Embed Size (px)
Citation preview

Scheduling Black-box Mutational Fuzzing
Maverick Woo Sang Kil Cha Samantha Gottlieb David BrumleyCarnegie Mellon University
poohsangkilcsgottliedbrumleycmuedu
ABSTRACTBlack-box mutational fuzzing is a simple yet effective tech-nique to find bugs in software Given a set of program-seedpairs we ask how to schedule the fuzzings of these pairs inorder to maximize the number of unique bugs found at anypoint in time We develop an analytic framework using amathematical model of black-box mutational fuzzing anduse it to evaluate 26 existing and new randomized onlinescheduling algorithms Our experiments show that one ofour new scheduling algorithms outperforms the multi-armedbandit algorithm in the current version of the CERT BasicFuzzing Framework (BFF) by finding 15times more unique bugsin the same amount of time
Categories and Subject DescriptorsD25 [Software Engineering] Testing and DebuggingmdashTesting Tools
General TermsSecurity
KeywordsSoftware Security Fuzz Configuration Scheduling
1 IntroductionA General (or professor) walks into a cramped cubicle tellingthe lone security analyst (or graduate student) that she hasone week to find a zero-day exploit against a certain popularOS distribution all the while making it sound as if this taskis as easy as catching the next bus Although our analysthas access to several program analysis tools for finding bugs[8 10 11 21] and generating exploits [4 9] she still faces aharsh reality the target OS distribution contains thousandsof programs each with potentially tens or even hundredsof yet undiscovered bugs What tools should she use forthis mission Which programs should she analyze and inwhat order How much time should she dedicate to a given
Permission to make digital or hard copies of all or part of this work for personal orclassroom use is granted without fee provided that copies are not made or distributedfor profit or commercial advantage and that copies bear this notice and the full cita-tion on the first page Copyrights for components of this work owned by others thanACM must be honored Abstracting with credit is permitted To copy otherwise or re-publish to post on servers or to redistribute to lists requires prior specific permissionandor a fee Request permissions from permissionsacmorgCCSrsquo13 November 4ndash8 2013 Berlin GermanyCopyright 2013 ACM 978-1-4503-2477-91311 $1500httpdxdoiorg10114525088592516736
program Above all how can she maximize her likelihood ofsuccess within the given time budget
In this paper we focus on the setting where our analysthas chosen to find bugs via black-box mutational fuzzing Ata high level this technique takes as input a program p and aseed s that is usually assumed to be a well-formed input for pThen a program known as a black-box mutational fuzzer isused to fuzz the program p with the seed s ie execute p ona potentially malformed input x obtained by randomly mu-tating s in a precise manner to be described in sect2 Throughrepeated fuzzings we may discover a number of inputs thatcrash p These crashing inputs are then passed to down-stream analyses to triage each crash into a correspondingbug test each newly-discovered bug for exploitability andgenerate exploits when possible
Intuitively our analyst may try to improve her chancesby finding the greatest number of unique bugs among theprograms to be analyzed within the given time budget Tomodel this let us introduce the notion of a fuzz campaignWe assume our analyst has already obtained a list of program-seed pairs (pi si) to be fuzzed through prior manual andorautomatic analysis A fuzz campaign takes this list as inputand reports each new (previously unseen) bug when it isdiscovered As a simplification we also assume that thefuzz campaign is orchestrated in epochs At the beginning ofeach epoch we select one program-seed pair based only oninformation obtained during the campaign and we fuzz thatpair for the entire epoch This latter assumption has twosubtle but important implications First though it does notlimit us to fuzzing with only one computer it does requirethat every computer in the campaign fuzz the same program-seed pair during an epoch Second while our definition ofa fuzz configuration in sect2 is more general than a program-seed pair we also explain our decision to equate these twoconcepts in our present work As such what we need toselect for each epoch is really a fuzz configuration whichgives rise to our naming of the Fuzz Configuration Scheduling(FCS) problem
To find the greatest number of unique bugs given the aboveproblem setting our analyst must allocate her time wiselySince initially she has no information on which configurationwill yield more new bugs she should explore the configu-rations and reduce her risk by fuzzing each configurationfor an adequate amount of time As she starts to identifysome configurations that she believes may yield more newbugs in the future she should also exploit this informationby increasing the time allocated to fuzz these configurationsOf course any increase in exploitation reduces exploration
which may cause our analyst to under-explore and miss con-figurations that are capable of yielding more new bugs Thisis the classic ldquoexploration vs exploitationrdquo trade-off whichsignifies that we are dealing with a Multi-Armed Bandit(MAB) problem [5]
Unfortunately merely recognizing the MAB nature of ourproblem is not sufficient to give us an easy solution As weexplain in sect3 even though there are many existing MABalgorithms and some even come with excellent theoreticalguarantees we are not aware of any MAB algorithm thatis designed to cater to the specifics of finding unique bugsusing black-box mutational fuzzing For example supposewe have just found a crash by fuzzing a program-seed pairand the crash gets triaged to a new bug Should an MABalgorithm consider this as a high reward thus steering itselfto fuzz this pair more frequently in the future Exactly whatdoes this information tell us about the probability of findinganother new bug from this pair in future fuzzes What if thebug was instead a duplicate ie one that has already beendiscovered in a previous fuzz run Does that mean we shouldassign a zero reward since this bug does not contribute tothe number of unique bugs found
As a first step to answer these questions and design moresuitable MAB algorithms for our problem we discover thatthe memoryless property of black-box mutational fuzzingallows us to formally model the repeated fuzzings of a con-figuration as a bug arrival process Our insight is that thisprocess is a weighted variant of the Coupon Collectorrsquos Prob-lem (CCP) where each coupon type has its own fixed butinitially unknown arrival probability We explain in sect41 howto view each fuzz run as the arrival of a coupon and eachunique bug as a coupon type Using this analogy it is easyto understand the need to use the weighted variant of theCCP (WCCP) and the challenge in estimating the arrivalprobabilities
The WCCP connection has proven to be more powerfulthan simply affording us clean and formal notationmdashnot onlydoes it explain why our problem is impossible to optimize inits most general setting due to the No Free Lunch Theorembut it also pinpoints how we can circumvent this impossibilityresult if we are willing to make certain assumptions aboutthe arrival probabilities in the WCCP (sect42) Of course wealso understand that our analyst may not be comfortablein making any such assumptions This is why we havealso investigated how she can use the statistical concept ofconfidence intervals to estimate an upperbound on the sumof the arrival probabilities of the unique bugs that remainto be discovered in a fuzz configuration We argue in sect43why this upperbound offers a pragmatic way to cope withthe above impossibility result
Having developed these analytical tools we explore thedesign space of online algorithms for our problem in sect44We investigate two epoch types five belief functions that es-timate future bug arrival using past observations two MABalgorithms that use such belief functions and three that donot By combining these dimensions we obtain 26 onlinealgorithms for our problem While some of these algorithmshave appeared in prior work the majority of them are newIn addition we also present offline algorithms for our prob-lem in sect45 In the case where the sets of unique bugs fromeach configuration are disjoint we obtain an efficient algo-rithm that computes the offline optimal ie the maximumnumber of unique bugs that can be found by any algorithm
in any given time budget In the other case where thesesets may overlap we also propose an efficient heuristic thatlowerbounds the offline optimal
To evaluate our online algorithms we built FuzzSim anovel replay-based fuzz simulation system that we present insect5 FuzzSim is capable of simulating any online algorithmusing pre-recorded fuzzing data We used it to implementnumerous algorithms including the 26 presented in thispaper We also collected two extensive sets of fuzzing databased on the most recent stable release of the Debian Linuxdistribution up to the time of our data collection To thisend we first assembled 100 program-seed pairs comprisingFFMpeg with 100 different seeds and another 100 pairscomprising 100 different Linux file conversion utilities eachwith an input seed that has been manually verified to be validThen we fuzzed each of these 200 program-seed pairs for10 days which amounts to 48 000 CPU hours of fuzzing intotal The performance of our online algorithms on these twodatasets is presented in sect6 In addition we are also releasingFuzzSim as well as our datasets in support of open scienceBesides replicating our experiments this will also enablefellow researchers to evaluate other algorithms For detailsplease visit httpsecurityececmuedufuzzsim
2 Problem Setting and NotationLet us start by setting out the definitions and assump-tions needed to mathematically model black-box mutationalfuzzing Our model is motivated by and consistent with real-world fuzzers such as zzuf [16] We then present our problemstatement and discuss several algorithmic considerations Forthe rest of this paper the terms ldquofuzzerrdquo and ldquofuzzingrdquo referto the black-box mutational variant unless otherwise stated
21 Black-box Mutational FuzzingBlack-box mutational fuzzing is a dynamic bug-finding tech-nique It endeavors to find bugs in a given program p byrunning it on a sequence of inputs generated by randomlymutating a given seed input s The program that generatesthese inputs and executes p on them is known as a black-boxmutational fuzzer In principle there is no restriction on sother than it being a string with a finite length however inpractice s is often chosen to be a well-formed input for pin the interest of finding bugs in p more effectively Witheach execution p either crashes or properly terminates Mul-tiple crashes however may be due to the same underlyingbug Thus there needs to be a bug-triage process to mapeach crash into its corresponding bug Understanding theeffects of these multiplicities is key to analyzing black-boxmutational fuzzing
To formally define black-box mutational fuzzing we need anotion of ldquorandom mutationsrdquo for bit strings In what followslet |s| denote the bit-length of s
Definition 21 A random mutation of a bit b is theexclusive-or1of the bit b and a uniformly-chosen bit Withrespect to a given mutation ratio r isin [0 1] a random mu-tation of a string s is generated by first selecting d = r middot |s|different bit-positions uniformly at random among the
(|s|d
)possible combinations and then randomly mutating those dbits in s
1Mutations in the form of unconditionally setting or unsettingthe bit are possible but they are both harder to analyzemathematically and less frequently used in practice Tojustify the latter we note that zzuf defaults to exclusive-or
Definition 22 A black-box mutational fuzzer is a ran-domized algorithm that takes as input a fuzz configurationwhich comprises (i) a program p (ii) a seed input s and (iii)a mutation ratio r isin [0 1] In a fuzz run the fuzzer generatesan input x by randomly mutating s with the mutation ratior and then runs p on x The outcome of this fuzz run is acrash or a proper termination of p
At this point it is convenient to set up one additionalnotation to complement Definition 21 Let Hd(s) denotethe set of all strings obtained by randomly-mutating s withthe mutation ratio r = d|s| This notation highlights theequivalence between the set of all obtainable inputs and theset of all |s|-bit strings within a Hamming distance of dfrom s In this notation the input string x in Definition 21is simply a string chosen uniformly at random from Hd(s)As we explain below in this paper we use a globally-fixedmutation ratio and therefore d is fixed once s is given Thisis why we simply write H(s) instead of Hd(s)
We now state and justify several assumptions of our math-ematical model all of which are satisfied by typical fuzzersin practice
Assumption 1 Each seed input has finite length
This assumption is always satisfied when fuzzing file inputsIn practice some fuzzers can also perform stream fuzzingwhich randomly mutates each bit in an input stream with auser-configurable probability Notice that while the expectednumber of randomly-mutated bits is fixed the actual numberis not We do not model stream fuzzing
Assumption 2 An execution of the program exhibits ex-actly one of the following two possible outcomesmdashit eithercrashes or properly terminates
In essence this assumption means we focus exclusively onfinding bugs that lead to crashes Finding logical bugs thatdo not lead to crashes would typically require a correctnessspecification of the program under test At present such spec-ifications are rare in practice and therefore this assumptiondoes not impose a severe restriction
Assumption 3 The outcome of an execution of the pro-gram depends solely on the input x generated by the fuzzer
This assumption ensures we are not finding bugs causedby input channels not under the fuzzerrsquos control Sincethe generated input alone determines whether the programcrashes or terminates properly all bugs found during fuzzingare deterministically reproducible In practice inputs thatdo not cause a crash in downstream analyses are discarded
Mutation Ratio We include the mutation ratio as a thirdparameter in our definition of fuzz configurations given inDefinition 22 Our choice reflects the importance of thisparameter in practice since different seeds may need to befuzzed at different mutation ratios to be effective in find-ing bugs However in order to evaluate a large number ofscheduling algorithms our work is based on a replay simula-tion as detailed in sect5 Gathering the ground-truth fuzzingdata for such simulations is resource-intensive prohibitivelyso if we examine multiple mutation ratios As such ourcurrent project globally fixes the mutation ratio at 00004the default value used in zzuf Accordingly we suppress thethird parameter of a fuzz configuration in this paper effec-tively equating program-seed pairs with fuzz configurationsFor further discussion related to the mutation ratio see sect66
22 Problem StatementGiven a list of K fuzz configurations (p1 s1) middot middot middot (pK sK)and a time budget T the Fuzz Configuration Schedulingproblem seeks to maximize the number of unique bugs dis-covered in a fuzz campaign that runs for a duration of lengthT A fuzz campaign is divided into epochs starting withepoch 1 We consider two epoch types fixed-run and fixed-time In a fixed-run campaign each epoch corresponds toa constant number of fuzz runs since the time required forindividual fuzz runs may vary fixed-run epochs may takevariable amounts of time On the other hand in a fixed-timecampaign each epoch corresponds to a constant amount oftime Thus the number of fuzz runs completed may varyacross fixed-time epochs
An online algorithm A for the Fuzz Configuration Schedul-ing problem operates before each epoch starts When thecampaign starts A receives the number K Suppose thecampaign has completed ` epochs so far Before epoch (`+1)begins A should select a number i isin [1K] based on theinformation it has received from the campaign Then theentire epoch (` + 1) is devoted to fuzzing (pi si ) Whenthe epoch ends A receives a sequence of IDs representingthe outcomes of the fuzz runs completed during the epochIf an outcome is a crash then the returned ID is the bugID computed by the bug triage process which we assumeis non-zero Otherwise the outcome is a proper termina-tion and the returned ID is 0 Also any ID that has neverbeen encountered by the campaign prior to epoch (` + 1)is marked as new Notice that a new ID can signify eitherthe first proper termination in the campaign or a new bugdiscovered during epoch (`+ 1) Besides the list of IDs Aalso receives statistical information about the epoch In afixed-run campaign it receives the time spent in the epochin a fixed-time campaign it receives the number of fuzz runsthat ended inside the epoch
Algorithmic Considerations We now turn to a few techni-cal issues that we withheld from the above problem statementFirst we allow A to be either deterministic or randomizedThis admits the use of various existing MAB algorithmsmany of which are indeed randomized
Second notice that A receives only the number of configu-rations K but not the actual configurations This formulationis to prevent A from analyzing the content of any pirsquos or sirsquosSimilarly we prevent A from analyzing bugs by sending itonly the bug IDs but not any concrete representation
Third A also does not receive the time budget T Thisforces A to make its decisions without knowing how muchtime is left Therefore A has to attempt to discover new bugsas early as possible While this rules out any algorithm thatadjusts its degree of exploration based on the time left weargue that this not a severe restriction from the perspectiveof algorithm design For example one of the algorithms weuse is the EXP3S1 algorithm [2] It copes with the unknowntime horizon by partitioning time into exponentially longerperiods and picking new parameters at the beginning of eachperiod which has a known length
Fourth our analysis assumes that the K fuzz configura-tions are chosen such that they yield disjoint sets of bugsThis assumption is needed so that we can consider the bugarrival process of fuzzing each configuration independentlyWhile this assumption may be valid when every configurationinvolves a different program as in one of our two datasets
satisfying it when one program can appear in multiple config-urations is non-trivial In practice it is achieved by selectingseeds that exercise different code regions For example inour other data set we use seeds of various file formats tofuzz the different file parsers in a media player
Finally at present we do not account for the time spentin bug triage though this process requires considerable timeIn practice triaging a crash takes approximately the sameamount of time as the fuzz run that initially found the crashTherefore bug triage can potentially account for over half ofthe time spent in an epoch if crashes are extremely frequentWe plan to incorporate this consideration into our project ata future time
3 Multi-Armed BanditsAs explained in sect1 the Fuzz Configuration Scheduling prob-lem is an instance of the classic Multi-Armed Bandit (MAB)problem This has already been observed by previous re-searchers For example the CERT Basic Fuzzing Framework(BFF) [14] which supports fuzzing a single program witha collection of seeds and a set of mutation ratios uses anMAB algorithm to select among the seed-ratio pairs duringa fuzz campaign However we must stress that recognizingthe MAB nature of our problem is merely a first step Inparticular we should not expect an MAB algorithm withprovably ldquogoodrdquo performance such as one from the UCB [3]or the EXP3 [2] families to yield good results in our problemsetting There are at least two reasons for this
First although many of these algorithms are proven tohave optimal regret in various forms the most commonform of regret does not actually give good guarantees in ourproblem setting In particular this form of regret measuresthe difference between the expected reward of an algorithmand the reward obtained by consistently fuzzing the singlebest configuration that yields the greatest number of uniquebugs However we are interested in evaluating performancerelative to the total number of unique bugs from all Kconfigurations which may be much greater than the numberfrom one fixed configuration Thus the low-regret guaranteeof many MAB algorithms is in fact measuring against atarget that is likely to be much lower than what we desireIn other words given our problem setting these algorithmsare not guaranteed to be competitive at all
Second while there exist algorithms with provably lowregret in a form suited to our problem setting the actual re-gret bounds of these algorithms often do not give meaningfulvalues in practice For example one of the MAB algorithmswe use is the EXP3S1 algorithm [2] proven to have an
expected worst-case regret of S+2eradic2minus1
radic2K` ln(K`) where S is
a certain hardness measure of the problem instance as de-fined in [2 sect8] and ` is the number of epochs in our problemsetting Even assuming the easiest case where S equals to 1and picking K to be a modest value of 10 the value of thisbound when ` = 4 is already slightly above 266 Howeveras we see in sect6 the number of bugs we found in our twodatasets are 200 and 223 respectively What this means isthat this regret bound is very likely to dwarf the number ofbugs that can be found in real-world software after a verysmall number of epochs In other words even though we havethe right kind of guarantee from EXP3S1 the guaranteequickly becomes meaningless in practical terms
Having said the above we remark that this simply meanssuch optimal regret guarantees may not be useful in ensuring
good results As we will see in sect6 EXP3S1 can still obtainreasonably good results in the right setting
4 Algorithms for the FCS ProblemOur goal in this section is to investigate how to design onlinealgorithms for the Fuzz Configuration Scheduling problemWe largely focus on developing the design space (sect44) mak-ing heavy use of the mathematical foundation we lay outin sect41 and sect43 Additionally we present two impossibilityresults in sect42 one of which requires a precise conditionthat greatly informs our algorithm design effort We alsopresent two offline algorithms for our problem While suchalgorithms may not be applicable in practice a unique aspectof our project allows us to use them as benchmarks whichwe measure our online algorithms against We explain thisalong with the offline algorithms in sect45
41 Fuzzing as a Weighted CCPLet us start by mathematically modeling the process ofrepeatedly fuzzing a configuration As we explained in sect2the output of this process is a stream of crashes intermixedwith proper terminations which is then transformed intoa stream of IDs by a bug triage process Since we want tomaximize the number of unique bugs found we are naturallyinterested in when a new bug arrives in this process Thisinsight quickly leads us to the Coupon Collectorrsquos Problem(CCP) a classical arrival process in probability theory
The CCP concerns a consumer who obtains one couponwith each purchase of a box of breakfast cereal Supposethere are M different coupon types in circulation One basicquestion about the CCP is what is the expected number ofpurchases required before the consumer amasses k (le M)unique coupons In its most elementary formulation eachcoupon is chosen uniformly at random among the M coupontypes In this setting many questions related to the CCPmdashincluding the one abovemdashare relatively easy to answer
Viewing Fuzzing as WCCP with Unknown Weights Un-fortunately our problem setting actually demands a weightedvariant of the CCP which we dub the WCCP Intuitively thisis because the probabilities of the different outcomes froma fuzz run are not necessarily (and unlikely to be) uniformThis observation has also been made by Arcuri et al [1]
Let (M minus 1) be the actual number of unique bugs discov-erable by fuzzing a certain configuration Then includingproper termination of a fuzz run as an outcome gives usexactly M distinct outcome types We thus relate the pro-cess of repeatedly fuzzing a configuration to the WCCP byviewing fuzz run outcomes as coupons and their associatedIDs as coupon types
However unlike usual formulations of the WCCP where thedistribution of outcomes across type is given in our problemsetting this distribution is unknown a priori In particularthere is no way to know the true value ofM for a configurationwithout exhaustively fuzzing all possible mutations As suchwe utilize statistical estimations of these distributions ratherthan the ground-truth in our algorithm design An importantquestion to consider is whether accurate estimations arefeasible
We now explain why we prefer the sets of bugs from differ-ent configurations used in a campaign to be disjoint Observethat our model of a campaign is a combination of multipleindependent WCCP processes If a bug that is new to oneprocess has already been discovered in another then this
bug cannot contribute to the total number of unique bugsThis means that overlap in the sets of bugs diminishes thefidelity of our model so that any algorithm relying on itspredictions may suffer in performance
WCCP Notation Before we go on let us set up some ad-ditional notation related to the WCCP In an effort to avoidexcessive indices our notation implicitly assumes a fixedconfiguration (pi si) that is made apparent by context Forexample M the number of possible outcomes when fuzzing agiven configuration as defined above follows this convention
(i) Consider the fixed sequence σ of outcomes we obtainin the course of fuzzing (pi si) during a campaign We labelan outcome as type k if it belongs to the kth distinct type ofoutcome in σ Let Pk denote the probability of encounteringa type-k outcome in σ ie
Pk =|x isin H(si) x triggers an outcome of type k|
|H(si)| (1)
(ii) Although both the number and frequency of outcometypes obtainable by fuzzing (pi si ) are unknown a prioriduring a campaign we do have empirical observations forthese quantities up to any point in σ Let M(`) be the numberof distinct outcomes observed from epoch 1 through epoch` Let nk(`) be the number of inputs triggering outcomesof type k observed throughout these ` epochs Notice thatover the course of a campaign the sequence σ is segmentedinto subsequences each of which corresponds to an epochin which (pi si ) is chosen Thus the values of M(middot) andnk(middot) will not change if (pi si) is not chosen for the currentepoch With this notation we can also express the empiricalprobability of detecting a type-k outcome following epoch `as
Pk(`) =nk(`)sumM(`)
kprime=1 nkprime(`)
42 Impossibility ResultsNo Free Lunch The absence of any assumption on the dis-tribution of outcome types in the WCCP quickly leads us toour first impossibility result In particular no algorithm canconsistently outperform other algorithms for the FCS prob-lem This follows from a well-known impossibility result inoptimization theory namely the ldquoNo Free Lunchrdquo theorem byWolpert and Macready [22] Quoting Wolpert and Macreadytheir theorem implies that ldquoany two optimization algorithmsare equivalent when their performance is averaged across allpossible problemsrdquo In our problem setting maximizing thenumber of bugs found in epoch (`+ 1) amounts to for eachconfiguration estimating its PM(`)+1 in equation (1) usingonly past observations from that configuration Intuitivelyby averaging across all possible outcome type distributionsany estimation will be incorrect sufficiently often and thuslead to suboptimal behavior that cancels any advantage ofone algorithm over another
While we may consider this result to be easy to obtainonce we have properly set up our problem using sect2 and sect41we consider it to be an important intellectual contribution forthe pragmatic practitioners who remain confident that theycan design algorithms that outperform others In particularthe statement of the No Free Lunch theorem itself revealsprecisely how we can circumvent its conclusionmdashour estima-tion procedure must assume the outcome type distributions
have particular characteristics Our motto is thus ldquothere isno free lunchmdashplease bring your own priorrdquo
Tight K-Competitiveness Our second impossibility resultshows that there are problem instances in which the timespent by any deterministic online algorithm to find a givennumber of unique bugs in a fixed-time campaign is at leastK times larger than the time spent by an optimal offlinealgorithm Using the terminology of competitive analysisthis shows that the competitive ratio of any deterministiconline algorithm for this problem is at least K
To show this we fix a deterministic algorithm A andconstruct a contrived problem instance in which there is onlyone bug among all the configurations in a campaign Since Ais deterministic there exists a unique pair (plowasti s
lowasti ) that gets
chosen last In other words the other (K minus 1) pairs have allbeen fuzzed for at least one epoch when (plowasti s
lowasti ) is fuzzed for
the first time If the lone bug is only triggered by fuzzing(plowasti s
lowasti ) then A will have to fuzz for at least K epochs to
find itFor an optimal offline algorithm handling this contrived
scenario is trivial Since it is offline it has full knowledgeof the outcome distributions enabling it to hone in on thespecial pair (plowasti s
lowasti ) and find the bug in the first epoch This
establishes that K is a lowerbound for the competitive ratioof any deterministic algorithm
Finally we observe that Round-Robin is a deterministiconline algorithm that achieves the competitive ratio K inevery problem instance It follows immediately that K istight
43 Upperbounding the Probability of Seeinga New Outcome During Fuzzing
Having seen such strong impossibility results let us considerwhat a pragmatist might do before bringing in any prior onthe outcome type distribution In other words if we do notwant to make any assumptions on this distribution is therea justifiable approach to designing online algorithms for theFCS problem
We argue that the answer is yes Consider two program-seed pairs (p1 s1) and (p2 s2) for which we have upperboundson the probability of finding a new outcome if we fuzz themonce more Assume that the upperbound for (p1 s1) is thehigher of the two
We stress that what we know are merely upperboundsmdashitis still possible that the true probability of yielding a newoutcome from fuzzing (p1 s1) is lower than that of (p2 s2)Nonetheless with no information beyond the ordering ofthese upperbounds fuzzing (p1 s1 ) first is arguably themore prudent choice This is because to do otherwise wouldindicate a belief that the actual probability of finding a newoutcome by fuzzing (p1 s1) in the next fuzz run is lower thanthe upperbound for (p2 s2)
Accepting this argument how might we obtain such upper-bounds We introduce the Rule of Three for this purpose
Rule of Three Consider an experiment of independentBernoulli trials with identical success and failure probabilitiesp and q = (1minus p) Suppose we have carried out N ge 1 trialsso far and every trial has been a success What can we sayabout q other than the fact that it must be (i) at least 0to be a valid probability and (ii) strictly less than 1 sincep is evidently positive In particular can we place a lowerupperbound on q
Unfortunately the answer is a resounding no even with qarbitrarily close to 1 we still have (pN gt 0) This means ourobservation really could have happened even if it is extremelyunlikely
Fortunately if we are willing to rule out the possibility ofencountering extremely unlikely events then we may com-pute a lower upperbound for q by means of a confidenceinterval For example a 95 confidence interval on q out-puts an interval that includes the true value of q of theunderlying experiment with 95 certainty In other wordsif the outputted interval does not contain the true value ofq for the experiment then the observed event must have alikelihood of at most 5
For the above situation there is particularly neat techniqueto compute a 95 confidence interval on q Known as theldquoRule of Threerdquo this method simply outputs 0 and 3N for thelowerbound and upperbound respectively The lowerboundis trivial and the upperbound has been shown to be a goodapproximation for N gt 30 See [15] for more informationon this technique including the relationship between 95confidence and the constant 3
How We Use Rule of Three In order to apply the Ruleof Three we must adapt our fuzzing experiments with anyM gt 1 possible outcome types to fit the mold of Bernoullitrials
We make use of a small trick Suppose we have just finishedepoch ` and consider a particular configuration (pi si) Using
our notation we have observed M(`) different outcomes so
far and for 1 le k le M(`) we have observed nk(`) counts of
outcome of type k Let N(`) =sumM(`)
k=1 nk(`) denote the totalnumber of fuzz runs for this pair through epoch ` The trickis to define a ldquosuccessrdquo to be finding an outcome of type 1through type M(`) Then in hindsight it is the case thatour experiment has only yielded success so far
