Java codeis executed, the JIT compiler transpar-ently converts the Java bytecodes into op-timized RISC primitives for a Very LongInstruction Word (VLIW) parallel archi-tecture. The VLIW code is saved in a por-tion of the main memory not visible tothe Java architecture. Each time a frag-ment of Java bytecode is accessed for exe-cution, the processor’s memory is checkedto see if the corresponding ILP code isalready available. If it is, then the ex-ecution jumps to the location in mem-ory where the ILP code is stored. Other-wise, the compiler is invoked to compilethe new Java bytecode fragment into thecode for the target processor, which is thenexecuted.
While Java processors can deliver sig-nificant performance speedups for Javaapplications, they cannot be used effi-ciently for applications written in anyother language. If we want to have bet-ter performance for Java applications, andto execute applications written in otherlanguages as well, Java processors willbe of limited use. With so many appli-cations written in other languages al-ready available, it may be desirable tohave general-purpose processors with en-hanced architectural features to supportfaster execution of Java applications.
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

226 I. H. Kazi et al.
4. HIGH-PERFORMANCE JAVA EXECUTIONTECHNIQUES
Direct compilers or bytecode-to-sourcetranslators can improve Java performanceby generating optimized native codes orintermediate language codes. However,this high performance may come at theexpense of a loss of portability and flex-ibility. JIT compilers, on the other hand,support both portability and flexibility, butthey cannot achieve performance compa-rable to directly compiled code as onlylimited-scope optimizations can be per-formed. A number of execution techniqueshave been developed that attempt to im-prove Java performance by optimizing theJava source code or the bytecodes so thatportability is not lost. Some techniques ap-ply dynamic optimizations to the JIT com-pilation approach to improve the quality ofthe compiled native machine code withinthe limited time available to a JIT com-piler. Some other techniques improve var-ious features of the JVM, such as threadsynchronization, remote method invoca-tion (RMI), and garbage collection, thataid in improving the overall performanceof Java programs. In this section, we de-scribe these high-performance Java exe-cution techniques.
4.1. Bytecode Optimization
One technique for improving the execu-tion time performance of Java programs isto optimize the bytecodes. The Briki com-piler applies a number of optimizations tobytecodes to improve the execution timeperformance [Cierniak and Li 1997a,b].The front-end of the offline mode of theBriki compiler [Cierniak and Li 1997a] re-constructs the high-level program struc-ture of the original Java program from thebytecodes. This high-level view of the in-put bytecodes is stored in an intermedi-ate representation called JavaIR. A num-ber of optimizations can then be applied tothis JavaIR. Finally, the optimized JavaIRis transformed back into Java source codeand executed by a Java compiler.
Converting Java bytecodes to JavaIRis very expensive, however, requiring an
order of magnitude more time than thetime required to perform the optimiza-tions themselves. In an on-line versionof Briki [Cierniak and Li 1997b], thesame optimizations are performed whilerecovering only as much of the structureinformation as needed and using fasteranalysis techniques than those used intraditional compilers. This on-line versionof Briki is integrated with the Kaffe JITcompiler [Wilkinson, Kaffe v0.10.0], usingKaffe to generate an IR. The compiler an-alyzes and transforms the Kaffe IR intoan optimized IR which the Kaffe JIT back-end then translates into native code.
One optimization in Briki attempts toimprove memory locality by data remap-ping. Briki groups together similar fieldswithin objects onto consecutive memorylocations, increasing the probability thatfields will reside on the same cache line.However, the specific criterion used by theBriki compiler to determine similar fieldshas not been described [Cierniak and Li1997a,b]. Briki also attempts to remap ar-ray dimensions when dimension remap-ping will improve memory access time.For example, in a two-dimensional arrayA, location A[i][ j ] might be remapped toA[ j ][i] if such a remapping is advanta-geous. However, this remapping poses anumber of problems. First, Java arraysare not standard rectangular arrays butrather are implemented as an array of ar-rays. Therefore, array elements in a givendimension are not guaranteed to be ofthe same size. A[i] might reference an ar-ray of size 2 while A[ j ] references an ar-ray of size 3, for instance. Since arrayremapping is valid only for rectangulararrays, Briki constrains remapping tocases where all dimensions of the arrayare accessed. Second, subscript expres-sions in arrays can have potential side-effects. For instance, the calculation of asubscript may, as a side-effect, assign avalue to a variable. Remapping the arraydimensions may cause problems since therenaming changes the evaluation order ofthese expressions. To remedy this prob-lem, Briki evaluates subscript expressionsin the correct order before the arrays areactually referenced.
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 227
The DashO Pro [DashO Pro] bytecodeoptimizer applies several optimizationtechniques to improve runtime perfor-mance and reduce the size of the Javaexecutable. These techniques includeshortening the names of all the classes,methods, and fields, removing all unusedmethods, fields, and constant-pool entries(both constants and instance variables),extracting classes from accessible third-party packages or libraries, and so on.DashO produces one file that contains onlythe class files needed for the Java programresulting in smaller and faster Java byte-code files.
Krintz et al. [1999] proposed a Javaclass file splitting and prefetching tech-nique to reduce the transfer delay ofbytecodes sent over the Internet. Classfile splitting partitions a Java class fileinto separate hot and cold class files toeliminate transferring code in the coldclass file that is very rarely (or never)used. Class file prefetching inserts specialprefetch instructions into the Java classfile to overlap bytecode transfer with ex-ecution. These optimizations use compile-time analysis and profiling to select codeto split and to insert prefetch instructions.Experimental results showed that classfile splitting was able to reduce startuptime for Java programs by 10% whileprefetching combined with splitting re-duced the overall bytecode transfer delayby 25% on average.
The Java application extractor Jax [Tipet al. 1999] applies several techniques,such as the elimination of redundantmethods/fields and class hierarchy spe-cialization [Tip and Sweeney 1997], to re-duce the size of a Java class file archive(e.g., zip or jar files). Jax performs a whole-program analysis on a Java class file todetermine the classes, methods, and fieldsthat must be retained to preserve pro-gram behavior. It then removes the un-necessary components of the class files toreduce the archive size. Additionally, Jaxapplies a class hierarchy transformationthat reduces the archive size by eliminat-ing classes entirely or by merging adjacentclasses in the hierarchy. It also replacesoriginal class, method, and field names
with shorter names. Once methods are re-moved from a class file, some entries inthe constant pool may appear to be redun-dant. Thus, when the archive is rewrit-ten after all the transformations are ap-plied, a new constant pool is created fromscratch to contain only the classes, meth-ods, fields, and constants that are refer-enced in the transformed class file. UsingJax on a number of Java archives resultedin a 13.4–90.2% reduction in size [Tip et al.1999].
4.2. Parallel and Distributed ExecutionTechniques
A number of techniques parallelize Javasource code or bytecodes to improve theexecution-time performance of the ap-plication. The parallelization typicallyis achieved through Java language-levelsupport for multithreading. Thus, thesetechniques maintain the portability of thetransformed parallel Java programs. Mostof these techniques exploit implicit paral-lelism in Java programs for parallel ex-ecution on shared-memory multiproces-sor systems using Java multithreadingand synchronization primitives. Some ap-proaches extend the Java language itselfto support parallel and distributed Javaprograms. The performance improvementobtained when using these techniquesdepends on the amount of parallelismthat can be exploited in the applicationprogram.
