Embed Size (px)
Citation preview

Search Engines e Question Search Engines e Question AnsweringAnswering
Giuseppe AttardiGiuseppe AttardiUniversità di PisaUniversità di Pisa
(some slides borrowed from C. Manning, H. Schütze)(some slides borrowed from C. Manning, H. Schütze)

OverviewOverview Information Retrieval ModelsInformation Retrieval Models
– Boolean and vector-space retrieval models; ranked retrieval; text-similarity metrics; TF-IDF (term frequency/inverse document frequency) weighting; cosine similarity; performance metrics: precision, recall, F-measure.
Indexing and SearchIndexing and Search– Indexing and inverted files; Compression; Postings Lists; Query
languages Web SearchWeb Search
– Search engines; Architecture; Crawling: parallel/distributed, focused; Link analysis (Google PageRank); Scaling
Text Categorization and ClusteringText Categorization and Clustering Question AnsweringQuestion Answering
– Information extraction; Named Entity Recognition; Natural Language Processing; Part of Speech tagging; Question analysis and semantic matching

ReferencesReferences
1.1. Modern Information Retrieval, R. Modern Information Retrieval, R. Baeza-Yates, B. Ribeiro-Nieto, Addison Baeza-Yates, B. Ribeiro-Nieto, Addison WesleyWesley
2.2. Managing Gigabytes, 2nd Edition, I.H. Managing Gigabytes, 2nd Edition, I.H. Witten, A. Moffat, T.C. Bell, Morgan Witten, A. Moffat, T.C. Bell, Morgan Kaufmann, 1999.Kaufmann, 1999.
3.3. Foundations of Statistical Natural Foundations of Statistical Natural Language Processing, MIT Statistical Language Processing, MIT Statistical Natural Language Processing, C. Natural Language Processing, C. Manning and Shutze, MIT Press, 1999.Manning and Shutze, MIT Press, 1999.

MotivationMotivation

Adaptive ComputingAdaptive Computing
Desktop Metaphor: highly successful Desktop Metaphor: highly successful in making computers popularin making computers popular– See Alan Kay 1975 presentation in Pisa
Limitations:Limitations:– Point and click involves very elementary
actions– People are required to perform more
and more clerical tasks– We have become: bank clerks,
typographers, illustrators, librarians

Illustrative problemIllustrative problem
Add a table to a document with Add a table to a document with results from latest benchmarks and results from latest benchmarks and send it to my colleague Antonio:send it to my colleague Antonio:– 7-8 point&click just to get to the
document– 7-8 point&click to get to the data– Lengthy fiddling with table layout– 3-4 point&click to retrieve mail address– Etc.

Success storySuccess story
Do I care where a document is Do I care where a document is stored?stored?
Shall I need a secretary for filing my Shall I need a secretary for filing my documents?documents?
Search Engines prove that you don’tSearch Engines prove that you don’t

Overcoming Desktop MetaphorOvercoming Desktop Metaphor
Could think of just one possibility:Could think of just one possibility:
– Raise the level of interaction with computers
How?How?Could think of just one possibility:Could think of just one possibility:
– Use natural language

AdaptivenessAdaptiveness
My language is different from yoursMy language is different from yoursShould be learned from user Should be learned from user
interactioninteractionSee: Steels’ talking heads language See: Steels’ talking heads language
gamesgamesThrough implicit interactionsThrough implicit interactions
– Many potential sources (e.g. file a message in a folder classification)

Research GoalResearch Goal
Question AnsweringQuestion AnsweringTechniques:Techniques:
– Traditional IR tools– NLP tools (POS tagging, parser)– Complement Knowledge Bases with
massive data sets of usage (Web)– Knowledge extraction tools (NE
tagging)– Continuous learning
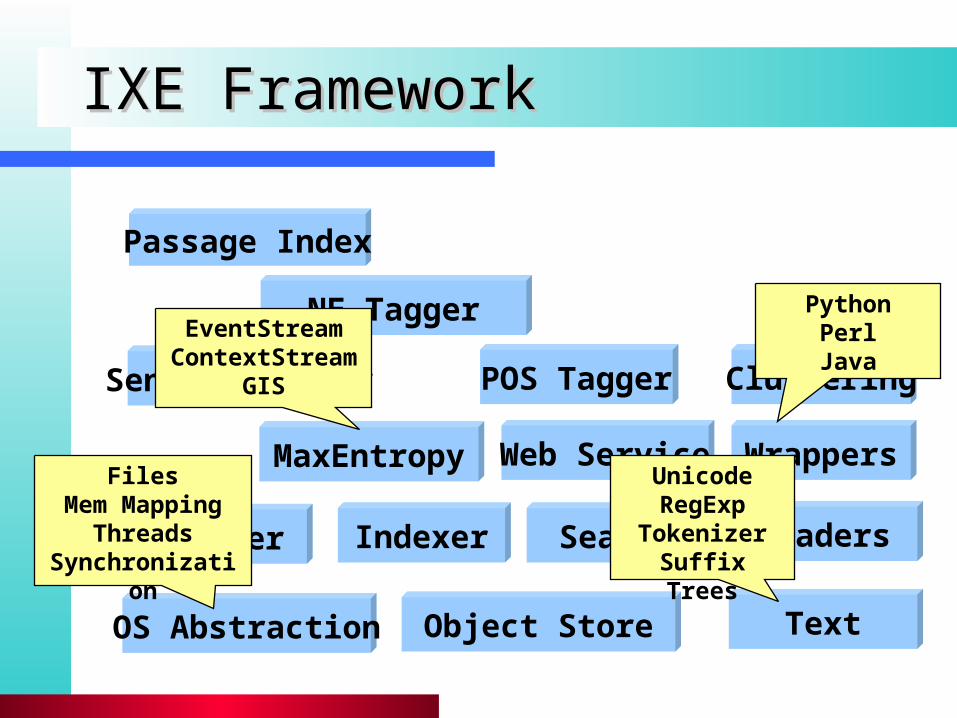
IXE FrameworkIXE Framework
Object Store
Indexer
OS Abstraction Text
MaxEntropy
Sent. Splitter
Readers
POS Tagger
NE Tagger
Passage Index
Clustering
Crawler Search
Web Service WrappersUnicodeRegExp
TokenizerSuffix Trees
FilesMem Mapping
ThreadsSynchronization
PythonPerlJava
EventStreamContextStream
GIS

