Embed Size (px)
Citation preview

EECC722 - ShaabanEECC722 - Shaaban#1 Lec # 2 Fall 2003 9-10-2003
Simultaneous Multithreading (SMT)Simultaneous Multithreading (SMT)• An evolutionary processor architecture originally
introduced in 1995 by Dean Tullsen at the Universityof Washington that aims at reducing resource waste inwide issue processors.
• SMT has the potential of greatly enhancingsuperscalar processor computational capabilities by:
– Exploiting thread-level parallelism (TLP), simultaneouslyissuing, executing and retiring instructions from differentthreads during the same cycle.
– Providing multiple hardware contexts, hardware threadscheduling and context switching capability.
– Providing effective long latency hiding.

EECC722 - ShaabanEECC722 - Shaaban#2 Lec # 2 Fall 2003 9-10-2003
SMT IssuesSMT Issues• SMT CPU performance gain potential.
• Modifications to Superscalar CPU architecture necessary to support SMT.
• SMT performance evaluation vs. Fine-grain multithreading, Superscalar,Chip Multiprocessors.
• Hardware techniques to improve SMT performance:
– Optimal level one cache configuration for SMT.
– SMT thread instruction fetch, issue policies.
– Instruction recycling (reuse) of decoded instructions.
• Software techniques:
– Compiler optimizations for SMT.
– Software-directed register deallocation.
– Operating system behavior and optimization.
• SMT support for fine-grain synchronization.
• SMT as a viable architecture for network processors.
• Current SMT implementation: Intel’s Hyper-Threading (2-way SMT)Microarchitecture and performance in compute-intensive workloads.
EECC722 - ShaabanEECC722 - Shaaban#3 Lec # 2 Fall 2003 9-10-2003
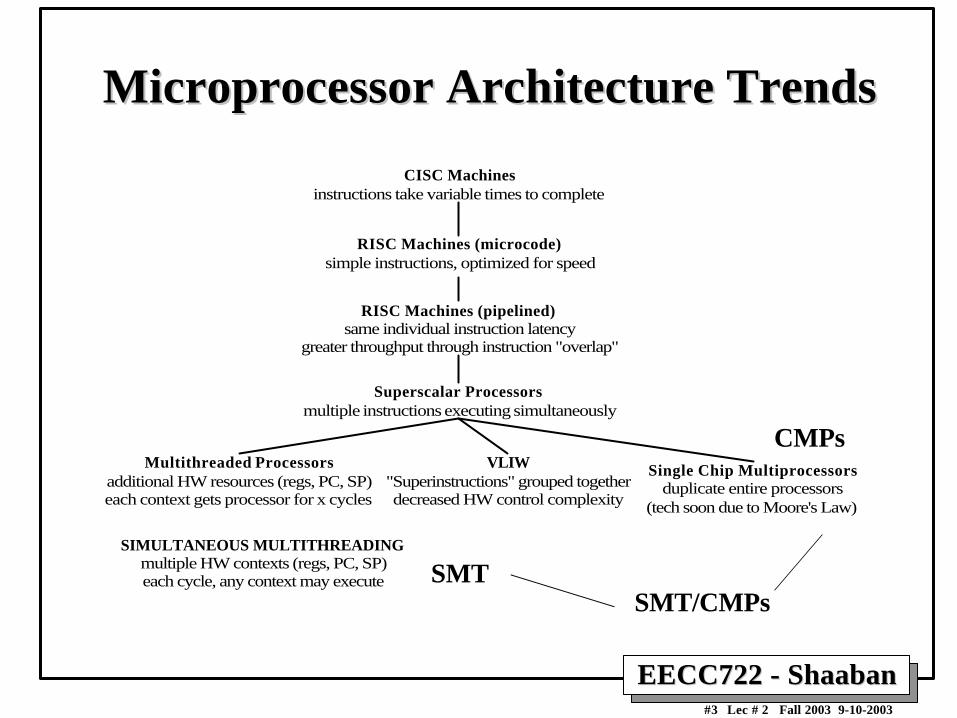
Microprocessor Architecture TrendsMicroprocessor Architecture Trends
CISC Machinesinstructions take variable times to complete
RISC Machines (microcode)simple instructions, optimized for speed
RISC Machines (pipelined)same individual instruction latency
greater throughput through instruction "overlap"
Superscalar Processorsmultiple instructions executing simultaneously
Multithreaded Processorsadditional HW resources (regs, PC, SP)each context gets processor for x cycles
VLIW"Superinstructions" grouped togetherdecreased HW control complexity
Single Chip Multiprocessorsduplicate entire processors
(tech soon due to Moore's Law)
SIMULTANEOUS MULTITHREADINGmultiple HW contexts (regs, PC, SP)each cycle, any context may execute
CMPs
SMTSMT/CMPs
EECC722 - ShaabanEECC722 - Shaaban#4 Lec # 2 Fall 2003 9-10-2003
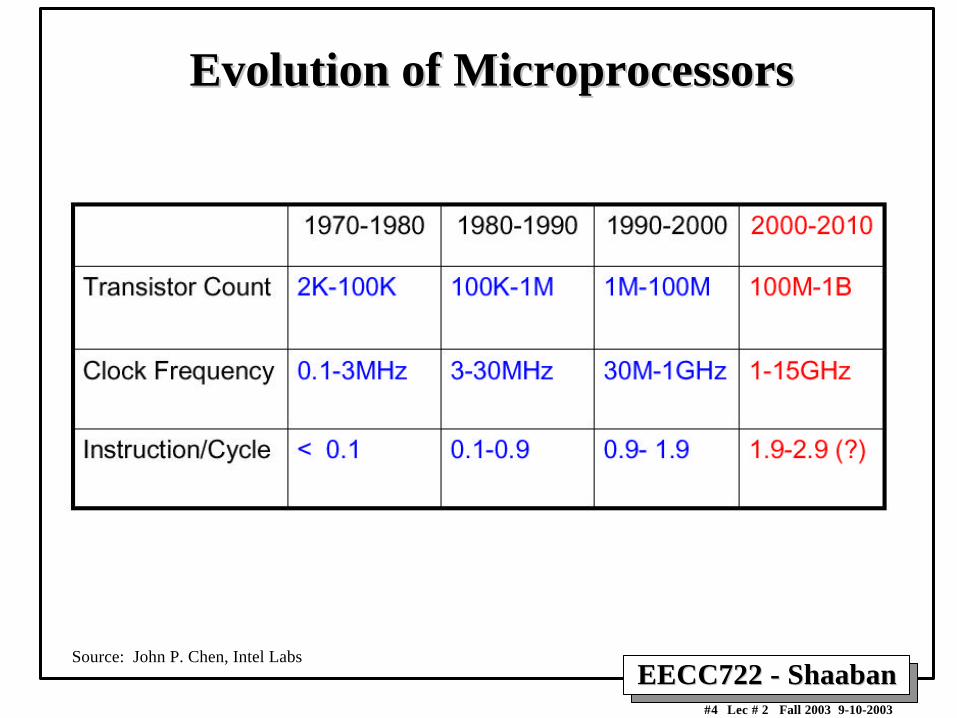
Evolution of MicroprocessorsEvolution of Microprocessors
Source: John P. Chen, Intel Labs
EECC722 - ShaabanEECC722 - Shaaban#5 Lec # 2 Fall 2003 9-10-2003
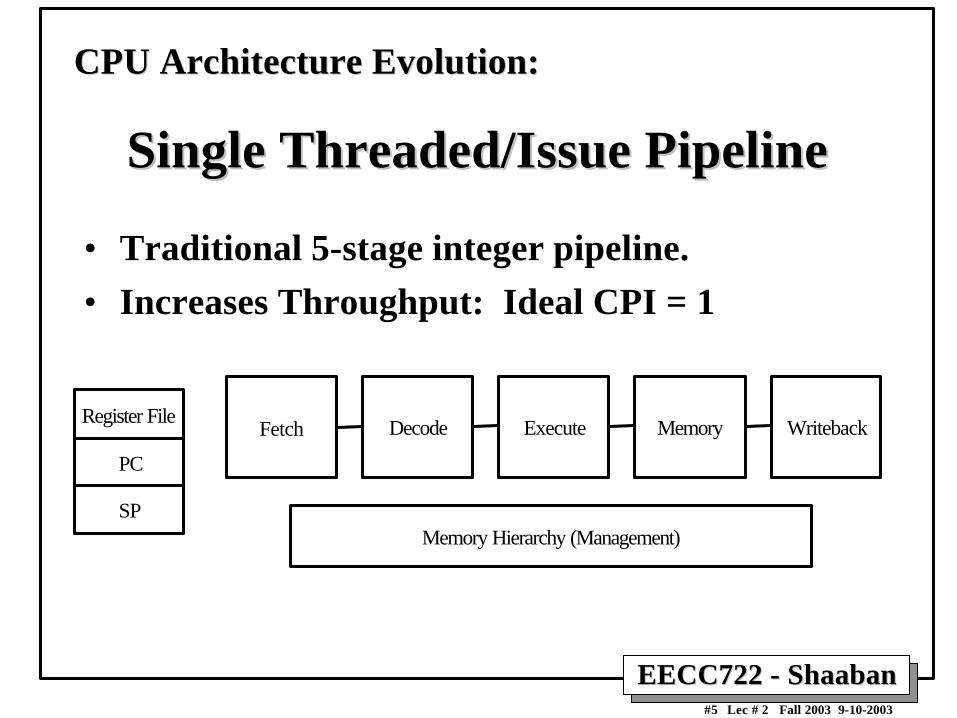
CPU Architecture Evolution:CPU Architecture Evolution:
Single Threaded/Issue PipelineSingle Threaded/Issue Pipeline
• Traditional 5-stage integer pipeline.
• Increases Throughput: Ideal CPI = 1
Fetch MemoryExecuteDecode Writeback
Memory Hierarchy (Management)
Register File
PC
SP
EECC722 - ShaabanEECC722 - Shaaban#6 Lec # 2 Fall 2003 9-10-2003
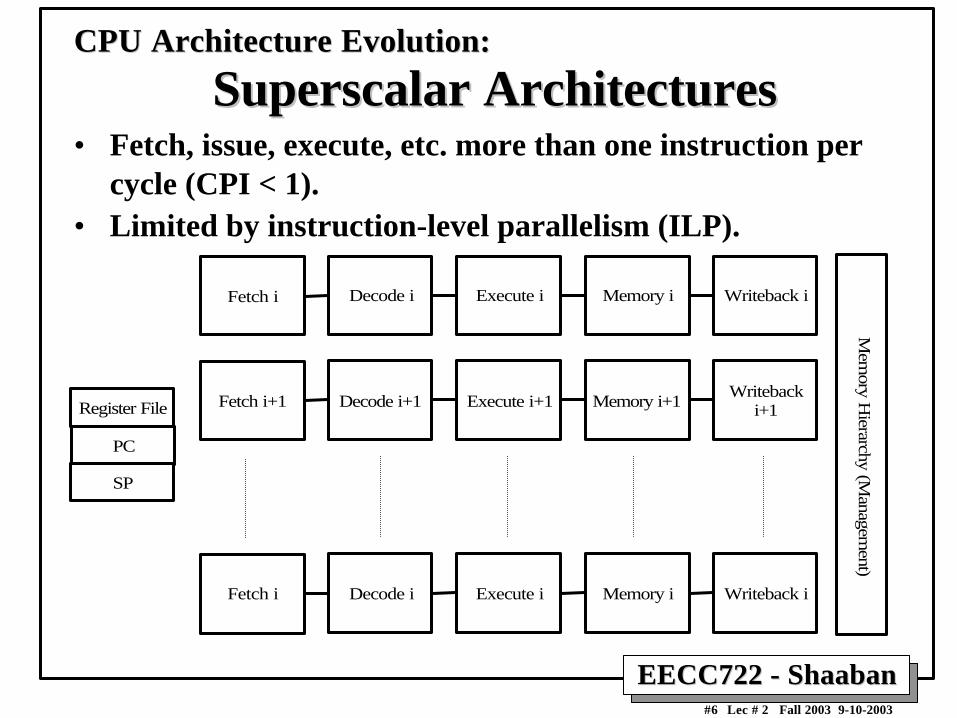
Fetch i Memory iExecute iDecode i Writeback i
Register File
PC
SP
Fetch i+1 Memory i+1Execute i+1Decode i+1Writeback
i+1
Mem
ory Hierarchy (M
anagement)
Fetch i Memory iExecute iDecode i Writeback i
CPU Architecture Evolution:CPU Architecture Evolution:
Superscalar ArchitecturesSuperscalar Architectures• Fetch, issue, execute, etc. more than one instruction per
cycle (CPI < 1).• Limited by instruction-level parallelism (ILP).
EECC722 - ShaabanEECC722 - Shaaban#7 Lec # 2 Fall 2003 9-10-2003
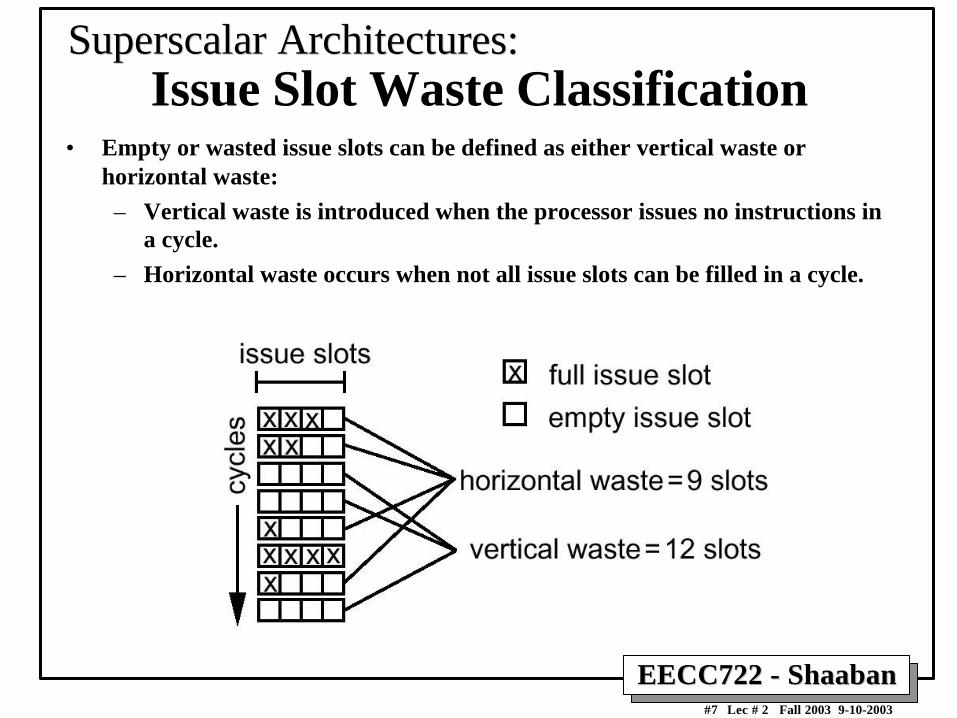
• Empty or wasted issue slots can be defined as either vertical waste orhorizontal waste:
– Vertical waste is introduced when the processor issues no instructions ina cycle.
– Horizontal waste occurs when not all issue slots can be filled in a cycle.
SuperscalarSuperscalar Architectures: Architectures:Issue Slot Waste Classification
EECC722 - ShaabanEECC722 - Shaaban#8 Lec # 2 Fall 2003 9-10-2003
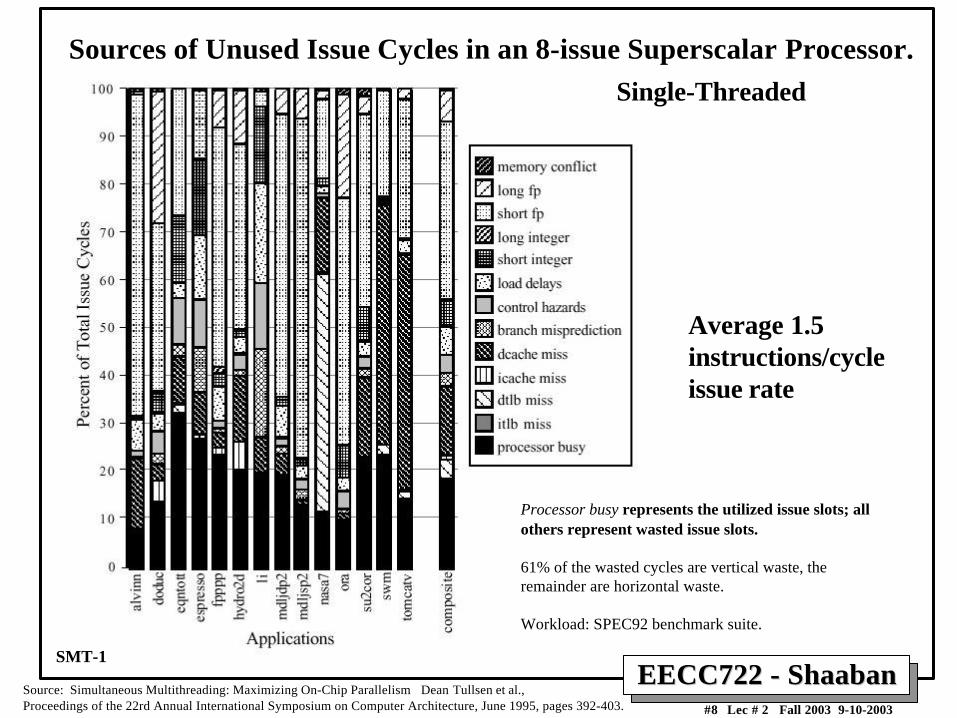
Sources of Unused Issue Cycles in an 8-issue Superscalar Processor.
Processor busy represents the utilized issue slots; allothers represent wasted issue slots.
61% of the wasted cycles are vertical waste, theremainder are horizontal waste.
Workload: SPEC92 benchmark suite.
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1
Average 1.5instructions/cycleissue rate
Single-Threaded
EECC722 - ShaabanEECC722 - Shaaban#9 Lec # 2 Fall 2003 9-10-2003
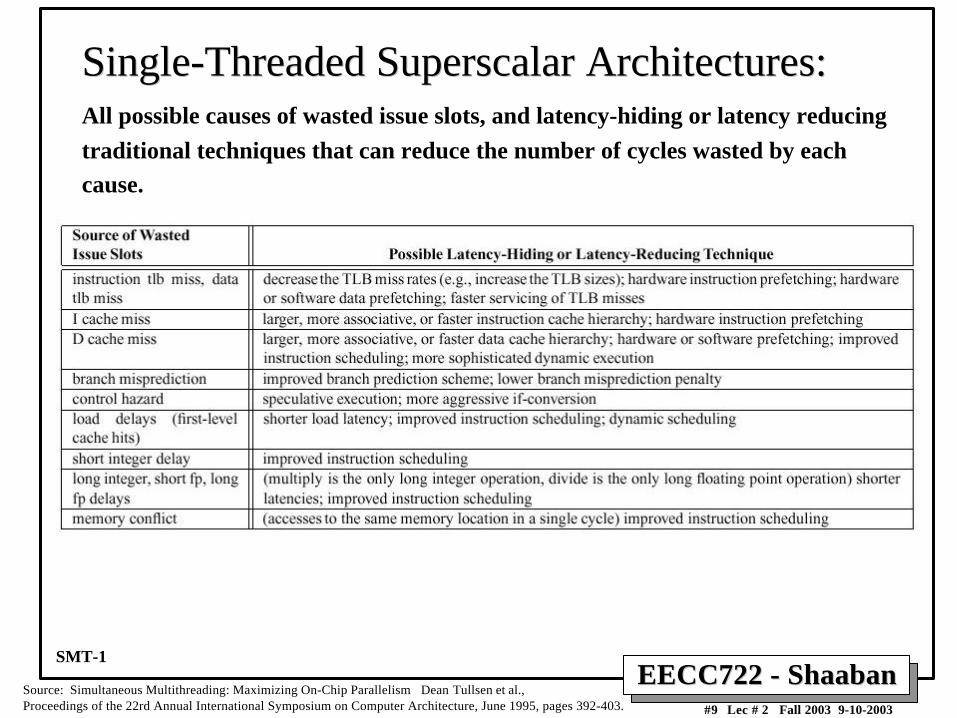
Single-ThreadedSingle-Threaded Superscalar Superscalar Architectures: Architectures:All possible causes of wasted issue slots, and latency-hiding or latency reducing
traditional techniques that can reduce the number of cycles wasted by each
cause.
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1

