Embed Size (px)
Citation preview

@noootsab @maasg#devoxx #sparkvoxx
Lighting Fast Big Data Analytics with
Apache .
Andy Petrella (@noootsab), Gerard Maas (@maasg)Data Processing Team LeadBig Data Hacker

@noootsab @maasg#devoxx #sparkvoxx
Agenda
What is Spark?Spark Foundation: The RDDDemoEcosystemExamplesResources

@noootsab @maasg#devoxx #sparkvoxx
Memory CPU’s(and don’t forget to throw some disks in the mix)
Network

@noootsab @maasg#devoxx #sparkvoxx
What is Spark?
Spark is a fast and general engine for large-scale distributed data processing.
Fast Functional
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Growing Ecosystem
@noootsab @maasg#devoxx #sparkvoxx
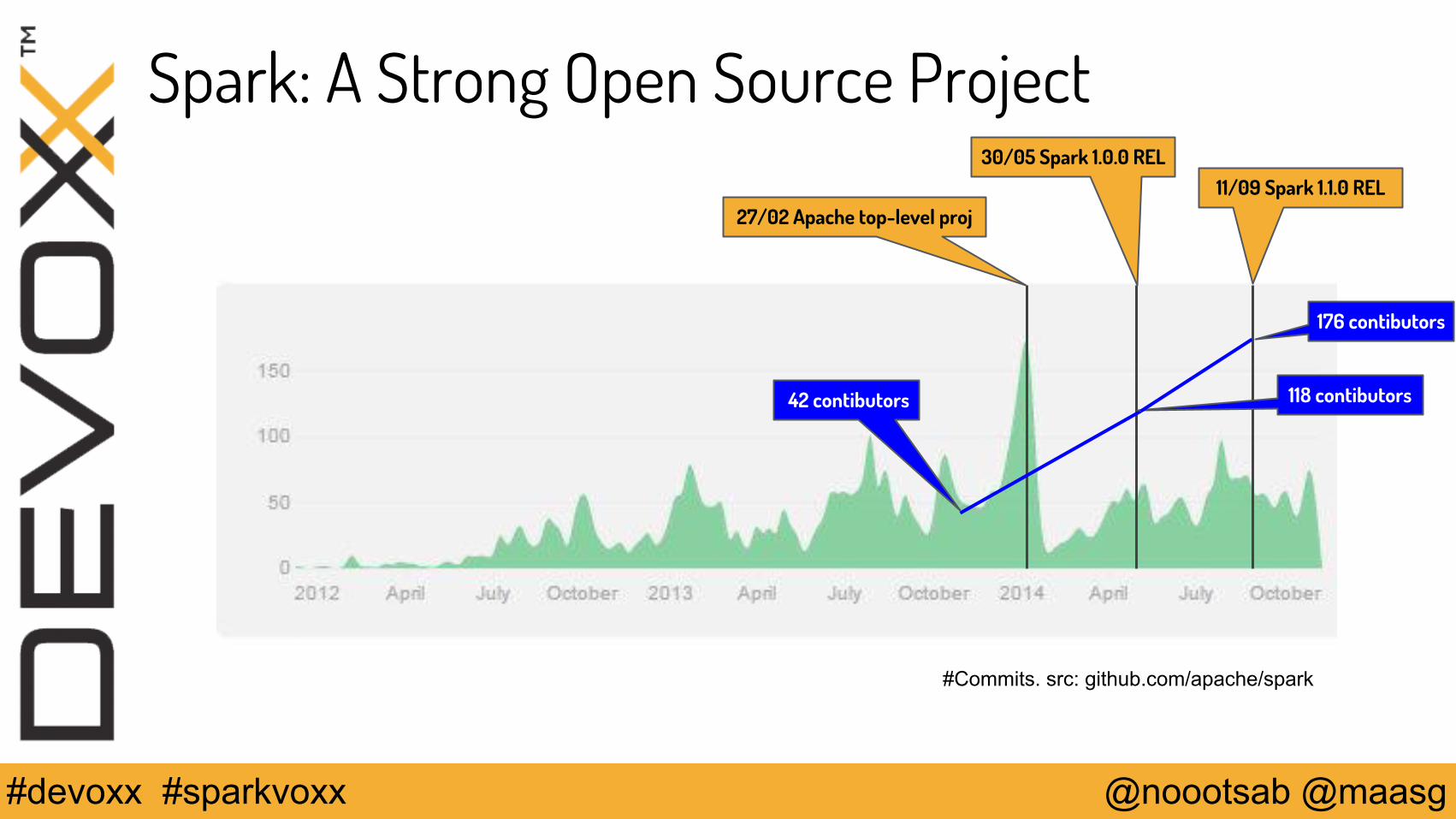
Spark: A Strong Open Source Project
#Commits. src: github.com/apache/spark
27/02 Apache top-level proj
30/05 Spark 1.0.0 REL11/09 Spark 1.1.0 REL
176 contibutors
42 contibutors 118 contibutors

@noootsab @maasg#devoxx #sparkvoxx
Compared to Map-Reducepublic class WordCount { public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = new Job(conf, "wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion( true); } }
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Spark

