Embed Size (px)
Citation preview

Structure of Nucleic Acids
Objectives: I. Describe the flow of information in the cell - The Central Dogma of Biochemistry II. Describe the primary structure of Deoxyribonucleic acid (DNA) and Ribonucleic Acid (RNA).
A. Identify the nucleotides that are present in each. 1. Differences and similarities 2. Distinguish between the numbering schemes for the two ring systems.
B. Type and direction of chemical bonds between the nucleotide monomers. III. Describe the secondary structure of DNA.
A. Chargaff’s Rules. B. Hydrogen bonding between adenine & thymine and between guanine and cytosine bases.
1. Can other pairs form that are stabilized by hydrogen bonded? C. Describe the Watson & Crick Model of DNA Secondary Structure.
1. Describe the forces that stabilize the double helical structure. a) Hydrogen bonds between complimentary bases; A-T & G-C. b) Base stacking
2. Describe the major and minor groove. a) Describe the structure and possible functions of these grooves.
3. Identify the direction of the individual DNA strands in the double helical molecule. D. Describe the other possible secondary structures that the DNA double helix can assume
1. Possible functions? E. Define the melting temperature (Tm) of double stranded DNA
IV. Describe the higher order structures of DNA. A. Describe the structure of Chromatin.
1. What are histones? 2. What comprises the Core Histone Particle? 3. What comprises the Nucleosome Core Particle? 4. What is linker DNA?
B. Describe the 30 nm Solenoid Structure. 1. How is it formed?
C. Describe the RNA-Protein Scaffold (Nuclear Scaffold or Nuclear Matrix). D. Describe a Rosette E. Describe a Miniband Unit.
V. Other Nucleic Acids A. Describe the types of RNA
1. hnRNA, mRNA, tRNA, rRNA, sRNA, RNAi B. Can these molecules assume secondary structures?
VI. Be able to write the complimentary nucleotide sequence to a given nucleotide sequence using the accepted conventions.
VII. Nucleases A. Distinguish between Ribonucleases (RNases), Deoxyribonucleases (DNases), Endonucleases,
and Exonucleases. B. Describe a Restriction Endonuclease.
1. What are their normal function within a bacterial cell?
©Kevin R. Siebenlist, 20171

2. What function do Molecular Biologists use these enzymes for? 3. What is a sticky end?
GCAT GCAT GCAT GCAT GCAT GCAT GCAT GCAT GCAT GCAT GCAT GCAT GCAT GCAT
Background
A cell requires three things for growth, maintenance, and reproduction. It requires energy to drive metabolic processes, precursors for energy generation and for the synthesis of complex biopolymers, and information to maintain, coordinate, and control the entire process.
The precursor molecules as well as some of the energy generating processes and biosynthetic processes have been discussed. In this section the third type of information carrying molecule will be examined. Allosteric enzymes and hormones are two types of information molecules that have been examined. In this section the primary cellular information molecule DEOXYRIBONUCLEIC ACID (DNA) and the working copy of this information in the form of RIBONUCLEIC ACID (RNA) will be examined. DNA and RNA are long linear polymers of deoxyribonucleotides or ribonucleotides, respectively. The archive copy of the cellular blueprint is carried on DNA. This information is duplicated (replicated) and passed on to each daughter cell during cell division. When needed to direct some cellular process, the information is copied (transcribed) into a molecule of RNA. RNA is the “working copy” of the cellular information. Some of the RNA molecules are used to direct the synthesis of proteins. The information on RNA is translated into the primary structure of proteins. Proteins, as allosteric enzymes, hormones, receptors, etc., control the moment to moment activity of the cell. The flow of information from DNA to RNA and then to the primary structure of a protein is the CENTRAL DOGMA of BIOCHEMISTRY.
In this section of the course:
1. The structure of nucleic acids, DNA and RNA, will be described. 2. The process by which DNA is duplicated (REPLICATION) before cell division will be examined.
REPLICATION produces two exact copies, two daughter strands, of DNA from the original DNA molecule, from the one parent strand.
3. Methods for DNA repair will be discussed. An accurate functional copy of the information on DNA must be maintained to assure proper cellular function. DNA is the only biomolecule with repair mechanisms.
4. The method for copying the information stored on DNA into a working copy of RNA will be discussed. This process is TRANSCRIPTION.
5. The control of transcription will be touched upon. This is the CONTROL of GENE EXPRESSION. 6. The TRANSLATION of the information on messenger RNA into the primary structure of a protein will
be examined. The control points of translation in the eukaryotic system will also be explored.
