Embed Size (px)
Citation preview

Corso di Sistemi e Architetture per Big Data A.A. 2018/19
Valeria Cardellini
Laurea Magistrale in Ingegneria Informatica
Apache Spark
MacroareadiIngegneriaDipartimentodiIngegneriaCivileeIngegneriaInformatica
The reference Big Data stack
1
Resource Management
Data Storage
Data Processing
High-level Interfaces Support / Integration
Valeria Cardellini - SABD 2018/19

MapReduce: weaknesses and limitations • Programming model
– Hard to implement everything as a MapReduce program
– Multiple MapReduce steps needed even for simple operations
• E.g., WordCount that sorts words by their frequency
– Lack of control, structures and data types • No native support for iteration
– Each iteration writes/reads data from disk: overhead – Need to design algorithms that minimize number of
iterations
2 Valeria Cardellini - SABD 2018/19
MapReduce: weaknesses and limitations
• Efficiency (recall HDFS) – High communication cost: computation (map),
communication (shuffle), computation (reduce) – Frequent writing of output to disk – Limited exploitation of main memory
• Not feasible for real-time data stream processing – A MapReduce job requires to scan the entire input
3 Valeria Cardellini - SABD 2018/19

Alternative programming models
• Based on directed acyclic graphs (DAGs) – E.g., Spark, Spark Streaming, Storm, Flink
• SQL-based – E.g., Hive, Pig, Spark SQL
• NoSQL data stores – We have already analyzed HBase, MongoDB,
Cassandra, …
4 Valeria Cardellini - SABD 2018/19
Alternative programming models • Based on Bulk Synchronous Parallel (BSP)
– Developed by Leslie Valiant during the 1980s – Considers communication actions en masse – Suitable for graph analytics at massive scale and
massive scientific computations (e.g., matrix, graph and network algorithms)
5
- Examples: Google’s Pregel, Apache Giraph, Apache Hama
- Giraph: open source counterpart to Pregel, used at Facebook to analyze the users’ social graph
Valeria Cardellini - SABD 2018/19

Apache Spark
• Fast and general-purpose engine for Big Data processing – Not a modified version of Hadoop – Leading platform for large-scale SQL, batch processing, stream
processing, and machine learning – Unified analytics engine for large-scale data processing
• In-memory data storage for fast iterative processing – At least 10x faster than Hadoop
• Suitable for general execution graphs and powerful optimizations
• Compatible with Hadoop’s storage APIs – Can read/write to any Hadoop-supported system, including
HDFS and HBase
6 Valeria Cardellini - SABD 2018/19
Spark project history
• Spark project started in 2009 • Developed originally at UC Berkeley’s
AMPLab by Matei Zaharia • Open sourced 2010, Apache project from
2013 • In 2014, Zaharia founded Databricks • The most active open source project for Big
Data processing • Current version: 2.4.1
7 Valeria Cardellini - SABD 2018/19

Spark popularity
• Stack Overflow trends
8 Valeria Cardellini - SABD 2018/19
Spark: why a new programming model?
• MapReduce simplified Big Data analysis – But it executes jobs in a simple but rigid structure
• Step to process or transform data (map) • Step to synchronize (shuffle) • Step to combine results (reduce)
• As soon as MapReduce got popular, users wanted: – Iterative computations (e.g., iterative graph algorithms and
machine learning algorithms, such as stochastic gradient descent, K-means clustering)
– More efficiency – More interactive ad-hoc queries – Faster in-memory data sharing across parallel jobs (required
by both iterative and interactive applications)
9 Valeria Cardellini - SABD 2018/19

Data sharing in MapReduce
• Slow due to replication, serialization, and disk I/O
10 Valeria Cardellini - SABD 2018/19
Data sharing in Spark
• Distributed in-memory: 10x-100x faster than disk and network
11 Valeria Cardellini - SABD 2018/19

Spark stack
12 Valeria Cardellini - SABD 2018/19
Spark core
• Provides basic functionalities (including task scheduling, memory management, fault recovery, interacting with storage systems) used by other components
• Provides a data abstraction called resilient distributed dataset (RDD), a collection of items distributed across many compute nodes that can be manipulated in parallel – Spark Core provides many APIs for building and
manipulating these collections • Written in Scala but APIs for Java, Python
and R
13 Valeria Cardellini - SABD 2018/19

