Embed Size (px)
Citation preview

B/W Confirming Pages
O b j e c t i v e s
After you have read and studied this chapter, you should be able to
• Describe the key features of the Stack ADT.
• Develop applications using stacks.
• Implement the Stack ADT by using an array.
• Implement the Stack ADT by using a linked list.
• Explain the key differences between the arrayand linked implementations of the Stack ADT.
1035
19Stack ADT
wu23399_ch19.qxd 1/2/07 20:46 Page 1035

B/W Confirming Pages
e continue our study of ADTs with the Stack ADT in this chapter. As we didin Chapter 18, we start with the definition of the Stack ADT and present twodifferent implementations. We conclude the chapter with sample applications ofthe Stack ADT.
The Stack ADT is modeled after a physical stack of items, such as a stackof pancakes or a stack of plates. If you were asked to remove any plate from a stackof plates, which one would you remove? The topmost one, of course. Similarly,the most effortless place to add a new plate is at the top of the stack. Like its phys-ical counterpart, the defining feature of the Stack ADT is its restrictive insertionand removal operations. An item can only be added to the top of the stack, andonly the topmost item of the stack can be removed. Because of this restriction, theStack ADT is quite simple. And consequently, its implementations are relativelystraightforward, compared to the List ADT. As simple as it may be, the Stack ADTis remarkably versatile and useful in many diverse types of applications.
19.1 The Stack ADTA stack is a linearly ordered collection of elements where elements, or items, areadded to and removed from the collection at the one end called the top of stack.This restriction will ensure that the last element added to a stack is the first to beremoved next. For this reason, a stack is characterized as a last-in, first-out (LIFO)list. Figure 19.1 shows a sample generic stack named sampleStack with five ele-ments and another stack named myStack with five three-letter animal names.
Items in a stack are said to be linearly ordered because the order in which theitems are added and removed follows the strict linear sequence. In other words, the itemat the ith position below the top of the stack moves to the (i � 1)st position when thetopmost item is removed. Similarly, the item at the ith position below the top of thestack moves to the (i � 1)st position when a new item is added to the top of the stack.
1036 Chapter 19 Stack ADT
I n t r o d u c t i o n
W
stack
top of stack
LIFO
TOP E4
E3
E2
E1
E0
sampleStack
TOP "bee"
"dog"
"ape"
"gnu"
"cat"
myStack
This is the top of stack. New element is added here, and only thetop-of-stack elementcan be removed.
Figure 19.1 A generic stack sampleStack with five elements and a stack myStack with three-letter animalnames.
wu23399_ch19.qxd 1/2/07 20:46 Page 1036

B/W Confirming Pages
Because the addition and removal operations are restricted, the methodsdefined for the Stack ADT are much simpler than those defined for the List ADT.The add operation named push adds a new item to the top of the stack. The removeoperation named pop removes the topmost item. The get operation named peekreturns the topmost item, without actually removing it. There are two query opera-tions named size and isEmpty. The size method returns the number of items in thestack, and the isEmpty method returns true if the size of the stack is 0. The updateoperation named clear empties the stack.
The push operation will add the designated element to the top of the stack. Thecurrent elements in the stack are pushed down one position. The stack does not haveany size restriction. It will grow without bound. Of course, the computer memory is notlimitless, so there will be a hardware limitation on how big a stack can grow, but therewill be no size restriction at theADT level.Also, there is no restriction on the elements.You can add duplicates, for instance. Figure 19.2 illustrates the push operation.
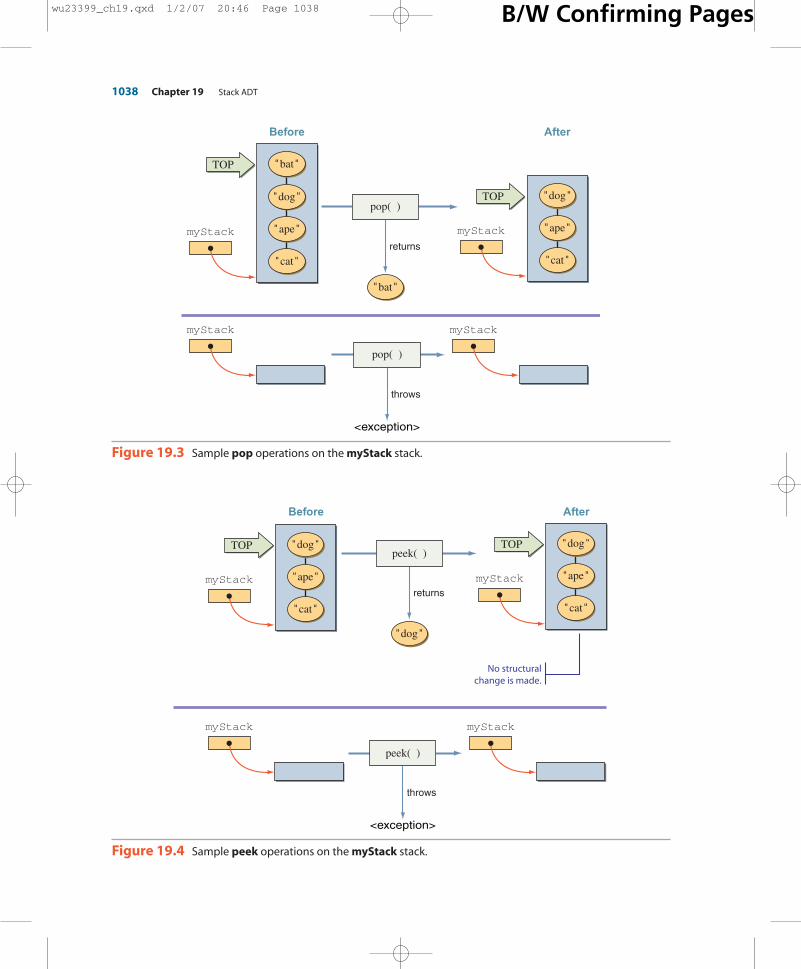
The pop operation is the reverse of the push operation. It will remove thetopmost element from the stack if there is any. If the stack is empty, then the opera-tion will throw an exception. There are a number of possible Java exceptions thatthe operation can throw, and we will discuss them in Section 19.2. For now, we’lljust say that the operation will throw some kind of exception. Figure 19.3 illustratesthe pop operation on nonempty and empty stacks.
The peek operation is just like the pop operation except that the top elementis not removed from the stack. Figure 19.4 illustrates the peek operation on non-empty and empty stacks.
The clear operation removes all elements in the stack. It causes no problemto call the clear operation on an empty stack. This operation becomes handy, forexample, when you want to clear the stack before reusing it for processing the nextbatch of input data. See Figures 19.5 and 19.6.
The size operation returns the number of elements in the stack. This operationis not as commonly used on the stacks as the isEmpty operation, but we will includeit in the specification as it is not costly to implement this operation. Including thisoperation maintains the consistent set of methods available on all types of collectionobjects.
The isEmpty operation tests whether the stack is empty. If it is, then true isreturned. Otherwise, false is returned. See Figure 19.7.
19.1 The Stack ADT 1037
pop
peek
clear
push
AfterBefore
TOP "bat"
"dog"
"ape"
"cat"
myStack
TOP "dog"
"ape"
"cat"
myStack
push("bat")
Figure 19.2 A sample push operation on the myStack stack.
size
isEmpty
wu23399_ch19.qxd 1/2/07 20:46 Page 1037
B/W Confirming Pages
1038 Chapter 19 Stack ADT
<exception>
returns
AfterBefore
"dog"
myStack
TOP TOP"dog"
"ape"
"cat"
myStack
"dog"
"ape"
"cat"
myStack
myStack
peek( )
throws
peek( )
No structuralchange is made.
Figure 19.4 Sample peek operations on the myStack stack.
<exception>
returns
AfterBefore
"dog"
"ape"
"cat"
"bat"
TOP
TOP
"bat"
"dog"
"ape"
"cat"
myStack
myStack
myStack
myStack
pop( )
throws
pop( )
Figure 19.3 Sample pop operations on the myStack stack.
wu23399_ch19.qxd 1/2/07 20:46 Page 1038

