Embed Size (px)
Citation preview

NoSQL Scaling Beyond Traditional SQL with
Cassandra
John SandaStefan Negrea

Summary
RHQ Journey
SQL + NoSQL hybrid architecture
Be a NoSQL hero!

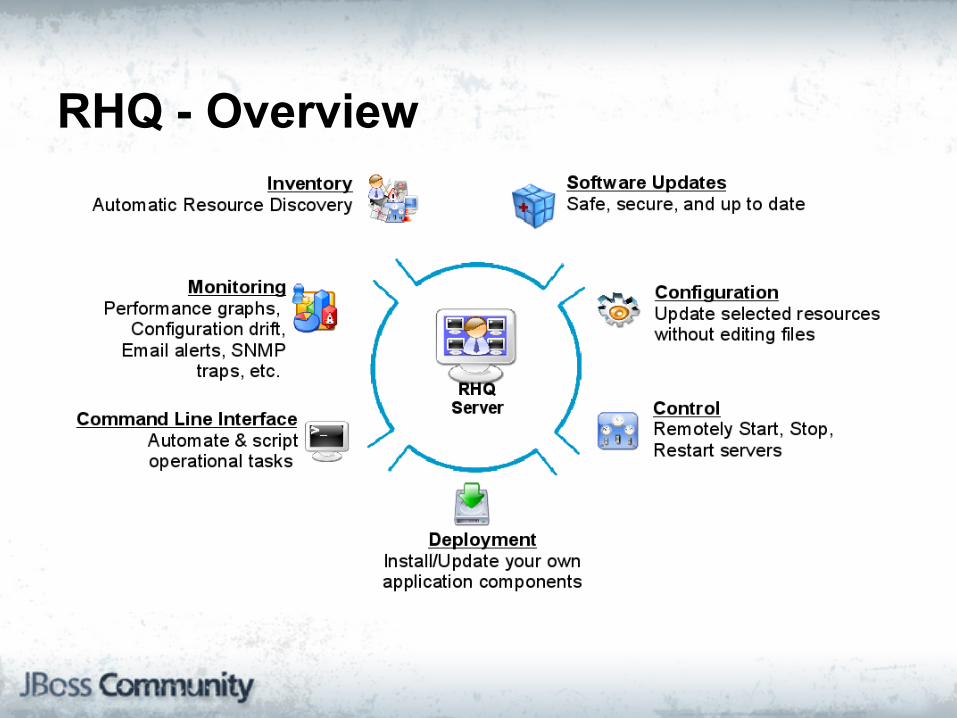
RHQ
"RHQ is an enterprise management solution for JBoss middleware projects, Tomcat, Apache Web Server, and numerous other server-side applications."
Key Points:● Generic management and monitoring platform
