Embed Size (px)
Citation preview

Sequential Cross-Modal Hashing Learning via Multi-scaleCorrelation Mining
ZHAODA YE, YUXIN PENG∗, Peking University, China.
Cross-modal hashing aims to map heterogeneous multimedia data into a common Hamming space throughhash function, and achieves fast and flexible cross-modal retrieval. Most existing cross-modal hashing methodslearn hash function by mining the correlation among multimedia data, but ignore the important property ofmultimedia data: Each modality of multimedia data has features of different scales, such as texture, objectand scene features in the image, which can provide complementary information for boosting retrieval task.The correlations among the multi-scale features are more abundant than the correlations between singlefeatures of multimedia data, which reveal finer underlying structure of the multimedia data and can be usedfor effective hashing function learning. Therefore we proposeMulti-scale Correlation Sequential Cross-modalHashing (MCSCH) approach, and its main contributions can be summarized as follows: 1) Multi-scalefeature guided sequential hashing learning method is proposed to share the information from featuresof different scales through a RNN based network and generate the hash codes sequentially. The features ofdifferent scales are used to guide the hash codes generation, which can enhance the diversity of the hashcodes and weaken the influence of errors in specific features, such as false object features caused by occlusion.2) Multi-scale correlation mining strategy is proposed to align the features of different scales in differentmodalities and mine the correlations among aligned features. These correlations reveal finer underlyingstructure of multimedia data and can help to boost the hash function learning. 3) Correlation evaluationnetwork evaluates the importance of the correlations to select the worthwhile correlations, and increases theimpact of these correlations for hash function learning. Experiments on two widely-used 2-media datasetsand a 5-media dataset demonstrate the effectiveness of our proposed MCSCH approach.
Additional Key Words and Phrases: Cross-modal Hashing, Correlation mining, Multi-scale, Sequential hashlearning
ACM Reference Format:Zhaoda Ye, Yuxin Peng. 2019. Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining.ACM Trans. Multimedia Comput. Commun. Appl. 1, 1 (August 2019), 21 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn
1 INTRODUCTIONCross-modal retrieval aims to retrieve multimedia content in different modalities with any singlemodality query that users are interested in. With the explosive growth of multimedia data, cross-modal hashing receives wide attention for its high retrieval efficiency. Cross-modal hashing methodmaps the original multimedia data into the Hamming space through the hash function. Then the
∗Corresponding author.
Author’s address: Zhaoda Ye, Yuxin Peng, Peking University, Insititute of Computer Science and Technology, Beijing, 100871,China. [email protected].
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without feeprovided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and thefull citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored.Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requiresprior specific permission and/or a fee. Request permissions from [email protected].© 2019 Copyright held by the owner/author(s). Publication rights licensed to ACM.1551-6857/2019/8-ART $15.00https://doi.org/10.1145/nnnnnnn.nnnnnnn
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

2 Zhaoda Ye, Yuxin Peng
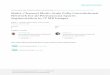
It's a sunshine morning. A group of children are playing
soccer at the seaside.
Object
Word
Word
Sentence
Scene
Scene
Fig. 1. The correlation between different modalities and scales
short binary codes in the Hamming space can accelerate retrieval with bit operations and hashtables, as well as reduce storage space compared with the original high-dimension features.
The hashing methods of single modality retrieval have been widely studied over the past years,such as image retrieval[1–7], text retrieval[8–11] and video retrieval [12, 13]. However, the require-ments of users are highly flexible, such as retrieving the relevant audio clips with a query of image,which leads to the issue of cross-modal retrieval. Unfortunately, "heterogeneous gap" makes itimpossible to apply these methods to cross-modal retrieval task directly. Such gap means the dataof different modalities is inconsistent and lies in different feature spaces, where the similaritiesbetween the data of different modalities cannot be measured directly.Most of the existing works address the problem of the "heterogeneous gap" by mining the
correlation among different modalities [14–17], such as Inter-Media Hashing (IMH) [15], Cross-ViewHashing (CVH) [16] and Composite Correlation Quantization (CCQ) [17]. These methods do not useany supervised information for correlation mining and achieve promising performance. However,they only learn hash function from the distribution of the data, which limits the performance onsemantic similar data retrieval. To improve the retrieval accuracy, some works consider to usesupervised information for better correlation mining, such as Cross-Modality Similarity SensitiveHashing (CMSSH) [18] and Semantic Correlation Maximization (SCM) [19], and achieve betterresults than the unsupervised methods. Recently, inspired by the success of deep learning in manyvisual tasks, some works adopt the deep learning framework for cross-modal hashing, such asCross-Media Neural Network Hashing (CMNNH) [20] and Cross Autoencoder Hashing (CAH) [21].
However, most of these works ignore the important property of multimedia data: Each modalityof multimedia data has the multi-scale features, such as texture, object and scene features inthe image, which indicates comprehensive characteristic of multimedia data, and can providecomplementary information for retrieval task. These complementary information can enhance thediversity of the hash codes, and weaken the influence of errors in specific features, such as falseobject features caused by occlusion. Some recent works, such as [22], have verified the effectivenessto use multi-level information. And the correlations among the multi-scale features reveal finerunderlying structure of multimedia data and can be used for effective hashing function learning. As
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 3
shown in Figure 1, we represent some correlations between different scales in two modalities. Forexample, the words "children" and "soccer" in text have correlation with the objects in the image,and the word "seaside" has correlation with the scene in the image. While the scene of the blue skyand sun in the image has correlation with a description sentence in the text.Therefore, we propose Multi-scale Correlation Sequential Cross-modal Hashing (MCSCH)
approach, where the multi-scale feature guided sequential hashing learning method fully utilizesthe multi-scale features, and multi-scale correlation mining strategy mines the correlations betweenthe multi-scale features. Furthermore, correlation evaluation network evaluates the importanceof the correlations to select the worthwhile correlations for hash function learning. The maincontributions of this paper can be summarized as follows:
1)Multi-scale feature guided sequential hashing learningmethod adopts a RNN structureto share the complementary information in multi-scale features, which takes the multi-scale featuresas inputs and generates the hash codes sequentially. The generation of the hash codes are guidedby two types of information: history information and guide information. The history informationcomes from the previous generation process, which is regarded as auxiliary information to reducethe error hash codes generation in current step. The guide information is the multi-scale features,which provide the complementary information of multimedia data for the hash code generation.
2) Multi-scale correlation mining strategy mines the correlation among the multi-scalefeatures, which can help the model learn more robust hash function. Concretely, we align themulti-scale features in different modalities by adjusting the input order of the guide information,where the hash codes guided by the aligned features have the same position and length in finalhash codes. Beyond the alignment of the hash codes, we can use correlation constraint functionsto mine the correlation from the aligned multi-scale features, which can boost the hash functionlearning.
3) Correlation evaluation network evaluates the importance of the correlations to select theworthwhile correlations, and increases the impact of these correlations in training stage. Specially,the network takes the last output features in the RNN structure as inputs to evaluate the importanceof the correlations, which can improve the impact of the worthwhile correlations in training stage.In this paper, we extend our previous conference work [23] to fit multimedia data that has
more than two modalities, and the main differences can be summarized as follows: 1) Whenthe type of modality increase, the constraints to associate different modalities will increase withthe square of modality types. However, too much constraints increases computation cost andlimits the generalization ability of the model. In this paper, we design a new way to keep thediscrimination of hash codes, which reduces the amount of constraints from squared relation withthe modality types to linear relation. 2) When the type of modality increases, the correlations amongthe different modalities become complex. To better model the correlations among multimedia datain different modalities, we propose a correlation evaluation network to evaluate the importanceof the correlations. The network exploits the worthwhile correlations and improves the impactof these correlations to boost the hash function learning. The experiments in 5-media datasetdemonstrate the effectiveness of the model and correlation evaluation network.The rest of this paper is organized as follows: Section 2 summaries the related works of the
cross-modal hashing methods. Section 3 presents our MCSCH approach in details, and Section 4introduces the experiments as well as the results analyses. Finally Section 5 concludes this paper.
2 RELATEDWORKSIn this section, we will briefly introduce the related works of the cross-modal hashing, which can besplit into three categories: unsupervised cross-modal hashing methods, supervised cross-modal hashing
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

4 Zhaoda Ye, Yuxin Peng
methods and deep neural networks (DNN) based methods. We will introduce them respectively asfollows.