EECC722 - ShaabanEECC722 - Shaaban#10 Lec # 2 Fall 2003 9-10-2003
Fine-grain or TraditionalFine-grain or TraditionalMultithreaded ProcessorsMultithreaded Processors
• Multiple HW contexts (PC, SP, and registers).
• Only one context or thread issues instructionseach cycle.
• Performance limited by Instruction-LevelParallelism (ILP) within each individual thread:– Can reduce some of the vertical issue slot waste.
– No reduction in horizontal issue slot waste.
• Example Architecture: The Tera Computer System
Advanced CPU Architectures:Advanced CPU Architectures:

EECC722 - ShaabanEECC722 - Shaaban#11 Lec # 2 Fall 2003 9-10-2003
Fine-grain or Traditional Multithreaded ProcessorsFine-grain or Traditional Multithreaded Processors
The Tera Computer System• The Tera computer system is a shared memory multiprocessor
that can accommodate up to 256 processors.
• Each Tera processor is fine-grain multithreaded:
– Each processor can issue one 3-operation Long Instruction Word (LIW)every 3 ns cycle (333MHz) from among as many as 128 distinct instructionstreams (hardware threads), thereby hiding up to 128 cycles (384 ns) ofmemory latency.
– In addition, each stream can issue as many as eight memory referenceswithout waiting for earlier ones to finish, further augmenting the memorylatency tolerance of the processor.
– A stream implements a load/store architecture with three addressingmodes and 31 general-purpose 64-bit registers.
– The instructions are 64 bits wide and can contain three operations: amemory reference operation (M-unit operation or simply M-op for short),an arithmetic or logical operation (A-op), and a branch or simplearithmetic or logical operation (C-op).
Source: http://www.cscs.westminster.ac.uk/~seamang/PAR/tera_overview.html

EECC722 - ShaabanEECC722 - Shaaban#12 Lec # 2 Fall 2003 9-10-2003
VLIW: Intel/HPVLIW: Intel/HP IA-64
Explicitly Parallel Instruction ComputingExplicitly Parallel Instruction Computing(EPIC)(EPIC)
• Strengths:– Allows for a high level of instruction parallelism (ILP).
– Takes a lot of the dependency analysis out of HW and placesfocus on smart compilers.
• Weakness:– Limited by instruction-level parallelism (ILP) in a single thread.
– Keeping Functional Units (FUs) busy (control hazards).
– Static FUs Scheduling limits performance gains.
– Resulting overall performance heavily depends on compilerperformance.
Advanced CPU Architectures:Advanced CPU Architectures:

EECC722 - ShaabanEECC722 - Shaaban#13 Lec # 2 Fall 2003 9-10-2003
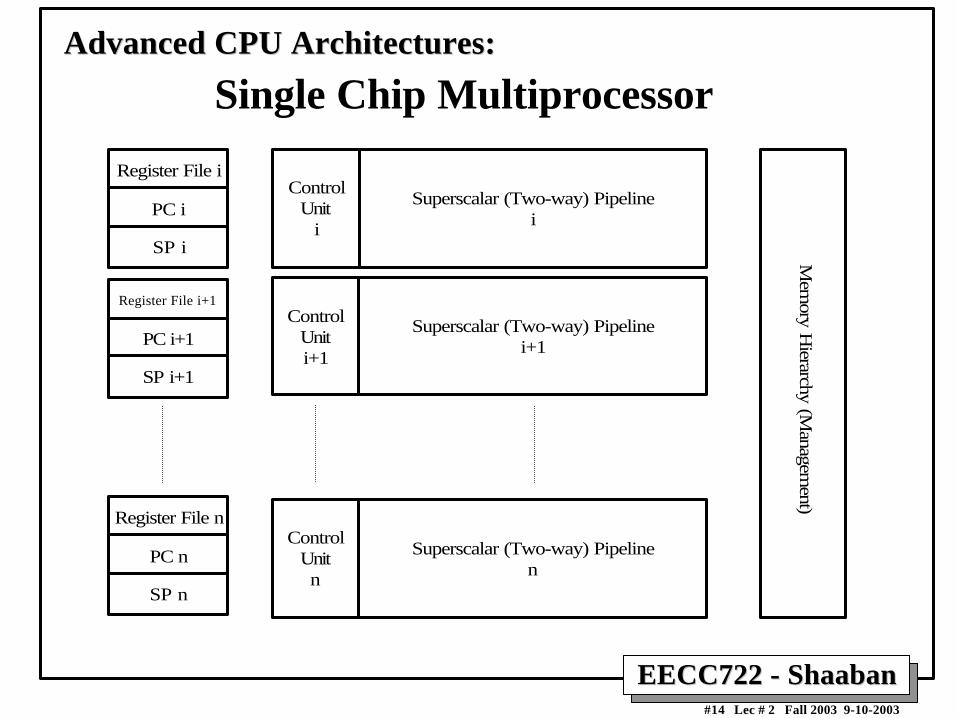
Single Chip MultiprocessorSingle Chip Multiprocessor• Strengths:
– Create a single processor block and duplicate.
– Exploits Thread-Level Parallelism.
– Takes a lot of the dependency analysis out of HW andplaces focus on smart compilers.
• Weakness:– Performance within each processor still limited by
individual thread performance (ILP).
– High power requirements using current VLSI processes.
Advanced CPU Architectures:Advanced CPU Architectures:
EECC722 - ShaabanEECC722 - Shaaban#14 Lec # 2 Fall 2003 9-10-2003
Advanced CPU Architectures:Advanced CPU Architectures:
Register File i
PC i
SP i
Register File i+1
PC i+1
SP i+1
Register File n
PC n
SP n
Superscalar (Two-way) Pipelinei
Superscalar (Two-way) Pipelinei+1
Superscalar (Two-way) Pipelinen
Mem
ory Hierarchy (M
anagement)
ControlUnit
i
ControlUniti+1
ControlUnitn
Single Chip Multiprocessor

EECC722 - ShaabanEECC722 - Shaaban#15 Lec # 2 Fall 2003 9-10-2003
SMT: Simultaneous Multithreading• Multiple Hardware Contexts running at the same time (HW
context: registers, PC, and SP etc.).
• Reduces both horizontal and vertical waste by having multiplethreads keeping functional units busy during every cycle.
• Builds on top of current time-proven advancements in CPUdesign: superscalar, dynamic scheduling, hardwarespeculation, dynamic HW branch prediction, multiple levels ofcache, hardware pre-fetching etc.
• Enabling Technology: VLSI logic density in the order ofhundreds of millions of transistors/Chip.
– Potential performance gain is much greater than theincrease in chip area and power consumption needed tosupport SMT.

