Embed Size (px)
Citation preview

IEEE Communications Magazine • March 201242 0163-6804/12/$25.00 © 2012 IEEE
INTRODUCTION
A significant amount of subscriber data is avail-able in telecommunication networks. Typicalexamples are subscriber profiles: the list of ser-vices to which a subscriber has subscribed, sub-scriber location, and even (sometimes)subscribers’ contact lists. Additional data couldbe captured — one example is subscribers’behavior (e.g., purchase habits). In this article,we are interested in the use of this data for pro-visioning a wide and varied range of novel value-added services.
We assume a next-generation telecommuni-cations network environment (third generation[3G] and beyond) and a business model withend-users, subscribers, multiple network opera-tors, and multiple service providers. As in anybusiness model, a single entity may play severalroles. A network operator may also be a serviceprovider. It is assumed that the service providershave agreements with the operators to access
and use this data. We further assume that thesubscribers have authorized their operators tocollect (and use) pertinent data.
Let us illustrate our vision with two novel ser-vices, “customer finder” and “my favorite dish.”When Alice goes shopping or dining out, shepays all the bills using her cell phone. The trans-actions she makes (e.g., name and brand of thepurchased items) are then transferred to a repos-itory (in her operator network) as part of herconsumption data. Let us assume that this month,she buys salmon, shrimp, oysters, and tuna (at asupermarket) three times, and she orders aseafood dish five times (at a restaurant).
Let us now assume that a new seafood restau-rant is going to open, and for its opening day,the restaurant owner wants to send an advertise-ment with a coupon to all the seafood loverswithin an area of 2 km. A “seafood lover” isdefined as someone who purchases seafood toprepare at home at least three times, or ordersseafood dishes five times or more in a typicalmonth.
The owner may use the novel “customer find-er” service which allows him to get a list of peo-ple, including Alice. The service relies onsubscribers’ consumption and location data.Alice and the restaurant owner may have differ-ent operators, and the location service may beprovided by a third operator, as allowed by thebusiness model.
In the restaurant, Alice may now use the “myfavorite dish” service to access the menu fromher phone and get a pop-up with her favoritedishes thanks to her consumption data stored inthe network. She may also get other customers’comments about the displayed dishes.
A key challenge for building such novel end-user services is how to organize, link, and utilizethe subscriber data. Provisioning novel value-added services such as “customer finder” and“my favorite dish” requires the combination ofsubscriber data from both location servers and
ABSTRACT
Telecommunication networks already store alarge amount of subscriber data (e.g., subscriberprofile, location data, presence information),and even more data could be captured. Althoughthis data is a key asset of telecommunicationnetwork operators, it is seldom fully exploited.This article proposes a novel architecture toenable the provisioning of new value-added ser-vices, based on subscriber data. This architectureuses semantic web to build a knowledge basefrom the subscriber data available in individualtelecommunication networks. KBs are then fed-erated across telecommunication networks toprovide a single and unified interface to serviceproviders for accessing the different KBs. Thearticle also illustrates the use of the proposedarchitecture in a concrete scenario, and presentsa proof-of-concept prototype.
CONVERGENCE OF APPLICATION SERVICES INNEXT GENERATION NETWORKS
Fatna Belqasmi, Concordia University
Chunyan Fu, Tekelec
Zhongwen Zhu, Ericsson Canada
Roch Glitho, Concordia University
Subscriber Data and Semantic Web forProvisioning Novel End-User Services inTelecommunication Networks
BELQASMI LAYOUT_Layout 1 2/22/12 3:01 PM Page 42

IEEE Communications Magazine • March 2012 43
consumption data servers. The location and con-sumption information for different subscribersmay be maintained by different operators.
Furthermore, data semantics should be cap-tured, and a certain amount of intelligence isrequired at each stage of the service provision-ing; for example, deriving a user’s preference,defining the keywords with which to search (e.g.,“seafood lover”), querying the keywords, andcombining the results. This article proposes anovel architecture that enables the provisioningof new services based on subscriber data storedin next-generation telecommunication networks(i.e., 3G and beyond). The architecture usessemantic web technology to build a knowledgebase (KB) using the stored data. We define aKB as a distributed repository that contains andlinks data residing in different data repositories(e.g., presence server, location server).
In our architecture, KBs are federated acrossnetworks to provide service providers with a sin-gle and unified interface to access the differentKBs. The federation is based on a peer-to-peer(P2P [1]) model, and the unified interface isbased on representational state transfer (REST),an architectural style for designing networkingclient-server applications [2]. P2P provides forthe dynamicity and self-organization expectedfrom such a federation, while REST enablesportability and simplicity.
The rest of the article is organized as follows.We give a synopsis of the semantic web. We pre-sent the requirements and related work. Wedescribe the proposed architecture, including theprocedures and the REST interface. We presentan illustrative scenario. We devote a section tothe validation, including a proof of concept pro-totype. The last section concludes the article.
A SYNOPSIS OF THE SEMANTIC WEBThis section introduces the semantic web, andthen discusses the related standards and othercontributions.
UNDERSTANDING SEMANTIC WEBUnlike a human-readable web of documents, asemantic web is a web of machine-comprehensi-ble data [3]. To better understand what a seman-tic web is, we consider the action of ordering aseafood dish online. Assuming that Alice wishesto find a seafood dish without onion, with today’shuman-readable web, Alice first goes to a restau-rant web page and finds a menu. Then she clickson the link of each seafood dish and checks itslisted ingredients. Each dish’s ingredients aredocumented, and Alice has to read and under-stand the meanings of these documents.