Unsupervised cross-modal hashing methods learn the hashing functions without any su-pervised information, which take similar idea of Canonical Correlation Analysis (CCA) [24] tomaximize the correlation of the different modalities. Song et al. [15] propose Inter-Media Hash-ing (IMH) that translates multimedia data into Hamming space by preserving inter-media andintra-media consistency. Kumar et al. [16] extend Spectral hashing (SH) [25] in image hashingmethod and propose Cross-view Hashing (CVH), which considers both intra-view and inter-viewsimilarities. Furthermore, Ding et al. [26] propose Collective Matrix Factorization Hashing (CMFH)to generate hash codes by collective matrix factorization with a latent factor model. Long et al. [17]propose Composite Correlation Quantization (CCQ) method, which joint learns the correlation-maximal mappings and composite quantizers. Hu et al.[27] propose termed collective reconstructiveembeddings (CRE) to learn two kernel-based hash functions, which simultaneously solve the het-erogeneity and integration complexity of multimodal data. Wang et al. [28] propose SemanticTopic Multimodal Hashing (STMH), which obtains multiple semantic topics of texts and conceptsof images and transformed the semantics topics and concepts into a common subspace. Finally,the hash codes are generated by figuring out whether a topic or concept is contained in originaldata. Zhang et al. [29] adopt GAN to model the underlying manifold structure and learn morerobust hash code for cross-modal retrieval. Unsupervised methods learn hash function from datadistributions, thus have limited performance on semantic similar data retrieval.
Supervised cross-modal hashing methods utilize supervised semantic information to bet-ter mine the correlations between different modalities for hashing functions learning, whichachieves better retrieval accuracy than the unsupervised methods. Bronsterin et al. [18] proposeCross-Modality Similarity Sensitive Hashing (CMSSH), which regards the hash learning as binaryclassification problem, which can be learned using boosting algorithms. Wei et al. [30] proposeHeterogeneous Translated Hashing (HTH), which learns the Hamming space for each modality, andaligns these Hamming space for cross-modal retrieval. Zhang et al. [19] propose Semantic Correla-tion Maximization (SCM) to learn hashing functions by constructing and preserving the semanticsimilarity matrix. Lin et al. [31] propose Semantics-Preserving Hashing (SePH), which transformsthe semantic matrix into probability distribution and learns a Hamming space by minimizingthe KL-divergence between the Hamming space distribution and semantic probability distribu-tion. Shen et al. [32] propose Semi-paired Discrete Hashing (SPDH) which applies factorizationbased scheme for latent space and hash code learning. Zheng et al. [33] transform the cross-modalhashing problem into hetero-manifold regularized support vector learning problem. They proposeHetero-Manifold Regularization(HMR) to integrate multiple sub-manifolds of different modalitiesdata and measures the similarity of data by three order random walks on the hetero-manifold.Luo et al. [34] propose Supervised Discrete Manifold-Embedded Cross-Modal Hashing(SDMCH),which generates the hash codes in an iterative algorithm without relaxing the binary constraints.Supervised methods utilize the semantic information, which achieve better accuracy on semanticsimilar data retrieval task than the unsupervised methods.
DNN based methods take advantages of the deep learning framework, whose performanceshave been demonstrated in many visual tasks [35, 36]. Zhuang et al. [20] propose Cross-MediaNeural Network Hashing (CMNNH) to preserve intra-modal discriminative ability and inter-modalpairwise correlation in deep learning framework for cross-modal hashing learning. Cao et al. [21]propose Cross Auto-encoder hashing (CAH) to maximize the feature and semantic correlation ofdifferent modalities in deep auto-encoder structure. Cao et al. [37] propose Deep Visual-semanticHashing (DVH) that combines both representation learning and hashing function learning inan end-to-end framework. Jiang et al. [38] propose Deep Cross-Modal Hashing (DCMH) which
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 5
combines both feature learning and hashing function learning. Deng et al. [39] propose a Triplet-based Deep Hashing (TDH) network, which considers inter-modal view and the intra-modal viewto boost the discriminative abilities of the hash codes. Song et al. [40] propose cross-modal memorynetwork(CMMN), which learns the memory contents across modalities in an end-to-end scheme asclews without any paired information of the multimedia data. Then the input data will be mappedin to a common space using related clews to generate the hash codes for retrieval task.
Compare to these existing works, our proposed approach mainly focuses on how to fully utilizethe complementary information of multi-scale features, and mine the correlations in scale level toboost the hash function learning.
3 THE PROPOSED APPROACH
Image
Text
Video
Th e ho rse (Eq uus f er us cabal lus ) i s one
of tw o extan t subspeci es o f Eq uus
f er us, or the w il d
hor se. I t i s a s ing le -hoo ved (ung ulat e)
m am ma l bel ongi ng to t he t axo nom ic
f am il y Equi dae . Th e
hor se has ev olv ed ov er t he p as t 45 t o 55
m il l io n ye ars f ro m a sm al l m ul ti -t oed
cr eat ure i nt o
t he l ar ge , s i ngl e-t oed anim al of t oday .
H um ans b egan to dom est icat e hor ses
ar ound 400 0 B C,
and t heir dom est icat i on i s beli eved t o
have been w ide sp read by 300 0 B C.
H or ses i n t he subspeci es ca ball us ar e
Image Feature
Text Feature
Video Feature
Audio Feature
3D model Feature
Image Hash Code
Text Hash Code
Video Hash Code
Audio Hash Code
3D Hash Code
Image
Text
Audio
3D model
Th e ho rse (Eq uus f er us cabal lus ) i s one
of tw o extan t subspeci es o f Eq uus
f er us, or the w il d
hor se. I t i s a s ing le -hoo ved (ung ulat e)
m am ma l bel ongi ng to t he t axo nom ic
f am il y Equi dae . Th e
hor se has ev olv ed ov er t he p as t 45 t o 55
m il l io n ye ars f ro m a sm al l m ul ti -t oed
cr eat ure i nt o
t he l ar ge , s i ngl e-t oed anim al of t oday .
H um ans b egan to dom est icat e hor ses
ar ound 400 0 B C,
and t heir dom est icat i on i s beli eved t o
have been w ide sp read by 300 0 B C.
H or ses i n t he subspeci es ca ball us ar e
Image Feature
Text Feature
Video Feature
Audio Feature
3D model Feature
Image Hash Code
Text Hash Code
Video Hash Code
Audio Hash Code
3D Hash CodeAttention
Weight
Hash
Code
Correlation
Evaluation
Network
Scale
Constraint
Inter Modal
Constraint
Intra Modal
Constraint
Multi-scale Feature Guided Sequential Hashing Learning StageRepresentation Extracting Stage
Fig. 2. The overall framework of MCSCH method for 5-media datasets
Here we give a formal definition of cross-modal hashing of this paper. The cross-modal dataset isdefined as D = {I ,T ,V ,TD,A}, where I = {ip }
np=1 represents image data and T ,V ,TD,A represent
similar definition of the text, video, 3D model and audio data respectively. Specifically, the data ofeach modality is consisted by scale features, for example, in image modality, we define the featuresas ip = {imp }
inm=1, while in is the amount of scale feature type in image modality. In the training
stage, we conduct the triplet tuples (xi ,x+i ,x−i ) through semantic labels , where (xi ,x+i ) share the
same semantic label and (xi ,x−i ) have different semantic labels. Additionally, the symbol xi is a
set of data with different modalities that xi = (ipi , tpi ,vpi , tdpi ,api ), which have the same semanticlabels. Finally, the framework uses the hash function to generate L bit hash codes for each data, sowe can retrieve the data of different modalities mutually in the Hamming space.
Firstly, we represent the overall framework of MCSCH approach for 5-media datasets in Figure 2.For each modality, we use an RNN based network to handle the multi-scale features. The featureswill be fed into the network as guide information to generate hash code sequentially. Multi-scalecorrelation mining strategy aligns the scale features of different modalities by adjusting the inputorder of the guide information. Then the correlation constraints are used to mine the correlationsbetween the aligned features for hash function learning. There are three kinds of constraints forthe framework: intra-modal constraint, inter-modal constraint and scale constraint.
