Embed Size (px)
Citation preview

Short Papers

Neural Networks for Adaptive Vehicle Control
J. Kaste(B), J. Hoedt(B), K. Van Ende(B), and F. Kallmeyer(B)
Volkswagen AG, Group Research, Berliner Ring 2, 38436 Wolfsburg, Germany{jonas.kaste,jens.hoedt,kristof.van.ende,felix.kallmeyer}@volkswagen.de
Abstract. With increasing computational performance and the pos-sibility to collect huge amounts of training data, Machine Learningapproaches gain a lot of interest in the automotive community [1]. Toprocess all the given information and enable an accurate and convenientdriving experience, a robust control strategy is required for autonomousvehicles. Recent work on vehicle control at the limit of handling hasshown good results for ensuring trajectories precisely under complexconditions [2]. In terms of changing conditions, deviations from the con-troller operating point, for example damages or inaccurate modeled sys-tems, might cause a heavy decrease in control performance. To over-come those issues, it is possible to combine classic model based controlapproaches with learning algorithms [4]. To evaluate the potential of arti-ficial neural networks in addition to a model based control approach thepresent study investigates different topologies and training methods foriteratively trained neural networks in the closed control loop. The neuralnetwork is implemented in a cascaded lateral controller, to compensateremaining control errors in yaw motion and lateral deviation.
The objective is to decrease the control errors, learning the dependen-cies between vehicle dynamic parameters and model errors and to showthe potential of artificial neural networks to increase control performanceover time. Related to [3] the potential for increased robustness in caseof heavy error intrusion (e.g. steering angle offset) is investigated foran autonomous vehicle at the limit of handling. The achieved results arepromising in terms of fast recovery and precise trajectory following, aftera steering angle offset up to 90◦. During the tests the observed long timestability indicated potential for further investigations regarding memorybased approaches e.g. recurrent networks.
Keywords: Autonomous driving · Online training · Adaptive control
References
1. Prokhorov, D.: Computational Intelligence in Automotive Applications. Springer-Verlag, Heidelberg (2008)
2. Kritayakirana, K.M.: Autonomous vehicle control at the limit of handling. Ph.D.thesis, Stanford University (2012)
3. Schnetter, P., Kaste, J., Krueger, T.: Advanced sliding mode online training forneural network flight control applications. (AIAA 2015-1323) (2015)
4. Urnes, J.: Intelligent flight systems: Progress and potential of this technology. In:Aviation Safety Technical Conference (2007)
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 417, 2017.https://doi.org/10.1007/978-3-319-68600-4

Brain–Computer Interface with Robot-AssistedTraining for Neurorehabilitation
Roman Rosipal1(B), Natalia Porubcova2, Peter Barancok3, Barbora Cimrova3,Michal Teplan1, and Igor Farkas3
1 Institute of Measurement Science, Slovak Academy of Sciences, Bratislava, Slovakia{roman.rosipal,michal.teplan}@savba.sk
2 EuroRehab, S.r.o., Bratislava, [email protected]
3 Faculty of Mathematics, Physics and Informatics, Comenius Universityin Bratislava, Bratislava, Slovakia
[email protected], {barbora.cimrova,igor.farkas}@fmph.uniba.skhttp://www.um.sav.sk/projects/BCI-RAS/
Abstract. To improve upper limb neurorehabilitation in chronic strokepatients, we apply new methods and tools of clinical training and machinelearning for the design and development of an intelligent system allowingthe users to go through the process of self-controlled training of impairedmotor pathways. We combine the brain–computer interface (BCI) tech-nology with a robotic splint into a compact system that can be used as arobot-assisted neurorehabilitation tool.
First, we use themirror therapy (MT)which represents amental processwhere an individual rehearses a specific limb movement by reflecting themovements of the non-paretic side in the mirror as if it were the affectedside. This step is not used for improving the motor functions only, butalso for identification of subject’s specific electroencephalogram (EEG)oscillatory elemental patterns or “atoms” associated with imagery or realhandmovements.We estimate theseEEGatomsusing amultiway analysis,specifically the parallel factor analysis (PARAFAC) for modeling. Usingthe data from a longitudinal case study, we will report statically signifi-cant effects of the MT on the modulation of sensorimotor EEG atoms of apatient with chronic upper limb impairment due to a stroke.
Second, we introduce the BCI-based robotic system operating on theprinciple of the motor imagery and incorporating a reward-based physicalmovement of the impaired upper limb. The novelty of this approach lies inthe design of the control protocol which uses spatial and frequency weightsof the previously estimated sensorimotor atoms during the MT sessions.By projecting the recorded EEG onto the spatial and frequency weights,one-dimensional time scores of the atoms are computed. Getting under theempirically preset threshold of the scores triggers the robotic splint whichexecutes the physical movement with the impaired hand (up and down).We will report analytical and clinical results of three patients with differentseverity of the upper limb impairment due to a stroke and different lengthsof the proposed neurorehabilitation training.
Keywords: Brain–computer interface ·Robotic arm ·Multiway analysis
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 418, 2017.https://doi.org/10.1007/978-3-319-68600-4

Unsupervised Learning of Factors of Variationin the Sensory Data of a Planar Agent
Oksana Hagen1(B) and Michael Garcia Ortiz2(B)
1 AI Lab, Softbank Robotics Europe and Plymouth University, Plymouth, [email protected]
2 AI Lab, Softbank Robotics Europe, Plymouth, [email protected]
Abstract. An autonomous agent needs means to perceive the outsideworld by interpreting its sensory data. In many cases it is not possibleto provide the agent with the detailed description of everything it mayencounter. So it has to build useful explanations of the world by itself,using only its own data.
In the case of a real robot with a set of IR sensors, which operates ina rectangular room, we assume that sensory data can be explained usinga finite number of factors of variation. We propose to build a genera-tive model of the observed data, where the finite number of probabilisticlatent variables z contributes to the observed data distribution P (x). Toinfer the latent distribution z we use a variational auto-encoder (VAE)[2]. It has been previously demonstrated in [1] that by manipulating theratio β between reconstruction and latent loss of the model it is possibleto recover the disentangled factors of variation in visual data.
We show, that VAE can efficiently learn to model noisy data distrib-ution from a real robot using a redundant set of latent variables, whilesimultaneously building sparse representation and extracting meaningfulstructure from the data. We illustrate in Fig. 1, that the latent variableslearned are indeed disentangled by showing how their variation influencesthe generated samples.
Keywords: Generative models · Representation learning · VAE
Fig. 1. Samples generated by varying two latent variables: each line corresponds toone generated sample with respect to change of one of the latent variables; each plotcorresponds to the change in the second latent variable. These variables independentlyencode distance and angle of the wall.
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 419–420, 2017.https://doi.org/10.1007/978-3-319-68600-4

420 O. Hagen and M.G. Ortiz
References
1. Higgins, I., Matthey, L., Pal, A., Burgess, C., Glorot, X., Botvinick, M.,Mohamed, S., Lerchner, A.: beta-VAE: learning basic visual concepts with a con-strained variational framework. In: ICLR (2017)
2. Kingma, D.P., Welling, M.: Auto-encoding variational bayes. In: ICLR (2014)

State Dependent Modulation of PerceptionBased on a Computational Model
of Conditioning
Jordi-Ysard Puigbo1,2(B), Miguel Angel Gonzalez-Ballester2,3(B),and Paul F.M.J. Verschure1,3(B)
1 Laboratory of Synthetic, Perceptive, Emotive and Cognitive Science (SPECS),DTIC, Universitat Pompeu Fabra (UPF), Barcelona, Spain
[email protected] Laboratory for Simulating, Imaging, and Modeling of Biological Systems(SIMBIOsys), DTIC, Universitat Pompeu Fabra (UPF), Barcelona, Spain
3 Catalan Research Institute and Advanced Studies (ICREA), Barcelona, Spain
Abstract. The embodied mammalian brain evolved to adapt to an onlypartially known and knowable world. The adaptive labeling of the worldis critically dependent on the neocortex which in turn is modulated bya range of subcortical systems such as the thalamus, ventral striatumand the amygdala. A particular case in point is the learning paradigmof classical conditioning where acquired representations of states of theworld such as sounds and visual features are associated with predefineddiscrete behavioral responses such as eye blinks and freezing. Learningprogresses in a very specific order, where the animal first identifies thefeatures of the task that are predictive of a motivational state and thenforms the association of the current sensory state with a particular actionand shapes this action to the specific contingency. This adaptive featureselection has both attentional and memory components, i.e. a behav-iorally relevant state must be detected while its representation must bestabilized to allow its interfacing to output systems. Here we present acomputational model of the neocortical systems that underlie this fea-ture detection process and its state dependent modulation mediated bythe amygdala and its downstream target, the nucleus basalis of Meyn-ert. Specifically, we analyze how amygdala driven cholinergic modula-tion switches between two perceptual modes [1], one for exploitation oflearned representations and prototypes and another one for the explo-ration of new representations that provoked these change in the moti-vational state, presenting a framework for rapid learning of behaviorallyrelevant perceptual representations. Beyond reward-driven learning thatis mostly based on exploitation, this paper presents a complementarymechanism for quick exploratory perception and learning grounded onthe understanding of fear and surprise.
Reference
1. Angela, J.Y., Dayan, P.: Uncertainty, neuromodulation, and attention. Neuron46(4), 681–692 (2005)
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 421, 2017.https://doi.org/10.1007/978-3-319-68600-4

Optimal Bases Representation for EmbodiedSupervised Learning
Ivan Herreros1(B), Xerxes D. Arsiwalla1(B), and Paul Verschure1,2
1 Synthetic Perceptive Emotive and Cognitive Systems (SPECS) Lab,Center of Autonomous Systems and Neurorobotics, Universitat Pompeu Fabra,
Barcelona, [email protected]
2 Institucio Catalana de Recerca i Estudis Avancats (ICREA), Barcelona, Spain
Abstract. Standard implementations of supervised learning for time-series predictions are disembodied, meaning that the learning systemdoes not affect the predicted events. However, in the case of embodiedsystems which learn to act in a supervised manner, predictions may leadto actions that change the forecasted events. For instance, in classicalconditioning, blinking to a predicted air-puff changes its physical conse-quences in the sensory channels. Hence, optimal learning requires takinginto account the dynamics of the process by which the learning agentcan act on those events [1]. Here we formalize this problem as learninga linear combination of basis signals in order to drive the output of adynamical system along a desired trajectory. Accordingly, we show that,in contrast to standard supervised learning schemes, wherein the opti-mal bases for learning are those which are maximally de-correlated, inembodied supervised learning the optimal bases are those that maximallyde-correlate their effects on the system’s output.
Keywords: Supervised learning · Adaptive control · Embodied agents ·Cerebellum
Acknowledgments. This work has been supported by the European Research Coun-cil’s CDAC project: “The Role of Consciousness in Adaptive Behavior: A CombinedEmpirical, Computational and Robot based Approach” (ERC-2013-ADG 341196).
Reference
1. Herreros, I., Arsiwalla, X., Verschure, P.: A forward model at Purkinje cell synapsesfacilitates cerebellar anticipatory control. Adv. Neural Inf. Process. Syst. 3828–3836(2016)
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 422, 2017.https://doi.org/10.1007/978-3-319-68600-4