This experience can be much enhanced if asemantic web is used, in which a machine under-stands the relationship between a dish and itsingredients. For example, we can assume that arestaurant web server understands that ‘tunasalad’ is a seafood dish that only has as ingredi-ents tuna, spinach, and mayonnaise. The webserver also understands that onion is an ingredi-ent. Alice can simply do a query for “seafooddish with no onion,” and the web answers “tunasalad” right away. In such a case, the web(machine) knows the reasoning behind concepts,
and is also capable of making a logical relationbetween concepts.
There are three key elements to the function-ing of a semantic web: ontology, data modeling,and query languages. Ontology refers to a for-mal representation of a set of concepts within adomain and the relationships between those con-cepts. A tutorial on ontology and its variousapplications is presented in [4]. The ontologyelement is powerful because it can create rela-tionships and accumulate knowledge from theinferences made from those relationships.
Some sort of data modeling is required toimplement a particular ontology. In other words, amachine-understandable means of data descriptionand interchange must be developed. A straightfor-ward method, similar to today’s object-orientedprogramming, is the abstraction of real-worldobjects into classes and introducing hierarchy andrelationships among these classes. For example, wecan define “seafood dish” as a class and “tunasalad” as a subclass of “seafood dish.”
When the data is properly modeled, storedand understood by a machine, a query languageis required to make use of the data.(e.g., to getAlice’s favorite seafood dish).
STANDARDS AND OTHER CONTRIBUTIONSSimilar to any other technology, the semanticweb cannot be landed without standardization.The World Wide Web Consortium (W3C) is themajor organization for specifications of thesemantic web. The work started as far back as1999, but only in the past five years has it gradu-ally come to the stage of being delivered. Refer-ence [5] summarizes the W3C specificationsrelated to the semantic web. The ResourceDescription Framework (RDF) along with RDFschema (RDFS) and Web Ontology Language(OWL) are the major W3C standards for datamodeling. RDF is a general purpose languagefor representing information (resources) on theweb. It provides simple semantics to describeobjects and the relations between them. RDFSserves as the vocabulary to define the propertiesand classes of RDF resources. It uses UniformResource Identifiers (URIs) for the naming ofresources.
OWL adds more vocabulary for describingthe properties and relations between objects,such as disjointness and cardinality. It facilitatesgreater machine interpretability of web contentthan is possible with RDF. OWL 2 is anenhanced version defined by W3C. It providesfor additional details, such as disjoint union andproperty chains. The relationships betweenRDF, OWL, and OWL 2 are backward-compati-ble (i.e., all the ontologies defined by RDF andOWL are still valid for OWL 2).
Two RDF query languages have been definedby W3C:a simpler and earlier version called RDFData Query Language (RDQL) and a newer andmore comprehensive version called SPARQL.RDQL defines basic query types for RDF triplepatterns. SPARQL includes all of the functionsin RDQL and also allows for a query to consistof conjunctions, disjunctions, and optional pat-terns. In addition, it describes an abstract inter-face independent of any concrete realization,implementation, or binding protocols.
Similar to any other
technology, the
semantic web
cannot be
landed without
standardization.
W3C is the major
organization for the
specifications of the
semantic web. The
work started as far
back as 1999, but
only in the past five
years has it gradually
come to the stage of
being delivered.
BELQASMI LAYOUT_Layout 1 2/22/12 3:01 PM Page 43

IEEE Communications Magazine • March 201244
In addition to the standards work, many stud-ies have been undertaken in academic researchareas. Reference [6] comprehensively comparesthe existing ontology languages, tools, andmethodologies.
A number of web communities and profes-sional groups are involved in semantic web workas well, via the building of metadata vocabular-ies. Some examples are Dbpedia, which coordi-nates efforts to extract structured informationfrom Wikipedia and then makes this informationavailable on the web; the Semantically-Inter-linked Online Communities (SIOC) project,organized to create and leverage a layer ofsemantic data in online communities; and theFriend of a Friend (FOAF) project, which cre-ates a web of machine-readable homepages thatdescribe people, the links between them, as wellas the things they do or create.
REQUIREMENTS AND RELATED WORK
REQUIREMENTSThe requirements can be organized into two cat-egories: KB-building-related and intelligent-search-related.
KB-Building-Related Requirements — Thefirst requirement is that the format of the datatransferred from a subscriber device to a KBshould be value-added service-independent. Thisallows the use of the same data for differentvalue-added services. Second, the KB shouldprovide the necessary intelligence to (re)orga-nize and derive new information from thereceived data (e.g., to get “seafood lovers” fromthe subscribers’ profiles). Third, it should allowthe composition of information from differentsources.
Intelligent-Search-Related Requirements —The first requirement is that the KB should pro-vide a search interface that supports both one-time search and subscriptions (with periodicalnotification). Second, the search interface shouldbe based on existing standard interfaces.
Third, network operators from differentdomains should be able to provide their ownsearch functionalities. This will allow the opera-tors to control the data access in their domains.Fourth, the searching functionalities from differ-ent domains should be federated, thereby pro-viding service providers with a single interface toaccess all the data. This will allow the restaurantowner, for instance, to get a list of potential cus-tomers from different domains using a singlerequest.
