Embed Size (px)
Citation preview

A Web Search Engine-Based Approach toMeasure Semantic Similarity between Words
Danushka Bollegala, Yutaka Matsuo, and Mitsuru Ishizuka, Member, IEEE
Abstract—Measuring the semantic similarity between words is an important component in various tasks on the web such as relation
extraction, community mining, document clustering, and automatic metadata extraction. Despite the usefulness of semantic similarity
measures in these applications, accurately measuring semantic similarity between two words (or entities) remains a challenging task.
We propose an empirical method to estimate semantic similarity using page counts and text snippets retrieved from a web search
engine for two words. Specifically, we define various word co-occurrence measures using page counts and integrate those with lexical
patterns extracted from text snippets. To identify the numerous semantic relations that exist between two given words, we propose a
novel pattern extraction algorithm and a pattern clustering algorithm. The optimal combination of page counts-based co-occurrence
measures and lexical pattern clusters is learned using support vector machines. The proposed method outperforms various baselines
and previously proposed web-based semantic similarity measures on three benchmark data sets showing a high correlation with
human ratings. Moreover, the proposed method significantly improves the accuracy in a community mining task.
Index Terms—Web mining, information extraction, web text analysis.
Ç
1 INTRODUCTION
ACCURATELY measuring the semantic similarity betweenwords is an important problem in web mining,
information retrieval, and natural language processing.Web mining applications such as, community extraction,relation detection, and entity disambiguation, require theability to accurately measure the semantic similaritybetween concepts or entities. In information retrieval, oneof the main problems is to retrieve a set of documents that issemantically related to a given user query. Efficientestimation of semantic similarity between words is criticalfor various natural language processing tasks such as wordsense disambiguation (WSD), textual entailment, andautomatic text summarization.
Semantically related words of a particular word arelisted in manually created general-purpose lexical ontolo-gies such as WordNet.1 In WordNet, a synset contains a setof synonymous words for a particular sense of a word.However, semantic similarity between entities changes overtime and across domains. For example, apple is frequentlyassociated with computers on the web. However, this senseof apple is not listed in most general-purpose thesauri ordictionaries. A user who searches for apple on the web,
might be interested in this sense of apple and not apple as afruit. New words are constantly being created as well asnew senses are assigned to existing words. Manuallymaintaining ontologies to capture these new words andsenses is costly if not impossible.
We propose an automatic method to estimate thesemantic similarity between words or entities using websearch engines. Because of the vastly numerous documentsand the high growth rate of the web, it is time consuming toanalyze each document separately. Web search enginesprovide an efficient interface to this vast information. Pagecounts and snippets are two useful information sourcesprovided by most web search engines. Page count of a queryis an estimate of the number of pages that contain the querywords. In general, page count may not necessarily be equalto the word frequency because the queried word mightappear many times on one page. Page count for the query PAND Q can be considered as a global measure of co-occurrence of words P and Q. For example, the page countof the query “apple” AND “computer” in Google is288,000,000, whereas the same for “banana” AND “computer”is only 3,590,000. The more than 80 times more numerouspage counts for “apple” AND “computer” indicate that appleis more semantically similar to computer than is banana.
Despite its simplicity, using page counts alone as ameasure of co-occurrence of two words presents severaldrawbacks. First, page count analysis ignores the position of aword in a page. Therefore, even though two words appear in apage, they might not be actually related. Second, page countof a polysemous word (a word with multiple senses) mightcontain a combination of all its senses. For example, pagecounts for apple contain page counts for apple as a fruit andapple as a company. Moreover, given the scale and noise onthe web, some words might co-occur on some pages withoutbeing actually related [1]. For those reasons, page countsalone are unreliable when measuring semantic similarity.
IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 23, NO. 7, JULY 2011 977
. D. Bollegala and M. Ishizuka are with the Department of Electronics andInformation, Graduate School of Information Sciences, The University ofTokyo, Room 111C1, Engineering Building 2, 7-3-1, Hongo, Bunkyo-ku,Tokyo 113-8656, Japan.E-mail: [email protected], [email protected].
. Y. Matsuo is with the Institute of Engineering Innovation, GraduateSchool of Engineering, The University of Tokyo, 2-11-6 Yayoi, Bunkyo-ku,Tokyo 113-8656. E-mail: [email protected].
Manuscript received 28 July 2009; revised 11 Feb. 2011; accepted 21 Mar.2010; published online 8 Sept. 2010.Recommended for acceptance by J. Zobel.For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference IEEECS Log Number TKDE-2009-07-0572.Digital Object Identifier no. 10.1109/TKDE.2010.172.
1. http://wordnet.princeton.edu/.
1041-4347/11/$26.00 � 2011 IEEE Published by the IEEE Computer Society

Snippets, a brief window of text extracted by a searchengine around the query term in a document, provideuseful information regarding the local context of the queryterm. Semantic similarity measures defined over snippets,have been used in query expansion [2], personal namedisambiguation [3], and community mining [4]. Processingsnippets is also efficient because it obviates the trouble ofdownloading webpages, which might be time consumingdepending on the size of the pages. However, a widelyacknowledged drawback of using snippets is that, becauseof the huge scale of the web and the large number ofdocuments in the result set, only those snippets for the top-ranking results for a query can be processed efficiently.Ranking of search results, hence snippets, is determined bya complex combination of various factors unique to theunderlying search engine. Therefore, no guarantee existsthat all the information we need to measure semanticsimilarity between a given pair of words is contained in thetop-ranking snippets.
We propose a method that considers both page countsand lexical syntactic patterns extracted from snippets thatwe show experimentally to overcome the above mentionedproblems. For example, let us consider the snippet shown inFig. 1 retrieved from Google for the query Jaguar AND cat.
Here, the phrase is the largest indicates a hypernymicrelationship between Jaguar and cat. Phrases such as alsoknown as, is a, part of, is an example of all indicate varioussemantic relations. Such indicative phrases have beenapplied to numerous tasks with good results, such ashypernym extraction [5] and fact extraction [6]. From theprevious example, we form the pattern X is the largest Y,where we replace the two words Jaguar and cat by twovariables X and Y.
Our contributions are summarized as follows:
. We present an automatically extracted lexical syn-tactic patterns-based approach to compute thesemantic similarity between words or entities usingtext snippets retrieved from a web search engine. Wepropose a lexical pattern extraction algorithm thatconsiders word subsequences in text snippets.Moreover, the extracted set of patterns are clusteredto identify the different patterns that describe thesame semantic relation.
. We integrate different web-based similarity mea-sures using a machine learning approach. We extractsynonymous word pairs from WordNet synsets aspositive training instances and automatically gen-erate negative training instances. We then train atwo-class support vector machine (SVM) to classifysynonymous and nonsynonymous word pairs. Theintegrated measure outperforms all existing web-based semantic similarity measures on a benchmarkdata set.
. We apply the proposed semantic similarity measureto identify relations between entities, in particularpeople, in a community extraction task. In thisexperiment, the proposed method outperforms thebaselines with statistically significant precision andrecall values. The results of the community miningtask show the ability of the proposed method tomeasure the semantic similarity between not onlywords, but also between named entities, for whichmanually created lexical ontologies do not exist orincomplete.
2 RELATED WORK
Given a taxonomy of words, a straightforward method tocalculate similarity between two words is to find the lengthof the shortest path connecting the two words in thetaxonomy [7]. If a word is polysemous, then multiple pathsmight exist between the two words. In such cases, only theshortest path between any two senses of the words isconsidered for calculating similarity. A problem that isfrequently acknowledged with this approach is that it relieson the notion that all links in the taxonomy represent auniform distance.
Resnik [8] proposed a similarity measure using informa-tion content. He defined the similarity between twoconcepts C1 and C2 in the taxonomy as the maximum ofthe information content of all concepts C that subsume bothC1 and C2. Then, the similarity between two words isdefined as the maximum of the similarity between anyconcepts that the words belong to. He used WordNet as thetaxonomy; information content is calculated using theBrown corpus.
Li et al. [9] combined structural semantic informationfrom a lexical taxonomy and information content from acorpus in a nonlinear model. They proposed a similaritymeasure that uses shortest path length, depth, and localdensity in a taxonomy. Their experiments reported a highPearson correlation coefficient of 0.8914 on the Miller andCharles [10] benchmark data set. They did not evaluatetheir method in terms of similarities among named entities.Lin [11] defined the similarity between two concepts as theinformation that is in common to both concepts and theinformation contained in each individual concept.
