Embed Size (px)
Citation preview

SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
Event Abstraction for Process Mining usingSupervised Learning Techniques
Niek TaxEindhoven University of Technology
Department of Mathematics and Computer SciencePO Box 513 5600MB Eindhoven
The NetherlandsEmail ntaxtuenl
Natalia SidorovaEindhoven University of Technology
Department of Mathematics and Computer SciencePO Box 513 5600MB Eindhoven
The NetherlandsEmail nsidorovatuenl
Reinder HaakmaPhilips ResearchProf Holstlaan 4
5665 AA EindhovenThe Netherlands
Email reinderhaakmaphilipscom
Wil M P van der AalstEindhoven University of Technology
Department of Mathematics and Computer SciencePO Box 513 5600MB Eindhoven
The NetherlandsEmail wmpvdaalsttuenl
AbstractmdashProcess mining techniques focus on extracting in-sight in processes from event logs In many cases events recordedin the event log are too fine-grained causing process discoveryalgorithms to discover incomprehensible process models or pro-cess models that are not representative of the event log We showthat when process discovery algorithms are only able to discoveran unrepresentative process model from a low-level event logstructure in the process can in some cases still be discovered byfirst abstracting the event log to a higher level of granularity Thisgives rise to the challenge to bridge the gap between an originallow-level event log and a desired high-level perspective on thislog such that a more structured or more comprehensible processmodel can be discovered We show that supervised learning canbe leveraged for the event abstraction task when annotations withhigh-level interpretations of the low-level events are available fora subset of the sequences (ie traces) We present a methodto generate feature vector representations of events based onXES extensions and describe an approach to abstract events inan event log with Condition Random Fields using these eventfeatures Furthermore we propose a sequence-focused metric toevaluate supervised event abstraction results that fits closely tothe tasks of process discovery and conformance checking Weconclude this paper by demonstrating the usefulness of supervisedevent abstraction for obtaining more structured andor morecomprehensible process models using both real life event dataand synthetic event data
KeywordsmdashProcess Mining Event Abstraction ProbabilisticGraphical Models
I INTRODUCTION
Process mining is a fast growing discipline that combinesknowledge and techniques from computational intelligencedata mining process modeling and process analysis [1] Pro-cess mining focuses on the analysis of event logs whichconsists of sequences of real-life events observed from processexecutions originating eg from logs from ERP systems Animportant subfield of process mining is process discoverywhich is concerned with the task of finding a process model
Fig 1 An excerpt of a rdquospaghettirdquo-like process model
that is representative of the behavior seen in an event logMany different process discovery algorithms exist ([2] [3][4] [5] [6]) and many different types of process models canbe discovered by process discovery methods including BPMNmodels Petri nets process trees and statecharts
As event logs are often not generated specifically for theapplication of process mining events granularity of the eventlog at hand might be too low level It is vital for successfulapplication of process discovery techniques to have eventlogs at an appropriate level of abstraction Process discoverytechniques when the input event log is too low level mightresult in process model with one or more undesired propertiesFirst of all the resulting process model might be rdquospaghettirdquo-like as shown in Figure 1 containing of an uninterpretablemess of nodes and connections The aim of process discoveryis to discover a structured rdquolasagnardquo-like process model asshown in Figure 2 which is much more interpretable than ardquospaghettirdquo-like model Secondly the activities in the process
IEEE 1 | P a g e
arX
iv1
606
0728
3v1
[cs
LG
] 2
3 Ju
n 20
16
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
Fig 2 A structured or rdquolasagnardquo-like process model
model might have too specific non-meaningful names Thirdas we show in section IV process discovery algorithms aresometimes not able to discover a process model that representsthe low-level event log well while being able to discover todiscover a representative process model from a correspondinghigh-level event log The problems mentioned illustrate theneed for a method to abstract too low-level event logs intohigher level event logs
Several methods have been explored within the processmining field that address the challenge of abstracting low-levelevents to higher level events ([7] [8] [9]) Existing event ab-straction methods rely on unsupervised learning techniques toabstract low-level into high-level events by clustering togethergroups of low-level events into one high-level event Howeverusing unsupervised learning introduces two new problemsFirst it is unclear how to label high-level events that areobtained by clustering low-level events Current techniquesrequire the user process analyst to provide high-level eventlabels themselves based on domain knowledge or generatelong labels by concatenating the labels of all low-level eventsincorporated in the cluster However long concatenated labelsquickly become unreadable for larger clusters and it is farfrom trivial for a user to come up with sensible labels man-ually In addition unsupervised learning approaches for eventabstraction give no guidance with respect to the desired level ofabstraction Many existing event abstraction methods containone or more parameters to control the degree in which eventsare clustered into higher level events Finding the right levelof abstraction providing meaningful results is often a matterof trial-and-error
In some cases training data with high-level target labelsof low-level events are available or can be obtained for asubset of the traces In many settings obtaining high-levelannotations for all traces in an event log is infeasible or tooexpensive Learning a supervised learning model on the set of
traces where high-level target labels are available and applyingthat model to other low-level traces where no high-level labelsare available allows us to build a high-level interpretation ofa low-level event log which can then be used as input forprocess mining techniques
In this paper we describe a method for supervised eventabstraction that enables process discovery from too fine-grained event logs This method can be applied to any eventlog where higher level training labels of low level eventsare available for a subset of the traces in the event log Westart by giving an overview of related work from the activityrecognition field in Section II In Section III we introduce basicconcepts and definitions used throughout the rest of the paperSection IV explains the problem of not being able to minerepresentative process models from low-level data in moredetail In Section V we describe a method to automaticallyretrieve a feature vector representation of an event that canbe used with supervised learning techniques making use ofcertain aspects of the XES standard definition for event logs[10] In the same section we describe a supervised learningmethod to map low-level events into target high-level eventsSections VI and VII respectively show the added value ofthe described supervised event abstraction method for processmining on a real life event log from a smart home environmentand on a synthetic log from a digital photocopier respectivelySection VIII concludes the paper
II RELATED WORK
Supervised event abstraction is an unexplored problem inprocess mining A related field is activity recognition withinthe field of ubiquitous computing Activity recognition focuseson the task of detecting human activity from either passivesensors [11] [12] wearable sensors [13] [14] or cameras [15]Activity recognition methods generally work on discrete timewindows over the time series of sensor values and aim to mapeach time window onto the correct type of human activityeg eating or sleeping Activity recognition methods can beclassified into probabilistic approaches [11] [12] [13] [14]and approaches based on ontology reasoning [16] [17] Thestrength of probabilistic system based approaches compared tomethods based on ontology reasoning is their ability to handlenoise uncertainty and incomplete in sensor data [16]
Tapia [12] was the first to explore supervised learningmethods to infer human activity from passive sensors usinga naive Bayes classifier More recently probabilistic graphicalmodels started to play an important role in the activity recog-nition field [11] [18] Van Kasteren et al [11] explored the useConditional Random Fields [19] and Hidden Markov Models[20] Van Kasteren and Krose [18] applied Bayesian Networks[21] on the activity recognition task Kim et al [22] foundHidden Markov Models to be incapable of capturing long-range or transitive dependencies between observations whichresults in difficulties recognizing multiple interacting activities(concurrent or interwoven) Conditional Random Fields do notposses these limitations
The main differences between existing work in activityrecognition and the approach presented in this paper are theinput data on which they can be applied and the generalityof the approach Activity recognition techniques consider the
IEEE 2 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
input data to be a multidimensional time series of the sensorvalues over time based on which time windows are mappedonto human activities An appropriate time window size isdetermined based on domain knowledge of the data set Insupervised event abstraction we aim for a generic method thatworks for all XES event logs in general A time windowbased approach contrasts with our aim for generality as nosingle time window size will be appropriate for all event logsFurthermore the durations of the events within a single eventlog might differ drastically (eg one event might take secondswhile another event takes months) in which case time windowbased approaches will either miss short events in case of largertime windows or resort to very large numbers of time windowsresulting in very long computational time Therefore we mapeach individual low-level event to a high-level event and donot use time windows In a smart home environment contextwith passive sensors each change in a binary sensor value canbe considered to be a low-level event
III PRELIMINARIES
In this section we introduce basic concepts used throughoutthe paper
We use the usual sequence definition and denote a se-quence by listing its elements eg we write 〈a1 a2 an〉for a (finite) sequence s 1 n rarr S of elements fromsome alphabet S where s(i) = ai for any i isin 1 n
A XES Event Logs
We use the XES standard definition of event logs anoverview of which is shown in Figure 3 XES defines anevent log as a set of traces which in itself is a sequence ofevents The log traces and events can all contain one or moreattributes which consist of a key and a value of a certaintype Event or trace attributes may be global which indicatesthat the attribute needs to be defined for each event or tracerespectively A log contains one or more classifiers which canbe seen as labeling functions on the events of a log defined onglobal event attributes Extensions define a set of attributes onlog trace or event level in such a way that the semanticsof these attributes are clearly defined One can view XESextensions as a specification of attributes that events tracesor event logs themselves frequently contain XES defines thefollowing standard extensions
Concept Specifies the generally understood nameof the eventtracelog (attribute rsquoCon-ceptnamersquo)
Lifecycle Specifies the lifecycle phase (attributersquoLifecycletransitionrsquo) that the event rep-resents in a transactional model of theirgenerating activity The Lifecycle exten-sion also specifies a standard transac-tional model for activities
Organizational Specifies three attributes forevents which identify the actorhaving caused the event (attributersquoOrganizationalresourcersquo) hisrole in the organization (attributersquoOrganizationalrolersquo) and the group ordepartment within the organization
Fig 3 XES event log meta-model as defined in [10]
where he is located (attributersquoOrganizationalgrouprsquo)
Time Specifies the date and time atwhich an event occurred (attributersquoTimetimestamprsquo)
Semantic Allows definition of an activity meta-model that specifies higher-level aggre-gate views on events (attribute rsquoSeman-ticmodelReferencersquo)
We introduce a special attribute of type String with key labelwhich represents a high-level version of the generally under-stood name of an event The concept name of a event is thenconsidered to be a low-level name of an event The Semanticextension closely resembles the label attribute however byspecifying relations between low-level and high-level eventsin a meta-model the Semantic extension assumes that allinstances of a low-level event type belong to the same high-level event type The label attribute specifies the high-levellabel for each event individually allowing for example onelow-level event of low-level type Dishes amp cups cabinet tobe of high-level type Taking medicine and another low-levelevent of the same type to be of high-level type Eating Notethat for some traces high-level annotations might be availablein which case its events contain the label attribute while othertraces might not be annotated High-level interpretations ofunannotated traces by inferring the label attribute based oninformation that is present in the annotated traces allow the useof unannotated traces for process discovery and conformancechecking on a high level
B Petri nets
A process modeling notation frequently used as output ofprocess discovery techniques is the Petri net Petri nets are
IEEE 3 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
directed bipartite graphs consisting of transitions and placesconnected by arcs Transitions represent activities while placesrepresent the status of the system before and after executionof a transition Labels are assigned to transitions to indicatethe type of activity that they represent A special label τ isused to represent invisible transitions which are only used forrouting purposes and do not represent any real activity
Definition 1 (Labeled Petri net) A labeled Petri net is atuple N = (P T FR `) where P is a finite set of places Tis a finite set of transitions such that P cap T = empty and F sube(P times T ) cup (T times P ) is a set of directed arcs called the flowrelation R is a finite set of labels representing event typeswith τ isin R is a label representing an invisible action and` T rarr R cup τ is a labeling function that assigns a label toeach transition
The state of a Petri net is defined wrt the state that aprocess instance can be in during its execution A state of aPetri net is captured by the marking of its places with tokens Ina given state each place is either empty or it contains a certainnumber of tokens A transition is enabled in a given markingif all places with an outgoing arc to this transitions containat least one token Once a transition fires (ie is executed)a token is removed from all places with outgoing arcs to thefiring transition and a token is put to all places with incomingarcs from the firing transition leading to a new state
Definition 2 (Marking Enabled transitions and Firing)A marked Petri net is a pair (NM) whereN = (P T F L `) is a labeled Petri net and whereM isin B(P ) denotes the marking of N For n isin (P cup T ) weuse bulln and nbull to denote the set of inputs and outputs of nrespectively Let C(s e) indicate the number of occurrences(count) of element e in multiset s A transition t isin T isenabled in a marking M of net N if forallp isin bullt C(Mp) gt 0An enabled transition t may fire removing one token fromeach of the input places bullt and producing one token for eachof the output places tbull
Figure 4 shows three Petri nets with the circles repre-senting places the squares representing transitions The blacksquares represent invisible transitions or τ transitions Placesannotated with an f belong to the final marking indicating thatthe process execution can terminate in this marking
The topmost Petri net in Figure 4 initially has one token inthe place p1 indicated by the dot Firing of silent transition t1takes the token from p1 and puts a token in both p2 and p3enabling both t2 and t3 When t2 fires it takes the token fromp2 and puts a token in p4 When t3 fires it takes the tokenfrom p3 and puts a token in p5 After t2 and t3 have bothfired resulting in a token in both p4 and p5 t4 is enabledExecuting t4 takes the token from both p4 and p5 and putsa token in p6 The f indicates that the process execution canstop in the marking consisting of this place Alternatively itcan fire t5 taking the token from p6 and placing a token in p2and p5 which allows for execution of MC and W to reach themarking consisting of p6 again We refer the interested readerto [23] for an extensive review of Petri nets
C Conditional Random Field
We view the recognition of high-level event labels asa sequence labeling task in which each event is classified
p1 t1
p2
p3
MC
t2
DCC
t3
p4
p5
W
t4
fp6
t5
Process of taking medicine
f
CDDCC
D
Process of eating
Taking Medicine
Eating
f
High-level process
Fig 4 A high-level process consisting of two unstructuredsubprocesses that overlap in event types
as one of the higher-level events from a high-level eventalphabet Conditional Random Fields (CRFs) [19] are a typeof probabilistic graphical model which has become popularin the fields of language processing and computer vision forthe task of sequence labeling A Conditional Random Fieldmodels the conditional probability distribution of the labelsequence given an observation sequence using a log-linearmodel We use Linear-chain Conditional Random Fields asubclass of Conditional Random Fields that has been widelyused for sequence labeling tasks which takes the followingform
p(y|x) = 1Z(x)exp(
sumt=1
sumk λkfk(t ytminus1 yt x))
where Z(x) is the normalization factor X = 〈x1 xn〉is an observation sequence Y = 〈y1 yn〉 is the associatedlabel sequence fk and λk respectively are feature functionsand their weights Feature functions which can be binaryor real valued are defined on the observations and are usedto compute label probabilities In contrast to Hidden MarkovModels [20] feature functions are not assumed to be mutuallyindependent
IV MOTIVATING EXAMPLE
Figure 4 shows on a simple example how a process can bestructured at a high level while this structure is not discoverablefrom a low-level log of this process The bottom right Petrinet shows the example process at a high-level The high-levelprocess model allows for any finite length alternating sequenceof Taking medicine and Eating activities The Taking medicinehigh-level activity is defined as a subprocess corresponding
IEEE 4 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
to the topmost Petri net which consists of low-level eventsMedicine cabinet (MC) Dishes amp cups cabinet (DCC) andWater (W) The Eating high-level event is also defined as asubprocess shown in the bottom left Petri net which consistsof low-level events Dishes amp cups cabinet (DCC) and Cutlerydrawer (CD) that can occur an arbitrary number of times inany order and low-level event Dishwasher (D) which occursexactly once but at an arbitrary point in the Eating process
When we apply the Inductive Miner process discoveryalgorithm [6] to low-level traces generated by the hierarchicalprocess of Figure 4 we obtain the process model shown inFigure 5 The obtained process model allows for almost all pos-sible sequences over the alphabet CDDDCCMCWas the only constraint introduced by the model is that DCCand D are required to be executed starting from the initialmarking to end up with the same marking Firing of allother transitions in the model can be skipped Behaviorallythis model is very close to the so called rdquoflowerrdquo model [1]the model that allows for all behavior over its alphabet Thealternating structure between Taking medicine and Eating thatwas present in the high-level process in Figure 4 cannot beobserved in the process model in Figure 5 This is caused byhigh variance in start and end events of the high-level eventsubprocesses of Taking medicine and Eating as well as by theoverlap in event types between these two subprocesses
When the event log would have consisted of the high-level Eating and Taking medicine events process discoverytechniques have no problems to discover the alternating struc-ture in the bottom right Petri net of Figure 4 To discoverthe high-level alternating structure from a low-level event logit is necessary to first abstract the events in the event logThrough supervised learning techniques the mapping fromlow-level events to high-level events can be learned fromexamples without requiring a hand-made ontology Similarapproaches have been explored in activity recognition in thefield of ubiquitous computing where low-level sensor signalsare mapped to high-level activities from a human behaviorperspective The input data in this setting are continuous timeseries from sensors Change points in these time series aretriggered by low-level activities like openingclosing the fridgedoor and the annotations of the higher level events (egcooking) are often obtained through manual activity diariesIn contrast to unsupervised event abstraction the annotationsin supervised event abstraction provide guidance on how tolabel higher level events and guidance for the target level ofabstraction
V EVENT ABSTRACTION AS A SEQUENCE LABELINGTASK
In this section we describe an approach to supervisedabstraction of events based on Conditional Random FieldsAdditionally we describe feature functions on XES event logsin a general way by using XES extensions Figure 6 providesa conceptual overview of the supervised event abstractionmethod The approach takes two inputs 1) a set of annotatedtraces which are traces where the high-level event that a low-level event belongs to (the label attribute of the low-levelevent) is known for all low-level events in the trace and 2)a set of unannotated traces which are traces where the low-level events are not mapped to high-level events Conditional
Fig 6 Conceptual overview of Supervised Event Abstraction
Random Fields are trained of the annotated traces to createa probabilistic mapping from low-level events to high-levelevents This mapping once obtained can be applied to theunannotated traces in order to estimate the correspondinghigh-level event for each low-level event (its label attribute)Often sequences of low-level events in the traces with high-level annotations will have the same label attribute We makethe working assumption that multiple high-level events areexecuted in parallel This enables us to interpret a sequenceof identical label attribute values as a single instance of ahigh-level event To obtain a true high-level log we collapsesequences of events with the same value for the label attributeinto two events with this value as concept name where thefirst event has a lifecycle rsquostartrsquo and the second has the lifecyclersquocompletersquo Table I illustrates this collapsing procedure throughan input and output event log
The method described in this section is implemented andavailable for use as a plugin for the ProM 6 [25] processmining toolkit and is based on the GRMM [26] implementationof Conditional Random Fields
We now show for each XES extension how it can be trans-lated into useful feature functions for event abstraction Notethat we do not limit ourselves to XES logs that contain all XESextensions when a log contains a subset of the extensions asubset of the feature functions will be available for the super-vised learning step This approach leads to a feature space ofunknown size potentially causing problems related to the curseof dimensionality therefore we use L1-regularized ConditionalRandom Fields L1 regularization causes the vector of featureweights to be sparse meaning that only a small fraction of thefeatures have a non-zero weight and are actually used by theprediction model Since the L1-norm is non-differentiable weuse OWL-QN [27] to optimize the model
A From a XES Log to a Feature Space
