Embed Size (px)
Citation preview

Task Based Execution of GPU Applications with Dynamic Data Dependencies
Mehmet E BelviranliChih H ChouLaxmi N BhuyanRajiv Gupta
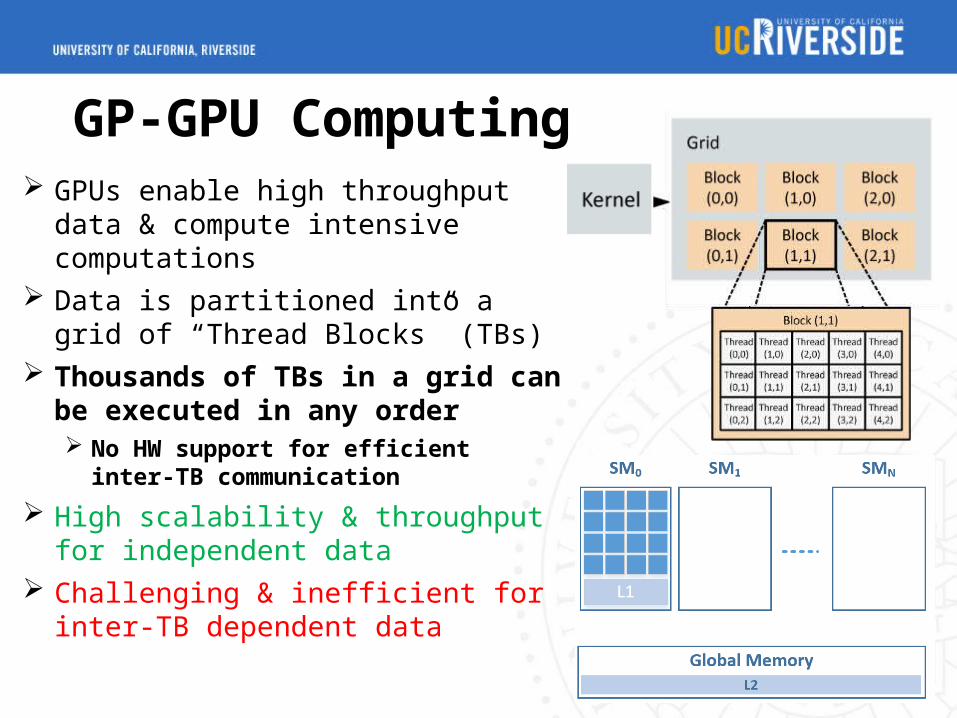
GP-GPU Computing GPUs enable high throughput data
& compute intensive computations Data is partitioned into a grid of
“Thread Blocks” (TBs) Thousands of TBs in a grid can
be executed in any order No HW support for efficient inter-TB
communication
High scalability & throughput for independent data
Challenging & inefficient for inter-TB dependent data
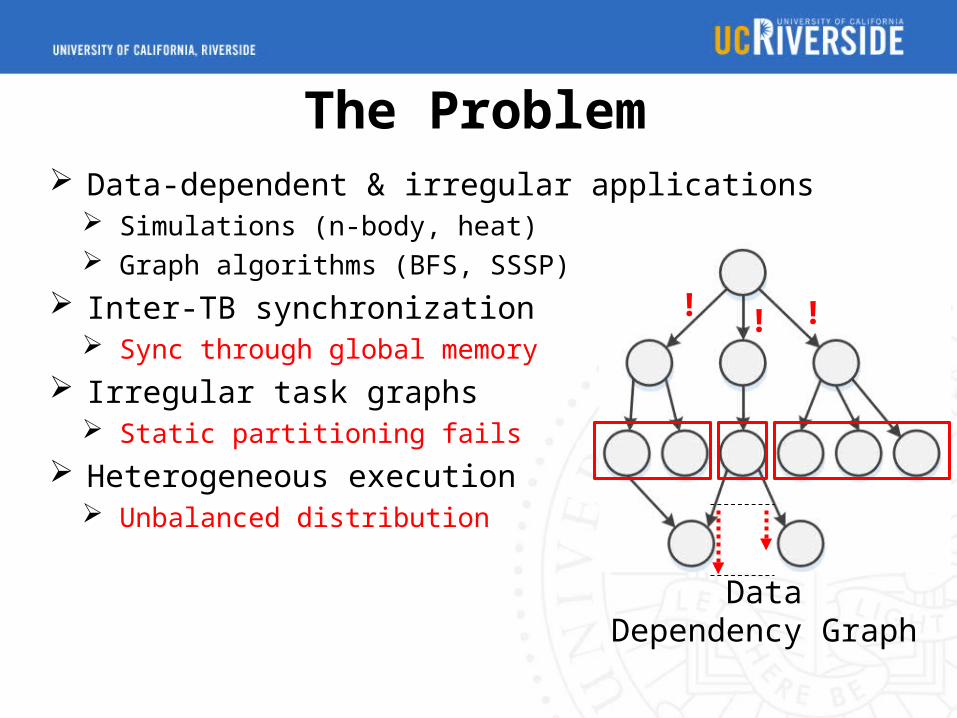
The Problem Data-dependent & irregular applications
Simulations (n-body, heat) Graph algorithms (BFS, SSSP)
Inter-TB synchronization Sync through global memory
Irregular task graphs Static partitioning fails
Heterogeneous execution Unbalanced distribution
! ! !