The High Performance Java project [Bikand Gannon 1997; Bik and Gannon 1998]exploits implicit parallelism in loops andmultiway recursive methods to generateparallel code using the standard Javamultithreading mechanism. The JAVAR[Bik and Gannon 1997] tool, which isa source-to-source restructuring compiler,relies on explicit annotations in a se-quential Java program to transform a se-quential Java source code into a corre-sponding parallel code. The transformedprogram can be compiled into bytecodesusing any standard Java compiler. TheJAVAB [Bik and Gannon 1998] tool, on theother hand, works directly on Java byte-codes to automatically detect and exploit
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

228 I. H. Kazi et al.
implicit loop parallelism. Since the par-allelism is expressed in Java itself usingJava’s thread libraries and synchroniza-tion primitives, the parallelized bytecodescan be executed on any platform with aJVM implementation that supports nativethreads.
The Java Speculative Multithreading(JavaSpMT) parallelization technique[Kazi and Lilja 2000] uses a speculativethread pipelining execution model toexploit implicit loop-level parallelismon shared-memory multiprocessors forgeneral-purpose Java application pro-grams. Its support of control specula-tion combined with its run-time data-dependence checking allows JavaSpMTto parallelize a wide variety of loopconstructs, including do–while loops.JavaSpMT is implemented using thestandard Java multithreading mecha-nism. The parallelism is expressed by aJava source-to-source transformation.
The Do! project [Launay and Pazat1997] provides a parallel frameworkembedded in Java to ease parallel anddistributed programming in Java. Theparallel framework supports both dataparallelism and control (or task) paral-lelism. The framework provides a modelfor parallel programming and a library ofgeneric classes. Relevant library classescan be extended for a particular applica-tion or new framework classes can be de-fined for better tuning of the application.
Tiny Data-Parallel Java [Ichisugi andRoudier 1997] is a Java language ex-tension for data-parallel programming.The language defines data-parallel classeswhose methods are executed on a largenumber of virtual processors. An exten-sible Java preprocessor, EPP, is used totranslate the data-parallel code into stan-dard Java code using the Java threadlibraries and synchronization primitives.The preprocessor can produce Java codefor multiprocessor and distributed sys-tems as well. However, the Tiny Data-Parallel Java language does not yethave sufficient language features to sup-port high-performance parallel programs.DPJ [Ivannikov et al. 1997] defines aparallel framework through a Java class
library for the development of data-parallel programs.
4.3. Dynamic Compilation
Since the compilation time in JIT compila-tion adds directly to the application’s totalexecution time, the quality of the code op-timization is severely constrained by com-pilation speed. Dynamic compilation ad-dresses this problem of JIT compilation byoptimizing only the portions of the codethat are most frequently executed, i.e.,program hotspots. Most programs spendthe majority of the time executing onlya small fraction of their code. Thus, opti-mizing only the hotspot methods shouldyield a large performance gain whilekeeping the compilation speed relativelyfast.
Sun’s Hotspot JVM [The Java HotspotPerformance Engine Architecture] usesdynamic compilation to generate opti-mized native machine code during run-time. The Hotspot engine contains both arun-time compiler and an interpreter. Thefirst time a method is executed, it is inter-preted using a profiling interpreter thatgathers run-time information about themethod. This information is used to de-tect hotspots in the program and to gatherinformation about program behavior thatcan be used to optimize generated nativecode in later stages of program execution.After the hotspot methods are identified,they are dynamically compiled to gener-ate optimized native machine code. Infre-quently executed code continues to be in-terpreted, decreasing the amount of timeand memory spent on native code gen-eration. Because a program is likely tospend the majority of its execution timein the hotspot regions detected by the in-terpreter, the compiler can spend moretime optimizing the generated code forthese sections of the program than a JIT-compiler while still producing an over-all improvement in execution time. Dur-ing code generation, the dynamic compilerperforms conventional compiler optimiza-tions, Java specific optimizations, and in-lining of static and dynamic methods. Theinlining optimizations are designed to be
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 229
reversible due to the problems associatedwith dynamic class loading.
IBM’s Jalapeno JVM [Burke et al. 1999]includes an adaptive dynamic optimizingcompiler that generates optimized ma-chine code as the program is executed. TheJalapeno JVM does not use an interpreter.Instead, the first execution of a methodis handled by quickly compiling a methodinto an unoptimized executable code. Thedynamic optimizing compiler later gener-ates optimized executable code from thebytecodes of the hotspot (i.e., frequentlyexecuted) methods as determined by run-time profile information.
The Jalapeno optimizing compiler firstcompiles Java bytecodes into a vir-tual register-based high-level intermedi-ate representation (HIR). It then gener-ates a control flow graph for the method.After applying compiler optimizations onthe HIR, the intermediate executable isconverted to a low-level representation(LIR) that includes references to spe-cific implementation details, such as pa-rameter passing mechanisms and objectlayouts in memory. The LIR is then opti-mized further and converted to a nativecode representation using a Bottom-UpRewrite System [Proebsting 1992] ap-proach. Finally, this machine specificrepresentation (MIR) is optimized andassembled into machine executable code.The optimizing compiler performs inlin-ing both during bytecode-to-IR translationand during HIR optimization. Inlining ofvirtual functions is handled by predictingthe type of the virtual function and per-forming a run-time check to determine thevalidity of the prediction. If the predic-tion is incorrect, the program performs anormal virtual function invocation. Oth-erwise, the program proceeds with theinlined function.
The program adaptation in Jalapenostarts with the instrumentation and re-compilation of executable code. The ex-ecutable code is instrumented to gathercontext sensitive profile information toaid optimization. The profile informa-tion is used to detect program hotspots.When a certain performance thresholdis reached, the dynamic optimizing com-
piler is invoked to recompile the hotspotmethods using context specific optimiza-tions at all levels of representations (HIR,LIR, and MIR). The unoptimized code isthen replaced by optimized code based onthe collected profile information. Programadaptation continues in this cycle, with ex-ecutable code being improved on every op-timization iteration.
4.4. Improved JVM Features
The underlying implementation of vari-ous JVM features, such as thread synchro-nization, RMI support, and garbage collec-tion, often has a significant effect on theexecution time performance of Java ap-plication programs. While these featuresmake Java more powerful as a program-ming language, they tend to add delays toa program’s execution time. Hence, it isimportant to efficiently implement thesefeatures to improve Java performance.Furthermore, Java, as it is now, is notsuitable for high-performance numericalcomputing. To support numerical applica-tions, Java should include features that al-low efficient execution of floating point andcomplex numbers.
4.4.1. Thread Synchronization
Thread synchronization is a potential per-formance problem in many Java programsthat use multithreading. Since Java li-braries are implemented in a thread-safemanner, the performance of even single-threaded applications may be degradeddue to synchronization. In Java, synchro-nization is provided through monitors,which are language-level constructs usedto guarantee mutually-exclusive access toshared data-structures [Silberschatz andGalvin 1997]. Unfortunately, monitors arenot efficiently implemented in the cur-rent Sun JDK. Since Java allows any ob-ject to be synchronizable (with or with-out any synchronized methods), using alock structure for each object can be verycostly in terms of memory. To minimizememory requirements, the Sun JDK keepsmonitors outside of the objects. This re-quires the run-time system to first queryeach monitor in a monitor cache before it
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

230 I. H. Kazi et al.
is used, which is quite inefficient. Further,the monitor cache itself needs to be lockedduring these queries to avoid race condi-tions. Thus, this monitor implementationapproach is not scalable.
