Embed Size (px)
DESCRIPTION
SQL
Citation preview

Database
DBMS Vs RDBMS
DBMS: DBMS Stands for Database mangment systemDatabase management systems (DBMSs) are the systems which were specially designed in a way that it can interact with the user, other applications, and the database itself to capture and analyze data.The various models of database management systems are:1. Hierarchical2. Network3. Object-oriented4. Associative5. Column-Oriented6. Navigational7. Distributed8. Real Time Relational9. SQL
Earlier there were File System Databases which were not as efficient as the DBMS because multiple users can’t work on FMS. There were no relation between the diffrent files. while with new dbms you can access the multiple objectsand store data accross multiple objects.The example of a flat file database is a basic name-and-address list, where the database consists of a small, fixed number of fields:Name, Address, and Phone Number. Another example is a simpleHTML table, consisting of rows and columns
RDBMS is a form of DBMS where RDBMS stands for Relational Database Management System in whihc data stores in form of table and these tables can have relations between them.Key are used to get relation between multiple system.RDBMS is proposed by codd.SQL Server, Oracle are the some of the RDBMS which are available.
ACID PROPERTIES
In Database, ACID (atomicity, consistency, isolation, durability) is a set of properties that guarantee that database transactions are processed reliably. In the context of databases, a single logical operation on the data is called a transaction.
An example of a transaction is a transfer of funds from one bank account to another, even though it might consist of multiple individual operations (such as debiting one account and crediting another).
Atomicity
Atomicity refers to the ability of the DBMS to guarantee that either all of the tasks of a transaction are performed or none of them are.

For example, the transfer of funds from one account to another can be completed or it can fail for a multitude of reasons, but atomicity guarantees that one account won’t be debited if the other is not credited.
Atomicity states that database modifications must follow an “all or nothing” rule. Each transaction is said to be “atomic” if when one part of the transaction fails, the entire transaction fails. It is critical that the database management system maintain the atomic nature of transactions in spite of any DBMS, operating system or hardware failure.
Consistency
The consistency property ensures that the database remains in a consistent state before the start of the transaction and after the transaction is over (whether successful or not).
Consistency states that only valid data will be written to the database. If, for some reason, a transaction is executed that violates the database’s consistency rules, the entire transaction will be rolled back and the database will be restored to a state consistent with those rules. On the other hand, if a transaction successfully executes, it will take the database from one state that is consistent with the rules to another state that is also consistent with the rules.
Isolation
Isolation refers to the requirement that other operations cannot access or see the data in an intermediate state during a transaction. This constraint is required to maintain the performance as well as the consistency between transactions in a DBMS. Thus, each transaction is unaware of other transactions executing concurrently in the system.
Durability
Durability refers to the guarantee that once the user has been notified of success, the transaction will persist, and not be undone. This means it will survive system failure, and that the database system has checked the integrity constraints and won’t need to abort the transaction.
Many databases implement durability by writing all transactions into a transaction log that can be played back to recreate the system state right before a failure. A transaction can only be deemed committed after it is safely in the log.
Durability does not imply a permanent state of the database. Another transaction may overwrite any changes made by the current transaction without hindering durability.
What is normalization in SQL Server Database?

Normalization means to separate the data in multiple related tables using formal methods. I.e. its major objective is to divide larger tables in to smaller table to reduce data redundancy and improve perfor4mance of the data base.
1. Some basic advantage of using normalize data base.
1. Database will be in more readable form as it will be represented in the form of small entities through tables.
2. Remove the data redundancy as if you are putting each value in same table which can be same for multiple records results in storing the data multiple times in data base. For example
To elaborate this we can take student example. Suppose we have to store the student general details and there subject details.
Name Age Class Phone Address Subject 1
Sub 2 Sub 3
Randheer
xx xyz 9313xxxxxx
Abc xyz Physic Chem Math
New 1 xx xyz 9313xxxxxx
Abc xyz Physic Chem Math
New 2 xx xyz 9313xxxxxx
Abc xyz Physic Chem Math
New-3 xx xyz 9313xxxxxx
Abc xyz Physic Chem Bio
In above example the Subject is always repeating so that redundant data is appearing. The normalization of this can be done by creating to separate table for student details and subject and relation can be created between them.
3. Table should avoid null values.
4. Table should have some identifier.
Normalization Denormalization
Database normalization is the process of organizing the fields and tables of a relational database to minimize redundancy and dependency. Normalization usually involves dividing large tables into smaller tables and relationships between them. The main goal is to isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships.Informally, a relational database table is often described as "normalized" if it is in the Third Normal Form. Most 3NF tables are free of insertion, update, and deletion anomalies.

Databases intended for online transaction processing (OLTP) are typically more normalized than databases intended for online analytical processing (OLAP). OLTP applications are characterized by a high volume of small transactions such as updating a sales record at a supermarket checkout counter. The expectation is that each transaction will leave the database in a consistent state. By contrast, databases intended for OLAP operations are primarily "read only" databases. OLAP applications tend to extract historical data that has accumulated over a long period of time. For such databases, redundant or "denormalized" data may facilitate business intelligence applications. Specifically, dimensional tables in a star schema often contain denormalized data. The denormalized or redundant data must be carefully controlled during extract, transform, load (ETL) processing, and users should not be permitted to see the data until it is in a consistent state. The normalized alternative to the star schema is the snowflake schema. In many cases, the need for denormalization has waned as computers and RDBMS software have become more powerful, but since data volumes have generally increased along with hardware and software performance, OLAP databases often still use denormalized schemas.Denormalization is also used to improve performance on smaller computers as in computerized cash-registers and mobile devices, since these may use the data for look-up only (e.g. price lookups). Denormalization may also be used when no RDBMS exists for a platform (such as Palm), or no changes are to be made to the data and a swift response is crucial
Table Design
TSQL Interview Questions: TableA table is a set of data elements (values) that is organized using a model of vertical columns (which are identified by their name) and horizontal rows, the cell being the unit where a row and column intersect. A table has a specified number of columns, but can have any number of rows [citation needed]. Each row is identified by the values appearing in a particular column subset which has been identified as a unique key index.
TSQL Iterview Questions: Data TypesData type: A data type is an attribute that specifies the type of data that the object can store: numeric data, character data, monetary data, date and time data, binary data, and so many more.SQL Server supplies a set of system data types that define all the types of data that can be used with SQL Server.Data type Range Storagebigint -2^63 (-9,223,372,036,854,775,808) to 2^63-1 (9,223,372,036,854,775,807) 8 Bytesint -2^31 (-2,147,483,648) to 2^31-1 (2,147,483,647) 4 Bytes smallint -2^15 (-32,768) to 2^15-1 (32,767) 2 Bytes tinyint 0 to 255 1 Byte

Difference between Varchar and NvarcharAs we all know the basic difference between varchar and Nvarchar is that one holds non Unicode and other holds Unicode data. But we are just aware theoretically and don’t know how it works actually.
Here I am showing an example of how varchar and nvarchar data types works in query analyzer
Declare @sampleVar varchar(10)Declare @sampleNVar nvarchar(10)set @sampleVar = 'VarSamp Ж'set @sampleNVar = 'NVarSamp Ж'
Select @sampleNVar, @sampleVar
set @sampleNVar = N'NVarSamp Ж'set @sampleVar = N'VarSamp Ж'
Select @sampleNVar, @sampleVar
If you will see we have added the suffix N while setting the Unicode data type and its display’s the results otherwise it shows the same result as varchar data type. By seeing this example we can say in Unicode data types can be handled through nvarchar so while developing bilingual application or if there is any possibility to use current application in different languages we should use Nvarchar data types.
Keywords: How to read nvarchar data in SQL Query Analyzer, SQL Server Data types, SQL Server Questions, Varchar ,Nvarchar.
TSQL Interview Questions: DateTime
There are two types of datetime data types
Datetime Stores dates from January 1, 1753 through December 31, 9999, to an accuracy of one three-hundredth of a second (equivalent to 3.33 milliseconds or 0.00333 seconds). Values are rounded to increments of .000, .003, or .007 seconds, as shown in the table.
Small DatetimeStores dates from January 1, 1900, through June 6, 2079, with accuracy to the minute. smalldatetime values with 29.998 seconds or lower are rounded down to the nearest minute; values with 29.999 seconds or higher are rounded up to the nearest minute.
Internally SQL server stores Datetime data in 2 4 bytes integers and smalldatetime stores as 2 2 byte integers. One part stores days before or after base date and next part stores the number of milliseconds after midnight.

Check Constraints in SQL ServerYou use check constraints to limit the range of possible values in a column or to enforce specific patterns for data. Check constraints must evaluate to a Boolean True/False and cannot reference columns in another table.You can create check constraints at two different levels
Column-level check constraints are applied only to the column and cannot reference data in another other column.
Table-level check constraints can reference any column within a table but cannot reference columns in other tables.The most basic constraints compares the data in a column to a specified value---- for example CHECK salary <= 50000. You can create any number of check constraints separated by AND, OR, or NOT to create more complex conditions. You can also use check constraints to enforce patterns within data. Using check constraints this way, you might enforce the pattern that an employee ID is required to start with an uppercase letter, followed by three digits and then six additional letters. Another example is to require an e-mail address to contain , in order, any number of character or digits, an @symbol , a number of characters or digits, a period (.), and then either three characters or two characters with a period (.) plus two more characters. The wildcard characters for pattern matching are underscore (_), which designates one value that can be a character, number or special character; and a percent symbol (%), which designates any number of a characters, numbers, or special characters. For example,a table –level check constraints to validate an e-mail address might look like this :CONSTRAINT chkEmail CHECK (Email like ‘%@% [a-z] [a-z]’ or Email like ‘%@%. [a-z] [a-z].[a-z] [a-z]’A column-level check constraints for the Employee ID looks like this:
CHECK (EmployeeID like ‘[(A-Z] [0-9] [0-9] [0-9] [A-Z] [A-Z] [A-Z] [A-Z] [A-Z] [A-Z] ‘)
TSQL Interview Questions: Primary Key
Uniquely defines the characteristics of each row (also known as record or tuple). The primary key has to consist of characteristics that cannot be duplicated by any other row. The primary key may consist of a single attribute or a multiple attributes in combination. For example, a birthday could be shared by many people and so would not be a prime candidate for the Primary Key, but a social security number or Driver's License number would be ideal since it correlates to one single data value. Another unique characteristic of a Primary Key as it pertains to a relational database is that a Primary Key must also serve as a Foreign Key on a related table.A table can have only one PRIMARY KEY constraint, and a column that participates in the PRIMARY KEY constraint cannot accept null values.The database engine enforces data uniqueness by creating unique index for primary key column.GO
/****** Object: Table [ASIA\NBKWHDR].[DataTest] Script Date: 08/20/2013 17:20:51 ******/SET ANSI_NULLS ONGO
SET QUOTED_IDENTIFIER ON

