Embed Size (px)
DESCRIPTION
Team : Louise Guthrie, Roberto Basili, Fabio Zanzotto, Hamish Cunningham, Kalina Boncheva, Jia Cui, Klaus Macherey, David Guthrie, Martin Holub, Marco Cammisa, Cassia Martin, Jerry Liu, Kris Haralambiev Fred Jelinek. Semantic Annotation – Week 3. Our Hypotheses. - PowerPoint PPT Presentation
Citation preview

JHU WORKSHOP - 2003July 30th, 2003
Semantic Annotation – Week 3
Team: Louise Guthrie, Roberto Basili, Fabio Zanzotto, Hamish Cunningham, Kalina Boncheva, Jia Cui, Klaus Macherey, David Guthrie, Martin Holub, Marco Cammisa, Cassia Martin, Jerry Liu, Kris Haralambiev
Fred Jelinek

JHU WORKSHOP - 2003July 30th, 2003
Our Hypotheses
● A transformation of a corpus to replace words and phrases with coarse semantic categories will help overcome the data sparseness problem encountered in language modeling
● Semantic category information will also help improve machine translation
● A noun-centric approach initially will allow bootstrapping for other syntactic categories

JHU WORKSHOP - 2003July 30th, 2003
An Example
● Astronauts aboard the space shuttle Endeavor were forced to dodge a derelict Air Force satellite Friday
● Humans aboard space_vehicle dodge satellite timeref.

JHU WORKSHOP - 2003July 30th, 2003
Our Progress – Preparing the data- Pre-Workshop
● Identify a tag set
● Create a Human annotated corpus
● Create a double annotated corpus
● Process all data for named entity and noun phrase recognition using GATE Tools
● Develop algorithms for mapping target categories to Wordnet synsets to support the tag set assessment

JHU WORKSHOP - 2003July 30th, 2003
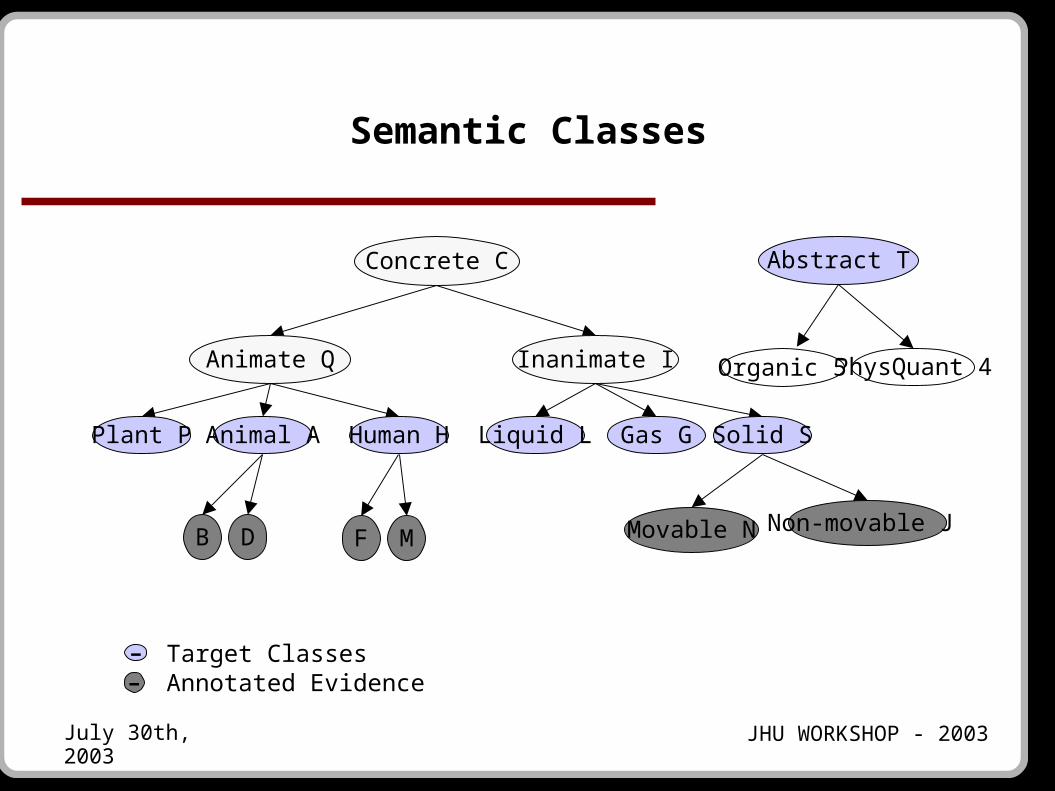
The Semantic Classes for Annotators
● A subset of classes available in Longman's Dictionary of contemporary English (LDOCE) Electronic version
● Rationale:
The number of semantic classes was smallThe classes are somewhat reliable since they were used by a team of lexicographers to code
Noun senses Adjective preferences Verb preferences
JHU WORKSHOP - 2003July 30th, 2003
Semantic Classes
Abstract T
B Movable N
Animate Q
Plant P Animal A Human H
Inanimate I
Liquid L Gas G Solid S
Concrete C
D F MNon-movable J
• Target Classes• Annotated Evidence--
PhysQuant 4Organic 5