Nucleotide Primary Structure
A quick review. Nucleic acids are long linear polymers of nucleotides. When nucleic acids are hydrolyzed, nucleoside monophosphates result. The monomeric unit of nucleic acids are nucleoside monophosphates. Nucleoside triphosphates are the precursors for the synthesis nucleic acids. The energy released by the
©Kevin R. Siebenlist, 20172
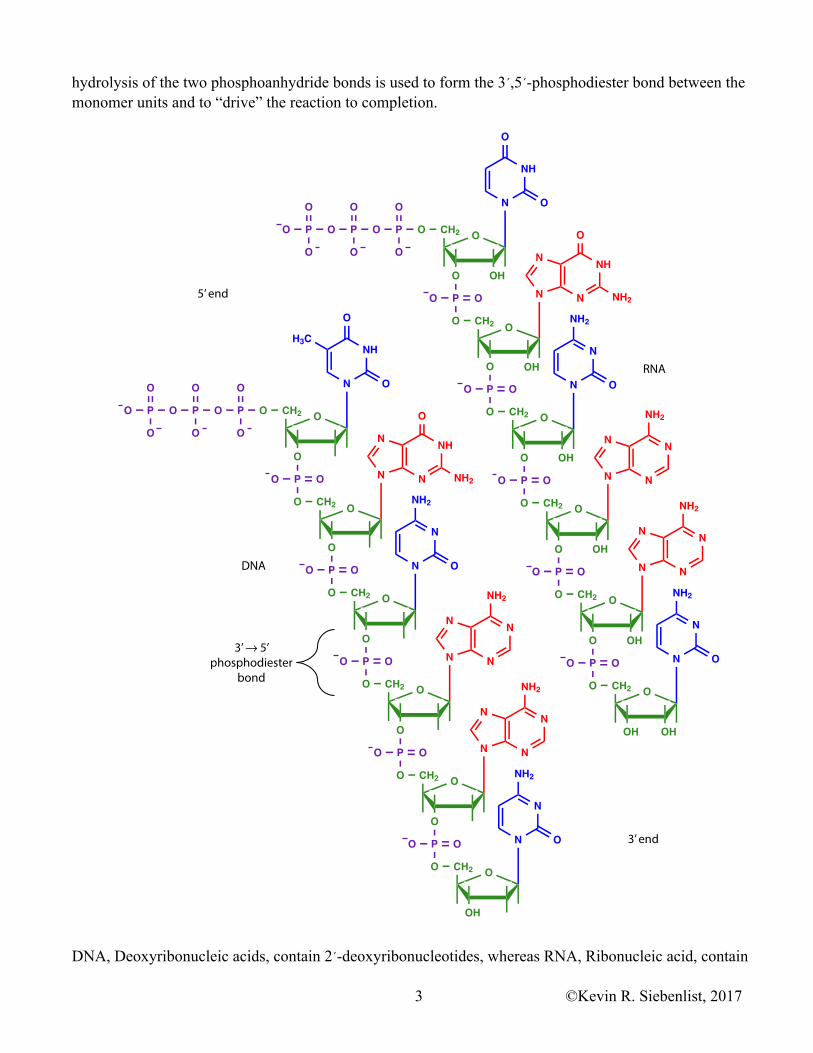
hydrolysis of the two phosphoanhydride bonds is used to form the 3´,5´-phosphodiester bond between the monomer units and to “drive” the reaction to completion.
DNA, Deoxyribonucleic acids, contain 2´-deoxyribonucleotides, whereas RNA, Ribonucleic acid, contain
DNA
RNA
O
NH
O
ON
O
OHO
CH2
PO
O
O
NH
N
N
O
NH2N
O
OH
CH2
O
PO
O
O
N
NH2
ON
O
OHO
CH2
P
O
O
N
NN
N
NH2
O
OHO
CH2
PO
O
O
N
NN
N
NH2
O
OHO
CH2
PO
O
O
N
NH2
ON
O
OHOH
CH2
O
POPOPO
O O O
OOO
O
NH
O
O
H3C
N
O
O
CH2
PO
O
O
NH
N
N
O
NH2N
OCH2
O
PO
O
O
N
NH2
ON
O
O
CH2
P
O
O
N
NN
N
NH2
O
O
CH2
PO
O
O
N
NN
N
NH2
O
O
CH2
PO
O
O
N
NH2
ON
O
OH
CH2
O
POPOPO
O O O
OOO
3’ end
5’ end
3’ 5’phosphodiester
bond
©Kevin R. Siebenlist, 20173

ribonucleotides. The backbone of the linear DNA and RNA polymers is comprised of repeating sugar and phosphate residues held together by 3´,5´ phosphodiester bonds. The heterocyclic bases on DNA are Adenine (A), Guanine (G), Cytosine (C), and Thymidine (T). In RNA thymidine is replaced by Uracil (U). Information of DNA and RNA is carried by the unique linear sequence of bases on the long linear polymer. At one end of each strand there is a 5´ triphosphate group that is not involved in a phosphodiester bond. This is the 5´ end of the molecule. At the other end there is a free, unreacted 3´ hydroxyl group. This is the 3´ end of the molecule
Nucleotide Secondary Structure
DNA was first isolated and purified by Friedrich Miescher in 1868.