● Highly extensible platforms
● Core platform developed in Java
RHQ - Overview
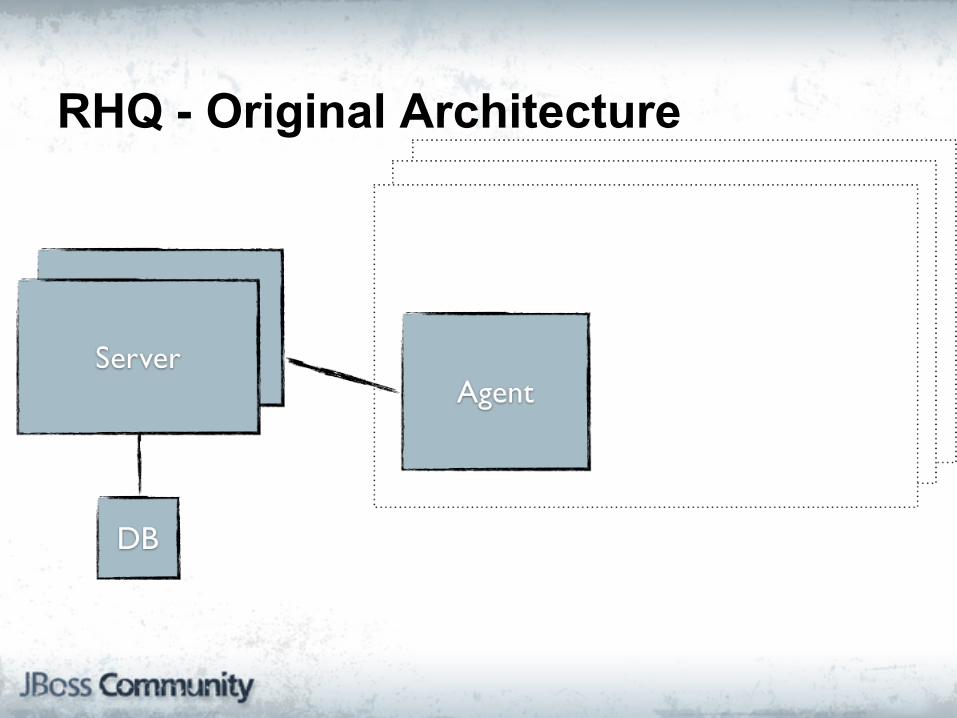
RHQ - Original Architecture
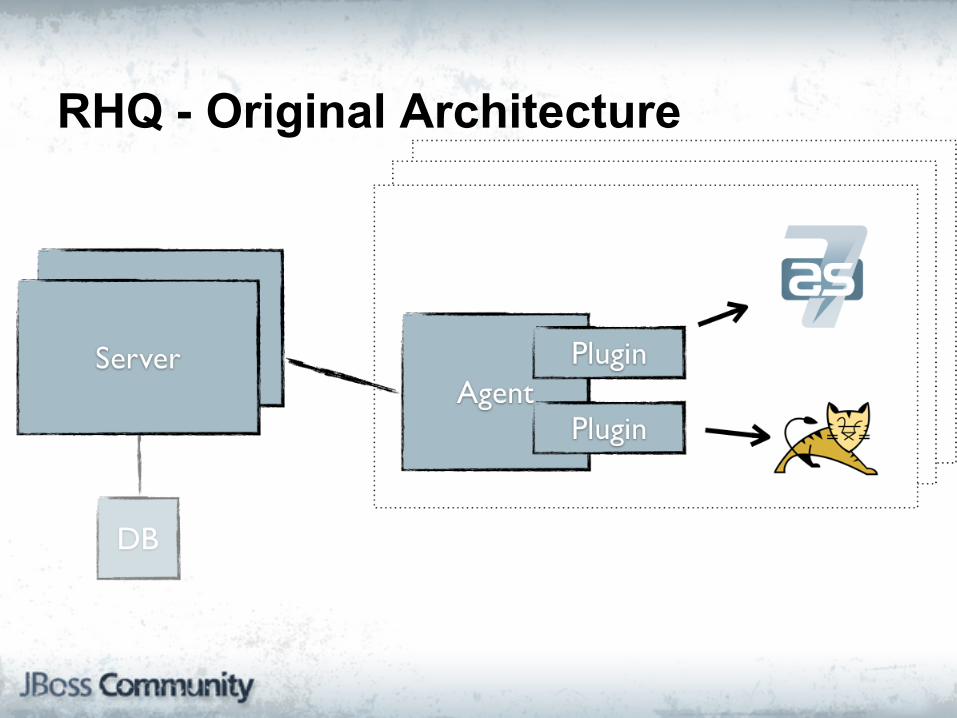
RHQ - Original Architecture
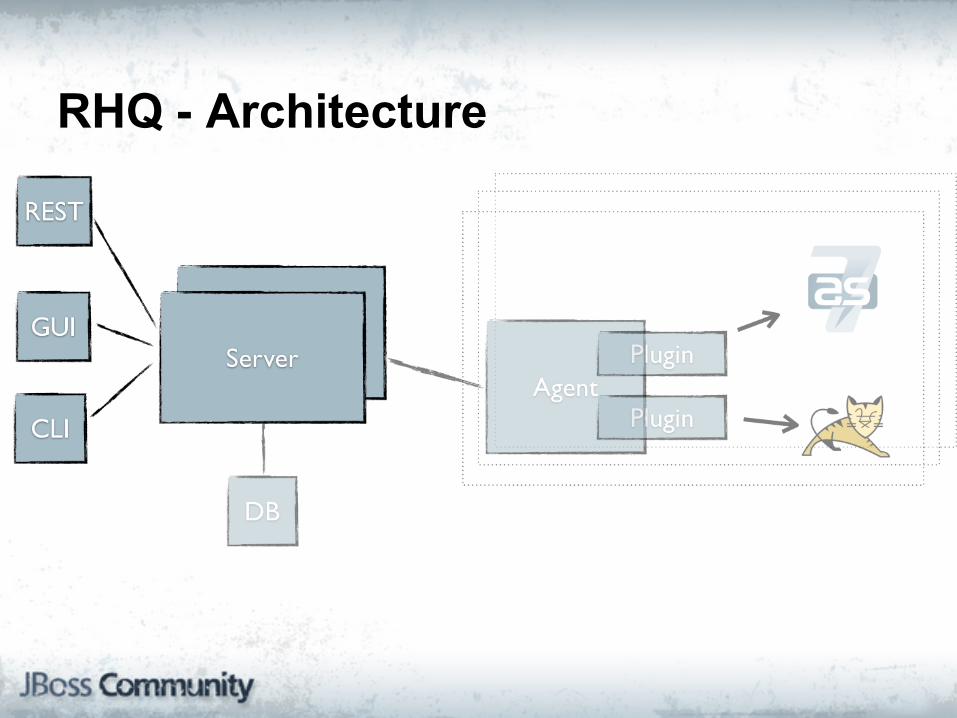
RHQ - Architecture
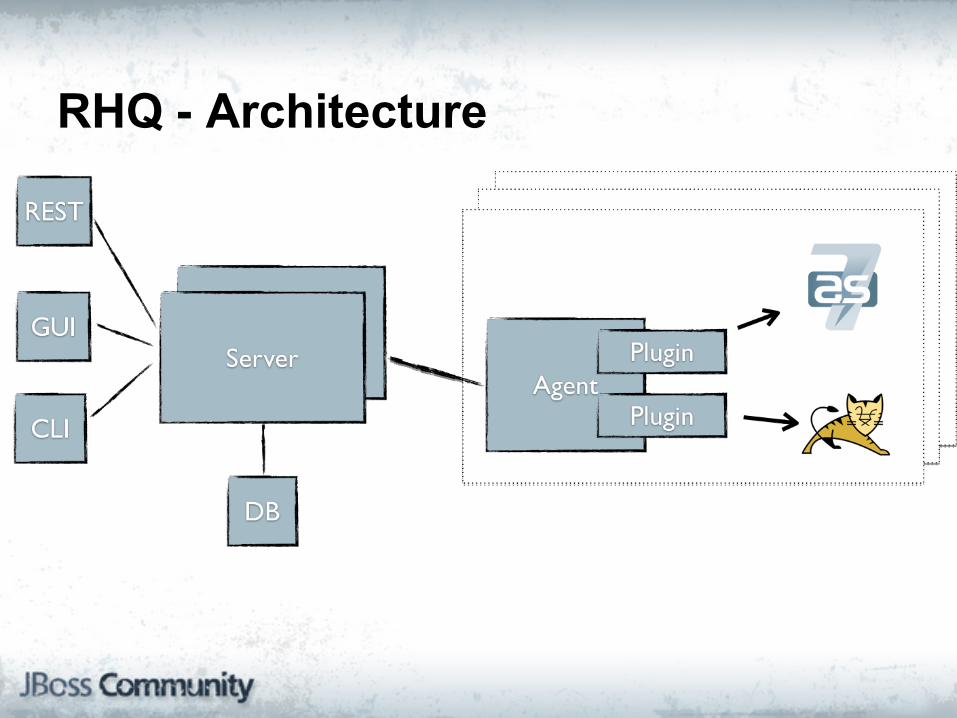
RHQ - Architecture
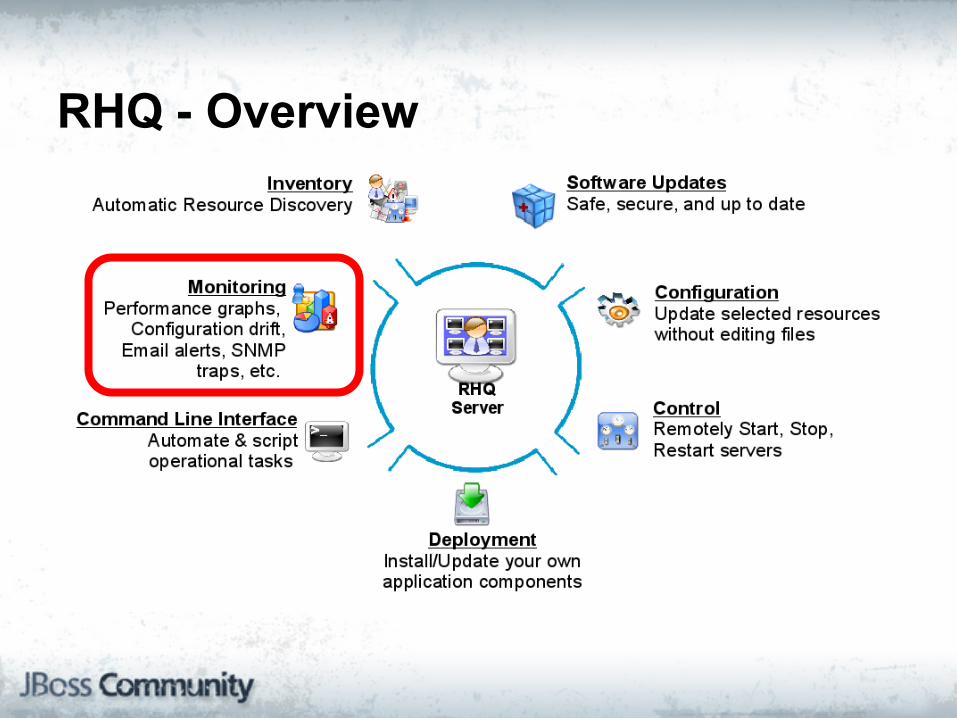
RHQ - Overview