JHU WORKSHOP - 2003July 30th, 2003
More Categories
● U: Collective● K: Male● R: Female● W: Not animate● X: Not concrete or animal● Z: Unmarked
We allowed annotators to choose “none of the above” (? in the slides that follow)

JHU WORKSHOP - 2003July 30th, 2003
Our Progress – Data Preparation
● Assess annotation format and define uniform descriptions for irregular phenomena and normalize them
● Determine the distribution of the tag set in the training corpus
● Analyze inter-annotator agreement
● Determine a reliable set of tags – T
● Parse all training data

JHU WORKSHOP - 2003July 30th, 2003
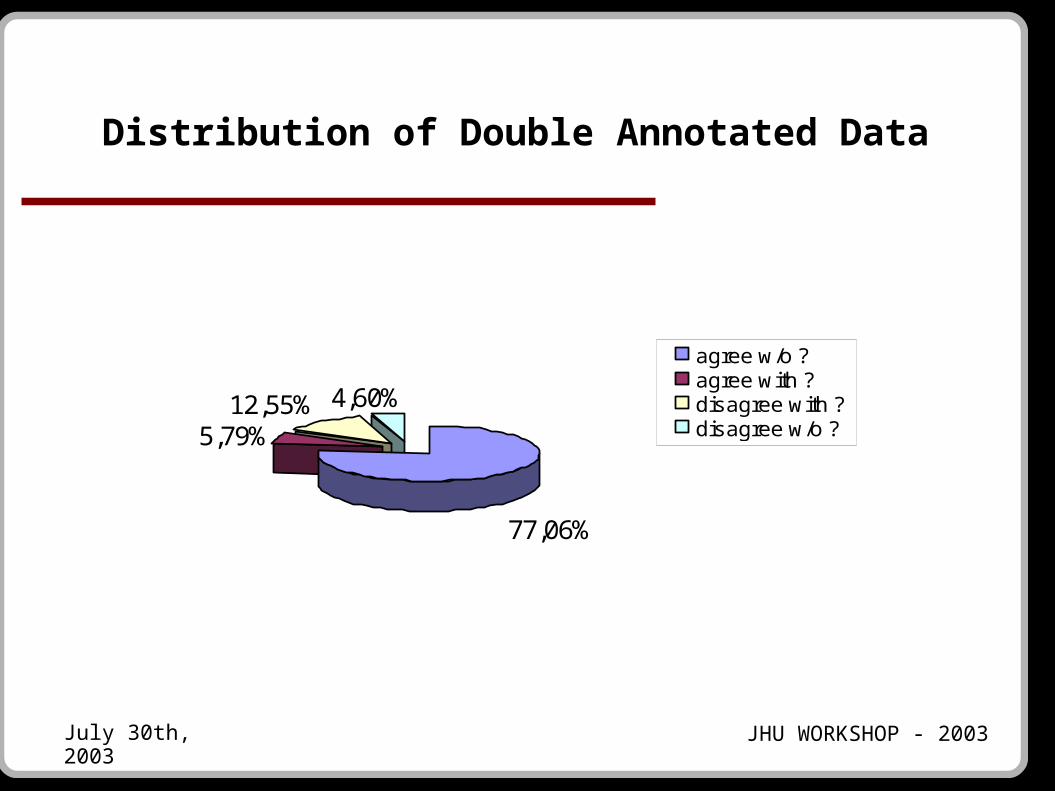
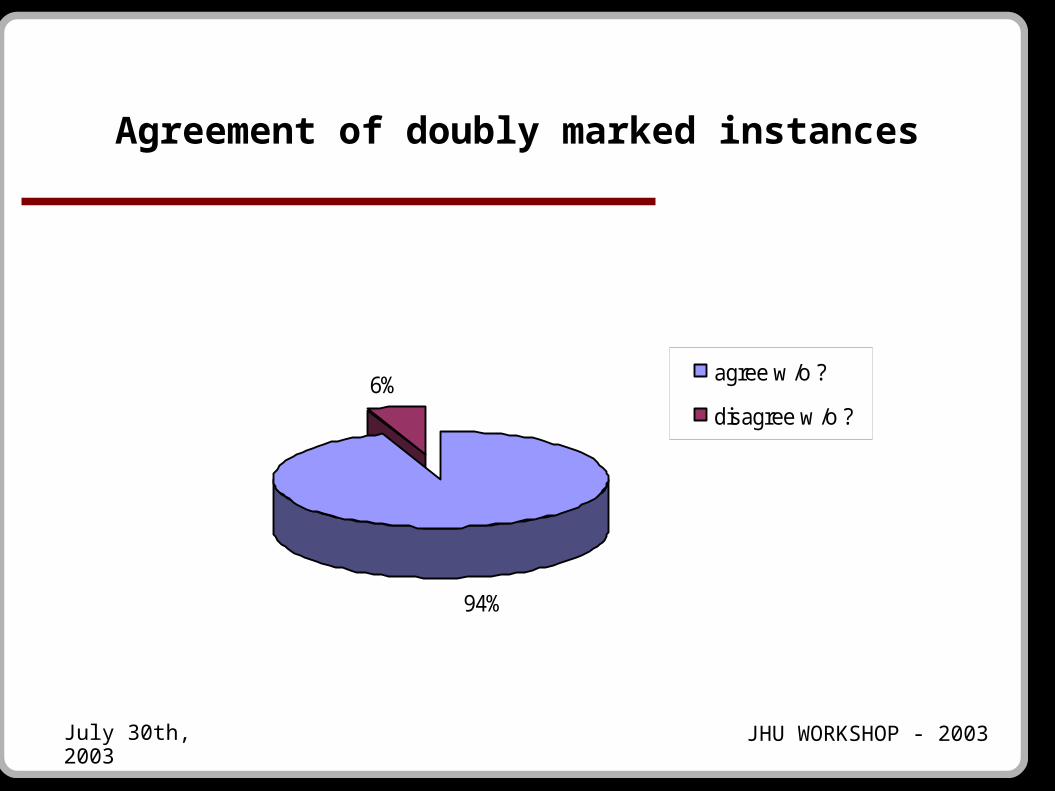
Doubly Annotated Data
● Instances (headwords): 10960
● 8,950 instances without question marks.
● 8,446 of those are marked the same.
● Inter-annotator agreement is 94% (83% including question marks)
●
Recall – these are non named entity noun phrases
JHU WORKSHOP - 2003July 30th, 2003
77,06%
5,79%12,55% 4,60%
agree w/o ?agree with ?disagree with ?disagree w/o ?
Distribution of Double Annotated Data
JHU WORKSHOP - 2003July 30th, 2003
Agreement of doubly marked instances
94%
6% agree w/o ?
disagree w/o ?
