Embed Size (px)
Citation preview

Sandia National Laboratories is a multi-program laboratory managed and operated by Sandia Corporation, a wholly owned subsidiary of Lockheed Martin Corporation, for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-AC04-94AL85000. SAND NO. 2016--3180 C
SustainabilityandPerformancethroughKokkos:ACaseStudywithLAMMPS
Chris&anTro,,SiHammond,StanMoore,[email protected]
CenterforCompu@ngResearchSandiaNa@onalLaboratories,NM
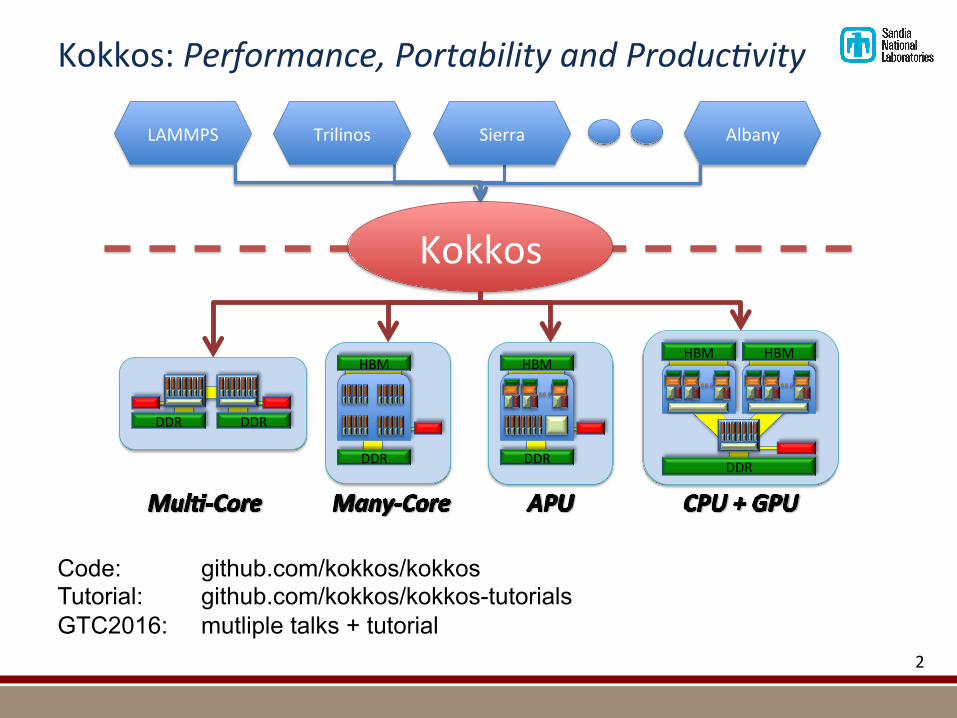
Kokkos:Performance,PortabilityandProduc3vity
2
DDR#
HBM#
DDR#
HBM#
DDR#DDR#
DDR#
HBM#HBM#
Kokkos#
LAMMPS# Sierra# Albany#Trilinos#
Code: github.com/kokkos/kokkos Tutorial: github.com/kokkos/kokkos-tutorials GTC2016: mutliple talks + tutorial

Kokkos:Performance,PortabilityandProduc3vity
§ AprogrammingmodelimplementedasaC++library§ Abstrac@onsforParallelExecu@onandDataManagement
§ Execu@onPa7ern:Whatkindofopera@on(for-each,reduc@on,scan,task)
§ Execu@onPolicy:Howtoexecute(RangePolicy,TeamPolicy,DAG)§ Execu@onSpace:Wheretoexecute(GPU,HostThreads,PIM)§ MemoryLayout:Howtomapindicestostorage(Column/RowMajor)§ MemoryTraits:Howtoaccessthedata(Random,Stream,Atomic)§ MemorySpace:Wheredoesthedatalive(HighBandwidth,DDR,NV)
§ Supportsmul@plebackends:OpenMP,Pthreads,Cuda,Qthreads,Kalmar(experimental)
§ ProfilingHooksarealwayscompiledin§ Standalonetools+interfacestoVtune/Nsightetc.available
3

