Embed Size (px)
Citation preview

Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 1 / 28
Mainz, 19. Juni 2017
Statistics, Data Analysis, andSimulation – SS 2017
08.128.730 Statistik, Datenanalyse undSimulation
Dr. Michael O. Distler<[email protected]>

6. Einführung in die Bayes-Statistik
Wiederholung von: 1.1 Wahrscheinlichkeitstheorie
Wahrscheinlichkeitstheorie, Mathematik:
−→ Axiome von Kolmogorov
Klassische Interpretation, frequentist probability:Pragmatische Interpretation der Wahrscheinlichkeit:
p(E) = limN→∞
nN
n(E) = Zahl der Ereignisse EN = Zahl der Versuche (Experimente)Experimente müssen (im Prinzip) wiederholbar sein.Nachteil: Genaugenommen können wir keine Aussagenüber die Wahrscheinlichkeit eines wahren Wertes machen.Nur untere und obere Grenzen können mit einerbestimmten Konfidenz festgelegt werden.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 2 / 28

Theory of probability
Wahrscheinlichkeitstheorie, MathematikKlassische Interpretation, frequentist probabilityBayesian Statistik, subjektive Wahrscheinlichkeit:Subjektive Vorurteile gehen in die Berechnung derWahrscheinlichkeit einer Hypothese H ein.
p(H) = Grad des Vertrauens, dass H wahr ist
Bildlich gesprochen: Wahrscheinlichkeiten ergeben sichaus dem Verhältnis von (maximalen) Einsatz undangenommenem Gewinn bei einer Wette.
Nachteil: DieVorurteile beeinflussen die Wahrscheinlichkeit.Vorteil für seltene und einmalige Ereignisse, wieverrauschte Signale oder Katastrophen-Modelle.
In diesem Kapitel werden wir die Bayes Sta-tistik behandeln. Statistische Rückschlüsse(z.B. Mittelwert, Varianz) werden ausschließ-lich den posterior Verteilungen entnommen.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 3 / 28

Theory of probability
Wahrscheinlichkeitstheorie, MathematikKlassische Interpretation, frequentist probabilityBayesian Statistik, subjektive Wahrscheinlichkeit:
Subjektive Vorurteile gehen in die Berechnung derWahrscheinlichkeit einer Hypothese H ein.
Nachteil: Die Vorurteile beeinflussen dieWahrscheinlichkeit.Vorteil für seltene und einmalige Ereignisse, wieverrauschte Signale oder Katastrophen-Modelle.
In diesem Kapitel werden wir die Bayes Sta-tistik behandeln. Statistische Rückschlüsse(z.B. Mittelwert, Varianz) werden ausschließ-lich den posterior Verteilungen entnommen.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 3 / 28

Theory of probability
Wahrscheinlichkeitstheorie, MathematikKlassische Interpretation, frequentist probabilityBayesian Statistik, subjektive Wahrscheinlichkeit:
Subjektive Vorurteile gehen in die Berechnung derWahrscheinlichkeit einer Hypothese H ein.
Nachteil: Die Vorurteile beeinflussen dieWahrscheinlichkeit.Vorteil für seltene und einmalige Ereignisse, wieverrauschte Signale oder Katastrophen-Modelle.
In dieser Vorlesung hatten wir uns zunächstauf die klassische Statistik konzentriert,d.h. Fehlerabschätzungen werden alsKonfidenzintervalle verstanden.
In diesem Kapitel werden wir die Bayes Sta-tistik behandeln. Statistische Rückschlüsse(z.B. Mittelwert, Varianz) werden ausschließ-lich den posterior Verteilungen entnommen.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 3 / 28