JHU WORKSHOP - 2003July 30th, 2003
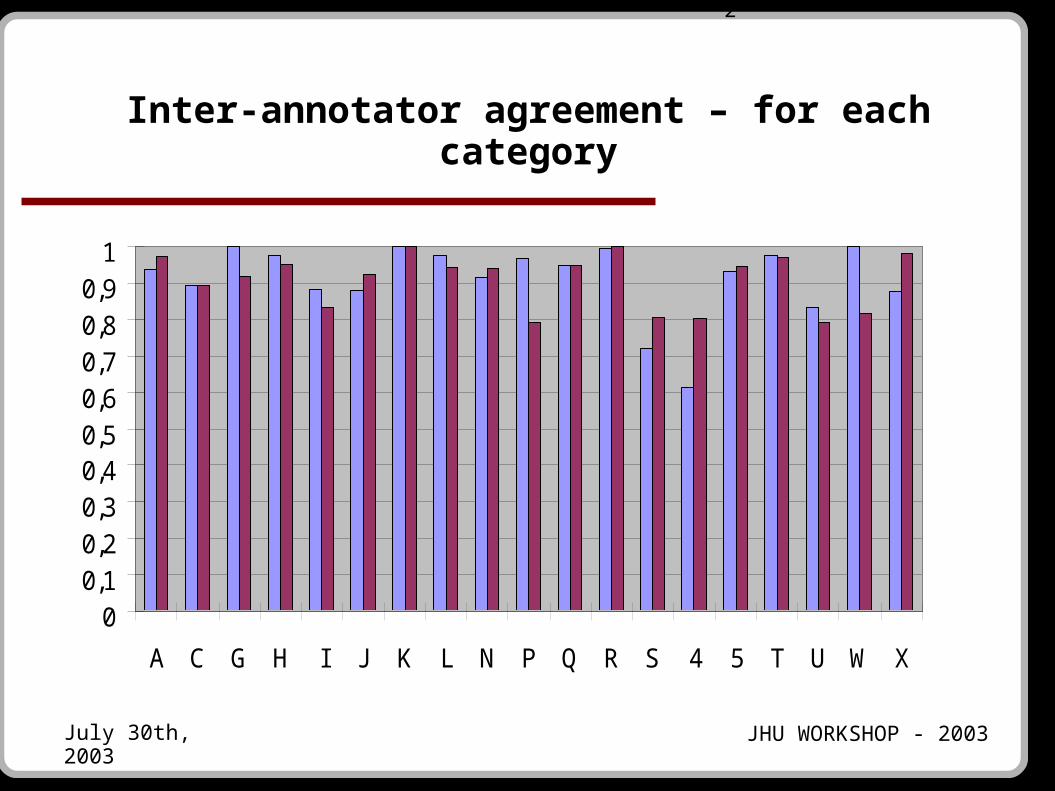
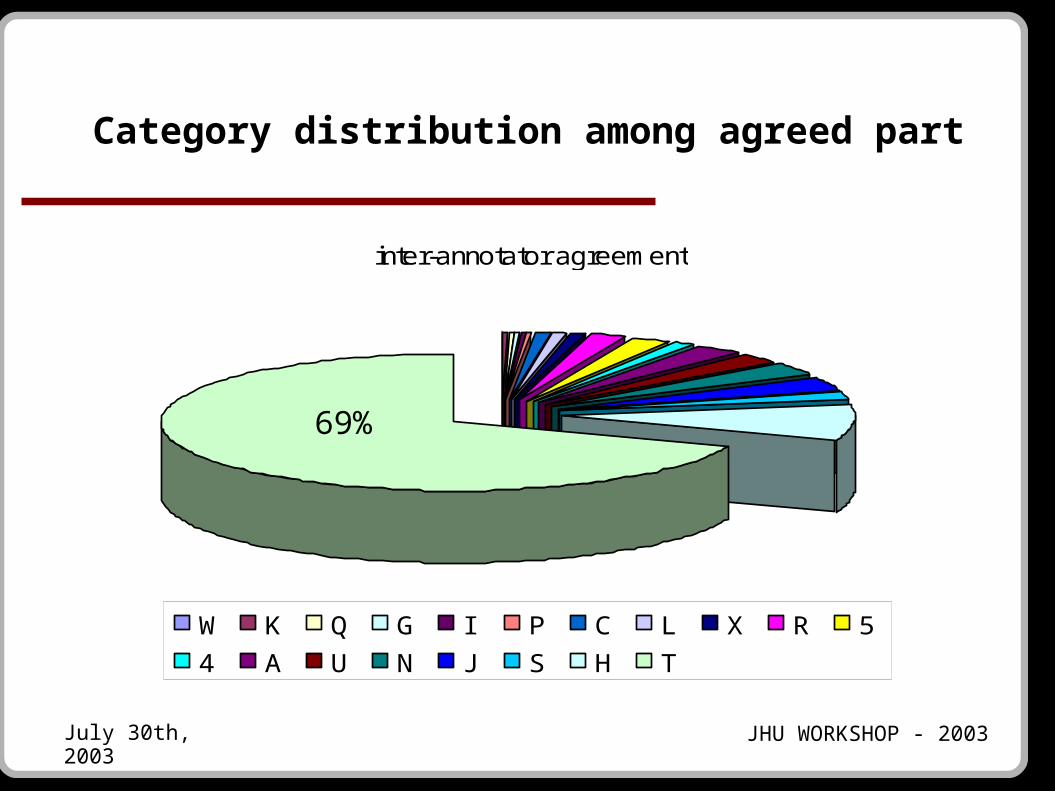
Inter-annotator agreement – for each category
00,10,20,30,40,50,60,70,80,9
1
A C G H I J K L N P Q R S 4 5 T U W X
2
JHU WORKSHOP - 2003July 30th, 2003
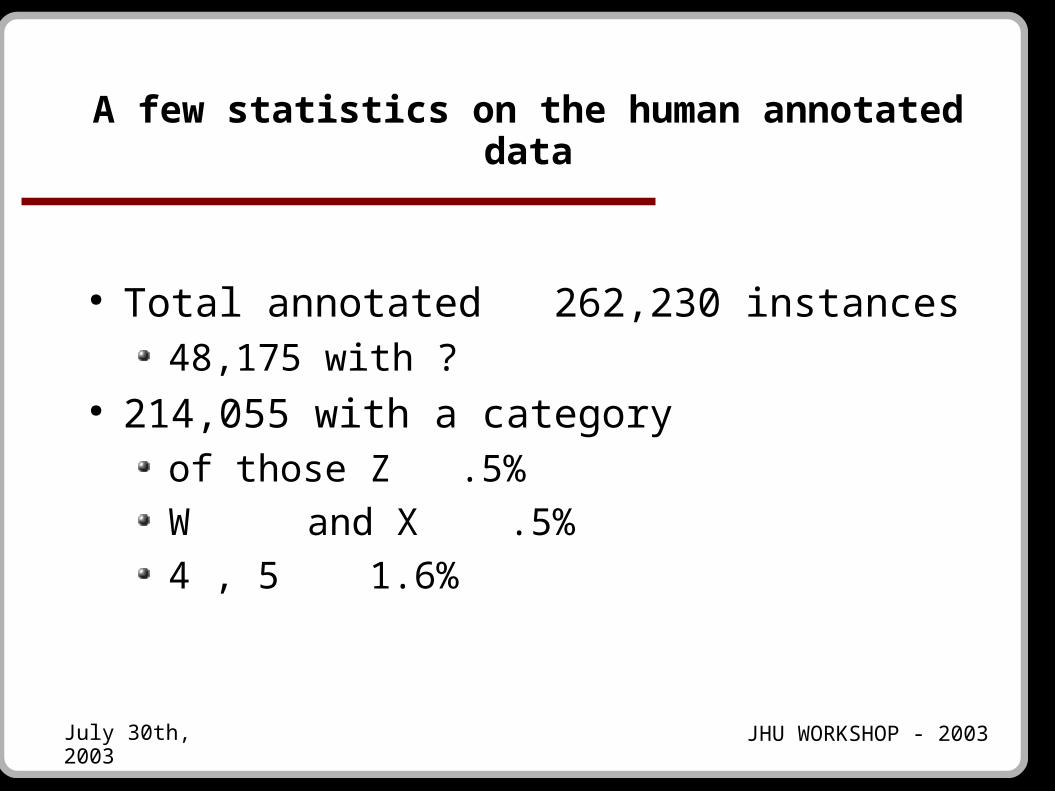
Category distribution among agreed part
inter-annotator agreement
W K Q G I P C L X R 5
4 A U N J S H T
69%
JHU WORKSHOP - 2003July 30th, 2003
A few statistics on the human annotated data
● Total annotated 262,230 instances48,175 with ?
● 214,055 with a categoryof those Z .5%
W and X .5%
4 , 5 1.6%