GO
CREATE TABLE dbo.[DataTest]( [ID] [int] NOT NULL, [Name] [nchar](10) NULL, CONSTRAINT [PK_DataTest] PRIMARY KEY CLUSTERED ( [ID] ASC)) ON [PRIMARY]
GO
Primary Foreign and Unique KeysIn a relational database, a "Primary Key" is a key that uniquely defines the characteristics of each row .The primary key has to consist of characteristics that cannot be duplicated by any other row. The primary key may consist of a single attribute or a multiple attributes in combination. For example, a birthday could be shared by many people and so would not be a prime candidate for the Primary Key, but a social security number or Driver's License number would be ideal since it correlates to one single data value. Another unique characteristic of a Primary Key as it pertains to a relational database, is that a Primary Key must also serve as a Foreign Key on a related table[. For example:
Author TABLE Schema:AuthorTable(AUTHOR_ID,AuthorName,CountryBorn,YearBorn)Book TABLE Schema:Book TABLE(ISBN,Author_ID,Title,Publisher,Price)Here we can see that AUTHOR_ID serves as the Primary Key in AuthorTable but also serves as the Foreign Key on the BookTable. The Foreign Key serves as the link and therefore the connection between the two "related" tables in this sample database.In a relational database, a unique key index can uniquely identify each row of data values in a database table. A unique key index comprises a single columns or a set of columns in a single database table. No two distinct rows or data records in a database table can have the same data value (or combination of data values) in those unique key index columns if NULL values are not used. Depending on its design, a database table may have many unique key indexes but at most one primary key index.A unique key constraint does not imply the NOT NULL constraint in practice. Because NULL is not an actual value (it represents the lack of a value), when two rows are compared, and both rows have NULL in a column, the column values are not considered to be equal. Thus, in order for a unique key to uniquely identify each row in a table, NULL values must not be used. According to the SQL standard and Relational Model theory, a unique key (unique constraint) should accept NULL in several rows/tuples — however not all RDBMS implement this feature correctly.A unique key should uniquely identify all possible rows that exist in a table and not only the currently existing rows. Examples of unique keys are Social Security numbers (associated with a specific person) or ISBNs (associated with a specific book). Telephone books and dictionaries cannot use names, words, or Dewey Decimal system numbers as candidate keys because they do not uniquely identify telephone numbers or words.A table can have at most one primary key, but more than one unique key. A primary key is a combination of columns which uniquely specify a row. It is a special case of unique keys. One difference is that primary keys have an implicit NOT NULL constraint while unique keys do not. Thus, the values in unique key columns may or may not be NULL, and in fact such a column may contain at most one NULL field. Another difference is that primary keys must be defined using another syntax

How to Get the Primary Key and foreign Key between two tablesThese are the few tables which can be used to check the foreign key and primary key column in a table.
It will give both columns from both tables.
INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS
INFORMATION_SCHEMA.TABLE_CONSTRAINTS
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
TSQL Interview Question: Identity column
Identity is the property of column which inserts incremental value in the column at the insert of new row in parent table of that column.
For example in Employee table when we set ID as identity then for every inserted employee record there will be an auto incremental value get inserted in the ID column automatically.
For Identity you can set the increment value i.e. the value by which next inserted value increment. So if you set increment by 10 then inserted value will be like 10, 20, 30, 40……..
These properties can be set in for table while designing it or opening existing table in design mode.
Identity key doesn't guarantee
Uniqueness of the value
Consecutive values within a transaction – If there are multiple transaction then the identity value for every row can be differ in a single transaction.
Reuse of values – if there is error while inserting row that the identity generated will lost and next time SQL server will insert new identity value. It doesn't reuse it.
The seed value is the value inserted into an identity column for the very first row loaded into the table.
How to Check Identity ValueDBCC CHECKIDENT
(
table_name
[, { NORESEED | { RESEED [, new_reseed_value ] } } ]
)

DBCC CHECKIDENT (table)
DBCC CHECKIDENT (table, NORESEED)
DBCC CHECKIDENT (table, RESEED, 10)
SCOPE_IDENTITY, IDENT_CURRENT, and @@IDENTITY
SCOPE_IDENTITY, IDENT_CURRENT, and @@IDENTITY are function used for same value type but different results.
IDENT_CURRENT returns the current identity value irrespective of session and scope.
SCOPE_IDENTITY returns last identity value generated the current scope Irrespective of tables. I.e. it could be value from last table which is updated in current scope.
@@IDENTITY returns the last identity values that are generated in any table in the current session. It’s not limited to any specific scope. I.e. while updating in current scope the trigger on this table insert data in some other table
For example, there are two tables, Table1 and Table2, and an INSERT trigger is defined on Table1.
When a row is inserted to Table1, the trigger inserts a row in Table2. This scenario illustrates two scopes: the insert on Table1 and the insert on Table2 by the trigger.
Table1 and Table2 have identity columns, @@IDENTITY and SCOPE_IDENTITY will return different values at the end of an INSERT statement on Table1.
@@IDENTITY will return the last identity column value inserted across any scope in the current session. This is the value inserted in Table2.
SCOPE_IDENTITY () will return the IDENTITY value inserted in Table1.
SCOPE_IDENTITY, IDENT_CURRENT, and @@IDENTITY
SCOPE_IDENTITY, IDENT_CURRENT, and @@IDENTITY are function used for same value type but different results.
IDENT_CURRENT returns the current identity value irrespective of session and scope.

SCOPE_IDENTITY returns last identity value generated the current scope Irrespective of tables. I.e. it could be value from last table which is updated in current scope.
@@IDENTITY returns the last identity values that are generated in any table in the current session. It’s not limited to any specific scope. I.e. while updating in current scope the trigger on this table insert data in some other table
For example, there are two tables, Table1 and Table2, and an INSERT trigger is defined on Table1.
When a row is inserted to Table1, the trigger inserts a row in Table2. This scenario illustrates two scopes: the insert on Table1 and the insert on Table2 by the trigger.
Table1 and Table2 have identity columns, @@IDENTITY and SCOPE_IDENTITY will return different values at the end of an INSERT statement on Table1.
@@IDENTITY will return the last identity column value inserted across any scope in the current session. This is the value inserted in Table2.
SCOPE_IDENTITY () will return the IDENTITY value inserted in Table1.
SCOPE_IDENTITY, IDENT_CURRENT, and @@IDENTITY
SCOPE_IDENTITY, IDENT_CURRENT, and @@IDENTITY are function used for same value type but different results.
IDENT_CURRENT returns the current identity value irrespective of session and scope.
SCOPE_IDENTITY returns last identity value generated the current scope Irrespective of tables. I.e. it could be value from last table which is updated in current scope.
@@IDENTITY returns the last identity values that are generated in any table in the current session. It’s not limited to any specific scope. I.e. while updating in current scope the trigger on this table insert data in some other table
For example, there are two tables, Table1 and Table2, and an INSERT trigger is defined on Table1.
When a row is inserted to Table1, the trigger inserts a row in Table2. This scenario illustrates two scopes: the insert on Table1 and the insert on Table2 by the trigger.
Table1 and Table2 have identity columns, @@IDENTITY and SCOPE_IDENTITY will return different values at the end of an INSERT statement on Table1.
@@IDENTITY will return the last identity column value inserted across any scope in the current session. This is the value inserted in Table2.
SCOPE_IDENTITY () will return the IDENTITY value inserted in Table1.
Timestamp Datatype in SQL Server“Timestamp is a data type that exposes automatically generated binary numbers, which are
guaranteed to be unique within a database. timestamp is used typically as a mechanism for
version-stamping table rows. The storage size is 8 bytes.”
Let us see one small example which proves above statement.

create table TimeStampTesting
(
Name varchar(10),
TS TimeStamp
)
Insert Into TimeStampTesting(Name)
Select 'Ritesh' union all
Select 'Rajan' union all
Select 'Bihag'
GO
--since we are making order by on TS
--Bihag should be first as that record was inserted last
Select * from TimeStampTesting order by TS desc
Go
Update TimeStampTesting set Name='Rajan S.' where Name='Rajan'
GO
--if you observe, this time Bihag wouldn't first
--but Rajan S. would be the first as it updated last
--so TS is a binary unique number which updates itself automatically
--for new upate and/or insert
Select * from TimeStampTesting order by TS desc
Go
BTW, now a day, you should use RowVersion datatype rather than TimeStamp as I told you above
too that TimeStamp will be deprecated and RowVersion is synonyms for TimeStamp.
http://msdn.microsoft.com/en-us/library/ms177566.aspx

SQL Server Joins
SQL Sevre Interview Question's : JOINS In SQL ServerWhat are Joins in SQL Server Joins is the functionality introduced in SQL server 2005. Joins are used to map two relative tables with relational key between them.
What are the different types of joins in SQL Server?
1. Inner join
2. Left join
3. Left outer join
4. Right outer join
5. Self-Join
For explaining all these joins I am taking the two sample table. First table is the employee and second table is employer.
Employee tables contain the data like employee name, employee Id, employee salary.
Employer table contains the data for employer with employer name and other details
Employee
ID Name Employer ID Salary1 Randheer 1 500002 Amit 2 700003 Anshu 1 650004 Sarub 3 700005 rahul 4 50000
Employer
EmplId Empl Name1 Accent2 XYX INC3 ABC4 PQR5 RST

Implementing Inner Join
Inner join means the common data between the two tables. I.e. you will get only those employer name for which employee exist in the table.
Select * from employee inner join employer on employer id=EmplId
For getting the result paste the SQL in SSMS Query Analyzer (it’s the window where you are executing the query)
Declare @Employee table(Id int identity(1,1),Name varchar(100),EmployerID int,Salary money)
insert into @Employee values ('randheer',1,50000)
insert into @Employee values ('Amit',2,70000)
insert into @Employee values ('Anshu',1,70000)
insert into @Employee values ('Sarub',3,70000)
insert into @Employee values ('rahul',4,50000)
insert into @Employee values ('gaur',6,50000)
Declare @Employer table(EmplId int identity(1,1),Name varchar(100))
insert into @Employer values ('Accent')
insert into @Employer values ('XYZ')
insert into @Employer values ('ABC')
insert into @Employer values ('POR')
insert into @Employer values ('RST')
insert into @Employer values ('OPR')
select * from @employee EM INNER JOIN @Employer EP on EP.EmplId=EM.EmployerID
Result of this query will be the common data between the two tables on the employer id.
1 randheer 1 50000.00 1 Accent

2 Amit 2 70000.00 2 XYZ
3 Anshu 1 70000.00 1 Accent
4 Sarub 3 70000.00 3 ABC
5 rahul 4 50000.00 4 POR
6 gaur 6 50000.00 6 OPR
Implementing Left Join
In Left join left tables complete data comes and from other table only the ommon data comes. Remaining columns from the other table will come null.
Run this query with the same above table.
select * from @employee EM LEFT JOIN @Employer EP on EP.EmplId=EM.EmployerID
1 randheer 1 50000.00 1 Accent
2 Amit 2 70000.00 2 XYZ
3 Anshu 1 70000.00 1 Accent
4 Sarub 3 70000.00 3 ABC
5 rahul 4 50000.00 4 POR
6 gaur 8 50000.00 NULL NULL
Null value are showing this and also all the rows which were in employer table are not in result.
Implementing the Right Join
In right join the right table all the value appears in the result and left table only common values.
Run the below query with same above mentioned table.
select * from @employee EM RIGHT JOIN @Employer EP on EP.EmplId=EM.EmployerID