Theory of probability
Wahrscheinlichkeitstheorie, MathematikKlassische Interpretation, frequentist probabilityBayesian Statistik, subjektive Wahrscheinlichkeit:
Subjektive Vorurteile gehen in die Berechnung derWahrscheinlichkeit einer Hypothese H ein.
Nachteil: Die Vorurteile beeinflussen dieWahrscheinlichkeit.Vorteil für seltene und einmalige Ereignisse, wieverrauschte Signale oder Katastrophen-Modelle.
In diesem Kapitel werden wir die Bayes Sta-tistik behandeln. Statistische Rückschlüsse(z.B. Mittelwert, Varianz) werden ausschließ-lich den posterior Verteilungen entnommen.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 3 / 28

Bayes–Theorem
Aus der Gleichung
p(AundB) = p(A) · p(B|A) = p(B) · p(A|B)
erhält man das Bayes-Theorem:
p(A|B) = p(B|A) · p(A)
p(B)
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 4 / 28

Bayes–Theorem für diskrete Ereignisse
p(A|B) = p(B|A) · p(A)
p(B)
Beispiel: In einem Experiment soll der leptonische Zerfall derK0-Mesonen studiert werden. Es ist geplant, einen Cerenkov-Detektor zu verwenden, um die Leptonen nachzuweisen. Dazu mussuntersucht werden, ob ein Detektor ausreicht, um die leptonischenEreignisse von dem kleinen Untergrund abzutrennen, der ebenfallsden Detektor auslösen kann.
p(B) ≡ Wahrscheinlichkeit, dass ein Ereignis denCerenkov-Detektor auslöst.
p(A) ≡ Wahrscheinlichkeit, dass sich ein echterleptonischer Zerfall ereignet.
p(B|A) ≡ Wahrscheinlichkeit, dass ein echtes leptonischesEreignis den Cerenkov-Detektor auslöst
p(A|B) ≡ Wahrscheinlichkeit, dass es sich bei einem Ereignisum einen echten leptonischen Zerfall handelt, unter derVoraussetzung, dass der Cerenkov-Detektor auslöst.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 5 / 28

Bayes–Theorem für diskrete Ereignisse
p(A|B) = p(B|A) · p(A)
p(B)
p(B) ≡ Wahrscheinlichkeit, dass ein Ereignis denCerenkov-Detektor auslöst.
p(A) ≡ Wahrscheinlichkeit, dass sich ein echterleptonischer Zerfall ereignet.
p(B|A) ≡ Wahrscheinlichkeit, dass ein echtes leptonischesEreignis den Cerenkov-Detektor auslöst
p(A|B) ≡ Wahrscheinlichkeit, dass es sich bei einem Ereignisum einen echten leptonischen Zerfall handelt, unter derVoraussetzung, dass der Cerenkov-Detektor auslöst.
p(B) kann gemessen werden. p(A) ergibt sich aus früherenMessungen bzw. Theorie. p(B|A) wird aus einer Simulation bestimmt.↪→ p(A|B)
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 6 / 28

Bayes-Theorem für Bayesianer
Wenn es sich bei A und B nicht um Ereignisklassen sondernum Hypothesen handelt, dann wird der Unterschied zwischenden beiden Statistik-Schulen offensichtlich. Als frequentist kannman einer Hypothese keine Wahrscheinlichkeit zuweisen. Derbayesian interpretiert p(H) als Grad des Vertrauens in dieHypothese.
p(H|E) =p(H) · p(E|H)
p(E)
p(H) ≡ prior WahrscheinlichkeitWissen (Grad des Vertrauens) vor der Datennahme
p(H|E) ≡ posterior Wahrscheinlichkeitp(E|H) ≡ likelihood
p(E) ≡ Normalisierungsfaktor
Das Ergebnis (Erwartungswert, Varianz, . . . ) einerBayes-Analyse wird allein dem posterior entnommen.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 7 / 28