With this observation we may now apply the Rule of Threeto conclude that [0 3N(`)] is a 95 confidence interval onthe ldquofailurerdquo probabilitymdashthe probability that fuzzing thisconfiguration will result in an outcome type that we havenot seen before ie a new outcome Then as desired wehave an easy-to-compute upperbound on the probability offinding a new outcome for each configuration
We introduce one more piece of notation before proceedingdefine the Remaining Probability Mass (RPM) of (pi si) atthe end of epoch ` denoted RPM(`) to be the probabilityof finding a new outcome if we fuzz (pi si) once more Notethat the pair in RPM(`) is implicit and that this valueis upperbounded by 3N(`) if we accept a 95 confidenceinterval
44 Design SpaceIn this section we explore the design space that a pragma-tist may attempt when designing online algorithms for theFuzz Configuration Scheduling problem A depiction of thedesign space along with our experimental results is given inTable 2 in sect6 Our focus here is to explain our motivation forchoosing the three dimensions we explore and the particularchoices we include in each dimension By combining thesedimensions we obtain 26 online algorithms for our prob-lem We implemented these algorithms inside a simulatorFuzzSim the detail of which is presented in sect5
Epoch Type We consider two possible definitions of anepoch in a fuzz campaign The first is the more traditional
choice and is used in the current version of CERT BFFv26 [14] the second is our proposal
Fixed-Run Each epoch executes a constant number offuzz runs In FuzzSim a fixed-run epoch consists of 200runs Note that any differential in fuzzing speed acrossconfigurations translates into variation in the time spent infixed-run epochs
Fixed-Time Each epoch is allocated a fixed amount oftime In FuzzSim a fixed-time epoch lasts for 10 secondsOur motivation to investigate this epoch type is to see howheavily epoch time variation affects the results obtained bysystems with fixed-run epochs
Belief Metrics Two of the MAB algorithms we presentbelow make use of a belief metric that is associated with eachconfiguration and is updated after each epoch Intuitivelythe metrics are designed such that fuzzing a configurationwith a higher metric should yield more bugs in expectationThe first two beliefs below use the concept of RPM to achievethis without invoking any prior the remaining three embracea ldquobug priorrdquo For now suppose epoch ` has just finishedand we are in the process of updating the belief for theconfiguration (pi si)
RPM We use the upperbound in the 95 confidence intervalgiven by the Rule of Three to approximate RPM(`) Thebelief is simply 3N(`)
Expected Waiting Time Until Next New Outcome(EWT) Since RPM does not take into account of the speedof each fuzz run we also investigate a speed-normalizedvariant of RPM Let Time(`) be the cumulative time spentfuzzing this configuration from epoch 1 to epoch ` Let
avgTime(`) be the average time of a fuzz run ie Time(`)N(`)
Let W be a random variable denoting the waiting time untilthe next new outcome Recall that RPM(`) is the probabilityof finding a new outcome in the next fuzz run and assume itis independent of avgTime(`) To compute E[W ] observethat either we find a new outcome in the next fuzz run orwe do not and we have to wait again Therefore
E[W ] = RPM(`)times avgTime(`)
+ (1minus RPM(`))times (avgTime(`) + E[W ])
(Notice that RPM does not change even in the second casewhat changes is our upperbound on RPM) Solving for E[W ]
yields avgTime(`)RPM(`)
and we substitute in the upperbound of
the 95 confidence interval for RPM(`) to obtain E[W ] geavgTime(`)3N(`)
= Time(`)3
Since a larger waiting time is less desir-
able the belief used is its reciprocal 3Time(`)
Rich Gets Richer (RGR) This metric is grounded inwhat we call the ldquobug priorrdquo which captures our empiricalobservation that code tends to be either robust or bug-riddenPrograms written by programmers of different skill levelsor past testing of a program might explain this real-worldphenomenon Accordingly demonstrated bugginess of aprogram serves as a strong indicator that more bugs will befound in that program and thus the belief is M(`)
Density This is a runs-normalized variant of RGR and isalso the belief used in CERT BFF v26 [14] The belief func-
tion is M(`)N(`) Observe that this is the belief function
of RPM scaled by M(`)3 In other words Density can beseen as RPM adapted with the bug prior
Rate This is a time-normalized variant of RGR The belieffunction is M(`)Time(`) Similar to Density Rate can beseen as EWT adapted with the bug prior
Bandit Algorithms Since the FCS problem is an instanceof an MAB problem naturally we explore a number of MABalgorithmsRound-Robin This simply loops through the configura-tions in a fixed order dedicating one epoch to each configura-tion Note that Round-Robin is a non-adaptive deterministicalgorithmUniform-Random This algorithm selects uniformly atrandom from the set of configurations for each epoch LikeRound-Robin this algorithm is non-adaptive however it israndomizedWeighted-Random Configurations are selected at randomin this algorithm with the probability associated with eachconfiguration is linked to the belief metric in use Theweight of a well-performing configuration is adjusted upwardvia the belief metric thereby increasingly the likelihood ofselecting that configuration in future epochs This mechanismfunctions in reverse for configurations yielding few or no bugsε-Greedy The ε-Greedy algorithm takes an intuitive ap-proach to the exploration vs exploitation trade-off inherentto MAB problems With probability ε the algorithm selectsa configuration uniformly at random for explorationWithprobability (1minus ε) it chooses the configuration with the high-est current belief allowing it to exploit its current knowledgefor gains The constant ε serves as a parameter balancingthe two competing goals with higher ε values correspondingto a greater emphasis on explorationEXP3S1 This is an advanced MAB algorithm by Aueret al [2] for the non-stochastic MAB problem We picked thisalgorithm for three reasons First it is from the venerableEXP3 family and so likely to be picked up by practitionersSecond this is one of the EXP3 algorithms that is not pa-rameterized by any constants and thus no parameter tuningis needed Third this algorithm is designed to have an op-timal worst-case regret which is a form of regret that suitsour problem setting Note that at its core EXP3S1 is aweighted-random algorithm However since we do not havea belief metric that corresponds to the one used in EXP3S1we did not put it inside the Weighted-Random group
45 Offline AlgorithmsEarly on in our research design we recognized the importanceof evaluating a large number of algorithms Out of budgetaryconstraints we have taken a simulation approach so thatwe can replay the events from previous fuzzings to try outnew algorithms Since we have recorded all the events thatmay happen during any fuzz campaign of the same inputconfigurations we can even attempt to compute what anoptimal offline algorithm would do and compare the results ofour algorithms against it In the case when the configurationsdo not yield duplicated bugs such as in our Inter-Programdataset (sect6) we devise a pseudo-polynomial time algorithmthat computes the offline optimal In the other case whereduplicated bugs are possible we propose a heuristic to post-process the solution from the above algorithm to obtain alowerbound on the offline optimal
No Duplicates Assuming that the sets of unique bugsfrom different configurations are disjoint our algorithm isa small variation on the dynamic programming solution tothe Bounded Knapsack problem Let K be the number of
Program
amp
Seed
(pi si)
Fuzzer
bugsScheduler
crashes
Simulator
Scheduling
Algorithms
Fuzzing Triage
Bug Triage
bugs
Simulation
logs
logs
Time
Budget (T)
Figure 1 FuzzSim architecture
configurations and B be the total number of unique bugsfrom all K configurations Let t(i b) be the minimum amountof time it takes for configuration i to produce b unique bugsNote that t(i b) is assumed to be infin when configuration inever produces b unique bugs in our dataset We claim thatt(i b) can be pre-computed for all i isin [1K] and b isin [0 B]where each entry takes amortized O(1) time given how eventsare recorded in our system
Let m(i b) be the minimum amount of time it takes forconfigurations 1 through i to produce b unique bugs We wantto compute m(K b) for b isin [0 B] By definition m(1 b) =t(1 b) for b isin [0 B] For i gt 1 observe that m(i b) =mincisin[0B]t(i c) +m(iminus 1 bminus c) This models partitioningthe b unique bugs into c unique bugs from configuration iand (bminus c) unique bugs from configurations 1 through (iminus1)Computing each m(i b) entry takes O(B) time Since thereare O(K timesB) entries the total running time is O(K timesB2)
Discounting Duplicates The above algorithm is incorrectwhen the sets of unique bugs from different configurationsare not disjoint This is because the recurrence formula ofm(i b) assumes that the c unique bugs from configuration iare different from the (bminus c) unique bugs from configurations1 through (i minus 1) In this case we propose a heuristic tocompute a lowerbound on the offline optimal
After obtaining the m(i b) table from the above we post-process bug counts by the following discount heuristic Firstwe compute the maximum number of bugs that can be foundat each time by the above algorithm by examining the K-throw of the table Then by scanning forward from time 0whenever the bug count goes up by one due to a duplicatedbug (which must have been found using another configura-tion) we discount the increment Since the optimal offlinealgorithm can also pick up exactly the same bugs in the sameorder as the dynamic programming algorithm our heuristicis a valid lowerbound on the maximum number of bugs thatan optimal offline algorithm would find
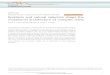
5 Design amp ImplementationThis section presents FuzzSim our replay-based fuzz simu-lation system built for this project We describe the threesteps in FuzzSim and explain the benefit of its design whichis then followed by its implementation detail Of special noteis that we are releasing our source code and our datasets insupport of open science at the URL found in sect52
51 OverviewFuzzSim is a simulation system for black-box mutationalfuzzing that is designed to run different configuration schedul-ing algorithms using logs from previous fuzzings Figure 1summarizes the design of FuzzSim which employs a three-step approach (1) fuzzing (2) triage and (3) simulation
Fuzzing The first step is fuzzing and collecting run logsfrom a fuzzer FuzzSim takes in a list of program-seedpairs (pi si) and a time budget T It runs a fuzzer on eachconfiguration for the full length of the time budget T andwrites to the log each time a crash occurs Log entries arerecorded as 5-tuples of the form (pi si time stamp runsmutation identifier)
In our implementation we fuzz with zzuf one of the mostpopular open-source fuzzers zzuf generates a random inputfrom a seed file as described in sect21 The randomization inzzuf can be reproduced given the mutation identifier thusenabling us to reproduce a crashing input from its seed fileand the log entry associated with the crash For example anoutput tuple of (FFMpeg aavi 100 42 1234) specifies thatthe program FFMpeg crashed at the 100-th second with aninput file obtained from ldquoaavirdquo according to the mutationidentifier 1234 Interested readers may refer to zzuf [16] fordetails on mutation identifiers and the actual implementation
The deterministic nature of zzuf allows FuzzSim to triagebugs after completing all fuzz runs first In other wordsFuzzSim does not compute bug identifiers during fuzzingand instead re-derives them using the log This does notaffect any of our algorithms since none of them relies on theactual IDs In our experiments we have turned off addressspace layout randomization (ASLR) in both the fuzzing andthe triage steps in order to reproduce the same crashes
Triage The second step of FuzzSim maps crashing inputsfound during fuzzings into bugs At a high level the triagephase takes in the list of 5-tuples (pi si time-stamp runsmutation identifier) logged during the fuzzing step and out-puts a new list of 5-tuples of the form (pi si time-stampruns bug identifier) More specifically FuzzSim replayseach recorded crash under a debugger to collect stack tracesIf FuzzSim does not detect a crash during a particular replaythen we classify that test case to be a non-deterministic bugand discard it
We then use the collected stack traces to produce bugidentifiers essentially hashes of the stack traces In particularwe use the fuzzy stack hash algorithm [19] which identifiesbugs by hashing the normalized line numbers from a stacktrace With this algorithm the number of stack frames tohash has a significant influence on the accuracy of bug triageFor example taking the full stack trace often leads to mis-classifying a single bug into multiple bugs whereas takingonly the top frame can easily lead to two different bugs beingmis-classified as one To match the state of the art FuzzSimuses the top 3 frames as suggested in [19] We stress that eventhough inaccurate bug triage may still occur with this choiceof parameter perfecting bug triage techniques is beyond thescope of this paper
Simulation The last step simulates a fuzz campaign onthe collected ground-truth data from the previous steps us-ing a user-specified scheduling algorithm More formallythe simulation step takes in a scheduling algorithm and alist of 5-tuples of the form (pi si timestamp runs bugidentifier) and outputs a list of 2-tuples (timestamp bugs)that represent the accumulated time before the correspond-ing number of unique bugs are observed under the givenscheduling algorithm
Since FuzzSim can simulate any scheduling algorithm inan offline fashion using the pre-recorded ground-truth datait enables us to efficiently compare numerous scheduling
algorithms without actually running a large number of fuzzcampaigns During replay FuzzSim outputs a timestampwhenever it finds a new bug Therefore we can easily plotand compare different scheduling algorithms by comparingthe number of bugs produced under the same time budget
We summarize FuzzSimrsquos three-step algorithm below
Fuzzing ((pi si) T )rarr pi si timestamp runs mutation id
Triage (pi si timestamp runs mutation id)rarr (pi si timestamp runs bug id)
Simulation (pi si timestamp runs bug id)rarr (timestamp bugs)
Algorithm 1 FuzzSim algorithms
52 Implementation amp Open ScienceWe have implemented our data collection and bug triage mod-ules in approximately 1000 lines of OCaml This includes thecapability to run and collect crash logs from Amazon EC2We used zzuf version 013 Our scheduling engine is alsoimplemented in OCaml and spans about 1600 lines Thiscovers the 26 online and the 2 offline algorithms presentedin this paper
We invite our fellow researchers to become involved inthis line of research In support of open science we releaseboth our datasets and the source code of our simulator athttpsecurityececmuedufuzzsim
6 EvaluationTo evaluate the performance of the 26 algorithms presentedin sect4 we focus on the following questions
1 Which scheduling algorithm works best for our datasets2 Why does one algorithm outperform the others3 Which of the two epoch typesmdashfixed-run or fixed-timemdash
works better and why
61 Experimental SetupOur experiments were performed on Amazon EC2 instancesthat have been configured with a single Intel 2GHz XeonCPU core and 4GB RAM each We used the most recentDebian Linux distribution at the time of our experiment(April 2013) and downloaded all programs from the then-latest Debian Squeeze repository Specifically the version ofFFMpeg we used is SVN-r0510-40510-1 which is basedon a June 2012 FFMpeg release with Debian-specific patches
62 Fuzzing Data CollectionOur evaluation makes use of two datasets (1) FFMpegwith 100 different input seeds and (2) 100 different Linuxapplications each with a corresponding input seed Werefer to these as the ldquointra-programrdquo and the ldquointer-programrdquodatasets respectively
For the intra-program dataset we downloaded 10 000videoimage sample files from the MPlayer website at http
samplesmplayerhqhu From these samples we selected100 files uniformly at random and took them as our input
Dataset runs crashes bugsIntra-program 636998978 906577 200Inter-program 4868416447 415699 223
Table 1 Statistics from fuzzing the two datasets
0
20
40
60
0 10 20 30 40
bugs
count
IntraminusProgram
0
20
40
60
0 10 20 30
bugs
count
InterminusProgram
Figure 2 Distribution of the number of bugs per configura-tion in each dataset
0
25
50
75
0 10 20 30 40
bugs
count
Figure 3 Distribution of bug overlaps across multiple seedsfor the intra-program dataset
seeds The collected seeds include various audio and videoformats such as ASF QuickTime MPEG FLAC etc Wethen used zzuf to fuzz FFMpeg with each seed for 10 days
For the inter-program dataset we downloaded 100 differ-ent file conversion utilities in Debian To select these 100programs we first enumerated all file conversion packagestagged as ldquouseconvertingrdquo in the Debian package tags in-terface (debtags) From this list of packages we manuallyidentified 100 applications that take a file name as a com-mand line argument Then we manually constructed a validseed for each program and the actual command line to run itwith the seed After choosing these 100 program-seed pairswe fuzzed each for 10 days as well In total we have spent48000 CPU hours fuzzing these 200 configurations
To perform bug triage we identified and re-ran everycrashing input from the log under a debugger to obtain stacktraces for hashing After triaging with the fuzzy stack hashalgorithm described in sect51 we found 200 bugs from theintra-program dataset and 223 bugs from the inter-programdataset Table 1 summarizes the data collected from ourexperiments The average fuzzing throughput was 8 runsper second for the intra-program dataset and 63 runs persecond for the inter-program dataset This difference is dueto the higher complexity of FFMpeg when compared to theprograms in the inter-program dataset
63 Data AnalysisWhat does the collected fuzzing data look like We studiedour data from fuzzing and triage to answer two questions (1)How many bugs does a configuration trigger (2) How manybugs are triggered by multiple seeds in the intra-programdataset
We first analyzed the distribution of the number of bugsin the two datasets On average the intra- and the inter-program datasets yielded 82 and 24 bugs per configurationrespectively Figure 2 shows two histograms each depict-
40
60
80
100
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(a) Intra-program
60
100
140
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(b) Inter-program
Figure 4 The average number of bugs over 100 runs foreach scheduling algorithm with error bars showing a 99confidence interval ldquoftrdquo represents fixed-time epoch ldquofrrdquorepresents fixed-run epoch ldquoerdquo represents ε-Greedy ldquowrdquo rep-resents Weighted-Random
ing the number of occurrences of bug counts There is amarked difference in the distributions from the two datasets64 of configurations in the inter-program dataset produceno bugs whereas the corresponding number in the intra-program dataset is 15 We study the bias of the bug countdistribution in sect64
Second we measured how many bugs are shared acrossseeds in the intra-program dataset As an extreme case wefound a bug that was triggered by 46 seeds The averagenumber of seeds leading to a given bug is 4 Out of the 200bugs 97 were discovered from multiple seeds Figure 3illustrates the distribution of bug overlaps Our resultssuggest that there is a small overlap in the code exercisedby different seed files even though they have been chosento be of different types Although this shows that our bugdisjointness assumption in the WCCP model does not alwayshold in practice the low average number of seeds leading toa given bug in our dataset means that the performance ofour algorithms should not have been severely affected
64 SimulationWe now compare the 26 scheduling algorithms based on the10-day fuzzing logs collected for the intra- and inter-programdatasets To compare the performance of scheduling algo-rithms we use the total number of unique bugs reportedby the bug triage process Recall from sect44 that these al-gorithms vary across three dimensions (1) epoch types (2)belief metrics and (3) MAB algorithms For each valid com-bination (see Table 2) we ran our simulator 100 times andaveraged the results to study the effect of randomness oneach scheduling algorithm In our experiments we allocated10 seconds to each epoch for fixed-time campaigns and 200runs for fixed-run campaigns For the ε-Greedy algorithmwe chose ε to be 01
Table 2 summarizes our results Each entry in the tablerepresents the average number of bugs found by 100 sim-
Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

which may cause our analyst to under-explore and miss con-figurations that are capable of yielding more new bugs Thisis the classic ldquoexploration vs exploitationrdquo trade-off whichsignifies that we are dealing with a Multi-Armed Bandit(MAB) problem [5]
Unfortunately merely recognizing the MAB nature of ourproblem is not sufficient to give us an easy solution As weexplain in sect3 even though there are many existing MABalgorithms and some even come with excellent theoreticalguarantees we are not aware of any MAB algorithm thatis designed to cater to the specifics of finding unique bugsusing black-box mutational fuzzing For example supposewe have just found a crash by fuzzing a program-seed pairand the crash gets triaged to a new bug Should an MABalgorithm consider this as a high reward thus steering itselfto fuzz this pair more frequently in the future Exactly whatdoes this information tell us about the probability of findinganother new bug from this pair in future fuzzes What if thebug was instead a duplicate ie one that has already beendiscovered in a previous fuzz run Does that mean we shouldassign a zero reward since this bug does not contribute tothe number of unique bugs found
As a first step to answer these questions and design moresuitable MAB algorithms for our problem we discover thatthe memoryless property of black-box mutational fuzzingallows us to formally model the repeated fuzzings of a con-figuration as a bug arrival process Our insight is that thisprocess is a weighted variant of the Coupon Collectorrsquos Prob-lem (CCP) where each coupon type has its own fixed butinitially unknown arrival probability We explain in sect41 howto view each fuzz run as the arrival of a coupon and eachunique bug as a coupon type Using this analogy it is easyto understand the need to use the weighted variant of theCCP (WCCP) and the challenge in estimating the arrivalprobabilities
The WCCP connection has proven to be more powerfulthan simply affording us clean and formal notationmdashnot onlydoes it explain why our problem is impossible to optimize inits most general setting due to the No Free Lunch Theorembut it also pinpoints how we can circumvent this impossibilityresult if we are willing to make certain assumptions aboutthe arrival probabilities in the WCCP (sect42) Of course wealso understand that our analyst may not be comfortablein making any such assumptions This is why we havealso investigated how she can use the statistical concept ofconfidence intervals to estimate an upperbound on the sumof the arrival probabilities of the unique bugs that remainto be discovered in a fuzz configuration We argue in sect43why this upperbound offers a pragmatic way to cope withthe above impossibility result
Having developed these analytical tools we explore thedesign space of online algorithms for our problem in sect44We investigate two epoch types five belief functions that es-timate future bug arrival using past observations two MABalgorithms that use such belief functions and three that donot By combining these dimensions we obtain 26 onlinealgorithms for our problem While some of these algorithmshave appeared in prior work the majority of them are newIn addition we also present offline algorithms for our prob-lem in sect45 In the case where the sets of unique bugs fromeach configuration are disjoint we obtain an efficient algo-rithm that computes the offline optimal ie the maximumnumber of unique bugs that can be found by any algorithm
in any given time budget In the other case where thesesets may overlap we also propose an efficient heuristic thatlowerbounds the offline optimal
To evaluate our online algorithms we built FuzzSim anovel replay-based fuzz simulation system that we present insect5 FuzzSim is capable of simulating any online algorithmusing pre-recorded fuzzing data We used it to implementnumerous algorithms including the 26 presented in thispaper We also collected two extensive sets of fuzzing databased on the most recent stable release of the Debian Linuxdistribution up to the time of our data collection To thisend we first assembled 100 program-seed pairs comprisingFFMpeg with 100 different seeds and another 100 pairscomprising 100 different Linux file conversion utilities eachwith an input seed that has been manually verified to be validThen we fuzzed each of these 200 program-seed pairs for10 days which amounts to 48 000 CPU hours of fuzzing intotal The performance of our online algorithms on these twodatasets is presented in sect6 In addition we are also releasingFuzzSim as well as our datasets in support of open scienceBesides replicating our experiments this will also enablefellow researchers to evaluate other algorithms For detailsplease visit httpsecurityececmuedufuzzsim
2 Problem Setting and NotationLet us start by setting out the definitions and assump-tions needed to mathematically model black-box mutationalfuzzing Our model is motivated by and consistent with real-world fuzzers such as zzuf [16] We then present our problemstatement and discuss several algorithmic considerations Forthe rest of this paper the terms ldquofuzzerrdquo and ldquofuzzingrdquo referto the black-box mutational variant unless otherwise stated
21 Black-box Mutational FuzzingBlack-box mutational fuzzing is a dynamic bug-finding tech-nique It endeavors to find bugs in a given program p byrunning it on a sequence of inputs generated by randomlymutating a given seed input s The program that generatesthese inputs and executes p on them is known as a black-boxmutational fuzzer In principle there is no restriction on sother than it being a string with a finite length however inpractice s is often chosen to be a well-formed input for pin the interest of finding bugs in p more effectively Witheach execution p either crashes or properly terminates Mul-tiple crashes however may be due to the same underlyingbug Thus there needs to be a bug-triage process to mapeach crash into its corresponding bug Understanding theeffects of these multiplicities is key to analyzing black-boxmutational fuzzing
To formally define black-box mutational fuzzing we need anotion of ldquorandom mutationsrdquo for bit strings In what followslet |s| denote the bit-length of s
Definition 21 A random mutation of a bit b is theexclusive-or1of the bit b and a uniformly-chosen bit Withrespect to a given mutation ratio r isin [0 1] a random mu-tation of a string s is generated by first selecting d = r middot |s|different bit-positions uniformly at random among the
(|s|d
)possible combinations and then randomly mutating those dbits in s
1Mutations in the form of unconditionally setting or unsettingthe bit are possible but they are both harder to analyzemathematically and less frequently used in practice Tojustify the latter we note that zzuf defaults to exclusive-or
Definition 22 A black-box mutational fuzzer is a ran-domized algorithm that takes as input a fuzz configurationwhich comprises (i) a program p (ii) a seed input s and (iii)a mutation ratio r isin [0 1] In a fuzz run the fuzzer generatesan input x by randomly mutating s with the mutation ratior and then runs p on x The outcome of this fuzz run is acrash or a proper termination of p
At this point it is convenient to set up one additionalnotation to complement Definition 21 Let Hd(s) denotethe set of all strings obtained by randomly-mutating s withthe mutation ratio r = d|s| This notation highlights theequivalence between the set of all obtainable inputs and theset of all |s|-bit strings within a Hamming distance of dfrom s In this notation the input string x in Definition 21is simply a string chosen uniformly at random from Hd(s)As we explain below in this paper we use a globally-fixedmutation ratio and therefore d is fixed once s is given Thisis why we simply write H(s) instead of Hd(s)
We now state and justify several assumptions of our math-ematical model all of which are satisfied by typical fuzzersin practice
Assumption 1 Each seed input has finite length
This assumption is always satisfied when fuzzing file inputsIn practice some fuzzers can also perform stream fuzzingwhich randomly mutates each bit in an input stream with auser-configurable probability Notice that while the expectednumber of randomly-mutated bits is fixed the actual numberis not We do not model stream fuzzing
Assumption 2 An execution of the program exhibits ex-actly one of the following two possible outcomesmdashit eithercrashes or properly terminates
In essence this assumption means we focus exclusively onfinding bugs that lead to crashes Finding logical bugs thatdo not lead to crashes would typically require a correctnessspecification of the program under test At present such spec-ifications are rare in practice and therefore this assumptiondoes not impose a severe restriction
Assumption 3 The outcome of an execution of the pro-gram depends solely on the input x generated by the fuzzer
This assumption ensures we are not finding bugs causedby input channels not under the fuzzerrsquos control Sincethe generated input alone determines whether the programcrashes or terminates properly all bugs found during fuzzingare deterministically reproducible In practice inputs thatdo not cause a crash in downstream analyses are discarded
Mutation Ratio We include the mutation ratio as a thirdparameter in our definition of fuzz configurations given inDefinition 22 Our choice reflects the importance of thisparameter in practice since different seeds may need to befuzzed at different mutation ratios to be effective in find-ing bugs However in order to evaluate a large number ofscheduling algorithms our work is based on a replay simula-tion as detailed in sect5 Gathering the ground-truth fuzzingdata for such simulations is resource-intensive prohibitivelyso if we examine multiple mutation ratios As such ourcurrent project globally fixes the mutation ratio at 00004the default value used in zzuf Accordingly we suppress thethird parameter of a fuzz configuration in this paper effec-tively equating program-seed pairs with fuzz configurationsFor further discussion related to the mutation ratio see sect66
22 Problem StatementGiven a list of K fuzz configurations (p1 s1) middot middot middot (pK sK)and a time budget T the Fuzz Configuration Schedulingproblem seeks to maximize the number of unique bugs dis-covered in a fuzz campaign that runs for a duration of lengthT A fuzz campaign is divided into epochs starting withepoch 1 We consider two epoch types fixed-run and fixed-time In a fixed-run campaign each epoch corresponds toa constant number of fuzz runs since the time required forindividual fuzz runs may vary fixed-run epochs may takevariable amounts of time On the other hand in a fixed-timecampaign each epoch corresponds to a constant amount oftime Thus the number of fuzz runs completed may varyacross fixed-time epochs
An online algorithm A for the Fuzz Configuration Schedul-ing problem operates before each epoch starts When thecampaign starts A receives the number K Suppose thecampaign has completed ` epochs so far Before epoch (`+1)begins A should select a number i isin [1K] based on theinformation it has received from the campaign Then theentire epoch (` + 1) is devoted to fuzzing (pi si ) Whenthe epoch ends A receives a sequence of IDs representingthe outcomes of the fuzz runs completed during the epochIf an outcome is a crash then the returned ID is the bugID computed by the bug triage process which we assumeis non-zero Otherwise the outcome is a proper termina-tion and the returned ID is 0 Also any ID that has neverbeen encountered by the campaign prior to epoch (` + 1)is marked as new Notice that a new ID can signify eitherthe first proper termination in the campaign or a new bugdiscovered during epoch (`+ 1) Besides the list of IDs Aalso receives statistical information about the epoch In afixed-run campaign it receives the time spent in the epochin a fixed-time campaign it receives the number of fuzz runsthat ended inside the epoch
Algorithmic Considerations We now turn to a few techni-cal issues that we withheld from the above problem statementFirst we allow A to be either deterministic or randomizedThis admits the use of various existing MAB algorithmsmany of which are indeed randomized
