Embed Size (px)
Citation preview

Shanda Innovations
Context-aware Ensemble of Multifaceted Factorization
Models for Recommendation
Kevin Y. W. Chen
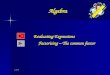
Performance
• 0.43959(public score)/0.41874(private score)
• 2nd place Honorable Mention

New Challenges
• Richer features in the social networks– follower/followee, actions
• Items are complicate– items are specific users
• Cold-start problem – 77.1% users do not have training
records• Training data is quite noisy
– ratio of negative samples is 92.82%

Outline
• Preprocessing– denoise– supplement
• Pairwise Training– Max-margin optimization problem
• Multifaceted Factorization Models– Extend the SVD++
• Context-aware Ensemble – Logistic Regression

Preprocess: Session analysis
• Negative : Positive = 92 : 8 ?– not all the negative ratings imply that
the users rejected to follow the recommended items
• Eliminating these “omitted” records is necessary– These negative samples can not indicate
users' interests

Preprocess: Session analysis
• Session slicing according to the time interval
• Select the right samples from the right session:

Preprocess: Session analysis
• Training dataset after preprocessing– Negative: 67,955,449 -> 7,594,443
(11.2%)– Positive: 5,253,828 ->4,999,118
• Benefits– improve precision (0.0037)– reduce computational complexity

Pairwise-training
• MAP– pairwise ranking job
• Training pair– (u, i) and (u, j)
• Objective function

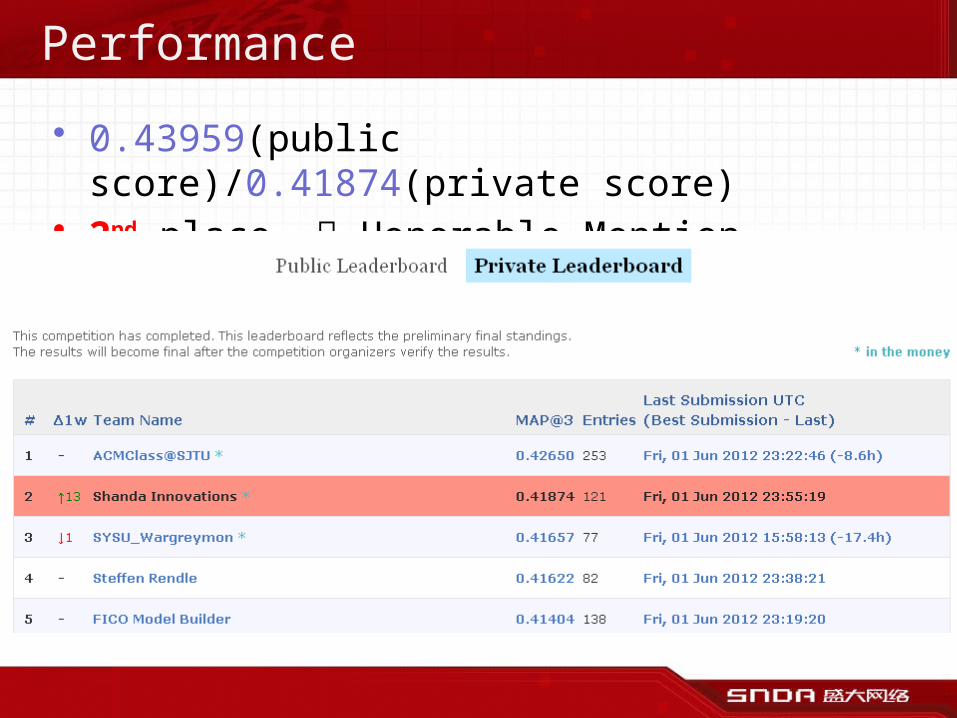
Preprocess: Supply positive samples• Lack of positive samples
– An ideal pairwise training requires a good balance between the number of negative and positive samples
• Choose the users– users who have a far smaller number of
positive samples than negative samples• Generate the positive samples
– Figure out from social graphs
The procedure of data preprocessing