GoingProduc@on§ KokkosreleasedongithubinMarch2015
§ Develop/Masterbranchsystem=>mergerequiresapplica@onpassing§ Tes@ngNightly:11Compilers,totalof90backendconfigura@ons,warningsaserrors§ ExtensiveTutorialsandDocumenta@on>300slides/pages
§ www.github.com/kokkos/kokkos§ www.github.com/kokkos/kokkos-tutorials
§ TrilinosNGPstackusesKokkosasonlybackend§ Tpetra,Belos,MueLuetc.§ Workingonthreadingallkernels,andsupportGPUs
§ SandiaSierraMechanicsandATDMcodesgoingtouseKokkos§ DecidedtogowithKokkosinsteadofOpenMP(onlyotherrealis@cchoice)§ SM:FY2016:prototypingthreadedalgorithms,explorecodepa7erns§ ATDM:primarydevelopmentonGPUsnow:“IfGPUswork,everythingelse
willtoo”
4

LAMMPSageneralpurposeMDcode
§ C++,MPIbasedopensourcecode:§ lammps.sandia.govandgithub.com/lammps/lammps
§ Modulardesignforeasyextensibilitybyexpertusers§ Widevarietyofsupportedpar@clephysics:
§ Biosimula@ons,semiconductors,metals,granularmaterials§ E.g.bloodtransport,strainsimula@ons,grainflow,glassforming,self
assemblyofnanomaterials,neutronstarma7er
§ Largeflexibilityinsystemconstraints§ Regions,walls,geometricshapes,externalforces,par@cleinjec@on,…
§ Scalable:simula@onswithupto6MillionMPIranksdemonstrated
5

LAMMPSageneralpurposeMDcode
§ C++,MPIbasedopensourcecode:§ lammps.sandia.govandgithub.com/lammps/lammps
§ Modulardesignforeasyextensibilitybyexpertusers§ Widevarietyofsupportedpar@clephysics:
§ Biosimula@ons,semiconductors,metals,granularmaterials§ E.g.bloodtransport,strainsimula@ons,grainflow,glassforming,self
assemblyofnanomaterials,neutronstarma7er
§ Largeflexibilityinsystemconstraints§ Regions,walls,geometricshapes,externalforces,par@cleinjec@on,…
§ Scalable:simula@onswithupto6MillionMPIranksdemonstrated
6
Estimate: 500 Performance Critical Kernels

LAMMPS–GenngonNGP§ Nextgenera@onplaoormsupportthroughpackages§ GPU
§ GPUsupportforNVIDIACudaandOpenCLsince2011§ Offloadsforcecalcula@ons(non-bonded,longrangecoulomb)
§ USER-CUDA§ GPUsupportforNVIDIACuda§ Aimsatminimizingdatatransfer=>runeverythingonGPU§ Reverseoffloadforlongrangecoulombandbondedinterac@on
§ OMP§ OpenMP3supportformul@threading§ Aimedatlowthreadcount(2-8)
§ INTEL§ IntelOffloadpragmasforXeonPhi§ Offloadsforcecalcula@ons(non-bonded,longrangecoulomb)
7

LAMMPS–GenngonNGP§ Nextgenera@onplaoormsupportthroughpackages§ GPU
§ GPUsupportforNVIDIACudaandOpenCLsince2011§ Offloadsforcecalcula@ons(non-bonded,longrangecoulomb)
§ USER-CUDA§ GPUsupportforNVIDIACuda§ Aimsatminimizingdatatransfer=>runeverythingonGPU§ Reverseoffloadforlongrangecoulombandbondedinterac@on
§ OMP§ OpenMP3supportformul@threading§ Aimedatlowthreadcount(2-8)
§ INTEL§ IntelOffloadpragmasforXeonPhi§ Offloadsforcecalcula@ons(non-bonded,longrangecoulomb)
8
Packages replicate existing physics modules:
Hard to maintain.
Prone to inconsistencies. Much more code.

GPUExecu@onModes
9
