Embed Size (px)
Citation preview

Simplifying Cluster-Based Internet Simplifying Cluster-Based Internet Service Construction with SDDSService Construction with SDDS
Steven D. GribbleSteven D. Gribble
Qualifying Exam ProposalQualifying Exam Proposal
April 19th, 1999April 19th, 1999
Committee Members:Committee Members:
Eric Brewer, David Culler, Joseph Hellerstein, and Eric Brewer, David Culler, Joseph Hellerstein, and
Marti HearstMarti Hearst

Clusters for Internet ServicesClusters for Internet Services
• Previous observation (TACC, Inktomi, NOW):Previous observation (TACC, Inktomi, NOW):– clusters of workstations are a natural platform for clusters of workstations are a natural platform for
constructing Internet servicesconstructing Internet services
• Internet service propertiesInternet service properties– support large, rapidly growing user populationssupport large, rapidly growing user populations
– must remain highly available, and cost-effectivemust remain highly available, and cost-effective
• Clusters offer a tantalizing solutionClusters offer a tantalizing solution– incremental scalability: incremental scalability: cluster grows with servicecluster grows with service
– natural parallelism: natural parallelism: high performance platformhigh performance platform
– software and hardware redundancy: software and hardware redundancy: fault-tolerancefault-tolerance

ProblemProblem
• Internet service construction on clusters is hardInternet service construction on clusters is hard– load balancing, process management, communications load balancing, process management, communications
abstractions, I/O balancing, fail-over and restart, …abstractions, I/O balancing, fail-over and restart, …
– toolkits proposed to help (TACC, AS1, River, … )toolkits proposed to help (TACC, AS1, River, … )
• Even harder if shared, persistent state is involvedEven harder if shared, persistent state is involved– data partitioning, replication, and consistency, data partitioning, replication, and consistency,
interacting with storage subsystem, …interacting with storage subsystem, …
– solutions not geared to clustered servicessolutions not geared to clustered services
• use (distributed) RDBMS: expensive, powerful semantic guarantees, generality at cost of performance
• use network/distributed FS: overly general, high overhead (e.g. double buffering penalties). Fault-tolerance?
• roll your own custom solution: not reusable, complex

Idea / HypothesisIdea / Hypothesis
• It is possible to:It is possible to:– isolate clustered services from vagaries of state mgmt.,isolate clustered services from vagaries of state mgmt.,
– to do so with adequately general abstractions,to do so with adequately general abstractions,
– to build those abstractions in a layered fashion (reuse),to build those abstractions in a layered fashion (reuse),
– and to exploit clusters for performance, and simplicity.and to exploit clusters for performance, and simplicity.
• Use SUse Scalable calable DDistributed istributed DData ata SStructures (SDDS)tructures (SDDS)– take conventional data structure (hash table, tree, log, … )take conventional data structure (hash table, tree, log, … )
– partition it across nodes in a clusterpartition it across nodes in a cluster
• parallel access, scalability, …
– replicate partitions within replica groups in clusterreplicate partitions within replica groups in cluster
• availability in face of failures, further parallelism
– store replicas on diskstore replicas on disk

Why SDDS?Why SDDS?
• 1st year ugrad software engineering principle:1st year ugrad software engineering principle:– separation of concernsseparation of concerns
• decouple persistency/consistency logic from rest of service
• simpler (and cleaner!) service implementations
• service authors understand data structuresservice authors understand data structures– familiar behavior and interfaces from single-node casefamiliar behavior and interfaces from single-node case
– should enable rapid development of new servicesshould enable rapid development of new services
• structure and access patterns are self-evidentstructure and access patterns are self-evident– access granularity manifestly a structure elementaccess granularity manifestly a structure element
– coincidence of logical and physical data units (ALF/ADU)coincidence of logical and physical data units (ALF/ADU)
• cf. file systems, SQL in RDBMS, VM pages in DSM

Challenges (== Research Agenda)Challenges (== Research Agenda)
• Overcoming complexities of distributed systemsOvercoming complexities of distributed systems– data consistency, data distribution, request load data consistency, data distribution, request load
balancing, hiding network latency and OS overhead, …balancing, hiding network latency and OS overhead, …
– ace up the sleeve: ace up the sleeve: cluster cluster wide area wide area
• single, controlled administrative domain
– engineer to (probabilistically) avoid network partitions
– use low-latency, high-throughput SAN (5 s, 40-120 MB/s)
– predictable behavior, controlled heterogeneity
• ““I/O is still a problem”I/O is still a problem”– plenty of work on fast network I/O, some on fast disk I/Oplenty of work on fast network I/O, some on fast disk I/O
– less work bridging network less work bridging network disk I/O in cluster disk I/O in cluster
environmentenvironment