Information Retrieval ModelsInformation Retrieval Models

Information Retrieval ModelsInformation Retrieval Models
A A modelmodel is an embodiment of the theory in is an embodiment of the theory in which we define a set of objects about which we define a set of objects about which assertions can be made and restrict which assertions can be made and restrict the ways in which classes of objects can the ways in which classes of objects can interactinteract
A A retrieval modelretrieval model specifies the specifies the representations used for documents and representations used for documents and information needs, and how they are information needs, and how they are comparedcompared(Turtle & Croft, 1992)

Information Retrieval ModelInformation Retrieval Model
Provides an abstract description of Provides an abstract description of the representation used for the representation used for documents, the representation of documents, the representation of queries, the indexing process, the queries, the indexing process, the matching process between a query matching process between a query and the documents and the ranking and the documents and the ranking criteriacriteria

Formal CharacterizationFormal Characterization
An Information Retrieval model is a An Information Retrieval model is a quadruple quadruple DD, , QQ, , FF, , RR where where– D is a set of representations for the documents
in the collection– Q is a set of representations for the user
information needs (queries)– F is a framework for modelling document
representations, queries, and their relationships
– R: Q D ℝ is a ranking function which associates a real number with a query qi Q and document representation dj D(Baeza-Yates & Ribeiro-Neto, 1999)

Information Retrieval ModelsInformation Retrieval Models
Three ‘classic’ models:Three ‘classic’ models:– Boolean Model– Vector Space Model– Probabilistic Model
Additional modelsAdditional models– Extended Boolean– Fuzzy matching– Cluster-based retrieval– Language models

Informationneed
Collections
Rank or Match
Query
text inputPre-process
Parse Index
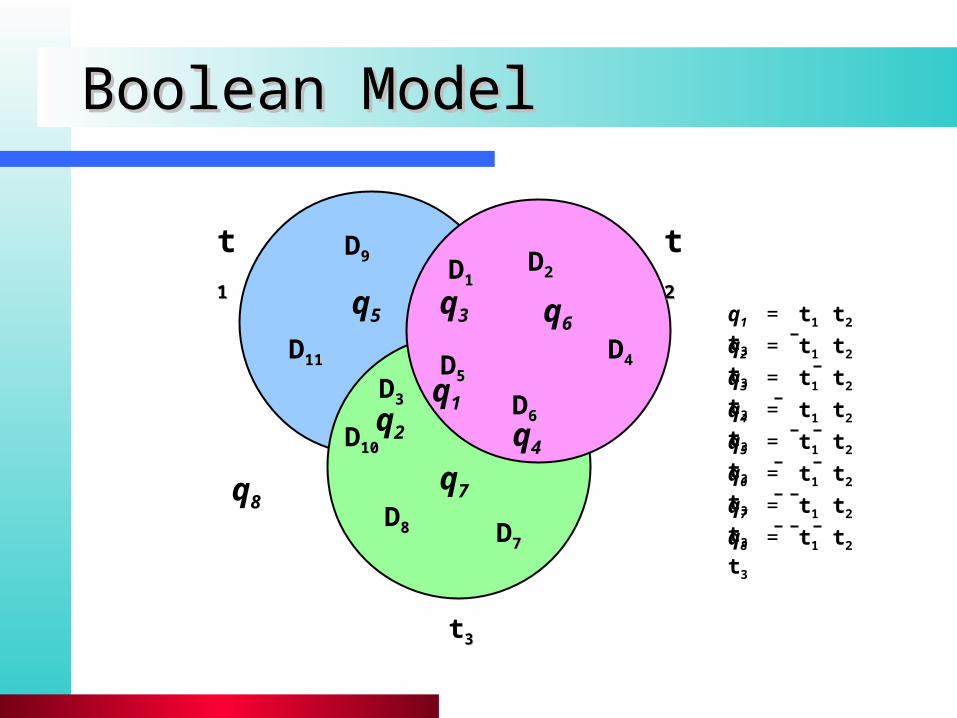
Boolean ModelBoolean Model
t33
t11 t22D11
D22
D33
D44D55
D66
D88 D77
D99
D1010
D1111
q1q2
q3q5
q4
q7q8
q6q2 = t1 t2 t3
q1 = t1 t2 t3
q4 = t1 t2 t3
q3 = t1 t2 t3
q6 = t1 t2 t3
q5 = t1 t2 t3
q8 = t1 t2 t3
q7 = t1 t2 t3
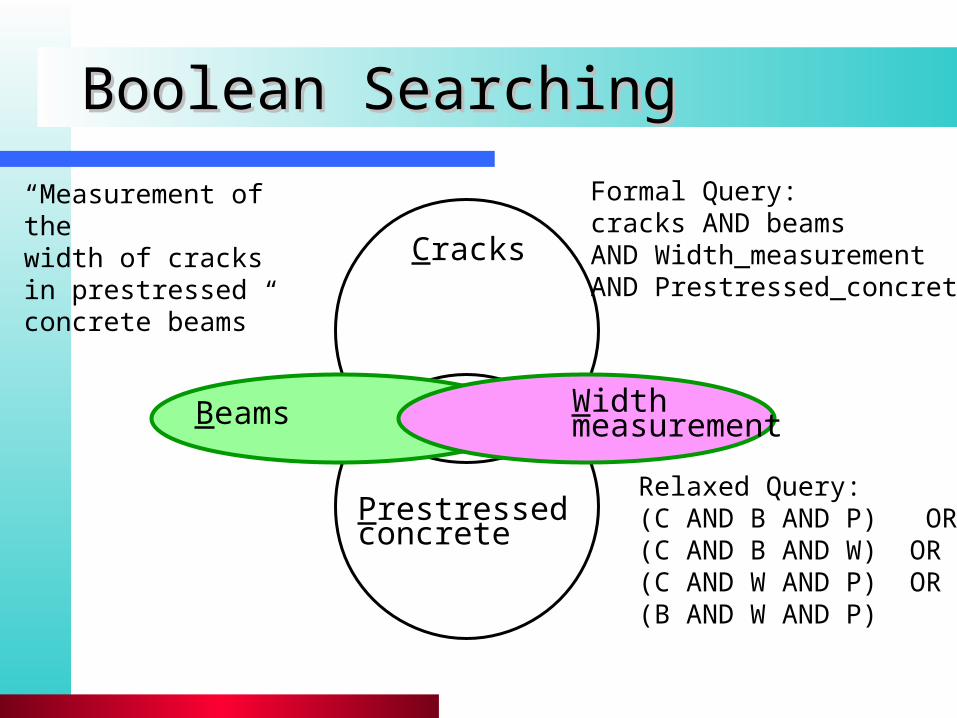
Boolean SearchingBoolean Searching
“Measurement of thewidth of cracks in prestressedconcrete beams”
Formal Query:cracks AND beamsAND Width_measurementAND Prestressed_concrete
Cracks
Beams Widthmeasurement
Prestressedconcrete
Relaxed Query:(C AND B AND P) OR(C AND B AND W) OR(C AND W AND P) OR(B AND W AND P)