Cilibrasi and Vitanyi [12] proposed a distance metricbetween words using only page counts retrieved from aweb search engine. The proposed metric is named Normal-ized Google Distance (NGD) and is given by
NGDðP;QÞ ¼ maxflogHðP Þ; logHðQÞg � logHðP;QÞlogN �minflogHðP Þ; logHðQÞg :
Here, P and Q are the two words between which distanceNGDðP;QÞ is to be computed, HðP Þ denotes the pagecount for the word P , and HðP;QÞ is the page count for thequery P AND Q. NGD is based on normalized informationdistance [13], which is defined using Kolmogorov complex-ity. Because NGD does not take into account the context inwhich the words co-occur, it suffers from the drawbacksdescribed in the previous section that are characteristic tosimilarity measures that consider only page counts.
978 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 23, NO. 7, JULY 2011
Fig. 1. A snippet retrieved for the query Jaguar AND cat.

Sahami and Heilman [2] measured semantic similaritybetween two queries using snippets returned for thosequeries by a search engine. For each query, they collectsnippets from a search engine and represent each snippet asa TF-IDF-weighted term vector. Each vector is L2 normal-ized and the centroid of the set of vectors is computed.Semantic similarity between two queries is then defined asthe inner product between the corresponding centroidvectors. They did not compare their similarity measurewith taxonomy-based similarity measures.
Chen et al. [4] proposed a double-checking model usingtext snippets returned by a web search engine to computesemantic similarity between words. For two words P andQ, they collect snippets for each word from a web searchengine. Then, they count the occurrences of word P in thesnippets for word Q and the occurrences of word Q in thesnippets for word P . These values are combined non-linearly to compute the similarity between P and Q. The Co-occurrence Double-Checking (CODC) measure is defined as
CODCðP;QÞ ¼0; if fðP@QÞ ¼ 0;
exp log fðP@QHðP Þ �
fðQ@P ÞHðQÞ
h i�� �; otherwise:
(
Here, fðP@QÞ denotes the number of occurrences of P inthe top-ranking snippets for the query Q in Google, HðP Þ isthe page count for query P , and � is a constant in this model,which is experimentally set to the value 0.15. This methoddepends heavily on the search engine’s ranking algorithm.Although two words P and Q might be very similar, wecannot assume that one can find Q in the snippets for P , orvice versa, because a search engine considers many otherfactors besides semantic similarity, such as publication date(novelty) and link structure (authority) when ranking theresult set for a query. This observation is confirmed by theexperimental results in their paper which reports zerosimilarity scores for many pairs of words in the Miller andCharles [10] benchmark data set.
Semantic similarity measures have been used in variousapplications in natural language processing such as wordsense disambiguation [14], language modeling [15], syno-nym extraction [16], and automatic thesauri extraction [17].Semantic similarity measures are important in many web-related tasks. In query expansion [18], a user query ismodified using synonymous words to improve the relevancyof the search. One method to find appropriate words toinclude in a query is to compare the previous user queriesusing semantic similarity measures. If there exists a previousquery that is semantically related to the current query, then itcan be either suggested to the user, or internally used by thesearch engine to modify the original query.
3 METHOD
3.1 Outline
Given two words P and Q, we model the problem ofmeasuring the semantic similarity between P and Q, as aone of constructing a function simðP;QÞ that returns a valuein range ½0; 1�. If P and Q are highly similar (e.g.,synonyms), we expect simðP;QÞ to be closer to 1. On the
other hand, if P and Q are not semantically similar, then weexpect simðP;QÞ to be closer to 0. We define numerousfeatures that express the similarity between P and Q usingpage counts and snippets retrieved from a web searchengine for the two words. Using this feature representationof words, we train a two-class support vector machine toclassify synonymous and nonsynonymous word pairs. Thefunction simðP;QÞ is then approximated by the confidencescore of the trained SVM.
Fig. 2 illustrates an example of using the proposedmethod to compute the semantic similarity between twowords, gem and jewel. First, we query a web search engineand retrieve page counts for the two words and for theirconjunctive (i.e., “gem,” “jewel,” and “gem AND jewel”). InSection 3.2, we define four similarity scores using pagecounts. Page counts-based similarity scores consider theglobal co-occurrences of two words on the web. However,they do not consider the local context in which two wordsco-occur. On the other hand, snippets returned by a searchengine represent the local context in which two words co-occur on the web. Consequently, we find the frequency ofnumerous lexical syntactic patterns in snippets returned forthe conjunctive query of the two words. The lexical patternswe utilize are extracted automatically using the methoddescribed in Section 3.3. However, it is noteworthy that asemantic relation can be expressed using more than onelexical pattern. Grouping the different lexical patterns thatconvey the same semantic relation, enables us to represent asemantic relation between two words accurately. For thispurpose, we propose a sequential pattern clusteringalgorithm in Section 3.4. Both page counts-based similarityscores and lexical pattern clusters are used to define variousfeatures that represent the relation between two words.Using this feature representation of word pairs, we train atwo-class support vector machine [19] in Section 3.5.
3.2 Page Count-Based Co-Occurrence Measures
Page counts for the query P AND Q can be considered as anapproximation of co-occurrence of two words (or multi-word phrases) P and Q on the web. However, page countsfor the query P AND Q alone do not accurately expresssemantic similarity. For example, Google returns 11,300,000as the page count for “car” AND “automobile,” whereas thesame is 49,000,000 for “car” AND “apple.” Although,
BOLLEGALA ET AL.: A WEB SEARCH ENGINE-BASED APPROACH TO MEASURE SEMANTIC SIMILARITY BETWEEN WORDS 979
Fig. 2. Outline of the proposed method.

automobile is more semantically similar to car than apple is,page counts for the query “car” AND “apple” are more thanfour times greater than those for the query “car” AND“automobile.” One must consider the page counts not just forthe query P AND Q, but also for the individual words P andQ to assess semantic similarity between P and Q.
We compute four popular co-occurrence measures;Jaccard, Overlap (Simpson), Dice, and Pointwise mutualinformation (PMI), to compute semantic similarity usingpage counts. For the remainder of this paper, we use thenotation HðP Þ to denote the page counts for the query P ina search engine. The WebJaccard coefficient between words(or multiword phrases) P and Q, WebJaccardðP;QÞ, isdefined as
WebJaccardðP;QÞ
¼0; if HðP \QÞ � c;
HðP \QÞHðP Þ þHðQÞ �HðP \QÞ ; otherwise:
8<:
Therein, P \Q denotes the conjunction query P AND Q.Given the scale and noise in web data, it is possible that twowords may appear on some pages even though they are notrelated. In order to reduce the adverse effects attributable tosuch co-occurrences, we set the WebJaccard coefficient to zeroif the page count for the queryP \Q is less than a threshold c.2
Similarly, we define WebOverlap, WebOverlapðP;QÞ, as
WebOverlapðP;QÞ
¼0; if HðP \QÞ � c;
HðP \QÞminðHðP Þ; HðQÞÞ ; otherwise:
8<:
WebOverlap is a natural modification to the Overlap(Simpson) coefficient. We define the WebDice coefficient asa variant of the Dice coefficient. WebDiceðP;QÞ is defined as
WebDiceðP;QÞ ¼0; if HðP \QÞ � c;
2HðP \QÞHðP Þ þHðQÞ ; otherwise:
8<: ð3Þ
Pointwise mutual information [20] is a measure that ismotivated by information theory; it is intended to reflect thedependence between two probabilistic events. We defineWebPMI as a variant form of pointwise mutual informationusing page counts as
WebPMIðP;QÞ
¼0; if HðP \QÞ � c;
log2
HðP\QÞN
HðP ÞN
HðQÞN
!; otherwise:
8><>:
Here, N is the number of documents indexed by the searchengine. Probabilities in (4) are estimated according to themaximum likelihood principle. To calculate PMI accuratelyusing (4), we must know N , the number of documentsindexed by the search engine. Although estimating thenumber of documents indexed by a search engine [21] is aninteresting task itself, it is beyond the scope of this work. In
the present work, we set N ¼ 1010 according to the numberof indexed pages reported by Google. As previouslydiscussed, page counts are mere approximations to actualword co-occurrences in the web. However, it has beenshown empirically that there exists a high correlationbetween word counts obtained from a web search engine(e.g., Google and Altavista) and that from a corpus (e.g.,British National corpus) [22]. Moreover, the approximatedpage counts have been successfully used to improve avariety of language modeling tasks [23].
3.3 Lexical Pattern Extraction
Page counts-based co-occurrence measures described inSection 3.2 do not consider the local context in which thosewords co-occur. This can be problematic if one or bothwords are polysemous, or when page counts are unreliable.On the other hand, the snippets returned by a search enginefor the conjunctive query of two words provide useful cluesrelated to the semantic relations that exist between twowords. A snippet contains a window of text selected from adocument that includes the queried words. Snippets areuseful for search because, most of the time, a user can readthe snippet and decide whether a particular search result isrelevant, without even opening the url. Using snippets ascontexts is also computationally efficient because it obviatesthe need to download the source documents from the web,which can be time consuming if a document is large. Forexample, consider the snippet in Fig. 3. Here, the phrase is aindicates a semantic relationship between cricket and sport.Many such phrases indicate semantic relationships. Forexample, also known as, is a, part of, is an example of all indicatesemantic relations of different types. In the example givenabove, words indicating the semantic relation betweencricket and sport appear between the query words. Replacingthe query words by variables X and Y , we can form thepattern X is a Y from the example given above.