EECC722 - ShaabanEECC722 - Shaaban#16 Lec # 2 Fall 2003 9-10-2003
SMT• With multiple threads running penalties from long-latency
operations, cache misses, and branch mispredictions will behidden:– Reduction of both horizontal and vertical waste and thus
improved Instructions Issued Per Cycle (IPC) rate.
• Functional units are shared among all contexts during everycycle:
– More complicated register read and writeback stages.
• More threads issuing to functional units results in higherresource utilization.
• CPU resources may have to resized to accommodate theadditional demands of the multiple threads running.– (e.g cache, TLBs, branch prediction tables, rename registers)
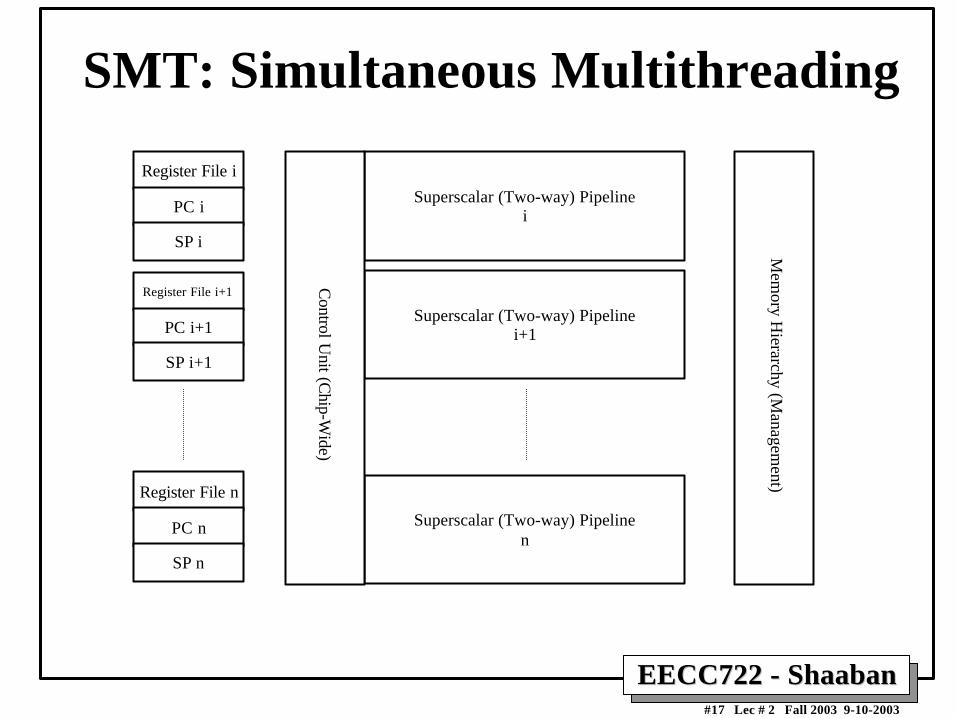
EECC722 - ShaabanEECC722 - Shaaban#17 Lec # 2 Fall 2003 9-10-2003
SMT: Simultaneous Multithreading
Register File i
PC i
SP i
Register File i+1
PC i+1
SP i+1
Register File n
PC n
SP n
Superscalar (Two-way) Pipelinei
Superscalar (Two-way) Pipelinei+1
Superscalar (Two-way) Pipelinen
Mem
ory Hierarchy (M
anagement)
Control U
nit (Chip-W
ide)

EECC722 - ShaabanEECC722 - Shaaban#18 Lec # 2 Fall 2003 9-10-2003
The Power Of SMTThe Power Of SMT1 1
1
1 1 1 1
1 1
1
1 1
2 2
3 3
4
5 5
1 1 1 1
2 2 2
3
4 4 4
1 1 2
2 2 3
3 3 4 5
2 2 4
4 5
1 1 1 1
2 2 3
1 2 4
1 2 5
Tim
e (p
roce
ssor
cyc
les)
Superscalar Traditional Multithreaded
Simultaneous Multithreading
Rows of squares represent instruction issue slotsBox with number x: instruction issued from thread xEmpty box: slot is wasted
EECC722 - ShaabanEECC722 - Shaaban#19 Lec # 2 Fall 2003 9-10-2003
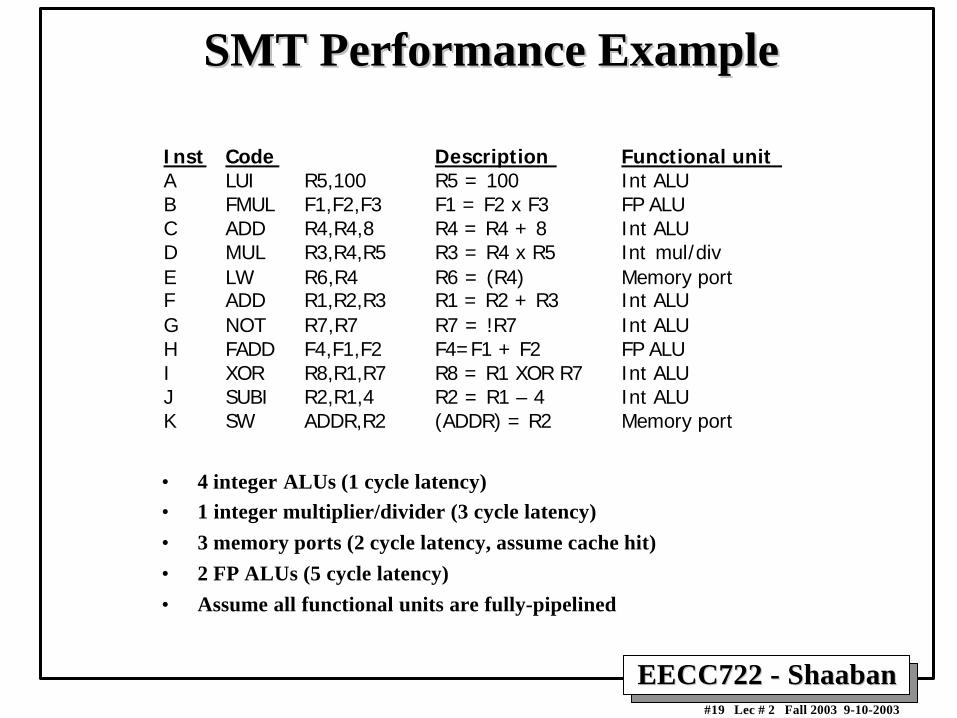
SMT Performance ExampleSMT Performance Example
Inst Code Description Functional unitA LUI R5,100 R5 = 100 Int ALUB FMUL F1,F2,F3 F1 = F2 x F3 FP ALUC ADD R4,R4,8 R4 = R4 + 8 Int ALUD MUL R3,R4,R5 R3 = R4 x R5 Int mul/divE LW R6,R4 R6 = (R4) Memory portF ADD R1,R2,R3 R1 = R2 + R3 Int ALUG NOT R7,R7 R7 = !R7 Int ALUH FADD F4,F1,F2 F4=F1 + F2 FP ALUI XOR R8,R1,R7 R8 = R1 XOR R7 Int ALUJ SUBI R2,R1,4 R2 = R1 – 4 Int ALUK SW ADDR,R2 (ADDR) = R2 Memory port
• 4 integer ALUs (1 cycle latency)
• 1 integer multiplier/divider (3 cycle latency)
• 3 memory ports (2 cycle latency, assume cache hit)
• 2 FP ALUs (5 cycle latency)
• Assume all functional units are fully-pipelined
EECC722 - ShaabanEECC722 - Shaaban#20 Lec # 2 Fall 2003 9-10-2003
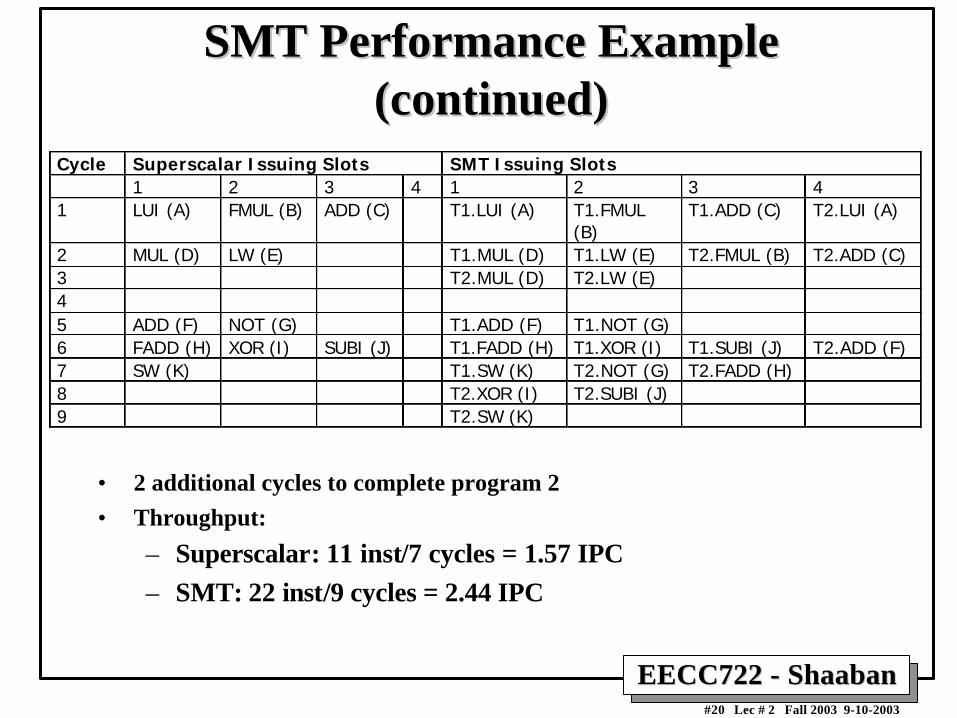
SMT Performance ExampleSMT Performance Example(continued)(continued)
Cycle Superscalar Issuing Slots SMT Issuing Slots1 2 3 4 1 2 3 4
1 LUI (A) FMUL (B) ADD (C) T1.LUI (A) T1.FMUL(B)
T1.ADD (C) T2.LUI (A)
2 MUL (D) LW (E) T1.MUL (D) T1.LW (E) T2.FMUL (B) T2.ADD (C)3 T2.MUL (D) T2.LW (E)45 ADD (F) NOT (G) T1.ADD (F) T1.NOT (G)6 FADD (H) XOR (I) SUBI (J) T1.FADD (H) T1.XOR (I) T1.SUBI (J) T2.ADD (F)7 SW (K) T1.SW (K) T2.NOT (G) T2.FADD (H)8 T2.XOR (I) T2.SUBI (J)9 T2.SW (K)
• 2 additional cycles to complete program 2
• Throughput:
– Superscalar: 11 inst/7 cycles = 1.57 IPC
– SMT: 22 inst/9 cycles = 2.44 IPC

EECC722 - ShaabanEECC722 - Shaaban#21 Lec # 2 Fall 2003 9-10-2003
Modifications toModifications to Superscalar Superscalar CPUs CPUsNecessary to support SMTNecessary to support SMT
• Multiple program counters and some mechanism by which one fetch unitselects one each cycle (thread instruction fetch policy).
• A separate return stack for each thread for predicting subroutine returndestinations.
• Per-thread instruction retirement, instruction queue flush, and trapmechanisms.
• A thread id with each branch target buffer entry to avoid predicting phantombranches.
• A larger register file, to support logical registers for all threads plus additionalregisters for register renaming. (may require additional pipeline stages).
• A higher available main memory fetch bandwidth may be required.
• Larger data TLB with more entries to compensate for increased virtual tophysical address translations.
• Improved cache to offset the cache performance degradation due to cachesharing among the threads and the resulting reduced locality.
– e.g Private per-thread vs. shared L1 cache.Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2