Spark as unified engine
• A number of integrated higher-level modules built on top of Spark
• Spark SQL – To work with structured data – Allows querying data via SQL as well as Hive QL
(Apache Hive variant of SQL) – Supports many data sources, including Hive
tables, Parquet, and JSON – Extends the Spark RDD API
• Spark Streaming – To process live streams of data – Extends the Spark RDD API
14 Valeria Cardellini - SABD 2018/19
PageRank performance (20 iterations, 3.7B edges)
Spark as unified engine
• MLlib – Scalable machine learning (ML)
library – Many distributed algorithms:
feature extraction, classification, regression, clustering, recommendation, …
15 Valeria Cardellini - SABD 2018/19
• GraphX – API for manipulating graphs and
performing graph-parallel computations – Includes also common graph algorithms
(e.g., PageRank) – Extends the Spark RDD API
Logistic regression performance

Spark on top of cluster managers
• Spark can exploit many cluster resource managers to execute its applications
• Spark standalone mode – Use a simple FIFO scheduler included in Spark
• Hadoop YARN • Mesos
– Mesos and Spark are both from AMPLab @ UC Berkeley
• Kubernetes
16 Valeria Cardellini - SABD 2018/19
Spark architecture
17
• Master/worker architecture
Valeria Cardellini - SABD 2018/19

Spark architecture
18
http://spark.apache.org/docs/latest/cluster-overview.html
• Driver program that talks to cluster manager • Worker nodes in which executors run
Valeria Cardellini - SABD 2018/19
Spark architecture
• Applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in the main program (the driver program)
• Each application gets its own executors, which are processes which stay up for the duration of the whole application and run tasks in multiple threads
• To run on a cluster, SparkContext connects to a cluster manager (Spark’s cluster manager, Mesos or YARN), which allocates resources
• Once connected, Spark acquires executors on cluster nodes and sends the application code (e.g., jar) to the executors. Finally, SparkContext sends tasks to the executors to run
19 Valeria Cardellini - SABD 2018/19

Spark data flow
20 Valeria Cardellini - SABD 2018/19
• Iterative computation is particularly useful when working with machine learning algorithms
Spark programming model
21 Valeria Cardellini - SABD 2018/19
Executor Executor

Spark programming model
22 Valeria Cardellini - SABD 2018/19
Resilient Distributed Datasets (RDDs)
• RDDs are the key programming abstraction in Spark: a distributed memory abstraction
• Immutable, partitioned and fault-tolerant collection of elements that can be manipulated in parallel – Like a LinkedList <MyObjects> – Cached in memory across the cluster nodes
• Each node of the cluster that is used to run an application contains at least one partition of the RDD(s) that is (are) defined in the application
23 Valeria Cardellini - SABD 2018/19

RDDs: distributed and partitioned
• Stored in main memory of the executors running in the worker nodes (when it is possible) or on node local disk (if not enough main memory)
• Allow executing in parallel the code invoked on them – Each executor of a worker node runs the specified code
on its partition of the RDD – Partition: atomic chunk of data (a logical division of data)
and basic unit of parallelism – Partitions of an RDD can be stored on different cluster
nodes
24 Valeria Cardellini - SABD 2018/19
RDDs: immutable and fault-tolerant
• Immutable once constructed – i.e., RDD content cannot be modified – Create new RDD based on existing RDD
• Automatically rebuilt on failure (but no replication) – Track lineage information so to efficiently recompute
missing or lost data due to node failures – For each RDD, Spark knows how it has been
constructed and can rebuild it if a failure occurs – This information is represented by means of RDD
lineage DAG connecting input data and RDDs
25 Valeria Cardellini - SABD 2018/19

Spark and RDDs
• Spark manages the split of RDDs in partitions and allocates RDDs’ partitions to cluster nodes
• Spark hides complexities of fault tolerance – RDDs are
automatically rebuilt in case of failure
26 Valeria Cardellini - SABD 2018/19
RDD: API and suitability • RDD API
– Clean language-integrated API for Scala, Python, Java, and R
– Can be used interactively from Scala console and PySpark console
– On top of Spark’s RDD API, high level APIs are provided (DataFrame API and Machine Learning API)
• RDD suitability – Best suited for batch applications that apply the
same operation to all the elements in a dataset – Less suited for applications that make
asynchronous fine-grained updates to shared state, e.g., storage system for a web application
27 Valeria Cardellini - SABD 2018/19

