Embed Size (px)
Citation preview

Support Vector Regression(Linear Case:f (x) = x0w+ b)
Given the training set:S = f (xi;yi)j xi 2 Rn; yi 2 R; i = 1; . . .; lg
Find a linear function,f (x) = x0w+ b where(w;b)is determined by solving a minimization
problem that guarantees the smallest overallexperiment error made by f (x) = x0w+ b
Motivated by SVM: jjwjj2should be as small as possible
Some tiny error should be discard

-Insensitive Loss Functionï -insensitive loss function:ï
jyi à f (xi)jï = maxf0; jyi à f (xi)j à ïg
The loss made by the estimation function, fat the data point(xi;yi) is
jøjï = maxf0; jøj à ïg= 0 if jøj6 ïjøj à ï otherwise
ú
If ø2 Rn then jøjï 2 Rn is defined as:
(jøjï)i = jøijï ; i = 1. . .n

x
x
x
x
x
x
x
x
x
"
"
-Insensitive Linear Regression"
f (x) = x0w+ b
yj à f (xj) à "f (xk) à yk à "
Find (w;b)with the smallest overall error

ï- insensitive Support Vector Regression Model
Motivated by SVM: jjwjj2should be as small as possible
Some tiny error should be discarded
min(w;b;ø)2Rn+1+m
21jjwjj22+ Ce0 øj jï
where øj jï 2 Rm; ( øj jï)i = max(0; A iw+ bà yij j à ï )

Reformulated - SVR as a Constrained Minimization Problem
min(w;b;ø;øã)2Rn+1+2m
21w0w+ Ce0(ø+ øã)
yà Awà eb 6 eï + øAw+ ebà y 6 eï + øã
ø;øã > 0
subject to
n+1+2m variables and 2m constrains minimization problem
ï
Enlarge the problem size and computational complexity for solving the problem

SV Regression by Minimizing Quadratic -Insensitive Lossï
We minimize jj(w;b)jj22at the same time Occam’s razor: the simplest is the best
min(w;b;ø)2R n+1+l
21(jjwjj22 + b2) + 2
C jj(jøj")jj22
We have the following (nonsmooth) problem:
where (jøj") i = jyi à (w0xi + b)j"
Have the strong convexity of the problem
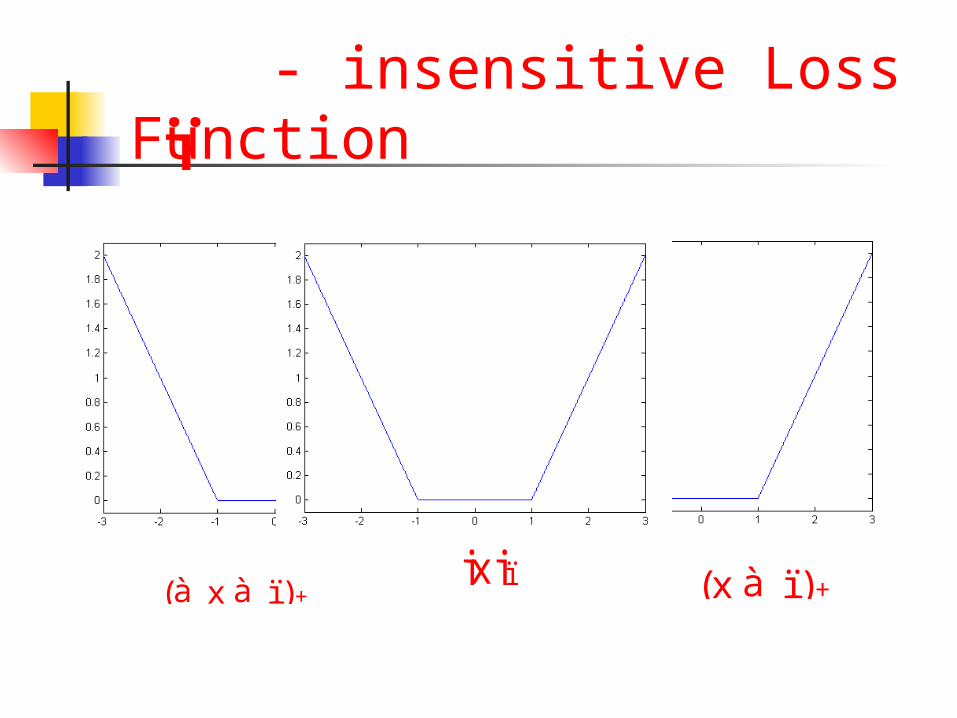
- insensitive Loss Functionï
(à x à ï )+ (x à ï )+xj jï