B/W Confirming Pages
19.1 The Stack ADT 1039
AfterBefore
TOP "dog"
"ape"
"cat"
myStack myStackclear( )
Figure 19.5 A sample clear operation on the myStack stack.
Figure 19.6 A sample clear operation on the myStack stack.
returns
3
AfterBefore
TOP TOP"dog"
"ape"
"cat"
myStack
"dog"
"ape"
"cat"
myStacksize( )
No structuralchange is made.
true
returns
AfterBefore
false
myStack
TOP TOP"dog"
"ape"
"cat"
myStack
"dog"
"ape"
"cat"
myStack
myStack
isEmpty( )
returns
isEmpty( )
Figure 19.7 Sample isEmpty operations on the myStack stack.
wu23399_ch19.qxd 1/2/07 20:46 Page 1039

B/W Confirming Pages
1040 Chapter 19 Stack ADT
1. Draw the stack after executing the following operations, starting with an emptystack called myStack.
String bee = new String("bee");String cat = new String("cat");
myStack.clear( );myStack.push(bee);myStack.push(cat);myStack.pop( );
2. Repeat Question 1 with the following statements:
String bee = new String("bee");String cat = new String("cat");String dog = new String("dog");
petStack.push(bee);petStack.push(cat);petStack.push(dog);petStack.peek( );petStack.pop( );petStack.pop( );petStack.push(dog);
19.2 The Stack InterfaceAs we did for the List ADT, we will use a Java interface to define the Stack ADT.We will continue to prefix our interfaces and classes with NPS. (There are no con-flicts because no interface named Stack and no classes named ArrayStack andLinkedStack exist in the java.util packages; but for consistency, we will prefix all ofour interfaces and classes with NPS.) Formalizing what we have presented inSection 19.1, we have the following definition:
package edu.nps.util;
public interface NPSStack<E> {
public void clear( );
public boolean isEmpty( );
public E peek( ) throws NPSStackEmptyException;
public E pop( ) throws NPSStackEmptyException;
public void push(E element);
public int size( );}
NPSStack
wu23399_ch19.qxd 1/2/07 20:46 Page 1040

B/W Confirming Pages
Table 19.1 summarizes the methods of the NPSStack interface.The peek and pop methods are defined to throw an NPSStackEmptyException.
We could have thrown an NPSNoSuchElementException because there is no such(top-of-stack) element when you attempt to pop or peek an empty stack. However,NPSNoSuchElementException is equally applicable, for example, when you searchfor an element that is not in a data structure. It is preferable to use an exception thatidentifies the error condition as precisely as possible, instead of using a genericexception. Because the specific error condition that would result in an exception forthe pop and peek operations is an empty stack, we chose to throw an exceptionspecifically defined for this purpose. The NPSNoSuchElementException class is avery simple class. Here’s the definition:
19.2 The Stack Interface 1041
Tab
leTABLE 19.1 The NPSStack interface
Interface:NPSStack
void clear( )
Removes all elements from the stack.
boolean isEmpty( )
Determines whether the stack is empty. Returns true if it is empty;false otherwise.
Object peek( ) throws NPSStackEmptyException
Returns the top-of-stack element without removing it from the stack. Throws anexception when the stack is empty.
Object pop( ) throws NPSStackEmptyException
Removes the top-of-stack element and returns it. Throws an exception when thestack is empty.
void push( Object element )
Adds an element to the stack. This element becomes the new top-of-stack element.
int size( )
Returns the number of elements in the stack.
package edu.nps.util;
public class NPSStackEmptyException extends RuntimeException {
public NPSStackEmptyException( ) {
this("Stack is empty");}
public NPSStackEmptyException(String message) {
super(message);}
}
NPSNoSuchElementException
wu23399_ch19.qxd 1/2/07 20:46 Page 1041

B/W Confirming Pages
1042 Chapter 19 Stack ADT
19.3 The Array ImplementationIn this section, we will implement the NPSStack interface by using an array to store thestack elements. Figure 19.8 illustrates the array implementation of the Stack ADT.
The NPSArrayStack DefinitionThe NPSArrayStack class implements the NPSStack interface, and its class declara-tion is as follows:
package edu.nps.util;
public class NPSArrayStack<E> implements NPSStack<E> {
//class body comes here
}
We use an array element to store the stack elements and an int variable count tokeep track of the number of elements currently in the stack. Since the Java array useszero-based indexing, the value of count is also the index of the array where we addthe next element. We will also define a constant for the default size we use when cre-ating the array in the zero-argument constructor. These data members are declared as
private static final int DEFAULT_SIZE = 25;private E[ ] element;private int count;
Array ImplementationADT Stack
TOP "bat"
"dog"
"ape"
"cat"
myStack
0
1
2
3
n-1
...
The array is drawn verticallyto capture the nature of
stack more clearly.
This value is also the indexof the array where we addthe next item.
:NPSArrayStack
count
element
4
myStack
:String
"bat"
:String
"dog"
:String
"ape"
:String
"cat"
Figure 19.8 An array implementation of the Stack ADT.
wu23399_ch19.qxd 1/2/07 20:46 Page 1042