In 1944 Oswald Avery, Colin MacLeod, and Maclyn McCarty demonstrated that DNA carried the genetic information for the cell.
The bases, Adenine, Guanine, Cytosine, Thymine, and Uracil, can form hydrogen bonds between themselves and each other. In 1947 J.M. Gulland demonstrated that Adenosine formed two very stable hydrogen bonds with Thymidine or Uracil and that Guanosine formed three very stable hydrogen bonds with Cytidine.
In the early 1950’s Erwin Chargaff observed that DNA isolated from a given species of organism contained equal molar amounts of the bases Adenine and Thymidine. The molar ratio of Cytosine to Guanine was also equal, and the ratio of purines to pyrimidines was 1:1 even when the amount of G and C was vastly different from the amount of A and T.
X-ray diffraction patterns of DNA were obtained in the very early 1950’s by Maurice Wilkins, Rosalind Franklin, and Linus Pauling. In 1953 James D. Watson and Francis H.C. Crick proposed a model for the secondary structure of DNA. Their model was based upon X-ray diffraction patterns obtained by Rosalind Franklin and her group, upon the stable hydrogen bonding between A&T and G&C, and upon the A/T & G/C ratios noted by Chargaff.
According to the Watson & Crick model, DNA as isolated from the cell is a double stranded molecule. The sugar phosphate backbone of the polymer is on the outside of the molecule with the sugars linked to one another by 3´,5´-phosphodiester bonds. In the interior of the molecule are the heterocyclic bases. The bases on one strand interact specifically with the bases on the opposite strand. Adenine hydrogen bonds / base pairs with Thymidine and Guanine hydrogen bonds / base pairs with Cytosine. The two stranded DNA molecule is twisted into a right handed helix. Double stranded DNA is held together / stabilized by several weak intermolecular forces. One of the forces is the hydrogen bonding between the bases. Adenine forming 2 hydrogen bonds with Thymidine and Guanine forming 3 hydrogen bonds with Cytosine. This double helical arrangement allows the strongest possible hydrogen bonds to form between the heterocyclic bases. BASE STACKING is the second stabilizing force. In BASE STACKING the delocalized pi (π) electrons of the aromatic heterocyclic bases overlap and interact with each other. The aromatic, π, electrons are delocalized (free to move) along the entire length of the DNA double helix. Base pairing stabilizes the DNA helix across the strands and stacking maximizes interactions between the bases up and down the DNA strand. There are electrostatic interactions along the backbone of the molecules. The high charge density of
©Kevin R. Siebenlist, 20174

the phosphate groups along the backbone would greatly destabilize the double helix. This charge density is reduced by Mg2+, polyamines, and histones interacting with the phosphates.
When the DNA double helix forms, two grooves are present on the surface of the molecule. These grooves are called the MAJOR GROOVE and MINOR GROOVE. The MAJOR GROOVE is larger / wider than the MINOR GROOVE. In the MINOR GROOVE the glycosidic bond between the base and deoxyribose is exposed, in the MAJOR GROOVE the opposite edge of the base is exposed. Small molecules and/or proteins can interact with the edges of the bases within the grooves. Proteins that are involved in DNA modification, DNA replication, DNA transcription, and gene regulation can “read” the base sequence of the DNA molecule along the major and/or minor grooves, recognize a specific sequence of bases, and bind to the double helix at these specific sites. Subsequent studies on the DNA molecule have proven the Watson & Crick model to be essentially correct and have added many details.
The DNA strands within the double helix have a directionality. As was noted above, at one end of each strand there is a 5´ triphosphate group that is not involved in a phosphodiester bond. This is the 5´ end of the molecule. At the other end there is a free, unreacted 3´ hydroxyl group. This is the 3´ end of the molecule. In the DNA double helix the two strands run in opposite directions, the two strands are ANTIPARALLEL to each other; i.e. the 5´ end of one strand is base paired to the 3´ end of the opposite strand.