High-level plan (10000’ view)High-level plan (10000’ view)
1) Implement several SDDS’s1) Implement several SDDS’s– hypothesis: log, tree, and hash table are sufficienthypothesis: log, tree, and hash table are sufficient
• investigate different consistency levels and mechanisms
• experiment with scalability mechanisms
– Get top and bottom interfaces correctGet top and bottom interfaces correct
• top interface: particulars of hash, tree, log implementation
– specialization hooks?
• bottom interface: segment-based cluster I/O layer
– filtered streams between disks, network, memory
2) Evaluate by deploying real services2) Evaluate by deploying real services– goal: measurable reduction of complexitygoal: measurable reduction of complexity
• port existing Ninja services to SDDS platform
– goal: ease of adoption by service authorsgoal: ease of adoption by service authors
• have co-researchers implement new services on SDDS

OutlineOutline
• Prototype descriptionPrototype description– distributed hash table implementationdistributed hash table implementation
– ““Parallelisms” service and lessonsParallelisms” service and lessons
• SDDS design and research issuesSDDS design and research issues
• Evaluation methodologyEvaluation methodology
• Segment-based I/O layer for clustersSegment-based I/O layer for clusters
• Related workRelated work
• Pro Forma timelinePro Forma timeline

OutlineOutline
• Prototype descriptionPrototype description– distributed hash table implementationdistributed hash table implementation
– ““Parallelisms” service and lessonsParallelisms” service and lessons
• SDDS design and research issuesSDDS design and research issues
• Evaluation methodologyEvaluation methodology
• Segment-based I/O layer for clustersSegment-based I/O layer for clusters
• Related workRelated work
• Pro Forma timelinePro Forma timeline
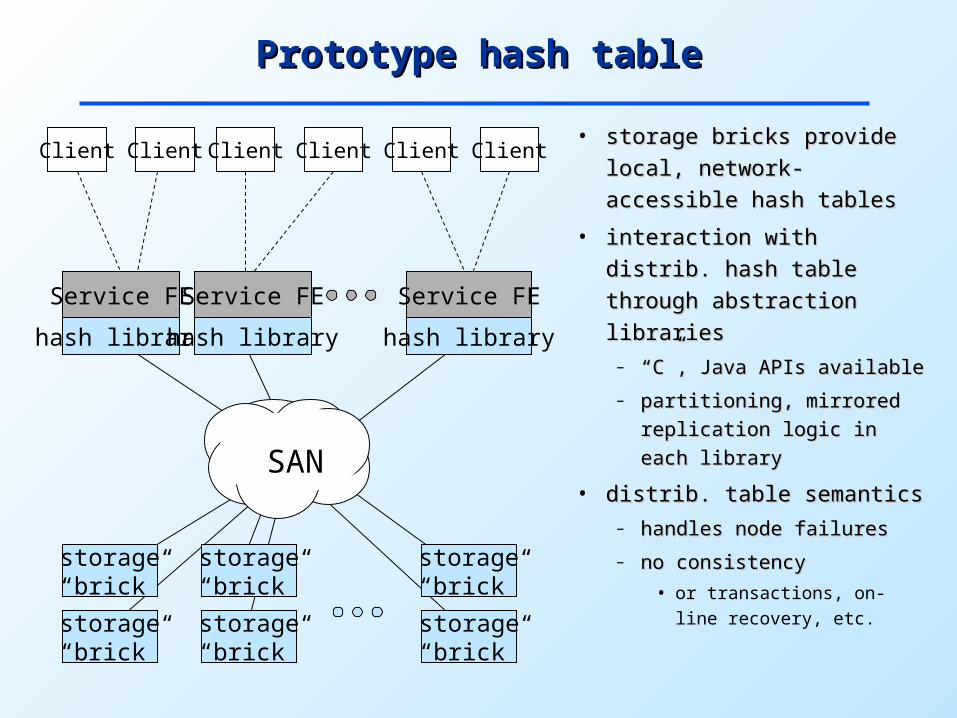
Prototype hash tablePrototype hash table
SAN
storage“brick”
Service FE Service FEService FE
Client Client ClientClient Client Client
storage“brick”
storage“brick”
storage“brick”
storage“brick”
storage“brick”
hash library hash library hash library
• storage bricks provide storage bricks provide
local, network-local, network-
accessible hash tablesaccessible hash tables
• interaction with distrib. interaction with distrib.
