Embed Size (px)
Citation preview

Knowledge-Based Systems 23 (2010) 94–109
Contents lists available at ScienceDirect
Knowledge-Based Systems
journal homepage: www.elsevier .com/locate /knosys
Sheepdog, parallel collaborative programming-by-demonstration
Vittorio Castelli a,*, Lawrence Bergman b, Tessa Lau c, Daniel Oblinger d,1
a IBM T.J. Watson Research Center, 1101 Kitchawan Road – Route 134, Yorktown Heights, NY 10598, United Statesb IBM T.J. Watson Research Center, 19 Skyline Drive, Hawthorne, NY 10532, United Statesc IBM Almaden Research Center, 650 Harry Road, San Jose, CA 95120, United Statesd DARPA/PTO, 3701 Fairfax Dr, Arlington, VA 22203, United States
a r t i c l e i n f o
Article history:Received 8 February 2008Received in revised form 27 May 2009Accepted 4 June 2009Available online 13 June 2009
Keywords:Programming-by-demonstrationIntelligent user interfacesArtificial intelligenceParallel collaborative programming-by-demonstrationArchitecture for programing-by-demonstration
0950-7051/$ - see front matter � 2009 Elsevier B.V. Adoi:10.1016/j.knosys.2009.06.008
* Corresponding author. Tel.: +1 914 945 2396.E-mail addresses: [email protected] (V. Cas
(L. Bergman), [email protected] (T. Lau), Daniel.Obling1 This work was done while the author was with t
Center.
a b s t r a c t
We introduce parallel collaborative programming-by-demonstration (PBD) as a principled approach to cap-turing knowledge on how to perform computer-based procedures by independently recording multipleexperts executing these tasks and combining the recordings via a learning algorithm. Traditional PBDhas focused on end-user programming for a single user, and does not support parallel collaborative pro-cedure model construction from examples provided by multiple experts. In this paper we discuss how toextend the main aspects of PBD (instrumentation, abstraction, learning, and execution), and we describethe implementation of these extensions in a system called Sheepdog.
� 2009 Elsevier B.V. All rights reserved.
1. Introduction software. Client self-assist is a win–win solution if the tools for
Programming-by-demonstration (PBD) [1,2] is a class oftechniques typically used for improving personal productivity byautomating repetitive tasks. PBD is generally considered an end-user-programming tool, where a single author demonstrates thetask. In this paper, we propose an alternative perspective andintroduce the concept of collaborative PBD, in which multipleauthors contribute demonstrations of the same task that are com-bined by a learning algorithm into a distributable procedure mod-el. We concentrate in particular on parallel collaborative PBD, inwhich the demonstrations are collected separately and combinedsimultaneously by the learning algorithm.
A motivating scenario for parallel collaborative PBD is offeredby IT support. A recent trend in this field is towards ‘‘client self-as-sist” [3] (CSA), that is, providing customers with the tools and con-tent necessary to resolve questions and problems with their ITproducts. A main motivation for CSA is the observation that a sub-stantial portion of the technical support cost results from repeat-edly providing solutions to a relatively small set of simpleproblems. Each such problem displays small variations thatdepend on the configuration of the customer’s hardware and
ll rights reserved.
telli), [email protected]@DARPA.MIL (D. Oblinger).he IBM T.J. Watson Research
customers are relatively inexpensive to produce and more effectiveto use than calling the help desk.
Parallel collaborative PBD offers an appealing approach to CSA.By recording the solutions produced by different experts and com-bining them via an appropriate learning algorithm, PBD is able toproduce a program that can fully automate the solution or guidethe end-user in a self-help scenario.
The Sheepdog system described in this paper demonstrates thefeasibility of using parallel collaborative PBD. Its design was drivenin part by the results of an informal survey of documentedtechnical support and maintenance procedures, as well as fromdiscussions with technical support personnel. The following obser-vations were instrumental in the design:
(1) Technical support procedures typically have branches thatreflect variations in the environment. For example, a proce-dure for establishing network connectivity has different sub-procedures depending on whether the connection is wiredLAN or broadband.
(2) Documentation and scripts rarely cover the full set of condi-tions that are encountered. Unexpected errors or unantici-pated configurations occur frequently.
(3) Documentation and scripts quickly become obsolete withsystem upgrades, and must be updated accordingly.
(4) Many maintenance procedures require human interventionand thus are not amenable to ‘‘one-click” automation.

V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109 95
These considerations also extend to other application domains,where procedures range from transaction processing, to businessprocesses, to application development tasks.
In this paper we make the following contributions:
� We propose parallel collaborative PBD as a new extension to tra-ditional PBD.
� We describe an architecture that extends the main PBD compo-nents to support parallel collaborative PBD.
� We provide an intuitive description of a novel learning algo-rithm for PBD based on Input/Output Hidden Markov Models[4].
� We report our experience with an implemented system for col-laborative PBD, Sheepdog, that learns technical support proce-dures by demonstration; and,
� We describe an empirical evaluation of Sheepdog’s learningalgorithm based on data collected from a user study.
Note that CSA by design does not cover two common classes ofprocesses: procedures executed in coordination by a team of ex-perts, and workflow-style procedures where multiple experts per-form different parts of a task in a predefined order. Both cases arebetter left to humans rather than automated or semi-automatedagents, especially because decisions made by an operator often de-pends on complex information obtained via interpersonal commu-nication rather than just on information automatically retrievablefrom the state of computer systems and applications [5]. Thus,we do not study the application of PBD to these situations, butacknowledge them as open problems.
The rest of the paper is organized as follows. In Section 2 weoutline the steps of recording, learning, authoring, and executinga Sheepdog procedure with the help of a simple scenario. In Section3 we discuss the functionalities of an architecture for parallel col-laborative PBD and describe their implementation in Sheepdog.Section 4 describes experimental results. Section 6 outlines relatedwork. Conclusions and open problems are presented in Section 7.
2. An IT Support usage scenario
This section contains a simplified example that illustrates themain challenges of Parallel Collaborative PBD. The example comesfrom the realm of IT support.
Fig. 1. The dialog with the ‘‘D
Assume that a network printer has been upgraded with newfeatures and users need to change their settings accordingly. Thefirst user, Alice, calls the help desk for assistance. The desk-sidesupport representative (DSR), Bob, connects to Alice’s computer(e.g., with Remote Desktop), activates Sheepdog on Alice’s ma-chine, starts recording, and performs the installation, as follows.First, he navigates to the ‘‘Printers and Faxes” panel, then opensthe ‘‘Options” dialog for the desired printer, and finally checkswhether the ‘‘Duplex” option is installed. In Alice’s case the optionis already installed (Fig. 1). Bob then clicks the OK button andcloses all the open dialogs. Sheepdog records all the actions andshows them in its GUI (Fig. 2, on the left) on Bob’s machine. Therecording becomes part of the problem report ticket and is turnedinto a procedure. Before closing the ticket, Bob lightly modifies(authors) the procedure representation, to group steps into seman-tically meaningful groups as shown in Fig. 2 on the right. An imme-diate benefit to Bob is that he does not have to manually record allthe steps as part of the ticket; an immediate benefit to the organi-zation is that all the steps taken to solve the procedure are auto-matically recorded, thus eliminating the risk of omitting orincorrectly reporting steps. The second user, Charlie, calls the helpdesk for assistance. The DSR, Dave, connects to Charlie’s computer,and start configuring the printer with the assistance of Sheepdog,using the procedure produced by Bob. As shown in Fig. 3, Sheepdogchanges the background of the first step in the procedure descrip-tion to yellow (A in the figure) and highlights the target widget onthe application UI (B in the figure). Dave has a choice: he can allowSheepdog to perform the entire procedure, he can use the step-by-step automation facility, or he can perform the actions manually.Dave selects single-step automation. Dave observes that the ‘‘Du-plex Option” is ‘‘Not Installed” and manually changes it to ‘‘In-stalled”, as depicted in Fig. 4. Sheepdog records these actions,detects a deviation from the loaded model, and refrains from sug-gesting the next step. Dave continues the procedure, and performsagain steps that are in the procedure model; Sheepdog observesDave’s actions, matches them to the model, and resumes offeringsuggestions. The learning algorithm later incorporates Dave’s ac-tions into the model and creates a decision point. Dave performsadditional editing to mark the decision point to the procedure rep-resentation in the position circled in Fig. 5.
Periodically, the most commonly executed procedures are eval-uated for inclusion in a CSA solution. Procedures that are com-monly executed and that are deemed to be sufficiently simple for
uplex” option installed.
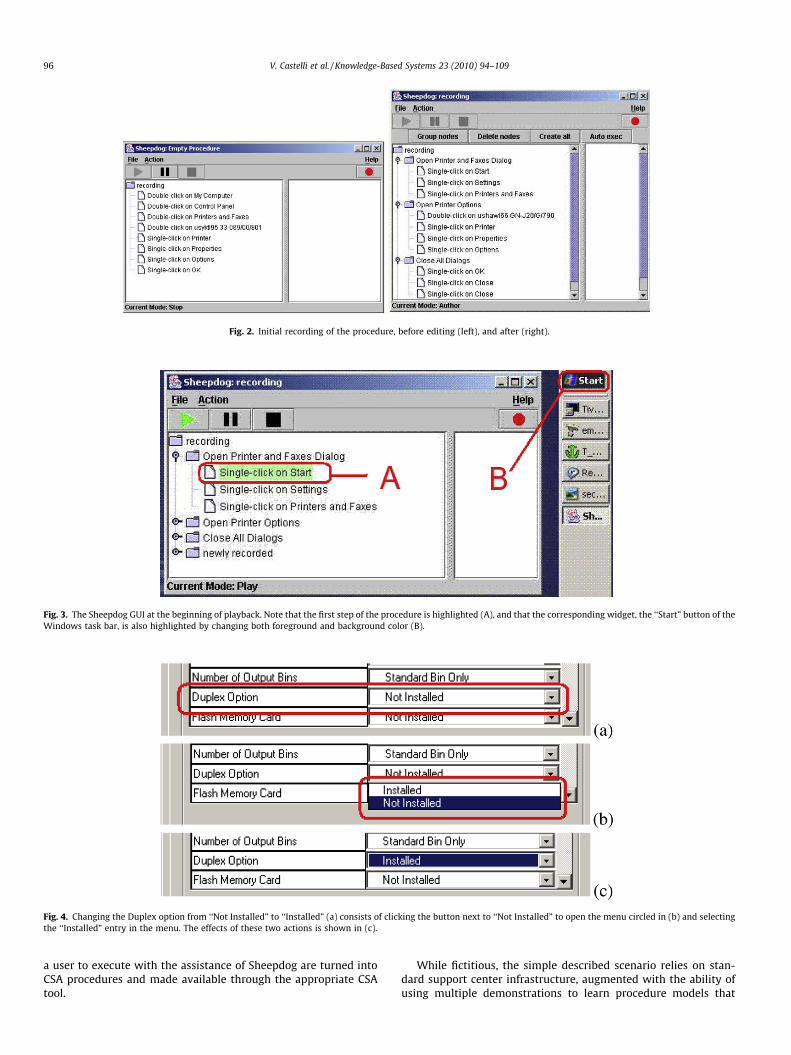
Fig. 3. The Sheepdog GUI at the beginning of playback. Note that the first step of the procedure is highlighted (A), and that the corresponding widget, the ‘‘Start” button of theWindows task bar, is also highlighted by changing both foreground and background color (B).
