Embed Size (px)
Citation preview

T3 report: - OxfordHEPSYSMAN
Sean BrisbaneJune 2015

Activities
T3Dominant experiments shifting
Storage HighlightsAWS hybrid cloud
T2Mostly moved off torque
Hybrid T2 & T3Finally started to happen

TIER 3

T3 usage
• Cluster very heavily used for 3 weeks – Borrowed ~100 CPUs from T2
• Seen a big shift away in recent months from LHCb and towards T2K and SNO+ use of T3– T2k data/MC analysis– SNO+ production + simulation work
• Seen reduction on data analysis type jobs from LHCb and to an extent Atlas for some time– Assuming due to long shutdown

T2K• Data processing workload requirement now at ~atlas
levels• But they only have 1 server• Only run 20 jobs at once before I/O maxed-out• Trying to avoid adding to lustre
– See http://indico.cern.ch/event/346931/session/1/contribution/40/material/slides/1.pdf
• Want access to ~100 files– Each sequential on disk– 100 clients + NFS means quite random i/o at block level
So, can we improve a single disk server by ~factor 5?
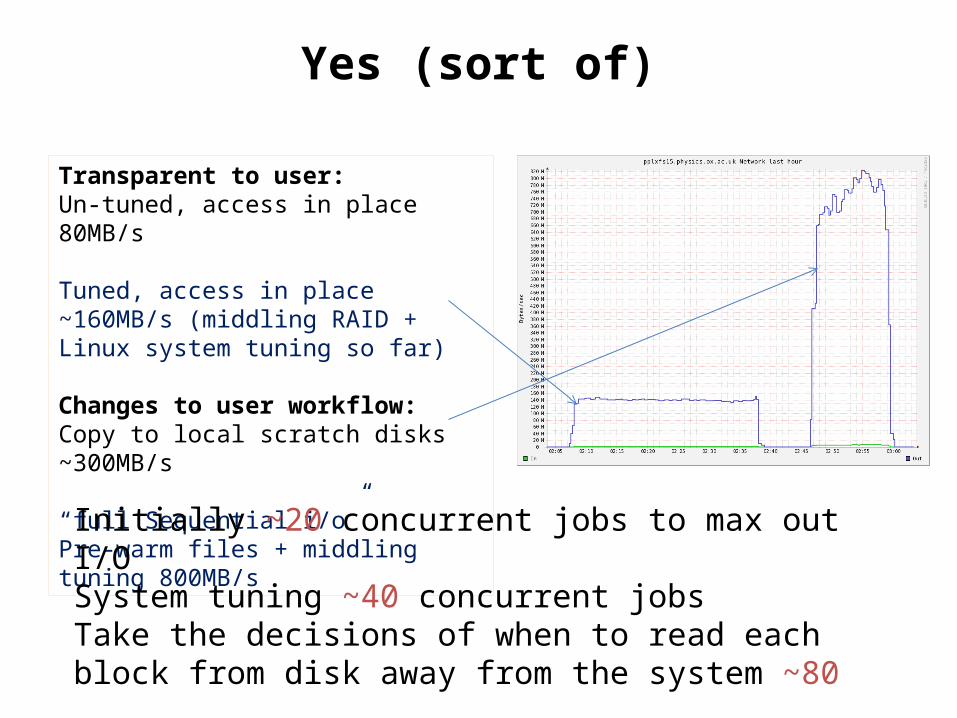
Yes (sort of)
Transparent to user:Un-tuned, access in place 80MB/s
Tuned, access in place ~160MB/s (middling RAID + Linux system tuning so far)
Changes to user workflow:Copy to local scratch disks ~300MB/s
“full Sequential i/o”Pre-warm files + middling tuning 800MB/s
Initially ~20 concurrent jobs to max out I/OSystem tuning ~40 concurrent jobsTake the decisions of when to read each block from disk away from the system ~80

AWS FOR TIER 3

The Amazon CPU Case
• Amazon massively over provisions so as to NEVER run out of compute instances for people paying in full.
• They sell off the spare capacity on the spot market for a more reasonable cost– They will terminate instances if someone is willing to pay more than
you and they are out of capacity• Cost per core hour is “similar” to running ones own hardware
flat-out• On demand Scalability:- So no need to over-buy on hardware• They gave me $5,000 to spend.
Note: There is no case to keep significant data on AWS

