Embed Size (px)
Citation preview

Sequence Analysis
Introduction to BioinformaticsBIMMS
December 2015
Gabriel TekuDepartment of Experimental Medical Science
Faculty of Medicine Lund University

Sequence analysis
Part 1
• Sequence analysis: general introduction
• Sequence features
• Motifs and Domains Part 2
• Galaxy
• EMBOSS
• Bioinformatics software for sequence analysis

Sequence analysis
Part 1
• Sequence analysis: general introduction
• Sequence features
• Motifs and Domains

Sequence analysis: definition
… refers to the process of subjecting a DNA, RNA or
peptide sequence to any of a wide range of analytical
methods to understand its features, function,
structure, or evolution...
[http://en.wikipedia.org/wiki/Sequence_analysis]

Quick sequence analysis example
1. Obtain the protein sequence encoded by Human elastase gene from Uniprot, P08246
2. Obtain the CDS sequence for the protein.
http://www.ebi.ac.uk/Tools/st
1. Translate the CDS sequence obtained above
http://www.ebi.ac.uk/Tools/st

Quick sequence analysis example
4. Compare the translated CDS to the protein sequence obtained from 1 above.
http://www.ebi.ac.uk/Tools/msa/clustalo/

Quick sequence analysis example
4. Compare the translated CDS to the protein sequence obtained from 1 above.
http://www.ebi.ac.uk/Tools/msa/clustalo/

Types of sequence analysis
Searching databases
Sequence alignments
Feature analyses

Feature analysis
Part 1
• General introduction
• Feature analyses
• Motifs and Domains

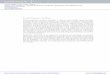
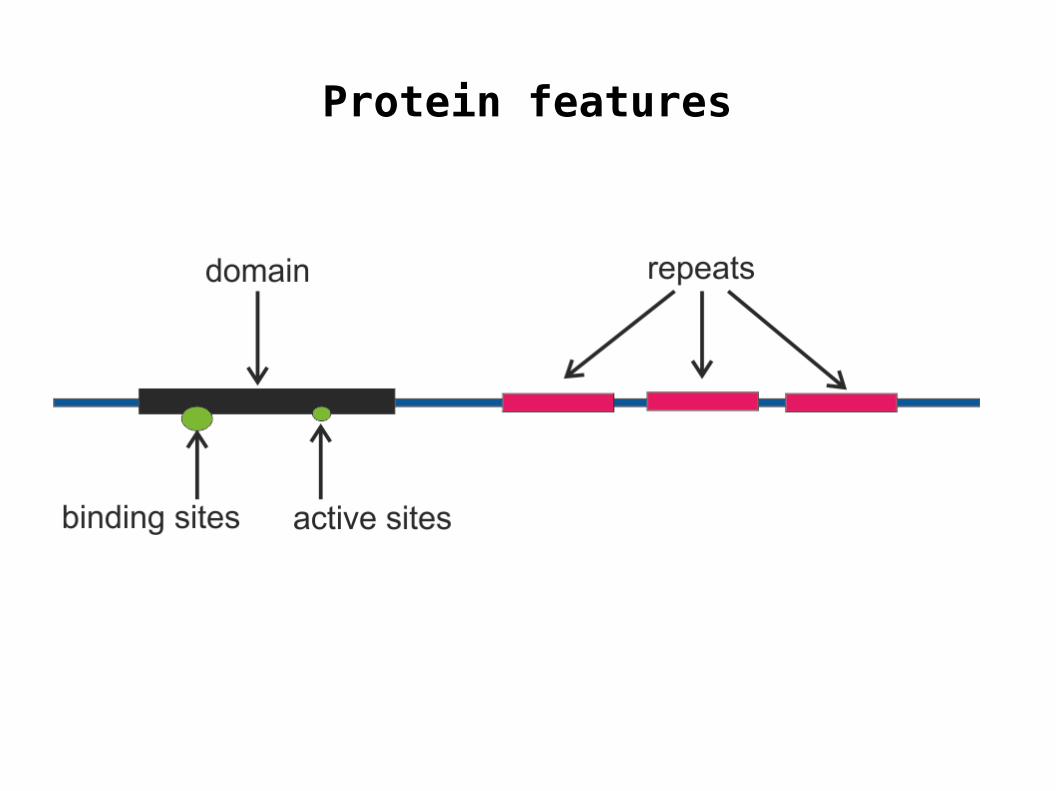
What is a feature
Sequence features are groups of nucleotides or amino
acids that confer certain characteristics upon a gene or
protein, and may be important for its overall function.
http://www.ebi.ac.uk/Tools/st
Protein features
Gene features

Exercise on features
1. Explore the features along the protein P08246
within UniProt
2. View the protein’s structure from pdb by following
the 3D structure link for 1h1b.