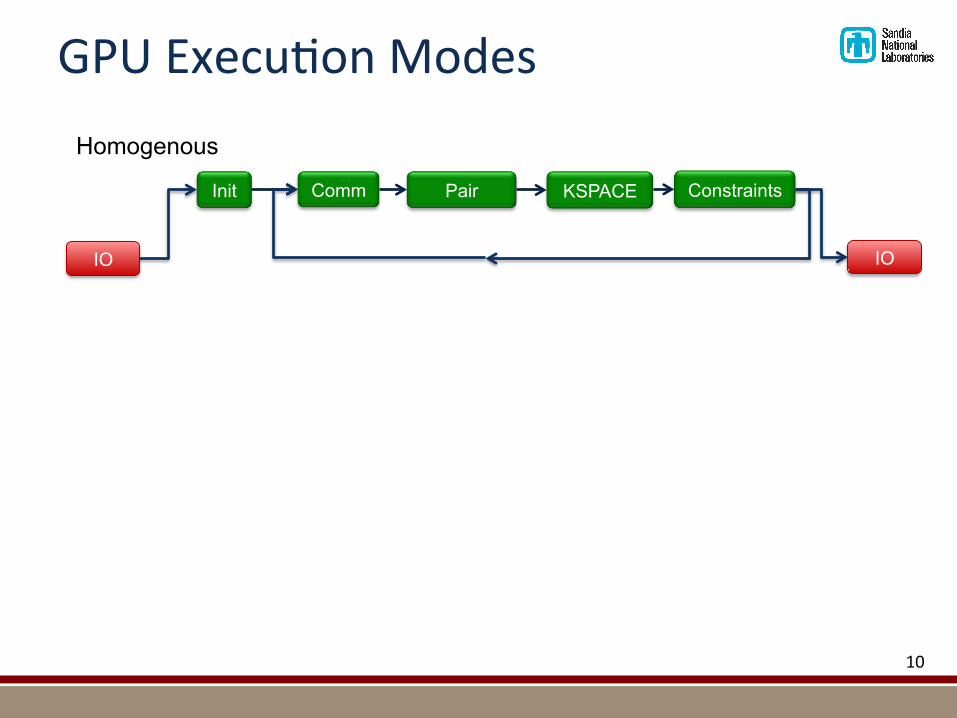
GPUExecu@onModes
10
IO
Init Comm Pair KSPACE Constraints
IO
Homogenous
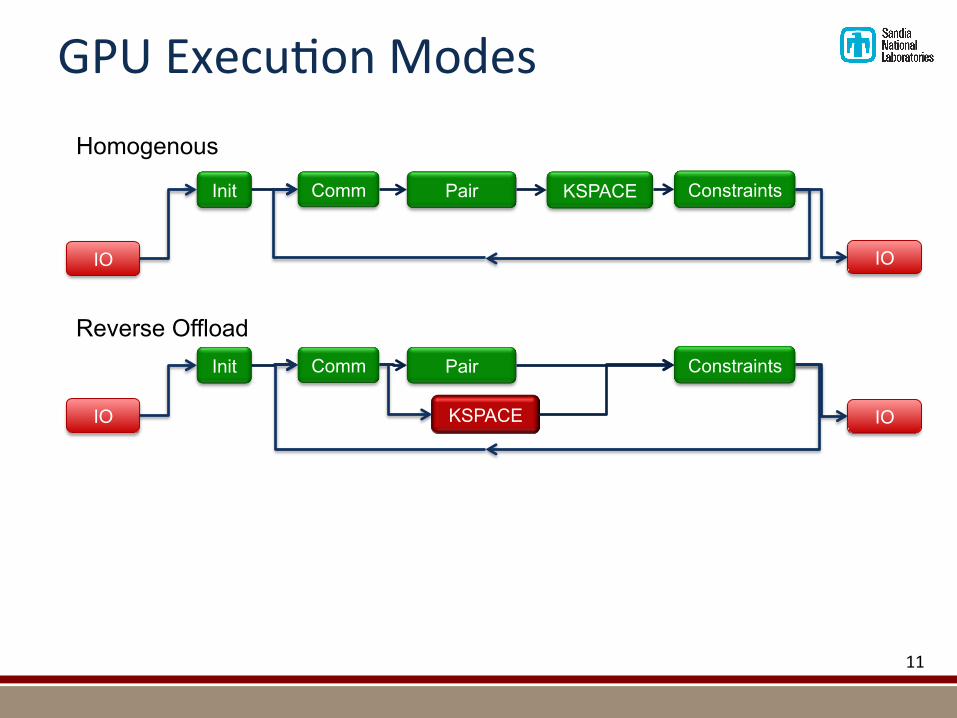
GPUExecu@onModes
11
IO
Init Comm Pair KSPACE Constraints
IO
IO
Init Comm Pair
KSPACE
Constraints
IO
Homogenous
Reverse Offload
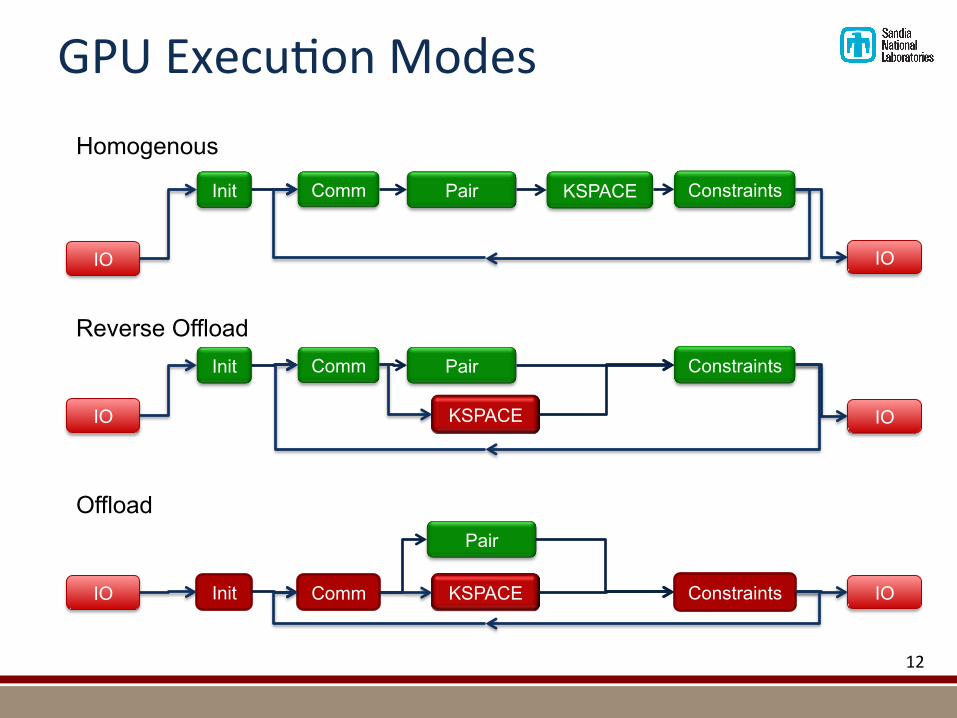
GPUExecu@onModes
12
IO
Init Comm Pair KSPACE Constraints
IO
IO
Init Comm Pair
KSPACE
Constraints
IO
IO Init Comm
Pair
KSPACE Constraints IO
Homogenous
Reverse Offload
Offload
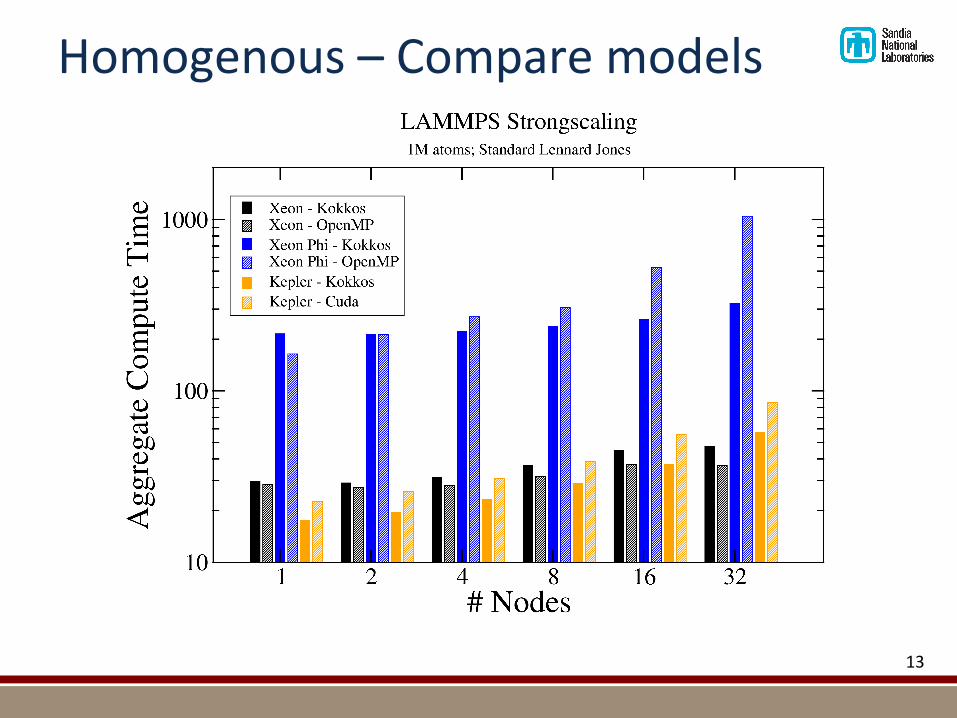
Homogenous–Comparemodels
13
!As!can!be!seen,!the!KOKKOS!package!consistently!outperforms!the!other!packages!on!the!next!generation!architectures!for!this!benchmark,!while!only!sacrificing!a!small!fraction!of!performance!on!classical!CPUs.!!!Another!demonstration!of!the!performance!achievable!is!the!recent!development!of!a!Kokkos!variant!of!the!ReaxFF!force!field,!which!is!significantly!more!complex!(many8body,!reactive,!
charge8equlibration)!than!the!simpler!Lennard!Jones!model.!We!did!investigations!both!on!a!BlueGene!Q!system!with!512!nodes,!where!performance!was!compared!to!MPI!only!runs!and!an!alternative!implementation!using!native!OpenMP,!as!well!as!on!a!standard!Cray!XC30!system!with!dual!Intel!Ivy!Bridge!CPUs!and!a!system!with!NVIDIA!K80!GPUs.!Again!the!performance!achieved!with!the!Kokkos!variant!is!as!well!as!or!better!than!the!alternative!implementations.!!