Cookie-Problem
Stellen Sie sich 2 gefüllte Keksdosen vor. Dose 1 enthält 10Chocolate Chip Cookies und 30 Plain Cookies. Bei Dose 2 istdes Verhältnis 20/20. Unser Freund Fred wählt zunächstzufällig eine Keksdose aus und entnimmt dann zufällig einenCookie. Es ist ein Plain Cookie. Mit welcher Wahrscheinlichkeitstammt er aus Dose 1?
Hypothesen: H1: der Keks stammt aus Dose 1.H2: der Keks stammt aus Dose 2.
Prior: p(H1) = p(H2) = 1/2Ereignis: E : der Keks ist ein Plain Cookie.Likelihood: p(E|H1) = 3/4
p(E|H2) = 1/2Bayes-Theorem:
p(H1|E) =p(H1)× p(E|H1)
p(H1) · p(E|H1) + p(H2) · p(E|H2)=
35
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 8 / 28

Bayessche Inferenz∗ für Binomialexperimente
Häufig hat man es mit großen Populationen zu tun, von der einAnteil p ein gewisse Eigenschaft aufweist. Beispiel: Für dieBevölkerung einer Stadt könnte die Eigenschaft lauten „plantKandidat A bei der Bürgermeisterwahl zu wählen“.
Wir zählen die Anzahl von “Erfolgen” in n unabhängigenVersuchen, wobei jeder Versuch nur zwei mögliche Ergebnissehaben kann: Erfolg oder Miserfolg. Erfolg bedeutet, dass beidem i-ten Versuch die geforderte Eigenschaft auftrat.
Die Anzahl von Erfolgen in n Versuchen, dieErfolgswahrscheinlichkeit bei jedem einzelnen Versuch sei p, istbinomialverteilt. Die bedingte Wahrscheinlichkeit ist:
f (k |p) =
(nk
)pk (1− p)n−k k ∈ [1,n]
∗ Inferenz = Schlussfolgerung
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 9 / 28

Betaverteilung
Wahrscheinlichkeitsdichte der Betaverteilung
f (x ; a,b) =1
B(a,b)xa−1 (1− x)b−1 x ∈ [0,1]
mit der Eulerschen Betafunktion
B(a,b) =Γ(a)Γ(b)
Γ(a + b)=
∫ 1
0ua−1(1− u)b−1 du
Extremum:
xextrem =
(1 +
b − 1a− 1
)−1
=a− 1
a + b − 2
Erwartungswert und Varianz:
E(X ) =a
a + bVar(X ) =
a · b(a + b + 1)(a + b)2
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 10 / 28
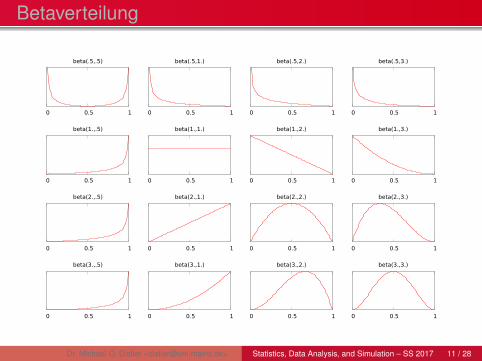
Betaverteilung
0 0.5 1
beta(.5,.5)
0 0.5 1
beta(.5,1.)
0 0.5 1
beta(.5,2.)
0 0.5 1
beta(.5,3.)
0 0.5 1
beta(1.,.5)
0 0.5 1
beta(1.,1.)
0 0.5 1
beta(1.,2.)
0 0.5 1
beta(1.,3.)
0 0.5 1
beta(2.,.5)
0 0.5 1
beta(2.,1.)
0 0.5 1
beta(2.,2.)
0 0.5 1
beta(2.,3.)
0 0.5 1
beta(3.,.5)
0 0.5 1
beta(3.,1.)
0 0.5 1
beta(3.,2.)
0 0.5 1
beta(3.,3.)
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 11 / 28