Id Name EmployerID Salary EmplId Name
1 randheer 1 50000.00 1 Accent
3 Anshu 1 70000.00 1 Accent
2 Amit 2 70000.00 2 XYZ
4 Sarub 3 70000.00 3 ABC
5 rahul 4 50000.00 4 POR
NULL NULL NULL NULL 5 RST
NULL NULL NULL NULL 6 OPR
RIGHT OUTER JOIN and LEFT OUTER JOIN are same as right join and left join just having different name.
These queries will give the Sme result as earlier there respective query given.
select * from @employee EM RIGHT OUTER JOIN @Employer EP on EP.EmplId=EM.EmployerID
select * from @employee EM RIGHT LEFT JOIN @Employer EP on EP.EmplId=EM.EmployerID
T SQL Tutorial: ORDER BYIn T SQL Tutorial check how to use ORDER BY clause with syntax and examples.
One LinerThe SQL ORDER BY clause is used to sort the records in the result set for a SELECT statement.
SyntaxThe syntax for the SQL ORDER BY clause is:
SELECT expressionsFROM tables
WHERE conditions
ORDER BY expression [ ASC | DESC ];
Thing to Remember

If the ASC or DESC option is not provided in the ORDER BY clause, the results will be sorted by expression in ascending order (which is equivalent to "ORDER BY expression ASC").Order by clause can’t be used in a view definition.Order by cant be used in a sub query having aggregate functions in select statement
TSQL Interview Questions: Sub Query
SubQuery is the query which returns resultset that can be used in main query. Subquery is like a table which joins with other tables in main query or can be used in where clause of main query. SubQuery is also reffered as derived table.Performance wise subquery is not a better option as SQL Server doesnt creates execution plan of sub query.Example: Let says user want the Employees who have more than one promotions in their carrer time.For this you need to join employee table with history table.Select EmpName from Empinner join (select EmpID , count(*) from EmpHist group by having Count(*)> 1 )A on A.EmpID=Emp.EmpIDthe statement in parenthesis is sub query.
Nested and Correlated Queries
If a subquery contains another sub query inside it the its called nested sub query. there could be multiple no of nesting possible in a sub query.if two sub queries or queries are dependent on each other then its called correlated subqueries.Exampleselect EmpName , (select Empname from emp where empid=a.managerid) as managerfrom Emp Ain this example a column is used in upper sub query then its correlated subquery.
Nested and Correlated Queries
If a subquery contains another sub query inside it the its called nested sub query. there could be multiple no of nesting possible in a sub query.if two sub queries or queries are dependent on each other then its called correlated subqueries.Exampleselect EmpName , (select Empname from emp where empid=a.managerid) as managerfrom Emp Ain this example a column is used in upper sub query then its correlated subquery.

What are the aggregate functions in SQL server?What are the aggregate functions in SQL server?
Count, Min, Max and Average are the few aggregate functions in SQL Server.
Count function: Select count (*) from Table1. It will deliver count of the table i.e. no of records. If you will put the filters in the query then it will give the count of filtered records.
table Employee as designed below.
Name Age Salary Total No of CARS
Randheer 19 10000 1
Nids 17 50000 2
Jayant null 3
Ruby 5 2000 0
Case 1
Question. Select Count (Salary) from Employee?
A) 4 B)0 C)3 D) 2
Answer: In this case answer will be C as the null values in a column doesn’t counts by the count function in SQL Server.
Case 2
Question. Select Count (Age) from Employee?
A) 4 B)0 C)3 D) 2
Answer: In this case answer will be A as the space will be consider as a value by count function in SQL Server.
Min function: Min function retrieves the minimum values in a column it works on group by function and also without any group by function.
select min(salary) from(select 1 as ID, 'Randheer' as Name,'10000' as salaryunion allselect 1 as ID, 'Randheer' as Name,null assalaryunion allselect 1 as ID, 'Randheer' as Name,'80000' as salary)
Result will 10000 in this case. it shows that min function is not considering the null value.

Max Function: Max function is used to get the max value of a column. A
Select Max (column1) from table1
Average Function: Average is used to get the average of the column. Average can be on the groups also. This functions returns value as mathematics average function returns.
Timestamp Datatype in SQL Server“Timestamp is a data type that exposes automatically generated binary numbers, which are
guaranteed to be unique within a database. timestamp is used typically as a mechanism for
version-stamping table rows. The storage size is 8 bytes.”
Let us see one small example which proves above statement.
create table TimeStampTesting
(
Name varchar(10),
TS TimeStamp
)
Insert Into TimeStampTesting(Name)
Select 'Ritesh' union all
Select 'Rajan' union all
Select 'Bihag'
GO
--since we are making order by on TS
--Bihag should be first as that record was inserted last
Select * from TimeStampTesting order by TS desc
Go
Update TimeStampTesting set Name='Rajan S.' where Name='Rajan'

GO
--if you observe, this time Bihag wouldn't first
--but Rajan S. would be the first as it updated last
--so TS is a binary unique number which updates itself automatically
--for new upate and/or insert
Select * from TimeStampTesting order by TS desc
Go
BTW, now a day, you should use RowVersion datatype rather than TimeStamp as I told you above
too that TimeStamp will be deprecated and RowVersion is synonyms for TimeStamp.
http://msdn.microsoft.com/en-us/library/ms177566.aspx
What is Sequence Container?
Sequence Containers handle the flow of a subset of a package and can help you divide a
Package into smaller, more manageable pieces. Some nice applications that you can use
Sequence containers for include the following:
Grouping tasks so that you can disable a part of the package that ’ s no longer needed Narrowing the scope of the variable to a container Managing the properties of multiple tasks in one step by setting the properties of the Container Using one method to ensure that multiple tasks have to execute successfully before the next task executes Creating a transaction across a series of data - related tasks, but not on the entire package Creating event handlers on a single container, wherein you could send an email if anything inside one container fails and perhaps page if anything else fails
Index Scan VS Index Seek

Index Scan
In index scan, SQL Server scans all the data pages from the first data page to the last data page. For example there is an index existing in the table and the query is fetching large amount of data which is more than 50 percent of the data then the Query Optimizer would just fetch all the data pages to retrieve the desired result sets.
Also if there is no indexes in the table, then SQL server will automatically do table scan. So table scan and index scan is same but while doing table scan you moved into one more level of data to retrieve original data.
Index Seek
When SQL Server does a seek then it knows where in the index the data is going to be or when fewer number of rows such as only 10% of the whole data needs to be fetched, so it loads the index and directly goes to the part of the index that it needs and reads till the required data is fetched. Most of the time query optimizer tries to use an Index Seek which indicates that it has found an useful index to fetch the desired result set. But in case it fails to use the index or using index would not help the cause because the fetched number of records is almost around 90% of the whole data then it does Index scan.Index scan is efficient if the table is small or most of the rows qualify for the record set.
Difference between STUFF and REPLACE
Difference between STUFF and REPLACE
STUFF function is used to overwrite existing characters using this syntax: STUFF (string_expression, start, length, replacement_characters), where string_expression is the string that will have characters substituted, start is the starting position, length is the number of characters in the string that are substituted, and replacement_characters are the new characters interjected into the string.
REPLACE function is used to replace existing characters of all occurrences. Using the syntax REPLACE (string_expression, search_string, replacement_string), every incidence of search_string found in the string_expression will be replaced with replacement string
DATEDIFF IN SQL SERVERDate diff tells the difference between the two dates in terms of the entity provided.

DATEDIFF (datepart , startdate , enddate )
Datepart could e mm or dd or yy or mi depends upon the requirement.
Below are the few points related to date diff.
DATEDIFF does not guarantee that the full number of the specified time units passed between
2 datetime Values.
-- Get difference in hours between 8:55 and 11:00
SELECT DATEDIFF(hh, '08:55', '11:00');
-- Returns 3 although only 2 hours and 5 minutes passed between times
-- Get difference in months between Sep 30, 2011 and Nov 02, 2011
SELECT DATEDIFF(mm, '2011-09-30', '2011-11-02')
-- Returns 2 although only 1 month and 2 days passed between date
To get the number of full time units passed between date times, you can calculate the difference
in lower Units and then divide by the appropriate number:
SELECT DATEDIFF(mi, '08:55', '11:00')/60;
-- Returns 2 hours now
ACID PROPERTIES

In Database, ACID (atomicity, consistency, isolation, durability) is a set of properties that guarantee that database transactions are processed reliably. In the context of databases, a single logical operation on the data is called a transaction.
An example of a transaction is a transfer of funds from one bank account to another, even though it might consist of multiple individual operations (such as debiting one account and crediting another).
Atomicity
Atomicity refers to the ability of the DBMS to guarantee that either all of the tasks of a transaction are performed or none of them are.
For example, the transfer of funds from one account to another can be completed or it can fail for a multitude of reasons, but atomicity guarantees that one account won’t be debited if the other is not credited.
Atomicity states that database modifications must follow an “all or nothing” rule. Each transaction is said to be “atomic” if when one part of the transaction fails, the entire transaction fails. It is critical that the database management system maintain the atomic nature of transactions in spite of any DBMS, operating system or hardware failure.
Consistency
The consistency property ensures that the database remains in a consistent state before the start of the transaction and after the transaction is over (whether successful or not).
Consistency states that only valid data will be written to the database. If, for some reason, a transaction is executed that violates the database’s consistency rules, the entire transaction will be rolled back and the database will be restored to a state consistent with those rules. On the other hand, if a transaction successfully executes, it will take the database from one state that is consistent with the rules to another state that is also consistent with the rules.
Isolation
Isolation refers to the requirement that other operations cannot access or see the data in an intermediate state during a transaction. This constraint is required to maintain the performance as well as the consistency between transactions in a DBMS. Thus, each transaction is unaware of other transactions executing concurrently in the system.
Durability

Durability refers to the guarantee that once the user has been notified of success, the transaction will persist, and not be undone. This means it will survive system failure, and that the database system has checked the integrity constraints and won’t need to abort the transaction.
Many databases implement durability by writing all transactions into a transaction log that can be played back to recreate the system state right before a failure. A transaction can only be deemed committed after it is safely in the log.
Durability does not imply a permanent state of the database. Another transaction may overwrite any changes made by the current transaction without hindering durability.
TEMP TABLE & GLOBAL TEMP TABLE & TABLE VARIABLE
Local Temporary Tables
These tables are created within a procedure and stored in the temp_db provided by
SQL server. They can be identified with a session specific identifier. It can be used when data is coming from another stored procedure. It also reduces the amount of locking required and also involves less logging. Still, there are few limitations such as character limit is 116 and transactions can create unnecessary locks in temp_db.
Syntax:
Create table #Student (Id int, Name varchar(50))
Global Temporary Tables:
These tables are same as local temporary table but the difference lies in the lifetime as it is available for all the sessions. This can be useful when the same set of data is required by one or more users. But the issue will come when the user, who should not be given access to this data, will have access to it as it is a global table and available for all users.
Syntax:
Create table ##Student (Id int, Name varchar(50))
See the difference of two #.
Table Variables:
Same structure as a normal table but only difference is the shortest life time among all the varieties. This table is created and stored in memory and its lifetime is decided by the stored procedure who have created it. Once stored procedure/DML statement exits, this table gets auto cleaned and memory gets free. Apart from that, log activity is truncated immediately. An important note, If we have a requirement to use a table structure in user

defined function then we have only one option as Table variable and no other variety can be used.
Syntax:
Declare @Student Table (Id int, Name varchar(50))
Union All and Union clause in SQL Server TSQL Development
Union all and union are two clauses which are part of TSQL development and used for performing multiple operation. Both perform same kind of activity with a marginal difference.Union and Union all both are used to merge multiple record-set and transform it into a single record-set.Let say there are record-setselect 1,1,1select 1,1,1then output would be1,1,11,1,1It has few condition to merge the record-setNo of columns in both record-sets should be the sameTh data types off these columns should be similar.
Now we need to understand what is the basic difference between the union and union all.Union all merge both the record-set as it is while union produce only unique rows from both the data set.Let say record-set 1 has 12 rows and record-set 2 has 15 rows and five rows are same in both record-set.So in this caseUnion all will return 12 + 15=27 rows.Union will return 7 unique from record-set 1 + 10 unique from record-set 2 and 5 common rows in both record-set = 7+10+5=22 rows.Performance:Union all is faster then Union as Union removes duplicate rows. SQL server need to do some extra comparison and compare each row with every row in the record-set. if suppose there are millions of rows then using Union will be a huge toll on performance.Avoid using union for better performance of query
TSQL Interview: Having Clause
Having clause work like a where clause with group clause. It is filter conditioning for group by data.

