Embed Size (px)
Citation preview

Systems and Computers in Japan, Vol. 26, No. 14, 1995 Translated from Denshi Joho Tsushin Gakkai Ronbunshi, Vol. J77-D-11, No. 8, August 1994, pp. 1417-1428
Spontaneous Speech Dialogue System TOSBURG 11- The User-Centered Multimodal Interface
Yoichi Takebayashi, Member
Senior Research Engineer, 3rd Communications System Lab., Research & Development Center, Toshiba Corporation, Kawasaki, Japan 210
SUMMARY
This paper considers the user-centered spon- taneous speech dialogue system TOSBURG-I1 (Task- oriented dialogue system based on speech under- standing and response generation), and discusses the design from the viewpoint of media technology and a multimodal interface. The authors have developed element techniques, including spontaneous speech un- derstanding, user-center dialogue control, multimodal response generation and speech response cancelling, all based on the noise-immune word-spotting and key- words. The concept is that "no constraint is imposed on the user." By integrating these techniques, the real- time speech dialogue system for an unspecified user is developed. The speech dialogue data acquisition/ evaluation system is constructed on the real system. The system can record real speech data as well as the intermediate result of processing in the dialogue sys- tem, such as keyword spotting, speech understanding and dialogue processing. The system can also be util- ized in the construction of the speech dialogue corpus and the evaluation/improvement of the human factor aspect, in addition to the evaluation of the system performance. As a result of trial use and evaluation experiment for the real system for unspecified users, it is verified that spontaneous speech understanding based on the interruption function by the user and the multimodal response and keywords, is useful in im- proving the naturalness of the dialogue and robustness.
Key words: Speech dialogue; multimodal; mul- timedia; speech understanding; human interface.
1. Introduction
In the use of a computer in various environ- ments, it is the interface that exists between the ap- plication and the human user. With the development of computer technology, the "remember and type" in- terface using characters and keyboard is replaced by the "see and point" type graphical user interface (GUI), using the bit-map display, mouse and icon. The interactive computer application environment is developed and the user range is expanded. Further- more, the audio interface is now a standard compo- nent of the computer and it is expected that the "ask and tell" interface, which is natural and friendly, be- ing helped by voice media, will be used widely [l].
In human daily communication, intention and emotion are transmitted in a natural and direct way, using facial expression, view-line and hand and body gestures, etc., in addition to speech [2,3]. It should be noted, however, that even if the multimedia environ- ment is available in the present human-computer inter- action technique, multiple media are simply input/ output (recorded/reproduced) at the bit-level. To im- prove the system for a more natural and easy-to-use information transmission, there must be a built-in in- terface with intelligent functions, such as the under- standing and generation of media contents [4, 51.
Humans execute diversifiedconversations accord- ing to the purpose and situation, using "spoken lan- guage." In studies of speech recognition, however, only the utterance with a strong constraint basedon the
77 ISSN0882- 1666/95/00 14-0077 0 1996 Scripta Technica, Inc.

grammar of the "written language" has been considered rather than the spoken language containing pauses and word-order inversions. Improvement in recognition rate has been a major concern. Although the highly precise large-vocabulary continuous-speech recognition system has been developed, robustness against noise, which is important in practical applications, is low. Also, it is pointed out that robustness is insufficient against spontaneous speech, which contains unneces- sary words and mispronunciations [6].
To realize further a natural dialogue with the computer, there has been pointed out the necessity for the study of the multimodal interface, which combines speech dialogue processing where the human and the computer create a dialogue that considers situation and context, and visual media other than speech, etc. [7-lo].
This paper describes the approach to a spontane- ous speech dialogue system TOSBURG 11, which was constructed aiming at user-centered dialogue with the computer and with natural speech. From the viewpoint of the multimodal interface, the element techniques and their integration are described. The acquisition/ evaluation system for the real dialogue data, which are useful in performance improvement and the study of human factors, is discussed. Finally, future topics of research concerning the multimodal interface are discussed.
2. Approach to Spontaneous Speech Dialogue System
2.1. Multimodal interface and speech media
It was pointed out by McLuhan in the 1960s that human beings are affected subconsciously by the media (techniques) they use themselves [ll]. Kay, who was strongly influenced by McLuhan, postulated the notion in the 1970s that a computer should be considered to be metamedia (personal dynamic media). He then pro-posed the concept of dynabook, which can assist hu-mans in intelligent and creative activities. He con- structed an experimental dialogue-type workstation, with bit-map display, window, mouse and icon (121. Kay's approach is to match as much as possible the media to the human who will use such. An innovative application is developed by integrating the most current techniques of the time, such as interactive graphics, hypertext, pen-input and object-oriented language.
The multimedia techniques at present, however, are concerned only with the expansion of the kind of
Uniinodal
Q__x, Multimodal
(a) Sirnple input-output conirriunicatioii
Inlormalion
(b) Intelligent interaction based on understanding function 0 Synthesis
(c) lntelligenl inlernction based on synthesis (unction
Fig. 1. Comparison of communication models using multimedia.
media and the amount of information (as is shown in Fig. l(a)). In most cases, multimedia are simply in- put/output at bit level. Although much multimedia information can be accessed by a high-speed computer and network, and not simply to transmit the informa- tion, to make this information valuable it is necessary to understand information content (pointed out by Omae [4]).
The function of the media shown in Fig. l(b) deals with the process necessary for the user to handle the input information, such as speech, keyboard, mouse and image. The purpose is to understand either user intention or the input information content. The media understanding process is a mapping from the pattern space containing a large amount of information to the internal representation of the computer, which has less information. Recognition error and ambiguity are pro- duced in the course of this information compression. In other words, it is necessary in the construction of the multimodal dialogue system to reduce the error and to cope with ambiguity. From the viewpoint of speech dialogue, it is more important to understand the content of the utterance, to understand the intention, and to integrate the content with other media, rather than to effect superficial transformation from a speech signal to other media such as word or sentence.
78