Fifth, the federation should be self-organiz-ing. The providers of the searching functionalityshould be able to join/leave the federationdynamically, without interrupting the service.The last requirement is that the system shouldbe scalable in terms of the number of networkoperators.
RELATED WORKTo the best of our knowledge, there is no com-prehensive solution (i.e., a solution that allowsKB building and intelligent search) that canmeet all of our requirements. However, there
have been some interesting studies in the area ofmobile payments, mobile interaction, KB cre-ation, and semantic search on P2P networks.
Reference [7] proposes a solution forenabling mobile phones to extract informationfrom physical objects and use it for service provi-sioning. In our scenario, such a solution can beused to allow mobile phones to collect end users’purchase data and send them to the appropriaterepository in the operator network.
KB creation is not a new area, and muchwork has been done on ontology building. Refer-ence [8] is an example that proposes a solutionfor automatic ontology construction based onmachine learning and natural language process-ing.
However, this solution does not provide thederived concepts (e.g., seafood lover) that arerequired in the value-added services we envision.Furthermore, it does not compose informationfrom different sources. In fact, the derived objectis one of the key concepts proposed in this arti-cle, serving as a magnet for the desired dataavailable in the network.
Reference [9] examines several architecturesfor querying distributed RDF repositories, includ-ing P2P architectures, and pinpoints their limita-tions. It then proposes two architectures for theintegration of semantic-based repositories: a hier-archical mediator architecture and a cooperativemediator architecture. The hierarchical architec-ture is less scalable because it is centralized, andthe root mediator constitutes a single point offailure. The cooperative architecture is morescalable, but each cooperative mediator has tomaintain the global schema, which does limit itsoverall scalability. Furthermore, this architecturedoes not provide self-organization.
THE PROPOSED ARCHITECTUREThe overall architecture is presented first, fol-lowed by the general procedures. The single andunified access interface based on REST is pre-sented last.
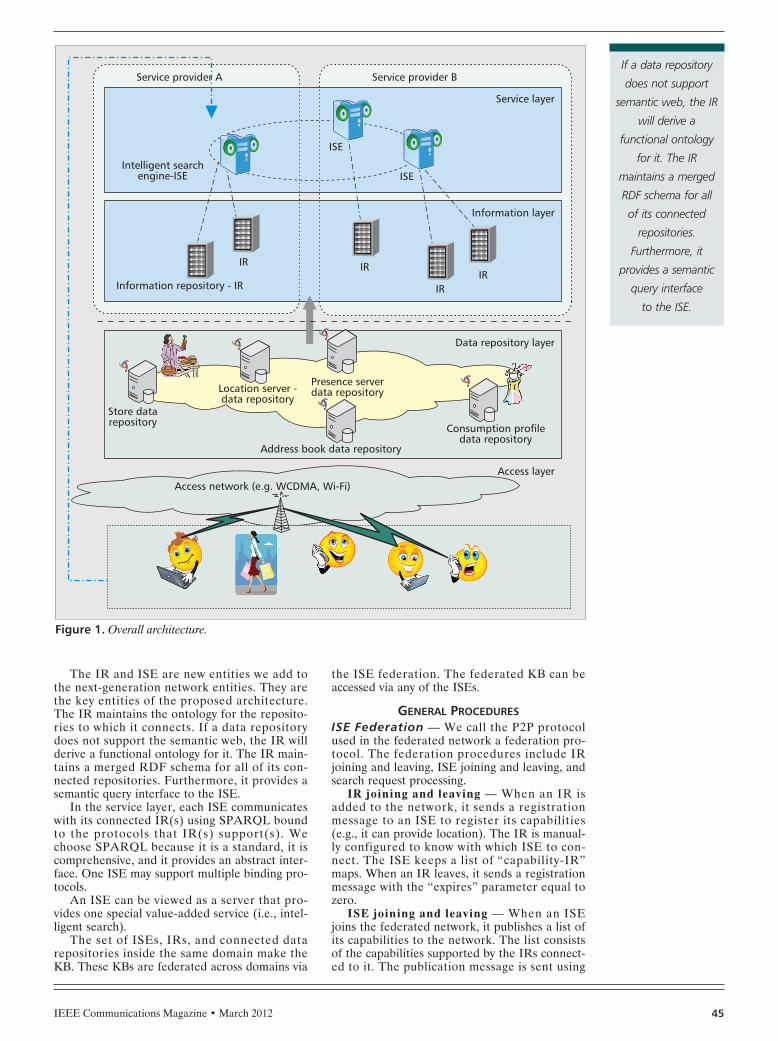
OVERALL ARCHITECTUREFigure 1 depicts the architecture. There are fourlayers. The access layer includes access networks,such as wideband code-division multiple access(WCDMA) and Wi-Fi, that are used in next-generation telecommunication networks’ set-tings. The data repository layer hosts the datarepositories. The data repositories may alreadyexist in the telecommunication network (e.g.,presence server, address book), or they may benew, such as consumption data repositories thatmaintain end users’ consumption profiles.
The information layer hides the details andheterogeneity of the data repositories, by meansof information repositories (IRs). An IR is anentity that endows data repositories with seman-tic intelligence and provides an intelligent inter-face to access these repositories. The servicelayer includes intelligent search engines (ISEs)that provide an interface for applications toquery the KB. Each ISE connects to one ormore IRs in the same domain. The ISEs are fed-erated, so they can provide a unified searchfunctionality.