Monitoring - Example
● Monitor server○ Metric = Number of open web sessions
○ Sample Value = 100
○ Metric value is sent to RHQ server every 30 seconds
○ Usage:
■ Calculate a baseline
■ Alert if the any reading is outside of the baseline
and take action (start, stop, restart)

Time Series Data● Raw data (value, timestamp) - (100, 124678)● Aggregate the data to save space and reduce query time
○ every hour aggregate raw data● Different aggregation techniques
○ average, largest value, median● Different retention periods each level
○ 6 hours data could be kept for 2 years● Need to balance fidelity vs space
○ raw data highest fidelity but large amount● Aggregation saves space but it's resource intensive
○ old data can be discarded at a cost
24 Hours Aggregate
6 Hours Aggregate 6 Hours Aggregate
1 Hour Aggregate 1 Hour Aggregate 1 Hour Aggregate 1 Hour Aggregate
Raw Data Raw Data Raw Data Raw Data Raw Data Raw Data Raw Data Raw Data

Metrics - Example
● server - managed resource
● Number of open sessions - schedule_id 123
● Every 30 seconds raw data sent to server○ (schedule_id=123,value=100,timestamp=1000)
● Raw data aggregated hourly, every 6 hours,
and every 24 hours

Metrics - ExampleAll consumers (CLI, REST, UI) ask the same question:
● Query:○ Show me the values between start date & end date for this
schedule id!● Decision:
○ Return raw or aggregate?○ Which aggregate version?
● Response:○ (1,100,200,1,3,5)
"What is the answer to life the universe and everything?" "42!!"

