Embed Size (px)
Citation preview

Section 4.1: Describing the Center of a Data Set

• Two most popular measures of center are the mean and the median
We will look at them separately, then compare the two.

• Mean – the average (sometimes called the sample mean)
• Sample mean – denoted by:
n
xx

Example: Range of Motion After Knee Surgery
• Traumatic knee dislocation often requires surgery to repair ruptured ligaments. One measure of recovery is range of motion. The article “Reconstruction of the Anterior and Posterior Cruciate Ligaments After Knee Dislocation” reported the following postsurgical range of motion for a sample of 13 patients:

• Range of Motion (degrees)
X1 = 154 x2 = 142 x3 = 137 x4 = 133 x5 = 122
X6 = 126 x7 = 135 x8 = 135 x9 = 108 x10 = 120
X11 = 127 x12 = 134 x13 = 122
38.13013
1695
n
xx

• Population mean – denoted by μ is the average of all x values in the entire populaton.

Example: County Population Sizes
• The 50 states plus the District of Columbia contain 3137 counties. Let x denote the number of residents of a country. Then there are 3137 values of the variable x in the population. The sum of these 3137 values is 248,709,873 (1990 census), so the population average value of x is:
7.282,793137
973,709,248

• One potential drawback to the mean as a measure of center is an outlier.
• Outlier – an unusually large or small observation in the data set

Example: Number of Visits to a class website
Forty students were enrolled in a section of STAT 130, a general education course in statistical reasoning. One month after the course began, the instructor requested a report that indicated how many times each student had accessed a web page on the class site. The 40 observations were:

20 37 4 20 0 84 14 36 5 331 19 00 22 3 13 14 36 4 0 18 8 0 264 0 5 23 19 7 12 8 13 16 21 713 12 8 42The sample mean for the data set is 23.10

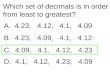
• Median – the middle value in the list• Sample median – obtained by first
ordering the n observations from smallest to largest (with any repeated values included, so that every sample observation appears in the ordered list).– The single middle value if n is odd– The average of the middle two values if n is
even

Example: Website data revisited
• The sample size for the website access data was n = 40, an even number. The median is the average of the 20th and 21st values (arrange the data in order from least to greatest).
0 0 0 0 0 0 3 4 4 4 5 5 7 7 8 8 8
12 12 13 13 13 14 14 16 18 19 19 20 20 21
22 23 26 36 36 37 42 84 331

• The median can now be determined:
Median = 13 + 13 = 13
2
This value appears to be more typical than 23.1

• Population median – the middle value of the ordered list consisting of all population observations.

Comparing Mean and Median
• Symmetric – mean = median• Longer upper tailed (positive skew) – mean is
greater than the median• Negatively skewed – mean is smaller than the
median

Sample Proportion of Success
n
sampletheinsSofnumberp
'
• Where s is the label used for the response designated as success

Example: Tampering with Automobile Antipollution Equipment
• The use of antipollution equipment on automobiles has substantially improved air quality in certain areas. Unfortunately, many car owners have tampered with smog control devices to improve performance. Suppose that a sample of n=15 cars is selected and that each car is classified as S or F, according to whether or not tampering has taken place. The resulting data are:

S F S S S F F S S F S S S F F
This sample contains nine S’s so:
p = 9 = .60 15That is 60% of the sample responses are
S’s.

• Population proportion of S’s = π (not 3.14)• Trimmed mean – computed by first
ordering the data values from smallest to largest, then deleting a selected number of values from each end of the ordered list, and finally averaging the remaining values.
• Trimming Percentage – Is the percentage of values deleted from each end of the ordered list

Example: Alcohol Exposure
• Alcohol Exposure in seconds
34 414 0 0 76 123 3 0 7 0 46 38
13 73 0 72 0 5 0 0 0 0 74 0
28 0 0 0 0 39
Let’s trim 10% off the mean. You will take away the three smallest and three largest numbers

• New data values are:
0 0 0 0 0 0 0 0 0 0 0 0 3 5 7 13 28 34 38 39 46 72 73 74
We deleted three zeros, 76, 123, and 414
The 10% trimmed mean is 18