JHU WORKSHOP - 2003July 30th, 2003
Our progress – baselines
● Determine baselines for automatic tagging of noun phrases
● Baselines for tagging observed words in new contexts (new instances of known words)
● Baselines for tagging unobserved words Unseen words – not in the training material but in dictionary
Novel words – not in the training material nor in the dictionary/Wordnet
JHU WORKSHOP - 2003July 30th, 2003
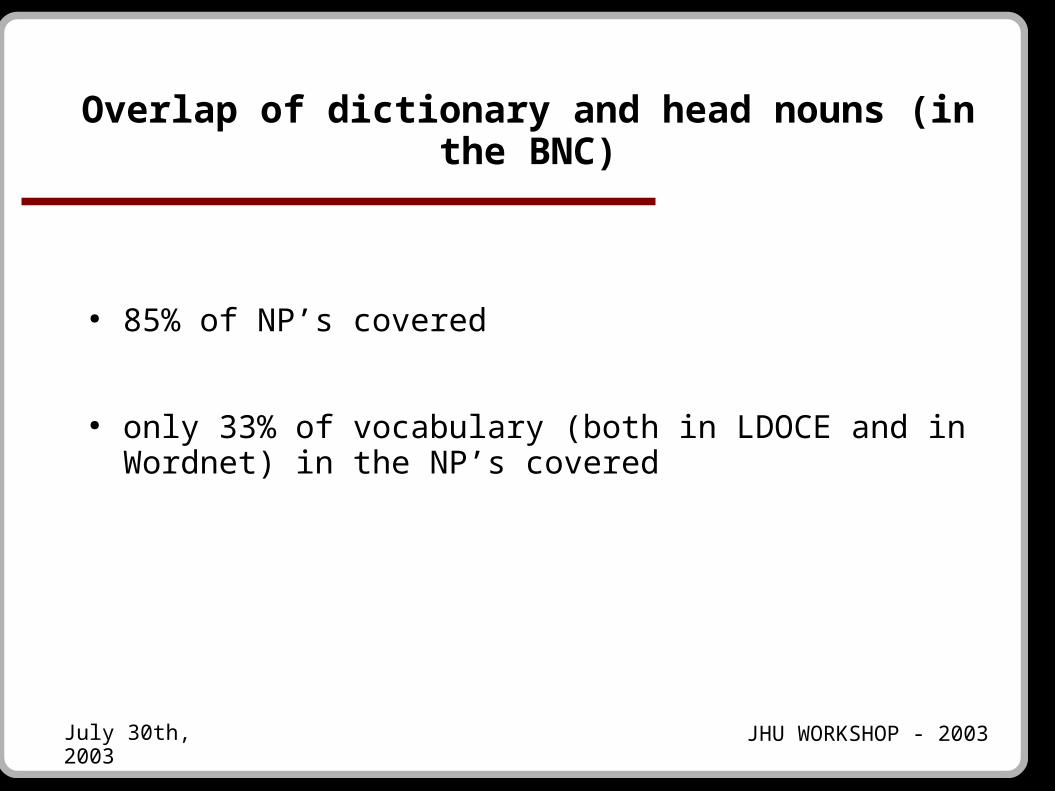
Overlap of dictionary and head nouns (in the BNC)
● 85% of NP’s covered
● only 33% of vocabulary (both in LDOCE and in Wordnet) in the NP’s covered

