Embed Size (px)
Citation preview

1. Attention in RNN
3. Transformer
2. Multi-head self-attention
Introduction of Attention and Transformer
Aprial 23, 2020
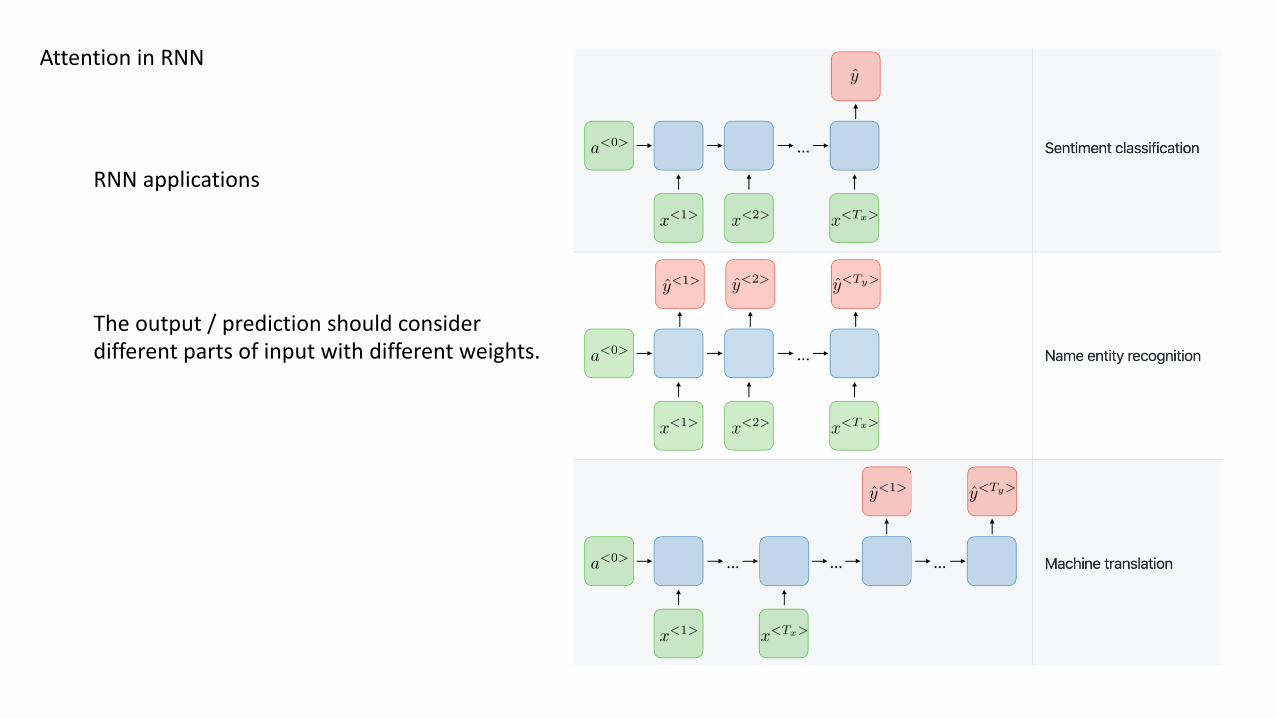
Attention in RNN
RNN applications
The output / prediction should consider different parts of input with different weights.