@noootsab @maasg#devoxx #sparkvoxx
The Big Idea...Express computations in terms of operations on a data set.
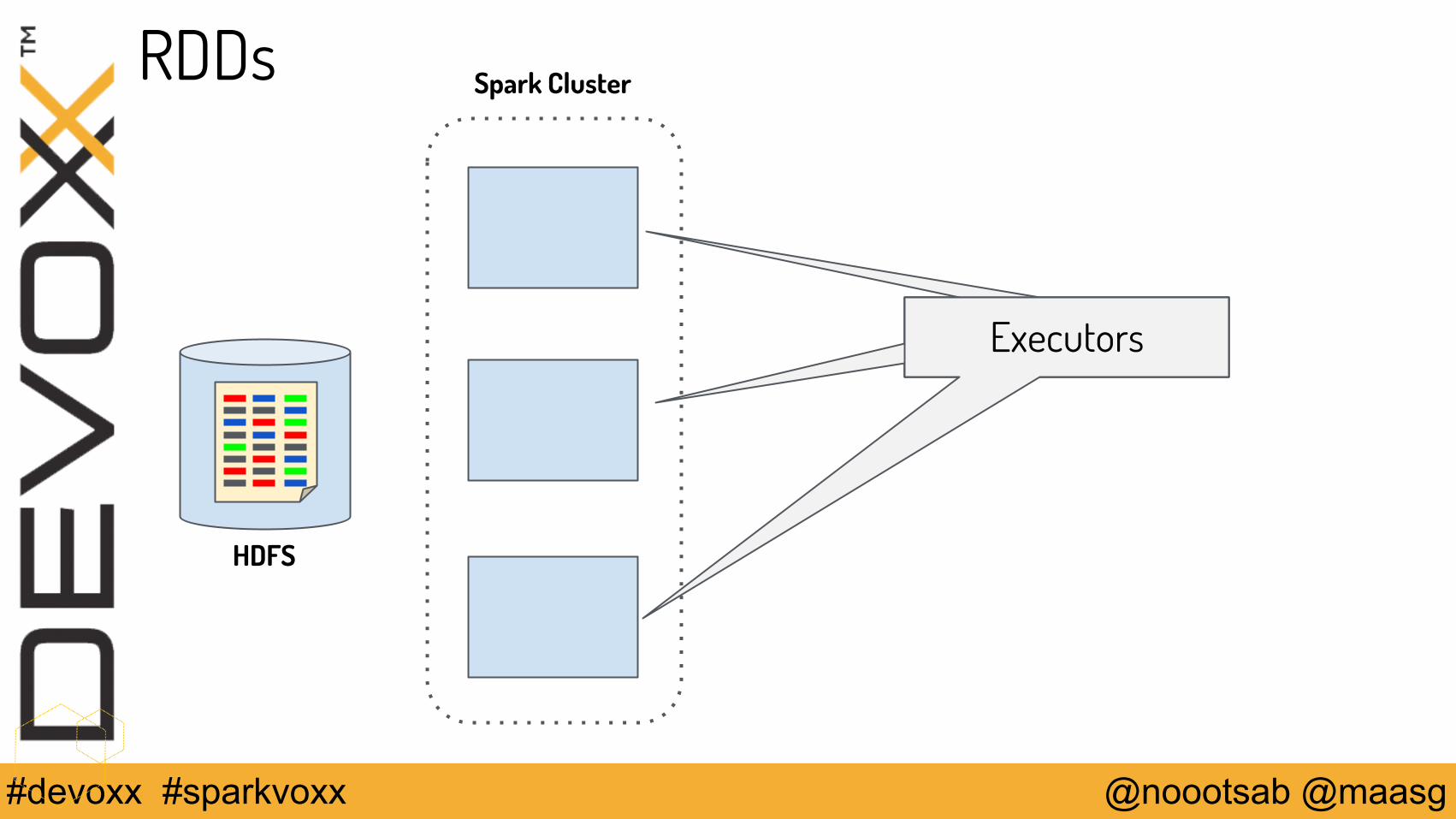
Spark Core Concept: RDD => Resilient Distributed Dataset
Think of an RDD as an immutable, distributed collection of objects
• Resilient => Can be reconstructed in case of failure• Distributed => Transformations are parallelizable operations• Dataset => Data loaded and partitioned across cluster nodes (executors)
RDDs are memory-intensive. Caching behavior is controllable.
@noootsab @maasg#devoxx #sparkvoxx
RDDs
ExecutorsExecutorsExecutors
Spark Cluster
HDFS