EECC722 - ShaabanEECC722 - Shaaban#22 Lec # 2 Fall 2003 9-10-2003
Current Implementations of SMTCurrent Implementations of SMT• Intel’s recent implementation of Hyper-Threading
Technology (2-thread SMT) in its current P4 Xeonprocessor family represent the first and only currentimplementation of SMT in a commercialmicroprocessor.
• The Alpha EV8 (4-thread SMT) originallyscheduled for production in 2001 is currently onindefinite hold :(
• Current technology has the potential for 4-8simultaneous threads:
– Based on transistor count and design complexity.
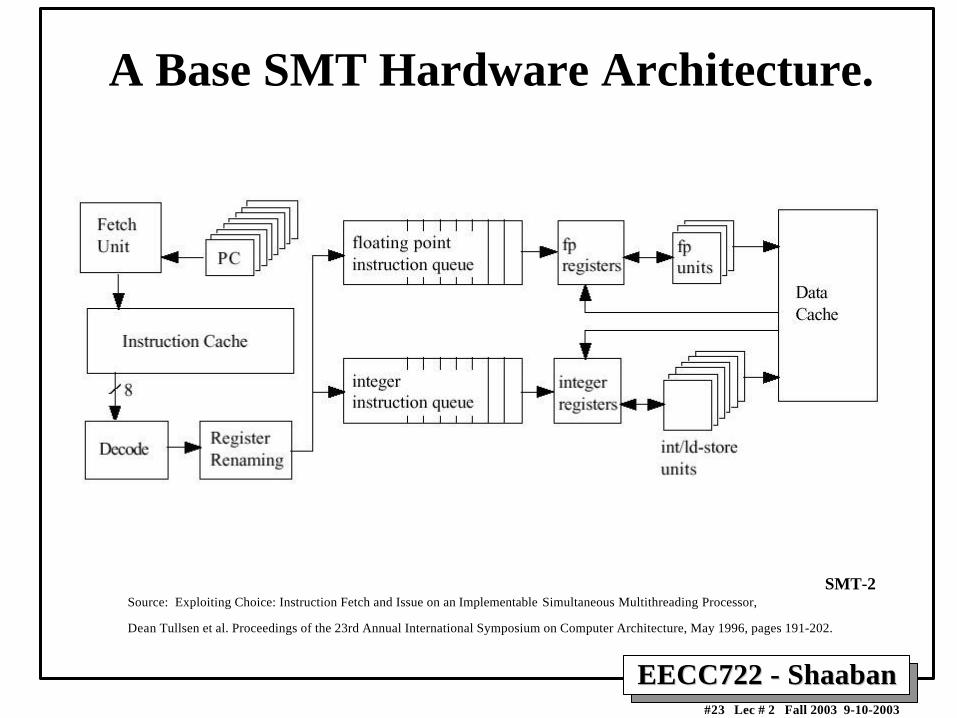
EECC722 - ShaabanEECC722 - Shaaban#23 Lec # 2 Fall 2003 9-10-2003
A Base SMT Hardware Architecture.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,
Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2
EECC722 - ShaabanEECC722 - Shaaban#24 Lec # 2 Fall 2003 9-10-2003
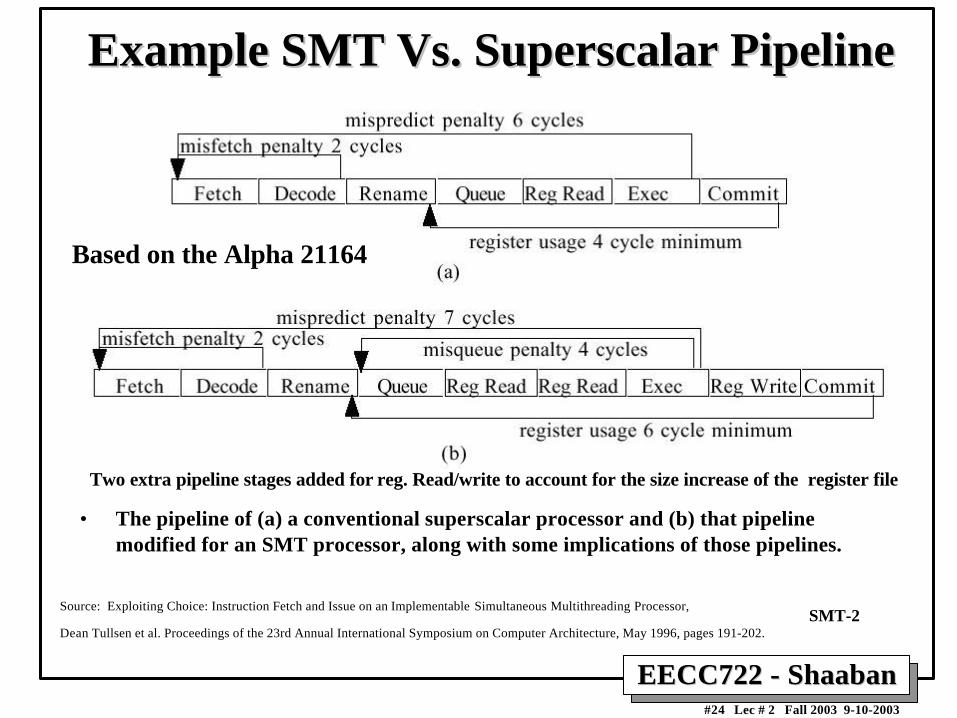
Example SMT Vs. Example SMT Vs. Superscalar Superscalar PipelinePipeline
• The pipeline of (a) a conventional superscalar processor and (b) that pipelinemodified for an SMT processor, along with some implications of those pipelines.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,
Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
Based on the Alpha 21164
SMT-2
Two extra pipeline stages added for reg. Read/write to account for the size increase of the register file
EECC722 - ShaabanEECC722 - Shaaban#25 Lec # 2 Fall 2003 9-10-2003
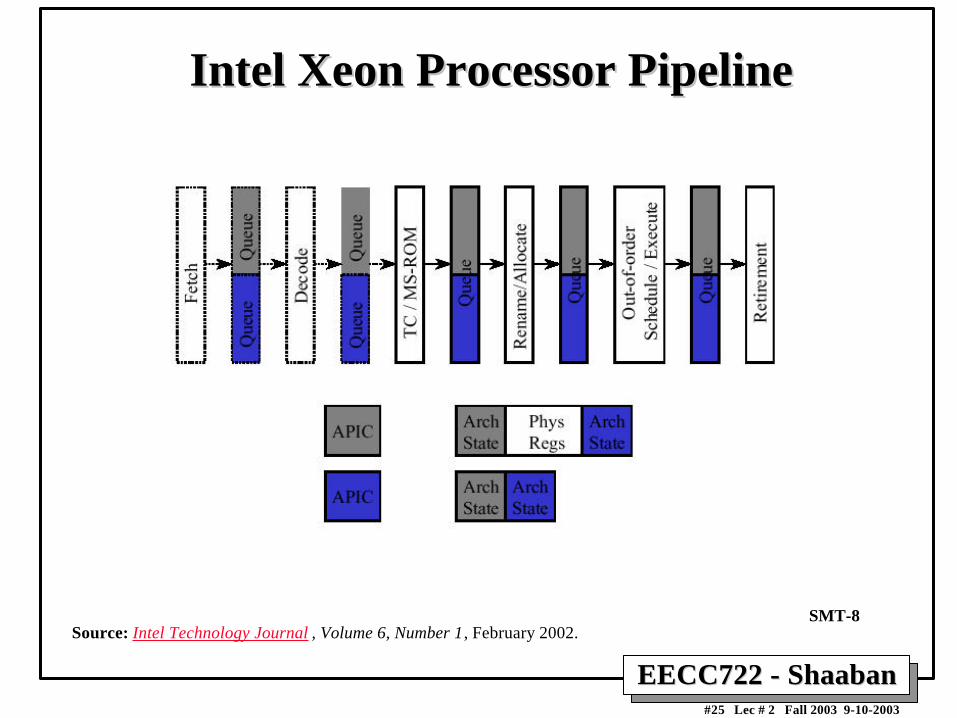
Intel Intel Xeon Xeon Processor PipelineProcessor Pipeline
Source: Intel Technology Journal , Volume 6, Number 1, February 2002. SMT-8
EECC722 - ShaabanEECC722 - Shaaban#26 Lec # 2 Fall 2003 9-10-2003
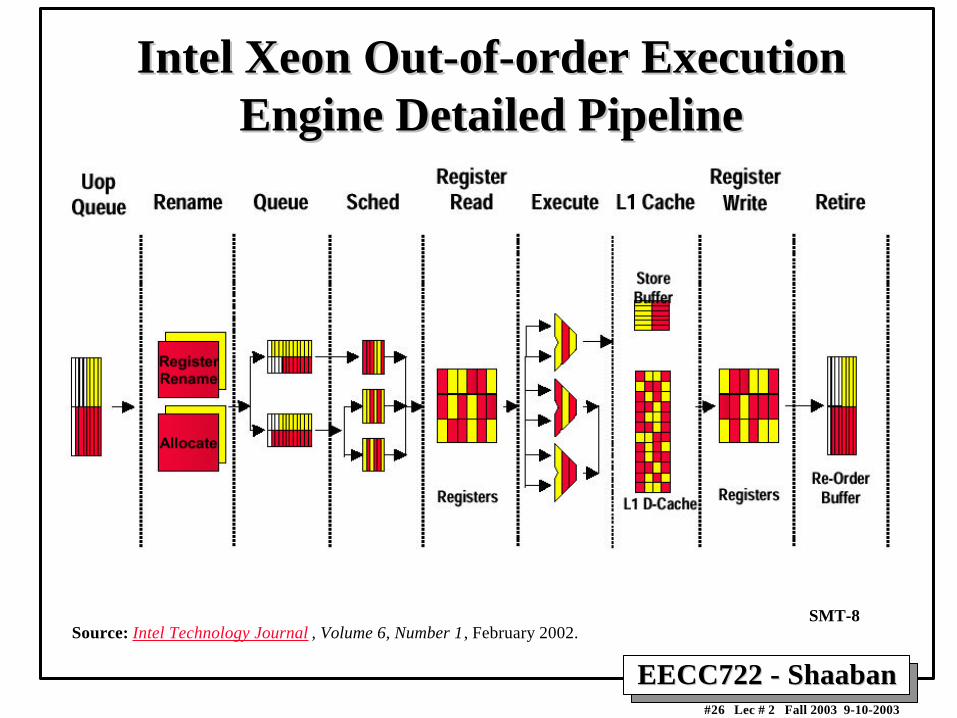
IntelIntel Xeon Xeon Out-of-order Execution Out-of-order ExecutionEngine Detailed PipelineEngine Detailed Pipeline
Source: Intel Technology Journal , Volume 6, Number 1, February 2002. SMT-8
EECC722 - ShaabanEECC722 - Shaaban#27 Lec # 2 Fall 2003 9-10-2003
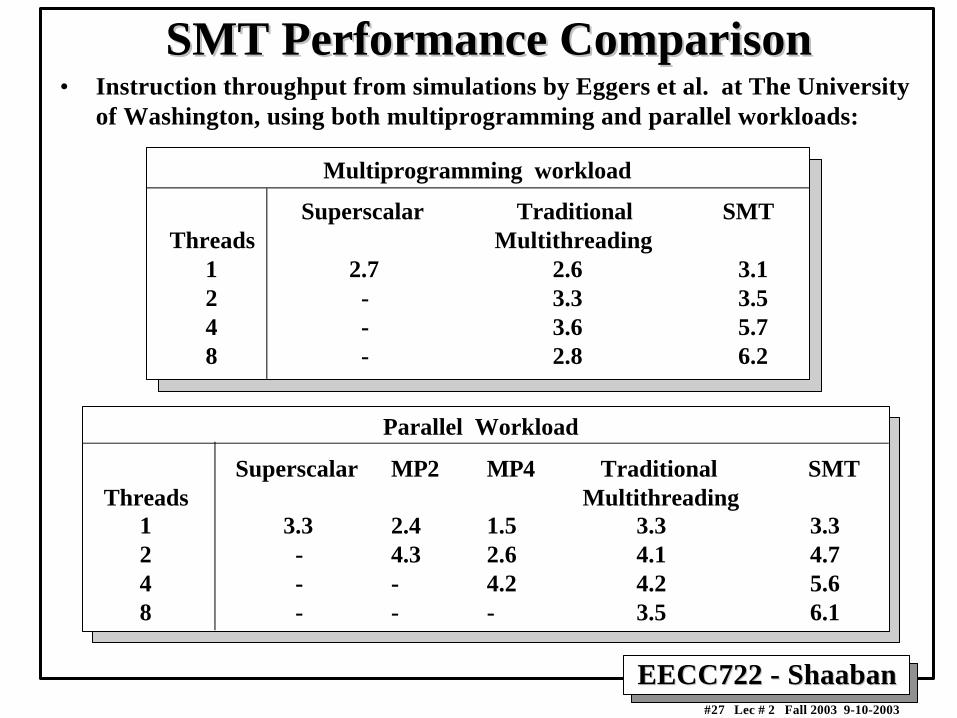
SMT Performance ComparisonSMT Performance Comparison• Instruction throughput from simulations by Eggers et al. at The University
of Washington, using both multiprogramming and parallel workloads:
Multiprogramming workload
Superscalar Traditional SMTThreads Multithreading 1 2.7 2.6 3.1 2 - 3.3 3.5 4 - 3.6 5.7 8 - 2.8 6.2
Parallel Workload
Superscalar MP2 MP4 Traditional SMTThreads Multithreading 1 3.3 2.4 1.5 3.3 3.3 2 - 4.3 2.6 4.1 4.7 4 - - 4.2 4.2 5.6 8 - - - 3.5 6.1