JHU WORKSHOP - 2003July 30th, 2003
Preparation of the test environment
● Selected the blind portion of the human annotated data for late evaluation
● Divided the remaining corpus into training and held-out portions
Random division of files
Unambiguous words for training – ambiguous for testing
JHU WORKSHOP - 2003July 30th, 2003
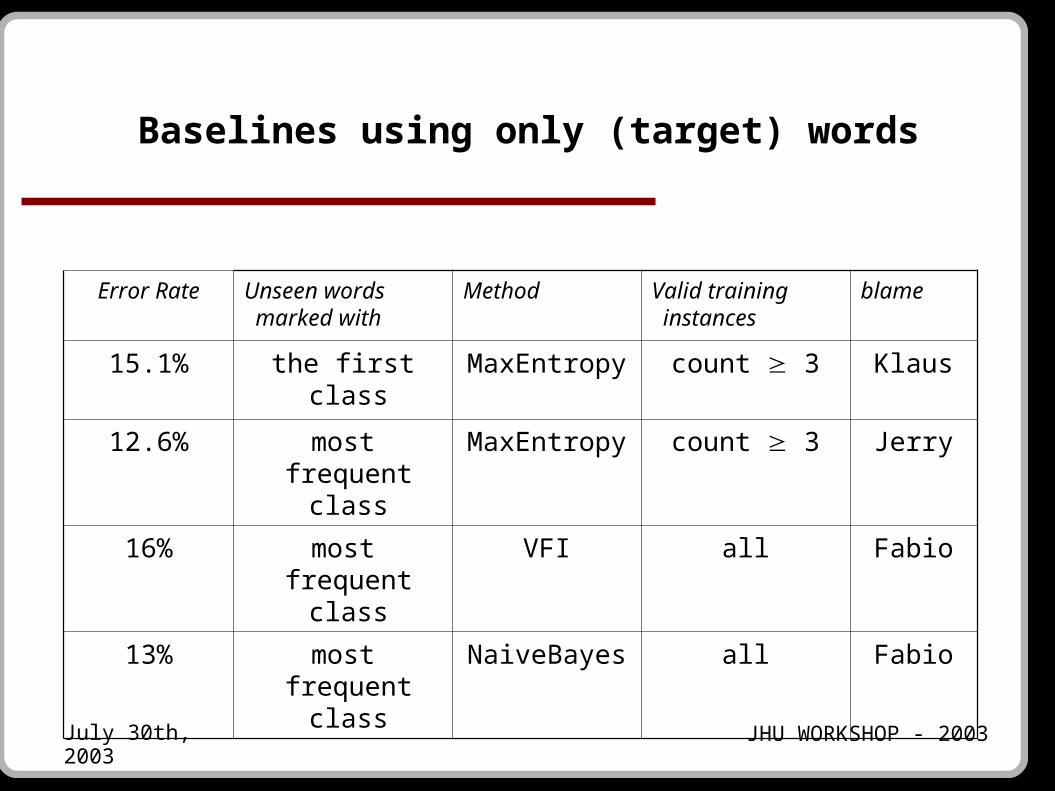
Baselines using only (target) words
Error Rate Unseen words marked with
Method Valid training instances
blame
15.1% the first class MaxEntropy count 3 Klaus
12.6% most frequent class
MaxEntropy count 3 Jerry
16% most frequent class
VFI all Fabio
13% most frequent class
NaiveBayes all Fabio