Boolean ProblemsBoolean Problems
Disjunctive (OR) queries lead to Disjunctive (OR) queries lead to information overloadinformation overload
Conjunctive (AND) queries lead to Conjunctive (AND) queries lead to reduced, and commonly zero resultreduced, and commonly zero result
Conjunctive queries imply reduction Conjunctive queries imply reduction in in RecallRecall

Boolean Model: AssessmentBoolean Model: Assessment
Complete Complete expressiveness for expressiveness for any identifiable any identifiable subset of collectionsubset of collection
Exact and simple to Exact and simple to programprogram
The whole panoply of The whole panoply of Boolean Algebra Boolean Algebra availableavailable
Advantages
Complex query syntax Complex query syntax is often is often misunderstood (if misunderstood (if understood at all)understood at all)
Problems of Null Problems of Null output and output and Information OverloadInformation Overload
Output is not ordered Output is not ordered in any useful fashionin any useful fashion
Disadvantages

Boolean ExtensionsBoolean Extensions
Fuzzy LogicFuzzy Logic– Adds weights to each term/concept– ta AND tb is interpreted as MIN(w(ta),w(tb))– ta OR tb is interpreted as MAX (w(ta),w(tb))
Proximity/Adjacency operatorsProximity/Adjacency operators– Interpreted as additional constraints on
Boolean AND Verity TOPIC systemVerity TOPIC system
– Uses various weighted forms of Boolean logic and proximity information in calculating Robertson Selection Values (RSV)

Vector Space ModelVector Space Model
Documents are represented as vectors in Documents are represented as vectors in term spaceterm space– Terms are usually stems– Documents represented by binary
vectors of terms Queries represented the same as Queries represented the same as
documentsdocuments Query and Document weights are based Query and Document weights are based
on length and direction of their vectoron length and direction of their vector A vector distance measure between the A vector distance measure between the
query and documents is used to rank query and documents is used to rank retrieved documentsretrieved documents
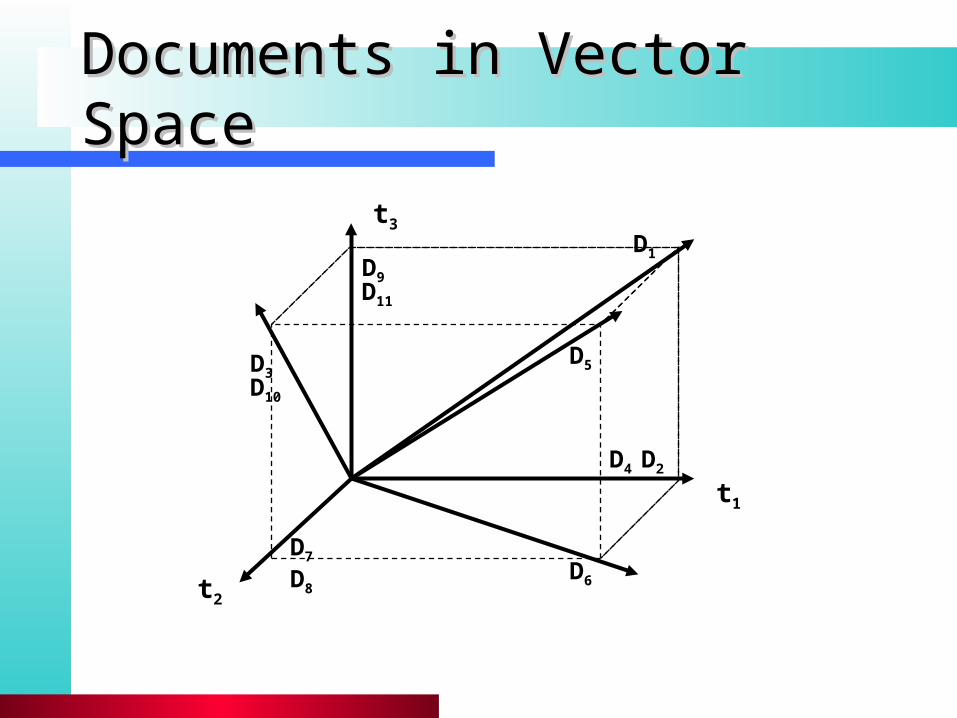
Documents in Vector SpaceDocuments in Vector Space
t1
t2
t3
D1
D2
D10
D3
D9
D4
D7
D8
D5
D11
D6

Vector Space Documents and QueriesVector Space Documents and Queries
D1
D2
D3
D4
D5
D6
D7
D8
D9
D10
D11
t2
t3
t1
docsdocs tt11 tt22 tt33 RSV=RSV=QQ.D.Dii
DD11 11 00 11 44
DD22 11 00 00 11
DD33 00 11 11 55
DD44 11 00 00 11
DD55 11 11 11 66
DD66 11 11 00 33
DD77 00 11 00 22
DD88 00 11 00 22
DD99 00 00 11 33
DD1010 00 11 11 55
DD1111 11 00 11 33
QQ 11 22 33 weightsweights
qq11 qq22 qq33

Similarity MeasuresSimilarity Measures
|)||,min(|
||
||||
||
||||
||||
||2
||
21
21
DQ
DQ
DQ
DQ
DQDQ
DQ
DQ
DQ
Simple matching (coordination level match)
Dice’s Coefficient
Jaccard’s Coefficient
Cosine Coefficient
Overlap Coefficient

Vector Space with Term WeightsVector Space with Term Weights
1.0
0.8
0.6
0.4
0.2
0.80.60.40.20 1.0
D2
D1
Q
1
2
Term B
Term A
Di=(wdi1, wdi2,… , wdit)Q =(wqi1, wqi2,… , wqit)
t
j
t
j dq
t
j dq
i
ijj
ijj
ww
wwDQsim
1 1
22
1
)()(),(
Q = (0.4, 0.8)D1=(0.8, 0.3)D2=(0.2, 0.7)
98.042.0
64.0
])7.0()2.0[(])8.0()4.0[(
)7.08.0()2.04.0(),(
22222
DQsim
74.058.0
56.),( 1 DQsim

Problems with Vector SpaceProblems with Vector Space
There is no real theoretical basis for There is no real theoretical basis for the assumption of a term spacethe assumption of a term space– it is more for visualization that having
any real basis– most similarity measures work about
the same regardless of modelTerms are not really orthogonal Terms are not really orthogonal
dimensionsdimensions– Terms are not independent of all other
terms