1) Concept extension The low-level labels of the preced-ing events in a trace can contain useful contextual informationfor high-level label classification Based on the n-gram of nlast-seen events in a trace we can calculate the probabilitythat the current event has a label l A multinoulli distributionis estimated for each n-gram of n consecutive events based
IEEE 5 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
Fig 5 Result of the Inductive Miner on the low-level traces reduced using Murata reduction rules [24]
TABLE I Left a trace with predicted high-level annotations (label) and Right the resulting high-level log after collapsingsubsequent identical label values
Case Timetimestamp Conceptname label
1 03112015 084523 Medicine cabinet Taking medicine1 03112015 084611 Dishes amp cups cabinet Taking medicine1 03112015 084645 Water Taking medicine1 03112015 084759 Dishes amp cups cabinet Eating1 03112015 084789 Dishwasher Eating1 03112015 171058 Dishes amp cups cabinet Taking medicine1 03112015 171069 Medicine cabinet Taking medicine1 03112015 171118 Water Taking medicine
Case Timetimestamp Conceptname Lifecycletransition
1 03112015 084523 Taking medicine Start1 03112015 084645 Taking medicine Complete1 03112015 084759 Eating Start1 03112015 084789 Eating Complete1 03112015 171058 Taking medicine Start1 03112015 171118 Taking medicine Complete
on the training data The Conditional Random Field modelrequires feature functions with numerical range A conceptextension based feature function with two parameters n andl is valued with the multinoulli-estimated probability of thecurrent event having high-level label l given the n-gram of thelast n low-level event labels
2) Organizational extension Similar to the concept exten-sion feature functions multinoulli distributions can be esti-mated on the training set for n-grams of resource role orgroup attributes of the last n events Likewise an organiza-tional extension based feature function with three parametersn-gram size n o isin resource role group and label l isvalued with the multinoulli-estimated probability of label lgiven the n-gram of the last n event resourcesrolesgroups
3) Time extension In terms of time there are severalpotentially existing patterns A certain high-level event mightfor example be concentrated in a certain parts of a day of aweek or of a month This concentration can however not bemodeled with a single Gaussian distribution as it might be thecase that a high-level event has high probability to occur inthe morning or in the evening but low probability to occurin the afternoon in-between Therefore we use a GaussianMixture Model (GMM) to model the probability of a high-levellabel l given the timestamp Bayesian Information Criterion(BIC) [28] is used to determine the number of componentsof the GMM which gives the model an incentive to notcombine more Gaussians in the mixture than needed A GMMis estimated on training data modeling the probabilities ofeach label based on the time passed since the start of the dayweek or month A time extension based feature function withtwo parameters t isin dayweekmonth and label l isvalued with the GMM-estimated probability of label l giventhe t view on the event timestamp
4) Lifecycle extension amp Time extension The XES stan-dard [10] defines several lifecycle stages of a process Whenan event log possesses both the lifecycle extension and the timeextension time differences can be calculated between differentstages of the life cycle of a single activity For a completeevent for example one could calculate the time differencewith the associated start event of the same activity Findingthe associated start event becomes nontrivial when multipleinstances of the same activity are in parallel as it is thenunknown which complete event belongs to which start eventWe assume consecutive lifecycle steps of activities running inparallel to occur in the same order as the preceding lifecyclestep For example when we observe two start events of anactivity of type A in a row followed by two complete eventsof type A we assume the first complete to belong to the firststart and the second complete to belong to the second start
We estimate a Gaussian Mixture Model (GMM) for eachtuple of two lifecycle steps for a certain activity on the timedifferences between those two lifecycle steps for this activityA feature based on both the lifecycle and the time extensionwith a label parameter l and lifecycle c is valued with theGMM-estimated probability of label l given the time betweenthe current event and lifecycle c Bayesian Information Cri-terion (BIC) [28] is again used to determine the number ofcomponents of the GMM
B Evaluating High-level Event Predictions for Process Min-ing Applications
Existing approaches in the field of activity recognition takeas input time windows where each time window is representedby a feature vector that describes the sensor activity or statusduring that time window Hence evaluation methods in theactivity recognition field are window-based using evaluationmetrics like the percentage of correctly classified time slices
IEEE 6 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
[12] [18] [11] There are two reasons to deviate from thisevaluation methodology in a process mining setting First ourmethod operates on events instead of time windows Secondthe accuracy of the resulting high level sequences is muchmore important for many process mining techniques (egprocess discovery conformance checking) than the accuracyof predicting each individual minute of the day
We use Levenshtein similarity that expresses the degreein which two traces are similar using a metric based onthe Levenshtein distance (also known as edit distance) [29]which is defined as Levenshtein similarity(a b) = 1 minusLevenshtein distance(ab)
max(|a||b|) The division of the Levenshtein dis-tance by max(|a| |b|) which is the worst case number of editoperations needed to transform any sequence of length |a| intoany sequence of length |b| causes the result to be a numberbetween 0 (completely different traces) and 1 (identical traces)
VI CASE STUDY 1 SMART HOME ENVIRONMENT
We use the smart home environment log described byVan Kasteren et al [11] to evaluate our supervised eventlog abstraction method The Van Kasteren log consists ofmultidimensional time series data with all dimensions binarywhere each binary dimension represents the state of an in-home sensor These sensors include motion sensors openclosesensors and power sensors (discretized to 01 states)
A Experimental setup
We transform the multidimensional time series data fromsensors into events by regarding each sensor change point asan event Cases are created by grouping events together thatoccurred in the same day with a cut-off point at midnightHigh-level labels are provided for the Van Kasteren data set
The generated event log based on the Van Kasteren dataset has the following XES extensions
Concept The sensor that generated the eventTime The time stamp of the sensor change pointLifecycle Start when the event represents a sensor value
change from 0 to 1 and Complete when itrepresents a sensor value change from 1 to0
Note that annotations are provided for all traces in theobtained event log To evaluate how well the supervisedevent abstraction method generalized to unannotated traces weartificially use a part of the traces to train the abstraction modeland apply them on a test set where we regard the annotationsto be non-existent We evaluate the obtained high-level labelsagainst the ground truth labels We use a variation on Leave-One-Out-Cross-Validation where we leave out one trace toevaluate how well this mapping generalizes to unseen eventsand cases
B Results
Figure 7a shows the result of the Inductive Miner [6] forthe low-level events in the Van Kasteren data set The resultingprocess model starts with many parallel activities that canbe executed in any order and contains many unobservabletransitions back This closely resembles the flower model
which allows for any behavior in any arbitrary order From theprocess model we can learn that toilet flush and cups cupboardfrequently co-exists Furthermore the process model indicatesthat groceries cupboard is often followed by dishwasherThere seems to be very little structure on this level of eventgranularity
The average Levenshtein similarity between the predictedhigh-level traces in the Leave-One-Trace-Out-Cross-Validationexperimental setup and the ground truth high-level traces is07042 which shows that the supervised event abstractionmethod produces traces which are fairly similar to the groundtruth
Figure 7b shows the result of the Inductive Miner on theaggregated set of predicted test traces Figure 7b shows thatthe process discovered at the high level of granularity is morestructured than the process discovered at the original levelof granularity (Figure 7a) In Figure 7b we can see that themain daily routine starts with breakfast followed by a showerafter which the subject leaves the house to go to work Afterwork the subject prepares dinner and has a drink The subjectmainstream behavior is to go to the toilet before going to bedbut he can then wake up later to go to the toilet and thencontinue sleeping Note that the day can also start with goingto bed This is related to the case cut-off point of a trace atmidnight Days when the subject went to bed after midnightresult in a case where going to bed occurs at the start of thetrace On these days the subject might have breakfast and thenperform the activity sequence use toilet take shower and leavehouse possibly multiple times Another possibility on dayswhen the subject went to bed after midnight is that he startsby using the toilet then has breakfast then has the possibilityto leave the house then takes a shower after which he alwaysleaves the house Prepare dinner activity is not performed onthese days
This case study shows that we can find a structured high-level process from a low-level event log where the low-levelprocess is unstructured using supervised event abstraction andprocess discovery
VII CASE STUDY 2 ARTIFICIAL DIGITAL PHOTOCOPIER
Bose et al [30] [31] created a synthetic event log based ona digital photocopier to evaluate his unsupervised methods ofevent abstraction In this case study we show that the describedsupervised event abstraction method can accurately abstract tohigh-level labels
A Experimental setup
We annotated each low-level event with the correct high-level event using domain knowledge from the actual processmodel as described by Bose et al [30] [31] This event logis generated by a hierarchical process where high-level eventsCapture Image Rasterize Image Image Processing and PrintImage are defined in terms of a process model The PrintImage subprocess amongst others contains the events WritingDeveloping and Fusing which are themselves defined as asubprocess In this case study we set the task to transformthe log such that subprocesses Capture Image Rasterize Im-age and Image Processing Writing Fusing and Developing
IEEE 7 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level events from the low-level Van Kasteren event log
(b) Inductive Miner result on the high-level events discovered from the low-level Van Kasteren event log
Fig 7 Comparison of process models discovered from the low-level and high-level van Kasteren event log
Subprocesses Writing and Developing both contain the low-level event types Drum Spin Start and Drum Spin Stop In thiscase study we focus in particular on the Drum Spin Start andDrum Spin Stop events as they make the abstraction task non-trivial in the sense that no one-to-one mapping from low-levelto high-level events exists
The artificial digital photocopier data set has the concepttime and lifecycle XES extensions On this event log anno-tations are available for all traces On this data set we use a10-Fold Cross-Validation setting on the traces to evaluate howwell the supervised event abstraction method abstracts low-
level events to high-level events on unannotated traces as thisdata set is larger than the Van Kasteren data set and Leave-One-Out-Cross Validation would take too much time
B Results
The confusion matrix in Table II shows the aggregatedresults of the mapping of low-level events Drum Spin Start andDrum Spin Stop to high-level events Developing and WritingThe results show that the supervised event abstraction methodis capable of detecting the many-to-many mappings betweenthe low-level and high-level labels as it maps these low-level
IEEE 8 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level Artificial Digital Photo Copier event log
(b) Inductive Miner result on the discovered high-level events on the Artificial Digital Photo Copier event log
Fig 8 Comparison of process models discovered from the low-level and high-level Artificial Digital Photo Copier event log
TABLE II Confusion matrix for classification of Drum SpinStart and Drum Spin Stop low-level events into high-levelevents Writing and Developing
Developing WritingDeveloping 6653 0Writing 0 917
events to the correct high-level event without making errorsThe Levenshtein similarity between the aggregated set of testfold high-level traces and the ground truth high-level traces isclose to perfect 09667
Figure 8a shows the process model obtained with theInductive Miner on the low-level events in the artificial digitalphotocopier dataset The two sections in the process modelthat are surrounded by dashed lines are examples of high-levelevents within the low-level process model Even though thelow-level process contains structure the size of the processmodel makes it hard to comprehend Figure 8b shows theprocess model obtained with the same process discoveryalgorithm on the aggregated high-level test traces of the 10-fold cross validation setting This model is in line with theofficial artificial digital photocopier model specification withthe Print Image subprocess unfolded as provided in [30][31] In contrast to the event abstraction method described byBose et al [31] which found the high-level events that matchspecification supervised event abstraction is also able to findsuitable event labels for the generated high-level events Thisallows us to discover human-readable process models on theabstracted events without performing manual labeling which
can be a tedious task and requires domain knowledge
Instead of event abstraction on the level of the event logunsupervised abstraction methods that work on the level of amodel (eg [32]) can also be applied to make large complexmodels more comprehensible Note that such methods also donot give guidance on how to label resulting transitions in theprocess model Furthermore such methods do not help in caseswhere the process on a low-level is unstructured like in thecase study as described in Section VI
This case study shows that supervised event abstractioncan help generating a comprehensible high-level process modelfrom a low-level event log when a low-level process modelwould be too large to be understandable
VIII CONCLUSION
In this paper we described a method to abstract events ina XES event log that is too low-level based on supervisedlearning The method consists of an approach to generate afeature representation of a XES event and of a ConditionalRandom Field based learning step An implementation of themethod described has been made available as a plugin to theProM 6 process mining toolkit We introduced an evaluationmetric for predicted high-level traces that is closer to processmining than time-window based methods that are often usedin the sequence labeling field Using a real life event logfrom a smart home domain we showed that supervised eventabstraction can be used to enable process discovery techniquesto generate high-level process insights even when processmodels discovered by process mining techniques on the orig-inal low-level events are unstructured Finally we showed on
IEEE 9 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e

SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
Fig 2 A structured or rdquolasagnardquo-like process model
model might have too specific non-meaningful names Thirdas we show in section IV process discovery algorithms aresometimes not able to discover a process model that representsthe low-level event log well while being able to discover todiscover a representative process model from a correspondinghigh-level event log The problems mentioned illustrate theneed for a method to abstract too low-level event logs intohigher level event logs
Several methods have been explored within the processmining field that address the challenge of abstracting low-levelevents to higher level events ([7] [8] [9]) Existing event ab-straction methods rely on unsupervised learning techniques toabstract low-level into high-level events by clustering togethergroups of low-level events into one high-level event Howeverusing unsupervised learning introduces two new problemsFirst it is unclear how to label high-level events that areobtained by clustering low-level events Current techniquesrequire the user process analyst to provide high-level eventlabels themselves based on domain knowledge or generatelong labels by concatenating the labels of all low-level eventsincorporated in the cluster However long concatenated labelsquickly become unreadable for larger clusters and it is farfrom trivial for a user to come up with sensible labels man-ually In addition unsupervised learning approaches for eventabstraction give no guidance with respect to the desired level ofabstraction Many existing event abstraction methods containone or more parameters to control the degree in which eventsare clustered into higher level events Finding the right levelof abstraction providing meaningful results is often a matterof trial-and-error
In some cases training data with high-level target labelsof low-level events are available or can be obtained for asubset of the traces In many settings obtaining high-levelannotations for all traces in an event log is infeasible or tooexpensive Learning a supervised learning model on the set of
traces where high-level target labels are available and applyingthat model to other low-level traces where no high-level labelsare available allows us to build a high-level interpretation ofa low-level event log which can then be used as input forprocess mining techniques
In this paper we describe a method for supervised eventabstraction that enables process discovery from too fine-grained event logs This method can be applied to any eventlog where higher level training labels of low level eventsare available for a subset of the traces in the event log Westart by giving an overview of related work from the activityrecognition field in Section II In Section III we introduce basicconcepts and definitions used throughout the rest of the paperSection IV explains the problem of not being able to minerepresentative process models from low-level data in moredetail In Section V we describe a method to automaticallyretrieve a feature vector representation of an event that canbe used with supervised learning techniques making use ofcertain aspects of the XES standard definition for event logs[10] In the same section we describe a supervised learningmethod to map low-level events into target high-level eventsSections VI and VII respectively show the added value ofthe described supervised event abstraction method for processmining on a real life event log from a smart home environmentand on a synthetic log from a digital photocopier respectivelySection VIII concludes the paper
II RELATED WORK
Supervised event abstraction is an unexplored problem inprocess mining A related field is activity recognition withinthe field of ubiquitous computing Activity recognition focuseson the task of detecting human activity from either passivesensors [11] [12] wearable sensors [13] [14] or cameras [15]Activity recognition methods generally work on discrete timewindows over the time series of sensor values and aim to mapeach time window onto the correct type of human activityeg eating or sleeping Activity recognition methods can beclassified into probabilistic approaches [11] [12] [13] [14]and approaches based on ontology reasoning [16] [17] Thestrength of probabilistic system based approaches compared tomethods based on ontology reasoning is their ability to handlenoise uncertainty and incomplete in sensor data [16]
Tapia [12] was the first to explore supervised learningmethods to infer human activity from passive sensors usinga naive Bayes classifier More recently probabilistic graphicalmodels started to play an important role in the activity recog-nition field [11] [18] Van Kasteren et al [11] explored the useConditional Random Fields [19] and Hidden Markov Models[20] Van Kasteren and Krose [18] applied Bayesian Networks[21] on the activity recognition task Kim et al [22] foundHidden Markov Models to be incapable of capturing long-range or transitive dependencies between observations whichresults in difficulties recognizing multiple interacting activities(concurrent or interwoven) Conditional Random Fields do notposses these limitations
The main differences between existing work in activityrecognition and the approach presented in this paper are theinput data on which they can be applied and the generalityof the approach Activity recognition techniques consider the
IEEE 2 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
input data to be a multidimensional time series of the sensorvalues over time based on which time windows are mappedonto human activities An appropriate time window size isdetermined based on domain knowledge of the data set Insupervised event abstraction we aim for a generic method thatworks for all XES event logs in general A time windowbased approach contrasts with our aim for generality as nosingle time window size will be appropriate for all event logsFurthermore the durations of the events within a single eventlog might differ drastically (eg one event might take secondswhile another event takes months) in which case time windowbased approaches will either miss short events in case of largertime windows or resort to very large numbers of time windowsresulting in very long computational time Therefore we mapeach individual low-level event to a high-level event and donot use time windows In a smart home environment contextwith passive sensors each change in a binary sensor value canbe considered to be a low-level event
III PRELIMINARIES
In this section we introduce basic concepts used throughoutthe paper
We use the usual sequence definition and denote a se-quence by listing its elements eg we write 〈a1 a2 an〉for a (finite) sequence s 1 n rarr S of elements fromsome alphabet S where s(i) = ai for any i isin 1 n
A XES Event Logs
We use the XES standard definition of event logs anoverview of which is shown in Figure 3 XES defines anevent log as a set of traces which in itself is a sequence ofevents The log traces and events can all contain one or moreattributes which consist of a key and a value of a certaintype Event or trace attributes may be global which indicatesthat the attribute needs to be defined for each event or tracerespectively A log contains one or more classifiers which canbe seen as labeling functions on the events of a log defined onglobal event attributes Extensions define a set of attributes onlog trace or event level in such a way that the semanticsof these attributes are clearly defined One can view XESextensions as a specification of attributes that events tracesor event logs themselves frequently contain XES defines thefollowing standard extensions
Concept Specifies the generally understood nameof the eventtracelog (attribute rsquoCon-ceptnamersquo)
Lifecycle Specifies the lifecycle phase (attributersquoLifecycletransitionrsquo) that the event rep-resents in a transactional model of theirgenerating activity The Lifecycle exten-sion also specifies a standard transac-tional model for activities
Organizational Specifies three attributes forevents which identify the actorhaving caused the event (attributersquoOrganizationalresourcersquo) hisrole in the organization (attributersquoOrganizationalrolersquo) and the group ordepartment within the organization
Fig 3 XES event log meta-model as defined in [10]
where he is located (attributersquoOrganizationalgrouprsquo)
Time Specifies the date and time atwhich an event occurred (attributersquoTimetimestamprsquo)
Semantic Allows definition of an activity meta-model that specifies higher-level aggre-gate views on events (attribute rsquoSeman-ticmodelReferencersquo)