DataDependency Graph
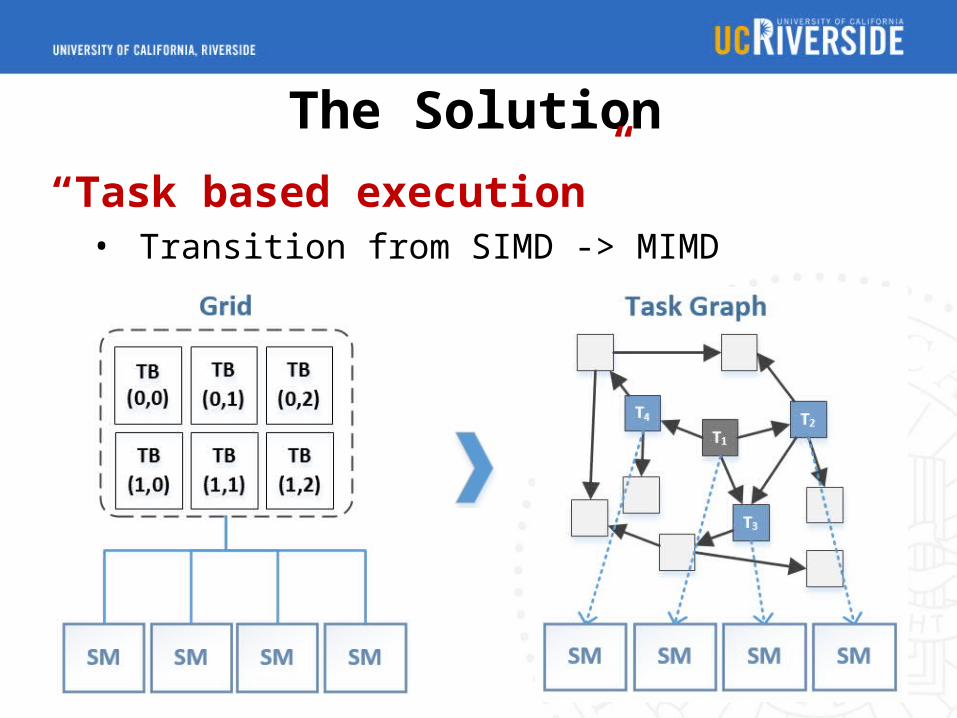
The Solution
“Task based execution”• Transition from SIMD -> MIMD

5
Challenges Breaking applications into tasks Task to SM assignment Dependency tracking Inter–SM communication Load Balancing

6
Proposed Task Based Execution Framework
Persistent Worker TBs (per SM) Distributed task queues (per SM) In-GPU dependency tracking &
scheduling Load balancing via different queue
insertion policies
7
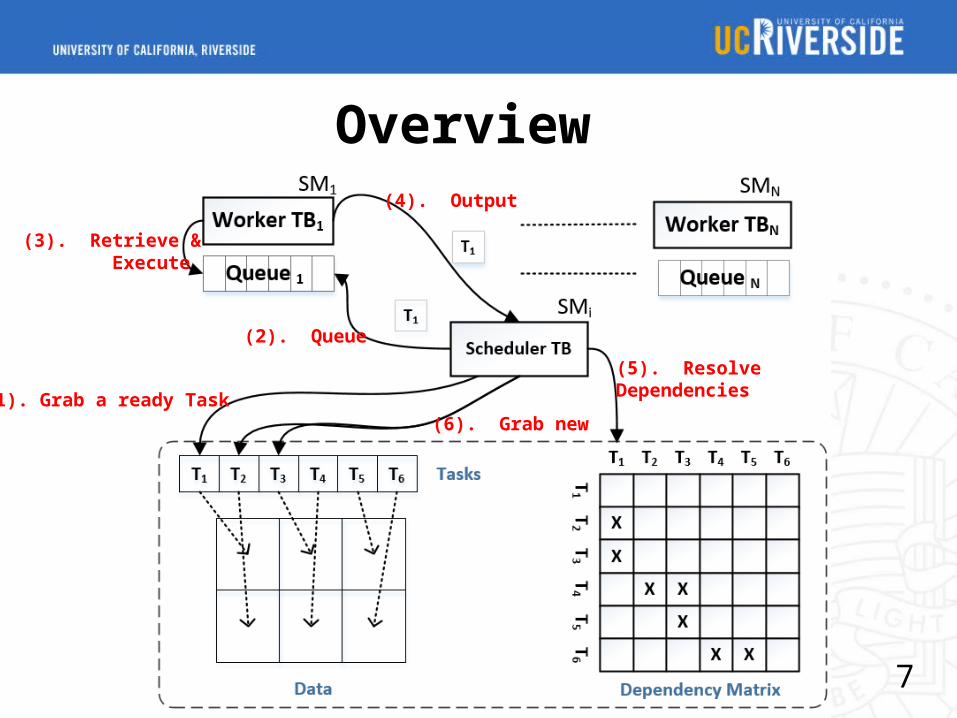