Cooperative
architecture is more
scalable, but each
cooperative mediator
has to maintain the
global schema,
which does limit its
overall scalability.
Furthermore, this
architecture does
not provide
self-organization.
BELQASMI LAYOUT_Layout 1 2/22/12 3:01 PM Page 44
IEEE Communications Magazine • March 2012 45
The IR and ISE are new entities we add tothe next-generation network entities. They arethe key entities of the proposed architecture.The IR maintains the ontology for the reposito-ries to which it connects. If a data repositorydoes not support the semantic web, the IR willderive a functional ontology for it. The IR main-tains a merged RDF schema for all of its con-nected repositories. Furthermore, it provides asemantic query interface to the ISE.
In the service layer, each ISE communicateswith its connected IR(s) using SPARQL boundto the protocols that IR(s) support(s). Wechoose SPARQL because it is a standard, it iscomprehensive, and it provides an abstract inter-face. One ISE may support multiple binding pro-tocols.
An ISE can be viewed as a server that pro-vides one special value-added service (i.e., intel-ligent search).
The set of ISEs, IRs, and connected datarepositories inside the same domain make theKB. These KBs are federated across domains via
the ISE federation. The federated KB can beaccessed via any of the ISEs.
GENERAL PROCEDURESISE Federation — We call the P2P protocolused in the federated network a federation pro-tocol. The federation procedures include IRjoining and leaving, ISE joining and leaving, andsearch request processing.
IR joining and leaving — When an IR isadded to the network, it sends a registrationmessage to an ISE to register its capabilities(e.g., it can provide location). The IR is manual-ly configured to know with which ISE to con-nect. The ISE keeps a list of “capability-IR”maps. When an IR leaves, it sends a registrationmessage with the “expires” parameter equal tozero.
ISE joining and leaving — When an ISEjoins the federated network, it publishes a list ofits capabilities to the network. The list consistsof the capabilities supported by the IRs connect-ed to it. The publication message is sent using
Figure 1. Overall architecture.
Access layerAccess network (e.g. WCDMA, Wi-Fi)
Store datarepository
Address book data repository
Consumption profiledata repository
Presence serverdata repositoryLocation server -
data repository
Data repository layer
Service layer
Information layer
ISE
IRIR
IRIR
Information repository - IR
ISE
Intelligent searchengine-ISE
Service provider A Service provider BIf a data repository
does not support
semantic web, the IR
will derive a
functional ontology
for it. The IR
maintains a merged
RDF schema for all
of its connected
repositories.
Furthermore, it
provides a semantic
query interface
to the ISE.
BELQASMI LAYOUT_Layout 1 2/22/12 3:01 PM Page 45

IEEE Communications Magazine • March 201246
the federation protocol. When an ISE leaves, itun-publishes all its capabilities from the net-work. In addition, an ISE is able to update itscapabilities using Publish/Un-Publish methodsdefined in Table 1.
Search request processing — The procedurerequires two functionalities: finding or discover-ing the ISE(s) that support(s) a specific capabili-ty; and sending a query to the correspondingISE(s). The federation protocol is used for thefirst functionality. Several existing P2P protocolsand middleware that supports the aforemen-tioned functionalities, such as JXTA [10], can beused as the federation protocol. Table 1describes the federated network messages.
Intelligent Search — When an ISE receives asearch request, it first determines a set of theISE capabilities required to answer the request.Then it checks its local ISE table. If the tabledoes not have any ISE for the required capabili-ties, the ISE sends a “Discover” request, definedin Table 1, to the federated network for thosemissing capabilities.
After the ISE obtains all the capability-ISEmap sets, it creates a query plan by splitting themain query in the received request into subqueriesbased on the capabilities. A query plan is a set ofsubqueries, their relevant data sources, and theexecution sequence to answer a given request.
The subqueries are created using SPARQLand sent to the corresponding ISE(s) using the“Query” message of the federation protocol.Each ISE forwards the received “Query” requestto all of the IRs that provide the inherentrequest capability.
When an IR receives a SPARQL from theISE, it first creates a local query plan using thelocal merged RDF schema. It then sends thesubqueries to the appropriate data repositories,gets their responses, merges them, and repliesback to the ISE. The ISE forwards the responseto the requesting ISE, which combines theresponses using the original query plan and thenresponds to the service requestor.
The data repositories comply with the localend users’ privacy when replying to an IR query(e.g., an end user may choose to share his/herconsumption data with service providers inhis/her domain only). The ISEs apply the domainlevel privacy rules (e.g., domain1 shares informa-tion with domain2 but not with domain3).
ISE REST INTERFACEREST models the datasets to operate on asresources and uses a URI to identify eachresource. The resources are then accessed via aunified and standard interface, which consists ofthe HTTP methods GET, POST, PUT, andDELETE. These methods are used to read, cre-ate, update, and delete a resource, respectively.
For the intelligent search service offered bythe proposed architecture, the dataset to bemanaged is composed of the searching requestsand responses. We therefore define one resourceas the “searching resource,” which we expose viathe following URI: http://www.ise.com/{searchid}. Each request has a unique “searchid”identifier.
To initiate a search request, the requestorsends a POST request to the ISE URI (i.e.,http://www.ise.com) and gets the URI of thenewly created resource. The request content(e.g., keywords) is included in the POST body.
