Embed Size (px)
Citation preview

Support Vector Machines in Data Mining
AFOSR Software & Systems Annual Meeting Syracuse, NY June 3-7, 2002
Olvi L. Mangasarian
Data Mining Institute
University of Wisconsin - Madison

What is a Support Vector Machine?
An optimally defined surface Linear or nonlinear in the input space Linear in a higher dimensional feature space Implicitly defined by a kernel function

What are Support Vector Machines Used For?
Classification Regression & Data Fitting Supervised & Unsupervised Learning

Principal ContributionsLagrangian support vector machine classification
Fast, simple, unconstrained iterative methodReduced support vector machine classification
Accurate nonlinear classifier using random samplingProximal support vector machine classification
Classify by proximity to planes instead of halfspacesMassive incremental classification
Classify by retiring old data & adding new dataKnowledge-based classification
Incorporate expert knowledge into classifierFast Newton method classifier
Finitely terminating fast algorithm for classificationBreast cancer prognosis & chemotherapy
Classify patients on basis of distinct survival curves

Principal Contributions
Proximal support vector machine classification

Support Vector MachinesMaximize the Margin between Bounding Planes
x0w = í + 1
x0w = í à 1
A+
A-
jjwjj22
w

Proximal Support Vector Machines Maximize the Margin between Proximal Planes
x0w = í + 1
x0w = í à 1
A+
A-
jjwjj22
w

Standard Support Vector MachineAlgebra of 2-Category Linearly Separable Case
Given m points in n dimensional space Represented by an m-by-n matrix A Membership of each in class +1 or –1 specified by:A i
An m-by-m diagonal matrix D with +1 & -1 entries
D(Awà eí )=e;
More succinctly:
where e is a vector of ones.
x0w = í æ1: Separate by two bounding planes,
A iw=í + 1; for D i i = + 1;A iw5í à 1; for D i i = à 1:

Standard Support Vector Machine Formulation
Margin is maximized by minimizing21kw;í k2
2
÷> 0 Solve the quadratic program for some :
2÷kyk2
2 + 21kw;í k2
2
D(Awà eí ) + y > ey;w;ímin
s. t.(QP)
,
, denoteswhere D ii = æ1 A+ Aàor membership.

PSVM Formulation
Standard SVM formulation:
w;í (QP)2÷kyk2
2 + 21kw;í k2
2
D(Awà eí ) + y
min
s. t. = e=
This simple, but critical modification, changes the nature of the optimization problem tremendously!!
Solving for in terms of and gives:
minw;í 2
÷keà D(Awà eí )k22 + 2
1kw; í k22
y w í

Advantages of New Formulation
Objective function remains strongly convex.
An explicit exact solution can be written in terms of the problem data.
PSVM classifier is obtained by solving a single system of linear equations in the usually small dimensional input space.
Exact leave-one-out-correctness can be obtained in terms of problem data.

Linear PSVM
We want to solve:
w;ímin
2÷keà D(Awà eí )k2
2 + 21kw; í k2
2
Setting the gradient equal to zero, gives a nonsingular system of linear equations.
Solution of the system gives the desired PSVM classifier.

Linear PSVM Solution
H = [A à e]Here,
íw
h i= (÷
I + H 0H)à 1H 0De
The linear system to solve depends on:
H 0H(n + 1) â (n + 1)which is of size
is usually much smaller than n m

Linear & Nonlinear PSVM MATLAB Code
function [w, gamma] = psvm(A,d,nu)% PSVM: linear and nonlinear classification% INPUT: A, d=diag(D), nu. OUTPUT: w, gamma% [w, gamma] = psvm(A,d,nu); [m,n]=size(A);e=ones(m,1);H=[A -e]; v=(d’*H)’ %v=H’*D*e; r=(speye(n+1)/nu+H’*H)\v % solve (I/nu+H’*H)r=v w=r(1:n);gamma=r(n+1); % getting w,gamma from r

Numerical experimentsOne-Billion Two-Class Dataset
Synthetic dataset consisting of 1 billion points in 10- dimensional input space Generated by NDC (Normally Distributed Clustered) dataset generatorDataset divided into 500 blocks of 2 million points each.Solution obtained in less than 2 hours and 26 minutes About 30% of the time was spent reading data from disk.Testing set Correctness 90.79%