Referendum
Beispiel: Es steht ein Referendum wegen eines Bauvorhabensin Ihrer Stadt aus. Da Sie im Bekanntenkreis das Themabereits diskutiert haben, gehen Sie von einer knappenEntscheidung aus, wobei Sie sich sicher sind (C.L.: 95%), dassweder Befürworter noch Gegner mehr als 60% der Stimmenerreichen werden.Aus Ihrem Vorwissen konstruieren Sie den Prior:
E(X ) =a
a + b= 0.5 ⇒ a = b
Var(X ) =a b
(a + b)2(a + b + 1)=
14(2a + 1)
= (0.05)2
Nähert man also die Betaverteilung mit der Normalverteilungund setzt 95%c.l. ' 2σ ' ±10% so ergibt sich
a = b ' 50
(die exakte Rechnung ergibt a = b = 47.2998).Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 12 / 28

Referendum (exakte Berechnung der Betaverteilung)
zu lösen ist: ∫ 0.6
0.4f (x ; a,a) dx = 0.95
Mathematica:f [α_] :=NIntegrate[PDF[BetaDistribution[α, α], x ], {x ,0.4,0.6}]FindRoot[f [α] == 0.95, {α,50}]
Python:from scipy.stats import betafrom scipy.optimize import newtondef f(x):
return (beta.cdf(0.6,x,x)-beta.cdf(0.4,x,x)-0.95)
print(newton(f, 50))
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 13 / 28

Referendum (Teil 2)
In einer repräsentativen Umfrage haben sich von N = 1500Betroffenen nur k = 720 Personen für das Bauvorhabenausgesprochen. Ermitteln Sie die Wahrscheinlichkeit, dass imReferendum die Gegner eine Mehrheit erzielen.
Die posterior Dichte g(x) ergibt sich aus:
prior × likelihoodBetaverteilung(x ; a,b) × Binomialverteilung(x ; N, k )Γ(a+b)
Γ(a)Γ(b) xa−1 (1− x)b−1 × N!k! (N−k)! xk (1− x)N−k
Im Falle eines Beta-Priors ergibt sich einfach:
g(x) = Beta(x ; a + k ,b + N − k) = Beta(x ; 770,830)
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 14 / 28
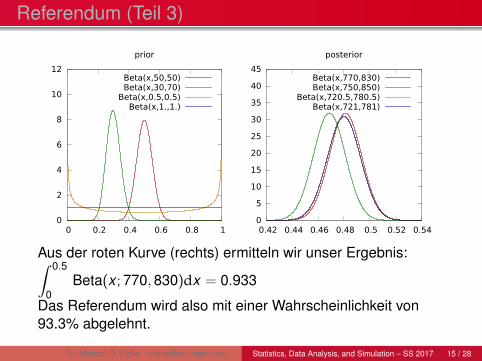
Referendum (Teil 3)
0
2
4
6
8
10
12
0 0.2 0.4 0.6 0.8 1
prior
Beta(x,50,50)Beta(x,30,70)
Beta(x,0.5,0.5)Beta(x,1.,1.)
0
5
10
15
20
25
30
35
40
45
0.42 0.44 0.46 0.48 0.5 0.52 0.54
posterior
Beta(x,770,830)Beta(x,750,850)
Beta(x,720.5,780.5)Beta(x,721,781)
Aus der roten Kurve (rechts) ermitteln wir unser Ergebnis:∫ 0.5
0Beta(x ; 770,830)dx = 0.933
Das Referendum wird also mit einer Wahrscheinlichkeit von93.3% abgelehnt.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 15 / 28
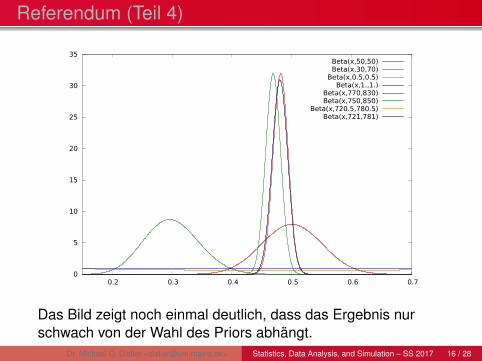
Referendum (Teil 4)
0
5
10
15
20
25
30
35
0.2 0.3 0.4 0.5 0.6 0.7
Beta(x,50,50)Beta(x,30,70)
Beta(x,0.5,0.5)Beta(x,1.,1.)
Beta(x,770,830)Beta(x,750,850)
Beta(x,720.5,780.5)Beta(x,721,781)
Das Bild zeigt noch einmal deutlich, dass das Ergebnis nurschwach von der Wahl des Priors abhängt.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 16 / 28