The media generation process in Fig. l(c), on the other hand, is the one-to-many ill-formed mapping from the internal representation of the computer to the pattern space. In other words, there can be a diversity of patterns that can be generated and various patterns can be presented to the user. This produces a kind of ambiguity that differs from that of the understanding process. When the information is presented to the user of the multimedia, the human tends to pay atten- tion to the added multimedia rather than to the con- tent of the information. Consequently, the media matched to human .perception and recognition charac- teristics must be generated.
We took the viewpoint of artificial media, and considered the "ask and tell" type interface. Speech is considered to assume a central role in dialogue media, not as a simple substitute for the keyboard or mouse. Thus it is intended to develop such techniques as speech recognition, speech synthesis and dialogue processing, together with a technique for their integration. *Speech media can be used in parallel with other media, which results in a better matching to the multimodal interface, where "there should be multiple sensation channels (modalities) by which the information can be perceived." The speech dialogue system is constructed using this system [ 13, 141.
with other element techniques and must furthermore be merged with the HI techniques.
For computer interfacing a widespread use of the 'kee and point" type dialogue is observed, using GUI and the desk-top metaphor. It is now easy to select the menu in GUI using speech recognition instead of the mouse [ 151. It is pointed out, however, that there is a limit in the present GUI [ 161. Our aim is the next- generation "ask and tell" type interface, thus we con- centrate on the design of the computer-user dialogue behavior by utilizing the features of the speech media.
It is intended to realize the intelligent interface with an agent. The agent has a tremendous knowledge to understand the intention of the user and to give an adequate response. To achieve the goal, it is intended first to develop a prototype for the user-centered mul- timodal interface. This is done by restricting the task and using the knowledge about the dialogue and the application problems. It is intended also to realize a robust real-time dialogue system that can cope with the recognition error in a flexible way, based on the con- cept that ''no constraint should be imposed on the user'' by employing the features of the speech media, i.e., the natural, friendly, fast and hand-free properties.
2.3. Design of speech dialogue system 2.2. User-centered speech dialogue system
We are studying a speech dialogue system, aiming at a realization of human-oriented and user-centered artificial dialogue media, not an improvement in dia- logue efficiency, based on knowledge regarding human beings.
In the field of artificial intelligence and cognitive science, studies on the dialogue model have been made. However, they are concerned mostly with hu- man-to-human dialogue, and there are few studies con- cerned with human-to-computer speech dialogue from the viewpoint of the artificial multimedia, e.g., those previously described studies done by McLuhan and Kay. Although the high-performance continuous speech recognition system has been developed at the laboratory level, it is pointed out that robustness is still low against noise and spontaneous speech. This pre- vents the system from being used in applications.
In the study of speech, techniquesother than the speech recognition technique are usually considered to be application technologies. We consider the speech recognition technique to be the core artificial media in the multimodal interface, which must be integrated
2.3.1. Design guide For the speech dialogue sys- tem
Hayes et al. introduced the idea called "graceful interaction," based on understanding the speech media [ 171. We defined the following principle in developing the speech dialogue system:
The task which is usual and easy to under- stand for the user should be defined. The adequate speech understanding and response generation should be realized based on the knowledge about the applications.
0 It is natural to return the speech output in response to the speech input. Consequently, both the speech recognition and the speech synthesis should be used to employ the fea- tures of the speech media as the multimodal interface.
In order to realize the naturalness of the spoken language, the system should cope with the spontaneous utterance of the user in a flexible way.
79

The dialogue should be continued in a flexible way even if an error in speech recognition or situation recognition arises.
The advantages of the speech media as the multimodal interface should be utilized.
The ability and the limit of the system should be described to the users.
23.2. Selection of task and design for system function
The task should be selected so that the perform- ance for speech recognition/understanding by unspeci- fied users as well as the human factors can be eval- uated based on the above design principle. The ticket vender and the seat reservation system for the bullet train may be considered as daily-life tasks, but the placing of an order in fast-food restaurant is selected as a daily task. The task is decided as adequate although on a small scale, since the input of numbers is important. This is indispensable in the practical application of speech recognition.
Speech understanding is based on the noise im- munity word-spotting, which is robust against environ- mental noise and the unnecessary word. The spon- taneous speech understanding system based on key words is developed in order to retain the naturalness of the spoken language.
233. Simulated dialogue experiment
To examine whether or not the order task in the fast-food restaurant can be realized as a user-centered dialogue based on the spontaneous speech understand- ing, a simulated dialogue experiment is conducted by dividing the roles between the dialogue system and the user. The subject as the user utters various sentences assuming the actual applications. The role of the sys- tem is played by the actual researcher. The dialogue progresses by setting the limit of the system so that the speech by the user is understood and the response is returned to the user. Sometimes the utterance is made in a low voice. It is the researcherwho visited the fast- food restaurant for reference to order food in various ways.
The following observations are made.
The start timing of the dialogue is important in realizing a natural dialogue.
The task can be achieved by an adequate dia- logue using several tens of keywords, which are necessary in executing the task.
The dialogue may stop if a recognition error arises.
There is a user who makes a fool of the clerk for fun.
It makes sense to cope with the user with few- er errors in an efficient way, but the user with frequent errors should be handled modifying the dialogue strategy.
The speech data are recorded in the simulated dialogue experiment, and transcribed. Then, the con- struction of the text-base spontaneous speech under- standing system and the dialogue system is started. From the early stage of the system development, it is anticipated that the utterance from those of the sim- ulated dialogue. Consequently, the data in the pre- liminary experiment are used only to verify the real- izability of the keyword-based spontaneous speech un- derstanding and the user-centered dialogue control.
2.3.4. Examination as a multimodal interface
The use of various media is investigated from the viewpoint of the multimodal interface, but the system is designed so that the dialogue can be continued using only the speech media. In other words, the speech response is returned so that the dialogue can easily be executed by telephone or in the state where the eyes are closed. A floor mat with a pressure sensor is used so that the dialogue can be started stably. The com- bined use of the fingertip and the voice also is con- sidered as the case of "Put that there" [ 181. However, the pointing device such as the touch screen is not used since the purpose is to investigate the speech- based system.
In addition, the system simulates the human per- sonality as if the dialogue is between humans. The col- or animation of the waiter is shown so that the natural response by speech is returned to the input speech. The use of 3D color graphics also is considered. The proposed technique, however, is only a personalized metaphor, and a simple 2D animation is presented varying only facial expressions and moving lips, since excessive information may confuse the user.
The following multimodal response is used. In the display of the response, such as the verification of
80