B/W Confirming Pages
We will define two constructors: one takes no argument and another takes oneargument that specifies the initial size of the array. They are defined as follows:
public NPSArrayStack( ) {this(DEFAULT_SIZE);
}
public NPSArrayStack(int size) {if (size <= 0) {
throw new IllegalArgumentException("Initial capacity must be positive");
}
element = (E[]) new Object[size];count = 0;
}
Notice that we first create an array of Object and then typecast it to an array of E, thetype parameter. This is necessary because it is not allowed to create an array ofgeneric type in Java.
We will set element[i] to null, where i = 0, . . . , count-1, so the objects referencedby element[i] will be garbage-collected. We will then reset the count variable to 0.
public void clear( ) {
for (int i = 0; i < count; i++) {element[i] = null;
}
count = 0;}
This operation is straightforward. If the value of count is 0, then the stack is empty.Otherwise, the stack is not empty.
public boolean isEmpty( ) {
return (count == 0);}
This is one of the two operations that can potentially throw an NPSStackEmpty-Exception. We throw an NPSStackEmptyException when the stack is empty. Other-wise, we return the top-of-stack element.
public E peek() throws NPSStackEmptyException {
if (isEmpty( )) {
throw new NPSStackEmptyException( );
} else {
return element[count-1];}
}
19.3 The Array Implementation 1043
clear
isEmpty
peek
Be careful! The current topof stack is at the (count-1)index position.
wu23399_ch19.qxd 1/2/07 20:46 Page 1043

B/W Confirming Pages
The pop operation removes the top-of-stack element. If the stack is not empty, weadjust the count data member and remove the topmost element by setting the valueof the corresponding index position to null. Here’s the method:
public E pop() throws NPSStackEmptyException {
if (isEmpty( )) {
throw new NPSStackEmptyException( );
} else {
count--;
E item = element[count];element[count] = null;
return item;}
}
Adding a new item to the top of a stack and updating the count data member can beexpressed easily and concisely as
element[count] = item;count++;
The complication will arise when the array is fully occupied. When the array isfull, we need to enlarge it to accommodate more items. We will define a privatemethod called expand to create a new array that is 1.5 times larger than the currentarray. This is the same technique we used in the NPSArrayList class. Here’s the method:
private void expand( ) {
// create a new array whose size is 150% of// the current arrayint newLength = (int) (1.5 * element.length);E[] temp = (E[]) new Object[newLength];
// now copy the data to the new arrayfor (int i = 0; i < element.length; i++) {
temp[i] = element[i];}
element = temp;}
The push method is defined as follows:
public void push(E item) {
if (count == element.length) {expand( );
}
element[count++] = item;}
1044 Chapter 19 Stack ADT
pop
push
Can be combined into onestatement as
element[count++] = item;
wu23399_ch19.qxd 1/2/07 20:46 Page 1044

B/W Confirming Pages
The last method is straightforward. We simply return the value of the count datamember.
public int size ( ) {
return count;}
Here’s the complete source code (for brevity, javadoc and most other com-ments in the actual source file are removed here):
19.3 The Array Implementation 1045
size
NPSArrayStack
package edu.nps.util;
public class NPSArrayStack<E> implements NPSStack<E> {
private static final int DEFAULT_SIZE = 25;
private E[ ] element;
private int count;
public NPSArrayStack( ) {this(DEFAULT_SIZE);
}
public NPSArrayStack(int size) {if (size <= 0) {
throw new IllegalArgumentException("Initial capacity must be positive");
}
element = (E[]) new Object[size];count = 0;
}
public void clear() {
for(int i = 0; i < count; i++) {element[i] = null;
}
count = 0;}
public boolean isEmpty() {
return count == 0;}
public E peek( ) throws NPSStackEmptyException {
if (isEmpty( )) {
Constructor
clear
isEmpty
peek
wu23399_ch19.qxd 1/2/07 20:46 Page 1045

B/W Confirming Pages
throw new NPSStackEmptyException( );
} else {
return element[count-1];}
}
public E pop() throws NPSStackEmptyException {
if (isEmpty( )) {
throw new NPSStackEmptyException( );
} else {
count--;
E item = element[count];element[count] = null;
return item;}
}
public void push(E item) {
if (count == element.length) {expand( );
}
element[count++] = item;}
public int size( ) {
return count;}
private void expand( ) {
int newLength = (int) (1.5 * element.length);E[] temp = (E[]) new Object[newLength];
for (int i = 0; i < element.length; i++) {temp[i] = element[i];
}
element = temp;}
}
1046 Chapter 19 Stack ADT
pop
push
size
expand
wu23399_ch19.qxd 1/2/07 20:46 Page 1046
B/W Confirming Pages
19.4 The Linked-List Implementation 1047
1. Draw the array stack (like the right-hand side diagram in Figure 19.8) afterexecuting the following operations, starting with an empty stack calledmyStack.
String bee = new String("bee");String cat = new String("cat");
myStack.clear();myStack.push(cat);myStack.push(bee);
2. What is the purpose of the enlarge method?
3. What will happen if you replace the statement inside the else block of the popmethod with the following?
return element[count--];
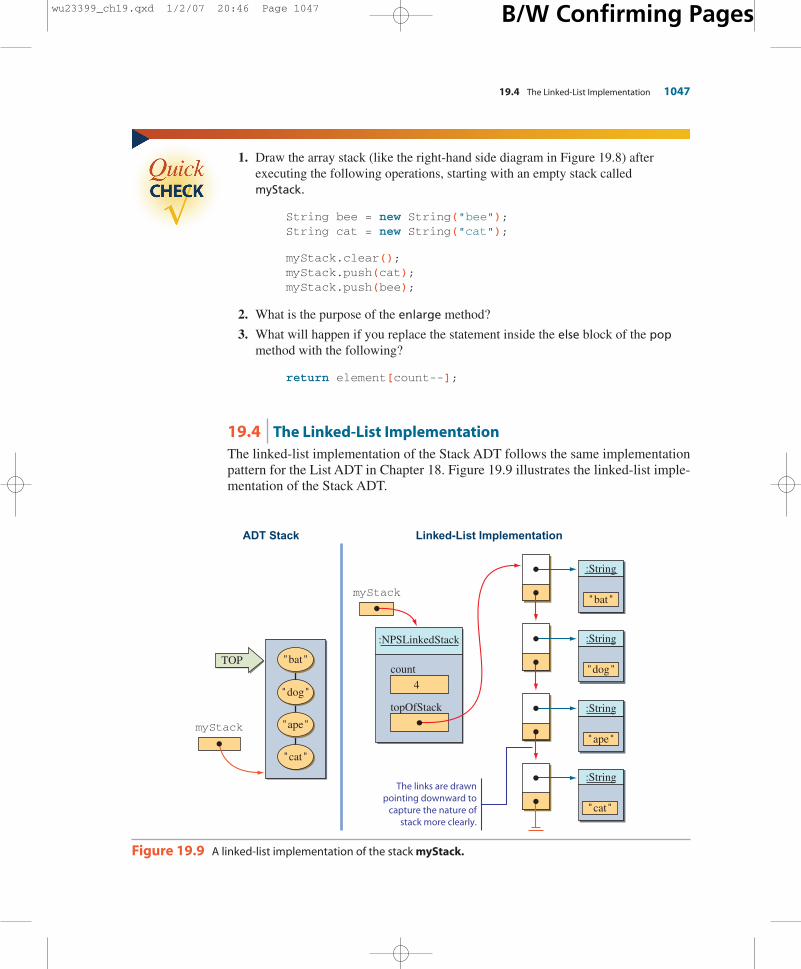
19.4 The Linked-List ImplementationThe linked-list implementation of the Stack ADT follows the same implementationpattern for the List ADT in Chapter 18. Figure 19.9 illustrates the linked-list imple-mentation of the Stack ADT.
Linked-List ImplementationADT Stack
TOP "bat"
"dog"
"ape"
"cat"
myStack
The links are drawnpointing downward to
capture the nature ofstack more clearly.
:NPSLinkedStack
count
topOfStack
4
myStack
:String
"bat"
:String
"dog"
:String
"ape"
:String
"cat"
Figure 19.9 A linked-list implementation of the stack myStack.
wu23399_ch19.qxd 1/2/07 20:46 Page 1047