Where clause work for filter condition on Normal Data while having clause works for group data such as count() > value or sum() > value.Create Table #Employee(Id int identity(1,1),Name Varchar(100),Designation Varchar(100),Salary int)
Insert into #Employee Values('Rahul','SSE',30000)Insert into #Employee Values('Rohit','SE',20000)Insert into #Employee Values('Ronit','SE',20000)Insert into #Employee Values('Rupesh','TL',40000)Insert into #Employee Values('Ahishek','AM',50000)Insert into #Employee Values('Rakesh','SSE',30000)Insert into #Employee Values ('Ashok','AM',50000)Insert into #Employee Values ('Puneet','SE',20000)Insert into #Employee Values ('Vineet','SSE',40000)
/* Having Clause data*/
Select count(*),Designation from #Employee group by Designationhaving count(*) > 2
Will return below two rows as the designation which are associated more than two people3 SE3 SSEWhere clause can also be used with having in that case first where filter at main data and then group operation will performed and then having filter the group data.
Keyword: Difference between having and where clause.Having Clause
TSQL Interview Question: Group By
Group by clause is used to group the data in a table. It groups same kind of data in one group. Generally group by used for aggregation function where requirement is to get count average sum etc for one particular group. Below is the example of group by and how it works.Create Table #Employee(Id int identity(1,1),Name Varchar(100),Designation Varchar(100),Salary int)
Insert into #Employee Values('Rahul','SSE',30000)Insert into #Employee Values('Rohit','SE',20000)Insert into #Employee Values('Ronit','SE',20000)Insert into #Employee Values('Rupesh','TL',40000)Insert into #Employee Values('Ahishek','AM',50000)Insert into #Employee Values('Rakesh','SSE',30000)Insert into #Employee Values ('Ashok','AM',50000)Insert into #Employee Values ('Puneet','SE',20000)Insert into #Employee Values ('Vineet','SSE',40000)
/* group by as order by *//*Let say i want the employee list where salary is decreasing to increasing */

select name,salary from #Employee group by salary,name
/* For Aggregate function : Query for getting count fr employee against designation */Select count(*),Designation from #Employee group by Designationdrop Table #Employee.
2 AM3 SE3 SSE1 TL
KeyWord: SQL Server Interview Questions, SQL Server interview Questions and Answers, TSQL Interview Question.
SCOPE_IDENTITY, IDENT_CURRENT, and @@IDENTITY
SCOPE_IDENTITY, IDENT_CURRENT, and @@IDENTITY are function used for same value type but different results.
IDENT_CURRENT returns the current identity value irrespective of session and scope.
SCOPE_IDENTITY returns last identity value generated the current scope Irrespective of tables. I.e. it could be value from last table which is updated in current scope.
@@IDENTITY returns the last identity values that are generated in any table in the current session. It’s not limited to any specific scope. I.e. while updating in current scope the trigger on this table insert data in some other table
For example, there are two tables, Table1 and Table2, and an INSERT trigger is defined on Table1.
When a row is inserted to Table1, the trigger inserts a row in Table2. This scenario illustrates two scopes: the insert on Table1 and the insert on Table2 by the trigger.
Table1 and Table2 have identity columns, @@IDENTITY and SCOPE_IDENTITY will return different values at the end of an INSERT statement on Table1.
@@IDENTITY will return the last identity column value inserted across any scope in the current session. This is the value inserted in Table2.
SCOPE_IDENTITY () will return the IDENTITY value inserted in Table1.
How to Check Identity ValueDBCC CHECKIDENT
(
table_name
[, { NORESEED | { RESEED [, new_reseed_value ] } } ]

)
DBCC CHECKIDENT (table)
DBCC CHECKIDENT (table, NORESEED)
DBCC CHECKIDENT (table, RESEED, 10)
TSQL Interview Question: Identity columnIdentity is the property of column which inserts incremental value in the column at the insert of new row in parent table of that column.
For example in Employee table when we set ID as identity then for every inserted employee record there will be an auto incremental value get inserted in the ID column automatically.
For Identity you can set the increment value i.e. the value by which next inserted value increment. So if you set increment by 10 then inserted value will be like 10, 20, 30, 40……..
These properties can be set in for table while designing it or opening existing table in design mode.
Identity key doesn't guarantee
Uniqueness of the value
Consecutive values within a transaction – If there are multiple transaction then the identity value for every row can be differ in a single transaction.
Reuse of values – if there is error while inserting row that the identity generated will lost and next time SQL server will insert new identity value. It doesn't reuse it.
The seed value is the value inserted into an identity column for the very first row loaded into the table.
Nested and Correlated Queries
If a subquery contains another sub query inside it the its called nested sub query. there could be multiple no of nesting possible in a sub query.if two sub queries or queries are dependent on each other then its called correlated subqueries.Exampleselect EmpName , (select Empname from emp where empid=a.managerid) as managerfrom Emp Ain this example a column is used in upper sub query then its correlated subquery.
TSQL Interview Questions: Sub Query

SubQuery is the query which returns resultset that can be used in main query. Subquery is like a table which joins with other tables in main query or can be used in where clause of main query. SubQuery is also reffered as derived table.Performance wise subquery is not a better option as SQL Server doesnt creates execution plan of sub query.Example: Let says user want the Employees who have more than one promotions in their carrer time.For this you need to join employee table with history table.Select EmpName from Empinner join (select EmpID , count(*) from EmpHist group by having Count(*)> 1 )A on A.EmpID=Emp.EmpIDthe statement in parenthesis is sub query.
TSQL Interview Questions: Primary Key
uniquely defines the characteristics of each row (also known as record or tuple). The primary key has to consist of characteristics that cannot be duplicated by any other row. The primary key may consist of a single attribute or a multiple attributes in combination. For example, a birthday could be shared by many people and so would not be a prime candidate for the Primary Key, but a social security number or Driver's License number would be ideal since it correlates to one single data value. Another unique characteristic of a Primary Key as it pertains to a relational database is that a Primary Key must also serve as a Foreign Key on a related table.A table can have only one PRIMARY KEY constraint, and a column that participates in the PRIMARY KEY constraint cannot accept null values.The database engine enforces data uniqueness by creating unique index for primary key column.GO
/****** Object: Table [ASIA\NBKWHDR].[DataTest] Script Date: 08/20/2013 17:20:51 ******/SET ANSI_NULLS ONGO
SET QUOTED_IDENTIFIER ONGO
CREATE TABLE dbo.[DataTest]( [ID] [int] NOT NULL, [Name] [nchar](10) NULL, CONSTRAINT [PK_DataTest] PRIMARY KEY CLUSTERED ( [ID] ASC)) ON [PRIMARY]
GO

TSQL Interview Questions: DateTimeThere are two types of datetime data types
Datetime Stores dates from January 1, 1753 through December 31, 9999, to an accuracy of one three-hundredth of a second (equivalent to 3.33 milliseconds or 0.00333 seconds). Values are rounded to increments of .000, .003, or .007 seconds, as shown in the table.
Small DatetimeStores dates from January 1, 1900, through June 6, 2079, with accuracy to the minute. smalldatetime values with 29.998 seconds or lower are rounded down to the nearest minute; values with 29.999 seconds or higher are rounded up to the nearest minute.
Internally SQL server stores Datetime data in 2 4 bytes integers and smalldatetime stores as 2 2 byte integers. One part stores days before or after base date and next part stores the number of milliseconds after midnight.
TSQL Iterview Questions: Data Types
Data type: A data type is an attribute that specifies the type of data that the object can store: numeric data, character data, monetary data, date and time data, binary data, and so many more.SQL Server supplies a set of system data types that define all the types of data that can be used with SQL Server.Data type Range Storagebigint -2^63 (-9,223,372,036,854,775,808) to 2^63-1 (9,223,372,036,854,775,807) 8 Bytesint -2^31 (-2,147,483,648) to 2^31-1 (2,147,483,647) 4 Bytes smallint -2^15 (-32,768) to 2^15-1 (32,767) 2 Bytes tinyint 0 to 255 1 Byte
TSQL Interview Questions: Table
A table is a set of data elements (values) that is organized using a model of vertical columns (which are identified by their name) and horizontal rows, the cell being the unit where a row and column intersect. A table has a specified number of columns, but can have any number of rows [citation needed]. Each row is identified by the values appearing in a particular column subset which has been identified as a unique key index.
Transactions in MS SQL Server
Transaction in unit of code in which if all the statement of code executes successfully then only changes will implemented in database else all the changes will reversed. I.e. it provides check for dependent insert update or deletes operations in database.If you are new and not aware about this the first question in your mind will be why we need

transaction.Let take an example if you are modifying the designation of employee in employee table and also you want to maintain history for earlier designation in history table. The steps you willFirst assign the current designation value in variableUpdate new designation in employee table.Insert row in history table with value in variable.Suppose the process show error at step no 3 then what will be the result your employee table updated and your history table not. You missed out one designation from employee history table. To avoid such kind of problem and maintain data consistency we use transactions.
There are four possible types of transaction
Auto commit TransactionEvery single statement in transaction. Writing general modification statement without Using Begin transactions in Query analyzer window or db objects. You cannot make any once the changes done.
Explicit TransactionEach transaction needs to be started by explicitly Begin Transaction Statement and end with commit or rollback statement.
Implicit transactions A new transaction is implicitly started when the prior transaction completes, but each transaction is explicitly completed with a COMMIT or ROLLBACK statement.
Batch-scoped transactionsIt is used for multiple active result sets (MARS) its part of C# coding.
Statements used in transactionsBegin Transaction A Modification statementsCommit transactions
@@TrancountThe BEGIN TRANSACTION statement increments @@TRANCOUNT by 1. ROLLBACK TRANSACTION decrements @@TRANCOUNT to 0,For ROLLBACK TRANSACTION savepoint_name, it does not change the variable value. COMMIT TRANSACTION or COMMIT WORK decrement @@TRANCOUNT by 1.PRINT @@TRANCOUNT
BEGIN TRAN PRINT @@TRANCOUNT “value will be 1” BEGIN TRAN PRINT @@TRANCOUNT “value will be 2”
ROLLBACKPRINT @@TRANCOUNT “value will be 0”