spotter semantlc
Semantic utterance ;:KF
Speech input Speech -+ response canceller
Speech ' Semantic
Fig. 2. A real-time speech dialogue system TOS- Fig. 3. Configuration of spontaneous speech dialogue BURG. system TOSBURG 11.
the speech recognition result, the name, the number and the size of the ordered items also are displayed together with the facial expression.
The content of the response sentence also is displayed as a text, and the speech is generated by the synthesis by the rule. Furthermore, to utilize the advantages of the speech media, the prosody of the speech response is controlled, and the ambiguous point is emphasized to ask for verification.
Based on the above design principle for the speech dialogue system, the element techniques are de- veloped and extended. The recognition dictionary is constructed, the grammar for the spontaneous speech understanding is organized, the dialogue processing is made sophisticated, the multimodal response is im- proved, and the real-time system also is developed.
3. Experimental Construction of Speech Dialogue System TOSBURG
3.1. Configuration of TOSBURG
Based on the concept that "no constraint should be imposed for the unspecified users, TOSBURG I was constructed as the first version of the real-time speech dialogue system, as is shown in Fig. 2 [19]. Based on the result of the previously described simu- lated dialogue experiment, the keywords to be used in realizing the dialogue task are set as 49 words in this system.
Figure 3 shows the configuration of TOSBURG 11, which is an extension of TOSBURG I. In TOS-
BURG 11, the speech response canceler is added to improve TOSBURG I. TOSBURG I is composed of the keyword detector, the spontaneous understanding unit, the user-centered dialogue controller and the multimodal response generator. The system operates in real-time using 4 DSP accelerators, [20], previously developed by the authors, and 3 workstations. The element techniques are described in the following.
'
3.2. Noise-immunity word-spotting method
We consider that the improvement of robustness is more important than the large-scale vocabulary in the speech recognition. The word-spotting is investi- gated, which does not require the detection of the speech interval, although a large amount of computa- tion is required. Robustness against noise is improved by using the word featurevector composed of the time- frequency spectrum as the unit in the word matching. Furthermore, to improve robustness against environ- ment noise and unnecessary utterances, the noise immunity learning shown in Fig. 4 is proposed [21].
By immunity is meant the mechanism whereby the structure of the system is modified to be adapted to the invasion of the antigen, so that the action of the antibody is initiated by a small dose of the antigen. In the noise immunity word-spotting, the noise is not eliminated, but the immunity is gradually enhanced by learning against environmental noise and unnecessary words, while increasing the ratio of the noise super- position. It is then expected that the noise immunity of the recognition dictionary for word spotting is improved. Figure 5 shows an example of the key word lattice detected by the word-spotting.
81

,...... ..................................................................... Recognilion process i Input speech
:--+ : + "iy- Spectral analysis 1 . I .......... .! ..................... I. .... I. ..... _I_. ............. .4 .. ! .... .................... .............................
speech
ground Noise
Learning process .............................................................................
Fig. 4. Block diagram of the noise immunity learning method.
, . -- II
I . . . . . . . . . . . . . . . . . . . . . . . . l a 0) I. " " I. ,I I. ** ,E,U", ,* I" I" I* "I D1 141 I" I
Fig. 5 . Example of keyword lattice. (Eh-one ham- burger and.-uhm-one french fries, please.)
3.3. Spontaneous speech recognition based on keyword
TOSBURG aims at the enhancement of robust- ness and naturalness. The dialogue progresses based on the spontaneous speech understanding using 49 keywords. The keyword lattice as shown in Fig. 5 is analyzed, and spontaneous speech containing unnec- essary words, tremolo, mispronunciation and reversal of word order, is understood [22].
Each time a keyword is detected, the parser is driven. The semantic representation is determined by the start-end free analysis of the keyword lattice. The multiple candidates for the speech semantic represen- tation are sent to the dialogue processing unit. The syntactic semantic analysis is composed .of deter- mination of the sentence start, the analysis of sentence candidates and the determination of the sentence end. While retaining the intermediate sentence candidates and the partial sentence candidates, the analysis progresses based on the extended LR parser. The semantic information is represented by the frame format. The semantic analysis procedure, such as the generation of frame or slot, is described in the ex-
Semantic utlerance represenlalion
(HAMB, NOSIZE
((act ORDER) (IiAMB NOSIZE NONUM) (COFFEE NOS17E 3))
........ ..... , ...........
......... Eh..one hamburger and . . ulim ..... coffee three please
Fig. 6. Example of tree structure and semantic repre- sentation.
System state User stale
n
Expecled utteran :e
Fig. 7. State-transition in user-initiative dialogue model.
tended term of the grammar, so that the semantic re- presentation is prepared in parallel to the analysis.
Figure 6 shows an example of the spontaneous speech analysis. Based on such keywords as "Hanba- agatt (hamburger) and "Kudasai" (give me), semantic contents such as the act for the "order," as well as the name, size and number of the order are derived. The system can cope with the omitted expression or unnec- essary words in the dialogue. For the ambiguous part, multiple candidates for the speech semantic expression are output which are processed by the dialogue pro- cessor.
82