Fig. 4. Changing the Duplex option from ‘‘Not Installed” to ‘‘Installed” (a) consists of clicking the button next to ‘‘Not Installed” to open the menu circled in (b) and selectingthe ‘‘Installed” entry in the menu. The effects of these two actions is shown in (c).
Fig. 2. Initial recording of the procedure, before editing (left), and after (right).
96 V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109
a user to execute with the assistance of Sheepdog are turned intoCSA procedures and made available through the appropriate CSAtool.
While fictitious, the simple described scenario relies on stan-dard support center infrastructure, augmented with the ability ofusing multiple demonstrations to learn procedure models that

Fig. 5. The procedure authored after the second recording, with the new decision point circled. Note that the decision point is marked by an icon labeled ‘‘ALT”. If the duplex isnot selected, the user first clicks on the selection combo box, which has value equal to ‘‘Not Installed”, and then selects the ‘‘Installed” entry in the pull down menu thatappears.
V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109 97
can automate a task or guide the user during its execution. Notethat, although Bob and Dave performed the procedure sequentially,it is clearly possible that multiple DSR’s could be simultaneouslyhelping different users to solve the same problem, and thereforethe tools and algorithms must also accommodate this case. Thepurpose of the present paper is to address the scientific and tech-nical problems associated with this learning challenge.
3. Supporting programming by demonstration
The functionalities required to support PBD, summarized inFig. 6, are: instrumentation, abstraction, learning, and execution.
In this paper we discuss the research challenges that arise inparallel collaborative PBD regarding each of these functionalitiesand describe how Sheepdog addresses them. We base our discus-sion on the conceptual architecture shown in Fig. 7. Here, an
ExecutionDo what the user
InstrumentationSee what the user doesSee what the user sees
wants to do
Learn what the userLearning
wants to do
AbstractionDecide what
the user means
Fig. 6. Essential functionalities of a general architecture for learning proceduralknowledge by demonstration.
instrumentation layer interfaces with the platform2 to recordevents and widget contents. An abstraction layer analyzes the infor-mation produced by the instrumentation and yields a snapshot-ac-tion model of the user/system interaction (described in the nextsection). Sequences of snapshot-action pairs are combined by alearning algorithm into an executable procedure model. During exe-cution, the procedure model is used to predict the next action, whichcan be executed on behalf of the user, or to track the user progress.
In the rest of this section we will describe each of the main com-ponents of a collaborative PBD system.
3.1. The snapshot-action model of interaction
We represent the interaction between user and application bymeans of a conversational turn-taking paradigm. The system re-sides in a particular system state. The user then chooses an actionto perform based on a mental model of the task, the content ofthe GUI (the GUI state, which partially reflects the system state),and information from previous turns. In the next turn, the systemupdates its internal state and updates the GUI. Each interaction canbe captured by an snapshot-action pair (SAP), denoted by (u, y),where the snapshot u is a description of the state of the GUI priorto the user operation, and the action y is a description of the actionperformed by the user. The snapshot-action model is akin to theSTRIPS representation used in planning [6], where the snapshotcaptures facts that are true in the world, and plan operators de-scribe the possible means for altering the state of the world.
2 We use the term platform to denote an environment in which applications run,such as an operating system, a web browser, the Eclipse IDE, or a JRE.

(Automation)
InteractionTracking
TaskExecution
ProcedureModel
Construction (Playback)
ExecutionAction
CaptureAction
CaptureState
API Messages/Events
Abstraction
Instrumentation
High−Level Functionality
Windows Platform
Snapshot−Action Model
Fig. 7. Conceptual architectural model of a collaborative PBD system.
98 V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109
3.2. Instrumentation
3.2.1. Instrumenting applications and platformsThe instrumentation monitors the interaction between user and
system, and describes it to the abstraction and execution layers. Itstwo main functions are ‘‘seeing what the user sees” (data-capture),and ‘‘seeing what the user does” (action-capture).
The data-capture instrumentation constructs the snapshot por-tions of the snapshot-action model. These consist of: informationvisible on the screen, used by the abstraction and the learning layersto construct the procedure model, and by the execution layer toplay back the procedure; and information available to the user butnot visible on the screen (e.g., the user name, the OS version, etc.),used to generalized actions during learning, and to translate gener-alize actions into system-specific actions during playback.
Desirable properties of the data-capture instrumentation in-clude: (1) wide widget-type coverage, especially if the PBD systemmust operate with any application supported by the platform;(2) richness of captured widget-property detail, to support the learn-ing of procedures where individual steps or decision points dependon properties of the visible widgets (e.g., push buttons, radio but-tons, and check boxes are often implemented by the same class,and differ in the value of specific properties; the action correspond-ing to clicking a radio button therefore depends on the values ofthese properties), and to solve the problem of correctly identifyingwidgets (described in detail in Section 3.7); and (3) complete screencoverage, including occluded or minimized widgets, which can beaction targets, sources of information, or both.
The action-capture instrumentation detects: mouse clicks (right,center, or left button, up or down click, pointer location, receivingwidget, and modifier-key states), key presses (key code, receivingwidget, position of the cursor, and modifier-key states), and higherlevel widget events, the nature of which varies substantially acrossplatforms (e.g., in MS Windows, the Accessibility hook captureswidget content changes; DOM3 [7] defines 33 different types ofevents, and Eclipse’s SWT defines a number of high-level events).Example of higher-level widget events and their use by a PBD in-clude: window creation and deletion (to maintain a coherent rep-resentation of the existing windows), changes in window geometry
(to correctly perform operations during playback), changes in win-dow content (for abstraction and learning), and changes in key-board focus and in foreground window (for abstraction andplayback). The following sections describe how the other compo-nents of a PBD system use the information produced by theabstraction layer.
3.2.2. The instrumentation layer of SheepdogSheepdog interfaces with Microsoft� Windows� 2000 and XP
system properties and system configuration parameters are re-trieved from the Windows Registry and from the Common Infor-mation Model (CIM) via the Windows ManagementInstrumentation (WMI). Analogous instrumentation layers areavailable for a number of operating systems, such as Linux, andthe Apple OS, for application platforms, such as Eclipse and webbrowsers, and for the Java virtual machine. A model of the screencontent is obtained through appropriate calls to the Windows win-dowing system and to the Microsoft Active Accessibility compo-nent. This model is initialized by ‘‘snapshotting” the entirescreen. The instrumentation captures user actions and systemreactions by registering system-wide callback functions for specificevents (e.g., mouse clicks, window creations, etc.). The screen-con-tent model is incrementally updated upon observing a user actionby selectively retrieving properties of the widgets receiving the ac-tion and of those showing its effects.
Sheepdog’s instrumentation is generic (i.e., application-agnos-tic), can simultaneously operate with multiple applications, andhas proven itself successful in a wide variety of scenarios. Its mainlimitations include an inability to inspect the content of windowsnot exposed by the owning application (which could be overcomewith OCR techniques) and a reliance on special-purpose code toprocess events that are generated in a non-standard fashion (afew Windows widget types exhibit non-standard behavior whengenerating specific events). The former limitation is of moderateconcern: lack of inspectability implies lack of accessibility to peo-ple with disabilities, an issue that an increasing number of soft-ware manufacturers are addressing. The latter required anadditional effort that was a small fraction of the overall program-ming cost.
3.3. Abstraction
3.3.1. The abstraction processThe abstraction process extracts high-level semantic informa-
tion from the low-level events reported by the instrumentationand produces the action part of a SAP. Abstraction makes the datamore understandable to the learning algorithm and to the user.More specifically, the task of the learning algorithm is simpler whenoperating on high-level actions, due to: (1) the more compactdescription of the procedure, (2) the use of the same descriptionfor equivalent actions, and (3) the simplified handling of non-essential actions, such as moving and resizing windows. The proce-dure model produced by the learning algorithm is clearer to the user,because it describes high-level actions rather than mouse clicksand key presses.
3.3.2. The abstraction layer of SheepdogSheepdog captures procedures performed on any existing appli-
cation running on MS Windows. Thus, its abstraction layer doesnot use application-specific knowledge. Instead, it relies on genericrules to produce a representation in terms of user actions (e.g., typ-ing a string into a type-in field, clicking a button, selecting a menuitem, etc.) from low-level events. This approach requires solvingseveral challenges: first, the same action can often be performedin different ways (e.g., using menus or keyboard shortcuts); sec-ond, different actions can consist of the same low-level events

V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109 99
(e.g., drag-and-drop, moving a slider, and resizing a window allconsist of mouse-down, mouse-move, mouse-up); finally, a se-quence of low-level events could either correspond to a full actionor be a precursor of a different action.
Sheepdog’s abstraction layer solves this problem by simulta-neously maintaining multiple chains of hypotheses, each of whichis a sequence of high-level actions that is consistent with the ob-served low-level events, and by implementing a decision mecha-nism that detects when one of these sequences correctlydescribes the actions performed by the user. The gist of the ap-proach is the following: when a new low-level event is observed,the existing chains of hypotheses that cannot explain this newevent are discarded, and some of the remaining are split into multi-ple chains of alternative hypotheses. The chains of hypotheses thatare not discarded are either verified (i.e., the most recent low-levelevent concludes the last action in the chain), or pending (i.e., addi-tional low-level events are needed to verify the last action in thechain). The selection mechanism is invoked when all survivingchains are verified, and picks the chain that best explains the ob-served low-level events.