B/W Confirming Pages
The StackNode ClassThe linked node structure for the stack is exactly the same as the one for the list. TheStackNode class is defined as the inner class of the NPSLinkedStack class. Here’s theclass definition:
class StackNode {
private E item;
private StackNode next;
public StackNode(E item) {this.item = item;this.next = null;
}}
The NPSLinkedStack ClassWe keep two data members in the class. The first data member is a reference vari-able topOfStack that points to the top-of-stack element. We adjust its value everytime we pop an item from or push an item onto the stack. The second data memberis an int variable count that keeps track of the number of elements currently in thestack. Their declarations are as follows:
private StackNode topOfStack;
Private int count;
We define only a single constructor that takes no arguments and sets thestack to its initial state, which is an empty stack. The constructor is defined asfollows:
public NPSLinkedStack( ) {clear( );
}
When we reset the topOfStack pointer to null, the topmost node will get garbage-collected (because no pointers point to it any more). When this topmost node getsgarbage-collected, the node below no longer has a pointer pointing to it, whichcauses this node to be garbage-collected also. This ripple effect will eventuallycause all nodes to be garbage-collected. Here’s the clear method:
public void clear( ) {topOfStack = null;count = 0;
}
1048 Chapter 19 Stack ADT
clear
wu23399_ch19.qxd 1/2/07 20:46 Page 1048

B/W Confirming Pages
The isEmpty method is implemented easily by checking the value of the data mem-ber count:
public boolean isEmpty( ) {return count == 0;
}
If the stack is empty, we throw an NPSstackEmptyException. Otherwise, we returnthe top-of-stack node (without actually removing it). Here’s the method:
public E peek( ) throws NPSStackEmptyException {
if (isEmpty( )) {
throw new NPSStackEmptyException( );
} else {
return topOfStack.item;}
}
If the stack is empty, we throw an NPSStackEmptyException. Otherwise, we seta temp pointer to the topmost item, update the topOfStack pointer, and return thetopmost item. Here’s the method:
public E pop( ) throws NPSStackEmptyException {
if (isEmpty( )) {
throw new NPSStackEmptyException( );
} else {
count--; E temp = topOfStack.item;
topOfStack = topOfStack.link;
return temp;}
}
Adding a new element to a link-based stack is simpler than adding to an array-basedstack because we do not have to worry about the overflow condition. All we needto do is to allocate a new node, adjust the topOfStack pointer, and increment thecounter. The method is defined as follows:
public void push(E element) {
StackNode newTop = new StackNode(element);
newTop.link = topOfStack; //add the new node to top
topOfStack = newTop; //set new node as top-of-stack
count++; }
19.4 The Linked-List Implementation 1049
isEmpty
peek
pop
push
wu23399_ch19.qxd 1/2/07 20:46 Page 1049

B/W Confirming Pages
The size method simply return the value of the data member count:
public int size( ) {return count;
}
We are now ready to list the complete NPSLinkedStack class. In the sourcecode listing, we do not show any javadoc comments, to keep the listing to a man-ageable size. The actual source code includes the full javadoc comments.
1050 Chapter 19 Stack ADT
size
NPSLinkedStack
package edu.nps.util;
public class NPSLinkedStack<E> implements NPSStack<E> {
private StackNode topOfStack;
private int count;
public NPSLinkedStack( ) {clear( );
}
public void clear( ) {
topOfStack = null;
count = 0;}
public boolean isEmpty( ) {
return (count == 0);}
public E peek( ) throws NPSStackEmptyException {
if (isEmpty( )) {
throw new NPSStackEmptyException( );
} else {
return topOfStack.item;}
}
public E pop( ) throws NPSStackEmptyException {
if (isEmpty( )) {
throw new NPSStackEmptyException( );
} else {
count--;E temp = topOfStack.item;
Constructor
clear
isEmpty
peek
pop
wu23399_ch19.qxd 1/2/07 20:46 Page 1050

B/W Confirming Pages
topOfStack = topOfStack.link;
return temp;}
}
public void push(E element) {
StackNode newTop = new StackNode(element);
newTop.link = topOfStack;
topOfStack = newTop;
count++;}
public int size( ) {
return count;}
class StackNode {
private E item;
private StackNode link; //points to the element//one position below this node
public StackNode(E item) {
this.item = item;this.link = null;
}}
}
19.4 The Linked-List Implementation 1051
push
size
StackNode
1. Draw the linked stack (like the right-hand side diagram in Figure 19.9) afterexecuting the following operations, starting with an empty stack calledmyStack.
String bee = new String("bee");String cat = new String("cat");
myStack.clear();myStack.push(cat);myStack.push(bee);
2. Instead of using count == 0 to check for an empty stack, can we usetopOfStack == null?
wu23399_ch19.qxd 1/2/07 20:46 Page 1051

B/W Confirming Pages
19.5 Implementation Using NPSListAt the beginning of this chapter, we wrote that a stack can be characterized asa special kind of a list called a LIFO list. A stack is a LIFO list because the lastitem to be added to a stack is the first item to be removed from the stack next. Wecan in fact implement the Stack ADT by using a list. Consider the followingNPSListStack class:
1052 Chapter 19 Stack ADT
NPSListStack
package edu.nps.util;
public class NPSListStack<E> implements NPSStack<E> {
private static final int FRONT = 0;
private NPSList<E> list;
public NPSListStack( ) {list = new NPSLinkedList<E>();
}
public void clear( ) {list.clear();
}
public boolean isEmpty( ) {return list.isEmpty();
}
public E peek( ) throws NPSStackEmptyException {
if (isEmpty( )) {
throw new NPSStackEmptyException( );
} else {
return list.get(FRONT);}
}
public E pop( ) throws NPSStackEmptyException {
if (isEmpty( )) {
throw new NPSStackEmptyException( );
} else {
return list.remove(FRONT);}
}
public void push(E element) {list.add(FRONT, element);
}
wu23399_ch19.qxd 1/2/07 20:46 Page 1052