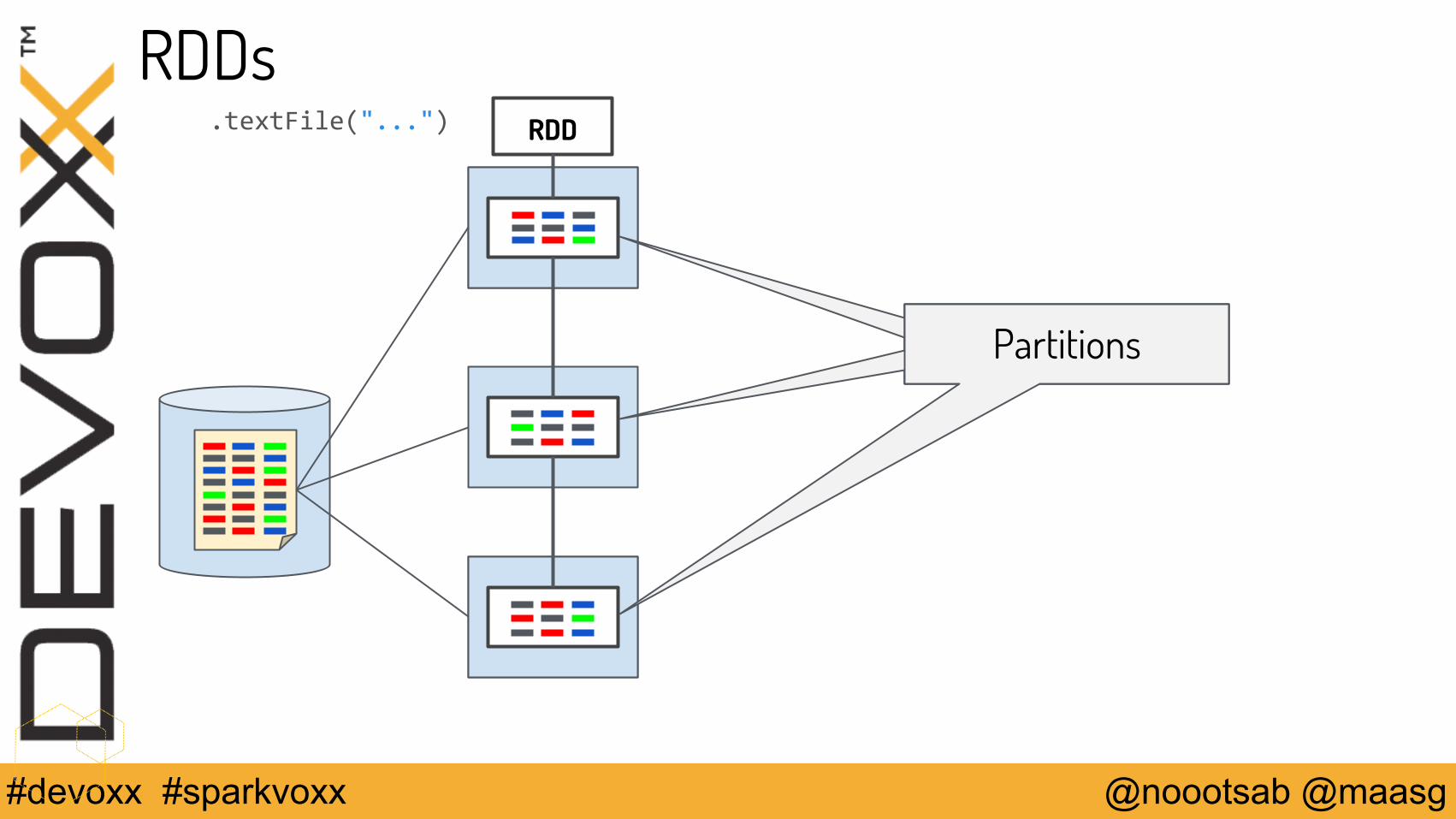
@noootsab @maasg#devoxx #sparkvoxx
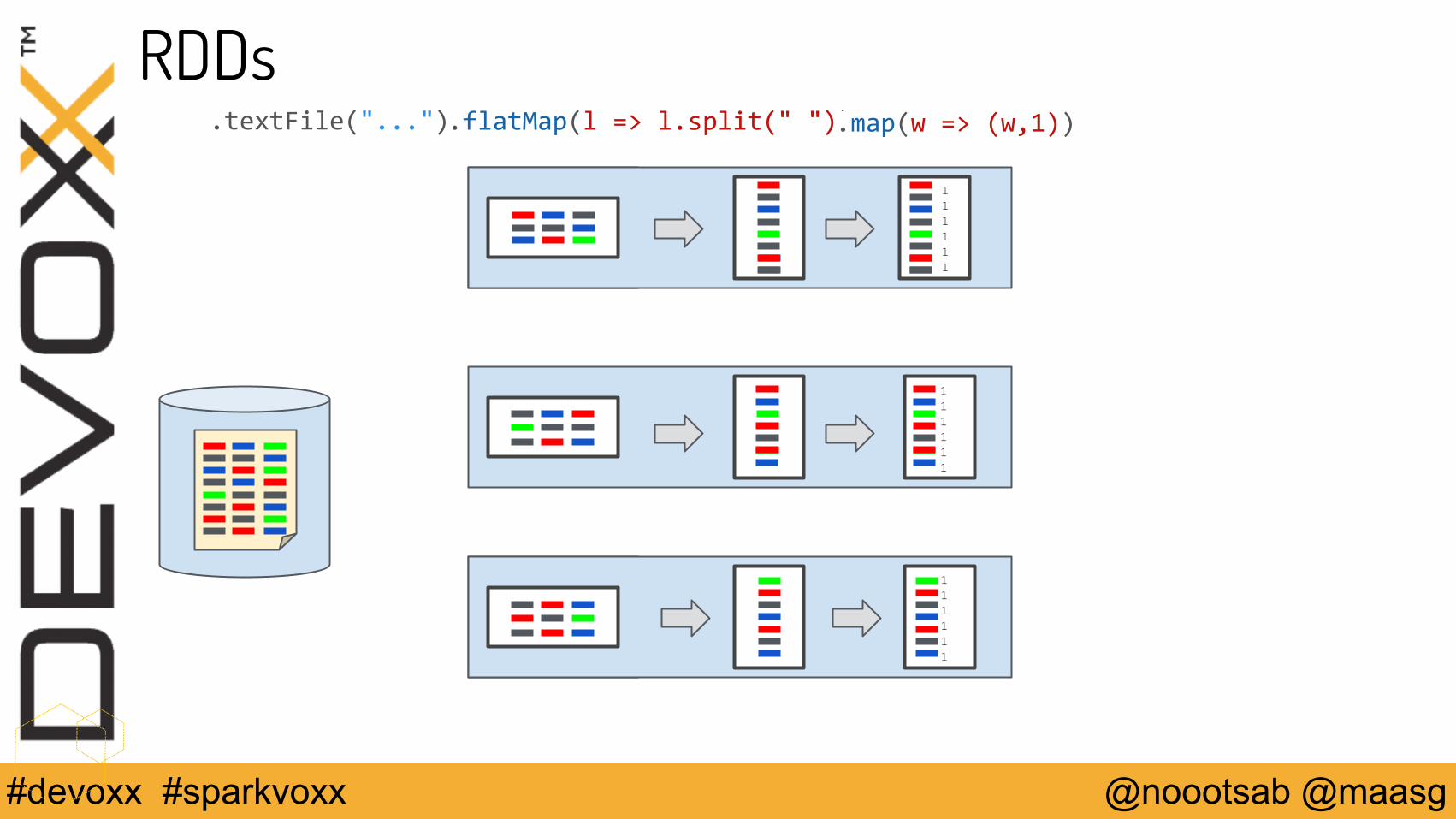
RDDs.textFile("...") RDD
PartitionsPartitionsPartitions
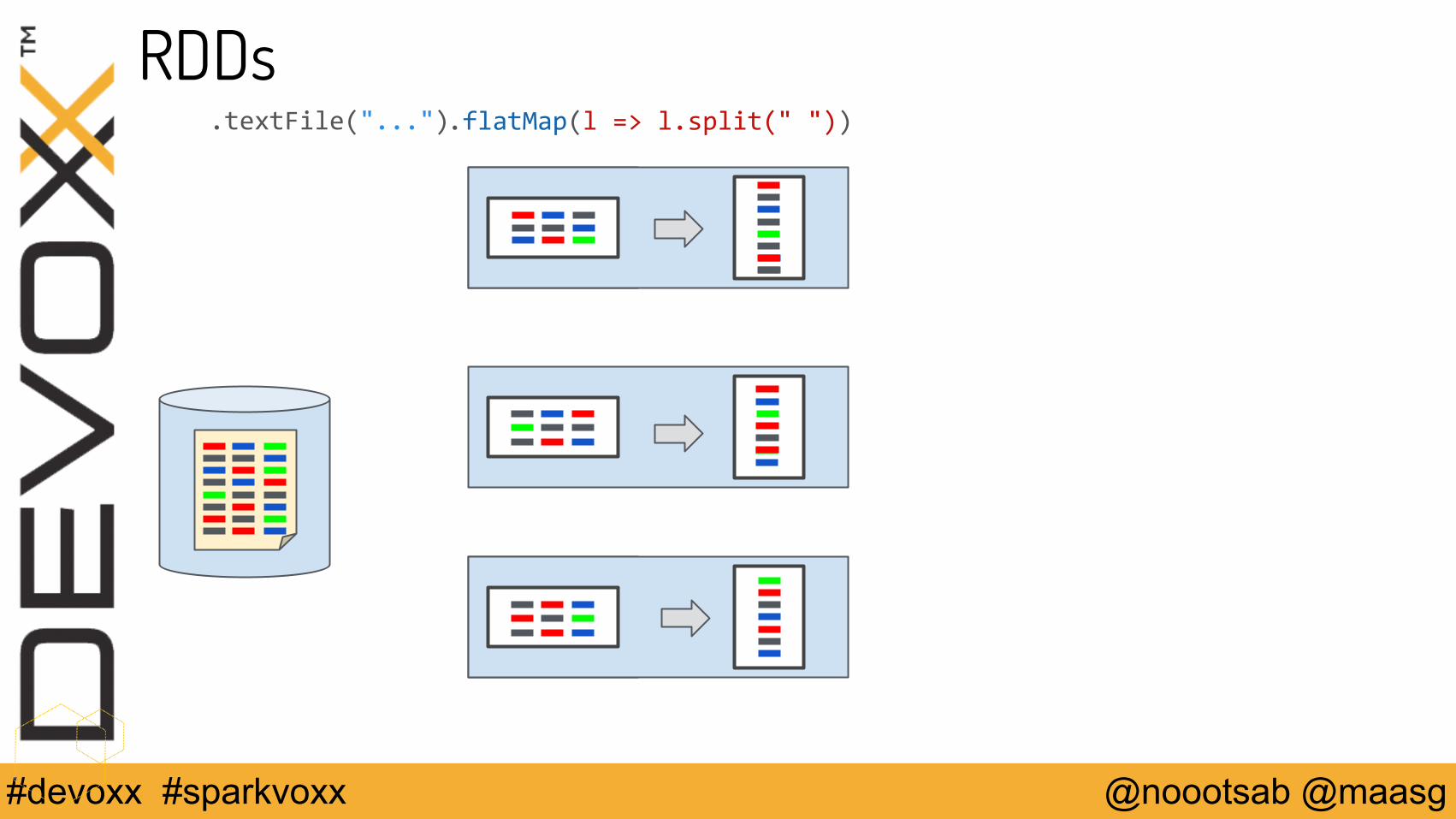
@noootsab @maasg#devoxx #sparkvoxx
RDDs.flatMap(l => l.split(" ")).textFile("...")
@noootsab @maasg#devoxx #sparkvoxx
RDDs.flatMap(l => l.split(" ")).textFile("...") .map(w => (w,1))
111111
111111
111111
@noootsab @maasg#devoxx #sparkvoxx
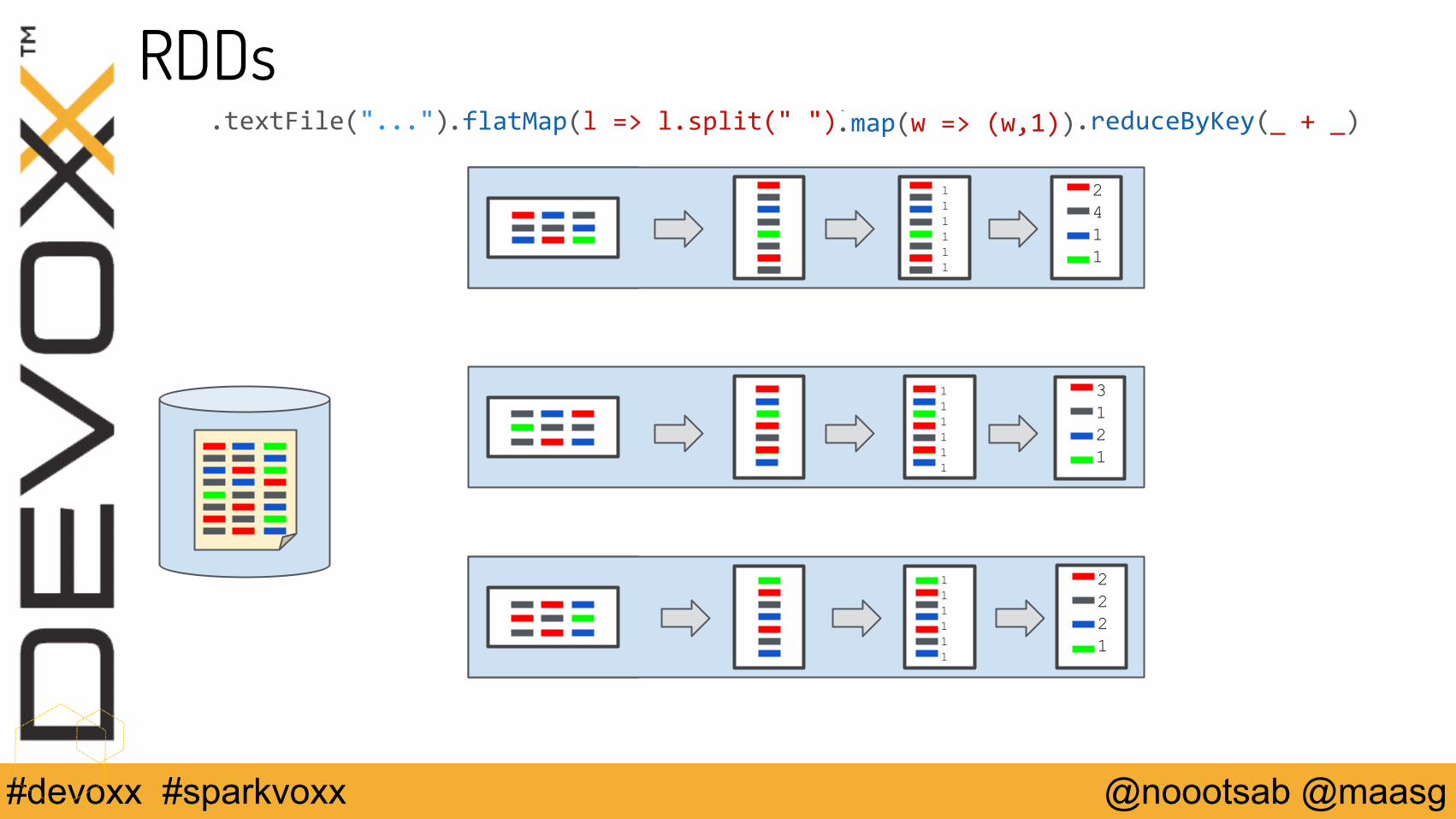
RDDs.flatMap(l => l.split(" ")).textFile("...") .map(w => (w,1))
111111
111111
111111
.reduceByKey(_ + _)
2411
2221
3121