System state User state
Fig. 8. Process of the dialogue manager.
3.4. User-centered dialogue processing
In most of the dialogue system at present, the system-centered "fill-in" type dialogue is used. In such a scheme, the user must utter a sentence following a specified format. Then, the dialogue is straight- jacketed, making it difficult to realize a comfortable speech dialogue. By contrast, in TOSBURG, the user is allowed to speak in diversified ways in various situations through the dialogue, and the user-centered spontaneous dialogue is realized in a natural way [ 191.
Figure 7 outlines the state transition of the user- centered dialogue model in TOSBURG. The adequate speech understanding and the response generation oc- cur according to the situation of the dialogue. The state of the dialogue is divided into the user state, to understand the speech from the user, and the system state, to manage the task and generate the response. The flow of the dialogue is modeled as the transition among the states. This model is independent of the procedure of achieving the task. Consequently, it can represent the state changes of the user and the system according to the progress of the dialogue, and can cope with the diversified user-centered flow of dialogue. The system is implemented by ATN (augmented transi- tion network) [23] in order to describe the complex dialogue control.
Figure 8 shows the flow of the dialogue speech understanding and the response generation in TOS- BURG. In the user-state unit, the analysis according to the user state is executed for the multiple semantic expression candidatessent from the speech understand- ing unit. The semantic match between the immediately preceding system response and the dialogue history in-
formation is examined, and the speech content of the user is understood. The size, for example, which is sometimes omitted in the spontaneous speech, is com- plemented based on the immediately preceding system response.
In the system state unit, the history data of the dialogue are updated based on the result of the dia- logue speech understanding, and the response semantic expression is generated. The input speech semantic expression, which is obtained as a result of the speech understanding, may contain an error or an ambiguity. Consequently, in TOSBURG, the dialogue progresses by outputting the response semantic expression in the response generator to clarify the ambiguity.
To show the user the certainty of the result of speech understanding, as well as the progress of the dialogue as the emotional information, the necessary information is generated and sent to the response/ generation output unit. Furthermore, when the ambig- uous content is to be verified in the speech response, the item to be emphasized is included in the response semantic expression, and the intonation of the speech response is controlled.
3.5. Multimodal response generation
The response generationoutput unit executes the following processings as is shown in Fig. 9. Based on the response semantic expression passed by the dia- logue controller as well as the internal state of the system, the multimodal response composed of the syn- thesized speech and the corresponding response text, the animation of the facial expression of the clerk, and
83

Animated facial expression
: I ' l - - l ' - I I+ Response , senlence
Oulpul response generator
Fig. 9. Configuration of response generator.
Ordered lood hems
I . Ted Lip shaped icon
Fig. 10. An example of visual response in a multi- modal dialogue system.
the screen display of the number and size of the or- dered item, are generated and output.
Figure 10 shows the screen display configuration. The synthesized speech and the response text are used for the message output, e.g., the greeting and veri- fication. The name, number and size of the ordered item, as understood by the system, are visualized and presented to the user. The facial expression of the clerk is varied according to the dialogue situation. The start timing and duration of the mouth movement are aligned to the synthesized speech [14].
Figure 11 shows the variation of the facial ex- pression of the clerk as varying with the dialogue situ- ation. It is designed as follows. The dialogue starts with a smile. When the dialogue stops or an error is pointed out, a sad expression is shown. The last dis- play is a bow of thanks.
In the generation and output of the synthesized
speech response, the prosody of the synthesized speech is controlled to give the emphasized expression accord- ing to the response semantic expression passed from the dialogue controller and the internal state of the system. When, for example, the user says "I need also cheeseburger" in adding to the order without indicating the number, the system assumes that the omitted num- ber is one. Then, the system outputs the synthesized speech by controlling the prosody as "Add one cheese- burger, right?" by emphasizing the number for verifi- cation. Such an elaboration makes the dialogue rich and efficient. The format synthesis is used in the speech synthesis, and Fujisaki's model is used in the synthesis of the prosodic features [24]. By such a control of the prosody, the emphasis, conviction and emotion can be represented, realizing the more natural and efficient dialogue by speech.
The above multimodal response is based on the features of various media. The synthesized speech, for example, transmits the message aurally according to the dialogue situation. At the same time, the response text is displayed visually. Consequently, the user can easily understand the response from the system, even if the quality of the synthesized speech is insufficient. This scheme also helps to complement the transient property of the speech media.
4. Spontaneous Speech Dialogue System TOSBURG I1
4.1. Spontaneous speech dialogue system
The speech response may be mixed in the input speech, which causes a misrecognition. Consequently, TOSBURG I is designed so that the lip icon as seen in Fig. 10 is shown during the speech response, and the speech input from the user is not accepted. In the
84