Second notice that A receives only the number of configu-rations K but not the actual configurations This formulationis to prevent A from analyzing the content of any pirsquos or sirsquosSimilarly we prevent A from analyzing bugs by sending itonly the bug IDs but not any concrete representation
Third A also does not receive the time budget T Thisforces A to make its decisions without knowing how muchtime is left Therefore A has to attempt to discover new bugsas early as possible While this rules out any algorithm thatadjusts its degree of exploration based on the time left weargue that this not a severe restriction from the perspectiveof algorithm design For example one of the algorithms weuse is the EXP3S1 algorithm [2] It copes with the unknowntime horizon by partitioning time into exponentially longerperiods and picking new parameters at the beginning of eachperiod which has a known length
Fourth our analysis assumes that the K fuzz configura-tions are chosen such that they yield disjoint sets of bugsThis assumption is needed so that we can consider the bugarrival process of fuzzing each configuration independentlyWhile this assumption may be valid when every configurationinvolves a different program as in one of our two datasets
satisfying it when one program can appear in multiple config-urations is non-trivial In practice it is achieved by selectingseeds that exercise different code regions For example inour other data set we use seeds of various file formats tofuzz the different file parsers in a media player
Finally at present we do not account for the time spentin bug triage though this process requires considerable timeIn practice triaging a crash takes approximately the sameamount of time as the fuzz run that initially found the crashTherefore bug triage can potentially account for over half ofthe time spent in an epoch if crashes are extremely frequentWe plan to incorporate this consideration into our project ata future time
3 Multi-Armed BanditsAs explained in sect1 the Fuzz Configuration Scheduling prob-lem is an instance of the classic Multi-Armed Bandit (MAB)problem This has already been observed by previous re-searchers For example the CERT Basic Fuzzing Framework(BFF) [14] which supports fuzzing a single program witha collection of seeds and a set of mutation ratios uses anMAB algorithm to select among the seed-ratio pairs duringa fuzz campaign However we must stress that recognizingthe MAB nature of our problem is merely a first step Inparticular we should not expect an MAB algorithm withprovably ldquogoodrdquo performance such as one from the UCB [3]or the EXP3 [2] families to yield good results in our problemsetting There are at least two reasons for this
First although many of these algorithms are proven tohave optimal regret in various forms the most commonform of regret does not actually give good guarantees in ourproblem setting In particular this form of regret measuresthe difference between the expected reward of an algorithmand the reward obtained by consistently fuzzing the singlebest configuration that yields the greatest number of uniquebugs However we are interested in evaluating performancerelative to the total number of unique bugs from all Kconfigurations which may be much greater than the numberfrom one fixed configuration Thus the low-regret guaranteeof many MAB algorithms is in fact measuring against atarget that is likely to be much lower than what we desireIn other words given our problem setting these algorithmsare not guaranteed to be competitive at all
Second while there exist algorithms with provably lowregret in a form suited to our problem setting the actual re-gret bounds of these algorithms often do not give meaningfulvalues in practice For example one of the MAB algorithmswe use is the EXP3S1 algorithm [2] proven to have an
expected worst-case regret of S+2eradic2minus1
radic2K` ln(K`) where S is
a certain hardness measure of the problem instance as de-fined in [2 sect8] and ` is the number of epochs in our problemsetting Even assuming the easiest case where S equals to 1and picking K to be a modest value of 10 the value of thisbound when ` = 4 is already slightly above 266 Howeveras we see in sect6 the number of bugs we found in our twodatasets are 200 and 223 respectively What this means isthat this regret bound is very likely to dwarf the number ofbugs that can be found in real-world software after a verysmall number of epochs In other words even though we havethe right kind of guarantee from EXP3S1 the guaranteequickly becomes meaningless in practical terms
Having said the above we remark that this simply meanssuch optimal regret guarantees may not be useful in ensuring
good results As we will see in sect6 EXP3S1 can still obtainreasonably good results in the right setting
4 Algorithms for the FCS ProblemOur goal in this section is to investigate how to design onlinealgorithms for the Fuzz Configuration Scheduling problemWe largely focus on developing the design space (sect44) mak-ing heavy use of the mathematical foundation we lay outin sect41 and sect43 Additionally we present two impossibilityresults in sect42 one of which requires a precise conditionthat greatly informs our algorithm design effort We alsopresent two offline algorithms for our problem While suchalgorithms may not be applicable in practice a unique aspectof our project allows us to use them as benchmarks whichwe measure our online algorithms against We explain thisalong with the offline algorithms in sect45
41 Fuzzing as a Weighted CCPLet us start by mathematically modeling the process ofrepeatedly fuzzing a configuration As we explained in sect2the output of this process is a stream of crashes intermixedwith proper terminations which is then transformed intoa stream of IDs by a bug triage process Since we want tomaximize the number of unique bugs found we are naturallyinterested in when a new bug arrives in this process Thisinsight quickly leads us to the Coupon Collectorrsquos Problem(CCP) a classical arrival process in probability theory
The CCP concerns a consumer who obtains one couponwith each purchase of a box of breakfast cereal Supposethere are M different coupon types in circulation One basicquestion about the CCP is what is the expected number ofpurchases required before the consumer amasses k (le M)unique coupons In its most elementary formulation eachcoupon is chosen uniformly at random among the M coupontypes In this setting many questions related to the CCPmdashincluding the one abovemdashare relatively easy to answer
Viewing Fuzzing as WCCP with Unknown Weights Un-fortunately our problem setting actually demands a weightedvariant of the CCP which we dub the WCCP Intuitively thisis because the probabilities of the different outcomes froma fuzz run are not necessarily (and unlikely to be) uniformThis observation has also been made by Arcuri et al [1]
Let (M minus 1) be the actual number of unique bugs discov-erable by fuzzing a certain configuration Then includingproper termination of a fuzz run as an outcome gives usexactly M distinct outcome types We thus relate the pro-cess of repeatedly fuzzing a configuration to the WCCP byviewing fuzz run outcomes as coupons and their associatedIDs as coupon types
However unlike usual formulations of the WCCP where thedistribution of outcomes across type is given in our problemsetting this distribution is unknown a priori In particularthere is no way to know the true value ofM for a configurationwithout exhaustively fuzzing all possible mutations As suchwe utilize statistical estimations of these distributions ratherthan the ground-truth in our algorithm design An importantquestion to consider is whether accurate estimations arefeasible
We now explain why we prefer the sets of bugs from differ-ent configurations used in a campaign to be disjoint Observethat our model of a campaign is a combination of multipleindependent WCCP processes If a bug that is new to oneprocess has already been discovered in another then this
bug cannot contribute to the total number of unique bugsThis means that overlap in the sets of bugs diminishes thefidelity of our model so that any algorithm relying on itspredictions may suffer in performance
WCCP Notation Before we go on let us set up some ad-ditional notation related to the WCCP In an effort to avoidexcessive indices our notation implicitly assumes a fixedconfiguration (pi si) that is made apparent by context Forexample M the number of possible outcomes when fuzzing agiven configuration as defined above follows this convention
(i) Consider the fixed sequence σ of outcomes we obtainin the course of fuzzing (pi si) during a campaign We labelan outcome as type k if it belongs to the kth distinct type ofoutcome in σ Let Pk denote the probability of encounteringa type-k outcome in σ ie
Pk =|x isin H(si) x triggers an outcome of type k|
|H(si)| (1)
(ii) Although both the number and frequency of outcometypes obtainable by fuzzing (pi si ) are unknown a prioriduring a campaign we do have empirical observations forthese quantities up to any point in σ Let M(`) be the numberof distinct outcomes observed from epoch 1 through epoch` Let nk(`) be the number of inputs triggering outcomesof type k observed throughout these ` epochs Notice thatover the course of a campaign the sequence σ is segmentedinto subsequences each of which corresponds to an epochin which (pi si ) is chosen Thus the values of M(middot) andnk(middot) will not change if (pi si) is not chosen for the currentepoch With this notation we can also express the empiricalprobability of detecting a type-k outcome following epoch `as
Pk(`) =nk(`)sumM(`)
kprime=1 nkprime(`)
42 Impossibility ResultsNo Free Lunch The absence of any assumption on the dis-tribution of outcome types in the WCCP quickly leads us toour first impossibility result In particular no algorithm canconsistently outperform other algorithms for the FCS prob-lem This follows from a well-known impossibility result inoptimization theory namely the ldquoNo Free Lunchrdquo theorem byWolpert and Macready [22] Quoting Wolpert and Macreadytheir theorem implies that ldquoany two optimization algorithmsare equivalent when their performance is averaged across allpossible problemsrdquo In our problem setting maximizing thenumber of bugs found in epoch (`+ 1) amounts to for eachconfiguration estimating its PM(`)+1 in equation (1) usingonly past observations from that configuration Intuitivelyby averaging across all possible outcome type distributionsany estimation will be incorrect sufficiently often and thuslead to suboptimal behavior that cancels any advantage ofone algorithm over another
While we may consider this result to be easy to obtainonce we have properly set up our problem using sect2 and sect41we consider it to be an important intellectual contribution forthe pragmatic practitioners who remain confident that theycan design algorithms that outperform others In particularthe statement of the No Free Lunch theorem itself revealsprecisely how we can circumvent its conclusionmdashour estima-tion procedure must assume the outcome type distributions
have particular characteristics Our motto is thus ldquothere isno free lunchmdashplease bring your own priorrdquo
Tight K-Competitiveness Our second impossibility resultshows that there are problem instances in which the timespent by any deterministic online algorithm to find a givennumber of unique bugs in a fixed-time campaign is at leastK times larger than the time spent by an optimal offlinealgorithm Using the terminology of competitive analysisthis shows that the competitive ratio of any deterministiconline algorithm for this problem is at least K
To show this we fix a deterministic algorithm A andconstruct a contrived problem instance in which there is onlyone bug among all the configurations in a campaign Since Ais deterministic there exists a unique pair (plowasti s
lowasti ) that gets
chosen last In other words the other (K minus 1) pairs have allbeen fuzzed for at least one epoch when (plowasti s
lowasti ) is fuzzed for
the first time If the lone bug is only triggered by fuzzing(plowasti s
lowasti ) then A will have to fuzz for at least K epochs to
find itFor an optimal offline algorithm handling this contrived
scenario is trivial Since it is offline it has full knowledgeof the outcome distributions enabling it to hone in on thespecial pair (plowasti s
lowasti ) and find the bug in the first epoch This
establishes that K is a lowerbound for the competitive ratioof any deterministic algorithm
Finally we observe that Round-Robin is a deterministiconline algorithm that achieves the competitive ratio K inevery problem instance It follows immediately that K istight
43 Upperbounding the Probability of Seeinga New Outcome During Fuzzing
Having seen such strong impossibility results let us considerwhat a pragmatist might do before bringing in any prior onthe outcome type distribution In other words if we do notwant to make any assumptions on this distribution is therea justifiable approach to designing online algorithms for theFCS problem
We argue that the answer is yes Consider two program-seed pairs (p1 s1) and (p2 s2) for which we have upperboundson the probability of finding a new outcome if we fuzz themonce more Assume that the upperbound for (p1 s1) is thehigher of the two
We stress that what we know are merely upperboundsmdashitis still possible that the true probability of yielding a newoutcome from fuzzing (p1 s1) is lower than that of (p2 s2)Nonetheless with no information beyond the ordering ofthese upperbounds fuzzing (p1 s1 ) first is arguably themore prudent choice This is because to do otherwise wouldindicate a belief that the actual probability of finding a newoutcome by fuzzing (p1 s1) in the next fuzz run is lower thanthe upperbound for (p2 s2)
Accepting this argument how might we obtain such upper-bounds We introduce the Rule of Three for this purpose
Rule of Three Consider an experiment of independentBernoulli trials with identical success and failure probabilitiesp and q = (1minus p) Suppose we have carried out N ge 1 trialsso far and every trial has been a success What can we sayabout q other than the fact that it must be (i) at least 0to be a valid probability and (ii) strictly less than 1 sincep is evidently positive In particular can we place a lowerupperbound on q
Unfortunately the answer is a resounding no even with qarbitrarily close to 1 we still have (pN gt 0) This means ourobservation really could have happened even if it is extremelyunlikely
Fortunately if we are willing to rule out the possibility ofencountering extremely unlikely events then we may com-pute a lower upperbound for q by means of a confidenceinterval For example a 95 confidence interval on q out-puts an interval that includes the true value of q of theunderlying experiment with 95 certainty In other wordsif the outputted interval does not contain the true value ofq for the experiment then the observed event must have alikelihood of at most 5
For the above situation there is particularly neat techniqueto compute a 95 confidence interval on q Known as theldquoRule of Threerdquo this method simply outputs 0 and 3N for thelowerbound and upperbound respectively The lowerboundis trivial and the upperbound has been shown to be a goodapproximation for N gt 30 See [15] for more informationon this technique including the relationship between 95confidence and the constant 3
How We Use Rule of Three In order to apply the Ruleof Three we must adapt our fuzzing experiments with anyM gt 1 possible outcome types to fit the mold of Bernoullitrials
We make use of a small trick Suppose we have just finishedepoch ` and consider a particular configuration (pi si) Using
our notation we have observed M(`) different outcomes so
far and for 1 le k le M(`) we have observed nk(`) counts of
outcome of type k Let N(`) =sumM(`)
k=1 nk(`) denote the totalnumber of fuzz runs for this pair through epoch ` The trickis to define a ldquosuccessrdquo to be finding an outcome of type 1through type M(`) Then in hindsight it is the case thatour experiment has only yielded success so far
With this observation we may now apply the Rule of Threeto conclude that [0 3N(`)] is a 95 confidence interval onthe ldquofailurerdquo probabilitymdashthe probability that fuzzing thisconfiguration will result in an outcome type that we havenot seen before ie a new outcome Then as desired wehave an easy-to-compute upperbound on the probability offinding a new outcome for each configuration
We introduce one more piece of notation before proceedingdefine the Remaining Probability Mass (RPM) of (pi si) atthe end of epoch ` denoted RPM(`) to be the probabilityof finding a new outcome if we fuzz (pi si) once more Notethat the pair in RPM(`) is implicit and that this valueis upperbounded by 3N(`) if we accept a 95 confidenceinterval
44 Design SpaceIn this section we explore the design space that a pragma-tist may attempt when designing online algorithms for theFuzz Configuration Scheduling problem A depiction of thedesign space along with our experimental results is given inTable 2 in sect6 Our focus here is to explain our motivation forchoosing the three dimensions we explore and the particularchoices we include in each dimension By combining thesedimensions we obtain 26 online algorithms for our prob-lem We implemented these algorithms inside a simulatorFuzzSim the detail of which is presented in sect5
Epoch Type We consider two possible definitions of anepoch in a fuzz campaign The first is the more traditional
choice and is used in the current version of CERT BFFv26 [14] the second is our proposal
Fixed-Run Each epoch executes a constant number offuzz runs In FuzzSim a fixed-run epoch consists of 200runs Note that any differential in fuzzing speed acrossconfigurations translates into variation in the time spent infixed-run epochs
Fixed-Time Each epoch is allocated a fixed amount oftime In FuzzSim a fixed-time epoch lasts for 10 secondsOur motivation to investigate this epoch type is to see howheavily epoch time variation affects the results obtained bysystems with fixed-run epochs
Belief Metrics Two of the MAB algorithms we presentbelow make use of a belief metric that is associated with eachconfiguration and is updated after each epoch Intuitivelythe metrics are designed such that fuzzing a configurationwith a higher metric should yield more bugs in expectationThe first two beliefs below use the concept of RPM to achievethis without invoking any prior the remaining three embracea ldquobug priorrdquo For now suppose epoch ` has just finishedand we are in the process of updating the belief for theconfiguration (pi si)
RPM We use the upperbound in the 95 confidence intervalgiven by the Rule of Three to approximate RPM(`) Thebelief is simply 3N(`)
Expected Waiting Time Until Next New Outcome(EWT) Since RPM does not take into account of the speedof each fuzz run we also investigate a speed-normalizedvariant of RPM Let Time(`) be the cumulative time spentfuzzing this configuration from epoch 1 to epoch ` Let
avgTime(`) be the average time of a fuzz run ie Time(`)N(`)
Let W be a random variable denoting the waiting time untilthe next new outcome Recall that RPM(`) is the probabilityof finding a new outcome in the next fuzz run and assume itis independent of avgTime(`) To compute E[W ] observethat either we find a new outcome in the next fuzz run orwe do not and we have to wait again Therefore
E[W ] = RPM(`)times avgTime(`)
+ (1minus RPM(`))times (avgTime(`) + E[W ])
(Notice that RPM does not change even in the second casewhat changes is our upperbound on RPM) Solving for E[W ]
yields avgTime(`)RPM(`)
and we substitute in the upperbound of
the 95 confidence interval for RPM(`) to obtain E[W ] geavgTime(`)3N(`)
= Time(`)3
Since a larger waiting time is less desir-
able the belief used is its reciprocal 3Time(`)
Rich Gets Richer (RGR) This metric is grounded inwhat we call the ldquobug priorrdquo which captures our empiricalobservation that code tends to be either robust or bug-riddenPrograms written by programmers of different skill levelsor past testing of a program might explain this real-worldphenomenon Accordingly demonstrated bugginess of aprogram serves as a strong indicator that more bugs will befound in that program and thus the belief is M(`)
Density This is a runs-normalized variant of RGR and isalso the belief used in CERT BFF v26 [14] The belief func-
tion is M(`)N(`) Observe that this is the belief function
of RPM scaled by M(`)3 In other words Density can beseen as RPM adapted with the bug prior
Rate This is a time-normalized variant of RGR The belieffunction is M(`)Time(`) Similar to Density Rate can beseen as EWT adapted with the bug prior
Bandit Algorithms Since the FCS problem is an instanceof an MAB problem naturally we explore a number of MABalgorithmsRound-Robin This simply loops through the configura-tions in a fixed order dedicating one epoch to each configura-tion Note that Round-Robin is a non-adaptive deterministicalgorithmUniform-Random This algorithm selects uniformly atrandom from the set of configurations for each epoch LikeRound-Robin this algorithm is non-adaptive however it israndomizedWeighted-Random Configurations are selected at randomin this algorithm with the probability associated with eachconfiguration is linked to the belief metric in use Theweight of a well-performing configuration is adjusted upwardvia the belief metric thereby increasingly the likelihood ofselecting that configuration in future epochs This mechanismfunctions in reverse for configurations yielding few or no bugsε-Greedy The ε-Greedy algorithm takes an intuitive ap-proach to the exploration vs exploitation trade-off inherentto MAB problems With probability ε the algorithm selectsa configuration uniformly at random for explorationWithprobability (1minus ε) it chooses the configuration with the high-est current belief allowing it to exploit its current knowledgefor gains The constant ε serves as a parameter balancingthe two competing goals with higher ε values correspondingto a greater emphasis on explorationEXP3S1 This is an advanced MAB algorithm by Aueret al [2] for the non-stochastic MAB problem We picked thisalgorithm for three reasons First it is from the venerableEXP3 family and so likely to be picked up by practitionersSecond this is one of the EXP3 algorithms that is not pa-rameterized by any constants and thus no parameter tuningis needed Third this algorithm is designed to have an op-timal worst-case regret which is a form of regret that suitsour problem setting Note that at its core EXP3S1 is aweighted-random algorithm However since we do not havea belief metric that corresponds to the one used in EXP3S1we did not put it inside the Weighted-Random group
45 Offline AlgorithmsEarly on in our research design we recognized the importanceof evaluating a large number of algorithms Out of budgetaryconstraints we have taken a simulation approach so thatwe can replay the events from previous fuzzings to try outnew algorithms Since we have recorded all the events thatmay happen during any fuzz campaign of the same inputconfigurations we can even attempt to compute what anoptimal offline algorithm would do and compare the results ofour algorithms against it In the case when the configurationsdo not yield duplicated bugs such as in our Inter-Programdataset (sect6) we devise a pseudo-polynomial time algorithmthat computes the offline optimal In the other case whereduplicated bugs are possible we propose a heuristic to post-process the solution from the above algorithm to obtain alowerbound on the offline optimal
No Duplicates Assuming that the sets of unique bugsfrom different configurations are disjoint our algorithm isa small variation on the dynamic programming solution tothe Bounded Knapsack problem Let K be the number of
Program
amp
Seed
(pi si)
Fuzzer
bugsScheduler
crashes
Simulator
Scheduling
Algorithms
Fuzzing Triage
Bug Triage
bugs
Simulation
logs
logs
Time
Budget (T)
Figure 1 FuzzSim architecture
configurations and B be the total number of unique bugsfrom all K configurations Let t(i b) be the minimum amountof time it takes for configuration i to produce b unique bugsNote that t(i b) is assumed to be infin when configuration inever produces b unique bugs in our dataset We claim thatt(i b) can be pre-computed for all i isin [1K] and b isin [0 B]where each entry takes amortized O(1) time given how eventsare recorded in our system
Let m(i b) be the minimum amount of time it takes forconfigurations 1 through i to produce b unique bugs We wantto compute m(K b) for b isin [0 B] By definition m(1 b) =t(1 b) for b isin [0 B] For i gt 1 observe that m(i b) =mincisin[0B]t(i c) +m(iminus 1 bminus c) This models partitioningthe b unique bugs into c unique bugs from configuration iand (bminus c) unique bugs from configurations 1 through (iminus1)Computing each m(i b) entry takes O(B) time Since thereare O(K timesB) entries the total running time is O(K timesB2)
Discounting Duplicates The above algorithm is incorrectwhen the sets of unique bugs from different configurationsare not disjoint This is because the recurrence formula ofm(i b) assumes that the c unique bugs from configuration iare different from the (bminus c) unique bugs from configurations1 through (i minus 1) In this case we propose a heuristic tocompute a lowerbound on the offline optimal
After obtaining the m(i b) table from the above we post-process bug counts by the following discount heuristic Firstwe compute the maximum number of bugs that can be foundat each time by the above algorithm by examining the K-throw of the table Then by scanning forward from time 0whenever the bug count goes up by one due to a duplicatedbug (which must have been found using another configura-tion) we discount the increment Since the optimal offlinealgorithm can also pick up exactly the same bugs in the sameorder as the dynamic programming algorithm our heuristicis a valid lowerbound on the maximum number of bugs thatan optimal offline algorithm would find
5 Design amp ImplementationThis section presents FuzzSim our replay-based fuzz simu-lation system built for this project We describe the threesteps in FuzzSim and explain the benefit of its design whichis then followed by its implementation detail Of special noteis that we are releasing our source code and our datasets insupport of open science at the URL found in sect52
51 OverviewFuzzSim is a simulation system for black-box mutationalfuzzing that is designed to run different configuration schedul-ing algorithms using logs from previous fuzzings Figure 1summarizes the design of FuzzSim which employs a three-step approach (1) fuzzing (2) triage and (3) simulation
Fuzzing The first step is fuzzing and collecting run logsfrom a fuzzer FuzzSim takes in a list of program-seedpairs (pi si) and a time budget T It runs a fuzzer on eachconfiguration for the full length of the time budget T andwrites to the log each time a crash occurs Log entries arerecorded as 5-tuples of the form (pi si time stamp runsmutation identifier)
In our implementation we fuzz with zzuf one of the mostpopular open-source fuzzers zzuf generates a random inputfrom a seed file as described in sect21 The randomization inzzuf can be reproduced given the mutation identifier thusenabling us to reproduce a crashing input from its seed fileand the log entry associated with the crash For example anoutput tuple of (FFMpeg aavi 100 42 1234) specifies thatthe program FFMpeg crashed at the 100-th second with aninput file obtained from ldquoaavirdquo according to the mutationidentifier 1234 Interested readers may refer to zzuf [16] fordetails on mutation identifiers and the actual implementation
The deterministic nature of zzuf allows FuzzSim to triagebugs after completing all fuzz runs first In other wordsFuzzSim does not compute bug identifiers during fuzzingand instead re-derives them using the log This does notaffect any of our algorithms since none of them relies on theactual IDs In our experiments we have turned off addressspace layout randomization (ASLR) in both the fuzzing andthe triage steps in order to reproduce the same crashes
Triage The second step of FuzzSim maps crashing inputsfound during fuzzings into bugs At a high level the triagephase takes in the list of 5-tuples (pi si time-stamp runsmutation identifier) logged during the fuzzing step and out-puts a new list of 5-tuples of the form (pi si time-stampruns bug identifier) More specifically FuzzSim replayseach recorded crash under a debugger to collect stack tracesIf FuzzSim does not detect a crash during a particular replaythen we classify that test case to be a non-deterministic bugand discard it
We then use the collected stack traces to produce bugidentifiers essentially hashes of the stack traces In particularwe use the fuzzy stack hash algorithm [19] which identifiesbugs by hashing the normalized line numbers from a stacktrace With this algorithm the number of stack frames tohash has a significant influence on the accuracy of bug triageFor example taking the full stack trace often leads to mis-classifying a single bug into multiple bugs whereas takingonly the top frame can easily lead to two different bugs beingmis-classified as one To match the state of the art FuzzSimuses the top 3 frames as suggested in [19] We stress that eventhough inaccurate bug triage may still occur with this choiceof parameter perfecting bug triage techniques is beyond thescope of this paper
Simulation The last step simulates a fuzz campaign onthe collected ground-truth data from the previous steps us-ing a user-specified scheduling algorithm More formallythe simulation step takes in a scheduling algorithm and alist of 5-tuples of the form (pi si timestamp runs bugidentifier) and outputs a list of 2-tuples (timestamp bugs)that represent the accumulated time before the correspond-ing number of unique bugs are observed under the givenscheduling algorithm
Since FuzzSim can simulate any scheduling algorithm inan offline fashion using the pre-recorded ground-truth datait enables us to efficiently compare numerous scheduling
algorithms without actually running a large number of fuzzcampaigns During replay FuzzSim outputs a timestampwhenever it finds a new bug Therefore we can easily plotand compare different scheduling algorithms by comparingthe number of bugs produced under the same time budget
We summarize FuzzSimrsquos three-step algorithm below
Fuzzing ((pi si) T )rarr pi si timestamp runs mutation id
Triage (pi si timestamp runs mutation id)rarr (pi si timestamp runs bug id)
Simulation (pi si timestamp runs bug id)rarr (timestamp bugs)
Algorithm 1 FuzzSim algorithms
52 Implementation amp Open ScienceWe have implemented our data collection and bug triage mod-ules in approximately 1000 lines of OCaml This includes thecapability to run and collect crash logs from Amazon EC2We used zzuf version 013 Our scheduling engine is alsoimplemented in OCaml and spans about 1600 lines Thiscovers the 26 online and the 2 offline algorithms presentedin this paper
We invite our fellow researchers to become involved inthis line of research In support of open science we releaseboth our datasets and the source code of our simulator athttpsecurityececmuedufuzzsim
6 EvaluationTo evaluate the performance of the 26 algorithms presentedin sect4 we focus on the following questions
1 Which scheduling algorithm works best for our datasets2 Why does one algorithm outperform the others3 Which of the two epoch typesmdashfixed-run or fixed-timemdash
works better and why
61 Experimental SetupOur experiments were performed on Amazon EC2 instancesthat have been configured with a single Intel 2GHz XeonCPU core and 4GB RAM each We used the most recentDebian Linux distribution at the time of our experiment(April 2013) and downloaded all programs from the then-latest Debian Squeeze repository Specifically the version ofFFMpeg we used is SVN-r0510-40510-1 which is basedon a June 2012 FFMpeg release with Debian-specific patches
62 Fuzzing Data CollectionOur evaluation makes use of two datasets (1) FFMpegwith 100 different input seeds and (2) 100 different Linuxapplications each with a corresponding input seed Werefer to these as the ldquointra-programrdquo and the ldquointer-programrdquodatasets respectively
For the intra-program dataset we downloaded 10 000videoimage sample files from the MPlayer website at http
samplesmplayerhqhu From these samples we selected100 files uniformly at random and took them as our input
Dataset runs crashes bugsIntra-program 636998978 906577 200Inter-program 4868416447 415699 223
Table 1 Statistics from fuzzing the two datasets
0
20
40
60
0 10 20 30 40
bugs
count
IntraminusProgram
0
20
40
60
0 10 20 30
bugs
count
InterminusProgram
Figure 2 Distribution of the number of bugs per configura-tion in each dataset
0
25
50
75
0 10 20 30 40
bugs
count
Figure 3 Distribution of bug overlaps across multiple seedsfor the intra-program dataset
seeds The collected seeds include various audio and videoformats such as ASF QuickTime MPEG FLAC etc Wethen used zzuf to fuzz FFMpeg with each seed for 10 days
For the inter-program dataset we downloaded 100 differ-ent file conversion utilities in Debian To select these 100programs we first enumerated all file conversion packagestagged as ldquouseconvertingrdquo in the Debian package tags in-terface (debtags) From this list of packages we manuallyidentified 100 applications that take a file name as a com-mand line argument Then we manually constructed a validseed for each program and the actual command line to run itwith the seed After choosing these 100 program-seed pairswe fuzzed each for 10 days as well In total we have spent48000 CPU hours fuzzing these 200 configurations