Vorsichtsmaßnahmen bei Verwendung eineskonjugierten Priors
z.B. Beta-Prior bei Binomialverteilungen1 Plotten Sie Ihren Beta(a,b)-Prior. Passen Sie notfalls
Mittelwert π0 und Varianz σ20 an, bis diese Ihren
Vorstellungen entsprechen.2 Berechnen Sie die äquivalente Stichprobengröße. Für
den Fall, dass diese unrealistisch groß ist, vergrößern Siedie Varianz Ihres Priors und berechnen diesen neu.
Für eine Binomialverteilung mit Trefferwahrscheinlichkeit π undVersuchsanzahl n ist die Varianz π(1− π)/n. Dies setzen wirder Prior-Varianz gleich:
π0(1− π0)
neq=
ab(a + b + 1)(a + b)2
Mit π0 = aa+b und (1− π0) = b
a+b ergibt sich
neq = a + b + 1
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 17 / 28

Nichtinformative Priori-Dichten
Ein nichtinformativer (engl. uninformative or objective)Prior drückt eine vage bzw. unbestimmte Kenntnis dergesuchten Größe aus. Die einfachste und älteste Methodeeinen nichtinformativen Prior zu konstruieren stellt dasIndifferenzprinzip dar. Demnach wird allen Möglichkeitendie gleiche Wahrscheinlichkeit zugewiesen.Dabei kann leicht ein uneigentlicher (engl. improper) Priorentstehen, d.h. der Prior ist nicht normiert und damit auchkeine Wahrscheinlichkeitsdichte. Das stellt jedoch imallgemeinen kein Problem dar, da sich die Posterior-Dichtemeist normieren lässt.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 18 / 28

Nichtinformative Priori-Dichten
Der “flache” Prior ist jedoch nicht wirklich “objektiv”, wovonman sich leicht überzeugen kann, wenn man eine(nicht-lineare) Variablentransformation durchführt. Nachder Transformation ist der flache Prior nicht mehr flach.Bessere Eigenschaften besitzt der Jeffreys Prior, derebenfalls als nichtinformativer Prior bezeichnet wird.Eine Bayes-Analyse mit einem nichtinformativen Priorliefert meist ähnliche oder identische Ergebnisse wie dieklassische Maximum Likelihood Methode.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 19 / 28

Bayessche Inferenz für Poisson
Die Poisson-Verteilung wird verwendet, um das Auftreten vonseltenen Ereignissen zu zählen. Die Ereignisse treten zufällig inZeit (oder Raum) auf, jedoch mit einer konstanten mittlerenRate.Die Poisson-Verteilung kann etwa verwendet werden, um dieAnzahl der Unfälle auf einer Autobahn innerhalb eines Monatszu modellieren. Allerdings kann es nicht verwendet werden, umdie Zahl der Todesopfer auf der Autobahn zu modellieren, daeinige Unfälle mehrere Todesopfer aufweisen können.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 20 / 28

Die Gammaverteilung
Wahrscheinlichkeitsdichte der Gammaverteilung
f (x) =
bp
Γ(p)xp−1e−bx x > 0
0 x ≤ 0
Maximum (für p > 1):
xmax =p − 1
b
Erwartungswert:E(X ) =
pb
Varianz:Var(X ) =
pb2
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 21 / 28
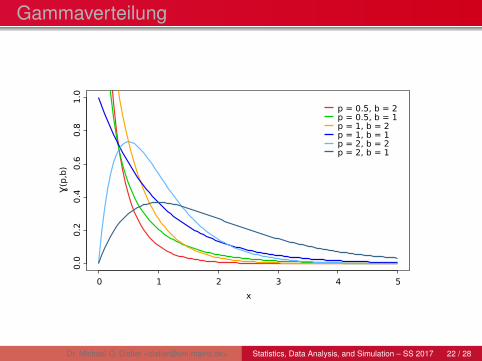
Gammaverteilung
0 1 2 3 4 5
0.0
0.2
0.4
0.6
0.8
1.0
x
Ɣ(p
,b)
p = 0.5, b = 2p = 0.5, b = 1p = 1, b = 2p = 1, b = 1p = 2, b = 2p = 2, b = 1
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 22 / 28