Q
Fig. 11. Examples of facial expression.
daily conversation of humans, however, one frequently interrupts the other who is speaking.
To realize the spontaneous interaction with less constraint, the speech response cancelling function is contained in TOSBURG I1 so that the speech input can be made at any time, interrupting the speech re-
ExamDle of sDontaneous dialoaue
(System) lade out
Your order IS one hamburger Thank you and a CUD
Interruption (User)
Yes it IS
ExarnDle of conventional dialoaue
(System)
Yes it is
Fig. 12. Comparison of timing of utterance between spontaneous dialogue and conventional dialogue.
sponse from the system [25]. The speech response canceler estimates successively the transfer function between the speaker and the microphone using the adaptive filter. By subtracting the speech response component from the microphone signal, the input is made possible, even if there is a speech response from the system.
Figure 12 compares the timings in the spontane- ous dialogue and the dialogue in the traditional system. In the multimodal interaction, the visual media are utilized so that the information of the counterpart can be understood without waiting for the end of the re- sponse output from the system. By inputting the next message at that point, a faster dialogue can be realized. By constructing the prototype for the dialogue by multimedia, the usefulness of the speech media in the dialogue can be demonstrated better than by laboratory experiment.
4.2. Speech response cancelling
The active noise control technique is used in cancelling the speech response. The speech response component is subtracted continuously from the signal composed of the user input speech from the micro- phone and the system response speech. In the can- cellation of the speech response, the synthesized speech must be handled, which is a nonstationary and wide- band signal. Furthermore, as is shown in Fig. 13, there is a component reflected from the surrounding objects, in addition to the direct transmission from the speaker to the microphone. Those components must be elimi- nated.
Especially, the component reflected by the body
85

Reflected sound SDeaker (Reflected from the user's body)
Y
Microp Reflected sound (Reflected from the wall)
)hone
b Wall
Fig. 13. Changes in reflected sound relative to the user's movement.
of the user is varied by the motion of the body. Con- sequently, the transfer characteristics from the speaker to the microphone must be estimated in real-time dur- ing the dialogue. For this purpose, the LMS algorithm is modified to fit the speech dialogue system, and a method that operates with a stability even in a noisy environment following the motion of the user, is devel- oped [25]. Using the already developed DSP accel- erator, the real-time processing is realized.
4.3. Speech dialogue data acquisition/evalua- tion system
In TOSBURG 11, the speech dialogue data acqui- sition and evaluation function is added to evaluate and improve the speech dialogue system. In the past acqui- sition of the speech dialogue data, only the utterance of the user, response of the system, and the result of system understanding are recorded. By taking the in- termediate data of the speech understanding and dia- logue processing (i.e., the result of internal processing in the system) into the database, in correspondence to the dialogue data, a more efficient evaluation and im- provement can be realized from various viewpoints.
TOSBURG 11 records as the dialogue data, in addition to the waveform of the input speech, the intermediate data generated in the course of the speech understanding by the system. They are the waveform data of the system response speech, the keyword lattice, the candidates for speech semantic expression, the speech semantic expression (result of dialogue processing), the state and history of dialogue, and the response semantic expression. Furthermore, the internal state of the system, and the type of the speech (such as order and addition) are recorded. By
those data, the speech understanding process in the system, as well as the dialogue including the internal state can faithfully be reproduced.
In constructing the database for the speech dia- logue sentence, the text must be constructed manually by listening to the dialogue sentence (transcription). Then, a problem arises in that a tremendous amount of effort and time is required. By contrast, TOSBURG I1 employs the scheme in which the content of the speech from the user is represented by key words, and does not have the details of the speech at hand. Considering this point, the key word input tool as shown in Fig. 14 is constructed to realize the efficient input of the key words of the speech dialogue data. In the course of acquisition of the dialogue data, the operator detects the keyword contained in the speech. By clicking the button-switch, the keyword file is constructed automatically.
The dialogue data evaluation tool reads in the collected dialogue data, and displays the dialogue sentence, the keyword lattice, the candidates for the keyword sentences, and the speech semantic expres- sion. By operating the mouse, the speech can be re- produced for each speech sentence, and the specified keyword can be reproduced. This tool not only verifies the dialogue data, but also supports the construction of the speech dialogue database (speech dialogue corpus) by adding the other necessary information to the data. Using the constructed speech dialogue database, the word-spotting rate, the speech sentence recognition/ understanding rate can be summarized. In other words, the component units, such as the word-spotting unit, the syntax semantic analyzer, and the dialogue processor, can be evaluated individually. Furthermore, the dialogue flow control in the system can be evalu- ated by examining the internal state data of the sys- tem.
4.4. Evaluation experiment
TOSBURG I1 is evaluated using the evaluation system for unspecified users. The following evaluation experiment is conducted in order to examine the effect of the response media on the dialogue time. Various response media are considered, e.g., the speech re- sponse, the text, the animation of the clerk and the graphics representing the kind and the number of the order (called tray). The dialogue experiment is con- ducted for the following four cases. All are output (condition 1). The tray is not displayed (condition 2). The tray and the text are not displayed (condition 3). The speech response is not output (condition 4). The
86