We introduce a special attribute of type String with key labelwhich represents a high-level version of the generally under-stood name of an event The concept name of a event is thenconsidered to be a low-level name of an event The Semanticextension closely resembles the label attribute however byspecifying relations between low-level and high-level eventsin a meta-model the Semantic extension assumes that allinstances of a low-level event type belong to the same high-level event type The label attribute specifies the high-levellabel for each event individually allowing for example onelow-level event of low-level type Dishes amp cups cabinet tobe of high-level type Taking medicine and another low-levelevent of the same type to be of high-level type Eating Notethat for some traces high-level annotations might be availablein which case its events contain the label attribute while othertraces might not be annotated High-level interpretations ofunannotated traces by inferring the label attribute based oninformation that is present in the annotated traces allow the useof unannotated traces for process discovery and conformancechecking on a high level
B Petri nets
A process modeling notation frequently used as output ofprocess discovery techniques is the Petri net Petri nets are
IEEE 3 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
directed bipartite graphs consisting of transitions and placesconnected by arcs Transitions represent activities while placesrepresent the status of the system before and after executionof a transition Labels are assigned to transitions to indicatethe type of activity that they represent A special label τ isused to represent invisible transitions which are only used forrouting purposes and do not represent any real activity
Definition 1 (Labeled Petri net) A labeled Petri net is atuple N = (P T FR `) where P is a finite set of places Tis a finite set of transitions such that P cap T = empty and F sube(P times T ) cup (T times P ) is a set of directed arcs called the flowrelation R is a finite set of labels representing event typeswith τ isin R is a label representing an invisible action and` T rarr R cup τ is a labeling function that assigns a label toeach transition
The state of a Petri net is defined wrt the state that aprocess instance can be in during its execution A state of aPetri net is captured by the marking of its places with tokens Ina given state each place is either empty or it contains a certainnumber of tokens A transition is enabled in a given markingif all places with an outgoing arc to this transitions containat least one token Once a transition fires (ie is executed)a token is removed from all places with outgoing arcs to thefiring transition and a token is put to all places with incomingarcs from the firing transition leading to a new state
Definition 2 (Marking Enabled transitions and Firing)A marked Petri net is a pair (NM) whereN = (P T F L `) is a labeled Petri net and whereM isin B(P ) denotes the marking of N For n isin (P cup T ) weuse bulln and nbull to denote the set of inputs and outputs of nrespectively Let C(s e) indicate the number of occurrences(count) of element e in multiset s A transition t isin T isenabled in a marking M of net N if forallp isin bullt C(Mp) gt 0An enabled transition t may fire removing one token fromeach of the input places bullt and producing one token for eachof the output places tbull
Figure 4 shows three Petri nets with the circles repre-senting places the squares representing transitions The blacksquares represent invisible transitions or τ transitions Placesannotated with an f belong to the final marking indicating thatthe process execution can terminate in this marking
The topmost Petri net in Figure 4 initially has one token inthe place p1 indicated by the dot Firing of silent transition t1takes the token from p1 and puts a token in both p2 and p3enabling both t2 and t3 When t2 fires it takes the token fromp2 and puts a token in p4 When t3 fires it takes the tokenfrom p3 and puts a token in p5 After t2 and t3 have bothfired resulting in a token in both p4 and p5 t4 is enabledExecuting t4 takes the token from both p4 and p5 and putsa token in p6 The f indicates that the process execution canstop in the marking consisting of this place Alternatively itcan fire t5 taking the token from p6 and placing a token in p2and p5 which allows for execution of MC and W to reach themarking consisting of p6 again We refer the interested readerto [23] for an extensive review of Petri nets
C Conditional Random Field
We view the recognition of high-level event labels asa sequence labeling task in which each event is classified
p1 t1
p2
p3
MC
t2
DCC
t3
p4
p5
W
t4
fp6
t5
Process of taking medicine
f
CDDCC
D
Process of eating
Taking Medicine
Eating
f
High-level process
Fig 4 A high-level process consisting of two unstructuredsubprocesses that overlap in event types
as one of the higher-level events from a high-level eventalphabet Conditional Random Fields (CRFs) [19] are a typeof probabilistic graphical model which has become popularin the fields of language processing and computer vision forthe task of sequence labeling A Conditional Random Fieldmodels the conditional probability distribution of the labelsequence given an observation sequence using a log-linearmodel We use Linear-chain Conditional Random Fields asubclass of Conditional Random Fields that has been widelyused for sequence labeling tasks which takes the followingform
p(y|x) = 1Z(x)exp(
sumt=1
sumk λkfk(t ytminus1 yt x))
where Z(x) is the normalization factor X = 〈x1 xn〉is an observation sequence Y = 〈y1 yn〉 is the associatedlabel sequence fk and λk respectively are feature functionsand their weights Feature functions which can be binaryor real valued are defined on the observations and are usedto compute label probabilities In contrast to Hidden MarkovModels [20] feature functions are not assumed to be mutuallyindependent
IV MOTIVATING EXAMPLE
Figure 4 shows on a simple example how a process can bestructured at a high level while this structure is not discoverablefrom a low-level log of this process The bottom right Petrinet shows the example process at a high-level The high-levelprocess model allows for any finite length alternating sequenceof Taking medicine and Eating activities The Taking medicinehigh-level activity is defined as a subprocess corresponding
IEEE 4 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
to the topmost Petri net which consists of low-level eventsMedicine cabinet (MC) Dishes amp cups cabinet (DCC) andWater (W) The Eating high-level event is also defined as asubprocess shown in the bottom left Petri net which consistsof low-level events Dishes amp cups cabinet (DCC) and Cutlerydrawer (CD) that can occur an arbitrary number of times inany order and low-level event Dishwasher (D) which occursexactly once but at an arbitrary point in the Eating process
When we apply the Inductive Miner process discoveryalgorithm [6] to low-level traces generated by the hierarchicalprocess of Figure 4 we obtain the process model shown inFigure 5 The obtained process model allows for almost all pos-sible sequences over the alphabet CDDDCCMCWas the only constraint introduced by the model is that DCCand D are required to be executed starting from the initialmarking to end up with the same marking Firing of allother transitions in the model can be skipped Behaviorallythis model is very close to the so called rdquoflowerrdquo model [1]the model that allows for all behavior over its alphabet Thealternating structure between Taking medicine and Eating thatwas present in the high-level process in Figure 4 cannot beobserved in the process model in Figure 5 This is caused byhigh variance in start and end events of the high-level eventsubprocesses of Taking medicine and Eating as well as by theoverlap in event types between these two subprocesses
When the event log would have consisted of the high-level Eating and Taking medicine events process discoverytechniques have no problems to discover the alternating struc-ture in the bottom right Petri net of Figure 4 To discoverthe high-level alternating structure from a low-level event logit is necessary to first abstract the events in the event logThrough supervised learning techniques the mapping fromlow-level events to high-level events can be learned fromexamples without requiring a hand-made ontology Similarapproaches have been explored in activity recognition in thefield of ubiquitous computing where low-level sensor signalsare mapped to high-level activities from a human behaviorperspective The input data in this setting are continuous timeseries from sensors Change points in these time series aretriggered by low-level activities like openingclosing the fridgedoor and the annotations of the higher level events (egcooking) are often obtained through manual activity diariesIn contrast to unsupervised event abstraction the annotationsin supervised event abstraction provide guidance on how tolabel higher level events and guidance for the target level ofabstraction
V EVENT ABSTRACTION AS A SEQUENCE LABELINGTASK
In this section we describe an approach to supervisedabstraction of events based on Conditional Random FieldsAdditionally we describe feature functions on XES event logsin a general way by using XES extensions Figure 6 providesa conceptual overview of the supervised event abstractionmethod The approach takes two inputs 1) a set of annotatedtraces which are traces where the high-level event that a low-level event belongs to (the label attribute of the low-levelevent) is known for all low-level events in the trace and 2)a set of unannotated traces which are traces where the low-level events are not mapped to high-level events Conditional
Fig 6 Conceptual overview of Supervised Event Abstraction
Random Fields are trained of the annotated traces to createa probabilistic mapping from low-level events to high-levelevents This mapping once obtained can be applied to theunannotated traces in order to estimate the correspondinghigh-level event for each low-level event (its label attribute)Often sequences of low-level events in the traces with high-level annotations will have the same label attribute We makethe working assumption that multiple high-level events areexecuted in parallel This enables us to interpret a sequenceof identical label attribute values as a single instance of ahigh-level event To obtain a true high-level log we collapsesequences of events with the same value for the label attributeinto two events with this value as concept name where thefirst event has a lifecycle rsquostartrsquo and the second has the lifecyclersquocompletersquo Table I illustrates this collapsing procedure throughan input and output event log
The method described in this section is implemented andavailable for use as a plugin for the ProM 6 [25] processmining toolkit and is based on the GRMM [26] implementationof Conditional Random Fields
We now show for each XES extension how it can be trans-lated into useful feature functions for event abstraction Notethat we do not limit ourselves to XES logs that contain all XESextensions when a log contains a subset of the extensions asubset of the feature functions will be available for the super-vised learning step This approach leads to a feature space ofunknown size potentially causing problems related to the curseof dimensionality therefore we use L1-regularized ConditionalRandom Fields L1 regularization causes the vector of featureweights to be sparse meaning that only a small fraction of thefeatures have a non-zero weight and are actually used by theprediction model Since the L1-norm is non-differentiable weuse OWL-QN [27] to optimize the model
A From a XES Log to a Feature Space
1) Concept extension The low-level labels of the preced-ing events in a trace can contain useful contextual informationfor high-level label classification Based on the n-gram of nlast-seen events in a trace we can calculate the probabilitythat the current event has a label l A multinoulli distributionis estimated for each n-gram of n consecutive events based
IEEE 5 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
Fig 5 Result of the Inductive Miner on the low-level traces reduced using Murata reduction rules [24]
TABLE I Left a trace with predicted high-level annotations (label) and Right the resulting high-level log after collapsingsubsequent identical label values
Case Timetimestamp Conceptname label
1 03112015 084523 Medicine cabinet Taking medicine1 03112015 084611 Dishes amp cups cabinet Taking medicine1 03112015 084645 Water Taking medicine1 03112015 084759 Dishes amp cups cabinet Eating1 03112015 084789 Dishwasher Eating1 03112015 171058 Dishes amp cups cabinet Taking medicine1 03112015 171069 Medicine cabinet Taking medicine1 03112015 171118 Water Taking medicine
Case Timetimestamp Conceptname Lifecycletransition
1 03112015 084523 Taking medicine Start1 03112015 084645 Taking medicine Complete1 03112015 084759 Eating Start1 03112015 084789 Eating Complete1 03112015 171058 Taking medicine Start1 03112015 171118 Taking medicine Complete
on the training data The Conditional Random Field modelrequires feature functions with numerical range A conceptextension based feature function with two parameters n andl is valued with the multinoulli-estimated probability of thecurrent event having high-level label l given the n-gram of thelast n low-level event labels
2) Organizational extension Similar to the concept exten-sion feature functions multinoulli distributions can be esti-mated on the training set for n-grams of resource role orgroup attributes of the last n events Likewise an organiza-tional extension based feature function with three parametersn-gram size n o isin resource role group and label l isvalued with the multinoulli-estimated probability of label lgiven the n-gram of the last n event resourcesrolesgroups
3) Time extension In terms of time there are severalpotentially existing patterns A certain high-level event mightfor example be concentrated in a certain parts of a day of aweek or of a month This concentration can however not bemodeled with a single Gaussian distribution as it might be thecase that a high-level event has high probability to occur inthe morning or in the evening but low probability to occurin the afternoon in-between Therefore we use a GaussianMixture Model (GMM) to model the probability of a high-levellabel l given the timestamp Bayesian Information Criterion(BIC) [28] is used to determine the number of componentsof the GMM which gives the model an incentive to notcombine more Gaussians in the mixture than needed A GMMis estimated on training data modeling the probabilities ofeach label based on the time passed since the start of the dayweek or month A time extension based feature function withtwo parameters t isin dayweekmonth and label l isvalued with the GMM-estimated probability of label l giventhe t view on the event timestamp
4) Lifecycle extension amp Time extension The XES stan-dard [10] defines several lifecycle stages of a process Whenan event log possesses both the lifecycle extension and the timeextension time differences can be calculated between differentstages of the life cycle of a single activity For a completeevent for example one could calculate the time differencewith the associated start event of the same activity Findingthe associated start event becomes nontrivial when multipleinstances of the same activity are in parallel as it is thenunknown which complete event belongs to which start eventWe assume consecutive lifecycle steps of activities running inparallel to occur in the same order as the preceding lifecyclestep For example when we observe two start events of anactivity of type A in a row followed by two complete eventsof type A we assume the first complete to belong to the firststart and the second complete to belong to the second start
We estimate a Gaussian Mixture Model (GMM) for eachtuple of two lifecycle steps for a certain activity on the timedifferences between those two lifecycle steps for this activityA feature based on both the lifecycle and the time extensionwith a label parameter l and lifecycle c is valued with theGMM-estimated probability of label l given the time betweenthe current event and lifecycle c Bayesian Information Cri-terion (BIC) [28] is again used to determine the number ofcomponents of the GMM
B Evaluating High-level Event Predictions for Process Min-ing Applications
Existing approaches in the field of activity recognition takeas input time windows where each time window is representedby a feature vector that describes the sensor activity or statusduring that time window Hence evaluation methods in theactivity recognition field are window-based using evaluationmetrics like the percentage of correctly classified time slices
IEEE 6 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
[12] [18] [11] There are two reasons to deviate from thisevaluation methodology in a process mining setting First ourmethod operates on events instead of time windows Secondthe accuracy of the resulting high level sequences is muchmore important for many process mining techniques (egprocess discovery conformance checking) than the accuracyof predicting each individual minute of the day
We use Levenshtein similarity that expresses the degreein which two traces are similar using a metric based onthe Levenshtein distance (also known as edit distance) [29]which is defined as Levenshtein similarity(a b) = 1 minusLevenshtein distance(ab)
max(|a||b|) The division of the Levenshtein dis-tance by max(|a| |b|) which is the worst case number of editoperations needed to transform any sequence of length |a| intoany sequence of length |b| causes the result to be a numberbetween 0 (completely different traces) and 1 (identical traces)
VI CASE STUDY 1 SMART HOME ENVIRONMENT
We use the smart home environment log described byVan Kasteren et al [11] to evaluate our supervised eventlog abstraction method The Van Kasteren log consists ofmultidimensional time series data with all dimensions binarywhere each binary dimension represents the state of an in-home sensor These sensors include motion sensors openclosesensors and power sensors (discretized to 01 states)
A Experimental setup
We transform the multidimensional time series data fromsensors into events by regarding each sensor change point asan event Cases are created by grouping events together thatoccurred in the same day with a cut-off point at midnightHigh-level labels are provided for the Van Kasteren data set
The generated event log based on the Van Kasteren dataset has the following XES extensions
Concept The sensor that generated the eventTime The time stamp of the sensor change pointLifecycle Start when the event represents a sensor value
change from 0 to 1 and Complete when itrepresents a sensor value change from 1 to0
Note that annotations are provided for all traces in theobtained event log To evaluate how well the supervisedevent abstraction method generalized to unannotated traces weartificially use a part of the traces to train the abstraction modeland apply them on a test set where we regard the annotationsto be non-existent We evaluate the obtained high-level labelsagainst the ground truth labels We use a variation on Leave-One-Out-Cross-Validation where we leave out one trace toevaluate how well this mapping generalizes to unseen eventsand cases
B Results
Figure 7a shows the result of the Inductive Miner [6] forthe low-level events in the Van Kasteren data set The resultingprocess model starts with many parallel activities that canbe executed in any order and contains many unobservabletransitions back This closely resembles the flower model
which allows for any behavior in any arbitrary order From theprocess model we can learn that toilet flush and cups cupboardfrequently co-exists Furthermore the process model indicatesthat groceries cupboard is often followed by dishwasherThere seems to be very little structure on this level of eventgranularity
The average Levenshtein similarity between the predictedhigh-level traces in the Leave-One-Trace-Out-Cross-Validationexperimental setup and the ground truth high-level traces is07042 which shows that the supervised event abstractionmethod produces traces which are fairly similar to the groundtruth
Figure 7b shows the result of the Inductive Miner on theaggregated set of predicted test traces Figure 7b shows thatthe process discovered at the high level of granularity is morestructured than the process discovered at the original levelof granularity (Figure 7a) In Figure 7b we can see that themain daily routine starts with breakfast followed by a showerafter which the subject leaves the house to go to work Afterwork the subject prepares dinner and has a drink The subjectmainstream behavior is to go to the toilet before going to bedbut he can then wake up later to go to the toilet and thencontinue sleeping Note that the day can also start with goingto bed This is related to the case cut-off point of a trace atmidnight Days when the subject went to bed after midnightresult in a case where going to bed occurs at the start of thetrace On these days the subject might have breakfast and thenperform the activity sequence use toilet take shower and leavehouse possibly multiple times Another possibility on dayswhen the subject went to bed after midnight is that he startsby using the toilet then has breakfast then has the possibilityto leave the house then takes a shower after which he alwaysleaves the house Prepare dinner activity is not performed onthese days
This case study shows that we can find a structured high-level process from a low-level event log where the low-levelprocess is unstructured using supervised event abstraction andprocess discovery
VII CASE STUDY 2 ARTIFICIAL DIGITAL PHOTOCOPIER
Bose et al [30] [31] created a synthetic event log based ona digital photocopier to evaluate his unsupervised methods ofevent abstraction In this case study we show that the describedsupervised event abstraction method can accurately abstract tohigh-level labels
A Experimental setup
We annotated each low-level event with the correct high-level event using domain knowledge from the actual processmodel as described by Bose et al [30] [31] This event logis generated by a hierarchical process where high-level eventsCapture Image Rasterize Image Image Processing and PrintImage are defined in terms of a process model The PrintImage subprocess amongst others contains the events WritingDeveloping and Fusing which are themselves defined as asubprocess In this case study we set the task to transformthe log such that subprocesses Capture Image Rasterize Im-age and Image Processing Writing Fusing and Developing
IEEE 7 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level events from the low-level Van Kasteren event log
(b) Inductive Miner result on the high-level events discovered from the low-level Van Kasteren event log
Fig 7 Comparison of process models discovered from the low-level and high-level van Kasteren event log
Subprocesses Writing and Developing both contain the low-level event types Drum Spin Start and Drum Spin Stop In thiscase study we focus in particular on the Drum Spin Start andDrum Spin Stop events as they make the abstraction task non-trivial in the sense that no one-to-one mapping from low-levelto high-level events exists
The artificial digital photocopier data set has the concepttime and lifecycle XES extensions On this event log anno-tations are available for all traces On this data set we use a10-Fold Cross-Validation setting on the traces to evaluate howwell the supervised event abstraction method abstracts low-
level events to high-level events on unannotated traces as thisdata set is larger than the Van Kasteren data set and Leave-One-Out-Cross Validation would take too much time
B Results
The confusion matrix in Table II shows the aggregatedresults of the mapping of low-level events Drum Spin Start andDrum Spin Stop to high-level events Developing and WritingThe results show that the supervised event abstraction methodis capable of detecting the many-to-many mappings betweenthe low-level and high-level labels as it maps these low-level
IEEE 8 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level Artificial Digital Photo Copier event log
(b) Inductive Miner result on the discovered high-level events on the Artificial Digital Photo Copier event log