@noootsab @maasg#devoxx #sparkvoxx
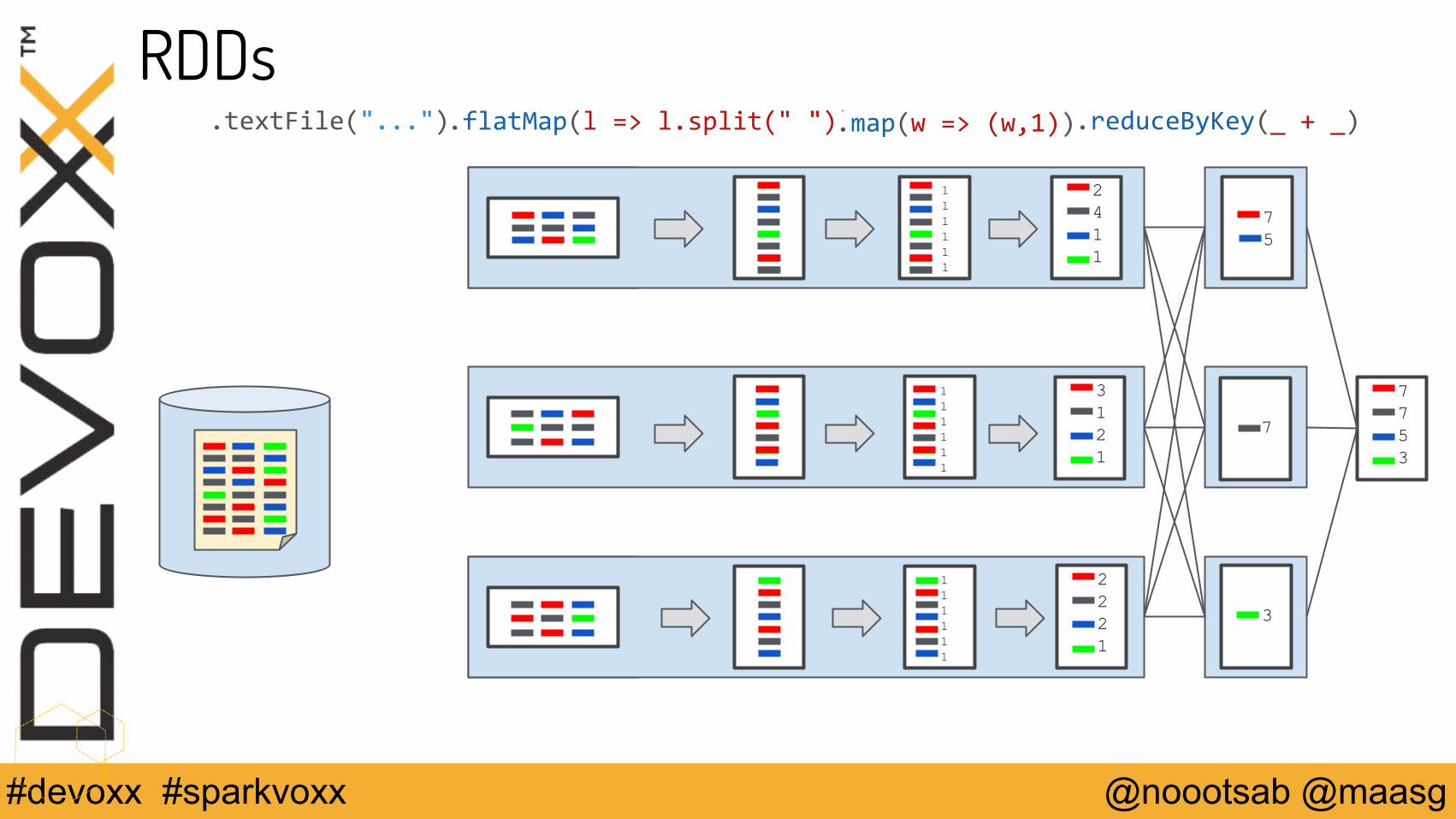
RDDs.flatMap(l => l.split(" ")).textFile("...") .map(w => (w,1))
111111
111111
111111
.reduceByKey(_ + _)
2411
2221
3121
75
7
3
@noootsab @maasg#devoxx #sparkvoxx
RDDs.flatMap(l => l.split(" ")).textFile("...") .map(w => (w,1))
111111
111111
111111
.reduceByKey(_ + _)
2411
2221
3121
75
7753
7
3
@noootsab @maasg#devoxx #sparkvoxx
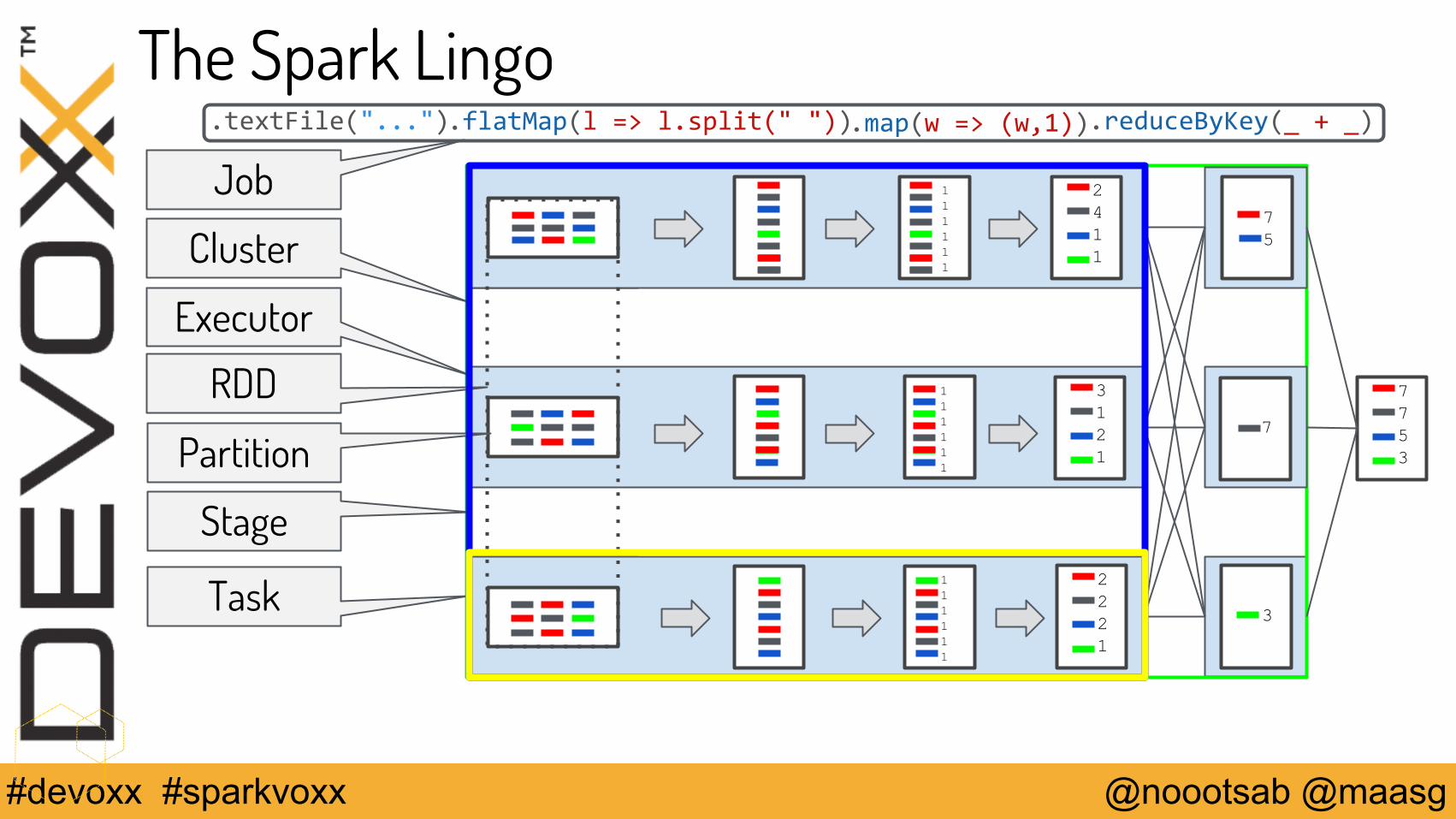
The Spark Lingo.flatMap(l => l.split(" ")).textFile("...") .map(w => (w,1))
111111
111111
111111
.reduceByKey(_ + _)
2411
2221
3121
75
7753
7
3
Partition
Executor
Job
RDD
Cluster
Stage
Task
@noootsab @maasg#devoxx #sparkvoxx
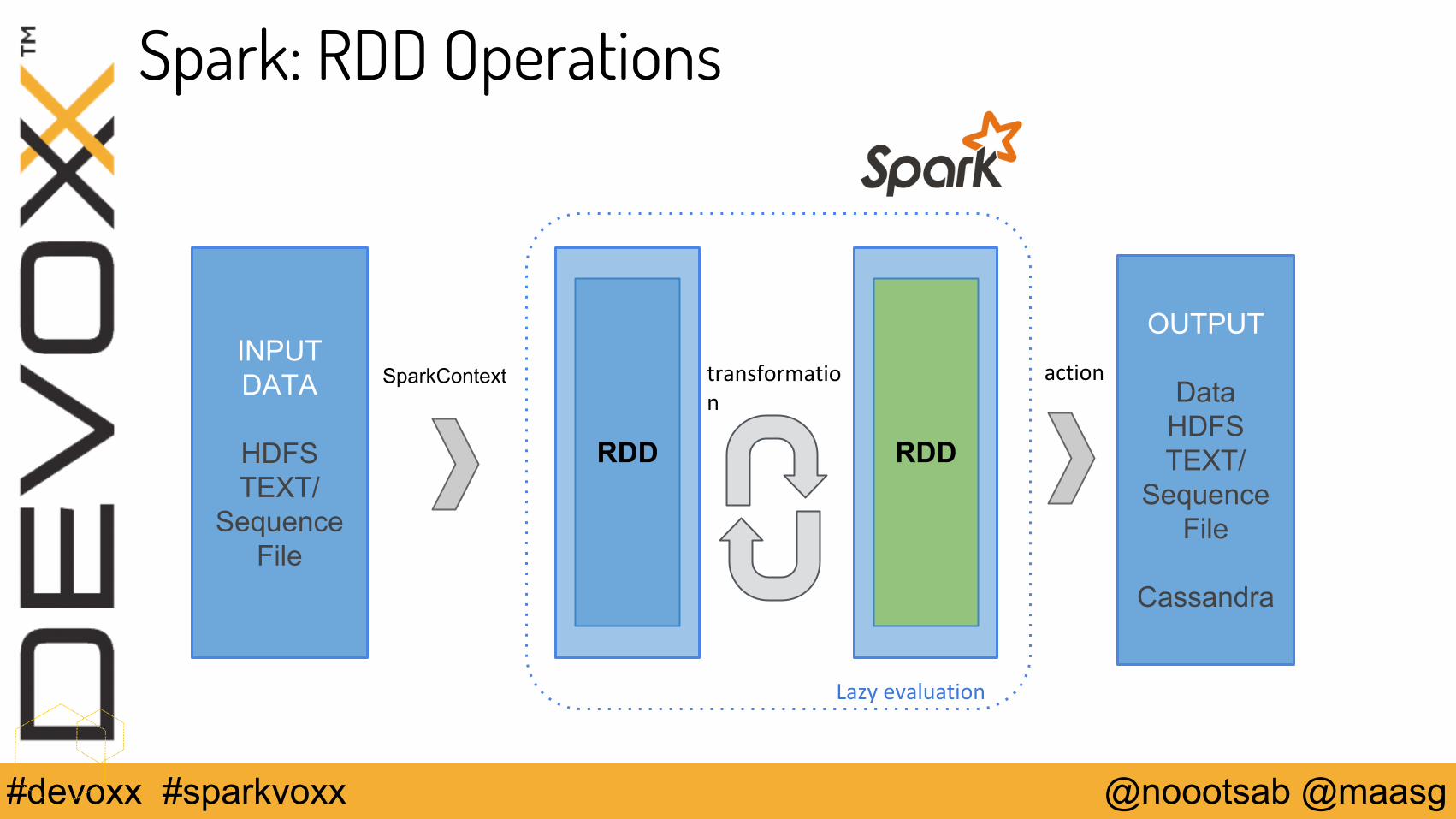
Spark: RDD Operations
INPUT DATA
HDFSTEXT/
Sequence File
RDD
SparkContext
RDD
OUTPUT
DataHDFSTEXT/
Sequence File
Cassandra