Quick exercise on motifs and domains
1. Identify the functional motif(s) of the protein P08246
Use PROSITE link from Uniprot Family & →Domains
2. What is the motif as represented by the database entry

Sequence analysis
Part 1
• General introduction
• Features
• Motifs and Domains

Motifs
• Short, conserved sequence patterns
• Associated to specific function(s)
Binding site
Active site
• ~ 10 - 30 amino acids
• Prosite
Motifs

Motifs: prosite
From CDS to protein sequence
Statistically significant motifs
Functional motifs
Protein family by virtue of similar functional sites

Quick exercise on scanning for motifs
1. Use the protein sequence of the gene ELANE to scan
prosite for motifs and domains.
2. Compare the results with that of the previous
exercise.

Motifs: prosite
Methodology
• Pattern development
Pattern from literature
Profiles

• Based on signature patterns
• Sensitivity
• Specificity
Pattern development

• Literature curated patterns
published
curated
tested against Swiss-Prot for specificity
Pattern development

• New patterns
start with review article
alignment of proteins from article
focus on biologically important regions
create core pattern
Pattern development

• New patterns (contd)
Search Swiss-Prot using core sites
Retain/discard core pattern
Refine core pattern and repeat search
Pattern development

Patterns
• Prosite syntax for patterns:
• one-letter codes for amino acids, e.g. G=Gly
• elements separated by a hyphen, “-”
• “X” used where any amino acid is accepted,

Patterns
Prosite syntax for patterns contd:• Ambiguities indicated by [ ],
e.g. [AG] means Ala or Gly,
• Amino acids that are not accepted at a given position are
listed between curly braces, “{ }”, e.g. {AG} means any amino acid except Ala and Gly,

Patterns
Prosite syntax for patterns contd:• repetitions are placed between braces,“( )”,
e.g. [AG](2,4) means Ala or Gly between 2 and 4 times,
• a pattern is anchored to the N-terminal or C-terminal by
“<“ and “>”, respectively.
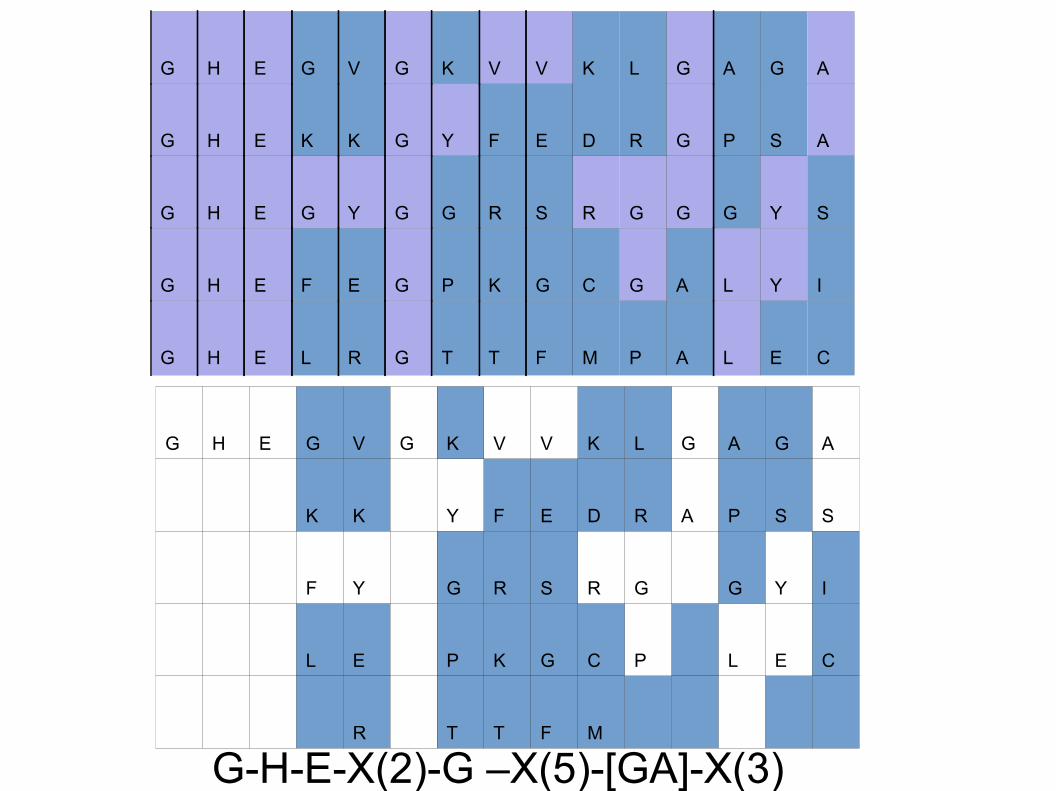
G H E G V G K V V K L G A G A
G H E K K G Y F E D R G P S A
G H E G Y G G R S R G G G Y S
G H E F E G P K G C G A L Y I
G H E L R G T T F M P A L E C
G H E G V G K V V K L G A G A
K K Y F E D R A P S S
F Y G R S R G G Y I
L E P K G C P L E C
R T T F M
G-H-E-X(2)-G –X(5)-[GA]-X(3)

Quick exercise
Interpret the motif you obtained from the previous exercise.