Operations in RDD API
• Spark programs are written in terms of operations on RDDs
• RDDs are created from external data or other RDDs
• RDDs are created and manipulated through: – Coarse-grained transformations, which define a
new dataset based on previous ones • Map, filter, join, …
– Actions, which kick off a job to execute on a cluster • Count, collect, save, …
28 Valeria Cardellini - SABD 2018/19
Spark programming model
• Based on parallelizable operators – Higher-order functions that execute user-defined
functions in parallel • Data flow is composed of any number of data
sources, operators, and data sinks by connecting their inputs and outputs
• Job description based on directed acyclic graph (DAG)
29 Valeria Cardellini - SABD 2018/19

Higher-order functions
• Higher-order functions: RDDs operators • Two types of RDD operators: transformations
and actions • Transformations: lazy operations that create
new RDDs – Lazy: the new RDD representing the result of a
computation is not immediately computed but is materialized on demand when an action is called
• Actions: operations that return a value to the driver program after running a computation on the dataset or write data to the external storage
30 Valeria Cardellini - SABD 2018/19
Higher-order functions
31
• Transformations and actions available on RDDs in Spark - Seq[T]: sequence of elements of type T
Valeria Cardellini - SABD 2018/19

How to create RDD
• RDD can be created by: – Parallelizing existing collections of the hosting
programming language (e.g., collections and lists of Scala, Java, Python, or R)
• Number of partitions specified by user • In RDD API: parallelize
– From (large) files stored in HDFS or any other file system
• One partition per HDFS block • In RDD API: textFile
– Transforming an existing RDD • Number of partitions depends on transformation type • In RDD API: transformation operations (map, filter, flatMap)
32 Valeria Cardellini - SABD 2018/19
How to create RDDs
• Turn an existing collection into an RDD
– sc is Spark context variable – Important parameter: number of partitions to cut the dataset
into – Spark will run one task for each partition of the cluster
(typical setting: 2-4 partitions for each CPU in the cluster) – Spark tries to set the number of partitions automatically – You can also set it manually by passing it as a second
parameter to parallelize, e.g., sc.parallelize(data, 10)
• Load data from storage (local file system, HDFS, or S3)
lines = sc.parallelize(["pandas", "i like pandas"])
lines = sc.textFile("/path/to/README.md")
Examples in Python

RDD transformations: map and filter
• map: takes as input a function which is applied to each element of the RDD and map each input item to another item
• filter: generates a new RDD by filtering the source dataset using the specified function
# transforming each element through a function nums = sc.parallelize([1, 2, 3, 4])
squares = nums.map(lambda x: x * x) # [1, 4, 9, 16]
# selecting those elements that func returns true even = squares.filter(lambda num: num % 2 == 0) # [4, 16]
RDD transformations: flatMap
• flatMap: takes as input a function which is applied to each element of the RDD; can map each input item to zero or more output items
# splitting input lines into words
lines = sc.parallelize(["hello world", "hi"])
words = lines.flatMap(lambda line: line.split(" "))
#[’hello', ’world', ’hi’]
# mapping each element to zero or more others
ranges = nums.flatMap(lambda x: range(0, x, 1)
# [0, 0, 1, 0, 1, 2, 0, 1, 2, 3]
Range function in Python: ordered sequence of integer values in range [start;end) with non-zero step

RDD transformations: reduceByKey
• reduceByKey: aggregates values with identical key using the specified function
• Runs several parallel reduce operations, one for each key in the dataset, where each operation combines values that have the same key
x = sc.parallelize([("a", 1), ("b", 1), ("a", 1), ("a", 1), ... ("b", 1), ("b", 1), ("b", 1), ("b", 1)], 3)
# Applying reduceByKey operation
y = x.reduceByKey(lambda accum, n: accum + n)
# [('b', 5), ('a', 3)]
RDD transformations: join • join: performs an equi-join on the
keys of two RDDs • Only keys that are present in both
RDDs are output • Join candidates are independently
processed
users = sc.parallelize([(0, "Alex"), (1, "Bert"), (2, "Curt"), (3, "Don")]) hobbies = sc.parallelize([(0, "writing"), (0, "gym"), (1, "swimming")])
users.join(hobbies).collect() # [(0, ('Alex', 'writing')), (0, ('Alex', 'gym')), (1, ('Bert', 'swimming'))]