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

6 Zhaoda Ye, Yuxin Peng
Image Hash Code
fc-7 feature fc-7 featurepool5 featurefc-6 feature
Hash Layer
RNN
Original Guide Information
Residual Guide Information
Softmax
Unrolled RNN Structure
Fig. 3. The unrolled structure in image hash function learning
3.1 Multi-scale Feature Guided Sequential Hashing LearningWe detail the multi-scale feature guided sequential hashing learning structure in image modality inFigure 3. The other modalities have the similar definition as the image modality. The RNN layer isa build-in memory cell, in which the history information from previous steps can be stored andshared through hidden states of the network. The guide information is fed into the RNN cell asinput to control the generation of current hash code. Formally, we can define the behaviour of theRNN cell as follows:
ct = tanh(Wxixt + bxi +Whict−1 + bhi ) (1)
where ct is the hidden state vector and xt is the guide information at t-th step,Wxi andWhi arethe weight matrices that map the input xt and the old hidden state ct−1 vectors to a new hiddenstate. bxi and bhi are corresponding bias terms.
In this paper, we design two types of the guide information: the residual guide information andthe original guide information. The residual guide information is the output of the RNN networkin previous step, which means the current hash code is guided by the same guide information asprevious step. The original guide information is the multi-scale features of multimedia data, whichmeans the hash code is guided by the input feature in current step. The guide information is definedas:
xt =
{ct−1 residual guide information (2)il itp original guide information (3)
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 7
while Li = {lit } is the order list of guide information, which is used to adjust the input order of theguide information for alignment, and will be introduced in section 3.2.
The design of the residual guide information aims to balance the effectiveness of the multi-scalefeatures. The multi-scale features have different importance to the retrieval task. For example,pool-5 feature is less important than the fc-7 feature in image, because the latter is more relevantto the semantic concept. For the features which are relevant to the retrieval task, we increase thelength of hash codes guided by these features with residual guide information and vice versa. Thusthe features which are more relevant to the retrieval task will play more important role in hashfunction learning.
Then the hash layer take the output of the RNN layer and generate the hash code which can bedefined as:
ht (x) = siдmoid(W Th ct +v)
h(x) = [h1(x),h1(x), ...,hL(x)](4)
where ct is the output of RNN layer in step t ,Wh denotes the weights, and v is the bias parameter.Finally, the network will output the result between [0, 1] for each hash code, and a thresholding
function is adopted for final binary codes:
bk (x) = sдn(hk − 0.5), k = 1, · · · ,L (5)
3.2 Multi-scale Correlation Mining StrategyThe multi-scale correlation mining strategy aligns the multi-scale features in different modalitiesby adjusting the input order of the guide information, where the hash codes guided by the alignedfeatures have the same position and length in final hash codes, so the constraint function can minethe correlations by constraining the hash codes.
For each modality, we define an order list to adjust the input order of the guide information andalign the features in different modalities. In image modality, the order list Li is defined as:
Li = [li1,li2, .., liL]
0 ≤ lik ≤ in , k = 1, · · · ,L (6)
For step t , lit equals to 0 which indicates that the guide information is residual information definedin equation (2). If lit is larger than 0, it indicates the index of scale features which defines originalguide information in equation (3). The order list of other modalities Lt ,Ltd,Lv,La have the similardefinition of the image.The "align" of the features is achieved by the order list defined above. For the features (ik1 ,tk2 ,
tdk3 ,vk4 , ak5 ) in different modalities that we try to align for scale correlation mining, where ki isthe index of scale features in each modality. We set the order list of the each modality as follows:
lidi = k1,Ltdi = k2,Ltddi = k3,Lvdi = k4,Ladi = k5
[lidi+1, lidi+2, ..., lidi+ri ] = 0[ltdi+1, ltdi+2, ..., ltdi+ri ] = 0[ltddi+1, ltddi+2, ..., ltddi+ri ] = 0[lvdi+1, lvdi+2, ..., lvdi+ri ] = 0[ladi+1, ladi+2, ..., ladi+ri ] = 0
(7)
The features (ik1 , tk2 , tdk3 ,vk4 ,ak5 ) are regarded as aligned scale features that start to guide the hashcode generation from di bit to di + ri bit in each modality, and ri defines the length of the residualguide information, which implies the importance of these features. So the constraint function can
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

8 Zhaoda Ye, Yuxin Peng
mine the correlations among the aligned features by constraining the hash codes to boost hashfunction learning.
Remarkably, it is available to input same feature into the RNN cell more than once, because theRNN based network generates the hash codes with the history information and guide information.Although the guided information might be same as a step before, the history information in currentstep is different. Besides, the feature is aligned with different features in other modalities, and thecorrelations among these features are different, which can help the model generate different hashcodes. It reminds us that we can input the same feature to the model repeatedly to obtain differentcombination of aligned features for hash function learning.
3.3 Correlation Evaluation Network and Constraint functionsCorrelation evaluation network is designed to evaluate the importance of the correlations andselect the worthwhile correlations to boost the hash function learning.
The correlation evaluation network adopts the hidden state vector of RNN based network in laststep as input. These hidden state vector consists the information of hash codes generation and canbe used for evaluating the importance of correlations among the multimedia data, which is definedas follows:
Fatten(xi ,x j ) = siдmoid(f (cxiL , cx jL )) (8)
where xi and x j are the multimedia data. cxiL and cx jL are the hidden state vectors in the RNN networkof corresponding multimedia data, which are defined in equation (1). f (·) is fully-connected layer,that combines two vectors as the input and output a single number as attention weight.
The scale constraint loss is used to constraint the hash codes to mine the correlations among thealigned features, which is defined as follows:
Lscale =1∑
w,v Fatten(wp ,vp )
∑w,v
Fatten(wp ,vp )Fcorr (hw (wp ),h
v (vp ))
w,v ∈ i, t , td,v,a
(9)
where w,v enumerate the modalities of the dataset, and wp and vp are the multimedia data ofcorresponding modalities. Fcorr (·) is the scale constraint function that used to mine the correlations.In this paper, we adopt the cosine embedding loss to mine the correlation in aligned features, whichis defined as:
Fcorr (x ,y) = 1 − cosine(x ,y) (10)Where the x ,y are the hash codes of multimedia data, and cosine is the cosine similarity distancefunction.For multi-scale feature guided sequential hashing learning, there are two kinds of constraints
named intra-modal constraint and inter-modal constraint, which are composed of triplet rankingloss. The triplet ranking loss is defined as follows:
J(h(xi ),h(x+i ),h(x
−i )) = max(0,mt + ∥h(xi ) − h(x+i )∥
2 − ∥h(xi ) − h(x−i )∥2) (11)
where ∥ · ∥2 denotes the Euclidean distance, h(·) denotes hash function that maps the features to thehash code.mt is the margins between the relative similarity of the two pairs (xi ,x+i ) and (xi ,x
−i ).
The goal of the triplet ranking loss is learning the hash code that the distance of dissimilar pair(xi ,x
−i ) to be larger than the distance of similar pair (xi ,x+i ) by a margin of at leastmt .
The intra-modal constraint is used to keep the discrimination of hash code in single modality,which is defined as follows:
Lintrai =∑
J(hi (ip ),hi (ip+ ),h
i (ip− )) (12)
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 9
Where Lintrai is the intra-modal loss in image modality, and we have the similar definitions T intrat ,
Lintrat , Lintratd , Lintrav , Lintraa to represent image, text, 3D model, video, and audio intra-modalconstraint losses. The final intra-modal constraint Lintra is the sum of intra-modal loss of eachmodality, which is defined as:
Lintra = Lintrai + Lintrat + Lintratd + Lintrav + Lintraa (13)
The inter-modal constraint loss is used to keep the discrimination of hash code in cross modalities,which is defined as follows:
Linteri =∑
J(hi (ip ),ht (tp+ ),h
t (tp− ))
Lintert =∑
J(ht (tp ),htd (tdp+ ),h
td (tdp− ))
Lintertd =∑
J(htd (tdp ),hv (vp+ ),h
v (vp− ))
Linterv =∑
J(hv (vp ),ha(ap+ ),h
a(ap− ))
Lintera =∑
J(ha(ip ),hi (ip+ ),h
i (ip− ))
Linter = Linteri + Lintert + Lintertd + Linterv + Lintera
(14)
Where Linteri , Linteri , Lintertd , Linterv and Lintera is the inter-modal constraint loss of each modality,and Linter is the final inter-modal constraint loss.For inter-modal constraint loss, we do not enumerate all the pairs of modalities, but use five
inter-modal constraint losses defined above in 5-media datasets, because too much constraints willlimit the generalization ability of the model and increase the computation cost. In this definition,we can reduce the amount of the inter-modal loss from N (N−1)
2 to N , where N is the amount ofmodalities, and can also keep the discrimination of hash code in cross modalities.