Despite the efficiency of using snippets, they pose twomain challenges: first, a snippet can be a fragmentedsentence, second, a search engine might produce a snippetby selecting multiple text fragments from different portionsin a document. Because most syntactic or dependencyparsers assume complete sentences as the input, deepparsing of snippets produces incorrect results. Conse-quently, we propose a shallow lexical pattern extractionalgorithm using web snippets, to recognize the semanticrelations that exist between two words. Lexical syntacticpatterns have been used in various natural languageprocessing tasks such as extracting hypernyms [5], [24], ormeronyms [25], question answering [26], and paraphraseextraction [27]. Although a search engine might produce asnippet by selecting multiple text fragments from differentportions in a document, a predefined delimiter is used toseparate the different fragments. For example, in Google,the delimiter “...” is used to separate different fragments in
980 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 23, NO. 7, JULY 2011
2. We set c ¼ 5 in our experiments.
Fig. 3. A snippet retrieved for the query “cricket” AND “sport.”

a snippet. We use such delimiters to split a snippet beforewe run the proposed lexical pattern extraction algorithm oneach fragment.
Given two words P and Q, we query a web search engineusing the wildcard query “P � � � � � Q” and downloadsnippets. The “�” operator matches one word or none in awebpage. Therefore, our wildcard query retrieves snippetsin which P and Q appear within a window of seven words.Because a search engine snippet contains ca. 20 words onaverage, and includes two fragments of texts selected from adocument, we assume that the seven word window issufficient to cover most relations between two words insnippets. In fact, over 95 percent of the lexical patternsextracted by the proposed method contain less than fivewords. We attempt to approximate the local context of twowords using wildcard queries. For example, Fig. 4 shows asnippet retrieved for the query “ostrich� � � � � bird.”
For a snippet �, retrieved for a word pair ðP;QÞ, first, wereplace the two words P and Q, respectively, with twovariables X and Y . We replace all numeric values by D, amarker for digits. Next, we generate all subsequences ofwords from � that satisfy all of the following conditions:
1. A subsequence must contain exactly one occurrenceof each X and Y .
2. The maximum length of a subsequence is L words.3. A subsequence is allowed to skip one or more
words. However, we do not skip more than gnumber of words consecutively. Moreover, the totalnumber of words skipped in a subsequence shouldnot exceed G.
4. We expand all negation contractions in a context. Forexample, didn’t is expanded to did not. We do notskip the word not when generating subsequences.For example, this condition ensures that from thesnippet X is not a Y, we do not produce thesubsequence X is a Y.
Finally, we count the frequency of all generated subse-quences and only use subsequences that occur more than Ttimes as lexical patterns.
The parameters L; g;G, and T are set experimentally, asexplained later in Section 3.6. It is noteworthy that theproposed pattern extraction algorithm considers all thewords in a snippet, and is not limited to extracting patternsonly from the mid fix (i.e., the portion of text in a snippetthat appears between the queried words). Moreover, theconsideration of gaps enables us to capture relationsbetween distant words in a snippet. We use a modifiedversion of the prefixspan algorithm [28] to generate sub-sequences from a text snippet. Specifically, we use theconstraints (2-4) to prune the search space of candidatesubsequences. For example, if a subsequence has reachedthe maximum length L, or the number of skipped words isG, then we will not extend it further. By pruning the search
space, we can speed up the pattern generation process.However, none of these modifications affect the accuracy ofthe proposed semantic similarity measure because themodified version of the prefixspan algorithm still generatesthe exact set of patterns that we would obtain if we used theoriginal prefixspan algorithm (i.e., without pruning) andsubsequently remove patterns that violate the abovementioned constraints. For example, some patterns ex-tracted from the snippet shown in Fig. 4 are: X, a large Y, X aflightless Y, and X, large Y lives.
3.4 Lexical Pattern Clustering
Typically, a semantic relation can be expressed using morethan one pattern. For example, consider the two distinctpatterns, X is a Y, and X is a large Y. Both these patternsindicate that there exists an is-a relation between X and Y.Identifying the different patterns that express the samesemantic relation enables us to represent the relationbetween two words accurately. According to the distribu-tional hypothesis [29], words that occur in the same contexthave similar meanings. The distributional hypothesis hasbeen used in various related tasks, such as identifyingrelated words [16], and extracting paraphrases [27]. If weconsider the word pairs that satisfy (i.e., co-occur with) aparticular lexical pattern as the context of that lexical pair,then from the distributional hypothesis, it follows that thelexical patterns which are similarly distributed over wordpairs must be semantically similar.
We represent a pattern a by a vector a of word-pairfrequencies. We designate a, the word-pair frequency vectorof pattern a. It is analogous to the document frequency vectorof a word, as used in information retrieval. The value of theelement corresponding to a word pair ðPi;QiÞ in a, is thefrequency, fðPi;Qi; aÞ, that the pattern a occurs with theword pair ðPi;QiÞ. As demonstrated later, the proposedpattern extraction algorithm typically extracts a largenumber of lexical patterns. Clustering algorithms basedon pairwise comparisons among all patterns are prohibi-tively time consuming when the patterns are numerous.Next, we present a sequential clustering algorithm toefficiently cluster the extracted patterns.
Given a set � of patterns and a clustering similaritythreshold �, Algorithm 1 returns clusters (of patterns) thatexpress similar semantic relations. First, in Algorithm 1, thefunction SORT sorts the patterns into descending order oftheir total occurrences in all word pairs. The total occur-rence �ðaÞ of a pattern a is the sum of frequencies over allword pairs, and is given by
�ðaÞ ¼Xi
fðPi;Qi; aÞ: ð5Þ
After sorting, the most common patterns appear at thebeginning in �, whereas rare patterns (i.e., patterns thatoccur with only few word pairs) get shifted to the end.Next, in line 2, we initialize the set of clusters, C, to theempty set. The outer for loop (starting at line 3), repeatedlytakes a pattern ai from the ordered set �, and in the innerfor loop (starting at line 6), finds the cluster, c� (2 C) that ismost similar to ai. First, we represent a cluster by thecentroid of all word-pair frequency vectors correspondingto the patterns in that cluster to compute the similarity
BOLLEGALA ET AL.: A WEB SEARCH ENGINE-BASED APPROACH TO MEASURE SEMANTIC SIMILARITY BETWEEN WORDS 981
Fig. 4. A snippet retrieved for the query “ostrich � � � � � bird.”

between a pattern and a cluster. Next, we compute thecosine similarity between the cluster centroid (cj), and theword-pair frequency vector of the pattern (ai). If thesimilarity between a pattern ai, and its most similar cluster,c�, is greater than the threshold �, we append ai to c� (line14). We use the operator � to denote the vector additionbetween c� and ai. Then, we form a new cluster faig andappend it to the set of clusters, C, if ai is not similar to anyof the existing clusters beyond the threshold �.
Algorithm 1. Sequential pattern clustering algorithm.Input: patterns � ¼ fa1; . . . ; ang, threshold �
Output: clusters C
1: SORT(�)
2: C fg3: for pattern ai 2 � do
4: max �15: c� null
6: for cluster cj 2 C do
7: sim cosineðai; cjÞ8: if sim > max then
9: max sim
10: c� cj
11: end if
12: end for
13: if max > � then
14: c� c� � ai
15: else
16: C C [ faig17: end if
18: end for
19: return C
By sorting the lexical patterns in the descending order oftheir frequency and clustering the most frequent patternsfirst, we form clusters for more common relations first. Thisenables us to separate rare patterns which are likely to beoutliers from attaching to otherwise clean clusters. Thegreedy sequential nature of the algorithm avoids pairwisecomparisons between all lexical patterns. This is particu-larly important because when the number of lexical patternsis large as in our experiments (e.g., over 100,000), pairwisecomparisons between all patterns are computationallyprohibitive. The proposed clustering algorithm attemptsto identify the lexical patterns that are similar to each othermore than a given threshold value. By adjusting thethreshold, we can obtain clusters with different granularity.
The only parameter in Algorithm 1, the similaritythreshold, �, ranges in ½0; 1�. It decides the purity of theformed clusters. Setting � to a high value ensures that thepatterns in each cluster are highly similar. However, high �values also yield numerous clusters (increased modelcomplexity). In Section 3.6, we investigate, experimentally,the effect of � on the overall performance of the proposedrelational similarity measure.