@noootsab @maasg#devoxx #sparkvoxx
Transformations
> map, flatMap, filter, distinct
Inner Manipulations
> union, subtract, intersection, join, cartesian
Cross RDD
> groupBy, aggregate, sort
Structural reorganization (Expensive)
> coalesce, repartition
Tuning

@noootsab @maasg#devoxx #sparkvoxx
Actions
> collect, take, first, takeSample
Fetch Data
> reduce, count, countByKey
Aggregate Results
> foreach, foreachPartition, save*
Output

@noootsab @maasg#devoxx #sparkvoxx
RDD LineageEach RDDs keeps track of its parent.This is the basis for DAG scheduling and fault recoveryval file = spark.textFile("hdfs://...")val wordsRDD = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)val scoreRdd = words.map{case (k,v) => (v,k)}
HadoopRDD
MappedRDD
FlatMappedRDD
MappedRDD
MapPartitionsRDD
ShuffleRDD
wordsRDD MapPartitionsRDD
MappedRDDscoreRDDrdd.toDebugString is your friend

@noootsab @maasg#devoxx #sparkvoxx
Spark has Support for...
Python
JavaNotebookScala
API
Shell
The Spark Shell is the best way to start exploring Spark
R API Shell
>
A
APIA
APIA
Shell> Notebook

@noootsab @maasg#devoxx #sparkvoxx
DemoExploring and transforming data with the Spark Shell
Acknowlegments: Book data provided by Project Gutenberg (http://www.gutenberg.org/)through https://www.opensciencedatacloud.org/Cluster computing resources provided by http://www.virdata.com

@noootsab @maasg#devoxx #sparkvoxx

@noootsab @maasg#devoxx #sparkvoxx
Agenda
What is Spark?Spark Foundation: The RDDDemoEcosystemExamplesResources

@noootsab @maasg#devoxx #sparkvoxx
Ecosystem
Now, we know what is Spark!At least, we know its Core, let’s say SDK.
Thanks to its great and enthusiastic community Spark Core have been used in an ever growing number of fields
Hence the ecosystem is evolving fast