Probabilistic RetrievalProbabilistic Retrieval
Goes back to 1960’s (Maron and Goes back to 1960’s (Maron and Kuhns)Kuhns)
Robertson’s “Probabilistic Ranking Robertson’s “Probabilistic Ranking Principle”Principle”– Retrieved documents should be ranked
in decreasing probability that they are relevant to the user’s query
– How to estimate these probabilities?• Several methods (Model 1, Model 2, Model
3) with different emphasis on how estimates are done

Probabilistic Models: NotationProbabilistic Models: Notation
D D = = all present and future documentsall present and future documentsQQ = = all present and future queriesall present and future queries((ddii, , qqjj) = a document query pair) = a document query pair
xx D = D = class of similar documentsclass of similar documentsyy Q = Q = class of similar queries class of similar queries Relevance is a relation:Relevance is a relation:
R = {(di, qj) | di D, qj Q, di is judged relevant by the user submitting qj}

Probabilistic modelProbabilistic model
Given D, estimate P(R|D) and P(NR|D)Given D, estimate P(R|D) and P(NR|D) P(R|D)=P(D|R)*P(R)/P(D) P(R|D)=P(D|R)*P(R)/P(D) (P(D), P(R) (P(D), P(R)
constant)constant)
P(D|R)P(D|R)
D = {tD = {t11=x=x11, t, t22=x=x22, …}, …}
i
ii
i
ii
i
ii
i
ii
ii
t
xi
xi
t
xi
xi
t
xi
xi
t
xi
xi
Dxtii
qqNRtPNRtPNRDP
ppRtPRtP
RxtPRDP
)1()1(
)1()1(
)(
)1()|0()|1()|(
)1()|0()|1(
)|()|(
absent
presentxi 0
1

Prob. model (cont’d)Prob. model (cont’d)
)1(
)1(log
1
1log
)1(
)1(log
)1(
)1(
log)|(
)|(log)(
)1(
)1(
ii
ii
ti
t i
i
ii
ii
ti
t
xi
xi
t
xi
xi
pq
qpx
q
p
pq
qpx
pp
NRDP
RDPDOdd
i
ii
i
ii
i
ii
For document ranking

Prob. model (cont’d)Prob. model (cont’d)
How to estimate pHow to estimate pii and and
qqii??
A set of A set of NN relevant and relevant and irrelevant samples:irrelevant samples:
rrii
Rel. doc. Rel. doc. with twith tii
nnii-r-rii
Irrel.doc. Irrel.doc.
with twith tii
nnii
Doc. Doc.
with twith tii
RRii-r-rii
Rel. doc. Rel. doc. without without ttii
N-RN-Rii–n+r–n+rii
Irrel.doc. Irrel.doc. without without ttii
N-nN-nii
Doc. Doc. without without titi
RRii
Rel. docRel. doc
N-RN-Rii
Irrel.doc.Irrel.doc.
NN
SamplesSamplesi
iii
i
ii RN
rnq
R
rp

Prob. model (cont’d)Prob. model (cont’d)
Smoothing Smoothing (Robertson-Sparck-Jones formula)(Robertson-Sparck-Jones formula)
When no sample is available:When no sample is available:ppii=0.5, =0.5, qqii=(ni+0.5)/(N+0.5)=(ni+0.5)/(N+0.5)ni/Nni/N
May be implemented as VSMMay be implemented as VSM
))((
)(
)1(
)1(log)(
iiii
iiii
ti
ii
ii
ti
rnrR
rnRNrx
pq
qpxDOdd
i
i
Dt
iiiii
iiii
ti
ii
wrnrR
rnRNrxDOdd
)5.0)(5.0(
)5.0)(5.0()(

Probabilistic ModelsProbabilistic Models
Model 1 Model 1 –– Probabilistic Indexing, Probabilistic Indexing, P(P(R R | | yy, , ddii))
Model 2 Model 2 –– Probabilistic Querying, Probabilistic Querying, P(P(RR | | qqjj, , xx))
Model 3 Model 3 –– Merged Model, P( Merged Model, P(R R | | qqjj, , ddii))
Model 0 Model 0 –– P( P(RR | | yy, , xx))Probabilities are estimated based on Probabilities are estimated based on
prior usage or relevance estimationprior usage or relevance estimation

Probabilistic ModelsProbabilistic Models
Rigorous formal model attempts to Rigorous formal model attempts to predict the probability that a given predict the probability that a given document will be relevant to a given document will be relevant to a given queryquery
Ranks retrieved documents Ranks retrieved documents according to this probability of according to this probability of relevance (Probability Ranking relevance (Probability Ranking Principle)Principle)
Relies on accurate estimates of Relies on accurate estimates of probabilities for accurate resultsprobabilities for accurate results

Vector and Probabilistic ModelsVector and Probabilistic Models
Support “natural language” queriesSupport “natural language” queries Treat documents and queries the sameTreat documents and queries the same Support relevance feedback searchingSupport relevance feedback searching Support ranked retrievalSupport ranked retrieval Differ primarily in theoretical basis and in Differ primarily in theoretical basis and in
how the ranking is calculatedhow the ranking is calculated– Vector assumes relevance – Probabilistic relies on relevance judgments or
estimates

IR RankingIR Ranking

Ranking models in IRRanking models in IR
Key idea:Key idea:– We wish to return in order the documents
most likely to be useful to the searcher To do this, we want to know which documents To do this, we want to know which documents
bestbest satisfy a query satisfy a query– An obvious idea is that if a document talks
about a topic more then it is a better match A query should then just specify terms that are A query should then just specify terms that are
relevant to the information need, without relevant to the information need, without requiring that all of them must be presentrequiring that all of them must be present– Document relevant if it has a lot of the terms

Binary term presence matricesBinary term presence matrices
Record whether a document contains a word: Record whether a document contains a word: document is binary vector in document is binary vector in {0,1}{0,1}vv
– What we have mainly assumed so far Idea: Query satisfaction = overlap measure:Idea: Query satisfaction = overlap measure:
YX Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 1 1 0 0 0 0
Brutus 1 1 0 1 0 0
Caesar 1 1 0 1 1 1
Calpurnia 0 1 0 0 0 0
Cleopatra 1 0 0 0 0 0
mercy 1 0 1 1 1 1
Worser 1 0 1 1 1 0

Overlap matchingOverlap matching
What are the problems with the What are the problems with the overlap measure?overlap measure?
It doesn’t consider:It doesn’t consider:– Term frequency in document– Term scarcity in collection (document
mention frequency)– Length of documents
• (AND queries: score not normalized)