EECC722 - ShaabanEECC722 - Shaaban#28 Lec # 2 Fall 2003 9-10-2003
• The following machine models for a multithreaded CPU that can issue 8 instruction per cyclediffer in how threads use issue slots and functional units:
• Fine-Grain Multithreading:
– Only one thread issues instructions each cycle, but it can use the entire issue width of theprocessor. This hides all sources of vertical waste, but does not hide horizontal waste.
• SM:Full Simultaneous Issue.
– This is a completely flexible simultaneous multithreaded superscalar: all eight threadscompete for each of the 8 issue slots each cycle. This is the least realistic model in terms ofhardware complexity, but provides insight into the potential for simultaneousmultithreading. The following models each represent restrictions to this scheme thatdecrease hardware complexity.
• SM:Single Issue,SM:Dual Issue, and SM:Four Issue:
– These three models limit the number of instructions each thread can issue, or have active in thescheduling window, each cycle.
– For example, in a SM:Dual Issue processor, each thread can issue a maximum of 2 instructionsper cycle; therefore, a minimum of 4 threads would be required to fill the 8 issue slots in one cycle.
• SM:Limited Connection.– Each hardware context is directly connected to exactly one of each type of functional unit.
– For example, if the hardware supports eight threads and there are four integer units, each integerunit could receive instructions from exactly two threads.
– The partitioning of functional units among threads is thus less dynamic than in the other models,but each functional unit is still shared (the critical factor in achieving high utilization).
Possible Machine Models for an 8-way Multithreaded Processor
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1
EECC722 - ShaabanEECC722 - Shaaban#29 Lec # 2 Fall 2003 9-10-2003
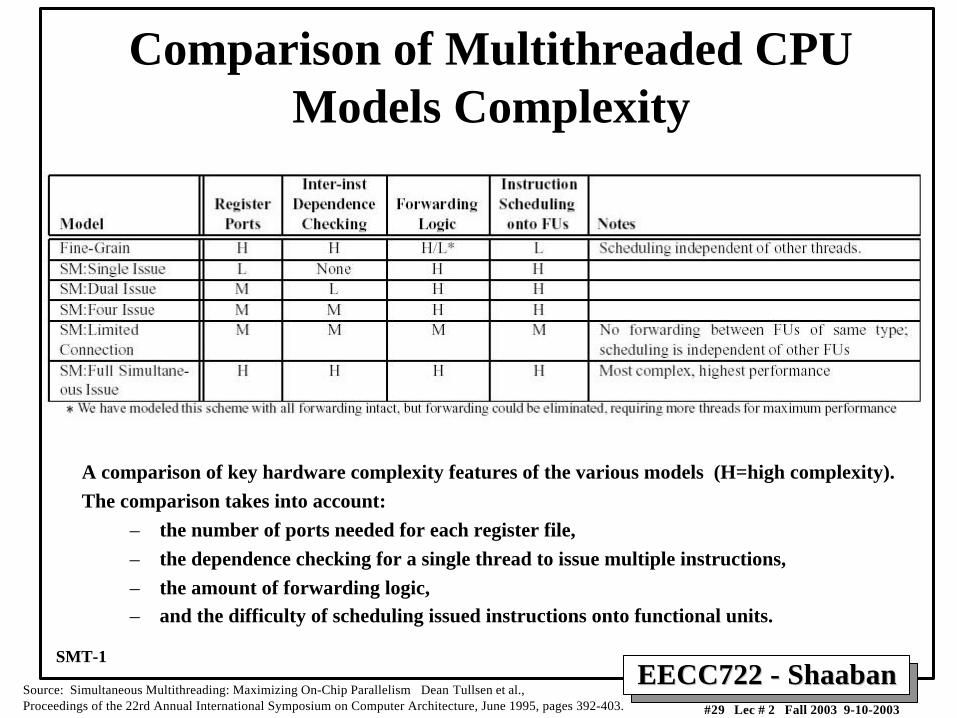
Comparison of Multithreaded CPUModels Complexity
A comparison of key hardware complexity features of the various models (H=high complexity).
The comparison takes into account:
– the number of ports needed for each register file,
– the dependence checking for a single thread to issue multiple instructions,
– the amount of forwarding logic,
– and the difficulty of scheduling issued instructions onto functional units.
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1
EECC722 - ShaabanEECC722 - Shaaban#30 Lec # 2 Fall 2003 9-10-2003
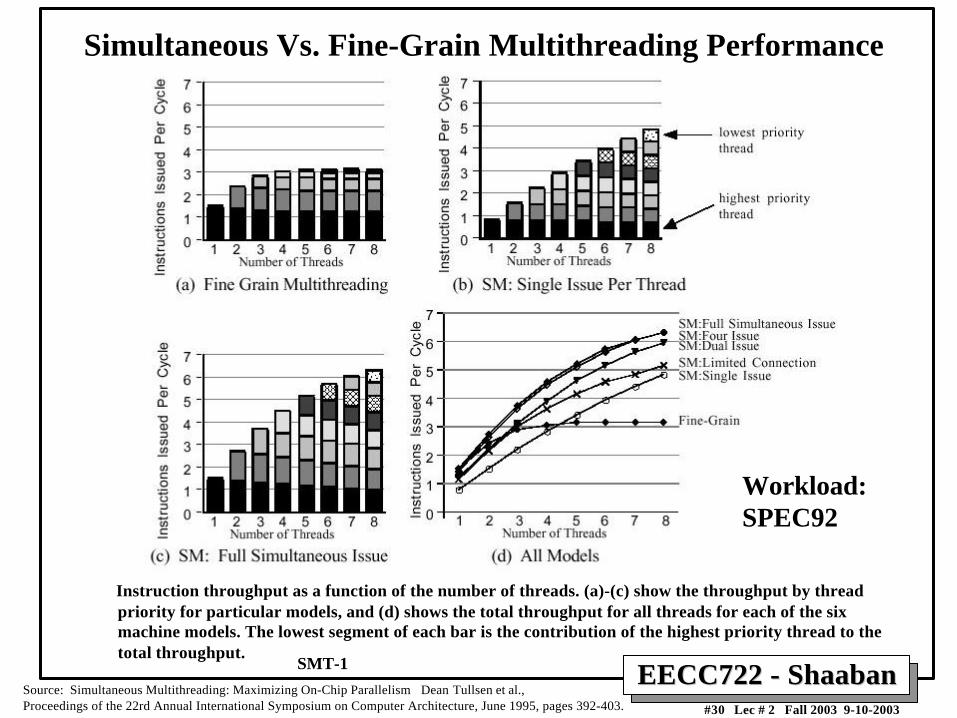
Simultaneous Vs. Fine-Grain Multithreading Performance
Instruction throughput as a function of the number of threads. (a)-(c) show the throughput by threadpriority for particular models, and (d) shows the total throughput for all threads for each of the sixmachine models. The lowest segment of each bar is the contribution of the highest priority thread to thetotal throughput.
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1
Workload:SPEC92
EECC722 - ShaabanEECC722 - Shaaban#31 Lec # 2 Fall 2003 9-10-2003
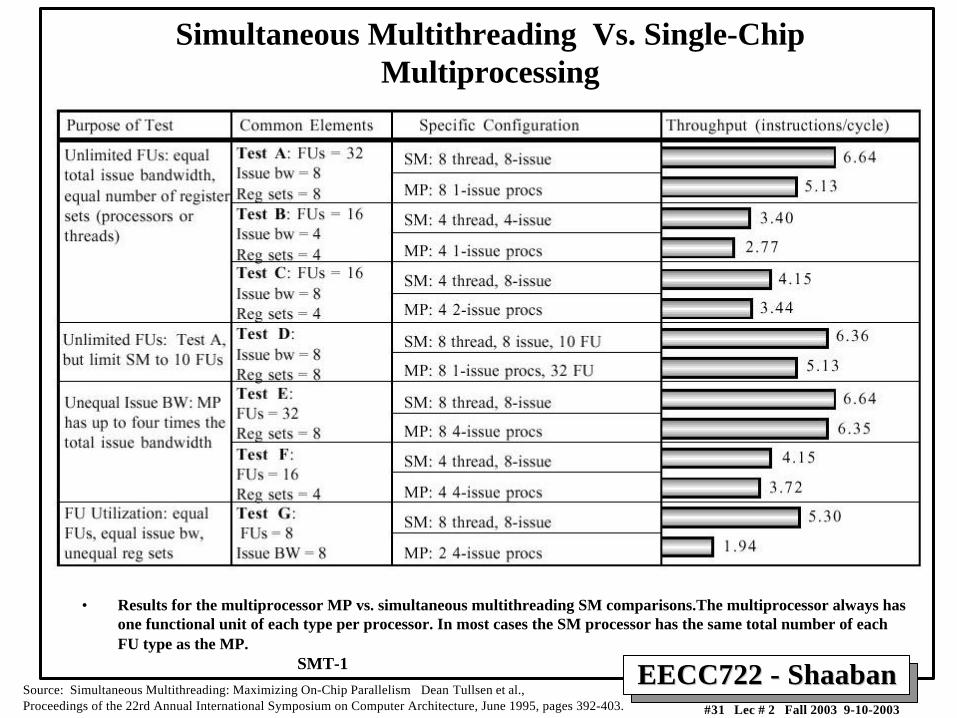
• Results for the multiprocessor MP vs. simultaneous multithreading SM comparisons.The multiprocessor always hasone functional unit of each type per processor. In most cases the SM processor has the same total number of eachFU type as the MP.
Simultaneous Multithreading Vs. Single-ChipMultiprocessing
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1
EECC722 - ShaabanEECC722 - Shaaban#32 Lec # 2 Fall 2003 9-10-2003
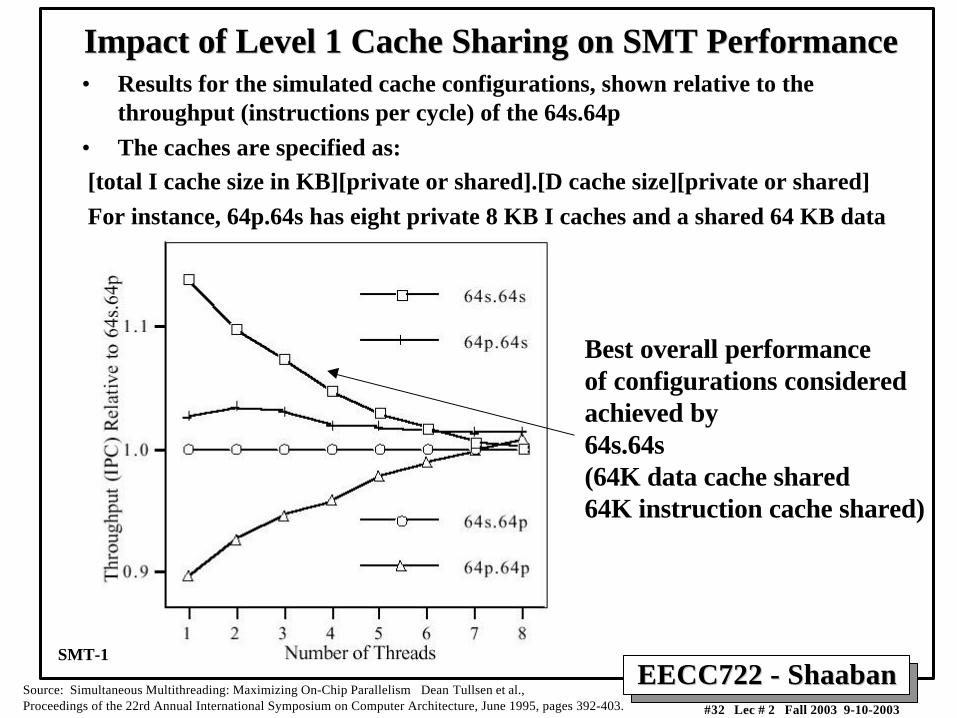
Impact of Level 1 Cache Sharing on SMT PerformanceImpact of Level 1 Cache Sharing on SMT Performance• Results for the simulated cache configurations, shown relative to the
throughput (instructions per cycle) of the 64s.64p
• The caches are specified as:
[total I cache size in KB][private or shared].[D cache size][private or shared]
For instance, 64p.64s has eight private 8 KB I caches and a shared 64 KB data
Source: Simultaneous Multithreading: Maximizing On-Chip Parallelism Dean Tullsen et al., Proceedings of the 22rd Annual International Symposium on Computer Architecture, June 1995, pages 392-403.
SMT-1
Best overall performance of configurations consideredachieved by 64s.64s(64K data cache shared64K instruction cache shared)
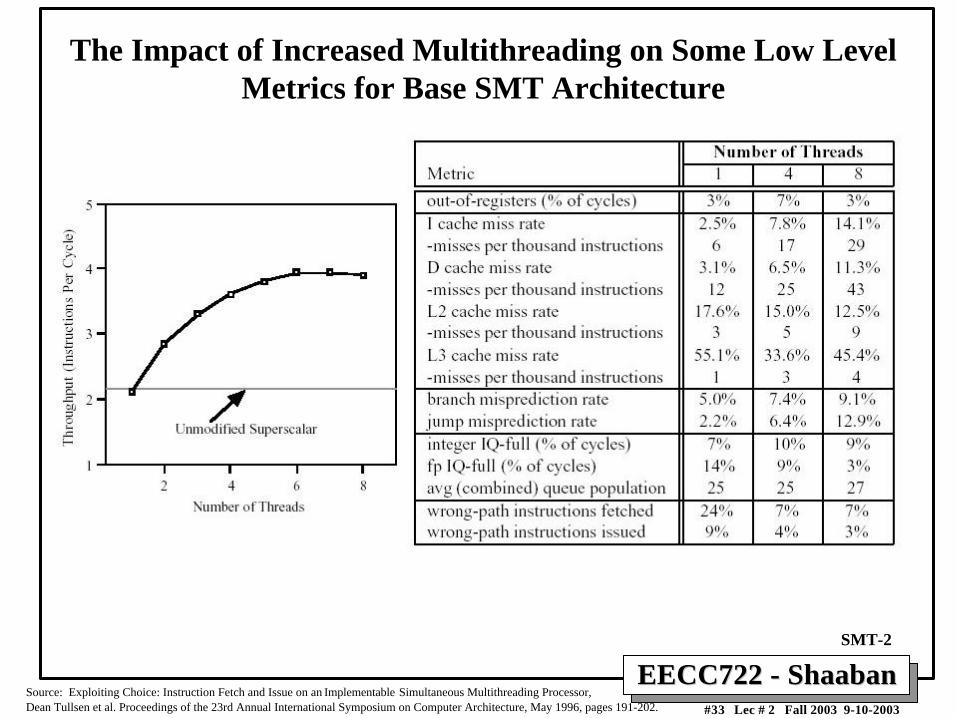
EECC722 - ShaabanEECC722 - Shaaban#33 Lec # 2 Fall 2003 9-10-2003
The Impact of Increased Multithreading on Some Low LevelMetrics for Base SMT Architecture
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2