hash table through hash table through
abstraction librariesabstraction libraries– ““C”, Java APIs C”, Java APIs
availableavailable
– partitioning, mirrored partitioning, mirrored
replication logic in replication logic in
each libraryeach library
• distrib. table semanticsdistrib. table semantics– handles node failureshandles node failures
– no consistencyno consistency
• or transactions, on-line recovery, etc.
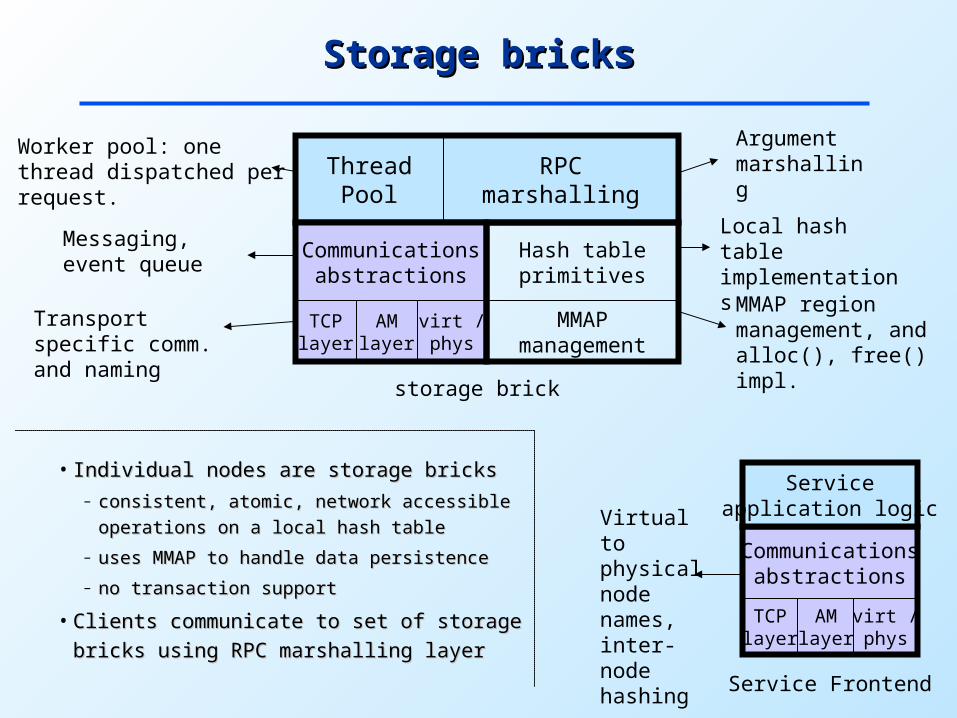
Storage bricksStorage bricks
storage brick
Communicationsabstractions
TCPlayer
AMlayer
virt /phys
Serviceapplication logic
Service Frontend
Worker pool: one thread dispatched per request.
Messaging, event queue
Transport specific comm. and naming
Argument marshalling
Local hash table implementations
MMAP region management, and alloc(), free() impl.
• Individual nodes are storage bricksIndividual nodes are storage bricks– consistent, atomic, network accessible consistent, atomic, network accessible
operations on a local hash tableoperations on a local hash table
– uses MMAP to handle data persistenceuses MMAP to handle data persistence
– no transaction supportno transaction support
• Clients communicate to set of storage Clients communicate to set of storage
bricks using RPC marshalling layerbricks using RPC marshalling layer
Virtual to physical node names, inter-node hashing
RPCmarshalling
ThreadPool
Communicationsabstractions
TCPlayer
AMlayer
virt /phys
Hash tableprimitives
MMAPmanagement

Parallelisms serviceParallelisms service
•Provides “relevant site” Provides “relevant site”
information given a URLinformation given a URL– an an inversioninversion of Yahoo! directory of Yahoo! directory
• Parallelisms: builds index of all URLs, returns other URLs in same topics
– read-mostly traffic, nearly no read-mostly traffic, nearly no
consistency requirementsconsistency requirements
– large database of URLslarge database of URLs
• ~ gigabyte of space for 1.5 million URLs and 80000 topics
• Service FE itself is very simpleService FE itself is very simple
– 400400 semicolons of C semicolons of C
• 130 for app-specific logic
• 270 for threads, HTTP munging, …
– hash table code: hash table code: 4K4K semicolons of semicolons of
CC
http://ninja.cs.berkeley.edu/~demos/paralllelisms/parallelisms.html