JHU WORKSHOP - 2003July 30th, 2003
Baselines using only (target) words and preceeding adjectives
Error Rate Unseen words marked with
Method Valid training instances
blame
13% most frequent class
MaxEntropy count 3 Jerry
13.2% most frequent class
MaxEntropy all Jerry
12.7% most frequent class
MaxEntropy count 3 Jerry

JHU WORKSHOP - 2003July 30th, 2003
Baselines using multiple knowledge sources
● Experiments in Sheffield
● Unambiguous tagger (assign only available semantic categories)
● bag-of-words tagger (IR inspired)window size 50 wordsnouns and verbs
● Frequency-based tagger (assign the most frequent semantic category)

JHU WORKSHOP - 2003July 30th, 2003
Baselines using multiple knowledge sources (cont’d)
● Frequency-based tagger
16-18% error rate
● bag-of-words tagger
17% error rate
● Combined architecture
14.5-15% error rate

JHU WORKSHOP - 2003July 30th, 2003
Bootstrapping to Unseen Words
● Problem: Automatically identify the semantic class of words in LDOCE whose behavior was not observed in the training data
● Basic Idea: We use the unambiguous words (unambiguous with respect to the our semantic tag set) to learn context for tagging unseen words.

JHU WORKSHOP - 2003July 30th, 2003
Bootstrapping: statistics
6,656 different unambiguous lemmas in the (visible) human tagged corpus
...these contribute to 166,249 instances of data
...134,777 instances were considered correct by the annotators
! Observation: Unambiguous words can be used in the corpus in an “unforeseen” way

JHU WORKSHOP - 2003July 30th, 2003
Bootstrapping baselines
Method % correct labelled instances
Assigning the most frequent semantic tag (i.e. Abstract)
52%
Using one previous word (Adjective, Noun, or Verb) (using Naive Bayes Classifier)
(with reliable tagged instances) 45%
(with all instances) 44.3%
1 previous and 1 following word (Adjective, Noun, or Verb) (using Naive Bayes Classifier)
(with reliable tagged instances) 46.8%
(with all instances) 44.5%
● Test Instances (instances of ambiguous words) : 62,853

JHU WORKSHOP - 2003July 30th, 2003
Metrics for Intrinsic Evaluation
● Need to take into account the hierarchical structure of the target semantic categories
● Two fuzzy measures based on:
dominance between categories
edge distance in the category tree/graph
● Results wrt inter annotator agreement is almost identical to exact match

JHU WORKSHOP - 2003July 30th, 2003
What’s next
● Investigate respective contribution of (independent) features
● Incorporate syntactic information
● Refine some coarse categories
Using subject codes
Using genus terms
Re-mapping via Wordnet

JHU WORKSHOP - 2003July 30th, 2003
What’s next (cont’d)
● Reduce the number of features/values via external resources:
lexical vs. semantic models of the context
use selectional preferences
● Concentrate on complex cases (e.g. unseen words)
● Preparation of test data for extrinsic evaluation (MT)





