Methodology
• Pattern development
Pattern from literature
New patterns
• Profiles
Motifs: prosite

Profiles
Popular approaches
• position weight matrix
• HMM
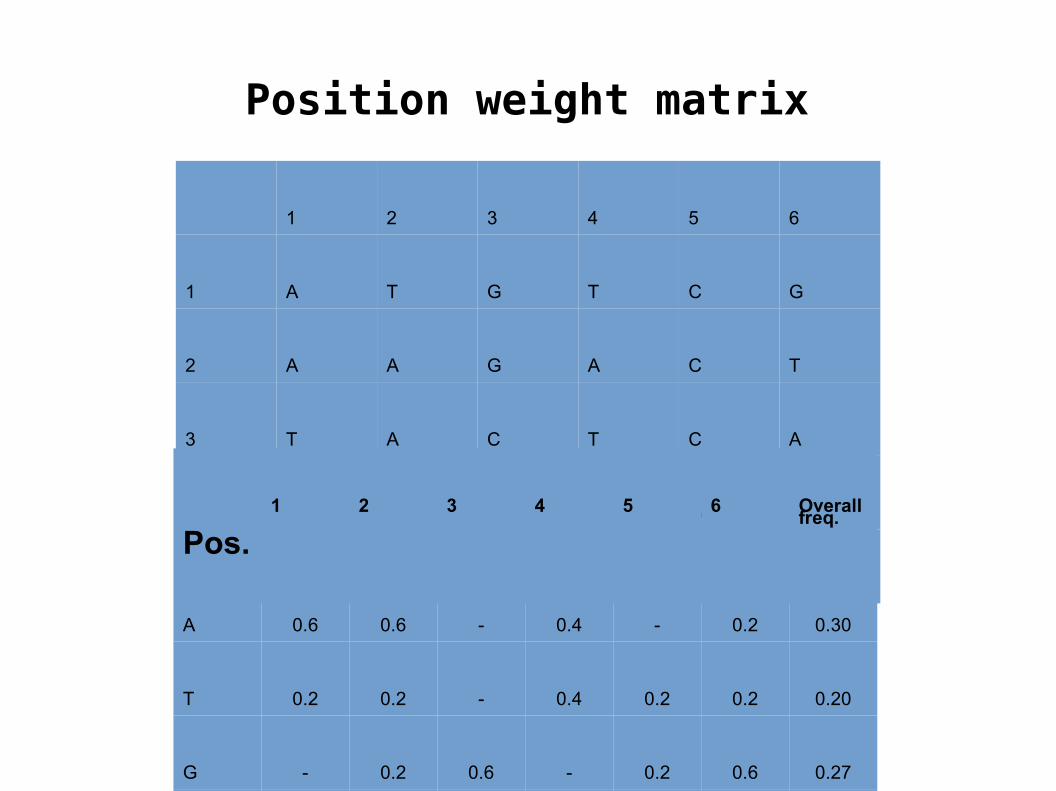
Position weight matrix
1 2 3 4 5 6
1 A T G T C G
2 A A G A C T
3 T A C T C A
4 C G G A G G
5 A A C C T G
Pos.1 2 3 4 5 6 Overall
freq.
A 0.6 0.6 - 0.4 - 0.2 0.30
T 0.2 0.2 - 0.4 0.2 0.2 0.20
G - 0.2 0.6 - 0.2 0.6 0.27
C 0.2 - 0.4 0.2 0.6 - 0.23
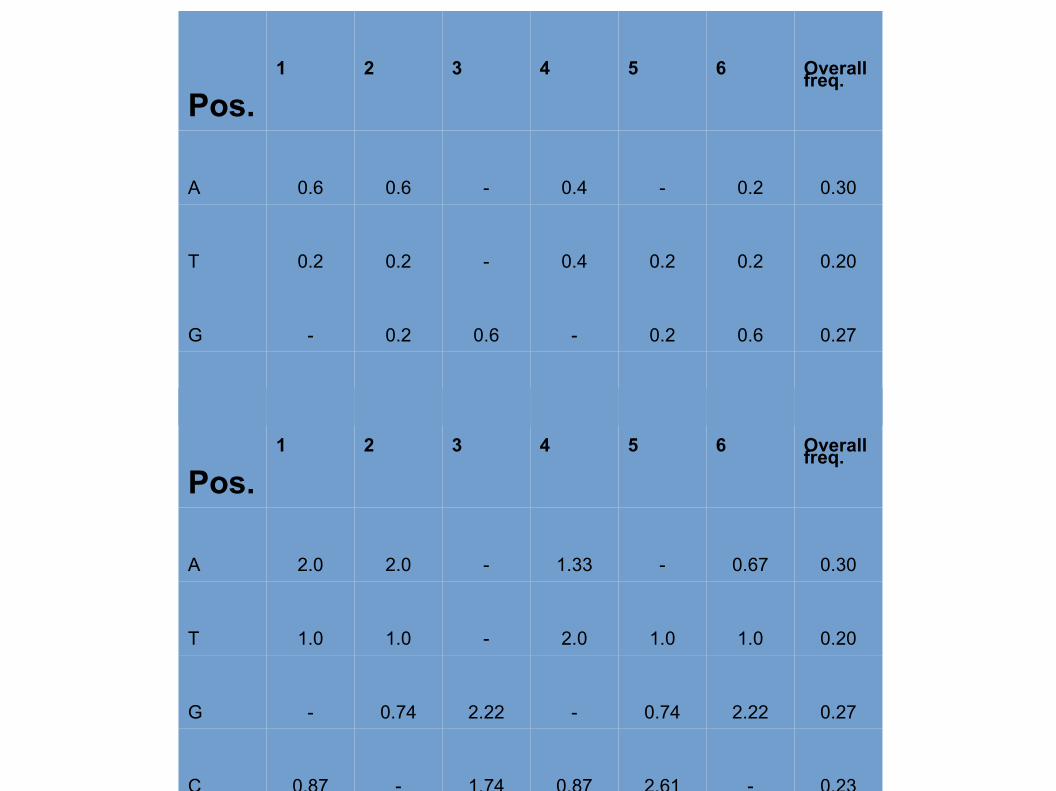
Pos.1 2 3 4 5 6 Overall
freq.
A 0.6 0.6 - 0.4 - 0.2 0.30
T 0.2 0.2 - 0.4 0.2 0.2 0.20
G - 0.2 0.6 - 0.2 0.6 0.27
C 0.2 - 0.4 0.2 0.6 - 0.23
Pos.1 2 3 4 5 6 Overall
freq.
A 2.0 2.0 - 1.33 - 0.67 0.30