Point need to be remembered for direct questions:Distributed transactions are the transactions in which if there is a stored procedure or database object is running on separate sql server.Local transactions will automatically convert in distributed transactions when there is any such procedure exists which will run on remote server.
Key words: SQL Server Transcation, What is transaction , Implement transaction in SQL
TSQL Tutorial : HavingHAVING
The HAVING clause is used to limit the rows returned by a SELECT with GROUP BY. Its relationship to
GROUP BY is similar to the relationship between the WHERE clause and the SELECT itself. Like the WHERE
clause, it restricts the rows returned by a SELECT statement. Unlike WHERE, it operates on the rows in the
result set rather than the rows in the query's tables. Here's the previous query modified to include a
HAVING clause:
SELECT customers.CustomerNumber, customers.LastName, SUM(orders.Amount) AS
TotalOrders
FROM customers JOIN orders ON customers.CustomerNumber=orders.CustomerNumber
GROUP BY customers.CustomerNumber, customers.LastName
HAVING SUM(orders.Amount) > 700
CustomerNumber LastName TotalOrders
-------------- -------- -----------
3 Citizen 86753.09
1 Doe 802.35
There is often a better way of qualifying a query than by using a HAVING clause. In general, HAVING is
Less efficient than WHERE because it qualifies the result set after it's been organized into groups; WHERE
does so beforehand. Here's an example that improperly uses the HAVING clause:
-- Bad SQL - don't do this
SELECT customers.LastName, COUNT(*) AS NumberWithName
FROM customers
GROUP BY customers.LastName
HAVING customers.LastName<>'Citizen'

Properly written, this query's filter criteria should be in its WHERE clause, like so:
SELECT customers.LastName, COUNT(*) AS NumberWithName
FROM customers
WHERE customers.LastName<> 'Citizen'
GROUP BY customers.LastName
In fact, SQL Server recognizes this type of HAVING misuse and translates HAVING into WHERE during
Query execution. Regardless of whether SQL Server catches errors like these, it's always better to write
Optimal code in the first place.
TSQL Tutorial...
TSQL Tutorial : HavingHAVING
The HAVING clause is used to limit the rows returned by a SELECT with GROUP BY. Its relationship to
GROUP BY is similar to the relationship between the WHERE clause and the SELECT itself. Like the WHERE
clause, it restricts the rows returned by a SELECT statement. Unlike WHERE, it operates on the rows in the
result set rather than the rows in the query's tables. Here's the previous query modified to include a
HAVING clause:
SELECT customers.CustomerNumber, customers.LastName, SUM(orders.Amount) AS
TotalOrders
FROM customers JOIN orders ON customers.CustomerNumber=orders.CustomerNumber
GROUP BY customers.CustomerNumber, customers.LastName
HAVING SUM(orders.Amount) > 700
CustomerNumber LastName TotalOrders
-------------- -------- -----------
3 Citizen 86753.09
1 Doe 802.35
There is often a better way of qualifying a query than by using a HAVING clause. In general, HAVING is
Less efficient than WHERE because it qualifies the result set after it's been organized into groups; WHERE
does so beforehand. Here's an example that improperly uses the HAVING clause:

-- Bad SQL - don't do this
SELECT customers.LastName, COUNT(*) AS NumberWithName
FROM customers
GROUP BY customers.LastName
HAVING customers.LastName<>'Citizen'
Properly written, this query's filter criteria should be in its WHERE clause, like so:
SELECT customers.LastName, COUNT(*) AS NumberWithName
FROM customers
WHERE customers.LastName<> 'Citizen'
GROUP BY customers.LastName
In fact, SQL Server recognizes this type of HAVING misuse and translates HAVING into WHERE during
Query execution. Regardless of whether SQL Server catches errors like these, it's always better to write
Optimal code in the first place.
TSQL Tutorial...
TSQL Tutorial : HavingHAVING
The HAVING clause is used to limit the rows returned by a SELECT with GROUP BY. Its relationship to
GROUP BY is similar to the relationship between the WHERE clause and the SELECT itself. Like the WHERE
clause, it restricts the rows returned by a SELECT statement. Unlike WHERE, it operates on the rows in the
result set rather than the rows in the query's tables. Here's the previous query modified to include a
HAVING clause:
SELECT customers.CustomerNumber, customers.LastName, SUM(orders.Amount) AS
TotalOrders
FROM customers JOIN orders ON customers.CustomerNumber=orders.CustomerNumber
GROUP BY customers.CustomerNumber, customers.LastName
HAVING SUM(orders.Amount) > 700
CustomerNumber LastName TotalOrders
-------------- -------- -----------

3 Citizen 86753.09
1 Doe 802.35
There is often a better way of qualifying a query than by using a HAVING clause. In general, HAVING is
Less efficient than WHERE because it qualifies the result set after it's been organized into groups; WHERE
does so beforehand. Here's an example that improperly uses the HAVING clause:
-- Bad SQL - don't do this
SELECT customers.LastName, COUNT(*) AS NumberWithName
FROM customers
GROUP BY customers.LastName
HAVING customers.LastName<>'Citizen'
Properly written, this query's filter criteria should be in its WHERE clause, like so:
SELECT customers.LastName, COUNT(*) AS NumberWithName
FROM customers
WHERE customers.LastName<> 'Citizen'
GROUP BY customers.LastName
In fact, SQL Server recognizes this type of HAVING misuse and translates HAVING into WHERE during
Query execution. Regardless of whether SQL Server catches errors like these, it's always better to write
Optimal code in the first place.
TEMP TABLE & GLOBAL TEMP TABLE & TABLE VARIABLE
Local Temporary Tables
These tables are created within a procedure and stored in the temp_db provided by
SQL server. They can be identified with a session specific identifier. It can be used when data is coming from another stored procedure. It also reduces the amount of locking required and also involves less logging. Still, there are few limitations such as character limit is 116 and transactions can create unnecessary locks in temp_db.
Syntax:
Create table #Student (Id int, Name varchar(50))
Global Temporary Tables:

These tables are same as local temporary table but the difference lies in the lifetime as it is available for all the sessions. This can be useful when the same set of data is required by one or more users. But the issue will come when the user, who should not be given access to this data, will have access to it as it is a global table and available for all users.
Syntax:
Create table ##Student (Id int, Name varchar(50))
See the difference of two #.
Table Variables:
Same structure as a normal table but only difference is the shortest life time among all the varieties. This table is created and stored in memory and its lifetime is decided by the stored procedure who have created it. Once stored procedure/DML statement exits, this table gets auto cleaned and memory gets free. Apart from that, log activity is truncated immediately. An important note, If we have a requirement to use a table structure in user defined function then we have only one option as Table variable and no other variety can be used.
Syntax:
Declare @Student Table (Id int, Name varchar(50))
TEMPORARY TABLE VS TABLE VARIABLE
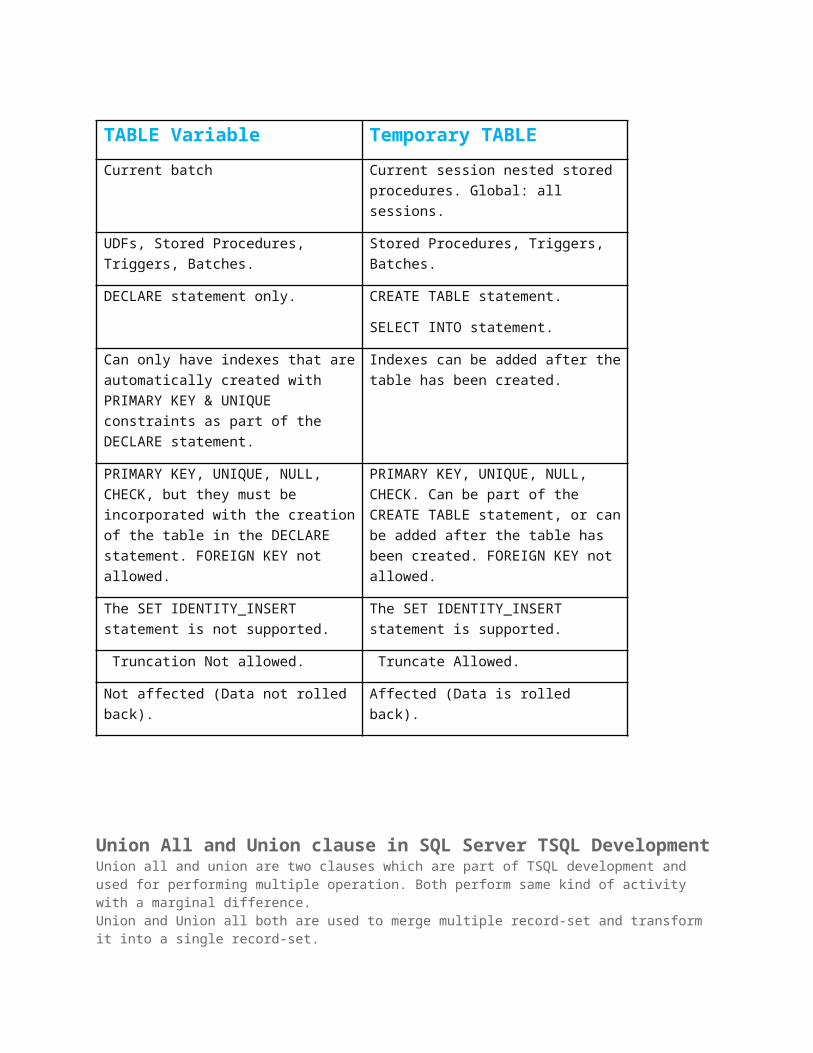
TABLE Variable Temporary TABLE
Current batch Current session nested stored procedures. Global: all sessions.
UDFs, Stored Procedures, Triggers, Batches.
Stored Procedures, Triggers, Batches.
DECLARE statement only. CREATE TABLE statement.
SELECT INTO statement.
Can only have indexes that are automatically created with PRIMARY KEY & UNIQUE constraints
Indexes can be added after the table has been created.

as part of the DECLARE statement.
PRIMARY KEY, UNIQUE, NULL, CHECK, but they must be incorporated with the creation of the table in the DECLARE statement. FOREIGN KEY not allowed.
PRIMARY KEY, UNIQUE, NULL, CHECK. Can be part of the CREATE TABLE statement, or can be added after the table has been created. FOREIGN KEY not allowed.
The SET IDENTITY_INSERT statement is not supported.
The SET IDENTITY_INSERT statement is supported.
Truncation Not allowed. Truncate Allowed.
Not affected (Data not rolled back). Affected (Data is rolled back).
Union All and Union clause in SQL Server TSQL DevelopmentUnion all and union are two clauses which are part of TSQL development and used for performing multiple operation. Both perform same kind of activity with a marginal difference.Union and Union all both are used to merge multiple record-set and transform it into a single record-set.Let say there are record-setselect 1,1,1select 1,1,1then output would be1,1,11,1,1It has few condition to merge the record-setNo of columns in both record-sets should be the sameTh data types off these columns should be similar.
Now we need to understand what is the basic difference between the union and union all.Union all merge both the record-set as it is while union produce only unique rows from both the data set.Let say record-set 1 has 12 rows and record-set 2 has 15 rows and five rows are same in both record-set.So in this caseUnion all will return 12 + 15=27 rows.Union will return 7 unique from record-set 1 + 10 unique from record-set 2 and 5 common rows in both record-set = 7+10+5=22 rows.Performance:Union all is faster then Union as Union removes duplicate rows. SQL server need to do some extra comparison and compare each row with every row in the record-set. if suppose there are millions of rows then using Union will be a huge toll on performance.Avoid using union for better performance of query
Trick questions for Union and Union all.