CACAO, in contrast, is a system thatimplements monitors using a hash tableindexed by the address of the associatedobject [Krall and Proebst 1998]. Becauseonly a small number of objects that re-quire mutually-exclusive access (called amutex object) are locked at any given time,this approach generally leads to decreasedmemory usage. Each of these objects main-tains a count of how many lock operationshave been performed on it without any cor-responding unlock operations. When thecount goes to zero, the lock is not ownedby any thread. A mutex object, however,is not destroyed when its count reacheszero under the assumption that the mu-tex object will be reused again soon. Themutex object is destroyed only when a newmutex object collides with it in the hashtable. This memory allocation approachhas the advantage of requiring less codeto implement lock and unlock operations.Since the hash table entries will be freeonly at the beginning of the program andwill never be freed again, the code to lockthe mutex need not check if the entry isfree. The unlocking code also does not needto check whether the hash entry should befreed.
The thin locks approach in IBM’s JDK1.1.2 for AIX improves thread synchro-nization by optimizing lock operations forthe most common cases [Bacon et al.1998]. Thin locks, which require only apartial word per object, are used for objectsthat are not subject to any contention, donot have wait/notify operations performedon them, and are not locked to an excessivenesting depth. Objects that do not meetthe criterion use fat locks, which are mul-tiword locks similar to those used in thestandard Java implementation. To min-imize the memory required for each ob-ject’s lock, 24 bits in the object’s headerare used for the lock structure. The othervalues stored in the header are compactedusing various encoding schemes to makethe 24 bits available for this lock struc-
ture. This 24-bit field stores either a thinlock directly, or a pointer to a fat lock. Thededicated lock for each object allows thelock/unlock operations on the thin locks tobe performed using only a few machineinstructions. This approach also elimi-nates the need to synchronize the monitorcache.
4.4.2. Remote Method Invocation
The Java Remote Method Invocation(RMI) [Remote Method Invocation Spec-ification] mechanism enables distributedprogramming by allowing methods of re-mote Java objects to be invoked from otherJVMs, possibly on different physical hosts.A Java program can invoke methods on aremote object once it obtains a referenceto the remote object. This remote objectreference is obtained either by looking upthe remote object in the bootstrap-namingservice provided by RMI, or by receivingthe reference as an argument or a returnvalue. RMI uses object serialization tomarshal and unmarshal parameters.
The current Java RMI is designed tosupport client-server applications thatcommunicate over TCP-based networks[Postel 1981]. Some of the RMI designgoals, however, result in severe perfor-mance limitations for high-performanceapplications on closely connected environ-ments, such as clusters of workstationsand distributed memory processors. TheApplications and Concurrency WorkingGroup (ACG) of the Java Grande Forum(JGF) [Java Grande Forum Report] as-sessed the suitability of RMI-based Javafor parallel and distributed computingbased on Java RMI. JGF proposed a set ofrecommendations for changes in the Javalanguage, Java libraries, and JVM imple-mentation to make Java more suitable forhigh-end computing. ACG emphasized im-provements in two key areas, object seri-alization and RMI implementation, thatwill potentially improve the performanceof parallel and distributed programs basedon Java RMI.
Experimental results [Java Grande Fo-rum Report] suggest that up to 30% ofthe execution time of a Java RMI is spent
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 231
in object serialization. Accordingly, ACGrecommended a number of improvements,including a slim encoding technique fortype information, more efficient serializa-tion of float and double data types, andenhancing the reflection mechanism to al-low fewer calls to be made to obtain infor-mation about a class. In the current RMIimplementation, a new socket connectionis created for every remote method invo-cation. In this implementation, establish-ing a network connection can take up to30% of the total execution of the remotemethod [Java Grande Forum Report]. Thekey recommendations of JGF to reducethe connection overhead include improvedsocket connection management, improvedresource management, and improved sup-port for custom transport.
4.4.3. Java for High-Performance NumericComputation
The current design and implementation ofJava does not support high-performancenumerical applications. To make the per-formance of Java numerical programscomparable to the performance obtainedthrough programming languages such asC or Fortran, the numeric features of theJava programming language must be im-proved. The Numerics Working Groupof the Java Grande Forum assessed thesuitability of Java for numerical pro-gramming and proposed a number ofimprovements in Java’s language fea-tures, including floating-point and com-plex arithmetic, multidimensional arrays,lightweight classes, and operator over-loading [Java Grande Forum Report].
To directly address these limitationsin Java, IBM has developed a speciallibrary that improves the performanceof numerically-intensive Java applica-tions [Moreira et al. 2000]. This librarytakes the form of the Java Array packageand is implemented in the IBM HPCJ. TheArray package supports such FORTRAN90 like features as complex numbers, mul-tidimensional arrays, and linear algebralibrary. A number of Java numeric appli-cations that used this library were shownto achieve between 55% and 90% of the
performance of corresponding highly opti-mized FORTRAN codes.
4.4.4. Garbage Collection
Most JVM implementations use conserva-tive garbage collectors that are very easyto implement, but demonstrate ratherpoor performance. Conservative garbagecollectors cannot always determine whereall object references are located. As aresult, they must be careful in markingobjects as candidates for garbage collec-tion to ensure that no objects that arepotentially in use are freed prematurely.This inaccuracy sometimes leads to mem-ory fragmentation due to the inability torelocate objects.
To reduce the negative performanceimpacts of garbage collection, Sun’sHotspot JVM [The Java Hotspot Perfor-mance Engine Architecture] implementsa fully accurate garbage collection (GC)mechanism. This implementation allowsall inaccessible memory objects to be re-claimed while the remaining objects can berelocated to eliminate memory fragmen-tation. Hotspot uses three different GCalgorithms to efficiently handle garbagecollection. A generational garbage collec-tor is used in most cases to increase thespeed and efficiency of garbage collection.Generational garbage collectors cannot,however, handle long-lived objects. Conse-quently, Hotspot needs to use an old-objectgarbage collector, such as a mark-compactgarbage collector to collect objects thataccumulate in the “Old Object” area ofthe generational garbage collector. Theold-object garbage collector is invokedwhen very little free memory is availableor through programmatic requests.
In applications where a large amount ofdata is manipulated, longer GC pauses areencountered when a mark-compact col-lector is used. These large latencies maynot be acceptable for latency-sensitive ordata-intensive Java applications, such asserver applications and animations. Tosolve this problem, Hotspot provides analternative incremental garbage collec-tor to collect objects in the “Old Object”area. Incremental garbage collectors can
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

232 I. H. Kazi et al.
Table 1. The Benchmark Programs in SPEC JVM98 Benchmark Suite
check A simple program to test various features of the JVMcompress A modified Lempel-Ziv (LZW) compression algorithmjess A Java Expert Shell System (JESS) based on NASA’s
CLIPS expert shell systemdb A database application that performs multiple
database functions on a memory resident databasejavac The Java compiler from Sun’s JDK 1.0.2mpegaudio An application that decompresses audio files conforming
to the ISO MPEG Layer-3 audio specificationmtrt A ray tracer program that works on a scene depicting a dinosaur,
where two threads each render the scene in the input filejack A Java parser generator that is based on the Purdue
Compiler Construction Tool Set (PCCTS)
potentially eliminate all user-perceivedGC pauses by interleaving the garbage col-lection with program execution.
