Embed Size (px)
Citation preview

Some studies on Vietnamese multi-document summarization and
semantic relation extraction
Laboratory of Data Mining & Knowledge Science
04/19/23 1Laboratory of Data Mining & Knowledge Science

Content
I. Vietnamese multi-document summarization1. Vietnamese VNSEN search engine2. Clustering3. Semantic similarity 4. Multi-document summarization
II. Semantic relation extraction1. Vietnamese medical ontology2. Object relation extraction3. Cause-and-effect relations4. Vietnamese entity search engine
04/19/23 2Laboratory of Data Mining & Knowledge Science

• Vietnamese VNSEN search engine– Based on NUTCH– Integrated Vietnamese word segmentation tool
• JvnSegmenter
– Indexed 500.000 pages from vi.wikipedia.org
04/19/23 3
Vietnamese multi-document summarization
Laboratory of Data Mining & Knowledge Science

Vietnamese multi-document summarization
• Clustering– Integrated clustering to VNSEN search engine• Using snippet results from VNSEN search engine• Hierarchical Agglomerative Clustering (HAC) algorithm
– Estimation with Clustering on Vivisimo search engine• Cluster labeling• Compactness of clusters• Isolation of clusters
04/19/23 4Laboratory of Data Mining & Knowledge Science

• Implementation of semantic similarity measures– Semantic similarity between words based on
Semantic Network• Path length (PL)• Information content (IC)
– Semantic similarity between sentences based on topic analysis
– Word order similarity between sentences
04/19/23 5
Vietnamese multi-document summarization
Laboratory of Data Mining & Knowledge Science

Vietnamese multi-document summarization
• Building Vietnamese semantic corpus– Hidden topic corpus
• Using Latent Dirichlet Allocation (LDA) model• Using JgibbsLDA tool to analyze topic
– Vietnamese Wikipedia corpus• Using category graph model
• Result• 120/150/200 hidden topics corpus based on
Vnexpress/Wikipedia data set• Category graph with 14.000 category nodes and 200.000
articles
04/19/23 6Laboratory of Data Mining & Knowledge Science
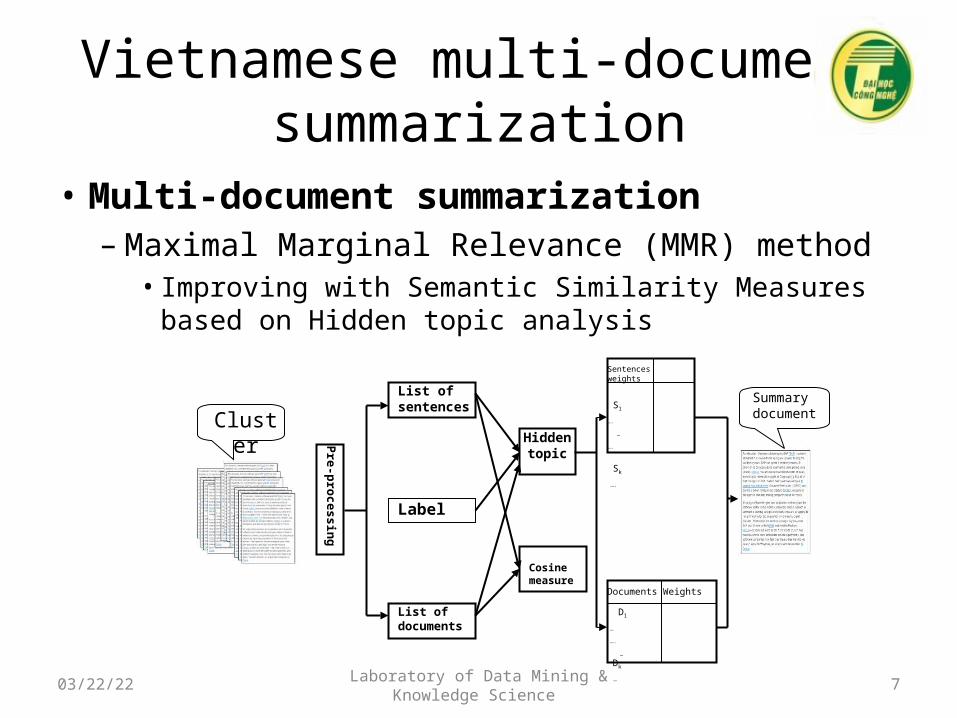
Vietnamese multi-document summarization
• Multi-document summarization– Maximal Marginal Relevance (MMR) method• Improving with Semantic Similarity Measures based on
Hidden topic analysis
04/19/23 7
List of sentences
List of documents
Label
Pre-processing
Sentences weights
S1 ….
… ….
Sk ….Hidden topic
Cosine measure
Documents Weights
D1 …
…. …
Dk …
ClusterSummary document
Laboratory of Data Mining & Knowledge Science