Hybrid cloud (for proof of concept)
Data
Fixed Compute
AWS
Scalable Virtual Private Cloud (s)
Batch Server(s)
VPN Server(s)

Tier 3 vs Tier0,1,2
• Grid computing favours maximum utilization – Should take of the bulk jobs for HEP
• T3 favours responsiveness – Left with fast turn-around and development jobs on T3
Period where High memory jobs were running on ~50% cores
Daily peaksWeekend lull
Scale-upIn this case by borrowing grid nodes
Trade-off between responsiveness and utilization for fixed size (CPU, RAM/core) cluster.
Empty SL5 nodes (old hardware)

Quantify Risks:- AWS hybrid cloud1. Amazon data transfer costs $0.09/GB.
– Data transfer costs could ~97% of cost of using AWS– Can we separate data heavy and data light jobs?– What does the JISC/Janet agreement do?
• Amazon say does not reduce bandwidth costs
2. Are the spot instances reliable enough for our use?– Jobs last many hours – jobs don’t checkpoint
3. What is the manpower needed to make this viable?– Lets get a feel for that

Quantify Data transfer costs
• Systemtap framework for writing kernel modules (for monitoring)
• $PBS_JOBID to track job
• Look at ways to categorize jobs – group (easy)– user (easy)– job-type e.g. MC prod, analysis, toy. (hard,
requires user to categorize)
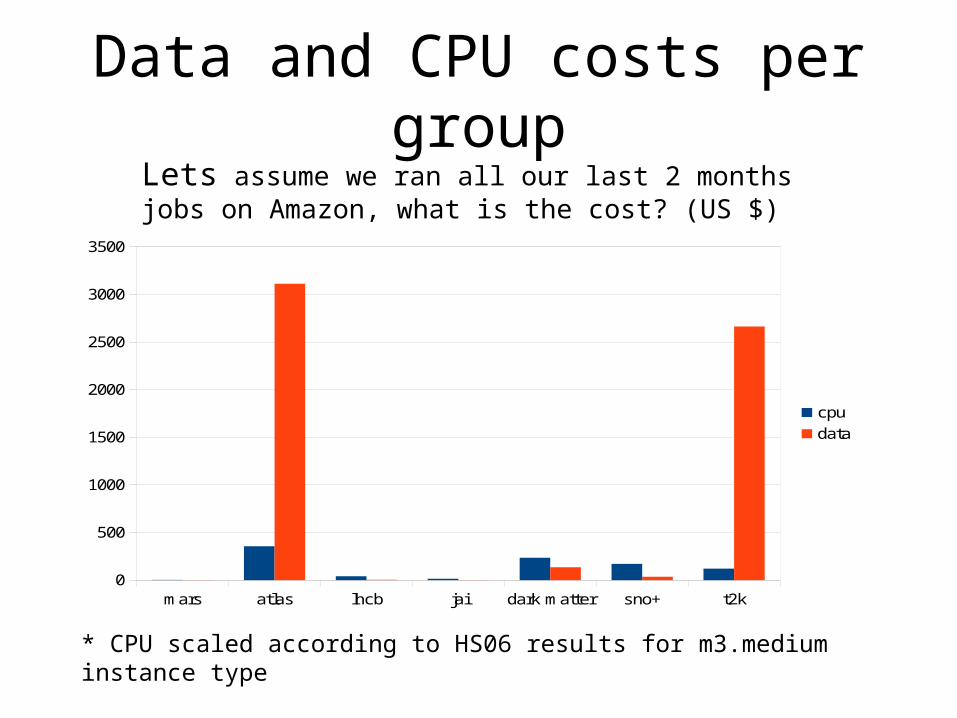
Data and CPU costs per group
mars atlas lhcb jai dark matter sno+ t2k0
500
1000
1500
2000
2500
3000
3500
cpu
data
Lets assume we ran all our last 2 months jobs on Amazon, what is the cost? (US $)
* CPU scaled according to HS06 results for m3.medium instance type