Adenine, Thymidine, Guanine, and Cytosine are the major bases present on DNA. However, they are not the only bases present on the molecule. There are a small number of modified bases within the DNA double
©Kevin R. Siebenlist, 20175

helix. The most common modification is METHYLATION and Cytosine is the base most often methylated. Adenine and guanine are also modified by methylation, but to a lesser extent. Modifications do not occur randomly, they occur by the action of specific enzymes. The DNA Methylases recognize specific sequences within the DNA molecule by “reading” them through the major or minor grooves and then transfer a methyl group from SAM to a specific base (C most often, A & G also) in or near the recognition sequence.
Like proteins, the DNA double helix can be DENATURED. High salt concentrations, extremes of pH, urea, and heat are common denaturing agents. When heat is used to denature DNA, a MELTING TEMPERATURE, or Tm, can be determined. This is defined as the temperature (°C) at which one half of the DNA molecule has been denatured or more precisely, the Tm is the temperature at which one half of the hydrogen bonds have been broken / melted. The Tm increases as the G/C content of the DNA increases. More energy is required to disrupt the three hydrogen bonds between G/C base pairs than the two hydrogen bonds that form between A and T. The aromatic bases of DNA absorb UV light and as DNA is denatured the absorption of UV light by the molecule increases.
The model of DNA as described by Watson & Crick’s was a hybrid composed of two common forms of DNA that have been identified and characterized. The most stable and most prevalent form of DNA within the cell is called B-form DNA. This molecule contains 10.4 bases per turn of the helix. With this pitch, possible interactions between the negatively charged phosphates along the backbone are minimized and the interactions between the bases are maximized. Other forms of the DNA double helix are possible and may
©Kevin R. Siebenlist, 20176

occur in the cell. One of the alternate forms is A-form DNA. A-form DNA is also a right handed helix, but it is wider in diameter, its minor groove is almost as wide as the major groove, and it contains 11 bases per turn. This form of DNA can be produced in vitro (in a test tube) by isolating the DNA with organic solvents. In vivo (in the cell) the A form of a double helix has be implicated as a DNA/RNA hybrid formed during transcription. Watson & Crick’s model was a hybrid of A & B form DNA. A third form of DNA is called Z-DNA or Z-form DNA. Z-DNA is a left handed helix with a very narrow diameter, a major groove but no minor groove, and 12 bases per turn. In vitro, Z-DNA forms in regions that are rich in G/C base pairs especially if some of the cytosine bases have been methylated. In vivo, methylated G/C rich regions have been implicated in gene regulation, suggesting that the occurrence of Z-DNA may play a role in gene regulation and expression.
Higher Order Structures of DNA
Many parallels can be drawn between DNA structure and protein structure. Both have primary structures; the unique sequence of bases or the unique sequence of amino acids, respectively. Likewise, both have secondary structures, the double helix of DNA or the α-helix, β-sheet and turns of proteins. DNA, like protein, is folded into more compact higher order structures, tertiary, quaternary, etc. Folding is required otherwise the DNA molecule would not fit within the cell, much less the nucleus of eukaryotic cells. For example, human cells range in diameter from 20 to 100 µm with an average diameter of about 65 µm. The nucleus in this cell has a diameter of perhaps 5 µm and a volume of about 65 µm3. The largest human chromosome contains 2.4 × 108 base pairs and if stretched out linearly it would have an overall length of 8.2 cm. Chromosomes have to be compacted about 10,000 fold to fit within the nucleus.
When DNA is condensed it is called CHROMATIN. DNA condenses into CHROMATIN when it specifically interacts with a group of proteins, the HISTONES. There are five different HISTONES, termed H1, H2A, H2B, H3, and H4. Histones are evolutionarily very old and very highly conserved proteins The histones are greater than 80% identical when the amino acid sequences in the oldest eukaryotic are compared to those in the newest. All five histones are very basic proteins. They have isoelectric points between 9 and 12 because they have a high content of lysine and arginine.
The CORE HISTONE PARTICLE is an octamer composed of two H2A, two H2B, two H3, and two H4 histones. 146 base pairs (bp) of DNA wrap around the outside of this core histone. This length of DNA (146 bp) wraps 1.75 times times around the histone octamer. DNA fits in a grove on the surface of the histone octamer and it is bound to the core histone particle by electrostatic interactions between the positive charges on the arginine and lysine side chains of the histones and the negative charges on the phosphates of the DNA sugar-phosphate backbone. This DNA-Histone complex is called the NUCLEOSOME CORE PARTICLE. The DNA molecule now looks like beads on a string. There are 54 base pairs of DNA between nucleosome particles. This length of DNA is called LINKER DNA. 200 bp of DNA are present on the Nucleosome Core Particle and its associated linker DNA. Histone H1 binds to the linker DNA and to the nucleosome core particle. Histone H1 prevents the core particle from unravelling and it is involved in the formation of the next higher order chromatin structure.
