Embed Size (px)
Citation preview

Stuart Wakefield Imperial College London 1
How (and why) HEP uses the Grid.

Stuart Wakefield Imperial College London 2
Overview
• Major challenges• Scope of talk• MC production• Data transfer• Data analysis• Conclusions

Stuart Wakefield Imperial College London 3
HEP in a nutshell•Workflows include:
•Monte Carlo production•Data calibration•Reconstruction of RAW data.•Skimming of RECO data.•Analysis of RAW/RECO/TAG data.
•1000 physicists per experiment•So far main activities are MC production and user analysis

Stuart Wakefield Imperial College London 4
Computing Challenges I• Large amounts of data.
– ~100 million electronics channels (per experiment).
– ~1MB per event.– 40 million events per second.– Record ~100 events per second.– ~billion events per year.– ~15PB per year.
• Trivially paralizable workflows
• Many users, O(1000), performing unstructured analysis
• Each analysis requires non-negligable data access (<1TB).
• Each analysis requires similar amounts of simulated (Monte Carlo) data.
Concorde(15 Km)
Balloon(30 Km)
CD stack with1 year LHC data!(~ 20 Km)
Mt. Blanc(4.8 Km)

Stuart Wakefield Imperial College London 5
Computing Challenges II• HEP requirements:
– Scalable workload management system with 10,000s of jobs, 1000s of users and 100s of sites worldwide.
– Useable by non computing experts.– High levels of data integrity / availability.– PBs of data storage– Automatic/reliable data transfers between 100s sites managed at a
high level.• Of a 120TB data transfer Mr DiBona, open source program manager at Google
said:• "The networks aren't basically big enough and you don't want to ship the data in
this manner, you want to ship it fast.”• http://news.bbc.co.uk/1/hi/technology/6425975.stm• We have no choice

Stuart Wakefield Imperial College London 6
Scope of talk
• I know most about LHC experiments, esp. CMS.• Many Grid projects/organisations/acronyms• Focus on EGEE/Glite == (mainly) Europe.• NGS not included - though plans for interoperability.• Illustrate the different approaches taken by LHC
experiments.• Attempt to give an idea of what works and what
doesn’t.

Stuart Wakefield Imperial College London 7
HEP approaches to grid• As many ways to use distributed computing as there are
experiments.• Differences due to:
– Computational requirements– Available resources (Hardware/Manpower)
• LCG systems used in a mix ‘n’ match fashion by each experiment– Workload management
• Jobs submitted to Resource Broker (RB) which then decides where to send job, monitors it and resubmits if failure.
– Data management• Similar syntax with jobs submitted to copy files between
sites. Includes concepts of transfer channel, fair share and multiple retries.
• File catalogue maps files to locations (can have multiple instances for different domains)

Stuart Wakefield Imperial College London 8
Computing modelATLAS (also ALICE / CMS)
Tier2 Centre ~200kSI2k
Event Builder
Event Filter~7.5MSI2k
T0 ~5MSI2k
UK Regional Centre (RAL)
US Regional Centre
French Regional Centre
Dutch Regional Centre
RHULUCLQMULImperial ~0.25TIPS
~100 Gb/sec
~3 Gb/sec raw
100 - 1000 Mb/s links
•Some data for calibration and monitoring to institutes
•Calibrations flow back
Each of ~30 Tier 2s have ~20 physicists (range) working on one or more channels
Each Tier 2 should have the full AOD, TAG & relevant Physics Group summary data
Tier 2 do bulk of simulation
Physics data cache
~Pb/sec
~ 75MB/s/T1 raw for ATLAS
Tier2 Centre ~200kSI2k
Tier2 Centre ~200kSI2k
622Mb/s links
Tier 0Tier 0
Tier 1Tier 1
DesktopDesktop
Average CPU = ~1-1.5 kSpecInt2k
London Tier ~200kSI2k
Tier 2Tier 2 ~200 TB/year/T2
~2MSI2k/T1 ~2 PB/year/T1
~5 PB/year No simulation
622Mb/s links10 Tier-1s reprocess
house simulation
Group Analysis

Stuart Wakefield Imperial College London 9
MC generation• Last few years conducted extensive analysis of simulated data.• Required massive effort from many people.• Only recently reached stage of large scale, automated
production with grid.• Taken a lot of work and still not perfect• Each experiment has own system which use LCG components
in different ways.• CMS adopts a “traditional” LCG approach
– I.e. jobs to RB to site.
• ATLAS bypasses the RB sends direct to known “good” sites.
• LHCb implement their own system using the RB but managing their own loadbalancing.