T 1.0 1.0 - 2.0 1.0 1.0 0.20
G - 0.74 2.22 - 0.74 2.22 0.27
C 0.87 - 1.74 0.87 2.61 - 0.23
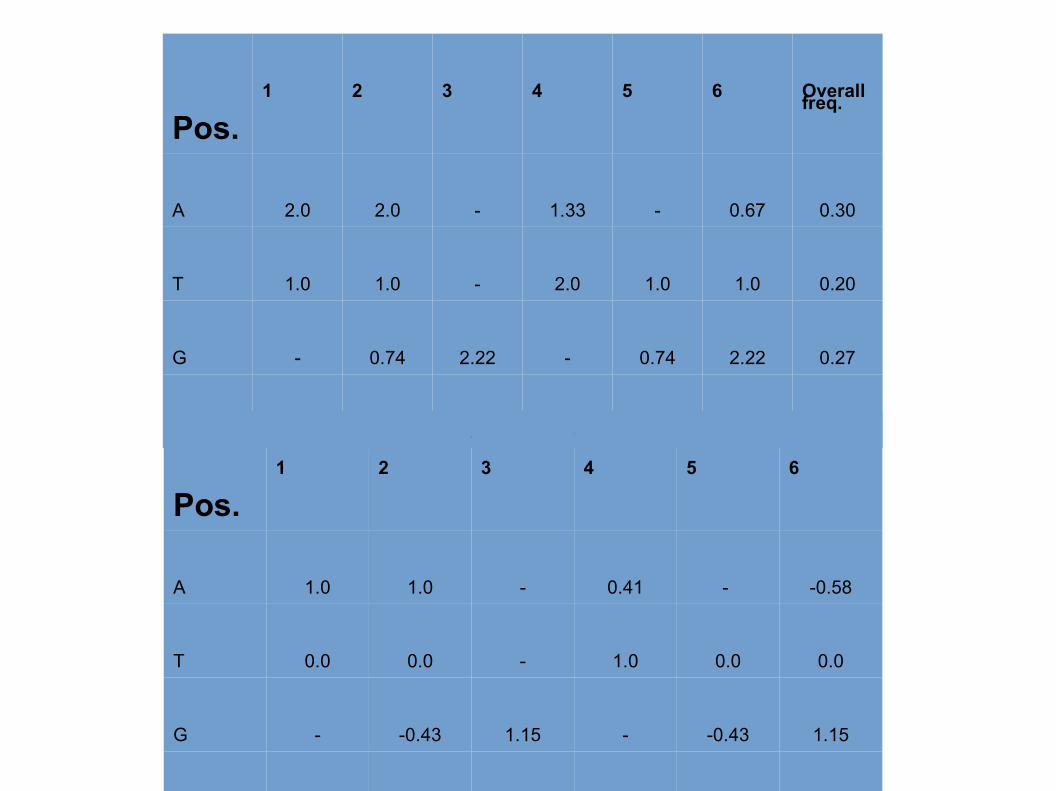
Pos.1 2 3 4 5 6 Overall
freq.
A 2.0 2.0 - 1.33 - 0.67 0.30
T 1.0 1.0 - 2.0 1.0 1.0 0.20
G - 0.74 2.22 - 0.74 2.22 0.27
C 0.87 - 1.74 0.87 2.61 - 0.23
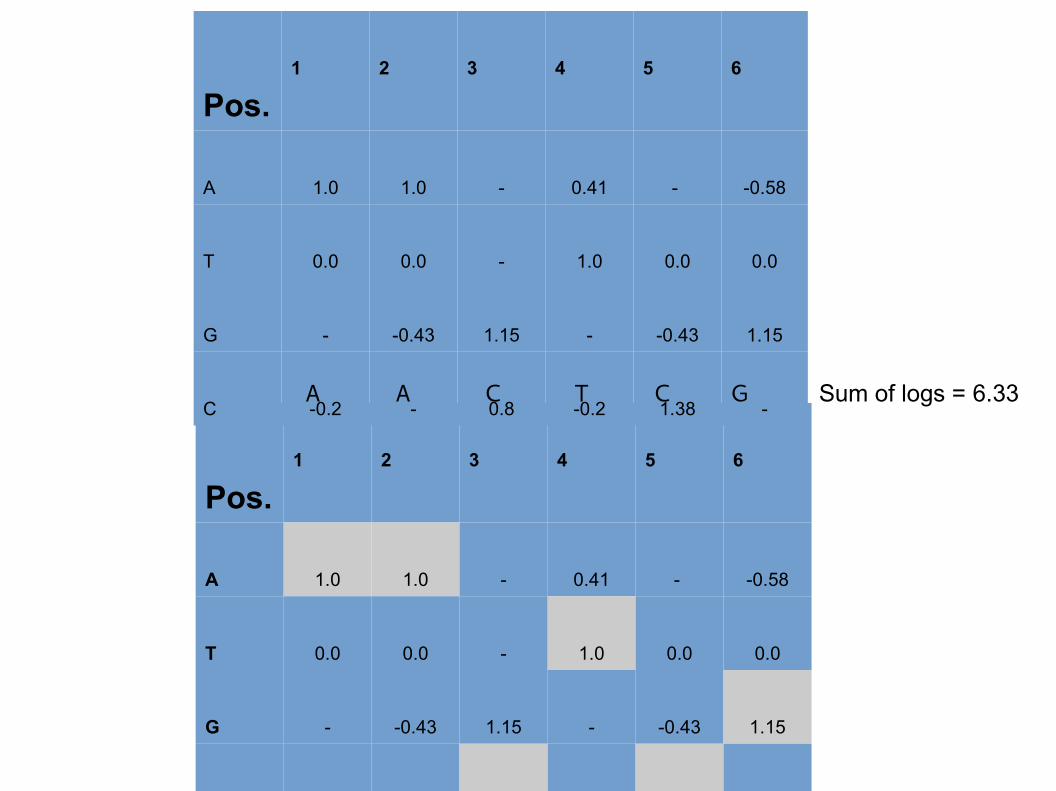
Pos.1 2 3 4 5 6
A 1.0 1.0 - 0.41 - -0.58
T 0.0 0.0 - 1.0 0.0 0.0
G - -0.43 1.15 - -0.43 1.15
C -0.2 - 0.8 -0.2 1.38 -
Pos.1 2 3 4 5 6
A 1.0 1.0 - 0.41 - -0.58
T 0.0 0.0 - 1.0 0.0 0.0
G - -0.43 1.15 - -0.43 1.15
C -0.2 - 0.8 -0.2 1.38 -
Pos.1 2 3 4 5 6
A 1.0 1.0 - 0.41 - -0.58
T 0.0 0.0 - 1.0 0.0 0.0
G - -0.43 1.15 - -0.43 1.15
C -0.2 - 0.8 -0.2 1.38 -Sum of logs = 6.33 A A C T C G