I Enastop of Experiment
I I don't want I
1 not but I
!nd of ut. erance
Fig. 14. Visual interface for inputting correct keywords.
Time (sec ) 1
Maximum
100 .-
50 -
oulpul wlttiout wilhoul wilhoul all l ray tray 8 speech
lexl
Fig. 15. Comparison of dialogue time using TOS- BURG 11.
time spent in a session of a dialogue is examined. The subjects are 5 males who have the experience of using this system. Subjects are told what media will be miss- ing. The task is to order 5 prespecified goods.
Figure 15 shows the result of experiment. In conditions 2 and 3, where the tray which visually dis-
end of dialogue
- -
plays the internal state of the system is missing, the time for dialogue is increased, compared to condition 1, where all media are output. In condition 3, there is no clue regarding the interval state of the system other than the speech response. In other words, it is seen that the response based on the visual media is im- portant in realizing the interaction that burdens the user less.
Especially, the difference between the maximum required dialogue time is large, which indicates that the multimodal response is useful when a large number of errors occurs in speech understanding. In the dialogue of condition 4, where there is no speech response, the average dialogue time is the shortest, since it is necessary to wait for the end of the speech response. There are subjects, however, who expressed their feelings after the experiment that the input timing is difficult. This suggests that the response to indicate the user of the next input is important for the smooth progress of the dialogue.
The effect of the training of the user and the dialogue condition on the performance is examined further. The subjects are 18 beginners and 8 experts. Two dialogue conditions, i.e., "with item specification"
87
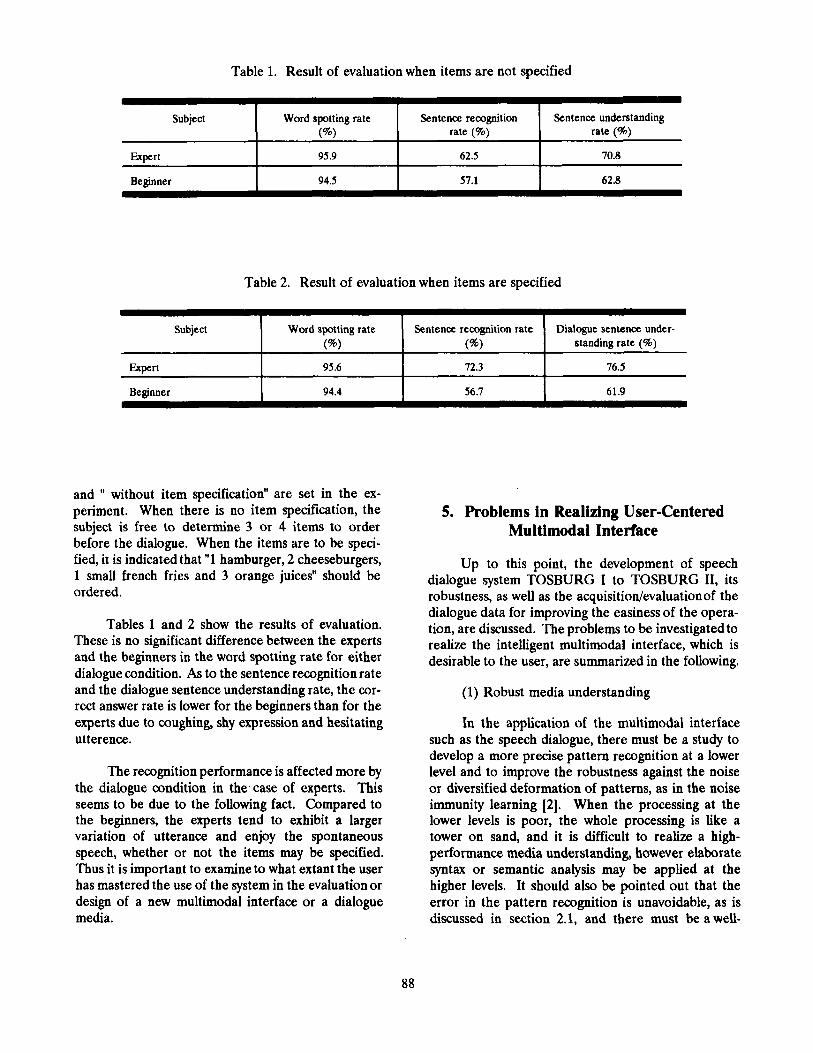
Table 1. Result of evaluation when items are not specified
~~
Subject
Expert
Beginner
Word spotting rate Sentence recognition Sentence understanding (%) rate (YO) rate (%)
95.9 62.5 70.8
94.5 57.1 62.8
Table 2. Result of evaluation when items are specified
Subject
Expert
Bemnner
Word spotting rate Sentence recognition rate Dialogue sentence under- (%I (%I standing rate (%)
95.6 72.3 76.5
94.4 56.7 61.9
and without item specification" are set in the ex- periment. When there is no item specification, the subject is free to determine 3 or 4 items to order before the dialogue. When the items are to be speci- fied, it is indicated that "1 hamburger, 2 cheeseburgers, 1 small french fries and 3 orange juices" should be ordered.
Tables 1 and 2 show the results of evaluation. These is no significant difference between the experts and the beginners in the word spotting rate for either dialogue condition. As to the sentence recognition rate and the dialogue sentence understanding rate, the cor- rect answer rate is lower for the beginners than for the experts due to coughing, shy expression and hesitating utterence.
The recognition performance is affected more by the dialogue condition in the. case of experts. This seems to be due to the following fact. Compared to the beginners, the experts tend to exhibit a larger variation of utterance and enjoy the spontaneous speech, whether or not the items may be specified. Thus it is important to examine to what extant the user has mastered the use of the system in the evaluation or design of a new multimodal interface or a dialogue media.
5. Problems in Realizing User-Centered Multimodal Interface
Up to this point, the development of speech dialogue system TOSBURG I to TOSBURG 11, its robustness, as well as the acquisitiodevaluationof the dialogue data for improving the easiness of the opera- tion, are discussed. The problems to be investigated to realize the intelligent multimodal interface, which is desirable to the user, are summarized in the following.
(1) Robust media understanding
In the application of the multimodal interface such as the speech dialogue, there must be a study to develop a more precise pattern recognition at a lower level and to improve the robustness against the noise or diversified deformation of patterns, as in the noise immunity learning (21. When the processing at the lower levels is poor, the whole processing is like a tower on sand, and it is difficult to realize a high- performance media understanding, however elaborate syntax or semantic analysis may be applied at the higher levels. It should also be pointed out that the error in the pattern recognition is unavoidable, as is discussed in section 2.1, and there must be a well-
88