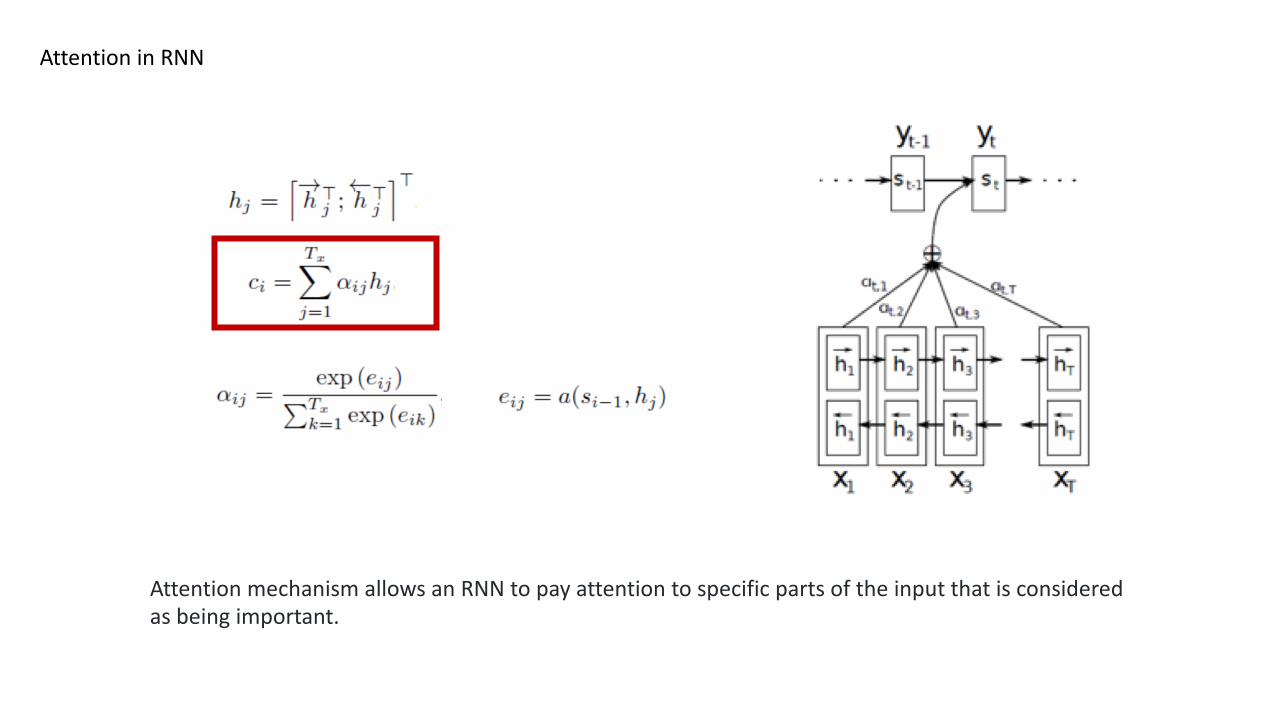
Attention in RNN
Attention mechanism allows an RNN to pay attention to specific parts of the input that is considered as being important.
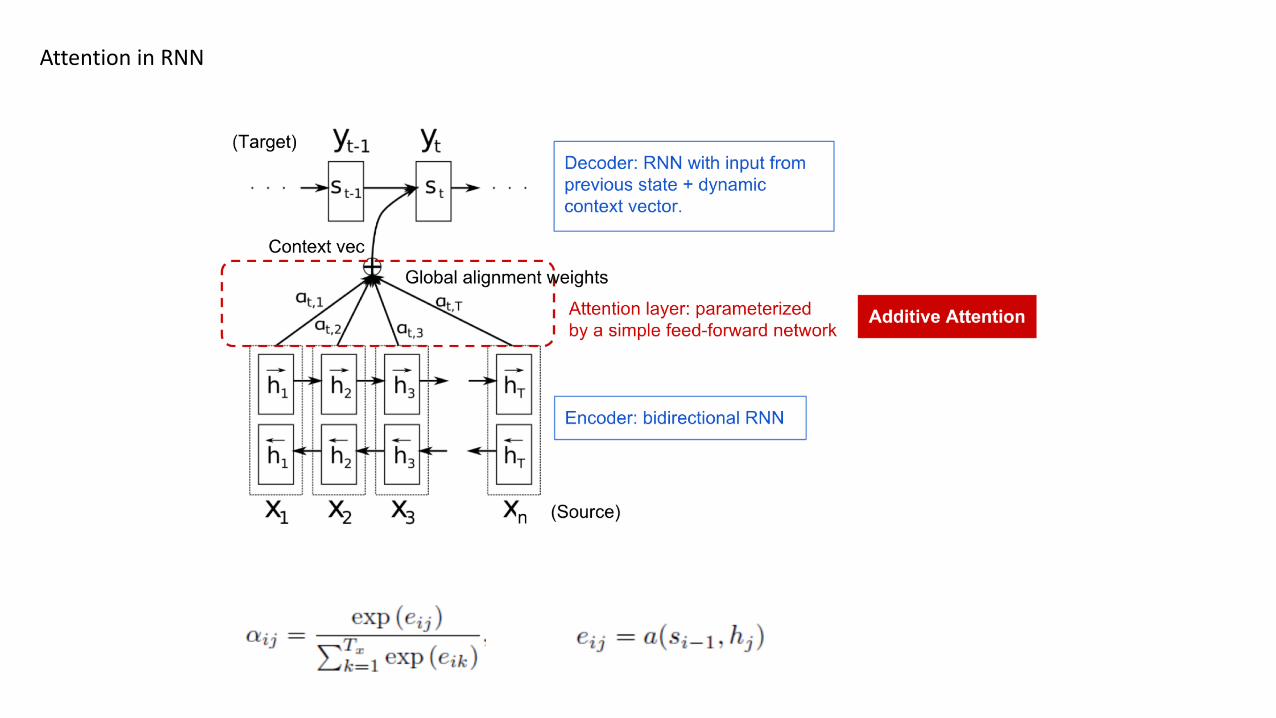
Attention in RNN

Attention in RNN

The major component in the transformer is the unit of multi-head self-attentionmechanism.