@noootsab @maasg#devoxx #sparkvoxx
Higher level primitives ...
If Spark Core is the fold of distributed computingThen we’re going to look at the map, filter, countBy, groupBy, ...
… or APIs… or the rise of the popolo
@noootsab @maasg#devoxx #sparkvoxx
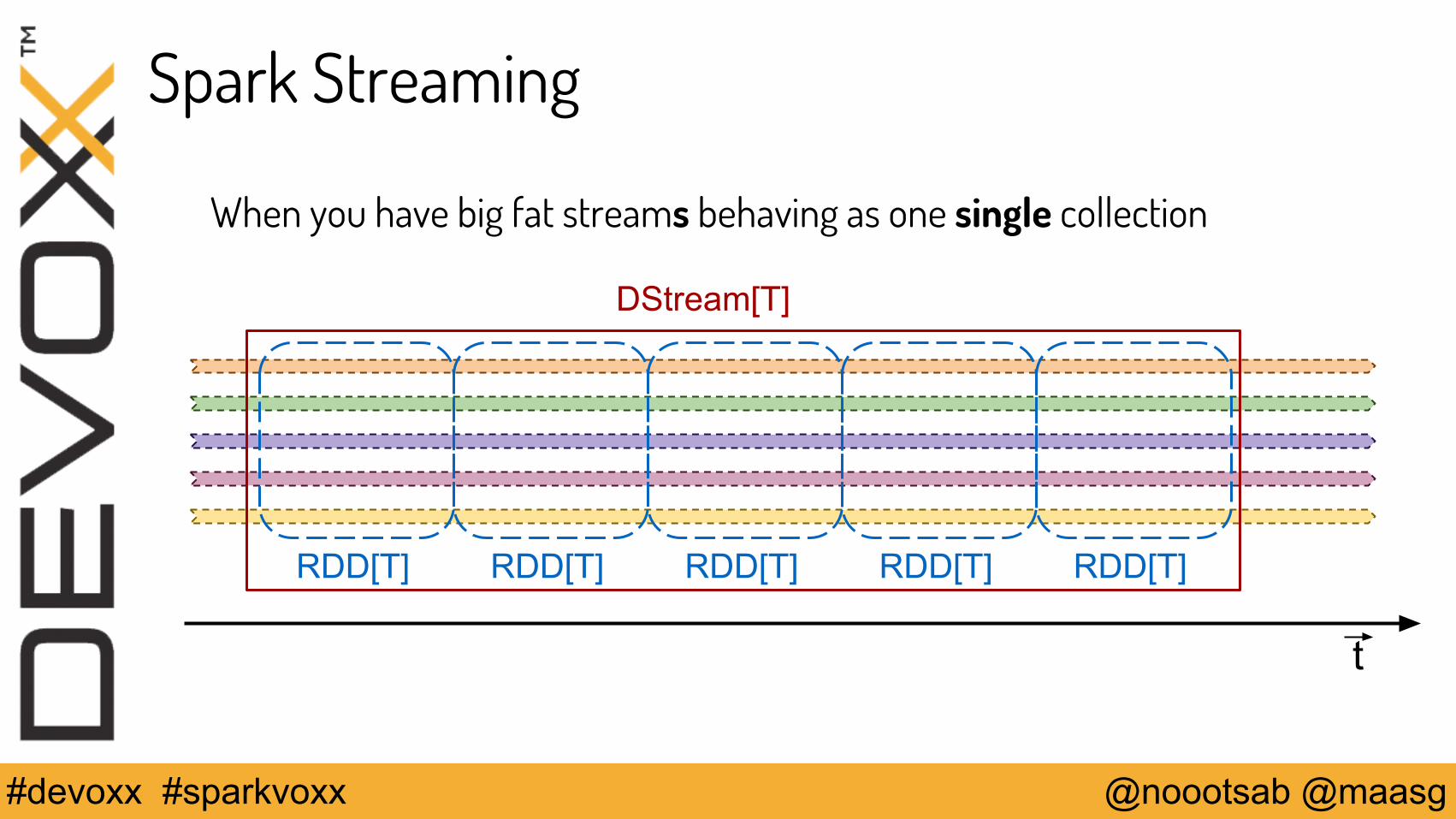
Spark Streaming
When you have big fat streams behaving as one single collection
t
DStream[T]
RDD[T] RDD[T] RDD[T] RDD[T] RDD[T]

@noootsab @maasg#devoxx #sparkvoxx
Spark Streaming

@noootsab @maasg#devoxx #sparkvoxx
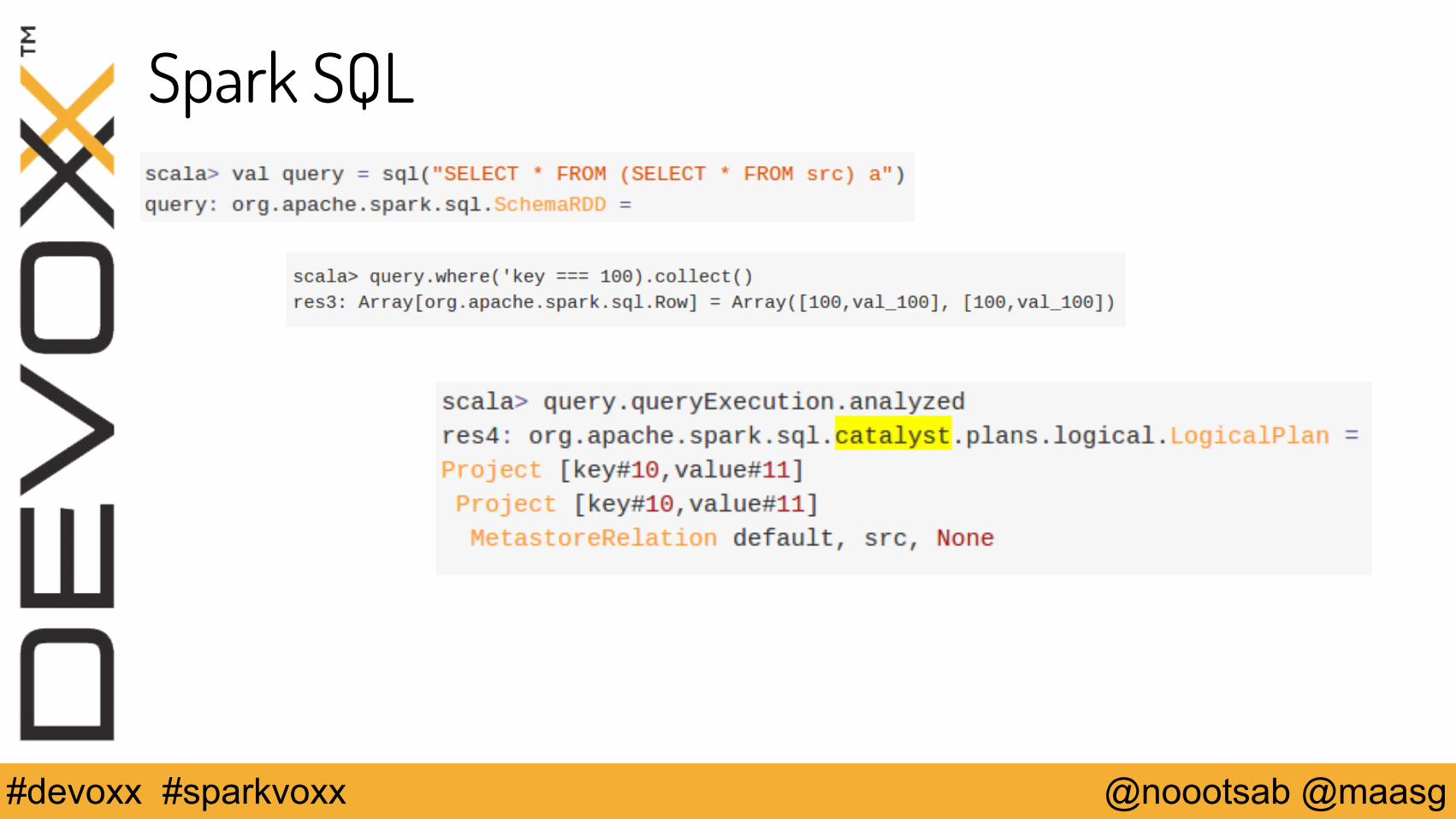
Spark SQL
From SQL to noSQL to SQL … to noSQL
Structured Query Language
We’re not really querying but we’re processing
SQL provides the mathematical (abstraction) structures to manipulate data
We can optimize, Spark has Catalyst
@noootsab @maasg#devoxx #sparkvoxx
Spark SQL