Profile
• Multiple sequence alignments with gaps
• Gap penalties
• Profile = PSSM that includes gap penalties
• Fine tuning gap parameters to achieve good profiles
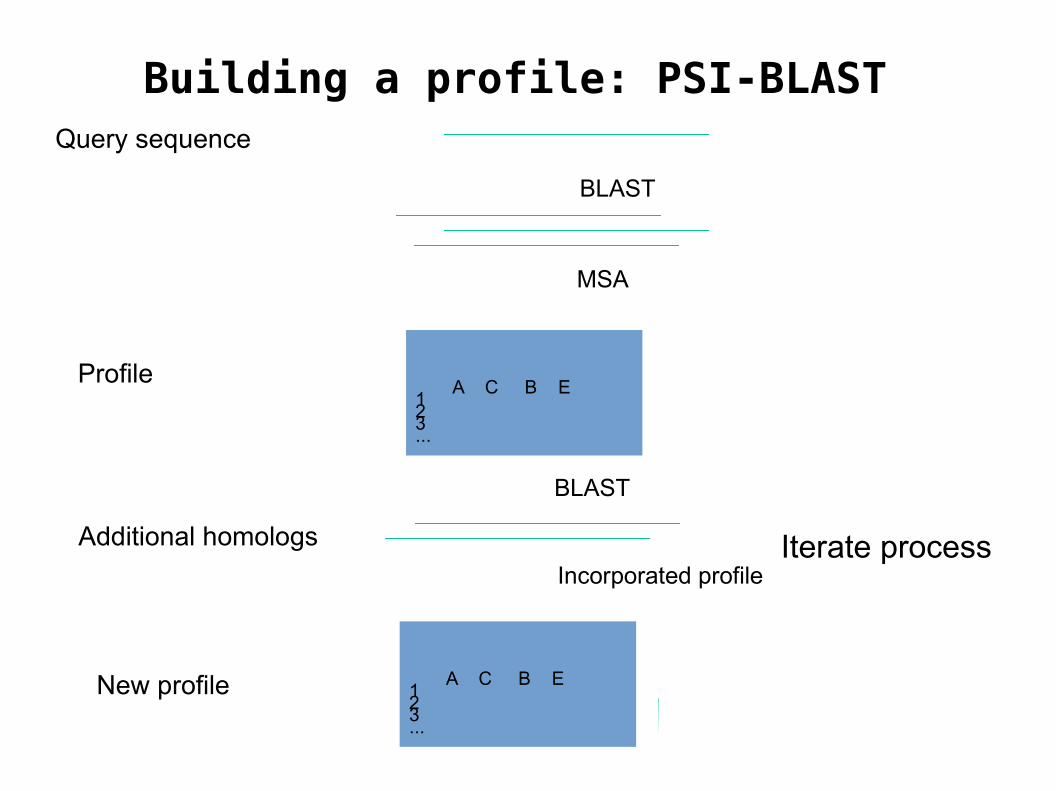
Building a profile: PSI-BLAST Query sequence
BLAST
MSA
Profile A C B E123...
BLAST
Additional homologs
Incorporated profile
New profile A C B E123...
Iterate process