Some Lessons LearnedSome Lessons Learned
• mmap()mmap() simplified implementation, but at a price simplified implementation, but at a price+ service “working sets” naturally applyservice “working sets” naturally apply
– no pointers: breaks usual linked list and hash table no pointers: breaks usual linked list and hash table
librarieslibraries
– little control over the order of writes, so cannot guarantee little control over the order of writes, so cannot guarantee
consistency if crashes occurconsistency if crashes occur
• if node goes down, may incur a lengthy sync before restart
• same for abstraction libraries: simplicity with a costsame for abstraction libraries: simplicity with a cost– each storage brick could be totally independenteach storage brick could be totally independent
• because policy embedded in abstraction libraries
– bad for administration and monitoringbad for administration and monitoring
• no place to “hook in” to get view of complete table
• each client makes isolated decisions
– load balancing and failure detection

More lessons learnedMore lessons learned
• service simplicity premise seems validservice simplicity premise seems valid– Parallelisms service code devoid of persistence logicParallelisms service code devoid of persistence logic
– Parallelisms front-ends contain only session stateParallelisms front-ends contain only session state
• no recovery necessary if they fail
• interface selection is criticalinterface selection is critical– originally, just supported originally, just supported put()put(), , get()get(), , remove()remove()
– wanted to support wanted to support java.util.hashtablejava.util.hashtable subclass subclass
• needed enumerations, containsKey(), containsObject()
• to efficiently support required significant replumbing
• thread subsystem was troublesomethread subsystem was troublesome– JDK has its own, and it conflicted. Had to remove JDK has its own, and it conflicted. Had to remove
threads from client-side abstraction library.threads from client-side abstraction library.

OutlineOutline
• Prototype descriptionPrototype description– distributed hash table implementationdistributed hash table implementation
– ““Parallelisms” service and lessonsParallelisms” service and lessons
• SDDS design and research issuesSDDS design and research issues
• Evaluation methodologyEvaluation methodology
• Segment-based I/O layer for clustersSegment-based I/O layer for clusters
• Related workRelated work
• Pro Forma timelinePro Forma timeline

SDDS goal: SDDS goal: simplicitysimplicity
• hypothesis: simplify construction of serviceshypothesis: simplify construction of services– evidence: Parallelismsevidence: Parallelisms
• distributed hash table prototype: 3000 lines of “C” code
• service: 400 lines of “C” code, 1/3 of which is service-specific
– evidence: Keiretsu serviceevidence: Keiretsu service
• instant messaging service between heterogeneous devices
• crux of service is in sharing of binding/routing state
• original: 131 lines of Java SDDS version: 80 lines of Java
• management/operational aspectsmanagement/operational aspects– to be successful, authors must want to adopt SDDSsto be successful, authors must want to adopt SDDSs
• simple to incorporate and understand
• operational management must be nearly transparent
– node fail-over and recovery, logging, etc. behind the scenes
– plug-n-play extensibility to add capacity

SDDS goal: SDDS goal: generalitygenerality
• potential criticism of SDDSs:potential criticism of SDDSs:– no matter which structures you provide, some services no matter which structures you provide, some services
simply can’t be built with only those primitivessimply can’t be built with only those primitives
– responseresponse: pick a basis to enable many interesting services: pick a basis to enable many interesting services
• log, hash table, and tree: our guess at a good basis
• layered-model will allow people to develop other SDDS’s
• allow GiST-style specialization hooks?
Web server
Proxy cache
Search engine
PIM server
read-mostly HT: static documents, cache. L: hit tracking
HT: soft-state cache. L: hit tracking
HT: query cache, doc. table. HT, T: indexes. L: crawl data, hit log
HT: repository HT, T: indexes. L: hit log, WAL for re-filing etc.

SDDS Research Ideas: SDDS Research Ideas: ConsistencyConsistency
• consistency / performance tradeoffsconsistency / performance tradeoffs– stricter consistency requirements imply worse performancestricter consistency requirements imply worse performance
– we know some intended services have weaker requirementswe know some intended services have weaker requirements
• rejected alternatives:rejected alternatives:– built strict consistency, and force people to usebuilt strict consistency, and force people to use
– investigate “extended transaction models”investigate “extended transaction models”
• our choiceour choice: pick small set of consistency guarantees: pick small set of consistency guarantees– level 0 (atomic but not isolated operations)level 0 (atomic but not isolated operations)
– level 3 (ACID)level 3 (ACID)
• get help with this one - it’s a bear

SDDS Research Ideas: SDDS Research Ideas: Consistency Consistency (2)(2)
• replica managementreplica management– what mechanism will we use between replicas?what mechanism will we use between replicas?
• 2 phase commit for distributed atomicity
• log-based on-line recovery
• exploiting cluster properties exploiting cluster properties – low network latency low network latency fast 2 phase commit fast 2 phase commit
• especially relative to WAN latency for Internet services
– given good UPS, node failures independentgiven good UPS, node failures independent
• “commit” to memory of peer in group, not to disk
– (probabilistically) engineer away network partitions(probabilistically) engineer away network partitions
• unavailable failure, therefore consensus algo. not needed