Fig 8 Comparison of process models discovered from the low-level and high-level Artificial Digital Photo Copier event log
TABLE II Confusion matrix for classification of Drum SpinStart and Drum Spin Stop low-level events into high-levelevents Writing and Developing
Developing WritingDeveloping 6653 0Writing 0 917
events to the correct high-level event without making errorsThe Levenshtein similarity between the aggregated set of testfold high-level traces and the ground truth high-level traces isclose to perfect 09667
Figure 8a shows the process model obtained with theInductive Miner on the low-level events in the artificial digitalphotocopier dataset The two sections in the process modelthat are surrounded by dashed lines are examples of high-levelevents within the low-level process model Even though thelow-level process contains structure the size of the processmodel makes it hard to comprehend Figure 8b shows theprocess model obtained with the same process discoveryalgorithm on the aggregated high-level test traces of the 10-fold cross validation setting This model is in line with theofficial artificial digital photocopier model specification withthe Print Image subprocess unfolded as provided in [30][31] In contrast to the event abstraction method described byBose et al [31] which found the high-level events that matchspecification supervised event abstraction is also able to findsuitable event labels for the generated high-level events Thisallows us to discover human-readable process models on theabstracted events without performing manual labeling which
can be a tedious task and requires domain knowledge
Instead of event abstraction on the level of the event logunsupervised abstraction methods that work on the level of amodel (eg [32]) can also be applied to make large complexmodels more comprehensible Note that such methods also donot give guidance on how to label resulting transitions in theprocess model Furthermore such methods do not help in caseswhere the process on a low-level is unstructured like in thecase study as described in Section VI
This case study shows that supervised event abstractioncan help generating a comprehensible high-level process modelfrom a low-level event log when a low-level process modelwould be too large to be understandable
VIII CONCLUSION
In this paper we described a method to abstract events ina XES event log that is too low-level based on supervisedlearning The method consists of an approach to generate afeature representation of a XES event and of a ConditionalRandom Field based learning step An implementation of themethod described has been made available as a plugin to theProM 6 process mining toolkit We introduced an evaluationmetric for predicted high-level traces that is closer to processmining than time-window based methods that are often usedin the sequence labeling field Using a real life event logfrom a smart home domain we showed that supervised eventabstraction can be used to enable process discovery techniquesto generate high-level process insights even when processmodels discovered by process mining techniques on the orig-inal low-level events are unstructured Finally we showed on
IEEE 9 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e

SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
input data to be a multidimensional time series of the sensorvalues over time based on which time windows are mappedonto human activities An appropriate time window size isdetermined based on domain knowledge of the data set Insupervised event abstraction we aim for a generic method thatworks for all XES event logs in general A time windowbased approach contrasts with our aim for generality as nosingle time window size will be appropriate for all event logsFurthermore the durations of the events within a single eventlog might differ drastically (eg one event might take secondswhile another event takes months) in which case time windowbased approaches will either miss short events in case of largertime windows or resort to very large numbers of time windowsresulting in very long computational time Therefore we mapeach individual low-level event to a high-level event and donot use time windows In a smart home environment contextwith passive sensors each change in a binary sensor value canbe considered to be a low-level event
III PRELIMINARIES
In this section we introduce basic concepts used throughoutthe paper
We use the usual sequence definition and denote a se-quence by listing its elements eg we write 〈a1 a2 an〉for a (finite) sequence s 1 n rarr S of elements fromsome alphabet S where s(i) = ai for any i isin 1 n
A XES Event Logs
We use the XES standard definition of event logs anoverview of which is shown in Figure 3 XES defines anevent log as a set of traces which in itself is a sequence ofevents The log traces and events can all contain one or moreattributes which consist of a key and a value of a certaintype Event or trace attributes may be global which indicatesthat the attribute needs to be defined for each event or tracerespectively A log contains one or more classifiers which canbe seen as labeling functions on the events of a log defined onglobal event attributes Extensions define a set of attributes onlog trace or event level in such a way that the semanticsof these attributes are clearly defined One can view XESextensions as a specification of attributes that events tracesor event logs themselves frequently contain XES defines thefollowing standard extensions
Concept Specifies the generally understood nameof the eventtracelog (attribute rsquoCon-ceptnamersquo)
Lifecycle Specifies the lifecycle phase (attributersquoLifecycletransitionrsquo) that the event rep-resents in a transactional model of theirgenerating activity The Lifecycle exten-sion also specifies a standard transac-tional model for activities
Organizational Specifies three attributes forevents which identify the actorhaving caused the event (attributersquoOrganizationalresourcersquo) hisrole in the organization (attributersquoOrganizationalrolersquo) and the group ordepartment within the organization
Fig 3 XES event log meta-model as defined in [10]
where he is located (attributersquoOrganizationalgrouprsquo)
Time Specifies the date and time atwhich an event occurred (attributersquoTimetimestamprsquo)
Semantic Allows definition of an activity meta-model that specifies higher-level aggre-gate views on events (attribute rsquoSeman-ticmodelReferencersquo)
We introduce a special attribute of type String with key labelwhich represents a high-level version of the generally under-stood name of an event The concept name of a event is thenconsidered to be a low-level name of an event The Semanticextension closely resembles the label attribute however byspecifying relations between low-level and high-level eventsin a meta-model the Semantic extension assumes that allinstances of a low-level event type belong to the same high-level event type The label attribute specifies the high-levellabel for each event individually allowing for example onelow-level event of low-level type Dishes amp cups cabinet tobe of high-level type Taking medicine and another low-levelevent of the same type to be of high-level type Eating Notethat for some traces high-level annotations might be availablein which case its events contain the label attribute while othertraces might not be annotated High-level interpretations ofunannotated traces by inferring the label attribute based oninformation that is present in the annotated traces allow the useof unannotated traces for process discovery and conformancechecking on a high level
B Petri nets
A process modeling notation frequently used as output ofprocess discovery techniques is the Petri net Petri nets are
IEEE 3 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
directed bipartite graphs consisting of transitions and placesconnected by arcs Transitions represent activities while placesrepresent the status of the system before and after executionof a transition Labels are assigned to transitions to indicatethe type of activity that they represent A special label τ isused to represent invisible transitions which are only used forrouting purposes and do not represent any real activity
Definition 1 (Labeled Petri net) A labeled Petri net is atuple N = (P T FR `) where P is a finite set of places Tis a finite set of transitions such that P cap T = empty and F sube(P times T ) cup (T times P ) is a set of directed arcs called the flowrelation R is a finite set of labels representing event typeswith τ isin R is a label representing an invisible action and` T rarr R cup τ is a labeling function that assigns a label toeach transition
The state of a Petri net is defined wrt the state that aprocess instance can be in during its execution A state of aPetri net is captured by the marking of its places with tokens Ina given state each place is either empty or it contains a certainnumber of tokens A transition is enabled in a given markingif all places with an outgoing arc to this transitions containat least one token Once a transition fires (ie is executed)a token is removed from all places with outgoing arcs to thefiring transition and a token is put to all places with incomingarcs from the firing transition leading to a new state
Definition 2 (Marking Enabled transitions and Firing)A marked Petri net is a pair (NM) whereN = (P T F L `) is a labeled Petri net and whereM isin B(P ) denotes the marking of N For n isin (P cup T ) weuse bulln and nbull to denote the set of inputs and outputs of nrespectively Let C(s e) indicate the number of occurrences(count) of element e in multiset s A transition t isin T isenabled in a marking M of net N if forallp isin bullt C(Mp) gt 0An enabled transition t may fire removing one token fromeach of the input places bullt and producing one token for eachof the output places tbull
Figure 4 shows three Petri nets with the circles repre-senting places the squares representing transitions The blacksquares represent invisible transitions or τ transitions Placesannotated with an f belong to the final marking indicating thatthe process execution can terminate in this marking
The topmost Petri net in Figure 4 initially has one token inthe place p1 indicated by the dot Firing of silent transition t1takes the token from p1 and puts a token in both p2 and p3enabling both t2 and t3 When t2 fires it takes the token fromp2 and puts a token in p4 When t3 fires it takes the tokenfrom p3 and puts a token in p5 After t2 and t3 have bothfired resulting in a token in both p4 and p5 t4 is enabledExecuting t4 takes the token from both p4 and p5 and putsa token in p6 The f indicates that the process execution canstop in the marking consisting of this place Alternatively itcan fire t5 taking the token from p6 and placing a token in p2and p5 which allows for execution of MC and W to reach themarking consisting of p6 again We refer the interested readerto [23] for an extensive review of Petri nets
C Conditional Random Field
We view the recognition of high-level event labels asa sequence labeling task in which each event is classified
p1 t1
p2
p3
MC
t2
DCC
t3
p4
p5
W
t4
fp6
t5
Process of taking medicine
f
CDDCC
D
Process of eating
Taking Medicine
Eating
f
High-level process
Fig 4 A high-level process consisting of two unstructuredsubprocesses that overlap in event types
as one of the higher-level events from a high-level eventalphabet Conditional Random Fields (CRFs) [19] are a typeof probabilistic graphical model which has become popularin the fields of language processing and computer vision forthe task of sequence labeling A Conditional Random Fieldmodels the conditional probability distribution of the labelsequence given an observation sequence using a log-linearmodel We use Linear-chain Conditional Random Fields asubclass of Conditional Random Fields that has been widelyused for sequence labeling tasks which takes the followingform
p(y|x) = 1Z(x)exp(
sumt=1
sumk λkfk(t ytminus1 yt x))
where Z(x) is the normalization factor X = 〈x1 xn〉is an observation sequence Y = 〈y1 yn〉 is the associatedlabel sequence fk and λk respectively are feature functionsand their weights Feature functions which can be binaryor real valued are defined on the observations and are usedto compute label probabilities In contrast to Hidden MarkovModels [20] feature functions are not assumed to be mutuallyindependent
IV MOTIVATING EXAMPLE
Figure 4 shows on a simple example how a process can bestructured at a high level while this structure is not discoverablefrom a low-level log of this process The bottom right Petrinet shows the example process at a high-level The high-levelprocess model allows for any finite length alternating sequenceof Taking medicine and Eating activities The Taking medicinehigh-level activity is defined as a subprocess corresponding
IEEE 4 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
to the topmost Petri net which consists of low-level eventsMedicine cabinet (MC) Dishes amp cups cabinet (DCC) andWater (W) The Eating high-level event is also defined as asubprocess shown in the bottom left Petri net which consistsof low-level events Dishes amp cups cabinet (DCC) and Cutlerydrawer (CD) that can occur an arbitrary number of times inany order and low-level event Dishwasher (D) which occursexactly once but at an arbitrary point in the Eating process
When we apply the Inductive Miner process discoveryalgorithm [6] to low-level traces generated by the hierarchicalprocess of Figure 4 we obtain the process model shown inFigure 5 The obtained process model allows for almost all pos-sible sequences over the alphabet CDDDCCMCWas the only constraint introduced by the model is that DCCand D are required to be executed starting from the initialmarking to end up with the same marking Firing of allother transitions in the model can be skipped Behaviorallythis model is very close to the so called rdquoflowerrdquo model [1]the model that allows for all behavior over its alphabet Thealternating structure between Taking medicine and Eating thatwas present in the high-level process in Figure 4 cannot beobserved in the process model in Figure 5 This is caused byhigh variance in start and end events of the high-level eventsubprocesses of Taking medicine and Eating as well as by theoverlap in event types between these two subprocesses
When the event log would have consisted of the high-level Eating and Taking medicine events process discoverytechniques have no problems to discover the alternating struc-ture in the bottom right Petri net of Figure 4 To discoverthe high-level alternating structure from a low-level event logit is necessary to first abstract the events in the event logThrough supervised learning techniques the mapping fromlow-level events to high-level events can be learned fromexamples without requiring a hand-made ontology Similarapproaches have been explored in activity recognition in thefield of ubiquitous computing where low-level sensor signalsare mapped to high-level activities from a human behaviorperspective The input data in this setting are continuous timeseries from sensors Change points in these time series aretriggered by low-level activities like openingclosing the fridgedoor and the annotations of the higher level events (egcooking) are often obtained through manual activity diariesIn contrast to unsupervised event abstraction the annotationsin supervised event abstraction provide guidance on how tolabel higher level events and guidance for the target level ofabstraction
V EVENT ABSTRACTION AS A SEQUENCE LABELINGTASK
In this section we describe an approach to supervisedabstraction of events based on Conditional Random FieldsAdditionally we describe feature functions on XES event logsin a general way by using XES extensions Figure 6 providesa conceptual overview of the supervised event abstractionmethod The approach takes two inputs 1) a set of annotatedtraces which are traces where the high-level event that a low-level event belongs to (the label attribute of the low-levelevent) is known for all low-level events in the trace and 2)a set of unannotated traces which are traces where the low-level events are not mapped to high-level events Conditional
Fig 6 Conceptual overview of Supervised Event Abstraction
Random Fields are trained of the annotated traces to createa probabilistic mapping from low-level events to high-levelevents This mapping once obtained can be applied to theunannotated traces in order to estimate the correspondinghigh-level event for each low-level event (its label attribute)Often sequences of low-level events in the traces with high-level annotations will have the same label attribute We makethe working assumption that multiple high-level events areexecuted in parallel This enables us to interpret a sequenceof identical label attribute values as a single instance of ahigh-level event To obtain a true high-level log we collapsesequences of events with the same value for the label attributeinto two events with this value as concept name where thefirst event has a lifecycle rsquostartrsquo and the second has the lifecyclersquocompletersquo Table I illustrates this collapsing procedure throughan input and output event log
The method described in this section is implemented andavailable for use as a plugin for the ProM 6 [25] processmining toolkit and is based on the GRMM [26] implementationof Conditional Random Fields
We now show for each XES extension how it can be trans-lated into useful feature functions for event abstraction Notethat we do not limit ourselves to XES logs that contain all XESextensions when a log contains a subset of the extensions asubset of the feature functions will be available for the super-vised learning step This approach leads to a feature space ofunknown size potentially causing problems related to the curseof dimensionality therefore we use L1-regularized ConditionalRandom Fields L1 regularization causes the vector of featureweights to be sparse meaning that only a small fraction of thefeatures have a non-zero weight and are actually used by theprediction model Since the L1-norm is non-differentiable weuse OWL-QN [27] to optimize the model
A From a XES Log to a Feature Space
1) Concept extension The low-level labels of the preced-ing events in a trace can contain useful contextual informationfor high-level label classification Based on the n-gram of nlast-seen events in a trace we can calculate the probabilitythat the current event has a label l A multinoulli distributionis estimated for each n-gram of n consecutive events based
IEEE 5 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
Fig 5 Result of the Inductive Miner on the low-level traces reduced using Murata reduction rules [24]
TABLE I Left a trace with predicted high-level annotations (label) and Right the resulting high-level log after collapsingsubsequent identical label values
Case Timetimestamp Conceptname label
1 03112015 084523 Medicine cabinet Taking medicine1 03112015 084611 Dishes amp cups cabinet Taking medicine1 03112015 084645 Water Taking medicine1 03112015 084759 Dishes amp cups cabinet Eating1 03112015 084789 Dishwasher Eating1 03112015 171058 Dishes amp cups cabinet Taking medicine1 03112015 171069 Medicine cabinet Taking medicine1 03112015 171118 Water Taking medicine
Case Timetimestamp Conceptname Lifecycletransition
1 03112015 084523 Taking medicine Start1 03112015 084645 Taking medicine Complete1 03112015 084759 Eating Start1 03112015 084789 Eating Complete1 03112015 171058 Taking medicine Start1 03112015 171118 Taking medicine Complete
on the training data The Conditional Random Field modelrequires feature functions with numerical range A conceptextension based feature function with two parameters n andl is valued with the multinoulli-estimated probability of thecurrent event having high-level label l given the n-gram of thelast n low-level event labels
2) Organizational extension Similar to the concept exten-sion feature functions multinoulli distributions can be esti-mated on the training set for n-grams of resource role orgroup attributes of the last n events Likewise an organiza-tional extension based feature function with three parametersn-gram size n o isin resource role group and label l isvalued with the multinoulli-estimated probability of label lgiven the n-gram of the last n event resourcesrolesgroups
3) Time extension In terms of time there are severalpotentially existing patterns A certain high-level event mightfor example be concentrated in a certain parts of a day of aweek or of a month This concentration can however not bemodeled with a single Gaussian distribution as it might be thecase that a high-level event has high probability to occur inthe morning or in the evening but low probability to occurin the afternoon in-between Therefore we use a GaussianMixture Model (GMM) to model the probability of a high-levellabel l given the timestamp Bayesian Information Criterion(BIC) [28] is used to determine the number of componentsof the GMM which gives the model an incentive to notcombine more Gaussians in the mixture than needed A GMMis estimated on training data modeling the probabilities ofeach label based on the time passed since the start of the dayweek or month A time extension based feature function withtwo parameters t isin dayweekmonth and label l isvalued with the GMM-estimated probability of label l giventhe t view on the event timestamp
4) Lifecycle extension amp Time extension The XES stan-dard [10] defines several lifecycle stages of a process Whenan event log possesses both the lifecycle extension and the timeextension time differences can be calculated between differentstages of the life cycle of a single activity For a completeevent for example one could calculate the time differencewith the associated start event of the same activity Findingthe associated start event becomes nontrivial when multipleinstances of the same activity are in parallel as it is thenunknown which complete event belongs to which start eventWe assume consecutive lifecycle steps of activities running inparallel to occur in the same order as the preceding lifecyclestep For example when we observe two start events of anactivity of type A in a row followed by two complete eventsof type A we assume the first complete to belong to the firststart and the second complete to belong to the second start
We estimate a Gaussian Mixture Model (GMM) for eachtuple of two lifecycle steps for a certain activity on the timedifferences between those two lifecycle steps for this activityA feature based on both the lifecycle and the time extensionwith a label parameter l and lifecycle c is valued with theGMM-estimated probability of label l given the time betweenthe current event and lifecycle c Bayesian Information Cri-terion (BIC) [28] is again used to determine the number ofcomponents of the GMM
B Evaluating High-level Event Predictions for Process Min-ing Applications
Existing approaches in the field of activity recognition takeas input time windows where each time window is representedby a feature vector that describes the sensor activity or statusduring that time window Hence evaluation methods in theactivity recognition field are window-based using evaluationmetrics like the percentage of correctly classified time slices
IEEE 6 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
[12] [18] [11] There are two reasons to deviate from thisevaluation methodology in a process mining setting First ourmethod operates on events instead of time windows Secondthe accuracy of the resulting high level sequences is muchmore important for many process mining techniques (egprocess discovery conformance checking) than the accuracyof predicting each individual minute of the day
We use Levenshtein similarity that expresses the degreein which two traces are similar using a metric based onthe Levenshtein distance (also known as edit distance) [29]which is defined as Levenshtein similarity(a b) = 1 minusLevenshtein distance(ab)
max(|a||b|) The division of the Levenshtein dis-tance by max(|a| |b|) which is the worst case number of editoperations needed to transform any sequence of length |a| intoany sequence of length |b| causes the result to be a numberbetween 0 (completely different traces) and 1 (identical traces)
VI CASE STUDY 1 SMART HOME ENVIRONMENT