To perform bug triage we identified and re-ran everycrashing input from the log under a debugger to obtain stacktraces for hashing After triaging with the fuzzy stack hashalgorithm described in sect51 we found 200 bugs from theintra-program dataset and 223 bugs from the inter-programdataset Table 1 summarizes the data collected from ourexperiments The average fuzzing throughput was 8 runsper second for the intra-program dataset and 63 runs persecond for the inter-program dataset This difference is dueto the higher complexity of FFMpeg when compared to theprograms in the inter-program dataset
63 Data AnalysisWhat does the collected fuzzing data look like We studiedour data from fuzzing and triage to answer two questions (1)How many bugs does a configuration trigger (2) How manybugs are triggered by multiple seeds in the intra-programdataset
We first analyzed the distribution of the number of bugsin the two datasets On average the intra- and the inter-program datasets yielded 82 and 24 bugs per configurationrespectively Figure 2 shows two histograms each depict-
40
60
80
100
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(a) Intra-program
60
100
140
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(b) Inter-program
Figure 4 The average number of bugs over 100 runs foreach scheduling algorithm with error bars showing a 99confidence interval ldquoftrdquo represents fixed-time epoch ldquofrrdquorepresents fixed-run epoch ldquoerdquo represents ε-Greedy ldquowrdquo rep-resents Weighted-Random
ing the number of occurrences of bug counts There is amarked difference in the distributions from the two datasets64 of configurations in the inter-program dataset produceno bugs whereas the corresponding number in the intra-program dataset is 15 We study the bias of the bug countdistribution in sect64
Second we measured how many bugs are shared acrossseeds in the intra-program dataset As an extreme case wefound a bug that was triggered by 46 seeds The averagenumber of seeds leading to a given bug is 4 Out of the 200bugs 97 were discovered from multiple seeds Figure 3illustrates the distribution of bug overlaps Our resultssuggest that there is a small overlap in the code exercisedby different seed files even though they have been chosento be of different types Although this shows that our bugdisjointness assumption in the WCCP model does not alwayshold in practice the low average number of seeds leading toa given bug in our dataset means that the performance ofour algorithms should not have been severely affected
64 SimulationWe now compare the 26 scheduling algorithms based on the10-day fuzzing logs collected for the intra- and inter-programdatasets To compare the performance of scheduling algo-rithms we use the total number of unique bugs reportedby the bug triage process Recall from sect44 that these al-gorithms vary across three dimensions (1) epoch types (2)belief metrics and (3) MAB algorithms For each valid com-bination (see Table 2) we ran our simulator 100 times andaveraged the results to study the effect of randomness oneach scheduling algorithm In our experiments we allocated10 seconds to each epoch for fixed-time campaigns and 200runs for fixed-run campaigns For the ε-Greedy algorithmwe chose ε to be 01
Table 2 summarizes our results Each entry in the tablerepresents the average number of bugs found by 100 sim-
Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

Definition 22 A black-box mutational fuzzer is a ran-domized algorithm that takes as input a fuzz configurationwhich comprises (i) a program p (ii) a seed input s and (iii)a mutation ratio r isin [0 1] In a fuzz run the fuzzer generatesan input x by randomly mutating s with the mutation ratior and then runs p on x The outcome of this fuzz run is acrash or a proper termination of p
At this point it is convenient to set up one additionalnotation to complement Definition 21 Let Hd(s) denotethe set of all strings obtained by randomly-mutating s withthe mutation ratio r = d|s| This notation highlights theequivalence between the set of all obtainable inputs and theset of all |s|-bit strings within a Hamming distance of dfrom s In this notation the input string x in Definition 21is simply a string chosen uniformly at random from Hd(s)As we explain below in this paper we use a globally-fixedmutation ratio and therefore d is fixed once s is given Thisis why we simply write H(s) instead of Hd(s)
We now state and justify several assumptions of our math-ematical model all of which are satisfied by typical fuzzersin practice
Assumption 1 Each seed input has finite length
This assumption is always satisfied when fuzzing file inputsIn practice some fuzzers can also perform stream fuzzingwhich randomly mutates each bit in an input stream with auser-configurable probability Notice that while the expectednumber of randomly-mutated bits is fixed the actual numberis not We do not model stream fuzzing
Assumption 2 An execution of the program exhibits ex-actly one of the following two possible outcomesmdashit eithercrashes or properly terminates
In essence this assumption means we focus exclusively onfinding bugs that lead to crashes Finding logical bugs thatdo not lead to crashes would typically require a correctnessspecification of the program under test At present such spec-ifications are rare in practice and therefore this assumptiondoes not impose a severe restriction
Assumption 3 The outcome of an execution of the pro-gram depends solely on the input x generated by the fuzzer
This assumption ensures we are not finding bugs causedby input channels not under the fuzzerrsquos control Sincethe generated input alone determines whether the programcrashes or terminates properly all bugs found during fuzzingare deterministically reproducible In practice inputs thatdo not cause a crash in downstream analyses are discarded
Mutation Ratio We include the mutation ratio as a thirdparameter in our definition of fuzz configurations given inDefinition 22 Our choice reflects the importance of thisparameter in practice since different seeds may need to befuzzed at different mutation ratios to be effective in find-ing bugs However in order to evaluate a large number ofscheduling algorithms our work is based on a replay simula-tion as detailed in sect5 Gathering the ground-truth fuzzingdata for such simulations is resource-intensive prohibitivelyso if we examine multiple mutation ratios As such ourcurrent project globally fixes the mutation ratio at 00004the default value used in zzuf Accordingly we suppress thethird parameter of a fuzz configuration in this paper effec-tively equating program-seed pairs with fuzz configurationsFor further discussion related to the mutation ratio see sect66
22 Problem StatementGiven a list of K fuzz configurations (p1 s1) middot middot middot (pK sK)and a time budget T the Fuzz Configuration Schedulingproblem seeks to maximize the number of unique bugs dis-covered in a fuzz campaign that runs for a duration of lengthT A fuzz campaign is divided into epochs starting withepoch 1 We consider two epoch types fixed-run and fixed-time In a fixed-run campaign each epoch corresponds toa constant number of fuzz runs since the time required forindividual fuzz runs may vary fixed-run epochs may takevariable amounts of time On the other hand in a fixed-timecampaign each epoch corresponds to a constant amount oftime Thus the number of fuzz runs completed may varyacross fixed-time epochs
An online algorithm A for the Fuzz Configuration Schedul-ing problem operates before each epoch starts When thecampaign starts A receives the number K Suppose thecampaign has completed ` epochs so far Before epoch (`+1)begins A should select a number i isin [1K] based on theinformation it has received from the campaign Then theentire epoch (` + 1) is devoted to fuzzing (pi si ) Whenthe epoch ends A receives a sequence of IDs representingthe outcomes of the fuzz runs completed during the epochIf an outcome is a crash then the returned ID is the bugID computed by the bug triage process which we assumeis non-zero Otherwise the outcome is a proper termina-tion and the returned ID is 0 Also any ID that has neverbeen encountered by the campaign prior to epoch (` + 1)is marked as new Notice that a new ID can signify eitherthe first proper termination in the campaign or a new bugdiscovered during epoch (`+ 1) Besides the list of IDs Aalso receives statistical information about the epoch In afixed-run campaign it receives the time spent in the epochin a fixed-time campaign it receives the number of fuzz runsthat ended inside the epoch
Algorithmic Considerations We now turn to a few techni-cal issues that we withheld from the above problem statementFirst we allow A to be either deterministic or randomizedThis admits the use of various existing MAB algorithmsmany of which are indeed randomized
Second notice that A receives only the number of configu-rations K but not the actual configurations This formulationis to prevent A from analyzing the content of any pirsquos or sirsquosSimilarly we prevent A from analyzing bugs by sending itonly the bug IDs but not any concrete representation
Third A also does not receive the time budget T Thisforces A to make its decisions without knowing how muchtime is left Therefore A has to attempt to discover new bugsas early as possible While this rules out any algorithm thatadjusts its degree of exploration based on the time left weargue that this not a severe restriction from the perspectiveof algorithm design For example one of the algorithms weuse is the EXP3S1 algorithm [2] It copes with the unknowntime horizon by partitioning time into exponentially longerperiods and picking new parameters at the beginning of eachperiod which has a known length
Fourth our analysis assumes that the K fuzz configura-tions are chosen such that they yield disjoint sets of bugsThis assumption is needed so that we can consider the bugarrival process of fuzzing each configuration independentlyWhile this assumption may be valid when every configurationinvolves a different program as in one of our two datasets
satisfying it when one program can appear in multiple config-urations is non-trivial In practice it is achieved by selectingseeds that exercise different code regions For example inour other data set we use seeds of various file formats tofuzz the different file parsers in a media player
Finally at present we do not account for the time spentin bug triage though this process requires considerable timeIn practice triaging a crash takes approximately the sameamount of time as the fuzz run that initially found the crashTherefore bug triage can potentially account for over half ofthe time spent in an epoch if crashes are extremely frequentWe plan to incorporate this consideration into our project ata future time
3 Multi-Armed BanditsAs explained in sect1 the Fuzz Configuration Scheduling prob-lem is an instance of the classic Multi-Armed Bandit (MAB)problem This has already been observed by previous re-searchers For example the CERT Basic Fuzzing Framework(BFF) [14] which supports fuzzing a single program witha collection of seeds and a set of mutation ratios uses anMAB algorithm to select among the seed-ratio pairs duringa fuzz campaign However we must stress that recognizingthe MAB nature of our problem is merely a first step Inparticular we should not expect an MAB algorithm withprovably ldquogoodrdquo performance such as one from the UCB [3]or the EXP3 [2] families to yield good results in our problemsetting There are at least two reasons for this
First although many of these algorithms are proven tohave optimal regret in various forms the most commonform of regret does not actually give good guarantees in ourproblem setting In particular this form of regret measuresthe difference between the expected reward of an algorithmand the reward obtained by consistently fuzzing the singlebest configuration that yields the greatest number of uniquebugs However we are interested in evaluating performancerelative to the total number of unique bugs from all Kconfigurations which may be much greater than the numberfrom one fixed configuration Thus the low-regret guaranteeof many MAB algorithms is in fact measuring against atarget that is likely to be much lower than what we desireIn other words given our problem setting these algorithmsare not guaranteed to be competitive at all
Second while there exist algorithms with provably lowregret in a form suited to our problem setting the actual re-gret bounds of these algorithms often do not give meaningfulvalues in practice For example one of the MAB algorithmswe use is the EXP3S1 algorithm [2] proven to have an
expected worst-case regret of S+2eradic2minus1
radic2K` ln(K`) where S is
a certain hardness measure of the problem instance as de-fined in [2 sect8] and ` is the number of epochs in our problemsetting Even assuming the easiest case where S equals to 1and picking K to be a modest value of 10 the value of thisbound when ` = 4 is already slightly above 266 Howeveras we see in sect6 the number of bugs we found in our twodatasets are 200 and 223 respectively What this means isthat this regret bound is very likely to dwarf the number ofbugs that can be found in real-world software after a verysmall number of epochs In other words even though we havethe right kind of guarantee from EXP3S1 the guaranteequickly becomes meaningless in practical terms
Having said the above we remark that this simply meanssuch optimal regret guarantees may not be useful in ensuring
good results As we will see in sect6 EXP3S1 can still obtainreasonably good results in the right setting
4 Algorithms for the FCS ProblemOur goal in this section is to investigate how to design onlinealgorithms for the Fuzz Configuration Scheduling problemWe largely focus on developing the design space (sect44) mak-ing heavy use of the mathematical foundation we lay outin sect41 and sect43 Additionally we present two impossibilityresults in sect42 one of which requires a precise conditionthat greatly informs our algorithm design effort We alsopresent two offline algorithms for our problem While suchalgorithms may not be applicable in practice a unique aspectof our project allows us to use them as benchmarks whichwe measure our online algorithms against We explain thisalong with the offline algorithms in sect45
41 Fuzzing as a Weighted CCPLet us start by mathematically modeling the process ofrepeatedly fuzzing a configuration As we explained in sect2the output of this process is a stream of crashes intermixedwith proper terminations which is then transformed intoa stream of IDs by a bug triage process Since we want tomaximize the number of unique bugs found we are naturallyinterested in when a new bug arrives in this process Thisinsight quickly leads us to the Coupon Collectorrsquos Problem(CCP) a classical arrival process in probability theory
The CCP concerns a consumer who obtains one couponwith each purchase of a box of breakfast cereal Supposethere are M different coupon types in circulation One basicquestion about the CCP is what is the expected number ofpurchases required before the consumer amasses k (le M)unique coupons In its most elementary formulation eachcoupon is chosen uniformly at random among the M coupontypes In this setting many questions related to the CCPmdashincluding the one abovemdashare relatively easy to answer
Viewing Fuzzing as WCCP with Unknown Weights Un-fortunately our problem setting actually demands a weightedvariant of the CCP which we dub the WCCP Intuitively thisis because the probabilities of the different outcomes froma fuzz run are not necessarily (and unlikely to be) uniformThis observation has also been made by Arcuri et al [1]
Let (M minus 1) be the actual number of unique bugs discov-erable by fuzzing a certain configuration Then includingproper termination of a fuzz run as an outcome gives usexactly M distinct outcome types We thus relate the pro-cess of repeatedly fuzzing a configuration to the WCCP byviewing fuzz run outcomes as coupons and their associatedIDs as coupon types
However unlike usual formulations of the WCCP where thedistribution of outcomes across type is given in our problemsetting this distribution is unknown a priori In particularthere is no way to know the true value ofM for a configurationwithout exhaustively fuzzing all possible mutations As suchwe utilize statistical estimations of these distributions ratherthan the ground-truth in our algorithm design An importantquestion to consider is whether accurate estimations arefeasible
We now explain why we prefer the sets of bugs from differ-ent configurations used in a campaign to be disjoint Observethat our model of a campaign is a combination of multipleindependent WCCP processes If a bug that is new to oneprocess has already been discovered in another then this
bug cannot contribute to the total number of unique bugsThis means that overlap in the sets of bugs diminishes thefidelity of our model so that any algorithm relying on itspredictions may suffer in performance
WCCP Notation Before we go on let us set up some ad-ditional notation related to the WCCP In an effort to avoidexcessive indices our notation implicitly assumes a fixedconfiguration (pi si) that is made apparent by context Forexample M the number of possible outcomes when fuzzing agiven configuration as defined above follows this convention
(i) Consider the fixed sequence σ of outcomes we obtainin the course of fuzzing (pi si) during a campaign We labelan outcome as type k if it belongs to the kth distinct type ofoutcome in σ Let Pk denote the probability of encounteringa type-k outcome in σ ie
Pk =|x isin H(si) x triggers an outcome of type k|
|H(si)| (1)
(ii) Although both the number and frequency of outcometypes obtainable by fuzzing (pi si ) are unknown a prioriduring a campaign we do have empirical observations forthese quantities up to any point in σ Let M(`) be the numberof distinct outcomes observed from epoch 1 through epoch` Let nk(`) be the number of inputs triggering outcomesof type k observed throughout these ` epochs Notice thatover the course of a campaign the sequence σ is segmentedinto subsequences each of which corresponds to an epochin which (pi si ) is chosen Thus the values of M(middot) andnk(middot) will not change if (pi si) is not chosen for the currentepoch With this notation we can also express the empiricalprobability of detecting a type-k outcome following epoch `as
Pk(`) =nk(`)sumM(`)
kprime=1 nkprime(`)
42 Impossibility ResultsNo Free Lunch The absence of any assumption on the dis-tribution of outcome types in the WCCP quickly leads us toour first impossibility result In particular no algorithm canconsistently outperform other algorithms for the FCS prob-lem This follows from a well-known impossibility result inoptimization theory namely the ldquoNo Free Lunchrdquo theorem byWolpert and Macready [22] Quoting Wolpert and Macreadytheir theorem implies that ldquoany two optimization algorithmsare equivalent when their performance is averaged across allpossible problemsrdquo In our problem setting maximizing thenumber of bugs found in epoch (`+ 1) amounts to for eachconfiguration estimating its PM(`)+1 in equation (1) usingonly past observations from that configuration Intuitivelyby averaging across all possible outcome type distributionsany estimation will be incorrect sufficiently often and thuslead to suboptimal behavior that cancels any advantage ofone algorithm over another
While we may consider this result to be easy to obtainonce we have properly set up our problem using sect2 and sect41we consider it to be an important intellectual contribution forthe pragmatic practitioners who remain confident that theycan design algorithms that outperform others In particularthe statement of the No Free Lunch theorem itself revealsprecisely how we can circumvent its conclusionmdashour estima-tion procedure must assume the outcome type distributions
have particular characteristics Our motto is thus ldquothere isno free lunchmdashplease bring your own priorrdquo
Tight K-Competitiveness Our second impossibility resultshows that there are problem instances in which the timespent by any deterministic online algorithm to find a givennumber of unique bugs in a fixed-time campaign is at leastK times larger than the time spent by an optimal offlinealgorithm Using the terminology of competitive analysisthis shows that the competitive ratio of any deterministiconline algorithm for this problem is at least K
To show this we fix a deterministic algorithm A andconstruct a contrived problem instance in which there is onlyone bug among all the configurations in a campaign Since Ais deterministic there exists a unique pair (plowasti s
lowasti ) that gets
chosen last In other words the other (K minus 1) pairs have allbeen fuzzed for at least one epoch when (plowasti s
lowasti ) is fuzzed for
the first time If the lone bug is only triggered by fuzzing(plowasti s
lowasti ) then A will have to fuzz for at least K epochs to
find itFor an optimal offline algorithm handling this contrived
scenario is trivial Since it is offline it has full knowledgeof the outcome distributions enabling it to hone in on thespecial pair (plowasti s
lowasti ) and find the bug in the first epoch This
establishes that K is a lowerbound for the competitive ratioof any deterministic algorithm
Finally we observe that Round-Robin is a deterministiconline algorithm that achieves the competitive ratio K inevery problem instance It follows immediately that K istight
43 Upperbounding the Probability of Seeinga New Outcome During Fuzzing
Having seen such strong impossibility results let us considerwhat a pragmatist might do before bringing in any prior onthe outcome type distribution In other words if we do notwant to make any assumptions on this distribution is therea justifiable approach to designing online algorithms for theFCS problem
We argue that the answer is yes Consider two program-seed pairs (p1 s1) and (p2 s2) for which we have upperboundson the probability of finding a new outcome if we fuzz themonce more Assume that the upperbound for (p1 s1) is thehigher of the two
We stress that what we know are merely upperboundsmdashitis still possible that the true probability of yielding a newoutcome from fuzzing (p1 s1) is lower than that of (p2 s2)Nonetheless with no information beyond the ordering ofthese upperbounds fuzzing (p1 s1 ) first is arguably themore prudent choice This is because to do otherwise wouldindicate a belief that the actual probability of finding a newoutcome by fuzzing (p1 s1) in the next fuzz run is lower thanthe upperbound for (p2 s2)
Accepting this argument how might we obtain such upper-bounds We introduce the Rule of Three for this purpose
Rule of Three Consider an experiment of independentBernoulli trials with identical success and failure probabilitiesp and q = (1minus p) Suppose we have carried out N ge 1 trialsso far and every trial has been a success What can we sayabout q other than the fact that it must be (i) at least 0to be a valid probability and (ii) strictly less than 1 sincep is evidently positive In particular can we place a lowerupperbound on q
Unfortunately the answer is a resounding no even with qarbitrarily close to 1 we still have (pN gt 0) This means ourobservation really could have happened even if it is extremelyunlikely
Fortunately if we are willing to rule out the possibility ofencountering extremely unlikely events then we may com-pute a lower upperbound for q by means of a confidenceinterval For example a 95 confidence interval on q out-puts an interval that includes the true value of q of theunderlying experiment with 95 certainty In other wordsif the outputted interval does not contain the true value ofq for the experiment then the observed event must have alikelihood of at most 5
For the above situation there is particularly neat techniqueto compute a 95 confidence interval on q Known as theldquoRule of Threerdquo this method simply outputs 0 and 3N for thelowerbound and upperbound respectively The lowerboundis trivial and the upperbound has been shown to be a goodapproximation for N gt 30 See [15] for more informationon this technique including the relationship between 95confidence and the constant 3
How We Use Rule of Three In order to apply the Ruleof Three we must adapt our fuzzing experiments with anyM gt 1 possible outcome types to fit the mold of Bernoullitrials
We make use of a small trick Suppose we have just finishedepoch ` and consider a particular configuration (pi si) Using
our notation we have observed M(`) different outcomes so
far and for 1 le k le M(`) we have observed nk(`) counts of
outcome of type k Let N(`) =sumM(`)
k=1 nk(`) denote the totalnumber of fuzz runs for this pair through epoch ` The trickis to define a ldquosuccessrdquo to be finding an outcome of type 1through type M(`) Then in hindsight it is the case thatour experiment has only yielded success so far
With this observation we may now apply the Rule of Threeto conclude that [0 3N(`)] is a 95 confidence interval onthe ldquofailurerdquo probabilitymdashthe probability that fuzzing thisconfiguration will result in an outcome type that we havenot seen before ie a new outcome Then as desired wehave an easy-to-compute upperbound on the probability offinding a new outcome for each configuration
We introduce one more piece of notation before proceedingdefine the Remaining Probability Mass (RPM) of (pi si) atthe end of epoch ` denoted RPM(`) to be the probabilityof finding a new outcome if we fuzz (pi si) once more Notethat the pair in RPM(`) is implicit and that this valueis upperbounded by 3N(`) if we accept a 95 confidenceinterval
44 Design SpaceIn this section we explore the design space that a pragma-tist may attempt when designing online algorithms for theFuzz Configuration Scheduling problem A depiction of thedesign space along with our experimental results is given inTable 2 in sect6 Our focus here is to explain our motivation forchoosing the three dimensions we explore and the particularchoices we include in each dimension By combining thesedimensions we obtain 26 online algorithms for our prob-lem We implemented these algorithms inside a simulatorFuzzSim the detail of which is presented in sect5
Epoch Type We consider two possible definitions of anepoch in a fuzz campaign The first is the more traditional
choice and is used in the current version of CERT BFFv26 [14] the second is our proposal
Fixed-Run Each epoch executes a constant number offuzz runs In FuzzSim a fixed-run epoch consists of 200runs Note that any differential in fuzzing speed acrossconfigurations translates into variation in the time spent infixed-run epochs
Fixed-Time Each epoch is allocated a fixed amount oftime In FuzzSim a fixed-time epoch lasts for 10 secondsOur motivation to investigate this epoch type is to see howheavily epoch time variation affects the results obtained bysystems with fixed-run epochs
Belief Metrics Two of the MAB algorithms we presentbelow make use of a belief metric that is associated with eachconfiguration and is updated after each epoch Intuitivelythe metrics are designed such that fuzzing a configurationwith a higher metric should yield more bugs in expectationThe first two beliefs below use the concept of RPM to achievethis without invoking any prior the remaining three embracea ldquobug priorrdquo For now suppose epoch ` has just finishedand we are in the process of updating the belief for theconfiguration (pi si)
RPM We use the upperbound in the 95 confidence intervalgiven by the Rule of Three to approximate RPM(`) Thebelief is simply 3N(`)
Expected Waiting Time Until Next New Outcome(EWT) Since RPM does not take into account of the speedof each fuzz run we also investigate a speed-normalizedvariant of RPM Let Time(`) be the cumulative time spentfuzzing this configuration from epoch 1 to epoch ` Let
avgTime(`) be the average time of a fuzz run ie Time(`)N(`)
Let W be a random variable denoting the waiting time untilthe next new outcome Recall that RPM(`) is the probabilityof finding a new outcome in the next fuzz run and assume itis independent of avgTime(`) To compute E[W ] observethat either we find a new outcome in the next fuzz run orwe do not and we have to wait again Therefore
E[W ] = RPM(`)times avgTime(`)
+ (1minus RPM(`))times (avgTime(`) + E[W ])
(Notice that RPM does not change even in the second casewhat changes is our upperbound on RPM) Solving for E[W ]
yields avgTime(`)RPM(`)
and we substitute in the upperbound of
the 95 confidence interval for RPM(`) to obtain E[W ] geavgTime(`)3N(`)
= Time(`)3
Since a larger waiting time is less desir-
able the belief used is its reciprocal 3Time(`)
Rich Gets Richer (RGR) This metric is grounded inwhat we call the ldquobug priorrdquo which captures our empiricalobservation that code tends to be either robust or bug-riddenPrograms written by programmers of different skill levelsor past testing of a program might explain this real-worldphenomenon Accordingly demonstrated bugginess of aprogram serves as a strong indicator that more bugs will befound in that program and thus the belief is M(`)
Density This is a runs-normalized variant of RGR and isalso the belief used in CERT BFF v26 [14] The belief func-
tion is M(`)N(`) Observe that this is the belief function
of RPM scaled by M(`)3 In other words Density can beseen as RPM adapted with the bug prior
Rate This is a time-normalized variant of RGR The belieffunction is M(`)Time(`) Similar to Density Rate can beseen as EWT adapted with the bug prior
Bandit Algorithms Since the FCS problem is an instanceof an MAB problem naturally we explore a number of MABalgorithmsRound-Robin This simply loops through the configura-tions in a fixed order dedicating one epoch to each configura-tion Note that Round-Robin is a non-adaptive deterministicalgorithmUniform-Random This algorithm selects uniformly atrandom from the set of configurations for each epoch LikeRound-Robin this algorithm is non-adaptive however it israndomizedWeighted-Random Configurations are selected at randomin this algorithm with the probability associated with eachconfiguration is linked to the belief metric in use Theweight of a well-performing configuration is adjusted upwardvia the belief metric thereby increasingly the likelihood ofselecting that configuration in future epochs This mechanismfunctions in reverse for configurations yielding few or no bugsε-Greedy The ε-Greedy algorithm takes an intuitive ap-proach to the exploration vs exploitation trade-off inherentto MAB problems With probability ε the algorithm selectsa configuration uniformly at random for explorationWithprobability (1minus ε) it chooses the configuration with the high-est current belief allowing it to exploit its current knowledgefor gains The constant ε serves as a parameter balancingthe two competing goals with higher ε values correspondingto a greater emphasis on explorationEXP3S1 This is an advanced MAB algorithm by Aueret al [2] for the non-stochastic MAB problem We picked thisalgorithm for three reasons First it is from the venerableEXP3 family and so likely to be picked up by practitionersSecond this is one of the EXP3 algorithms that is not pa-rameterized by any constants and thus no parameter tuningis needed Third this algorithm is designed to have an op-timal worst-case regret which is a form of regret that suitsour problem setting Note that at its core EXP3S1 is aweighted-random algorithm However since we do not havea belief metric that corresponds to the one used in EXP3S1we did not put it inside the Weighted-Random group
45 Offline AlgorithmsEarly on in our research design we recognized the importanceof evaluating a large number of algorithms Out of budgetaryconstraints we have taken a simulation approach so thatwe can replay the events from previous fuzzings to try outnew algorithms Since we have recorded all the events thatmay happen during any fuzz campaign of the same inputconfigurations we can even attempt to compute what anoptimal offline algorithm would do and compare the results ofour algorithms against it In the case when the configurationsdo not yield duplicated bugs such as in our Inter-Programdataset (sect6) we devise a pseudo-polynomial time algorithmthat computes the offline optimal In the other case whereduplicated bugs are possible we propose a heuristic to post-process the solution from the above algorithm to obtain alowerbound on the offline optimal
No Duplicates Assuming that the sets of unique bugsfrom different configurations are disjoint our algorithm isa small variation on the dynamic programming solution tothe Bounded Knapsack problem Let K be the number of
Program
amp
Seed
(pi si)
Fuzzer
bugsScheduler
crashes
Simulator
Scheduling
Algorithms
Fuzzing Triage
Bug Triage
bugs
Simulation
logs
logs
Time
Budget (T)
Figure 1 FuzzSim architecture
configurations and B be the total number of unique bugsfrom all K configurations Let t(i b) be the minimum amountof time it takes for configuration i to produce b unique bugsNote that t(i b) is assumed to be infin when configuration inever produces b unique bugs in our dataset We claim thatt(i b) can be pre-computed for all i isin [1K] and b isin [0 B]where each entry takes amortized O(1) time given how eventsare recorded in our system