When DNA is wrapped around the core histone particle a torsional stress is applied to the DNA molecule. This torsional stress causes the DNA molecule to super coil. (Examples of supercoils can be produced by over winding a rubber band or by coiling a long extension cord or telephone cord with one end fixed.) The
©Kevin R. Siebenlist, 20177

cell contains two classes of enzymes to relieve this torsional stress. They are the Topoisomerase I (Swivelases) and Topoisomerase II (Gyrases) enzymes. Topoisomerase I hydrolyzes one phosphodiester bond in one strand of the double helix (they “nick” one strand of the double helix), it allows the supercoils to relax, and then it reseals the nick. Topoisomerase II nicks both strands of the double helix (they hydrolyzes phosphodiester bonds on both strands), it allows the supercoils to relax, and then it reseals the nicks. Topoisomerase II requires ATP to reform the phosphodiester bonds.
Packaging DNA into nucleosomes reduces its length by six to seven fold. Higher levels of packaging results in additional condensation. The nucleosomes are coiled into a 30nm SOLENOID STRUCTURE. The solenoid structure forms when adjacent H1 histones interact with each other bringing the nucleosomes together into the helical solenoid structure. Each turn of the solenoid helix contains six nucleosomes.
The 30nm solenoid fibers form large loops of variable length that are attached to a RNA-PROTEIN SCAFFOLD (NUCLEAR SCAFFOLD or NUCLEAR MATRIX). Because the loops are fixed (tightly bound) to the scaffold supercoils accumulate in the DNA and the topoisomerases function to relieve these supercoils, to
©Kevin R. Siebenlist, 20178
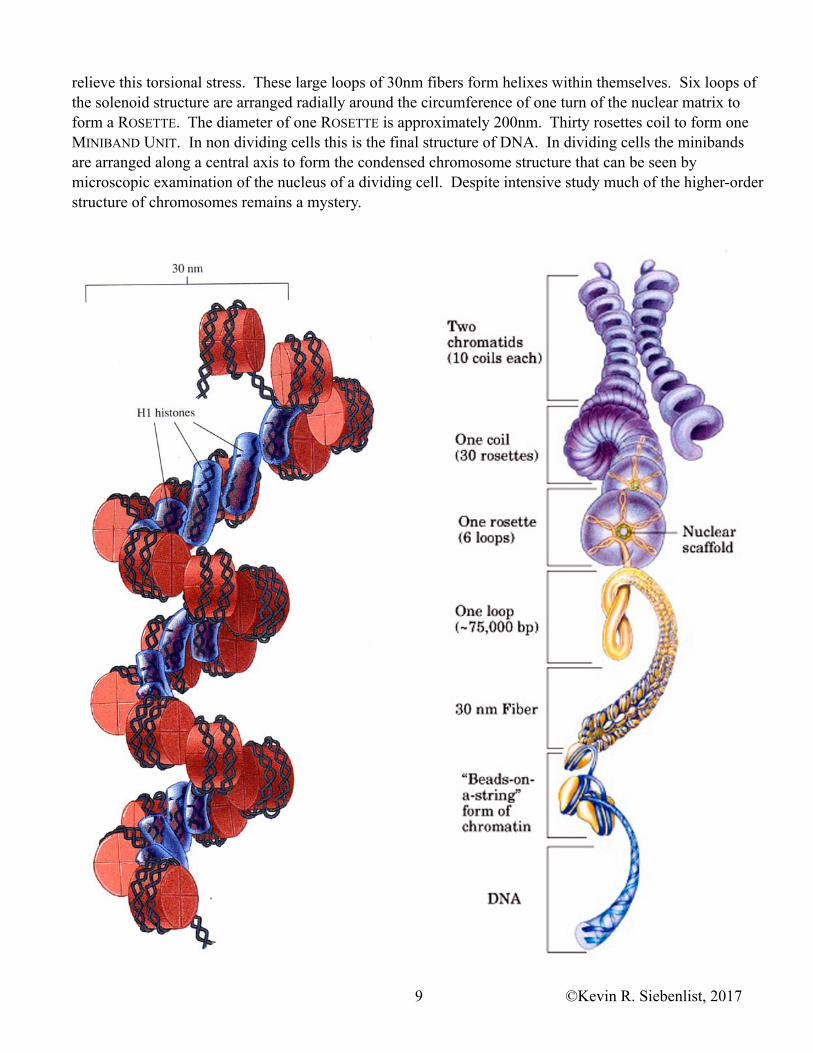
relieve this torsional stress. These large loops of 30nm fibers form helixes within themselves. Six loops of the solenoid structure are arranged radially around the circumference of one turn of the nuclear matrix to form a ROSETTE. The diameter of one ROSETTE is approximately 200nm. Thirty rosettes coil to form one MINIBAND UNIT. In non dividing cells this is the final structure of DNA. In dividing cells the minibands are arranged along a central axis to form the condensed chromosome structure that can be seen by microscopic examination of the nucleus of a dividing cell. Despite intensive study much of the higher-order structure of chromosomes remains a mystery.