Scalability Problems● Multiple metrics collected per managed resource
● Agents sends metric reports to server every 30 seconds
● Number of writes is a function of collection frequency
and inventory size
● Write intensive
○ Hundreds of agents, thousands of resources,
millions of data points
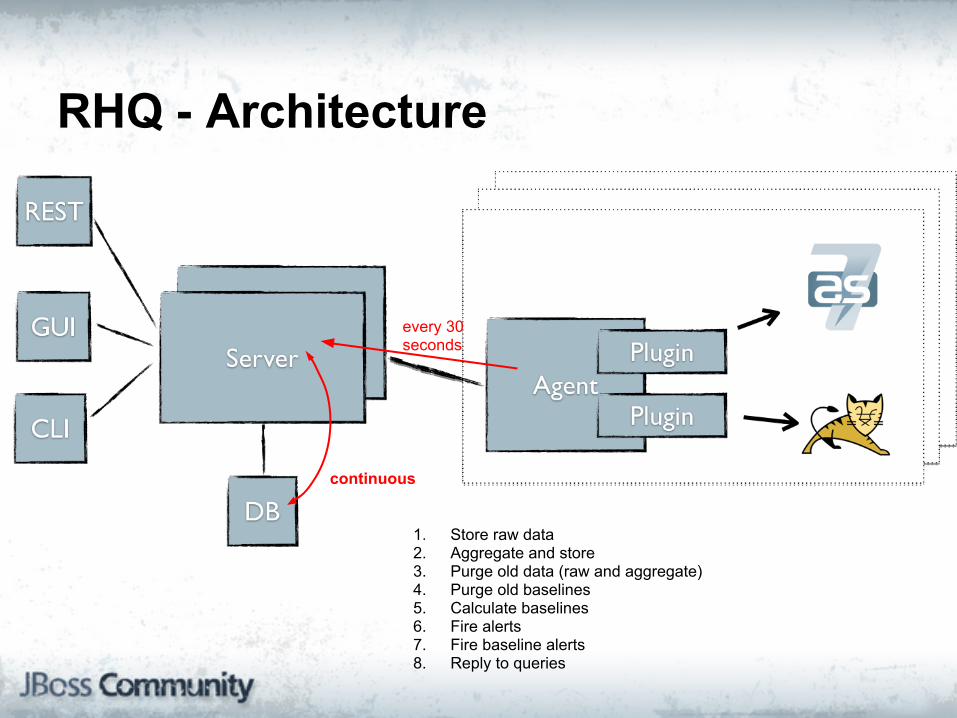
RHQ - Architecture
every 30 seconds
continuous
1. Store raw data2. Aggregate and store3. Purge old data (raw and aggregate)4. Purge old baselines5. Calculate baselines6. Fire alerts7. Fire baseline alerts8. Reply to queries

Performance HitNATIVE_QUERY_CALC_FIRST_AUTOBASELINE_POSTGRES = "" // + " INSERT INTO RHQ_MEASUREMENT_BLINE ( id, BL_MIN, BL_MAX, BL_MEAN, BL_COMPUTE_TIME, SCHEDULE_ID ) " // + " SELECT nextval('RHQ_MEASUREMENT_BLINE_ID_SEQ'), " // + " MIN(data1h.minvalue) AS bline_min, " // + " MAX(data1h.maxvalue) AS bline_max, " // + " AVG(data1h.value) AS bline_mean, " // + " ? AS bline_ts, " // ?1=computeTime + " data1h.SCHEDULE_ID AS bline_sched_id " // + " FROM RHQ_MEASUREMENT_DATA_NUM_1H data1h " // baselines are 1H data statistics + " INNER JOIN RHQ_MEASUREMENT_SCHED sched " // baselines are aggregates of schedules + " ON data1h.SCHEDULE_ID = sched.id " // + " INNER JOIN RHQ_MEASUREMENT_DEF def " // only compute off of dynamic types + " ON sched.definition = def.id " // + "LEFT OUTER JOIN RHQ_MEASUREMENT_BLINE bline " // we want null entries on purpose + " ON sched.id = bline.SCHEDULE_ID " // + " WHERE ( def.numeric_type = 0 ) " // only dynamics (NumericType.DYNAMIC) + " AND ( bline.id IS NULL ) " // no baseline means it was deleted or never calculated + " AND ( data1h.TIME_STAMP BETWEEN ? AND ? ) " // ?2=startTime, ?3=endTime + " GROUP BY data1h.SCHEDULE_ID " // baselines are aggregates per schedule // but only calculate baselines for schedules where we have data that fills (startTime, endTime) + " HAVING data1h.SCHEDULE_ID in ( SELECT distinct (mdata.SCHEDULE_ID) " + " FROM RHQ_MEASUREMENT_DATA_NUM_1H mdata " // + " WHERE mdata.TIME_STAMP <= ? ) " // ?4=startTime + " LIMIT 100000 "; // batch at most 100K inserts at a time to shrink the xtn size
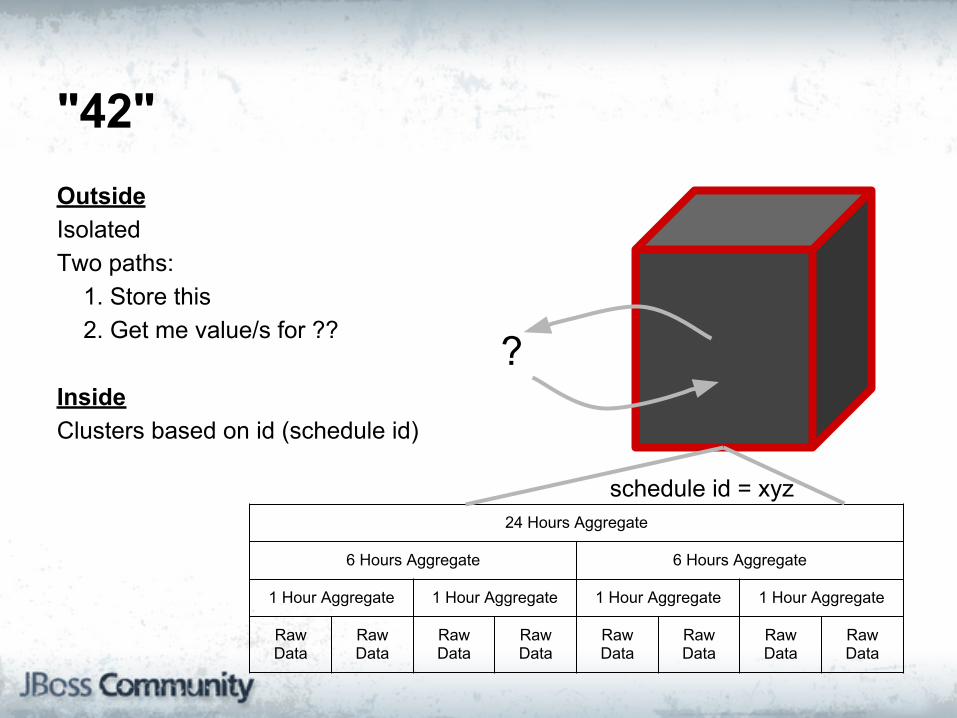
"42"OutsideIsolatedTwo paths: 1. Store this 2. Get me value/s for ??
InsideClusters based on id (schedule id)
24 Hours Aggregate
6 Hours Aggregate 6 Hours Aggregate
1 Hour Aggregate 1 Hour Aggregate 1 Hour Aggregate 1 Hour Aggregate
Raw Data
Raw Data
Raw Data
Raw Data
Raw Data
Raw Data
Raw Data
Raw Data
?
schedule id = xyz