The transformer views the encoded representation of the input as a set of key-value pairs, (K,V),both of dimension n (input sequence length); in the context of NMT, both the keys and values arethe encoder hidden states
In the decoder, the previous output is compressed into a query (Q of dimension m) and the nextoutput is produced by mapping this query and the set of keys and values.
2. Multi-head self-attention
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. "Attention is all you need." In Advances in neural information processing systems, pp. 5998-6008. 2017.
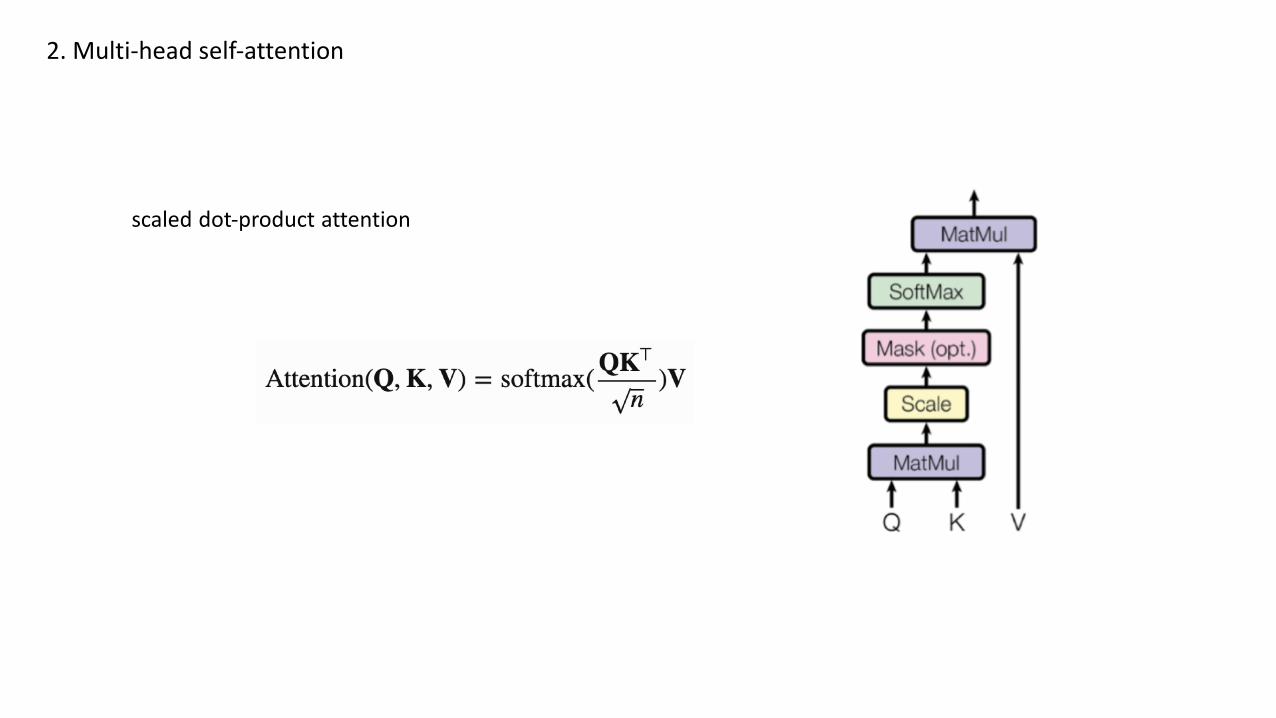
scaled dot-product attention
2. Multi-head self-attention
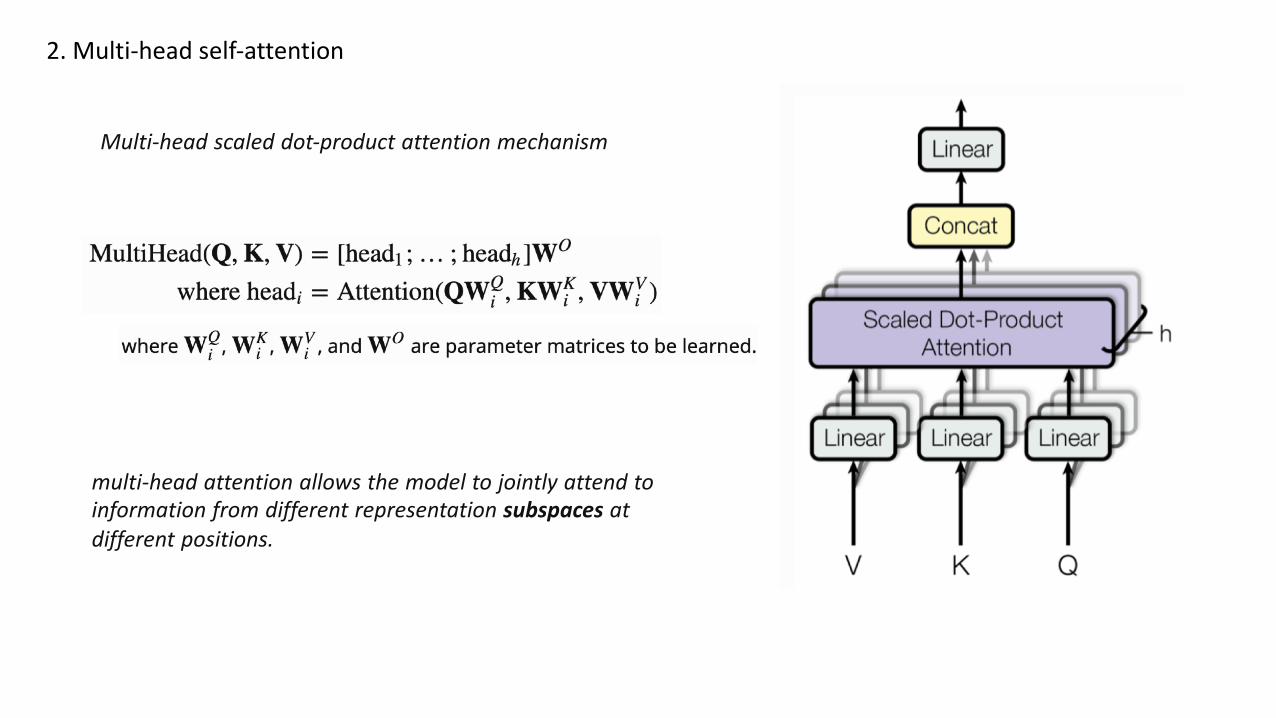
Multi-head scaled dot-product attention mechanism
multi-head attention allows the model to jointly attend toinformation from different representation subspaces atdifferent positions.
2. Multi-head self-attention