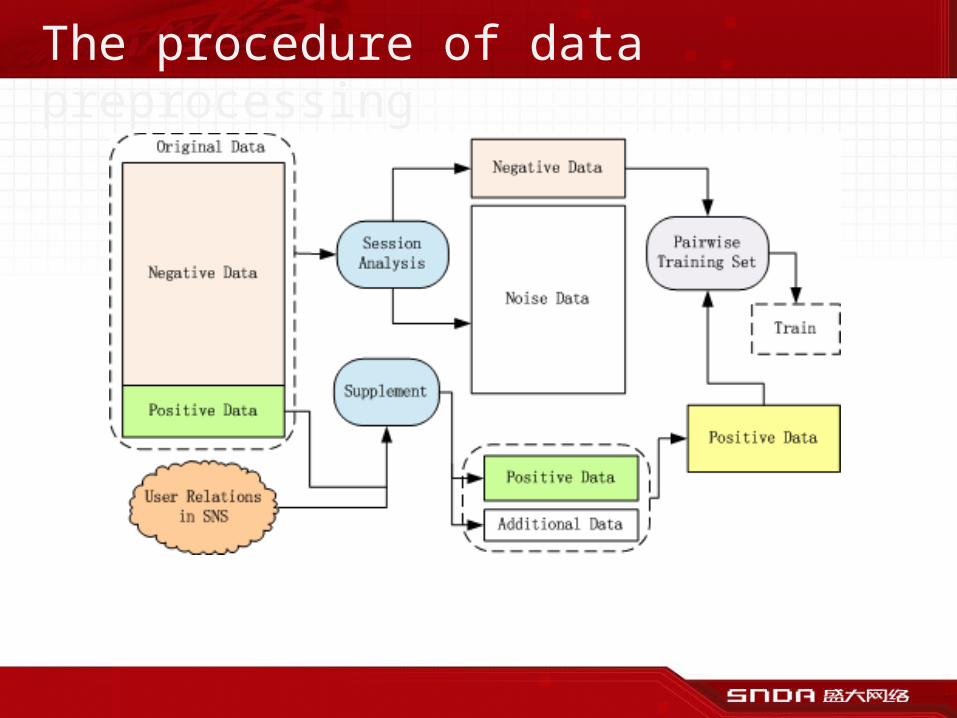
Multifaceted Factorization Models
• Latent Factor Model– stochastic gradient descent
• MFM extends the SVD++– integrate all kinds of valuable features
in social networks

MFM: Demographic features
• User and item profiles– age(u), age(i)– gender(u), gender(i)– tweetnum(u)
• Combinations– uid*gender(i)– uid*age(i)– gender(u)*iid– age(u)*iid

MFM: Integrate Social Relationships• Influence of social relations• Cold start:
– 77.1% users do not have any rating records in the training set
• User feature vector:– Incorporate SNS relations and actions
• Bring significant improvement– MAP: 0.3495 ->0.3688 ->0.3701

MFM: Utilizing Keywords and Tags
• Share common interests– explicit feedbacks
• User feature vectors:

MFM: Date-Time Dependent Biases
• Users' action differs when time changes
• The popularities of items change over time

k-Nearest Neighbors
• Similar to SVD++• Find the neighbors
– calculate the distance based on Keywords and tags
• Intersection of explicit and implicit feedbacks

Ensemble
• When will the user follow an item?– pay attention to the item– be interested in the item
• User behavior modeling– predict whether the user noticed the
recommendation area at that time• User interest modeling
– a item meet the user’s tastes -- MFM