The Effects of Neuronal Diversityon Network Synchronization
Aubin Tchaptchet(B) and Hans Albert Braun
Institute of Physiology, Philipps University of Marburg, Marburg, [email protected], [email protected]
Abstract. We are examining the synchronization characteristics of a netof gap junction coupled neurons under the particular assumption that thenetwork is composed of diversity of individual Hodgkin-Huxley type neu-rons with randomized parameter values as implemented in the virtual Sim-Neuron laboratories (www.virtual-physiology.com, see also [1]). Uniformdistributions of basic parameters, like ion concentrations or half activationvalues, lead to distributions of different shape of the dynamically relevantion currents.
With the chosen randomization values there are typically around 80%of the neurons in the steady state while the others are periodically firingwith different firing rates in a broad range of about 10 to 200 Hz leading inan uncoupled array to seemingly irregular firing with tiny fluctuations inthe field potential. Introducing gap-junction coupling with Ic = gc(V–Vn)tends to synchronize the spiking of the individual neurons but, in contrastto a homogeneous net, a certain spike timing variability always remains.Some previously spiking neurons disappear some others are coming upwhile the majority of the neurons will mostly remain silent.
At high coupling strengths, the intervals between spike-generation canbe considerably lengthened which may be due to the strengthening of repo-larizing bias currents from the silent neurons slowing down the depolariza-tion of the spontaneously active neurons.This can even lead to a completelysilent net. In some other nets, at a certain coupling strength,more andmoreneurons are recruited to fire until only a few silent neurons remain. Suchopposite effects may essentially depend on the rheobase and, on the size ofthe neurons of which the network is composed.
These data demonstrate that the experimentally well known neuronaldiversity can be a relevant factor in determining neuronal network synchro-nization and therefore, beyond the mostly examined coupling strength,should also be considered in network simulations. Which parameters, orcombinations of them, are the relevant determinants of the network behav-ior shall be systematically examined in future simulations.
Keywords: Randomness · Pattern · Field potential
Reference
1. Tchaptchet, A., Postnova, S., Finke, C., Schneider, H., Huber, M.T., Braun, H.A.:Modeling neuronal activity in relation to experimental voltage-/patch-clamp record-ings. Brain Res. 1536, 159–167 (2013)
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 423, 2017.https://doi.org/10.1007/978-3-319-68600-4

Temporal Regions for Activity Recognition
Joao Paulo Aires(B), Juarez Monteiro, Roger Granada, Felipe Meneguzzi,and Rodrigo C. Barros
Faculdade de Informatica, Pontifıcia Universidade Catolica do Rio Grande do Sul,Av. Ipiranga, 6681, Porto Alegre, RS 90619-900, Brazil
{joao.aires.001,juarez.santos,roger.granada}@acad.pucrs.br,{felipe.meneguzzi,rodrigo.barros}@pucrs.br
Abstract. Recognizing activities in videos is an important task forhumans, since it helps the identification of different types of interactionswith other agents. To perform such task, we need an approach that isable to process the frames of a video and extract enough information inorder to determine the activity. When dealing with activity recognitionwe also have to consider the temporal aspect of videos since activitiestend to occur through the frames. In this work, we propose an approachto obtain temporal information from a video by dividing its frames intoregions. Thus, instead of classifying an activity using only the informa-tion from each image frame, we extract and merge the information fromseveral regions of the video in order to obtain its temporal aspect. Tomake a composition of different parts of the video, we take one frame ofeach region and either concatenate or take the mean of their features. Forexample, consider a video divided into three regions and each frame con-taining ten features, the resulting vector of a concatenation will containthirty features, while the resulting vector of the mean will contain tenfeatures. Our pipeline includes pre-processing, which consists of resizingimages to a fixed resolution of 256×256; Convolutional Neural Networks,which extract features from the activity in each frame; region divisions,which divides each sequence of frames of a video into n regions of thesame size; and classification, where we apply a Support Vector Machine(SVM) on the features from the concatenation or mean phase in orderto predict the activity. Experiments are performed using The DogCen-tric Activity dataset [1] that contains videos with 10 different activitiesperformed by 4 dogs, showing that our approach can improve the activ-ity recognition task. We test our approach using two networks AlexNetand GoogLeNet, increasing up to 10% of precision when using regions toclassify activities.
Keywords: Neural networks · Convolutional neural networks · Activityrecognition
References
1. Iwashita, Y., Takamine, A., Kurazume, R., Ryoo, M.S.: First-person animal activityrecognition from egocentric videos. In: ICPR 2014 (2014)
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 424, 2017.https://doi.org/10.1007/978-3-319-68600-4

Computational Capacity of a Cerebellum Model
Robin De Gernier1(B), Sergio Solinas2, Christian Rossert3, Jonathan Mapelli4,Marc Haelterman1, and Serge Massar1
1 Universite libre de Bruxelles, Brussels, [email protected]
2 University of Sassari, Sassari, Italy3 Ecole polytechnique Federale de Lausanne, Lausanne, Switzerland4 Universita degli Studi di Modena E Reggio Emilia, Modena, Italy
Abstract. Linking network structure to function is a long standing issuein the neuroscience field. An outstanding example is the cerebellum. Itsstructure was known in great detail for decades but the full range ofcomputations it performs is yet unknown. This reflects a need for newsystematic methods to characterize the computational capacities of thecerebellum. In the present work, we apply a method borrowed from thefield of machine learning to evaluate the computational capacity and theworking memory of a prototypical cerebellum model.
The model that we study is a reservoir computing rate model ofthe cerebellar granular layer in which granule cells form a recurrentinhibitory network and Purkinje cells are modelled as linear trainablereadout neurons. It was introduced by [2, 3] to demonstrate how therecurrent dynamics of the granular layer is needed to perform typicalcerebellar tasks (e.g. : timing-related tasks).
The method, described in detail in [1], consists in feeding the modelwith a random time dependent input signal and then quantifying howwell a complete set of functions (each function representing a differenttype of computation) of the input signal can be reconstructed by taking alinear combination of the neuronal activations. We conducted simulationswith 1000 granule cells. Relevant parameters were optimized within a bio-logically plausible range using a Bayesian Learning approach. Our resultsshow that the cerebellum prototypical model can compute both linearfunctions - as expected from previous work -, and - surprisingly - highlynonlinear functions of its input (specifically, up to the 10th degree Legen-dre polynomial functions). Moreover, the model has a working memoryof the input up to 100ms in the past. These two properties are essen-tial to perform typical cerebellar functions, such as fine-tuning nonlinearmotor control tasks or, we believe, even higher cognitive functions.
Keywords: Cerebellum ·Computational capacity ·Reservoir computing
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 425–426, 2017.https://doi.org/10.1007/978-3-319-68600-4

426 R. De Gernier et al.
References
1. Dambre, J., Verstraeten, D., Schrauwen, B., Massar, S.: Information processingcapacity of dynamical systems. Sci. Rep. 2(514) (2012)
2. Rossert, C., Dean, P., Porrill, J.: At the edge of chaos: how cerebellar granular layernetwork dynamics can provide the basis for temporal filters. PLoS Comput. Biol.11(10), e1004515 (2015)
3. Yamazaki, T., Tanaka, S.: Neural modeling of an internal clock. Neural Comput.17(5), 1032–1058 (2005)

The Role of Inhibition in Selective Attention
Sock Ching Low1, Riccardo Zucca1, and Paul F.M.J. Verschure1,2(B)
1 SPECS, Universitat Pompeu Fabra, Barcelona, Spain{sockching.low,riccardo.zucca,paul.verschure}@upf.edu
2 Institucio Catalana de Recerca i Estudis Avancats (ICREA), Barcelona, Spainhttps://www.specs.upf.edu
Abstract. The phenomenon of attending to a stimulus is at the neu-ronal level usually assumed to mean an increase in excitation of the neu-rons representing that stimulus and or its underlying features. This isstrongly influenced by the notion that attention works like a spot light.Increased neuronal activity is not only observed in the presence of anattended stimulus [7], but such an increased activity has been also foundin the absence of the stimulus as long as it is expected to be present [4]. Itis thus demonstrated that attention can be affected by both bottom-upinformation from the environment, and top-down typically informationconsidered to originate in the prefrontal cortex (PFC). This bottom-up/top-down interaction results in a selection of stimuli to attend to [5].In the case of visual information, there are established pathways in thehuman brain that allow for excitatory influences from the frontal corticeson the input processing pathways of the thalamus [1, 2]. However, otherpuzzling attentional effects, such as inattentional blindness, exist andseem to contradict this mechanism. A complementary view on attentionis the concept of the Validation Gate (VG) [6]. It posits that throughboth excitation and inhibition, predicted features can be downregulatedto increase sensitivity to novelty. The same aforementioned pathwayscould also allow for such indirect inhibition of input to the thalamus viathe thalamic reticular nucleus (TRN) [9–11]. Here, we investigate theviability of this thalamocortical substrate by computationally modellingit with a network consisting of four distinct populations of spiking neu-rons: specific and non-specific nuclei of the thalamus, the thalamic retic-ular nucleus, and a cortical map [3, 8]. We validate the model using anexperimental protocol in which the network has to attend to a region ofinterest (ROI). Only stimuli appearing within the ROI is task-relevant.We show that in the absence of PFC influence, the modelled corticalmap exhibits activity proportional to the size of the stimulus. However,PFC activity can bias the cortical response through a marked decrease inactivity in response to stimuli outside of the ROI and a slight increase forthat within the ROI. This modulatory effect ensures that stimuli withinthe ROI consistently elicit stronger activation than those outside of it,regardless of size. Our results thus provide support for the mechanism ofinhibitory attention with the TRN as its hub.
Keywords: Selective attention · Thalamocortical system ·Computational models
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 427–428, 2017.https://doi.org/10.1007/978-3-319-68600-4

428 S.C. Low et al.
References
1. Behrens, T.E.J., Johansen-Berg, H., Woolrich, M.W., Smith, S.M.:Wheeler-Kingshott, C.A.M., Boulby, P.A., Barker, G.J., Sillery, E.L., Sheehan, K.,Ciccarelli, O., Thompson, A.J., Brady, J.M., Matthews, P.M.: Non-invasivemapping of connections between human thalamus and cortex using diffusionimaging. Nature Neurosci. 6(7), 750–757 (2003)
2. Gollo, L.L., Mirasso, C., Villa, A.E.: Dynamic control for synchronization of sep-arated cortical areas through thalamic relay. Neuroimage 52(3), 947–955 (2010)
3. Izhikevich, E.M.: Simple model of spiking neurons. IEEE Trans. Neural Netw.14(6), 1569–1572 (2003)
4. Kastner, S., Pinsk, M.A., De Weerd, P., Desimone, R., Ungerleider, L.G.: Increasedactivity in human visual cortex during directed attention in the absence of visualstimulation. Neuron 22(4), 751–61 (1999)
5. Kastner, S., Ungerleider, L.G.: Mechanisms of visual attention in the human cortex.Ann. Rev. Neurosci. 23, 315–341 (2000)
6. Mathews, Z., Cetnarski, R., Verschure, P.: Visual anticipation biases consciousdecision making but not bottom-up visual processing. Front. Psychol. 6 (2015)
7. Watanabe, M., Cheng, K., Murayama, Y., Ueno, K., Asamizuya, T., Tanaka, K.,Logothetis, N.: Attention but not awareness modulates the BOLD signal in thehuman V1 during binocular suppression. Science 334(6057), 829–831 (2011)
8. van Wijngaarden, J.B.G., Zucca, R., Finnigan, S., Verschure, P.F.M.J.: The impactof cortical lesions on thalamo-cortical network dynamics after acute ischaemicstroke: a combined experimental and theoretical study. PLOS Comput. Biol. 12(8),e1005048 (2016)
9. Wimmer, R.D., Schmitt, L.I., Davidson, T.J., Nakajima, M., Deisseroth, K.,Halassa, M.M.: Thalamic control of sensory selection in divided attention. Nature(2015)
10. Zikopoulos, B., Barbas, H.: Prefrontal projections to the thalamic reticular nucleusform a unique circuit for attentional mechanisms. J. Neurosci. 26(28), 7348–7361(2006)
11. Zikopoulos, B., Barbas, H.: Circuits for multisensory integration and attentionalmodulation through the prefrontal cortex and the thalamic reticular nucleus inprimates. Rev. Neurosci. 18(6), 417–38 (2007)