B/W Confirming Pages
public int size( ) {
return list.size();}
}
19.6 Sample Application 1053
See how easily and succinctly the whole class can be implemented. Notice thatin this implementation, we treat the first item in the linked list as the top-of-stack item.Do you know why? Instead of the NPSLinkedList class, we can use the NPSArrayListclass. But with the NPSArrayList class, we should treat the last item in the list as thetop-of-stack element to avoid the shifting of items when a new item is added.
Sample Application 19.6 Sample Application
Matching HTML Tags
The use of the Stack ADT is quite common in many different applications. In this sectionwe will illustrate a typical use of a stack.We will write a program that checks the correctnessof a given HTML document. An HTML, which stands for Hyper Text Markup Language, is amarkup language designed for creating a web page. HTML uses a set of predefined tagsto describe the structure of a document.The tags are used, for example, to specify the title,different levels of headings, numbered lists, and tables in a document. XML, or eXtendedMarkup Language, is another markup language that is used widely in today’s computingworld.
It is not necessary to understand HTML fully to appreciate the use of a stack inchecking the syntax of an HTML document.We only need to know how the HTML tags areorganized in a document.The following is a very small (and valid) HTML document:
<html><head><title>A sample HTML page</title></head><body><h1>Sample HTML</h1><p>See how the tags are matched in pairs?</p><h4>This is a table</h4><table border="2">
<tr><td>row 1 column 1</td><td>row 1 column 2</td>
</tr></table></body></html>
wu23399_ch19.qxd 1/2/07 20:46 Page 1053

B/W Confirming Pages
19.6 Sample Application—continued
Figure 19.10 shows how this HTML document is displayed in a Web browser. TheWeb browser interprets the tags in the given HTML document and renders the pageaccordingly.
The key characteristic of HTML tags is that the tags come in pairs: the openingand matching closing tags. There’s an exception to this rule, but we will ignore it for thesake of simplicity in the following discussion (see Exercise 11). For example, the openingtag for the title is
<title>
and its matching closing tag is
</title>
The closing tag includes the forward slash (/) before the tag name. The tag names are case-insensitive, so it doesn’t matter, for example, if we specify the opening tag for the title as
<title>
or as
<TITLE>
The tags in the example HTML document are displayed in blue for easy viewing. Thetext in black is the content that gets displayed in the Web browser. If we strip the content,
1054 Chapter 19 Stack ADT
Figure 19.10 A Web browser displaying the sample HTML document.
wu23399_ch19.qxd 1/2/07 20:46 Page 1054

B/W Confirming Pages
this is what we get (tags are indented to show the structure clearly):
Notice how the matching tags are nested. We will never encounter a situation in whichthe matching tags cross over. In other words, in a valid HTML document,we will never facea situation like this:
We can characterize the formulation of tags in a valid HTML document asfollows:
1. All opening tags have matching closing tags.
2. When a closing tag is encountered in the document, its corresponding openingtag was already encountered. That is, opening tags always come before theclosing tags.
3. Tags can be nested, but they never overlap.
<body>
<table>
</body>
</table>
InvalidThis type of crossover will not happenin a valid HTML file.
<html>
<head>
<title>
</title>
</head>
<body>
<h1>
</h1>
<p>
</p>
<h4>
</h4>
<table border=”2”>
<tr>
<td>
</td>
<td>
</td>
</tr>
</table>
</body>
</html>
19.6 Sample Application 1055
wu23399_ch19.qxd 1/2/07 20:46 Page 1055

B/W Confirming Pages
19.6 Sample Application—continued
These characteristics call for a stack to check the validity of a given HTML document.Here’s the pseudocode for the syntax checker:
NPSStack tagStack = new NPSArrayStack( );
boolean hasError = false, done = false;
while (!done) {
if (no more tags in a file) {done = true;if (!tagStack.isEmpty( )) {
hasError = true;}
} else {nextTag = get next tag from the file;
if (nextTag is an opening tag) {
tagStack.push(nextTag); //every opening tag gets//stacked exactly once
} else { //it's a closing tag
topTag = tagStack.pop( );
if (topTag does not match nextTag) {done = true;hasError = true;
}}
}}
if (hasError) {//Invalid HTML
} else {//Valid HTML
}
To concentrate on the stack processing, we assume the two helper classes—HTMLTagRetriever and HTMLTag. An HTMLTagRetriever object handles the retrieval of HTMLtags from the specified file. An HTMLTag object represents a single HTML tag.Implementation of these classes is left as an exercise. Table 19.2 lists the methods ofHTMLTagRetriever, and Table 19.3 lists the method of HTMLTag.
Now we are ready to implement the pseudocode. Let’s define a class named HTMLTagChecker. The major portion of the logic expressed in the pseudocode is implementedin the key method called isValid. This method returns true if the tags in the designated
1056 Chapter 19 Stack ADT
If all tags areprocessed and yet
the stack is notempty, then it means
there were openingtags with no match-
ing closing tags.
If the next incoming tag is aclosing tag, its corresponding
opening tag must be thecurrent top-of-stack element
because of the properlynested characteristic.
wu23399_ch19.qxd 1/2/07 20:46 Page 1056