Vietnamese multi-document summarization
• Multi-document summarization for simple Vietnamese Medical Q&A system– Semantic Similarity Measures based on
Vietnamese Wikipedia corpus– Medical Ontology– Hidden topic analysis– Clustering
04/19/23 8Laboratory of Data Mining & Knowledge Science
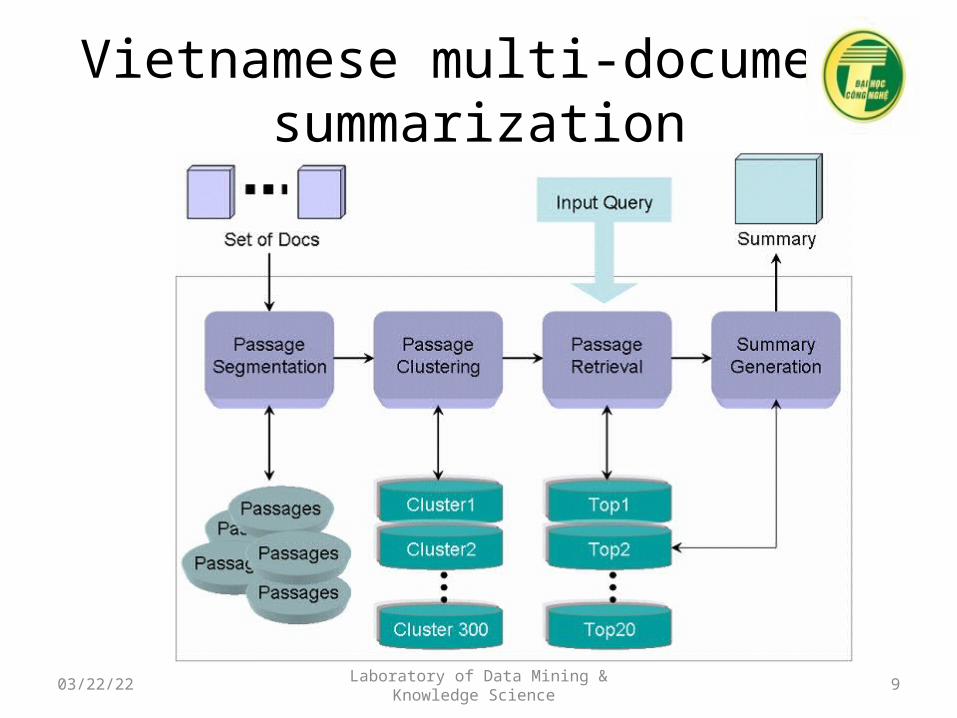
Vietnamese multi-document summarization
04/19/23 9Laboratory of Data Mining & Knowledge Science

• Table-of-Contents generation– Using some solutions of Text Segmentation and
Title Generation for automatically generating a Table-of-Contents.
04/19/23 10
Vietnamese multi-document summarization
Laboratory of Data Mining & Knowledge Science

Vietnamese multi-document summarization
• Some our Vietnamese language processing utilities– Nguyen Cam Tu, Phan Xuan Hieu. JvnSegmenter. A Java-
based Vietnamese Word Segmentation – Nguyen Cam Tu. JVnTextpro: A Java-based Vietnamese
Text Processing Toolkit– Nguyen Cam Tu. JGibbsLDA: A Java and Gibbs Sampling
based Implementation of Latent Dirichlet Allocation (LDA)– http://203.113.130.205:8080/sise: VNSEN Search Engine
(Implementers: Nguyen Thu Trang, Nguyen Cam Tu, Nguyen Viet Cuong, Tran Mai Vu, Nguyen Minh Tuan etc.)
04/19/23 11Laboratory of Data Mining & Knowledge Science