Let m(i b) be the minimum amount of time it takes forconfigurations 1 through i to produce b unique bugs We wantto compute m(K b) for b isin [0 B] By definition m(1 b) =t(1 b) for b isin [0 B] For i gt 1 observe that m(i b) =mincisin[0B]t(i c) +m(iminus 1 bminus c) This models partitioningthe b unique bugs into c unique bugs from configuration iand (bminus c) unique bugs from configurations 1 through (iminus1)Computing each m(i b) entry takes O(B) time Since thereare O(K timesB) entries the total running time is O(K timesB2)
Discounting Duplicates The above algorithm is incorrectwhen the sets of unique bugs from different configurationsare not disjoint This is because the recurrence formula ofm(i b) assumes that the c unique bugs from configuration iare different from the (bminus c) unique bugs from configurations1 through (i minus 1) In this case we propose a heuristic tocompute a lowerbound on the offline optimal
After obtaining the m(i b) table from the above we post-process bug counts by the following discount heuristic Firstwe compute the maximum number of bugs that can be foundat each time by the above algorithm by examining the K-throw of the table Then by scanning forward from time 0whenever the bug count goes up by one due to a duplicatedbug (which must have been found using another configura-tion) we discount the increment Since the optimal offlinealgorithm can also pick up exactly the same bugs in the sameorder as the dynamic programming algorithm our heuristicis a valid lowerbound on the maximum number of bugs thatan optimal offline algorithm would find
5 Design amp ImplementationThis section presents FuzzSim our replay-based fuzz simu-lation system built for this project We describe the threesteps in FuzzSim and explain the benefit of its design whichis then followed by its implementation detail Of special noteis that we are releasing our source code and our datasets insupport of open science at the URL found in sect52
51 OverviewFuzzSim is a simulation system for black-box mutationalfuzzing that is designed to run different configuration schedul-ing algorithms using logs from previous fuzzings Figure 1summarizes the design of FuzzSim which employs a three-step approach (1) fuzzing (2) triage and (3) simulation
Fuzzing The first step is fuzzing and collecting run logsfrom a fuzzer FuzzSim takes in a list of program-seedpairs (pi si) and a time budget T It runs a fuzzer on eachconfiguration for the full length of the time budget T andwrites to the log each time a crash occurs Log entries arerecorded as 5-tuples of the form (pi si time stamp runsmutation identifier)
In our implementation we fuzz with zzuf one of the mostpopular open-source fuzzers zzuf generates a random inputfrom a seed file as described in sect21 The randomization inzzuf can be reproduced given the mutation identifier thusenabling us to reproduce a crashing input from its seed fileand the log entry associated with the crash For example anoutput tuple of (FFMpeg aavi 100 42 1234) specifies thatthe program FFMpeg crashed at the 100-th second with aninput file obtained from ldquoaavirdquo according to the mutationidentifier 1234 Interested readers may refer to zzuf [16] fordetails on mutation identifiers and the actual implementation
The deterministic nature of zzuf allows FuzzSim to triagebugs after completing all fuzz runs first In other wordsFuzzSim does not compute bug identifiers during fuzzingand instead re-derives them using the log This does notaffect any of our algorithms since none of them relies on theactual IDs In our experiments we have turned off addressspace layout randomization (ASLR) in both the fuzzing andthe triage steps in order to reproduce the same crashes
Triage The second step of FuzzSim maps crashing inputsfound during fuzzings into bugs At a high level the triagephase takes in the list of 5-tuples (pi si time-stamp runsmutation identifier) logged during the fuzzing step and out-puts a new list of 5-tuples of the form (pi si time-stampruns bug identifier) More specifically FuzzSim replayseach recorded crash under a debugger to collect stack tracesIf FuzzSim does not detect a crash during a particular replaythen we classify that test case to be a non-deterministic bugand discard it
We then use the collected stack traces to produce bugidentifiers essentially hashes of the stack traces In particularwe use the fuzzy stack hash algorithm [19] which identifiesbugs by hashing the normalized line numbers from a stacktrace With this algorithm the number of stack frames tohash has a significant influence on the accuracy of bug triageFor example taking the full stack trace often leads to mis-classifying a single bug into multiple bugs whereas takingonly the top frame can easily lead to two different bugs beingmis-classified as one To match the state of the art FuzzSimuses the top 3 frames as suggested in [19] We stress that eventhough inaccurate bug triage may still occur with this choiceof parameter perfecting bug triage techniques is beyond thescope of this paper
Simulation The last step simulates a fuzz campaign onthe collected ground-truth data from the previous steps us-ing a user-specified scheduling algorithm More formallythe simulation step takes in a scheduling algorithm and alist of 5-tuples of the form (pi si timestamp runs bugidentifier) and outputs a list of 2-tuples (timestamp bugs)that represent the accumulated time before the correspond-ing number of unique bugs are observed under the givenscheduling algorithm
Since FuzzSim can simulate any scheduling algorithm inan offline fashion using the pre-recorded ground-truth datait enables us to efficiently compare numerous scheduling
algorithms without actually running a large number of fuzzcampaigns During replay FuzzSim outputs a timestampwhenever it finds a new bug Therefore we can easily plotand compare different scheduling algorithms by comparingthe number of bugs produced under the same time budget
We summarize FuzzSimrsquos three-step algorithm below
Fuzzing ((pi si) T )rarr pi si timestamp runs mutation id
Triage (pi si timestamp runs mutation id)rarr (pi si timestamp runs bug id)
Simulation (pi si timestamp runs bug id)rarr (timestamp bugs)
Algorithm 1 FuzzSim algorithms
52 Implementation amp Open ScienceWe have implemented our data collection and bug triage mod-ules in approximately 1000 lines of OCaml This includes thecapability to run and collect crash logs from Amazon EC2We used zzuf version 013 Our scheduling engine is alsoimplemented in OCaml and spans about 1600 lines Thiscovers the 26 online and the 2 offline algorithms presentedin this paper
We invite our fellow researchers to become involved inthis line of research In support of open science we releaseboth our datasets and the source code of our simulator athttpsecurityececmuedufuzzsim
6 EvaluationTo evaluate the performance of the 26 algorithms presentedin sect4 we focus on the following questions
1 Which scheduling algorithm works best for our datasets2 Why does one algorithm outperform the others3 Which of the two epoch typesmdashfixed-run or fixed-timemdash
works better and why
61 Experimental SetupOur experiments were performed on Amazon EC2 instancesthat have been configured with a single Intel 2GHz XeonCPU core and 4GB RAM each We used the most recentDebian Linux distribution at the time of our experiment(April 2013) and downloaded all programs from the then-latest Debian Squeeze repository Specifically the version ofFFMpeg we used is SVN-r0510-40510-1 which is basedon a June 2012 FFMpeg release with Debian-specific patches
62 Fuzzing Data CollectionOur evaluation makes use of two datasets (1) FFMpegwith 100 different input seeds and (2) 100 different Linuxapplications each with a corresponding input seed Werefer to these as the ldquointra-programrdquo and the ldquointer-programrdquodatasets respectively
For the intra-program dataset we downloaded 10 000videoimage sample files from the MPlayer website at http
samplesmplayerhqhu From these samples we selected100 files uniformly at random and took them as our input
Dataset runs crashes bugsIntra-program 636998978 906577 200Inter-program 4868416447 415699 223
Table 1 Statistics from fuzzing the two datasets
0
20
40
60
0 10 20 30 40
bugs
count
IntraminusProgram
0
20
40
60
0 10 20 30
bugs
count
InterminusProgram
Figure 2 Distribution of the number of bugs per configura-tion in each dataset
0
25
50
75
0 10 20 30 40
bugs
count
Figure 3 Distribution of bug overlaps across multiple seedsfor the intra-program dataset
seeds The collected seeds include various audio and videoformats such as ASF QuickTime MPEG FLAC etc Wethen used zzuf to fuzz FFMpeg with each seed for 10 days
For the inter-program dataset we downloaded 100 differ-ent file conversion utilities in Debian To select these 100programs we first enumerated all file conversion packagestagged as ldquouseconvertingrdquo in the Debian package tags in-terface (debtags) From this list of packages we manuallyidentified 100 applications that take a file name as a com-mand line argument Then we manually constructed a validseed for each program and the actual command line to run itwith the seed After choosing these 100 program-seed pairswe fuzzed each for 10 days as well In total we have spent48000 CPU hours fuzzing these 200 configurations
To perform bug triage we identified and re-ran everycrashing input from the log under a debugger to obtain stacktraces for hashing After triaging with the fuzzy stack hashalgorithm described in sect51 we found 200 bugs from theintra-program dataset and 223 bugs from the inter-programdataset Table 1 summarizes the data collected from ourexperiments The average fuzzing throughput was 8 runsper second for the intra-program dataset and 63 runs persecond for the inter-program dataset This difference is dueto the higher complexity of FFMpeg when compared to theprograms in the inter-program dataset
63 Data AnalysisWhat does the collected fuzzing data look like We studiedour data from fuzzing and triage to answer two questions (1)How many bugs does a configuration trigger (2) How manybugs are triggered by multiple seeds in the intra-programdataset
We first analyzed the distribution of the number of bugsin the two datasets On average the intra- and the inter-program datasets yielded 82 and 24 bugs per configurationrespectively Figure 2 shows two histograms each depict-
40
60
80
100
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(a) Intra-program
60
100
140
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(b) Inter-program
Figure 4 The average number of bugs over 100 runs foreach scheduling algorithm with error bars showing a 99confidence interval ldquoftrdquo represents fixed-time epoch ldquofrrdquorepresents fixed-run epoch ldquoerdquo represents ε-Greedy ldquowrdquo rep-resents Weighted-Random
ing the number of occurrences of bug counts There is amarked difference in the distributions from the two datasets64 of configurations in the inter-program dataset produceno bugs whereas the corresponding number in the intra-program dataset is 15 We study the bias of the bug countdistribution in sect64
Second we measured how many bugs are shared acrossseeds in the intra-program dataset As an extreme case wefound a bug that was triggered by 46 seeds The averagenumber of seeds leading to a given bug is 4 Out of the 200bugs 97 were discovered from multiple seeds Figure 3illustrates the distribution of bug overlaps Our resultssuggest that there is a small overlap in the code exercisedby different seed files even though they have been chosento be of different types Although this shows that our bugdisjointness assumption in the WCCP model does not alwayshold in practice the low average number of seeds leading toa given bug in our dataset means that the performance ofour algorithms should not have been severely affected
64 SimulationWe now compare the 26 scheduling algorithms based on the10-day fuzzing logs collected for the intra- and inter-programdatasets To compare the performance of scheduling algo-rithms we use the total number of unique bugs reportedby the bug triage process Recall from sect44 that these al-gorithms vary across three dimensions (1) epoch types (2)belief metrics and (3) MAB algorithms For each valid com-bination (see Table 2) we ran our simulator 100 times andaveraged the results to study the effect of randomness oneach scheduling algorithm In our experiments we allocated10 seconds to each epoch for fixed-time campaigns and 200runs for fixed-run campaigns For the ε-Greedy algorithmwe chose ε to be 01
Table 2 summarizes our results Each entry in the tablerepresents the average number of bugs found by 100 sim-
Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

satisfying it when one program can appear in multiple config-urations is non-trivial In practice it is achieved by selectingseeds that exercise different code regions For example inour other data set we use seeds of various file formats tofuzz the different file parsers in a media player
Finally at present we do not account for the time spentin bug triage though this process requires considerable timeIn practice triaging a crash takes approximately the sameamount of time as the fuzz run that initially found the crashTherefore bug triage can potentially account for over half ofthe time spent in an epoch if crashes are extremely frequentWe plan to incorporate this consideration into our project ata future time
3 Multi-Armed BanditsAs explained in sect1 the Fuzz Configuration Scheduling prob-lem is an instance of the classic Multi-Armed Bandit (MAB)problem This has already been observed by previous re-searchers For example the CERT Basic Fuzzing Framework(BFF) [14] which supports fuzzing a single program witha collection of seeds and a set of mutation ratios uses anMAB algorithm to select among the seed-ratio pairs duringa fuzz campaign However we must stress that recognizingthe MAB nature of our problem is merely a first step Inparticular we should not expect an MAB algorithm withprovably ldquogoodrdquo performance such as one from the UCB [3]or the EXP3 [2] families to yield good results in our problemsetting There are at least two reasons for this
First although many of these algorithms are proven tohave optimal regret in various forms the most commonform of regret does not actually give good guarantees in ourproblem setting In particular this form of regret measuresthe difference between the expected reward of an algorithmand the reward obtained by consistently fuzzing the singlebest configuration that yields the greatest number of uniquebugs However we are interested in evaluating performancerelative to the total number of unique bugs from all Kconfigurations which may be much greater than the numberfrom one fixed configuration Thus the low-regret guaranteeof many MAB algorithms is in fact measuring against atarget that is likely to be much lower than what we desireIn other words given our problem setting these algorithmsare not guaranteed to be competitive at all
Second while there exist algorithms with provably lowregret in a form suited to our problem setting the actual re-gret bounds of these algorithms often do not give meaningfulvalues in practice For example one of the MAB algorithmswe use is the EXP3S1 algorithm [2] proven to have an
expected worst-case regret of S+2eradic2minus1
radic2K` ln(K`) where S is
a certain hardness measure of the problem instance as de-fined in [2 sect8] and ` is the number of epochs in our problemsetting Even assuming the easiest case where S equals to 1and picking K to be a modest value of 10 the value of thisbound when ` = 4 is already slightly above 266 Howeveras we see in sect6 the number of bugs we found in our twodatasets are 200 and 223 respectively What this means isthat this regret bound is very likely to dwarf the number ofbugs that can be found in real-world software after a verysmall number of epochs In other words even though we havethe right kind of guarantee from EXP3S1 the guaranteequickly becomes meaningless in practical terms
Having said the above we remark that this simply meanssuch optimal regret guarantees may not be useful in ensuring
good results As we will see in sect6 EXP3S1 can still obtainreasonably good results in the right setting
4 Algorithms for the FCS ProblemOur goal in this section is to investigate how to design onlinealgorithms for the Fuzz Configuration Scheduling problemWe largely focus on developing the design space (sect44) mak-ing heavy use of the mathematical foundation we lay outin sect41 and sect43 Additionally we present two impossibilityresults in sect42 one of which requires a precise conditionthat greatly informs our algorithm design effort We alsopresent two offline algorithms for our problem While suchalgorithms may not be applicable in practice a unique aspectof our project allows us to use them as benchmarks whichwe measure our online algorithms against We explain thisalong with the offline algorithms in sect45
41 Fuzzing as a Weighted CCPLet us start by mathematically modeling the process ofrepeatedly fuzzing a configuration As we explained in sect2the output of this process is a stream of crashes intermixedwith proper terminations which is then transformed intoa stream of IDs by a bug triage process Since we want tomaximize the number of unique bugs found we are naturallyinterested in when a new bug arrives in this process Thisinsight quickly leads us to the Coupon Collectorrsquos Problem(CCP) a classical arrival process in probability theory
The CCP concerns a consumer who obtains one couponwith each purchase of a box of breakfast cereal Supposethere are M different coupon types in circulation One basicquestion about the CCP is what is the expected number ofpurchases required before the consumer amasses k (le M)unique coupons In its most elementary formulation eachcoupon is chosen uniformly at random among the M coupontypes In this setting many questions related to the CCPmdashincluding the one abovemdashare relatively easy to answer
Viewing Fuzzing as WCCP with Unknown Weights Un-fortunately our problem setting actually demands a weightedvariant of the CCP which we dub the WCCP Intuitively thisis because the probabilities of the different outcomes froma fuzz run are not necessarily (and unlikely to be) uniformThis observation has also been made by Arcuri et al [1]
Let (M minus 1) be the actual number of unique bugs discov-erable by fuzzing a certain configuration Then includingproper termination of a fuzz run as an outcome gives usexactly M distinct outcome types We thus relate the pro-cess of repeatedly fuzzing a configuration to the WCCP byviewing fuzz run outcomes as coupons and their associatedIDs as coupon types
However unlike usual formulations of the WCCP where thedistribution of outcomes across type is given in our problemsetting this distribution is unknown a priori In particularthere is no way to know the true value ofM for a configurationwithout exhaustively fuzzing all possible mutations As suchwe utilize statistical estimations of these distributions ratherthan the ground-truth in our algorithm design An importantquestion to consider is whether accurate estimations arefeasible
We now explain why we prefer the sets of bugs from differ-ent configurations used in a campaign to be disjoint Observethat our model of a campaign is a combination of multipleindependent WCCP processes If a bug that is new to oneprocess has already been discovered in another then this
bug cannot contribute to the total number of unique bugsThis means that overlap in the sets of bugs diminishes thefidelity of our model so that any algorithm relying on itspredictions may suffer in performance
WCCP Notation Before we go on let us set up some ad-ditional notation related to the WCCP In an effort to avoidexcessive indices our notation implicitly assumes a fixedconfiguration (pi si) that is made apparent by context Forexample M the number of possible outcomes when fuzzing agiven configuration as defined above follows this convention
(i) Consider the fixed sequence σ of outcomes we obtainin the course of fuzzing (pi si) during a campaign We labelan outcome as type k if it belongs to the kth distinct type ofoutcome in σ Let Pk denote the probability of encounteringa type-k outcome in σ ie
Pk =|x isin H(si) x triggers an outcome of type k|
|H(si)| (1)
(ii) Although both the number and frequency of outcometypes obtainable by fuzzing (pi si ) are unknown a prioriduring a campaign we do have empirical observations forthese quantities up to any point in σ Let M(`) be the numberof distinct outcomes observed from epoch 1 through epoch` Let nk(`) be the number of inputs triggering outcomesof type k observed throughout these ` epochs Notice thatover the course of a campaign the sequence σ is segmentedinto subsequences each of which corresponds to an epochin which (pi si ) is chosen Thus the values of M(middot) andnk(middot) will not change if (pi si) is not chosen for the currentepoch With this notation we can also express the empiricalprobability of detecting a type-k outcome following epoch `as
Pk(`) =nk(`)sumM(`)
kprime=1 nkprime(`)
42 Impossibility ResultsNo Free Lunch The absence of any assumption on the dis-tribution of outcome types in the WCCP quickly leads us toour first impossibility result In particular no algorithm canconsistently outperform other algorithms for the FCS prob-lem This follows from a well-known impossibility result inoptimization theory namely the ldquoNo Free Lunchrdquo theorem byWolpert and Macready [22] Quoting Wolpert and Macreadytheir theorem implies that ldquoany two optimization algorithmsare equivalent when their performance is averaged across allpossible problemsrdquo In our problem setting maximizing thenumber of bugs found in epoch (`+ 1) amounts to for eachconfiguration estimating its PM(`)+1 in equation (1) usingonly past observations from that configuration Intuitivelyby averaging across all possible outcome type distributionsany estimation will be incorrect sufficiently often and thuslead to suboptimal behavior that cancels any advantage ofone algorithm over another
While we may consider this result to be easy to obtainonce we have properly set up our problem using sect2 and sect41we consider it to be an important intellectual contribution forthe pragmatic practitioners who remain confident that theycan design algorithms that outperform others In particularthe statement of the No Free Lunch theorem itself revealsprecisely how we can circumvent its conclusionmdashour estima-tion procedure must assume the outcome type distributions
have particular characteristics Our motto is thus ldquothere isno free lunchmdashplease bring your own priorrdquo
Tight K-Competitiveness Our second impossibility resultshows that there are problem instances in which the timespent by any deterministic online algorithm to find a givennumber of unique bugs in a fixed-time campaign is at leastK times larger than the time spent by an optimal offlinealgorithm Using the terminology of competitive analysisthis shows that the competitive ratio of any deterministiconline algorithm for this problem is at least K
To show this we fix a deterministic algorithm A andconstruct a contrived problem instance in which there is onlyone bug among all the configurations in a campaign Since Ais deterministic there exists a unique pair (plowasti s
lowasti ) that gets
chosen last In other words the other (K minus 1) pairs have allbeen fuzzed for at least one epoch when (plowasti s
lowasti ) is fuzzed for
the first time If the lone bug is only triggered by fuzzing(plowasti s
lowasti ) then A will have to fuzz for at least K epochs to
find itFor an optimal offline algorithm handling this contrived
scenario is trivial Since it is offline it has full knowledgeof the outcome distributions enabling it to hone in on thespecial pair (plowasti s
lowasti ) and find the bug in the first epoch This
establishes that K is a lowerbound for the competitive ratioof any deterministic algorithm
Finally we observe that Round-Robin is a deterministiconline algorithm that achieves the competitive ratio K inevery problem instance It follows immediately that K istight
43 Upperbounding the Probability of Seeinga New Outcome During Fuzzing
Having seen such strong impossibility results let us considerwhat a pragmatist might do before bringing in any prior onthe outcome type distribution In other words if we do notwant to make any assumptions on this distribution is therea justifiable approach to designing online algorithms for theFCS problem
We argue that the answer is yes Consider two program-seed pairs (p1 s1) and (p2 s2) for which we have upperboundson the probability of finding a new outcome if we fuzz themonce more Assume that the upperbound for (p1 s1) is thehigher of the two
We stress that what we know are merely upperboundsmdashitis still possible that the true probability of yielding a newoutcome from fuzzing (p1 s1) is lower than that of (p2 s2)Nonetheless with no information beyond the ordering ofthese upperbounds fuzzing (p1 s1 ) first is arguably themore prudent choice This is because to do otherwise wouldindicate a belief that the actual probability of finding a newoutcome by fuzzing (p1 s1) in the next fuzz run is lower thanthe upperbound for (p2 s2)
Accepting this argument how might we obtain such upper-bounds We introduce the Rule of Three for this purpose
Rule of Three Consider an experiment of independentBernoulli trials with identical success and failure probabilitiesp and q = (1minus p) Suppose we have carried out N ge 1 trialsso far and every trial has been a success What can we sayabout q other than the fact that it must be (i) at least 0to be a valid probability and (ii) strictly less than 1 sincep is evidently positive In particular can we place a lowerupperbound on q
Unfortunately the answer is a resounding no even with qarbitrarily close to 1 we still have (pN gt 0) This means ourobservation really could have happened even if it is extremelyunlikely
Fortunately if we are willing to rule out the possibility ofencountering extremely unlikely events then we may com-pute a lower upperbound for q by means of a confidenceinterval For example a 95 confidence interval on q out-puts an interval that includes the true value of q of theunderlying experiment with 95 certainty In other wordsif the outputted interval does not contain the true value ofq for the experiment then the observed event must have alikelihood of at most 5
For the above situation there is particularly neat techniqueto compute a 95 confidence interval on q Known as theldquoRule of Threerdquo this method simply outputs 0 and 3N for thelowerbound and upperbound respectively The lowerboundis trivial and the upperbound has been shown to be a goodapproximation for N gt 30 See [15] for more informationon this technique including the relationship between 95confidence and the constant 3
How We Use Rule of Three In order to apply the Ruleof Three we must adapt our fuzzing experiments with anyM gt 1 possible outcome types to fit the mold of Bernoullitrials
We make use of a small trick Suppose we have just finishedepoch ` and consider a particular configuration (pi si) Using
our notation we have observed M(`) different outcomes so
far and for 1 le k le M(`) we have observed nk(`) counts of
outcome of type k Let N(`) =sumM(`)
k=1 nk(`) denote the totalnumber of fuzz runs for this pair through epoch ` The trickis to define a ldquosuccessrdquo to be finding an outcome of type 1through type M(`) Then in hindsight it is the case thatour experiment has only yielded success so far
With this observation we may now apply the Rule of Threeto conclude that [0 3N(`)] is a 95 confidence interval onthe ldquofailurerdquo probabilitymdashthe probability that fuzzing thisconfiguration will result in an outcome type that we havenot seen before ie a new outcome Then as desired wehave an easy-to-compute upperbound on the probability offinding a new outcome for each configuration
We introduce one more piece of notation before proceedingdefine the Remaining Probability Mass (RPM) of (pi si) atthe end of epoch ` denoted RPM(`) to be the probabilityof finding a new outcome if we fuzz (pi si) once more Notethat the pair in RPM(`) is implicit and that this valueis upperbounded by 3N(`) if we accept a 95 confidenceinterval
44 Design SpaceIn this section we explore the design space that a pragma-tist may attempt when designing online algorithms for theFuzz Configuration Scheduling problem A depiction of thedesign space along with our experimental results is given inTable 2 in sect6 Our focus here is to explain our motivation forchoosing the three dimensions we explore and the particularchoices we include in each dimension By combining thesedimensions we obtain 26 online algorithms for our prob-lem We implemented these algorithms inside a simulatorFuzzSim the detail of which is presented in sect5
Epoch Type We consider two possible definitions of anepoch in a fuzz campaign The first is the more traditional
choice and is used in the current version of CERT BFFv26 [14] the second is our proposal
Fixed-Run Each epoch executes a constant number offuzz runs In FuzzSim a fixed-run epoch consists of 200runs Note that any differential in fuzzing speed acrossconfigurations translates into variation in the time spent infixed-run epochs
Fixed-Time Each epoch is allocated a fixed amount oftime In FuzzSim a fixed-time epoch lasts for 10 secondsOur motivation to investigate this epoch type is to see howheavily epoch time variation affects the results obtained bysystems with fixed-run epochs
Belief Metrics Two of the MAB algorithms we presentbelow make use of a belief metric that is associated with eachconfiguration and is updated after each epoch Intuitivelythe metrics are designed such that fuzzing a configurationwith a higher metric should yield more bugs in expectationThe first two beliefs below use the concept of RPM to achievethis without invoking any prior the remaining three embracea ldquobug priorrdquo For now suppose epoch ` has just finishedand we are in the process of updating the belief for theconfiguration (pi si)
RPM We use the upperbound in the 95 confidence intervalgiven by the Rule of Three to approximate RPM(`) Thebelief is simply 3N(`)
Expected Waiting Time Until Next New Outcome(EWT) Since RPM does not take into account of the speedof each fuzz run we also investigate a speed-normalizedvariant of RPM Let Time(`) be the cumulative time spentfuzzing this configuration from epoch 1 to epoch ` Let
avgTime(`) be the average time of a fuzz run ie Time(`)N(`)
Let W be a random variable denoting the waiting time untilthe next new outcome Recall that RPM(`) is the probabilityof finding a new outcome in the next fuzz run and assume itis independent of avgTime(`) To compute E[W ] observethat either we find a new outcome in the next fuzz run orwe do not and we have to wait again Therefore
E[W ] = RPM(`)times avgTime(`)
+ (1minus RPM(`))times (avgTime(`) + E[W ])
(Notice that RPM does not change even in the second casewhat changes is our upperbound on RPM) Solving for E[W ]
yields avgTime(`)RPM(`)
and we substitute in the upperbound of
the 95 confidence interval for RPM(`) to obtain E[W ] geavgTime(`)3N(`)
= Time(`)3
Since a larger waiting time is less desir-
able the belief used is its reciprocal 3Time(`)
Rich Gets Richer (RGR) This metric is grounded inwhat we call the ldquobug priorrdquo which captures our empiricalobservation that code tends to be either robust or bug-riddenPrograms written by programmers of different skill levelsor past testing of a program might explain this real-worldphenomenon Accordingly demonstrated bugginess of aprogram serves as a strong indicator that more bugs will befound in that program and thus the belief is M(`)
Density This is a runs-normalized variant of RGR and isalso the belief used in CERT BFF v26 [14] The belief func-
tion is M(`)N(`) Observe that this is the belief function
of RPM scaled by M(`)3 In other words Density can beseen as RPM adapted with the bug prior
Rate This is a time-normalized variant of RGR The belieffunction is M(`)Time(`) Similar to Density Rate can beseen as EWT adapted with the bug prior