Overlap matchingOverlap matching
One can normalize in various ways:One can normalize in various ways:– Jaccard coefficient:
– Cosine measure:
What documents would score best using What documents would score best using Jaccard against a typical query?Jaccard against a typical query?– Does the cosine measure fix this problem?
YXYX /
YXYX /
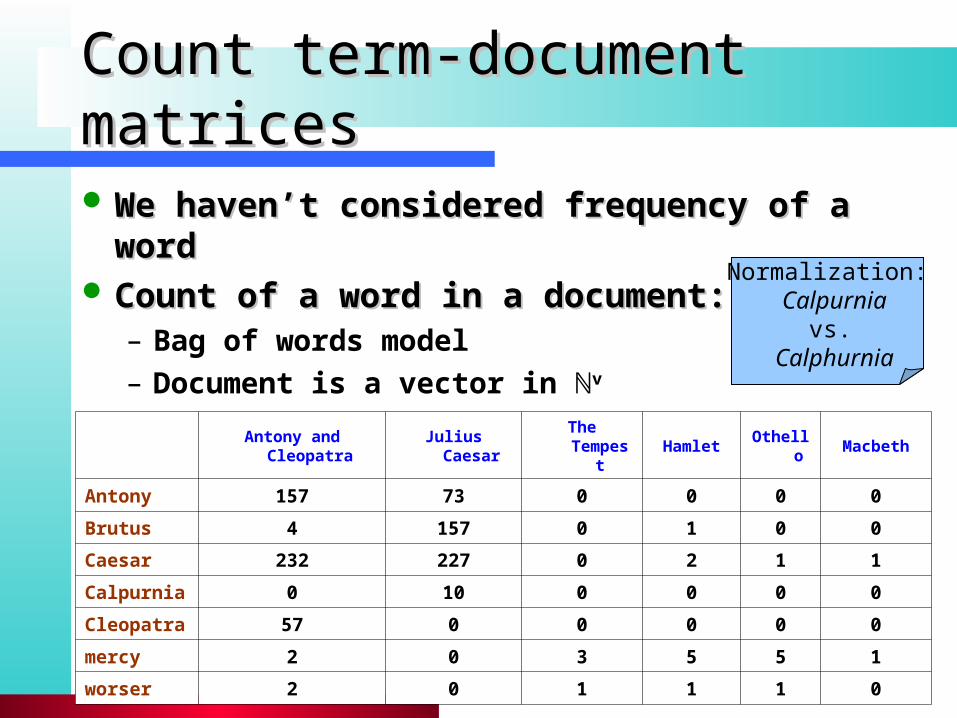
Count term-document matricesCount term-document matrices
We haven’t considered frequency of a wordWe haven’t considered frequency of a word Count of a word in a document: Count of a word in a document:
– Bag of words model– Document is a vector in ℕv
Normalization: Calpurnia
vs. Calphurnia
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 157 73 0 0 0 0
Brutus 4 157 0 1 0 0
Caesar 232 227 0 2 1 1
Calpurnia 0 10 0 0 0 0
Cleopatra 57 0 0 0 0 0
mercy 2 0 3 5 5 1
worser 2 0 1 1 1 0

Weighting term frequency: tfWeighting term frequency: tf
What is the relative importance ofWhat is the relative importance of– 0 vs. 1 occurrence of a term in a doc– 1 vs. 2 occurrences– 2 vs. 3 occurrences …
Unclear: but it seems that more is Unclear: but it seems that more is better, but a lot isn’t necessarily better, but a lot isn’t necessarily better than a fewbetter than a few– Can just use raw score– Another option commonly used in
practice: 0:log1?0 ,, dtdt tftf

Dot product matchingDot product matching
Match is dot product of query and documentMatch is dot product of query and document
[Note: 0 if orthogonal (no words in common)][Note: 0 if orthogonal (no words in common)] Rank by matchRank by match
It still doesn’t consider:It still doesn’t consider:– Term scarcity in collection (document mention
frequency)– Length of documents and queries
• Not normalized
i diqi tftfdq ,,

Weighting should depend on the term overallWeighting should depend on the term overall
Which of these tells you more about a doc?Which of these tells you more about a doc?– 10 occurrences of hernia?– 10 occurrences of the?
Suggest looking at collection frequency (Suggest looking at collection frequency (cfcf)) But document frequency (But document frequency (dfdf) may be better:) may be better:
WordWord cfcf dfdf
trytry 1042210422 87608760
insuranceinsurance 1044010440 39973997 Document frequency weighting is only possible Document frequency weighting is only possible
in known (static) collectionin known (static) collection

tftf x x idfidf term weights term weights
tftf x x idfidf measure combines: measure combines:– term frequency (tf)
• measure of term density in a doc
– inverse document frequency (idf) • measure of informativeness of term: its rarity across the
whole corpus
• could just be raw count of number of documents the term occurs in (idfi = 1/dfi)
• but by far the most commonly used version is:
See Kishore Papineni, NAACL 2, 2002 for theoretical justificationSee Kishore Papineni, NAACL 2, 2002 for theoretical justification
dfnidf
i
i log