5. BENCHMARKS
Appropriate benchmarks must be identi-fied to effectively evaluate and comparethe performance of the various Javaexecution techniques. A benchmark canbe thought of as a test used to measurethe performance of a specific task [Lilja2000]. As existing execution techniquesare improved and new techniques aredeveloped, the benchmarks serve as avehicle to provide consistency amongevaluations for comparison purposes. Theproblem that exists in the Java researchcommunity is that no benchmarks havebeen agreed upon as the standard set tobe used for Java performance analysis.Instead, researchers have used a varietyof different benchmarks making it verydifficult to compare results and determinewhich techniques yield the best perfor-mance. In this section, we identify some ofthe popular benchmarks that have beenused to compare various Java executiontechniques.
Application benchmarks are used toevaluate the overall system performance.Microbenchmarks, on the other hand, areused to evaluate the performance of in-dividual system or language features,such as storing an integer in a localvariable, incrementing a byte, or creatingan object [Java Microbenchmarks, UCSDBenchmarks for Java].
The Open Systems Group (OSG) ofthe Standard Performance EvaluationCorporation (SPEC) [SPEC JVM98Benchmarks] developed a Java bench-mark suite, SPEC JVM98, to measure theperformance of JVMs. The benchmarksin this suite are expected to serve as astandard for performance evaluation ofdifferent JVM implementations to pro-vide a means for comparing the differenttechniques using a common basis. SPECJVM98 is a collection of eight general-purpose Java application programs, aslisted in Table 1.
SYSmark J [SYSmark] is anotherbenchmark suite that consists of four Javaapplications: JPhoto Works, which is animage editor using filters, the JNotePadtext editor, JSpreadSheet, which is aspreadsheet that supports built-in func-tions in addition to user-defined formulas;and the MPEG video player.
A series of microbenchmark tests,known as CaffeineMark [CaffeineMark],has been developed to measure specificaspects of Java performance, includingloop performance (loop test), the execu-tion of decision-making instructions (logictest), and the execution of recursive func-tion calls (method test). Each of thetests is weighted to determine the over-all CaffeineMark score. However, since theCaffeineMark benchmark does not em-ulate the operations of real-world pro-grams [Armstrong 1998], there is a ques-tion as to whether this benchmark makesreliable measurements of performance.The Embedded CaffeineMark benchmark
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 233
[CaffeineMark] is similar to the Caffeine-Mark benchmark except that all graphicaltests are excluded. This benchmark is in-tended as a test for embedded systems.
The JMark benchmark [PC MagazineTest Center, Welcome to JMark 2.0], fromPC Magazine, consists of eleven syn-thetic microbenchmarks used to evalu-ate Java functionality. Among the testsare the graphics mix test, stack test,bubble sort test, memory allocation andgarbage collection test, and the graph-ics thread test. JMark is one of thefew benchmarks that attempt to evaluatemultithreading performance. VolanoMark[Java Benchmarks] is a new server-sideJava benchmarking tool developed to as-sess JVM performance under highly mul-tithreaded and networked conditions. Itgenerates ten groups of 20 connectionseach with a server. Ten messages arebroadcast by each client connection toits respective group. VolanoMark thenreturns the average number of mes-sages transferred per second as the finalscore.
The Java Grande Forum has devel-oped a benchmark suite, called the JavaGrande Forum Benchmark Suite [JavaGrande Forum Benchmark Suite], thatconsists of benchmarks in three cate-gories. The first category, the low-leveloperations, measures the performance ofsuch JVM operations as arithmetic andmath library operations, garbage collec-tion, method calls and casting. The bench-marks in the kernel category are smallprogram kernels, including Fourier coef-ficient analysis, LU factorization, alpha–beta pruned search, heapsort, and IDEAencryption. The Large Scale Applica-tions category is intended to representreal application programs. Currently, theonly application program in this cate-gory is Euler, which solves the time-dependent Euler equations for flow in achannel.
The Linpack benchmark is a popu-lar Fortran benchmark that has beentranslated into C and is now availablein Java [Linpack Benchmark]. This nu-merically intensive benchmark measuresthe floating-point performance of a Java
system by solving a dense system of linearequations, A x= b. JavaLex [JLex] (a lex-ical analyzer generator), JavaCup [CUPParser Generator for Java] (a Java parsergenerator), JHLZip [JHLZip] (combinesmultiple files into one archive file with nocompression), and JHLUnzip [JHLUnzip](extracts multiple files from JHLZiparchives) are some other Java applicationbenchmarks. Other available bench-marks include JByte, which is a Javaversion of the BYTEmark benchmarkavailable from BYTE magazine [TurboJBenchmark’s Results]; the Symantecbenchmark, which incorporates testssuch as sort and sieve [Symantec, TurboJBenchmark’s Results]; the DhrystoneCPU benchmark [Dhrystone Benchmark,Dhrystone Benchmark in Java]; Jell, aparser generator [Jell]; Jax, a scannergenerator [Jax]; Jas, a bytecode assem-bler [Jas]; and EspressoGrinder, a Javasource program-to-bytecode translator[EspressoGrinder]. Additional bench-mark references are available on the JavaGrande Forum Benchmark website [JavaGrande Forum Benchmark].
To compare the performance of the var-ious Java execution techniques, a stan-dard set of benchmarks must be used. Thebenchmarks must be representative ofreal-world applications to provide any use-ful performance evaluations. Many of theJava benchmarks discussed earlier, suchas CaffeineMark, Jmark, and Symantec,consist of small programs designed to testspecific features of a JVM implementa-tion. Since they do not test the perfor-mance of the JVM as a whole, the per-formance results obtained through thesebenchmarks will be of little significancewhen the JVM is used to execute realapplications. Some benchmarks, such asJHLZip and JHLUnzip, are I/O bound ap-plications that are not suitable for mea-suring the performance obtained throughcompiler optimizations. The SPEC JVM98suite includes several applications, suchas a compiler, a database, and an mpe-gaudio application, that represent real ap-plications very well. Benchmarks such asthese will, therefore, help in understand-ing the potential performance of various
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

234 I. H. Kazi et al.
Table 2. Reported Relative Performance of Different Java Execution Techniques andCompiled C
Interpreters Interpreters JIT compilers C performanceSun JDK (w.r.t.) (w.r.t.) 10–50× slower
JIT CompilersMicrosoft JIT Visual 5.6× faster 4× slowerJ++ v1.0 (SUN JDK1.0.2)Symantec Cafe 5× fasterversion 1.0 (SUN JDK1.0.2)IBM JIT 6.6× fasterversion 3.0 (IBM JDK1.16)Kaffe 2.4× fasterversion 0.9.2 (SUN JDK1.1.1)CACAO 5.4× faster 1.66× slower
(SUN JDK1.1)AJIT 3.5× faster 1.46× faster
(SUN JDK1.1.1) (Kaffe v0.9.2)Direct Compilers
NET 17.3× faster 3× faster 1.85× slower(SUN JDK1.0.2) (MS JIT v1.0)
Caffeine 20× faster 4.7× faster 1.47× slower(SUN JDK1.0.2) (Symantec Cafe)
HPCJ 10× faster 6× faster(IBM AIX1.0.2) (IBM JIT v1.0)
Bytecode TranslatorsToba 5.4× faster 1.6× faster
(SUN JDK1.0.2) (Guava 1.0b1)Harissa 5× faster 3.2× faster
(SUN JDK1.0.2) (Guava 1.0b4)Java Processors
pica Java-I 12× faster 5× faster(SUN JDK1.0.2) (Symantec Cafe 1.5)
This table shows that the Caffeine compiler produces code that is approximately 20times faster than the Java code interpreted with Sun’s JDK1.0.2 JVM, approximately4.7 times faster than the Symantec Cafe JIT compiler, and approximately 1.47 timesslower than an equivalent compiled C program.