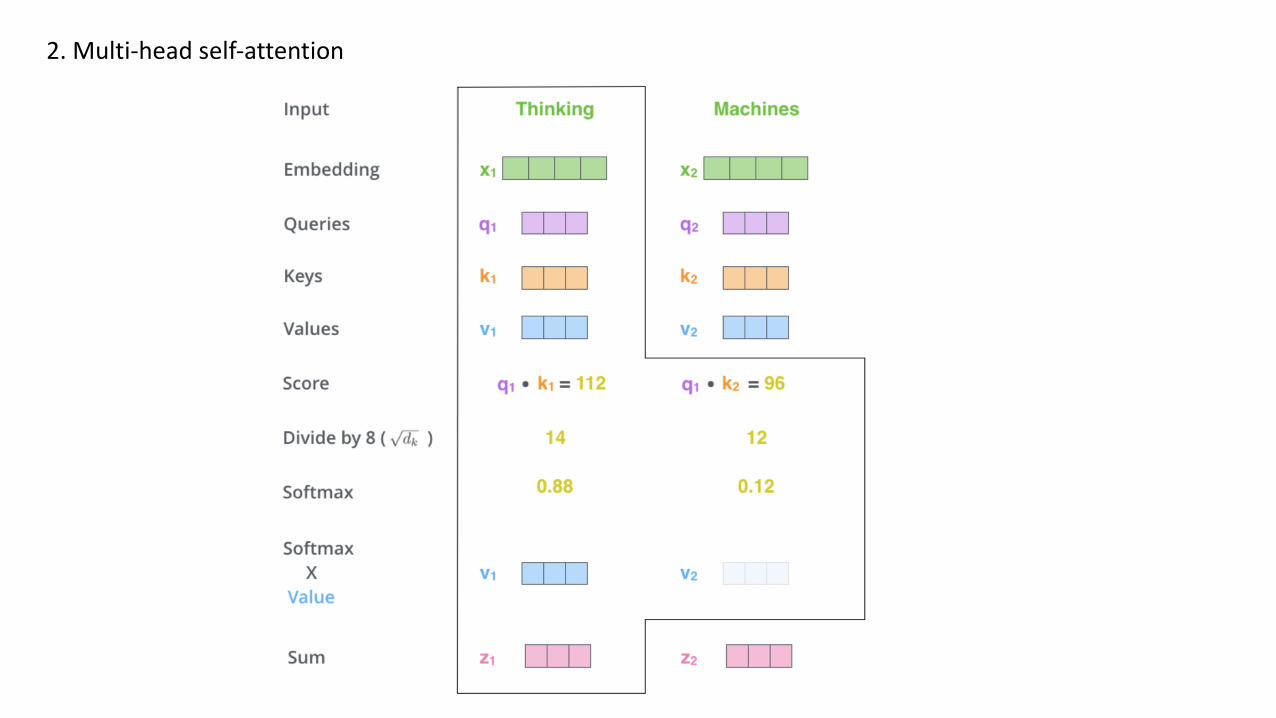
2. Multi-head self-attention
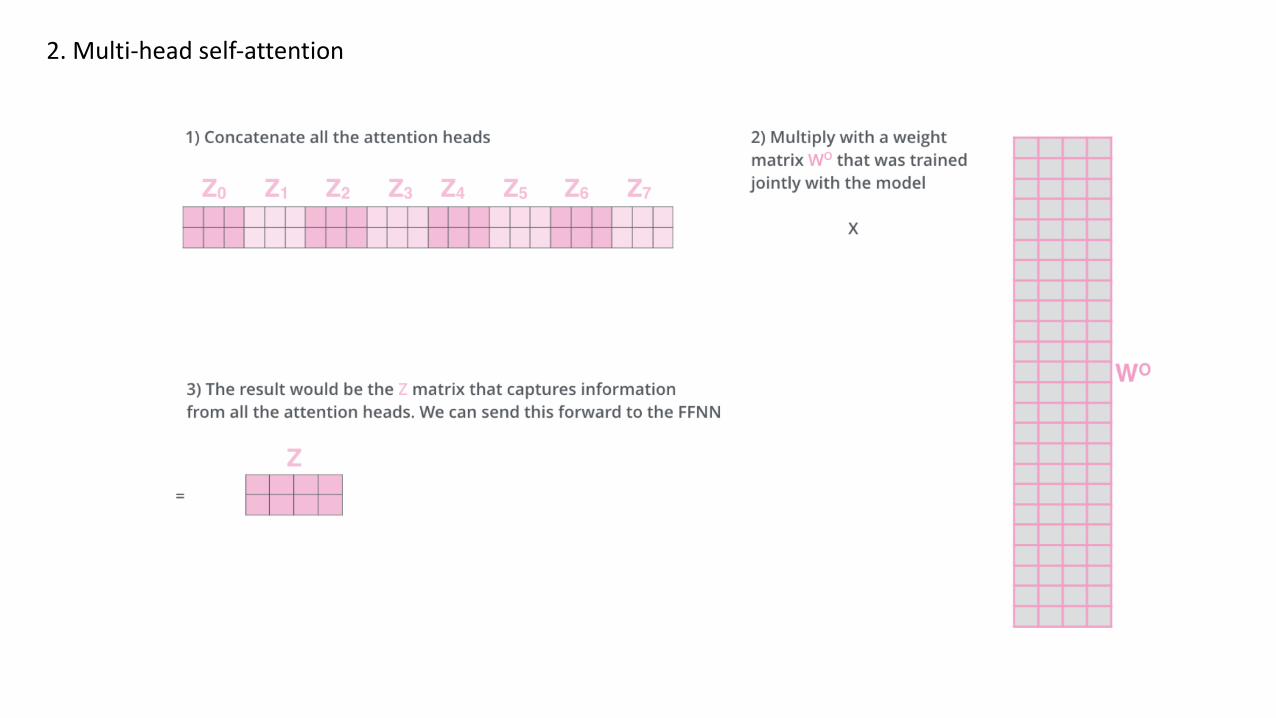
2. Multi-head self-attention
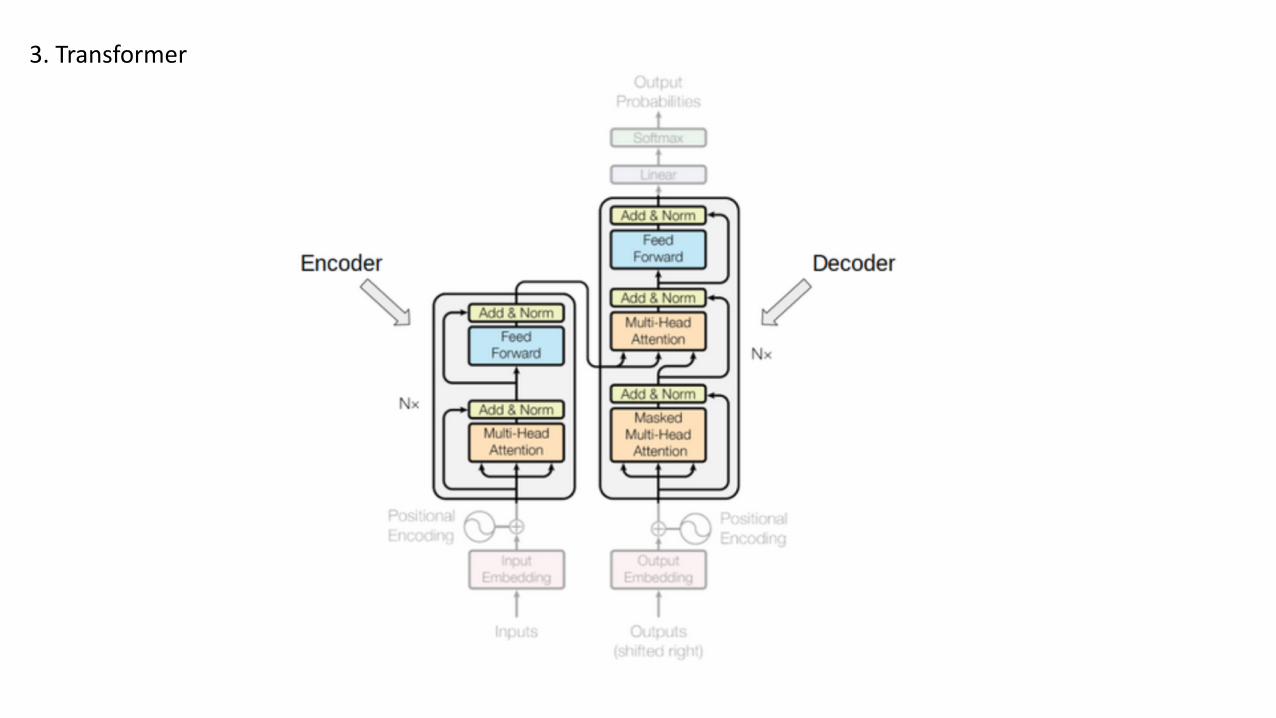
3. Transformer

The encoder generates an attention-based representation with capability to locate a specific piece ofinformation from a potentially infinitely-large context.
• A stack of N=6 identical layers.• Each layer has a multi-head self-attention layer and a simple position-wise fully connected feed-