Summary: Summary: tftf x x idfidf
Assign a Assign a tftf..idfidf weight to each term weight to each term ii in each in each document document dd
tfi,d = frequency of term i in document dn = total number of documentsdfi = number of documents that contain term i
Increases with the number of occurrences Increases with the number of occurrences withinwithin a doc a doc Increases with the rarity of the term Increases with the rarity of the term acrossacross the whole corpus the whole corpus
)/log(,, ididi dfntfw What is the wtof a term thatoccurs in allof the docs?
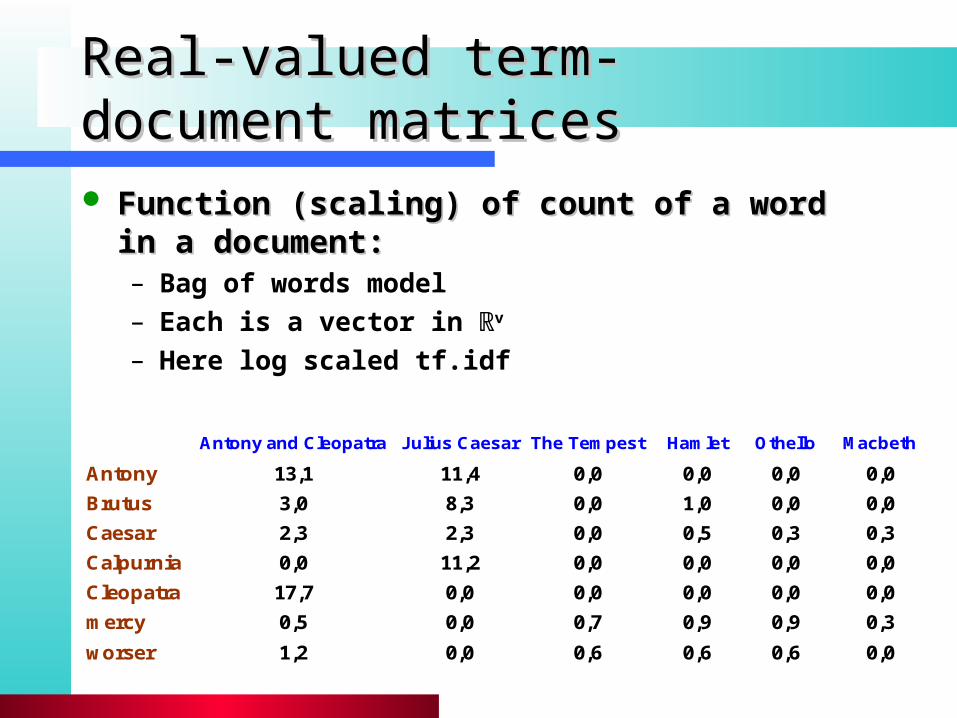
Real-valued term-document matricesReal-valued term-document matrices
Function (scaling) of count of a word in a Function (scaling) of count of a word in a document: document: – Bag of words model– Each is a vector in ℝv
– Here log scaled tf.idf
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 13,1 11,4 0,0 0,0 0,0 0,0
Brutus 3,0 8,3 0,0 1,0 0,0 0,0
Caesar 2,3 2,3 0,0 0,5 0,3 0,3
Calpurnia 0,0 11,2 0,0 0,0 0,0 0,0
Cleopatra 17,7 0,0 0,0 0,0 0,0 0,0
mercy 0,5 0,0 0,7 0,9 0,9 0,3
worser 1,2 0,0 0,6 0,6 0,6 0,0

Documents as vectorsDocuments as vectors
Each doc Each doc jj can now be viewed as a vector of can now be viewed as a vector of tftfidfidf values, one component for each term values, one component for each term
So we have a vector spaceSo we have a vector space– terms are axes– docs live in this space– even with stemming, may have 20,000+
dimensions (The corpus of documents gives us a matrix, (The corpus of documents gives us a matrix,
which we could also view as a vector space in which we could also view as a vector space in which words live – transposable data)which words live – transposable data)

Why turn docs into vectors?Why turn docs into vectors?
First application: Query-by-exampleFirst application: Query-by-example– Given a doc d, find others “like” it
Now that Now that dd is a vector, find vectors is a vector, find vectors (docs) “near” it(docs) “near” it
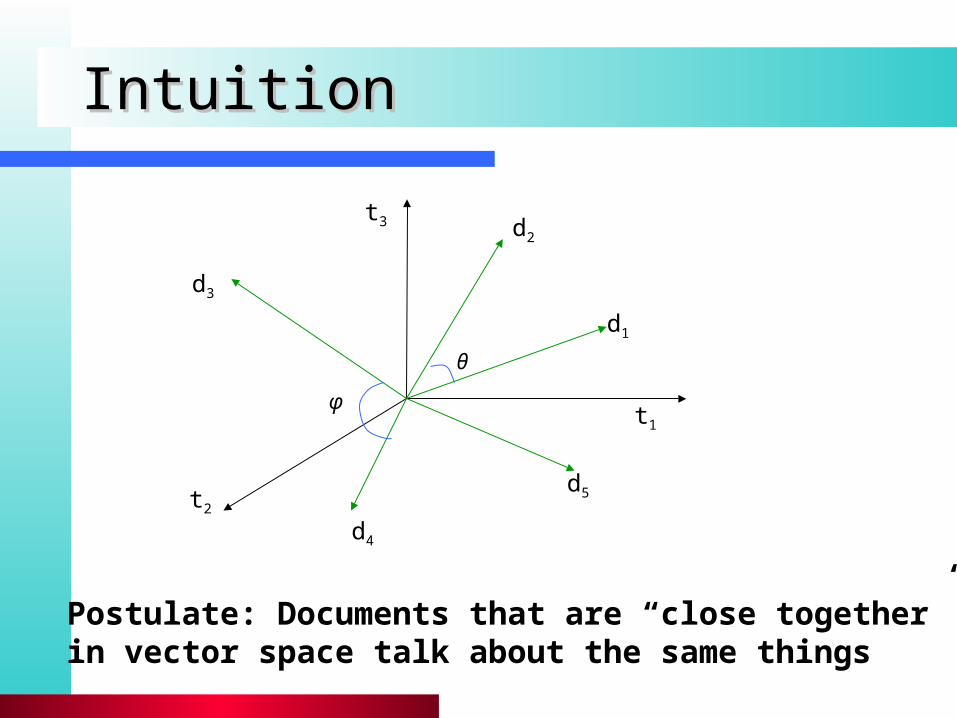
IntuitionIntuition
Postulate: Documents that are “close together” in vector space talk about the same things
t1
d2
d1
d3
d4
d5
t3
t2
θ
φ

The vector space modelThe vector space model
Query as vector:Query as vector:We regard query as short documentWe regard query as short documentWe return the documents ranked by We return the documents ranked by
the closeness of their vectors to the the closeness of their vectors to the query, also represented as a vectorquery, also represented as a vector
Developed in the SMART system Developed in the SMART system (Salton, c.(Salton, c. 1970) and standardly used 1970) and standardly used by TREC participants and web IR by TREC participants and web IR systemssystems

Desiderata for proximityDesiderata for proximity
If If dd11 is near is near dd22, then , then dd22 is near is near dd11
If If dd11 near near dd22, and , and dd22 near near dd33, then , then dd11 is is
not far from not far from dd33
No doc is closer to No doc is closer to dd than than dd itself itself

First cutFirst cut
Distance between vectors Distance between vectors dd11 and and dd22 is the is the length of the vector |length of the vector |dd11 – – dd22||– Euclidean distance
Why is this not a great idea?Why is this not a great idea? We still haven’t dealt with the issue of We still haven’t dealt with the issue of
length normalizationlength normalization– Long documents would be more similar
to each other by virtue of length, not topic
However, we can implicitly normalize by However, we can implicitly normalize by looking at looking at angles angles insteadinstead

Cosine similarityCosine similarity
Distance between vectors Distance between vectors dd11 and and dd22
capturedcaptured by the cosine of the angle by the cosine of the angle xx between them.between them.
Note – this is Note – this is similaritysimilarity, not distance, not distance
t 1
d2
d1
t 3
t 2
θ

