Embed Size (px)
Citation preview

Support Vector Machines
Mei-Chen Yeh04/20/2010

The Classification Problem
• Label instances, usually represented by feature vectors, into one of the predefined categories.
• Example: Image classification

Starting from the simplest setting
• Two-class• Samples are linearly separable
Class 1
Class 2
Hyperplaneg(x) = wTx + w0 = 0
How many classifiers we may have to separate the data? infinite!
weight vector threshold
> 0< 0

Formulation
• Given training data: (xi, yi), i = 1, 2, …, N,– xi: feature vector– yi: label
• Learn a hyper-plane which separates all data– variables: w and w0
• Testing: decision function f(x) = sign(wTx + w0)– x: test data

Class 1
Class 2
H1
H2H3
Hyperplanes H1, H2, and H3 are candidate classifiers.Which one is preferred? Why?

Choose the one with large margin!
Class 1
Class 2
Class 1
Class 2
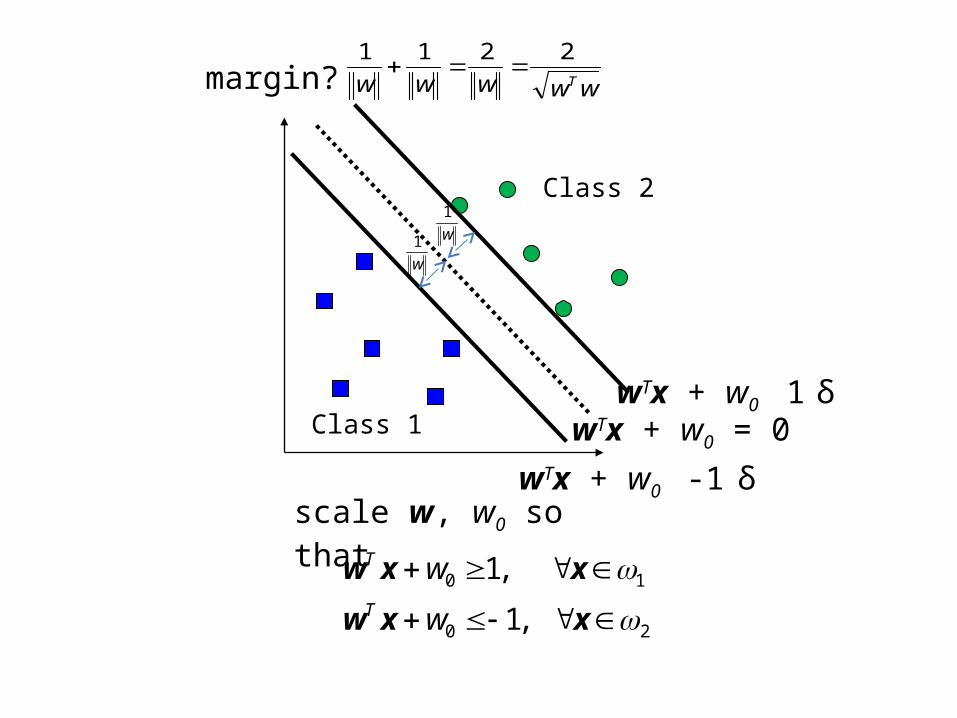
Class 1
Class 2
wTx + w0 = 0
scale w, w0 so that
20
10
,1
,1
xxw
xxw
w
wT
T
margin?
w
1 w
1
wwwww T
2211
wTx + w0 = δ
wTx + w0 = -δ
1
-1

Formulation
• Compute w, w0 so that to:
Niwy
J
Ti
T
,...,2,1 ,1)( subject to
2
1)( minimize
0
ixw
www
Side information:

Formulation
• The problem is equal to the optimization task:
• w can be recovered by• Classification rule:– Assign x to ω1 (ω2) if
0,0 subject to
2
1max
1
1 ,
i
N
ii
N
i
Tj
jiijii
y
yy ji xx
N
iiii y
1
x
0)( 01
i
N
i
Tiii y xx
Lagrange multipliers

Remarks• Just some λ are not zeros.• xi with non-zero λ are called
support vectors.• The hyperplane is
determined only by the support vectors.
• The cost function is in the form of inner products.– does not depend explicitly on
the dimensionality of the input space!
Class 1
Class 2

Non-separable Classes
Class 1
Class 2
Allow training errors!
Previous constraint:yi(wTxi + w0) ≥ 1
Introduce errors:yi(wTxi + w0) ≥ 1- ξi
ξi > 1
0 < ξi ≤ 1
others, ξi = 0

Formulation
• Compute w, w0 so that to:
Ni
Niwy
J
i
iT
i
iT
,...,2,1 ,0
,,...,2,1 ,1)( subject to
2
1 minimize
0
i
N
1i
xw
Cww
penalty parameter

Formulation
• The dual problem:
0
,...,2,1,0 subject to
2
1max
1
1 ,
i
N
ii
i
N
i
Tj
jiijii
y
NiC
yy
ji xx