EECC722 - ShaabanEECC722 - Shaaban#34 Lec # 2 Fall 2003 9-10-2003
Possible SMT Thread Instruction Fetch Scheduling PoliciesPossible SMT Thread Instruction Fetch Scheduling Policies
• Round Robin:– Instruction from Thread 1, then Thread 2, then Thread 3, etc.
(eg RR 1.8 : each cycle one thread fetches up to eight instructions
RR 2.4 each cycle two threads fetch up to four instructions each)
• BR-Count:– Give highest priority to those threads that are least likely to be on a wrong path
by by counting branch instructions that are in the decode stage, the renamestage, and the instruction queues, favoring those with the fewest unresolvedbranches.
• MISS-Count:– Give priority to those threads that have the fewest outstanding Data cache
misses.
• ICount:– Highest priority assigned to thread with the lowest number of instructions in
static portion of pipeline (decode, rename, and the instruction queues).
• IQPOSN:– Give lowest priority to those threads with instructions closest to the head of
either the integer or floating point instruction queues (the oldest instruction is atthe head of the queue).
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2
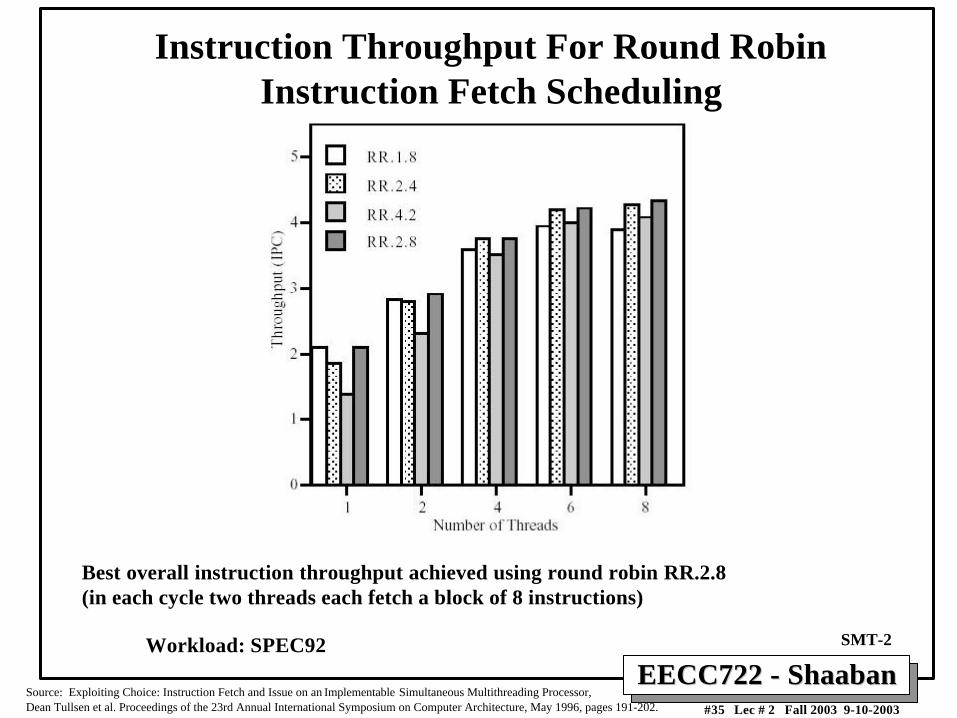
EECC722 - ShaabanEECC722 - Shaaban#35 Lec # 2 Fall 2003 9-10-2003
Instruction Throughput For Round RobinInstruction Fetch Scheduling
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202.
SMT-2
Best overall instruction throughput achieved using round robin RR.2.8(in each cycle two threads each fetch a block of 8 instructions)
Workload: SPEC92
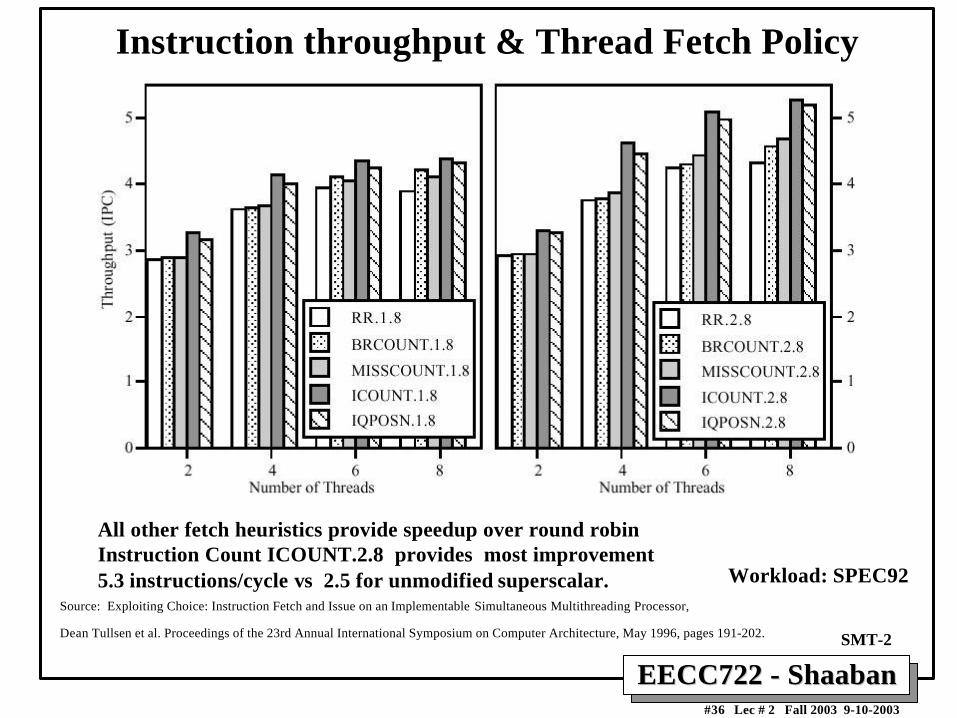
EECC722 - ShaabanEECC722 - Shaaban#36 Lec # 2 Fall 2003 9-10-2003
Instruction throughput & Thread Fetch Policy
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,
Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202. SMT-2
Workload: SPEC92
All other fetch heuristics provide speedup over round robinInstruction Count ICOUNT.2.8 provides most improvement5.3 instructions/cycle vs 2.5 for unmodified superscalar.
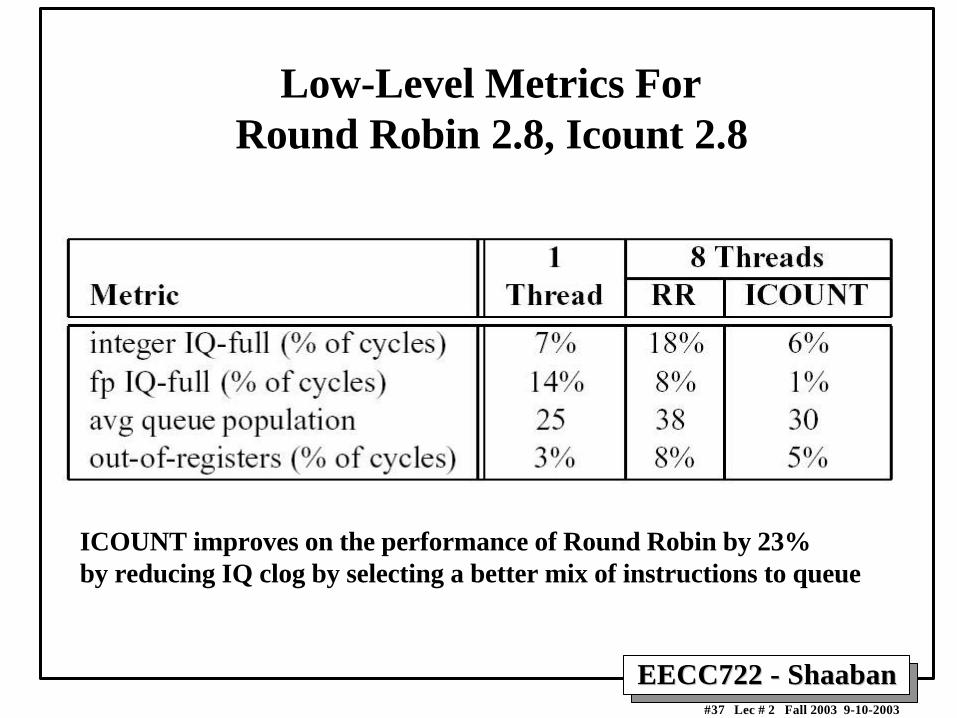
EECC722 - ShaabanEECC722 - Shaaban#37 Lec # 2 Fall 2003 9-10-2003
Low-Level Metrics ForRound Robin 2.8, Icount 2.8
ICOUNT improves on the performance of Round Robin by 23%by reducing IQ clog by selecting a better mix of instructions to queue
EECC722 - ShaabanEECC722 - Shaaban#38 Lec # 2 Fall 2003 9-10-2003
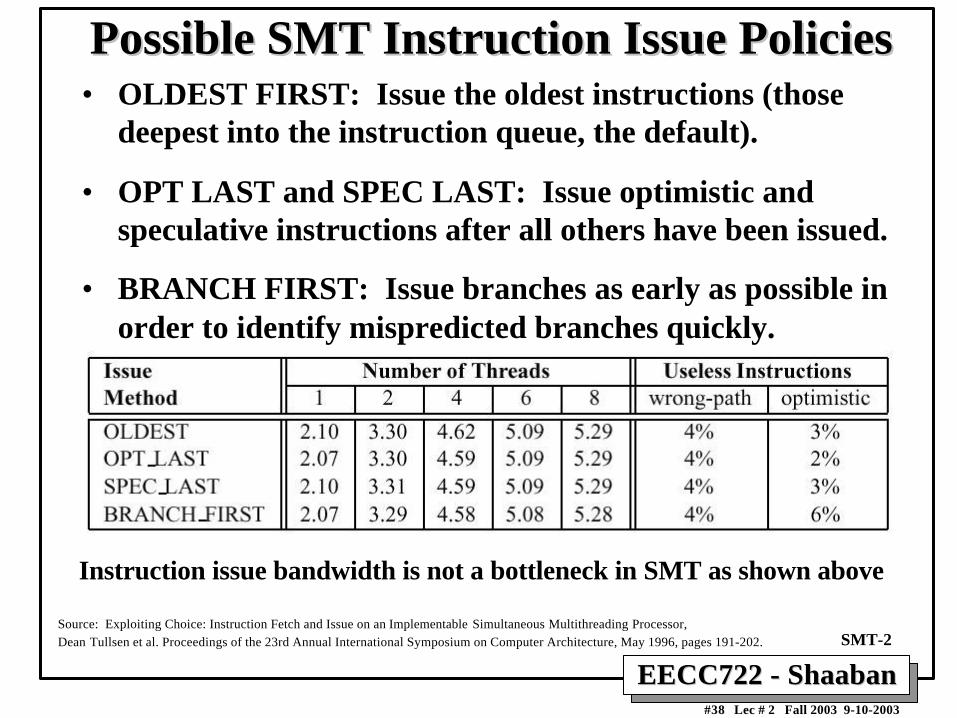
Possible SMT Instruction Issue PoliciesPossible SMT Instruction Issue Policies• OLDEST FIRST: Issue the oldest instructions (those
deepest into the instruction queue, the default).
• OPT LAST and SPEC LAST: Issue optimistic andspeculative instructions after all others have been issued.
• BRANCH FIRST: Issue branches as early as possible inorder to identify mispredicted branches quickly.
Source: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor,Dean Tullsen et al. Proceedings of the 23rd Annual International Symposium on Computer Architecture, May 1996, pages 191-202. SMT-2
Instruction issue bandwidth is not a bottleneck in SMT as shown above