The initial sort operation in Algorithm 1 can be carriedout in time complexity of OðnlognÞ, where n is the numberof patterns to be clustered. Next, the sequential assignmentof lexical patterns to the clusters requires complexity ofOðnjCjÞ, where jCj is the number of clusters. Typically, n ismuch larger than jCj (i.e., n�jCj). Therefore, the overall
time complexity of Algorithm 1 is dominated by the sortoperation, hence OðnlognÞ. The sequential nature of thealgorithm avoids pairwise comparisons among all patterns.Moreover, sorting the patterns by their total word-pairfrequency prior to clustering ensures that the final set ofclusters contains the most common relations in the data set.
3.5 Measuring Semantic Similarity
In Section 3.2, we defined four co-occurrence measuresusing page counts. Moreover, in Sections 3.3 and 3.4, weshowed how to extract clusters of lexical patterns fromsnippets to represent numerous semantic relations that existbetween two words. In this section, we describe a machinelearning approach to combine both page counts-based co-occurrence measures, and snippets-based lexical patternclusters to construct a robust semantic similarity measure.
Given N clusters of lexical patterns, first, we represent apair of words ðP;QÞ by an ðN þ 4Þ-dimensional featurevector fPQ. The four page counts-based co-occurrencemeasures defined in Section 3.2 are used as four distinctfeatures in fPQ. For completeness, let us assume thatðN þ 1Þst, ðN þ 2Þnd, ðN þ 3Þrd, and ðN þ 4Þth featuresare set, respectively, to WebJaccard, WebOverlap, WebDice,and WebPMI. Next, we compute a feature from each of theN clusters as follows: first, we assign a weight wij to apattern ai that is in a cluster cj as follows:
wij ¼�ðaiÞPt2cj �ðtÞ
: ð6Þ
Here, �ðaÞ is the total frequency of a pattern a in all wordpairs, and it is given by (5). Because we perform a hardclustering on patterns, a pattern can belong to only onecluster (i.e., wij ¼ 0 for ai 62 cj). Finally, we compute thevalue of the jth feature in the feature vector for a word pairðP;QÞ as follows: X
ai2cjwijfðP;Q; aiÞ: ð7Þ
The value of the jth feature of the feature vector fPQrepresenting a word pair ðP;QÞ can be seen as the weightedsum of all patterns in cluster cj that co-occur with words Pand Q. We assume all patterns in a cluster to represent aparticular semantic relation. Consequently, the jth featurevalue given by (7) expresses the significance of the semanticrelation represented by cluster j for word pair ðP;QÞ. Forexample, if the weight wij is set to 1 for all patterns ai in acluster cj, then the jth feature value is simply the sum offrequencies of all patterns in cluster cj with words P and Q.However, assigning an equal weight to all patterns in acluster is not desirable in practice because some patterns cancontain misspellings and/or can be grammatically incorrect.Equation (6) assigns a weight to a pattern proportionate toits frequency in a cluster. If a pattern has a high frequency ina cluster, then it is likely to be a canonical form of therelation represented by all the patterns in that cluster.Consequently, the weighting scheme described by (6)prefers high frequent patterns in a cluster.
To train a two-class SVM to detect synonymous andnonsynonymous word pairs, we utilize a training data setS ¼ fðPk;Qk; ykÞg of word pairs. S consists of synonymous
982 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 23, NO. 7, JULY 2011

word pairs (positive training instances) and nonsynonymousword pairs (negative training instances). Training data setS isgenerated automatically from WordNet synsets as describedlater in Section 3.6. Label yk 2 f�1; 1g indicates whether theword pair ðPk;QkÞ is a synonymous word pair (i.e., yk ¼ 1) ora nonsynonymous word pair (i.e., yk ¼ �1). For each wordpair in S, we create an ðN þ 4Þ-dimensional feature vector asdescribed above. To simplify the notation, let us denote thefeature vector of a word pair ðPk;QkÞ by fk. Finally, we train atwo-class SVM using the labeled feature vectors.
Once we have trained an SVM using synonymous andnonsynonymous word pairs, we can use it to compute thesemantic similarity between two given words. Following thesame method, we used to generate feature vectors fortraining, we create an ðN þ 4Þ-dimensional feature vector f �
for a pair of words ðP �; Q�Þ, between which we must measuresemantic similarity. We define the semantic similaritysimðP �; Q�Þ between P � and Q� as the posterior probability,pðy� ¼ 1jf �Þ, that the feature vector f� corresponding to theword pair ðP �; Q�Þ belongs to the synonymous-words class(i.e., y� ¼ 1). simðP �; Q�Þ is given by
simðP �; Q�Þ ¼ pðy� ¼ 1jf�Þ: ð8Þ
Because SVMs are large margin classifiers, the output of anSVM is the distance from the classification hyperplane. Thedistance dðf �Þ to an instance f � from the classificationhyperplane is given by
dðf �Þ ¼ hðf �Þ þ b:
Here, b is the bias term and the hyperplane, hðf �Þ, is given by
hðf�Þ ¼Xi
yk�kKðfk; f �Þ:
Here, �k is the Lagrange multiplier corresponding to thesupport vector fk,3 and Kðfk; f�Þ is the value of the kernelfunction for a training instance fk and the instance to classify,f �. However, dðf �Þ is not a calibrated posterior probability.Following Platt [30], we use sigmoid functions to convert thisuncalibrated distance into a calibrated posterior probability.The probability, pðy ¼ 1jdðfÞÞ, is computed using a sigmoidfunction defined over dðfÞ as follows:
pðy ¼ 1jdðfÞÞ ¼ 1
1þ expð�dðfÞ þ �Þ :
Here, � and � are parameters which are determined bymaximizing the likelihood of the training data. Loglikelihood of the training data is given by
Lð�; �Þ ¼XNk¼1
log pðykjfk;�; �Þ
¼XNk¼1
ftk logðpkÞ þ ð1� tkÞ logð1� pkÞg:
Here, to simplify the notation, we have used tk ¼ ðyk þ 1Þ=2and pk ¼ pðyk ¼ 1jfkÞ. The maximization in (9) with respectto parameters � and � is performed using model-trustminimization [31].
3.6 Training
To train the two-class SVM described in Section 3.5, werequire both synonymous and nonsynonymous word pairs.We use WordNet, a manually created English dictionary, togenerate the training data required by the proposedmethod. For each sense of a word, a set of synonymouswords is listed in WordNet synsets. We randomly select3,000 nouns from WordNet, and extract a pair of synon-ymous words from a synset of each selected noun. If aselected noun is polysemous, then we consider the synsetfor the dominant sense. Obtaining a set of nonsynonymousword pairs (negative training instances) is difficult, becausethere does not exist a large collection of manually creatednonsynonymous word pairs. Consequently, to create a setof nonsynonymous word pairs, we adopt a randomshuffling technique. Specifically, we first randomly selecttwo synonymous word pairs from the set of synonymousword pairs created above, and exchange two wordsbetween word pairs to create two new word pairs. Forexample, from two synonymous word pairs ðA;BÞ andðC;DÞ, we generate two new pairs ðA;CÞ and ðB;DÞ. If thenewly created word pairs do not appear in any of the wordnet synsets, we select them as nonsynonymous word pairs.We repeat this process until we create 3,000 nonsynon-ymous word pairs. Our final training data set contains6,000 word pairs (i.e., 3,000 synonymous word pairs and3,000 nonsynonymous word pairs).
Next, we use the lexical pattern extraction algorithmdescribed in Section 3.3 to extract numerous lexical patternsfor the word pairs in our training data set. We experimen-tally set the parameters in the pattern extraction algorithmto L ¼ 5, g ¼ 2, G ¼ 4, and T ¼ 5. Table 1 shows the numberof patterns extracted for synonymous and nonsynonymousword pairs in the training data set. As can be seen fromTable 1, the proposed pattern extraction algorithm typicallyextracts a large number of lexical patterns. Figs. 5 and 6,respectively, show the distribution of patterns extracted forsynonymous and nonsynonymous word pairs. Because ofthe noise in web snippets such as, ill-formed snippets andmisspells, most patterns occur only a few times in the list ofextracted patterns. Consequently, we ignore any patternsthat occur less than five times. Finally, we deduplicate thepatterns that appear for both synonymous and nonsynon-ymous word pairs to create a final set of 3,02,286 lexicalpatterns. The remainder of the experiments described in thepaper use this set of lexical patterns.