NOSQL!?!?!?!?!?!?!?!?

NoSQLHadoop / HBase APICassandraAccumulo Stratosphere MongoDB Elasticsearch Couchbase CouchDBRethinkDB RavenDB Clusterpoint ServerThruDB Terrastore TerracottaRaptorDB JasDB SisoDBdjondbEJDB Reality (Northgate IS)OpenQMPrevayler
densodb RiakRedisAerospikeFoundationDBLevelDBBerkeley DBGenieDB BangDB Chordless ScalarisTokyo CabinetTyrant LinksKyoto CabinetScalienVoldemortDynomiteMemcacheDB Faircom C-Tree LSM Key-ValueDB ISIS Family
HamsterDBSTSdb APITarantoolMaxtable PincasterRaptorDBTIBCO Active Spaces allegro-CnessDB HyperDex LightCloud Hibari Genomu Neo4J Infinite Graph InfoGridHyperGraphDBTrinityAllegroGraphBrightstarDBYserial BtrieveVaultDB
Meronymy RDFVertexDBFlockDBBrightstarDBExecom IOGDatomic ArangoDBOrientDBFatDBVersantdb4oGemstoneStarcounterPerstVelocityDB HSS ZODBMagma Smalltalk DBNEO CodernityDBDiscoESENT eXtreme
siaqodbSterlingMorantex EyeDB FramerD NDatabasePicoLispacid-stateGemFire InfinispanQueplixHazelcast GridGainGalaxyJoafipCoherenceeXtremeScaleMultivalue DatabaseOpenInsightTigerLogic PICK KirbyBaseTokutekRecutils

NoSQL
Infinispan

Selection Criteria
● Management and support
○ Solution needs to be black boxed, self-managed
○ Has to be fully supported
● Developer/support tooling
● Performance and scalability
● Support single machine install
Infinispan

Developer and Support ToolingInfinispan
Implemented in Java
Difficult to implement range queries
Difficult to do indexing efficiently
CassandraImplemented in Java
Cassandra Query Language (CQL)
Tools (cqlsh, nodetool, ccm)
MongoDBImplemented in C++
Rich query language
Flexible, intuitive data model
HBaseImplemented in Java
Client libraries (Java, Thrift, REST)
Complex architecture

Management & SupportInfinispan
Already supported
No single point of failure
No specialized node roles
CassandraMinimal configuration
Highly available, fault tolerant
No specialized node roles
MongoDBLots of components with sharding
Different deployment models (sharding vs.
non-sharding)
Specialized node roles (arbiter, config
server, mongos)
HBaseName node is single point of failure
Complex configuration (HDFS,HBase,
ZooKeeper)
Specialized node roles (master server,
region server)