Data and CPU costs per group
mars atlas lhcb jai dark matter sno+ t2k0
100
200
300
400
500
600
cpu
data
2 Groups stand out as easy targetsDiscount LHCb as their usage has been anomalous for the last few months* CPU scaled according to HS06 results for m3.medium instance type

Spot pricing + reliability• A) If spot price goes above bid :- instance
dies– Bid fairly high & keep an eye on it– AWS provide historical plots– Some availability zones much better value
than others
So far, spot instance lifetime 2 weeks and counting if the right zone is used
• Sometimes spot price is up to 10x on-demand price
• Once, instance just died– Maybe AWS killed it for kernel updates?– Only saw this once at beginning

AWS POC selected highlights:The Good
• Create cluster that scales in response to batch queue depth – Amazon has done this for us using Cloud
Formation*– Caveat:- Centos image + torque + all *systems
must be cloud based• Security: Default security is pretty good on
AWS. Virtual private VLAN, firewalls and rich ACL available*http://cfncluster.readthedocs.org/en/latest/

AWS POC: The Bad
• Customizing the image AND keep auto-scaling• Much harder than I expected (I was warned!)
– Simplest customization:- Boot image, touch helloworld, clean-up & shutdown
• Spend ~3 days (inc 4 hrs with Amazon tech guy)• Workflow established (not complicated)• However, clean-up script exists but doesn’t always work.
• Feeling of latency maybe worse than I hoped (except Ireland + east coast)
• Spikey spot pricing? • Long term reliability of market?

AWS POC: The ugly
• Shared data-access, auth + authz piece:– VPN +NFS +NIS over wan, software on cvmfs– NFS is slow over WAN, even for directory walk
• 1 shared torque server very difficult to get working– L3 VPN + NAT or on multi-homed systems is
problematic– Past time we ditched torque
• Use manual scp to share VPN secrets – AWS supports cloud-init user-data

SUMMARY

Summary
• Had issues with lustre storage• Shift away from LHCb/Atlas to SNO+/t2k• T2K I/O requirement is ballooning• Looking at AWS
• T2 Mostly moved away from torque

Backup

Reality bites• Real workload: Raid tuning to chunk size 256k didn’t help much (factor
~50%)• We don’t actually have sequential i/o
– Each file is sequential on disk, but ~100 concurrent accesses to different files from workers over NFS randomizes this too much
– Linux Read-ahead not helping, must consider this random I/O– LSI raid card can only re-order ~1MB requests to select best read rate[3]. Raid
card read-ahead doesn’t help• https://bugzilla.redhat.com/show_bug.cgi?id=806405
• Linux system tuning on top of RAID got me ~factor 50%, mainly switching to deadline scheduler
– http://www.beegfs.com/wiki/StorageServerTuning– https
://translate.google.co.uk/translate?sl=auto&tl=en&js=y&prev=_t&hl=en&ie=UTF-8&u=https%3A%2F%2Fwww.thomas-krenn.com%2Fde%2Fwiki%2FMax-hw-sectors-kb_bei_MegaRAID_Controllern_anpassen&edit-text=&act=url
• Status 80MB/s -> 160MB/s, not enough

Storage outlook
• So far, only been able to experiment with non-destructive optimizations for realistic case– Benchmarks now show ~12Gb/s possible, with 12 disks
and 1M raid chunk size.• Buying 24 bay server
– More disks, more sequential throughput• Try software raid
– Perhaps Linux can queue multiple sequential read requests• Need to change my pre-warming method and buy
new fileserver to get > 10GB/s

Storage tuning:- benchmark Chunk Size
• Raid layout chunk size better tuned for large files sequential i/o – Iozone bench for (mostly) sequential i/o– iozone -r 1M -s 128g -t 6g
Chunk Size R720xd benchmark local access
NFSv4
64k 270MB/s 250MB/s
256k 640-690MB/s 570MB/s
1024k 1160-1300MB/s ?
1024 (sw raid6) 690MB/s ?

Creating Sequential I/O
• Huge improvements if we can create sequential i/o:– Single, supervisory process controls access to raid array – All blocks needed in the near future are read at once from
disk, – All other disk access is blocked.– Multiple clients served from the RAM cache.
• Call the above pre-warm.• Currently, doing this at application level.• T2k were already using a supervisor script to filter
jobs onto batch queue, modify this script.





























