Embed Size (px)
Citation preview

Learning Discriminative Projections for Text Similarity Measures
Scott Wen-tau YihJoint work with Kristina Toutanova, John Platt, Chris Meek
Microsoft Research
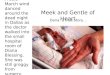
Cross-language Document Retrieval
English Query Doc
Spanish Document Set
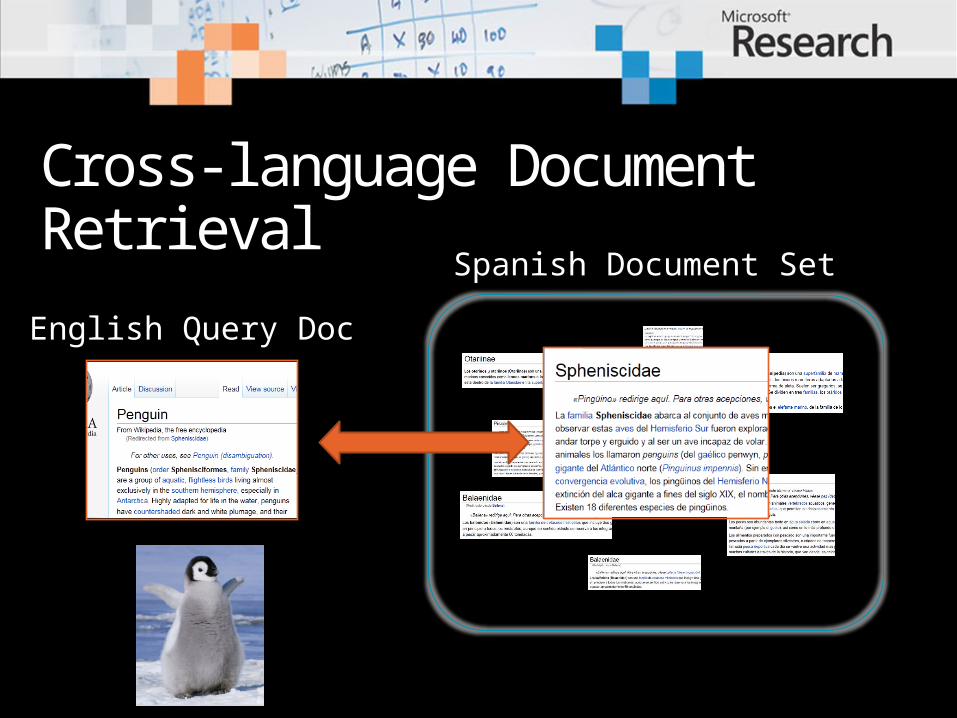
Web Search & Advertising
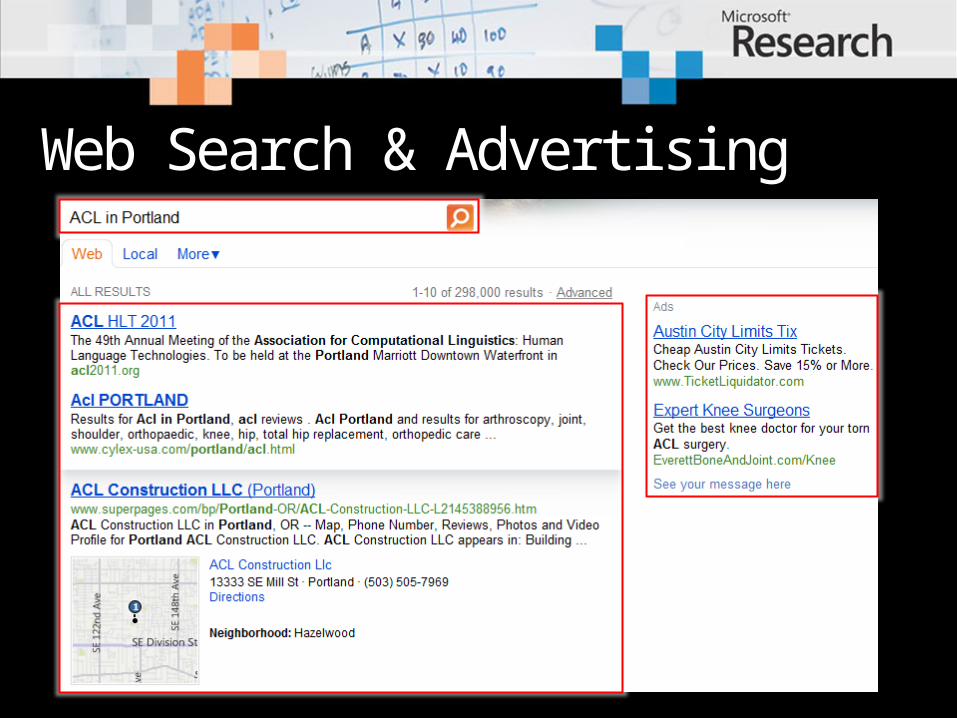
Web Search & Advertising
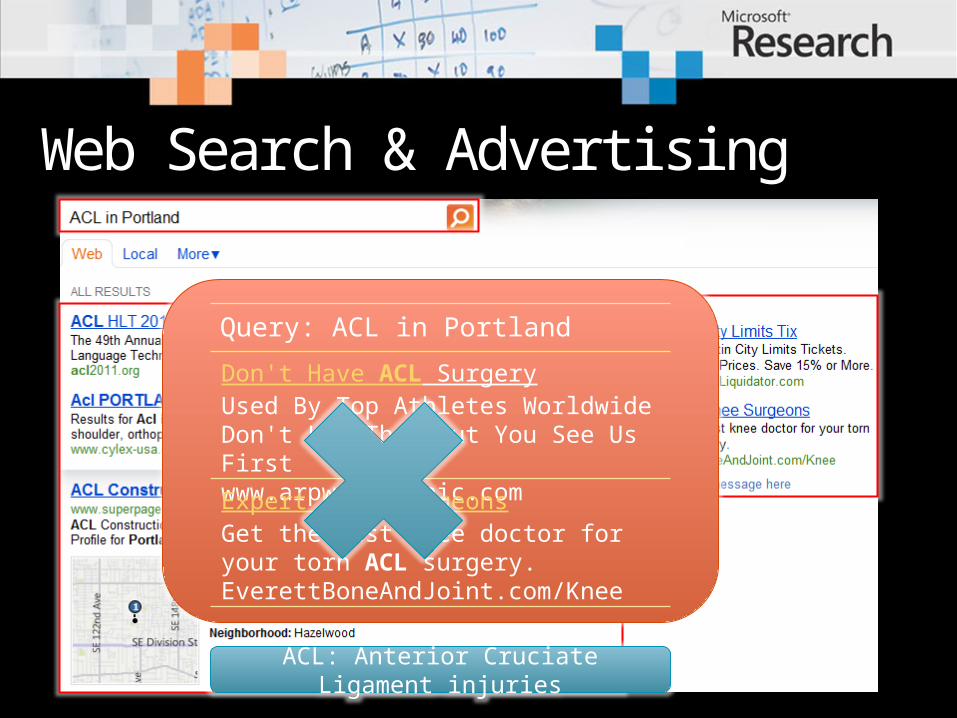
Query: ACL in Portland
ACL Construction LLC (Portland)ACL Construction LLC in Portland, OR -- Map, Phone Number, Reviews, …www.superpages.comACL HLT 2011The 49th Annual Meeting of the Association for Computational Linguistics…acl2011.org
Web Search & Advertising
Query: ACL in Portland