B/W Confirming Pages
file are syntactically correct. Otherwise, it returns false. The name of the file to process ispassed to the constructor of HTMLTagChecker. Here’s the class:
19.6 Sample Application 1057
import edu.nps.util.*;
import java.io.IOException;
public class HTMLTagChecker {
private NPSStack<HTMLTag> tagStack;
private HTMLTagRetriever tagRetriever;
public HTMLTagChecker(String filename) throws IOException {
tagStack = new NPSArrayStack<HTMLTag>( );
tagRetriever = new HTMLTagRetriever(filename);}
HTMLTagChecker
Tab
le
Table 19.2 The HTMLTagRetriever class
Class:HTMLTagRetriever
HTMLTagRetriever( String filename ) throws IOException
Constructs a new HTMLTagRetriever object and associates it to thefile with the name filename. Throws an IOException if the said filecannot be opened.
void reset( )
Resets this object so the processing of the tags can be repeated from thebeginning.
void reset( String filename ) throws IOException
Same as the reset method with no parameter. This method, however,associates the object to the new file.Throws an IOException if said filecannot be opened.
boolean hasMoreTags( )
Returns true if there are more tags in the file. Otherwise, returnsfalse.
HTMLTag nextTag( ) throws NoSuchElementException
Returns the next HTMLTag object in the file. If there are no more tags,then the NoSuchElementException exception is thrown.
wu23399_ch19.qxd 1/2/07 20:46 Page 1057
B/W Confirming Pages
19.6 Sample Application—continued
public boolean isValid( ) {
HTMLTag nextTag = null,topTag = null;
tagStack.clear( );
boolean hasError = false,done = false;
while (!done) {
if (!tagRetriever.hasMoreTags( )) { //no more tags
done = true;
1058 Chapter 19 Stack ADT
Tab
leTable 19.3 The HTMLTag class
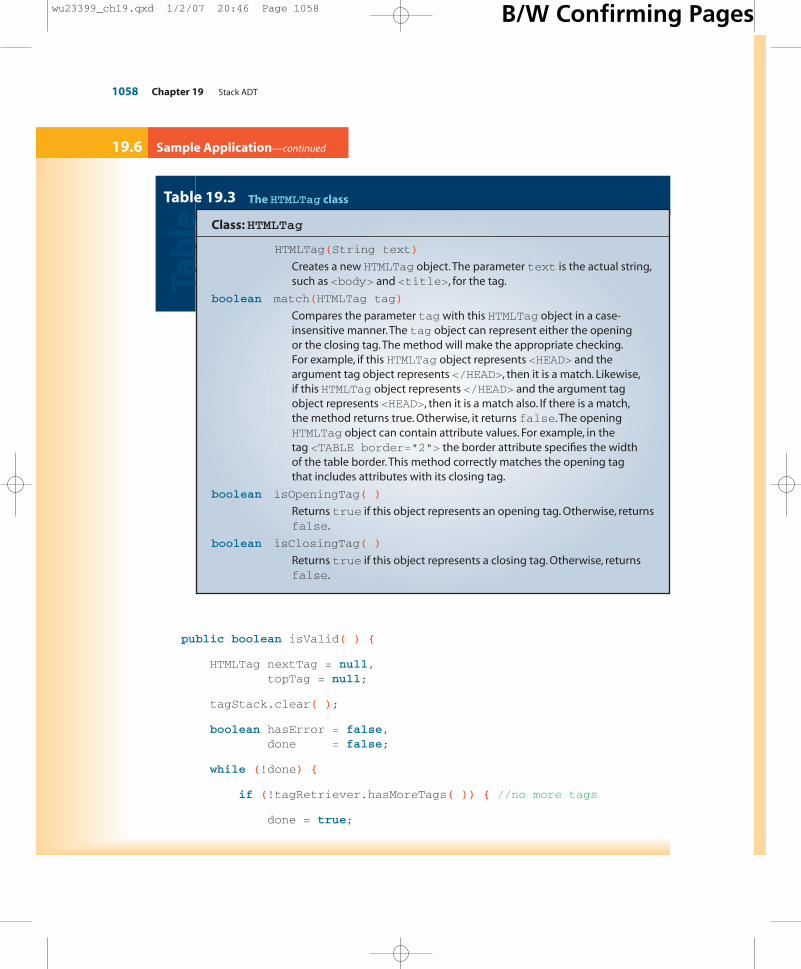
Class:HTMLTag
HTMLTag(String text)
Creates a new HTMLTag object.The parameter text is the actual string,such as <body> and <title>, for the tag.
boolean match(HTMLTag tag)
Compares the parameter tag with this HTMLTag object in a case-insensitive manner.The tag object can represent either the openingor the closing tag.The method will make the appropriate checking.For example, if this HTMLTag object represents <HEAD> and theargument tag object represents </HEAD>, then it is a match. Likewise,if this HTMLTag object represents </HEAD> and the argument tagobject represents <HEAD>, then it is a match also. If there is a match,the method returns true. Otherwise, it returns false.The openingHTMLTag object can contain attribute values. For example, in thetag <TABLE border="2"> the border attribute specifies the widthof the table border.This method correctly matches the opening tagthat includes attributes with its closing tag.
boolean isOpeningTag( )
Returns true if this object represents an opening tag. Otherwise, returnsfalse.
boolean isClosingTag( )
Returns true if this object represents a closing tag. Otherwise, returnsfalse.
wu23399_ch19.qxd 1/2/07 20:46 Page 1058

B/W Confirming Pages
if (!tagStack.isEmpty( )) { //there are some//leftover opening tags
hasError = true; //with no matching closing tags
done = true;}
} else {
nextTag = tagRetriever.nextTag( );
if (nextTag.isOpeningTag( )) {
tagStack.push(nextTag);
} else { //it's a closing tag
topTag = tagStack.pop( );
if (!topTag.match(nextTag)) {
done = true;hasError = true;
}}
}}
return hasError;}
///------------ M A I N m e t h o d ---------------------//public static void main(String[] arg) {
try {
HTMLTagChecker checker = new HTMLTagChecker("index.html");
if (checker.isValid()) {System.out.println("Input HTML file is valid");
} else {System.out.println("Input HTML file is NOT valid");
}
} catch (IOException e) {System.out.println("Error opening the designated file");
}}
}
19.6 Sample Application 1059
wu23399_ch19.qxd 1/2/07 20:46 Page 1059

B/W Confirming Pages
1060 Chapter 19 Stack ADT
Solving a Maze with Backtracking
Many computer problems can be solved by the technique called backtracking. The namecharacterizes how the solution to a problem is found. Consider a maze problem. We definea maze to be a two-dimensional array of cells.Each cell has four sides with at most three sideshaving a wall. You can move from one cell to an adjacent cell if there is no wall between thetwo cells. Two special cells are indentified as the entry and exit cells. The problem is to find apath that takes you from the entry cell to the exit cell of a given maze.Figure 19.11 shows asample 5-by-5 maze. For humans, finding a solution path for a such small maze is almostimmediate. But when the maze gets larger, say, 100 by100, finding a solution is not an easymatter anymore.(We’re talking here about a human finding a solution for a maze drawn ona sheet of paper,and not about finding solution for a real-life maze or labyrinth.)
What kind of a computer solution can we devise to find a solution path? We assumehere that a given maze includes at least one solution path. A maze is represented by aMaze object that consists of N-by-M cells. A cell is represented by a MazeCell object. TheMaze and MazeCell classes are described in Tables 19.4 and 19.5, respectively. It is left asan exercise to implement these two classes.
One brute-force solution is to visit cells randomly, starting from the entry cell. This isakin to a human walking blindly around the maze. This simplistic approach can beexpressed in the following manner:
public void solveRandom(Maze maze) {
MazeCell current = maze.getEntryCell();MazeCell exit = maze.getExitCell();
Sample Development19.7 Sample Application
backtracking
Figure 19.11 A sample maze with 5-by-5 cells.The entry cell is marked with S and the exit cell with E.The dotted line shows the solution path from S to E. For this maze, there’s exactly one solution path.
0
0
1
2
3
4
S
E
(0,3)(0,2)(1,2)(2,2)(3,2)(1,3)(3,0)(4,0)(4,1)(4,2)(4,3)(3,3)(3,4)(2,4)
Solution PathS
E
Cell is identified bythe row and column
numbers. This cell,for example, is (2,0).
4321
wu23399_ch19.qxd 1/2/07 20:46 Page 1060