We determine the clustering threshold � as follows: first,we run Algorithm 1 for different � values, and with each setof clusters, we compute feature vectors for synonymousword pairs as described in Section 3.5. Let W denote the setof synonymous word pairs (i.e., W ¼ fðPi;QiÞjðPi;Qi; yiÞ 2S; yi ¼ 1g). Moreover, let fW be the centroid vector of all
BOLLEGALA ET AL.: A WEB SEARCH ENGINE-BASED APPROACH TO MEASURE SEMANTIC SIMILARITY BETWEEN WORDS 983
3. From K.K.T. conditions, it follows that the Lagrange multiplierscorresponding to nonsupport vectors become zero.
TABLE 1Number of Patterns Extracted for Training Data
feature vectors representing synonymous word pairs,which is given by
fW ¼1
jW jX
ðP;QÞ2WfPQ: ð10Þ
Next, we compute the average Mahalanobis distance, Dð�Þ,between fW and feature vectors that represent synonymousas follows:
Dð�Þ ¼ 1
jW jX
ðP;QÞ2WMahalaðfW; fPQÞ: ð11Þ
Here, jW j is the number of word pairs in W , andmahalaðfW; fPQÞ is the Mahalanobis distance defined by
mahalaðfw; fPQÞ ¼ ðfw � fPQÞTC�1ðfw � fPQÞ: ð12Þ
Here, C�1 is the inverse of the intercluster correlationmatrix, C, where the ði; jÞ element of C is defined to be theinner product between the vectors ci, cj corresponding toclusters ci and cj. Finally, we set the optimum value of
clustering threshold, �̂, to the value of � that minimizes theaverage Mahalanobis distance as follows:
�̂ ¼ arg min�2½0;1�
Dð�Þ:
Alternatively, we can define the reciprocal of Dð�Þ asaverage similarity, and minimize this quantity. Note thatthe average in (11) is taken over a large number ofsynonymous word pairs (3,000 word pairs in W ), whichenables us to determine � robustly. Moreover, we considerMahalanobis distance instead of euclidean distances,because a set of pattern clusters might not necessarily beindependent. For example, we would expect a certain levelof correlation between the two clusters that represent an is-arelation and a has-a relation. Mahalanobis distance con-siders the correlation between clusters when computingdistance. Note that if we take the identity matrix as C in(12), then we get the euclidean distance.
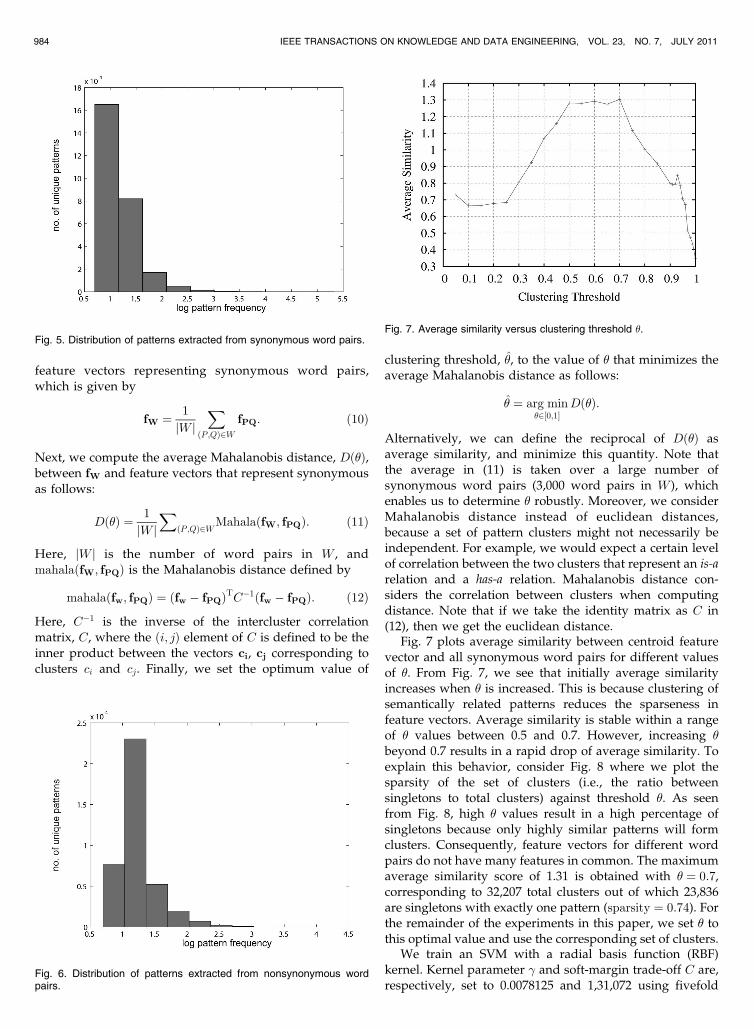
Fig. 7 plots average similarity between centroid featurevector and all synonymous word pairs for different valuesof �. From Fig. 7, we see that initially average similarityincreases when � is increased. This is because clustering ofsemantically related patterns reduces the sparseness infeature vectors. Average similarity is stable within a rangeof � values between 0.5 and 0.7. However, increasing �
beyond 0.7 results in a rapid drop of average similarity. Toexplain this behavior, consider Fig. 8 where we plot thesparsity of the set of clusters (i.e., the ratio betweensingletons to total clusters) against threshold �. As seenfrom Fig. 8, high � values result in a high percentage ofsingletons because only highly similar patterns will formclusters. Consequently, feature vectors for different wordpairs do not have many features in common. The maximumaverage similarity score of 1.31 is obtained with � ¼ 0:7,corresponding to 32,207 total clusters out of which 23,836are singletons with exactly one pattern (sparsity ¼ 0:74). Forthe remainder of the experiments in this paper, we set � tothis optimal value and use the corresponding set of clusters.
We train an SVM with a radial basis function (RBF)kernel. Kernel parameter � and soft-margin trade-off C are,respectively, set to 0.0078125 and 1,31,072 using fivefold
984 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 23, NO. 7, JULY 2011
Fig. 6. Distribution of patterns extracted from nonsynonymous wordpairs.
Fig. 7. Average similarity versus clustering threshold �.Fig. 5. Distribution of patterns extracted from synonymous word pairs.

cross validation on training data. We used LibSVM4 as theSVM implementation. Remainder of the experiments in thepaper use this trained SVM model.
4 EXPERIMENTS
4.1 Benchmark Data Sets
Following the previous work, we evaluate the proposedsemantic similarity measure by comparing it with humanratings in three benchmark data sets: Miller-Charles (MC)[10], Rubenstein-Goodenough (RG) [32], and WordSimilar-ity-353 (WS) [33]. Each data set contains a list of word pairsrated by multiple human annotators (MC: 28 pairs, 38annotators, RG: 65 pairs, 36 annotators, and WS: 353 pairs,13 annotators). A semantic similarity measure is evaluatedusing the correlation between the similarity scores producedby it for the word pairs in a benchmark data set and thehuman ratings. Both Pearson correlation coefficient andSpearman correlation coefficient have been used as evalua-tion measures in previous work on semantic similarity. It isnoteworthy that Pearson correlation coefficient can getseverely affected by nonlinearities in ratings. Contrastingly,Spearman correlation coefficient first assigns ranks to eachlist of scores, and then computes correlation between thetwo lists of ranks. Therefore, Spearman correlation is moreappropriate for evaluating semantic similarity measures,which might not be necessarily linear. In fact, as we shall seelater, most semantic similarity measures are nonlinear.Previous work that used RG and WS data sets in theirevaluations has chosen Spearman correlation coefficient asthe evaluation measure. However, for the MC data set,which contains only 28 word pairs, Pearson correlationcoefficient has been widely used. To be able to compare ourresults with previous work, we use both Pearson andSpearman correlation coefficients for experiments con-ducted on MC data set, and Spearman correlation coefficientfor experiments on RG and WS data sets. It is noteworthythat we exclude all words that appear in the benchmark dataset from the training data created from WordNet asdescribed in Section 3.6. Benchmark data sets are reserved
for evaluation purposes only and we do not train or tuneany of the parameters using benchmark data sets.