Don't Have ACL Surgery Used By Top Athletes WorldwideDon't Let Them Cut You See Us Firstwww.arpwaveclinic.com
Expert Knee SurgeonsGet the best knee doctor for your torn ACL surgery.EverettBoneAndJoint.com/Knee
ACL: Anterior Cruciate Ligament injuries
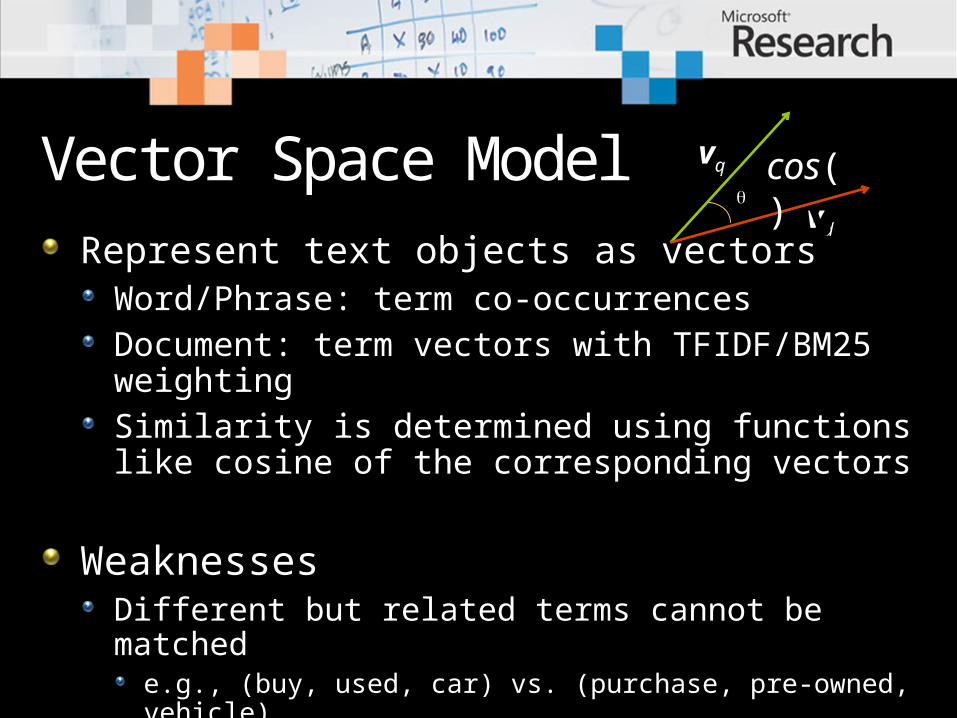
Vector Space ModelRepresent text objects as vectors
Word/Phrase: term co-occurrencesDocument: term vectors with TFIDF/BM25 weightingSimilarity is determined using functions like cosine of the corresponding vectors
WeaknessesDifferent but related terms cannot be matched
e.g., (buy, used, car) vs. (purchase, pre-owned, vehicle)
Not suitable for cross-lingual settings
qvcos()vq
vd

Learning Concept Vector RepresentationAre and relevant or semantically similar?
Input: high-dimensional, sparse term vectorsOutput: low-dimensional, dense concept vectorsModel requirements