Bandit Algorithms Since the FCS problem is an instanceof an MAB problem naturally we explore a number of MABalgorithmsRound-Robin This simply loops through the configura-tions in a fixed order dedicating one epoch to each configura-tion Note that Round-Robin is a non-adaptive deterministicalgorithmUniform-Random This algorithm selects uniformly atrandom from the set of configurations for each epoch LikeRound-Robin this algorithm is non-adaptive however it israndomizedWeighted-Random Configurations are selected at randomin this algorithm with the probability associated with eachconfiguration is linked to the belief metric in use Theweight of a well-performing configuration is adjusted upwardvia the belief metric thereby increasingly the likelihood ofselecting that configuration in future epochs This mechanismfunctions in reverse for configurations yielding few or no bugsε-Greedy The ε-Greedy algorithm takes an intuitive ap-proach to the exploration vs exploitation trade-off inherentto MAB problems With probability ε the algorithm selectsa configuration uniformly at random for explorationWithprobability (1minus ε) it chooses the configuration with the high-est current belief allowing it to exploit its current knowledgefor gains The constant ε serves as a parameter balancingthe two competing goals with higher ε values correspondingto a greater emphasis on explorationEXP3S1 This is an advanced MAB algorithm by Aueret al [2] for the non-stochastic MAB problem We picked thisalgorithm for three reasons First it is from the venerableEXP3 family and so likely to be picked up by practitionersSecond this is one of the EXP3 algorithms that is not pa-rameterized by any constants and thus no parameter tuningis needed Third this algorithm is designed to have an op-timal worst-case regret which is a form of regret that suitsour problem setting Note that at its core EXP3S1 is aweighted-random algorithm However since we do not havea belief metric that corresponds to the one used in EXP3S1we did not put it inside the Weighted-Random group
45 Offline AlgorithmsEarly on in our research design we recognized the importanceof evaluating a large number of algorithms Out of budgetaryconstraints we have taken a simulation approach so thatwe can replay the events from previous fuzzings to try outnew algorithms Since we have recorded all the events thatmay happen during any fuzz campaign of the same inputconfigurations we can even attempt to compute what anoptimal offline algorithm would do and compare the results ofour algorithms against it In the case when the configurationsdo not yield duplicated bugs such as in our Inter-Programdataset (sect6) we devise a pseudo-polynomial time algorithmthat computes the offline optimal In the other case whereduplicated bugs are possible we propose a heuristic to post-process the solution from the above algorithm to obtain alowerbound on the offline optimal
No Duplicates Assuming that the sets of unique bugsfrom different configurations are disjoint our algorithm isa small variation on the dynamic programming solution tothe Bounded Knapsack problem Let K be the number of
Program
amp
Seed
(pi si)
Fuzzer
bugsScheduler
crashes
Simulator
Scheduling
Algorithms
Fuzzing Triage
Bug Triage
bugs
Simulation
logs
logs
Time
Budget (T)
Figure 1 FuzzSim architecture
configurations and B be the total number of unique bugsfrom all K configurations Let t(i b) be the minimum amountof time it takes for configuration i to produce b unique bugsNote that t(i b) is assumed to be infin when configuration inever produces b unique bugs in our dataset We claim thatt(i b) can be pre-computed for all i isin [1K] and b isin [0 B]where each entry takes amortized O(1) time given how eventsare recorded in our system
Let m(i b) be the minimum amount of time it takes forconfigurations 1 through i to produce b unique bugs We wantto compute m(K b) for b isin [0 B] By definition m(1 b) =t(1 b) for b isin [0 B] For i gt 1 observe that m(i b) =mincisin[0B]t(i c) +m(iminus 1 bminus c) This models partitioningthe b unique bugs into c unique bugs from configuration iand (bminus c) unique bugs from configurations 1 through (iminus1)Computing each m(i b) entry takes O(B) time Since thereare O(K timesB) entries the total running time is O(K timesB2)
Discounting Duplicates The above algorithm is incorrectwhen the sets of unique bugs from different configurationsare not disjoint This is because the recurrence formula ofm(i b) assumes that the c unique bugs from configuration iare different from the (bminus c) unique bugs from configurations1 through (i minus 1) In this case we propose a heuristic tocompute a lowerbound on the offline optimal
After obtaining the m(i b) table from the above we post-process bug counts by the following discount heuristic Firstwe compute the maximum number of bugs that can be foundat each time by the above algorithm by examining the K-throw of the table Then by scanning forward from time 0whenever the bug count goes up by one due to a duplicatedbug (which must have been found using another configura-tion) we discount the increment Since the optimal offlinealgorithm can also pick up exactly the same bugs in the sameorder as the dynamic programming algorithm our heuristicis a valid lowerbound on the maximum number of bugs thatan optimal offline algorithm would find
5 Design amp ImplementationThis section presents FuzzSim our replay-based fuzz simu-lation system built for this project We describe the threesteps in FuzzSim and explain the benefit of its design whichis then followed by its implementation detail Of special noteis that we are releasing our source code and our datasets insupport of open science at the URL found in sect52
51 OverviewFuzzSim is a simulation system for black-box mutationalfuzzing that is designed to run different configuration schedul-ing algorithms using logs from previous fuzzings Figure 1summarizes the design of FuzzSim which employs a three-step approach (1) fuzzing (2) triage and (3) simulation
Fuzzing The first step is fuzzing and collecting run logsfrom a fuzzer FuzzSim takes in a list of program-seedpairs (pi si) and a time budget T It runs a fuzzer on eachconfiguration for the full length of the time budget T andwrites to the log each time a crash occurs Log entries arerecorded as 5-tuples of the form (pi si time stamp runsmutation identifier)
In our implementation we fuzz with zzuf one of the mostpopular open-source fuzzers zzuf generates a random inputfrom a seed file as described in sect21 The randomization inzzuf can be reproduced given the mutation identifier thusenabling us to reproduce a crashing input from its seed fileand the log entry associated with the crash For example anoutput tuple of (FFMpeg aavi 100 42 1234) specifies thatthe program FFMpeg crashed at the 100-th second with aninput file obtained from ldquoaavirdquo according to the mutationidentifier 1234 Interested readers may refer to zzuf [16] fordetails on mutation identifiers and the actual implementation
The deterministic nature of zzuf allows FuzzSim to triagebugs after completing all fuzz runs first In other wordsFuzzSim does not compute bug identifiers during fuzzingand instead re-derives them using the log This does notaffect any of our algorithms since none of them relies on theactual IDs In our experiments we have turned off addressspace layout randomization (ASLR) in both the fuzzing andthe triage steps in order to reproduce the same crashes
Triage The second step of FuzzSim maps crashing inputsfound during fuzzings into bugs At a high level the triagephase takes in the list of 5-tuples (pi si time-stamp runsmutation identifier) logged during the fuzzing step and out-puts a new list of 5-tuples of the form (pi si time-stampruns bug identifier) More specifically FuzzSim replayseach recorded crash under a debugger to collect stack tracesIf FuzzSim does not detect a crash during a particular replaythen we classify that test case to be a non-deterministic bugand discard it
We then use the collected stack traces to produce bugidentifiers essentially hashes of the stack traces In particularwe use the fuzzy stack hash algorithm [19] which identifiesbugs by hashing the normalized line numbers from a stacktrace With this algorithm the number of stack frames tohash has a significant influence on the accuracy of bug triageFor example taking the full stack trace often leads to mis-classifying a single bug into multiple bugs whereas takingonly the top frame can easily lead to two different bugs beingmis-classified as one To match the state of the art FuzzSimuses the top 3 frames as suggested in [19] We stress that eventhough inaccurate bug triage may still occur with this choiceof parameter perfecting bug triage techniques is beyond thescope of this paper
Simulation The last step simulates a fuzz campaign onthe collected ground-truth data from the previous steps us-ing a user-specified scheduling algorithm More formallythe simulation step takes in a scheduling algorithm and alist of 5-tuples of the form (pi si timestamp runs bugidentifier) and outputs a list of 2-tuples (timestamp bugs)that represent the accumulated time before the correspond-ing number of unique bugs are observed under the givenscheduling algorithm
Since FuzzSim can simulate any scheduling algorithm inan offline fashion using the pre-recorded ground-truth datait enables us to efficiently compare numerous scheduling
algorithms without actually running a large number of fuzzcampaigns During replay FuzzSim outputs a timestampwhenever it finds a new bug Therefore we can easily plotand compare different scheduling algorithms by comparingthe number of bugs produced under the same time budget
We summarize FuzzSimrsquos three-step algorithm below
Fuzzing ((pi si) T )rarr pi si timestamp runs mutation id
Triage (pi si timestamp runs mutation id)rarr (pi si timestamp runs bug id)
Simulation (pi si timestamp runs bug id)rarr (timestamp bugs)
Algorithm 1 FuzzSim algorithms
52 Implementation amp Open ScienceWe have implemented our data collection and bug triage mod-ules in approximately 1000 lines of OCaml This includes thecapability to run and collect crash logs from Amazon EC2We used zzuf version 013 Our scheduling engine is alsoimplemented in OCaml and spans about 1600 lines Thiscovers the 26 online and the 2 offline algorithms presentedin this paper
We invite our fellow researchers to become involved inthis line of research In support of open science we releaseboth our datasets and the source code of our simulator athttpsecurityececmuedufuzzsim
6 EvaluationTo evaluate the performance of the 26 algorithms presentedin sect4 we focus on the following questions
1 Which scheduling algorithm works best for our datasets2 Why does one algorithm outperform the others3 Which of the two epoch typesmdashfixed-run or fixed-timemdash
works better and why
61 Experimental SetupOur experiments were performed on Amazon EC2 instancesthat have been configured with a single Intel 2GHz XeonCPU core and 4GB RAM each We used the most recentDebian Linux distribution at the time of our experiment(April 2013) and downloaded all programs from the then-latest Debian Squeeze repository Specifically the version ofFFMpeg we used is SVN-r0510-40510-1 which is basedon a June 2012 FFMpeg release with Debian-specific patches
62 Fuzzing Data CollectionOur evaluation makes use of two datasets (1) FFMpegwith 100 different input seeds and (2) 100 different Linuxapplications each with a corresponding input seed Werefer to these as the ldquointra-programrdquo and the ldquointer-programrdquodatasets respectively
For the intra-program dataset we downloaded 10 000videoimage sample files from the MPlayer website at http
samplesmplayerhqhu From these samples we selected100 files uniformly at random and took them as our input
Dataset runs crashes bugsIntra-program 636998978 906577 200Inter-program 4868416447 415699 223
Table 1 Statistics from fuzzing the two datasets
0
20
40
60
0 10 20 30 40
bugs
count
IntraminusProgram
0
20
40
60
0 10 20 30
bugs
count
InterminusProgram
Figure 2 Distribution of the number of bugs per configura-tion in each dataset
0
25
50
75
0 10 20 30 40
bugs
count
Figure 3 Distribution of bug overlaps across multiple seedsfor the intra-program dataset
seeds The collected seeds include various audio and videoformats such as ASF QuickTime MPEG FLAC etc Wethen used zzuf to fuzz FFMpeg with each seed for 10 days
For the inter-program dataset we downloaded 100 differ-ent file conversion utilities in Debian To select these 100programs we first enumerated all file conversion packagestagged as ldquouseconvertingrdquo in the Debian package tags in-terface (debtags) From this list of packages we manuallyidentified 100 applications that take a file name as a com-mand line argument Then we manually constructed a validseed for each program and the actual command line to run itwith the seed After choosing these 100 program-seed pairswe fuzzed each for 10 days as well In total we have spent48000 CPU hours fuzzing these 200 configurations
To perform bug triage we identified and re-ran everycrashing input from the log under a debugger to obtain stacktraces for hashing After triaging with the fuzzy stack hashalgorithm described in sect51 we found 200 bugs from theintra-program dataset and 223 bugs from the inter-programdataset Table 1 summarizes the data collected from ourexperiments The average fuzzing throughput was 8 runsper second for the intra-program dataset and 63 runs persecond for the inter-program dataset This difference is dueto the higher complexity of FFMpeg when compared to theprograms in the inter-program dataset
63 Data AnalysisWhat does the collected fuzzing data look like We studiedour data from fuzzing and triage to answer two questions (1)How many bugs does a configuration trigger (2) How manybugs are triggered by multiple seeds in the intra-programdataset
We first analyzed the distribution of the number of bugsin the two datasets On average the intra- and the inter-program datasets yielded 82 and 24 bugs per configurationrespectively Figure 2 shows two histograms each depict-
40
60
80
100
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(a) Intra-program
60
100
140
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(b) Inter-program
Figure 4 The average number of bugs over 100 runs foreach scheduling algorithm with error bars showing a 99confidence interval ldquoftrdquo represents fixed-time epoch ldquofrrdquorepresents fixed-run epoch ldquoerdquo represents ε-Greedy ldquowrdquo rep-resents Weighted-Random
ing the number of occurrences of bug counts There is amarked difference in the distributions from the two datasets64 of configurations in the inter-program dataset produceno bugs whereas the corresponding number in the intra-program dataset is 15 We study the bias of the bug countdistribution in sect64
Second we measured how many bugs are shared acrossseeds in the intra-program dataset As an extreme case wefound a bug that was triggered by 46 seeds The averagenumber of seeds leading to a given bug is 4 Out of the 200bugs 97 were discovered from multiple seeds Figure 3illustrates the distribution of bug overlaps Our resultssuggest that there is a small overlap in the code exercisedby different seed files even though they have been chosento be of different types Although this shows that our bugdisjointness assumption in the WCCP model does not alwayshold in practice the low average number of seeds leading toa given bug in our dataset means that the performance ofour algorithms should not have been severely affected
64 SimulationWe now compare the 26 scheduling algorithms based on the10-day fuzzing logs collected for the intra- and inter-programdatasets To compare the performance of scheduling algo-rithms we use the total number of unique bugs reportedby the bug triage process Recall from sect44 that these al-gorithms vary across three dimensions (1) epoch types (2)belief metrics and (3) MAB algorithms For each valid com-bination (see Table 2) we ran our simulator 100 times andaveraged the results to study the effect of randomness oneach scheduling algorithm In our experiments we allocated10 seconds to each epoch for fixed-time campaigns and 200runs for fixed-run campaigns For the ε-Greedy algorithmwe chose ε to be 01
Table 2 summarizes our results Each entry in the tablerepresents the average number of bugs found by 100 sim-
Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

bug cannot contribute to the total number of unique bugsThis means that overlap in the sets of bugs diminishes thefidelity of our model so that any algorithm relying on itspredictions may suffer in performance
WCCP Notation Before we go on let us set up some ad-ditional notation related to the WCCP In an effort to avoidexcessive indices our notation implicitly assumes a fixedconfiguration (pi si) that is made apparent by context Forexample M the number of possible outcomes when fuzzing agiven configuration as defined above follows this convention
(i) Consider the fixed sequence σ of outcomes we obtainin the course of fuzzing (pi si) during a campaign We labelan outcome as type k if it belongs to the kth distinct type ofoutcome in σ Let Pk denote the probability of encounteringa type-k outcome in σ ie
Pk =|x isin H(si) x triggers an outcome of type k|
|H(si)| (1)
(ii) Although both the number and frequency of outcometypes obtainable by fuzzing (pi si ) are unknown a prioriduring a campaign we do have empirical observations forthese quantities up to any point in σ Let M(`) be the numberof distinct outcomes observed from epoch 1 through epoch` Let nk(`) be the number of inputs triggering outcomesof type k observed throughout these ` epochs Notice thatover the course of a campaign the sequence σ is segmentedinto subsequences each of which corresponds to an epochin which (pi si ) is chosen Thus the values of M(middot) andnk(middot) will not change if (pi si) is not chosen for the currentepoch With this notation we can also express the empiricalprobability of detecting a type-k outcome following epoch `as
Pk(`) =nk(`)sumM(`)
kprime=1 nkprime(`)
42 Impossibility ResultsNo Free Lunch The absence of any assumption on the dis-tribution of outcome types in the WCCP quickly leads us toour first impossibility result In particular no algorithm canconsistently outperform other algorithms for the FCS prob-lem This follows from a well-known impossibility result inoptimization theory namely the ldquoNo Free Lunchrdquo theorem byWolpert and Macready [22] Quoting Wolpert and Macreadytheir theorem implies that ldquoany two optimization algorithmsare equivalent when their performance is averaged across allpossible problemsrdquo In our problem setting maximizing thenumber of bugs found in epoch (`+ 1) amounts to for eachconfiguration estimating its PM(`)+1 in equation (1) usingonly past observations from that configuration Intuitivelyby averaging across all possible outcome type distributionsany estimation will be incorrect sufficiently often and thuslead to suboptimal behavior that cancels any advantage ofone algorithm over another
While we may consider this result to be easy to obtainonce we have properly set up our problem using sect2 and sect41we consider it to be an important intellectual contribution forthe pragmatic practitioners who remain confident that theycan design algorithms that outperform others In particularthe statement of the No Free Lunch theorem itself revealsprecisely how we can circumvent its conclusionmdashour estima-tion procedure must assume the outcome type distributions
have particular characteristics Our motto is thus ldquothere isno free lunchmdashplease bring your own priorrdquo
Tight K-Competitiveness Our second impossibility resultshows that there are problem instances in which the timespent by any deterministic online algorithm to find a givennumber of unique bugs in a fixed-time campaign is at leastK times larger than the time spent by an optimal offlinealgorithm Using the terminology of competitive analysisthis shows that the competitive ratio of any deterministiconline algorithm for this problem is at least K
To show this we fix a deterministic algorithm A andconstruct a contrived problem instance in which there is onlyone bug among all the configurations in a campaign Since Ais deterministic there exists a unique pair (plowasti s
lowasti ) that gets
chosen last In other words the other (K minus 1) pairs have allbeen fuzzed for at least one epoch when (plowasti s
lowasti ) is fuzzed for
the first time If the lone bug is only triggered by fuzzing(plowasti s
lowasti ) then A will have to fuzz for at least K epochs to
find itFor an optimal offline algorithm handling this contrived
scenario is trivial Since it is offline it has full knowledgeof the outcome distributions enabling it to hone in on thespecial pair (plowasti s
lowasti ) and find the bug in the first epoch This
establishes that K is a lowerbound for the competitive ratioof any deterministic algorithm
Finally we observe that Round-Robin is a deterministiconline algorithm that achieves the competitive ratio K inevery problem instance It follows immediately that K istight
43 Upperbounding the Probability of Seeinga New Outcome During Fuzzing
Having seen such strong impossibility results let us considerwhat a pragmatist might do before bringing in any prior onthe outcome type distribution In other words if we do notwant to make any assumptions on this distribution is therea justifiable approach to designing online algorithms for theFCS problem
We argue that the answer is yes Consider two program-seed pairs (p1 s1) and (p2 s2) for which we have upperboundson the probability of finding a new outcome if we fuzz themonce more Assume that the upperbound for (p1 s1) is thehigher of the two
We stress that what we know are merely upperboundsmdashitis still possible that the true probability of yielding a newoutcome from fuzzing (p1 s1) is lower than that of (p2 s2)Nonetheless with no information beyond the ordering ofthese upperbounds fuzzing (p1 s1 ) first is arguably themore prudent choice This is because to do otherwise wouldindicate a belief that the actual probability of finding a newoutcome by fuzzing (p1 s1) in the next fuzz run is lower thanthe upperbound for (p2 s2)
Accepting this argument how might we obtain such upper-bounds We introduce the Rule of Three for this purpose
Rule of Three Consider an experiment of independentBernoulli trials with identical success and failure probabilitiesp and q = (1minus p) Suppose we have carried out N ge 1 trialsso far and every trial has been a success What can we sayabout q other than the fact that it must be (i) at least 0to be a valid probability and (ii) strictly less than 1 sincep is evidently positive In particular can we place a lowerupperbound on q
Unfortunately the answer is a resounding no even with qarbitrarily close to 1 we still have (pN gt 0) This means ourobservation really could have happened even if it is extremelyunlikely
Fortunately if we are willing to rule out the possibility ofencountering extremely unlikely events then we may com-pute a lower upperbound for q by means of a confidenceinterval For example a 95 confidence interval on q out-puts an interval that includes the true value of q of theunderlying experiment with 95 certainty In other wordsif the outputted interval does not contain the true value ofq for the experiment then the observed event must have alikelihood of at most 5
For the above situation there is particularly neat techniqueto compute a 95 confidence interval on q Known as theldquoRule of Threerdquo this method simply outputs 0 and 3N for thelowerbound and upperbound respectively The lowerboundis trivial and the upperbound has been shown to be a goodapproximation for N gt 30 See [15] for more informationon this technique including the relationship between 95confidence and the constant 3
How We Use Rule of Three In order to apply the Ruleof Three we must adapt our fuzzing experiments with anyM gt 1 possible outcome types to fit the mold of Bernoullitrials
We make use of a small trick Suppose we have just finishedepoch ` and consider a particular configuration (pi si) Using
our notation we have observed M(`) different outcomes so
far and for 1 le k le M(`) we have observed nk(`) counts of
outcome of type k Let N(`) =sumM(`)
k=1 nk(`) denote the totalnumber of fuzz runs for this pair through epoch ` The trickis to define a ldquosuccessrdquo to be finding an outcome of type 1through type M(`) Then in hindsight it is the case thatour experiment has only yielded success so far
With this observation we may now apply the Rule of Threeto conclude that [0 3N(`)] is a 95 confidence interval onthe ldquofailurerdquo probabilitymdashthe probability that fuzzing thisconfiguration will result in an outcome type that we havenot seen before ie a new outcome Then as desired wehave an easy-to-compute upperbound on the probability offinding a new outcome for each configuration
We introduce one more piece of notation before proceedingdefine the Remaining Probability Mass (RPM) of (pi si) atthe end of epoch ` denoted RPM(`) to be the probabilityof finding a new outcome if we fuzz (pi si) once more Notethat the pair in RPM(`) is implicit and that this valueis upperbounded by 3N(`) if we accept a 95 confidenceinterval
44 Design SpaceIn this section we explore the design space that a pragma-tist may attempt when designing online algorithms for theFuzz Configuration Scheduling problem A depiction of thedesign space along with our experimental results is given inTable 2 in sect6 Our focus here is to explain our motivation forchoosing the three dimensions we explore and the particularchoices we include in each dimension By combining thesedimensions we obtain 26 online algorithms for our prob-lem We implemented these algorithms inside a simulatorFuzzSim the detail of which is presented in sect5
Epoch Type We consider two possible definitions of anepoch in a fuzz campaign The first is the more traditional
choice and is used in the current version of CERT BFFv26 [14] the second is our proposal
Fixed-Run Each epoch executes a constant number offuzz runs In FuzzSim a fixed-run epoch consists of 200runs Note that any differential in fuzzing speed acrossconfigurations translates into variation in the time spent infixed-run epochs
Fixed-Time Each epoch is allocated a fixed amount oftime In FuzzSim a fixed-time epoch lasts for 10 secondsOur motivation to investigate this epoch type is to see howheavily epoch time variation affects the results obtained bysystems with fixed-run epochs
Belief Metrics Two of the MAB algorithms we presentbelow make use of a belief metric that is associated with eachconfiguration and is updated after each epoch Intuitivelythe metrics are designed such that fuzzing a configurationwith a higher metric should yield more bugs in expectationThe first two beliefs below use the concept of RPM to achievethis without invoking any prior the remaining three embracea ldquobug priorrdquo For now suppose epoch ` has just finishedand we are in the process of updating the belief for theconfiguration (pi si)
RPM We use the upperbound in the 95 confidence intervalgiven by the Rule of Three to approximate RPM(`) Thebelief is simply 3N(`)
Expected Waiting Time Until Next New Outcome(EWT) Since RPM does not take into account of the speedof each fuzz run we also investigate a speed-normalizedvariant of RPM Let Time(`) be the cumulative time spentfuzzing this configuration from epoch 1 to epoch ` Let
avgTime(`) be the average time of a fuzz run ie Time(`)N(`)
Let W be a random variable denoting the waiting time untilthe next new outcome Recall that RPM(`) is the probabilityof finding a new outcome in the next fuzz run and assume itis independent of avgTime(`) To compute E[W ] observethat either we find a new outcome in the next fuzz run orwe do not and we have to wait again Therefore
E[W ] = RPM(`)times avgTime(`)
+ (1minus RPM(`))times (avgTime(`) + E[W ])
(Notice that RPM does not change even in the second casewhat changes is our upperbound on RPM) Solving for E[W ]
yields avgTime(`)RPM(`)
and we substitute in the upperbound of
the 95 confidence interval for RPM(`) to obtain E[W ] geavgTime(`)3N(`)
= Time(`)3
Since a larger waiting time is less desir-
able the belief used is its reciprocal 3Time(`)
Rich Gets Richer (RGR) This metric is grounded inwhat we call the ldquobug priorrdquo which captures our empiricalobservation that code tends to be either robust or bug-riddenPrograms written by programmers of different skill levelsor past testing of a program might explain this real-worldphenomenon Accordingly demonstrated bugginess of aprogram serves as a strong indicator that more bugs will befound in that program and thus the belief is M(`)
Density This is a runs-normalized variant of RGR and isalso the belief used in CERT BFF v26 [14] The belief func-
tion is M(`)N(`) Observe that this is the belief function
of RPM scaled by M(`)3 In other words Density can beseen as RPM adapted with the bug prior
Rate This is a time-normalized variant of RGR The belieffunction is M(`)Time(`) Similar to Density Rate can beseen as EWT adapted with the bug prior
Bandit Algorithms Since the FCS problem is an instanceof an MAB problem naturally we explore a number of MABalgorithmsRound-Robin This simply loops through the configura-tions in a fixed order dedicating one epoch to each configura-tion Note that Round-Robin is a non-adaptive deterministicalgorithmUniform-Random This algorithm selects uniformly atrandom from the set of configurations for each epoch LikeRound-Robin this algorithm is non-adaptive however it israndomizedWeighted-Random Configurations are selected at randomin this algorithm with the probability associated with eachconfiguration is linked to the belief metric in use Theweight of a well-performing configuration is adjusted upwardvia the belief metric thereby increasingly the likelihood ofselecting that configuration in future epochs This mechanismfunctions in reverse for configurations yielding few or no bugsε-Greedy The ε-Greedy algorithm takes an intuitive ap-proach to the exploration vs exploitation trade-off inherentto MAB problems With probability ε the algorithm selectsa configuration uniformly at random for explorationWithprobability (1minus ε) it chooses the configuration with the high-est current belief allowing it to exploit its current knowledgefor gains The constant ε serves as a parameter balancingthe two competing goals with higher ε values correspondingto a greater emphasis on explorationEXP3S1 This is an advanced MAB algorithm by Aueret al [2] for the non-stochastic MAB problem We picked thisalgorithm for three reasons First it is from the venerableEXP3 family and so likely to be picked up by practitionersSecond this is one of the EXP3 algorithms that is not pa-rameterized by any constants and thus no parameter tuningis needed Third this algorithm is designed to have an op-timal worst-case regret which is a form of regret that suitsour problem setting Note that at its core EXP3S1 is aweighted-random algorithm However since we do not havea belief metric that corresponds to the one used in EXP3S1we did not put it inside the Weighted-Random group
45 Offline AlgorithmsEarly on in our research design we recognized the importanceof evaluating a large number of algorithms Out of budgetaryconstraints we have taken a simulation approach so thatwe can replay the events from previous fuzzings to try outnew algorithms Since we have recorded all the events thatmay happen during any fuzz campaign of the same inputconfigurations we can even attempt to compute what anoptimal offline algorithm would do and compare the results ofour algorithms against it In the case when the configurationsdo not yield duplicated bugs such as in our Inter-Programdataset (sect6) we devise a pseudo-polynomial time algorithmthat computes the offline optimal In the other case whereduplicated bugs are possible we propose a heuristic to post-process the solution from the above algorithm to obtain alowerbound on the offline optimal
No Duplicates Assuming that the sets of unique bugsfrom different configurations are disjoint our algorithm isa small variation on the dynamic programming solution tothe Bounded Knapsack problem Let K be the number of
Program
amp
Seed
(pi si)
Fuzzer
bugsScheduler
crashes
Simulator
Scheduling
Algorithms
Fuzzing Triage
Bug Triage
bugs
Simulation
logs
logs
Time
Budget (T)
Figure 1 FuzzSim architecture
configurations and B be the total number of unique bugsfrom all K configurations Let t(i b) be the minimum amountof time it takes for configuration i to produce b unique bugsNote that t(i b) is assumed to be infin when configuration inever produces b unique bugs in our dataset We claim thatt(i b) can be pre-computed for all i isin [1K] and b isin [0 B]where each entry takes amortized O(1) time given how eventsare recorded in our system
Let m(i b) be the minimum amount of time it takes forconfigurations 1 through i to produce b unique bugs We wantto compute m(K b) for b isin [0 B] By definition m(1 b) =t(1 b) for b isin [0 B] For i gt 1 observe that m(i b) =mincisin[0B]t(i c) +m(iminus 1 bminus c) This models partitioningthe b unique bugs into c unique bugs from configuration iand (bminus c) unique bugs from configurations 1 through (iminus1)Computing each m(i b) entry takes O(B) time Since thereare O(K timesB) entries the total running time is O(K timesB2)
Discounting Duplicates The above algorithm is incorrectwhen the sets of unique bugs from different configurationsare not disjoint This is because the recurrence formula ofm(i b) assumes that the c unique bugs from configuration iare different from the (bminus c) unique bugs from configurations1 through (i minus 1) In this case we propose a heuristic tocompute a lowerbound on the offline optimal
After obtaining the m(i b) table from the above we post-process bug counts by the following discount heuristic Firstwe compute the maximum number of bugs that can be foundat each time by the above algorithm by examining the K-throw of the table Then by scanning forward from time 0whenever the bug count goes up by one due to a duplicatedbug (which must have been found using another configura-tion) we discount the increment Since the optimal offlinealgorithm can also pick up exactly the same bugs in the sameorder as the dynamic programming algorithm our heuristicis a valid lowerbound on the maximum number of bugs thatan optimal offline algorithm would find