©Kevin R. Siebenlist, 20179

Notes on Writing Nucleic Acid Sequences
By convention single letters are used to designate the bases in DNA (A, G, C, T) or RNA (A, G, C, U). When a double stranded DNA sequence is written numbers, 5´ or 3´, are often included to indicate the direction of the individual strands. For example:
5´AAGGATTACCGCTT3´3´TTCCTAATGGCGAA5´
When a single stranded sequence is written, by convention it is always written from the 5´ to the 3´ end. For example:
AATCGATTCG
Its complementary sequence would be written as
CGAATCGATT
Other Nucleic Acids
In addition to DNA the cell contains RIBONUCLEIC ACID, RNA. Six classes of RNA have been well characterized. More RNA molecules are being discovered and the cell is explored with better tools. Whether these new molecules belong to new classes of RNA or to those already know is yet to be determined.
1. HETERONUCLEAR RNA or hnRNA is the RNA as it is initially copied (transcribed) from a gene. Heteronuclear RNA is also called the PRIMARY TRANSCRIPT. hnRNA is subsequently processed / modified to form the other types of RNA
2. RIBOSOMAL RNA or rRNA is the most abundant final form of RNA in the cell. RIBOSOMAL RNA is an integral part of RIBOSOMES, the scaffold upon which protein synthesis takes place.
3. TRANSFER RNA or tRNA is the second most abundant form of RNA. tRNA carries activated amino acids to the ribosome for incorporation into a growing polypeptide chain. tRNA is the genetic code reader.
4. MESSENGER RNA or mRNA carries the information that codes for the primary structure of a protein.
All cells contain these four types of RNA. Eukaryotes contain two additional types of RNA that play unique roles.
5. SMALL RNA or sRNA has cofactor like activity. sRNA plays a role in the processing of hnRNA into mRNA in eukaryotes. There is only a small amount of sRNA present in eukaryotic cells.
6. Last but not least there is INHIBITORY RNA, which is designated as either RNAi or siRNA. The small RNAi molecules bind to mRNA and inhibit its translation into protein; RNAi plays a role in controlling gene expression.
For the most part, RNA is a single stranded molecule. However, it is not necessarily a linear molecule. Complimentary sequences within the strand of RNA can and do base pair. The resulting RNA molecule has a unique secondary structure. One of the common secondary structures of RNA is termed a HAIRPIN or
©Kevin R. Siebenlist, 201710
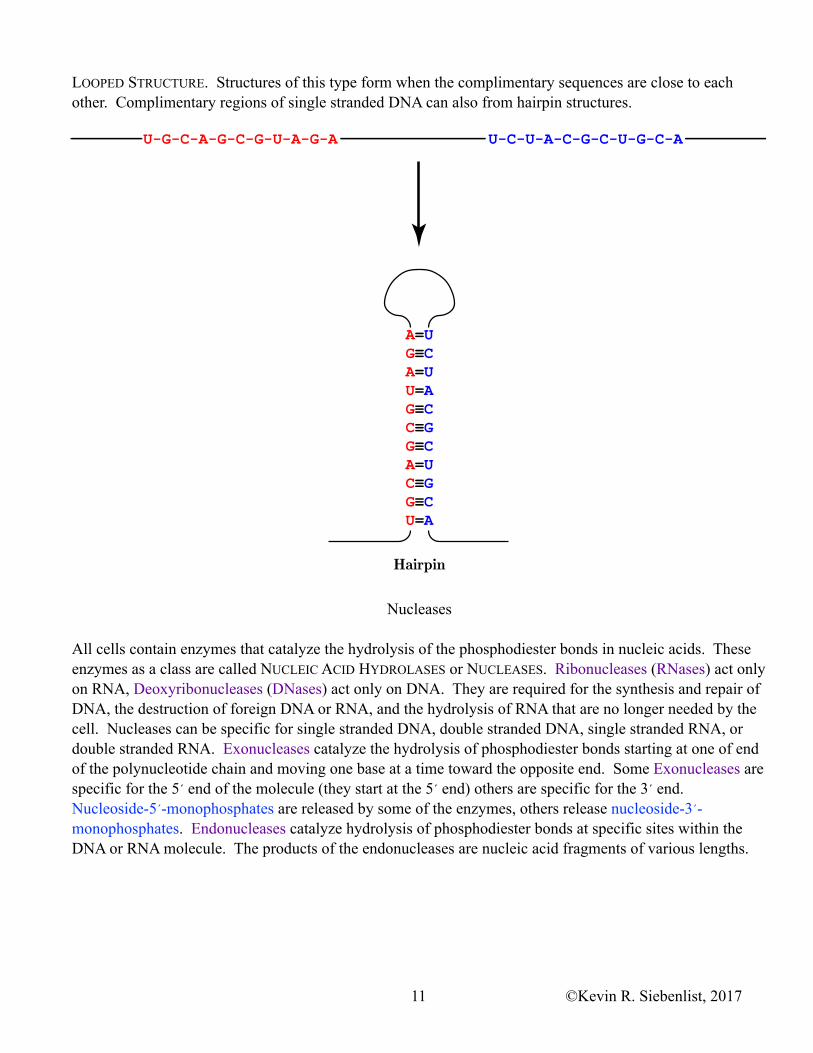
LOOPED STRUCTURE. Structures of this type form when the complimentary sequences are close to each other. Complimentary regions of single stranded DNA can also from hairpin structures.