To support subscriptions, we use the persis-tent connections defined in HTTP 1.1 to notifythe requestor whenever the requested informa-tion becomes available or changes. The requestorcan still actively ask for new updates on aresource by sending a GET request to theresource URI. This may be needed if the con-nection between the requestor and the ISE isbroken (e.g., due to a network failure).
A created subscription resource is kept untilthe requestor cancels the search request (bysending a DELETE request to the resourceURI), the subscription times out, or the connec-tion with the requestor is broken beyond a givenserver timeout threshold. For a one-time search,the subscription timeout (specified in the POSTmessage body) is set to zero.
SCENARIOThis section studies a simplified version of thescenario presented in the introduction and showshow it can be realized using the proposed archi-tecture. It first describes how a consumptionprofile is built, and then discusses the buildingprocess for the keyword-search database, fol-lowed by the intelligent searching sequence.
CONSUMPTION PROFILE BUILDINGWe assume that the consumption data (contain-ing the name of the purchased items) is collect-ed through the user’s electronic or magneticTable 1. Messages defined in ISE federation.
RegisterDescription: registers the capabilities of IS.Message flow: IS → ISEParameters: The IS capabilities, expires (=0 for deregister).
Publish
Description: publishes the ISE capabilities to the federated net-work.Message flow: ISE → federated network
–Publish message is sent when an ISE joins and when an ISEcapability changes (such as an IS joins)Parameters: a list of capabilities
Un-Publish
Description: unpublishes some ISE capabilities from the feder-ated network.Message flow: ISE → federated network
–Is sent when ISE leaves and ISE capability changes (e.g., anIS leaves)Parameters: a list of capabilities
Discover
Description: discover the ISE(s) that provides a given capabilityand/or provides support for a given key word.Message flow: ISE → federated networkParameters: The IS capability and/or key word to be supportedby the ISE(s)Response content: ISE(s) address(es)
Query
Description: sends a SPARQL queryMessage flow: ISE → ISEParameters: SPARQL queryResponse content: query result (e.g. a list of people, places andobjects)
BELQASMI LAYOUT_Layout 1 2/22/12 3:01 PM Page 46

IEEE Communications Magazine • March 2012 47
payment device (e.g., cell phone or credit card)and transferred to the consumption profile datarepository.
We have designed an ontology we term thebehavior building ontology to capture and processuser behavior. The IR uses this ontology to rea-son about the content of the consumption repos-itories that are connected to it. Figure 2a showsthe ontology designed for the scenario. For eachperson, the ontology maintains the records foreach purchased “Merchandise” (i.e., “Pur-chaseRecord”). It also defines the “Dish” thathe/she ordered in a restaurant (i.e., “Order-Record”). A “Merchandise” is either of type“Food” or “NonFood.” “Food” has four sub-cat-egories: “Seafood,” “Meat,” “Vegetable” and“Dairy.”
Each “Dish” can be described through itsmajor ingredient, which is of type “Food.” Theontology also defines a “Seafoodlover” as some-one who purchased seafood more than threetimes, or who ordered a seafood dish in a restau-rant more than five times, between date x anddate y (Fig. 2b). “Seafoodlover” is one of thesearchable keywords in the KB.
The behavior building ontology is implement-ed in each IR and is applied to the data collect-ed from the user’s daily activities (e.g., Alice’sshopping and dining behaviors).
KEYWORD DATABASE BUILDINGFigure 3 shows a network setup for the scenario.The owner of the restaurant has a service agree-ment with the ISE provider in domain1 (i.e.,ISE1), which does not own an IR or a datarepository. ISE1 is federated with ISE2 andISE3 from domains 2 and 3.
IR2 is connected to a presence and a locationdata repository; hence it registers to ISE2 withtwo capabilities: presence and location. IR3 reg-isters to ISE3 with address-book and consump-tion-profile capabilities. Each IR maintains amap between the supported capabilities and theassociated keywords; for example, “presence” isassociated with “mood,” “status,” and “location,”the type of information we can get from thelocal presence-data repository. An IR also pro-vides a SPARQL interface to query the map. Inthis example, it is IR3 that maintains the behav-ior-building ontology since it connects to theconsumption profile data repository.
Each ISE maintains a table in which key-words such as “Seafoodlover” are linked to therelated capabilities and addresses of ISEs. At theinitial stage, the table is empty. The mechanismto build and maintain the table is as follows.When ISE1, for instance, receives a requestfrom the owner of the restaurant, it retrieves thelist of keywords it contains (i.e., “location” and“Seafoodlover”). ISE1 checks its table to see if itknows which ISE(s) can provide the relateddata. If it cannot determine which ISE to query,ISE1 sends a “Discover” request (Table 1) to allthe ISEs in the federation with these keywords.When ISE2 and ISE3 receive the request, theysend SPARQL requests to their associated IRsto check if they support any of the keywords.Each IR replies with the keywords it supportsand the associated capability. ISE2 and ISE3then forward the received capability/keyword
sets to ISE1, which updates its table. ISE1 thenuses the updated table to build and execute thequery plan: it sends the subquery for “location”to ISE2 and “Seafoodlover” to ISE3.
INTELLIGENT SEARCHThe search sequence diagram is given in Fig. 4.The first step shows a data model example thatis used to transfer the records from the end-userdevice (e.g., Alice’s cell phone) to the consump-tion profile data repository. The record isdescribed using an XML document that can beembedded in any underlining transfer service(e.g., SIP messaging).