forward network.• Each sub-layer adopts a residual connection and a layer normalization. All the sub-layers output data
of the same dimension (512).
3. Transformer
Encoder
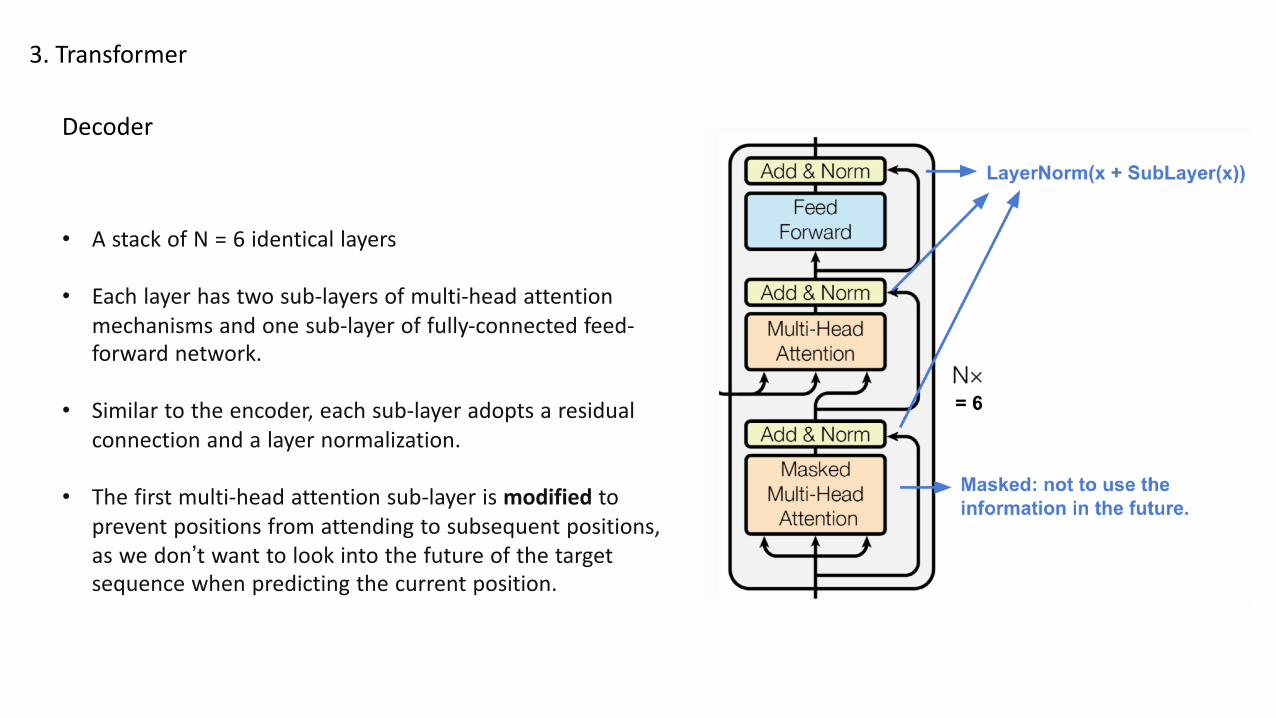
• A stack of N = 6 identical layers
• Each layer has two sub-layers of multi-head attentionmechanisms and one sub-layer of fully-connected feed-forward network.