Transformation is easy to computeProvide good similarity measures
𝐷𝑝𝐷𝑝 𝐷𝑞
𝐷𝑞
𝑠𝑖𝑚(𝐷𝑝 ,𝐷𝑞)
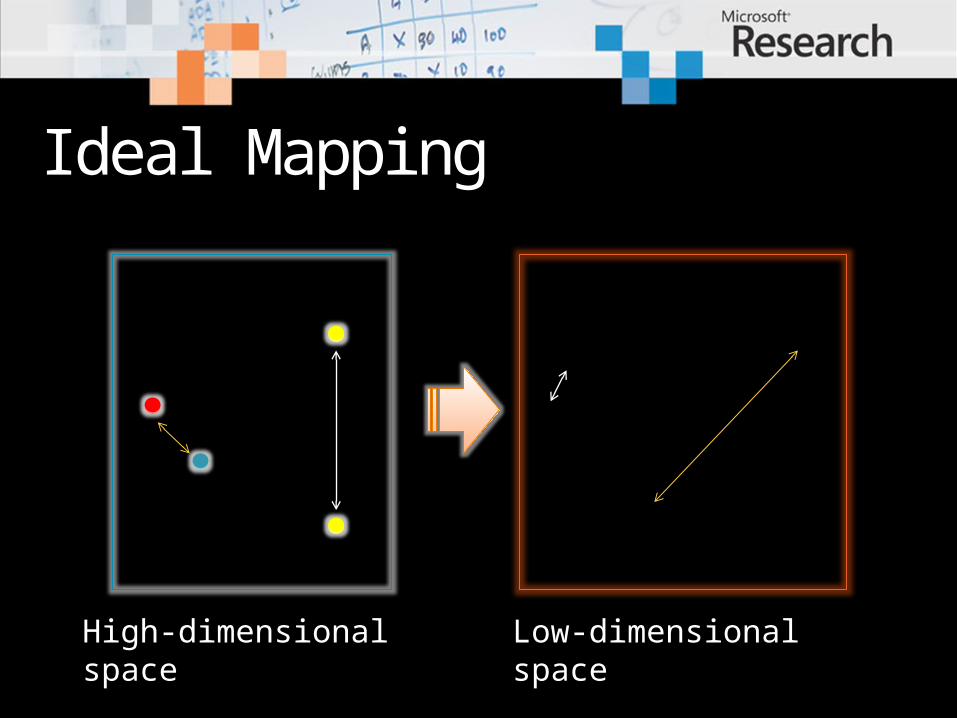
Ideal Mapping
High-dimensional space
Low-dimensional space

Dimensionality Reduction Methods
ProjectionProbabilistic
Supe
rvis
ed
Uns
uper
vise
d
PLSA
LDAPCA
LSA
OPCA
CCAHDLR
CL-LSIJPLSA
CPLSA
PLTM
S2Net

OutlineIntroductionProblem & ApproachExperiments
Cross-language document retrievalAd relevance measuresWeb search ranking
Discussion & Conclusions
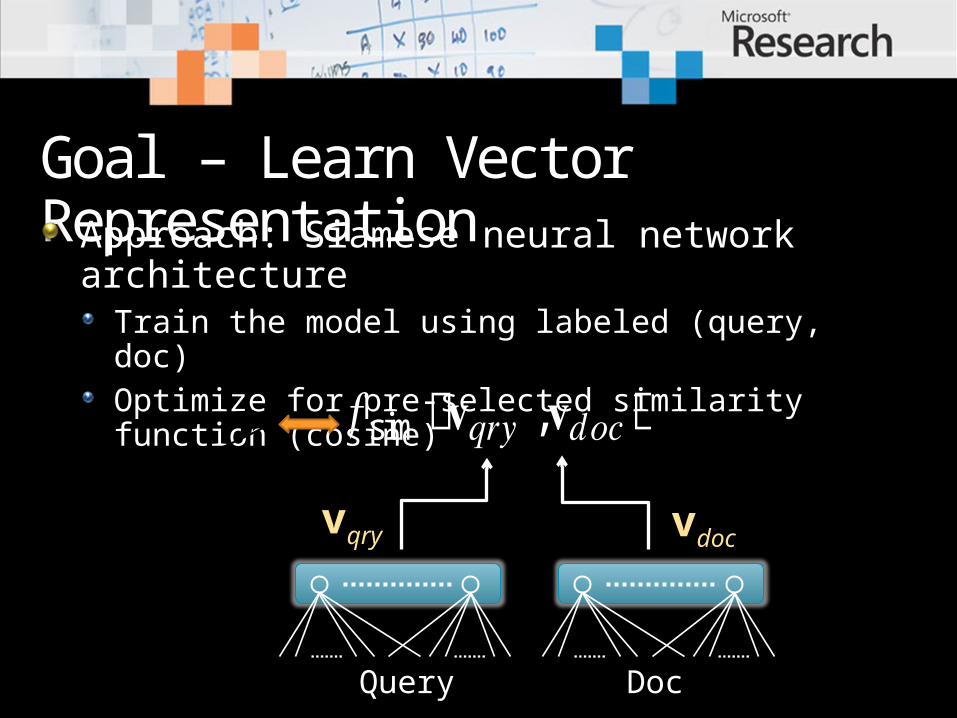
Goal – Learn Vector RepresentationApproach: Siamese neural network
architectureTrain the model using labeled (query, doc)Optimize for pre-selected similarity function (cosine)
vqry vdoc
𝑓sim൫𝐯𝑞𝑟𝑦,𝐯𝑑𝑜𝑐൯ 𝑦
Query Doc