Stochasticity, Spike Timing, and a LayeredArchitecture for Finding Iterative Roots
Adam Frick1 and Nicolangelo Iannella2(B)
1 School of Electrical and Electronic Engineering, The University of Adelaide,Adelaide, Australia
[email protected] School of Mathematical Sciences, University of Nottingham, Nottingham, UK
https://www.researchgate.net/profile/Nicolangelo Iannella,
http://www.nottingham.ac.uk/mathematics/people/nicolangelo.iannella
Abstract. The human brain and human intelligence has come a longway having evolved the ability to do many things including solving diffi-cult mathematical problems and understanding complex operations andcomputations. How these abilities are implemented within the brain ispoorly understood, but typically tackled by asking what type of compu-tations networks of neurons are capable of? Previous studies have shownhow both artificial neural networks (based upon MultiLayer PerceptronsMLPs) and networks of (biologically inspired) spiking neurons can solvesingle tasks efficiently, such as character recognition or nonlinear functionapproximation [1, 5, 6]. There are, however, many nontrivial yet impor-tant industrial and physical problems that rely upon computations basedon iteration and composition. There have been rare demonstrations ofneural networks solving multiple tasks simultaneously but the few avail-able examples have shown they are able to solve functional equations.This exemplifies the likelihood that the computational power of neuralpopulations has been under estimated and their true capabilities arefar greater than than previously thought. Significantly, previous studieshave shown that the solution to a particular class of functional equa-tions, called the functional iterative root or half-iterate, is attainableusing MLPs and is continuous in nature [3, 4]. Methods which employnetworks of spiking neurons have, til now, shown that piecewise con-tinuous solutions are obtainable [2]. Here, we demonstrate that takingadvantage of the stochastic or probabilistic nature of spike generationand population coding, spiking neural networks can learn to find solu-tions to iterative root that are continuous in nature. Specifically, we showhow plasticity, the stochastic nature of neuronal spike generation, andpopulation coding allows spiking neural networks to find solutions tofunctional equations, like the iterative root of monotonically increasingfunctions, in a continuous manner. Significantly, our work expands thefoundations of neural-based computation by demonstrating a nontrivialunderlying computational principle: robustness through uncertainty.
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 429–430, 2017.https://doi.org/10.1007/978-3-319-68600-4_57

430 A. Frick and N. Iannella
Keywords: Spiking neural network · Functional equations · Iterativeroot · Artificial intelligence
References
1. Iannella, N., Back, A.: A spiking neural network architecture for nonlinear functionapproximation. Neural Netw. 14, 933–939 (2001)
2. Iannella, N., Kindermann, L.: Finding iterative roots with a spiking neural network.Inform. Proc. Lett. 95, 545–551 (2005)
3. Kindermann, L., Georgiev, P.: Modelling iterative roots of mappings in multidi-mensional spaces. In: Proceedings of the 9th International Conference on NeuralInformation Systems, pp. 2655–2659 (2002)
4. Kindermann, L.: Computing iterative roots with neural networks. In: The 5th Inter-national Conference on Neural Information Systems, pp. 713–715 (1998)
5. Maass, W.: Fast sigmoidal networks via spiking neurons. Neural Comput. 9, 279–304(1997)
6. Sanger, T.D.: Probability density methods for smooth function approximation andlearning in populations of tuned spiking neurons. Neural Comput. 10, 1567–1586(1998)

Matching Mesoscopic Neural Modelsto Microscopic Neural Networks in Stationary
and Non-stationary Regimes
Lara Escuain-Poole(B), Alberto Hernandez-Alcaina, and Antonio J. Pons
Department of Physics, Universitat Politecnica de Catalunya–BarcelonaTech,Barcelona, Spain
Abstract. A whole group of mesoscopic neural models, often calledneural mass models, reflect the averaged activity of networks of thou-sands of neurons. A general statistical approach may be taken to reducethe complex microscopic dynamics to that described by these very simplemesoscopic models. The approach is limited, however, to situations wherethe input that feeds the microscopic network does not vary in time. Thiscondition limits the general validity of mesoscopic models. In particular,the parameters that result from the derivation of the mesoscopic modelare valid only in stationary regimes and, therefore, in transient regimesthey cannot be well defined. This limitation raises reasonable doubtsabout the validity of the dynamical description of networks of mesoscopicmodels, where the output of one mesoscopic model becomes the input ofothers. In this work, we explore the variation in time of these mesoscopicparameters when the inputs of the microscopic neural networks whichthey aim to characterize are not stationary. By using Kalman filteringtechniques we estimate the evolution of these parameters in both station-ary and non-stationary regimes. By doing this, we match the descriptionof a mesoscopic model to that of a neural network. Our results showthat this matching is possible in stationary regimes, but in some non-stationary regimes, memory effects appear which are not accounted forin the standard mesoscopic derivation.
Keywords: Mesoscopic neural models · Microscopic neural networks ·Scale bridging · Non-stationary regimes
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 431, 2017.https://doi.org/10.1007/978-3-319-68600-4

Hyper Neuron - One Neuronwith Infinite States
Shabab Bazrafkan(B), Joseph Lemley, and Peter Corcoran
National University of Ireland, Galway, Galway, Ireland{s.bazrafkan1,peter.corcoran}@nuigalway.ie
http://www.c3imaging.org
Abstract. Neural networks learn by creating a decision boundary. Theshape and smoothness of the decision boundary is ultimately deter-mined by the activation function and the architecture. As the number ofneurons in an artificial neural network increase to infinity, the decisionfunction becomes smooth. A network with an infiniete number of neu-rons is impossible to implement with finite resources, but the behaviorof such a network can be modeled to an arbitrary degree of precisionby using standard numerical techniques. We named the resulting modelHyper Neuron.
A flexible characteristic function controlling the rate of variations inthe weights of these neurons is used. The Hyper Neuron does not requireany assumptions about the parameter distribution. It utilizes a numer-ical methodology that contrasts with previous work (such as infiniteneural networks) which relies on assumptions about the distribution.
In the classical model of a neuron, each neuron has a single state andoutput which is determined by an input, the weights, and the bias. Con-sider a neuron with more than one distinct output for the same input.A layer made from an infinite number of these neurons can be mod-eled as a single neuron with an infinite number of states and an infiniteweight field. This kind of neuron is called a “Hyper Neuron” indicatedby symbol �. Now consider the independent variable x where the HyperNeuron is defined over it i.e., the function �(x) is defined over the spacex ∈ R
N To model the data in such a way that it represents the targetdistribution, we use weighted inputs and non-linearity functions, wherethe weights are not vectors but instead are multidimensional functionsfk,k+1ch (xk,xk+1;pk+1) which define the weight field between two HyperNeurons when the input is given by another Hyper Neuron. This func-tion is simplified as f
ik,k+1ch (xk+1;pk+1) when the input is a feature
space or a conventional layer. In these equations k is the previous layer,k + 1 is the layer with the Hyper Neuron, ik is the ith element in theprevious layer and p represents parameters of the weight field function.
Hyper Neurons follow naturally from numerical models involving aninfinite number of conventional neurons in a single layer and the associ-ated weight fields are described by characteristic functions. To validatethis idea, experiments were performed that used sinusoidal functions for
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 432–433, 2017.https://doi.org/10.1007/978-3-319-68600-4

Hyper Neuron - One Neuron with Infinite States 433
the weight fields, because they allowed rapid changes due to the inclu-sion of their frequency as a parameter that the network learned fromthe input data. A comparison between the proposed model and a con-ventional model containing up to 7 neurons was performed.
Keywords: Artificial neural networks · Numerical modeling · Infiniteneural networks

Sparse Pattern Representation in a RealisticRecurrent Spiking Neural Network
Jesus A. Garrido(B) and Eduardo Ros(B)
Department of Computer Architecture and Technology, CITIC-UGR,University of Granada, Granada, Spain
{jesusgarrido,eros}@ugr.es
Abstract. The reliability of brain learning strongly depends on thequality of spatio-temporal pattern representation. However, the way neu-ronal mechanisms contribute to generate distinguishable representationsremains largely unknown. In this sense, sparse codes combine the rep-resentational capacity of dense codes and the accuracy of learning withlocal codes. The most representative structure of sparse coding in thenervous system is the cerebellum since it accounts in its input layer witharound 50 billion granule cells (which represent half of the neurons in thebrain). Each granule cell receives input, on average, from only 4 mossyfibers [2].
In this work we have reproduced a 100um-length cube of the cerebellarinput layer according to experimental data of neuronal density, electri-cal properties of neurons, connectivity constraints and dendritic length.The network was equipped with leaky integrate and fire neurons withadaptive threshold, since this neuron model has shown very effective inpattern transmission [1]. The input layer has been stimulated with fouroverlapping current patterns and oscillations in theta-frequency band(8Hz) as previously presented in [3]. By connecting the resulting activ-ity of the granule cells to a single-layer perceptron we have assessed thequality of pattern representation.
The perceptron obtained 97 percent of pattern recognition accuracyin the test subset. Both recurrent inhibition and adaptive threshold con-tributed to keep granule cell activity sparse, while theta-band frequencyoscillations at the input enabled synchronization between successive neu-ronal layers.
Keywords: Pattern representation · Recurrent networks · Oscillations ·Cerebellum
References
1. Asai, Y., Villa, A.E.: Integration and transmission of distributed deterministicneural activity in feed-forward networks. Brain Res. 1434, 17–33 (2012)
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 434–435, 2017.https://doi.org/10.1007/978-3-319-68600-4

Sparse Pattern Representation in a Realistic Recurrent 435
2. Cayco-Gajic, A., Clopath, C., Silver, R.A.: Sparse synaptic connectivity is requiredfor decorrelation and pattern separation in feedforward networks, p. 108431 (2017).bioRxiv
3. Garrido, J.A., Luque, N.R., Tolu, S.: Oscillation-driven spike-timing dependent plas-ticity allows multiple overlapping pattern recognition in inhibitory interneuron net-works. Int. J. Neural Syst. 26, 1650020 (2016)

Gender Differences in Spontaneous RiskyDecision-Making Behavior: A Hyperscanning
Study Using Functional Near-InfraredSpectroscopy
Mingming Zhang1(B), Tao Liu2, Matthew Pelowski3, and Dongchuan Yu1(B)
1 Key Laboratory of Child Development and Learning Science,Ministry of Education, Research Center for Learning Science, Southeast University,
Nanjing, China{230149278,dcyu}@seu.edu.cn
2 Department of Marketing, School of Management, Zhejiang University,Hangzhou, [email protected]
3 Department of Basic Psychological Research and Research Methods,Faculty of Psychology, Vienna University, Vienna, Austria
Abstract. Previous studies have demonstrated that genders tend toshow different behavioral and neural patterns in risky decision-makingsituations. These studies, however, mainly focused on intra-brain mech-anisms in single participants. To examine neural substrates underly-ing risky decision behaviors in realistic, interpersonal interactions, thepresent study employed a functional near-infrared spectroscopy (fNIRS)hyperscanning technique to simultaneously measure pairs of participants’frontotemporal activations in a face-to-face gambling card-game. Thisresulted in two main findings: The intra-brain analysis revealed higheractivations in the orbitofrontal cortex (OFC), the medial prefrontal cor-tex (mPFC) and the posterior superior temporal sulcus (pSTS) in casesinvolving decisions carrying higher, versus more conservative, risk. Thisaligns with previous literature, indicating the importance of the mental-izing network in such decision-making tasks. Second, while both malesand females showed interpersonal neural synchronization (INS) in theirdlPFC in both risky and conservative decisions, as well as in the pSTSfor females. Furthermore, females also showed INS in their mPFC inconservative decisions. The inter-brain analysis suggests that males andfemales may have different strategies in risky decision tasks. Males maymake a risky decision depending on their non-social cognitive ability, andfemales may use their social cognitive ability to yield a choice. To ourbest knowledge, the present study is the first to investigate the interbrainprocessing of risky decision-making behavior in real face-to-face interac-tions. The implications of this outcome are also discussed for the generaltopics of human interaction and two-person neuroscience.
Keywords: Gender differences · Risky decision-making ·Hyperscanning · fNIRS · Interpersonal neural synchronization
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 436, 2017.https://doi.org/10.1007/978-3-319-68600-4