EECC722 - ShaabanEECC722 - Shaaban#39 Lec # 2 Fall 2003 9-10-2003
RIT-CE SMT Project GoalsRIT-CE SMT Project Goals• Investigate performance gains from exploiting Thread-
Level Parallelism (TLP) in addition to current Instruction-Level Parallelism (ILP) in processor design.
• Design and simulate an architecture incorporatingSimultaneous Multithreading (SMT) including OSinteraction (LINUX-based kernel?).
• Study operating system and compiler optimizations toimprove SMT processor performance.
• Performance studies with various workloads using thesimulator/OS/compiler:– Suitability for fine-grained parallel applications?– Effect on multimedia applications?
EECC722 - ShaabanEECC722 - Shaaban#40 Lec # 2 Fall 2003 9-10-2003
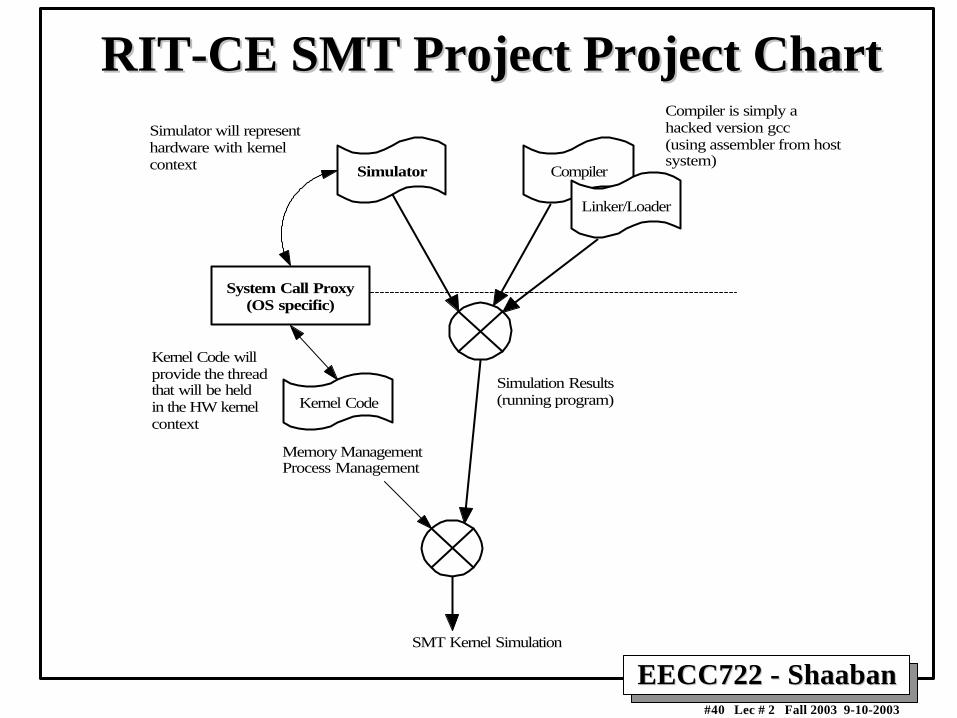
RIT-CE SMT Project Project ChartRIT-CE SMT Project Project Chart
Simulator Compiler
Linker/Loader
Simulation Results(running program)
System Call Proxy(OS specific)
Kernel Code
Simulator will representhardware with kernelcontext
Kernel Code willprovide the threadthat will be heldin the HW kernelcontext
Compiler is simply ahacked version gcc(using assembler from hostsystem)
Process ManagementMemory Management
SMT Kernel Simulation

EECC722 - ShaabanEECC722 - Shaaban#41 Lec # 2 Fall 2003 9-10-2003
Simulator (Simulator (simsim-SMT) @ RIT CE-SMT) @ RIT CE• Execution-driven, performance simulator.
• Derived from Simple Scalar tool set.
• Simulates cache, branch prediction, five pipeline stages
• Flexible:
– Configuration File controls cache size, buffer sizes, number offunctional units.
• Cross compiler used to generate Simple Scalar assembly language.
• Binary utilities, compiler, and assembler available.
• Standard C library (libc) has been ported.
•• SimSim-SMT Simulator Limitations:-SMT Simulator Limitations:
– Does not keep precise exceptions.
– System Call’s instructions not tracked.
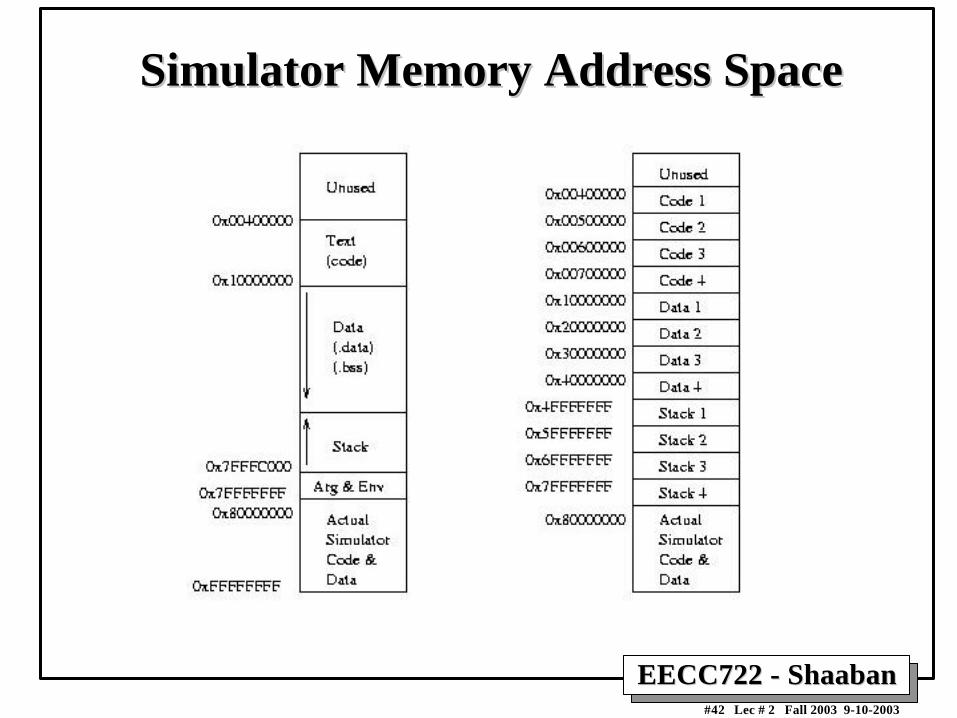
– Limited memory space:
• Four test programs’ memory spaces running on one simulatormemory space
• Easy to run out of stack space
EECC722 - ShaabanEECC722 - Shaaban#42 Lec # 2 Fall 2003 9-10-2003
Simulator Memory Address SpaceSimulator Memory Address Space