Java execution techniques when used in areal programming environment.
6. PERFORMANCE COMPARISON
Several studies have attempted to eval-uate the different execution techniquesfor Java programs using various combi-nations of the benchmarks mentioned inSection 5. The performance evaluationof the different execution techniques areincomplete, however, due to the lack ofa standardized set of Java benchmarks.Also, many of the techniques that havebeen evaluated are not complete imple-mentations of the JVM and the bench-marks have been run on a wide varietyof underlying hardware configurations.While incomplete and difficult to com-pare directly, these performance results
do provide a limited means of comparingthe alternative techniques to determinewhich ones may potentially provide an im-provement in performance and to whatdegree.
Table 2 summarizes the relative perfor-mance of the various techniques based onreported results. However, the numbersalone do not prove the superiority of onetechnique over another. When comparingalternative techniques for Java execution,it is important to consider the imple-mentation details of each technique. Tosupport a complete implementation ofthe JVM, any runtime approach shouldinclude garbage collection, exception han-dling, and thread support. However, eachof these features can produce possiblysubstantial execution overhead. Hence, atechnique that includes garbage collection
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 235
Table 3. Support for Exception Handling, Multithreading, and GarbageCollection as Reported for the Various Stand-alone Java Execution
Techniques Compared in Table 2
Exception handling Multithreading Garbage collection
NET Yes Yes YesCaffeine Yes No NoHPCJ Yes Yes YesToba Yes Yes YesHarissa Yes No YespicoJava-I Yes Yes Yes
will require more time to execute a Javacode than a similar technique that doesnot support garbage collection. The readeris cautioned that some of the reportedvalues apparently do not include theseoverhead effects. Table 3 lists whethereach execution technique includes supportfor exception handling, multithreading,and garbage collection. Furthermore, theperformance evaluations used a varietyof different benchmarks making it dif-ficult to directly compare the differentexecution techniques.
At present, the performance of Java in-terpreters is typically about 10–50 timesslower than compiled C performance [JavaCompiler Technology]. The Microsoft JITcompiler included in Visual J++ v2.0has been reported to achieve approxi-mately 23% of “typical” compiled C per-formance. That is, this JIT compiler pro-duces code that executes approximately 4times slower than compiled C code. Whencompared to the Sun JDK1.0.2 interpreter,however, an average speedup of 5.6 wasobtained [Hsieh et al. 1997]. This perfor-mance evaluation was performed as partof evaluating the NET direct compilerusing a variety of benchmark programs,in particular, the Unix utilities wc, cmp,des, and grep; Java versions of the SPECbenchmarks 026.compress, 099.go, 130.li,and 129.compress; the C/C++ codes Sieve,Linpack, Pi, othello, and cup; and the javacJava bytecode compiler.
The Symantec Cafe JIT compiler hasbeen shown to be about 5 times faster,on average, than the Sun JDK1.0.2 in-terpreter based on the Java version ofthe C programs cmp, grep, wc, Pi, Sieve,and compress [Hsieh et al. 1996]. The
IBM JIT compiler v3.0, which applies anextensive set of optimizations, performsabout 6.6 times faster than IBM’s en-hanced port of Sun JDK1.1.6 [Burke et al.1999]. The performance analysis was per-formed using four SPEC JVM98 bench-mark programs—compress, db, javac, andjack.
Kaffe (version 0.9.2) typically performsabout 2.4 times faster than the SunJDK1.1.1 interpreter for the benchmarksNeighbor (performs a nearest-neighboraveraging), EM3D (performs electromag-netic simulation on a graph), Huffman(performs a string compression/decom-pression algorithm), and Bitonic Sort[Azevedo et al. 1999].
CACAO improves Java execution timeby a factor of 5.4, on average, over the SunJava interpreter [Krall and Grafl 1997].These performance results were obtainedusing the benchmark programs JavaLex,javac, espresso, Toba, and java cup. Whencompared to compiled C programs op-timized at the highest level, though,CACAO (with array bounds check and pre-cise floating point exception disabled) per-forms about 1.66 times slower. This com-parison with compiled C programs wasperformed using the programs Sieve, ad-dition, and Linpack. Since these are verysmall programs, the performance differ-ence compared to compiled C code is likelyto be higher when applied to real applica-tions.
The AJIT compiler performs about 3.4times better than the Sun JDK1.1.1 inter-preter and about 1.46 times faster thanthe Kaffe JIT compiler for the benchmarksNeigbor, EM3D, Huffman, and BitonicSort [Azevedo et al. 1999].
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

236 I. H. Kazi et al.
Performance evaluation results of anumber of direct compilers show theirhigher performance compared to the in-terpreters and JIT compilers. The NETcompiler, for instance, achieves a speedupof up to 45.6 when compared to theSun JDK1.0.2 interpreter, with an aver-age speedup of about 17.3 [Hsieh et al.1997]. Compared to the Microsoft JIT,NET is about 3 times faster, on average,and currently achieves 54% of the per-formance of compiled C code. The NETcompiler uses a mark-and-sweep basedgarbage collector. The overhead of thegarbage collection is somewhat reducedby invoking the garbage collector onlywhen the memory usage reaches some pre-defined limit. The benchmarks used inevaluating NET include the Unix utili-ties wc, cmp, des, and grep; Java versionsof the SPEC benchmarks 026.compress,099.go, 132.ijpeg, and 129.compress; theC/C++ codes Sieve, Linpack, Pi, othello,and cup; and the Java codes JBYTEmarkand javac.
The Caffeine compiler yields, on aver-age, 68 percent of the speed of compiled Ccode [Hseih et al. 1996]. It runs 4.7 timesfaster than the Symantec Cafe JIT com-piler and 20 times faster than the SunJDK1.0.2 interpreter. The reported perfor-mance of Caffeine is better than the NETcompiler since it does not include garbagecollection and thread support. The bench-marks used are cmp, grep, wc, Pi, Sieve,and compress.
The performance results obtained forthe HPCJ show an average speedup of10 over the IBM AIX JVM1.0.2 inter-preter [Seshadri 1997]. HPCJ is about 6times faster than the IBM AIX JIT com-piler (version 1.0). The HPCJ results in-clude the effects of a conservative garbagecollection mechanism, exception handling,and thread support. Its performance wasevaluated using a number of languageprocessing benchmarks, namely, javac,JacorB (a CORBA/IDL to Java translator),Toba, JavaLex, JavaParser, JavaCup, andJobe.