Goal – Learn Vector RepresentationApproach: Siamese neural network
architectureTrain the model using labeled (query, doc)Optimize for pre-selected similarity function (cosine)
vqry vdoc
𝑓sim൫𝐯𝑞𝑟𝑦,𝐯𝑑𝑜𝑐൯ 𝑦
Query Doc
Model
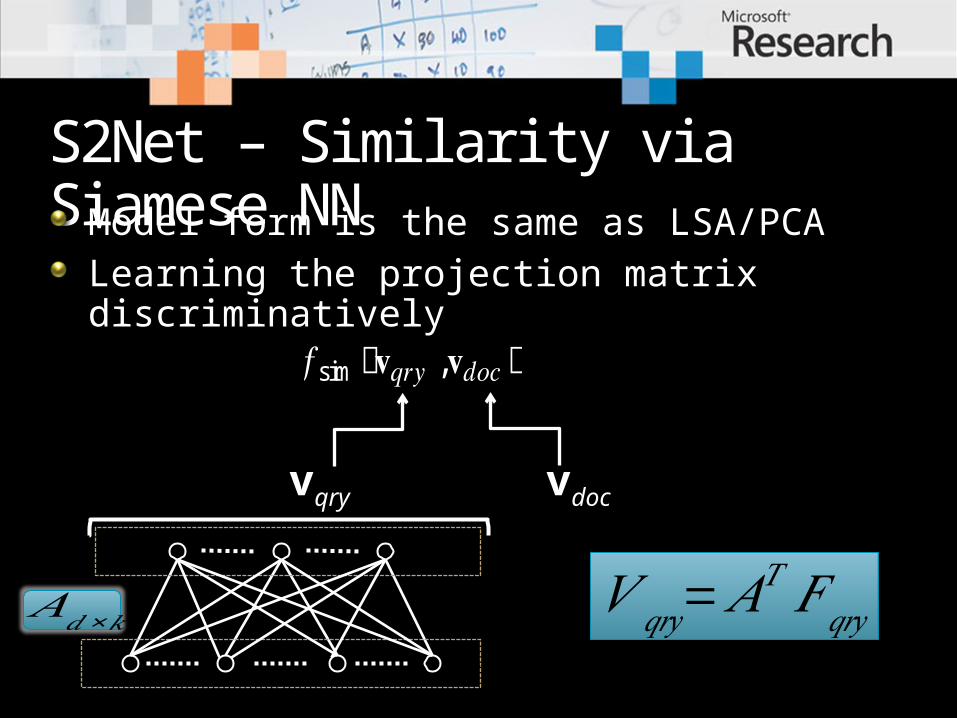
S2Net – Similarity via Siamese NNModel form is the same as LSA/PCALearning the projection matrix discriminatively
vqry vdoc
𝑓sim൫𝐯𝑞𝑟𝑦,𝐯𝑑𝑜𝑐൯
𝑐𝑘𝑐1
𝑡1 𝑡𝑑𝐴𝑑×𝑘 𝑉 𝑞𝑟𝑦=𝐴𝑇 𝐹 𝑞𝑟𝑦

Pairwise Loss – MotivationIn principle, we can use a simple loss function like mean-squared error: . But…
𝑄𝑢𝑒𝑟𝑦

Pairwise LossConsider a query and two documents and
Assume is more related to , compared to : original term vectors of and
: scaling factor, as in the experiments
-2 -1 0 1 20
5
10
15
20

Model TrainingMinimizing the loss function can be done using standard gradient-based methods