Cosine similarityCosine similarity
Cosine of angle between two vectorsCosine of angle between two vectors The denominator involves the lengths of The denominator involves the lengths of
the vectorsthe vectors So the cosine measure is also known as So the cosine measure is also known as
the the normalized inner productnormalized inner product
n
i ki
n
i ji
n
i kiji
kj
kjkj
ww
ww
dd
ddddsim
1
2,1
2,
1 ,,),(
n
i jij wd1
2,

Normalized vectorsNormalized vectors
A vector can be normalized (given a length A vector can be normalized (given a length of 1) by dividing each of its components of 1) by dividing each of its components by the vector's lengthby the vector's length
This maps vectors onto the unit circle:This maps vectors onto the unit circle:
Then, Then,
Longer documents don’t get more weightLonger documents don’t get more weight For normalized vectors, the cosine is For normalized vectors, the cosine is
simply the dot product:simply the dot product:
11 ,
n
i jij wd
kjkj dddd
),cos(

Okapi BM25Okapi BM25
where:where:
and:and:
WWdd = document length = document length WWALAL = average document length = average document length
kk11, , kk33, , bb: : parametersparameters NN = number of docs in collection = number of docs in collection
tftfq,tq,t = query-term frequency = query-term frequency tftfd,td,t = within-document frequency= within-document frequency
dfdftt = collection frequency (# of docs that t occurs in) = collection frequency (# of docs that t occurs in)
tq
tq
Qt td
tdt tfk
tfk
tfK
tfkw
,3
,3
,
,1 11
5.0
5.0log
t
tet df
dfNw
AL
d
W
WbbkK 11

Evaluating an IR systemEvaluating an IR system

Evaluating an IR systemEvaluating an IR system
What are some measures for evaluating an IR What are some measures for evaluating an IR system’s performance?system’s performance?– Speed of indexing– Index/corpus size ratio– Speed of query processing– “Relevance” of results
Note: Note: information needinformation need is translated into a is translated into a boolean queryboolean query
Relevance is assessed relative to the Relevance is assessed relative to the information information needneed not not thethe query query

Standard relevance benchmarksStandard relevance benchmarks
TREC - National Institute of Standards and TREC - National Institute of Standards and Testing (NIST) has run large IR testbed for Testing (NIST) has run large IR testbed for many yearsmany years
Reuters and other benchmark sets usedReuters and other benchmark sets used ““Retrieval tasks” specifiedRetrieval tasks” specified
– sometimes as queries Human experts mark, for each query and Human experts mark, for each query and
for each doc, “Relevant” or “Not relevant”for each doc, “Relevant” or “Not relevant”– or at least for subset that some system
returned

The TREC experimentsThe TREC experiments
Once per yearOnce per year A set of documents and queries are A set of documents and queries are
distributed to the participants (the standard distributed to the participants (the standard answers are unknown) (April)answers are unknown) (April)
Participants work (very hard) to construct, Participants work (very hard) to construct, fine-tune their systems, and submit the fine-tune their systems, and submit the answers (1000/query) at the deadline (July)answers (1000/query) at the deadline (July)
NIST people manually evaluate the answers NIST people manually evaluate the answers and provide correct answers (and and provide correct answers (and classification of IR systems) (July – August)classification of IR systems) (July – August)
TREC conference (November)TREC conference (November)

TREC evaluation methodologyTREC evaluation methodology
Known document collection (>100K) and query Known document collection (>100K) and query set (50)set (50)
Submission of 1000 documents for each query by Submission of 1000 documents for each query by each participanteach participant
Merge 100 first documents of each participant Merge 100 first documents of each participant into global poolinto global pool
Human relevance judgment of the global poolHuman relevance judgment of the global pool The other documents are assumed to be The other documents are assumed to be
irrelevantirrelevant Evaluation of each system (with 1000 answers)Evaluation of each system (with 1000 answers)
– Partial relevance judgments– But stable for system ranking

Tracks (tasks)Tracks (tasks)
Ad Hoc track: given document collection, Ad Hoc track: given document collection, different topicsdifferent topics
Routing (filtering): stable interests (user profile), Routing (filtering): stable interests (user profile), incoming document flowincoming document flow
CLIR: Ad Hoc, but with queries in a different CLIR: Ad Hoc, but with queries in a different languagelanguage
Web: a large set of Web pagesWeb: a large set of Web pages Question-Answering: When did Nixon visit Question-Answering: When did Nixon visit
China?China? Interactive: put users into action with systemInteractive: put users into action with system Spoken document retrievalSpoken document retrieval Image and video retrievalImage and video retrieval Information tracking: new topic / follow upInformation tracking: new topic / follow up

Precision and recallPrecision and recall
PrecisionPrecision: fraction of retrieved docs that : fraction of retrieved docs that are relevant = P(relevant|retrieved)are relevant = P(relevant|retrieved)
RecallRecall: fraction of relevant docs that are : fraction of relevant docs that are retrieved = P(retrieved|relevant)retrieved = P(retrieved|relevant)
Precision P = tp/(tp + fp)Precision P = tp/(tp + fp) Recall R = tp/(tp + fn)Recall R = tp/(tp + fn)
RelevantRelevant Not RelevantNot Relevant
RetrievedRetrieved tptp fpfp
Not RetrievedNot Retrieved fnfn tntn

Other measuresOther measures
Precision at a particular cutoff:Precision at a particular cutoff:– p@10
Uninterpolated average precisionUninterpolated average precision Interpolated average precisionInterpolated average precision
AccuracyAccuracy
ErrorError
fnfptntp
tntp
fnfptntp
fnfp

Other measures (cont.)Other measures (cont.)
Noise = retrieved irrelevant docs / Noise = retrieved irrelevant docs / retrieved docsretrieved docs
Silence = non-retrieved relevant docs / Silence = non-retrieved relevant docs / relevant docsrelevant docs– Noise = 1 – Precision; Silence = 1 – Recall
Fallout = retrieved irrel. docs / irrel. docsFallout = retrieved irrel. docs / irrel. docs Single value measures:Single value measures:
– Average precision = average at 11 points of recall
– Expected search length (no. irrelevant documents to read before obtaining n relevant doc.)