Performance & ScalabilityInfinispan
Fast reads (key lookup)
Inefficient range scans
Inefficient index updates
CassandraOptimized for writes
Caching, bloom filters
Data compression
MongoDBFast reads/writes (working set in memory)
Global write lock (yield mitigates lock
contention)
B-tree indexes
HBaseFast writes
Data locality
Caching, bloom filters
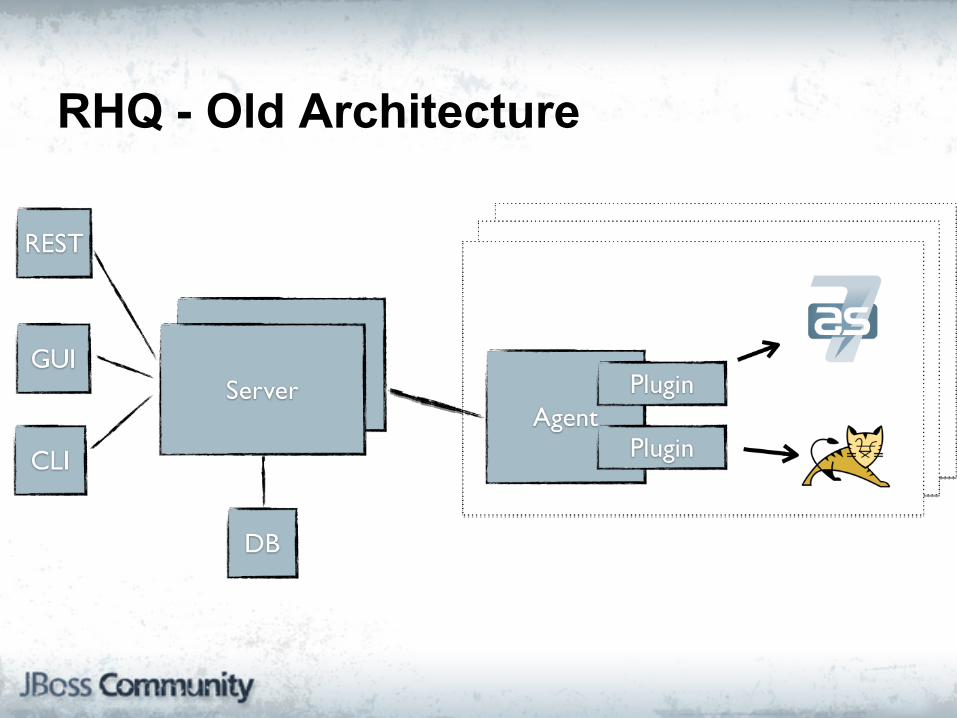
RHQ - Old Architecture
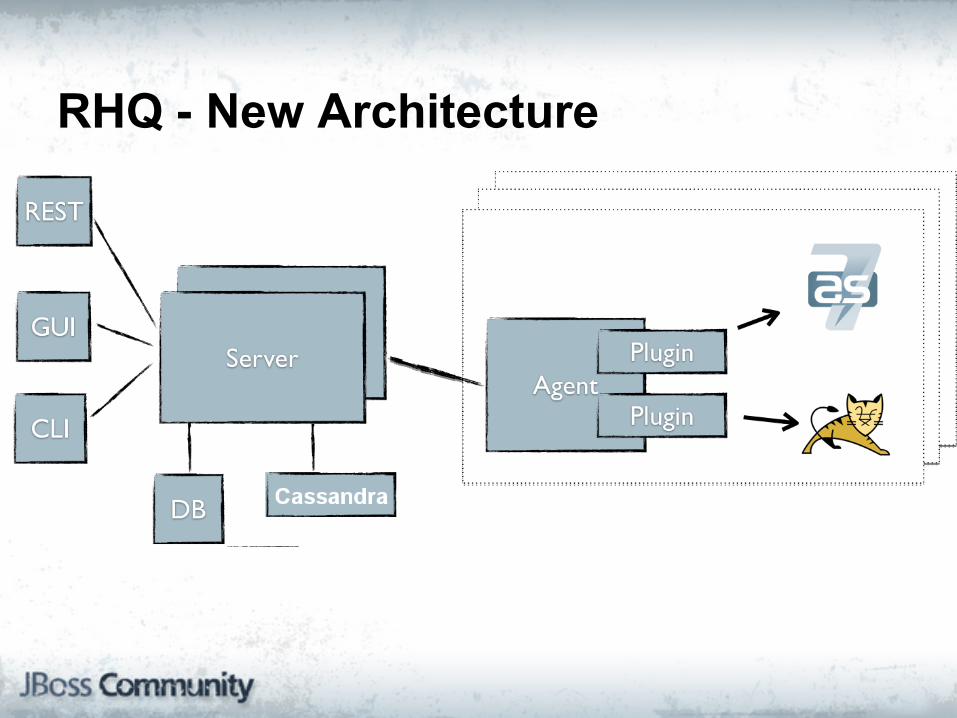
RHQ - New Architecture