In the figure, the owner of the Italian restau-rant (“DeliItaly”) first sends an HTTP POSTrequest to its service provider ISE1 (step 2),along with the search query. The request body isshown in the figure. From its local table, ISE1finds out that the queries for “location” and“Seafoodlover” should be forwarded to ISE2and ISE3, respectively. ISE1 creates the queryplan based on this information. Using an inter-nal query optimization algorithm, ISE1 decides
Figure 2. An example of a behaviour building ontology.
a)
b)
Merchandise ≡ Food ∪ NonFoodSeafoodDish ≡ Dish ∩ (hasMajorIngredient ∃ Seafood)
Seafoodlover ≡ Person ∩ (SeafoodPurchaseLover ∪ SeafoodOrderLover)SeafoodPurchaseLover ≡ (hasRecord ≥3 (PurchaseRecord ∩ (hasDate ∃ date [>= xxxx-xx-xx, <= yyyy-yy-yy]) ∩ (hasItem ∃ Seafood)))SeafoodOrderLover ≡ (hasRecord ≥5 (OrderRecord ∩ (hasDate ∃ [>= xxxx-xx-xx, <= yyyy-yy-yy]) ∩ (hasItem ∃ SeafoodDish)))
hasDate
NonFood
Seafood VegetableMeat Dairy
hasItembelongTo
hasRecord
hasDate
hasRecord
belongTo
hasItem
orderpurchase
hasMajorIngredient
OrderRecordPurchaseRecord
Dish
Person
Food
Merchandise
BELQASMI LAYOUT_Layout 1 2/22/12 3:01 PM Page 47

IEEE Communications Magazine • March 201248
to send the location query first. As a result, ISE1gets three users, including Alice. ISE1 thensends the second query to ISE3 to ask who,among the three users, are Seafoodlovers. ISE3then responds with Alice. ISE1 forwards thatresponse back to the owner of the restaurant.
VALIDATIONThe scenario in the introduction was implement-ed as a proof of concept. Figure 5 depicts theimplementation architecture. Two ISEs, two IRs,and two data repositories are involved. Each ISEconnects with one IR, and each IR connects withone data repository. The presence server datarepository is a Session Initiation Protocol (SIP)presence server that provides location service.The consumption profile data repository is arelational database that stores the end user’sconsumption profile.
The functional entities are described next,followed by the protocols and bindings used.
FUNCTIONAL ENTITIESThe software architectures for the ISE and IRare shown in Fig. 5. The ISE architectureincludes a query handler, a federation handler,and a set of protocol agents. There is an agentfor each supported protocol. The incomingrequests are received by the REST agent, andthen passed to the query handler. The queryhandler instantiates a new query agent, which
will create the query plan, and sends the sub-queries using appropriate protocol agents. Themessage router is used to find the protocol agentfor each destination. The communication withthe federated network is handled by the federa-tion handler.
The IR is composed of a query processor anda converter. The query processor is responsiblefor processing the ISE queries that are receivedthrough the ISE interface. It creates and exe-cutes the query plans. The converter uses thedata repository interface to communicate withthe repositories. It has two functionalities. It getsand merges the schema from the repositorieswith which it connects. Existing tools can beused for this purpose. For example, D2R [11] isused for deriving RDF schema from relationaldatabases. It also translates requests/responsesbetween the query processor (i.e., SPARQL)and the data repository interface (e.g., OpenDataBase Connectivity-ODBC SQL and SIPSubscribe).
PROTOCOLS AND BINDINGSFederated Network Protocol Bindings —The ISE federation architecture is implement-ed using JXTA as middleware. JXTA is a setof open protocols that allow devices on thenetwork to communicate and collaborate in aP2P manner [10]. The JXTA Peer DiscoveryProtocol (PeerDP) is used as the federationprotocol. PeerDP enables both the publication
Figure 3. ISE table creation.
salmon
Locationdata
repository
Presencedata
repository
Address bookdata
repository
Consumption profiledata repository
Restaurant
Keyword
Location
Seafoodlover
Capability
location, presence
consumption-profile
ISE address
ISE2@domain2
ISE2@domain2
IR2@domain2 IR3@domain3
Alice@domain3
ISE3@domain3
ISE3@domain3
ISE1@domain1
Capability
location
presence
Keyword
Location
Status, Mood,Location
Capability
address-book
consumption-profile
Keyword
Contact
Seafoodlover,Meatlover,Sportfan
Capability
location
presence
Looking forSeafoodlover in
Mont-royal
Directions for future
work include seman-
tic interface provi-
sioning for other
types of repositories
(i.e., other than SQL),
investigation into
charging, security
and privacy capabili-
ties for the searching
service, and the
exploration of vari-
ous methods for
automatic keyword-
base building.
BELQASMI LAYOUT_Layout 1 2/22/12 3:01 PM Page 48

IEEE Communications Magazine • March 2012 49
of the ISEs’ capabilities and the ISE discoverybased on a given capability. The “Publish,”“UnPublish,” and “Discover” messagesdefined in Table 1 are implemented using thesame protocol.
The ISE federation “Query” message (Table1) is implemented using a SIP SUBSCRIBEmessage. We choose SIP because it is simple,supports multiple notifications, and does notplace any limitations on the message body. Wedefined a new event, “query,” that we put in theEvent header field of SUBSCRIBE. The SPAR-QL query is embedded in the message body. Theresponses to the “query” are conveyed by theSIP NOTIFY messages.