MEME Suite Example

Quick exercise
1. BLAST the protein P08246 against the Uniprot proteins.2. Select the first 5 hits and download the sequences in
fasta format3. Launch the MEME program at http://meme-suite.org/
4. Using the downloaded sequence file above, search for possible motifs using the MEME program.
5. Compare the results to that from Prosite.6. Leave the results open for later.

Profiles from Hidden Markov Models
• More efficient
• From speech recognition
• Based on Markov Models
• Statistical approach

Some motif resources
• PROSITE
• PRINTS
• SMART
• InterProhttp://www.ebi.ac.uk/interpro/about.html

Domains
• Longer than motifs
• conserved sequence patterns
• Independent structural and functional unit
• Average length, 100 aa
• May (not) include motifs along boundries

Domains
• HMM applied in domain identification due to its
robustness.
• Some domain databases include
• Pfam-A
• Pfam-B
• Prodom
• MEME suite

Quick exercise
1. Identify the domain(s) of the P08246 protein.
2. Explain how you accomplished the task.

PART 2
• Galaxy
• EMBOSS
• Bioinformatics software for sequence analysis
• Open source tools
• Commercial softwares

Galaxy
• https://usegalaxy.org/
• One-stop shop
• from single sequence to NGS
• Open source
Sequence Analysis Introduction

Introduction to galaxy
http://galaxy.bmc.lu.se/
Introduction to galaxy

Introduction to galaxy
Which coding exon has the highest number of single nucleotide polymorphisms (SNPs) on chromosome 22?