More specifically, the abstraction layer relies on platform-dependent recognizers that operate in parallel (a recognizer is a fi-nite-state automaton that produces a score when it recognizes aspecific action) and on a mechanism for disambiguating the actionsproduced by the recognizers, called the segmenter. Recognizersconceptually operate as shown in Fig. 8. Upon receiving a low-levelevent �, an INACTIVE recognizer for action a becomes ACTIVE if itrecognizes � as the beginning of a; an ACTIVE recognizer becomesCOMPLETE if � completes a; it remains ACTIVE if � is a valid eventwithin a; and it becomes DISCARDED otherwise. Recognizers canalso be in a FINAL state described below.
The segmenter maintains a current recognizer, C, and a set ofACTIVE recognizers, A. Upon receiving the first low-level event�0, the segmenter instantiates a complete set of recognizers andpasses the event to each. DISCARDED recognizer are not invokedwhen the next event is observed. The COMPLETE recognizer withhighest score becomes C and the others are removed from A. TheACTIVE recognizers with score lower than that of C are discarded,and the remaining form the set of active recognizers A. If A isempty, the COMPLETE recognizer becomes FINAL, the correspond-ing action is recognized, and the process is restarted. When A isnot empty, the segmenter cannot tell whether (1) the user per-formed the action recognized by C or (2) is in the process of per-forming one of the actions of the ACTIVE recognizers. If (1)holds, the next low-level event is part of a new user action; if (2)holds, it is part of an action being performed and not yet com-pleted. To simultaneously consider multiple hypotheses, the seg-menter recursively maintains a list of pairs ðC1;A1Þ; ðC2;A2Þ; . . .,
Event
FINAL
ACTIVE
COMPLETE
INACTIVE
No Active Recognizers
RecognizedEvent
Non
Lower SNo Acti
−
LowerNon −
Highest Score AND
Recognized Action
Recognized
Fig. 8. State-transition dia
called successors of C, constructed as described above. When anew low-level event is observed, it is passed to each recognizerin A, and recursively propagated through the list of successors ofC. Note that the size of A is non-increasing: no new recognizersare added to it and recognizers in A can become DISCARDED orCOMPLETE. If one or more recognizers in A become COMPLETE,the one with highest score replaces C, and all the successors of Care discarded. When A is empty, C becomes FINAL and the corre-sponding action is recognized. The segmenter then replaces C andA with the immediate successors of C, (C1 and A1) and continuesoperating as described.
3.4. Learning
Sheepdog uses sequences of actions produced by the abstrac-tion layer to construct a model of the procedure. In PBD systems,this task is typically performed by a machine learning algorithm.This section first provides an intuitive overview of the learningchallenges encountered in parallel collaborative PBD—a more for-mal framework is delegated to Appendix A. The second part ofthe section discusses the learning algorithm at the heart ofSheepdog.
3.4.1. Inducing a procedure modelThe learning algorithm converts a training set T, composed of
traces (i.e., sequences of SAPs, fðui; yiÞgni¼1), into an executable pro-
cedure model, which can predict the correct actions during play-back of the procedure. Parallel collaborative PBD imposes twomain requirements on the learning algorithm beyond those im-posed by traditional PBD: the ability to learn in batch mode, becausemultiple users can simultaneously record the same procedure; andthe ability to construct models from demonstrations alone, becauseit is not desirable to ask the user for additional input in the scenar-ios targeted by parallel collaborative PBD (see Section 6 for a dis-cussion of the user’s role in PBD systems). No system predatingSheepdog satisfies both requirements.
The starting point for induction is the training set. Consider twotraces from the training set; typically, it is possible to find corre-sponding sections across the traces (i.e., where the users were per-forming equivalent actions) as well as sections of one trace that donot have a corresponding section in the other (i.e., where the users’executions diverged). The goal of learning a procedure model, thatis, to build a model that describes the procedure captured by thetraining set, consists of: (1) identifying the common and divergingsections in the training data, and (2) explaining why divergencesoccurred.
Note that the details of corresponding actions could be differentin different traces. For example, when filling a form with personal
Event
DISCARDEDcore than FINAL
ve Recognizers
Recognized
ScoreRecognized Event
than COMPLETE
AND
OR
grams of recognizers.

100 V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109
information, different authors would provide different values forthe name fields. Similarly, the details of the action consisting ofselecting the first entry in a list vary depending on the content ofthe list. Thus, the problem arises in PBD of how to explain the dif-ferences between corresponding actions. This is the well-knowngeneralization problem, which can be formulated as follows: con-struct a generalized action that synthetically captures the variabil-ity of a collection of recorded equivalent actions; we call this asimple generalized action.
In collaborative PBD, the concept of simple generalized actioncan be extended in at least two directions. The first extension isthe conditional generalized action, which consists of a collectionof simple generalized actions and a function that selects one suchactions using, for example, information contained in the snapshotor, more generally, in the snapshot and in the preceding SAPs.The benefit of such extension are clarified by the following exam-ple. Assume that the goal is to use parallel collaborative PBD tobuild documentation for providing step-by-step guidance: there-fore the PBD program should explain in detail how to perform eachaction to the user. Consider a specific action that is performed indifferent ways depending on the version of the application, forexample, by clicking a toolbar button in a certain version and byselecting a menu item in a different version. A conditional general-ized action would easily capture the variability by means of aselection function that uses the version of the application as input;however the simple generalized actions described in the PBD liter-ature would fail to accomplish the same goal.
The second extension is the probabilistic generalized action,which consists of a collection of simple generalized actions en-dowed with a probability distribution. Probabilistic generalized ac-tions can be used to capture variability in user behavior due topersonal preferences or information not available to the PBD sys-tem. These two extensions can be combined to define a conditionalprobabilistic generalized action, which consists of a collection ofsimple generalized actions endowed with a conditional probabilitydistribution given, for example, the snapshot, or, more generally,the snapshot and the sequence of preceding SAPs.
An orthogonal and, in our opinion, often more complex problemis how to correctly align sub-sequences of non-identical but equiv-alent actions belonging to the same or to different traces. This isthe alignment problem. The two most common sub-problems ofthe alignment problem are: identifying corresponding sequencesof actions in different traces (e.g., finding the portions of differenttraces corresponding to the same sub-task), and identifying the dif-ferent iterations of the same loop within a single trace. The align-ment problem has been solved in the PBD community only undervery restrictive assumptions on the structure of the procedure(e.g., by considering only repetitive tasks consisting of fixed se-quences of actions). With these limitations, the alignment problemcan be solved by brute force, by enumerating all allowed align-ments and selecting the one that best describes the data. In gen-eral, the problem is substantially more complex, for example,when the structure of the task is allowed to have any number ofdecision points and loops in arbitrary positions, and no PBD algo-rithm predating Sheepdog addressed this problem.
Trace alignment is the prerequisite for identifying the structureof the task collectively captured by the traces and for selecting theappropriate data to induce the generalized actions. Learning a pro-cedure model with loops and decision points in arbitrary positionsfrom a collection of traces requires the simultaneous solutions ofboth both alignment and generalization problems, which we callalignment-and-generalization problem.
Traditional PBD has side-stepped the alignment-and-general-ization problem by restricting to very simple procedure structures,by requiring the user to explicitly perform the alignment, or byrequiring the user to direct the learning algorithm via a variety
of feedback mechanisms. These solutions are not viable in parallelcollaborative PBD, for at least two main reasons. First, a substantialpart of the value of collaborative PBD comes from capturing thecollective knowledge of an expert population on how to solve com-plex problems. Second, it is not possible to ask users to align tracesnor to direct the learning algorithm, because the traces are col-lected in parallel and no user is the actual ‘‘owner” of the proce-dure model. The next section describes how Sheepdog overcomesthese difficulties.
3.4.2. The learning algorithm of the Sheepdog systemThe ideas described in the previous section suggest a general
conceptual representation of a procedure model as a probabilisticflow-chart. Nodes in the graph represent procedure steps; eachnode n has a conditional probabilistic generalized action that wecall action probability measure (this is a conditional probabilitymeasure on actions given a snapshot u). Directed edges denotesequentiality; each edge has a transition probability (the condi-tional probability that the specific edge is followed, given a snap-shot). The transition probability captures both the presence ofdifferent paths that are followed depending on the environment,application state, etc., and the user preferences in selecting alterna-tive ways of performing the same procedure. A procedure execu-tion is then a walk on the graph from a source to a sink node.Each action in the execution corresponds to a specific node, andconsecutive actions correspond to directly connected nodes inthe graph.
Given such a graph and an execution trace, it is then possible toalign the trace to the graph, that is, to reconstruct the walk on thegraph captured by the trace. This creates a correspondence be-tween SAPs in the trace and node in the graph such that adjacentSAPs correspond to nodes connected by edges that captures thesequentiality of the SAPs. The alignment has a probability, com-puted as the product of the action probabilities of the nodes corre-sponding to the SAPs and of the transition probabilities of theoriented edges connecting the nodes associated with adjacentSAPs. In general there are multiple alignments of a trace to a graphthat have non-zero probability.
By aligning all the traces in the training set to the same proce-dure model, one effectively aligns the traces with each other. In itssimplest form (think of the case in which each trace has a singlealignment with the model), this process could be described as fol-lows: for each node in the model, create an empty set of SAPs. Aligneach trace to the model, and add each SAP in the trace to the setassociated with the aligned node. Then, we say that SAPs in eachset are aligned with each other (e.g., if two SAPs from the sametrace are in the same set, they describe the same step in differentexecutions of a loop, and, if they are from different traces, they de-scribe the same step in a linear sequence of steps). The notion ofalignment of traces can be immediately extended in a probabilisticdirection, that is, by describing the membership of a SAP to eachset with a probability.
Given a training set where the traces are aligned with eachother, it is possible to construct a procedure model as follows: con-struct a node for each set of aligned SAPs; construct directed edgesbetween nodes aligned to subsequent SAPs; for each node, com-pute an action probability measure; for each node, compute a tran-sition probability measure over the outgoing edges. Computing theaction probability can be done by combining off-the-shelf PBD gen-eralization techniques with off-the-shelf learning algorithms; eachnode will have an action classifier, trained using the data alignedwith the node, that predicts the next action given the current snap-shot. The transition probability can also be computed using an off-the-shelf learning algorithm; each node will have a transition clas-sifier, also trained with the data aligned with the node, that pre-dicts the next node given the current snapshot.

V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109 101
Sheepdog’s learning algorithm, the SimIOHMM (described indetail in [8]), is based on the above discussion. It is the first PBDlearning algorithm that solves the alignment-and-generalizationproblem. Learning is iterative: the SimIOHMM constructs the pro-cedure model by alternating an alignment step, where the trainingtraces are aligned to a model, and a generalization step, where anew model is created with the traces aligned to the previous mod-el. The SimIOHMM belongs to a well-understood class of modelsknown as Hidden Markov Models (HMMs) [9], and, more specifi-cally, to a subclass known as Input–Output Hidden Markov Models(IOHMMs) [10]. The process of alternating the alignment step(called the ‘‘E-Step” in the HMM jargon) with the generalizationstep (the ‘‘M-Step”) for HMM models can be efficiently performedwith an extension to the Baum-Welch algorithm, which in turn is aspecialization of the classical E–M Algorithm [11] to HMMs.