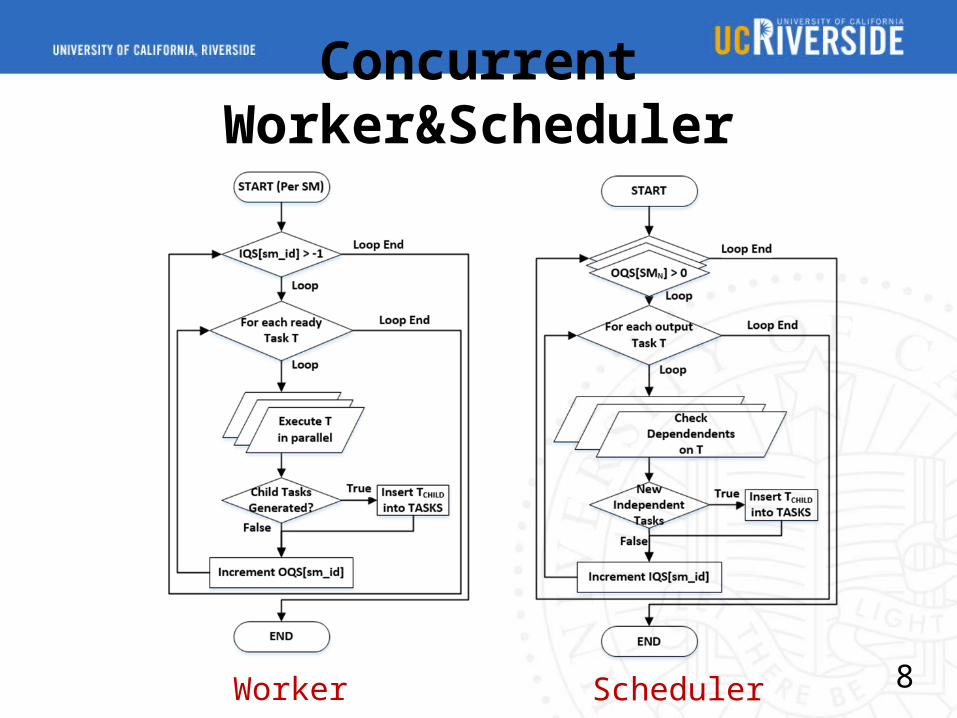
Overview
(1). Grab a ready Task
(2). Queue
(3). Retrieve & Execute
(4). Output
(5). Resolve Dependencies
(6). Grab new
8
Concurrent Worker&Scheduler
Worker Scheduler

Queue Access &Dependency Tracking
IQS and OQS Efficient signaling mechanism via
global memory Parallel task pointer retrieval
Queues store pointers to tasks Parallel dependency check
10
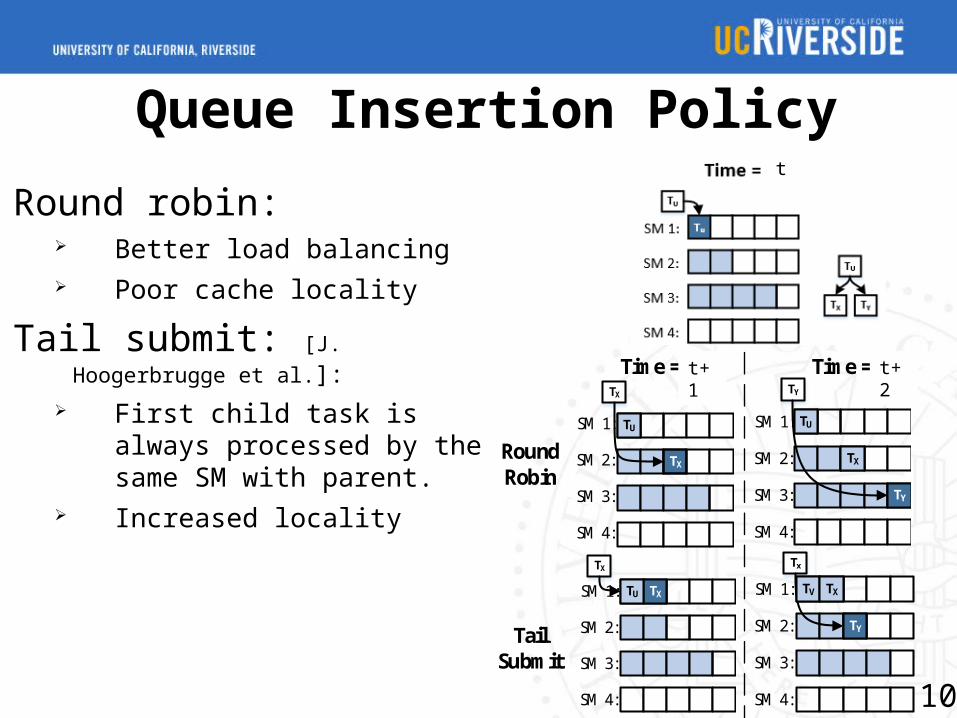
Queue Insertion Policy
Round robin: Better load balancing Poor cache locality