3.4 OptimizationThe final loss of our proposed framework can be defined as:
Loss = λ1Linter + λ2L
intra + λ3Lscale (15)
which is composed with two kinds of loss functions: triplet ranking loss (Lintra and Linter ) andcosine embedding loss (Lscale ). λ1, λ2, λ3 are hyper-parameters. In this paper, we adopt gradientdecent method to optimize the loss for our proposed approach.
Firstly, we introduce the sub-gradient of the triplet ranking loss:
∂J
∂h(xi )= 2(h(x−i ) − h(x+i )) × Ic
∂J
∂h(x−i )= 2(h(x+i ) − h(xi )) × Ic
∂J
∂h(x+i )= 2(h(xi ) − h(x−i )) × Ic
Ic = Imt+∥h(xLi )−h(xL+i ) ∥2−∥h(xLi )−h(x
L−i ) ∥2>0
(16)
where Ic is an indicator function, Ic = 1 if c is true, otherwise Ic = 0.
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

10 Zhaoda Ye, Yuxin Peng
Secondly,we give the sub-gradient of our correlation constraint loss Fcorr :
∂Fcorr∂X
=
XT Y ∥Y ∥√XTX
X − ∥X ∥∥Y ∥Y
∥X ∥2∥Y ∥2
∂Fcorr∂Y
=
XT Y ∥X ∥√YT Y
Y − ∥X ∥∥Y ∥X
∥X ∥2∥Y ∥2
(17)
With the given sub-gradient of the loss functions, we can optimize the whole framework withgradient decent method.
4 EXPERIMENTSIn this section, we conduct experiments on 4 cross-modal datasets to demonstrate the effectivenessof the proposed method. First, we give the implementation details of our MCSCH approach. Thenwe introduce the datasets, evaluation protocol and compared methods in our experiments, andshow the results of our MCSCH approach as well as compared methods. Furthermore, we conductbaseline experiments to investigate the influence of different parts of proposed method.
4.1 Implementation DetailsIn this subsection, we present the implementation details of our MCSCH approach. For imagefeatures, we take 4096-dimensional features extracted from the fc-7 layer, 4096-dimensional featuresextracted from the fc-6 layer and 25088-dimensional features extracted from the pool-5 layer of19-layer VGGNet [41]. For text features, BoW method is adopted to model the word scale featuresfrom texts or tag. Then Text-CNN [42] is used to learn the sentence scale features for hash codesgeneration (In MIRFlickr and NUS-WIDE datasets, since the text data has no sentence, we regardthe word features as sentence features). For video features, C3D [43] and dense trajectory [44] areused to model the multi-scale features. For audio features, 78-dimensional features are extractedby jAudio [45], and 3D model features are concatenated 4700-dimensional vectors of a LightFielddescriptor set [46]. Furthermore, the dimension of fully-connected layer in whole network is set tobe 1024, and the hashing layer’s dimension is 1 which implies to generate one bit hash code in eachstep. We implement the proposed MCSCH by pytorch1.Moreover, we train the proposed MCSCH in a mini-batch way and set the batch size as 32. We
train the proposed MCSCH with Stochastic gradient descent (SGD) with learning rate as 0.001,momentum as 0.9 and weight decay as 0.0005. We decrease the learning rate by a factor of 10 every10000 steps.
For the compared methods, we apply the implementations provided by their authors, and followtheir best settings to preform the experiments. For a fair comparison between different methods,we use the same image and text features for all compared methods. Since the compared methodscan only model single feature in each media, the compared methods take the fc-7 features imagefeatures, word-level text features, C3D video features, jAudio audio features and LightField 3d-model features, which can reach the best performance for compared methods. It is noted that thecompared methods can only address the retrieval task on two modalities multimedia data, so wetrain the models between any two modalities and combine the ranking list with the Hammingdistance.
1http://pytorch.org/
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 11
4.2 Datasets and Evaluation Protocol4.2.1 Datasets. We evaluate the proposed approach and compared methods on 4 widely-useddatasets: MIRFlickr[47], Wikepedia[48], NUS-WIDE[49] and PKU XMedia[50, 51].
• MIRFlickr dataset contains 25,000 images collected from Flickr, and each image is associatedwith textual tags and labeled with one or more of 24 provided semantic labels. Following[31],we randomly sample 5,000 images-tag pairs to build the supervised training set. In theremaining 20,000 pairs, we take 5% of the dataset as query set and the others as retrievaldatabase.
• Wikipedia dataset is a widely-used dataset for cross-modal retrieval, which is collected from"featured articles" with 10 most populated categories and contains 2,866 image/text pairs inWikipedia. Following [31], Wikipedia dataset is split into a training set of 2,173 pairs and atest set of 693 pairs. Since Wikipedia dataset is small, the training set is used as the retrievaldatabase, while the test set works as query.
• NUS-WIDE dataset[49] is a large-scale image/tag dataset with 269498 pairs of images andcorresponding textual tags. The tags are regarded as the text modality in our experiments.Following [31], we select the 10 largest categories and with 186557 images. We take 1% dataof NUS-WIDE dataset as the query set, and the rest as the retrieval database. We randomlyselected 5000 images as training set for the supervised methods.
• PKU XMedia dataset is a cross-modal retrieval dataset with five modalities, which consistsof 5,000 texts, 5,000 images, 500 videos, 1,000 audio clips and 500 3D models. Each mediainstance has its corresponding category label in 20 classes. For this dataset, we randomlyselect 2,400 instances as query set, while the remaining 9,600 instances are retrieval database.
4.2.2 Evaluation protocol. We perform two kinds of retrieval task for the 2-media datasets: imagequery text (image→text) and text query image (text→image). Concretely, for example, in imagequery text task, we obtain the hash codes of image as query and retrieve related text hash codes. Wecompute the Hamming distance between the image and text hash codes to obtain the ranking listas retrieval result. For 5-media datasets, we have five retrieval tasks: image query all (image→all),text query all (text→all), audio query all (audio→all), video query all (video→all) and 3d queryall (3d→all), that we obtain the hash codes of one modality multimedia data and retrieve relatedmultimedia data in all modalities.
We use three evaluation metrics to measure the retrieval effectiveness: Mean Average Precision(MAP), precision at top k returned results (topK-precision) and precision recall curve (PR-curve),which are defined as follows:
• The MAP scores are computed as the mean of average precision (AP) for all queries, and APis computed as:
AP =1R
n∑k=1
Rkk
× relk (18)
where n is the size of database, R is the number of relevant images in database, Rk is thenumber of relevant images in the top k returns, and relk = 1 if the image ranks at k-thposition is relevant and 0 otherwise.
• Precision at top k returned results (topK-precision): The precision with respect to differentnumbers of retrieved samples from the ranking list.
• Precision recall curve (PR-curve): The precision at certain level of recall of the retrievedranking list, which is widely used to measure the information retrieval performance.
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

12 Zhaoda Ye, Yuxin Peng
4.3 Compared MethodsWe compare with 9 state-of-the-art methods to verify the effectiveness of our proposed approach,including unsupervised methods CVH[16], CMFH[26] and CCQ[17], supervised methods CMSSH[18], SCM [19], SePH [31] DCMH[38], UGACH[52] and SSAH[53]. We briefly introduce thesecompared methods as follows.
• CVH [16] extends Spectral Hashing to consider both intra-view and inter-view similaritieswith a generalized eigenvalue formulation.
• CMFH [26] learns unified hash codes from different modalities of one instance by collectivematrix factorization with a latent factor model.
• CCQ [17] jointly learns the correlation-maximal mappings that transform different modalitiesinto isomorphic latent space, and learns composite quantizers that convert the isomorphiclatent features into compact binary codes.
• CMSSH[18] models hashing learning as a classification problem, and it is learned in aboosting manner.
• SCM [19] constructs semantic similarity matrix based on labels and learns hashing functionsto preserve the constructed matrix. The approach has two version with different learningmethods, named SCM_orth and SCM_seq, which imply the orthogonal projection learningmethod and the sequential learning method of SCM respectively.