!In!summary,!we!believe!that!the!strategy!we!have!outlined!will!allow!us!to!more!easily!maintain!a!smaller!code!base!while!delivering!consistently!good!performance!across!the!diversity!of!current!(and!hopefully!future)!hardware!architectures.!Our!choice!to!use!Kokkos!has!primarily!been!driven!by!the!large!number!of!kernels!in!LAMMPS!to!optimize;!other!programming!models!such!as!OpenMP!4.0!have!a!similar!goal!of!enabling!hardware8independent!performance!portability.!!Codes!with!fewer!key!kernels!to!optimize!may!well!be!better!off!following!the!strategy!of!replicating!kernels!in!architecture8specific!programming!models.!!This!allows!for!easier!hardware8specific!tailoring!of!individual!kernels!to!achieve!maximal!performance.!!![1]!H.C.!Edwards,!C.R.!Trott,!D.!Sunderland,!Kokkos:&Enabling&manycore&performance&portability&through&polymorphic&memory&access&patterns,!JPDC!74!(12)!(2014)!320283216.![2]!M.A.!Heroux,!R.A.!Bartlett,!V.E.!Howle,!R.J.!Hoekstra.!J.J.!Hu,!T.G.!Kolda,!R.B.!Lehoucq,!K,R.!Long,!R.P.!Pawlowski,!E.T.!Phipps,!!A.G.!Salinger,!H.K.!Thornquist,!R.S.!Tuminaro,!J.M.!Willenbring,!A.Williams,!K.S.!Stanley,!An&overview&of&the&Trilinos&project,!ACM!Trans.!Math.!Softw.!31!(3)!(2005)!3978423.!
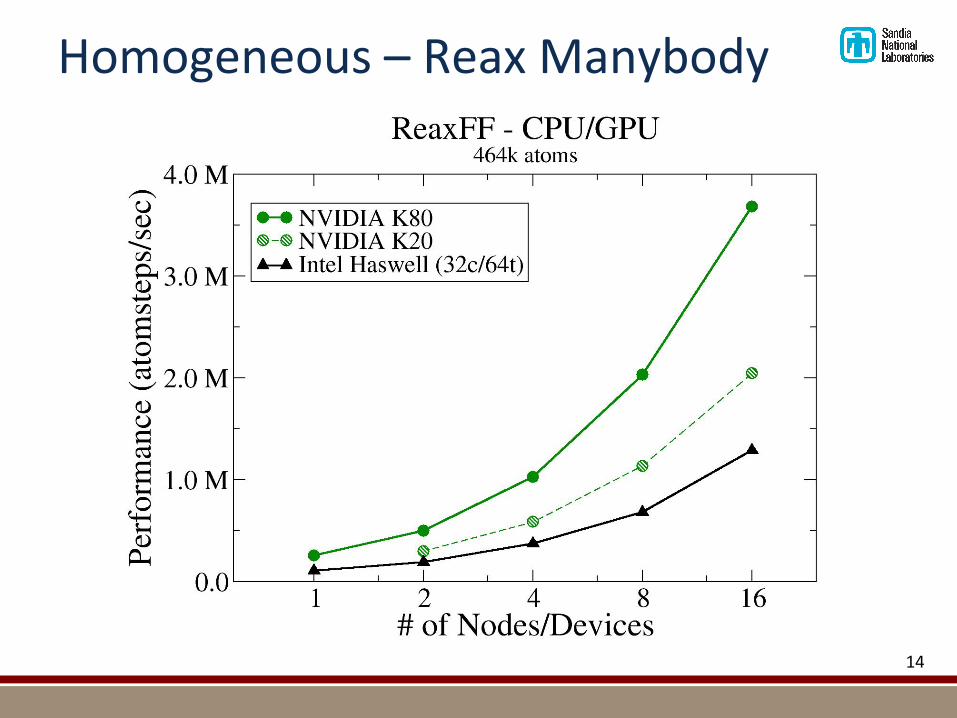
Homogeneous–ReaxManybody
14

ReverseOffload–UsingAsynchronousDeepCopy
§ deep_copy(Execu@onSpace(),src,dst)§ GuaranteedsynchronouswithrespecttoExecu@onSpace§ Reality:requiresDMAengine,worksbetweenCudaHostPinnedSpace
andCudaSpace
15