SDDS Research Ideas: SDDS Research Ideas: load load managementmanagement
• data distribution affects request distributiondata distribution affects request distribution– start simple: static data distribution (except extensibility)start simple: static data distribution (except extensibility)
– given request, lookup or hash to determine partitiongiven request, lookup or hash to determine partition
• optimizationsoptimizations– locality aware request dist. (LARD) within replicaslocality aware request dist. (LARD) within replicas
• if no failures, replicas further “partition” data in memory
– ““front ends” often colocated with storage nodesfront ends” often colocated with storage nodes
• front end selection based on data distribution knowledge
• smart clients (Ninja redirector stubs..?)
• IssuesIssues– graceful degradation: RED/LRP techniques to drop requestsgraceful degradation: RED/LRP techniques to drop requests
– given many simultaneous requests, service ordering policy?given many simultaneous requests, service ordering policy?
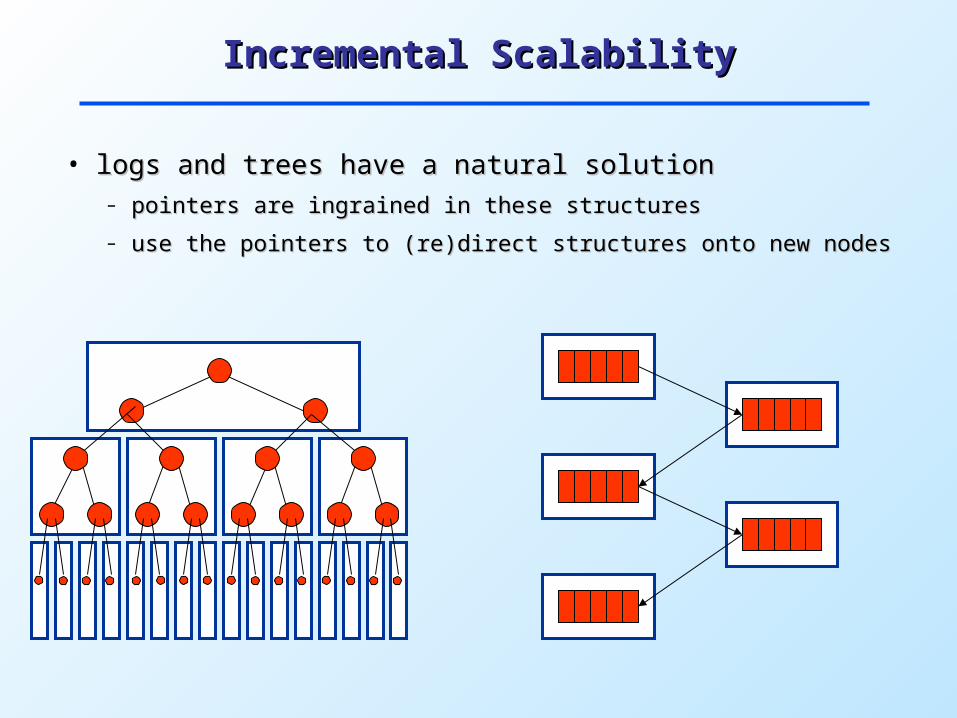
Incremental ScalabilityIncremental Scalability
• logs and trees have a natural solutionlogs and trees have a natural solution– pointers are ingrained in these structurespointers are ingrained in these structures
– use the pointers to (re)direct structures onto new nodesuse the pointers to (re)direct structures onto new nodes

Incremental Scalability - Hash TablesIncremental Scalability - Hash Tables
• hash table is the tricky onehash table is the tricky one– why? mapping is done by client-side hash functionswhy? mapping is done by client-side hash functions
• unless table is chained, no pointers inside hash structure
• need to change client-side functions to scale structure
– Litwin’s linear hashing?Litwin’s linear hashing?
• client-side hash function evolves over time
• clients independently discovery when to evolve functions
– Directory-based map?Directory-based map?
• move hashing into infrastructure (inefficient)
• or, have infrastructure inform clients when to change function
– AFS-style registration and callbacks?