5 Design amp ImplementationThis section presents FuzzSim our replay-based fuzz simu-lation system built for this project We describe the threesteps in FuzzSim and explain the benefit of its design whichis then followed by its implementation detail Of special noteis that we are releasing our source code and our datasets insupport of open science at the URL found in sect52
51 OverviewFuzzSim is a simulation system for black-box mutationalfuzzing that is designed to run different configuration schedul-ing algorithms using logs from previous fuzzings Figure 1summarizes the design of FuzzSim which employs a three-step approach (1) fuzzing (2) triage and (3) simulation
Fuzzing The first step is fuzzing and collecting run logsfrom a fuzzer FuzzSim takes in a list of program-seedpairs (pi si) and a time budget T It runs a fuzzer on eachconfiguration for the full length of the time budget T andwrites to the log each time a crash occurs Log entries arerecorded as 5-tuples of the form (pi si time stamp runsmutation identifier)
In our implementation we fuzz with zzuf one of the mostpopular open-source fuzzers zzuf generates a random inputfrom a seed file as described in sect21 The randomization inzzuf can be reproduced given the mutation identifier thusenabling us to reproduce a crashing input from its seed fileand the log entry associated with the crash For example anoutput tuple of (FFMpeg aavi 100 42 1234) specifies thatthe program FFMpeg crashed at the 100-th second with aninput file obtained from ldquoaavirdquo according to the mutationidentifier 1234 Interested readers may refer to zzuf [16] fordetails on mutation identifiers and the actual implementation
The deterministic nature of zzuf allows FuzzSim to triagebugs after completing all fuzz runs first In other wordsFuzzSim does not compute bug identifiers during fuzzingand instead re-derives them using the log This does notaffect any of our algorithms since none of them relies on theactual IDs In our experiments we have turned off addressspace layout randomization (ASLR) in both the fuzzing andthe triage steps in order to reproduce the same crashes
Triage The second step of FuzzSim maps crashing inputsfound during fuzzings into bugs At a high level the triagephase takes in the list of 5-tuples (pi si time-stamp runsmutation identifier) logged during the fuzzing step and out-puts a new list of 5-tuples of the form (pi si time-stampruns bug identifier) More specifically FuzzSim replayseach recorded crash under a debugger to collect stack tracesIf FuzzSim does not detect a crash during a particular replaythen we classify that test case to be a non-deterministic bugand discard it
We then use the collected stack traces to produce bugidentifiers essentially hashes of the stack traces In particularwe use the fuzzy stack hash algorithm [19] which identifiesbugs by hashing the normalized line numbers from a stacktrace With this algorithm the number of stack frames tohash has a significant influence on the accuracy of bug triageFor example taking the full stack trace often leads to mis-classifying a single bug into multiple bugs whereas takingonly the top frame can easily lead to two different bugs beingmis-classified as one To match the state of the art FuzzSimuses the top 3 frames as suggested in [19] We stress that eventhough inaccurate bug triage may still occur with this choiceof parameter perfecting bug triage techniques is beyond thescope of this paper
Simulation The last step simulates a fuzz campaign onthe collected ground-truth data from the previous steps us-ing a user-specified scheduling algorithm More formallythe simulation step takes in a scheduling algorithm and alist of 5-tuples of the form (pi si timestamp runs bugidentifier) and outputs a list of 2-tuples (timestamp bugs)that represent the accumulated time before the correspond-ing number of unique bugs are observed under the givenscheduling algorithm
Since FuzzSim can simulate any scheduling algorithm inan offline fashion using the pre-recorded ground-truth datait enables us to efficiently compare numerous scheduling
algorithms without actually running a large number of fuzzcampaigns During replay FuzzSim outputs a timestampwhenever it finds a new bug Therefore we can easily plotand compare different scheduling algorithms by comparingthe number of bugs produced under the same time budget
We summarize FuzzSimrsquos three-step algorithm below
Fuzzing ((pi si) T )rarr pi si timestamp runs mutation id
Triage (pi si timestamp runs mutation id)rarr (pi si timestamp runs bug id)
Simulation (pi si timestamp runs bug id)rarr (timestamp bugs)
Algorithm 1 FuzzSim algorithms
52 Implementation amp Open ScienceWe have implemented our data collection and bug triage mod-ules in approximately 1000 lines of OCaml This includes thecapability to run and collect crash logs from Amazon EC2We used zzuf version 013 Our scheduling engine is alsoimplemented in OCaml and spans about 1600 lines Thiscovers the 26 online and the 2 offline algorithms presentedin this paper
We invite our fellow researchers to become involved inthis line of research In support of open science we releaseboth our datasets and the source code of our simulator athttpsecurityececmuedufuzzsim
6 EvaluationTo evaluate the performance of the 26 algorithms presentedin sect4 we focus on the following questions
1 Which scheduling algorithm works best for our datasets2 Why does one algorithm outperform the others3 Which of the two epoch typesmdashfixed-run or fixed-timemdash
works better and why
61 Experimental SetupOur experiments were performed on Amazon EC2 instancesthat have been configured with a single Intel 2GHz XeonCPU core and 4GB RAM each We used the most recentDebian Linux distribution at the time of our experiment(April 2013) and downloaded all programs from the then-latest Debian Squeeze repository Specifically the version ofFFMpeg we used is SVN-r0510-40510-1 which is basedon a June 2012 FFMpeg release with Debian-specific patches
62 Fuzzing Data CollectionOur evaluation makes use of two datasets (1) FFMpegwith 100 different input seeds and (2) 100 different Linuxapplications each with a corresponding input seed Werefer to these as the ldquointra-programrdquo and the ldquointer-programrdquodatasets respectively
For the intra-program dataset we downloaded 10 000videoimage sample files from the MPlayer website at http
samplesmplayerhqhu From these samples we selected100 files uniformly at random and took them as our input
Dataset runs crashes bugsIntra-program 636998978 906577 200Inter-program 4868416447 415699 223
Table 1 Statistics from fuzzing the two datasets
0
20
40
60
0 10 20 30 40
bugs
count
IntraminusProgram
0
20
40
60
0 10 20 30
bugs
count
InterminusProgram
Figure 2 Distribution of the number of bugs per configura-tion in each dataset
0
25
50
75
0 10 20 30 40
bugs
count
Figure 3 Distribution of bug overlaps across multiple seedsfor the intra-program dataset
seeds The collected seeds include various audio and videoformats such as ASF QuickTime MPEG FLAC etc Wethen used zzuf to fuzz FFMpeg with each seed for 10 days
For the inter-program dataset we downloaded 100 differ-ent file conversion utilities in Debian To select these 100programs we first enumerated all file conversion packagestagged as ldquouseconvertingrdquo in the Debian package tags in-terface (debtags) From this list of packages we manuallyidentified 100 applications that take a file name as a com-mand line argument Then we manually constructed a validseed for each program and the actual command line to run itwith the seed After choosing these 100 program-seed pairswe fuzzed each for 10 days as well In total we have spent48000 CPU hours fuzzing these 200 configurations
To perform bug triage we identified and re-ran everycrashing input from the log under a debugger to obtain stacktraces for hashing After triaging with the fuzzy stack hashalgorithm described in sect51 we found 200 bugs from theintra-program dataset and 223 bugs from the inter-programdataset Table 1 summarizes the data collected from ourexperiments The average fuzzing throughput was 8 runsper second for the intra-program dataset and 63 runs persecond for the inter-program dataset This difference is dueto the higher complexity of FFMpeg when compared to theprograms in the inter-program dataset
63 Data AnalysisWhat does the collected fuzzing data look like We studiedour data from fuzzing and triage to answer two questions (1)How many bugs does a configuration trigger (2) How manybugs are triggered by multiple seeds in the intra-programdataset
We first analyzed the distribution of the number of bugsin the two datasets On average the intra- and the inter-program datasets yielded 82 and 24 bugs per configurationrespectively Figure 2 shows two histograms each depict-
40
60
80
100
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(a) Intra-program
60
100
140
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(b) Inter-program
Figure 4 The average number of bugs over 100 runs foreach scheduling algorithm with error bars showing a 99confidence interval ldquoftrdquo represents fixed-time epoch ldquofrrdquorepresents fixed-run epoch ldquoerdquo represents ε-Greedy ldquowrdquo rep-resents Weighted-Random
ing the number of occurrences of bug counts There is amarked difference in the distributions from the two datasets64 of configurations in the inter-program dataset produceno bugs whereas the corresponding number in the intra-program dataset is 15 We study the bias of the bug countdistribution in sect64
Second we measured how many bugs are shared acrossseeds in the intra-program dataset As an extreme case wefound a bug that was triggered by 46 seeds The averagenumber of seeds leading to a given bug is 4 Out of the 200bugs 97 were discovered from multiple seeds Figure 3illustrates the distribution of bug overlaps Our resultssuggest that there is a small overlap in the code exercisedby different seed files even though they have been chosento be of different types Although this shows that our bugdisjointness assumption in the WCCP model does not alwayshold in practice the low average number of seeds leading toa given bug in our dataset means that the performance ofour algorithms should not have been severely affected
64 SimulationWe now compare the 26 scheduling algorithms based on the10-day fuzzing logs collected for the intra- and inter-programdatasets To compare the performance of scheduling algo-rithms we use the total number of unique bugs reportedby the bug triage process Recall from sect44 that these al-gorithms vary across three dimensions (1) epoch types (2)belief metrics and (3) MAB algorithms For each valid com-bination (see Table 2) we ran our simulator 100 times andaveraged the results to study the effect of randomness oneach scheduling algorithm In our experiments we allocated10 seconds to each epoch for fixed-time campaigns and 200runs for fixed-run campaigns For the ε-Greedy algorithmwe chose ε to be 01
Table 2 summarizes our results Each entry in the tablerepresents the average number of bugs found by 100 sim-
Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

Unfortunately the answer is a resounding no even with qarbitrarily close to 1 we still have (pN gt 0) This means ourobservation really could have happened even if it is extremelyunlikely
Fortunately if we are willing to rule out the possibility ofencountering extremely unlikely events then we may com-pute a lower upperbound for q by means of a confidenceinterval For example a 95 confidence interval on q out-puts an interval that includes the true value of q of theunderlying experiment with 95 certainty In other wordsif the outputted interval does not contain the true value ofq for the experiment then the observed event must have alikelihood of at most 5
For the above situation there is particularly neat techniqueto compute a 95 confidence interval on q Known as theldquoRule of Threerdquo this method simply outputs 0 and 3N for thelowerbound and upperbound respectively The lowerboundis trivial and the upperbound has been shown to be a goodapproximation for N gt 30 See [15] for more informationon this technique including the relationship between 95confidence and the constant 3
How We Use Rule of Three In order to apply the Ruleof Three we must adapt our fuzzing experiments with anyM gt 1 possible outcome types to fit the mold of Bernoullitrials
We make use of a small trick Suppose we have just finishedepoch ` and consider a particular configuration (pi si) Using
our notation we have observed M(`) different outcomes so
far and for 1 le k le M(`) we have observed nk(`) counts of
outcome of type k Let N(`) =sumM(`)
k=1 nk(`) denote the totalnumber of fuzz runs for this pair through epoch ` The trickis to define a ldquosuccessrdquo to be finding an outcome of type 1through type M(`) Then in hindsight it is the case thatour experiment has only yielded success so far
With this observation we may now apply the Rule of Threeto conclude that [0 3N(`)] is a 95 confidence interval onthe ldquofailurerdquo probabilitymdashthe probability that fuzzing thisconfiguration will result in an outcome type that we havenot seen before ie a new outcome Then as desired wehave an easy-to-compute upperbound on the probability offinding a new outcome for each configuration
We introduce one more piece of notation before proceedingdefine the Remaining Probability Mass (RPM) of (pi si) atthe end of epoch ` denoted RPM(`) to be the probabilityof finding a new outcome if we fuzz (pi si) once more Notethat the pair in RPM(`) is implicit and that this valueis upperbounded by 3N(`) if we accept a 95 confidenceinterval
44 Design SpaceIn this section we explore the design space that a pragma-tist may attempt when designing online algorithms for theFuzz Configuration Scheduling problem A depiction of thedesign space along with our experimental results is given inTable 2 in sect6 Our focus here is to explain our motivation forchoosing the three dimensions we explore and the particularchoices we include in each dimension By combining thesedimensions we obtain 26 online algorithms for our prob-lem We implemented these algorithms inside a simulatorFuzzSim the detail of which is presented in sect5
Epoch Type We consider two possible definitions of anepoch in a fuzz campaign The first is the more traditional
choice and is used in the current version of CERT BFFv26 [14] the second is our proposal
Fixed-Run Each epoch executes a constant number offuzz runs In FuzzSim a fixed-run epoch consists of 200runs Note that any differential in fuzzing speed acrossconfigurations translates into variation in the time spent infixed-run epochs
Fixed-Time Each epoch is allocated a fixed amount oftime In FuzzSim a fixed-time epoch lasts for 10 secondsOur motivation to investigate this epoch type is to see howheavily epoch time variation affects the results obtained bysystems with fixed-run epochs
Belief Metrics Two of the MAB algorithms we presentbelow make use of a belief metric that is associated with eachconfiguration and is updated after each epoch Intuitivelythe metrics are designed such that fuzzing a configurationwith a higher metric should yield more bugs in expectationThe first two beliefs below use the concept of RPM to achievethis without invoking any prior the remaining three embracea ldquobug priorrdquo For now suppose epoch ` has just finishedand we are in the process of updating the belief for theconfiguration (pi si)
RPM We use the upperbound in the 95 confidence intervalgiven by the Rule of Three to approximate RPM(`) Thebelief is simply 3N(`)
Expected Waiting Time Until Next New Outcome(EWT) Since RPM does not take into account of the speedof each fuzz run we also investigate a speed-normalizedvariant of RPM Let Time(`) be the cumulative time spentfuzzing this configuration from epoch 1 to epoch ` Let
avgTime(`) be the average time of a fuzz run ie Time(`)N(`)
Let W be a random variable denoting the waiting time untilthe next new outcome Recall that RPM(`) is the probabilityof finding a new outcome in the next fuzz run and assume itis independent of avgTime(`) To compute E[W ] observethat either we find a new outcome in the next fuzz run orwe do not and we have to wait again Therefore
E[W ] = RPM(`)times avgTime(`)
+ (1minus RPM(`))times (avgTime(`) + E[W ])
(Notice that RPM does not change even in the second casewhat changes is our upperbound on RPM) Solving for E[W ]
yields avgTime(`)RPM(`)
and we substitute in the upperbound of
the 95 confidence interval for RPM(`) to obtain E[W ] geavgTime(`)3N(`)
= Time(`)3
Since a larger waiting time is less desir-
able the belief used is its reciprocal 3Time(`)
Rich Gets Richer (RGR) This metric is grounded inwhat we call the ldquobug priorrdquo which captures our empiricalobservation that code tends to be either robust or bug-riddenPrograms written by programmers of different skill levelsor past testing of a program might explain this real-worldphenomenon Accordingly demonstrated bugginess of aprogram serves as a strong indicator that more bugs will befound in that program and thus the belief is M(`)
Density This is a runs-normalized variant of RGR and isalso the belief used in CERT BFF v26 [14] The belief func-
tion is M(`)N(`) Observe that this is the belief function
of RPM scaled by M(`)3 In other words Density can beseen as RPM adapted with the bug prior
Rate This is a time-normalized variant of RGR The belieffunction is M(`)Time(`) Similar to Density Rate can beseen as EWT adapted with the bug prior
Bandit Algorithms Since the FCS problem is an instanceof an MAB problem naturally we explore a number of MABalgorithmsRound-Robin This simply loops through the configura-tions in a fixed order dedicating one epoch to each configura-tion Note that Round-Robin is a non-adaptive deterministicalgorithmUniform-Random This algorithm selects uniformly atrandom from the set of configurations for each epoch LikeRound-Robin this algorithm is non-adaptive however it israndomizedWeighted-Random Configurations are selected at randomin this algorithm with the probability associated with eachconfiguration is linked to the belief metric in use Theweight of a well-performing configuration is adjusted upwardvia the belief metric thereby increasingly the likelihood ofselecting that configuration in future epochs This mechanismfunctions in reverse for configurations yielding few or no bugsε-Greedy The ε-Greedy algorithm takes an intuitive ap-proach to the exploration vs exploitation trade-off inherentto MAB problems With probability ε the algorithm selectsa configuration uniformly at random for explorationWithprobability (1minus ε) it chooses the configuration with the high-est current belief allowing it to exploit its current knowledgefor gains The constant ε serves as a parameter balancingthe two competing goals with higher ε values correspondingto a greater emphasis on explorationEXP3S1 This is an advanced MAB algorithm by Aueret al [2] for the non-stochastic MAB problem We picked thisalgorithm for three reasons First it is from the venerableEXP3 family and so likely to be picked up by practitionersSecond this is one of the EXP3 algorithms that is not pa-rameterized by any constants and thus no parameter tuningis needed Third this algorithm is designed to have an op-timal worst-case regret which is a form of regret that suitsour problem setting Note that at its core EXP3S1 is aweighted-random algorithm However since we do not havea belief metric that corresponds to the one used in EXP3S1we did not put it inside the Weighted-Random group
45 Offline AlgorithmsEarly on in our research design we recognized the importanceof evaluating a large number of algorithms Out of budgetaryconstraints we have taken a simulation approach so thatwe can replay the events from previous fuzzings to try outnew algorithms Since we have recorded all the events thatmay happen during any fuzz campaign of the same inputconfigurations we can even attempt to compute what anoptimal offline algorithm would do and compare the results ofour algorithms against it In the case when the configurationsdo not yield duplicated bugs such as in our Inter-Programdataset (sect6) we devise a pseudo-polynomial time algorithmthat computes the offline optimal In the other case whereduplicated bugs are possible we propose a heuristic to post-process the solution from the above algorithm to obtain alowerbound on the offline optimal
No Duplicates Assuming that the sets of unique bugsfrom different configurations are disjoint our algorithm isa small variation on the dynamic programming solution tothe Bounded Knapsack problem Let K be the number of
Program
amp
Seed
(pi si)
Fuzzer
bugsScheduler
crashes
Simulator
Scheduling
Algorithms
Fuzzing Triage
Bug Triage
bugs
Simulation
logs
logs
Time
Budget (T)
Figure 1 FuzzSim architecture
configurations and B be the total number of unique bugsfrom all K configurations Let t(i b) be the minimum amountof time it takes for configuration i to produce b unique bugsNote that t(i b) is assumed to be infin when configuration inever produces b unique bugs in our dataset We claim thatt(i b) can be pre-computed for all i isin [1K] and b isin [0 B]where each entry takes amortized O(1) time given how eventsare recorded in our system
Let m(i b) be the minimum amount of time it takes forconfigurations 1 through i to produce b unique bugs We wantto compute m(K b) for b isin [0 B] By definition m(1 b) =t(1 b) for b isin [0 B] For i gt 1 observe that m(i b) =mincisin[0B]t(i c) +m(iminus 1 bminus c) This models partitioningthe b unique bugs into c unique bugs from configuration iand (bminus c) unique bugs from configurations 1 through (iminus1)Computing each m(i b) entry takes O(B) time Since thereare O(K timesB) entries the total running time is O(K timesB2)
Discounting Duplicates The above algorithm is incorrectwhen the sets of unique bugs from different configurationsare not disjoint This is because the recurrence formula ofm(i b) assumes that the c unique bugs from configuration iare different from the (bminus c) unique bugs from configurations1 through (i minus 1) In this case we propose a heuristic tocompute a lowerbound on the offline optimal
After obtaining the m(i b) table from the above we post-process bug counts by the following discount heuristic Firstwe compute the maximum number of bugs that can be foundat each time by the above algorithm by examining the K-throw of the table Then by scanning forward from time 0whenever the bug count goes up by one due to a duplicatedbug (which must have been found using another configura-tion) we discount the increment Since the optimal offlinealgorithm can also pick up exactly the same bugs in the sameorder as the dynamic programming algorithm our heuristicis a valid lowerbound on the maximum number of bugs thatan optimal offline algorithm would find
5 Design amp ImplementationThis section presents FuzzSim our replay-based fuzz simu-lation system built for this project We describe the threesteps in FuzzSim and explain the benefit of its design whichis then followed by its implementation detail Of special noteis that we are releasing our source code and our datasets insupport of open science at the URL found in sect52
51 OverviewFuzzSim is a simulation system for black-box mutationalfuzzing that is designed to run different configuration schedul-ing algorithms using logs from previous fuzzings Figure 1summarizes the design of FuzzSim which employs a three-step approach (1) fuzzing (2) triage and (3) simulation
Fuzzing The first step is fuzzing and collecting run logsfrom a fuzzer FuzzSim takes in a list of program-seedpairs (pi si) and a time budget T It runs a fuzzer on eachconfiguration for the full length of the time budget T andwrites to the log each time a crash occurs Log entries arerecorded as 5-tuples of the form (pi si time stamp runsmutation identifier)
In our implementation we fuzz with zzuf one of the mostpopular open-source fuzzers zzuf generates a random inputfrom a seed file as described in sect21 The randomization inzzuf can be reproduced given the mutation identifier thusenabling us to reproduce a crashing input from its seed fileand the log entry associated with the crash For example anoutput tuple of (FFMpeg aavi 100 42 1234) specifies thatthe program FFMpeg crashed at the 100-th second with aninput file obtained from ldquoaavirdquo according to the mutationidentifier 1234 Interested readers may refer to zzuf [16] fordetails on mutation identifiers and the actual implementation
The deterministic nature of zzuf allows FuzzSim to triagebugs after completing all fuzz runs first In other wordsFuzzSim does not compute bug identifiers during fuzzingand instead re-derives them using the log This does notaffect any of our algorithms since none of them relies on theactual IDs In our experiments we have turned off addressspace layout randomization (ASLR) in both the fuzzing andthe triage steps in order to reproduce the same crashes
Triage The second step of FuzzSim maps crashing inputsfound during fuzzings into bugs At a high level the triagephase takes in the list of 5-tuples (pi si time-stamp runsmutation identifier) logged during the fuzzing step and out-puts a new list of 5-tuples of the form (pi si time-stampruns bug identifier) More specifically FuzzSim replayseach recorded crash under a debugger to collect stack tracesIf FuzzSim does not detect a crash during a particular replaythen we classify that test case to be a non-deterministic bugand discard it
We then use the collected stack traces to produce bugidentifiers essentially hashes of the stack traces In particularwe use the fuzzy stack hash algorithm [19] which identifiesbugs by hashing the normalized line numbers from a stacktrace With this algorithm the number of stack frames tohash has a significant influence on the accuracy of bug triageFor example taking the full stack trace often leads to mis-classifying a single bug into multiple bugs whereas takingonly the top frame can easily lead to two different bugs beingmis-classified as one To match the state of the art FuzzSimuses the top 3 frames as suggested in [19] We stress that eventhough inaccurate bug triage may still occur with this choiceof parameter perfecting bug triage techniques is beyond thescope of this paper
Simulation The last step simulates a fuzz campaign onthe collected ground-truth data from the previous steps us-ing a user-specified scheduling algorithm More formallythe simulation step takes in a scheduling algorithm and alist of 5-tuples of the form (pi si timestamp runs bugidentifier) and outputs a list of 2-tuples (timestamp bugs)that represent the accumulated time before the correspond-ing number of unique bugs are observed under the givenscheduling algorithm
Since FuzzSim can simulate any scheduling algorithm inan offline fashion using the pre-recorded ground-truth datait enables us to efficiently compare numerous scheduling
algorithms without actually running a large number of fuzzcampaigns During replay FuzzSim outputs a timestampwhenever it finds a new bug Therefore we can easily plotand compare different scheduling algorithms by comparingthe number of bugs produced under the same time budget
We summarize FuzzSimrsquos three-step algorithm below
Fuzzing ((pi si) T )rarr pi si timestamp runs mutation id
Triage (pi si timestamp runs mutation id)rarr (pi si timestamp runs bug id)
Simulation (pi si timestamp runs bug id)rarr (timestamp bugs)
Algorithm 1 FuzzSim algorithms
52 Implementation amp Open ScienceWe have implemented our data collection and bug triage mod-ules in approximately 1000 lines of OCaml This includes thecapability to run and collect crash logs from Amazon EC2We used zzuf version 013 Our scheduling engine is alsoimplemented in OCaml and spans about 1600 lines Thiscovers the 26 online and the 2 offline algorithms presentedin this paper
We invite our fellow researchers to become involved inthis line of research In support of open science we releaseboth our datasets and the source code of our simulator athttpsecurityececmuedufuzzsim
6 EvaluationTo evaluate the performance of the 26 algorithms presentedin sect4 we focus on the following questions
1 Which scheduling algorithm works best for our datasets2 Why does one algorithm outperform the others3 Which of the two epoch typesmdashfixed-run or fixed-timemdash
works better and why
61 Experimental SetupOur experiments were performed on Amazon EC2 instancesthat have been configured with a single Intel 2GHz XeonCPU core and 4GB RAM each We used the most recentDebian Linux distribution at the time of our experiment(April 2013) and downloaded all programs from the then-latest Debian Squeeze repository Specifically the version ofFFMpeg we used is SVN-r0510-40510-1 which is basedon a June 2012 FFMpeg release with Debian-specific patches
62 Fuzzing Data CollectionOur evaluation makes use of two datasets (1) FFMpegwith 100 different input seeds and (2) 100 different Linuxapplications each with a corresponding input seed Werefer to these as the ldquointra-programrdquo and the ldquointer-programrdquodatasets respectively
For the intra-program dataset we downloaded 10 000videoimage sample files from the MPlayer website at http
samplesmplayerhqhu From these samples we selected100 files uniformly at random and took them as our input
Dataset runs crashes bugsIntra-program 636998978 906577 200Inter-program 4868416447 415699 223
Table 1 Statistics from fuzzing the two datasets
0
20
40
60
0 10 20 30 40
bugs
count
IntraminusProgram
0
20
40
60
0 10 20 30
bugs
count
InterminusProgram
Figure 2 Distribution of the number of bugs per configura-tion in each dataset
0
25
50
75
0 10 20 30 40
bugs
count
Figure 3 Distribution of bug overlaps across multiple seedsfor the intra-program dataset
seeds The collected seeds include various audio and videoformats such as ASF QuickTime MPEG FLAC etc Wethen used zzuf to fuzz FFMpeg with each seed for 10 days
For the inter-program dataset we downloaded 100 differ-ent file conversion utilities in Debian To select these 100programs we first enumerated all file conversion packagestagged as ldquouseconvertingrdquo in the Debian package tags in-terface (debtags) From this list of packages we manuallyidentified 100 applications that take a file name as a com-mand line argument Then we manually constructed a validseed for each program and the actual command line to run itwith the seed After choosing these 100 program-seed pairswe fuzzed each for 10 days as well In total we have spent48000 CPU hours fuzzing these 200 configurations
To perform bug triage we identified and re-ran everycrashing input from the log under a debugger to obtain stacktraces for hashing After triaging with the fuzzy stack hashalgorithm described in sect51 we found 200 bugs from theintra-program dataset and 223 bugs from the inter-programdataset Table 1 summarizes the data collected from ourexperiments The average fuzzing throughput was 8 runsper second for the intra-program dataset and 63 runs persecond for the inter-program dataset This difference is dueto the higher complexity of FFMpeg when compared to theprograms in the inter-program dataset
63 Data AnalysisWhat does the collected fuzzing data look like We studiedour data from fuzzing and triage to answer two questions (1)How many bugs does a configuration trigger (2) How manybugs are triggered by multiple seeds in the intra-programdataset
We first analyzed the distribution of the number of bugsin the two datasets On average the intra- and the inter-program datasets yielded 82 and 24 bugs per configurationrespectively Figure 2 shows two histograms each depict-
40
60
80
100
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(a) Intra-program
60
100
140
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(b) Inter-program
Figure 4 The average number of bugs over 100 runs foreach scheduling algorithm with error bars showing a 99confidence interval ldquoftrdquo represents fixed-time epoch ldquofrrdquorepresents fixed-run epoch ldquoerdquo represents ε-Greedy ldquowrdquo rep-resents Weighted-Random
ing the number of occurrences of bug counts There is amarked difference in the distributions from the two datasets64 of configurations in the inter-program dataset produceno bugs whereas the corresponding number in the intra-program dataset is 15 We study the bias of the bug countdistribution in sect64
Second we measured how many bugs are shared acrossseeds in the intra-program dataset As an extreme case wefound a bug that was triggered by 46 seeds The averagenumber of seeds leading to a given bug is 4 Out of the 200bugs 97 were discovered from multiple seeds Figure 3illustrates the distribution of bug overlaps Our resultssuggest that there is a small overlap in the code exercisedby different seed files even though they have been chosento be of different types Although this shows that our bugdisjointness assumption in the WCCP model does not alwayshold in practice the low average number of seeds leading toa given bug in our dataset means that the performance ofour algorithms should not have been severely affected