• Similar to the encoder, each sub-layer adopts a residualconnection and a layer normalization.
• The first multi-head attention sub-layer is modified toprevent positions from attending to subsequent positions,as we don’t want to look into the future of the targetsequence when predicting the current position.
Decoder
3. Transformer
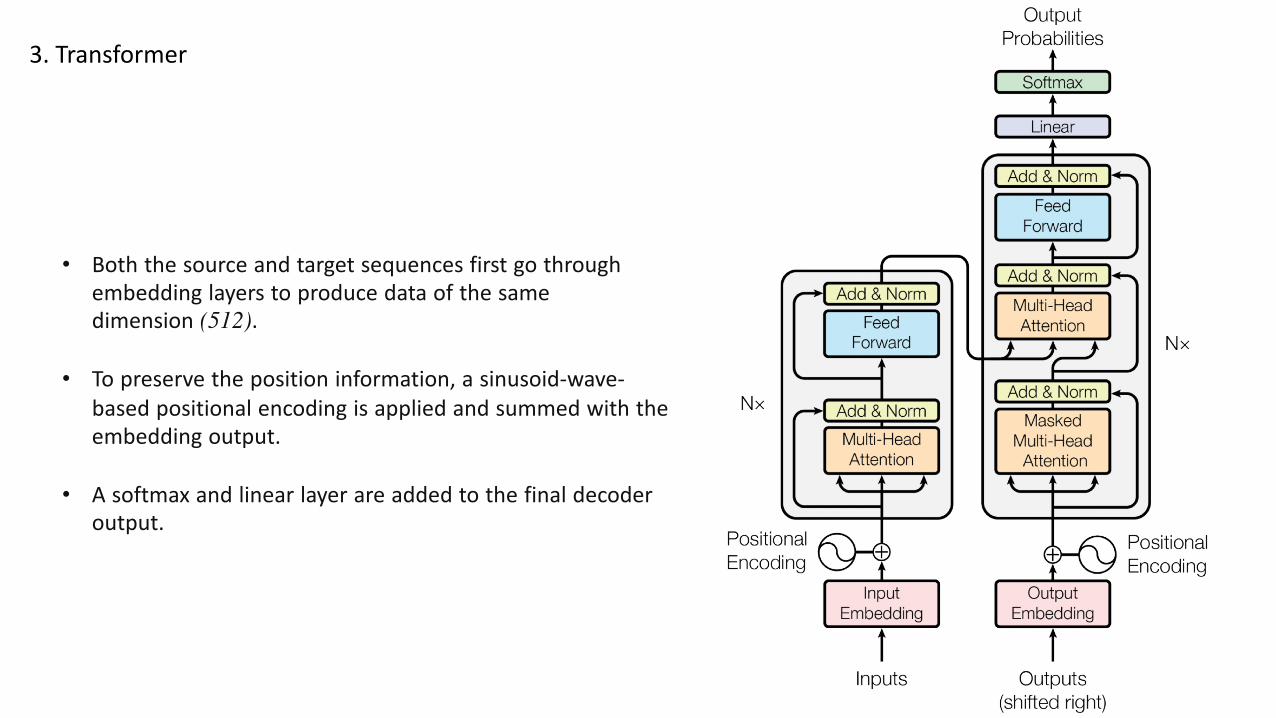
• Both the source and target sequences first go throughembedding layers to produce data of the samedimension (512).
