Embed Size (px)
Citation preview

Semantic and phonetic automatic reconstruction ofmedical dictationsSTEFAN PETRIK , CHRISTINA DREXEL, LEO FESSLER , JEREMY JANCSARY , ALEXANDRA KLEIN ,GERNOT KUBIN , JOHANNES MATIASEK , FRANZ PERNKOPF , HARALD TROST

About•ASR in Medical Dictation.•Reconstruction of literal transcripts to improve .•Retraining of Standard Language Model with reconstructed transcripts.

IntroductionASR eliminated the need to type whole documents instead the medical transcriptionists just need to do post-processing which too is a bit time consuming and tedious
To train the ASR system to perform better literal transcripts are required

• A way of getting over this problem is unsupervised or lightly supervised learning.• Although these methodologies reduce WER they do not give
explanations for the mismatch

SPARC approach•A framework for reconstruction of literal transcripts from the recognition result and final medical reports•Available data: Audio Files, Draft Transcripts and Final report•Error Categorization: recognition error or Reformulation


Phonetics
similar dissimilar
Semantics similar Match Reformulation
dissimilar Correction Reformulation and correction
The SPARC approach to text reconstruction. Based on semantic and phonetic similarity measurements, chunks of written and recognized text can be classified as either matches, reformulations, corrections or a combination of both.

Data Description•Define a mismatch region as a contiguous sequence of mismatch edit operations in order to establish correspondences between matched words.•A statistical study of a corpus of 80,000 medical reports with 38 million words revealed an average length of 2.3 words for a mismatch region and an average occurrence of 3.6 times for this region within the corpus.

Text alignment•During alignment, both input documents are viewed as sequences of tokens. A generalized Levenshtein alignment algorithm is then applied to these sequences.•Based on the algorithm three actions are performed:•Substitution• Insertion•Deletion

Kitten Sitting1. Sitten substitution2. Sittin Substitution3. Sitting Addition


Similarity measures•Similarity measure are used in both text alignment and reconstruction.•These measures are consulted by the levenshtein algorithm to improve accuracy•The measures are used to condition the reconstruction rules .

Semantic similarity•To measure semantic similarity the following resources are used a reference:•Unified Medical Language System•WordNet lexical database
•The morphosyntactic information from the lexicon was worked into the finite-state transducer that is used as a morphological lexicon.

7 identical (modulo case or 5 synonymous 2 same UMLS semantic type
6 same root (only inflection)parent(word1,word2)or parent(word2,word1)
1 direct hierarchical relationbetween semantic types
4 morphologically derived 0 no similarity at all
3 conceptual siblings

Phonetic similarity•Requires three sets of input:•Phonetic symbol sequence from the recognized text•The orthographic word sequence from the recognized text•Word sequence from the written text
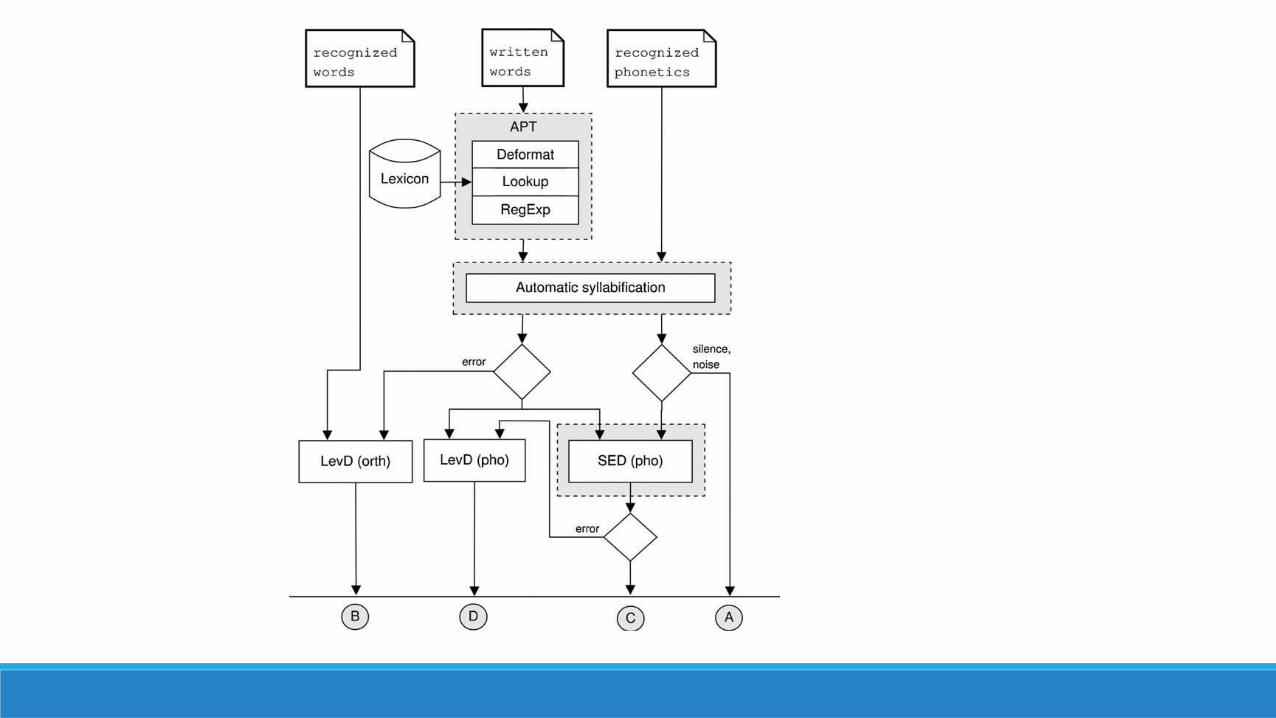