An Implementation of a Spiking Neural NetworkUsing Digital Spiking Silicon Neuron Model
on a SIMD Processor
Sansei Hori1(B), Mireya Zapata2, Jordi Madrenas2, Takashi Morie1,and Hakaru Tamukoh1
1 Graduate School of Life Science and Systems Engineering,Kyushu Institute of Technology, Kitakyushu, Japan
[email protected], {morie,tamukoh}@brain.kyutech.ac.jp2 Department of Electronics Engineering, Universitat Politecnica de Catalunya,
Barcelona, Spain{mireya.zapata,jordi.madrenas}@upc.edu
Abstract. We implement a digital spiking silicon neuron (DSSN) [1] ina single instruction multiple data (SIMD) processor. The SIMD proces-sor is a scalable, reconfigurable, and real-time spiking neural networkemulator based on field programmable gate arrays [2]. We implementthe DSSN model in the SIMD processor for the first time. The behaviorof the membrane potential of one neuron based on the DSSN model isshown in Fig. 1. The operation results of the SIMD processor with 16-bit fixed-point operation are compared with software simulation resultsbased on 64-bit floating-point operation. From the results, it is concludedthat the SIMD processor successfully emulated the behavior of the mem-brane potential. In addition, a full-connection network consisting of 100neurons is simulated in a software using fixed-point binary numbers toevaluate the bit width for the SIMD processor. In this experiment, thenetwork stores two patterns selected from [1]. In the recall phase, the firstpattern with noise is given to this network to recall the pattern. Exper-imental results show that the network with 16-bit fixed-point numbers,each of which includes a 12-bit fraction, a 3-bit integer, and a 1-bit sign,successfully recalled the input pattern as shown in Fig. 2. Here, Mu is arecall rate [1]. From this result, a large DSSN network simulation on theSIMD processor is promising.
Keywords: SNN · DSSN · SIMD processor · FPGA
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 437–438, 2017.https://doi.org/10.1007/978-3-319-68600-4
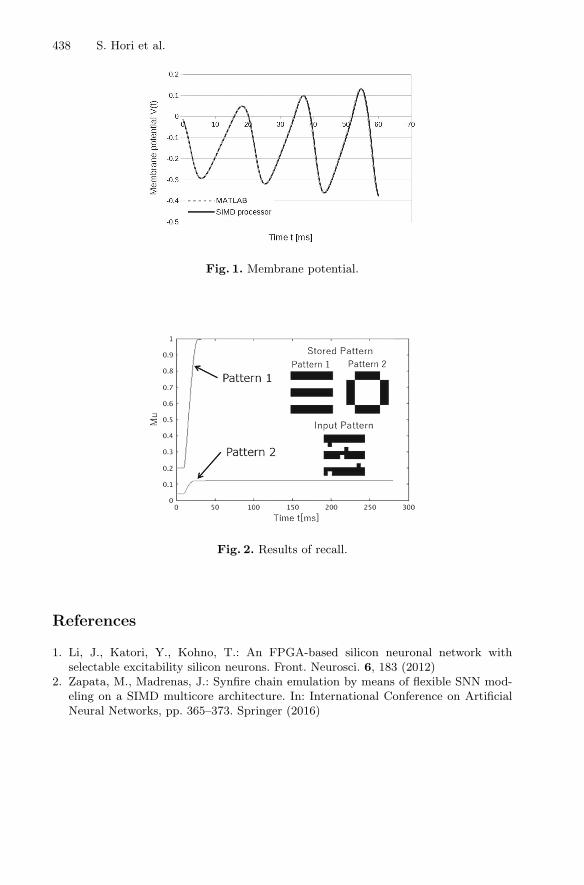
438 S. Hori et al.
Fig. 1. Membrane potential.
Fig. 2. Results of recall.
References
1. Li, J., Katori, Y., Kohno, T.: An FPGA-based silicon neuronal network withselectable excitability silicon neurons. Front. Neurosci. 6, 183 (2012)
2. Zapata, M., Madrenas, J.: Synfire chain emulation by means of flexible SNN mod-eling on a SIMD multicore architecture. In: International Conference on ArtificialNeural Networks, pp. 365–373. Springer (2016)

Hardware Implementation of DeepSelf-organizing Map Networks
Yuichiro Tanaka(B) and Hakaru Tamukoh(B)
Kyushu Institute of Technology, Kyushu, [email protected], [email protected]
http://www.brain.kyutech.ac.jp/ tamukoh/
Abstract. We aim to develop a recognition system of high accuracy andlow power consumption by designing a digital circuit for deep neuralnetworks (DNNs), and by implementing the circuit on field program-mable gate arrays (FPGAs). DNNs include numerous multiply opera-tions, whereas FPGAs include a limited number of multipliers. We aimto reduce the number of multiply operations generated by the algo-rithms within DNNs. Deep self-organizing map networks (DSNs) [1] areDNNs comprising self-organizing maps (SOMs) [2] as shown in Fig. 1. Ahardware-oriented algorithm for SOMs has been proposed herein [3]. Thealgorithm represents SOMs by replacing multiply operations with bitshiftoperations. DSNs that include only a few multiply operations can thenbe represented by employing the algorithm. In this paper, we propose ahardware-oriented algorithm and a hardware architecture for DSNs. Thehardware-oriented algorithm reduces multiply operations and exponen-tial functions in a computation of SOM Module as shown in Fig. 1. Inaddition, we confirm that the algorithm does not worsen performanceof DSN by a software simulation. Figure 2 shows error rates of DSNduring learning MNIST Dataset [4]. The performance of the proposedalgorithm achieve comparable results to the conventional algorithm. Wealso describe a DSN comprising three layers by Verilog-HDL as shownin Fig. 1, and implement it on a Xilinx Vertex-6 XC6VLX240T FPGA.Experimental results showed that the proposed DSN circuit estimates alabel of an input image in 2µs while the software implemented using anIntel Core i5-3470 (3.20 GHz) CPU estimates it in about 1 ms. Thusthe hardware is 500 times faster than the software. Its logic utilizationis shown in Table 1.
Keywords: Deep neural networks · Self-organizing maps · FPGAs
Table 1. Logic Utilization of DSN circuit
Used Utilization
Number of Slice Registers 26803 8%
Number of Slice LUTs 47830 31%
Number of Block RAM/FIFO 136 32%
Number of DSP48E1s 544 70%
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 439–441, 2017.https://doi.org/10.1007/978-3-319-68600-4
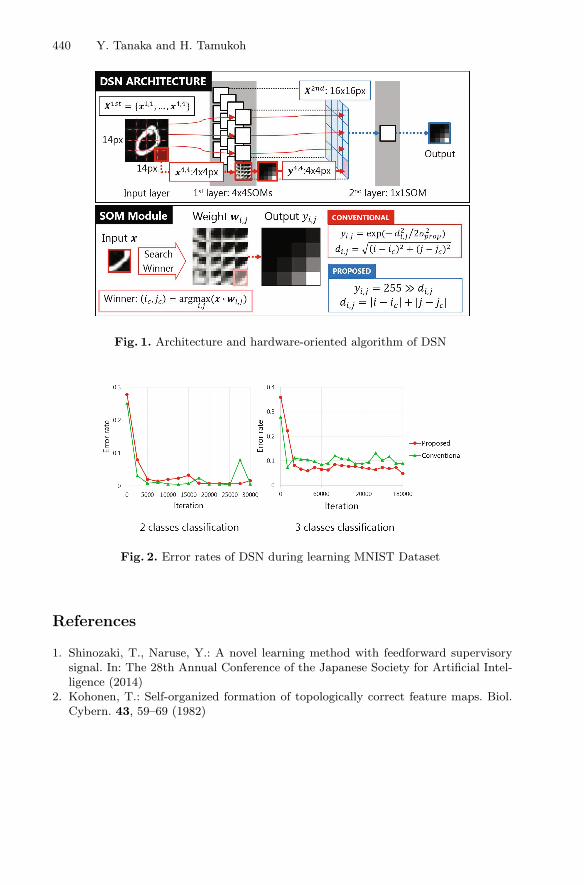
440 Y. Tanaka and H. Tamukoh
Fig. 1. Architecture and hardware-oriented algorithm of DSN
Fig. 2. Error rates of DSN during learning MNIST Dataset
References
1. Shinozaki, T., Naruse, Y.: A novel learning method with feedforward supervisorysignal. In: The 28th Annual Conference of the Japanese Society for Artificial Intel-ligence (2014)
2. Kohonen, T.: Self-organized formation of topologically correct feature maps. Biol.Cybern. 43, 59–69 (1982)

Hardware Implementation of Deep Self-organizing Map Networks 441
3. Tamukoh, H., Horio, K., Yamakawa, T.: Fast learning algorithms for self-organizingmap employing rough comparison WTA and its digital hardware implementation.IEICE Trans. Electron. E87-C(11), 1787–1794 (2004)
4. LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied todocument recognition. Proc. IEEE 86(11), 2278–2324 (1998)

A Model of Synaptic Normalizationand Heterosynaptic Plasticity Basedon Competition for a Limited Supply
of AMPA Receptors
Jochen Triesch(B)
Frankfurt Institute for Advanced Studies, Goethe University,Frankfurt am Main, Germany
Abstract. Simple models of Hebbian learning exhibit an unconstrainedgrowth of synaptic efficacies. To avoid this unconstrained growth, somemechanism for limiting weights needs to be present. There is a long tradi-tion of addressing this problem in neural network models using synapticnormalization rules. A particularly interesting normalization rule scalessynapses multiplicatively such that the sum of a neuron’s afferent exctia-tory synaptic weights remains constant. One attractive feature of such arule, next to its conceptual simplicity, is that in combination with Heb-bian mechanisms it can give rise to lognormal-like weight distributions asobserved experimentally. While such a normalization mechanism is notconsidered implausible, its link to neurobiology has been tenuous. A fullunderstanding of such synaptic plasticity arguably requires the devel-opment of models that capture its complexities at the molecular level.Inspired by recent findings on the trafficking of neurotransmitter recep-tors across a neuron’s dendritic tree, I propose a mathematical model ofsynaptic normalization and homeostatic heterosynaptic plastictiy basedon competition between a neuron’s afferent excitatory synapses for a lim-ited supply of AMPA receptors.
In the model, synapses on the dendritic tree of a neuron compete for alimited supply of AMPA receptors, which are produced and distributedacross the dendritic tree and stochastically transition into and out ofreceptor slots in the synapses, or simply disintegrate at a low rate. Usingminimal assumptions, the model produces fast multiplicative normaliza-tion behavior and leads to a homeostatic form heterosynaptic plasticityas observed experimentally. If the production rate of AMPA receptors iscontrolled homeostatically, the model also accounts for slow multiplica-tive synaptic scaling. Thus, the model offers a parsimonious and unifiedaccount of both fast normalization and slow scaling processes, which itboth predicts to act multiplicatively. It therefore supports the use of such
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 442–443, 2017.https://doi.org/10.1007/978-3-319-68600-4

A Model of Synaptic Normalization and Heterosynaptic Plasticity 443
rules in neural network models. Because of its simplicity and analyticaltractability, the model provides a convenient starting point for the devel-opment of more detailed models of the molecular mechanisms underlyingdifferent forms of synaptic plasticity.
Keywords: Heterosynaptic plastictiy · Synaptic scaling
Acknowledgment. I thank C. Tetzlaff, A.-S. Hafner, E. Schuman, and the QuandtFoundation.