User Behavior Modeling
• Durations of users on each recommendation are very valuable clues
• Context of durations
Experiment
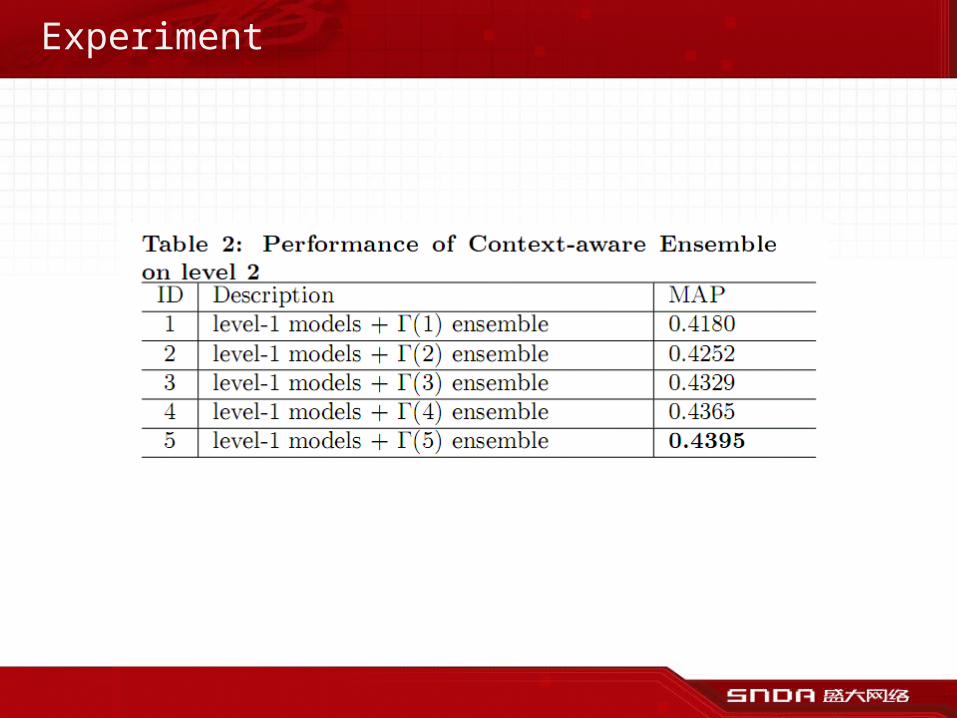
Experiment
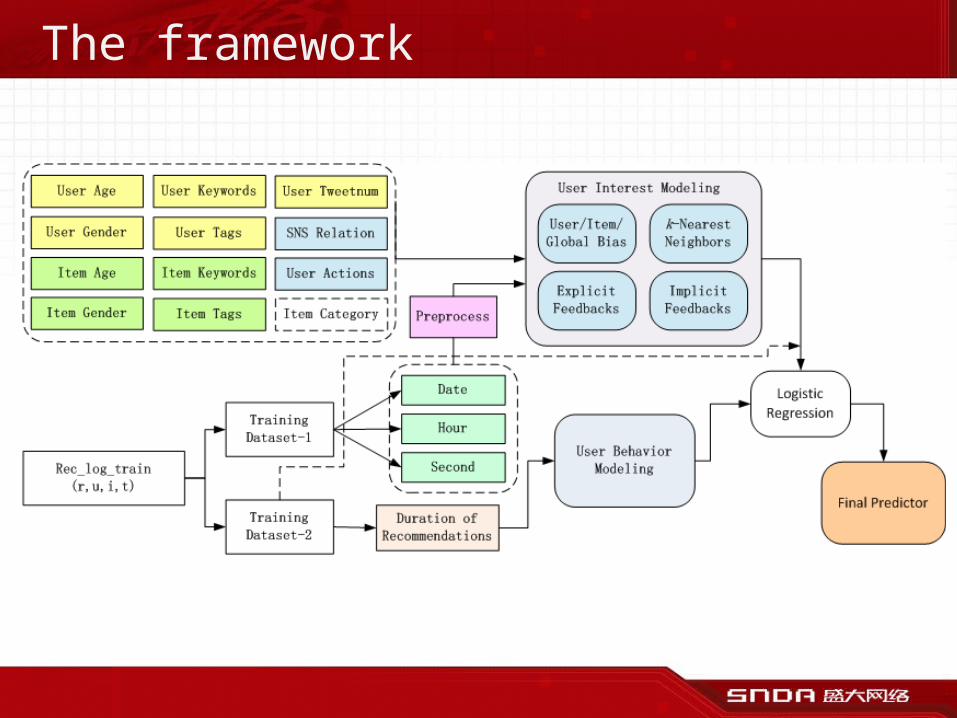
The framework

Summary
• A proper data preprocessing is necessary• Pairwise training (top-N recommendation)• Social relations and actions can be used as
implicit feedbacks• Integrate all kinds of valuable features• Users' interests and users' behaviors are
both need to be considered

Shanda Innovations Team
Yunwen Chen, Zuotao Liu, Daqi Ji, Yingwei Xin, Wenguang Wang, Lu Yao, Yi Zou