Codes generated by the bytecode com-piler Toba when using a conservativegarbage collector, thread package, and ex-
ception handling, are shown to run 5.4times faster than the Sun JDK1.0.2 in-terpreter and 1.6 times faster than theGuava JIT compiler [Proebsting et al.1997]. The results are based on the bench-marks JavaLex, JavaCup, javac, espresso,Toba, JHLZip, and JHLUnzip.
The Harissa bytecode-to-C translatorperforms about 5 times faster than theSun JDK1.0.2 interpreter and 3.2 timesfaster than the Guava JIT compiler basedon the javac and javadoc benchmark pro-grams [Muller et al. 1997]. This version ofHarissa includes a conservative garbagecollector but does not provide thread sup-port.
In addition to analyzing the perfor-mance of the various interpreters andcompilers, the improvement in perfor-mance due to the use of Java proces-sors has also been considered. The perfor-mance of the picoJava-I core was analyzedby executing two Java benchmarks, javacand Raytracer, on a simulated picoJava-Icore [O’Connor and Tremblay 1997]. Theresults show that the simulated picoJava-I core executes the Java codes about 12times faster than the Sun JDK1.0.2 in-terpreter, and about 5 times faster thanthe Symantec Cafe v1.5 JIT compiler ex-ecuting on a Pentium processor, at anequal clock rate. In the simulation ofthe picoJava-I core, the effect of garbagecollection was minimized by allocating alarge amount of memory to the applica-tions.
A simulation-based performance anal-ysis of the proposed Java processor[Vijaykrishnan et al. 1998] shows thatthe virtual address object cache reducesup to 1.95 cycles per object access com-pared to the serialized handle and objectlookup scheme. The extended folding oper-ation feature eliminates redundant loadsand stores that constitute about 9% ofthe dynamic instructions of the bench-marks studied (javac, javadoc, disasmb,sprdsheet, and JavaLex).
To roughly summarize this array of per-formance comparisons, assume we havea Java program that takes 100 sec-onds to execute with an interpreter. AJIT compiler would execute this program
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 237
in 10–50 seconds. A bytecode translatorwould likely produce an execution time ofapproximately 20 seconds. A direct Javato native code compilation would resultin an execution time of around 5 secondsrunning on the same hardware as the in-terpreter. A Java processor implementedwith an equivalent technology is likely torecord an execution time of 5–10 seconds.Finally, an equivalent C program runningon the same hardware would complete in2–10 seconds.
7. CONCLUSION
Java, as a programming language, of-fers enormous potential by providing plat-form independence and by combining awide variety of language features foundin different programming paradigms, suchas, an object-orientation model, multi-threading, automatic garbage collection,and so forth. The same features thatmake Java so attractive, however, comeat the expense of very slow performance.The main reason behind Java’s slow per-formance is the high degree of hard-ware abstraction it offers. To make Javaprograms portable across all hardwareplatforms, Java source code is compiled togenerate platform-independent bytecodes.These bytecodes are generated with noknowledge of the native CPU on which thecode will be executed, however. Therefore,some translation or interpretation mustoccur at run-time, which directly adds tothe application program’s execution time.
Memory management through auto-matic garbage collection is an importantfeature of the Java programming languagesince it releases programmers from the re-sponsibility for deallocating memory whenit is no longer needed. However, this auto-matic garbage collection process also addsto the overall execution time. Additionaloverhead is added by such features as ex-ception handling, multithreading, and dy-namic loading.
In the standard interpreted mode ofexecution, Java is about 10–50 timesslower than an equivalent compiled C pro-gram. Unless the performance of Javaprograms becomes comparable to com-
piled programming languages such as Cor C++, however, Java is unlikely tobe widely accepted as a general-purposeprogramming language. Consequently, re-searchers have been developing a varietyof techniques to improve the performanceof Java programs. This paper surveyedthese alternative Java execution tech-niques. Although some of these techniques(e.g., direct Java compilers) provide per-formance close to compiled C programs,they do so at the possible expense ofthe portability and flexibility of Java pro-grams. Java bytecode-to-source transla-tors convert bytecodes to an intermediatesource code and attempt to improve perfor-mance by applying existing optimizationtechniques for the chosen intermediatelanguage. Some other techniques attemptto maintain portability by applying stan-dard compiler optimizations directly tothe Java bytecodes. Only a limited num-ber of optimization techniques can be ap-plied to bytecodes, though, since the entireprogram structure is unavailable at thislevel. Hence, bytecode optimizers may notprovide performance comparable to directcompilation.
Another technique to maintain porta-bility while providing higher performanceis to parallelize loops or recursive proce-dures. However, the higher performance ofsuch techniques is obtained only in multi-processor systems and only on applicationprograms that exhibit significant amountsof inherent parallelism. Yet another ap-proach to high performance Java is a Javaprocessor that directly executes the Javabytecodes as its native instruction set. Al-though these processors will execute Javaprograms much faster than either inter-preters or compiled programs, they are oflimited use since applications written inother programming languages cannot berun efficiently on these processors.
The current state-of-the-art research inJava execution techniques is being pur-sued along several directions. To matchthe performance of compiled programs,Java bytecodes must be translated to na-tive machine code. However, the gener-ation of this native machine code mustbe done dynamically during the program’s
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

238 I. H. Kazi et al.
execution to support Java’s portabilityand flexibility. Researchers are continu-ally improving JIT compilation techniquesto generate more highly optimized codewithin the limited amount of time avail-able for the JIT compilation. Dynamiccompilation techniques based on programexecution profiles are also being applied.These techniques dynamically generatehighly optimized native code as the pro-gram is executed. This dynamic compila-tion allows the program execution to adaptitself to its varying behavior to therebyprovide improved performance.
Another trend for obtaining greater lev-els of performance is to improve the perfor-mance of the various individual JVM fea-tures, such as garbage collection, threadsynchronization, and exception handling,that add overhead directly to the execu-tion of the native code. Yet another trendis to execute Java programs in parallel anddistributed environments. Different par-allelization models are being developed toextract parallelism from serial Java pro-grams without modifying the underlyingJVM implementation. The bottleneck inthis case, however, is the performance ofthe Java RMI and multithreading mech-anisms, although research is also beingpursued to provide efficient implementa-tions of Java RMI and thread supportmechanisms that will improve the per-formance of parallel and distributed Javaprograms.
The choice of a particular Java exe-cution technique must be guided by therequirements of the application programas well as the performance offered bythe technique. However, as was pointedout earlier, the performance evaluation ofthese various execution techniques is in-complete due to the lack of a standard-ized set of Java benchmark programs.Also, many of the techniques that havebeen evaluated were not complete imple-mentations of the JVM. Some includedgarbage collection and exception handling,for instance, while others did not. Thesemethodological variations make it ex-tremely difficult to compare one techniqueto another even with a standard bench-mark suite.
While Java has tremendous potentialas a programming language, there is atremendous amount yet to be done to makeJava execution-time performance compa-rable to more traditional approaches.