Some RDD actions
• collect: returns all the elements of the RDD as a list
• take: returns an array with the first n elements in the RDD
• count: returns the number of elements in the RDD
nums = sc.parallelize([1, 2, 3, 4]) nums.collect() # [1, 2, 3, 4]
nums.take(3) # [1, 2, 3]
nums.count() # 4
Some RDD actions
• reduce: aggregates the elements in the RDD using the specified function
• saveAsTextFile: writes the elements of the RDD as a text file either to the local file system or HDFS
sum = nums.reduce(lambda x, y: x + y)
nums.saveAsTextFile(“hdfs://file.txt”)

Lazy transformations
• Transformations are lazy: they are not computed till an action requires a result to be returned to the driver program
• This design enables Spark to perform operations more efficiently as operations can be grouped together – E.g., if there were multiple filter or map operations, Spark
can fuse them into one pass – E.g., if Sparks knows that data is partitioned, it can avoid
moving it over the network for groupBy
40 Valeria Cardellini - SABD 2018/19
First examples
• Let us analyze some simple examples that use the Spark API – WordCount – Pi estimation
• See http://spark.apache.org/examples.html
41 Valeria Cardellini - SABD 2018/19

Example: WordCount in Scala
42
val textFile = sc.textFile("hdfs://…") val words = textFile.flatMap(line => line.split(" "))
val ones = words.map(word => (word, 1)) val counts = ones.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Valeria Cardellini - SABD 2018/19
Example: WordCount in Scala with chaining
43
• Transformations and actions can be chained together – We use a few transformations to build a dataset of (String,
Int) pairs called counts and then save it to a file val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Valeria Cardellini - SABD 2018/19

Example: WordCount in Python text_file = sc.textFile("hdfs://...”)
counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b)
output = counts.collect()
output.saveAsTextFile("hdfs://...")
44 Valeria Cardellini - SABD 2018/19
Example: WordCount in Java 7 (and earlier) JavaRDD<String> textFile = sc.textFile("hdfs://..."); JavaRDD<String> words = textFile.flatMap(new FlatMapFunction<String, String>() { public Iterable<String> call(String s) { return Arrays.asList(s.split(" ")); } }); JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairRDD<String, Integer> counts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call(Integer a, Integer b) { return a + b; } }); counts.saveAsTextFile("hdfs://...");
45
Spark’s Java API allows to create tuples using the scala.Tuple2 class
Pair RDDs are RDDs containing key/value pairs
Valeria Cardellini - SABD 2018/19

Example: WordCount in Java 8 • Example in Java 7: too verbose • Support for lambda expressions from Java 8
– Anonymous methods (methods without names) used to implement a method defined by a functional interface
– New arrow operator -> divides the lambda expressions in two parts
• Left side: parameters required by the lambda expression • Right side: actions of the lambda expression
46
JavaRDD<String> textFile = sc.textFile("hdfs://..."); JavaPairRDD<String, Integer> counts = textFile
.flatMap(s -> Arrays.asList(s.split(" ")).iterator()) .mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((a, b) -> a + b);
counts.saveAsTextFile("hdfs://..."); Valeria Cardellini - SABD 2018/19
Example: Pi estimation • How to estimate π? Let’s use Monte Carlo
method • By definition, π is the area of a circle with
radius equal to 1 1. Pick a large number of points randomly inside
the circumscribed unit square – A certain number of these points will end up inside
the area described by the circle, while the remaining number of these points will lie outside of it (but inside the square)
2. Count the fraction of points that end up inside the circle out of a total population of points randomly thrown at the circumscribed square
47

Example: Pi estimation
• In formulas:
• The more points generated, the greater the accuracy of the estimation
48
See animation at https://academo.org/demos/estimating-pi-monte-carlo/
(x, y) . x2 + y2 < 1?
Example: Pi estimation in Scala
val count = sc.parallelize(1 to NUM_SAMPLES).filter { _ => val x = math.random val y = math.random x*x + y*y < 1 }.count() println(s"Pi is roughly ${4.0 * count / NUM_SAMPLES}")
Valeria Cardellini - SABD 2018/19
49