Nucleases
All cells contain enzymes that catalyze the hydrolysis of the phosphodiester bonds in nucleic acids. These enzymes as a class are called NUCLEIC ACID HYDROLASES or NUCLEASES. Ribonucleases (RNases) act only on RNA, Deoxyribonucleases (DNases) act only on DNA. They are required for the synthesis and repair of DNA, the destruction of foreign DNA or RNA, and the hydrolysis of RNA that are no longer needed by the cell. Nucleases can be specific for single stranded DNA, double stranded DNA, single stranded RNA, or double stranded RNA. Exonucleases catalyze the hydrolysis of phosphodiester bonds starting at one of end of the polynucleotide chain and moving one base at a time toward the opposite end. Some Exonucleases are specific for the 5´ end of the molecule (they start at the 5´ end) others are specific for the 3´ end. Nucleoside-5´-monophosphates are released by some of the enzymes, others release nucleoside-3´-monophosphates. Endonucleases catalyze hydrolysis of phosphodiester bonds at specific sites within the DNA or RNA molecule. The products of the endonucleases are nucleic acid fragments of various lengths.
Hairpin
©Kevin R. Siebenlist, 201711
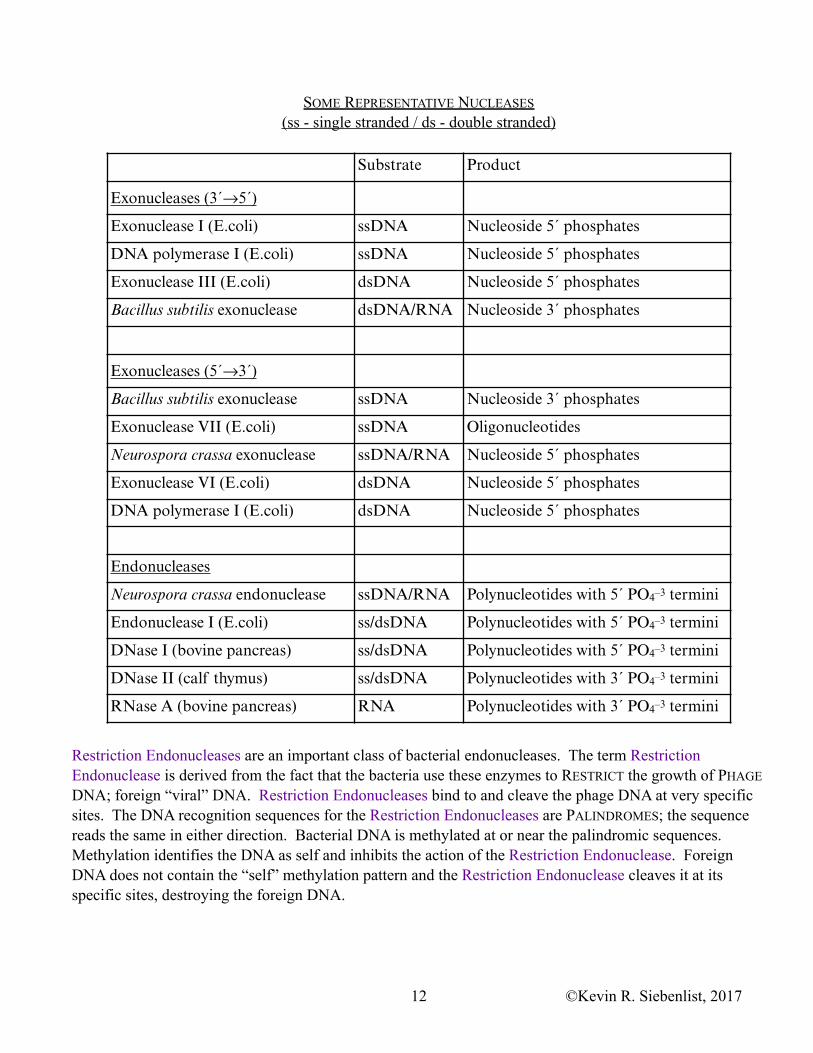
SOME REPRESENTATIVE NUCLEASES (ss - single stranded / ds - double stranded)
Restriction Endonucleases are an important class of bacterial endonucleases. The term Restriction Endonuclease is derived from the fact that the bacteria use these enzymes to RESTRICT the growth of PHAGE DNA; foreign “viral” DNA. Restriction Endonucleases bind to and cleave the phage DNA at very specific sites. The DNA recognition sequences for the Restriction Endonucleases are PALINDROMES; the sequence reads the same in either direction. Bacterial DNA is methylated at or near the palindromic sequences. Methylation identifies the DNA as self and inhibits the action of the Restriction Endonuclease. Foreign DNA does not contain the “self” methylation pattern and the Restriction Endonuclease cleaves it at its specific sites, destroying the foreign DNA.
Substrate Product
Exonucleases (3´→5´)
Exonuclease I (E.coli) ssDNA Nucleoside 5´ phosphates
DNA polymerase I (E.coli) ssDNA Nucleoside 5´ phosphates
Exonuclease III (E.coli) dsDNA Nucleoside 5´ phosphates
Bacillus subtilis exonuclease dsDNA/RNA Nucleoside 3´ phosphates