Ranking Functions in SQL Server
What is Ranking Function?
In SQL Server Ranking functions are used to give a rank to each record among all records or in a group.
Let’s understand what does this means. I will take a simple real world example to make you understand this. Let’s go to in your school days. Our class teacher maintains a register in which all student names are written. Each student is given a roll number based on their names for example if there are 50 students then each student will get one roll number between 1 to 50, this is nothing but teacher has given a serial number to each student. When your result comes out, based on student marks now student will be given rank, which will be different from roll number (serial number) i.e roll number 10 came first, roll number 21 cane second and so on. This is nothing but teacher has given a rank based on the student marks. In some case suppose two students get the same marks, then same rank will be given to both the students.
All Ranking functions are non deterministic function, for more information see Deterministic and Non Deterministic functions in SQLServer.
What are the different Ranking Functions in SQL Server?
In SQL Server there are four types of Ranking Functions
1. RANK
2. DENSE_RANK
3. ROW_NUMBER
4. NTILE
Let’s understand each ranking function one by one.
Before we start, let's populate some data into our TEACHMESQLSERVER Database. If you don’t have database created then use the below query to create.
CREATE DATABASE TEACHMESQLSERVER

Let’s create one table name as EMP in our database and populate data. To create and populate data you can run below set of SQL statements.
USE TEACHMESQLSERVER
GO
IF EXISTS(SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME='EMP')
DROP TABLE EMP
GO
CREATE TABLE EMP(EMPNAME VARCHAR(MAX),DEPARTMENT VARCHAR(MAX), SALARY MONEY)
GO
INSERT INTO EMP VALUES ('GHANESH','IT',18000)
INSERT INTO EMP VALUES ('PRASAD','HR',2000)
INSERT INTO EMP VALUES ('GAUTAM','SALES',5000)
INSERT INTO EMP VALUES ('KUMAR','HR',85000)
INSERT INTO EMP VALUES ('SUMIT','IT',18000)
INSERT INTO EMP VALUES ('PRIYANKA','HR',25000)
INSERT INTO EMP VALUES ('KAPIL','SALES',5000)
INSERT INTO EMP VALUES ('GOLDY','HR',12000)
INSERT INTO EMP VALUES ('SACHIN','IT',21500)
INSERT INTO EMP VALUES ('OJAL','SALES',19500)
INSERT INTO EMP VALUES ('ISHU','HR',28000)
INSERT INTO EMP VALUES ('GAURAV','IT',15500)
INSERT INTO EMP VALUES ('SAURABH','SALES',20500)
INSERT INTO EMP VALUES ('MADHU','IT',18000)
INSERT INTO EMP VALUES('ATUL','SALES',35000)
GO
SELECT * FROM EMPAs you can see from the above query result set, data has been successfully populated. I will be using this data set in coming examples to explain all ranking functions.

RANK
Rank function returns the rank of each record among all records or in a partition.If two or more rows tie for a rank, each tied rows receives the same rank but RANKfunction does not always return consecutive integers. Don’t worry if second point is notclear to you I will explain this with example.
Syntax: RANK () OVER (PARTITION BY [column_list] ORDER BY [column_list])
PARTITION BY [Column_list] – This is optional if you want to divide the result set intopartitions to which the function is applied then must give the column name,if you don’t use this clause then the function treats all records of the query result set asa single group.
ORDER BY [Column_list] – This is not optional it is must clause; this determines the order of the data before the function is applied.
Let’s understand the RANK function using example.
Problem 1:
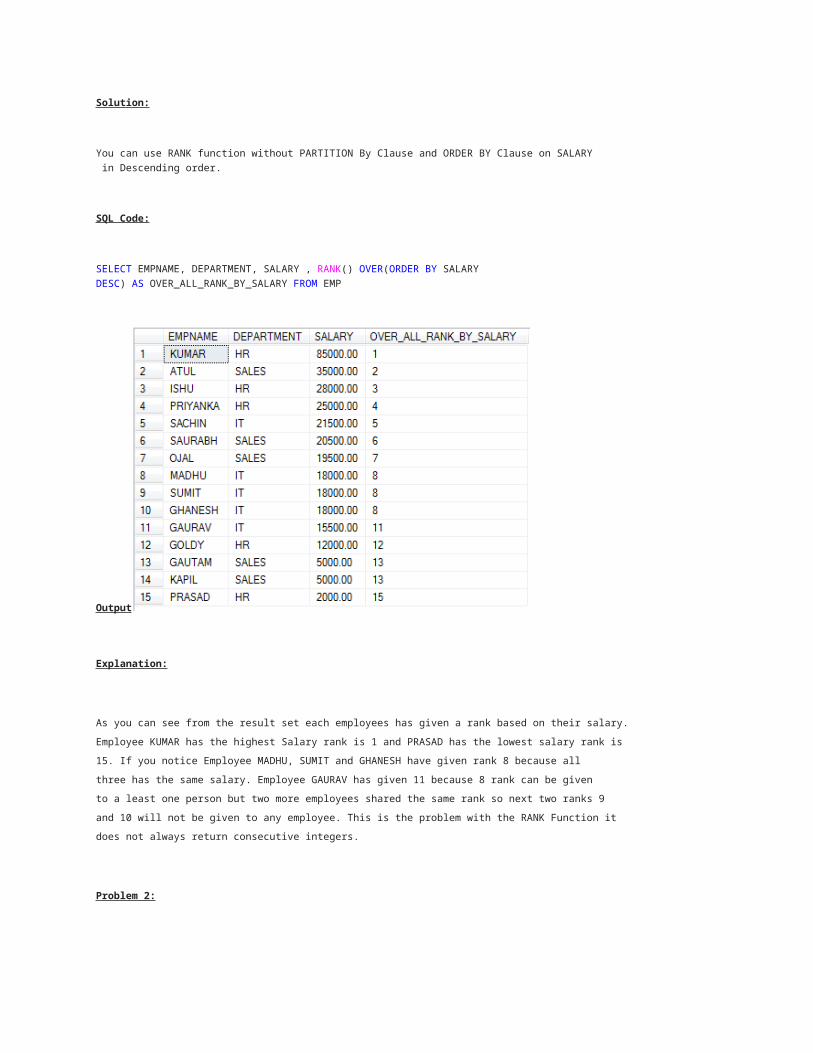
You want to get each employee rank among all other employees based on their highestsalary.
Solution:

You can use RANK function without PARTITION By Clause and ORDER BY Clause on SALARY in Descending order.
SQL Code:
SELECT EMPNAME, DEPARTMENT, SALARY , RANK() OVER(ORDER BY SALARY DESC) AS OVER_ALL_RANK_BY_SALARY FROM EMP
Output
Explanation:
As you can see from the result set each employees has given a rank based on their salary.
Employee KUMAR has the highest Salary rank is 1 and PRASAD has the lowest salary rank is
15. If you notice Employee MADHU, SUMIT and GHANESH have given rank 8 because all
three has the same salary. Employee GAURAV has given 11 because 8 rank can be given
to a least one person but two more employees shared the same rank so next two ranks 9
and 10 will not be given to any employee. This is the problem with the RANK Function it
does not always return consecutive integers.
Problem 2:
You want to get each employee rank in their department based on their highest salary.
Solution:

You can use RANK function with PARTITION BY Clause on DEPARTMENT
and ORDER BY Clause on SALARY in Descending order.
SQL Code:
SELECT EMPNAME, DEPARTMENT, SALARY , RANK() OVER(PARTITION BY DEPARTMENT
ORDER BY SALARY DESC) ASRANK_IN_DEP_BY_SALARY FROM EMP
Output:
Explanation:
As you can see from the result set each employees has given a rank based on their salary
in their department. In HR Department every employee has distinct salary so each has given
different rank but in IT Department three employees has same salary so they has given rank
2 and next employee gets rank 5.This is the problem with the RANK Function it does not
always return consecutive integers.
DENSE_RANK

RANK function does not always return consecutive integers to overcome this problem we
have another Ranking function in SQL Server which is known as DENSE_RANK. DENSE_RANK
function Returns the rank of rows within the partition of a result set or within all records,
without any gaps in the ranking. The rank of a row is one plus the number of distinct ranks
that come from the previous row.
Syntax: DENSE_RANK () OVER (PARTITION BY [column_list] ORDER BY [column_list])
PARTITION BY [Column_list] – This is optional if you want to divide the result set into
partitions to which the function is applied then you must give the column name, if you
don’t use this clause then the function treats all records of the query result set as a single
group.
ORDER BY [Column_list] – This is not optional it is a must clause; this determines the order
of the data before the function is applied.
Let’s understand the DENSE_RANK function using the old examples.
Problem 1:
You want to get each employee rank without gap among all other employees based on their
highest salary.
Solution:
You can use DENSE_RANK function without PARTITION By Clause and ORDER BY Clause on
SALAY in Descending order.
SQL Code:
SELECT EMPNAME, DEPARTMENT, SALARY , DENSE_RANK() OVER(ORDER BY SALARY DESC)
AS OVER_ALL_RANK_BY_SALARY FROMEMP
Output:
Explanation:
As you can see from the result set each employees has given a rank based on their salary.
Whoever is having same salary has been given same rank i.e 8 and 11 but there is no gap in
the ranking like RANK function.
Problem 2:
You want to get each employee rank without any gap in their department based on their
highest salary.
Solution:
You can use DENSE_RANK function with PARTITION BY Clause on DEPARTMENT and
ORDER BY Clause on SALAY in Descending order.
SQL Code:

SELECT EMPNAME, DEPARTMENT, SALARY , DENSE_RANK() OVER(PARTITION BY
DEPARTMENT ORDER BY SALARY DESC) ASRANK_IN_DEP_BY_SALARY FROM EMP
Output:
Explanation:
As you can see from the result set each employees has given a rank based on their salaryin their department. In HR Department every employee has distinct salary so each hasgiven different rank but in IT Department three employees has same salary so they has given rank 2 and next Employee gets rank as 3.
ROW_NUMBER
ROW_NUMBER function Returns the serial number of each record within a partition of aresult set or within all records. It starts serial number as 1 for the first record and for next records it adds one. We get unique serial number for each record if using ROW_NUMBERfunction. If we are using ROW_NUMBER function within a partition of a result set then itstarts with 1 in each partition.
Syntax: ROW_NUMBER () OVER (PARTITION BY [column_list] ORDER BY [column_list])
PARTITION BY [Column_list] – This is optional if you want to divide the result set intopartitions to which the function is applied then you must give the column name,if you don’t use this clause then the function treats all records of the query result setas a single group.
ORDER BY [Column_list] – This is not optional it is a must clause; this determines theorder of the data before the function is applied.
Let’s understand the ROW_NUMBER function with simple examples.

Problem 1:
You want to get serial number for each employee among all employees based on theirhighest salary.
Solution:
You can use ROW_NUMBER function without PARTITION By Clause and ORDER BY Clause onSALAY in Descending order.
SQL Code:
SELECT EMPNAME, DEPARTMENT, SALARY, ROW_NUMBER() OVER(ORDER BY SALARY DESC) AS ROW_NUMBER_BY_SALARY FROM EMP
Output:
Explanation:
As you can see from the result set each employees has given a serial number based on their salary among all employees. Serial number starts with 1 and goes till 15 (because we have total 15 records in EMP table).Whoever is having same salary has not given same serialnumber like DENSE_RANK function.
Problem 2:
You want to get serial number for each employee in their department based on their highest salary.