We use the smart home environment log described byVan Kasteren et al [11] to evaluate our supervised eventlog abstraction method The Van Kasteren log consists ofmultidimensional time series data with all dimensions binarywhere each binary dimension represents the state of an in-home sensor These sensors include motion sensors openclosesensors and power sensors (discretized to 01 states)
A Experimental setup
We transform the multidimensional time series data fromsensors into events by regarding each sensor change point asan event Cases are created by grouping events together thatoccurred in the same day with a cut-off point at midnightHigh-level labels are provided for the Van Kasteren data set
The generated event log based on the Van Kasteren dataset has the following XES extensions
Concept The sensor that generated the eventTime The time stamp of the sensor change pointLifecycle Start when the event represents a sensor value
change from 0 to 1 and Complete when itrepresents a sensor value change from 1 to0
Note that annotations are provided for all traces in theobtained event log To evaluate how well the supervisedevent abstraction method generalized to unannotated traces weartificially use a part of the traces to train the abstraction modeland apply them on a test set where we regard the annotationsto be non-existent We evaluate the obtained high-level labelsagainst the ground truth labels We use a variation on Leave-One-Out-Cross-Validation where we leave out one trace toevaluate how well this mapping generalizes to unseen eventsand cases
B Results
Figure 7a shows the result of the Inductive Miner [6] forthe low-level events in the Van Kasteren data set The resultingprocess model starts with many parallel activities that canbe executed in any order and contains many unobservabletransitions back This closely resembles the flower model
which allows for any behavior in any arbitrary order From theprocess model we can learn that toilet flush and cups cupboardfrequently co-exists Furthermore the process model indicatesthat groceries cupboard is often followed by dishwasherThere seems to be very little structure on this level of eventgranularity
The average Levenshtein similarity between the predictedhigh-level traces in the Leave-One-Trace-Out-Cross-Validationexperimental setup and the ground truth high-level traces is07042 which shows that the supervised event abstractionmethod produces traces which are fairly similar to the groundtruth
Figure 7b shows the result of the Inductive Miner on theaggregated set of predicted test traces Figure 7b shows thatthe process discovered at the high level of granularity is morestructured than the process discovered at the original levelof granularity (Figure 7a) In Figure 7b we can see that themain daily routine starts with breakfast followed by a showerafter which the subject leaves the house to go to work Afterwork the subject prepares dinner and has a drink The subjectmainstream behavior is to go to the toilet before going to bedbut he can then wake up later to go to the toilet and thencontinue sleeping Note that the day can also start with goingto bed This is related to the case cut-off point of a trace atmidnight Days when the subject went to bed after midnightresult in a case where going to bed occurs at the start of thetrace On these days the subject might have breakfast and thenperform the activity sequence use toilet take shower and leavehouse possibly multiple times Another possibility on dayswhen the subject went to bed after midnight is that he startsby using the toilet then has breakfast then has the possibilityto leave the house then takes a shower after which he alwaysleaves the house Prepare dinner activity is not performed onthese days
This case study shows that we can find a structured high-level process from a low-level event log where the low-levelprocess is unstructured using supervised event abstraction andprocess discovery
VII CASE STUDY 2 ARTIFICIAL DIGITAL PHOTOCOPIER
Bose et al [30] [31] created a synthetic event log based ona digital photocopier to evaluate his unsupervised methods ofevent abstraction In this case study we show that the describedsupervised event abstraction method can accurately abstract tohigh-level labels
A Experimental setup
We annotated each low-level event with the correct high-level event using domain knowledge from the actual processmodel as described by Bose et al [30] [31] This event logis generated by a hierarchical process where high-level eventsCapture Image Rasterize Image Image Processing and PrintImage are defined in terms of a process model The PrintImage subprocess amongst others contains the events WritingDeveloping and Fusing which are themselves defined as asubprocess In this case study we set the task to transformthe log such that subprocesses Capture Image Rasterize Im-age and Image Processing Writing Fusing and Developing
IEEE 7 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level events from the low-level Van Kasteren event log
(b) Inductive Miner result on the high-level events discovered from the low-level Van Kasteren event log
Fig 7 Comparison of process models discovered from the low-level and high-level van Kasteren event log
Subprocesses Writing and Developing both contain the low-level event types Drum Spin Start and Drum Spin Stop In thiscase study we focus in particular on the Drum Spin Start andDrum Spin Stop events as they make the abstraction task non-trivial in the sense that no one-to-one mapping from low-levelto high-level events exists
The artificial digital photocopier data set has the concepttime and lifecycle XES extensions On this event log anno-tations are available for all traces On this data set we use a10-Fold Cross-Validation setting on the traces to evaluate howwell the supervised event abstraction method abstracts low-
level events to high-level events on unannotated traces as thisdata set is larger than the Van Kasteren data set and Leave-One-Out-Cross Validation would take too much time
B Results
The confusion matrix in Table II shows the aggregatedresults of the mapping of low-level events Drum Spin Start andDrum Spin Stop to high-level events Developing and WritingThe results show that the supervised event abstraction methodis capable of detecting the many-to-many mappings betweenthe low-level and high-level labels as it maps these low-level
IEEE 8 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level Artificial Digital Photo Copier event log
(b) Inductive Miner result on the discovered high-level events on the Artificial Digital Photo Copier event log
Fig 8 Comparison of process models discovered from the low-level and high-level Artificial Digital Photo Copier event log
TABLE II Confusion matrix for classification of Drum SpinStart and Drum Spin Stop low-level events into high-levelevents Writing and Developing
Developing WritingDeveloping 6653 0Writing 0 917
events to the correct high-level event without making errorsThe Levenshtein similarity between the aggregated set of testfold high-level traces and the ground truth high-level traces isclose to perfect 09667
Figure 8a shows the process model obtained with theInductive Miner on the low-level events in the artificial digitalphotocopier dataset The two sections in the process modelthat are surrounded by dashed lines are examples of high-levelevents within the low-level process model Even though thelow-level process contains structure the size of the processmodel makes it hard to comprehend Figure 8b shows theprocess model obtained with the same process discoveryalgorithm on the aggregated high-level test traces of the 10-fold cross validation setting This model is in line with theofficial artificial digital photocopier model specification withthe Print Image subprocess unfolded as provided in [30][31] In contrast to the event abstraction method described byBose et al [31] which found the high-level events that matchspecification supervised event abstraction is also able to findsuitable event labels for the generated high-level events Thisallows us to discover human-readable process models on theabstracted events without performing manual labeling which
can be a tedious task and requires domain knowledge
Instead of event abstraction on the level of the event logunsupervised abstraction methods that work on the level of amodel (eg [32]) can also be applied to make large complexmodels more comprehensible Note that such methods also donot give guidance on how to label resulting transitions in theprocess model Furthermore such methods do not help in caseswhere the process on a low-level is unstructured like in thecase study as described in Section VI
This case study shows that supervised event abstractioncan help generating a comprehensible high-level process modelfrom a low-level event log when a low-level process modelwould be too large to be understandable
VIII CONCLUSION
In this paper we described a method to abstract events ina XES event log that is too low-level based on supervisedlearning The method consists of an approach to generate afeature representation of a XES event and of a ConditionalRandom Field based learning step An implementation of themethod described has been made available as a plugin to theProM 6 process mining toolkit We introduced an evaluationmetric for predicted high-level traces that is closer to processmining than time-window based methods that are often usedin the sequence labeling field Using a real life event logfrom a smart home domain we showed that supervised eventabstraction can be used to enable process discovery techniquesto generate high-level process insights even when processmodels discovered by process mining techniques on the orig-inal low-level events are unstructured Finally we showed on
IEEE 9 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e

SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
directed bipartite graphs consisting of transitions and placesconnected by arcs Transitions represent activities while placesrepresent the status of the system before and after executionof a transition Labels are assigned to transitions to indicatethe type of activity that they represent A special label τ isused to represent invisible transitions which are only used forrouting purposes and do not represent any real activity
Definition 1 (Labeled Petri net) A labeled Petri net is atuple N = (P T FR `) where P is a finite set of places Tis a finite set of transitions such that P cap T = empty and F sube(P times T ) cup (T times P ) is a set of directed arcs called the flowrelation R is a finite set of labels representing event typeswith τ isin R is a label representing an invisible action and` T rarr R cup τ is a labeling function that assigns a label toeach transition
The state of a Petri net is defined wrt the state that aprocess instance can be in during its execution A state of aPetri net is captured by the marking of its places with tokens Ina given state each place is either empty or it contains a certainnumber of tokens A transition is enabled in a given markingif all places with an outgoing arc to this transitions containat least one token Once a transition fires (ie is executed)a token is removed from all places with outgoing arcs to thefiring transition and a token is put to all places with incomingarcs from the firing transition leading to a new state
Definition 2 (Marking Enabled transitions and Firing)A marked Petri net is a pair (NM) whereN = (P T F L `) is a labeled Petri net and whereM isin B(P ) denotes the marking of N For n isin (P cup T ) weuse bulln and nbull to denote the set of inputs and outputs of nrespectively Let C(s e) indicate the number of occurrences(count) of element e in multiset s A transition t isin T isenabled in a marking M of net N if forallp isin bullt C(Mp) gt 0An enabled transition t may fire removing one token fromeach of the input places bullt and producing one token for eachof the output places tbull
Figure 4 shows three Petri nets with the circles repre-senting places the squares representing transitions The blacksquares represent invisible transitions or τ transitions Placesannotated with an f belong to the final marking indicating thatthe process execution can terminate in this marking
The topmost Petri net in Figure 4 initially has one token inthe place p1 indicated by the dot Firing of silent transition t1takes the token from p1 and puts a token in both p2 and p3enabling both t2 and t3 When t2 fires it takes the token fromp2 and puts a token in p4 When t3 fires it takes the tokenfrom p3 and puts a token in p5 After t2 and t3 have bothfired resulting in a token in both p4 and p5 t4 is enabledExecuting t4 takes the token from both p4 and p5 and putsa token in p6 The f indicates that the process execution canstop in the marking consisting of this place Alternatively itcan fire t5 taking the token from p6 and placing a token in p2and p5 which allows for execution of MC and W to reach themarking consisting of p6 again We refer the interested readerto [23] for an extensive review of Petri nets
C Conditional Random Field
We view the recognition of high-level event labels asa sequence labeling task in which each event is classified
p1 t1
p2
p3
MC
t2
DCC
t3
p4
p5
W
t4
fp6
t5
Process of taking medicine
f
CDDCC
D
Process of eating
Taking Medicine
Eating
f
High-level process
Fig 4 A high-level process consisting of two unstructuredsubprocesses that overlap in event types
as one of the higher-level events from a high-level eventalphabet Conditional Random Fields (CRFs) [19] are a typeof probabilistic graphical model which has become popularin the fields of language processing and computer vision forthe task of sequence labeling A Conditional Random Fieldmodels the conditional probability distribution of the labelsequence given an observation sequence using a log-linearmodel We use Linear-chain Conditional Random Fields asubclass of Conditional Random Fields that has been widelyused for sequence labeling tasks which takes the followingform
p(y|x) = 1Z(x)exp(
sumt=1
sumk λkfk(t ytminus1 yt x))
where Z(x) is the normalization factor X = 〈x1 xn〉is an observation sequence Y = 〈y1 yn〉 is the associatedlabel sequence fk and λk respectively are feature functionsand their weights Feature functions which can be binaryor real valued are defined on the observations and are usedto compute label probabilities In contrast to Hidden MarkovModels [20] feature functions are not assumed to be mutuallyindependent
IV MOTIVATING EXAMPLE
Figure 4 shows on a simple example how a process can bestructured at a high level while this structure is not discoverablefrom a low-level log of this process The bottom right Petrinet shows the example process at a high-level The high-levelprocess model allows for any finite length alternating sequenceof Taking medicine and Eating activities The Taking medicinehigh-level activity is defined as a subprocess corresponding
IEEE 4 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
to the topmost Petri net which consists of low-level eventsMedicine cabinet (MC) Dishes amp cups cabinet (DCC) andWater (W) The Eating high-level event is also defined as asubprocess shown in the bottom left Petri net which consistsof low-level events Dishes amp cups cabinet (DCC) and Cutlerydrawer (CD) that can occur an arbitrary number of times inany order and low-level event Dishwasher (D) which occursexactly once but at an arbitrary point in the Eating process
When we apply the Inductive Miner process discoveryalgorithm [6] to low-level traces generated by the hierarchicalprocess of Figure 4 we obtain the process model shown inFigure 5 The obtained process model allows for almost all pos-sible sequences over the alphabet CDDDCCMCWas the only constraint introduced by the model is that DCCand D are required to be executed starting from the initialmarking to end up with the same marking Firing of allother transitions in the model can be skipped Behaviorallythis model is very close to the so called rdquoflowerrdquo model [1]the model that allows for all behavior over its alphabet Thealternating structure between Taking medicine and Eating thatwas present in the high-level process in Figure 4 cannot beobserved in the process model in Figure 5 This is caused byhigh variance in start and end events of the high-level eventsubprocesses of Taking medicine and Eating as well as by theoverlap in event types between these two subprocesses
When the event log would have consisted of the high-level Eating and Taking medicine events process discoverytechniques have no problems to discover the alternating struc-ture in the bottom right Petri net of Figure 4 To discoverthe high-level alternating structure from a low-level event logit is necessary to first abstract the events in the event logThrough supervised learning techniques the mapping fromlow-level events to high-level events can be learned fromexamples without requiring a hand-made ontology Similarapproaches have been explored in activity recognition in thefield of ubiquitous computing where low-level sensor signalsare mapped to high-level activities from a human behaviorperspective The input data in this setting are continuous timeseries from sensors Change points in these time series aretriggered by low-level activities like openingclosing the fridgedoor and the annotations of the higher level events (egcooking) are often obtained through manual activity diariesIn contrast to unsupervised event abstraction the annotationsin supervised event abstraction provide guidance on how tolabel higher level events and guidance for the target level ofabstraction
V EVENT ABSTRACTION AS A SEQUENCE LABELINGTASK
In this section we describe an approach to supervisedabstraction of events based on Conditional Random FieldsAdditionally we describe feature functions on XES event logsin a general way by using XES extensions Figure 6 providesa conceptual overview of the supervised event abstractionmethod The approach takes two inputs 1) a set of annotatedtraces which are traces where the high-level event that a low-level event belongs to (the label attribute of the low-levelevent) is known for all low-level events in the trace and 2)a set of unannotated traces which are traces where the low-level events are not mapped to high-level events Conditional
Fig 6 Conceptual overview of Supervised Event Abstraction
Random Fields are trained of the annotated traces to createa probabilistic mapping from low-level events to high-levelevents This mapping once obtained can be applied to theunannotated traces in order to estimate the correspondinghigh-level event for each low-level event (its label attribute)Often sequences of low-level events in the traces with high-level annotations will have the same label attribute We makethe working assumption that multiple high-level events areexecuted in parallel This enables us to interpret a sequenceof identical label attribute values as a single instance of ahigh-level event To obtain a true high-level log we collapsesequences of events with the same value for the label attributeinto two events with this value as concept name where thefirst event has a lifecycle rsquostartrsquo and the second has the lifecyclersquocompletersquo Table I illustrates this collapsing procedure throughan input and output event log
The method described in this section is implemented andavailable for use as a plugin for the ProM 6 [25] processmining toolkit and is based on the GRMM [26] implementationof Conditional Random Fields
We now show for each XES extension how it can be trans-lated into useful feature functions for event abstraction Notethat we do not limit ourselves to XES logs that contain all XESextensions when a log contains a subset of the extensions asubset of the feature functions will be available for the super-vised learning step This approach leads to a feature space ofunknown size potentially causing problems related to the curseof dimensionality therefore we use L1-regularized ConditionalRandom Fields L1 regularization causes the vector of featureweights to be sparse meaning that only a small fraction of thefeatures have a non-zero weight and are actually used by theprediction model Since the L1-norm is non-differentiable weuse OWL-QN [27] to optimize the model
A From a XES Log to a Feature Space
1) Concept extension The low-level labels of the preced-ing events in a trace can contain useful contextual informationfor high-level label classification Based on the n-gram of nlast-seen events in a trace we can calculate the probabilitythat the current event has a label l A multinoulli distributionis estimated for each n-gram of n consecutive events based
IEEE 5 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
Fig 5 Result of the Inductive Miner on the low-level traces reduced using Murata reduction rules [24]
TABLE I Left a trace with predicted high-level annotations (label) and Right the resulting high-level log after collapsingsubsequent identical label values
Case Timetimestamp Conceptname label
1 03112015 084523 Medicine cabinet Taking medicine1 03112015 084611 Dishes amp cups cabinet Taking medicine1 03112015 084645 Water Taking medicine1 03112015 084759 Dishes amp cups cabinet Eating1 03112015 084789 Dishwasher Eating1 03112015 171058 Dishes amp cups cabinet Taking medicine1 03112015 171069 Medicine cabinet Taking medicine1 03112015 171118 Water Taking medicine
Case Timetimestamp Conceptname Lifecycletransition
1 03112015 084523 Taking medicine Start1 03112015 084645 Taking medicine Complete1 03112015 084759 Eating Start1 03112015 084789 Eating Complete1 03112015 171058 Taking medicine Start1 03112015 171118 Taking medicine Complete
on the training data The Conditional Random Field modelrequires feature functions with numerical range A conceptextension based feature function with two parameters n andl is valued with the multinoulli-estimated probability of thecurrent event having high-level label l given the n-gram of thelast n low-level event labels
2) Organizational extension Similar to the concept exten-sion feature functions multinoulli distributions can be esti-mated on the training set for n-grams of resource role orgroup attributes of the last n events Likewise an organiza-tional extension based feature function with three parametersn-gram size n o isin resource role group and label l isvalued with the multinoulli-estimated probability of label lgiven the n-gram of the last n event resourcesrolesgroups
3) Time extension In terms of time there are severalpotentially existing patterns A certain high-level event mightfor example be concentrated in a certain parts of a day of aweek or of a month This concentration can however not bemodeled with a single Gaussian distribution as it might be thecase that a high-level event has high probability to occur inthe morning or in the evening but low probability to occurin the afternoon in-between Therefore we use a GaussianMixture Model (GMM) to model the probability of a high-levellabel l given the timestamp Bayesian Information Criterion(BIC) [28] is used to determine the number of componentsof the GMM which gives the model an incentive to notcombine more Gaussians in the mixture than needed A GMMis estimated on training data modeling the probabilities ofeach label based on the time passed since the start of the dayweek or month A time extension based feature function withtwo parameters t isin dayweekmonth and label l isvalued with the GMM-estimated probability of label l giventhe t view on the event timestamp
4) Lifecycle extension amp Time extension The XES stan-dard [10] defines several lifecycle stages of a process Whenan event log possesses both the lifecycle extension and the timeextension time differences can be calculated between differentstages of the life cycle of a single activity For a completeevent for example one could calculate the time differencewith the associated start event of the same activity Findingthe associated start event becomes nontrivial when multipleinstances of the same activity are in parallel as it is thenunknown which complete event belongs to which start eventWe assume consecutive lifecycle steps of activities running inparallel to occur in the same order as the preceding lifecyclestep For example when we observe two start events of anactivity of type A in a row followed by two complete eventsof type A we assume the first complete to belong to the firststart and the second complete to belong to the second start