Derive batch gradient and apply L-BFGS
Non-convex lossStarting from a good initial matrix helps reduce training time and converge to a better local minimum
RegularizationModel parameters can be regularized by adding a smoothing term in the loss functionEarly stopping can be effective in practice

OutlineIntroductionProblem & ApproachExperiments
Cross-language document retrievalAd relevance measuresWeb search ranking
Discussion & Conclusions
Cross-language Document Retrieval
Dataset: pairs of Wiki documents in EN and ES
Same setting as in [Platt et al. EMNLP-10]
#document in each language Training: 43,380, Validation: 8,675, Test: 8,675
Effectively, billion training examplesPositive: EN-ES documents in the same pairNegative: All other pairs
Evaluation: find the comparable document in the different language for each query document
0
0.2
0.4
0.6
0.8
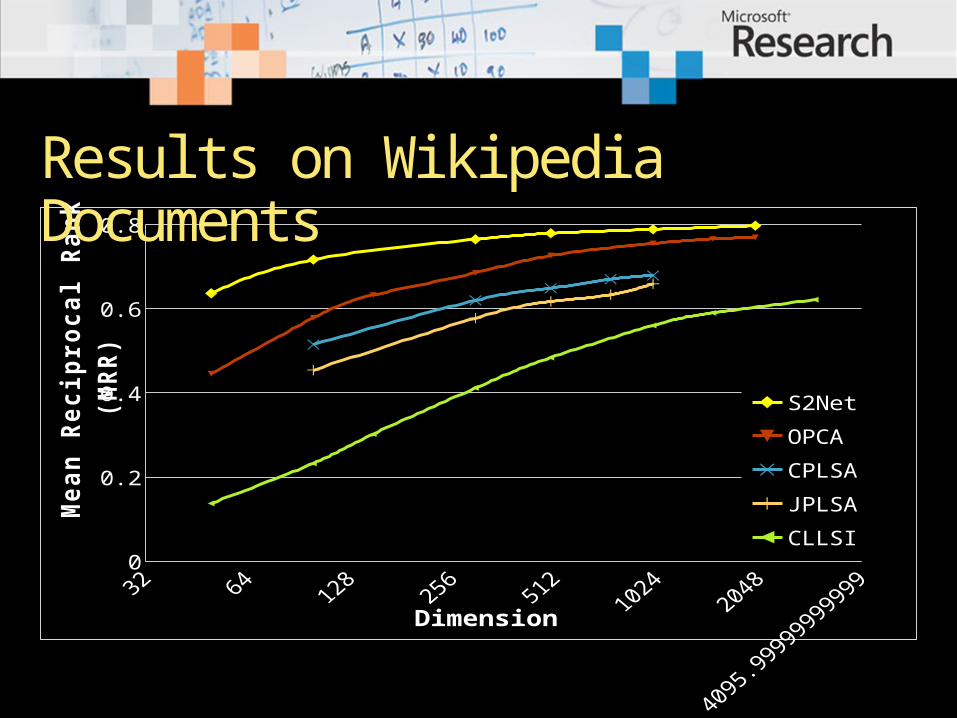
S2Net
OPCA
CPLSA
JPLSA
CLLSI
Dimension
Mean
Recip
rocal R
an
k
(MR
R)
Results on Wikipedia Documents

Ad Relevance MeasuresTask: Decide whether a paid-search ad is relevant to the query
Filter irrelevant ads to ensure positive search experience: pseudo-document from Web relevance feedback: ad landing page
Data: query-ad human relevance judgmentTraining: 226k pairsValidation: 169k pairsTesting: 169k pairs
0.05 0.1 0.15 0.2 0.250.3
0.4
0.5
0.6
0.7
0.8
0.9
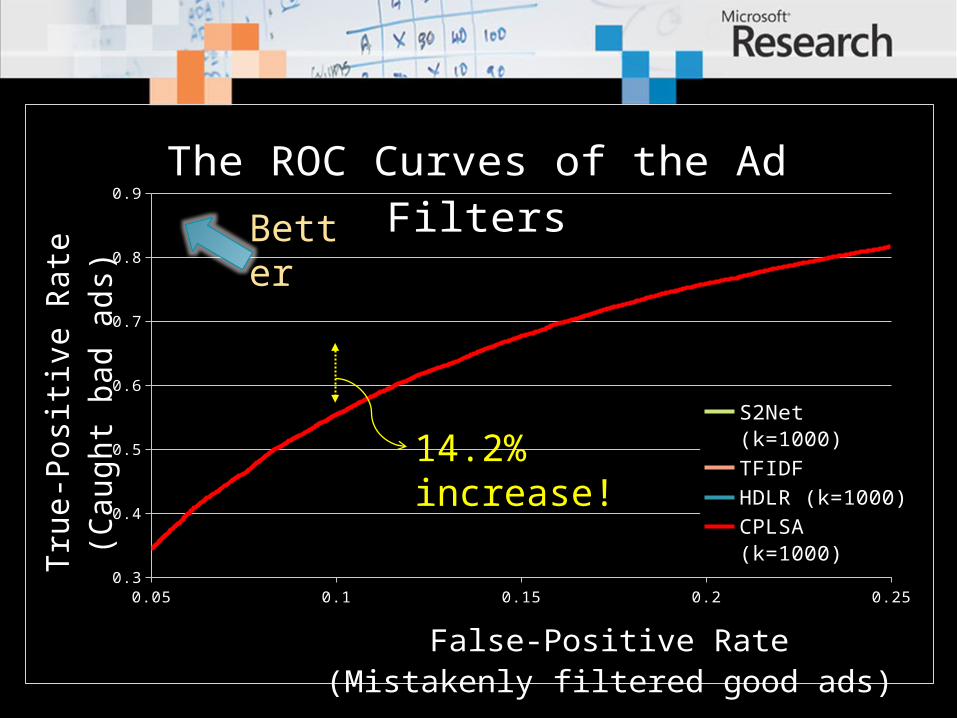
The ROC Curves of the Ad Filters
S2Net (k=1000)
TFIDF
HDLR (k=1000)
CPLSA (k=1000)
False-Positive Rate(Mistakenly filtered good ads)
Tru
e-P
osi
tive R
ate
(Caught
bad a
ds)
14.2% increase!