Tail submit: [J. Hoogerbrugge et al.]:
First child task is always processed by the same SM with parent.
Increased locality
Time = 1 Time = 2
SM 1:
SM 2:
SM 3:
SM 4:
TX
TX
Round Robin
TU
TY
TX
TY
TUSM 1:
SM 2:
SM 3:
SM 4:
TX
TX
Tail Submit
SM 1:
SM 2:
SM 3:
SM 4:
TU
Tx
TV
TY
SM 1:
SM 2:
SM 3:
SM 4:
TX
t
t+1 t+2

11
API
Application specific data is added under WorkerContext and Task
user_task is called by worker_kernel

12
Experimental Results NVIDIA Tesla 2050
14 SMs, 3GB memory Applications:
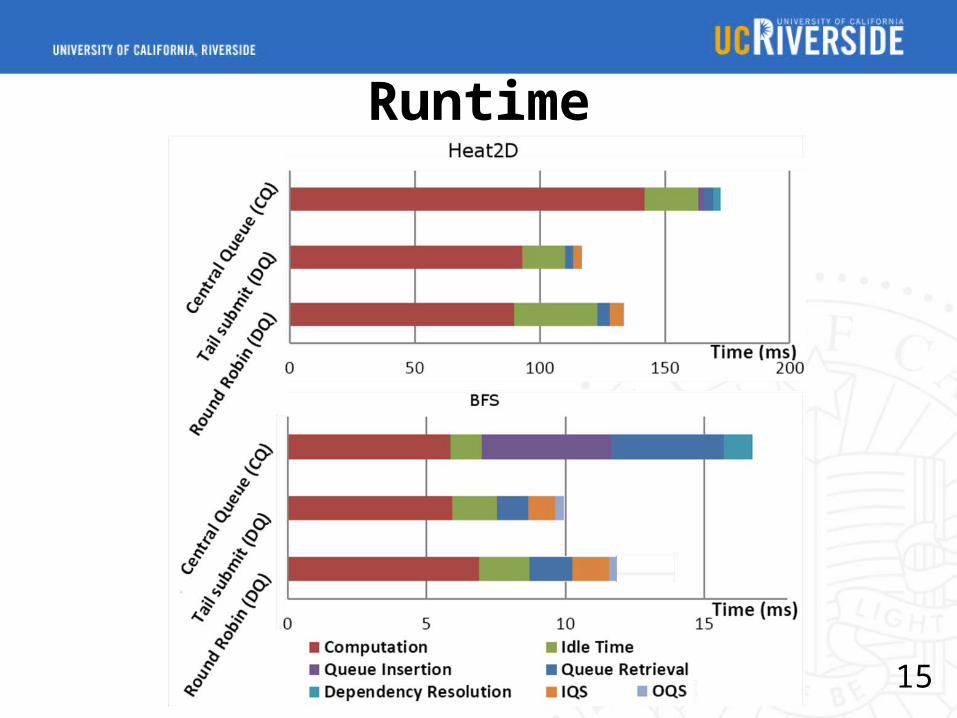
Heat 2D: Simulation of heat dissipation over a 2D surface
BFS: Breadth-first-search Comparison:
Central queue vs. distributed queue
13
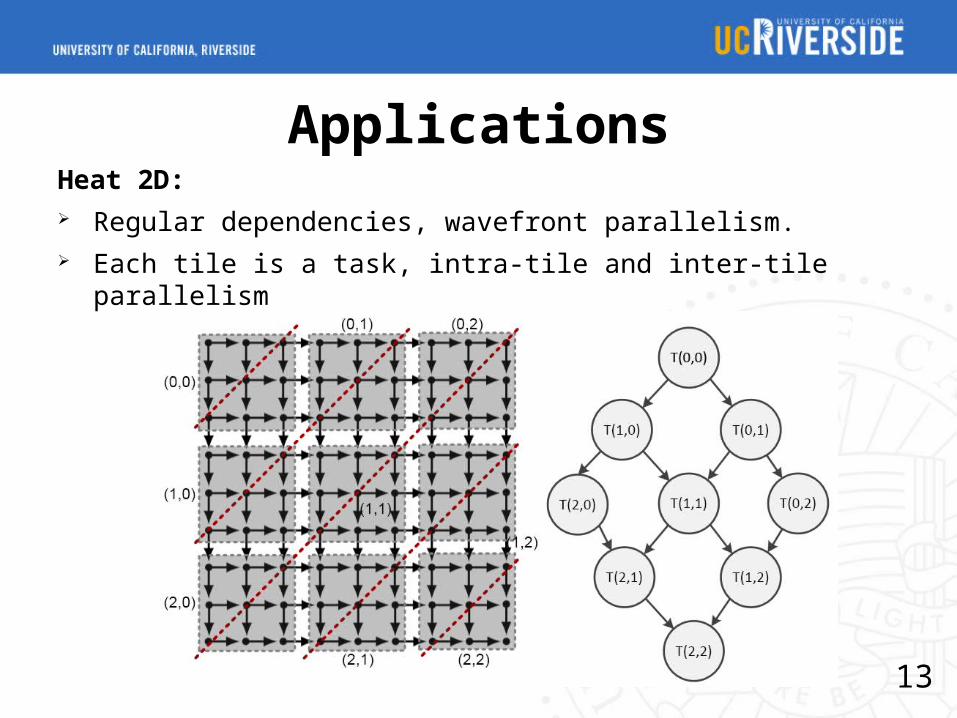
ApplicationsHeat 2D: Regular dependencies, wavefront parallelism. Each tile is a task, intra-tile and inter-tile parallelism
14
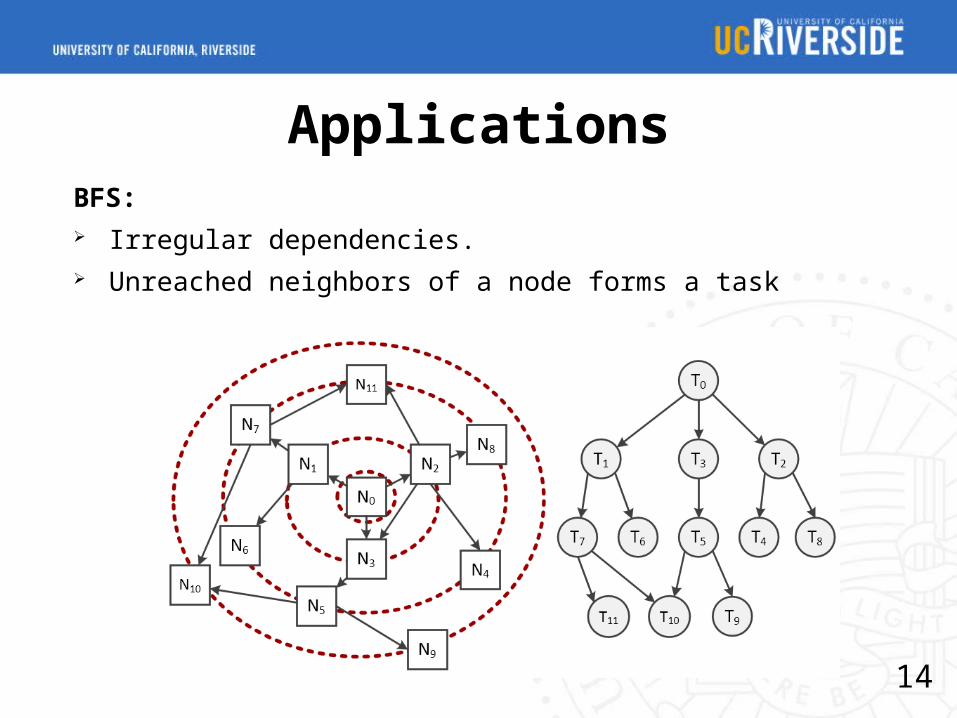
ApplicationsBFS: Irregular dependencies. Unreached neighbors of a node forms a task
15
Runtime
16
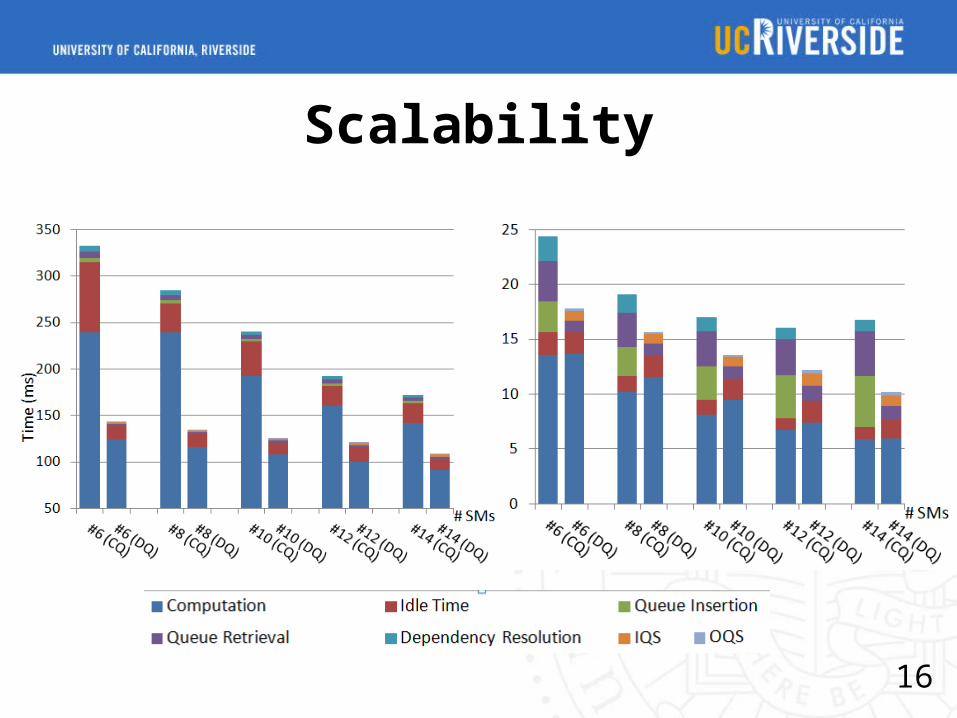
Scalability

17
Future Work
S/W support for:• Better task representation• More task insertion policies• Automated task graph partitioning for
higher SM utilization.

18
Future Work
H/W support for:• Fast inter-TB sync• Support for TB to SM affinity• “Sleep” support for TBs

19
Conclusion Transition from SIMD -> MIMD Task-based execution model
Per-SM task assignment In-GPU dependency tracking Locality aware queue management
Room for improvement with added HW and SW support





