B/W Confirming Pages
while (current != exit) {
//move to a random adjacent cellcurrent = maze.getNextRandomCell(current);
}
System.out.println("Solution Path Found");}
Since the method does not keep track of the cells visited, all it does is to output the mes-sage Solution Path Found when the exit cell is reached. It does not (cannot) print out thesolution path.
A much more elegant solution would be backtracking. Here’s how it works. Markthe entry cell visited. Visit an adjacent cell that is not yet visited. Mark this cell visited (sowe won’t visit this cell again). Repeat this visit-and-mark-visited routine until either theexit cell is visited or there is no adjacent cell to visit from the current cell. If the exit cell isvisited, then we found the solution. If there are no more adjacent cells to visit from the
19.7 Sample Development 1061
Tab
le
Table 19.4 The Maze class
Class:Maze
Maze( int rowSize, int columnSize )
Creates a new rowSize-by-columnSize maze. In its initial state, allcells are marked unvisited. One cell is designated as the entry cell andanother cell as the exit cell. The entry and exit cells border one of theouter boundaries.
void clear( )
Resets the maze to its initial state.
int getColumnCount( )
Returns the number of columns of this maze.
int getRowCount( )
Returns the number of rows of this maze.
MazeCell getEntryCell( )
Returns the entry cell.
MazeCell getExitCell( )
Returns the exit cell.
MazeCell getNextCell( MazeCell currentCell )
Returns a visitable cell adjacent to currentCell. Returns null ifthere is no visitable adjacent cell.
MazeCell getNextRandomCell( MazeCell currentCell )
Randomly selects and returns a cell adjacent to currentCell.Thestate of cell (visitable or not) is ignored by this method.
wu23399_ch19.qxd 1/2/07 20:46 Page 1061

B/W Confirming Pages
19.7 Sample Application—continued
current node, we backtrack to the cell before the current cell and repeat the process againfrom that cell. Figure 19.12 illustrates two backtracking steps.
The key aspect of implementing this backtracking algorithm is to remember thecell to backtrack to.The ADT that goes hand in hand with backtracking is a stack.When wevisit a cell, we push it onto a stack. The current cell is at the top of stack, and the adjacentcell we visit next from the current cell will be the new top of stack (and it will be the cur-rent cell in the next iteration). When we backtrack from a cell, we simply pop a stack. Thenew top of stack is the cell we’re backtracking to. Figure 19.13 shows the correspondencebetween the path and the stack content.
We use the setVisited method of the MazeCell class to mark a visited cell. ThegetNextCell method of the Maze class returns a next visitable cell (a cell that is not yet
1062 Chapter 19 Stack ADT
Tab
leTable 19.5 The MazeCell class
Class:MazeCell
MazeCell( int rowNum, int columnNum )
Creates a new cell. Each cell is identified by its row number andcolumn number, the position it occupies in a maze. In its initial state, allfour walls are up.
int getColumnNumber( )
Returns the column number of this cell.
int getRowNumber( )
Returns the row number of this cell.
boolean isVisited( )
Returns true if the cell is not visited yet (i.e., it is visitable) and falseif the cell is visited.
boolean isWallUp( int side )
Returns true if the wall of the specified side of this cell is up. Possiblevalues for the parameter are MazeCell.NORTH,MazeCell.SOUTH,MazeCell.EAST, and MazeCell.WEST.
void putWallDown( int side )
Knocks down the wall of the specified side of this cell. Possible valuesfor the parameter are MazeCell.NORTH,MazeCell.SOUTH,MazeCell.EAST, and MazeCell.WEST.
void setVisited( boolean state )
Sets the state of this cell.The value of true means the cell is visitedand false means not visited.
wu23399_ch19.qxd 1/2/07 20:46 Page 1062

B/W Confirming Pages
visited) from a given cell. If there are no more visitable cells from a given cell, the methodreturns null. Here’s the method that finds a solution path by backtracking:
public void solveBacktracking(Maze maze) {
MazeCell current = maze.getEntryCell();MazeCell exit = maze.getExitCell();
NPSStack<MazeCell> stack= new NPSArrayStack<MazeCell>( );
stack.push(current);
while (current != exit) {
current = maze.getNextCell(current);
19.7 Sample Development 1063
Figure 19.12 This illustrates how the backtracking works.Visited cells are marked with a red circle.Diagram A: There are no more adjacent cells to visit from the current cell (C), so we backtrack to cell (1,0).Diagram B: Again, there are no more adjacent from the current cell, so we backtrack. Diagram C: From thecurrent cell, we can visit cell (0,1), so we visit it next (N).
0 1 2 3 4
0
1
2
3
4
A
S
C
0 1 2 3 4
0
1
2
3
4
B
S
C
0 1 2 3 4
0
1
2
3
4
C
S
C
N
backtrack
from (2,0)to (1,0)
backtrack
from (1,0)to (1,1)
Figure 19.13 The stack content shows the order of visiting cells in the path currently underconsideration.
0 1 2 3 4
0
1
2
3
4
S
C
(2,1)
(2,2)
(1,2)
(0,2)
(0,3)
stack
wu23399_ch19.qxd 1/2/07 20:46 Page 1063

B/W Confirming Pages
19.7 Sample Application—continued
if (current != null) {
current.setVisited(true); //mark it visitedstack.push(current);
} else { //no more visitable cells from the//top-of-stack cell, so backtrack
current = stack.pop();}
}
System.out.println("Solution Path:");
while (stack.isEmpty()) { //print out the solutionSystem.out.println(stack.pop()); //path backward
}}
Because we are using a stack, the solution path found is printed backward from theexit cell to the entry cell. It is more natural to print out the path forward from the entry cellto the exit cell. This is left as an exercise.
1064 Chapter 19 Stack ADT
• A stack is a linearly ordered last-in, first-out (LIFO) collection ofelements.
• An item can be added to only the top of a stack, and only the top item of astack can be removed.
• An array and a linked-list are two possible implementations of the StackADT.
• The Stack ADT can be implemented easily by using a list (an instance of aclass that implements the List ADT).
• Base implementation of the Stack ADT does not support any traversaloperation.
• The use of the Stack ADT is illustrated in two sample applications: anHTML syntax checker and a maze solver.
• Backtracking is a technique used in finding a solution for a searchproblem. The Stack ADT is used in implementing the backtrackingalgorithm.
S u m m a r y
wu23399_ch19.qxd 1/2/07 20:46 Page 1064

B/W Confirming Pages
Exercises 1065
K e y C o n c e p t s
Stack ADT
array implementation of Stack ADT
E x e r c i s e s
1. Draw a state-of-memory diagram that shows the effect of the pop operationon a NPSLinkedStack. Use the state where there are four items in the stackbefore the pop operation.
2. Draw a state-of-memory diagram that shows the effect of the push operationon a NPSLinkedStack. Use the state where there are three items in the stackbefore the push operation.
3. Draw a state-of-memory diagram that shows the result of executing each ofthe following two sets of code.
a.NPSStack stack = new NPSLinkedStack( );
Person p = new Person(...);
stack.push(p);stack.push(p);
b.NPSStack stack = new NPSLinkedStack( );
Person p1 = new Person(...);Person p2 = new Person(...);
stack.push(p1);stack.push(p2);
4. Add a new method toArray to the NPSStack interface and implement the methodin both NPSArrayStack and NPSLinkedStack. The toArray method will return anarray with the bottommost element at position 0, element 1 above the bottom atposition 1, and so forth. For a mathematically pure Stack ADT, we do not definesuch conversion operation. But in the actual use of stacks, we often need toaccess every element in the stack. For example, in the maze sample application,if the toArray method is available, we can easily print out the solution path inthe forward direction (from the entry cell to the exit cell) instead of thebackward direction that we printed in the solveBacktracking method.
5. Adding the toArray method is one way to provide access to all elements in astack. Another way is to include the iterator method to the NPSStackinterface that returns an iterator. Implement the iterator method in bothNPSArrayStack and NPSLinkedStack. The iterator will access the items in thestack from top to bottom.
linked-list implementation of Stack ADT
backtracking
wu23399_ch19.qxd 1/2/07 20:46 Page 1065