The SimIOHMM is specifically tailored to support parallel col-laborative PBD. It is a batch algorithm, that is, it learns from sepa-rately recorded traces. Additionally, it simplifies the generalizationstep over that of a regular IOHMM by biasing the alignment pro-cess using a similarity measure: SAPs are aligned using a cost func-tion based on a similarity index. This simplification offsets thedifficulty of learning from traces recorded in heterogeneous envi-ronments on different user machines. The SimIOHMM is also ableto capture ‘‘well-worn paths” through the procedure even with asmall number of training examples; this is an important aspectof the SimIOHMM’s capability to effectively model the collectiveknowledge of multiple experts.
3.5. Authoring in Sheepdog
The procedure model produced by the SimIOHMM cannot beeasily represented in a human-readable fashion. For procedureslarger than a few steps, an important component of readability isa structure of hierarchical subs-tasks. Rather than attempting tocreate such structure automatically (an open problem in PBD),Sheepdog provides the author with facilities for organizing the pro-cedure representation for display to the user. The authoring inter-face enables hierarchical grouping of the actions produced by the
Fig. 9. Components of the Sheepdog GUI. A: VCR-style controls. B: mode-specific but
SimIOHMM, manual annotation of individual steps and stepgroups, and explicit identification and labeling of decision points(branch points).
A user executing the procedure is presented with a graphicaldescription of the task (Fig. 5), which might contain authoredinformation. Grouped user actions are represented by a folder icon,while individual steps are marked by a ‘‘page” icon. The user canexplore a group of actions by recursively opening the correspond-ing folder.
Authoring is separate from model abstraction and inference: thelearning algorithm uses the actions recognized by the abstractionlayer but not the manual authoring operations.
3.6. Execution
A PBD system must be able to perform a task described by aprocedure model produced by the learning algorithm. The compo-nent devoted to executing the procedure on behalf of or in cooper-ation with the user is called the execution engine.
3.6.1. Execution for collaborative PBDA collaborative PBD execution engine should: (i) be able to emu-
late individual user actions from their description within the proce-dure model; (ii) be robust to variations in the target-application GUI,to deal with variability across different user machines; (iii) providean explanation of each step and of the procedure, to gain the trust ofconsumers of the model. Additional features that support differentuses of the PBD system include:
(a) providing a tutoring mode, where the user is directed step-by-step, while being shown what has already been accom-plished and what remains to be done;
(b) supporting mixed-initiative execution, where the user can takeover the execution and the PBD system can track the pro-gress being made even when the user deviates from the pro-cedure model (e.g., for technical support procedures, wherethe DSR often wants to take control of the execution of crit-ical parts of the procedure);
tons. C: procedure pane. D: step annotation pane. E: indicator of current mode.

102 V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109
(c) supporting execution at multiple granularities (examples ofdifferent granularity include executing one step at a time,a group of steps, or the entire procedure), where the granu-larity could vary across the procedure.
3.6.2. Sheepdog’s execution engine and Execution GUISheepdog can execute the procedure either automatically in its
entirety, or in cooperation with the user. For the latter purpose,Sheepdog has an Execution GUI, depicted in Fig. 9, which describesthe structure of the procedure, graphically guides the user throughthe execution, and explains individual steps. Prior to execution, theexecutable procedure model is loaded into the execution engine,and the manually authored procedure representation is loaded intothe Execution GUI. The procedure representation is graphically de-picted in the procedure pane, on the left-hand side of the ExecutionGUI.
An intuitive way of describing the playback capability of Sheep-dog is to start from the familiar concepts of playback in a macro re-corder, and explore how Sheepdog departs from it. The two maindifferences are: (1) Sheepdog relies on the procedure model to se-lect the next action taken using the content of the target GUI—amacro recorder just reproduces a fixed sequence of recorded ac-tions; (2) Sheepdog can execute a procedure in mixed-initiativemode. We explore each difference in detail.
3.6.3. Selecting the next actionThe next action is predicted using the procedure model as fol-
lows. First, Sheepdog requests a snapshot of the system from theinstrumentation; then the snapshot is used to predict the next ac-tion via the well known Viterbi algorithm [12] applied to the Sim-IOHMM model. The selected action is highlighted in the left panelof the Execution GUI, available annotations are displayed in theright panel, and the target widget for the action is flashed on thetarget application (by a sequence of reverse highlights of the wid-get background under the control of a timer).
Before selecting and executing a new action, Sheepdog must en-sure that the effects of performing the previous action are visible inthe UI. Sheepdog relies on two heuristics to decide when to predictand execute the next action:
Preconditions are requirements on the target GUI that need to besatisfied for an action to be performed (for example, the targetof the action must be visible).Quiescence is the state reached when all the effects of a useraction have been reflected on the target GUI.
Quiescence is detected by a timer that is reset when a change tothe GUI is observed, and fires when the target application GUI hasnot shown changes for a predefined period of time. When quies-cence is reached, Sheepdog issues a snapshot, infers the next ac-tion, and checks the preconditions. When quiescence andpreconditions are satisfied, Sheepdog selects the next step on theExecution GUI.
3.6.4. Mixed-initiative procedure executionIn mixed-initiative execution, a mode in which the user and
Sheepdog cooperatively perform the task, the user can take controland manually perform actions. The user can either continue to per-form the procedure steps in the same order or in a different orderthan Sheepdog, or can perform actions that are extraneous to theprocedure—for example, writing an e-mail or responding to an in-stant message. We call the first case on-track mixed-initiative, whilethe term off-track mixed-initiative denotes any deviation of the userfrom the model. While the user retains the initiative, Sheepdogmatches the observed user actions to the model using the Viterbi
algorithm [12]. Sheepdog decides that the user actions are consis-tent with the HMM if the probability of the most likely path is suf-ficiently high, otherwise Sheepdog decides that the user is off-track, notifies the user, and refrains from regaining the initiative.
As soon as the user goes off-track, Sheepdog attempts to realignthe user actions with the model. The gist of the approach is the fol-lowing. Assume that the user goes off-track for a while and then re-sumes the execution of the procedure in the way described by themodel, but not necessarily from the point where the deviation oc-curred. For sake of discussion, say that the user goes off-track, thenresumes the execution of the task and performs three consecutiveactions of the procedure captured in the document. This meansthat the best alignment of these three actions with three consecu-tive steps in the model has a high posterior probability. The sameholds for aligning the two most recent actions as well as for align-ing the most recent action. However, the best alignments of thelast four, five, etc., actions have small probabilities because theuser was off-track. This means that there is a ‘‘discontinuity” (achange point [13]) between the best alignment probability of thelast three observed action and that of the last four. Sheepdog relieson a user-selectable parameter k, typically set between two andfour: when the probability of the best alignment of the last k ac-tions is high and there is a change point between k and kþ 1,Sheepdog declares that the user is back on track, and again startsoffering suggestions to the user on what actions to take next.
3.7. Finding the right widget
When executing parallel collaborative PBD procedures, a diffi-culty arises that is typically not present in traditional, end-user-programming-oriented PBD: differences in environment (versionsof the OS or of applications, user settings, and system configura-tions) in which the procedure is executed can complicate the iden-tification of a target widget. Fig. 10 illustrates this concept: the‘‘Stop” button in two versions of Internet Explorer is substantiallydifferent in appearance and location on the screen. In both cases,it is a button in a toolbar within a window belonging to the iex-
plore.exe process. In both cases, it is contained in the same tool-bar as the ‘‘Reload” button, but these toolbars have differentcontents. Finally, the accessibility Name fields are similar, but notidentical: Stop, in the top case, and Stop (Esc) in the bottom case.
Sheepdog finds the target widget using a variety of widgetproperties as well as hierarchical information on the containingwidgets states, and on the owning application. The matching algo-rithm relies on a set of hard constraints and on a set of soft con-straints on the characteristics of the target widgets. A constraintis hard if the desired search target can never violate it, otherwiseit is soft. Examples of hard constraints are the type of the targetwidget and the application name. Examples of soft constraintsare the position relative to the containing window, the list ofancestor windows, and the icon.
When searching for a widget, Sheepdog first attempts to matchthe widget description exactly, using a greedy algorithm. If a singlewidget satisfies all the hard constraints, a match is declared andthe widget returned. If no widget satisfies the hard constraints, afailure is declared. If two or more widgets satisfy the hard con-straints, they are scored using the soft constraints, and the bestmatch is returned. The described matching algorithm is used dur-ing playback—for action prediction, for display, and for execution—and during learning—to assist the alignment.
The matching algorithm works well empirically and in ourexperiments we have not encountered cases in which it fails. How-ever, the algorithm will fail to find the desired widget when themodel is constructed for a particular version of an applicationand is applied to another version with a radically different GUI. Ifthe nature of a target control is changed, the algorithm fails. This

Fig. 10. The ‘‘Stop” button in two different versions of Internet Explorer.
V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109 103
is a known open problem, particularly onerous in automated-GUI-testing applications. For the same reason, a procedure learned onan operating system (e.g., Windows) cannot typically be appliedon a machine running a different OS (e.g., Linux). However, the pro-cedure described in the user study below was constructed on Win-dows 2000 machines, and runs unchanged on Windows XPmachines.
4. User study
We now describe and discuss a user study designed to: evaluatethe ability of users to follow written documentation composed oftext and screen shots; compare the performance of Sheepdogtrained with expert traces to that of actual users; and evaluateSheepdog’s ability to learn from noisy data. Portions of the resultsin this section first appeared in [14].
4.1. Materials and methods
Eleven subjects checked and corrected the network settings of alaptop computer by following printed instructions obtained froman internal IT web site. The instructions contained both text andfigure, and describe a procedure of typical length and difficultyamong those for which detailed instructions are available withinthe IBM intranet. Fig. 11 shows the flow-chart of the procedure.The subjects were asked to follow the instructions as closely as pos-sible, in a controlled environment, they were told that there was no
Fig. 11. Network configuration procedure. Ovals represent steps in the procedure; stackopening the TCP/IP property dialog box; shaded ovals denote actions whose execution i
time limit to complete the task. They were presented with a laptopcomputer (an IBM Thinkpad model T20 with 256 Mb of main mem-ory, running Windows 2000, equipped with a wireless networkcard—a model with which all subjects were familiar). Each subjecthad a machine with a different initial configuration of the networkconnection, and had to execute a different path through the proce-dure. To execute the procedure, the users have to interact withthree different applications: explorer.exe (the Windows GUI, fornavigation purposes), the Network Connection Control Panel, andDOS.