SparkContext • Main entry point for Spark functionality
– Represents the connection to a Spark cluster, and can be used to create RDDs on that cluster
– Also available in shell (as variable sc)
• Only one SparkContext may be active per JVM – You must stop() the active SparkContext before creating a
new one
• SparkConf class: configuration for a Spark application – Used to set various Spark parameters as key-value pairs
50 Valeria Cardellini - SABD 2018/19
WordCount in Java (complete - 1)
51 Valeria Cardellini - SABD 2018/19

WordCount in Java (complete - 2)
52 Valeria Cardellini - SABD 2018/19
RDD persistence • By default, each transformed RDD may be
recomputed each time an action is run on it • Spark also supports the persistence (or caching) of
RDDs in memory across operations for rapid reuse – When RDD is persisted, each node stores any partitions of it
that it computes in memory and reuses them in other actions on that dataset (or datasets derived from it)
– This allows future actions to be much faster (even 100x) – To persist RDD, use persist() or cache()methods on it – Spark’s cache is fault-tolerant: a lost RDD partition is
automatically recomputed using the transformations that originally created it
• Key tool for iterative algorithms and fast interactive use
53 Valeria Cardellini - SABD 2018/19

RDD persistence: storage level
• Using persist() you can specify the storage level for persisting an RDD – cache() is the same as calling persist() with the default
storage level (MEMORY_ONLY)
• Storage levels for persist(): – MEMORY_ONLY– MEMORY_AND_DISK– MEMORY_ONLY_SER,MEMORY_AND_DISK_SER (Java
and Scala) • In Python, stored objects will always be serialized with the
Pickle library
– DISK_ONLY, …
54 Valeria Cardellini - SABD 2018/19
RDD persistence: storage level
• Which storage level is best? Few things to consider: – Try to keep in-memory as much as possible – Serialization make the objects much more space-
efficient • But select a fast serialization library (e.g., Kryo library)
– Try not to spill to disk unless the functions that computed your datasets are expensive (e.g., filter a large amount of the data)
– Use replicated storage levels only if you want fast fault recovery
55 Valeria Cardellini - SABD 2018/19

Persistence: example of iterative algorithm
• Let us consider logistic regression using gradient descent as example of iterative algorithm
• A brief introduction to logistic regression – A widely applied supervised ML algorithm used to classify
input data into categories (e.g., spam and non-spam emails) – Probabilistic classification – Binomial (or binary) logistic regression: output can take only
two categories (yes/no) – Sigmoid or logistic function:
f(x) = 1 / (1+ e-x)
56 Valeria Cardellini - SABD 2018/19
Persistence: example of iterative algorithm • Idea: search for a hyperplane w that best separates
two sets of points – Input values (x) are linearly combined using weights (w) to
predict output values (y) – x: input variables, our training data – y: output or target variables that we are trying to predict
given x – w: weights or parameters that must be estimated using
training data
• Iterative algorithm that uses gradient descent to minimize the error – Start w at a random value – On each iteration, sum a function of w over the data to move
w in a direction that improves it
57
For details see https://www.youtube.com/watch?v=SB2vz57eKgc Valeria Cardellini - SABD 2018/19

Persistence: example of iterative algorithm // Load data into an RDD val points = sc.textFile(...).map(readPoint).persist() // Start with a random parameter vector var w = DenseVector.random(D) // On each iteration, update param vector with a sum for (i <- 1 to ITERATIONS) { val gradient = points.map { p => p.x * (1 / (1 + exp(-p.y*(w.dot(p.x)))) - 1) * p.y }.reduce((a, b) => a+b) w -= gradient } • Persisting the RDD points in memory across
iterations can yield 100x speedup (see next slide)
58
Gradient formula (based on logistic function)
Valeria Cardellini - SABD 2018/19 Source: “Apache Spark: A Unified Engine for Big Data Processing”
Initial parameter vector
We ask Spark to persist RDD if
needed for reuse
Persistence: example of iterative algorithm • Spark outperforms Hadoop by up to 100x in iterative
machine learning – Speedup comes from avoiding I/O and deserialization costs
by storing data in memory
59 Valeria Cardellini - SABD 2018/19
Source: “Apache Spark: A Unified Engine for Big Data Processing”
110 s/iteration
1st iteration 80 s Further iterations 1 s