// Launch short range force compute on GPU parallel_for(RangePolicy<Cuda>(0,N), PairFunctor); // Asynchronously update data needed by kspace calculation deep_copy(OpenMP(), x_host, x_device); // Launch Kspace force compute on Host using OpenMP parallel_for(RangePolicy<OpenMP>(0,N), KSpaceFunctor); // Asynchronously copy Kspace part of force to GPU deep_copy(OpenMP(), f_kspace, f_host); // Wait for short range force compute to finish Cuda::fence(); // Merge the force contributions parallel_for(RangePolicy<Cuda>(0,N), Merge(f_device,f_kspace));
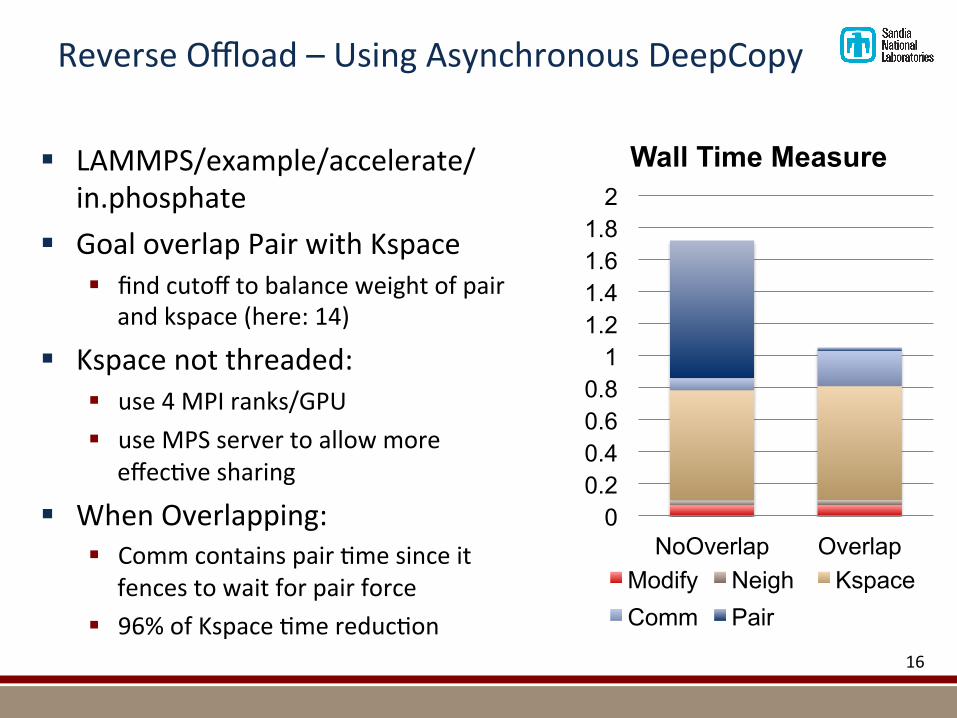
ReverseOffload–UsingAsynchronousDeepCopy
§ LAMMPS/example/accelerate/in.phosphate
§ GoaloverlapPairwithKspace§ findcutofftobalanceweightofpair
andkspace(here:14)
§ Kspacenotthreaded:§ use4MPIranks/GPU§ useMPSservertoallowmore
effec@vesharing
§ WhenOverlapping:§ Commcontainspair@mesinceit
fencestowaitforpairforce§ 96%ofKspace@mereduc@on
16
0 0.2 0.4 0.6 0.8
1 1.2 1.4 1.6 1.8
2
NoOverlap Overlap
Wall Time Measure
Modify Neigh Kspace Comm Pair

KokkosPProfilingInterface§ DynamicRun@meLinkableprofilingtools
§ NotLD_PRELOADbased(hooray!)§ Profilinghooksarealwaysenabled(i.e.alsoinreleasebuilds)
§ Compileonce,runany@me,profileany@me,noconfusionorrecompile!
§ ToolChainingallowed(manyresultsfromonerun)§ Verylowoverheadifnotenabled
§ SimpleCInterfaceforToolConnectors§ Users/Vendorscanwritetheirownprofilingtools§ VTune,NSightandLLNL-Caliper
§ ParallelDispatchcanbenamedtoimprovecontextmapping§ Ini@altools:simplekernel@ming,memoryprofiling,thread
affinitychecker,vectoriza@onconnector(APEX-ECLDRD),vtuneconnector,nsightconnector
§ www.github.com/kokkos/kokkos-tools17

BasicProfiling