Exonucleases (5´→3´)
Bacillus subtilis exonuclease ssDNA Nucleoside 3´ phosphates
Exonuclease VII (E.coli) ssDNA Oligonucleotides
Neurospora crassa exonuclease ssDNA/RNA Nucleoside 5´ phosphates
Exonuclease VI (E.coli) dsDNA Nucleoside 5´ phosphates
DNA polymerase I (E.coli) dsDNA Nucleoside 5´ phosphates
Endonucleases
Neurospora crassa endonuclease ssDNA/RNA Polynucleotides with 5´ PO4–3 termini
Endonuclease I (E.coli) ss/dsDNA Polynucleotides with 5´ PO4–3 termini
DNase I (bovine pancreas) ss/dsDNA Polynucleotides with 5´ PO4–3 termini
DNase II (calf thymus) ss/dsDNA Polynucleotides with 3´ PO4–3 termini
RNase A (bovine pancreas) RNA Polynucleotides with 3´ PO4–3 termini
©Kevin R. Siebenlist, 201712

SPECIFICITY'S OF SOME COMMON RESTRICTION NUCLEASES
The arrow (↓) indicates cleavage sites.
Some Restriction Endonucleases catalyze staggered cleavage, producing fragments that end with single-stranded extensions (as illustrated above). These single-stranded extensions are called STICKY ENDS because they are complementary to each other, they can hydrogen bond to each other and they can reform a double stranded molecule. Other Restriction Endonucleases catalyze reactions that produce BLUNT ENDS,
In the bacteria the palindromic sequenceis methylated. Methylation identifies thissequence of DNA as “self” to therestriction endonuclease
The restriction endonuclease recognizes the unmethylatedGAATTC sequence as foreign and cleaves both strands ofthe foreign DNA to produce fragments with staggered ends.
RESTRICTION
Source Enzyme Recognition sequence
Bacillus amyloliquefaciens H BamHI G↓GATCC
Bacillus globigii BglII A↓GATCT
Escherichia coli RY13 EcoRI G↓AATTC
Escherichia coli R245 EcoRII ↓CCTGG
Haemophilus aegyptius HaeIII GG↓CC
Haemophilus influenzae Rd HindII GTPy↓PuAC
Haemophilus influenzae Rd HindIII A↓AGCTT
Haemophilus parainfluenzae HpaII C↓CGG
Nocardia otitidis-caviarum NotI GC↓GGCCGC
Providencia stuartii 164 PstI CTGCA↓G
Serratia marcescens Sb SmaI CCC↓GGG
©Kevin R. Siebenlist, 201713

molecules/fragments without the single-stranded extension. Restriction Endonucleases have proven to be indispensable reagents for molecular biology. Some of the more commonly used Restriction Endonucleases are listed above.
©Kevin R. Siebenlist, 201714
