Stuart Wakefield Imperial College London 10
MC generation (CMS)• LCG submission uses RB, multiple instances also
can be multi-threaded.• Adopts a “if fail try-try again” approach to failures.• Does not use LCG file catalogues due to
performance/scalability concerns.• Instead use a custom system with an entry per
dataset, O(10-100 GB).
ProdRequest
ProdMgr
ProdAgent
ProdAgent
ProdAgent
Resource
Resource
Resource
User Request
Get Work
Jobs
Jobs
Jobs
ReportProgress
User Interface
Accountant
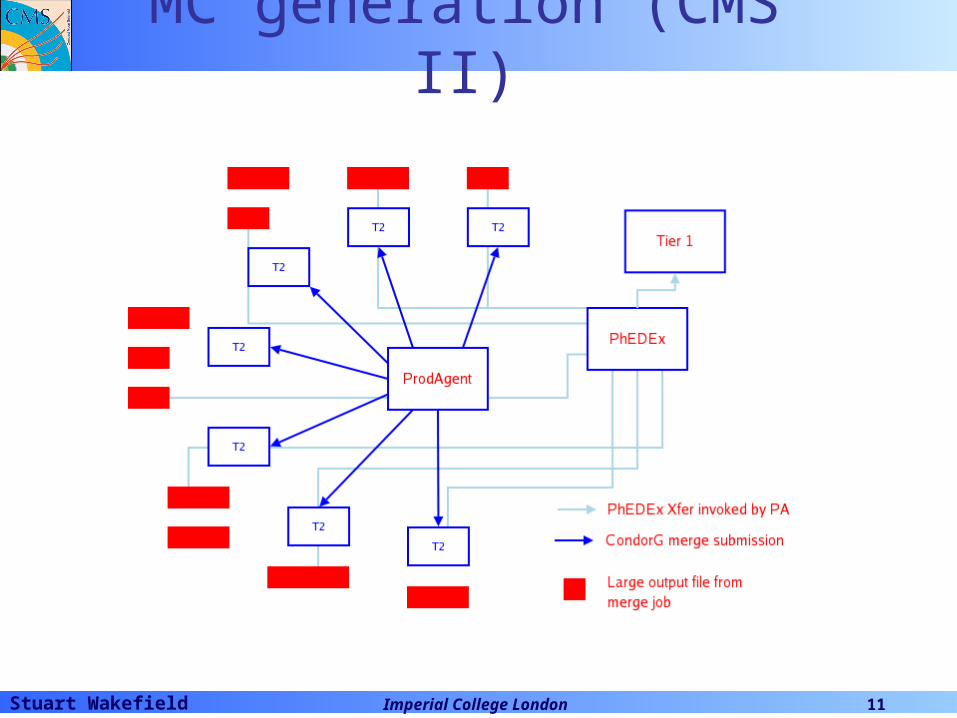
Stuart Wakefield Imperial College London 11
MC generation (CMS II)

Stuart Wakefield Imperial College London 12
MC generation (CMS III)
• Large scale production round started 22 March.

Stuart Wakefield Imperial College London 13
MC generation (LHCb)• Completely custom workload management framework
– “Pilot” jobs
– Late binding
– Pull mechanism
– Dynamic job priorities
– Single point of failure
• Use standard LCG file tools
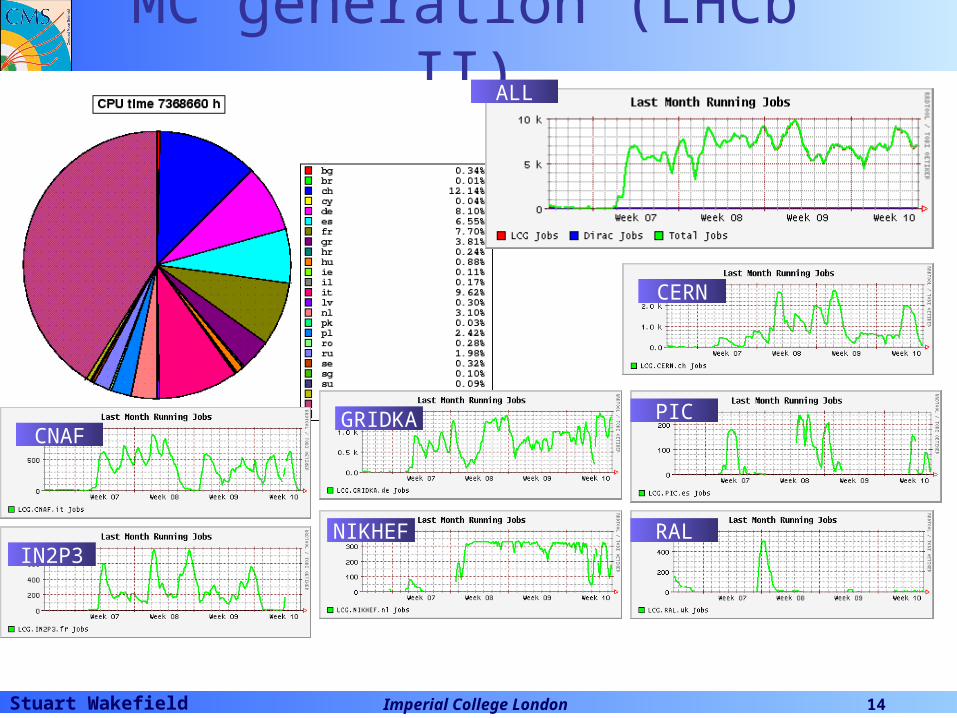
Stuart Wakefield Imperial College London 14
MC generation (LHCb II)
CNAFGRIDKA
IN2P3NIKHEF
PIC
RAL
ALL
CERN