§ Providenamesforparallelopera@ons:§ parallel_for(“MyUserProvidedString”,N,KOKKOS_LAMBDA…);
§ Bydefault:typenameoffunctor/lambdaisused
§ Willintroducebarriersazereachparallelopera@on§ ProfilehooksforbothGPUandCPUexecu@on§ SimpleTimer:
§ exportKOKKOS_PROFILE_LIBRARY=${KP_TOOLS}/[email protected]§ ${KP_TOOLS}/kp_readermachinename-PROCESSID.dat§ Collect:Timecall-numbers@me-per-call%of-kokkos-@me%of-total-@me
18
Pair::Compute 0.32084 101 0.00318 40.517 27.254 Neigh::Build 0.24717 17 0.01454 31.214 20.996 N6Kokkos4Impl20ViewDefaultConstructINS_6OpenMPEdLb1EEE 0.04194 113 0.00037 5.297 3.563 N6Kokkos4Impl20ViewDefaultConstructINS_4CudaEiLb1EEE 0.03112 223 0.00014 3.930 2.643 NVE::initial 0.02929 100 0.00029 3.699 2.488 32AtomVecAtomicKokkos_PackCommSelfIN6Kokkos4CudaELi1ELi0EE 0.02215 570 0.00004 2.797 1.881 NVE::final 0.02112 100 0.00021 2.667 1.794
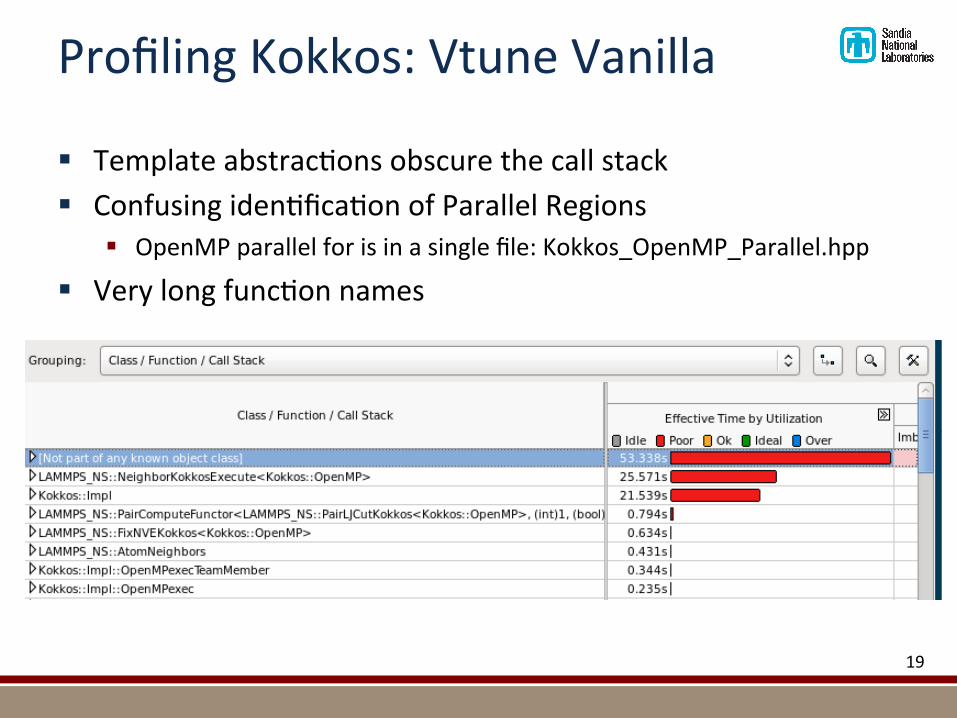
ProfilingKokkos:VtuneVanilla
§ Templateabstrac@onsobscurethecallstack§ Confusingiden@fica@onofParallelRegions
§ OpenMPparallelforisinasinglefile:Kokkos_OpenMP_Parallel.hpp
§ Verylongfunc@onnames
19
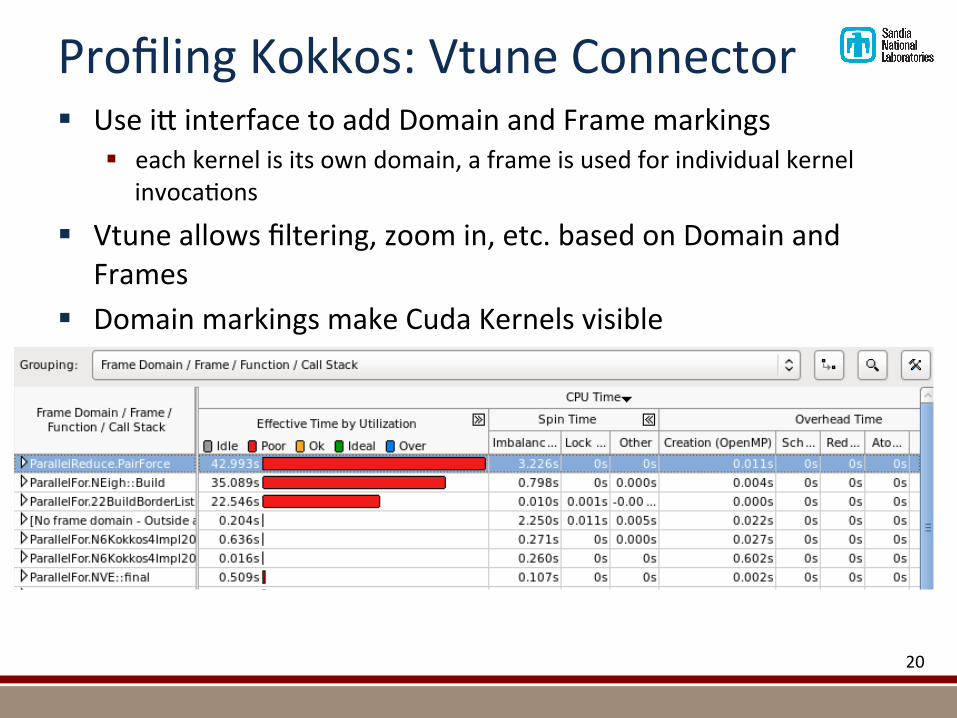
ProfilingKokkos:VtuneConnector§ Usei7interfacetoaddDomainandFramemarkings
§ eachkernelisitsowndomain,aframeisusedforindividualkernelinvoca@ons
§ Vtuneallowsfiltering,zoomin,etc.basedonDomainandFrames
§ DomainmarkingsmakeCudaKernelsvisible
20

ProfilingKokkos:Nsight
21
§ Nsightcri@calforperformanceop@miza@on§ Bandwidthanalysis§ Memoryaccesspa7erns§ Stallreasons
§ Problem:againtemplatebasedabstrac@onlayersmakeawfulfunc@onnames,evenworsethaninvtune