Non-linear Case
• Linear separable in other spaces?• Idea: map the feature vector to higher
dimensional space
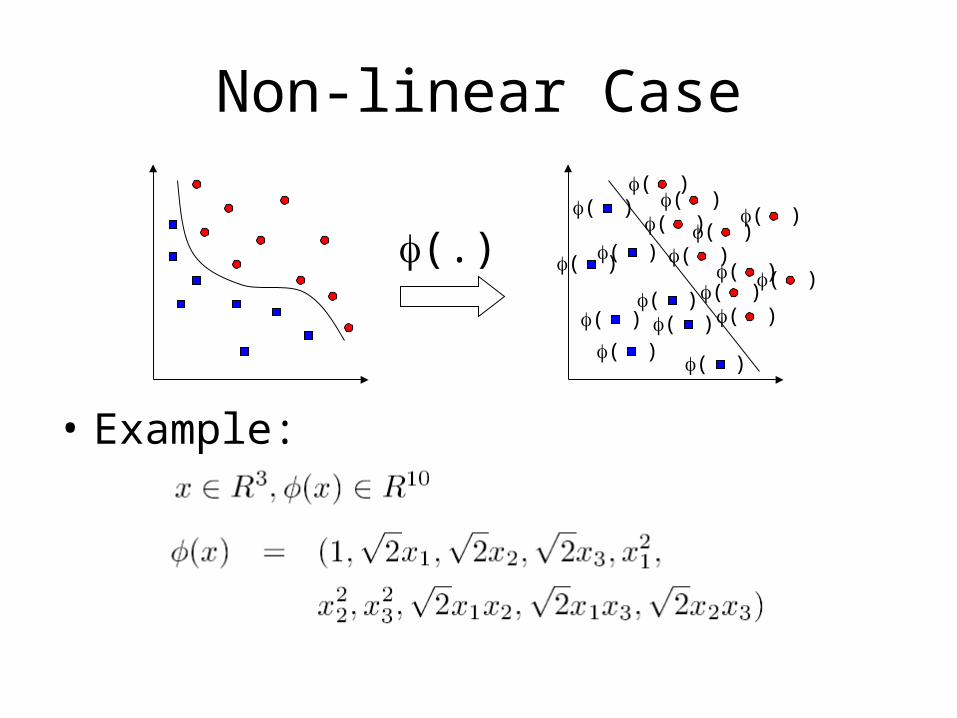
Non-linear Case
• Example:
( )
( )
( )( )( )
( )
( )( )
(.)( )
( )
( )
( )( )
( )
( )
( )( )
( )

Ni
Niwy
J
i
iT
i
iT
,...,2,1 ,0
,,...,2,1 ,1))( subject to
2
1 minimize
0
i
N
1i
xw
Cww
(
• Problems– High computation burden– Hard to get a good estimate

Kernel Trick
• Recall that in the dual problem, w can be recovered by
• g(x) = wTx + w0
=
N
iiii y
1
x
01
wysN
ii
Tiii
xx
All we need here is the inner product of (transformed) feature vectors!

Kernel Trick
• Decision function
• Kernel function– K(xi, xj) = (xi)(xj)
01
0
)()(
)(
wy
wsN
ii
Tiii
T
xx
xw

Example
kernel
The inner product can be directly computed without going through the mapping (.)

Remarks
• In practice, we specify K, thereby specifying (.) indirectly, instead of choosing (.)
• Intuitively, K(x, y) represents the similarity between data x and y
• K(x, y) needs to satisfy the Mercer condition in order for (.) to exist

Examples of Kernel Functions
• Polynomial kernel with degree d
• Radial basis function kernel with width
• Sigmoid with parameter and

Pros and Cons
• Strengths– Training is relatively easy – It scales relatively well to high dimensional data– Tradeoff between classifier complexity and error
can be controlled explicitly• Weaknesses– No practical method for the best selection of the
kernel function– Binary classification alone

Combing SVM binary classifiers for multi-class problem (1)
• M-category classification (ω1, ω2, … , ωM)
• Two popular approaches1. One-against-all (ωi, M-1 others)• M classifiers• Choose the one with the largest outputExample: 5 categories
Winner: ω1

Combing SVM binary classifiers for multi-class problem (2)
2. Pair-wise coupling (ωi, ωj)• M(M-1)/2 classifiers• Aggregate the outputsExample: 5 categories
svm outputs
decision
Voting!1: 42: 13: 34: 05: 2
Winner: ω1

Data normalization
• The features may have different ranges.Example: We use weight (w) and height (h) for classifying male and female college students.– male: avg.(w) = 69.80 kg, avg.(h) = 174.36 cm– female: avg.(w) = 52.86 kg, avg.(h) = 159.77 cm
Different scales!

Data normalization
• “Data pre-processing”• Equalize scales among different features– Zero mean and unit variance– Two cases in practice• (0, 1) if all feature values are positive• (-1, 1) if feature values may be positive or negative

Data normalization
• xik : feature k, sample i,
• Mean and variance
• Normalization
back

Assignment #4
• Develop a SVM classifier using either– OpenCV, or– LIBSVM (http://www.csie.ntu.edu.tw/~cjlin/libsvm/)
• Use “training.txt” to train your classifier, and evaluate the performance “test.txt”
• Write a 1-page report that summarizes how you implement your classifier, and the classification accuracy rate.

Final project announcement
• Please prepare a short (<5 minutes) presentation on what you’re going to develop for the final project.