Cassandra = RHQ Storage Node
● Only raw metrics and aggregates
● CQL - query data
● JMX to manage
● Management done via RHQ Agents
● Installation, management, repair handled through RHQ
● Scaled by the users on demand
○ just install another storage node
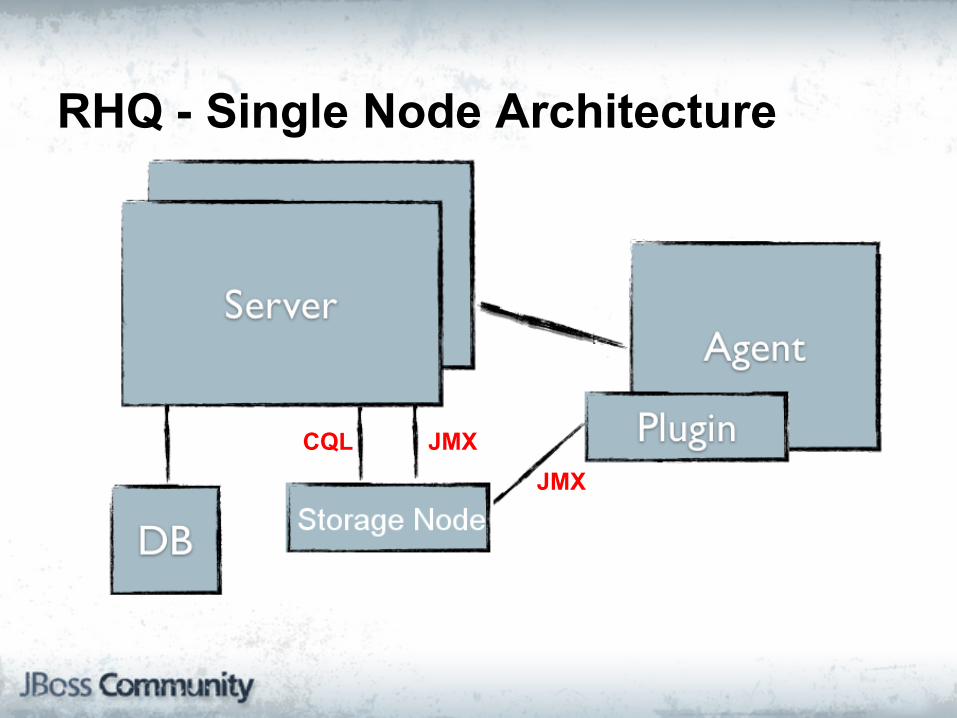
RHQ - Single Node Architecture
CQL JMXJMX
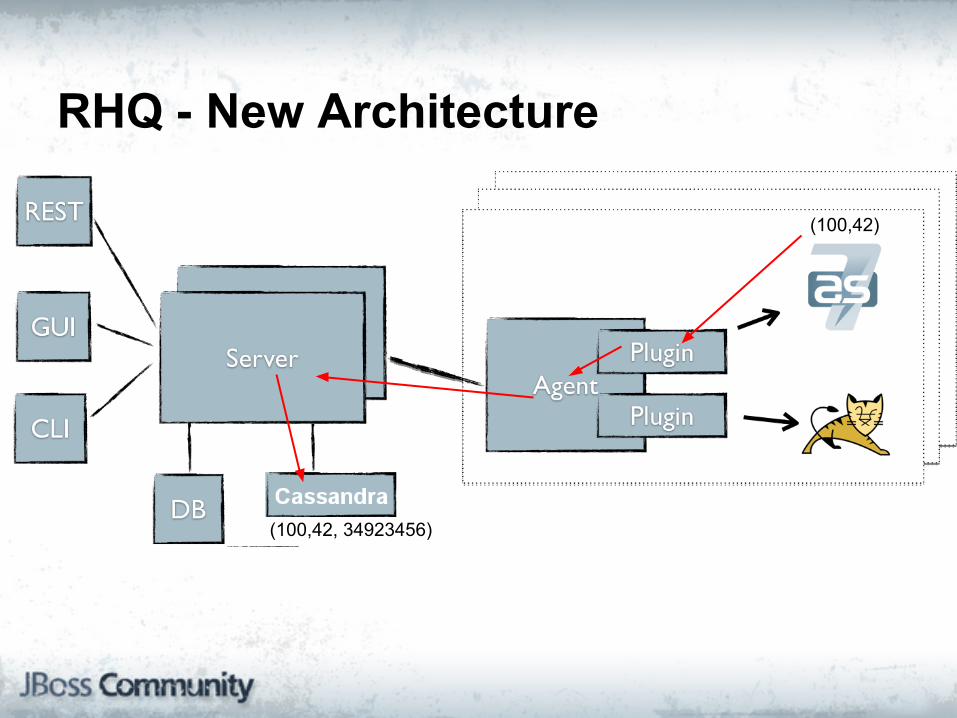
RHQ - New Architecture
(100,42)
(100,42, 34923456)
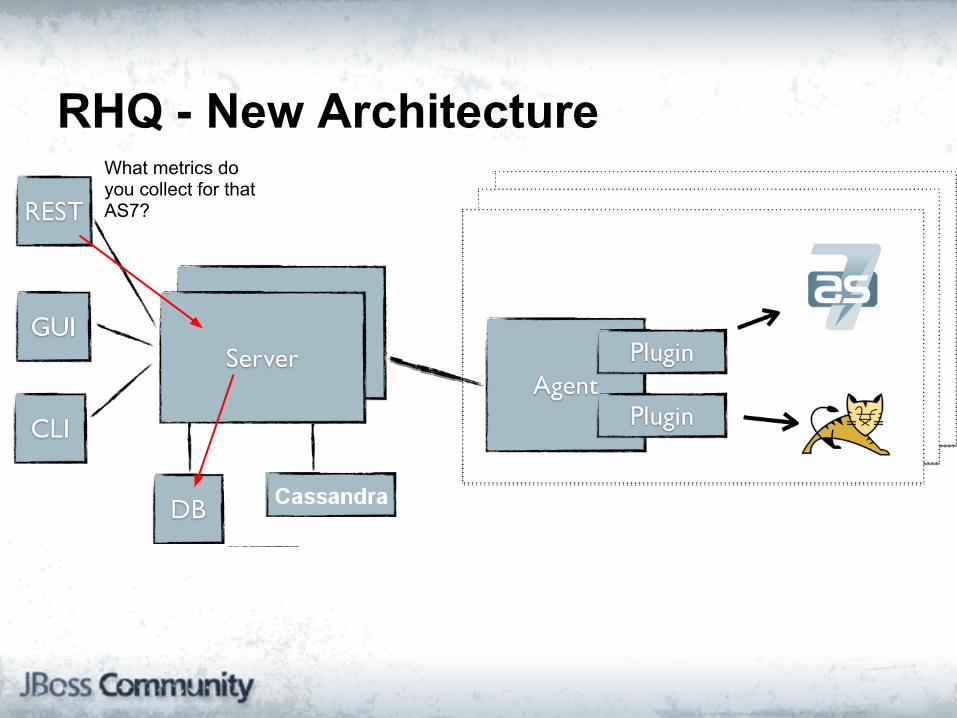
RHQ - New ArchitectureWhat metrics do you collect for that AS7?
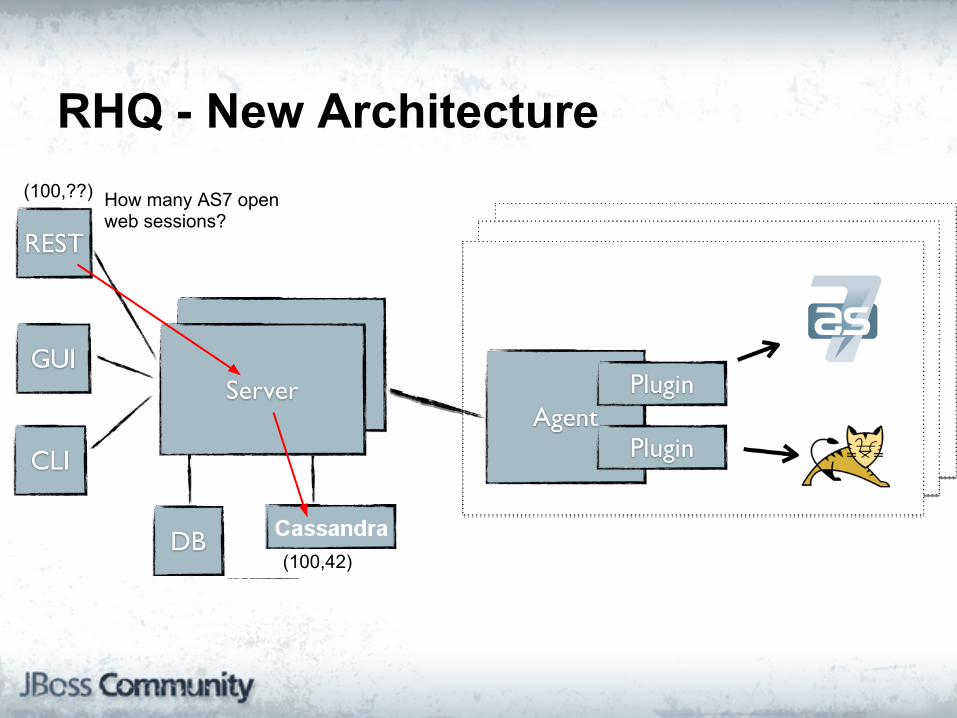
RHQ - New Architecture
(100,42)
(100,??) How many AS7 open web sessions?
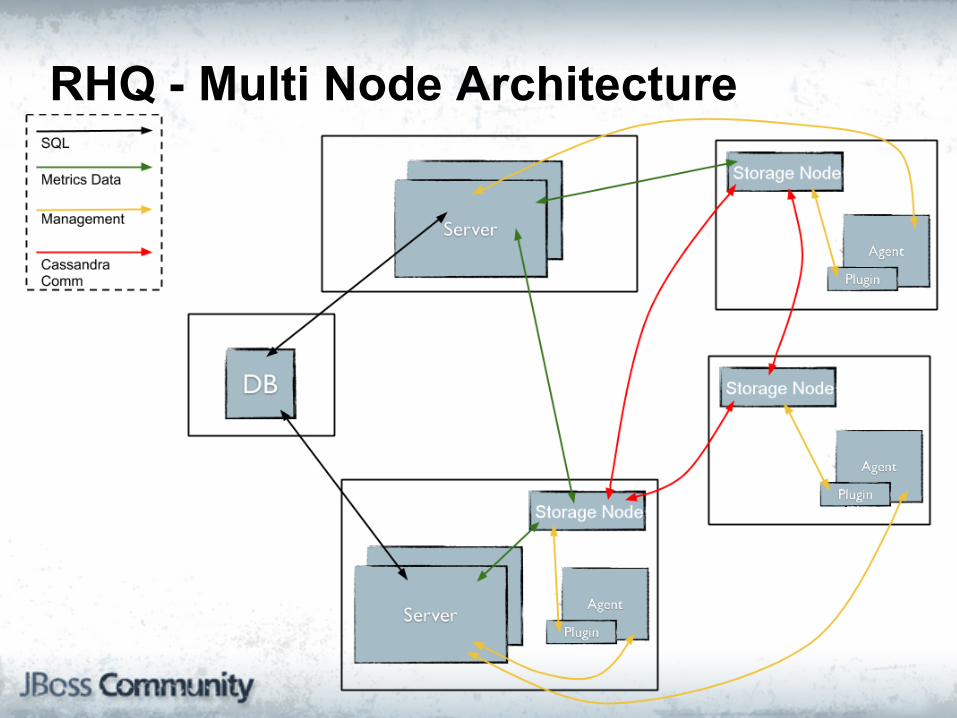
RHQ - Multi Node Architecture