• SePH [31] is a two-step supervised hashing method. It firstly transforms the given semanticmatrix of training data into a probability distribution, and approximates it with learned hashcodes in Hamming space via minimizing the KL-divergence.
• DCMH [38] is an end-to-end deep learning based method, which performs feature learningand hashing function learning simultaneously.
• UGACH [52] is a deep learning based method with generative adversarial network, whichproposes a adversarial way to promote hashing function learning.
• SSAH [53] conducts a self-supervised semantic network to discover high-level semanticinformation from labels, and leverages two adversarial networks to maximize the semanticcorrelation and consistency between different modalities.
4.4 Experimental Results and Analysis4.4.1 The result in 2-media datasets. FromTables 1, 2 and 3, comparedwith state-of-the-art methods,it can be observed that our proposed MCSCH approach achieves the best retrieval performanceon 3 datasets. We categorize the methods into three parts: unsupervised compared methods,supervised compared methods and baseline methods. On MIRFlickr dataset, our proposed MCSCHapproach keeps the best average MAP score of 0.753 on image→text and 0.788 on text→image tasks.Compared with the unsupervised methods UGACH [52], our MCSCH approach achieves accuracyimprovement from 0.696 to 0.753 on image→text task, and from 0.681 to 0.788 on text→imagetask. Compared with supervised methods SSAH [53], our MCSCH approach improves averageMAP scores from 0.743 to 0.753 on image→text task, and from 0.777 to 0.788 on text→imagetask. We can see that, supervised methods can achieve better accuracy than the unsupervisedmethods, since the semantic information can provide semantic relation for effective hash codeslearning. Our proposed approach has better performance than these methods, because we considerthe complementary information and correlations between the multi-scale features. We can alsoobserve the similar trends on Wikipedia and NUS-WIDE dataset, as shown in Table 2 and 3.Figures 4 shows the topK-precision results on two datasets with 64 bit code length. Figures 5
shows the PR-curves on two datasets with 64 bit code length. We can observe that on both image
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 13
Table 1. The MAP scores of two retrieval tasks on MIRFlickr dataset with different lengths of hash codes.
Methods image→text text→image16 32 64 128 16 32 64 128
MCSCH (Ours) 0.748 0.757 0.766 0.743 0.779 0.790 0.795 0.788Baseline-mul 0.735 0.743 0.746 0.733 0.767 0.778 0.776 0.770Baseline-sig 0.730 0.734 0.740 0.728 0.774 0.769 0.772 0.762CVH [16] 0.602 0.587 0.578 0.572 0.607 0.591 0.581 0.574CMFH [26] 0.659 0.660 0.663 0.653 0.611 0.606 0.575 0.563CCQ [17] 0.637 0.639 0.639 0.638 0.628 0.628 0.622 0.618
UGACH [52] 0.685 0.693 0.704 0.702 0.673 0.676 0.686 0.690CMSSH [18] 0.611 0.602 0.599 0.591 0.612 0.604 0.592 0.585
SCM_orth [19] 0.585 0.576 0.570 0.566 0.585 0.584 0.574 0.568SCM_seq [19] 0.636 0.640 0.641 0.643 0.661 0.664 0.668 0.670SePH [31] 0.704 0.711 0.716 0.711 0.699 0.705 0.711 0.710DCMH [38] 0.721 0.729 0.735 0.731 0.764 0.771 0.774 0.760SSAH [53] 0.742 0.743 0.746 0.741 0.771 0.776 0.779 0.782
Table 2. The MAP scores of two retrieval tasks on Wikipedia dataset with different lengths of hash codes.
Methods image→text text→image16 32 64 128 16 32 64 128
MCSCH (Ours) 0.529 0.524 0.539 0.547 0.834 0.837 0.846 0.826Baseline-mul 0.496 0.495 0.499 0.523 0.776 0.792 0.817 0.809Baseline-sig 0.489 0.486 0.493 0.516 0.770 0.774 0.782 0.778CVH [16] 0.193 0.161 0.144 0.134 0.297 0.225 0.187 0.167CMFH [26] 0.439 0.496 0.473 0.461 0.484 0.548 0.573 0.568CCQ [17] 0.463 0.471 0.470 0.456 0.744 0.788 0.785 0.741
UGACH [52] 0.405 0.443 0.457 0.459 0.551 0.568 0.572 0.585CMSSH [18] 0.160 0.159 0.157 0.156 0.206 0.208 0.206 0.205
SCM_orth [19] 0.229 0.192 0.171 0.161 0.238 0.171 0.145 0.131SCM_seq [19] 0.396 0.459 0.462 0.442 0.442 0.557 0.538 0.510SePH [31] 0.515 0.518 0.533 0.538 0.748 0.781 0.792 0.805DCMH [38] 0.475 0.508 0.507 0.503 0.819 0.828 0.788 0.720SSAH [53] 0.493 0.498 0.509 0.512 0.807 0.818 0.815 0.816
→ text and text → image tasks, MCSCH achieves the best accuracy among all compared methods,which further demonstrates the effectiveness of our proposed approach.
4.4.2 The result in 5-media dataset. From Tables 4 and 5, we compare our MCSCH approach withstate-of-the-art methods. Similar to the results in 2-media datasets, we categorize the methodsinto three parts. We can observe that the MCSCH keeps the best average MAP scores of 0.519on image→all task, 0.451 on text→all task, 0.407 on audio→all task, 0.522 on video→all task,and 0.448 on 3d→all tasks. The MSCSH approach has better performance than all the comparedmethods, because of two advantages: 1) The MCSCH considers the complementary informationand correlations between multi-scale features. 2) The MCSCH models the data of five modalities ina unified framework, so we can consider the correlation among five modalities multimedia datasimultaneously. Furthermore, Figure 6 shows the topK-precision results and Figure 7 shows the
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

14 Zhaoda Ye, Yuxin Peng
Table 3. The MAP scores of two retrieval tasks on NUS-WIDE dataset with different lengths of hash codes.
Methods image→text text→image16 32 64 128 16 32 64 128
MCSCH (Ours) 0.714 0.721 0.728 0.729 0.768 0.778 0.779 0.780Baseline-mul 0.689 0.701 0.702 0.700 0.768 0.778 0.779 0.780Baseline-sig 0.675 0.687 0.685 0.691 0.735 0.738 0.745 0.743CVH [16] 0.458 0.432 0.410 0.392 0.474 0.445 0.419 0.398CMFH [26] 0.517 0.550 0.547 0.520 0.439 0.416 0.377 0.349CCQ [17] 0.504 0.505 0.506 0.505 0.499 0.496 0.492 0.488
UGACH [52] 0.613 0.623 0.628 0.631 0.603 0.614 0.640 0.641CMSSH [18] 0.512 0.470 0.479 0.466 0.519 0.498 0.456 0.488
SCM_orth [19] 0.389 0.376 0.368 0.360 0.388 0.372 0.360 0.353SCM_seq [19] 0.517 0.514 0.518 0.518 0.518 0.510 0.517 0.518SePH [31] 0.701 0.712 0.719 0.726 0.642 0.653 0.657 0.662DCMH [38] 0.631 0.653 0.653 0.671 0.702 0.695 0.694 0.693SSAH [53] 0.642 0.645 0.658 0.643 0.684 0.697 0.696 0.695
0 100 200 300 400 500 600 700 800 900 1000
Top K
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
Prec
isio
n
(a) The TopK curves of image->text on the MIRFlickr dataset
0 100 200 300 400 500 600 700 800 900 1000
Top K
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
0.6
Prec
isio
n
(b) The TopK curves of image->text on the Wikipedia dataset
0 100 200 300 400 500 600 700 800 900 1000
Top K
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Prec
isio
n
(e) The TopK curves of image->text on the NUS-WIDE dataset
0 100 200 300 400 500 600 700 800 900 1000
Top K
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
Prec
isio
n
(b) The TopK curves of text->image on the MIRFlickr dataset
0 100 200 300 400 500 600 700 800 900 1000
Top K
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Prec
isio
n
(d) The TopK curves of text->image on the Wikipedia dataset
0 100 200 300 400 500 600 700 800 900 1000
Top K
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Prec
isio
n
(e) The TopK curves of text->image on the NUS-WIDE dataset
MSSCH
SSAH
DCMH
UGACH
SePH
SCM_seq
SCM_orthCMSSH
CCQ
CMFH
CVH
Fig. 4. The topK-precision curves with 64 bit hash codes on Wikipedia, MIRFlickr and NUS-WIDE datasets.