The subject actions were recorded by Sheepdog and stored astraces. Subjects were administered a survey with questions onexpertise and background as well as on aspects of the experienceduring the session. Subjects also rated (on a Likert scale �1 = low-est to 5 = highest) their familiarity with Windows 2000, the per-ceived clarity of the instructions, the confidence of havingfollowed the instructions correctly, and the confidence of havingproduced a correct configuration of the machine. A single expertalso performed the procedure starting from the same 11 differentconfigurations, and his actions were similarly recorded.
The recorded traces were analyzed to investigate the perfor-mance of the individuals compared to that of the expert. Statisticalanalysis were performed using GNU Octave. We report both p-val-ues from standard parametric tests ðptÞ and p-values from non-parametric resampling estimates ðpnÞ.
The subject traces and the expert traces were respectively usedto train two separate SimIOHMMs. Each model was tested againstits training set and against the other set of traces. The testing
ed ovals represent a sequence of steps required to accomplish a single task, such ass required only for certain initial configurations.
104 V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109
methodology was the following: for each trace, the SimIOHMMwas initialized. Then, for each SAP of the trace, the SimIOHMM pre-dicted an action given the snapshot in the SAP; this prediction wasrecorded, and the action performed by the user was disclosed tothe SimIOHMM, which in turn updated the probability distributionover the nodes. This approach tests the ability of the SimIOHMMmodel to predict the next step. The prediction accuracy estimatedby this methodology is likely a lower bound to the predictive abil-ity of Sheepdog when used in mixed-initiative, because the SimI-OHMM is required to produce a guess even when it detects thatthe user is off-track.
We tested the procedure learned with the expert traces againstits training set. The training error rate measures how well the sys-tem learns the decision points demonstrated in the traces. We alsotested the procedure learned with the expert traces against thesubject traces. The test error rate measures how often an actionperformed by a user could not be inferred from expert demonstra-tions. Finally, we tested a procedure learned with subject tracesagainst the expert traces. The test error rate indicates how wellthe Sheepdog system can ‘‘smooth out” the noise and learn well-worn paths through the procedure.
4.2. Experimental results
4.2.1. Survey resultsThe results of the subject survey are summarized in Table 1.
� Self-assessed level of Knowledge of Windows (col. 2). The sub-jects generally felt comfortable with the Windows environment:the mode and median were both ‘‘familiar” (4).
Table 2Counts of user actions: the table reports the total number of correct, on-track actions; of off-that the user are not following the directions correctly); of spurious actions (i.e., actions notthe user is following the directions incorrectly); of skipped steps; and the total number of ofor the same task, while the last column denotes whether the subject correctly completed
Subject On-Track Off -Track Spurious
1 15 13 02 41 16 53 21 1 14 19 28 105 43 4 46 16 0 07 18 59 108 22 5 19 15 31 110 21 0 111 36 7 10
Table 1The result of the entry survey, by subject. Each subject selected, on a scale from 1(lowest) to 5 (highest), their knowledge of the Windows environment, the perceivedclarity of the instructions, the belief that they followed the instructions literally, andthe belief that they produced the desired configuration.
Subject Knowledge Clarity Followed Configured
1 5 5 4 52 4 3 5 53 5 5 5 54 5 3 4 15 3 3 4 26 3 4 4 47 1 3 2 38 4 4 4 49 4 4 4 410 4 5 5 511 2 3 4 4
� Perceived Clarity of the instructions (col. 3). Five users found theinstructions ‘‘only moderately clear” (3), three users found theinstructions ‘‘somewhat clear” (4), and three users found theinstructions ‘‘perfectly clear” (5).
� Belief of having Followed the instructions correctly (col. 4).Seven subjects were‘‘somewhat confident” of having followedthe instruction correctly (4), three were ‘‘entirely confident” ofhaving failed to follow the instructions (1), and one was ‘‘some-what confident” of having failed (2).
� Belief of having Configured the machine correctly (col. 5). Foursubjects were ‘‘completely confident” (5) of having configuredthe machine correctly and four were ‘‘somewhat confident”(4). One subject was ‘‘completely confident” of having failed(1) one was somewhat confident of having failed (2), and the lastwas undecided (3).
We tested whether the quantities in Table 1 were pairwisedependent, using the traditional chi-square test and a non-para-metric permutation chi-square test with 20,000 iterations. Inter-estingly, all pairs appear independent, except Clarity andFollowed ðpt ¼ 0:102896; pn ¼ 0:0305Þ, but this barely significantresult is probably a multiple-testing effect.
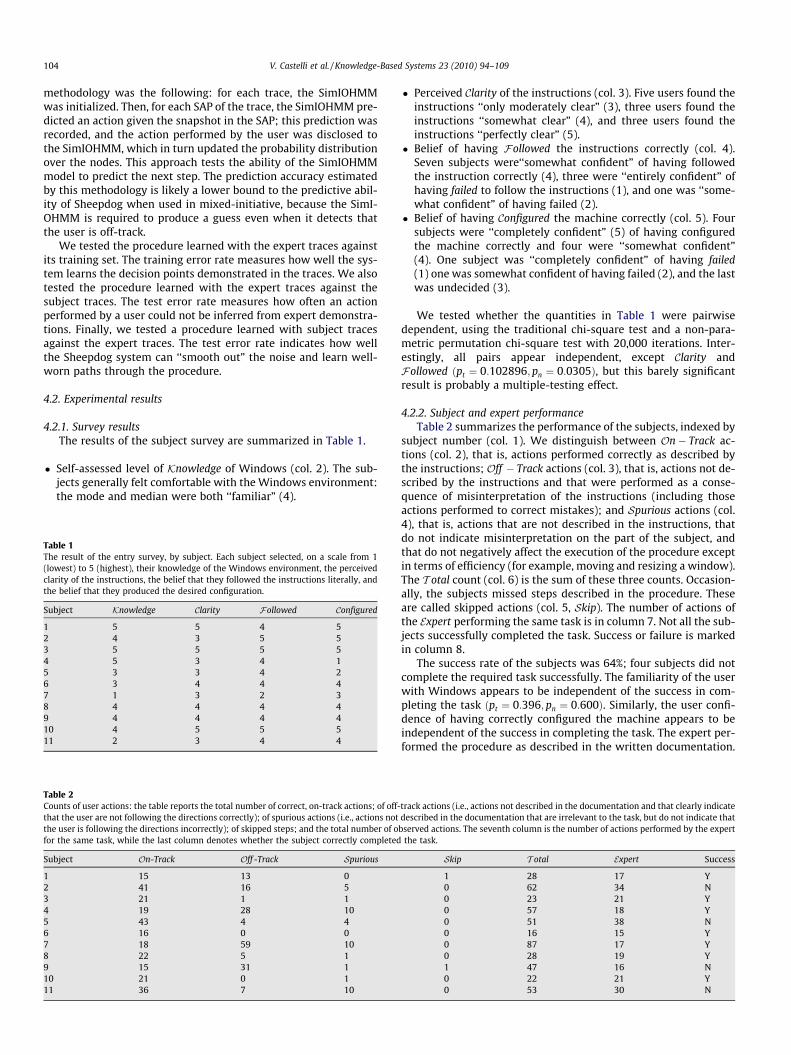
4.2.2. Subject and expert performanceTable 2 summarizes the performance of the subjects, indexed by
subject number (col. 1). We distinguish between On� Track ac-tions (col. 2), that is, actions performed correctly as described bythe instructions; Off � Track actions (col. 3), that is, actions not de-scribed by the instructions and that were performed as a conse-quence of misinterpretation of the instructions (including thoseactions performed to correct mistakes); and Spurious actions (col.4), that is, actions that are not described in the instructions, thatdo not indicate misinterpretation on the part of the subject, andthat do not negatively affect the execution of the procedure exceptin terms of efficiency (for example, moving and resizing a window).The T otal count (col. 6) is the sum of these three counts. Occasion-ally, the subjects missed steps described in the procedure. Theseare called skipped actions (col. 5, Skip). The number of actions ofthe Expert performing the same task is in column 7. Not all the sub-jects successfully completed the task. Success or failure is markedin column 8.
The success rate of the subjects was 64%; four subjects did notcomplete the required task successfully. The familiarity of the userwith Windows appears to be independent of the success in com-pleting the task ðpt ¼ 0:396; pn ¼ 0:600Þ. Similarly, the user confi-dence of having correctly configured the machine appears to beindependent of the success in completing the task. The expert per-formed the procedure as described in the written documentation.
track actions (i.e., actions not described in the documentation and that clearly indicatedescribed in the documentation that are irrelevant to the task, but do not indicate that
bserved actions. The seventh column is the number of actions performed by the expertthe task.