We estimate a Gaussian Mixture Model (GMM) for eachtuple of two lifecycle steps for a certain activity on the timedifferences between those two lifecycle steps for this activityA feature based on both the lifecycle and the time extensionwith a label parameter l and lifecycle c is valued with theGMM-estimated probability of label l given the time betweenthe current event and lifecycle c Bayesian Information Cri-terion (BIC) [28] is again used to determine the number ofcomponents of the GMM
B Evaluating High-level Event Predictions for Process Min-ing Applications
Existing approaches in the field of activity recognition takeas input time windows where each time window is representedby a feature vector that describes the sensor activity or statusduring that time window Hence evaluation methods in theactivity recognition field are window-based using evaluationmetrics like the percentage of correctly classified time slices
IEEE 6 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
[12] [18] [11] There are two reasons to deviate from thisevaluation methodology in a process mining setting First ourmethod operates on events instead of time windows Secondthe accuracy of the resulting high level sequences is muchmore important for many process mining techniques (egprocess discovery conformance checking) than the accuracyof predicting each individual minute of the day
We use Levenshtein similarity that expresses the degreein which two traces are similar using a metric based onthe Levenshtein distance (also known as edit distance) [29]which is defined as Levenshtein similarity(a b) = 1 minusLevenshtein distance(ab)
max(|a||b|) The division of the Levenshtein dis-tance by max(|a| |b|) which is the worst case number of editoperations needed to transform any sequence of length |a| intoany sequence of length |b| causes the result to be a numberbetween 0 (completely different traces) and 1 (identical traces)
VI CASE STUDY 1 SMART HOME ENVIRONMENT
We use the smart home environment log described byVan Kasteren et al [11] to evaluate our supervised eventlog abstraction method The Van Kasteren log consists ofmultidimensional time series data with all dimensions binarywhere each binary dimension represents the state of an in-home sensor These sensors include motion sensors openclosesensors and power sensors (discretized to 01 states)
A Experimental setup
We transform the multidimensional time series data fromsensors into events by regarding each sensor change point asan event Cases are created by grouping events together thatoccurred in the same day with a cut-off point at midnightHigh-level labels are provided for the Van Kasteren data set
The generated event log based on the Van Kasteren dataset has the following XES extensions
Concept The sensor that generated the eventTime The time stamp of the sensor change pointLifecycle Start when the event represents a sensor value
change from 0 to 1 and Complete when itrepresents a sensor value change from 1 to0
Note that annotations are provided for all traces in theobtained event log To evaluate how well the supervisedevent abstraction method generalized to unannotated traces weartificially use a part of the traces to train the abstraction modeland apply them on a test set where we regard the annotationsto be non-existent We evaluate the obtained high-level labelsagainst the ground truth labels We use a variation on Leave-One-Out-Cross-Validation where we leave out one trace toevaluate how well this mapping generalizes to unseen eventsand cases
B Results
Figure 7a shows the result of the Inductive Miner [6] forthe low-level events in the Van Kasteren data set The resultingprocess model starts with many parallel activities that canbe executed in any order and contains many unobservabletransitions back This closely resembles the flower model
which allows for any behavior in any arbitrary order From theprocess model we can learn that toilet flush and cups cupboardfrequently co-exists Furthermore the process model indicatesthat groceries cupboard is often followed by dishwasherThere seems to be very little structure on this level of eventgranularity
The average Levenshtein similarity between the predictedhigh-level traces in the Leave-One-Trace-Out-Cross-Validationexperimental setup and the ground truth high-level traces is07042 which shows that the supervised event abstractionmethod produces traces which are fairly similar to the groundtruth
Figure 7b shows the result of the Inductive Miner on theaggregated set of predicted test traces Figure 7b shows thatthe process discovered at the high level of granularity is morestructured than the process discovered at the original levelof granularity (Figure 7a) In Figure 7b we can see that themain daily routine starts with breakfast followed by a showerafter which the subject leaves the house to go to work Afterwork the subject prepares dinner and has a drink The subjectmainstream behavior is to go to the toilet before going to bedbut he can then wake up later to go to the toilet and thencontinue sleeping Note that the day can also start with goingto bed This is related to the case cut-off point of a trace atmidnight Days when the subject went to bed after midnightresult in a case where going to bed occurs at the start of thetrace On these days the subject might have breakfast and thenperform the activity sequence use toilet take shower and leavehouse possibly multiple times Another possibility on dayswhen the subject went to bed after midnight is that he startsby using the toilet then has breakfast then has the possibilityto leave the house then takes a shower after which he alwaysleaves the house Prepare dinner activity is not performed onthese days
This case study shows that we can find a structured high-level process from a low-level event log where the low-levelprocess is unstructured using supervised event abstraction andprocess discovery
VII CASE STUDY 2 ARTIFICIAL DIGITAL PHOTOCOPIER
Bose et al [30] [31] created a synthetic event log based ona digital photocopier to evaluate his unsupervised methods ofevent abstraction In this case study we show that the describedsupervised event abstraction method can accurately abstract tohigh-level labels
A Experimental setup
We annotated each low-level event with the correct high-level event using domain knowledge from the actual processmodel as described by Bose et al [30] [31] This event logis generated by a hierarchical process where high-level eventsCapture Image Rasterize Image Image Processing and PrintImage are defined in terms of a process model The PrintImage subprocess amongst others contains the events WritingDeveloping and Fusing which are themselves defined as asubprocess In this case study we set the task to transformthe log such that subprocesses Capture Image Rasterize Im-age and Image Processing Writing Fusing and Developing
IEEE 7 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level events from the low-level Van Kasteren event log
(b) Inductive Miner result on the high-level events discovered from the low-level Van Kasteren event log
Fig 7 Comparison of process models discovered from the low-level and high-level van Kasteren event log
Subprocesses Writing and Developing both contain the low-level event types Drum Spin Start and Drum Spin Stop In thiscase study we focus in particular on the Drum Spin Start andDrum Spin Stop events as they make the abstraction task non-trivial in the sense that no one-to-one mapping from low-levelto high-level events exists
The artificial digital photocopier data set has the concepttime and lifecycle XES extensions On this event log anno-tations are available for all traces On this data set we use a10-Fold Cross-Validation setting on the traces to evaluate howwell the supervised event abstraction method abstracts low-
level events to high-level events on unannotated traces as thisdata set is larger than the Van Kasteren data set and Leave-One-Out-Cross Validation would take too much time
B Results
The confusion matrix in Table II shows the aggregatedresults of the mapping of low-level events Drum Spin Start andDrum Spin Stop to high-level events Developing and WritingThe results show that the supervised event abstraction methodis capable of detecting the many-to-many mappings betweenthe low-level and high-level labels as it maps these low-level
IEEE 8 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level Artificial Digital Photo Copier event log
(b) Inductive Miner result on the discovered high-level events on the Artificial Digital Photo Copier event log
Fig 8 Comparison of process models discovered from the low-level and high-level Artificial Digital Photo Copier event log
TABLE II Confusion matrix for classification of Drum SpinStart and Drum Spin Stop low-level events into high-levelevents Writing and Developing
Developing WritingDeveloping 6653 0Writing 0 917
events to the correct high-level event without making errorsThe Levenshtein similarity between the aggregated set of testfold high-level traces and the ground truth high-level traces isclose to perfect 09667
Figure 8a shows the process model obtained with theInductive Miner on the low-level events in the artificial digitalphotocopier dataset The two sections in the process modelthat are surrounded by dashed lines are examples of high-levelevents within the low-level process model Even though thelow-level process contains structure the size of the processmodel makes it hard to comprehend Figure 8b shows theprocess model obtained with the same process discoveryalgorithm on the aggregated high-level test traces of the 10-fold cross validation setting This model is in line with theofficial artificial digital photocopier model specification withthe Print Image subprocess unfolded as provided in [30][31] In contrast to the event abstraction method described byBose et al [31] which found the high-level events that matchspecification supervised event abstraction is also able to findsuitable event labels for the generated high-level events Thisallows us to discover human-readable process models on theabstracted events without performing manual labeling which
can be a tedious task and requires domain knowledge
Instead of event abstraction on the level of the event logunsupervised abstraction methods that work on the level of amodel (eg [32]) can also be applied to make large complexmodels more comprehensible Note that such methods also donot give guidance on how to label resulting transitions in theprocess model Furthermore such methods do not help in caseswhere the process on a low-level is unstructured like in thecase study as described in Section VI
This case study shows that supervised event abstractioncan help generating a comprehensible high-level process modelfrom a low-level event log when a low-level process modelwould be too large to be understandable
VIII CONCLUSION
In this paper we described a method to abstract events ina XES event log that is too low-level based on supervisedlearning The method consists of an approach to generate afeature representation of a XES event and of a ConditionalRandom Field based learning step An implementation of themethod described has been made available as a plugin to theProM 6 process mining toolkit We introduced an evaluationmetric for predicted high-level traces that is closer to processmining than time-window based methods that are often usedin the sequence labeling field Using a real life event logfrom a smart home domain we showed that supervised eventabstraction can be used to enable process discovery techniquesto generate high-level process insights even when processmodels discovered by process mining techniques on the orig-inal low-level events are unstructured Finally we showed on
IEEE 9 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e

SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
to the topmost Petri net which consists of low-level eventsMedicine cabinet (MC) Dishes amp cups cabinet (DCC) andWater (W) The Eating high-level event is also defined as asubprocess shown in the bottom left Petri net which consistsof low-level events Dishes amp cups cabinet (DCC) and Cutlerydrawer (CD) that can occur an arbitrary number of times inany order and low-level event Dishwasher (D) which occursexactly once but at an arbitrary point in the Eating process
When we apply the Inductive Miner process discoveryalgorithm [6] to low-level traces generated by the hierarchicalprocess of Figure 4 we obtain the process model shown inFigure 5 The obtained process model allows for almost all pos-sible sequences over the alphabet CDDDCCMCWas the only constraint introduced by the model is that DCCand D are required to be executed starting from the initialmarking to end up with the same marking Firing of allother transitions in the model can be skipped Behaviorallythis model is very close to the so called rdquoflowerrdquo model [1]the model that allows for all behavior over its alphabet Thealternating structure between Taking medicine and Eating thatwas present in the high-level process in Figure 4 cannot beobserved in the process model in Figure 5 This is caused byhigh variance in start and end events of the high-level eventsubprocesses of Taking medicine and Eating as well as by theoverlap in event types between these two subprocesses
When the event log would have consisted of the high-level Eating and Taking medicine events process discoverytechniques have no problems to discover the alternating struc-ture in the bottom right Petri net of Figure 4 To discoverthe high-level alternating structure from a low-level event logit is necessary to first abstract the events in the event logThrough supervised learning techniques the mapping fromlow-level events to high-level events can be learned fromexamples without requiring a hand-made ontology Similarapproaches have been explored in activity recognition in thefield of ubiquitous computing where low-level sensor signalsare mapped to high-level activities from a human behaviorperspective The input data in this setting are continuous timeseries from sensors Change points in these time series aretriggered by low-level activities like openingclosing the fridgedoor and the annotations of the higher level events (egcooking) are often obtained through manual activity diariesIn contrast to unsupervised event abstraction the annotationsin supervised event abstraction provide guidance on how tolabel higher level events and guidance for the target level ofabstraction
V EVENT ABSTRACTION AS A SEQUENCE LABELINGTASK
In this section we describe an approach to supervisedabstraction of events based on Conditional Random FieldsAdditionally we describe feature functions on XES event logsin a general way by using XES extensions Figure 6 providesa conceptual overview of the supervised event abstractionmethod The approach takes two inputs 1) a set of annotatedtraces which are traces where the high-level event that a low-level event belongs to (the label attribute of the low-levelevent) is known for all low-level events in the trace and 2)a set of unannotated traces which are traces where the low-level events are not mapped to high-level events Conditional
Fig 6 Conceptual overview of Supervised Event Abstraction
Random Fields are trained of the annotated traces to createa probabilistic mapping from low-level events to high-levelevents This mapping once obtained can be applied to theunannotated traces in order to estimate the correspondinghigh-level event for each low-level event (its label attribute)Often sequences of low-level events in the traces with high-level annotations will have the same label attribute We makethe working assumption that multiple high-level events areexecuted in parallel This enables us to interpret a sequenceof identical label attribute values as a single instance of ahigh-level event To obtain a true high-level log we collapsesequences of events with the same value for the label attributeinto two events with this value as concept name where thefirst event has a lifecycle rsquostartrsquo and the second has the lifecyclersquocompletersquo Table I illustrates this collapsing procedure throughan input and output event log
The method described in this section is implemented andavailable for use as a plugin for the ProM 6 [25] processmining toolkit and is based on the GRMM [26] implementationof Conditional Random Fields
We now show for each XES extension how it can be trans-lated into useful feature functions for event abstraction Notethat we do not limit ourselves to XES logs that contain all XESextensions when a log contains a subset of the extensions asubset of the feature functions will be available for the super-vised learning step This approach leads to a feature space ofunknown size potentially causing problems related to the curseof dimensionality therefore we use L1-regularized ConditionalRandom Fields L1 regularization causes the vector of featureweights to be sparse meaning that only a small fraction of thefeatures have a non-zero weight and are actually used by theprediction model Since the L1-norm is non-differentiable weuse OWL-QN [27] to optimize the model
A From a XES Log to a Feature Space
1) Concept extension The low-level labels of the preced-ing events in a trace can contain useful contextual informationfor high-level label classification Based on the n-gram of nlast-seen events in a trace we can calculate the probabilitythat the current event has a label l A multinoulli distributionis estimated for each n-gram of n consecutive events based
IEEE 5 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
Fig 5 Result of the Inductive Miner on the low-level traces reduced using Murata reduction rules [24]
TABLE I Left a trace with predicted high-level annotations (label) and Right the resulting high-level log after collapsingsubsequent identical label values
Case Timetimestamp Conceptname label
1 03112015 084523 Medicine cabinet Taking medicine1 03112015 084611 Dishes amp cups cabinet Taking medicine1 03112015 084645 Water Taking medicine1 03112015 084759 Dishes amp cups cabinet Eating1 03112015 084789 Dishwasher Eating1 03112015 171058 Dishes amp cups cabinet Taking medicine1 03112015 171069 Medicine cabinet Taking medicine1 03112015 171118 Water Taking medicine
Case Timetimestamp Conceptname Lifecycletransition
1 03112015 084523 Taking medicine Start1 03112015 084645 Taking medicine Complete1 03112015 084759 Eating Start1 03112015 084789 Eating Complete1 03112015 171058 Taking medicine Start1 03112015 171118 Taking medicine Complete
on the training data The Conditional Random Field modelrequires feature functions with numerical range A conceptextension based feature function with two parameters n andl is valued with the multinoulli-estimated probability of thecurrent event having high-level label l given the n-gram of thelast n low-level event labels
2) Organizational extension Similar to the concept exten-sion feature functions multinoulli distributions can be esti-mated on the training set for n-grams of resource role orgroup attributes of the last n events Likewise an organiza-tional extension based feature function with three parametersn-gram size n o isin resource role group and label l isvalued with the multinoulli-estimated probability of label lgiven the n-gram of the last n event resourcesrolesgroups
3) Time extension In terms of time there are severalpotentially existing patterns A certain high-level event mightfor example be concentrated in a certain parts of a day of aweek or of a month This concentration can however not bemodeled with a single Gaussian distribution as it might be thecase that a high-level event has high probability to occur inthe morning or in the evening but low probability to occurin the afternoon in-between Therefore we use a GaussianMixture Model (GMM) to model the probability of a high-levellabel l given the timestamp Bayesian Information Criterion(BIC) [28] is used to determine the number of componentsof the GMM which gives the model an incentive to notcombine more Gaussians in the mixture than needed A GMMis estimated on training data modeling the probabilities ofeach label based on the time passed since the start of the dayweek or month A time extension based feature function withtwo parameters t isin dayweekmonth and label l isvalued with the GMM-estimated probability of label l giventhe t view on the event timestamp
4) Lifecycle extension amp Time extension The XES stan-dard [10] defines several lifecycle stages of a process Whenan event log possesses both the lifecycle extension and the timeextension time differences can be calculated between differentstages of the life cycle of a single activity For a completeevent for example one could calculate the time differencewith the associated start event of the same activity Findingthe associated start event becomes nontrivial when multipleinstances of the same activity are in parallel as it is thenunknown which complete event belongs to which start eventWe assume consecutive lifecycle steps of activities running inparallel to occur in the same order as the preceding lifecyclestep For example when we observe two start events of anactivity of type A in a row followed by two complete eventsof type A we assume the first complete to belong to the firststart and the second complete to belong to the second start
We estimate a Gaussian Mixture Model (GMM) for eachtuple of two lifecycle steps for a certain activity on the timedifferences between those two lifecycle steps for this activityA feature based on both the lifecycle and the time extensionwith a label parameter l and lifecycle c is valued with theGMM-estimated probability of label l given the time betweenthe current event and lifecycle c Bayesian Information Cri-terion (BIC) [28] is again used to determine the number ofcomponents of the GMM
B Evaluating High-level Event Predictions for Process Min-ing Applications
Existing approaches in the field of activity recognition takeas input time windows where each time window is representedby a feature vector that describes the sensor activity or statusduring that time window Hence evaluation methods in theactivity recognition field are window-based using evaluationmetrics like the percentage of correctly classified time slices
IEEE 6 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
[12] [18] [11] There are two reasons to deviate from thisevaluation methodology in a process mining setting First ourmethod operates on events instead of time windows Secondthe accuracy of the resulting high level sequences is muchmore important for many process mining techniques (egprocess discovery conformance checking) than the accuracyof predicting each individual minute of the day
We use Levenshtein similarity that expresses the degreein which two traces are similar using a metric based onthe Levenshtein distance (also known as edit distance) [29]which is defined as Levenshtein similarity(a b) = 1 minusLevenshtein distance(ab)
max(|a||b|) The division of the Levenshtein dis-tance by max(|a| |b|) which is the worst case number of editoperations needed to transform any sequence of length |a| intoany sequence of length |b| causes the result to be a numberbetween 0 (completely different traces) and 1 (identical traces)
VI CASE STUDY 1 SMART HOME ENVIRONMENT
We use the smart home environment log described byVan Kasteren et al [11] to evaluate our supervised eventlog abstraction method The Van Kasteren log consists ofmultidimensional time series data with all dimensions binarywhere each binary dimension represents the state of an in-home sensor These sensors include motion sensors openclosesensors and power sensors (discretized to 01 states)
A Experimental setup
We transform the multidimensional time series data fromsensors into events by regarding each sensor change point asan event Cases are created by grouping events together thatoccurred in the same day with a cut-off point at midnightHigh-level labels are provided for the Van Kasteren data set
The generated event log based on the Van Kasteren dataset has the following XES extensions
Concept The sensor that generated the eventTime The time stamp of the sensor change pointLifecycle Start when the event represents a sensor value
change from 0 to 1 and Complete when itrepresents a sensor value change from 1 to0
Note that annotations are provided for all traces in theobtained event log To evaluate how well the supervisedevent abstraction method generalized to unannotated traces weartificially use a part of the traces to train the abstraction modeland apply them on a test set where we regard the annotationsto be non-existent We evaluate the obtained high-level labelsagainst the ground truth labels We use a variation on Leave-One-Out-Cross-Validation where we leave out one trace toevaluate how well this mapping generalizes to unseen eventsand cases