Bayes-Theorem für Poisson Parameter
Wir betrachten eine Stichprobe y1, . . . , yn aus einer Poisson(µ)Verteilung. Die Proportionalitätsform des Bayes-Theoremslautet:
posterior ∝ prior× likelihoodg(µ|y1, . . . , yn) ∝ g(µ)× f (y1, . . . , yn|µ)
Durch Normierung erhalten wir die tatsächliche PosteriorDichte:
g(µ|y1, . . . , yn) =g(µ)× f (y1, . . . , yn|µ)∫∞
0 g(µ)× f (y1, . . . , yn|µ) dµ
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 23 / 28

Likelihood für Poisson Parameter
Die Likelihood für eine einmalige Ziehung von einerPoisson-Verteilung ist bekannt:
f (y |µ) =µy e−µ
y !
Die Form wird dabei festgelegt durch
f (y |µ) ∝ µy e−µ
Für eine größere Stichprobe werden die ursprünglichenLikelihoods multipliziert:
f (y1, . . . , yn|µ) =n∏
i=1
f (yi |µ)
∝ µ∑
yi e−nµ
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 24 / 28

Gleichverteilte Prior Dichte
Wenn wir keine Information über µ haben, bevor wir die Datenbetrachten, dann wäre ein gleichverteilter Prior eine möglicheWahl:
g(µ) = 1 fürµ > 0
Dies ist ein uneigentlicher (improper) Prior!
g(µ|y1, . . . , yn) ∝ g(µ)× f (y1, . . . , yn|µ)
∝ 1× µ∑
yi e−nµ
Dies entspricht einer gamma(p,b) Verteilung mit p =∑
y + 1und b = n. Somit erhalten wir einen normierten Posterior,obwohl wir mit einem improper Prior gestartet waren.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 25 / 28

Jeffreys Prior für Poisson
Ein Jeffreys Prior ist objektiv in dem Sinne, dass er invariant istunter bestimmten Transformationen des Parameters. DerJeffreys Prior für Poisson lautet:
g(µ) ∝ 1√µ
fürµ > 0
Dies ist ebenfalls ein uneigentlicher (improper) Prior!
g(µ|y1, . . . , yn) ∝ g(µ)× f (y1, . . . , yn|µ)
∝ 1√µ× µ
∑yi e−nµ
∝ µ∑
yi−1/2 e−nµ
Dies entspricht einer gamma(p,b) Verteilung mit p =∑
y + 12
und b = n. Wiederum erhalten wir einen normierten Posterior,obwohl wir mit einem improper Prior gestartet waren.
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 26 / 28

Konjugierte Priors für Poisson
Die Gammaverteilung bildet die Familie von konjugierten Priorsfür Poisson, d.h. sowohl Prior als auch Posterior stammen ausder gleichen Familie. Für eine Stichprobe y1, . . . , yn aus einerPoissonverteilung und einer Prior gamma(p,b) ergibt sich derPosterior:
gamma(p′,b′) mit p′ = p +∑
y , b′ = b + n
Der Prior lässt sich leicht aus einer Kenntnis von Mittelwert µund Varianz s2 konstruieren. Aus
µ =pb
und s2 =pb2
folgt
p =µ2
s2 und b =µ
s2
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 27 / 28

press any key
Dr. Michael O. Distler <[email protected]> Statistics, Data Analysis, and Simulation – SS 2017 28 / 28