Introduction to galaxy

Galaxy tutorial
Register
Login
Familiarize

Galaxy tutorial
https://github.com/nekrut/galaxy/wiki/Galaxy101-1

Galaxy tutorial: demo and exercise
1. Complete the galaxy 101 tutorial.
2. Share the final workflow.
3. Briefly describe the workflow in your own words.
4. Re-use the workflow, but this time; choose All SNPs
dataset as feature.

Galaxy Demo&
Exercise

EMBOSS
The European Molecular Biology Open Software Suite
Large user community
Available on the web, for many OS, servers and stand-alone
If you know how to use one, then you know how to use all
Mature and stable
Sequence Analysis Introduction

EMBOSS
What is it good for? Sequence alignment Database search with sequence patterns Motif identification and domain analysis Nucleotide sequence pattern analysis
Sequence Analysis Introduction
http://emboss.sourceforge.net/
EMBOSS FROM SOURCEFORGE
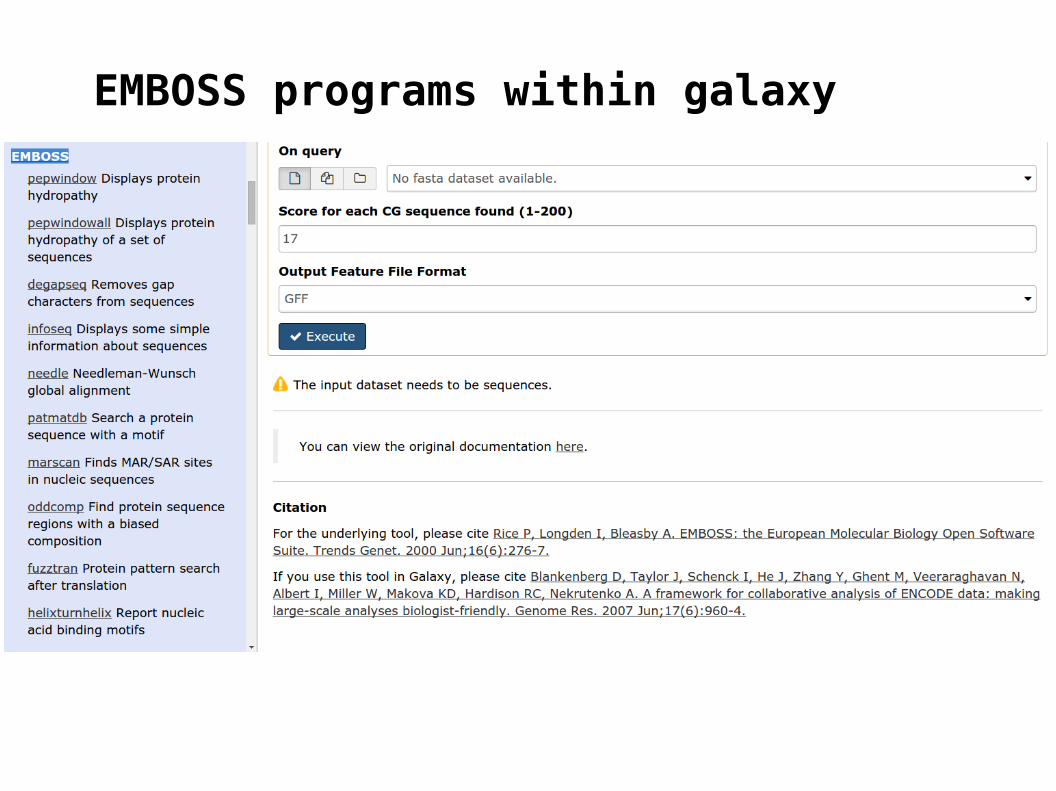
EMBOSS programs within galaxy

Many other portals
http://www.ebi.ac.uk/Tools/emboss/
http://emboss.bioinformatics.nl/
http://imed.med.ucm.es/EMBOSS/
http://www.bioinformatics2.wsu.edu/emboss/
http://pro.genomics.purdue.edu/emboss/

Quick CpG islands background for next exercise
Region of high density CG dinucleotides along the DNA 200 – 500 nucleotides, enriched with CG Enriched CpG nucleotides
The p in CpG islands represent the phosphodiester bond between the C and G nucleotides
Mostly occur within the promoter of eukaryotic genes Lock gene in an inactive stateHelps identify the transcription start site of a gene

Exercise
From galaxy, emboss toolshed:
List all tools that analyze CpG islands
On the search field, type in “cpg”
Access the documentation for two of these tools,
Preferably cpgplot and newcpgreport

Exercise• Write down the expected result
• Run the tools on the human gene ELANE
• Interpret the results.