B Results
Figure 7a shows the result of the Inductive Miner [6] forthe low-level events in the Van Kasteren data set The resultingprocess model starts with many parallel activities that canbe executed in any order and contains many unobservabletransitions back This closely resembles the flower model
which allows for any behavior in any arbitrary order From theprocess model we can learn that toilet flush and cups cupboardfrequently co-exists Furthermore the process model indicatesthat groceries cupboard is often followed by dishwasherThere seems to be very little structure on this level of eventgranularity
The average Levenshtein similarity between the predictedhigh-level traces in the Leave-One-Trace-Out-Cross-Validationexperimental setup and the ground truth high-level traces is07042 which shows that the supervised event abstractionmethod produces traces which are fairly similar to the groundtruth
Figure 7b shows the result of the Inductive Miner on theaggregated set of predicted test traces Figure 7b shows thatthe process discovered at the high level of granularity is morestructured than the process discovered at the original levelof granularity (Figure 7a) In Figure 7b we can see that themain daily routine starts with breakfast followed by a showerafter which the subject leaves the house to go to work Afterwork the subject prepares dinner and has a drink The subjectmainstream behavior is to go to the toilet before going to bedbut he can then wake up later to go to the toilet and thencontinue sleeping Note that the day can also start with goingto bed This is related to the case cut-off point of a trace atmidnight Days when the subject went to bed after midnightresult in a case where going to bed occurs at the start of thetrace On these days the subject might have breakfast and thenperform the activity sequence use toilet take shower and leavehouse possibly multiple times Another possibility on dayswhen the subject went to bed after midnight is that he startsby using the toilet then has breakfast then has the possibilityto leave the house then takes a shower after which he alwaysleaves the house Prepare dinner activity is not performed onthese days
This case study shows that we can find a structured high-level process from a low-level event log where the low-levelprocess is unstructured using supervised event abstraction andprocess discovery
VII CASE STUDY 2 ARTIFICIAL DIGITAL PHOTOCOPIER
Bose et al [30] [31] created a synthetic event log based ona digital photocopier to evaluate his unsupervised methods ofevent abstraction In this case study we show that the describedsupervised event abstraction method can accurately abstract tohigh-level labels
A Experimental setup
We annotated each low-level event with the correct high-level event using domain knowledge from the actual processmodel as described by Bose et al [30] [31] This event logis generated by a hierarchical process where high-level eventsCapture Image Rasterize Image Image Processing and PrintImage are defined in terms of a process model The PrintImage subprocess amongst others contains the events WritingDeveloping and Fusing which are themselves defined as asubprocess In this case study we set the task to transformthe log such that subprocesses Capture Image Rasterize Im-age and Image Processing Writing Fusing and Developing
IEEE 7 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level events from the low-level Van Kasteren event log
(b) Inductive Miner result on the high-level events discovered from the low-level Van Kasteren event log
Fig 7 Comparison of process models discovered from the low-level and high-level van Kasteren event log
Subprocesses Writing and Developing both contain the low-level event types Drum Spin Start and Drum Spin Stop In thiscase study we focus in particular on the Drum Spin Start andDrum Spin Stop events as they make the abstraction task non-trivial in the sense that no one-to-one mapping from low-levelto high-level events exists
The artificial digital photocopier data set has the concepttime and lifecycle XES extensions On this event log anno-tations are available for all traces On this data set we use a10-Fold Cross-Validation setting on the traces to evaluate howwell the supervised event abstraction method abstracts low-
level events to high-level events on unannotated traces as thisdata set is larger than the Van Kasteren data set and Leave-One-Out-Cross Validation would take too much time
B Results
The confusion matrix in Table II shows the aggregatedresults of the mapping of low-level events Drum Spin Start andDrum Spin Stop to high-level events Developing and WritingThe results show that the supervised event abstraction methodis capable of detecting the many-to-many mappings betweenthe low-level and high-level labels as it maps these low-level
IEEE 8 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level Artificial Digital Photo Copier event log
(b) Inductive Miner result on the discovered high-level events on the Artificial Digital Photo Copier event log
Fig 8 Comparison of process models discovered from the low-level and high-level Artificial Digital Photo Copier event log
TABLE II Confusion matrix for classification of Drum SpinStart and Drum Spin Stop low-level events into high-levelevents Writing and Developing
Developing WritingDeveloping 6653 0Writing 0 917
events to the correct high-level event without making errorsThe Levenshtein similarity between the aggregated set of testfold high-level traces and the ground truth high-level traces isclose to perfect 09667
Figure 8a shows the process model obtained with theInductive Miner on the low-level events in the artificial digitalphotocopier dataset The two sections in the process modelthat are surrounded by dashed lines are examples of high-levelevents within the low-level process model Even though thelow-level process contains structure the size of the processmodel makes it hard to comprehend Figure 8b shows theprocess model obtained with the same process discoveryalgorithm on the aggregated high-level test traces of the 10-fold cross validation setting This model is in line with theofficial artificial digital photocopier model specification withthe Print Image subprocess unfolded as provided in [30][31] In contrast to the event abstraction method described byBose et al [31] which found the high-level events that matchspecification supervised event abstraction is also able to findsuitable event labels for the generated high-level events Thisallows us to discover human-readable process models on theabstracted events without performing manual labeling which
can be a tedious task and requires domain knowledge
Instead of event abstraction on the level of the event logunsupervised abstraction methods that work on the level of amodel (eg [32]) can also be applied to make large complexmodels more comprehensible Note that such methods also donot give guidance on how to label resulting transitions in theprocess model Furthermore such methods do not help in caseswhere the process on a low-level is unstructured like in thecase study as described in Section VI
This case study shows that supervised event abstractioncan help generating a comprehensible high-level process modelfrom a low-level event log when a low-level process modelwould be too large to be understandable
VIII CONCLUSION
In this paper we described a method to abstract events ina XES event log that is too low-level based on supervisedlearning The method consists of an approach to generate afeature representation of a XES event and of a ConditionalRandom Field based learning step An implementation of themethod described has been made available as a plugin to theProM 6 process mining toolkit We introduced an evaluationmetric for predicted high-level traces that is closer to processmining than time-window based methods that are often usedin the sequence labeling field Using a real life event logfrom a smart home domain we showed that supervised eventabstraction can be used to enable process discovery techniquesto generate high-level process insights even when processmodels discovered by process mining techniques on the orig-inal low-level events are unstructured Finally we showed on
IEEE 9 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e

SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
Fig 5 Result of the Inductive Miner on the low-level traces reduced using Murata reduction rules [24]
TABLE I Left a trace with predicted high-level annotations (label) and Right the resulting high-level log after collapsingsubsequent identical label values
Case Timetimestamp Conceptname label
1 03112015 084523 Medicine cabinet Taking medicine1 03112015 084611 Dishes amp cups cabinet Taking medicine1 03112015 084645 Water Taking medicine1 03112015 084759 Dishes amp cups cabinet Eating1 03112015 084789 Dishwasher Eating1 03112015 171058 Dishes amp cups cabinet Taking medicine1 03112015 171069 Medicine cabinet Taking medicine1 03112015 171118 Water Taking medicine
Case Timetimestamp Conceptname Lifecycletransition
1 03112015 084523 Taking medicine Start1 03112015 084645 Taking medicine Complete1 03112015 084759 Eating Start1 03112015 084789 Eating Complete1 03112015 171058 Taking medicine Start1 03112015 171118 Taking medicine Complete
on the training data The Conditional Random Field modelrequires feature functions with numerical range A conceptextension based feature function with two parameters n andl is valued with the multinoulli-estimated probability of thecurrent event having high-level label l given the n-gram of thelast n low-level event labels
2) Organizational extension Similar to the concept exten-sion feature functions multinoulli distributions can be esti-mated on the training set for n-grams of resource role orgroup attributes of the last n events Likewise an organiza-tional extension based feature function with three parametersn-gram size n o isin resource role group and label l isvalued with the multinoulli-estimated probability of label lgiven the n-gram of the last n event resourcesrolesgroups
3) Time extension In terms of time there are severalpotentially existing patterns A certain high-level event mightfor example be concentrated in a certain parts of a day of aweek or of a month This concentration can however not bemodeled with a single Gaussian distribution as it might be thecase that a high-level event has high probability to occur inthe morning or in the evening but low probability to occurin the afternoon in-between Therefore we use a GaussianMixture Model (GMM) to model the probability of a high-levellabel l given the timestamp Bayesian Information Criterion(BIC) [28] is used to determine the number of componentsof the GMM which gives the model an incentive to notcombine more Gaussians in the mixture than needed A GMMis estimated on training data modeling the probabilities ofeach label based on the time passed since the start of the dayweek or month A time extension based feature function withtwo parameters t isin dayweekmonth and label l isvalued with the GMM-estimated probability of label l giventhe t view on the event timestamp
4) Lifecycle extension amp Time extension The XES stan-dard [10] defines several lifecycle stages of a process Whenan event log possesses both the lifecycle extension and the timeextension time differences can be calculated between differentstages of the life cycle of a single activity For a completeevent for example one could calculate the time differencewith the associated start event of the same activity Findingthe associated start event becomes nontrivial when multipleinstances of the same activity are in parallel as it is thenunknown which complete event belongs to which start eventWe assume consecutive lifecycle steps of activities running inparallel to occur in the same order as the preceding lifecyclestep For example when we observe two start events of anactivity of type A in a row followed by two complete eventsof type A we assume the first complete to belong to the firststart and the second complete to belong to the second start
We estimate a Gaussian Mixture Model (GMM) for eachtuple of two lifecycle steps for a certain activity on the timedifferences between those two lifecycle steps for this activityA feature based on both the lifecycle and the time extensionwith a label parameter l and lifecycle c is valued with theGMM-estimated probability of label l given the time betweenthe current event and lifecycle c Bayesian Information Cri-terion (BIC) [28] is again used to determine the number ofcomponents of the GMM
B Evaluating High-level Event Predictions for Process Min-ing Applications
Existing approaches in the field of activity recognition takeas input time windows where each time window is representedby a feature vector that describes the sensor activity or statusduring that time window Hence evaluation methods in theactivity recognition field are window-based using evaluationmetrics like the percentage of correctly classified time slices
IEEE 6 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
[12] [18] [11] There are two reasons to deviate from thisevaluation methodology in a process mining setting First ourmethod operates on events instead of time windows Secondthe accuracy of the resulting high level sequences is muchmore important for many process mining techniques (egprocess discovery conformance checking) than the accuracyof predicting each individual minute of the day
We use Levenshtein similarity that expresses the degreein which two traces are similar using a metric based onthe Levenshtein distance (also known as edit distance) [29]which is defined as Levenshtein similarity(a b) = 1 minusLevenshtein distance(ab)
max(|a||b|) The division of the Levenshtein dis-tance by max(|a| |b|) which is the worst case number of editoperations needed to transform any sequence of length |a| intoany sequence of length |b| causes the result to be a numberbetween 0 (completely different traces) and 1 (identical traces)
VI CASE STUDY 1 SMART HOME ENVIRONMENT
We use the smart home environment log described byVan Kasteren et al [11] to evaluate our supervised eventlog abstraction method The Van Kasteren log consists ofmultidimensional time series data with all dimensions binarywhere each binary dimension represents the state of an in-home sensor These sensors include motion sensors openclosesensors and power sensors (discretized to 01 states)
A Experimental setup
We transform the multidimensional time series data fromsensors into events by regarding each sensor change point asan event Cases are created by grouping events together thatoccurred in the same day with a cut-off point at midnightHigh-level labels are provided for the Van Kasteren data set
The generated event log based on the Van Kasteren dataset has the following XES extensions
Concept The sensor that generated the eventTime The time stamp of the sensor change pointLifecycle Start when the event represents a sensor value
change from 0 to 1 and Complete when itrepresents a sensor value change from 1 to0
Note that annotations are provided for all traces in theobtained event log To evaluate how well the supervisedevent abstraction method generalized to unannotated traces weartificially use a part of the traces to train the abstraction modeland apply them on a test set where we regard the annotationsto be non-existent We evaluate the obtained high-level labelsagainst the ground truth labels We use a variation on Leave-One-Out-Cross-Validation where we leave out one trace toevaluate how well this mapping generalizes to unseen eventsand cases
B Results
Figure 7a shows the result of the Inductive Miner [6] forthe low-level events in the Van Kasteren data set The resultingprocess model starts with many parallel activities that canbe executed in any order and contains many unobservabletransitions back This closely resembles the flower model
which allows for any behavior in any arbitrary order From theprocess model we can learn that toilet flush and cups cupboardfrequently co-exists Furthermore the process model indicatesthat groceries cupboard is often followed by dishwasherThere seems to be very little structure on this level of eventgranularity
The average Levenshtein similarity between the predictedhigh-level traces in the Leave-One-Trace-Out-Cross-Validationexperimental setup and the ground truth high-level traces is07042 which shows that the supervised event abstractionmethod produces traces which are fairly similar to the groundtruth
Figure 7b shows the result of the Inductive Miner on theaggregated set of predicted test traces Figure 7b shows thatthe process discovered at the high level of granularity is morestructured than the process discovered at the original levelof granularity (Figure 7a) In Figure 7b we can see that themain daily routine starts with breakfast followed by a showerafter which the subject leaves the house to go to work Afterwork the subject prepares dinner and has a drink The subjectmainstream behavior is to go to the toilet before going to bedbut he can then wake up later to go to the toilet and thencontinue sleeping Note that the day can also start with goingto bed This is related to the case cut-off point of a trace atmidnight Days when the subject went to bed after midnightresult in a case where going to bed occurs at the start of thetrace On these days the subject might have breakfast and thenperform the activity sequence use toilet take shower and leavehouse possibly multiple times Another possibility on dayswhen the subject went to bed after midnight is that he startsby using the toilet then has breakfast then has the possibilityto leave the house then takes a shower after which he alwaysleaves the house Prepare dinner activity is not performed onthese days
This case study shows that we can find a structured high-level process from a low-level event log where the low-levelprocess is unstructured using supervised event abstraction andprocess discovery
VII CASE STUDY 2 ARTIFICIAL DIGITAL PHOTOCOPIER
Bose et al [30] [31] created a synthetic event log based ona digital photocopier to evaluate his unsupervised methods ofevent abstraction In this case study we show that the describedsupervised event abstraction method can accurately abstract tohigh-level labels
A Experimental setup
We annotated each low-level event with the correct high-level event using domain knowledge from the actual processmodel as described by Bose et al [30] [31] This event logis generated by a hierarchical process where high-level eventsCapture Image Rasterize Image Image Processing and PrintImage are defined in terms of a process model The PrintImage subprocess amongst others contains the events WritingDeveloping and Fusing which are themselves defined as asubprocess In this case study we set the task to transformthe log such that subprocesses Capture Image Rasterize Im-age and Image Processing Writing Fusing and Developing
IEEE 7 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level events from the low-level Van Kasteren event log
(b) Inductive Miner result on the high-level events discovered from the low-level Van Kasteren event log
Fig 7 Comparison of process models discovered from the low-level and high-level van Kasteren event log
Subprocesses Writing and Developing both contain the low-level event types Drum Spin Start and Drum Spin Stop In thiscase study we focus in particular on the Drum Spin Start andDrum Spin Stop events as they make the abstraction task non-trivial in the sense that no one-to-one mapping from low-levelto high-level events exists
The artificial digital photocopier data set has the concepttime and lifecycle XES extensions On this event log anno-tations are available for all traces On this data set we use a10-Fold Cross-Validation setting on the traces to evaluate howwell the supervised event abstraction method abstracts low-
level events to high-level events on unannotated traces as thisdata set is larger than the Van Kasteren data set and Leave-One-Out-Cross Validation would take too much time
B Results
The confusion matrix in Table II shows the aggregatedresults of the mapping of low-level events Drum Spin Start andDrum Spin Stop to high-level events Developing and WritingThe results show that the supervised event abstraction methodis capable of detecting the many-to-many mappings betweenthe low-level and high-level labels as it maps these low-level
IEEE 8 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level Artificial Digital Photo Copier event log
(b) Inductive Miner result on the discovered high-level events on the Artificial Digital Photo Copier event log
Fig 8 Comparison of process models discovered from the low-level and high-level Artificial Digital Photo Copier event log
TABLE II Confusion matrix for classification of Drum SpinStart and Drum Spin Stop low-level events into high-levelevents Writing and Developing
Developing WritingDeveloping 6653 0Writing 0 917
events to the correct high-level event without making errorsThe Levenshtein similarity between the aggregated set of testfold high-level traces and the ground truth high-level traces isclose to perfect 09667
Figure 8a shows the process model obtained with theInductive Miner on the low-level events in the artificial digitalphotocopier dataset The two sections in the process modelthat are surrounded by dashed lines are examples of high-levelevents within the low-level process model Even though thelow-level process contains structure the size of the processmodel makes it hard to comprehend Figure 8b shows theprocess model obtained with the same process discoveryalgorithm on the aggregated high-level test traces of the 10-fold cross validation setting This model is in line with theofficial artificial digital photocopier model specification withthe Print Image subprocess unfolded as provided in [30][31] In contrast to the event abstraction method described byBose et al [31] which found the high-level events that matchspecification supervised event abstraction is also able to findsuitable event labels for the generated high-level events Thisallows us to discover human-readable process models on theabstracted events without performing manual labeling which
can be a tedious task and requires domain knowledge
Instead of event abstraction on the level of the event logunsupervised abstraction methods that work on the level of amodel (eg [32]) can also be applied to make large complexmodels more comprehensible Note that such methods also donot give guidance on how to label resulting transitions in theprocess model Furthermore such methods do not help in caseswhere the process on a low-level is unstructured like in thecase study as described in Section VI
This case study shows that supervised event abstractioncan help generating a comprehensible high-level process modelfrom a low-level event log when a low-level process modelwould be too large to be understandable
VIII CONCLUSION
In this paper we described a method to abstract events ina XES event log that is too low-level based on supervisedlearning The method consists of an approach to generate afeature representation of a XES event and of a ConditionalRandom Field based learning step An implementation of themethod described has been made available as a plugin to theProM 6 process mining toolkit We introduced an evaluationmetric for predicted high-level traces that is closer to processmining than time-window based methods that are often usedin the sequence labeling field Using a real life event logfrom a smart home domain we showed that supervised eventabstraction can be used to enable process discovery techniquesto generate high-level process insights even when processmodels discovered by process mining techniques on the orig-inal low-level events are unstructured Finally we showed on
IEEE 9 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e

SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
[12] [18] [11] There are two reasons to deviate from thisevaluation methodology in a process mining setting First ourmethod operates on events instead of time windows Secondthe accuracy of the resulting high level sequences is muchmore important for many process mining techniques (egprocess discovery conformance checking) than the accuracyof predicting each individual minute of the day