Getting the Interfaces RightGetting the Interfaces Right
• upper interfaces: sufficient generalityupper interfaces: sufficient generality– setting the bar for functionality (e.g. setting the bar for functionality (e.g. java.util.hashtablejava.util.hashtable))
– opportunity: reuse of existing software (e.g. Berkeley opportunity: reuse of existing software (e.g. Berkeley
DB)DB)
• lower interfaces: use a segment-based I/O layer?lower interfaces: use a segment-based I/O layer?– log, tree: natural sequentiality, segments make senselog, tree: natural sequentiality, segments make sense
– hash table is much more challenginghash table is much more challenging
• aggregating small, random accesses into large, sequential ones
• rely on commits to other nodes’ memory
– periodically dump deltas to disk LFS-style

OutlineOutline
• Prototype descriptionPrototype description– distributed hash table implementationdistributed hash table implementation
– ““Parallelisms” service and lessonsParallelisms” service and lessons
• SDDS design and research issuesSDDS design and research issues
• Evaluation methodologyEvaluation methodology
• Segment-based I/O layer for clustersSegment-based I/O layer for clusters
• Related workRelated work
• Pro Forma timelinePro Forma timeline

Evaluation: use real servicesEvaluation: use real services
• metrics for successmetrics for success
1) measurable reduction in complexity to author Internet svcs.1) measurable reduction in complexity to author Internet svcs.
2) widespread adoption of SDDS by Ninja researchers2) widespread adoption of SDDS by Ninja researchers
1) port/reimplement existing Ninja services1) port/reimplement existing Ninja services– Keiretsu, Ninja Jukebox, the multispace Log serviceKeiretsu, Ninja Jukebox, the multispace Log service
– explicitly demonstrate code reduction & performance boonexplicitly demonstrate code reduction & performance boon
2) convince people to use SDDS for new services2) convince people to use SDDS for new services– NinjaMail, Service Discovery Service, ICEBERG servicesNinjaMail, Service Discovery Service, ICEBERG services
– will force us to tame operational aspects of SDDSwill force us to tame operational aspects of SDDS
• goal: as simple to use SDDS as single-node, non-persistent case

OutlineOutline
• Prototype descriptionPrototype description– distributed hash table implementationdistributed hash table implementation
– ““Parallelisms” service and lessonsParallelisms” service and lessons
• SDDS design and research issuesSDDS design and research issues
• Evaluation methodologyEvaluation methodology
• Segment-based I/O layer for clustersSegment-based I/O layer for clusters
• Related workRelated work
• Pro Forma timelinePro Forma timeline

Segment layer (motivation)Segment layer (motivation)
• it’s all about disk bandwidth & avoiding seeksit’s all about disk bandwidth & avoiding seeks– 8 ms random seek, 25-80 MB/s throughput8 ms random seek, 25-80 MB/s throughput
• must read 320 KB per seek to break even
• build disk abstraction layer based on segmentsbuild disk abstraction layer based on segments– 1-2 MB regions on disk, read and written in their entirety1-2 MB regions on disk, read and written in their entirety
– force upper layers to design with this in mindforce upper layers to design with this in mind
– small reads/writes treated as uncommon failure casesmall reads/writes treated as uncommon failure case
• SAN throughput is comparable to disk throughputSAN throughput is comparable to disk throughput– stream from disk to network and saturate both channelsstream from disk to network and saturate both channels
• stream through service-specific filter functions
• selection, transformation, …
– apply lessons from high-performance networksapply lessons from high-performance networks

Segment layer challengesSegment layer challenges
• thread and event modelthread and event model– lowest level model dictates entire application stacklowest level model dictates entire application stack
• dependency on particular thread subsystem is undesirable
– asynchronous interfaces are essentialasynchronous interfaces are essential
• especially for Internet services w/ thousands of connections
– potential model: VIA completion queuespotential model: VIA completion queues
• reusability for many components reusability for many components – toughest customer: Telegraph DBtoughest customer: Telegraph DB
• dictate write ordering, be able to “roll back” mods for aborts
• if content is paged, make sure don’t overwrite on disk
• no mmap( ) !

Segment Implementation PlanSegment Implementation Plan
• Two versions plannedTwo versions planned– one version using POSIX syscalls and vanilla filesystemone version using POSIX syscalls and vanilla filesystem
• definitely won’t perform well (copies to handle shadowing)
• portable to many platforms
• good for prototyping and getting API right
– one version on Linux with kernel modules for one version on Linux with kernel modules for
specializationspecialization
• I/O-lite style buffer unification
• use VIA or AM for network I/O
• modify VM subsystem for copy-on-write segments, and/or paging dirty data to separate region

OutlineOutline
• Prototype descriptionPrototype description– distributed hash table implementationdistributed hash table implementation
– ““Parallelisms” service and lessonsParallelisms” service and lessons
• SDDS design and research issuesSDDS design and research issues
• Evaluation methodologyEvaluation methodology
• Segment-based I/O layer for clustersSegment-based I/O layer for clusters
• Related workRelated work
• Pro Forma timelinePro Forma timeline