ACKNOWLEDGMENTS
We thank Amit Verma and Shakti Davis for theirhelp in gathering some of the information used inthis paper.
REFERENCES
ARMSTRONG, E. 1998. HotSpot: A new breed of vir-tual machine. Java World, Mar.
ARNOLD, K. AND GOSLING, J. 1996. The Java Program-ming Language. Addison-Wesley, Reading, MA.
AHO, A. V., SETHI, R., AND ULLMAN, J. D. 1986.Compilers Principles, Techniques, and Tools.Addison-Wesley, Reading, MA.
AZEVEDO, A., NICOLAU, A., AND HUMMEL, J. 1999. Javaannotation-aware just-in-time (AJIT) compila-tion system. In Proceedings of the ACM 1999Conference on Java Grande, 142–151.
ADL-TABATABAI, A., CIERNIAK, M., LUEH, G. Y., PARIKH,V. M., AND STICHNOTH, J. M. 1998. Fast, effectivecode generation in a just-in-time Java compiler.In Proceedings of the ACM SIGPLAN ’98 Con-ference on Programming Language Design andImplementation, 280–290.
BIK, A. AND GANNON, D. 1997. Automatically exploit-ing implicit parallelism in Java. In Concurrency:Practice and Experience, vol. 9, no. 6, 579–619.
BIK, A. AND GANNON, D. 1998. Javab—A proto-type bytecode parallelization tool, ACM Work-shop on Java for High-Performance NetworkComputing.
BACON, D. F., KONURU, R., MURTHY, C., AND SERRANO,M. 1998. Thin locks: Featherweight synchro-nization for Java. In Proceedings of the ACMSIGPLAN ’98 Conference on Programming Lan-guage Design and Implementation, 258–268.
BURKE, M. G., CHOI, J.-D, FINK, S., GROVE, D., HIND,M., SARKAR, V., SERRANO, M., SREEDHAR, V. C., AND
SRINIVASAN, H. 1999. The Jalapeno dynamic op-timizing compiler for Java. In Proceedings of theACM 1999 Conference on Java Grande, 129–141.
ByteMark, http://www.byte.com.CIERNIAK, M. AND LI, W. 1997a. Optimizing Java
bytecodes. In Concurrency: Practice and Expe-rience, vol. 9, no. 6, 427–444.
CIERNIAK, M. AND LI, W. 1997b. Just-in-time opti-mizations for high-performance Java programs.In Concurrency: Practice and Experience, vol. 9,no. 11, 1063–1073.
CHANG, P. P., MAHLKE, S. A., CHEN, W. Y., WATER,N. J., AND HWU, W. W. 1991. IMPACT: An ar-chitectural framework for multiple-instruction-
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

High Performance in Java Programs 239
issue processors. In Proceedings of the 18thAnnual International Symposium on ComputerArchitecture, May 28, 266–275.
CaffeineMark, http://www.pendragon-software.com/pendragon/cm3/info.html.
CUP Parser Generator for Java, http://www.cs.princeton.edu/˜ appel/modern/java/CUP.
DEAN, J., GROVE, D., AND CHAMBERS, C. 1995. Op-timization of object-oriented programs usingstatic class hierarchy analysis. In Proceedingsof ECOOP ’95, vol. 952 of Lecture Notes inComputer Science. Springer-Verlag, New York,77–101.
DEAN, J., DEFOUW, G., GROVE, D., LITVINOV, V., AND
CHAMBERS, C. 1996. Vortex: An optimizingcompiler for object-oriented languages. InConference on Object-Oriented ProgrammingSystems, Languages, and Applications (OOP-SLA), 93–100.
DashO Pro, http://www.preemptive.com/DashO/.Dhrystone Benchmark, http://www.netlib.org/
benchmark/dhry-c.Dhrystone Benchmark in Java, http://www.c-
creators.co.jp/okayan/DhrystoneApplet/.EBCIOGLU, K., ALTMAN, E., AND HOKENEK, E. 1997.
A Java ILP machine based on fast dynamiccompilation. In International Workshop onSecurity and Efficiency Aspects of Java, Eilat,Israel, Jan. 9–10.
EspressoGrinder, http://wwwipd.ira.uka.de/∼esp-resso/.
FAJITA FAJITA Compiler Project, http://www.ri.silicomp.fr/adv-dvt/java/fajita/index-b.htm.
GOSLING, J., JOY, B., and STEELE, G. 1996. TheJava Language Specification. Addison-Wesley,Reading, MA.
HSIEH, C. A., GYLLENHAAL, J. C., AND HWU, W. W. 1996.Java bytecode to native code translation: Thecaffeine prototype and preliminary results. InInternational Symposium on MicroarchitectureMICRO 29, 90–97.
HSIEH, C. A., CONTE, M. T., GYLLENHAAL, J. C., AND
HWU, W. W. 1997. Optimizing NET compilersfor improved Java performance. Computer,June, 67–75.
ICHISUGI, Y. AND ROUDIER, Y. 1997. Integratingdata-parallel and reactive constructs into Java.In Proceedings of France–Japan Workshopon Object-Based Parallel and DistributedComputation (OBPDC ’97), France.
IVANNIKOV, V., GAISSARAYAN, S., DOMRACHEV, M.,ETCH, V., AND SHTALTOVNAYA, N. 1997. DPJ:Java Class Library for Development of Data-Parallel Programs. Institute for SystemsProgramming, Russian Academy of Sciences,http://www.ispras.ru/∼dpj/.
ISHIZAKI, K., KAWAHITO, M., YASUE, T., TAKEUCHI,M., OLASAWARA, T., SULANUMA, T., ONODERA, T.,KOMATSU, H., AND NAKATANI, T. 1999. Design,implementation, and evaluation of optimiza-tions in a just-in-time compiler. In Proceedings
of the ACM 1999 Conference on Java Grande,June, 119–128.
Jas: Bytecode Assembler, http://www.meurrens.org/ip-Links/Java/codeEngineering/blackDown/jas.html.
Java Benchmarks—VolanoMark, http://www.volano.com/mark.html.
Java Compiler Technology, http://www.gr.opengroup.org/compiler/index.htm.
Java Grande Forum Benchmark: Links to OtherJava Benchmarks, http://www.epcc.ed.ac.uk/research/javagrande/links.html.
Java Grande Forum Benchmark Suite, http://www.epcc.ed.ac.uk/research/javagrande/benchmarking.
html.Java Grande Forum Report: Making Java Work
for High-End Computing, JavaGrande ForumPanel, SC98, Nov. 1998, http://www.javagrande.org/reports.htm.
Java Microbenchmarks, http://www.cs.cmu.edu/jch/java/benchmarks.html.
Jax: Scanner Generator, http://www.meurrens.org/ip-Links/Java/codeEngineering/blackDown/jax.html.
Jell: Parser Generator, http://www.meurrens.org/ip-Links/Java/codeEngineering/blackDown/jell.html.
JHLUnzip—A Zippy Utility, http://www.easynet.it/jhl/apps/zip/unzip.html.
JHLZip–Another Zippy Utility, http://www. easynet.it/˜ jhl/apps/zip/zip.html.
JLex: A Lexical Analyzer Generator for Java,http://www.cs.princeton.edu/appel/modern/java/JLex.