Protocols between ISEs and IRs — The pro-tocol between an ISE and an IR depends on theIR. In Fig. 5, the protocols between ISE1 andIR1 and between ISE2 and IR2 are bound toSIP and TCP, respectively.
To register to ISE1, IR1 uses SIP REGIS-TER. The IR1 capability list (i.e., “presence”) issent as an XML document in the body of theSIP message. To register to ISE2, IR2 sends asimilar XML document over a TCP socket, withthe capability indicated as “consumption pro-file.”
ISE1 sends SPARQL queries to IR1 usingSIP SUBSCRIBE messages, with the “event”parameter set to “query.” The SPARQL isembedded in the message body. The queryresponses are embedded in SIP NOTIFY mes-sage bodies. The SPARQL query/response mes-
sages exchanged between ISE2 and IR2 aredirectly conveyed over a TCP socket.
BEHAVIOR-BUILDING ONTOLOGY VALIDATIONThe behavior-building ontology of Fig. 2 was val-idated using Protégé 4.1, a free open sourceontology editor that supports OWL 2.0. The vali-dation reasoner is HermiT1.1, installed as a pro-tégé plug-in. A few individuals with differentpurchase/order records were input to the ontolo-gy, which was then queried to get the list of the“Seafood lovers.”
CONCLUSIONSThis article proposes a novel architecture thatenables the provisioning of new value-added ser-vices based on the subscriber data stored in next-generation telecommunication networks. Thearchitecture uses semantic web technology tobuild a knowledge base (KB) from the subscriberdata available in individual telecommunicationnetworks. It also federates the KBs across net-works to provide service providers with a unifiedinterface with which to access the different KBs.The federation is based on a P2P model, and theunified interface is REST-based.
Directions for future work include semanticinterface provisioning for other types of reposi-tories (i.e., other than SQL), investigation intocharging, security, and privacy capabilities forthe searching service, and the exploration of var-ious methods for automatic keyword-base build-ing.
Figure 4. Example of a search sequence diagram.
<PurchaseRecord> <Merchandise> <Food> <Seafood>Salmon</Seafood> <Vegetable>Broccoli</Vegetable> </Food> </Merchandise> <Date>2010-02-24</Date></PurchaseRecord>
1 : UploadPurchaseRecord
Alice@domain3ISE3@domain3ISE2@domain2ISE1@domain1
2: POST(XML query)
4 : getDestinationISEs()
5 : ISE@domain2(location)ISE@domain3(seafoodLover)
6 : Query(SPARQL:2km from the address:expire12h)7 : SPARQL
8 : Alice, Bob, Charles9 : Alice, Bob, Charles10 : Query)(SPARQL:Seafoodlover:expire0: Alice, Bob, Charles)
11 : SPARQL(Seafoodlover: Alice, Bob, Charles)
13 : Alice@domain312 : Alice@domain3
14 : 200(chunk2: Alice@domain3)
3 : 200(chunk1: http://www.intelse.com/33)
IS2@domain2(for location)
DeliItally
IS3@domain3(for consumption
profile)
SPARQL example query:SELECT ?uriFROM <http://www.semanticweb.org/ontologies/2010/1/OntologyISE_1.owl>WHERE { ?person a Seafoodlover; hasUri ?uri; hasName “Alice”, “Bob”, “Charles”. }
POST query body<query> <constraints> <interest>SeafoodLover</Interest> <location> <geopriv> <location-info> <civicAddress> <country>Canada</country> <A1>Quebec</A1> <A3>Mont-Royal</A3> <A6>Decarie</A6> <HNO>1111</HNO> <PC>H4P1K8</PC> <NAM>DeliItally</NAM> </civicAddress> </location-info> </geopriv> <range>2km</range> <location> </constraints></query>
BELQASMI LAYOUT_Layout 1 2/22/12 3:01 PM Page 49

IEEE Communications Magazine • March 201250
REFERENCES[1] E. K. Lua et al., “A Survey and Comparison of Peer-to-
Peer Overlay Network Schemes,” IEEE Commun. Surveys& Tutorials, vol. 7, no. 2, 2nd qtr. 2005, pp. 72–93.
[2] L. Richardson and S. Ruby, RESTful Web Services, O’Reilly & Associates, May 2007.
[3] J. Cardoso, “The Semantic Web Vision: Where AreWe?,” IEEE Intell. Sys., Sept./Oct. 2007, pp. 22–26.
[4] T. C. Jepsen, “Just What is an Ontology, Anyway?,” IEEEIT Professional, Sep/Oct 2009, pp. 22–27.
[5] D. Ayers, “Delivered Deliverables The State of theSemantic Web, Part I,” IEEE Internet Computing,Jan./Feb. 2009, vol. 13, issue 1, pp. 86–89.
[6] N. Islam et al., “Semantic Web: Choosing the RightMethodologies, Tools and Standards,” IEEE ICIET ’10,pp. 1–5.
[7] G. Broll et al., “Supporting Mobile Service Usagethrough Physical Mobile Interaction,” 5th Annual IEEEInt’l. Conf. Pervasive Computing and Commun., WhitePlains, NY, 2007.
[8] C. Brewster, F. Ciravegna, and Y. Wilks, “User-CentredOntology Learning for Knowledge Management,” Proc.7th Int’l. Conf. Applications of Natural Language toInfo. Sys., Stockholm, LNCS, Springer Verlag, June2002.