Related workRelated work
• (S)DSM(S)DSM– structural element is a better atomic unit than pagestructural element is a better atomic unit than page
– fault tolerance as goalfault tolerance as goal
• Distributed/networked FS Distributed/networked FS [NFS, AFS, xFS, LFS, ..][NFS, AFS, xFS, LFS, ..]
– FS more general, has less chance to exploit structureFS more general, has less chance to exploit structure
– often not in clustered environment (except xFS, Frangipani)often not in clustered environment (except xFS, Frangipani)
• Litwin SDDS Litwin SDDS [LH, LH*, RP, RP*][LH, LH*, RP, RP*]
– significant overlap in goalssignificant overlap in goals
– but little implementation experiencebut little implementation experience
• little exploitation of cluster characteristics
– consistency model not clearconsistency model not clear

Related Work (continued)Related Work (continued)
• Distributed & Parallel Databases Distributed & Parallel Databases [R*, Mariposa, Gamma, …][R*, Mariposa, Gamma, …]
– different goal (generality in structure/queries, xacts)different goal (generality in structure/queries, xacts)
– stronger and richer semantics, but at coststronger and richer semantics, but at cost
• both $$ and performance
• Fast I/O research Fast I/O research [U-Net, AM, VIA, IO-lite, fbufs, x-kernel, …][U-Net, AM, VIA, IO-lite, fbufs, x-kernel, …]
– network and disk subsystemsnetwork and disk subsystems
• main results: get OS out of way, avoid (unnecessary) copies
– use results in our fast I/O layeruse results in our fast I/O layer
• Cluster platforms Cluster platforms [TACC, AS1, River, Beowulf, Glunix, …][TACC, AS1, River, Beowulf, Glunix, …]
– many issues we aren’t tacklingmany issues we aren’t tackling
• harvesting idle resources, process migration, single-system view
– our work is mostly complementaryour work is mostly complementary

OutlineOutline
• Prototype descriptionPrototype description– distributed hash table implementationdistributed hash table implementation
– ““Parallelisms” service and lessonsParallelisms” service and lessons
• SDDS design and research issuesSDDS design and research issues
• Evaluation methodologyEvaluation methodology
• Segment-based I/O layer for clustersSegment-based I/O layer for clusters
• Related workRelated work
• Pro Forma timelinePro Forma timeline

Pro Forma TimelinePro Forma Timeline
• Phase 1 (0-6 months)Phase 1 (0-6 months)– preliminary distributed log and extensible hash table SDDSpreliminary distributed log and extensible hash table SDDS
• weak consistency for hash table, strong for log
– prototype design/implementation of segment I/O layerprototype design/implementation of segment I/O layer
• both POSIX and linux-optimized versions
• Phase 2 (6-12 months)Phase 2 (6-12 months)– measure/optimize SDDSs, improve hash table consistencymeasure/optimize SDDSs, improve hash table consistency
– port existing services to these SDDS’s, help with new svcs.port existing services to these SDDS’s, help with new svcs.
• Phase 3 (12-18 months)Phase 3 (12-18 months)– add tree/treap SDDS to repertoireadd tree/treap SDDS to repertoire
– incorporate lessons learned from phase 2 servicesincorporate lessons learned from phase 2 services
– measure, optimize, measure, optimize, … , write, graduate.measure, optimize, measure, optimize, … , write, graduate.

SummarySummary
• SDDS hypothesisSDDS hypothesis– simplification of cluster-based Internet service constructionsimplification of cluster-based Internet service construction
– possible to achieve generality, simplicity, efficiencypossible to achieve generality, simplicity, efficiency
• exploit properties of clusters to our benefit
– build in layered fashion on segment-based I/O substratebuild in layered fashion on segment-based I/O substrate
• Many interesting research issuesMany interesting research issues– consistency vs. efficiency, replica management, load consistency vs. efficiency, replica management, load
balancing and request distribution, extensibility, balancing and request distribution, extensibility,
specialization, …specialization, …
• Measurable success metricMeasurable success metric– simplification of existing Ninja servicessimplification of existing Ninja services
– adoption for use in construction new Ninja servicesadoption for use in construction new Ninja services

Taxonomy of Clustered ServicesTaxonomy of Clustered Services
simplify the job of constructing theseclasses of servicesGoal:Goal:
StatelessStateless Soft-stateSoft-state Persistent StatePersistent State
TACC distillersRiver modules
Video Gateway
TACC aggregatorsAS1 servents or RMX
Squid web cache
ParallelismsScalable PIM appsHINDE mint
ExamplesExamples
State Mgmt.State Mgmt.RequirementsRequirements
Little or none
• high availability• perhaps consistency• persistence is an optimization
• high availability and completeness• perhaps consistency• persistence necessary
Inktomi search engine