How Spark works at runtime
• A Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster
60 Valeria Cardellini - SABD 2018/19
How Spark works at runtime • The application creates RDDs, transforms them, and
runs actions – This results in a DAG of operators
• DAG is compiled into stages – Stages are sequences of RDDs without a shuffle in between
• Each stage is executed as a series of tasks (one task for each partition)
• Actions drive the execution
61
task
Valeria Cardellini - SABD 2018/19

Stage execution
• Spark: – Creates a task for each partition in the new RDD – Schedules and assigns tasks to worker nodes
• All this happens internally (you need to do anything)
62 Valeria Cardellini - SABD 2018/19
Summary of Spark components
• RDD: parallel dataset with partitions
• DAG: logical graph of RDD operations
• Stage: set of tasks that run in parallel
• Task: fundamental unit of execution in Spark
63
Coarse grain
Fine grain
Valeria Cardellini - SABD 2018/19

Fault tolerance in Spark • RDDs track the series of
transformations used to build them (their lineage)
• Lineage information is used to recompute lost data
• RDDs are stored as a chain of objects capturing the lineage of each RDD
64 Valeria Cardellini - SABD 2018/19
Job scheduling in Spark • Spark job scheduling takes into
account which partitions of persistent RDDs are available in memory
• When a user runs an action on an RDD: the scheduler builds a DAG of stages from the RDD lineage graph
• A stage contains as many pipelined transformations with narrow dependencies
• The boundary of a stage: – Shuffles for wide dependencies – Already computed partitions
65 Valeria Cardellini - SABD 2018/19

Job scheduling in Spark
• The scheduler launches tasks to compute missing partitions from each stage until it computes the target RDD
• Tasks are assigned to machines based on data locality – If a task needs a partition, which is available in
the memory of a node, the task is sent to that node
66 Valeria Cardellini - SABD 2018/19
Spark stack
67 Valeria Cardellini - SABD 2018/19

Spark SQL
68
• Spark library for structured data processing that allows to run SQL queries on top of Spark
• Compatible with existing Hive data – You can run unmodified Hive queries
• Speedup up to 40x • Motivation:
– Hive is great, but Hadoop’s execution engine makes even the smallest queries take minutes
– Many users know SQL – Can we extend Hive to run on Spark? – Started with the Shark project
Valeria Cardellini - SABD 2018/19
Spark SQL: the beginning
• Shark project modified Hive’s backend to run over Spark
• Shark employed in-memory column-oriented storage • Limitations
– Limited integration with Spark programs – Hive optimizer not designed for Spark
69 Valeria Cardellini - SABD 2018/19
Hive on Hadoop MapReduce Shark on Spark

Spark SQL • Borrows from Shark
– Hive data loading – In-memory column store
• Adds: – RDD-aware optimizer (Catalyst Optimizer) – Schema to RDD (DataFrame and Dataset APIs) – Rich language interfaces
70 Valeria Cardellini - SABD 2018/19
Evolution of Spark APIs with Spark SQL
Valeria Cardellini - SABD 2018/19
71
See: “A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets”
Dataset is a new interface added in Spark 1.6

Spark SQL: Datasets and DataFrames • DataFrame and Dataset APIs
– DataFrame API introduced the concept of a schema to describe the data
• Like an RDD, a DataFrame is an immutable distributed collection of data
• Unlike an RDD, data is organized into named columns, like a table in a relational database
– Starting in Spark 2.0, Dataset took on two distinct APIs characteristics: a strongly-typed API and an untyped API
• Consider DataFrame as an alias for a collection of generic objects Dataset[Row], where a Row is a generic untyped JVM object
• Dataset, by contrast, is a collection of strongly-typed JVM objects
• SparkSession: entry point to programming Spark with the Dataset and DataFrame APIs
Valeria Cardellini - SABD 2018/19
72
Spark SQL: Datasets • Dataset: a distributed collection of data
– Provides the benefits of RDDs (strongly typed, ability to use lambda functions) plus Spark SQL’s optimized execution engine
– Can be constructed from JVM objects and manipulated using functional transformations (map, filter, ...)
– Available in Scala and Java (no Python and R) – Lazy, i.e. computations are only triggered when an
action is invoked • Internally, it represents a logical plan that describes the
computation required to produce the data. When an action is invoked, Spark's query optimizer optimizes the logical plan and generates a physical plan for efficient execution in a parallel and distributed manner
Valeria Cardellini - SABD 2018/19
73