PR-curves on PKU XMedia dataset with 64 bit code length, which demonstrates the effectivenessof our proposed approach.
4.4.3 The result of baseline methods. To verify the effectiveness of our proposed approach, weconduct three different baseline experiments for different parts in our MCSCH approach. The firstexperiment is single feature sequential hashing learning (Baseline-sig), which learns the hash codeby single scale features without multi-scales correlation mining strategy. Specially, we use thesame features as the compared methods to train the model. The second experiment is multi-scaleinformation features hashing learning (Baseline-mul), which learns the hash code with all multi-scale features without multi-scales correlation mining strategy. The third experiment is the methodwithout correlation evaluation network in 5-media dataset (Baseline-avg), which learns the hashcode with average function instead of correlation evaluate network.
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 15
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
Prec
isio
n
(a) The PR curves of image->text on the MIRFlickr dataset
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
0.6
Prec
isio
n
(b) The PR curves of image->text on the Wikipedia dataset
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Prec
isio
n
(e) The PR curves of image->text on the NUS-WIDE dataset
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
Prec
isio
n
(b) The PR curves of text->image on the MIRFlickr dataset
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Pr
ecis
ion
(d) The PR curves of text->image on the Wikipedia dataset
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Prec
isio
n
(f) The PR curves of text->image on the NUS-WIDE dataset
MSSCH
SSAH
DCMH
UGACH
SePH
SCM_seq
SCM_orthCMSSH
CCQ
CMFH
CVH
Fig. 5. The PR curves with 64 bit hash codes on Wikipedia, MIRFlickr and NUS-WIDE datasets.
Table 4. The MAP scores of PKU XMedia dataset with different lengths of hash codes.
Methods image→all text→all16 32 64 128 16 32 64 128
MCSCH (Ours) 0.515 0.526 0.521 0.514 0.435 0.457 0.460 0.452Baseline-avg 0.507 0.514 0.511 0.509 0.431 0.439 0.440 0.439Baseline-mul 0.497 0.505 0.501 0.495 0.424 0.429 0.427 0.427Baseline-sig 0.488 0.492 0.493 0.481 0.412 0.424 0.414 0.417CVH [16] 0.070 0.065 0.061 0.055 0.248 0.127 0.094 0.072CMFH [26] 0.174 0.160 0.135 0.108 0.074 0.071 0.066 0.062CCQ [17] 0.056 0.057 0.080 0.194 0.213 0.246 0.267 0.289
UGACH [52] 0.290 0.333 0.389 0.422 0.237 0.262 0.319 0.334CMSSH [18] 0.079 0.085 0.088 0.085 0.079 0.084 0.084 0.085
SCM_orth [19] 0.125 0.101 0.075 0.060 0.186 0.176 0.151 0.072SCM_seq [19] 0.070 0.069 0.100 0.337 0.217 0.199 0.261 0.206SePH [31] 0.435 0.446 0.452 0.451 0.267 0.253 0.258 0.251DCMH [38] 0.273 0.304 0.319 0.307 0.211 0.242 0.256 0.260SSAH [53] 0.412 0.423 0.435 0.434 0.267 0.279 0.277 0.275
On MIRFlickr dataset, comparing Baseline-sig and Baseline-mul, Baseline-mul has average MAPscore improvement from 0.733 to 0.739 on image→text task, and from 0.769 to 0.772 on text→imagetask. Comparing Baseline-mul and MCSCH approach, our MCSCH approach has an improvementfrom 0.739 to 0.753 on image→text task, and from 0.772 to 0.788 on text→image task. Similartrends can be observed in the Wikipedia dataset and PKU XMedia dataset. On PKU XMedia dataset,we can observe that method with correlation evaluation network has better performance than theBaseline-avg.
From the comparing of Baseline-sig and Baseline-mul method, we can observe the effectivenessof the complementary information in multi-scale features, which enhances the diversity of the hashcodes and reduces the errors caused by specific feature. From the comparing of Baseline-mul and
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

16 Zhaoda Ye, Yuxin Peng
Table 5. The MAP scores of PKU XMedia dataset with different lengths of hash codes.
Methods audio→all video→all 3d→all16 32 64 128 16 32 64 128 16 32 64 128
MCSCH (Ours) 0.389 0.407 0.419 0.415 0.514 0.533 0.522 0.519 0.421 0.448 0.465 0.457Baseline-avg 0.380 0.388 0.391 0.402 0.501 0.523 0.519 0.499 0.419 0.432 0.443 0.449Baseline-mul 0.368 0.376 0.384 0.397 0.487 0.508 0.507 0.485 0.413 0.424 0.432 0.436Baseline-sig 0.354 0.365 0.370 0.382 0.478 0.502 0.502 0.480 0.407 0.412 0.427 0.430CVH [16] 0.062 0.076 0.076 0.051 0.143 0.125 0.086 0.069 0.073 0.058 0.056 0.055CMFH [26] 0.063 0.064 0.064 0.064 0.100 0.111 0.112 0.118 0.103 0.107 0.117 0.126CCQ [17] 0.086 0.083 0.091 0.180 0.109 0.116 0.147 0.176 0.120 0.122 0.130 0.165
UGACH [52] 0.137 0.142 0.154 0.172 0.269 0.268 0.347 0.376 0.219 0.224 0.291 0.306CMSSH [18] 0.086 0.080 0.080 0.080 0.075 0.083 0.086 0.088 0.084 0.084 0.087 0.082
SCM_orth [19] 0.125 0.132 0.144 0.051 0.213 0.130 0.088 0.061 0.156 0.146 0.129 0.078SCM_seq [19] 0.082 0.077 0.066 0.113 0.258 0.256 0.263 0.255 0.103 0.111 0.213 0.255SePH [31] 0.298 0.302 0.310 0.312 0.334 0.332 0.342 0.345 0.345 0.342 0.351 0.350DCMH [38] 0.201 0.225 0.235 0.247 0.305 0.337 0.329 0.317 0.267 0.271 0.272 0.268SSAH [53] 0.268 0.272 0.285 0.302 0.314 0.322 0.334 0.338 0.345 0.353 0.355 0.352
Table 6. Comparison of the average retrieval time cost (Millisecond per Image) on MIRFlickr dataset by fixingthe code length 64.
Methods Time cost (ms) Methods Time cost (ms)CVH [16] 11.789 CMFH [26] 11.398CCQ [17] 11.672 CMSSH [18] 11.370
SCM_orth [19] 11.393 SCM_seq [19] 11.607SePH [31] 11.542 DCMH [38] 135.604
UGACH [52] 11.875 SSAH [53] 13.241MCSCH (Ours) 14.061
MCSCH, we can observe the effectiveness of multi-scale correlation mining strategy, which canmine correlation to boost hash function learning. From the comparing of Baseline-avg and MCSCHin 5-media dataset, we can see the effectiveness of the correlation evaluation network, which canbalance the importance of the correlation among multimedia data in different modalities.
4.4.4 The result of parameters sensitive experiment. To investigate the effect of hyper-parameters inequation (15), we conduct the parameters sensitive experiment with 64 bit hash codes in MIRFlickrdataset, and the results are reported in Figure 8. We keep other parameters fixed (equal to 1) andchange one parameter from 0.5 to 1.5 with a step size of 0.25. From the Figure 8, we can observe thatour approach is insensitive to the hyper-parameters in this scope, and achieves the best retrieveaccuracy when hyper-parameters are balanced.