PerformancePerformance
• Bulk-loading of database dominated by disk access Bulk-loading of database dominated by disk access
timetime– can achieve can achieve 1500 inserts per second1500 inserts per second per node on 100 Mb/s per node on 100 Mb/s
Ethernet cluster, if hash table fits in memory (dominant cost Ethernet cluster, if hash table fits in memory (dominant cost
is messaging layer)is messaging layer)
– otherwise, degrades to about otherwise, degrades to about 30 inserts per second30 inserts per second
(dominant cost is disk write time)(dominant cost is disk write time)
• In steady state, all nodes operate primarily out of In steady state, all nodes operate primarily out of
memory, as the working set is fully paged inmemory, as the working set is fully paged in– similar principle to research Inktomi cluster similar principle to research Inktomi cluster
– handles hundreds of queries per s. on 4 node cluster w/ 2 handles hundreds of queries per s. on 4 node cluster w/ 2
FE’sFE’s
loglog
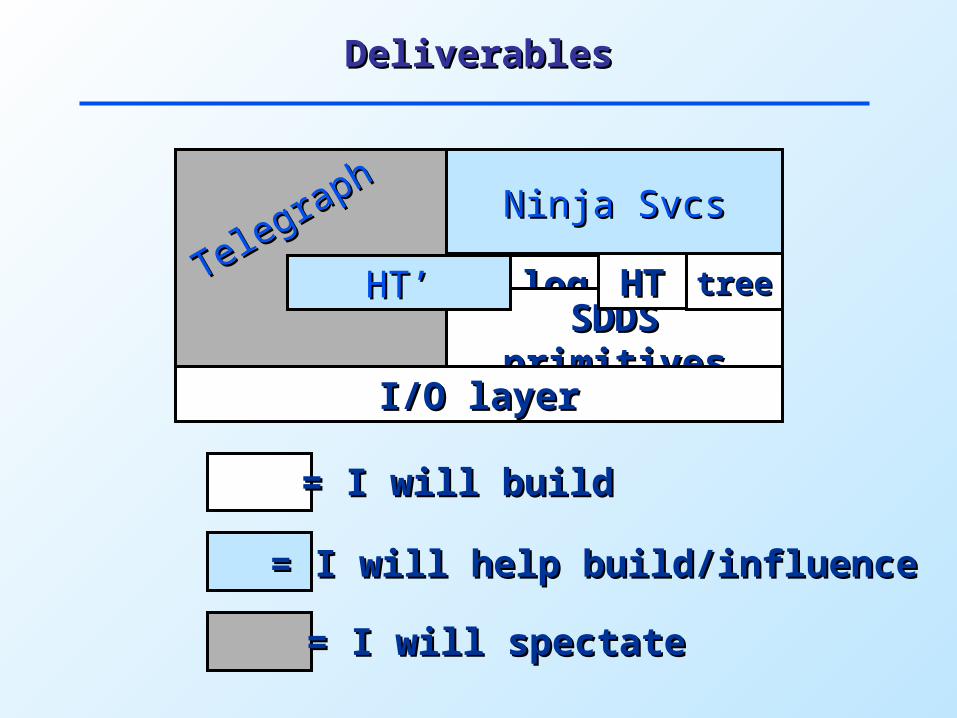
DeliverablesDeliverables
SDDS SDDS primitivesprimitives
HTHT treetreeHT’HT’Telegraph
TelegraphNinja SvcsNinja Svcs
= I will build= I will build
I/O layerI/O layer
= I will help build/influence= I will help build/influence
= I will spectate= I will spectate










![[27] S.D. Gribble, G.S. Manku, and E. Brewer. Self ...users.eecs.northwestern.edu/~peters/references/... · of network services can get by with BASE, a weaker-than-ACID data semantics](https://img.pdfslide.us/doc/110x75/60a36388344d2f4a0475c540/27-sd-gribble-gs-manku-and-e-brewer-self-userseecs-petersreferences.jpg)

![[27] S.D. Gribble, G.S. Manku, and E. Brewer. Self-Similarity in File …brewer/papers/sosp... · 1998-09-08 · ments of our reviewers, especially our shepherd Hank Levy. We thank](https://img.pdfslide.us/doc/110x75/5e751b835f85050bd5705cd2/27-sd-gribble-gs-manku-and-e-brewer-self-similarity-in-file-brewerpaperssosp.jpg)
