Why not just use accuracy?Why not just use accuracy?
How to build a 99.9999% accurate search How to build a 99.9999% accurate search engine on a low budget….engine on a low budget….
People doing information retrieval want to People doing information retrieval want to find find somethingsomething quicklyquickly and have a certain and have a certain tolerance for junktolerance for junk
Search for:

Precision/RecallPrecision/Recall
Can get high recall (but low precision) by Can get high recall (but low precision) by retrieving all docs for all queries!retrieving all docs for all queries!
Recall is a non-decreasing function of the Recall is a non-decreasing function of the number of docs retrievednumber of docs retrieved– Precision usually decreases (in a good
system) Difficulties in using precision/recall Difficulties in using precision/recall
– Should average over large corpus/query ensembles
– Need human relevance judgments– Heavily skewed by corpus/authorship
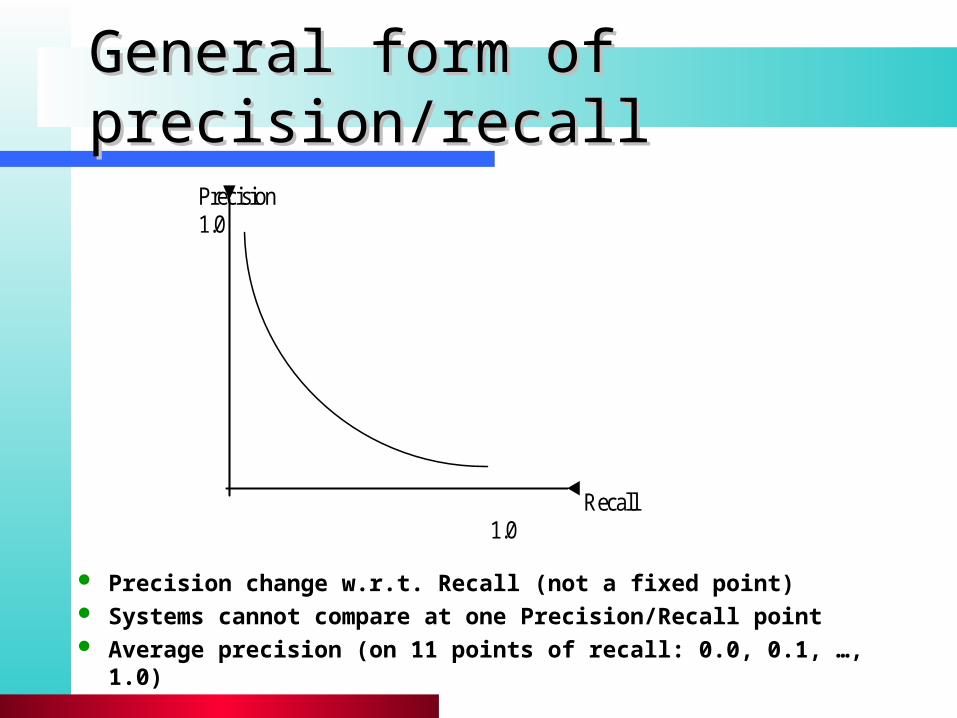
General form of precision/recallGeneral form of precision/recall
Precision 1.0 Recall 1.0
Precision change w.r.t. Recall (not a fixed point) Systems cannot compare at one Precision/Recall point Average precision (on 11 points of recall: 0.0, 0.1, …, 1.0)

A combined measure: FA combined measure: F
Combined measure that assesses this tradeoff is Combined measure that assesses this tradeoff is F measure (weighted harmonic mean):F measure (weighted harmonic mean):
People usually use balanced FPeople usually use balanced F1 1 measuremeasure
– i.e., with = 1 or = ½ Harmonic mean is conservative averageHarmonic mean is conservative average
– See CJ van Rijsbergen, Information Retrieval
RP
PR
RP
F
2
2 )1(1
)1(1
1
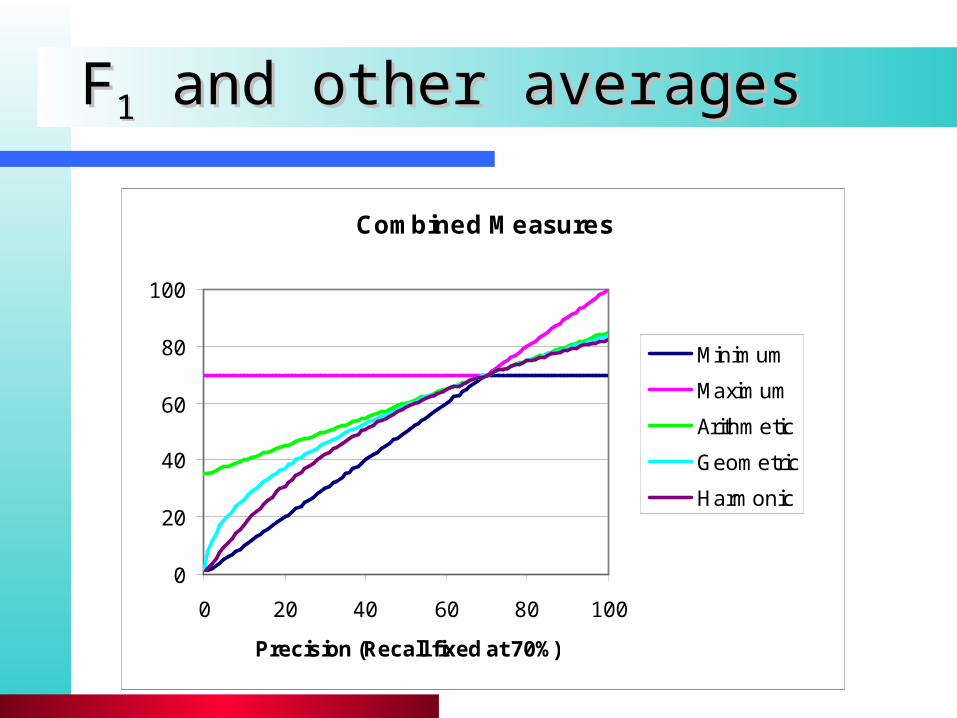
FF11 and other averages and other averages
Combined Measures
0
20
40
60
80
100
0 20 40 60 80 100
Precision (Recall fixed at 70%)
Minimum
Maximum
Arithmetic
Geometric
Harmonic

MAP (Mean Average Precision)MAP (Mean Average Precision)
rrijij = rank of the j-th relevant document for Q = rank of the j-th relevant document for Q ii
|R|Rii| = #rel. doc. for Q| = #rel. doc. for Qii
n = # test queriesn = # test queries E.g. Rank:E.g. Rank: 11 44 11stst rel. doc. rel. doc.
55 88 22ndnd rel. doc. rel. doc.
1010 33rdrd rel. doc. rel. doc.
i ijQ RD iji r
j
RnMAP
||
11
)]8
2
4
1(
2
1)
10
3
5
2
1
1(
3
1[
2
1MAP












![Web Mining Giuseppe Attardi [includes slides borrowed from C. Manning]](https://img.pdfslide.us/doc/110x75/56649de55503460f94adc8ce/web-mining-giuseppe-attardi-includes-slides-borrowed-from-c-manning.jpg)
