and the higher levels to cope with the ambiguity in the media understanding.
(2) User-centered media generation
The multimedia data to be presented to the user by the system can be constructed by the automatic generation function or the multimedia editing tool. As is pointed out in section 2.1, however, there can be more than one pattern that can be generated by the automatic generation function for the media, and the ambiguity is unavoidable. To generate the media matched to the purpose or taste of the user, the pro- posal-type interface is considered as promising, where multiple pattern candidates are presented by the auto- matic generation function, from which the user makes the final selection [26,27]. It is also expected that the study of the learning function for the preference of the user will be emphasized in the future [9].
(3) Intention and emotion
To realize a natural dialogue with the computer, it is important to transmit the intention and the emotion [28-31). In human-to-human communication, various channels, such as facial expression, non- linguistic voice and gesture, are used. In the dialogue with the computer, it will also be possible to improve the naturalness and easiness of use by introducing the cognitive model for the intention and the emotion using the new media.
AIl media have advantages and disadvantages, as discussed in section 4.2. To realize robust and friendly multimodal interface, it is necessary to define clearly the properties of all media for an appropriate applica- tion. It is especially important to consider knowledge as the media which give the basis to the multimodal interface. By using the large-scale knowledgebase such as Cyc [32] and EDR electronic dictionary [33], it is hoped to construct the intelligent dialogue system. Furthermore, according to Minsky, the human mind also is composed of several hundreds of computers with various architecture. Consequently, to realize a natural multimodal interface, there must be studies on the integration of various intelligent functions, in addition to the studies of generation and understanding of various media [34].
( 5 ) Evaluation of system
To evaluate the multimodal dialogue system con- sisting of the artificial media communicating with the computer, there must be developed ample media, a precise understanding function and the real-time pro-
cessing. If those conditions are not satisfied, the developed dialogue system will only be a toy for dem- onstration. It is essential to construct the real-time system for the unspecified user, such as TOSBURG 11, in the study of the multimodal interface. The under- standing of the media and the generation function should be evaluated by the human interface researcher on the real-time system. By such an approach, ac- curate and quantitative evaluation is realized, and the multimodal interface method to the human for recog- nition and emotion can be realized.
6. Conclusions
This paper described the development for the spontaneous speech dialogue system TOSBURG 11, as well as the element techniques, integration techniques and system evaluation. As is claimed by Kay, the human-computer interface is evolving toward the "ask and tell" type multimodal interface by including various sensors, input-output devices, pattern recognition function and large-scale knowledgebase.
We take the standpoint of artificial media, and experimentally constructed the spontaneous speech dialogue system as the first step toward the natural and easy multimodal interface by investigating the speech media desirable to the human. It is intended as future study to aim at the new computer applications, and to develop the element techniques such as the dialogue device, speech processing, natural language processing and knowledge processing, as well as the integration technique. By promoting the integration with other aspects such as robotics, computer architecture and basic software, the user-centered intelligent multimodal interface will be developed.
Acknowledgement. Many suggestions were given by Prof. K. Takei, Aeronautics Tech., Coll., on the cognitive aspects of speech dialogue. The element techniques and the system of the spontaneous speech dialogue system were developed by cooperative studies with Mr. H. Tsuboi, Mr. H. Kanazawa, Mr. H. Nagata, Mr. S. Set0 and Mr. M. Tatemori of Toshiba R&D Center, as well as Mr. H. Shinchi and Mr. H. Hashi- mot0 of Toshiba Soft Engineering Co. The author is grateful for their assistance and advice.
REFERENCES
1. F. Mclaughlin. ICSE 11 prompts engineers to reflect on yesterday, look to tomorrow. IEEE COMPUTER, pp. 110-112 (July 1989).
89