Hebbian Learning Deducedfrom the Stationarity Principle Leadsto Balanced Chaos in Fully Adapting
Autonomously Active Networks
Claudius Gros1(B), Philip Trapp1, and Rodrigo Echeveste2
1 Institute for Theoretical Physics, Goethe University Frankfurt, Frankfurt, [email protected]
2 CBL, Department of Engineering, University of Cambridge, Cambridge, UK
Neural information processing includes the extraction of information presentin the statistics of afferent signals. For this, the afferent synaptic weights wj
are continuously adapted, changing in turn the distribution pθ(y) of the post-synaptic neural activity y, which is in turn dependent on parameters θ of theprocessing neuron. The functional form of pθ(y) will hence continue to evolve aslong as learning is ongoing, becoming stationary only when learning is completed.This stationarity principle can be captured by the Fisher information
Fθ =∫
pθ(y)(
∂
∂θln
(pθ(y)
))2
dy,∂
∂θ→
∑j
wj∂
∂wj
of the neural activity with respect to the afferent synaptic weights wj . The learn-ing rules derived from the stationarity principle are self-limiting [1], performinga standard principal component analysis with a bias towards a negative excessKurtosis [2].
798 799 800time [seconds]-40
-20
0
20
40
mem
bran
e po
tent
ial
excitatory inputtotal inputinhibitory input
200 (160,40) neurons (excitatory,inhibitory)For large autonomous networks
of continuous-time rate-encoding neu-rons, respecting Dale’s law and whosesynapses evolve under these plasticityrules, plus synaptic pruning, we find:(a) The continuously ongoing adap-tion of all synaptic weights leads to ahomeostatic self-regulation of the typ-ical magnitude of the synaptic weightsand of the neural activities. (b) The system settles into autonomously ongoingchaotic neural activity (the usual starting point for learning of coherent patternsof activity [3]) in which the excitatory and inhibitory inputs tend to balance eachother. (c) Short-term synaptic plasticity stabilizes the balanced state.
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 444–445, 2017.https://doi.org/10.1007/978-3-319-68600-4

Stationarity Principle for Hebbian Learning 445
References
1. Echeveste, R., Gros, C.: Generating functionals for computational intelligence: thefisher information as an objective function for self-limiting hebbian learning rules.Front. Robot. AI 1, 1 (2014)
2. Echeveste, R., Eckmann, S., Gros, C.: The fisher information as a neural guidingprinciple for independent component analysis. Entropy 17, 3838–3856 (2015)
3. Sussillo, D., Abbott, L.F.: Generating coherent patterns of activity from chaoticneural networks. Neuron 63(4), 544–557 (2009)

A Granule-Pyramidal Cell Model for Learningand Predicting Trajectories Online
Mehdi Abdelwahed1,2, Ihor Kuras1,2, Artem Meltnyk1,2,and Pierre Andry1,2(B)
1 ETIS UMR 8051, Universite Paris Seine, Cergy, France{mehdi.abdelwahed,pierre.andry}@ensea.fr
2 ENSEA, CNRS, Universite Cergy-Pontoise, Cergy, France
Abstract. In this poster, we outline a NN model for trajectories learn-ing and prediction online, i.e. to learn without knowing the future ofthe trajectory. Our model is based on the idea that a trajectory can belearned and recognized by chunks. Each chunk is learned by a predictionunit (PU). Hence, our problem can be divided in two parts: (1) how aPU can learn and recognize online a given chunk as a temporal category;and (2) how a global architecture allow the competition of many predic-tion units to provide the prediction of the whole trajectory thru time.The current poster aims at showing how (1) is feasible online providingdetails about tuning parameters, geometric scaling, time scaling, gener-alization, and starts to investigate possible mechanims for (2), from ARTinternal competition to synchronization with the external environment.Central to our model, one PU is based on a self-conditionning WidrowHoff rule for synapses connecting many granule cells (GC) that act astemporal gaussian filters of time, with one pyramidal cell (PC) learn-ing sensory-motor trajectories. One novelty of such PU is the use of arandom spacing of the learning through time and result in an efficientgradient descent while allowing a limited number of presentations of theinput (Fig. 1).
We have tested the PU on (1) handwritted letters with a graphic tabletand (2) a hydraulic humanoid robot for mass discrimination that lacks alow level information about the oil pressure level (no direct return aboutthe joint’s effort). We show that mass discrimination is possible by com-paring the robot’s arm trajectories with the prediction of the movementwith different mass.
Keywords: Spectrum generator · Granular cells · Cerebellum model ·Adaptive resonance theory · Motor trajectory
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 446–447, 2017.https://doi.org/10.1007/978-3-319-68600-4

A Granule-Pyramidal Cell Model for Learning 447
Fig. 1. Online evolution of the prediction and error accumulation of 3 categories ofhandwritten letters.

Single Neurons Can Memorize PreciseSpike Trains Immediately:A Computational Approach
Hubert Loeffler(&)
Independent Scholar, Bregenz, [email protected]
Abstract. Neuronal oscillations build the basis of the presented computationalmodel of memory of temporally precise spike trains. In particular, subthresholdmembrane potential oscillations (SMOs) of neuronal units enable a conversionof temporal properties of an input into spatial ones by phase coding [1, 2]. Sincethe excitability of units varies over time based on different phases of SMO, theinput spikes activate different units at different time points. For the storage, theconnections to the spatially distributed active units are enhanced by spiketiming-dependent plasticity (STDP). When the spatial distribution is realized bydifferent branches of a single neuron, the memory of the entire spike train islocated by the input connections to this neuron. At this local level, plasticitychanges emerge by dendritic spiking. As the prototype model was simulated viaa spiking neuronal network, a spike burst from the input unit could exactly recallevery randomly generated temporal input spike train. The time span of thememory is limited by the duration of unchanged oscillations between encodingand recall. This memory could act as working memory by replacing sustainedactivity. For now, the model combining oscillations and learning mechanisms isonly a theoretical realization of the memory of precise spike trains. However, itcomplements the so-called ReSuMe-models as a kind of implicit memory ofspike trains by learning associations between input and desired output spiketrains [e.g. 3].
Keywords: Temporally precise spike trains � Phase coding � Oscillations �Working memory
References
1. Nadasdy, Z.: Information encoding and reconstruction from the phase of action potentials.Front. Syst. Neurosci. 3, Article 6 (2009). doi:10.3389/neuro.06.006.2009.d
2. Maris, E., Fries, P.: Diverse Phase Relations among Neuronal Rhythms and Their PotentialFunction. Trends Neurosci. (2016). doi:10.1016/j.tins.2015.12.004
3. Ponulak, F., Kasinski, A.: Supervised learning in spiking neuronal networks with ReSuMe:sequence learning, classification, and spike shifting. Neuronal Comput. 22(2), 467–510(2010)
© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 448, 2017.https://doi.org/10.1007/978-3-319-68600-4

Learning Stable Recurrent Excitationin Simulated Biological Neural Networks
Michael Teichmann(B) and Fred H. Hamker
Department of Computer Science, Technische Universitat Chemnitz,Chemnitz, Germany
{michael.teichmann,fred.hamker}@informatik.tu-chemnitz.de
Abstract. Recurrent excitation is required to model advanced effectsof cortical processing, e.g. attentional feedback within the visual cortex.However, recurrent processing allows an exponential growth of activi-ties with time. We use a minimal model with two excitatory and twoinhibitory neurons to illustrate under which conditions recurrent excita-tion can be stable. In our solution recurrent inhibition balances the recur-rent excitation: Recurrent excitation, returned from the second excita-tory neuron to the first, is routed in parallel to the inhibitory interneuronconnected to the first excitatory neuron. This parallel routing of excita-tory feedback onto excitatory and inhibitory neurons is also found as ageneral principle in the cortex [1].
We use this principle in a large-scale network implementing the layers4 and 2/3 of the visual areas V1 and V2. Each layer consists of exci-tatory and inhibitory neurons with neuroscientifically grounded connec-tivity (delay 1ms). The cortico-cortical feedback projects from V2-L2/3to both neuron types in V1-L2/3 [2]. Excitatory synapses are learnedwith an improved version of our Hebbian learning rule [3], able to learnV1 complex-cells as well as simple-cells. Inhibitory synapses are learnedwith an anti-Hebbian rule [4]. The network is trained on natural scenes,five times longer as required for convergence. The neurons learned properreceptive fields and achieve good recognition accuracy, tested on COIL-100. The feedback mechanism leads to balanced modulation of activitiesin the different layers without any exponential amplifications. In thetop layer, where feedback emanates, rate activity slightly increases forthe neuron’s preferred stimuli. Thus, parallel feedback onto excitatoryand inhibitory circuit parts enables stable networks while providing thedemanded modulation properties of feedback.
Keywords: Recurrent excitation · Hebbian learning
References
1. Isaacson, J.S., Scanziani, M.: How inhibition shapes cortical activity. Neuron 72(2),231–243 (2011)
2. Douglas, R.J., Martin, K.C.: Neuronal circuits of the neocortex. Annu. Rev. Neu-rosci. 27, 419–51 (2004)
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 449–450, 2017.https://doi.org/10.1007/978-3-319-68600-4

450 M. Teichmann and F.H. Hamker
3. Teichmann, M., Wiltschut, J., Hamker, F.H.: Learning invariance from naturalimages inspired by observations in the primary visual cortex. Neural Comput. 24(5),1271–1296 (2012)
4. Wiltschut, J., Hamker, F.H.: Efficient coding correlates with spatial frequency tun-ing in a model of V1 receptive field organization. Vis. Neurosci. 26(1), 21–34 (2009)

Speech Emotion Recognition: RecurrentNeural Networks Compared to SVM
and Linear Regression
Leila Kerkeni1,2(B), Youssef Serrestou1, Mohamed Mbarki2,Mohamed Ali Mahjoub2, Kosai Raoof1, and Catherine Cleder3
1 Acoustics Laboratory,University of Maine, Orono, [email protected]
2 Laboratory of Advanced Technology and Intelligent Systems, Sousse, Tunisia3 Research Centre for Education, University of Nantes, Nantes, France
Abstract. Emotion recognition in spoken dialogues has been gainingincreasing interest all through current years. A speech emotion recogni-tion (SER) is a challenging research area in the field of Human ComputerInteraction (HCI). It refers to the ability of detection the current emo-tional state of a human being from his or her voice. SER has potentiallywide applications, such as the interface with robots, banking, call cen-ters, car board systems, computer games etc. In our research we areinterested to how, emotion recognition, can top enhance the quality ofteaching for both of classroom orchestration and E-learnning. Integra-tion of SER into aided teaching system, can guide teacher to decide whatsubjects can be taught and must be able to develop strategies for man-aging emotions within the learning environment. In linguistic activity,from student’s interaction and articulation, we can extract informationabout their emotional state. That is why learner’s emotional state shouldbe considered in the language classroom. In general, the SER is a com-putational task consisting of two major parts: feature extraction andemotion machine classification. The questions that arise here: What arethe acoustic features needed for a most robust automatic recognition of aspeaker’s emotion? Which methods is most appropriate for classification?How the database used influence the recognition of emotion in speech?Thus came the idea to compare a RNN method with the basic method(LR) [1] and the most widely used method (SVM). Most of previouslypublished works generally use the berlin database. In this work we useanother database. To our knowledge the spanish emotional database hasnever been used before. In recent years in speech emotion recognition,many researchers [2] proposed important speech features which containemotion information and many classification algorithms. The aim of thispaper is to compare firstly differents approachs that have proven theirefficiency for emotions recognition task. Then to propose an efficient solu-tion based on combination of these approachs. For classification, Linearregression (LR), Support vector machine (SVM) and Recurrent neuralnetwork (RNN) classifiers are used to classify seven different emotionspresent in the German and Spanish databases. The explored features
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 451–453, 2017.https://doi.org/10.1007/978-3-319-68600-4