[9] R. Vdovjak et al., “RDF and Traditional Query Architec-tures,” Semantic Web and Peer-to-Peer, 2006, pp.41–58.
[10] “JXTA v2.0 Protocols Specification,” https://jxta-spec.dev.java.net/JXTAProtocols.pdf, Mar. 2010.
[11] C. Bizer and A. Schultz, “The Berlin SPARQL Bech-mark,” Int’l. J. Semantic Web and Info. Sys., SpecialIssue on Scalability and Performance of Semantic WebSystems, issue 2, 2009, pp. 1–24.
BIOGRAPHIESFATNA BELQASMI ([email protected]) holdsPh.D. and M.Sc. degrees in electrical and computer engi-neering from Concordia University, Canada. She is aresearch associate at Concordia University. In the past, sheworked as a researcher at Ericsson Canada. She was partof the IST Ambient Network project (a research projectsponsored by the European Commission within the SixthFramework Programme, FP6). She worked as an R&D engi-neer for Maroc Telecom in Morocco. Her research interestsinclude next-generation networks, service engineering, dis-tributed systems, and networking technologies for emerg-ing economies.
CHUNYAN FU ([email protected]) currently works atTekelec. She worked for Ericsson Canada as a researcherfrom 2008 to 2010. She received her M.Sc. and Ph.D.degrees in electrical and computer engineering from Con-cordia University in 2004 and 2008, respectively. Shereceived her Bachelor’s degree in computer engineeringfrom Nanjing University of Posts and Telecommunications.From 1997 to 2001 she worked at China Mobile as a sys-tem integration engineer. Her research interests includesignaling, ad hoc networks, IMS, and services in next-gen-eration networks.
ZHONGWEN ZHU ([email protected]) holds aPh.D. degree in applied science from the Free Univeristy ofBrussels, Belgium, and an M.Sc. degree in mechnical engi-neering from Shanghai Jiao Tong University. After gradua-tion, he worked in the fields of genetic algorithms, neuralnetworks, and artifical intelligence in the National ResearchCouncil of Canada. In 1998 he joined BombardierAerospace as an engineering specialist, and led a team todevelop a three-dimensional numerical simulation model(computaional fluid dynamics) for the aerodynamic designof commerical aircraft. Then in 2001, he was attracted towork in Ericsson Canada to develop the application plat-form and service for a wireless communication network. Heis currently working as a senior system manager in theDepartment of Social Media. He holds and has filed 31patent applications around the world. He is also an Associ-ate Editor for the Journal of Security and CommunicationNetworks (Wiley). His current research interests are cloudcomputing, multimedia applications in IMS and non-IMSnetworks, M2M (Internet of Things), security, license con-trol mechanisms, and interworking between different socialnetwork communities.
ROCH GLITHO [SM] ([email protected]) holds a Ph.D.(Tekn. Dr.) in tele-informatics (Royal Institute of Technolo-gy, Stockholm, Sweden) and three M.Sc. degrees: businesseconomics (University of Grenoble, France), pure mathe-matics (University of Geneva, Switzerland), and computerscience (University of Geneva). He is an associate professorof networking and telecommunications at Concordia Uni-versity, where he holds the Canada Research Chair in End-User Service Engineering for Communications Networks,and leads the Telecommunications Service Engineering Lab-oratory (TSE Lab). He is also an adjunct professor at theDepartment of Computer Technology, University of Milan,Italy, and at the Institut de Mathématiques et SciencesPhysiques (IMSP), University of Abomey-Calavi, Republic ofBenin, West Africa. In the past he worked in industry foralmost a quarter of a century, and has held several seniortechnical positions at LM Ericsson in Sweden and Canada(e.g., expert, principal engineer, senior specialist). He is amember of several editorial boards including IEEE Networkand IEEE Communications Surveys & Tutorials. In the pasthe has served as an IEEE Communications Society Distin-guished Lecturer, Editor-In-Chief of IEEE CommunicationsMagazine, and Editor-In-Chief of IEEE Communications Sur-veys & Tutorials. His research areas include architecturesfor end-users services, distributed systems, non convention-al networking, and networking technologies for emergingeconomies. In these areas, he has authored more than 100peer-reviewed papers, more than 30 of which have beenpublished in refereed journals. He also holds 24 patents inthe aforementioned areas and has several pending applica-tions.
Figure 5. Implementation architecture.
ISs
ISEs
ISE2
ISE1
Information repository
Queryprocessor Converter
Data repositoryinterface
ISE interface
IR1IR2
SIPODBC
Presence server datarepository
Consumption profile datarepository
SPARQL/TCPSPARQL/SIP
ClientIntelligent search engine
RESTagent
SIPagent
ODBCagent
Message router
Federationhandler
Query handler
Query agent
RDF/OWLrepository
BELQASMI LAYOUT_Layout 1 2/22/12 3:01 PM Page 50




























![CONTENT & MEDIA HANDLING IN TODAY'S NETWORKS...Integrated provisioning, filter and route functions Integrated management, service and subscriber-aware functions [Future] MLC NAND DIMMS](https://img.pdfslide.us/doc/110x75/5e961d8d1a9bc545fc4430b3/content-media-handling-in-todays-networks-integrated-provisioning-filter.jpg)