Better
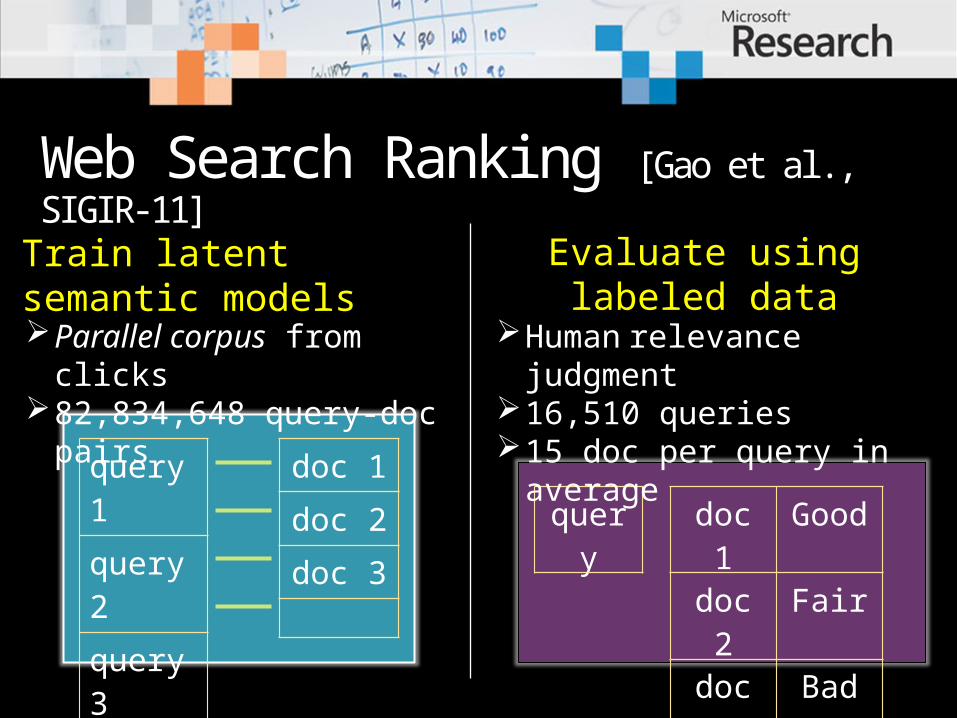
Web Search Ranking [Gao et al., SIGIR-11]
query 1
query 2
query 3
doc 1
doc 2
doc 3
Parallel corpus from clicks
82,834,648 query-doc pairs
query
doc 1
Good
doc 2
Fair
doc 3
Bad
Human relevance judgment
16,510 queries15 doc per query in
average
Train latent semantic models Evaluate using labeled data
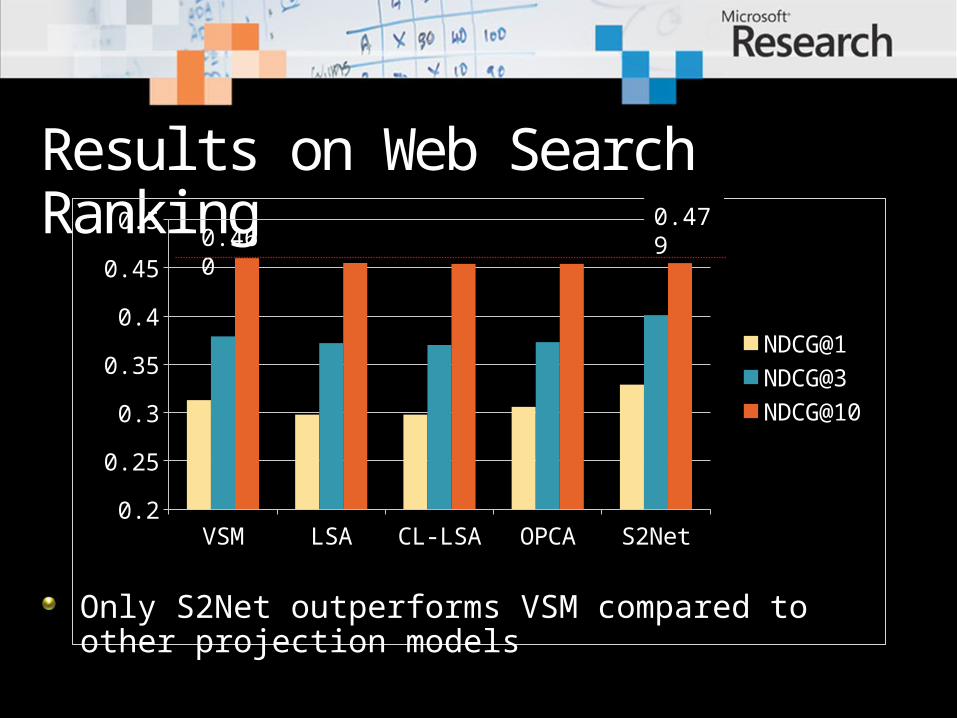
Results on Web Search Ranking
VSM LSA CL-LSA OPCA S2Net0.2
0.25
0.3
0.35
0.4
0.45
0.5
NDCG@1NDCG@3NDCG@10
0.4790.46
0
Only S2Net outperforms VSM compared to other projection models
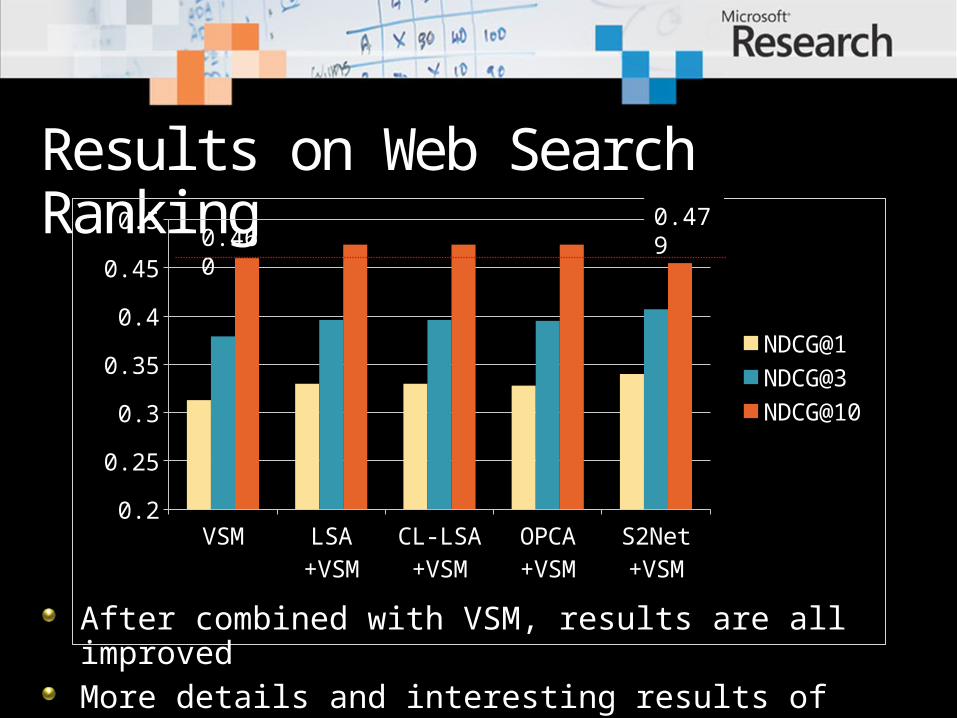
Results on Web Search Ranking
VSM LSA +VSM
CL-LSA +VSM
OPCA +VSM
S2Net +VSM
0.2
0.25
0.3
0.35
0.4
0.45
0.5
NDCG@1NDCG@3NDCG@10
0.4790.46
0
After combined with VSM, results are all improvedMore details and interesting results of generative topic models can be found in [SIGIR-11]

OutlineIntroductionProblem & ApproachExperiments
Cross-language document retrievalAd relevance measuresWeb search ranking
Discussion & Conclusions

Model ComparisonsS2Net vs. generative topic models
Can handle explicit negative examplesNo special constraints on input vectors
S2Net vs. linear projection methodsLoss function designed to closely match the true objectiveComputationally more expensive
S2Net vs. metric learningTarget high-dimensional input spaceScale well as the number of examples increases

Why Does S2Net Outperform Other Methods?
Loss functionCloser to the true evaluation objective
Slight nonlinearityCosine instead of inner-product
Leverage a large amount of training dataEasily parallelizable: distributed gradient computation

ConclusionsS2Net: Discriminative learning framework for dimensionality reduction
Learns a good projection matrix that leads to robust text similarity measuresStrong empirical results on different tasks
Future workModel improvement
Handle Web-scale parallel corpus more efficientlyConvex loss function
Explore more applicationse.g., word/phrase similarity