B/W Confirming Pages
6. Code a new implementation class for the Stack interface called NoDupStackthat does not allow a duplicate of the existing element to be pushed onto thestack. We define an element e2 to be a duplicate of e1 if e1.equals(e2) istrue. Define a new exception class called NPSDuplicateException and throwthis exception from the push method when an attempt is made to push aduplicate. Use an array for this implementation.
7. Repeat Exercise 6, but this time use the linked nodes instead of an array.
8. In the NPSLinkStack class, the data member list is an instance ofNPSLinkedList we use to maintain the stack elements. If a stack is a LIFO list(i.e., a stack IS-A a list), shouldn’t we define it as a subclass of theNPSLinkedList class? Why is it wrong to so?
9. When implementing the NPSListStack class, we treat the first item in a list as thetop-of-stack item. Modify the class so the last item in the linked list is treatedas the top-of-stack item. Which implementation is more efficient? Why?
10. Implement the NPSListStack class using the NPSArrayList class.
11. Implement the HTMLTagRetriever class. There are some HTML tags that donot have the matching closing tags. For this exercise, assume such tags are<br>, <hr>, and <img> tags. The nextTag method must ignore these tags.
12. Implement the HTMLTag class. Pay close attention to the match method.Some opening tags, such as the <table> tag, can contain attributes inaddition to the tag name. For example, the <table> tag can be
<table>
or
<table border="2">
When you match the opening and closing tags, you have to ignore theattributes in the opening tags.
13. In this chapter, we assumed that a given maze has at least one solution path.Modify the solveBacktracking method so it will handle the case when a givenmaze does not have any solution. Terminate the method after displaying themessage No Solution Path if there is no solution path.
14. The solveBacktracking method prints out the solution path backward. Modifythe method so the solution path is printed forward from the entry cell to theexit cell. Assume the original definition of the NPSStack interface. Specifically,you cannot use the toArray method (see Exercise 4). Hint: Use another stack.
15. Implement the Maze and MazeCell classes. Their public methods aredescribed in Tables 19.4 and 19.5, respectively. The most difficult aspect ofthis exercise is the creation of a maze, which is carried out in the constructorof the Maze class. Here’s one way to create a maze that has exactly onesolution path from the entry cell to the exit cell:
1. Start with all four walls up for every cell in the maze.2. Knock down the walls to create paths.
1066 Chapter 19 Stack ADT
wu23399_ch19.qxd 1/2/07 20:46 Page 1066

B/W Confirming Pages
3. Randomly select the entry and exit cells. Make sure these are selected fromthe boundary cells (those that face the boundary of the maze).
The basic idea of the algorithm for step 2 goes like this: Start from a randomcell. Remember this cell in a list. Mark this cell as visited. (You will visitevery cell in the maze exactly once.) Set this cell as current. Find an adjacentcell of the current cell that is not yet visited. Knock down the walls betweenthis cell and the current cell. Set this cell as the current cell and repeat theprocess. If there are no more visitable cells from the current cell, remove arandom cell from the list and repeat the process. Stop the routine when allcells in the maze are visited. Expressing this basic idea in a more “formal”pseudocode, we have the following:
mark all cells as 'not visited';
currentCell = pick a random cell;
list.add(currentCell);
while (there are unvisited cells) {
currentCell = list.get(random location);
while (currentCell has a 'not visited' adjacent cell) {
if (currentCell has more than 1'not visited' adjacent cell) {
list.add(currentCell); //put it back in the list} //so other adjacent cells are
//considered later
previousCell = currentCell;currentCell = getNextCell(previousCell);
mark currentCell as 'visited';
knock down the wall betweenpreviousCell and currentCell;
list.add(currentCell);}
}
To support some of the operations expressed in the pseudocode, you mayhave to define additional methods in the MazeCell class.
16. Write a program that checks if the input arithmetic expression issyntactically correct. Assume the arithmetic expressions include only integerconstants, four arithmetic operators, and parentheses. Nested parentheses areallowed. Here are examples of valid arithmetic expressions:
4 + 548 * (2 + 7)(23 / (3 - 4)) / 812
Exercises 1067
wu23399_ch19.qxd 1/2/07 20:46 Page 1067

B/W Confirming Pages
And here are examples of invalid arithmetic expressions:
3 + - 89 * (4 + 2))) 4 + 3 (
17. Forth is a unique and interesting programming language. It can becharacterized as a stack-oriented programming language where programsare written in postfix notation. If we write arithmetic expressions usingpostfix notation, we write them as
<leftOperand> <rightOperand> <operator>
For example, instead of writing
45 + 9
we write
45 9 +
in postfix notation. The ordinary way we write arithmetic expressions usesthe notation called infix. Here are some examples that compare the infix andpostfix expressions:
Infix Postfix
4 � 8 � 5 4 8 � 5 �4 � (8 � 5) 4 8 5 � �4 * 8 � 5 4 8 * 5 �4 * (8 � 5) 4 8 5 � *
Notice that postfix expressions do not include parentheses because they arenot necessary. Write a program that evaluates a given postfix arithmeticexpression that consists of integer constants and four arithmetic operators �,�, /, and *. You use a stack to remember the operands. Whenever youencounter an operand in the input postfix expression, stack it. When youencounter an operator in the input postfix expression, its left and rightoperands are in the stack. Pop the stack twice to get the left and rightoperands, compute the result, and push the result back to the stack. Whenthere are no more operators left in the expression, the top-of-stack elementin the stack is the result of the whole expression. You may assume the inputpostfix expression is syntactically correct, so you do not have to do anyerror checking.
1068 Chapter 19 Stack ADT
wu23399_ch19.qxd 1/2/07 20:46 Page 1068





























![ADT Stack Implementazione in Linguaggio C - diee.unica.itarmano/LT1/pdf/LT1-7C.pdf · 3 3 Specifica Algebrica dell’ADT Stack STACK type Stack [Item] uses Item, Boolean syntax NEWSTACK](https://img.pdfslide.us/doc/110x75/5c67720509d3f23a018bccde/adt-stack-implementazione-in-linguaggio-c-dieeunicait-armanolt1pdflt1-7cpdf.jpg)