Just-In-Time Compilation and the Microsoft VMfor Java, http://premium.microsoft.com/msdn/library/sdkdoc/java/htm/Jit Structure.htm.
KAZI, I. H. AND LILJA, D. J. 2000. JavaSpMT: Aspeculative thread pipelining parallelizationmodel for Java programs. In Proceedings ofthe International Parallel and DistributedProcessing Symposium (IPDPS), May, 559–564.
KRALL, A. AND GRAFL, R. 1997. CACAO—A 64 bitJava VM just-in-time compiler. In Principles &Practice of Parallel Programming (PPoPP) ’97Java Workshop.
KRALL, A. AND PROBST, M. 1998. Monitors and ex-ceptions: How to implement Java efficiently. InACM Workshop on Java for High-PerformanceNetwork Computing.
KRINTZ, C., CALDER, B., AND, HOLZLE, U. 1999. Re-ducing transfer delay using Java class filesplitting and prefetching. In OOPSLA ’99,276–291.
LILJA, DAVID J. 2000. Measuring Computer Per-formance: A Practitioner’s Guide. CambridgeUniversity Press, New York.
LAUNAY, P. AND PAZAT, J. L. 1997. A Framework forParallel Programming in Java. IRISA, France,Tech. Rep. 1154, Dec.
ACM Computing Surveys, Vol. 32, No. 3, September 2000.

240 I. H. Kazi et al.
LINDHOLM, T. AND YELLIN, F. 1997. The Java Vir-tual Machine Specification. Addison-Wesley,Reading, MA.
Linpack Benchmark—Java Version, http://www.netlib.org/benchmark/linpackjava/.
MCGHAN, H. AND O’CONNOR M. 1998. PicoJava: Adirect execution engine for Java bytecode. IEEEComputer, Oct., 22–30.
MEYER, J. AND DOWNING, T. 1997. Java Virtual Ma-chine. O’Reilly & Associates, Inc., Sebastopol,CA.
MULLER, G., MOURA, B., BELLARD, F., AND CONSEL, C.1997. Harissa: A flexible and efficient Java en-vironment mixing bytecode and compiled code.In Conference on Object-Oriented Technologiesand Systems (COOTS).
MATSUOKA, S., OGAWA, H., SHIMURA, K., KIMURA, Y.,HOTTA, K., AND TAKAGI, H. 1998. OpenJIT—Areflective Java JIT compiler. In Proceed-ings of OOPSLA ’98 Workshop on Re-flective Programming in C++ and Java,16–20.
MOREIRA, J. E., MIDKIFF, S. P., GUPTA, M., ARTIGAS,P. V., SNIR, M., AND LAWRENCE, D. 2000. Javaprogramming for high-performance numericalcomputing. IBM System Journal, vol. 39, no. 1,21–56.
Microsoft SDK Tools, http://premium.microsoft.com/msdn/library/sdkdoc/java/htm.
O’CONNOR, J. M. AND TREMBLAY, M. 1997. PicoJava-I:The Java virtual machine in hardware. IEEEMicro, Mar./Apr., 45–53.
POSTEL, J. B. 1981. Transmission Control Protocol.RFC 791, Sept.
PROEBSTING, T. A. 1992. Simple and efficient BURStable generation. In Proceedings of the ACMSIGPLAN ’92 Conference on ProgrammingLanguage Design and Implementation (PLDI),June, 331–340.
PROEBSTING, T. A., TOWNSEND, G., BRIDGES, P.,HARTMAN, J. H., NEWSHAM, T., AND WATTERSON,S. A. 1997. Toba: Java for applications a wayahead of time (WAT) compiler. In Conferenceon Object-Oriented Technologies and Systems(COOTS).
Patriot Scientific Corporation. Java on Patriot’sPSC1000 Microprocessor, http://www.ptsc.com/PSC1000/java psc1000.html.
PC Magazine Test Center: JMark 1.01, http:// www8.zdnet.com/pcmag/pclabs/bench/benchjm.htm.
Remote Method Invocation Specification, http://java.sun.com/products/jdk/1.1/docs/guide/rmi-/spec/rmiTOC.doc.html.
SESHADRI, V. 1997. IBM high performance compilerfor Java. AIXpert Magazine, Sept., http://www.developer.ibm.com/library/aixpert.
SILBERSCHATZ, A. AND GALVIN, P. 1997. OperatingSystem Concepts. Addison-Wesley LongmanInc., Reading, MA.
SUGANUMA, T., OLASAWARA, T., TAKEUCHI, M., YASUE,T., KAWAHITO, M., ISHIZAKI, K., KOMATSU, H., AND
NAKATANI, T. 2000. Overview of the IBM Javajust-in-time compiler, IBM Systems Journal,vol. 39, no. 1, 175–193.
SPEC JVM98 Benchmarks, http://www.spec.org/org/jvm98/.
Sun Microsystems—The Source for Java Technology,http://java.sun.com.
Sun Microsystems. MicroJava-701 Processor, http://www.sun.com/microelectronics/microJava-701.
Symantec—Just-In-Time Compiler PerformanceAnalysis, http://www.symantec.com/jit/jit pa.html.
SYSmark J, http://www.bapco.com/SYSmarkJ.html.TURLEY, J. 1997. MicroJava Pushes Bytecode
Performance—Sun’s MicroJava 701 Based onNew Generation of PicoJava Core. Microproces-sor Rep., vol. 11, no. 15, Nov. 17.
TIP, F. AND SWEENEY, P. 1997. Class hierarchyspecialization. In OOPSLA ’97, 271–285.
TIP, F., LAFFRA, C., SWEENEY, P. F., AND STREETER, D.1999. Practical experience with an applicationextractor for Java. In OOPSLA ’99, 292–305.
The Java Hotspot Performance Engine Architecture,http://java.sun.com/products/hotspot/-whitepaper.html.
TurboJ Benchmark’s Results, http://www.camb.opengroup.org/openitsol/turboj/technical/benchmarks.htm.
TurboJ Java to Native Compiler, http://www.ri.silicomp.fr/adv-dvt/java/turbo/index-b.htm.
UCSD Benchmarks for Java, http://www-cse.ucsd.edu/users/wgg/JavaProf/javaprof.html.
UW Cecil/Vortex Project, http://www.cs.washington.edu/research/projects/cecil.
VIJAYKRISHNAN, N., RANGANATHAN, N., AND GADEKARLA,R. 1998. Object-oriented architectural sup-port for a Java processor. In Proceeding of the12th European Conference on Object-OrientedProgramming (ECOOP), 330–354.
WILSON, P. R. 1992. Uniprocessor garbage collec-tion techniques. In Proceedings of InternationalWorkshop on Memory Management, vol. 637 ofLecture Notes in Computer Science. Springer-Verlag, New York, Sept. 17–19, 1–42.
Welcome to Harissa, http://www.irisa.fr/compose/harissa/.
Welcome to JMark 2.0, http://www.zdnet.com/zdbop/jmark/jmark.html.
Wilkinson, T., Kaffe v0.10.0—A Free Virtual Ma-chine to Run Java Code, Mar. 1997. Available athttp://www.kaffe.org/.
Received December 1998; revised July 2000; accepted August 2000
ACM Computing Surveys, Vol. 32, No. 3, September 2000.