Stuart Wakefield Imperial College London 15
MC generation overview• Couple of different approaches.• LCG can cope with workload requirements but
concerns over reliability, speed and scalability– Multiple RBs with multiple (multi-threaded) submitters– Automatic retry– ATLAS Bypass RB and submit direct to known sites
(x10 faster)– LHCb implement their own late binding
• File handling– Again scalability and performance concerns over
central file catalogues.– New LCG architecture allows multiple catalogues but
some still have concerns• Instead of tracking individual files use entire datasets

Stuart Wakefield Imperial College London 16
Data analysis• Generally less developed than MC production system.• So far less jobs - but need to be ready for experiment start up.• Experiment use similar methodologies to their production systems.• LHCb adopts a late bindng approach with pilot jobs.• CMS submits via resource broker• Generally send jobs to data• Additional requirements from MC production
– Local storage throughput of 1-5MB/s per job– Ease of use– Gentle learning curve– Pretty interface etc.– Sensible defaults etc.
Stuart Wakefield Imperial College London 17
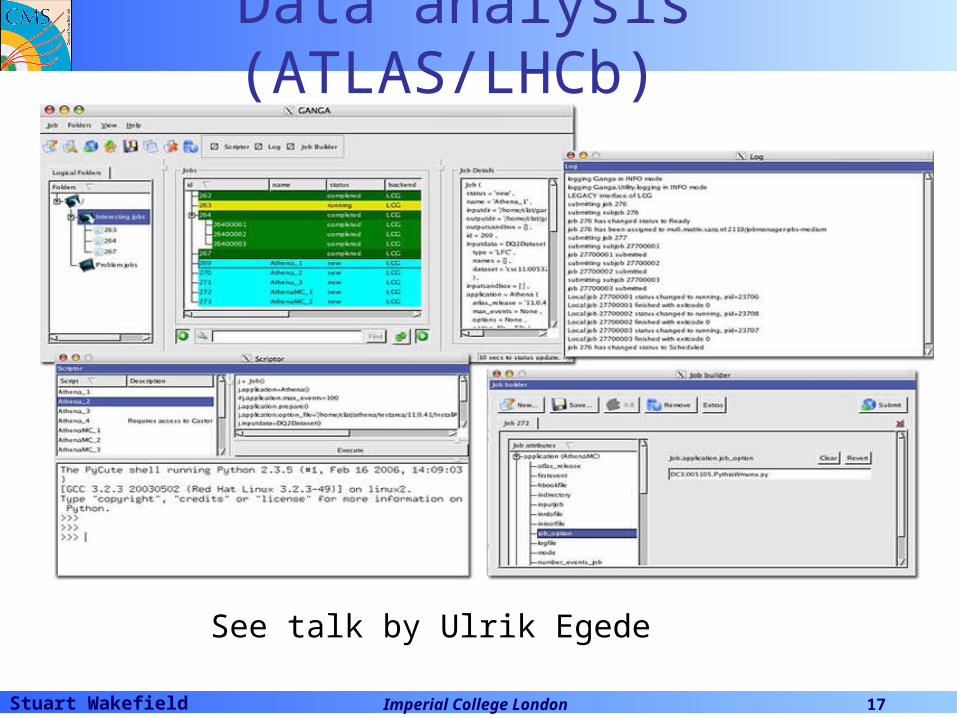
Data analysis (ATLAS/LHCb)
See talk by Ulrik Egede

Stuart Wakefield Imperial College London 18
Data analysis (CMS)• Standard grid model again
using the RB.• Requires large software
(~4GB) install at site.– Site provides nfs area to
all worker nodes– Software installed with
apt,rpm (over nfs)– Trivial to use tar etc…
• User provides application + config
• CRAB creates, submits and tracks jobs.
• Output returned to user or stored to a site
• Plans for server architecture to handle retries
QuickTime™ and aTIFF (LZW) decompressor
are needed to see this picture.