Skip T otal Expert Success
1 28 17 Y0 62 34 N0 23 21 Y0 57 18 Y0 51 38 N0 16 15 Y0 87 17 Y0 28 19 Y1 47 16 N0 22 21 Y0 53 30 N
V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109 105
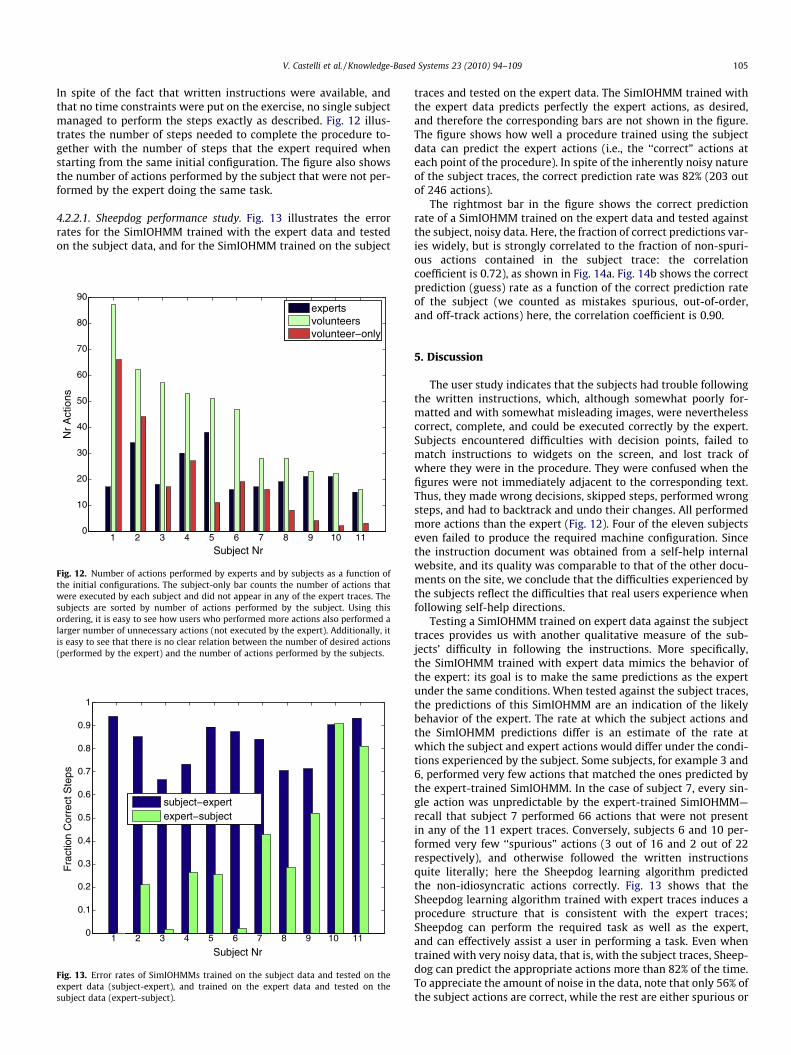
In spite of the fact that written instructions were available, andthat no time constraints were put on the exercise, no single subjectmanaged to perform the steps exactly as described. Fig. 12 illus-trates the number of steps needed to complete the procedure to-gether with the number of steps that the expert required whenstarting from the same initial configuration. The figure also showsthe number of actions performed by the subject that were not per-formed by the expert doing the same task.
4.2.2.1. Sheepdog performance study. Fig. 13 illustrates the errorrates for the SimIOHMM trained with the expert data and testedon the subject data, and for the SimIOHMM trained on the subject
1 2 3 4 5 6 7 8 9 10 110
10
20
30
40
50
60
70
80
90
Subject Nr
Nr
Act
ions
expertsvolunteersvolunteer−only
Fig. 12. Number of actions performed by experts and by subjects as a function ofthe initial configurations. The subject-only bar counts the number of actions thatwere executed by each subject and did not appear in any of the expert traces. Thesubjects are sorted by number of actions performed by the subject. Using thisordering, it is easy to see how users who performed more actions also performed alarger number of unnecessary actions (not executed by the expert). Additionally, itis easy to see that there is no clear relation between the number of desired actions(performed by the expert) and the number of actions performed by the subjects.
1 2 3 4 5 6 7 8 9 10 110
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Subject Nr
Fra
ctio
n C
orre
ct S
teps
subject−expertexpert−subject
Fig. 13. Error rates of SimIOHMMs trained on the subject data and tested on theexpert data (subject-expert), and trained on the expert data and tested on thesubject data (expert-subject).
traces and tested on the expert data. The SimIOHMM trained withthe expert data predicts perfectly the expert actions, as desired,and therefore the corresponding bars are not shown in the figure.The figure shows how well a procedure trained using the subjectdata can predict the expert actions (i.e., the ‘‘correct” actions ateach point of the procedure). In spite of the inherently noisy natureof the subject traces, the correct prediction rate was 82% (203 outof 246 actions).
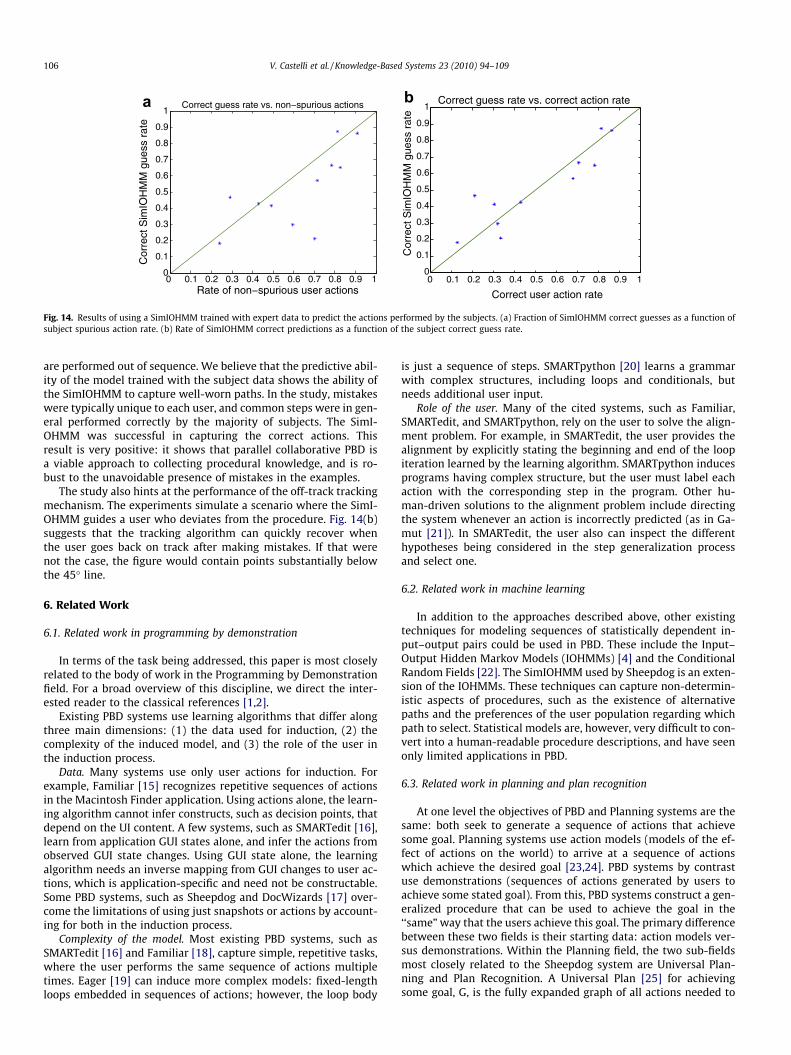
The rightmost bar in the figure shows the correct predictionrate of a SimIOHMM trained on the expert data and tested againstthe subject, noisy data. Here, the fraction of correct predictions var-ies widely, but is strongly correlated to the fraction of non-spuri-ous actions contained in the subject trace: the correlationcoefficient is 0.72), as shown in Fig. 14a. Fig. 14b shows the correctprediction (guess) rate as a function of the correct prediction rateof the subject (we counted as mistakes spurious, out-of-order,and off-track actions) here, the correlation coefficient is 0.90.
5. Discussion
The user study indicates that the subjects had trouble followingthe written instructions, which, although somewhat poorly for-matted and with somewhat misleading images, were neverthelesscorrect, complete, and could be executed correctly by the expert.Subjects encountered difficulties with decision points, failed tomatch instructions to widgets on the screen, and lost track ofwhere they were in the procedure. They were confused when thefigures were not immediately adjacent to the corresponding text.Thus, they made wrong decisions, skipped steps, performed wrongsteps, and had to backtrack and undo their changes. All performedmore actions than the expert (Fig. 12). Four of the eleven subjectseven failed to produce the required machine configuration. Sincethe instruction document was obtained from a self-help internalwebsite, and its quality was comparable to that of the other docu-ments on the site, we conclude that the difficulties experienced bythe subjects reflect the difficulties that real users experience whenfollowing self-help directions.
Testing a SimIOHMM trained on expert data against the subjecttraces provides us with another qualitative measure of the sub-jects’ difficulty in following the instructions. More specifically,the SimIOHMM trained with expert data mimics the behavior ofthe expert: its goal is to make the same predictions as the expertunder the same conditions. When tested against the subject traces,the predictions of this SimIOHMM are an indication of the likelybehavior of the expert. The rate at which the subject actions andthe SimIOHMM predictions differ is an estimate of the rate atwhich the subject and expert actions would differ under the condi-tions experienced by the subject. Some subjects, for example 3 and6, performed very few actions that matched the ones predicted bythe expert-trained SimIOHMM. In the case of subject 7, every sin-gle action was unpredictable by the expert-trained SimIOHMM—recall that subject 7 performed 66 actions that were not presentin any of the 11 expert traces. Conversely, subjects 6 and 10 per-formed very few ‘‘spurious” actions (3 out of 16 and 2 out of 22respectively), and otherwise followed the written instructionsquite literally; here the Sheepdog learning algorithm predictedthe non-idiosyncratic actions correctly. Fig. 13 shows that theSheepdog learning algorithm trained with expert traces induces aprocedure structure that is consistent with the expert traces;Sheepdog can perform the required task as well as the expert,and can effectively assist a user in performing a task. Even whentrained with very noisy data, that is, with the subject traces, Sheep-dog can predict the appropriate actions more than 82% of the time.To appreciate the amount of noise in the data, note that only 56% ofthe subject actions are correct, while the rest are either spurious or
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Rate of non−spurious user actions
Cor
rect
Sim
IOH
MM
gue
ss r
ate
Correct guess rate vs. non−spurious actions
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Correct user action rate
Cor
rect
Sim
IOH
MM
gue
ss r
ate
Correct guess rate vs. correct action ratea b
Fig. 14. Results of using a SimIOHMM trained with expert data to predict the actions performed by the subjects. (a) Fraction of SimIOHMM correct guesses as a function ofsubject spurious action rate. (b) Rate of SimIOHMM correct predictions as a function of the subject correct guess rate.
106 V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109
are performed out of sequence. We believe that the predictive abil-ity of the model trained with the subject data shows the ability ofthe SimIOHMM to capture well-worn paths. In the study, mistakeswere typically unique to each user, and common steps were in gen-eral performed correctly by the majority of subjects. The SimI-OHMM was successful in capturing the correct actions. Thisresult is very positive: it shows that parallel collaborative PBD isa viable approach to collecting procedural knowledge, and is ro-bust to the unavoidable presence of mistakes in the examples.
The study also hints at the performance of the off-track trackingmechanism. The experiments simulate a scenario where the SimI-OHMM guides a user who deviates from the procedure. Fig. 14(b)suggests that the tracking algorithm can quickly recover whenthe user goes back on track after making mistakes. If that werenot the case, the figure would contain points substantially belowthe 45� line.
6. Related Work
6.1. Related work in programming by demonstration
In terms of the task being addressed, this paper is most closelyrelated to the body of work in the Programming by Demonstrationfield. For a broad overview of this discipline, we direct the inter-ested reader to the classical references [1,2].