Solution:
You can use ROW_NUMBER function with PARTITION BY Clause on DEPARTMENT and ORDER BY Clause on SALARY in Descending order.
SQL Code:
SELECT EMPNAME, DEPARTMENT, SALARY, ROW_NUMBER() OVER(PARTITION BY DEPARTMENT ORDER BY SALARY DESC) AS ROW_NUMBER_IN_DEP_BY_SALARY FROM EMP
Output:
Explanation:
As you can see from the result set each employee has given a serial number based on their salary in their department and it’s unique, it starts with 1 and goes till 5 because eachdepartment has max 5 employees.
NTILE
NTILE function distributes all your records in an ordered groups with a specified groupnumber. The groups are numbered, starting at 1 for the first group and adds 1 for the next group. For each record, NTILE returns the number of the group to which the record belongs.
Syntax: NTILE (Interger_Expression) OVER (PARTITION BY [column_list] ORDER BY [column_list])
Integer_Expression – It is a positive integer constant expression that specifies the number of groups into which each partition must be divided

PARTITION BY [Column_list] – This is optional if you want to divide the result set into partitions to which the function is applied then you must give the column name, if you don’t use this clause then the function treats all records of the query result set as a single group.
ORDER BY [Column_list] – This is not optional it is a must clause; this determines the order of the data before the function is applied.
Let’s understand the NTILE function with simple examples.
Problem 1:
You want to divide all employees into 3 groups based on their highest salary.
Solution:
You can use NTILE function without PARTITION By Clause and with Inter_expression equals to 3 and ORDER BY Clause on SALAY in Descending order.
SQL Code:
SELECT EMPNAME, DEPARTMENT, SALARY , NTILE(3) OVER(ORDER BY SALARY DESC) AS GROUP_NUMBER_BY_SALARY FROM EMP
Output:
Explanation:
As you can see from the result set there are total 15 records in EMP table. All records have been divided into three groups. Each group has it group number with 5 records.
Problem 2:
You want divide each employee in their department based on their highest salary into 2 groups.
Solution:
You can use NTILE function with INTEGER EXPRESSION value equal to 2, PARTITION BY Clause on DEPARTMENT and ORDER BY Clause on SALAY in Descending order.
SQL Code:
SELECT EMPNAME, DEPARTMENT, SALARY , NTILE(3) OVER(PARTITION BY DEPARTMENT ORDER BY SALARY DESC) ASGROUP_NUMBER_IN_DEP_BY_SALARY FROM EMP
Output:
Explanation:
As you can see from the result set there are total 3 Departments, each department has 5 records in it. All records in each department have been divided into 3 groups. Each group has it group number with its records.
RANK() VS DENSE_RANK() The RANK () function in SQL Server returns the position of a value within the partition of a result set, with gaps in the ranking where there are ties.

The DENSE_RANK () function in SQL Server returns the position of a value within the partition of a result set, leaving no gaps in the ranking where there are ties.
Let us understand this difference with an example and then observe the results while using these two functions:
Example for RANK
Rank Name Age
1 Ram 20
2 Shayam 21
2 Sohan 21
4 Rohit 23
4 Rohan 23
4 Raj 23
7 XYZ 24
8 YZ 25
Example of Dense Rank
Dense Rank
Name Age
1 Ram 20
2 Shayam 21
2 Sohan 21
3 Rohit 23
3 Rohan 23
3 Raj 23
4 XYZ 24
5 YZ 25
Keyword: TSQL Interview Questions, SQL Server Interview Questions and Answers,Rank Vs Dense Rank.
TOP Operator in SQL Server
Limits the rows returned in a query result set to a specified number of rows or percentage of rows in SQL Server 2014. When TOP is used in conjunction with the ORDER BY clause, the result set is limited to the first N number of ordered rows; otherwise, it returns the first N number of rows in an undefined order. Use this clause to specify the number of rows returned from a SELECT statement or affected by an INSERT, UPDATE, MERGE, or DELETE statement.
Syntax
[ TOP (expression) [PERCENT] [ WITH TIES ]]
Argumentsexpression
Is the numeric expression that specifies the number of rows to be returned. expression is implicitly converted to a float value if PERCENT is specified; otherwise, it is converted to bigint.
PERCENT
Indicates that the query returns only the first expression percent of rows from the result set. Fractional values are rounded up to the next integer value.
WITH TIES
Used when you want to return two or more rows that tie for last place in the limited results set. Must be used with the ORDER BY clause. WITH TIES may cause more rows to be returned than the value specified in expression. For example, if expression is set to 5 but 2 additional rows match the values of the ORDER BY columns in row 5, the result set will contain 7 rows.
TOP...WITH TIES can be specified only in SELECT statements, and only if an ORDER BY clause is specified. The returned order of tying records is arbitrary. ORDER BY does not affect this rule.
Best Practices
In a SELECT statement, always use an ORDER BY clause with the TOP clause. This is the only way to predictably indicate which rows are affected by TOP.
Use OFFSET and FETCH in the ORDER BY clause instead of the TOP clause to implement a query paging solution. A paging solution (that is, sending chunks or "pages" of data to the client) is easier to implement using OFFSET and FETCH clauses. For more information, see ORDER BY Clause (Transact-SQL).

Use TOP (or OFFSET and FETCH) instead of SET ROWCOUNT to limit the number of rows returned. These methods are preferred over using SET ROWCOUNT for the following reasons:
As a part of a SELECT statement, the query optimizer can consider the value of expression in the TOP or FETCH clauses during query optimization. Because SET ROWCOUNT is used outside a statement that executes a query, its value cannot be considered in a query plan.
TableSample in SQL ServerThe TABLESAMPLE clause limits the number of rows returned from a table in the FROM clause to a sample number or PERCENT of rows. For example:TABLESAMPLE (10 PERCENT) /*Return a sample 10 percent of the rows of the result set. */TABLESAMPLE (15 ROWS) /* Return a sample of 15 rows from the result set. */.
TABLESAMPLE cannot be applied to derived tables, tables from linked servers, and tables derived from table-valued functions, rowset functions, or OPENXML. TABLESAMPLE cannot be specified in the definition of a view or an inline table-valued function.The syntax for the TABLESPACE clause is as follows:TABLESAMPLE [SYSTEM] (sample_number [ PERCENT | ROWS ] )[ REPEATABLE (repeat_seed) ]You can use TABLESAMPLE to quickly return a sample from a large table when either of the following conditions is true: The sample does not have to be a truly random sample at the level of individual rows.
Rows on individual pages of the table are not correlated with other rows on the same page.
TableSample in SQL ServerThe TABLESAMPLE clause limits the number of rows returned from a table in the FROM clause to a sample number or PERCENT of rows. For example:TABLESAMPLE (10 PERCENT) /*Return a sample 10 percent of the rows of the result set. */TABLESAMPLE (15 ROWS) /* Return a sample of 15 rows from the result set. */.
TABLESAMPLE cannot be applied to derived tables, tables from linked servers, and tables derived from table-valued functions, rowset functions, or OPENXML. TABLESAMPLE cannot be specified in the definition of a view or an inline table-valued function.The syntax for the TABLESPACE clause is as follows:TABLESAMPLE [SYSTEM] (sample_number [ PERCENT | ROWS ] )[ REPEATABLE (repeat_seed) ]You can use TABLESAMPLE to quickly return a sample from a large table when either of the following conditions is true:

The sample does not have to be a truly random sample at the level of individual rows.
Rows on individual pages of the table are not correlated with other rows on the same page.
T SQL Tutorial: DELETE
Learn how to use the T SQL DELETE statement with syntax, examples, and practice exercises.
DescriptionThe T SQL DELETE statement is a used to delete a one or more records from a table.
SyntaxThe syntax for the T SQL DELETE statement is:
DELETE FROM tableWHERE conditions;
You do not need to list fields in the T SQL DELETE statement since you are deleting the entire row from the table.
Delete With One condition
Let's look at an example showing how to use the T SQL DELETE statement.For example:
DELETE FROM customerWHERE customer_name = 'Rohit';
This T SQL DELETE example would delete all records from the suppliers table where the Customer_name is rohit.
Delete With Two conditionsLet's look at a T SQL DELETE example, where we just have two conditions in the T SQL DELETE statement.
For example:
DELETE FROM order
WHERE price >= 20
AND custid = 222;
This T SQL DELETE example would delete all records from the products table where the price is greater than or equal to 20 and the custid is 222.

DELETE VS TRUNCATE
DELETE
1. DELETE is a DML Command. 2. DELETE statement is executed using a row lock, each row in the table is locked for deletion. 3. We can specify filters in where clause 4. It deletes specified data if where condition exists. 5. Delete activates a trigger because the operation is logged individually. 6. Slower than truncate because, it keeps logs. 7. Rollback is possible.
TRUNCATE 1. TRUNCATE is a DDL command. 2. TRUNCATE TABLE always locks the table and page but not each row. 3. Cannot use Where Condition. 4. It Removes all the data. 5. TRUNCATE TABLE cannot activate a trigger because the operation does not log individual row deletions. 6. Faster in performance wise, because it doesn't keep any logs. 7. Rollback is not possible.
DELETE and TRUNCATE both can be rolled back when used with TRANSACTION.
If Transaction is done, means COMMITED, then we cannot rollback TRUNCATE command, but we can still rollback DELETE command from LOG files, as DELETE write records them in Log file in case it is needed to rollback in future from LOG files.
T SQL Tutorial: DISTINCTT SQL (Transact) Tutorial: DISTINCT
Check T SQL DISTINCT clause with syntax and examples.
Theory
The SQL DISTINCT clause is used to remove duplicates result set.The syntax for the SQL DISTINCT clause is:
SELECT DISTINCT expressions
FROM tables
WHERE conditions;
Point to remember
When only one expression is provided in the DISTINCT clause, the query will return the unique values for that expression.

When more than one expression is provided in the DISTINCT clause, the query will retrieve unique combinations for the expressions listed.
Distinct With Single field
Let's look at the simplest SQL DISTINCT query example. We can use the SQL DISTINCT clause to return a single field that removes the duplicates from the result set.
For example:
SELECT DISTINCT city
FROM Customers;
This SQL DISTINCT example would return all unique city values from the Customers table.
Distinct With Multiple fields
Let's look at how you might use the SQL DISTINCT clause to remove duplicates from more than one field in your SQL SELECT statement.
For example:
SELECT DISTINCT city, state
FROM Customers;
This SQL DISTINCT clause example would return each unique city and state combination. In this case, the DISTINCT applies to each field listed after the DISTINCT keyword. If there are multiple column distinct will apply that many time with multiple of rows.
T SQL Tutorial: DISTINCTT SQL (Transact) Tutorial: DISTINCT
Check T SQL DISTINCT clause with syntax and examples.
Theory
The SQL DISTINCT clause is used to remove duplicates result set.The syntax for the SQL DISTINCT clause is:
SELECT DISTINCT expressions
FROM tables
WHERE conditions;
Point to remember
When only one expression is provided in the DISTINCT clause, the query will return the unique values for that expression.