4.4.5 The result of efficiency experiments. We provide the runtime estimation of our proposedMCSCH approach and compared methods, and the results are shown in Table 6. Specifically, weconduct the efficiency experiment on a PC with a NVIDIA Titan X GPU, an Intel Core i7-5930k3.50GHz CPU and 64 GB memory. Hashing based cross-modal retrieval process generally consistsof 3 parts: feature extraction, hash codes generation and retrieval among database. We sum thetime cost of the above three parts as final retrieval time cost. We can observe that our proposedMCSCH achieves comparable retrieval speed with other hashing methods, and our approach has
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 17
0 100 200 300 400 500 600 700 800 900 1000
Top K
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Prec
isio
n
(a) The TopK curves of video->all on the PKU XMedia dataset
0 100 200 300 400 500 600 700 800 900 1000
Top K
0
0.1
0.2
0.3
0.4
0.5
0.6
Prec
isio
n
(b) The TopK curves of audio->all on the PKU XMedia dataset
0 100 200 300 400 500 600 700 800 900 1000
Top K
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Prec
isio
n
(c) The TopK curves of image->all on the PKU XMedia dataset
0 100 200 300 400 500 600 700 800 900 1000
Top K
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Prec
isio
n
(d) The TopK curves of txt->all on the PKU XMedia dataset
0 100 200 300 400 500 600 700 800 900 1000
Top K
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Prec
isio
n
(e) The TopK curves of 3d->all on the PKU XMedia dataset
MSSCH
SSAH
DCMH
UGACH
SePH
SCM_seq
SCM_orthCMSSH
CCQ
CMFH
CVH
Fig. 6. The topK-precision curves with 64 bit hash codes of the five retrieval tasks on PKU XMedia dataset.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Prec
isio
n
(a) The PR curves of video->all on the PKU XMedia dataset
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0
0.1
0.2
0.3
0.4
0.5
0.6
Prec
isio
n
(b) The PR curves of audio->all on the PKU XMedia dataset
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Prec
isio
n
(c) The PR curves of image->all on the PKU XMedia dataset
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Prec
isio
n
(d) The PR curves of txt->all on the PKU XMedia dataset
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Prec
isio
n
(e) The PR curves of 3d->all on the PKU XMedia dataset
MSSCH
SSAH
DCMH
UGACH
SePH
SCM_seq
SCM_orthCMSSH
CCQ
CMFH
CVH
Fig. 7. The PR-curves of the MCSCH approach and compared methods in PKU XMedia
higher time cost due to the feature extraction in different scales. But it can mine the correlationsfrom different scales to effectively improve the accuracy of the retrieval, which makes the extratime cost tolerable.
4.4.6 Samples of retrieval results. Finally, we show some retrieval results of our approach andcompared methods on Wikipedia and PKU XMedia dataset, as shown in Figure 9 and Figure 10. We
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

18 Zhaoda Ye, Yuxin Peng
0.5 0.75 1 1.25 1.50.755
0.757
0.759
0.761
0.763
0.765
0.767
0.769
MaP
Sensitivity Analysis on MIRFlickr (image->text)
0.5 0.75 1 1.25 1.50.785
0.787
0.789
0.791
0.793
0.795
0.797
0.799
MaP
Sensitivity Analysis on MIRFlickr (text->image)
1
2
3
Fig. 8. The parameters sensitive experiment of MCSCH with 64 bit hash codes in MIRFlickr dataset
Task Query Method Top 5 Result
Image→Text
Text→Image
DCMH[38]
SSAH[53]
MCSCH
DCMH[38]
SSAH[53]
MCSCH
geography
music
Fig. 9. The retrieval results in Wikipedia dataset. The green rectangles denote the correct retrieval results.The red rectangles indicate wrong retrieval results.
can observe: (1) Our approach mines the correlation among features in different scales, which canretrieve the data with different scales. For example, in Figure 9, our MCSCH approach can retrievethe related images about music in object and scene level, which demonstrates the effectivenessof the scale correlation mining. (2) Our proposed MCSCH return results with more diverse mediatypes than compared methods in PKU XMedia dataset, because our approach models all modalitiessimultaneously, while the compared methods have to model two modalities separately and combinethe results for retrieval.
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 19
Task Query Method Top 5 Result
video→ALL
Image→ALL
DCMH[38]
SSAH[53]
MCSCH
DCMH[38]
SSAH[53]
MCSCH
Piano
dog
Fig. 10. The retrieval results in PKU XMedia dataset. The green rectangles denote the correct retrieval results.The red rectangles indicate wrong retrieval results.
5 CONCLUSIONSIn this paper, we have proposed a Multi-Scale Correlation Sequential Cross-modal Hashing (MC-SCH) approach, which considers the information and correlations among the multi-scale featuresin multimedia data. We introduce a correlation evaluation network to select the worthwhile cor-relations and increase the impact of these correlations in training stage. The proposed approachachieves the best performance than the compared methods for three advantages: 1) The approachfully utilizes the multi-scale features through an RNN based network, and the implementationinformation of features enhances the diversity of the hash codes and reduces the errors causedby specific single features. 2) The approach mines the correlation among the multi-scale featuresthrough multi-scale correlation mining strategy to boost the hash function learning. 3) A correlationevaluation network selects the worthwhile correlations for hash function learning and improves theimpact of these correlations in training stage. Experiments on 4 widely-used datasets demonstratethe effectiveness of our proposed approach.
The future work lies in two aspects. First, some well-designed graph algorithms can be appliedto model the correlations among the multi-scale features to find more complex correlations andboost the hash function learning. Second, we will extend our MCSCH approach for unsupervisedcase that makes the approach suitable for more situations.
ACKNOWLEDGMENTThis work was supported by the National Natural Science Foundation of China under Grant61771025.
REFERENCES[1] Xianglong Liu, YadongMu, Bo Lang, and Shih-Fu Chang. Mixed image-keyword query adaptive hashing over multilabel
images. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 10(2):22, 2014.
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

20 Zhaoda Ye, Yuxin Peng
[2] Mengqiu Hu, Yang Yang, Fumin Shen, Ning Xie, and Heng Tao Shen. Hashing with angular reconstructive embeddings.IEEE Transactions on Image Processing (TIP), 27(2):545–555, 2018.
[3] Dong Liu, Shuicheng Yan, Rong-Rong Ji, Xian-Sheng Hua, and Hong-Jiang Zhang. Image retrieval with query-adaptivehashing. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 9(1):2, 2013.
[4] Ruimao Zhang, Liang Lin, Rui Zhang, Wangmeng Zuo, and Lei Zhang. Bit-scalable deep hashing with regularizedsimilarity learning for image retrieval and person re-identification. IEEE Transactions on Image Processing (TIP),24(12):4766–4779, 2015.
[5] Yunchao Gong, Svetlana Lazebnik, Albert Gordo, and Florent Perronnin. Iterative quantization: A procrustean approachto learning binary codes for large-scale image retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI), 35(12):2916–2929, 2013.
[6] Dong Liu, Shuicheng Yan, Rong-Rong Ji, Xian-Sheng Hua, and Hong-Jiang Zhang. Image retrieval with query-adaptivehashing. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 9(1):2, 2013.
[7] J. Wang, W. Liu, S. Kumar, and S. F. Chang. Learning to hash for indexing big data-a survey. Proceedings of the IEEE,104(1):34–57, 2016.
[8] Gerard Salton and Christopher Buckley. Term-weighting approaches in automatic text retrieval. Information processingand management, 24(5):513–523, 1988.
[9] Gerard Salton. Another look at automatic text-retrieval systems. Communications of the ACM, 29(7):648–656, 1986.[10] Budi Yuwono and Dik L Lee. Server ranking for distributed text retrieval systems on the internet. In Database Systems
for Advanced Applications (DASFAA), pages 41–49. World Scientific, 1997.[11] Ricardo Baeza-Yates and Berthier Ribeiro-Neto. Modern information retrieval, volume 463. ACM press New York, 1999.[12] Yuxin Peng and Chong-Wah Ngo. Clip-based similarity measure for query-dependent clip retrieval and video
summarization. IEEE Transactions on Circuits and Systems for Video Technology, 16(5):612–627, 2006.[13] Xinmei Tian, Dacheng Tao, and Yong Rui. Sparse transfer learning for interactive video search reranking. ACM
Transactions on Multimedia Computing, Communications, and Applications (TOMM), 8(3):26, 2012.[14] Yuxin Peng, Jinwei Qi, and Yuxin Yuan. Cm-gans: Cross-modal generative adversarial networks for common represen-
tation learning. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 2018.[15] Jingkuan Song, Yang Yang, Yi Yang, Zi Huang, and Heng Tao Shen. Inter-media hashing for large-scale retrieval from
heterogeneous data sources. In ACM Special Interest Group on Management of Data (SIGMOD), pages 785–796. ACM,2013.