Spark SQL: Datasets
• How to create a Dataset? – From a file using read function – From an existing RDD by converting it – Through transformations applied on existing
Datasets • Example in Scala:
valnames=people.map(_.name)//namesisaDataset[String]Dataset<String>names=people.map((Personp)->p.name,
Encoders.STRING));
Valeria Cardellini - SABD 2018/19
74
Spark SQL: DataFrames
• DataFrame: a Dataset organized into named columns
• Equivalent to a table in a relational database • Can be manipulated in similar ways to RDDs • DataFrame API is available in Scala, Java,
Python, and R – In Scala and Java, a DataFrame is represented by a
Dataset of Rows • Can be constructed from existing RDDs, tables
in Hive, structured data files – Spark SQL supports a variety of data sources,
including Parquet, JSON, Hive tables, Avro
75 Valeria Cardellini - SABD 2018/19

Parquet file format
• Parquet is an efficient columnar data storage format
• Supported not only by Spark but also by many other data processing frameworks – Hive, Impala, Pig, ...
• Interoperable with other data storage formats – Avro, Thrift, Protocol Buffers, ...
Valeria Cardellini - SABD 2018/19
76
Parquet file format
Valeria Cardellini - SABD 2018/19
77
• Supports efficient compression and encoding schemes
• Example: Parquet vs. CSV

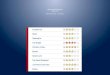
Spark SQL example: using Parquet
Valeria Cardellini - SABD 2018/19
78
See https://spark.apache.org/docs/latest/sql-data-sources-parquet.html
Spark on Amazon EMR
• Example in Scala using Hive on Spark: query about domestic flights in the US http://amzn.to/2r9vgme
val df = session.read.parquet("s3://us-east-1.elasticmapreduce.samples/flightdata/input/")
//Parquet files can be registered as tables and used in SQL statements df.createOrReplaceTempView("flights")
//Top 10 airports with the most departures since 2000 val topDepartures = session.sql("SELECT origin, count(*) AS total_departures \ FROM flights WHERE year >= '2000' \ GROUP BY origin \ ORDER BY total_departures DESC LIMIT 10")
79 Valeria Cardellini - SABD 2018/19

Spark Streaming
• Spark Streaming: extension that allows to analyze streaming data – Ingested and analyzed in micro-batches
• Uses a high-level abstraction called Dstream (discretized stream) which represents a continuous stream of data – A sequence of RDDs
80 Valeria Cardellini - SABD 2018/19
Spark Streaming
• Internally, it works as:
• We will study Spark Streaming later
81 Valeria Cardellini - SABD 2018/19

Combining processing tasks with Spark
Valeria Cardellini - SABD 2018/19
82
• Since Spark’s libraries all operate on RDDs as the data abstraction, it is easy to combine them in applications
• Example combining the SQL, machine learning, and streaming libraries in Spark – Read some historical Twitter data using Spark
SQL – Trains a K-means clustering model using MLlib – Apply the model to a new stream of tweets
Combining processing tasks with Spark
// Load historical data as an RDD using Spark SQL val trainingData = sql( “SELECT location, language FROM old_tweets”) // Train a K-means model using MLlib val model = new KMeans() .setFeaturesCol(“location”) .setPredictionCol(“language”) .fit(trainingData) // Apply the model to new tweets in a stream TwitterUtils.createStream(...) .map(tweet => model.predict(tweet.location))
Valeria Cardellini - SABD 2018/19
83

References
• Zaharia et al., “Spark: Cluster Computing with Working Sets”, HotCloud’10. http://bit.ly/2rj0uqH
• Zaharia et al., “Resilient Distributed Datasets: A Fault-tolerant Abstraction for In-memory Cluster Computing”, NSDI’12. http://bit.ly/1XWkOFB
• Zaharia et al., “Apache Spark: A Unified Engine For Big Data Processing”, Commun. ACM, 2016. https://bit.ly/2r9t8cI
• Karau et al., “Learning Spark - Lightning-Fast Big Data Analysis”, O’Reilly, 2015.
• Online resources and MOOCs: https://sparkhub.databricks.com
84 Valeria Cardellini - SABD 2018/19