452 L. Kerkeni et al.
included: mel-frequency cepstrum coefficients (MFCC) [2] and modula-tion spectral features (MSFs) [3]. Table 1 show the recognition rate foreach combination of various features and classifiers for Berlin and Span-ish databases. The overall experimental results reveal that the featurecombination of MFCC and MS has the highest accuracy rate on bothSpanish emotional database using RNN classifier 90,05% and Berlin emo-tional database using LR 82,41%. These results can be explained as fol-lows: LR classifier performed better results with feature combination ofMFCC and MS for both databases. And under the conditions of limitedtraining data (Berlin database), it can have a very good classification per-formance compared to other classifiers. A high dimension can maximizethe rate of LR. As regarding the SVM method, we found the same resultsas these presented in [3]. The MS is the most appropriate features forSVM classifier. To improve the performance of SVM, we need to changethe model for each types of features. To the spanish database, the featurecombination of MFCC and MS using RNN has the best recognition rate90.05%. For Berlin database, combination both types of features has theworst recognition rate. That because the RNN model having too manyparameters (155 coefficients in total)and a poor training data. This isthe phenomena of overfitting. The performance of SER system is influ-enced by many factors, especially the quality of samples, the featuresextracted and classification algorithms. Nowadays, a lot of uncertaintiesare still present for the best algorithm to classify emotions and what fea-tures influence the recognition of emotion in speech. To extract the moreeffective features of speech, seek for an efficient classification techniquesand enhance the emotion recognition accuracy is our future work. Morework is needed to improve the system so that it can be better used inclassroom orchestration.
Keywords: Speech emotion recognition · Recurrent neural networks ·SVM · Linear regression · MFCC · Modulation spectral features.
Table 1. Recognition results using RNN, SVM and LR classfiers based on Berlin andSpanish databases
Dataset Feature RNN (%) SVM (%) LR (%)
Berlin MS 66.32 63.30 60.70
MFCC 69.55 56.60 67.10
MFCC+MS 58.51 59.50 75.90
Spanish MS 82.30 77.63 70.60
MFCC 86.56 70.69 76.08
MFCC+MS 90.05 68.11 82.41

Speech Emotion Recognition: Recurrent Neural Networks Compared to SVM 453
References
1. Naseem, I., Togneri, R., Bennamoun., M.: Linear regression for face recognition.IEEE Trans. Pattern Anal. Mach. Intell. 32 (2010)
2. Surabhi, V., Saurabh, M.: Speech emotion recognition: a review. IRJET 03 (2016)3. Wua, S., Falk, T.H., Chan, W.Y.: Automatic speech emotion recognition using.
Speech Commun. 53, 768–785 (2011)

Pelagic Species Identification by Using a PNNNeural Network and Echo-Sounder Data
Ignazio Fontana1(B), Giovanni Giacalone1, Angelo Bonanno1,Salvatore Mazzola1, Gualtiero Basilone1, Simona Genovese1,
Salvatore Aronica1, Solon Pissis5, Costas S. Iliopoulos5, Ritu Kundu5,Antonino Fiannaca2, Alessio Langiu2, Giosue’ Lo Bosco3,4, Massimo La Rosa2,
and Riccardo Rizzo2
1 IAMC-CNR, Capo Granitola, Torretta Granitola, Italy{ignazio.fontana,giovanni.giacalone,angelo.bonanno,salvatore.mazzola,
gualtiero.basilone,simona.genovese,salvatore.aronica}@cnr.it2 ICAR-CNR, Palermo, Italy
{antonino.fiannaca,alessio.langiu,massimo.rosa,riccardo.rizzo}@icar.cnr.it
3 DMI, Universita’ Degli Studi di Palermo, Palermo, [email protected]
4 Dipartimento SIT, IEMEST, Palermo, Italy5 King’s College, Strand, London, UK
{solon.pissis,costas.iliopoulos,ritu.kundu}@kcl.ac.uk
Abstract. For several years, a group of CNR researchers conductedacoustic surveys in the Sicily Channel to estimate the biomass of smallpelagic species, their geographical distribution and their variations overtime. The instrument used to carry out these surveys is the scientificecho-sounder, set for different frequencies. The processing of the backscattered signals in the volume of water under investigation determinesthe abundance of the species. These data are then correlated with thebiological data of experimental catches, to attribute the composition ofthe various fish schools investigated. Of course, the recognition of the fishschools helps to produce very good results, that is very close to the truthabout the abundances associated with the various species. In this work,only the acoustic traces of biological monospecific catches, exclusivelyof two species of pelagic fish. The ecograms where pre-processed usingvarious software tools [1, 2]. For this work, the potential fish schools aredetected and isolated using the SHAPES algorithm in Echoview. At theend of the pre-processing phase, the signals are labelled using the twospecies of pelagic fish: Engraulis encrasicolus and Sardina pilchardus.These labelled signals were used to train a Probabilistic Neural Network(PNN) [3].
Keywords: Probabilistic neural networks · Pelagic speciesidentification · Classification
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 454–455, 2017.https://doi.org/10.1007/978-3-319-68600-4

Pelagic Species Identification by Using a PNN Neural Network 455
References
1. De Robertis, A., Higginbottom, I.: A post-processing technique to estimate thesignal-to-noise ratio and remove echosounder background noise. ICES J. Mar. Sci.64, 1282–1291 (2007)
2. Swartzman, G., Brodeur, R., Napp, J., Walsh, D., Hewitt, R., Demer, D., Hunt,G., Logerwell, E.: Relating spatial distributions of acoustically determined patchesof fish and plankton: data viewing, image analysis, and spatial proximity. Can. J.Fish. Aquat. Sci. 56(S1), 188–198 (1999). doi:10.1139/f99-206
3. Specht, D.F.: Probabilistic neural networks. Neural Netw. 3(1), 109–118 (1990)

The Impact of Ozone on Crop Yieldsby Combining Multi-model Results Through
a Neural Network Approach
A. Riccio1(B), E. Solazzo2, and S. Galmarini2
1 Department of Science and Technology, Universita degli Studi di Napoli“Parthenope”, Naples, Italy
[email protected] EC/DG-Joint Research Center, Ispra, Italy
{efisio.solazzo,stefano.galmarini}@ec.europa.eu
Abstract. Field experiments have demonstrated that atmosphericozone can damage crops, leading to yield reduction and a deteriorat-ing crop quality [3]. The availability of regional scale air pollution modelsallows one to combine modeled ozone fields, exposure-response functions,crop location and growing season, to obtain regional estimates of croplosses. Since 2008 the Air Quality Model Evaluation International Initia-tive (AQMEII) coordinated by the EC/Joint Research Center and theUS EPA has worked toward knowledge and experience sharing on airquality modeling in Europe and North America [1]. Within this contextmulti-model ensemble has been exercised proving to be very instrumen-tal for a number of applications (e.g. [2]).
In this work we explore the capabilities of neural networks to combinemodel results and improve ozone predictions, under current and futurescenarios, over the European region. The ability of neural networks toaccount for both nonlinear input-output relationships and interactionsbetween inputs has made them popular in areas where model interpre-tation is of secondary importance to predictive skill. The possibility toimprove the predictive capabilities of the existing models has fundamen-tal implications both on the model forecasting ability necessary to sketchfuture scenarios and on legislation to regulate the impact of air quality.
Keywords: Ozone · Crop losses · Ensemble modeling · AQMEII
References
1. Rao, S.T., Galmarini, S., Puckett, K.: Air quality model evaluation internationalinitiative (AQMEII): advancing the state of the science in regional photochemicalmodeling and its applications. Bull. Am. Meteorol. Soc. 92(1), 23–30 (2011)
2. Riccio, A., Ciaramella, A., Giunta, G., Galmarini, S., Solazzo, E., Potempski, S.: Onthe systematic reduction of data complexity in multimodel atmospheric dispersionensemble modeling. J. Geophys. Res.: Atmos. 117(D5) (2012)
3. Van Dingenen, R., Dentener, F.J., Raes, F., Krol, M.C., Emberson, L., Cofala, J.:The global impact of ozone on agricultural crop yields under current and future airquality legislation. Atmos. Environ. 43(3), 604–618 (2009)
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 456, 2017.https://doi.org/10.1007/978-3-319-68600-4

Artificial Neural Networks for Fault Tolleranceof an Air-Pressure Sensor Network
Salvatore Aronica1, Gualtiero Basilone1, Angelo Bonanno1, Ignazio Fontana1,Simona Genovese1, Giovanni Giacalone1, Alessio Langiu3,
Giosue Lo Bosco2(B), Salvatore Mazzola1, and Riccardo Rizzo3
1 IAMC, CNR, Campobello di Mazara, TP, Italy2 DMI, Universita Degli Studi di Palermo, Palermo, PA, Italy
[email protected] ICAR, CNR, Palermo, PA, Italy
Abstract. A meteorological tsunami, commonly called Meteotsunami,is a tsunami-like wave originated by rapid changes in barometric pres-sure that involve the displacement of a body of water. This phenom-enon is usually present in the sea cost area of Mazara del Vallo (Sicily,Italy), in particular in the internal part of the seaport canal, sometimesmaking local population at risk. The Institute for Coastal Marine Envi-ronment (IAMC) of the National Research Council in Italy (CNR) havealready conducted several studies upon meteotsunami phenomenon. Oneof the project has regarded the creation of a sensors network composedby micro-barometric sensors, located in 4 different stations close to theseaport of Mazara del Vallo, for the purpose of studying meteotsunamiphenomenon. Each station sends all the measurements to a collecting onethat elaborates them with the purpose of identifying the direction andspeed of pressure fronts. Unfortunately, four stations provide the mini-mum amount of data necessary to a reliable characterization of pressurefronts so that the failure of only one is a serious issue. Such failuresregard blackouts, connection loss, hardware failures or maintenances. Inthis context we have developed a fault tolerance system that is based onneural networks. A feed forward neural network i is associated with eachstation i, and is trained to predict its measurements using as inputs theones of the other three station j with j �= i. In the normal condition,the collecting station receives the measurements from each station. Inthe case of failure of only one station k, the related neural network kcan be used to predict the missing measurements. We have conductedpreliminary experiments using a two layer feed forward neural networkwith sigmoid and linear activation functions for the hidden and outputlayer respectively. In order to simulate failures, we have removed groupof data from each station measurements that follow inside a fixed tem-poral range. The related networks have been used to predict the missingmeasurements, and the mean square error (MSE) from the real measuredvalue has been computed as performance index. The very low values ofobtained MSE lead to the suggestion of a certain effectiveness of theproposed system.
Keywords: Meteotsunami · Pressure sensors · Neural networks
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, p. 457, 2017.https://doi.org/10.1007/978-3-319-68600-4

Modelling the Impact of GM Plantsand Insecticides on Arthropod Populations
of Agricultural Interest
Alberto Lanzoni(B), Edison Pasqualini, and Giovanni Burgio
Dipartimento di Scienze Agrarie - Entomologia,Alma Mater Studiorum-Universita di Bologna, Bologna, Italy
{alberto.lanzoni2,edison.pasqualini,giovanni.burgio}@unibo.it
Abstract. Matrix population models (MPM) are nowadays not widelyused to simulate arthropod population dynamics with applications torisk assessment. However, an increasing body of studies are promptingthe finding of optimization techniques to reduce uncertainty in matrixparameters estimation. Indeed, uncertainty in parameters estimates maylead to significant management implications. Here we present two casestudies where MPM are used for assessing the potential impact of genet-ically modified (GM) plants on beneficial insect species (the coccinellidAdalia bipunctata) and for evaluating spider mites (the two-spotted spi-der mite Teranychus urticae) resurgence after insecticide application.In both studies the data obtained, consisting of population time series,were used to generate a stage-classified projection matrix. The generalmodel used to simulate population dynamics consists of a matrix con-taining (i) survival probabilities (the probability of growing and mov-ing to the next stage and the probability of surviving and remainingin the same stage), and (ii) fecundities of the population. Most of themethods utilized for estimate the parameter values of stage-classifiedmodels rely on following cohorts of identified individuals [1]. Howeverin these studies the observed data consisted of a time-series of popula-tion vectors n(t), for t = T0, T1, . . . , Tn, where individuals are not dis-tinguished. The relationship between the observed data and the valuesof the matrix parameters that produced the series involves an estima-tion process called inverse problem. The set of parameters that minimizethe residual between the collected data and the model output for thetwo studies presented here was estimated using the quadratic program-ming method [2]. The set of estimated parameters for the A. bipunc-tata Rhopalosiphum maidis maize tritrophic system model supports thehypothesis that GM maize does not negatively influences A. bipunctatapopulation growth in the tritrophic system studied [3]. Otherwise, inthe case of the two-spotted spider mite resurgence, some insecticides,namely etofenprox, deltamethrin and betacifluthrin, fostered a highermite population growth than the untreated control. This was princi-pally due to higher adult fecundity and egg fertility, clearly explainedby Life Table Response Experiments, performed starting from estimatedmatrices, indicating a likely trophobiotic effect. A variety of inverse mod-elling approaches have been applied to demographic models other than
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 458–459, 2017.https://doi.org/10.1007/978-3-319-68600-4