[16] Shaishav Kumar and Raghavendra Udupa. Learning hash functions for cross-view similarity search. In InternationalJoint Conference on Artificial Intelligence (IJCAI), volume 22, page 1360, 2011.
[17] Mingsheng Long, Yue Cao, Jianmin Wang, and Philip S Yu. Composite correlation quantization for efficient multimodalretrieval. In ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), pages 579–588. ACM,2016.
[18] Michael M Bronstein, Alexander M Bronstein, Fabrice Michel, and Nikos Paragios. Data fusion through cross-modalitymetric learning using similarity-sensitive hashing. In IEEE Conference on Computer Vision and Pattern Recognition(CVPR), pages 3594–3601. IEEE, 2010.
[19] Dongqing Zhang and Wu-Jun Li. Large-scale supervised multimodal hashing with semantic correlation maximization.In AAAI Conference on Artifcial Intelligence (AAAI), volume 1, page 7, 2014.
[20] Yueting Zhuang, Zhou Yu, Wei Wang, Fei Wu, Siliang Tang, and Jian Shao. Cross-media hashing with neural networks.In ACM International Conference on Multimedia (ACM MM), pages 901–904. ACM, 2014.
[21] Yue Cao, Mingsheng Long, Jianmin Wang, and Han Zhu. Correlation autoencoder hashing for supervised cross-modalsearch. In International Conference on Multimedia Retrieval (ICMR), pages 197–204. ACM, 2016.
[22] Yang Yang, Yaqian Duan, Xinze Wang, Zi Huang, Ning Xie, and Heng Tao Shen. Hierarchical multi-clue modellingfor poi popularity prediction with heterogeneous tourist information. IEEE Transactions on Knowledge and DataEngineering (TKDE), 31(4):757–768, 2019.
[23] Zhaoda Ye and Yuxin Peng. Multi-scale correlation for sequential cross-modal hashing learning. In ACM InternationalConference on Multimedia (ACM MM), 2018.
[24] H. Hotelling. Relations between two sets of variates. Biometrika, 28(3/4):321–377, 1936.[25] Yair Weiss, Antonio Torralba, and Rob Fergus. Spectral hashing. In Advances in neural information processing systems
(NIPS), pages 1753–1760, 2009.[26] Guiguang Ding, Yuchen Guo, Jile Zhou, and Yue Gao. Large-scale cross-modality search via collective matrix
factorization hashing. IEEE Transactions on Image Processing (TIP), 25(11):5427–5440, 2016.[27] Mengqiu Hu, Yang Yang, Fumin Shen, Ning Xie, Richang Hong, and Heng Tao Shen. Collective reconstructive
embeddings for cross-modal hashing. IEEE Transactions on Image Processing (TIP), 28(6):2770–2784, 2019.[28] Di Wang, Xinbo Gao, Xiumei Wang, and Lihuo He. Semantic topic multimodal hashing for cross-media retrieval. In
International Joint Conference on Artificial Intelligence (IJCAI), pages 3890–3896, 2015.
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.

Sequential Cross-Modal Hashing Learning via Multi-scale Correlation Mining 21
[29] Jian Zhang, Yuxin Peng, and Mingkuan Yuan. Unsupervised generative adversarial cross-modal hashing. arXiv preprintarXiv:1712.00358, 2017.
[30] Ying Wei, Yangqiu Song, Yi Zhen, Bo Liu, and Qiang Yang. Scalable heterogeneous translated hashing. In ACM SIGKDDinternational conference on Knowledge discovery and data mining (KDD), pages 791–800. ACM, 2014.
[31] Zijia Lin, Guiguang Ding, Mingqing Hu, and Jianmin Wang. Semantics-preserving hashing for cross-view retrieval. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3864–3872, 2015.
[32] Xiaobo Shen, Fumin Shen, Quan-Sen Sun, Yang Yang, Yun-Hao Yuan, and Heng Tao Shen. Semi-paired discrete hashing:Learning latent hash codes for semi-paired cross-view retrieval. IEEE transactions on cybernetics, 47(12):4275–4288,2017.
[33] Feng Zheng, Yi Tang, and Ling Shao. Hetero-manifold regularisation for cross-modal hashing. IEEE Transactions onPattern Analysis and Machine Intelligence(TPAMI), 40(5):1059–1071, 2018.
[34] Xin Luo, Xiao-Ya Yin, Liqiang Nie, Xuemeng Song, Yongxin Wang, and Xin-Shun Xu. Sdmch: Supervised discretemanifold-embedded cross-modal hashing. In International Joint Conference on Artificial Intelligence (IJCAI), pages2518–2524, 2018.
[35] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neuralnetworks. In Advances in neural information processing systems (NIPS), pages 1097–1105, 2012.
[36] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Computer Vision (ICCV), 2017 IEEEInternational Conference on, pages 2980–2988. IEEE, 2017.
[37] Yue Cao, Mingsheng Long, Jianmin Wang, Qiang Yang, and Philip S Yuy. Deep visual-semantic hashing for cross-modalretrieval. In ACM SIGKDD international conference on Knowledge discovery and data mining (KDD), page 1445, 2016.
[38] Qing-Yuan Jiang and Wu-Jun Li. Deep cross-modal hashing. In IEEE Conference on Computer Vision and PatternRecognition (CVPR), pages 3232–3240, 2017.
[39] Cheng Deng, Zhaojia Chen, Xianglong Liu, Xinbo Gao, and Dacheng Tao. Triplet-based deep hashing network forcross-modal retrieval. IEEE Transactions on Image Processing, 27(8):3893–3903, 2018.
[40] Ge Song, Dong Wang, and Xiaoyang Tan. Deep memory network for cross-modal retrieval. IEEE Transactions onMultimedia, 2018.
[41] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXivpreprint arXiv:1409.1556, 2014.
[42] Yoon Kim. Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882, 2014.[43] Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with
3d convolutional networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4489–4497,2015.
[44] Heng Wang and Cordelia Schmid. Action recognition with improved trajectories. In IEEE Conference on ComputerVision and Pattern Recognition (CVPR), Sydney, Australia, 2013.
[45] Cory McKay, Ichiro Fujinaga, and Philippe Depalle. jaudio: A feature extraction library. In Proceedings of theInternational Conference on Music Information Retrieval, pages 600–3, 2005.
[46] Ding-Yun Chen, Xiao-Pei Tian, Yu-Te Shen, and Ming Ouhyoung. On visual similarity based 3d model retrieval.22(3):223–232, 2003.
[47] Mark J Huiskes and Michael S Lew. The mir flickr retrieval evaluation. In Proceedings of the 1st ACM internationalconference on Multimedia information retrieval, pages 39–43. ACM, 2008.
[48] Jose Costa Pereira, Emanuele Coviello, Gabriel Doyle, Nikhil Rasiwasia, Gert RG Lanckriet, Roger Levy, and NunoVasconcelos. On the role of correlation and abstraction in cross-modal multimedia retrieval. IEEE Transactions onPattern Analysis and Machine Intelligence (TPAMI), 36(3):521–535, 2014.
[49] Tat-Seng Chua, Jinhui Tang, Richang Hong, Haojie Li, Zhiping Luo, and Yantao Zheng. Nus-wide: a real-world webimage database from national university of singapore. In Proceedings of the ACM international conference on image andvideo retrieval, page 48. ACM, 2009.
[50] Yuxin Peng, Xiaohua Zhai, Yunzhen Zhao, and Xin Huang. Semi-supervised cross-media feature learning with unifiedpatch graph regularization. IEEE Transactions on Circuits and Systems for Video Technology(TCSVT), 26(3):583–596,2016.
[51] Xiaohua Zhai, Yuxin Peng, and Jianguo Xiao. Learning cross-media joint representation with sparse and semisupervisedregularization. IEEE Transactions on Circuits and Systems for Video Technology, 24(6):965–978, 2014.
[52] Jian Zhang, Yuxin Peng, and Mingkuan Yuan. Unsupervised generative adversarial cross-modal hashing. In AAAIConference on Artifcial Intelligence (AAAI), 2018.
[53] Chao Li, Cheng Deng, Ning Li, Wei Liu, Xinbo Gao, and Dacheng Tao. Self-supervised adversarial hashing networksfor cross-modal retrieval. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4242–4251,2018.
ACM Trans. Multimedia Comput. Commun. Appl., Vol. 1, No. 1, Article . Publication date: August 2019.