Automatic phonetic transcription•In a first step, the written text is transferred to the phonetic domain with automatic phonetic transcription (APT). This is done by a simple lexicon lookup•A simple regular expression syntax was defined to encode the possibly many speaking and pronunciation variants in a single string

Automatic syllabification•An online automatic syllabification algorithm was implemented to determine syllables directly from the texts.•For syllabification, a number of competing syllabification constraints are applied to the input words. But due to lack of primary stress information the “noonset” Constraint was removed


Combined similarity measurement•The semantic and phonetic scoring functions are used as building blocks for a combined scoring function that best exhibits the behavior that is required for further processing.•Semantic matching is applied in the first place to filter out clear cases and avoid overstretched regions of correspondence, before phonetic matching is used to find detailed matches.

Text reconstruction • Deformatting • Identifying and retracing moved blocks • Application of reconstruction rules • Reconstructing moved blocks


Rule engine The reconstruction rules that are interpreted by this engine provide a mechanism for inspecting a sliding window that is moved over multiple columns according to their alignment
rule rulename
match -w/window regexp/
# inspect sliding window
do
# specify reconstruction result
done


Rule definitions1. Baseline:2. Recognised-only3. Written-only4. Context (CTX)5. Overlap, greedy 6. Overlap, selective

Experiments•The quality of the reconstruction was tested.•The speech recognition performance using reconstructed texts is measured

Reconstruction quality Metrics:•Recall = | COR | / |COR | + | MISS |•Precision = | COR | / |COR | + |WRONG|•harmonic mean F1



Rule-based vs. data-driven reconstruction•k-NN•NN•SVM


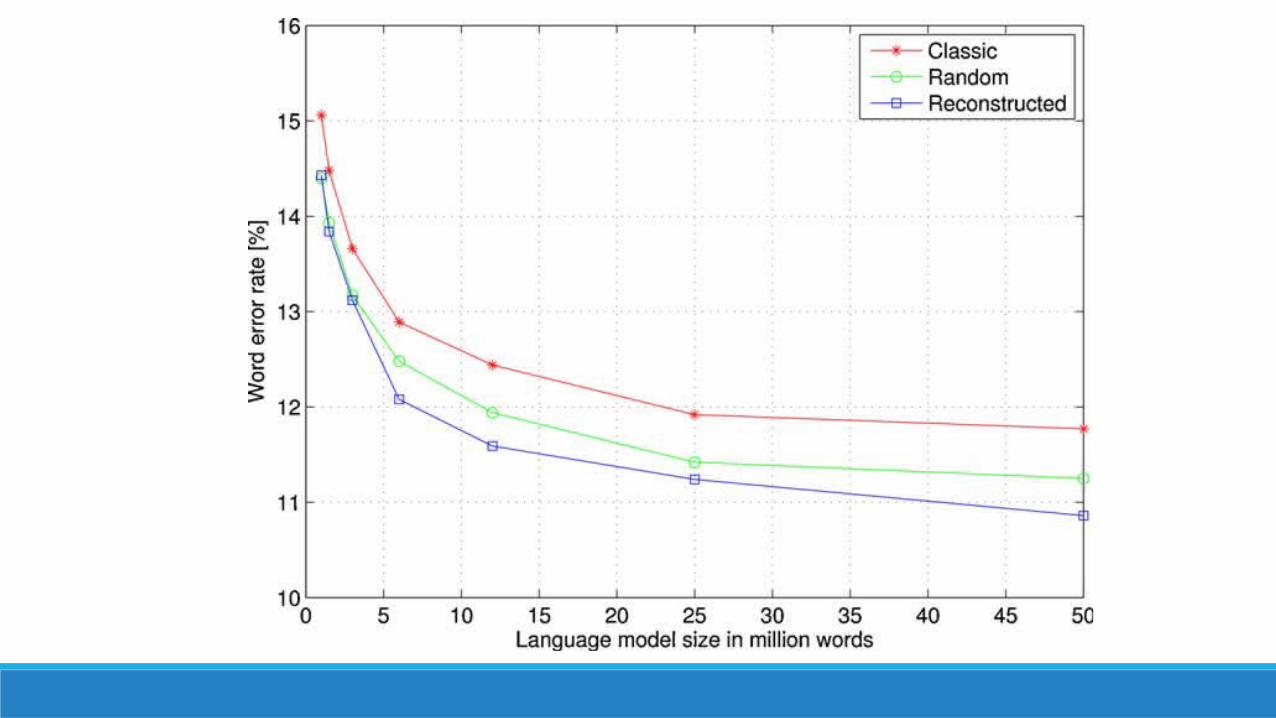
Automatic speech recognition The SPARC method was compared to the standard method for language model training and to a random generation of reconstructed text.










![Regularization - Electrical Engineering and Computer Scienceweb.eecs.umich.edu/~fessler/book/c-reg.pdf · c J. Fessler.[license]April 7, 2017 2.3 2.2 Splines and nonparametric function](https://img.pdfslide.us/doc/110x75/6012e001c0bf144fc62e63f9/regularization-electrical-engineering-and-computer-fesslerbookc-regpdf-c.jpg)




![Image Restoration - web.eecs.umich.eduweb.eecs.umich.edu/~fessler/book/c-restore.pdf · c J. Fessler.[license]March 20, 2018 1.4 Although (1.2.3) is the classical model for image](https://img.pdfslide.us/doc/110x75/5b9a269809d3f210688d3c4d/image-restoration-webeecsumich-fesslerbookc-restorepdf-c-j-fesslerlicensemarch.jpg)