@noootsab @maasg#devoxx #sparkvoxx
MLLib
“The library to teach them all”
SciPy, SciKitLearn, R, MatLab and c° → learn on one machine (sadly often, one core)
SVM lm
NaiveBayesALSK-Means
SVD
PCA

@noootsab @maasg#devoxx #sparkvoxx
GraphX
Connecting the dots
Graph processing at scale. > Takes edges > Add some nodes > Combine = Send messages (Pregel)

@noootsab @maasg#devoxx #sparkvoxx
GraphX
Connecting the dots
Graph processing at scale. > Take edges > Link nodes > Combine/Send messages

@noootsab @maasg#devoxx #sparkvoxx
ADAM
The new kid on the block in the Spark community (with the uncovered Thunder)
Game changing library for processing DNA, Genotypes, Variant and co.
Comes with the right stack for processing … … legacy huge bunch of vital data

@noootsab @maasg#devoxx #sparkvoxx
Tooling (NoIDE)
Besides the classical Eclipse, IntellijIDEA, Netbeans, Sublime Text and family!
An IDE is not enough because not only softwares or services are crafted.
Spark is for data analysis, and data scientist need > interactivity (exploration)> reproducibility (environment, data and logic)> shareability (results)
@noootsab @maasg#devoxx #sparkvoxx
ISparkSpark-Shell backend for IPython (Worksheet for data analysts)

@noootsab @maasg#devoxx #sparkvoxx
Zeppelin
Well shaped Notebook based on Kibana, offering Spark dedicated features> Multi languages (Scala, sql, markdown, shell)> Dynamic forms (generating inputs)> Data visualization (and export)
Check the website!

@noootsab @maasg#devoxx #sparkvoxx
Spark Notebook
Scala-Notebook fork, enhanced for Spark peculiarities.Full Scala, Akka and RxScala.Features including:> Multi languages (Scala, sql, markdown, javascript)> Data visualization> Spark work tracking
Try it: curl https://raw.githubusercontent.com/andypetrella/spark-notebook/spark/run.sh | bash -s dev

@noootsab @maasg#devoxx #sparkvoxx
Databricks Cloud
The amazing product crafted by the company behind Spark!
Cannot say more than this product will be amazing.
Fully collaborative, dashboard creation and publication.
Register for a beta account (Still eagerly waiting for mine �)
Go there

@noootsab @maasg#devoxx #sparkvoxx
Examples

@noootsab @maasg#devoxx #sparkvoxx
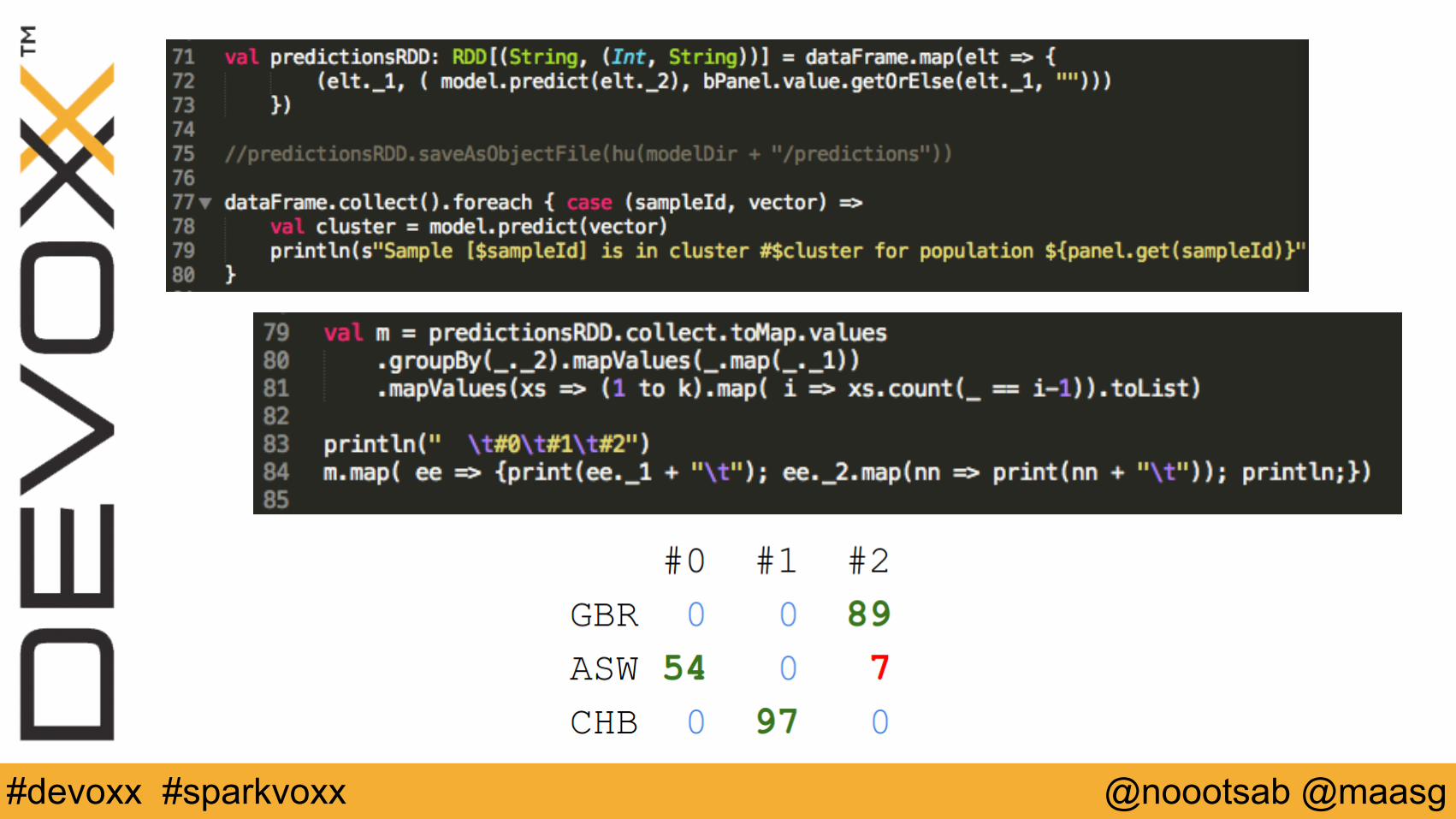
Mining DNA
@noootsab @maasg#devoxx #sparkvoxx