Quadratic -insensitive Loss Function ï
xj j2ï = ((x à ï )+ + (à x à ï )+)2
= (x à ï )2+ + (à x à ï )2
+
(x à ï )+ á(à x à ï )+ = 0

p2ï -function replace Us
e ïQuadratic -insensitive Function
p(x; ì )
p2ï (x; ì ) = (p(x à ï ; ì ))2 + (p(à x à ï ; ì ))2
which
is defined byp(x; ì ) = x + ì
1 log(1+ expà ì x)
p-function withë = 10; p(x;10); x 2 [à 3;3]

xj j2ï p2ï (x; ì ); ï = 1; ì = 5

-insensitive Smooth Support Vector Regression
ï
min(w;b)2Rn+1
21(w0w+ b2) + 2
C P
i=1
m
p2ï (A iw+ bà yi; ì )2
C P
i=1
m
A iw+ bà yij j2ï
This problem is a strongly convexstrongly convex minimization problem without any constrainsThe object function is twice twice differentiabledifferentiable thus we can use a fast Newton-Armijo methodNewton-Armijo method to solve this problem
min(w;b)2Rn+1
Ðï ;ë(w;b) :=

Nonlinear -SVR ï
w = A0ë; ë 2 R m
Based on duality theorem and KKT–optimality conditions
y ù Aw+ eb
y ù AA0ë + eby ù K (A;A0)ë + ebIn nonlinear
case :

Nonlinear SVR
min(ë;b)2R m+1
21jjëjj22 + C
P
i=1
m
K (A i;A0)ë + bà yij jï
A 2 R mâ n;B 2 R nâ l
K (A;B)
ï à
Letand R mâ n â R nâ l=) R mâ l
K (A i ;A 0) 2 R 1â mand
Nonlinear regression function : f (x) = K (x;A0)ë + b

min(ë;b)2R m+1
21(ë0ë + b2)
+ 2C P
i=1
m
p2ï (K (A i;A0)ë + bà yi; ì )+ 2
C P
i=1
m
K (A i;A0)ë + bà yij j2ï
Nonlinear Smooth Support Vector
-insensitive Regressionï

Training set and testing set (Slice methodSlice method) Gaussian kernelGaussian kernel is used to generate
nonlinear -SVR in all experiments Reduced kernel techniqueReduced kernel technique is utilized when
training dataset is bigger then 1000 Error measure : 2-norm relative error
Numerical Results
ï
yk k2
yà yêk k2 : observations: predicted values
yê
y

f (x) = 0:5ãsinc(ù10x)+nois
e
Noise: mean=0
x 2 [à 1;1], 101 points
û = 0:04Parameter:
÷= 50; ö = 5; " = 0:02
Training time : 0.3 sec.
101 Data Points in R â RNonlinear SSVR with Kernel:expà öjjxià xj jj22

First Artificial Dataset
f (x) = 0:5ãù30x
sinc( ù30x)
+ ú úrandom noise with mean=0,standard deviation 0.04
Training Time : 0.016 sec.Error : 0.059
Training Time : 0.015 sec.Error : 0.068
ï - SSVR LIBSVM

Original Function
Noise : mean=0 ,
û = 0:4
Parameter :
÷= 50; ö = 1; " = 0:5
Training time : 9.61 sec.Mean Absolute Error (MAE) of 49x49 mesh points : 0.1761
Estimated Function
481 Data Points in
R2 â R

Noise : mean=0 ,
û = 0:4
Estimated Function
Original Function
Using Reduced Kernel:
K (A;A0) 2 R28900â 300
Parameter :
Training time : 22.58 sec.MAE of 49x49 mesh points : 0.0513
C = 10000; ö = 1; ï = 0:2

Real Datasets

Linear -SSVRTenfold Numerical Result
ï

Nonlinear -SSVRTenfold Numerical Result
1/2ï

Nonlinear -SSVRTenfold Numerical Result 2/2
ï





