EECC722 - ShaabanEECC722 - Shaaban#43 Lec # 2 Fall 2003 9-10-2003
simsim-SMT-SMT Simulation Runs & Results Simulation Runs & Results• Test Programs used:
– Newton interpolation.– Matrix Solver using LU decomposition.– Integer Test Program.– FP Test Program.
• Simulations of a single program– 1,2, and 4 threads.
• System simulations involve a combination of allprograms simultaneously– Several different combinations were run
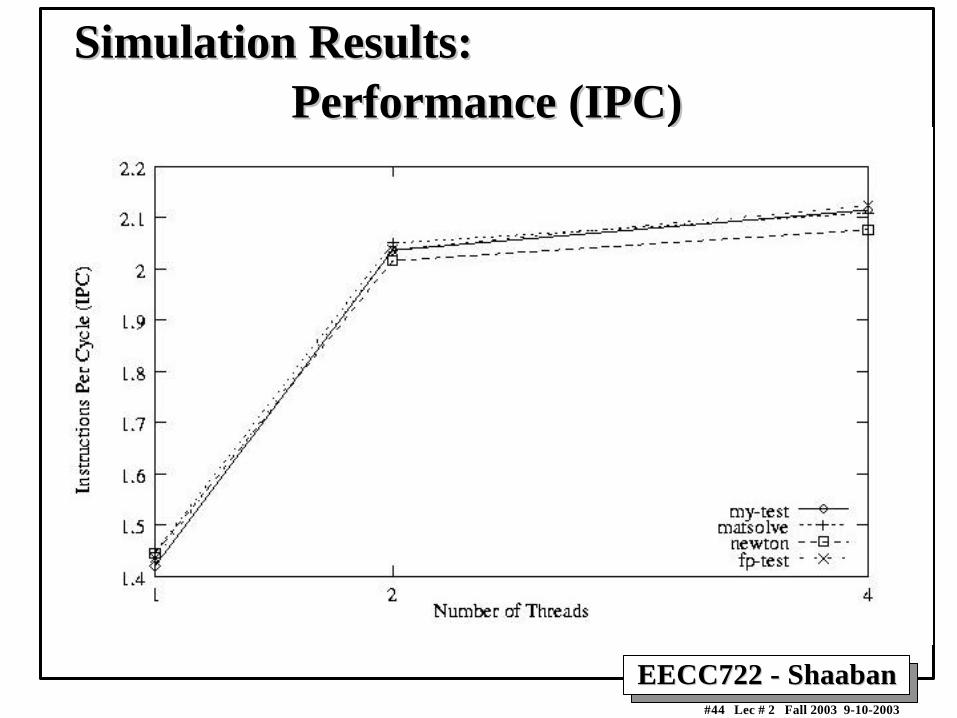
• From simulation results:– Performance increase:
• Biggest increase occurs when changing from one to twothreads.
– Higher issue rate, functional unit utilization.
EECC722 - ShaabanEECC722 - Shaaban#44 Lec # 2 Fall 2003 9-10-2003
Performance (IPC)Performance (IPC)Simulation Results:Simulation Results:
EECC722 - ShaabanEECC722 - Shaaban#45 Lec # 2 Fall 2003 9-10-2003
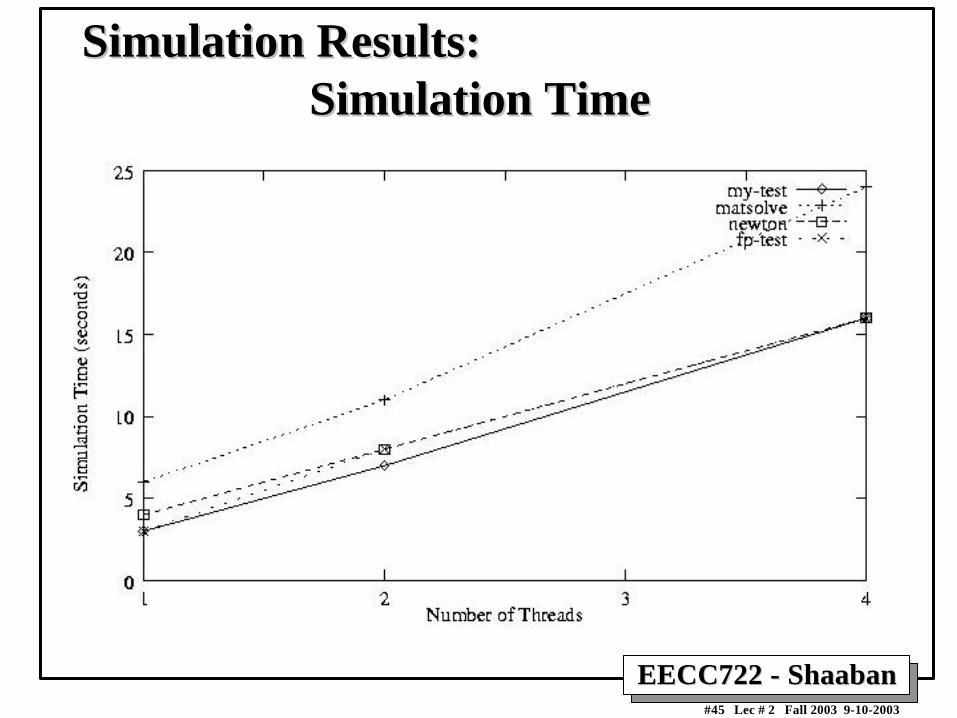
Simulation Results:Simulation Results: Simulation Time Simulation Time
EECC722 - ShaabanEECC722 - Shaaban#46 Lec # 2 Fall 2003 9-10-2003
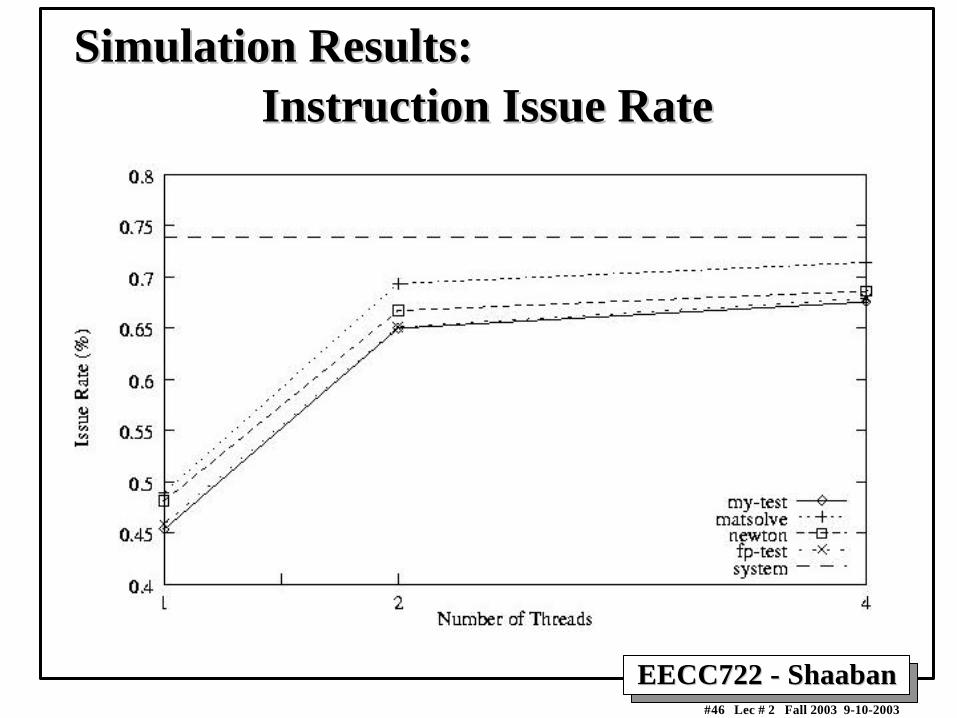
Instruction Issue RateInstruction Issue RateSimulation Results:Simulation Results:
EECC722 - ShaabanEECC722 - Shaaban#47 Lec # 2 Fall 2003 9-10-2003
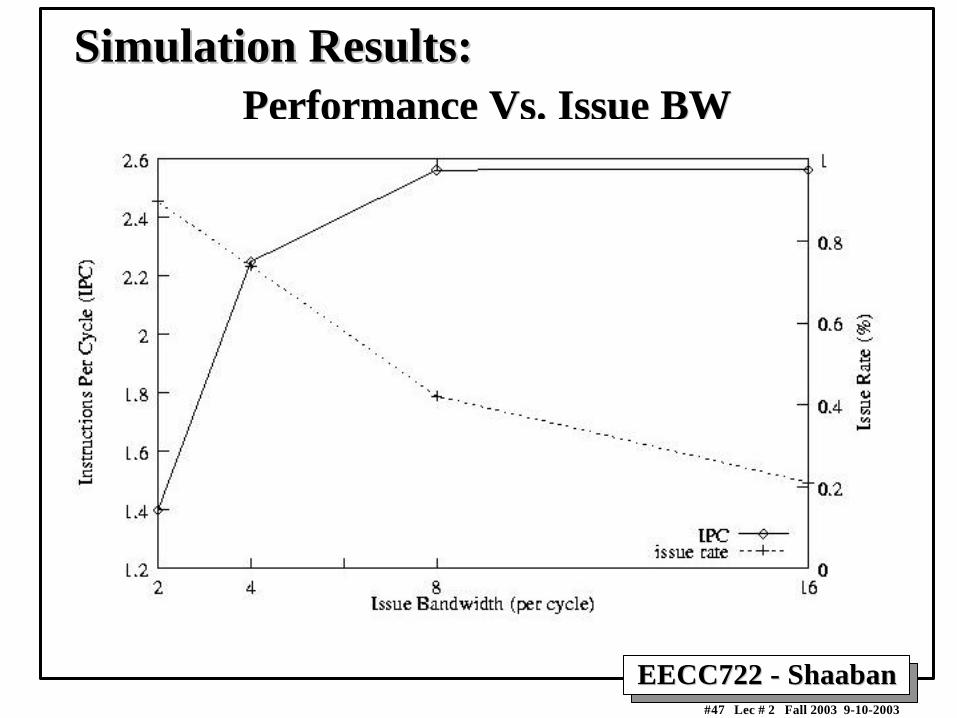
Performance Vs. Issue BWPerformance Vs. Issue BWSimulation Results:Simulation Results:
EECC722 - ShaabanEECC722 - Shaaban#48 Lec # 2 Fall 2003 9-10-2003
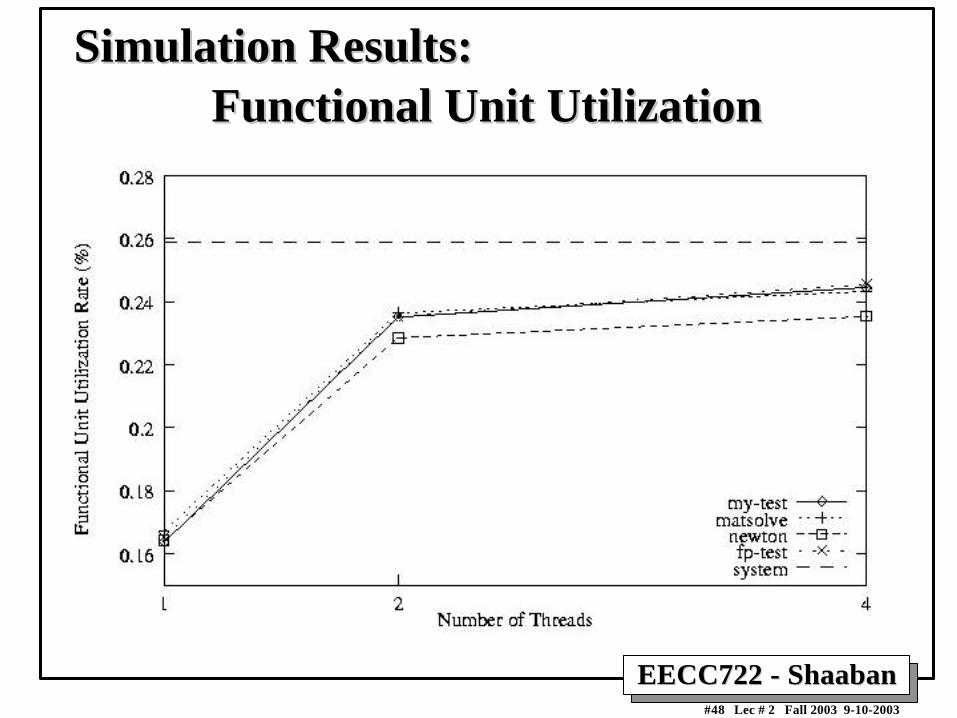
Functional Unit UtilizationFunctional Unit UtilizationSimulation Results:Simulation Results:
EECC722 - ShaabanEECC722 - Shaaban#49 Lec # 2 Fall 2003 9-10-2003
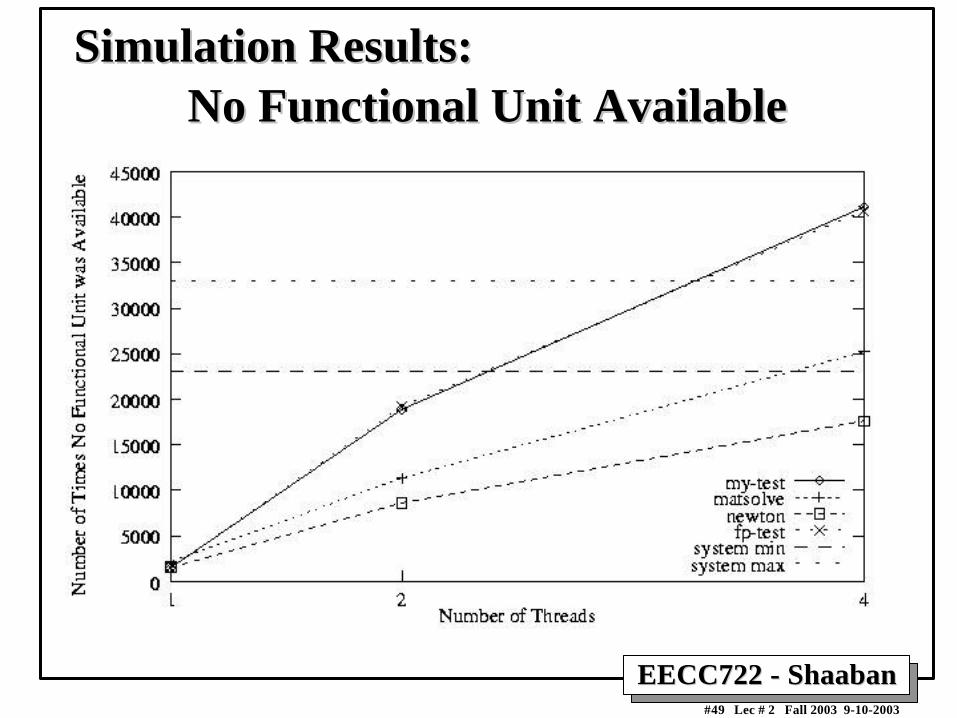
No Functional Unit AvailableNo Functional Unit AvailableSimulation Results:Simulation Results:
EECC722 - ShaabanEECC722 - Shaaban#50 Lec # 2 Fall 2003 9-10-2003
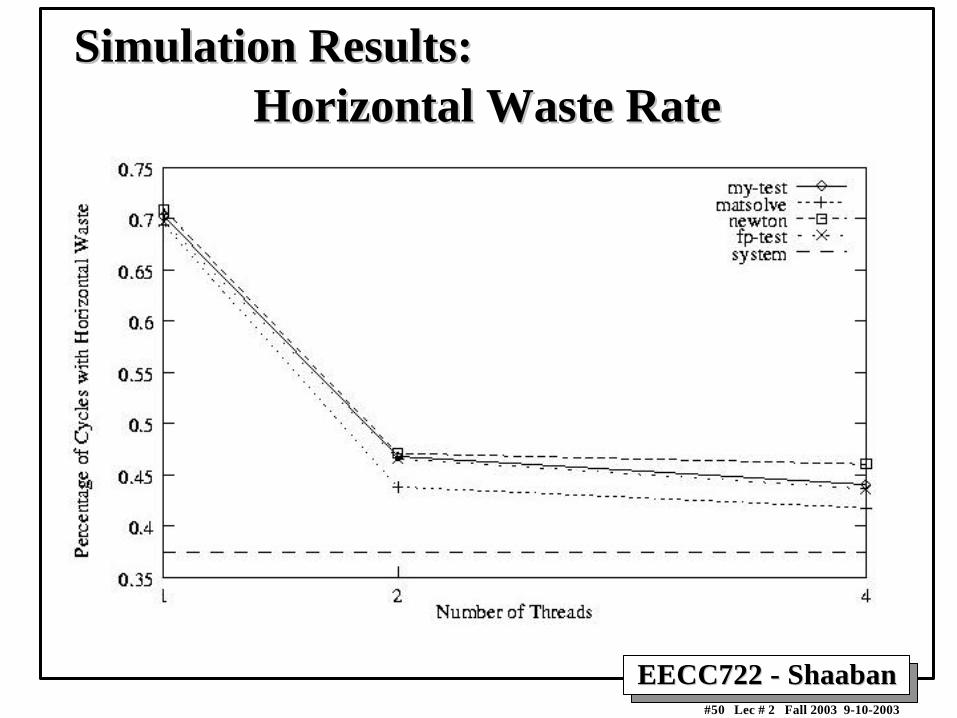
Horizontal Waste RateHorizontal Waste RateSimulation Results:Simulation Results:
EECC722 - ShaabanEECC722 - Shaaban#51 Lec # 2 Fall 2003 9-10-2003
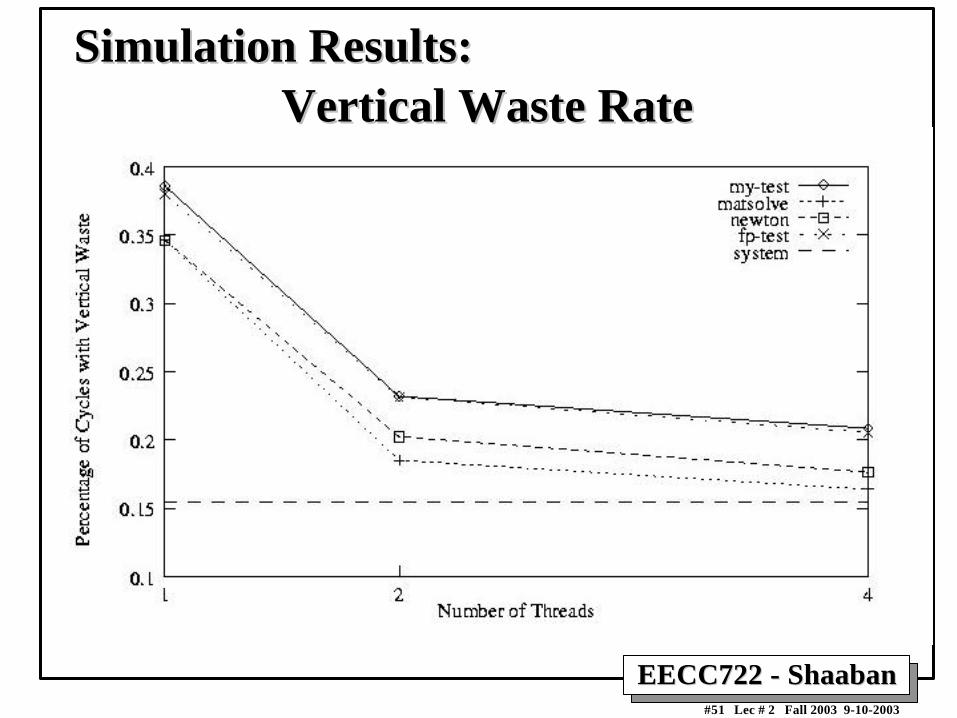
Vertical Waste RateVertical Waste RateSimulation Results:Simulation Results:

EECC722 - ShaabanEECC722 - Shaaban#52 Lec # 2 Fall 2003 9-10-2003
SMT: Simultaneous Multithreading• Strengths:
– Overcomes the limitations imposed by low single threadinstruction-level parallelism.
– Multiple threads running will hide individual controlhazards (branch mispredictions).
• Weaknesses:– Additional stress placed on memory hierarchy Control
unit complexity.
– Sizing of resources (cache, branch prediction, TLBs etc.)
– Accessing registers (32 integer + 32 FP for each HWcontext):
• Some designs devote two clock cycles for both register readsand register writes.





