@noootsab @maasg#devoxx #sparkvoxx
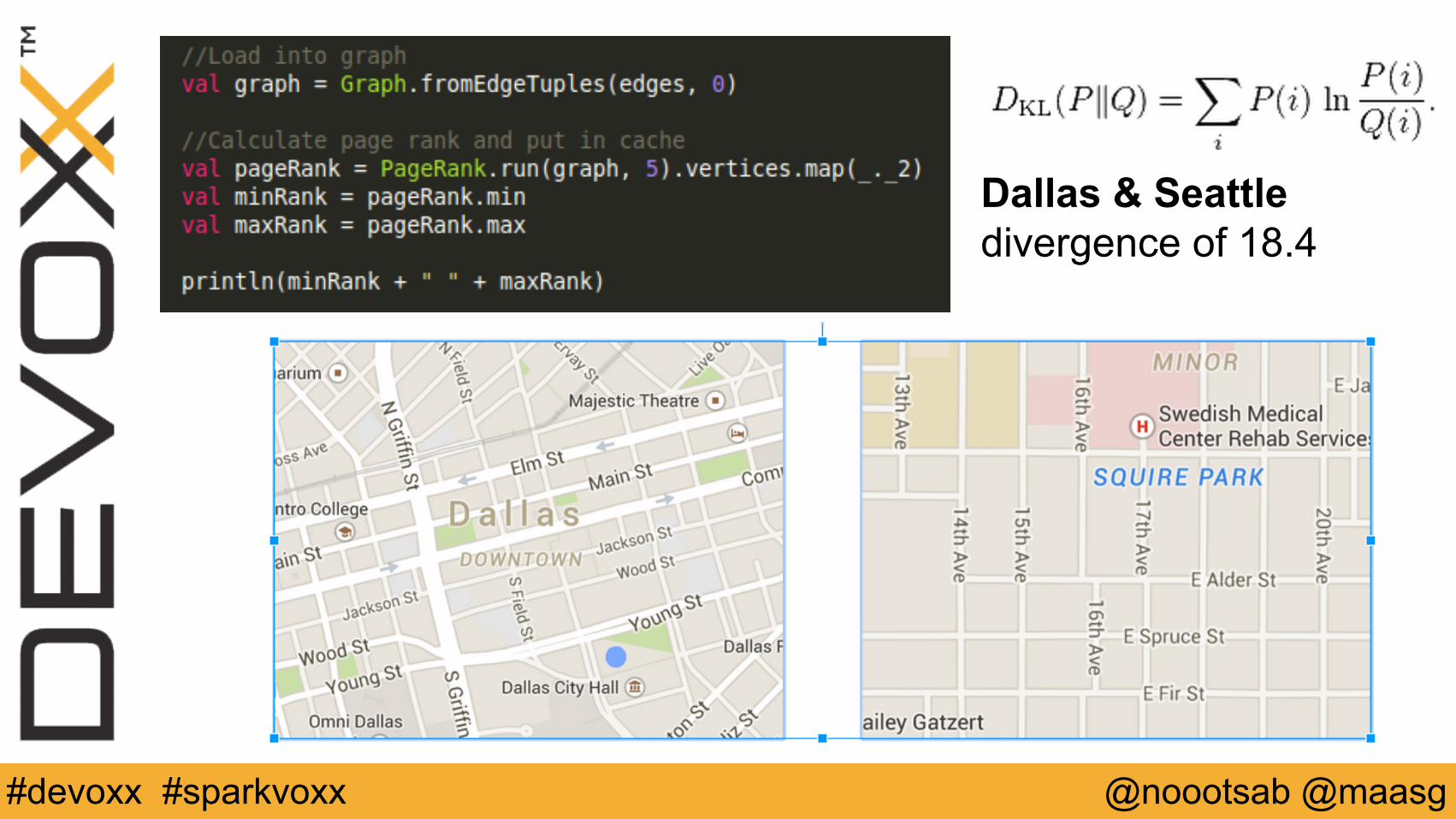
Mining Geodata
@noootsab @maasg#devoxx #sparkvoxx
Dallas & Seattle divergence of 18.4

@noootsab @maasg#devoxx #sparkvoxx
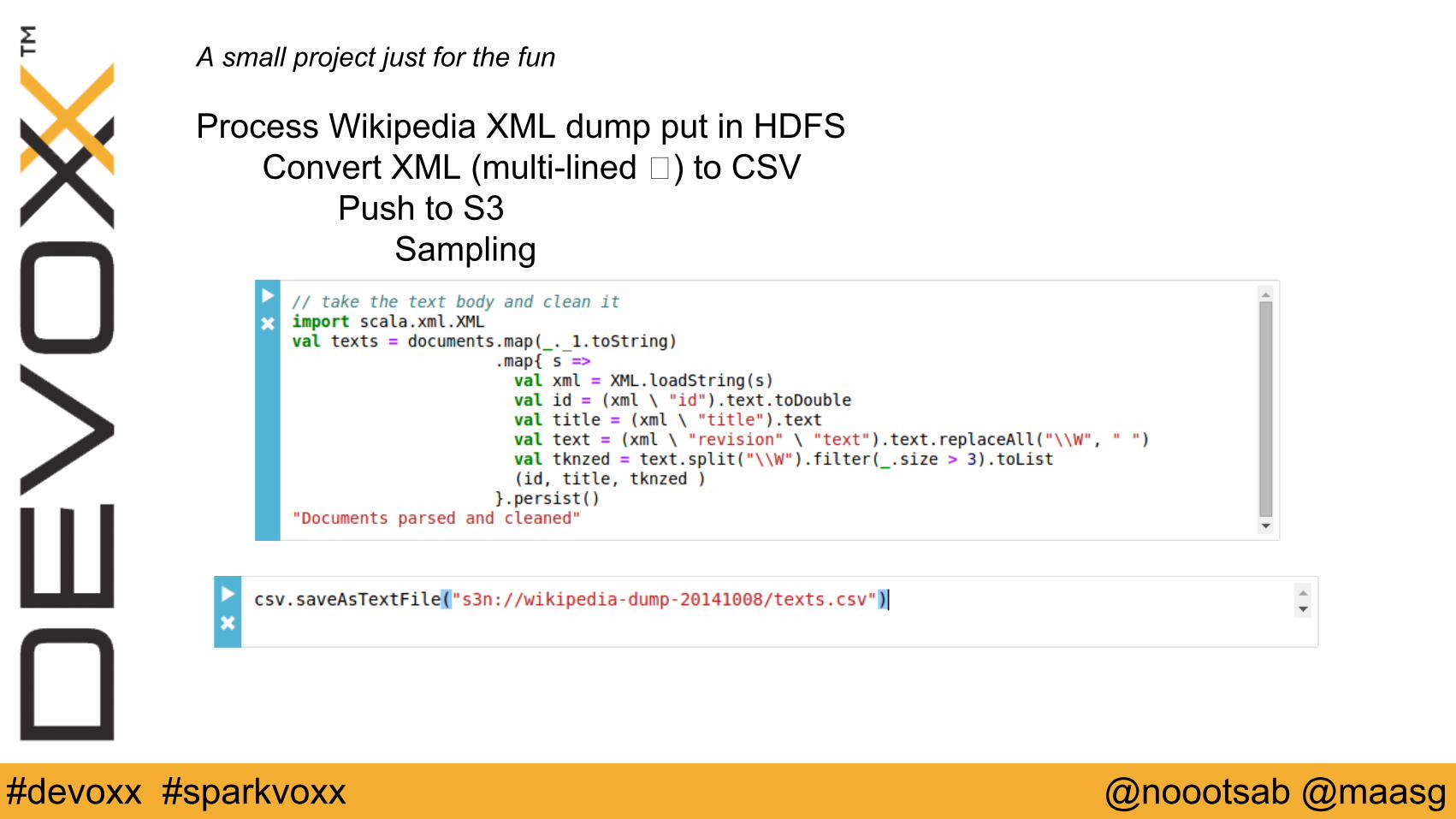
Mining Texts
@noootsab @maasg#devoxx #sparkvoxx
A small project just for the fun
Process Wikipedia XML dump put in HDFS Convert XML (multi-lined �) to CSV Push to S3 Sampling

@noootsab @maasg#devoxx #sparkvoxx
A small project just for the fun
Compute some stats: TF-IDF Train a NaiveBayes classifier

@noootsab @maasg#devoxx #sparkvoxx
A small project just for the fun
See what the machine can say

@noootsab @maasg#devoxx #sparkvoxx
A small project just for the fun
But… quite some data

@noootsab @maasg#devoxx #sparkvoxx
A Word of Advice
Spark beautiful simplicity is often overshadowed by the complexity of building and maintaining a working distributed system.
Sharpen up your Ops skills…
… or ooops

@noootsab @maasg#devoxx #sparkvoxx
Resources
Project website: http://spark.apache.org/Spark presentations: http://spark-summit.org/2014Starting Questions: http://stackoverflow.com/questions/tagged/apache-sparkMore Advanced Questions: [email protected] Code: https://github.com/apache/sparkGetting involved: http://spark.apache.org/community.html

@noootsab @maasg#devoxx #sparkvoxx
AcknowledgmentsDevoxx !
Virdata → Shell Demo cluster
NextLab → Wikipedia ML Cluster
Rand Hindi (Snips) → Geodata example
Xavier Tordoir (SilicoCloud) → DNA example

@noootsab @maasg#devoxx #sparkvoxx
Answers!













![[Spark meetup] Spark Streaming Overview](https://img.pdfslide.us/doc/110x75/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)