Modelling the Impact of GM Plants and Insecticides 459
quadratic programming. Bayesian approaches [4] and evolutionary algo-rithms, such as Genetic Algorithms [5] have also been used for inversemodelling and parameters fitting. In order to find a better model fit forthe observed stage class distributions on two case studies, we would liketo explore Neural Networks or more generally machine learning possi-bilities in finding a set of parameter values that successfully describesobserved data.
Keywords: Matrix population model · Inverse problem · Parameterestimate · Adalia bipunctata · Ecological risk assessment Teranychusurticae · Spider mites resurgence
References
1. Caswell, H.: Matrix Population Models. John Wiley & Sons, Ltd (2001)2. Wood, S.N.: Obtaining birth and mortality patterns from structured population
trajectories. Ecol. Monogr. 64(1), 23–44 (1994)3. Lanzoni, A.: Evaluation of the effects of Bt-maize on non target insects using a
demographic approach. Ph.D. dissertation thesis, Alma Mater Studiorum Universitadi Bologna (2016)
4. Gross, K., Ives, A.R., Nordheim, E.V.: Estimating fluctuating vital rates from time-series data: a case study of aphid biocontrol. Ecology 86(3), 740–752 (2005)
5. Cropper, W.P., Holm, J.A., Miller, C.J.: An inverse analysis of a matrix populationmodel using a genetic algorithm. Ecol. Inf. 7(1), 41–45 (2012)

Deep Neural Networks for Emergency Detection
Emanuele Cipolla(B), Riccardo Rizzo, and Filippo Vella
Institute for High-Performance Computing and Networking, National ResearchCouncil of Italy (ICAR-CNR), Rende, Italy
{Emanuele.Cipolla,Riccardo.Rizzo,Filippo.Vella}@icar.cnr.it
Abstract. The increasing deployment of sensor networks has resulted inan high availability of geophysical data that can be used for classificationand predictions of environmental features and conditions. In particular,detecting emergency situations would be desirable to reduce damages topeople and things. In this work we propose the use of a deep neural net-work architecture to detect pluvial-flood emergencies, building upon andextending our previous works [1, 2] in which we gathered a large set ofrain measures coming from a sensor and surveillance network deployedin the last decade in the Italian region of Tuscany and built a databaseof verified emergency events using a manually annotated set of resourcesfound on the World Wide Web.
We used a stacked LSTM [3] network to classify 4-day-long sequences(the measures for a given day and the three days prior) of pluvial mea-surements gathered from the whole set of stations belonging to ServizioIdrogeologico Regionale in Tuscany. After empirical tests, we chose two2 LSTM layers with 256 outputs each for the hidden part of the network.Using multiple layers we exploit the abstraction power for pattern recog-nition in time sequences that has been previously recognized for LSTMs:lower layers are able to detect the most significant variations, while thehigher ones use these patterns to spot emergency events.
As they are very infrequent, a balanced subset of quiet days has tobe considered to build a binary classifier to avoid overfitting. To increasethe number of relevant true examples we performed a linear interpolationof existing sequences, generating 10 new examples for each original one.After training the network using 560 examples, we tested its performanceusing 1276 sequences. We had 131 true positives, 1074 true negatives, 64false positives and 7 false negatives.
This leads to a precision of 0.67 and a recall of 0.95, so the F1-score is0.79. Accuracy is also high (0.94). We are planning to train this networkon a bigger dataset, and then perform transfer learning to have an overallbetter classifier.
Keywords: LSTM · Neural network · Rain · Flood · Emergency · Deeplearning
References
1. Cipolla, E., Maniscalco, U., Rizzo, R., Vella, F.: Analysis and visualization of mete-orological emergencies. J. Ambient Intell. Humanized Comput. 8(1), 57–68 (2017)
c© Springer International Publishing AG 2017A. Lintas et al. (Eds.): ICANN 2017, Part I, LNCS 10613, pp. 460–461, 2017.https://doi.org/10.1007/978-3-319-68600-4

Deep Neural Networks for Emergency Detection 461
2. Cipolla, E., Rizzo, R., Stabile, D., Vella, F.: A tool for emergency detection withdeep learning neural networks. In: Proceedings of the 2nd Internatinal Workshopon Knowledge Discovery KDWeb 2016 (2016)
3. Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8),1735–1780 (1997). http://dx.doi.org/10.1162/neco.1997.9.8.1735

Author Index
Abdelwahed, Mehdi I-446Abdullatif, A. II-768Ai, Na II-565Aiolli, Fabio II-183, II-279Aires, João Paulo I-424Aizono, Toshiko II-655Almodfer, Rolla II-260Alpay, Tayfun I-3Andaluz, Víctor H. II-590Andonie, Răzvan II-64, II-512Andras, Peter I-121Andry, Pierre I-446Anguita, Davide II-331, II-385Antonelo, Eric A. II-503Anvik, John II-64Araújo, Daniel II-359Arie, Hiroaki I-35Aronica, Salvatore I-454, I-457Arruda, Helder M. I-254, II-520Arsiwalla, Xerxes D. I-326, I-422Aulestia, Pablo S. II-590Awad, Mariette II-749Azuma, Yoshiki I-199
Bahroun, Yanis I-354, I-364Barančok, Peter I-418Barros, Rodrigo C. I-424Basilone, Gualtiero I-454, I-457Basu, Saikat II-617Bauckhage, Christian I-219, II-663Bauer-Wersing, Ute II-200Bazrafkan, Shabab I-432Beerel, Peter A. I-273Beigl, Michael II-233Bekkouche, Bo I-397Belić, Jovana J. I-129Benalcázar, Marco E. II-590Berberian, Nareg I-110Biswas, Anmol II-763, II-765Bogdan, Martin I-389Bohte, Sander II-729Boldt, Brendon II-268Bollenbacher, J. II-743Bonanno, Angelo I-454, I-457
Borovykh, Anastasia II-729Bosco, Giosué Lo I-457Bothe, Chandrakant II-477Boubaker, Houcine II-450Braun, Hans Albert I-423Bueno, Leonardo de A. e II-582Burgio, Giovanni I-458Burikov, Sergey II-751Butz, Martin V. I-227, I-262, II-745Buza, Krisztian II-663
Cabessa, Jérémie I-245, I-334Cabri, Alberto II-434Caggiano, Vittorio I-19Camastra, Francesco I-407, II-626Canessa, Andrea II-192Canuto, Anne M.P. II-467Canuto, Anne II-359Cao, Ru I-92Carvalho, Eduardo II-72, II-761Carvalho, Hanna V. II-520Castellano, Giovanna II-770Caţaron, Angel II-512Chartier, Sylvain I-110, I-345Chechik, Gal II-287Chen, JiaXin II-305Chen, Peng I-208Chen, Wei I-373Cherla, Srikanth II-111Cheruku, Ramalingaswamy II-411Chesmore, David II-349Chmielewski, Leszek J. II-128Chugg, Keith M. I-273Ciaramella, Angelo I-407Cimrová, Barbora I-418Cipolla, Emanuele I-460Cipollini, Francesca II-385Cleder, Catherine I-451Cleophas, Toine II-385Cohen, Ido II-287Coraddu, Andrea II-385Corcoran, Peter I-432Coroiu, Adriana Mihaela II-782Cosovan, Doina II-250

Costa, Fabrizio II-155Crielaard, Wim II-778Cui, Hongyuan II-556Cyr, André I-110
d’Avila Garcez, Artur II-111, II-120da Silva, João C.P. II-376da Silva, Ricardo A.M. II-402Dantas, Carine A. II-467David, Eli (Omid) II-91, II-287, II-725,
II-741de Carvalho, Eduardo C. I-254de Carvalho, Francisco de A.T. II-402De Gernier, Robin I-425de Souza, Paulo I-254, II-520Del Carpio, Christian II-635Delbruck, Tobi I-179Delgado, Carla II-376Delgado-Martínez, Ignacio I-60Deng, Pan II-680Deng, Xiangyang II-785Dengel, Andreas II-165Dey, Sourya I-273Dharavath, Ramesh II-411DiBiano, Robert II-617Dillmann, Rüdiger I-43, II-3Ding, Meng II-727Dolenko, Sergey II-751, II-757, II-774Dolenko, Tatiana II-751Donat, Heiko I-43Dornaika, F. II-792dos Santos, Filipa I-121Dou, Zi-Yi II-696Duan, Pengfei II-260Durand-Dubief, Françoise II-643Dzwinel, Witold II-756
Echeveste, Rodrigo I-444Edla, Damodar Reddy II-411Efitorov, Alexander II-751Eleftheriou, Evangelos I-281Ellatihy, Karim I-389Endres, Dominik I-291Escuain-Poole, Lara I-431
Fabian, Joseph I-397Fanelli, Anna Maria II-770Farkaš, Igor I-418Feng, Jiawen II-785
Feng, Weijiang II-574Feng, Zhiyong I-92Ferreira, Bruno II-761Fiannaca, Antonino I-454Filho, Geraldo P.R. II-761Fischer, Lydia II-200Fleer, Sascha I-68Florea, Adrian-Cătălin II-64Fontana, Ignazio I-454, I-457Fortunato, Guglielmo I-60Fouss, François II-423Frajberg, Darian II-12Fraternali, Piero II-12Frick, Adam I-429Friston, Karl I-227Furusho, Wataru I-171
Gajowniczek, Krzysztof II-128Gallardo, Jhair II-635Galmarini, S. I-456Gama, Fernando II-520Ganguly, Udayan II-763, II-765Gao, Min II-208García, Gabriel II-635García-Ródenas, Ricardo II-600Garrido, Jesús A. I-434Gavriluţ, Dragoş II-250Geng, Yanyan II-539Genovese, Simona I-454, I-457Giacalone, Giovanni I-454, I-457Gibaldi, Agostino II-192Giese, Martin I-19Gomes, Pedro A.B. I-254Gonzalez-Ballester, Miguel Angel I-421Gorse, Denise II-495Graham, Bruce P. I-381Granada, Roger I-424Gros, Claudius I-444Gu, Feng II-442Gu, Xiaodong II-40, II-733Gu, Yi II-539Gu, Yiwei II-733Guermeur, Yann II-767
Haelterman, Marc I-425Hagen, Oksana I-419Hamker, Fred H. I-449Hao, Jianye I-92Hara, Kazuyuki II-747
464 Author Index