Semantic Relation Extraction
• Vietnamese Medical Ontology– 23 classes entity– 14 relations– 200 entities
• Technique to improve ontology– Named Entity Recognition – Relation extraction– …
04/19/23 12Laboratory of Data Mining & Knowledge Science
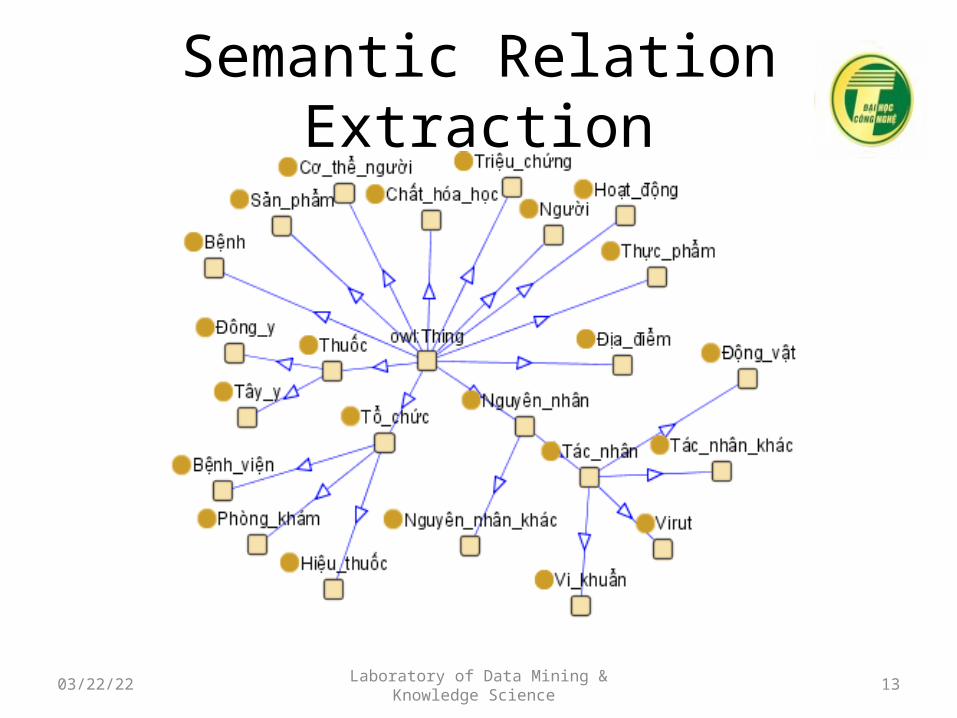
Semantic Relation Extraction
04/19/23 13Laboratory of Data Mining & Knowledge Science

Semantic Relation Extraction
• Object relation extraction – Product domain– Medical domain
• Technique– Using Wrapper technique for structured data
(HTML/XML/Table)– NLP for unstructured data (Text)
• HMM Model• CRF Model• …
04/19/23 14Laboratory of Data Mining & Knowledge Science

Semantic Relation Extraction• Cause-and-effect relations
Using the researching result by Corina Roxana Girju to investigated some cause-and-effect relations such as :• Adverbial causal link• Preposition causal link• Subordination causal link• Clause integrated link
[Rox08] Corina Roxana Girju (2008). Semantic Relation Extraction and its Applications, Invited tutorial at the European Summer School in Logic, Language and Information (ESSLLI 2008), Hamburg, Germany, August 2008.
04/19/23 15Laboratory of Data Mining & Knowledge Science

Semantic Relation Extraction• Vietnamese entity search engine on the field
of Medical Healthy Care– Using Medical Ontology, Object relation extraction,
Cause-and-effect relation extraction…– Associating UIUC-DB&IS Lab (University of Illinois at
Urbana-Champaign)• Object Search • Query Log Mining • Object Extraction
[Cha08] Kevin C. Chang (2008). Data-Aware Search on the Web, Act. 2: Entity Search, Technical Report, University of Illinois at Urbana-Charmpaign (a talking at College of Technology, Vietnam National University, Hanoi, July 08, 2008).
04/19/23 16Laboratory of Data Mining & Knowledge Science

Some articles in 2008[LNH08] Dieu-Thu Le, Cam-Tu Nguyen, Quang-Thuy Ha, Xuan-Hieu Phan, and Susumu
Horiguchi (2008). Matching and Ranking with Hidden Topics towards Online Contextual Advertising, The 2008 IEEE/WIC/ACM International Conference on Web Intelligence (WI-08), University of Technology, Sydney, Australia, December 9 - 12, 2008 (accepted)
[PNL08] Xuan-Hieu Phan, Cam-Tu Nguyen, Dieu-Thu Le, Le-Minh Nguyen, Susumu Horiguchi, and Quang-Thuy Ha (2008). Classification and Contextual Match on the Web with Hidden Topics from Large Data Collections, IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING (Submitted)
[VUH08] Tran Mai Vu, Pham Thi Thu Uyen, Hoang Minh Hien, Ha Quang Thuy (2008). Semantic Similarity of sentences and application for multi-document summarization to evalute on clustering component of Vietnamese search engine, Workshop on Information Communication Technology (ICTFIT08), College of Science, Vietnam National University, Ho Chi Minh City, November 14, 2008 (in Vietnamese, accepted).
04/19/23 17Laboratory of Data Mining & Knowledge Science

THANK YOU
04/19/23 18Laboratory of Data Mining & Knowledge Science





