When more than one expression is provided in the DISTINCT clause, the query will retrieve unique combinations for the expressions listed.
Distinct With Single field
Let's look at the simplest SQL DISTINCT query example. We can use the SQL DISTINCT clause to return a single field that removes the duplicates from the result set.
For example:
SELECT DISTINCT city
FROM Customers;
This SQL DISTINCT example would return all unique city values from the Customers table.
Distinct With Multiple fields
Let's look at how you might use the SQL DISTINCT clause to remove duplicates from more than one field in your SQL SELECT statement.
For example:
SELECT DISTINCT city, state
FROM Customers;
This SQL DISTINCT clause example would return each unique city and state combination. In this case, the DISTINCT applies to each field listed after the DISTINCT keyword. If there are multiple column distinct will apply that many time with multiple of rows.
T SQL Tutorial: ORDER BYIn T SQL Tutorial check how to use ORDER BY clause with syntax and examples.
One LinerThe SQL ORDER BY clause is used to sort the records in the result set for a SELECT statement.
SyntaxThe syntax for the SQL ORDER BY clause is:
SELECT expressionsFROM tables
WHERE conditions
ORDER BY expression [ ASC | DESC ];
Thing to Remember
If the ASC or DESC option is not provided in the ORDER BY clause, the results will be sorted by expression in ascending order (which is equivalent to "ORDER BY expression ASC").Order by clause can’t be used in a view definition.Order by cant be used in a sub query having aggregate functions in select statement

@@ERROR (Transact-SQL)
@@ERROR (Transact-SQL) Returns the error number for the last Transact-SQL statement executed.
Returns 0 if the previous Transact-SQL statement encountered no errors.
Returns an error number if the previous statement encountered an error. If the error was oneof the errors in the sys.messages catalog view, then @@ERROR contains the value from thesys.messages.message_id column for that error. You can view the text associated with an@@ERROR error number in sys.messages.Because @@ERROR is cleared and reset on each statement executed, check it immediatelyfollowing the statement being verified, or save it to a local variable that can be checked later.Use the TRY...CATCH construct to handle errors. The TRY...CATCH construct also supportsadditional system functions (ERROR_LINE, ERROR_MESSAGE, ERROR_PROCEDURE,ERROR_SEVERITY, and ERROR_STATE) that return more error information than @@ERROR.TRY...CATCH also supports an ERROR_NUMBER function that is not limited to returning theerror number in the statement immediately after the statement that generated an error.
RAISERROR TSQL SQL Server
Generates an error message and initiates error processing for the session. RAISERROR can either reference a user-defined message stored in the sys.messages catalog view or build a message dynamically.
The errors generated by RAISERROR operate the same as errors generated by the Database Engine code. The values specified by RAISERROR are reported by the ERROR_LINE, ERROR_MESSAGE, ERROR_NUMBER, ERROR_PROCEDURE, ERROR_SEVERITY, ERROR_STATE, and @@ERROR system functions. When RAISERROR is run with a severity of 11 or higher in a TRY block, it transfers control to the associated CATCH block. The error is returned to the caller if RAISERROR is run:
Outside the scope of any TRY block.
With a severity of 10 or lower in a TRY block.
With a severity of 20 or higher that terminates the database connection.
CATCH blocks can use RAISERROR to rethrow the error that invoked the CATCH block by using system functions such as ERROR_NUMBER and ERROR_MESSAGE to retrieve the original error information. @@ERROR is set to 0 by default for messages with a severity from 1 through 10.
When msg_id specifies a user-defined message available from the sys.messages catalog

view, RAISERROR processes the message from the text column using the same rules as are applied to the text of a user-defined message specified using msg_str. The user-defined message text can contain conversion specifications, and RAISERROR will map argument values into the conversion specifications. Use sp_addmessage to add user-defined error messages and sp_dropmessage to delete user-defined error messages.
RAISERROR can be used as an alternative to PRINT to return messages to calling applications. RAISERROR supports character substitution similar to the functionality of the printf function in the C standard library, while the Transact-SQL PRINT statement does not. The PRINT statement is not affected by TRY blocks, while a RAISERROR run with a severity of 11 to 19 in a TRY block transfers control to the associated CATCH block. Specify a severity of 10 or lower to use RAISERROR to return a message from a TRY block without invoking the CATCH block.
Typically, successive arguments replace successive conversion specifications; the first argument replaces the first conversion specification, the second argument replaces the second conversion specification, and so on
TSQL SQL Server Interview Questions
DATEDIFF IN SQL SERVERDate diff tells the difference between the two dates in terms of the entity provided.
DATEDIFF (datepart , startdate , enddate )
Datepart could e mm or dd or yy or mi depends upon the requirement.
Below are the few points related to date diff.
DATEDIFF does not guarantee that the full number of the specified time units passed between
2 datetime Values.
-- Get difference in hours between 8:55 and 11:00
SELECT DATEDIFF(hh, '08:55', '11:00');
-- Returns 3 although only 2 hours and 5 minutes passed between times
-- Get difference in months between Sep 30, 2011 and Nov 02, 2011

SELECT DATEDIFF(mm, '2011-09-30', '2011-11-02')
-- Returns 2 although only 1 month and 2 days passed between date
To get the number of full time units passed between date times, you can calculate the difference
in lower Units and then divide by the appropriate number:
SELECT DATEDIFF(mi, '08:55', '11:00')/60;
-- Returns 2 hours now
COALESCE (Transact-SQL)SQL Server 2012Other VersionsEvaluates the arguments in order and returns the current value of the first expression that initially does not evaluate to NULL.
Applies to: SQL Server (SQL Server 2008 through current version), Windows Azure SQL Database (Initial release through current release).Transact-SQL Syntax ConventionsSyntax
COALESCE ( expression [ ,...n ] )Arguments
expressionIs an expression of any type.Return Types
Returns the data type of expression with the highest data type precedence. If all expressions are nonnullable, the result is typed as nonnullable
If all arguments are NULL, COALESCE returns NULL. At least one of the null values must be a typed NULL.Comparing COALESCE and CASEThe COALESCE expression is a syntactic shortcut for the CASE expression. That is, the code COALESCE(expression1,...n) is rewritten by the query optimizer as the following CASE expression:CASE WHEN (expression1 IS NOT NULL) THEN expression1

WHEN (expression2 IS NOT NULL) THEN expression2 ... ELSE expressionNENDThis means that the input values (expression1, expression2, expressionN, etc.) will be evaluated multiple times. Also, in compliance with the SQL standard, a value expression that contains a subquery is considered non-deterministic and the subquery is evaluated twice. In either case, different results can be returned between the first evaluation and subsequent evaluations.For example, when the code COALESCE((subquery), 1) is executed, the subquery is evaluated twice. As a result, you can get different results depending on the isolation level of the query. For example, the code can return NULL under the READ COMMITTED isolation level in a multi-user environment. To ensure stable results are returned, use the SNAPSHOT ISOLATION isolation level, or replace COALESE with the ISNULL function. Alternatively, you can rewrite the query to push the subquery into a subselect as shown in the following example.SELECT CASE WHEN x IS NOT NULL THEN x ELSE 1 ENDFROM(SELECT (SELECT Nullable FROM Demo WHERE SomeCol = 1) AS x) AS T;Comparing COALESCE and ISNULLThe ISNULL function and the COALESCE expression have a similar purpose but can behave differently.Because ISNULL is a function, it is evaluated only once. As described above, the input values for the COALESCE expression can be evaluated multiple times.
Data type determination of the resulting expression is different. ISNULL uses the data type of the first parameter, COALESCE follows the CASE expression rules and returns the data type of value with the highest precedence.
The NULLability of the result expression is different for ISNULL and COALESCE. The ISNULL return value is always considered NOT NULLable (assuming the return value is a non-nullable one) whereas COALESCE with non-null parameters is considered to be NULL. So the expressions ISNULL(NULL, 1) and COALESCE(NULL, 1) although equivalent have different nullability values. This makes a difference if you are using these expressions in computed columns, creating key constraints or making the return value of a scalar UDF deterministic so that it can be indexed as shown in the following example.
USE tempdb; GO -- This statement fails because the PRIMARY KEY cannot accept NULL values -- and the nullability of the COALESCE expression for col2 -- evaluates to NULL. CREATE TABLE #Demo ( col1 integer NULL, col2 AS COALESCE(col1, 0) PRIMARY KEY, col3 AS ISNULL(col1, 0) ); -- This statement succeeds because the nullability of the -- ISNULL function evaluates AS NOT NULL. CREATE TABLE #Demo (

col1 integer NULL,col2 AS COALESCE(col1, 0),col3 AS ISNULL(col1, 0) PRIMARY KEY );Validations for ISNULL and COALESCE are also different. For example, a NULL value for ISNULL is converted to int whereas for COALESCE, you must provide a data type.
ISNULL takes only 2 parameters whereas COALESCE takes a variable number of parameters.
Examples
A. Running a simple exampleThe following example shows how COALESCE selects the data from the first column that has a nonnull value. This example uses the AdventureWorks2012 database.SELECT Name, Class, Color, ProductNumber,COALESCE(Class, Color, ProductNumber) AS FirstNotNullFROM Production.Product;B. Running a complex exampleIn the following example, the wages table includes three columns that contain information about the yearly wages of the employees: the hourly wage, salary, and commission. However, an employee receives only one type of pay. To determine the total amount paid to all employees, use COALESCE to receive only the nonnull value found in hourly_wage, salary, and commission. SET NOCOUNT ON;GOUSE tempdb;IF OBJECT_ID('dbo.wages') IS NOT NULL DROP TABLE wages;GOCREATE TABLE dbo.wages( emp_id tinyint identity, hourly_wage decimal NULL, salary decimal NULL, commission decimal NULL, num_sales tinyint NULL);GOINSERT dbo.wages (hourly_wage, salary, commission, num_sales)VALUES (10.00, NULL, NULL, NULL), (20.00, NULL, NULL, NULL), (30.00, NULL, NULL, NULL), (40.00, NULL, NULL, NULL), (NULL, 10000.00, NULL, NULL), (NULL, 20000.00, NULL, NULL), (NULL, 30000.00, NULL, NULL), (NULL, 40000.00, NULL, NULL), (NULL, NULL, 15000, 3), (NULL, NULL, 25000, 2), (NULL, NULL, 20000, 6), (NULL, NULL, 14000, 4);GOSET NOCOUNT OFF;GO

SELECT CAST(COALESCE(hourly_wage * 40 * 52, salary, commission * num_sales) AS money) AS 'Total Salary'FROM dbo.wagesORDER BY 'Total Salary';GO
Here is the result set.Total Salary------------10000.0020000.0020800.0030000.0040000.0041600.0045000.0050000.0056000.0062400.0083200.00120000.00(12 row(s) affected)
Difference between STUFF and REPLACE
Difference between STUFF and REPLACE
STUFF function is used to overwrite existing characters using this syntax: STUFF (string_expression, start, length, replacement_characters), where string_expression is the string that will have characters substituted, start is the starting position, length is the number of characters in the string that are substituted, and replacement_characters are the new characters interjected into the string.
REPLACE function is used to replace existing characters of all occurrences. Using the syntax REPLACE (string_expression, search_string, replacement_string), every incidence of search_string found in the string_expression will be replaced with replacement string





























