Embed Size (px)
Citation preview

Search engines 2
Øystein TorbjørnsenFast Search and Transfer

Outline
• Inverted index• Constructing inverted indexes• Compression• Succinct index (Holger Bast)• Hierarchical inverted indexes• Skip lists
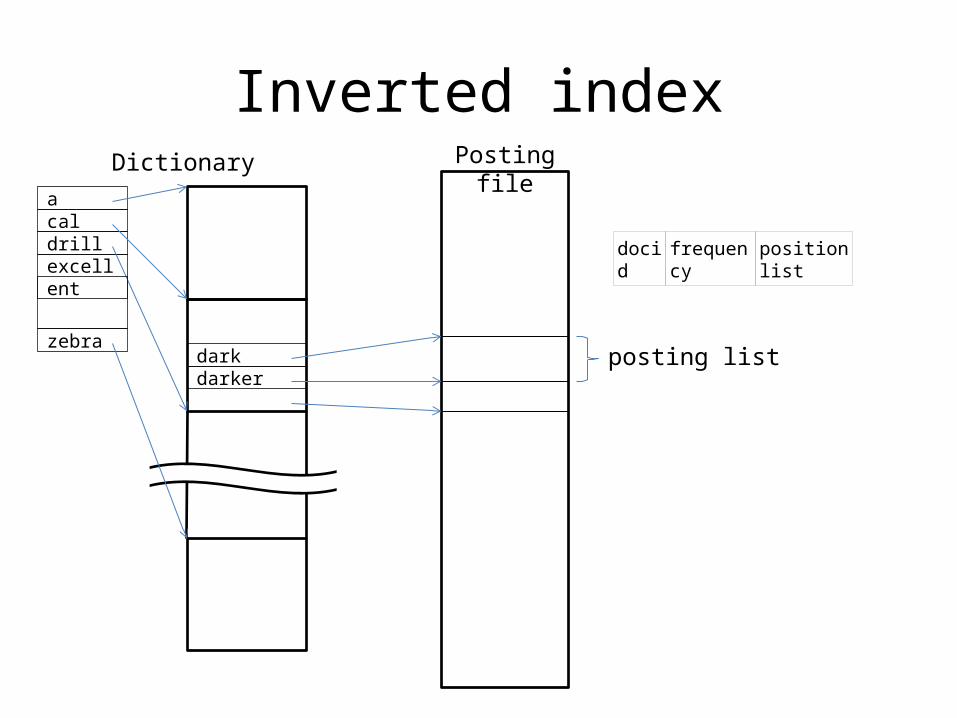
Inverted index
darkdarker
Dictionary Posting file
acaldrillexcellent
zebra
docid frequency position list
posting list

Inverted index
• Posting list is sorted on docid• Usually 2 disk IOs to look up one term, O(1)– One to read the dictionary entry– One to read the posting list (possibly large)

Construction
• Create sorted subfiles• Merge the subfiles into one large file
Needs twice the disk storage as the final index

Compression
• Basic idea:– Use knowledge of value distribution to compress data
• Costly to compress and decompress, but– Less disk IO– More data fits in main memory– Better locality in memory
• Many different schemes:– Delta coding– vByte– PFOR-DELTA– Huffman, Golomb, Rice, Simple9, Simple16

Delta coding
• Works on sorted lists• Encoded as difference
from previous entry• To be combined with
other compression
173162888997113187199
1714312618167412

vByte
• Variable-byte encoding• Using full bytes• 1 marker bit +
7 value bits• Fast encoding and
decoding
byte
end marker value
0 1001100 = 76 *128*128 = 12451840 0111001 = 57 *128 = 7296 1 1101010 = 106 = 106
= 1252586

PFOR-DELTA
• Combination of three techniques– P=Prefix suppression– FOR=Frame Of Reference– DELTA = delta coding
• Blocks of e.g. 128 values• Fixed number of bits per
value• Exception list for outliers

Succinct index
• Variation of inverted index• Index ranges of words• Prefix and range search• Smaller dictionary• Longer lists to process• Better compression• Less disk IOs– Disk position vs. transfer times