4.2 Semantic Similarity
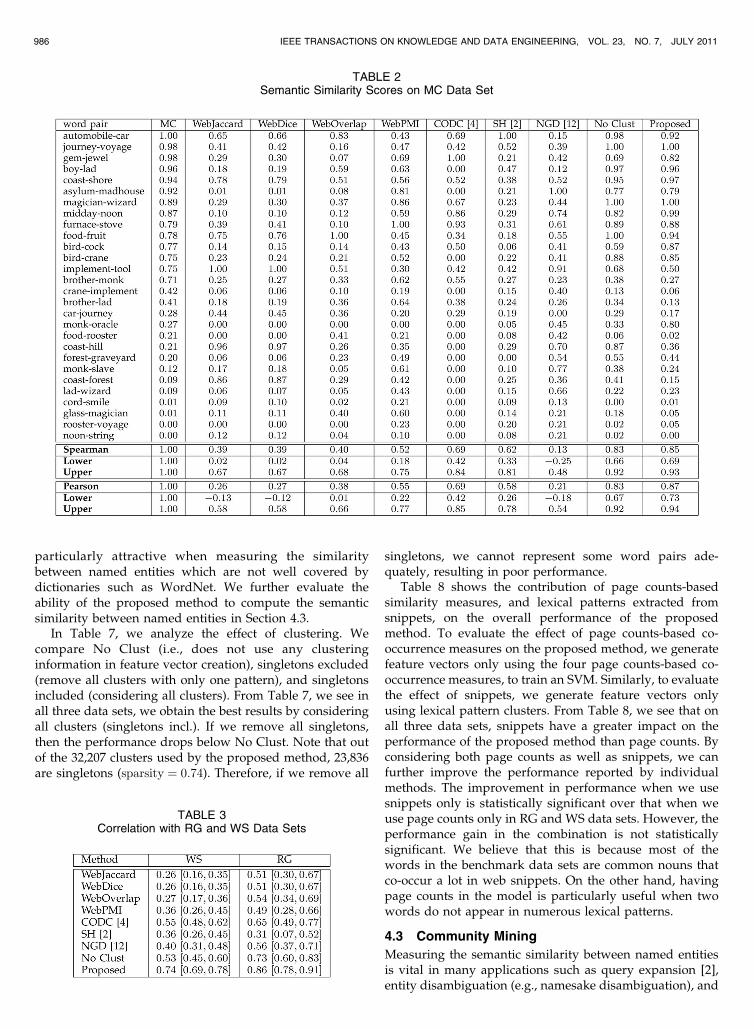
Table 2 shows the experimental results on MC data set forthe proposed method (Proposed); previously proposed web-based semantic similarity measures: Sahami and Heilman[2] (SH), Co-occurrence double-checking model [4], andNormalized Google Distance [12]; and the four page counts-based co-occurrence measures in Section 3.2. No Clustbaseline , which resembles our previously published work[34], is identical to the proposed method in all aspects exceptfor that it does not use cluster information. It can beunderstood as the proposed method with each extractedlexical pattern in its own cluster. No Clust is expected toshow the effect of clustering on the performance of theproposed method. All similarity scores in Table 2 arenormalized into ½0; 1� range for the ease of comparison, andFisher’s confidence intervals are computed for Spearmanand Pearson correlation coefficients. NGD is a distancemeasure and was converted to a similarity score by takingthe inverse. Original papers that proposed NGD and SHmeasures did not present their results on MC data set.Therefore, we reimplemented those systems following theoriginal papers. The proposed method achieves the highestPearson and Spearman coefficients in Table 2 and outper-forms all other web-based semantic similarity measures.WebPMI reports the highest correlation among all pagecounts-based co-occurrence measures. However, methodsthat use snippets such as SH and CODC, have bettercorrelation scores. MC data set contains polysemous wordssuch as father (priest versus parent), oracle (priest versusdatabase system), and crane (machine versus bird), whichare problematic for page counts-based measures that do notconsider the local context of a word. The No Clust baselinewhich combines both page counts and snippets outperformsthe CODC measure by a wide margin of 0.2 points.Moreover, by clustering the lexical patterns, we can furtherimprove the No Clust baseline.
Table 3 summarizes the experimental results on RG andWS data sets. Likewise on the MC data set, the proposedmethod outperforms all other methods on RG and WS datasets. In contrast to MC data set, the proposed methodoutperforms the No Clust baseline by a wide margin in RGand WS data sets. Unlike the MC data set which containsonly 28 word pairs, RG and WS data sets contain a largenumber of word pairs. Therefore, more reliable statisticscan be computed on RG and WS data sets. Fig. 9 shows thesimilarity scores produced by six methods against humanratings in the WS data set. We see that all methods deviatefrom the y ¼ x line, and are not linear. We believe thisjustifies the use of Spearman correlation instead of Pearsoncorrelation by previous work on semantic similarity as thepreferred evaluation measure.
Tables 4, 5, and 6, respectively, compare the proposedmethod against previously proposed semantic similaritymeasures. Despite the fact that the proposed method doesnot require manually created resources such as WordNet,Wikipedia, or fixed corpora, the performance of theproposed method is comparable with methods that usesuch resources. The nondependence on dictionaries is
BOLLEGALA ET AL.: A WEB SEARCH ENGINE-BASED APPROACH TO MEASURE SEMANTIC SIMILARITY BETWEEN WORDS 985
4. http://www.csie.ntu.edu.tw/cjlin/libsvm/.
Fig. 8. Sparsity versus clustering threshold �.
particularly attractive when measuring the similaritybetween named entities which are not well covered bydictionaries such as WordNet. We further evaluate theability of the proposed method to compute the semanticsimilarity between named entities in Section 4.3.
In Table 7, we analyze the effect of clustering. Wecompare No Clust (i.e., does not use any clusteringinformation in feature vector creation), singletons excluded(remove all clusters with only one pattern), and singletonsincluded (considering all clusters). From Table 7, we see inall three data sets, we obtain the best results by consideringall clusters (singletons incl.). If we remove all singletons,then the performance drops below No Clust. Note that outof the 32,207 clusters used by the proposed method, 23,836are singletons (sparsity ¼ 0:74). Therefore, if we remove all
singletons, we cannot represent some word pairs ade-quately, resulting in poor performance.
Table 8 shows the contribution of page counts-basedsimilarity measures, and lexical patterns extracted fromsnippets, on the overall performance of the proposedmethod. To evaluate the effect of page counts-based co-occurrence measures on the proposed method, we generatefeature vectors only using the four page counts-based co-occurrence measures, to train an SVM. Similarly, to evaluatethe effect of snippets, we generate feature vectors onlyusing lexical pattern clusters. From Table 8, we see that onall three data sets, snippets have a greater impact on theperformance of the proposed method than page counts. Byconsidering both page counts as well as snippets, we canfurther improve the performance reported by individualmethods. The improvement in performance when we usesnippets only is statistically significant over that when weuse page counts only in RG and WS data sets. However, theperformance gain in the combination is not statisticallysignificant. We believe that this is because most of thewords in the benchmark data sets are common nouns thatco-occur a lot in web snippets. On the other hand, havingpage counts in the model is particularly useful when twowords do not appear in numerous lexical patterns.
4.3 Community Mining
Measuring the semantic similarity between named entitiesis vital in many applications such as query expansion [2],entity disambiguation (e.g., namesake disambiguation), and
986 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 23, NO. 7, JULY 2011
TABLE 3Correlation with RG and WS Data Sets
TABLE 2Semantic Similarity Scores on MC Data Set
community mining [46]. Because most named entities are
not covered by WordNet, similarity measures that are based
on WordNet cannot be used directly in these tasks. Unlike
common English words, named entities are being created
constantly. Manually maintaining an up-to-date taxonomy
of named entities is costly, if not impossible. The proposed
semantic similarity measure is appealing for these applica-
tions because it does not require precompiled taxonomies.In order to evaluate the performance of the proposed
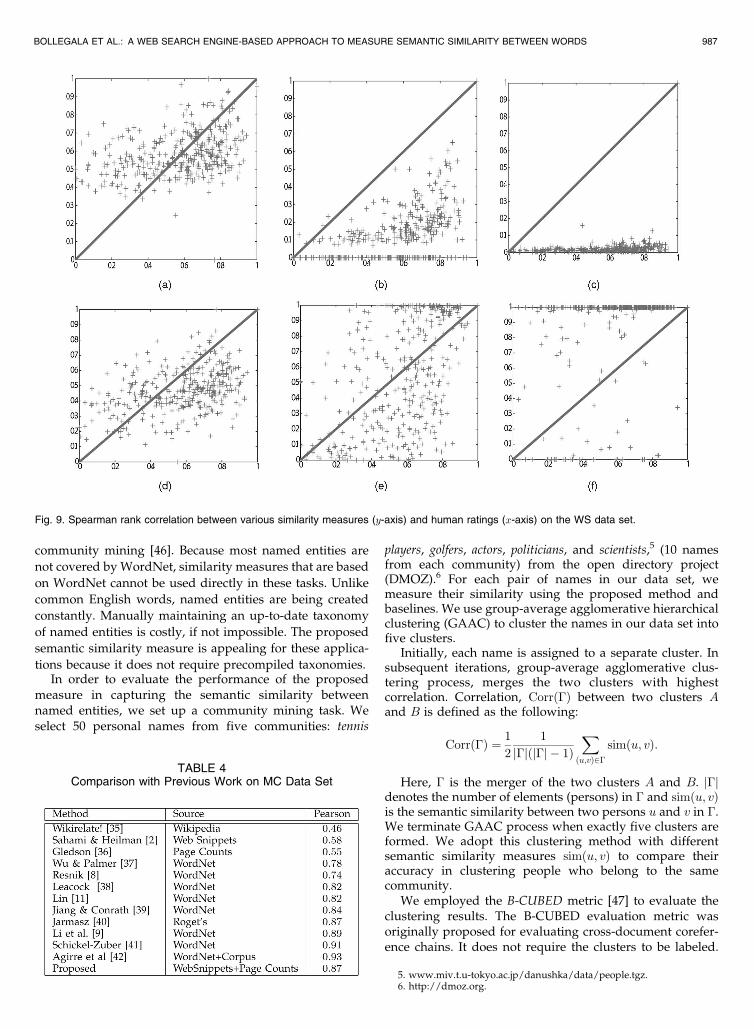
measure in capturing the semantic similarity betweennamed entities, we set up a community mining task. Weselect 50 personal names from five communities: tennis
players, golfers, actors, politicians, and scientists,5 (10 namesfrom each community) from the open directory project(DMOZ).6 For each pair of names in our data set, wemeasure their similarity using the proposed method andbaselines. We use group-average agglomerative hierarchicalclustering (GAAC) to cluster the names in our data set intofive clusters.