Principal Contributions
Knowledge-based classification

Conventional Data-Based SVM

Knowledge-Based SVM via Polyhedral Knowledge Sets
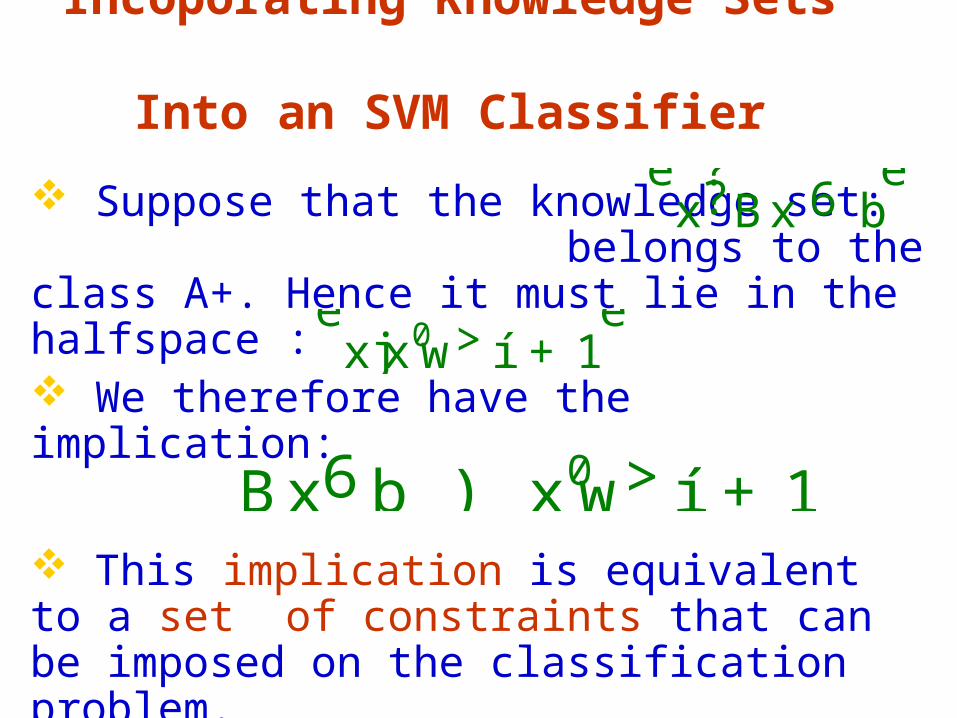
Incoporating Knowledge Sets Into an SVM Classifier
This implication is equivalent to a set of constraints that can be imposed on the classification problem.
Suppose that the knowledge set: belongs to the class A+. Hence it must lie in the halfspace :
èx??Bx 6 b
é
èxjx0w>í + 1
é
Bx6b ) x0w>í + 1
We therefore have the implication:

Numerical TestingThe Promoter Recognition Dataset
Promoter: Short DNA sequence that precedes a gene sequence.
A promoter consists of 57 consecutive DNA nucleotides belonging to {A,G,C,T} .
Important to distinguish between promoters and nonpromoters
This distinction identifies starting locations of genes in long uncharacterized DNA sequences.

The Promoter Recognition DatasetComparative Test Results

Wisconsin Breast Cancer Prognosis Dataset Description of the data
110 instances corresponding to 41 patients whose cancer had recurred and 69 patients whose cancer had not recurred
32 numerical features The domain theory: two simple rules used by doctors:

Wisconsin Breast Cancer Prognosis Dataset Numerical Testing Results
Doctor’s rules applicable to only 32 out of 110 patients.
Only 22 of 32 patients are classified correctly by this rule (20% Correctness).
KSVM linear classifier applicable to all patients with correctness of 66.4%.
Correctness comparable to best available results using conventional SVMs.
KSVM can get classifiers based on knowledge without using any data.

Principal Contributions
Fast Newton method classifier

Fast Newton Algorithm for Classification
Standard quadratic programming (QP) formulation of SVM:

Newton Algorithm
f (z) = 21íí (eà D(Awà ew))+
ww2
+ 21íí w; í
íí 2
zi+1 = zi à @2f (zi)à 1r f (zi)Newton algorithm terminates in a finite number of steps
Termination at global minimum
Error rate decreases linearlyCan generate complex nonlinear classifiers
By using nonlinear kernels: K(x,y)

Nonlinear Spiral Dataset94 Red Dots & 94 White Dots

Principal Contributions
Breast cancer prognosis & chemotherapy

Kaplan-Meier Curves for Overall Patients:With & Without Chemotherapy

Breast Cancer Prognosis & ChemotherapyGood, Intermediate & Poor Patient Clustering

Kaplan-Meier Survival Curvesfor Good, Intermediate & Poor Patients

Kaplan-Meier Survival Curves for Intermediate Group: With & Without Chemotherapy

ConclusionNew methods for classification proposedAll based on rigorous mathematical foundationFast computational algorithms capable of classifying massive datasetsClassifiers based on both abstract prior knowledge as well as conventional datasetsIdentification of breast cancer patients that can benefit from chemotherapy

Future WorkExtend proposed methods to standard optimization problems
Linear & quadratic programming Preleminary results beat state-of-the-art software
Incorporate abstract concepts into optimization problems as constraintsDevelop fast online algorithms for intrusion and fraud detection Classify the effectiveness of new drug cocktails in combating various forms of cancer
Encouraging preliminary results





