• To preserve the position information, a sinusoid-wave-based positional encoding is applied and summed with theembedding output.
• A softmax and linear layer are added to the final decoderoutput.
3. Transformer

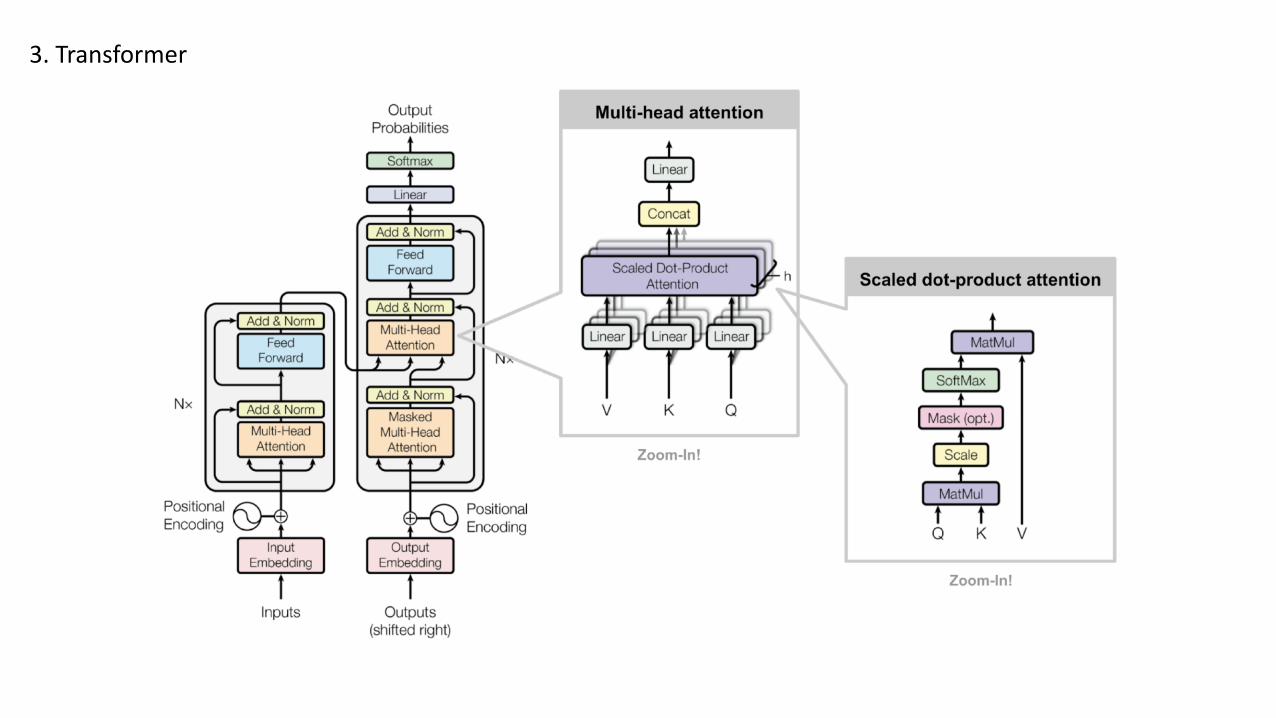
The Transformer uses multi-head attention in three different ways:
• In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models.
• The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
• Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
3. Transformer
3. Transformer

Reference:
Recurrent Neural Networks cheatsheethttps://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
A Comprehensive Guide to Attention Mechanism in Deep Learning for Everyonehttps://www.analyticsvidhya.com/blog/2019/11/comprehensive-guide-attention-mechanism-deep-learning/
Attention Is All You Need, NIPS 2017.
The Illustrated Transformerhttp://jalammar.github.io/illustrated-transformer/
Attention? Attention!https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html





