ProfilingKokkos:NsightCuda8
22
§ Cuda8extendsNVTXinterface§ NamedDomainsinaddi@ontonamedRanges§ UsingNVProf-Connectortopassuser-providednamesthrough§ ShowsHostRegions+GPURegions
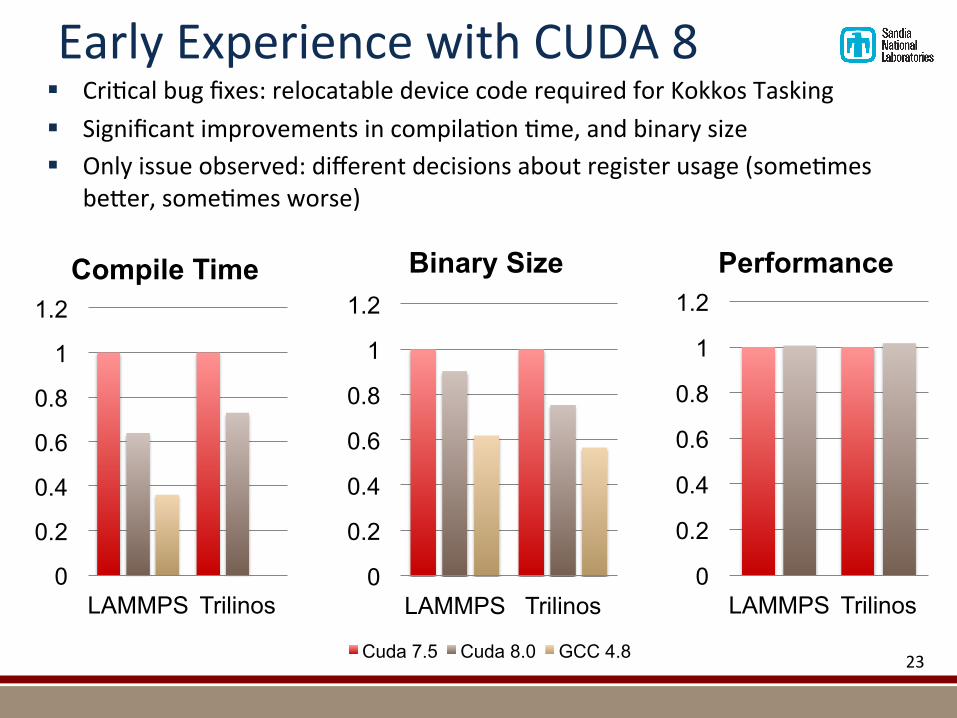
EarlyExperiencewithCUDA8§ Cri@calbugfixes:relocatabledevicecoderequiredforKokkosTasking§ Significantimprovementsincompila@on@me,andbinarysize§ Onlyissueobserved:differentdecisionsaboutregisterusage(some@mes
be7er,some@mesworse)
23
0
0.2
0.4
0.6
0.8
1
1.2
LAMMPS Trilinos
Compile Time
0
0.2
0.4
0.6
0.8
1
1.2
LAMMPS Trilinos
Binary Size
Cuda 7.5 Cuda 8.0 GCC 4.8
0
0.2
0.4
0.6
0.8
1
1.2
LAMMPS Trilinos
Performance

MoreInforma@on
24
www.github.com/kokkos/kokkos: Kokkos Core Repository www.github.com/kokkos/kokkos-tutorials: Kokkos Tutorial Material www.github.com/kokkos/kokkos-tools: Kokkos Profiling Tools www.github.com/trilinos/Trilinos: Trilinos Repository www.github.com/lammps/lammps: LAMMPS Repository http://lammps.sandia.gov: LAMMPS homepage Presentations:
http://cs.sandia.gov: go to Publications, search for “Kokkos”
Code Projects:
At GTC: L6108 - Kokkos, Manycore Performance Portability Made Easy for C++ HPC Applications S6212 - Complex Application Proxy Implementation on the GPU Through Use of Kokkos and Legion S6292 - Gradually Porting an In-Use Sparse Matrix Library to Use CUDA (Wed 14:30 212A) S6145 - Kokkos Hierarchical Task-Data Parallelism for C++ HPC Applications (Thur 10:00 211A) S6257 - Kokkos Implementation of Albany: Towards Performance Portable Finite Element Code (Thur 10:30 211A) Previous Talks at GTC 2014,2015





