We use Levenshtein similarity that expresses the degreein which two traces are similar using a metric based onthe Levenshtein distance (also known as edit distance) [29]which is defined as Levenshtein similarity(a b) = 1 minusLevenshtein distance(ab)
max(|a||b|) The division of the Levenshtein dis-tance by max(|a| |b|) which is the worst case number of editoperations needed to transform any sequence of length |a| intoany sequence of length |b| causes the result to be a numberbetween 0 (completely different traces) and 1 (identical traces)
VI CASE STUDY 1 SMART HOME ENVIRONMENT
We use the smart home environment log described byVan Kasteren et al [11] to evaluate our supervised eventlog abstraction method The Van Kasteren log consists ofmultidimensional time series data with all dimensions binarywhere each binary dimension represents the state of an in-home sensor These sensors include motion sensors openclosesensors and power sensors (discretized to 01 states)
A Experimental setup
We transform the multidimensional time series data fromsensors into events by regarding each sensor change point asan event Cases are created by grouping events together thatoccurred in the same day with a cut-off point at midnightHigh-level labels are provided for the Van Kasteren data set
The generated event log based on the Van Kasteren dataset has the following XES extensions
Concept The sensor that generated the eventTime The time stamp of the sensor change pointLifecycle Start when the event represents a sensor value
change from 0 to 1 and Complete when itrepresents a sensor value change from 1 to0
Note that annotations are provided for all traces in theobtained event log To evaluate how well the supervisedevent abstraction method generalized to unannotated traces weartificially use a part of the traces to train the abstraction modeland apply them on a test set where we regard the annotationsto be non-existent We evaluate the obtained high-level labelsagainst the ground truth labels We use a variation on Leave-One-Out-Cross-Validation where we leave out one trace toevaluate how well this mapping generalizes to unseen eventsand cases
B Results
Figure 7a shows the result of the Inductive Miner [6] forthe low-level events in the Van Kasteren data set The resultingprocess model starts with many parallel activities that canbe executed in any order and contains many unobservabletransitions back This closely resembles the flower model
which allows for any behavior in any arbitrary order From theprocess model we can learn that toilet flush and cups cupboardfrequently co-exists Furthermore the process model indicatesthat groceries cupboard is often followed by dishwasherThere seems to be very little structure on this level of eventgranularity
The average Levenshtein similarity between the predictedhigh-level traces in the Leave-One-Trace-Out-Cross-Validationexperimental setup and the ground truth high-level traces is07042 which shows that the supervised event abstractionmethod produces traces which are fairly similar to the groundtruth
Figure 7b shows the result of the Inductive Miner on theaggregated set of predicted test traces Figure 7b shows thatthe process discovered at the high level of granularity is morestructured than the process discovered at the original levelof granularity (Figure 7a) In Figure 7b we can see that themain daily routine starts with breakfast followed by a showerafter which the subject leaves the house to go to work Afterwork the subject prepares dinner and has a drink The subjectmainstream behavior is to go to the toilet before going to bedbut he can then wake up later to go to the toilet and thencontinue sleeping Note that the day can also start with goingto bed This is related to the case cut-off point of a trace atmidnight Days when the subject went to bed after midnightresult in a case where going to bed occurs at the start of thetrace On these days the subject might have breakfast and thenperform the activity sequence use toilet take shower and leavehouse possibly multiple times Another possibility on dayswhen the subject went to bed after midnight is that he startsby using the toilet then has breakfast then has the possibilityto leave the house then takes a shower after which he alwaysleaves the house Prepare dinner activity is not performed onthese days
This case study shows that we can find a structured high-level process from a low-level event log where the low-levelprocess is unstructured using supervised event abstraction andprocess discovery
VII CASE STUDY 2 ARTIFICIAL DIGITAL PHOTOCOPIER
Bose et al [30] [31] created a synthetic event log based ona digital photocopier to evaluate his unsupervised methods ofevent abstraction In this case study we show that the describedsupervised event abstraction method can accurately abstract tohigh-level labels
A Experimental setup
We annotated each low-level event with the correct high-level event using domain knowledge from the actual processmodel as described by Bose et al [30] [31] This event logis generated by a hierarchical process where high-level eventsCapture Image Rasterize Image Image Processing and PrintImage are defined in terms of a process model The PrintImage subprocess amongst others contains the events WritingDeveloping and Fusing which are themselves defined as asubprocess In this case study we set the task to transformthe log such that subprocesses Capture Image Rasterize Im-age and Image Processing Writing Fusing and Developing
IEEE 7 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level events from the low-level Van Kasteren event log
(b) Inductive Miner result on the high-level events discovered from the low-level Van Kasteren event log
Fig 7 Comparison of process models discovered from the low-level and high-level van Kasteren event log
Subprocesses Writing and Developing both contain the low-level event types Drum Spin Start and Drum Spin Stop In thiscase study we focus in particular on the Drum Spin Start andDrum Spin Stop events as they make the abstraction task non-trivial in the sense that no one-to-one mapping from low-levelto high-level events exists
The artificial digital photocopier data set has the concepttime and lifecycle XES extensions On this event log anno-tations are available for all traces On this data set we use a10-Fold Cross-Validation setting on the traces to evaluate howwell the supervised event abstraction method abstracts low-
level events to high-level events on unannotated traces as thisdata set is larger than the Van Kasteren data set and Leave-One-Out-Cross Validation would take too much time
B Results
The confusion matrix in Table II shows the aggregatedresults of the mapping of low-level events Drum Spin Start andDrum Spin Stop to high-level events Developing and WritingThe results show that the supervised event abstraction methodis capable of detecting the many-to-many mappings betweenthe low-level and high-level labels as it maps these low-level
IEEE 8 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level Artificial Digital Photo Copier event log
(b) Inductive Miner result on the discovered high-level events on the Artificial Digital Photo Copier event log
Fig 8 Comparison of process models discovered from the low-level and high-level Artificial Digital Photo Copier event log
TABLE II Confusion matrix for classification of Drum SpinStart and Drum Spin Stop low-level events into high-levelevents Writing and Developing
Developing WritingDeveloping 6653 0Writing 0 917
events to the correct high-level event without making errorsThe Levenshtein similarity between the aggregated set of testfold high-level traces and the ground truth high-level traces isclose to perfect 09667
Figure 8a shows the process model obtained with theInductive Miner on the low-level events in the artificial digitalphotocopier dataset The two sections in the process modelthat are surrounded by dashed lines are examples of high-levelevents within the low-level process model Even though thelow-level process contains structure the size of the processmodel makes it hard to comprehend Figure 8b shows theprocess model obtained with the same process discoveryalgorithm on the aggregated high-level test traces of the 10-fold cross validation setting This model is in line with theofficial artificial digital photocopier model specification withthe Print Image subprocess unfolded as provided in [30][31] In contrast to the event abstraction method described byBose et al [31] which found the high-level events that matchspecification supervised event abstraction is also able to findsuitable event labels for the generated high-level events Thisallows us to discover human-readable process models on theabstracted events without performing manual labeling which
can be a tedious task and requires domain knowledge
Instead of event abstraction on the level of the event logunsupervised abstraction methods that work on the level of amodel (eg [32]) can also be applied to make large complexmodels more comprehensible Note that such methods also donot give guidance on how to label resulting transitions in theprocess model Furthermore such methods do not help in caseswhere the process on a low-level is unstructured like in thecase study as described in Section VI
This case study shows that supervised event abstractioncan help generating a comprehensible high-level process modelfrom a low-level event log when a low-level process modelwould be too large to be understandable
VIII CONCLUSION
In this paper we described a method to abstract events ina XES event log that is too low-level based on supervisedlearning The method consists of an approach to generate afeature representation of a XES event and of a ConditionalRandom Field based learning step An implementation of themethod described has been made available as a plugin to theProM 6 process mining toolkit We introduced an evaluationmetric for predicted high-level traces that is closer to processmining than time-window based methods that are often usedin the sequence labeling field Using a real life event logfrom a smart home domain we showed that supervised eventabstraction can be used to enable process discovery techniquesto generate high-level process insights even when processmodels discovered by process mining techniques on the orig-inal low-level events are unstructured Finally we showed on
IEEE 9 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e
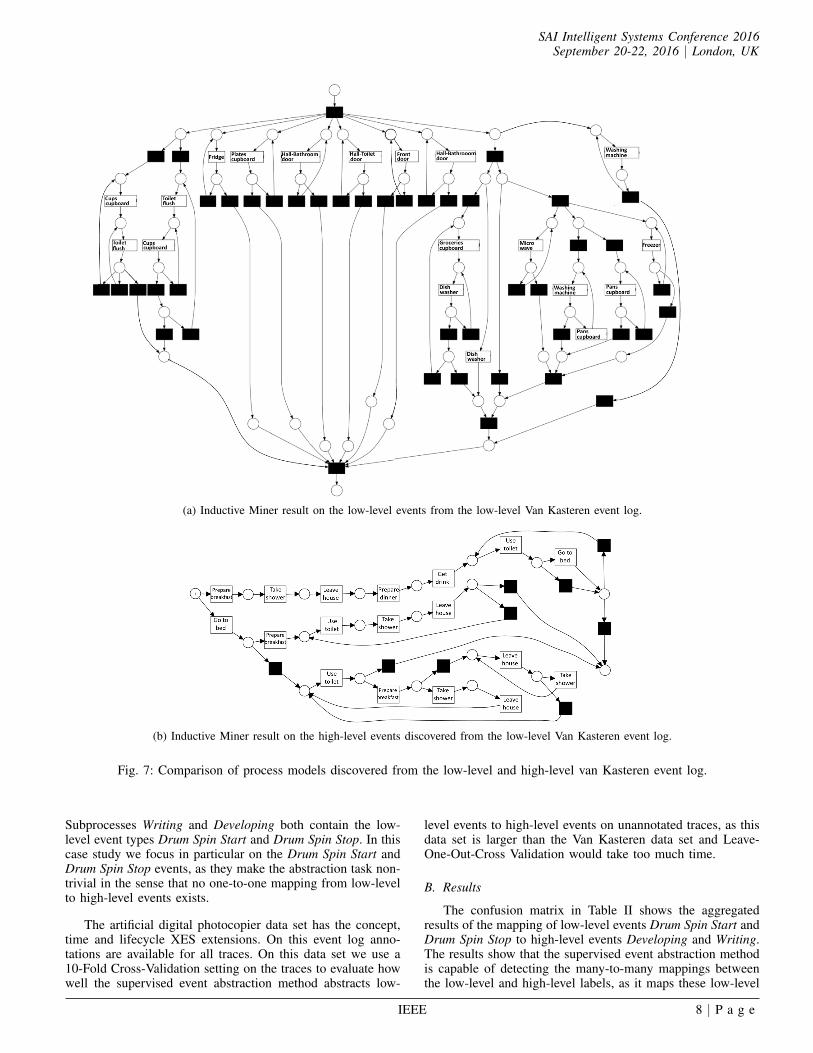
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level events from the low-level Van Kasteren event log
(b) Inductive Miner result on the high-level events discovered from the low-level Van Kasteren event log
Fig 7 Comparison of process models discovered from the low-level and high-level van Kasteren event log
Subprocesses Writing and Developing both contain the low-level event types Drum Spin Start and Drum Spin Stop In thiscase study we focus in particular on the Drum Spin Start andDrum Spin Stop events as they make the abstraction task non-trivial in the sense that no one-to-one mapping from low-levelto high-level events exists
The artificial digital photocopier data set has the concepttime and lifecycle XES extensions On this event log anno-tations are available for all traces On this data set we use a10-Fold Cross-Validation setting on the traces to evaluate howwell the supervised event abstraction method abstracts low-
level events to high-level events on unannotated traces as thisdata set is larger than the Van Kasteren data set and Leave-One-Out-Cross Validation would take too much time
B Results
The confusion matrix in Table II shows the aggregatedresults of the mapping of low-level events Drum Spin Start andDrum Spin Stop to high-level events Developing and WritingThe results show that the supervised event abstraction methodis capable of detecting the many-to-many mappings betweenthe low-level and high-level labels as it maps these low-level
IEEE 8 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level Artificial Digital Photo Copier event log
(b) Inductive Miner result on the discovered high-level events on the Artificial Digital Photo Copier event log
Fig 8 Comparison of process models discovered from the low-level and high-level Artificial Digital Photo Copier event log
TABLE II Confusion matrix for classification of Drum SpinStart and Drum Spin Stop low-level events into high-levelevents Writing and Developing
Developing WritingDeveloping 6653 0Writing 0 917
events to the correct high-level event without making errorsThe Levenshtein similarity between the aggregated set of testfold high-level traces and the ground truth high-level traces isclose to perfect 09667
Figure 8a shows the process model obtained with theInductive Miner on the low-level events in the artificial digitalphotocopier dataset The two sections in the process modelthat are surrounded by dashed lines are examples of high-levelevents within the low-level process model Even though thelow-level process contains structure the size of the processmodel makes it hard to comprehend Figure 8b shows theprocess model obtained with the same process discoveryalgorithm on the aggregated high-level test traces of the 10-fold cross validation setting This model is in line with theofficial artificial digital photocopier model specification withthe Print Image subprocess unfolded as provided in [30][31] In contrast to the event abstraction method described byBose et al [31] which found the high-level events that matchspecification supervised event abstraction is also able to findsuitable event labels for the generated high-level events Thisallows us to discover human-readable process models on theabstracted events without performing manual labeling which
can be a tedious task and requires domain knowledge
Instead of event abstraction on the level of the event logunsupervised abstraction methods that work on the level of amodel (eg [32]) can also be applied to make large complexmodels more comprehensible Note that such methods also donot give guidance on how to label resulting transitions in theprocess model Furthermore such methods do not help in caseswhere the process on a low-level is unstructured like in thecase study as described in Section VI
This case study shows that supervised event abstractioncan help generating a comprehensible high-level process modelfrom a low-level event log when a low-level process modelwould be too large to be understandable
VIII CONCLUSION
In this paper we described a method to abstract events ina XES event log that is too low-level based on supervisedlearning The method consists of an approach to generate afeature representation of a XES event and of a ConditionalRandom Field based learning step An implementation of themethod described has been made available as a plugin to theProM 6 process mining toolkit We introduced an evaluationmetric for predicted high-level traces that is closer to processmining than time-window based methods that are often usedin the sequence labeling field Using a real life event logfrom a smart home domain we showed that supervised eventabstraction can be used to enable process discovery techniquesto generate high-level process insights even when processmodels discovered by process mining techniques on the orig-inal low-level events are unstructured Finally we showed on
IEEE 9 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e

SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
(a) Inductive Miner result on the low-level Artificial Digital Photo Copier event log
(b) Inductive Miner result on the discovered high-level events on the Artificial Digital Photo Copier event log
Fig 8 Comparison of process models discovered from the low-level and high-level Artificial Digital Photo Copier event log
TABLE II Confusion matrix for classification of Drum SpinStart and Drum Spin Stop low-level events into high-levelevents Writing and Developing
Developing WritingDeveloping 6653 0Writing 0 917
events to the correct high-level event without making errorsThe Levenshtein similarity between the aggregated set of testfold high-level traces and the ground truth high-level traces isclose to perfect 09667
Figure 8a shows the process model obtained with theInductive Miner on the low-level events in the artificial digitalphotocopier dataset The two sections in the process modelthat are surrounded by dashed lines are examples of high-levelevents within the low-level process model Even though thelow-level process contains structure the size of the processmodel makes it hard to comprehend Figure 8b shows theprocess model obtained with the same process discoveryalgorithm on the aggregated high-level test traces of the 10-fold cross validation setting This model is in line with theofficial artificial digital photocopier model specification withthe Print Image subprocess unfolded as provided in [30][31] In contrast to the event abstraction method described byBose et al [31] which found the high-level events that matchspecification supervised event abstraction is also able to findsuitable event labels for the generated high-level events Thisallows us to discover human-readable process models on theabstracted events without performing manual labeling which
can be a tedious task and requires domain knowledge
Instead of event abstraction on the level of the event logunsupervised abstraction methods that work on the level of amodel (eg [32]) can also be applied to make large complexmodels more comprehensible Note that such methods also donot give guidance on how to label resulting transitions in theprocess model Furthermore such methods do not help in caseswhere the process on a low-level is unstructured like in thecase study as described in Section VI
This case study shows that supervised event abstractioncan help generating a comprehensible high-level process modelfrom a low-level event log when a low-level process modelwould be too large to be understandable
VIII CONCLUSION
In this paper we described a method to abstract events ina XES event log that is too low-level based on supervisedlearning The method consists of an approach to generate afeature representation of a XES event and of a ConditionalRandom Field based learning step An implementation of themethod described has been made available as a plugin to theProM 6 process mining toolkit We introduced an evaluationmetric for predicted high-level traces that is closer to processmining than time-window based methods that are often usedin the sequence labeling field Using a real life event logfrom a smart home domain we showed that supervised eventabstraction can be used to enable process discovery techniquesto generate high-level process insights even when processmodels discovered by process mining techniques on the orig-inal low-level events are unstructured Finally we showed on
IEEE 9 | P a g e
SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e

SAI Intelligent Systems Conference 2016September 20-22 2016 | London UK
a synthetic event log that supervised event abstraction canbe used to discover smaller more comprehensible high-levelprocess models when the process model discovered on lowlevel events is too large to be interpretable
REFERENCES
[1] W M P van der Aalst Process mining Discovery conformance andenhancement of business processes Springer Science amp BusinessMedia 2011
[2] W M P van der Aalst A J M M Weijters and L MarusterldquoWorkflow mining Discovering process models from event logsrdquo IEEETransactions on Knowledge and Data Engineering vol 16 no 9 pp1128ndash1142 2004
[3] C W Gunther and W M P van der Aalst ldquoFuzzy miningndashadaptiveprocess simplification based on multi-perspective metricsrdquo in BusinessProcess Management Springer 2007 pp 328ndash343
[4] J M E M Van der Werf B F van Dongen C A J Hurkens andA Serebrenik ldquoProcess discovery using integer linear programmingrdquoin Applications and Theory of Petri Nets Springer 2008 pp 368ndash387
[5] A J M M Weijters and J T S Ribeiro ldquoFlexible heuristics miner(fhm)rdquo in Proceedings of the 2011 IEEE Symposium on ComputationalIntelligence and Data Mining IEEE 2011 pp 310ndash317
[6] S J J Leemans D Fahland and W M P van der Aalst ldquoDiscov-ering block-structured process models from event logs - a constructiveapproachrdquo in Application and Theory of Petri Nets and Concurrencyser LNCS Springer 2013 pp 311ndash329
[7] R P J C Bose and W M P van der Aalst ldquoAbstractions in processmining A taxonomy of patternsrdquo in Business Process Managementser LNCS Springer 2009 pp 159ndash175
[8] C W Gunther A Rozinat and W M P van der Aalst ldquoActivitymining by global trace segmentationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 128ndash139
[9] B F van Dongen and A Adriansyah ldquoProcess mining Fuzzy cluster-ing and performance visualizationrdquo in Business Process ManagementWorkshops ser LNBIP Springer 2010 pp 158ndash169
[10] C W Gunther and H M W Verbeek ldquoXES-standard definitionrdquoBPMcenterorg 2014
[11] T van Kasteren A Noulas G Englebienne and B Krose ldquoAccurateactivity recognition in a home settingrdquo in Proceedings of the 10thInternational Conference on Ubiquitous Computing ACM 2008 pp1ndash9
[12] E M Tapia S S Intille and K Larson ldquoActivity recognition in thehome using simple and ubiquitous sensorsrdquo in Pervasive Computingser LNCS A Ferscha and F Mattern Eds Springer 2004 pp 158ndash175
[13] L Bao and S S Intille ldquoActivity recognition from user-annotatedacceleration datardquo in Pervasive Computing ser LNCS A Ferscha andF Mattern Eds Springer 2004 pp 1ndash17
[14] J R Kwapisz G M Weiss and S A Moore ldquoActivity recognition us-ing cell phone accelerometersrdquo ACM SIGKDD Explorations Newslettervol 12 no 2 pp 74ndash82 2011
[15] R Poppe ldquoA survey on vision-based human action recognitionrdquo Imageand Vision Computing vol 28 no 6 pp 976ndash990 2010
[16] L Chen and C Nugent ldquoOntology-based activity recognition in intelli-gent pervasive environmentsrdquo International Journal of Web InformationSystems vol 5 no 4 pp 410ndash430 2009
[17] D Riboni and C Bettini ldquoOWL 2 modeling and reasoning withcomplex human activitiesrdquo Pervasive and Mobile Computing vol 7no 3 pp 379ndash395 2011
[18] T van Kasteren and B Krose ldquoBayesian activity recognition inresidence for eldersrdquo in Proceedings of the 3rd IET InternationalConference on Intelligent Environments IEEE 2007 pp 209ndash212
[19] J Lafferty A McCallum and F C N Pereira ldquoConditional randomfields probabilistic models for segmenting and labeling sequence datardquoin Proceedings of the 18th International Conference on MachineLearning Morgan Kaufmann 2001
[20] L R Rabiner and B-H Juang ldquoAn introduction to hidden Markovmodelsrdquo ASSP Magazine vol 3 no 1 pp 4ndash16 1986
[21] N Friedman D Geiger and M Goldszmidt ldquoBayesian networkclassifiersrdquo Machine Learning vol 29 no 2-3 pp 131ndash163 1997
[22] E Kim S Helal and D Cook ldquoHuman activity recognition and patterndiscoveryrdquo Pervasive Computing vol 9 no 1 pp 48ndash53 2010
[23] W Reisig Petri nets an introduction Springer Science amp BusinessMedia 2012 vol 4
[24] T Murata ldquoPetri nets Properties analysis and applicationsrdquo Proceed-ings of the IEEE vol 77 no 4 pp 541ndash580 1989
[25] H M W Verbeek J C A M Buijs B F Van Dongen and W M Pvan der Aalst ldquoProM 6 The process mining toolkitrdquo in Proceedingsof the Business Process Management Demonstration Track ser CEUR-WSorg 2010 pp 34ndash39
[26] C Sutton ldquoGRMM Graphical models in malletrdquo Implementationavailable at httpmalletcsumassedugrmm 2006
[27] G Andrew and J Gao ldquoScalable training of L1-regularized log-linear modelsrdquo in Proceedings of the 24th International Conferenceon Machine Learning ACM 2007 pp 33ndash40
[28] G Schwarz ldquoEstimating the dimension of a modelrdquo The Annals ofStatistics vol 6 no 2 pp 461ndash464 1978
[29] V I Levenshtein ldquoBinary codes capable of correcting deletions in-sertions and reversalsrdquo Soviet Physics Doklady vol 10 pp 707ndash7101966
[30] R P J C Bose H M W Verbeek and W M P van der AalstldquoDiscovering hierarchical process models using ProMrdquo in IS OlympicsInformation Systems in a Diverse World ser LNBIP Springer 2012pp 33ndash48
[31] R P J C Bose ldquoProcess mining in the large Preprocessing discoveryand diagnosticsrdquo PhD dissertation Technische Universiteit Eindhoven2012
[32] J Vanhatalo H Volzer and J Koehler ldquoThe refined process structuretreerdquo Data amp Knowledge Engineering vol 68 no 9 pp 793ndash8182009
IEEE 10 | P a g e





