Initially, each name is assigned to a separate cluster. Insubsequent iterations, group-average agglomerative clus-tering process, merges the two clusters with highestcorrelation. Correlation, Corrð�Þ between two clusters Aand B is defined as the following:
Corrð�Þ ¼ 1
2
1
j�jðj�j � 1ÞXðu;vÞ2�
simðu; vÞ:
Here, � is the merger of the two clusters A and B. j�jdenotes the number of elements (persons) in � and simðu; vÞis the semantic similarity between two persons u and v in �.We terminate GAAC process when exactly five clusters areformed. We adopt this clustering method with differentsemantic similarity measures simðu; vÞ to compare theiraccuracy in clustering people who belong to the samecommunity.
We employed the B-CUBED metric [47] to evaluate theclustering results. The B-CUBED evaluation metric wasoriginally proposed for evaluating cross-document corefer-ence chains. It does not require the clusters to be labeled.
BOLLEGALA ET AL.: A WEB SEARCH ENGINE-BASED APPROACH TO MEASURE SEMANTIC SIMILARITY BETWEEN WORDS 987
5. www.miv.t.u-tokyo.ac.jp/danushka/data/people.tgz.6. http://dmoz.org.
Fig. 9. Spearman rank correlation between various similarity measures (y-axis) and human ratings (x-axis) on the WS data set.
TABLE 4Comparison with Previous Work on MC Data Set

We compute precision, recall, and F -score for each name inthe data set and average the results over the data set. Foreach person p in our data set, let us denote the cluster that pbelongs to by CðpÞ. Moreover, we use AðpÞ to denote theaffiliation of person p, e.g., Að“Tiger Woods”Þ ¼ “TennisPlayer.” Then, we calculate precision and recall for personp as
PrecisionðpÞ ¼ No: of people in CðpÞ with affiliation AðpÞNo: of people in CðpÞ ;
RecallðpÞ ¼ No: of people in CðpÞ with affiliation AðpÞTotal No: of people with affiliation AðpÞ :
Since, we selected 10 people from each of the fivecategories, the total number of people with a particularaffiliation is 10 for all the names p. Then, the F -score ofperson p is defined as
FðpÞ ¼ 2� Precision ðpÞ �RecallðpÞPrecisionðpÞ þ RecallðpÞ :
Overall precision, recall, and F -score are computed bytaking the averaged sum over all the names in the data set.
Precision ¼ 1
N
Xp2Data Set
PrecisionðpÞ
Recall ¼ 1
N
Xp2Data Set
RecallðpÞ
F -Score ¼ 1
N
Xp2Data Set
FðpÞ:
Here, Data Set is the set of 50 names selected from the opendirectory project. Therefore, N ¼ 50 in our evaluations.
Experimental results are shown in Table 9. The proposedmethod shows the highest entity clustering accuracy inTable 9 with a statistically significant (p � 0:01 Tukey HSD)F-score of 0.86. Sahami and Heilman’s [2] snippet-basedsimilarity measure, WebJaccard, WebDice, and WebOver-lap measures yield similar clustering accuracies. By cluster-ing semantically related lexical patterns, we see that bothprecision as well as recall can be improved in a communitymining task.
5 CONCLUSION
We proposed a semantic similarity measure using both pagecounts and snippets retrieved from a web search engine fortwo words. Four word co-occurrence measures werecomputed using page counts. We proposed a lexical patternextraction algorithm to extract numerous semantic relationsthat exist between two words. Moreover, a sequential patternclustering algorithm was proposed to identify differentlexical patterns that describe the same semantic relation.Both page counts-based co-occurrence measures and lexicalpattern clusters were used to define features for a word pair.A two-class SVM was trained using those features extractedfor synonymous and nonsynonymous word pairs selectedfrom WordNet synsets. Experimental results on threebenchmark data sets showed that the proposed methodoutperforms various baselines as well as previously pro-posed web-based semantic similarity measures, achieving ahigh correlation with human ratings. Moreover, the pro-posed method improved the F -score in a community mining
988 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 23, NO. 7, JULY 2011
TABLE 9Results for Community MiningTABLE 6
Comparison with Previous Work on WS Data Set
TABLE 7Effect of Pattern Clustering (Spearman)
TABLE 8Page Counts versus Snippets (Spearman)
TABLE 5Comparison with Previous Work on RG Data Set

task, thereby underlining its usefulness in real-world tasks,
that include named entities not adequately covered by
manually created resources.
REFERENCES
[1] A. Kilgarriff, “Googleology Is Bad Science,” ComputationalLinguistics, vol. 33, pp. 147-151, 2007.
[2] M. Sahami and T. Heilman, “A Web-Based Kernel Function forMeasuring the Similarity of Short Text Snippets,” Proc. 15th Int’lWorld Wide Web Conf., 2006.
[3] D. Bollegala, Y. Matsuo, and M. Ishizuka, “DisambiguatingPersonal Names on the Web Using Automatically Extracted KeyPhrases,” Proc. 17th European Conf. Artificial Intelligence, pp. 553-557, 2006.
[4] H. Chen, M. Lin, and Y. Wei, “Novel Association MeasuresUsing Web Search with Double Checking,” Proc. 21st Int’l Conf.Computational Linguistics and 44th Ann. Meeting of the Assoc. forComputational Linguistics (COLING/ACL ’06), pp. 1009-1016,2006.
[5] M. Hearst, “Automatic Acquisition of Hyponyms from Large TextCorpora,” Proc. 14th Conf. Computational Linguistics (COLING),pp. 539-545, 1992.
[6] M. Pasca, D. Lin, J. Bigham, A. Lifchits, and A. Jain, “Organizingand Searching the World Wide Web of Facts - Step One: The One-Million Fact Extraction Challenge,” Proc. Nat’l Conf. ArtificialIntelligence (AAAI ’06), 2006.
[7] R. Rada, H. Mili, E. Bichnell, and M. Blettner, “Development andApplication of a Metric on Semantic Nets,” IEEE Trans. Systems,Man and Cybernetics, vol. 19, no. 1, pp. 17-30, Jan./Feb. 1989.
[8] P. Resnik, “Using Information Content to Evaluate SemanticSimilarity in a Taxonomy,” Proc. 14th Int’l Joint Conf. AritificialIntelligence, 1995.
[9] D. Mclean, Y. Li, and Z.A. Bandar, “An Approach for MeasuringSemantic Similarity between Words Using Multiple InformationSources,” IEEE Trans. Knowledge and Data Eng., vol. 15, no. 4,pp. 871-882, July/Aug. 2003.
[10] G. Miller and W. Charles, “Contextual Correlates of SemanticSimilarity,” Language and Cognitive Processes, vol. 6, no. 1, pp. 1-28,1998.
[11] D. Lin, “An Information-Theoretic Definition of Similarity,” Proc.15th Int’l Conf. Machine Learning (ICML), pp. 296-304, 1998.
[12] R. Cilibrasi and P. Vitanyi, “The Google Similarity Distance,” IEEETrans. Knowledge and Data Eng., vol. 19, no. 3, pp. 370-383, Mar.2007.
[13] M. Li, X. Chen, X. Li, B. Ma, and P. Vitanyi, “The SimilarityMetric,” IEEE Trans. Information Theory, vol. 50, no. 12, pp. 3250-3264, Dec. 2004.
[14] P. Resnik, “Semantic Similarity in a Taxonomy: An InformationBased Measure and Its Application to Problems of Ambiguity inNatural Language,” J. Artificial Intelligence Research, vol. 11, pp. 95-130, 1999.