Hasler, Stephan II-200He, Ben II-56He, Hongjun II-609He, Liang II-547He, Wei II-790Heidemann, Gunther I-84Hellgren Kotaleski, Jeanette I-129Hernández-Alcaina, Alberto I-431Herreros, Ivan I-422Hinakawa, Nobuhiro I-155Hoedt, J. I-417, II-788Hoffmann, Matej I-101Horcholle-Bossavit, Ginette I-245Hori, Sansei I-437Hosino, Tikara II-672Hovaidi-Ardestani, Mohammad I-19Hu, Jinxing I-373Hu, Qinghua II-340Hua, Qingsong II-680Huang, Shu-Jian II-696Huang, Xuhui II-442, II-574Hunsicker, Eugénie I-364
Iannella, Nicolangelo I-429Ichisugi, Yuuji I-163Iliopoulos, Costas S. I-454Imangaliyev, Sultan II-778Ion-Mărgineanu, Adrian II-643Isaev, Igor II-757Ishii, Shin I-199, II-100Ito, Saki I-35Izquierdo, Eduardo J. I-236
Jablonski, Adrian II-233Jackevicius, Rokas I-381Jaquerod, Manon I-191Jesus, Jhoseph II-359Jiang, Wanwan II-772Jimenez-Lepe, Edwin II-780Jin, Z. II-792Johnson, Melissa I-345
Kaiser, Jacques I-43, II-3Kallmeyer, F. I-417, II-788Kalou, Katerina II-192Karatzoglou, Antonios II-233Karki, Manohar II-617Karpenko, Olena II-385Kaste, J. I-417, II-788Kawakami, Hajimu II-174
Keijser, Bart J.F. II-778Kerkeni, Leila I-451Kerzel, Matthias I-27Keshavamurthy, Bettahally N. II-786Kherallah, Monji II-450Kitano, Katsunori I-155Knopp, Benjamin I-291Kocevar, Gabriel II-643Kohjima, Masahiro II-146Koprinska, Irena II-486Král, Pavel II-368Kreger, Jennifer II-200Kumar, Arvind I-129Kundu, Ritu I-454Kuppili, Venkatanareshbabu II-411Kuras, Ihor I-446Kuroe, Yasuaki II-174
La Rosa, Massimo I-454Ladwani, Vandana M. II-753Lam, K.P. I-121Lan, Qiang II-609Langiu, Alessio I-454, I-457Lanzoni, Alberto I-458Laptinskiy, Kirill II-751Lauer, Fabien II-767Lauriola, Ivano II-183, II-279Leblebici, Yusuf I-281Lehman, Constantin I-84Lemley, Joseph I-432Lenc, Ladislav II-368Leng, Biao II-80Levin, Evgeni II-778Li, Guoqing II-556Li, Jianrong II-297Li, Shu II-305Li, Shuqin II-727Li, Weizhi II-539Li, Xiaohong I-92Li, Yujian II-30Lian, Yahong II-305Liang, Dongyun II-394Liang, Gaoyuan II-539Liang, Ru-Ze II-539Lima, Priscila II-376Lin, Xin II-547Linares, Luis Jiménez II-600Linares-Barranco, Alejandro I-179Lintas, Alessandra I-191Liscovitch, Noa II-287
Author Index 465

Liu, Chang II-784Liu, Hongjie I-179Liu, Jingshuang II-208Liu, Qiang II-242Liu, Siqi II-735Liu, Tao I-436Liu, Wenjie II-242Liu, Ying II-556Liu, Zhaoying II-30Liu, Zhichao II-49Liu, Zhiqiang II-735Liwicki, Marcus II-165Lo Bosco, Giosue’ I-454Loeffler, Hubert I-448Loos, Bruno G. II-778López, Jorge II-635López-Gómez, Julio Alberto II-600Low, Sock Ching I-427Lu, Yao II-322Luchian, Henri II-250Lulli, Alessandro II-331Luo, Zhigang II-442, II-574
Madrenas, Jordi I-437Maffei, Giovanni I-309Magg, Sven II-477Mahjoub, Mohamed Ali I-451Maiolo, Luca I-60Maji, Partha II-21Mann, Andrew D. II-495Mapelli, Jonathan I-425Martínez-Muñoz, Gonzalo II-224Marzullo, Aldo II-626Massar, Serge I-425Masuda, Wataru I-11Masulli, Francesco II-434, II-768Masulli, Paolo I-317Matwin, Stan II-756Mauricio, Antoni II-635Mazzola, Salvatore I-454, I-457Mbarki, Mohamed I-451Medhat, Fady II-349Meltnyk, Artem I-446Mendez-Vazquez, Andres II-780Meneguzzi, Felipe I-424Meng, Kun II-727Meng, Xianglai II-80Moeys, Diederik Paul I-179Monteiro, Juarez I-424Morie, Takashi I-437
Morioka, Hiroshi I-199Mudhsh, Mohammed II-260Mukhopadhyay, Supratik II-617Mullins, Robert II-21Murakami, Kaichi II-739Murata, Shingo I-11Musayeva, Khadija II-767Myagkova, Irina II-774
Nachtigall, Karl II-528Navarro, Xavier I-60Netanyahu, Nathan S. II-287, II-725, II-741Ni, Mengjun II-547Nie, Feiping II-790Nishimoto, Takashi I-199Nunes, Rômulo O. II-467
O’Carroll, David C. I-397Oba, Sigeyuki II-100Odense, Simon II-120Ogata, Tetsuya I-11, I-35Ohashi, Orlando II-72Ohsawa, Yukio II-705Okada, Tatsuuya II-713Okadome, Yuya II-655Oliveira, Adriano L.I. II-582Oneto, Luca II-331, II-385Oosterlee, Cornelis W. II-729Orłowski, Arkadiusz II-128Ortiz, Michaël Garcia I-76, I-419Osana, Yuko I-52, II-713, II-739Osawa, Kazuki II-459Otte, Sebastian I-227, I-262, II-745Oztop, Erhan I-146
Palacio, Sebastian II-165Pantazi, Angeliki I-281Pasqualini, Edison I-458Patil, Nitin II-539Pazzini, Luca I-60Pelowski, Matthew I-436Peng, Jinye II-565Pérez-Lemonche, Ángel II-224Peric, Igor I-43Pessin, Gustavo I-254, II-72, II-520, II-761Phumphuang, Pantaree II-759Pipa, Gordon I-84Pissis, Solon I-454Plastino, Angel R. I-300Polato, Mirko II-183, II-279
466 Author Index

Polese, Davide I-60Pons, Antonio J. I-431Porubcová, Natália I-418Prasad, Sidharth II-763, II-765Prasad, Shitala II-786Puigbò, Jordi-Ysard I-421Pulido-Cañabate, Estrella II-224
Qi, Jin II-565Qin, Zhengcai II-56Quenet, Brigitte I-245
Ramamurthy, Rajkumar II-663Ramasubramanian, V. II-753Rana, Mashud II-486Ravindran, Balaraman II-776Raoof, Kosai I-451Raue, Federico II-165Reitmann, Stefan II-528Ren, Gang II-680Rhein, B. II-743Riccio, A. I-456Rigosi, Elisa I-397Rios-Navarro, Antonio I-179Ritter, Helge I-68Rizk, Yara II-749Rizzo, Riccardo I-454, I-457, I-460Robinson, John II-349Roennau, Arne I-43, II-3Rong, Wenge II-208Ros, Eduardo I-434Rosenberg, Ishai II-91Rosipal, Roman I-418Ross, Matt I-110Rössert, Christian I-425Rovetta, Stefano II-434, II-768
Sabatini, Silvio P. II-192Saerens, Marco II-423Saiprasert, Chalermpol II-759Sánchez-Fibla, Martí I-309Sanetti, Paolo II-385Sano, Takashi I-163Sappey-Marinier, Dominique II-643Saudargiene, Ausra I-381Schleif, Frank-Michael II-313Schmitt, Theresa I-227Sentürk, Harun II-233Serrestou, Youssef I-451
Sezener, Can Eren I-146Shao, Yinan I-273Sharifirad, Sima II-756Shen, Yanyan I-373Shi, Yuanchun II-735Shoemaker, Patrick A. I-397Sicard, Guillaume II-91Sidler, Severin I-281Sima, Diana M. II-643Solazzo, E. I-456Solinas, Sergio I-425Soltoggio, Andrea I-354, I-364Sommer, Felix II-423Song, Guanglu II-80Song, Jianglong II-242Sperduti, Alessandro II-155Staiano, Antonino I-407Stamile, Claudio II-626, II-643State, Radu II-503Straka, Zdenek I-101Su, Yi-Fan II-696Sugano, Shigeki I-11Sun, Fuchun II-784Sun, Guangyu II-49Sun, Shangdi II-40Sütfeld, Leon I-84Svetlov, Vsevolod II-757
T.N., Chandramohan II-776Talahua, Jonathan S. II-590Tamukoh, Hakaru I-437, I-439Tanaka, Yuichiro I-439Tanisaro, Pattreeya I-84Tao, Pin II-735Tchaptchet, Aubin I-423Teichmann, Michael I-449Temma, Daisuke I-52Teplan, Michal I-418Terracina, Giorgio II-626Thajchayapong, Suttipong II-759Thériault, Frédéric I-110Tian, Chuan II-208Tian, Tian II-216Tieck, J. Camilo Vasquez I-43, II-3Tietz, Marian I-3Tomioka, Saki I-11Torres, Renato II-72Torres, Rocio Nahime II-12
Author Index 467

Tran, Son N. II-111Tran-Van, Dinh II-155Trapp, Philip I-444Triesch, Jochen I-442Tu, Shanshan II-737Twiefel, Johannes I-3
Uchida, Shihori II-100Ueyama, Jó II-761Ulbrich, Stefan I-43, II-3ur Rehman, Sadaqat II-737
Vaishnavi, Y. II-753van der Veen, Monique H. II-778Van Ende, K. I-417, II-788Van Huffel, Sabine II-643Vasu, Madhavun Candadai I-236Vatamanu, Cristina II-250Vella, Filippo I-460Velychko, Dmytro I-291Verschure, Paul F.M.J. I-309, I-421, I-422,
I-427Verschure, Paul I-326Viana, Thais II-376Villa, Alessandro E.P. I-191, I-317, I-334Volgenant, Catherine M.C. II-778Vysyaraju, Sarat Chandra I-191
Wanderley, Miguel D. de S. II-582Wang, Changhu II-784Wang, Chenxu II-442Wang, Guangxia II-340Wang, Jingbin II-539Wang, Jing-Yan II-539Wang, Jun II-565Wang, Lin II-565Wang, Qi II-56Wang, Shuqiang I-373Wang, Zelong II-609Wang, Zheng II-486Watanabe, Sumio II-146Wazarkar, Seema II-786Weber, Cornelius I-137, II-477Wedemann, Roseli S. I-300Wei, Wenpeng II-655Weisswange, Thomas H. II-200Wen, He II-688Weng, L. II-792Wermter, Stefan I-3, I-27, I-137, II-477
Weyde, Tillman II-111Wiederman, Steven D. I-397Woźniak, Stanisław I-281Wrobel, Stefan II-663Wu, Bingzhe II-49Wu, Charles II-49Wu, Yanbin II-539
Xavier-Júnior, João C. II-467Xiao, Taihong II-688Xiao, Tengfei I-373Xie, Yuan II-735Xiong, Shengwu II-260Xiong, Zhang II-208Xu, Jungang II-56Xu, Lingyu II-731, II-772Xu, WeiRan II-216Xu, Weiran II-322, II-394
Yamada, Tatsuro I-35Yamazaki, Tadashi I-171Yang, Chao II-680Yang, Jing II-547Yang, Rui II-705Yokota, Rio II-459Yoshikawa, Yuya II-137Yu, Chun II-735Yu, Dongchuan I-436Yu, Haixing II-731, II-772Yu, Hong II-305Yu, Zhijun II-785Yuan, Zhihang II-49
Ząbkowski, Tomasz II-128Zanchettin, Cleber II-582Zapata, Mireya I-437Zhang, Changqing II-340Zhang, Chunyuan II-609Zhang, Chunyun II-322Zhang, Guohui II-539Zhang, Jianhua I-208, II-297Zhang, Limin II-785Zhang, Mingming I-436Zhang, Ting II-30Zhang, Wenju II-442Zhang, Xiang II-442, II-574Zhang, Yipeng II-727Zhao, Haifeng II-790Zhao, Wentao II-242Zhao, Yinge II-394
468 Author Index

Zhou, Shuchang II-688Zhou, Xiaomao I-137Zhou, Xinyu II-688Zhu, Chengzhang II-242Zhu, Pengfei II-340
Zimmerer, David II-3Zöllner, Marius I-43Zouari, Ramzi II-450Zucca, Riccardo I-427Zwiener, Adrian I-262
Author Index 469














![[Kotak] 5Jul18 Strategy Previewimages.moneycontrol.com/static-mcnews/2018/07/Strategy-Kotak.pdf · Nischint Chawathe Murtuza Arsiwalla Chirag Talati, CFA (NBFC) (Real Estate, Utilities,](https://img.pdfslide.us/doc/110x75/60132193b7d03c4e02238ae9/kotak-5jul18-strategy-nischint-chawathe-murtuza-arsiwalla-chirag-talati-cfa-nbfc.jpg)