Software for sequence analysis
• Open source tools
• Commercial tools

Software for sequence analysis
• Websites with links to open source tools and services
http://www.ebi.ac.uk/services
http://www.ncbi.nlm.nih.gov/guide/sequence-analysis/
http://bioinformatics.ca/links_directory/
http://bioinformatics.ca/links_directory/category/dna/structure-and-sequence-
feature-detection

Software for sequence analysis
Open source GNU general public licenses (GNU GPL)
• Continuous evolution of code• Community supported
Examples• EMBOSS• mothur

Software for sequence analysis

Software for sequence analysis

Software for sequence analysis
Commercial tools Proprietary Expensive licenses Examples
• Geneious (Biomatters Ltd., Auckland, New Zealand)
• CLC Genomics Workbench (CLC bio, Aarhus, Denmark)
• Sequencher (Gene Codes Corporation, MI, USA)
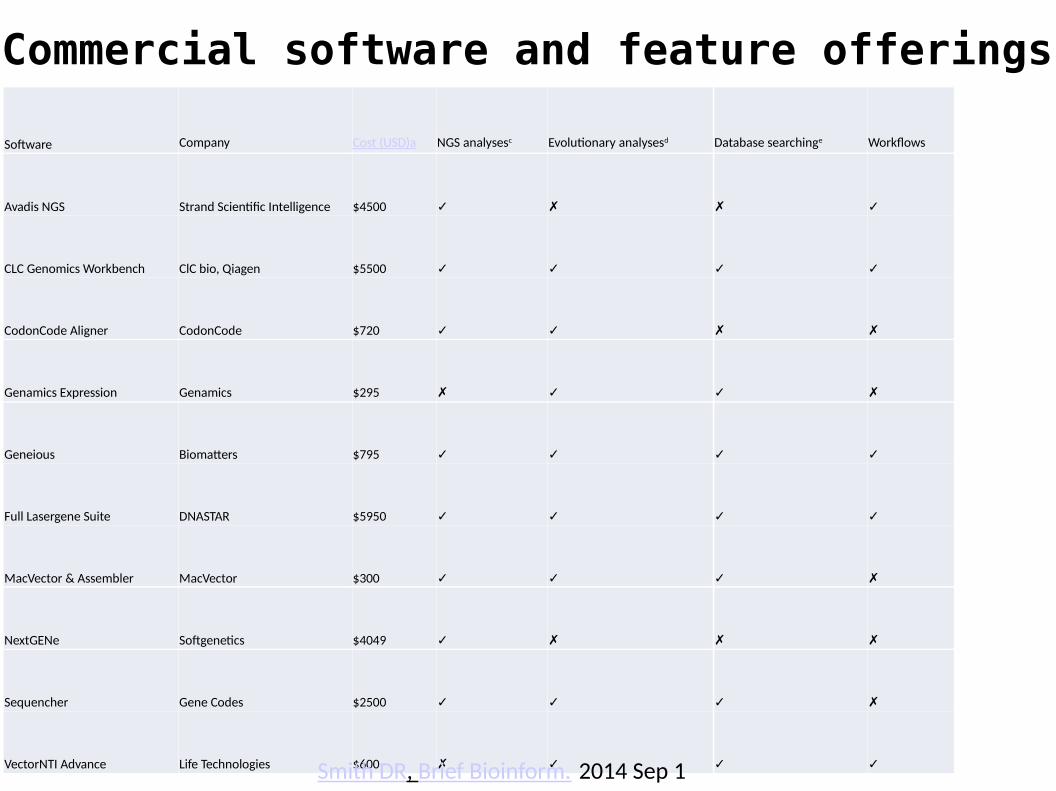
Software Company Cost (USD)a NGS analysesc Evolutionary analysesd Database searchinge Workflows
Avadis NGS Strand Scientific Intelligence $4500 ✓ ✗ ✗ ✓
CLC Genomics Workbench ClC bio, Qiagen $5500 ✓ ✓ ✓ ✓
CodonCode Aligner CodonCode $720 ✓ ✓ ✗ ✗
Genamics Expression Genamics $295 ✗ ✓ ✓ ✗
Geneious Biomatters $795 ✓ ✓ ✓ ✓
Full Lasergene Suite DNASTAR $5950 ✓ ✓ ✓ ✓
MacVector & Assembler MacVector $300 ✓ ✓ ✓ ✗
NextGENe Softgenetics $4049 ✓ ✗ ✗ ✗
Sequencher Gene Codes $2500 ✓ ✓ ✓ ✗
VectorNTI Advance Life Technologies $600 ✗ ✓ ✓ ✓Smith DR, Brief Bioinform. 2014 Sep 1
Commercial software and feature offerings