Hierarchical inverted indexes
• Incremental indexing• Build vs lookup time

Never merge
• Just keep subfiles and never merge into large file
• Construction is O(n)• Fastest possible construction time• Slow lookup with many files O(n)
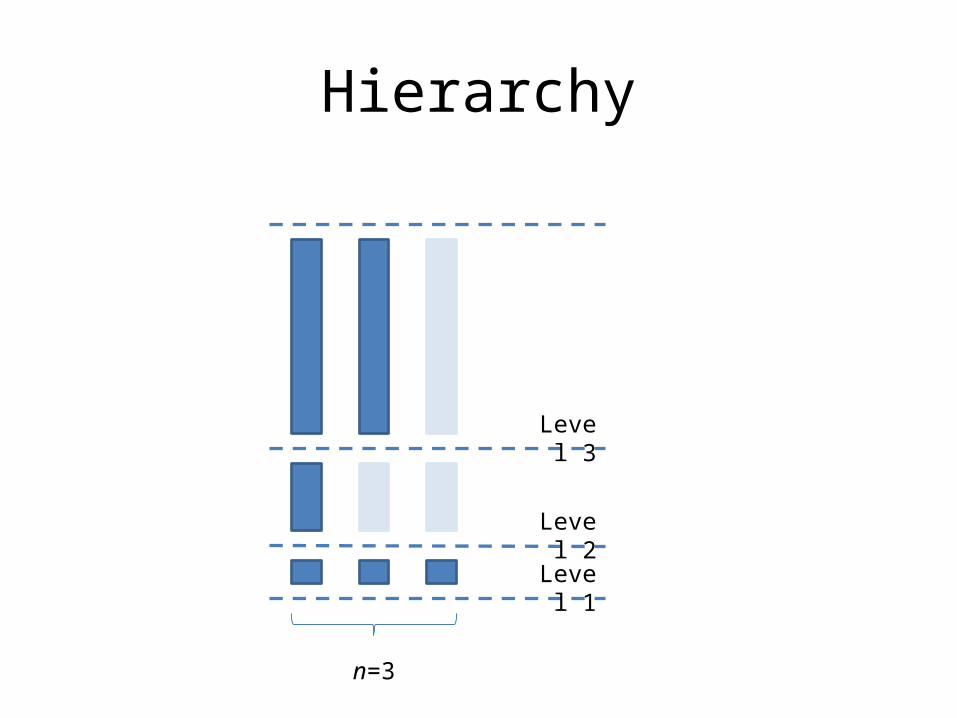
Hierarchy
n=3
Level 1
Level 2
Level 3

Merging strategy
Merge into same level Merge to level above
m=2 n=3

Issues
• Needs twice the space• Merge of upper layer takes a long time• Larger initial files leads to fewer merges• Lookup times varies over time depending on
number of files at each level

Column organization
• Field selection– Based on query• Phrase queries and proximity scoring needs position• Simple boolean queries does not need position and
frequency• Relevance scoring needs frequency
– Don’t decompress what you don’t need– Don’t read from disk what you don’t need– Locality

More than text search
• Context info• Meta data
• Values
docid frequency position list context
docid date
docid size
docid owner
docid person
docid zip code
docid company
position
position
position
docid URI

Skipping
• Search engine and skipping– Used in merging (AND queries)– Semi sequential access– Direct lookup– Disk based
• Skip list• Vs Btree• Variants
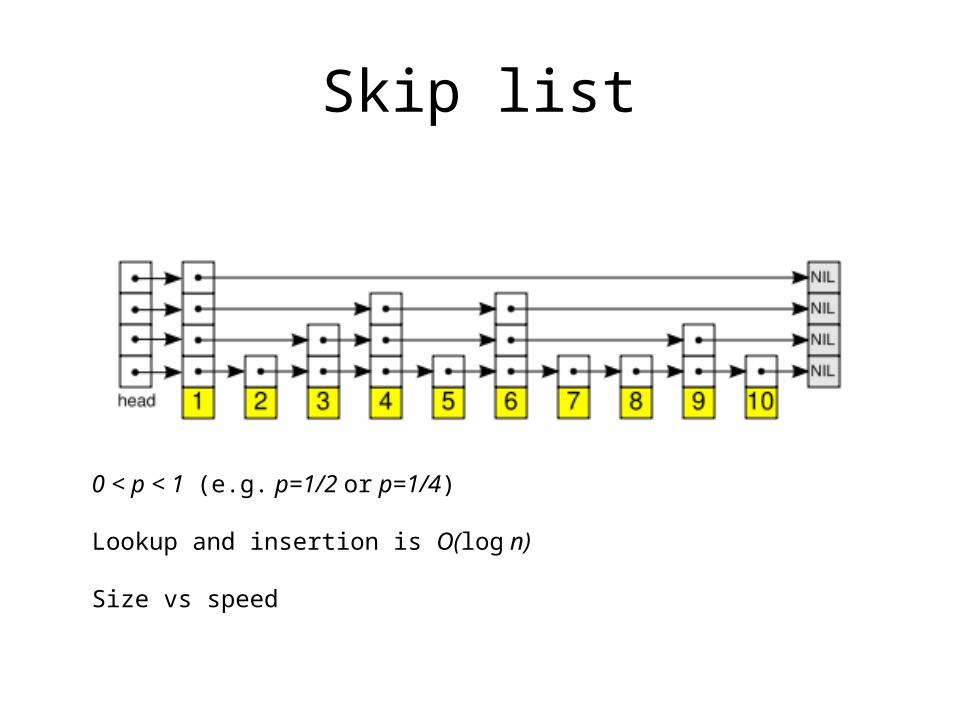
Skip list
0 < p < 1 (e.g. p=1/2 or p=1/4)
Lookup and insertion is O(log n)
Size vs speed

Issues
• Compression• Can be skewed

Skip list vs B-Tree
Skip list• Main-memory structure• Less space
B-Tree• Disk based structure• Better locality

Variations
• Deterministic skip list• 1 level skips• Separate skip table