Performance ImprovementServer Max
Metrics/MinTimeout Memory
UtilizationResult
Blade Server4GB RAMiSCI disk
Postgres Collocated
45 Agents
~60K 30 seconds 1.4 GB Postgres timeout errors
~250K 60 seconds 1.8 GB Server CrashedLock Exceptions!!Errors!!
+
Cassandra Collocated (1GB Heap)
45 Agents
~380K N/A 3.5 GB No errors!
Single Cassandra

Metrics SimulatorServer Raw Metrics
/ MinuteHeap
Blade ServeriSCI disk
2 Cassandra Nodes
680K 512 MBper Node
Slower due to virtualized environment
Bare MetalSSD2 Cassandra Nodes
1 million 512 MB per node
Increased the number of agents
More metrics = more CPU load

Lessons
● Convincing an entire community might the hardest thing
ever
● NoSQL has come a long way in the past 5 years
(management + stability)
● Performance is always there for the specific use case
solved by the NoSQL solution
● Finding the right NoSQL solution is the key

Be a NoSQL Hero!
● What we've done can be replicated
● Hybrid architecture is well worth if there is a significant
performance boost
● All NoSQL or nothing is expensive, incremental is easier
● Each NoSQL solution has strengths & limitations; but
there are so many impossible not to find one that fits

How to be a NoSQL Hero
1. Find the data bottleneck 2. Discover it's properties and relationships3. Try to decouple data entities in question4. Design a selection criteria for NoSQL5. Go through a selection process6. Prototype (if not satisfied, go back to Step 4).7. Implement & Deploy

RHQ 4.8 - Announcement
RHQ 4.8 CR available soon!
Cassandra = RHQ Storage Node





