Existing PBD systems use learning algorithms that differ alongthree main dimensions: (1) the data used for induction, (2) thecomplexity of the induced model, and (3) the role of the user inthe induction process.
Data. Many systems use only user actions for induction. Forexample, Familiar [15] recognizes repetitive sequences of actionsin the Macintosh Finder application. Using actions alone, the learn-ing algorithm cannot infer constructs, such as decision points, thatdepend on the UI content. A few systems, such as SMARTedit [16],learn from application GUI states alone, and infer the actions fromobserved GUI state changes. Using GUI state alone, the learningalgorithm needs an inverse mapping from GUI changes to user ac-tions, which is application-specific and need not be constructable.Some PBD systems, such as Sheepdog and DocWizards [17] over-come the limitations of using just snapshots or actions by account-ing for both in the induction process.
Complexity of the model. Most existing PBD systems, such asSMARTedit [16] and Familiar [18], capture simple, repetitive tasks,where the user performs the same sequence of actions multipletimes. Eager [19] can induce more complex models: fixed-lengthloops embedded in sequences of actions; however, the loop body
is just a sequence of steps. SMARTpython [20] learns a grammarwith complex structures, including loops and conditionals, butneeds additional user input.
Role of the user. Many of the cited systems, such as Familiar,SMARTedit, and SMARTpython, rely on the user to solve the align-ment problem. For example, in SMARTedit, the user provides thealignment by explicitly stating the beginning and end of the loopiteration learned by the learning algorithm. SMARTpython inducesprograms having complex structure, but the user must label eachaction with the corresponding step in the program. Other hu-man-driven solutions to the alignment problem include directingthe system whenever an action is incorrectly predicted (as in Ga-mut [21]). In SMARTedit, the user also can inspect the differenthypotheses being considered in the step generalization processand select one.
6.2. Related work in machine learning
In addition to the approaches described above, other existingtechniques for modeling sequences of statistically dependent in-put–output pairs could be used in PBD. These include the Input–Output Hidden Markov Models (IOHMMs) [4] and the ConditionalRandom Fields [22]. The SimIOHMM used by Sheepdog is an exten-sion of the IOHMMs. These techniques can capture non-determin-istic aspects of procedures, such as the existence of alternativepaths and the preferences of the user population regarding whichpath to select. Statistical models are, however, very difficult to con-vert into a human-readable procedure descriptions, and have seenonly limited applications in PBD.
6.3. Related work in planning and plan recognition
At one level the objectives of PBD and Planning systems are thesame: both seek to generate a sequence of actions that achievesome goal. Planning systems use action models (models of the ef-fect of actions on the world) to arrive at a sequence of actionswhich achieve the desired goal [23,24]. PBD systems by contrastuse demonstrations (sequences of actions generated by users toachieve some stated goal). From this, PBD systems construct a gen-eralized procedure that can be used to achieve the goal in the‘‘same” way that the users achieve this goal. The primary differencebetween these two fields is their starting data: action models ver-sus demonstrations. Within the Planning field, the two sub-fieldsmost closely related to the Sheepdog system are Universal Plan-ning and Plan Recognition. A Universal Plan [25] for achievingsome goal, G, is the fully expanded graph of all actions needed to

V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109 107
move from any starting state to a world where the fixed goal isachieved. ‘‘Some universal planning systems [26] achieve robust-ness against actions with unintended effects by determining, ateach step, the action that best moves toward the fixed goal, basedon the state of the observed world.” Sheepdog procedures (whichare grown as users demonstrate appropriate actions from increas-ingly diverse world states) asymptotically approach such universalplans. The key difference here is the information used to constructthese universal plans: in the former it is demonstrations, in the lat-ter it is action models. The second sub-field relates to the align-ment process that Sheepdog performs. In Plan Recognition [27]the objective is to map a sequence of actions onto an ongoing planwhich achieves some unstated goal. By analogy, Sheepdog mustmap an ongoing sequence of actions onto a point within the Sheep-dog procedure to determine what part of that procedure should bemodified to match the ongoing demonstration. Sheepdog achievesthis mapping by aligning the surface state of the world (the userinterface) over multiple actions, whereas Plan Recognition systemsalign observed actions, with actions from possible plans. Whenmany actions align with a single plan, these systems ‘‘recognize”the plan is being executed by user to achieve the goal of the recog-nized plan. Again the key difference is the starting knowledge:Sheepdog is told the user’s intended goal, and uses the demonstra-tions of that goal to build a model of action for achieving it. PlanRecognition systems, by contrast, are roughly performing the in-verse operation: they are given the action model, and use it toguess the unstated goal of the user.
Sheepdog has additional features that, to our knowledge, do notappear in previous PBD, machine learning, or planning systems.The first is an authoring facility that allows the user to edit thedescription of the procedure that is presented to the user, withoutaffecting the underlying automatically induced task representa-tion. The second is the ability to track a user who diverges fromthe learned procedure model and to regain the initiative whenthe user is back on track.
7. Conclusions and future work
This paper presents the field of parallel collaborative PBD as aprocedural know-how capture mechanism. A parallel collaborativePBD system independently records multiple experts who perform aspecific task and combines the recording into an executable proce-dure model, via a learning algorithm. We have analyzed the differ-ent components of a PBD systems—instrumentation, abstraction,learning, and playback—and identified where traditional PBD (fo-cused on end-user-programming) fails to provide the methodsand techniques to support parallel collaborative PBD. We have sug-gested solutions to these shortcomings and described their imple-mentation in a system called Sheepdog.
The algorithms and methods proposed in this paper have gen-eral applicability. The architecture described is highly modularand its extensions have been used to support collaborative PBDon a variety of platforms: operating systems such as Windows(as in this paper) and Linux, Eclipse [17], and Lotus Expeditor[28], and web-browsers (and on individual applications built onthe mentioned platforms), by appropriately modifying the instru-mentation and the abstraction layer. Initial experiments conductedusing Sheepdog are very promising. They suggest that PBD can cor-rectly learn procedures that regular users often fail to perform cor-rectly, even when following written instructions.
The Sheepdog experience is the only the first step in the explo-ration of collaborative PBD. It is well suited for situations wherenumerous experts are available, where the data collection shouldbe done unobtrusively, and where the end user’s goal is completingthe task rather than learning how to perform it. The main features
of Sheepdog that makes this system appealing for these situationsare: the recording layer, which operates with a simple user inter-face; the learning algorithm, which combines independently re-corded traces into a probabilistic model of the task that outlinesthe well-worn paths through the procedure; the authoring UI,which allows an author to create a human-readable descriptionof the task containing only the details deemed necessary for the in-tended end-users; the playback engine, which allows the end-userto take over and deviate from the prescribed path; and the widgetfinding algorithm, which deals with differences across user envi-ronment configurations.
The space of collaborative PBD includes scenarios where theSheepdog learning algorithm is not ideal: when the number of ex-perts from whom data is collected is small, or where the authorwants immediate, real-time feedback on how the learning algo-rithm is interpreting the observations, SimIOHMM is not a viablechoice and different algorithms should be used. For example, whenboth incremental learning and the ability to directly edit the proce-dure model are desired, Augmentation-Based Learning [29] wouldbe the algorithm of choice. When different authors are allowed toincrementally modify a procedure model in parallel, DistributedAugmentation-Based Learning [30] provides an additional recon-ciliation facility.
Similarly, when the goal of the PBD system is shifted from auto-matic or collaborative execution towards intelligent documenta-tion or tutorials, a different user experience, such as the oneprovided by the DocWizards system [17] might be preferable tothat offered by Sheepdog.
Nevertheless, the majority of the lessons learned while develop-ing Sheepdog carry over to these new scenarios and form a founda-tion for general distributed PBD.
Acknowledgements
We would like to thank Stephen S. Lavenberg, for his support,encouragement, and guidance; Peter Franaszek, for the insightfuldiscussions that lead to the formulation of this project; and JohnTurek, for his support and for providing useful suggestions ondirections in which to steer our investigation.
Appendix A. Learning for Collaborative PBD
This appendix contains a more formal discussion of the learningchallenges encountered in PBD, and complements the intuitive dis-cussion of Section 3.4.1.
Note that a probabilistic procedure model can be representedby a graph akin to a flow-chart, where steps have action probabil-ities (conditional probabilities over actions given snapshots) andedges have transition probabilities (conditional probabilities of fol-lowing the edge given the snapshots).
The term procedure structure denotes a directed graph obtainedby discarding action and transition probabilities. We say that aprocedure model is an instantiated version of its procedure struc-ture. Inducing a procedure model involves identifying a procedurestructure, constructing the node action probabilities, and inferringthe transition probabilities associated with the edges.
Our discussion of the learning challenges encountered in Paral-lel Collaborative PBD relies on the concept of alignment.
Definition 1. An alignment of a trace fðui; yiÞgmi¼1 with a sequence
of steps n1; . . . ;nm (equiv. nm1 ) is a one-to-one correspondence that
maps ðui; yiÞ to ni. The trace is said to be aligned with the path(equivalently, with the procedure structure).
Thus, an alignment consists of labeling the SAPs in a trace usinggraph steps (i.e., graph nodes) as labels.

108 V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109
For a given alignment, the step action probabilities, the transi-tion probabilities, and a probability distribution over the sourcenode define a conditional probability P ym
1 ;nm1 jum
1
� �. Its marginal
P ym1 ; jum
1 ;� �
¼Xnm
1f gP ym
1 ;nm1 jum
1
� �ðA:1Þ
is the probability of observing the sequence of actions given the se-quence of inputs according to the model. If Eq. A.1 is zero, the modelcannot explain the trace, and the trace and the model are mutuallyinconsistent, otherwise they are consistent. Learning from a trainingset T can then be cast as estimating the model that maximizes theproduct of the probabilities of Eq. A.1 for the traces in T—that is, themodel that best explains the evidence in the training set (more gen-erally, one would add a penalty term to smooth the result, wherebyreducing the risk of overfitting).
If the procedure model and the alignment of the traces in T aregiven, then learning reduces to estimating the probability distribu-tion over the source nodes (by counting), the action probabilities,and the transition probabilities. We call this the generalizationproblem, and we propose a sufficient characterization of itssolutions
Proposition 1 (Solution to the generalization problem). A modelM is a solution to the generalization problem if:
[a] The action probability of each node n is induced using only SAPshaving alignment probability greater than zero with n, and, poten-tially their preceding SAPs in the same trace;[b] The transition probability from n1 to n2 are computed only withsubsequent pairs of SAPs where the first is aligned with n1 and thesecond with n2, and, potentially their preceding SAPs in the sametrace;[c] M is consistent with all the traces in T.