2.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
Y. Suenaga, K. Mase, M. Fukumoto and H. Watabe. Human reader: Intelligent interface by human image and speech. Trans. (D-11) I.E.I.C.E., Japan J75-D-II, 2, pp. 190-202 (Feb. 1992). M. T. Vo and A. Waibel. Multimodal Hu- man-Computer Interaction. Proc. Int. Sympo. Spoken Dialogue, pp. 95-101 (Nov. 1993). K. Omae. Package of emotion and intelli- gence. Proc. I.E.I.C.E., Japan, 75, 11, pp.
Y. Takebayashi. Integration of understand- ing and synthesis functions for multimedia interfaces. In: Multimedia Interface Design, Blattner ed., pp. 233-256, ACM Press Book (1992). S. Furui. Future problems in continuous speech recognition. Tech. Rep., I.E.I.C.E., Japan, SPREC-91-2, p. 41 (Feb. 1992). R. Bolt. The Integrated Multi-Modal Inter- face. Trans. (D), I.E.I.C.E., Japan, J70-D, 11,
R. Dannenburg and M. Blattner. The trend toward multimedia interfaces. In: Multimedia Interface Design. Blattner ed., ACM Press Book (1992). Y. Takebayashi. Dialogue by multimedia. Proc. Nat. Lang. Proc., pp. 49-64 (May 1993). Y. Anzai. Cooperative functional module model for human-computer integrating infor- mation processing mechanism. Trans. (D-11) I.E.I.C.E., Japan, J’lO-D-II, 11, pp. 2026-2037 (Nov. 1987). M. McLuhan (Tr. Kurihara et al.). Essays of Media. Misuzu Shobo Co. (1987). A. Kay. Personal Dynamic Media. IEEE COMPUTER, pp. 31-41 (March 1977). Y. Takebayashi, H. Tsuboi, Y. Sadamoto, H. Hashimoto and H. Shinchi. An experimental speech dialogue system for unspecified users. Tech. Rep. Soc. Artif. Intel., SIG-SLUD-9201- 4 (April 1992). Y. Tamashita, S. Seto, H. Tsuboi and Y. Takebayashi. Response generation in real- time speech dialogue system TOSBURG by spontaneous utterance. Tech. Rep. Soc. Artif. Intel. SIG-HICG-9201 (May 1992). Y. Takebayashi, H. Nagata and Y. Sadamoto. Realization of real-time speech recognition function on workstation by software. 7th HI Symp., pp. 485-490 (Oct. 1991). B. Laurel. Computers as Theatre. Addison- Wesley Publishing Company (1991). P. Hayes. Steps Towards Graceful Interac- tion in Spoken and Written Man-Machine
1169-1174 (Nov. 1992).
pp. 2017-2025 (Nov. 1987).
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
Communication. International Journal, Chap. 5, pp. 133-159, Alex Publishing (1985). C. Schmandt. Voice communication with computers. In: Advances in Human-Computer Interaction. Hartson ed., Chap. 5 , pp. 133- 159, Alex Publishing (1985). Y. Takebayashi, H. Tsuboi, H. Kanazawa, Y. Sadamoto, Y. Yamashita, H. Nagata, S. Seto, T. Arai, H. Hashimoto and H. Shinchi. Development of spontaneous speech dialogue system for unspecified speaker TOSBURG. Proc. Acoust. Soc., 1992 Spr., 1-P-16, (March 1992). H. Tsuboi, H. Kanazawa and Y. Takebayashi. Development of real-time processing system for speech recognition study. Tech. Rep. I.E.I.C.E., Japan, SP90-37 (Aug. 1990). Y. Takebayashi and H. Kanazawa. Noise im- munity learning in speech recognition by word- spotting. Trans. (D-11) I.E.I.C.E., Japan, 574-D-II, 2, pp. 121-129 (Feb. 1991). H. Tsuboi, H. Hashimoto and Y. Takebayashi. Continuous speech understanding based on keyword-spotting. Tech. Rep. I.E.I.C.E., Ja- pan, SP91-95 (1991). W. A. Woods. Transition Network Grammars for Natural Language Analysis. Proc. CACM,
H. Fujisaki and H. Sudo. Fundamental fre- quency pattern of Japanese word accent and a model for generating mechanism. J. Acoust. Soc. Jap., 27, 9, pp. 445-453 (1971). H. Nagata, D. Gleaves and Y. Takebayashi. A study of response speech cancelling in speech dialogue system. Proc. Acoust. Soc. Jap., 1992 Spr. 1-P-21 (March 1992). I. Iwai, M. Doi, K. Yamaguchi, M. Fukui and Y. Takebayashi. A Document Layout System Using Automatic Document Architecture Ex- traction. Proc. CHI’89, pp. 369-374 (Apr. 1989). M. Fukui, H. Yamaguchi and I. Iwai. A doc- ument construction system with proposal type user interface. Spr. Nat. Conv. Inf. Proc. Soc., pp 610-611 (March 1990). K. Maeda, Y. Yamashita and Y. Takebayashi. Enhancement of Human-Computer Interac- tion through the Synthesis of Nonverbal Expressions. Proc. ICSLP ’90, 19.15, pp. 821- 824 (Nov. 1990). Y. Takebayashi, K. Maeda and H. Kanazawa. Recognition of nonlinguisticvoice for dialogue with computer. 7th HI Symp., pp. 123-128 (Oct. 1991).
13, pp. 591-606 (1970).
90

30. M. Toda. Machine with Heart. Diamond Co. (1987).
31. P. R. Cohen and H. J. Levesque. Persistence, Intention, and Commitment. In: Intentions in Communication. Cohen, P. R., Morgan, J. and Pollack M. E. (eds.), pp. 33-70, MIT Press (1990).
32. D. Lenat and R. Guha. Building Large Knowledge-Based Systems. Addison-Wesley (1989).
33. T. Yokoi. Information-Oriented Japanese- Its Technology. Kyoritsu Publ. Co. (1990).
34. M. Minsky. The Society of Mind. Simon and Schuster (1985).
AUTHOR
Yoichi Takebayshi received his B.E. degree in 1974 from Dept. Electrical Eng., Keio Univ., and his Ph.D. degree in 1980 from Tohoku Univ. He affiliated in 1980 with Toshiba Corp. He is engaged in research on speech recognition and intelligent interface. Presently, Chief Researcher, 3rd Comm. System Lab. in R&D Center. Visiting Researcher 1985-1987 MIT Media Lab. Head of 5th Lab. 1992-1993 Jap. Electr. Dictionary Lab. Paper Award 1992 Nat. Conv. Soc. Artif. Intel., Tech. Dev. Award 1993 Acost. Soc. Jap. He is a member of Inf. Proc. Soc.; Acoust. Soc. Jap.; and Soc. Artif. Intel.
91


















![Monitoria multimodal cerebral multimodal monitoring[2]](https://img.pdfslide.us/doc/110x75/552957004a79599a158b46fd/monitoria-multimodal-cerebral-multimodal-monitoring2.jpg)