Stuart Wakefield Imperial College London 19
Data analysis (CMS II)
arda-dashboard.cern.ch/cms

Stuart Wakefield Imperial College London 20
Data analysis summary
• More requirements on sites - harder for smaller sites to support.
• Non expert users cause a large user support workload.

Stuart Wakefield Imperial College London 21
Data Transfer
• Require reliable, prioritisable, autonomous large scale file transfers.
• LCG file transfer functionality relatively new and still under development.
• Can submit a job to a file management system that will attempt file transfers for you.
• All(?) experiments have created their own systems to provide high level management and to overcome failures

Stuart Wakefield Imperial College London 22
Data Transfer (CMS)
• PhEdEx– Agents at each site connect to a central DB and
receive work (transfers and deletions).
Web-based management of whole system.• With web interface
– Subscribe data– Delete data– All from any site in system– Authentication with X509 certificates

Stuart Wakefield Imperial College London 23
Data transfer (CMS II)
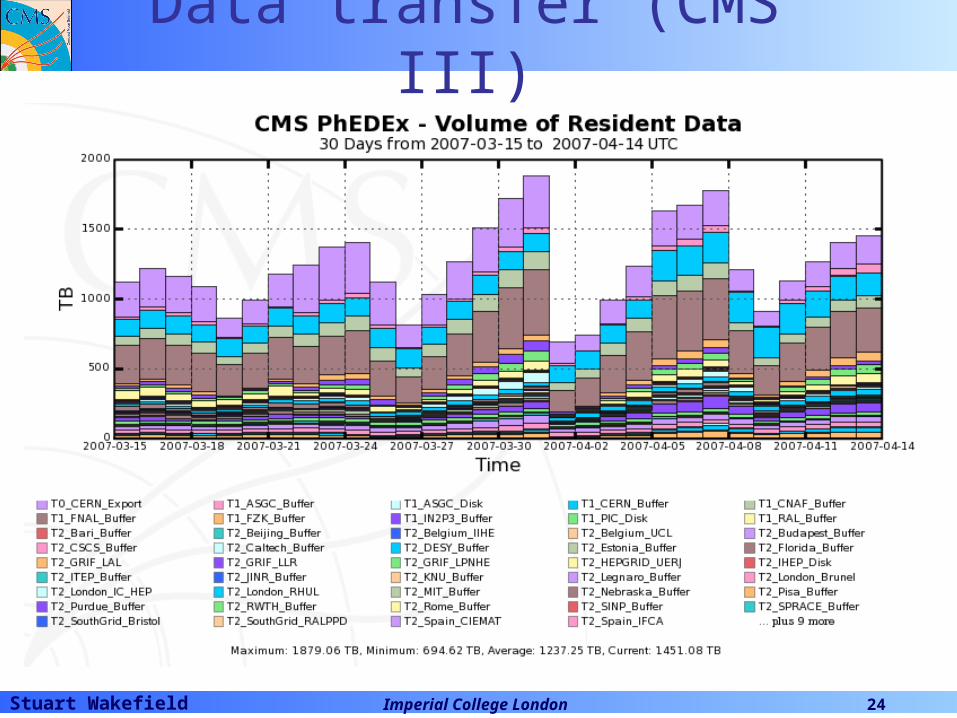
Stuart Wakefield Imperial College London 24
Data transfer (CMS III)

Stuart Wakefield Imperial College London 25
Data transfer overview
• LCG provides tools for low level (file) access and transfer.
• For higher level management (I.e. multi-TB) need to write own system.

Stuart Wakefield Imperial College London 26
Conclusions
• The (LCG) grid is a vast computational resource ready for exploitation.
• Still far from perfect– More failures than local resources– Less performance than local resources– But probably much larger!
• The less your requirements the more successful you will be.

Stuart Wakefield Imperial College London 27
Backup

Stuart Wakefield Imperial College London 28
Computing model IILHCb
QuickTime™ and aTIFF (LZW) decompressor
are needed to see this picture.
•Similar but places lower resource requirements on smaller sites.•Allows uncontrolled user access to vital Tier-1 resources.
•Possibility for conflict

Stuart Wakefield Imperial College London 29
MC generation (ATLAS)• Submission via Resource Broker slow >5-10 secs per
job.• Limit of 10,000 jobs per day per submitter.• LCG submission bypassing the RB, goes direct to
site, load balancing handled by experiment software.

Stuart Wakefield Imperial College London 30
Data Transfer (ATLAS)• Similar approach to CMS.
• Throughput (MB/s)
Total Errors