Many existing PBD systems solve only the generalization prob-lem, and the user must provide, either directly (e.g., by labeling ac-tion) or indirectly (via feedback mechanisms), the structure andthe alignment. An important contribution of this work is learningfrom multiple demonstrations when the structure and the align-ment between the steps of the demonstrations are unknown. Inthis case, the learner must build a procedure structure using T,align each trace to the procedure structure, and solve the general-ization problem. We call this the alignment-and-generalizationproblem and we now characterize sufficient properties of itssolutions.
Proposition 2 (Solution to the alignment-and-generalizationproblem). A model M with structure ðN ; EÞ together with a (prob-abilistic) alignment of the training set to the structure, are a solution ofthe alignment-and-generalization problem if:
[a] For each node inN there is at least one SAP in T with alignmentprobability greater than zero; hence, data is available to instantiateeach step.[b] For each edge ei;j (where ei;j is from ni to nj) there must be atleast two SAPs in a trace of T, ðut ; ytÞ and ðutþ1; ytþ1Þ immediatelyfollowing ðut ; ytÞ such that the probability that ðut ; ytÞ is alignedwith ni and ðutþ1; ytþ1Þ is aligned with nj is greater than zero; thus,data is available to infer the transition probability from ni to nj.[c] Given the alignment, the generalization problem is solved as inProposition 1.
A.1. The SimIOHMM
The SimIOHMM is the first PBD algorithm that solves the align-ment-and-generalization problem. The learning process is per-
formed in batch mode and yields probabilistic models fromwhich well-worn paths emerge even with few training examples.Rather than estimating an unconstrained probability measure thatmaximizes the product of the probabilities of Eq. A.1 (which cannotbe done in general with a finite amount of data), the SimIOHMMbelongs to a class of models for which an efficient learning algo-rithm exists, and that are sufficiently flexible to capture long-rangedependencies: the Input/Output Hidden Markov Models, orIOHMMs [10,4]. These are stochastic Mealy machines, finite-stateautomata where the input ut , the output yt at time t are linkedby a ‘‘state” variable xt , and where ut , yt , xt and xt�1 are relatedby the pair of equations: xt ¼ f ðxt�1;utÞ, yt ¼ gðxt ;utÞ. Thus, anIOHMM models the conditional probability of an output sequenceYtf g given an input sequence Utf g as a Hidden Markov Model:
P ðUt;Yt;XtÞjfðUj;Yj;XjÞgt�1j¼1
n o¼ P ðUt;Yt ;XtÞjXt�1f g:
In our case, snapshots play the role of inputs; thus, the two termsare used interchangeably. The output is a user action, and thereforean input–output pair is a SAP as defined in Section 3.1. The hiddenstate captures long-term statistical dependencies between actions,and could be interpreted as capturing ‘‘the current place” withinthe procedure.
Simple algebra shows that inducing an IOHMM is equivalent toestimating the initial probability measure over the states, P X0f g(where we use the convention that the first input is observed att ¼ 1), the transition probabilities P Xt jUt;Xt�1f g, and the condi-tional output probabilities P YtjXt ;Utf g, which can be easily com-puted if the traces are aligned with the nodes.
A.2. IOHMM and the alignment-and-generalization problem
The alignment-and-generalization problem is efficiently solvedby the Baum–Welch [9] algorithm, consisting of alternating twosteps until convergence. These are the Expectation step (E-step),which aligns the data to the model produced by the previous M-step (thus, it solves the alignment problem given the previousM-Step), and the Maximization step (M-step), which updates themodel given the alignment produced by the previous E-step (thus,it solves the generalization problem given the previous E-step).
A.3. Extending the IOHMM: the SimIOHMM
The SimIOHMM extends the IOHMM by associating one or moreSAPs (called a representative SAPs) with each state of the hiddenMarkov chain. The representative SAPs of a state describe the typ-ical content of the GUI (and, potentially, the typical user action) atthe place in the procedure captured by that state. The representa-tive SAPs are used during the E-step to compute the probabilitiesand are updated during the M-step. Intuitively, a training SAP is‘‘attracted” towards Markov states whose representative SAPs are‘‘similar” to it, and away from Markov states whose representativeSAPs are ‘‘dissimilar” (mathematical details can be found in [8]).Adding the bias term yields four main benefits over the IOHMM:the training time is substantially reduced; the classification accu-racy can increase; the states typically represent actual proceduresteps (this does not hold for the general IOHMM); and efficientalgorithms exist for selecting the number of Markov states [31].
References
[1] A. Cypher (Ed.), Watch What I Do: Programming by Demonstration, MIT Press,Cambridge, MA, 1993.
[2] H. Lieberman (Ed.), Your Wish is My Command: Programming By Example,Morgan Kaufman, 2001.
[3] Notes from lotus support, March 2008, <http://www-10.lotus.com/ldd/nflsblog.nsf/dx/CSA_Tools>.

V. Castelli et al. / Knowledge-Based Systems 23 (2010) 94–109 109
[4] Y. Bengio, P. Frasconi, Input–output HMM’s for sequence processing, IEEETrans. Neural Networks 7 (5) (1996) 1231–1249.
[5] R. Barrett, E. Haber, E. Kandogan, P.P. Maglio, M. Prabaker, L.A. Takayama, Fieldstudies of computer system administrators: analysis of system managementtools and practices, in: Proceedings of ACM Conference on Computer-Supported Collaborative Work (CSCW 2004), 2004, pp. 388–395.
[6] R. Fikes, P. Hart, N. Nilsson, Learning and executing generalized robot plans,Artif. Int. 3 (1973) 251–288.
[7] W3C Working Draft, Document Object Model Events, 13 April, 2006, <http://www.w3.org/tr/dom-level-3-events/events.html>.
[8] D. Oblinger, V. Castelli, T. Lau, L.D. Bergman, Similarity-based alignment andgeneralization, in: Proceedings of the 16th European Conference on MachineLearning, Springer, Berlin, 2005, pp. 657–664.
[9] L. Rabiner, B. Juang, An introduction to hidden Markov models, IEEE Acoust.Speech Signal Proc. Mag. (1986) 4–15.
[10] P. Frasconi, Y. Bengio, An EM approach to grammatical inference: input/outputHMMs, in: Proceedings of the IEEE International Conference PatternRecognition, ICPR’94, Jerusalem, 1994, pp. 289–294.
[11] G.J. McLachlan, T. Krishnan, The EM Algorithm and Extensions, first ed., WileyInterscience, 1999.
[12] A. Viterbi, Error bounds for convolutional codes and an asymptoticallyoptimum decoding algorithm, IEEE Trans. Inform. Theory 13 (2) (1967) 260–269.
[13] M. Basseville, I.V. Nikiforov, Detection of Abrupt Changes: Theory andApplication, Prentice Hall, 1992.
[14] T. Lau, L.D. Bergman, V. Castelli, D. Oblinger, Sheepdog: Learning proceduresfor technical support, in: Proceedings of the 2004 International Conference onIntelligent User Interfaces, Madeira, Portugal, 2004, pp. 106–116.
[15] G. Paynter, I.H. Witten, Automating iteration with programming bydemonstration: learning the user’s task, in: Proceedings IJCAI Workshop onLearning About Users, Morgan Kaufmann, Stockholm, Sweden, 1999.
[16] T. Lau, S.A. Wolfman, P. Domingos, D.S. Weld, Programming by demonstrationusing version space algebra, Mach. Learn. 53 (1–2) (2003) 111–156.
[17] L.D. Bergman, V. Castelli, T. Lau, D. Oblinger, DocWizards: a system forauthoring follow-me documentation wizards, in: Proceedings of the 18th ACMSymposium on User Interface Software and Technology, UIST2005, 2005, pp.191–200.
[18] G. Paynter, Automating iterative tasks with programming by demonstration,Ph.D. Dissertation, The University of Waikato, New Zeland, 2000.
[19] A. Cypher, Eager: programming repetitive tasks by demonstration, in: A.Cypher (Ed.), Watch What I Do: Programming by Demonstration, MIT Press,Cambridge, MA, 1993, pp. 205–217.
[20] T. Lau, P. Domingos, D.S. Weld, Learning programs from traces using versionspace algebra, in: Proceedings of the Second International Conference onKnowledge Capture, 2003.
[21] R. McDaniel, B. Myers, Building applications using only demonstration, in:Proceedings of the 1998 International Conference on Intelligent UserInterfaces, 1998, pp. 282–289.
[22] J. Lafferty, A. McCallum, F. Pereira, Conditional random field: probabilisticmodels for segmenting and labeling sequence data, in: Proceedings of the 18thInternational Conference on Machine Learning, 2001, pp. 282–289.
[23] R.E. Fikes, N.J. Nilsson, Strips: a new approach to the application of theoremproving to problem solving, Artif. Int. 2 (3–4) (1971) 189–208.<http://dx.doi.org/10.1016/0004-3702(71)90010-5>.
[24] D. Mcallester, R. D., Systematic nonlinear planning, in: Proceedings of theNineth National Conference Artificial Intelligence, 1991, pp. 634–639.
[25] M. Ghallab, A. Milani (Eds.), New directions in AI planning, IOS Press,Amsterdam, The Netherlands, 1996.
[26] M. Schoppers, Universal plans for reactive robots in unpredictableenvironments, in: Proceedings of the Interanational Joint Conference onArtificial Intelligence (IJCAI), 1987, pp. 1039–1046.
[27] H. Kautz, A formal theory of plan recognition, Ph.D. Thesis, Rochester, NY, USA,1987.
[28] L.D. Bergman, V. Castelli, Using the personal wizards plug-in in ibm lotusexpeditor, <http://www.ibm.com/developerworks/lotus/library/expeditor-wizards/>.
[29] D. Oblinger, V. Castelli, L.D. Bergman, Augmentation-based learning:combining observations and user edits for programming-by-demonstration,in: Proceedings of the 2006 International Conference on Intelligent UserInterfaces, Sidney, Australia, 2006, pp. 202–209.
[30] V. Castelli, L.D. Bergman, Distributed augmentation-based learning: a learningalgorithm for distributed collaborative programming-by-demonstration, in:Proceedings of the 2007 International Conference on Intelligent UserInterfaces, 2007, pp. 160–169.
[31] V. Castelli, D. Oblinger, L.D. Bergman, T.A. Lau, Dynamic model selection inIOHMMs, Research Report RC23395, IBM T.J. Watson Research Center,Yorktown Heights, NY, 2004.





