[15] R. Rosenfield, “A Maximum Entropy Approach to AdaptiveStatistical Modelling,” Computer Speech and Language, vol. 10,pp. 187-228, 1996.
[16] D. Lin, “Automatic Retrieval and Clustering of Similar Words,”Proc. 17th Int’l Conf. Computational Linguistics (COLING), pp. 768-774, 1998.
[17] J. Curran, “Ensemble Methods for Automatic Thesaurus Extrac-tion,” Proc. ACL-02 Conf. Empirical Methods in Natural LanguageProcessing (EMNLP), 2002.
[18] C. Buckley, G. Salton, J. Allan, and A. Singhal, “Automatic QueryExpansion Using Smart: Trec 3,” Proc. Third Text REtreival Conf.,pp. 69-80, 1994.
[19] V. Vapnik, Statistical Learning Theory. Wiley, 1998.[20] K. Church and P. Hanks, “Word Association Norms, Mutual
Information and Lexicography,” Computational Linguistics, vol. 16,pp. 22-29, 1991.
[21] Z. Bar-Yossef and M. Gurevich, “Random Sampling from a SearchEngine’s Index,” Proc. 15th Int’l World Wide Web Conf., 2006.
[22] F. Keller and M. Lapata, “Using the Web to Obtain Frequencies forUnseen Bigrams,” Computational Linguistics, vol. 29, no. 3, pp. 459-484, 2003.
[23] M. Lapata and F. Keller, “Web-Based Models for NaturalLanguage Processing,” ACM Trans. Speech and Language Processing,vol. 2, no. 1, pp. 1-31, 2005.
[24] R. Snow, D. Jurafsky, and A. Ng, “Learning Syntactic Patterns forAutomatic Hypernym Discovery,” Proc. Advances in NeuralInformation Processing Systems (NIPS), pp. 1297-1304, 2005.
[25] M. Berland and E. Charniak, “Finding Parts in Very LargeCorpora,” Proc. Ann. Meeting of the Assoc. for ComputationalLinguistics on Computational Linguistics (ACL ’99), pp. 57-64, 1999.
[26] D. Ravichandran and E. Hovy, “Learning Surface Text Patterns fora Question Answering System,” Proc. Ann. Meeting on Assoc. forComputational Linguistics (ACL ’02), pp. 41-47, 2001.
[27] R. Bhagat and D. Ravichandran, “Large Scale Acquisition ofParaphrases for Learning Surface Patterns,” Proc. Assoc. forComputational Linguistics: Human Language Technologies (ACL ’08:HLT), pp. 674-682, 2008.
[28] J. Pei, J. Han, B. Mortazavi-Asi, J. Wang, H. Pinto, Q. Chen, U.Dayal, and M. Hsu, “Mining Sequential Patterns by Pattern-Growth: The Prefixspan Approach,” IEEE Trans. Knowledge andData Eng., vol. 16, no. 11, pp. 1424-1440, Nov. 2004.
[29] Z. Harris, “Distributional Structure,” Word, vol. 10, pp. 146-162,1954.
[30] J. Platt, “Probabilistic Outputs for Support Vector Machines andComparison to Regularized Likelihood Methods,” Advances inLarge Margin Classifiers, pp. 61-74, MIT Press, 2000.
[31] P. Gill, W. Murray, and M. Wright, Practical Optimization.Academic Press, 1981.
[32] H. Rubenstein and J. Goodenough, “Contextual Correlates ofSynonymy,” Comm. ACM, vol. 8, pp. 627-633, 1965.
[33] L. Finkelstein, E. Gabrilovich, Y. Matias, E. Rivlin, Z. Solan, G.Wolfman, and E. Ruppin, “Placing Search in Context: The ConceptRevisited,” ACM Trans. Information Systems, vol. 20, pp. 116-131,2002.
[34] D. Bollegala, Y. Matsuo, and M. Ishizuka, “Measuring SemanticSimilarity between Words Using Web Search Engines,” Proc. Int’lConf. World Wide Web (WWW ’07), pp. 757-766, 2007.
[35] M. Strube and S.P. Ponzetto, “Wikirelate! Computing SemanticRelatedness Using Wikipedia,” Proc. Nat’l Conf. Artificial Intelli-gence (AAAI ’06), pp. 1419-1424, 2006.
[36] A. Gledson and J. Keane, “Using Web-Search Results to MeasureWord-Group Similarity,” Proc. Int’l Conf. Computational Linguistics(COLING ’08), pp. 281-288, 2008.
[37] Z. Wu and M. Palmer, “Verb Semantics and Lexical Selection,”Proc. Ann. Meeting on Assoc. for Computational Linguistics (ACL ’94),pp. 133-138, 1994.
[38] C. Leacock and M. Chodorow, “Combining Local Context andWordnet Similarity for Word Sense Disambiguation,” WordNet:An Electronic Lexical Database, vol. 49, pp. 265-283, MIT Press, 1998.
[39] J. Jiang and D. Conrath, “Semantic Similarity Based on CorpusStatistics and Lexical Taxonomy,” Proc. Int’l Conf. Research inComputational Linguistics (ROCLING X), 1997.
[40] M. Jarmasz, “Roget’s Thesaurus as a Lexical Resource for NaturalLanguage Processing,” technical report, Univ. of Ottowa, 2003.
[41] V. Schickel-Zuber and B. Faltings, “OSS: A Semantic SimilarityFunction Based on Hierarchical Ontologies,” Proc. Int’l Joint Conf.Artificial Intelligence (IJCAI ’07), pp. 551-556, 2007.
[42] E. Agirre, E. Alfonseca, K. Hall, J. Kravalova, M. Pasca, and A.Soroa, “A Study on Similarity and Relatedness Using Distribu-tional and Wordnet-Based Approaches,” Proc. Human LanguageTechnologies: The 2009 Ann. Conf. North Am. Chapter of the Assoc. forComputational Linguistics (NAACL-HLT ’09), 2009.
[43] G. Hirst and D. St-Onge, “Lexical Chains as Representations ofContext for the Detection and Correction of Malapropisms,”WordNet: An Electronic Lexical Database, pp. 305-332, MIT Press,1998.
[44] T. Hughes and D. Ramage, “Lexical Semantic Relatedness withRandom Graph Walks,” Proc. Joint Conf. Empirical Methods inNatural Language Processing and Computational Natural LanguageLearning (EMNLP-CoNLL ’07), pp. 581-589, 2007.
[45] E. Gabrilovich and S. Markovitch, “Computing Semantic Related-ness Using Wikipedia-Based Explicit Semantic Analysis,” Proc.Int’l Joint Conf. Artificial Intelligence (IJCAI ’07), pp. 1606-1611, 2007.
[46] Y. Matsuo, J. Mori, M. Hamasaki, K. Ishida, T. Nishimura, H.Takeda, K. Hasida, and M. Ishizuka, “Polyphonet: An AdvancedSocial Network Extraction System,” Proc. 15th Int’l World Wide WebConf., 2006.
[47] A. Bagga and B. Baldwin, “Entity-Based Cross DocumentCoreferencing Using the Vector Space Model,” Proc. 36th Ann.Meeting of the Assoc. for Computational Linguistics and 17th Int’l Conf.Computational Linguistics (COLING-ACL), pp. 79-85, 1998.
BOLLEGALA ET AL.: A WEB SEARCH ENGINE-BASED APPROACH TO MEASURE SEMANTIC SIMILARITY BETWEEN WORDS 989

Danushka Bollegala received the BS, MS, andPhD degrees from the University of Tokyo,Japan, in 2005, 2007, and 2009, respectively.He is currently a research fellow of the Japanesesociety for the promotion of science (JSPS). Hisresearch interests are natural language proces-sing, web mining, and artificial intelligence.
Yutaka Matsuo received the BS, MS, and PhDdegrees from the University of Tokyo, in 1997,1999, and 2002, respectively. He is an associateprofessor at the Institute of Engineering Innova-tion, the University of Tokyo, Japan. He joinedthe National Institute of Advanced IndustrialScience and Technology (AIST) from 2002 to2007. He is interested in social network mining,text processing, and semantic web in the contextof artificial intelligence research.
Mitsuru Ishizuka (M’79) received the BS andPhD degrees in electronic engineering from theUniversity of Tokyo in 1971 and 1976. He is aprofessor at the Graduate School of InformationScience and Technology, the University ofTokyo, Japan. His research interests includeartificial intelligence, web intelligence, and life-like agents. He is a member of the IEEE.
. For more information on this or any other computing topic,please visit our Digital Library at www.computer.org/publications/dlib.
990 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 23, NO. 7, JULY 2011





