64 SimulationWe now compare the 26 scheduling algorithms based on the10-day fuzzing logs collected for the intra- and inter-programdatasets To compare the performance of scheduling algo-rithms we use the total number of unique bugs reportedby the bug triage process Recall from sect44 that these al-gorithms vary across three dimensions (1) epoch types (2)belief metrics and (3) MAB algorithms For each valid com-bination (see Table 2) we ran our simulator 100 times andaveraged the results to study the effect of randomness oneach scheduling algorithm In our experiments we allocated10 seconds to each epoch for fixed-time campaigns and 200runs for fixed-run campaigns For the ε-Greedy algorithmwe chose ε to be 01
Table 2 summarizes our results Each entry in the tablerepresents the average number of bugs found by 100 sim-
Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

Rate This is a time-normalized variant of RGR The belieffunction is M(`)Time(`) Similar to Density Rate can beseen as EWT adapted with the bug prior
Bandit Algorithms Since the FCS problem is an instanceof an MAB problem naturally we explore a number of MABalgorithmsRound-Robin This simply loops through the configura-tions in a fixed order dedicating one epoch to each configura-tion Note that Round-Robin is a non-adaptive deterministicalgorithmUniform-Random This algorithm selects uniformly atrandom from the set of configurations for each epoch LikeRound-Robin this algorithm is non-adaptive however it israndomizedWeighted-Random Configurations are selected at randomin this algorithm with the probability associated with eachconfiguration is linked to the belief metric in use Theweight of a well-performing configuration is adjusted upwardvia the belief metric thereby increasingly the likelihood ofselecting that configuration in future epochs This mechanismfunctions in reverse for configurations yielding few or no bugsε-Greedy The ε-Greedy algorithm takes an intuitive ap-proach to the exploration vs exploitation trade-off inherentto MAB problems With probability ε the algorithm selectsa configuration uniformly at random for explorationWithprobability (1minus ε) it chooses the configuration with the high-est current belief allowing it to exploit its current knowledgefor gains The constant ε serves as a parameter balancingthe two competing goals with higher ε values correspondingto a greater emphasis on explorationEXP3S1 This is an advanced MAB algorithm by Aueret al [2] for the non-stochastic MAB problem We picked thisalgorithm for three reasons First it is from the venerableEXP3 family and so likely to be picked up by practitionersSecond this is one of the EXP3 algorithms that is not pa-rameterized by any constants and thus no parameter tuningis needed Third this algorithm is designed to have an op-timal worst-case regret which is a form of regret that suitsour problem setting Note that at its core EXP3S1 is aweighted-random algorithm However since we do not havea belief metric that corresponds to the one used in EXP3S1we did not put it inside the Weighted-Random group
45 Offline AlgorithmsEarly on in our research design we recognized the importanceof evaluating a large number of algorithms Out of budgetaryconstraints we have taken a simulation approach so thatwe can replay the events from previous fuzzings to try outnew algorithms Since we have recorded all the events thatmay happen during any fuzz campaign of the same inputconfigurations we can even attempt to compute what anoptimal offline algorithm would do and compare the results ofour algorithms against it In the case when the configurationsdo not yield duplicated bugs such as in our Inter-Programdataset (sect6) we devise a pseudo-polynomial time algorithmthat computes the offline optimal In the other case whereduplicated bugs are possible we propose a heuristic to post-process the solution from the above algorithm to obtain alowerbound on the offline optimal
No Duplicates Assuming that the sets of unique bugsfrom different configurations are disjoint our algorithm isa small variation on the dynamic programming solution tothe Bounded Knapsack problem Let K be the number of
Program
amp
Seed
(pi si)
Fuzzer
bugsScheduler
crashes
Simulator
Scheduling
Algorithms
Fuzzing Triage
Bug Triage
bugs
Simulation
logs
logs
Time
Budget (T)
Figure 1 FuzzSim architecture
configurations and B be the total number of unique bugsfrom all K configurations Let t(i b) be the minimum amountof time it takes for configuration i to produce b unique bugsNote that t(i b) is assumed to be infin when configuration inever produces b unique bugs in our dataset We claim thatt(i b) can be pre-computed for all i isin [1K] and b isin [0 B]where each entry takes amortized O(1) time given how eventsare recorded in our system
Let m(i b) be the minimum amount of time it takes forconfigurations 1 through i to produce b unique bugs We wantto compute m(K b) for b isin [0 B] By definition m(1 b) =t(1 b) for b isin [0 B] For i gt 1 observe that m(i b) =mincisin[0B]t(i c) +m(iminus 1 bminus c) This models partitioningthe b unique bugs into c unique bugs from configuration iand (bminus c) unique bugs from configurations 1 through (iminus1)Computing each m(i b) entry takes O(B) time Since thereare O(K timesB) entries the total running time is O(K timesB2)
Discounting Duplicates The above algorithm is incorrectwhen the sets of unique bugs from different configurationsare not disjoint This is because the recurrence formula ofm(i b) assumes that the c unique bugs from configuration iare different from the (bminus c) unique bugs from configurations1 through (i minus 1) In this case we propose a heuristic tocompute a lowerbound on the offline optimal
After obtaining the m(i b) table from the above we post-process bug counts by the following discount heuristic Firstwe compute the maximum number of bugs that can be foundat each time by the above algorithm by examining the K-throw of the table Then by scanning forward from time 0whenever the bug count goes up by one due to a duplicatedbug (which must have been found using another configura-tion) we discount the increment Since the optimal offlinealgorithm can also pick up exactly the same bugs in the sameorder as the dynamic programming algorithm our heuristicis a valid lowerbound on the maximum number of bugs thatan optimal offline algorithm would find
5 Design amp ImplementationThis section presents FuzzSim our replay-based fuzz simu-lation system built for this project We describe the threesteps in FuzzSim and explain the benefit of its design whichis then followed by its implementation detail Of special noteis that we are releasing our source code and our datasets insupport of open science at the URL found in sect52
51 OverviewFuzzSim is a simulation system for black-box mutationalfuzzing that is designed to run different configuration schedul-ing algorithms using logs from previous fuzzings Figure 1summarizes the design of FuzzSim which employs a three-step approach (1) fuzzing (2) triage and (3) simulation
Fuzzing The first step is fuzzing and collecting run logsfrom a fuzzer FuzzSim takes in a list of program-seedpairs (pi si) and a time budget T It runs a fuzzer on eachconfiguration for the full length of the time budget T andwrites to the log each time a crash occurs Log entries arerecorded as 5-tuples of the form (pi si time stamp runsmutation identifier)
In our implementation we fuzz with zzuf one of the mostpopular open-source fuzzers zzuf generates a random inputfrom a seed file as described in sect21 The randomization inzzuf can be reproduced given the mutation identifier thusenabling us to reproduce a crashing input from its seed fileand the log entry associated with the crash For example anoutput tuple of (FFMpeg aavi 100 42 1234) specifies thatthe program FFMpeg crashed at the 100-th second with aninput file obtained from ldquoaavirdquo according to the mutationidentifier 1234 Interested readers may refer to zzuf [16] fordetails on mutation identifiers and the actual implementation
The deterministic nature of zzuf allows FuzzSim to triagebugs after completing all fuzz runs first In other wordsFuzzSim does not compute bug identifiers during fuzzingand instead re-derives them using the log This does notaffect any of our algorithms since none of them relies on theactual IDs In our experiments we have turned off addressspace layout randomization (ASLR) in both the fuzzing andthe triage steps in order to reproduce the same crashes
Triage The second step of FuzzSim maps crashing inputsfound during fuzzings into bugs At a high level the triagephase takes in the list of 5-tuples (pi si time-stamp runsmutation identifier) logged during the fuzzing step and out-puts a new list of 5-tuples of the form (pi si time-stampruns bug identifier) More specifically FuzzSim replayseach recorded crash under a debugger to collect stack tracesIf FuzzSim does not detect a crash during a particular replaythen we classify that test case to be a non-deterministic bugand discard it
We then use the collected stack traces to produce bugidentifiers essentially hashes of the stack traces In particularwe use the fuzzy stack hash algorithm [19] which identifiesbugs by hashing the normalized line numbers from a stacktrace With this algorithm the number of stack frames tohash has a significant influence on the accuracy of bug triageFor example taking the full stack trace often leads to mis-classifying a single bug into multiple bugs whereas takingonly the top frame can easily lead to two different bugs beingmis-classified as one To match the state of the art FuzzSimuses the top 3 frames as suggested in [19] We stress that eventhough inaccurate bug triage may still occur with this choiceof parameter perfecting bug triage techniques is beyond thescope of this paper
Simulation The last step simulates a fuzz campaign onthe collected ground-truth data from the previous steps us-ing a user-specified scheduling algorithm More formallythe simulation step takes in a scheduling algorithm and alist of 5-tuples of the form (pi si timestamp runs bugidentifier) and outputs a list of 2-tuples (timestamp bugs)that represent the accumulated time before the correspond-ing number of unique bugs are observed under the givenscheduling algorithm
Since FuzzSim can simulate any scheduling algorithm inan offline fashion using the pre-recorded ground-truth datait enables us to efficiently compare numerous scheduling
algorithms without actually running a large number of fuzzcampaigns During replay FuzzSim outputs a timestampwhenever it finds a new bug Therefore we can easily plotand compare different scheduling algorithms by comparingthe number of bugs produced under the same time budget
We summarize FuzzSimrsquos three-step algorithm below
Fuzzing ((pi si) T )rarr pi si timestamp runs mutation id
Triage (pi si timestamp runs mutation id)rarr (pi si timestamp runs bug id)
Simulation (pi si timestamp runs bug id)rarr (timestamp bugs)
Algorithm 1 FuzzSim algorithms
52 Implementation amp Open ScienceWe have implemented our data collection and bug triage mod-ules in approximately 1000 lines of OCaml This includes thecapability to run and collect crash logs from Amazon EC2We used zzuf version 013 Our scheduling engine is alsoimplemented in OCaml and spans about 1600 lines Thiscovers the 26 online and the 2 offline algorithms presentedin this paper
We invite our fellow researchers to become involved inthis line of research In support of open science we releaseboth our datasets and the source code of our simulator athttpsecurityececmuedufuzzsim
6 EvaluationTo evaluate the performance of the 26 algorithms presentedin sect4 we focus on the following questions
1 Which scheduling algorithm works best for our datasets2 Why does one algorithm outperform the others3 Which of the two epoch typesmdashfixed-run or fixed-timemdash
works better and why
61 Experimental SetupOur experiments were performed on Amazon EC2 instancesthat have been configured with a single Intel 2GHz XeonCPU core and 4GB RAM each We used the most recentDebian Linux distribution at the time of our experiment(April 2013) and downloaded all programs from the then-latest Debian Squeeze repository Specifically the version ofFFMpeg we used is SVN-r0510-40510-1 which is basedon a June 2012 FFMpeg release with Debian-specific patches
62 Fuzzing Data CollectionOur evaluation makes use of two datasets (1) FFMpegwith 100 different input seeds and (2) 100 different Linuxapplications each with a corresponding input seed Werefer to these as the ldquointra-programrdquo and the ldquointer-programrdquodatasets respectively
For the intra-program dataset we downloaded 10 000videoimage sample files from the MPlayer website at http
samplesmplayerhqhu From these samples we selected100 files uniformly at random and took them as our input
Dataset runs crashes bugsIntra-program 636998978 906577 200Inter-program 4868416447 415699 223
Table 1 Statistics from fuzzing the two datasets
0
20
40
60
0 10 20 30 40
bugs
count
IntraminusProgram
0
20
40
60
0 10 20 30
bugs
count
InterminusProgram
Figure 2 Distribution of the number of bugs per configura-tion in each dataset
0
25
50
75
0 10 20 30 40
bugs
count
Figure 3 Distribution of bug overlaps across multiple seedsfor the intra-program dataset
seeds The collected seeds include various audio and videoformats such as ASF QuickTime MPEG FLAC etc Wethen used zzuf to fuzz FFMpeg with each seed for 10 days
For the inter-program dataset we downloaded 100 differ-ent file conversion utilities in Debian To select these 100programs we first enumerated all file conversion packagestagged as ldquouseconvertingrdquo in the Debian package tags in-terface (debtags) From this list of packages we manuallyidentified 100 applications that take a file name as a com-mand line argument Then we manually constructed a validseed for each program and the actual command line to run itwith the seed After choosing these 100 program-seed pairswe fuzzed each for 10 days as well In total we have spent48000 CPU hours fuzzing these 200 configurations
To perform bug triage we identified and re-ran everycrashing input from the log under a debugger to obtain stacktraces for hashing After triaging with the fuzzy stack hashalgorithm described in sect51 we found 200 bugs from theintra-program dataset and 223 bugs from the inter-programdataset Table 1 summarizes the data collected from ourexperiments The average fuzzing throughput was 8 runsper second for the intra-program dataset and 63 runs persecond for the inter-program dataset This difference is dueto the higher complexity of FFMpeg when compared to theprograms in the inter-program dataset
63 Data AnalysisWhat does the collected fuzzing data look like We studiedour data from fuzzing and triage to answer two questions (1)How many bugs does a configuration trigger (2) How manybugs are triggered by multiple seeds in the intra-programdataset
We first analyzed the distribution of the number of bugsin the two datasets On average the intra- and the inter-program datasets yielded 82 and 24 bugs per configurationrespectively Figure 2 shows two histograms each depict-
40
60
80
100
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(a) Intra-program
60
100
140
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(b) Inter-program
Figure 4 The average number of bugs over 100 runs foreach scheduling algorithm with error bars showing a 99confidence interval ldquoftrdquo represents fixed-time epoch ldquofrrdquorepresents fixed-run epoch ldquoerdquo represents ε-Greedy ldquowrdquo rep-resents Weighted-Random
ing the number of occurrences of bug counts There is amarked difference in the distributions from the two datasets64 of configurations in the inter-program dataset produceno bugs whereas the corresponding number in the intra-program dataset is 15 We study the bias of the bug countdistribution in sect64
Second we measured how many bugs are shared acrossseeds in the intra-program dataset As an extreme case wefound a bug that was triggered by 46 seeds The averagenumber of seeds leading to a given bug is 4 Out of the 200bugs 97 were discovered from multiple seeds Figure 3illustrates the distribution of bug overlaps Our resultssuggest that there is a small overlap in the code exercisedby different seed files even though they have been chosento be of different types Although this shows that our bugdisjointness assumption in the WCCP model does not alwayshold in practice the low average number of seeds leading toa given bug in our dataset means that the performance ofour algorithms should not have been severely affected
64 SimulationWe now compare the 26 scheduling algorithms based on the10-day fuzzing logs collected for the intra- and inter-programdatasets To compare the performance of scheduling algo-rithms we use the total number of unique bugs reportedby the bug triage process Recall from sect44 that these al-gorithms vary across three dimensions (1) epoch types (2)belief metrics and (3) MAB algorithms For each valid com-bination (see Table 2) we ran our simulator 100 times andaveraged the results to study the effect of randomness oneach scheduling algorithm In our experiments we allocated10 seconds to each epoch for fixed-time campaigns and 200runs for fixed-run campaigns For the ε-Greedy algorithmwe chose ε to be 01
Table 2 summarizes our results Each entry in the tablerepresents the average number of bugs found by 100 sim-
Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

Fuzzing The first step is fuzzing and collecting run logsfrom a fuzzer FuzzSim takes in a list of program-seedpairs (pi si) and a time budget T It runs a fuzzer on eachconfiguration for the full length of the time budget T andwrites to the log each time a crash occurs Log entries arerecorded as 5-tuples of the form (pi si time stamp runsmutation identifier)
In our implementation we fuzz with zzuf one of the mostpopular open-source fuzzers zzuf generates a random inputfrom a seed file as described in sect21 The randomization inzzuf can be reproduced given the mutation identifier thusenabling us to reproduce a crashing input from its seed fileand the log entry associated with the crash For example anoutput tuple of (FFMpeg aavi 100 42 1234) specifies thatthe program FFMpeg crashed at the 100-th second with aninput file obtained from ldquoaavirdquo according to the mutationidentifier 1234 Interested readers may refer to zzuf [16] fordetails on mutation identifiers and the actual implementation
The deterministic nature of zzuf allows FuzzSim to triagebugs after completing all fuzz runs first In other wordsFuzzSim does not compute bug identifiers during fuzzingand instead re-derives them using the log This does notaffect any of our algorithms since none of them relies on theactual IDs In our experiments we have turned off addressspace layout randomization (ASLR) in both the fuzzing andthe triage steps in order to reproduce the same crashes
Triage The second step of FuzzSim maps crashing inputsfound during fuzzings into bugs At a high level the triagephase takes in the list of 5-tuples (pi si time-stamp runsmutation identifier) logged during the fuzzing step and out-puts a new list of 5-tuples of the form (pi si time-stampruns bug identifier) More specifically FuzzSim replayseach recorded crash under a debugger to collect stack tracesIf FuzzSim does not detect a crash during a particular replaythen we classify that test case to be a non-deterministic bugand discard it
We then use the collected stack traces to produce bugidentifiers essentially hashes of the stack traces In particularwe use the fuzzy stack hash algorithm [19] which identifiesbugs by hashing the normalized line numbers from a stacktrace With this algorithm the number of stack frames tohash has a significant influence on the accuracy of bug triageFor example taking the full stack trace often leads to mis-classifying a single bug into multiple bugs whereas takingonly the top frame can easily lead to two different bugs beingmis-classified as one To match the state of the art FuzzSimuses the top 3 frames as suggested in [19] We stress that eventhough inaccurate bug triage may still occur with this choiceof parameter perfecting bug triage techniques is beyond thescope of this paper
Simulation The last step simulates a fuzz campaign onthe collected ground-truth data from the previous steps us-ing a user-specified scheduling algorithm More formallythe simulation step takes in a scheduling algorithm and alist of 5-tuples of the form (pi si timestamp runs bugidentifier) and outputs a list of 2-tuples (timestamp bugs)that represent the accumulated time before the correspond-ing number of unique bugs are observed under the givenscheduling algorithm
Since FuzzSim can simulate any scheduling algorithm inan offline fashion using the pre-recorded ground-truth datait enables us to efficiently compare numerous scheduling
algorithms without actually running a large number of fuzzcampaigns During replay FuzzSim outputs a timestampwhenever it finds a new bug Therefore we can easily plotand compare different scheduling algorithms by comparingthe number of bugs produced under the same time budget
We summarize FuzzSimrsquos three-step algorithm below
Fuzzing ((pi si) T )rarr pi si timestamp runs mutation id
Triage (pi si timestamp runs mutation id)rarr (pi si timestamp runs bug id)
Simulation (pi si timestamp runs bug id)rarr (timestamp bugs)
Algorithm 1 FuzzSim algorithms
52 Implementation amp Open ScienceWe have implemented our data collection and bug triage mod-ules in approximately 1000 lines of OCaml This includes thecapability to run and collect crash logs from Amazon EC2We used zzuf version 013 Our scheduling engine is alsoimplemented in OCaml and spans about 1600 lines Thiscovers the 26 online and the 2 offline algorithms presentedin this paper
We invite our fellow researchers to become involved inthis line of research In support of open science we releaseboth our datasets and the source code of our simulator athttpsecurityececmuedufuzzsim
6 EvaluationTo evaluate the performance of the 26 algorithms presentedin sect4 we focus on the following questions
1 Which scheduling algorithm works best for our datasets2 Why does one algorithm outperform the others3 Which of the two epoch typesmdashfixed-run or fixed-timemdash
works better and why
61 Experimental SetupOur experiments were performed on Amazon EC2 instancesthat have been configured with a single Intel 2GHz XeonCPU core and 4GB RAM each We used the most recentDebian Linux distribution at the time of our experiment(April 2013) and downloaded all programs from the then-latest Debian Squeeze repository Specifically the version ofFFMpeg we used is SVN-r0510-40510-1 which is basedon a June 2012 FFMpeg release with Debian-specific patches
62 Fuzzing Data CollectionOur evaluation makes use of two datasets (1) FFMpegwith 100 different input seeds and (2) 100 different Linuxapplications each with a corresponding input seed Werefer to these as the ldquointra-programrdquo and the ldquointer-programrdquodatasets respectively
For the intra-program dataset we downloaded 10 000videoimage sample files from the MPlayer website at http
samplesmplayerhqhu From these samples we selected100 files uniformly at random and took them as our input
Dataset runs crashes bugsIntra-program 636998978 906577 200Inter-program 4868416447 415699 223
Table 1 Statistics from fuzzing the two datasets
0
20
40
60
0 10 20 30 40
bugs
count
IntraminusProgram
0
20
40
60
0 10 20 30
bugs
count
InterminusProgram
Figure 2 Distribution of the number of bugs per configura-tion in each dataset
0
25
50
75
0 10 20 30 40
bugs
count
Figure 3 Distribution of bug overlaps across multiple seedsfor the intra-program dataset
seeds The collected seeds include various audio and videoformats such as ASF QuickTime MPEG FLAC etc Wethen used zzuf to fuzz FFMpeg with each seed for 10 days
For the inter-program dataset we downloaded 100 differ-ent file conversion utilities in Debian To select these 100programs we first enumerated all file conversion packagestagged as ldquouseconvertingrdquo in the Debian package tags in-terface (debtags) From this list of packages we manuallyidentified 100 applications that take a file name as a com-mand line argument Then we manually constructed a validseed for each program and the actual command line to run itwith the seed After choosing these 100 program-seed pairswe fuzzed each for 10 days as well In total we have spent48000 CPU hours fuzzing these 200 configurations
To perform bug triage we identified and re-ran everycrashing input from the log under a debugger to obtain stacktraces for hashing After triaging with the fuzzy stack hashalgorithm described in sect51 we found 200 bugs from theintra-program dataset and 223 bugs from the inter-programdataset Table 1 summarizes the data collected from ourexperiments The average fuzzing throughput was 8 runsper second for the intra-program dataset and 63 runs persecond for the inter-program dataset This difference is dueto the higher complexity of FFMpeg when compared to theprograms in the inter-program dataset
63 Data AnalysisWhat does the collected fuzzing data look like We studiedour data from fuzzing and triage to answer two questions (1)How many bugs does a configuration trigger (2) How manybugs are triggered by multiple seeds in the intra-programdataset
We first analyzed the distribution of the number of bugsin the two datasets On average the intra- and the inter-program datasets yielded 82 and 24 bugs per configurationrespectively Figure 2 shows two histograms each depict-
40
60
80
100
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(a) Intra-program
60
100
140
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(b) Inter-program
Figure 4 The average number of bugs over 100 runs foreach scheduling algorithm with error bars showing a 99confidence interval ldquoftrdquo represents fixed-time epoch ldquofrrdquorepresents fixed-run epoch ldquoerdquo represents ε-Greedy ldquowrdquo rep-resents Weighted-Random
ing the number of occurrences of bug counts There is amarked difference in the distributions from the two datasets64 of configurations in the inter-program dataset produceno bugs whereas the corresponding number in the intra-program dataset is 15 We study the bias of the bug countdistribution in sect64
Second we measured how many bugs are shared acrossseeds in the intra-program dataset As an extreme case wefound a bug that was triggered by 46 seeds The averagenumber of seeds leading to a given bug is 4 Out of the 200bugs 97 were discovered from multiple seeds Figure 3illustrates the distribution of bug overlaps Our resultssuggest that there is a small overlap in the code exercisedby different seed files even though they have been chosento be of different types Although this shows that our bugdisjointness assumption in the WCCP model does not alwayshold in practice the low average number of seeds leading toa given bug in our dataset means that the performance ofour algorithms should not have been severely affected
64 SimulationWe now compare the 26 scheduling algorithms based on the10-day fuzzing logs collected for the intra- and inter-programdatasets To compare the performance of scheduling algo-rithms we use the total number of unique bugs reportedby the bug triage process Recall from sect44 that these al-gorithms vary across three dimensions (1) epoch types (2)belief metrics and (3) MAB algorithms For each valid com-bination (see Table 2) we ran our simulator 100 times andaveraged the results to study the effect of randomness oneach scheduling algorithm In our experiments we allocated10 seconds to each epoch for fixed-time campaigns and 200runs for fixed-run campaigns For the ε-Greedy algorithmwe chose ε to be 01
Table 2 summarizes our results Each entry in the tablerepresents the average number of bugs found by 100 sim-
Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

0
20
40
60
0 10 20 30 40
bugs
count
IntraminusProgram
0
20
40
60
0 10 20 30
bugs
count
InterminusProgram
Figure 2 Distribution of the number of bugs per configura-tion in each dataset
0
25
50
75
0 10 20 30 40
bugs
count
Figure 3 Distribution of bug overlaps across multiple seedsfor the intra-program dataset
seeds The collected seeds include various audio and videoformats such as ASF QuickTime MPEG FLAC etc Wethen used zzuf to fuzz FFMpeg with each seed for 10 days
For the inter-program dataset we downloaded 100 differ-ent file conversion utilities in Debian To select these 100programs we first enumerated all file conversion packagestagged as ldquouseconvertingrdquo in the Debian package tags in-terface (debtags) From this list of packages we manuallyidentified 100 applications that take a file name as a com-mand line argument Then we manually constructed a validseed for each program and the actual command line to run itwith the seed After choosing these 100 program-seed pairswe fuzzed each for 10 days as well In total we have spent48000 CPU hours fuzzing these 200 configurations
To perform bug triage we identified and re-ran everycrashing input from the log under a debugger to obtain stacktraces for hashing After triaging with the fuzzy stack hashalgorithm described in sect51 we found 200 bugs from theintra-program dataset and 223 bugs from the inter-programdataset Table 1 summarizes the data collected from ourexperiments The average fuzzing throughput was 8 runsper second for the intra-program dataset and 63 runs persecond for the inter-program dataset This difference is dueto the higher complexity of FFMpeg when compared to theprograms in the inter-program dataset
63 Data AnalysisWhat does the collected fuzzing data look like We studiedour data from fuzzing and triage to answer two questions (1)How many bugs does a configuration trigger (2) How manybugs are triggered by multiple seeds in the intra-programdataset
We first analyzed the distribution of the number of bugsin the two datasets On average the intra- and the inter-program datasets yielded 82 and 24 bugs per configurationrespectively Figure 2 shows two histograms each depict-
40
60
80
100
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(a) Intra-program
60
100
140
fre
dens
ity
fre
ewt
fre
rate
fre
rgr
fre
rpm
frro
und
robin
frun
iran
d
frwd
ensity
frwe
wt
frwra
te
frwrg
r
frwrp
m
fte
dens
ity
fte
ewt
fte
rate
fte
rgr
fte
rpm
ftro
und
robin
ftun
iran
d
ftwd
ensity
ftwe
wt
ftwra
te
ftwrg
r
ftwrp
m
bugs
(b) Inter-program
Figure 4 The average number of bugs over 100 runs foreach scheduling algorithm with error bars showing a 99confidence interval ldquoftrdquo represents fixed-time epoch ldquofrrdquorepresents fixed-run epoch ldquoerdquo represents ε-Greedy ldquowrdquo rep-resents Weighted-Random
ing the number of occurrences of bug counts There is amarked difference in the distributions from the two datasets64 of configurations in the inter-program dataset produceno bugs whereas the corresponding number in the intra-program dataset is 15 We study the bias of the bug countdistribution in sect64
Second we measured how many bugs are shared acrossseeds in the intra-program dataset As an extreme case wefound a bug that was triggered by 46 seeds The averagenumber of seeds leading to a given bug is 4 Out of the 200bugs 97 were discovered from multiple seeds Figure 3illustrates the distribution of bug overlaps Our resultssuggest that there is a small overlap in the code exercisedby different seed files even though they have been chosento be of different types Although this shows that our bugdisjointness assumption in the WCCP model does not alwayshold in practice the low average number of seeds leading toa given bug in our dataset means that the performance ofour algorithms should not have been severely affected
64 SimulationWe now compare the 26 scheduling algorithms based on the10-day fuzzing logs collected for the intra- and inter-programdatasets To compare the performance of scheduling algo-rithms we use the total number of unique bugs reportedby the bug triage process Recall from sect44 that these al-gorithms vary across three dimensions (1) epoch types (2)belief metrics and (3) MAB algorithms For each valid com-bination (see Table 2) we ran our simulator 100 times andaveraged the results to study the effect of randomness oneach scheduling algorithm In our experiments we allocated10 seconds to each epoch for fixed-time campaigns and 200runs for fixed-run campaigns For the ε-Greedy algorithmwe chose ε to be 01
Table 2 summarizes our results Each entry in the tablerepresents the average number of bugs found by 100 sim-
Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

Dataset Epoch MAB algorithmbugs found for each belief
RPM EWT Density Rate RGR
Intra-Program
Fixed-Run
ε-Greedy 72 77 87 88 32Weighted-Random 72 84 84 93 85Uniform-Random 72EXP3S1 58Round-Robin 74
Fixed-Time
ε-Greedy 51 94 51 109 58Weighted-Random 67 94 58 100 108Uniform-Random 94EXP3S1 95Round-Robin 94
Inter-Program
Fixed-Run
ε-Greedy 90 119 89 89 41Weighted-Random 90 131 92 135 94Uniform-Random 89EXP3S1 72Round-Robin 90
Fixed-Time
ε-Greedy 126 158 111 164 117Weighted-Random 152 157 100 167 165Uniform-Random 158EXP3S1 161Round-Robin 158
Table 2 Comparison between scheduling algorithms
ulations of a 10-day campaign We present ε-Greedy andWeighted-Random at the top of each epoch-type row groupeach showing five entries that correspond to the belief metricused For the other three MAB algorithms we only show asingle entry in the center because these algorithms do notuse our belief metrics Figure 4 describes the variability ofour data using error bars showing a 99 confidence inter-val Notice that 94 of our scheduling algorithms have aconfidence interval that is less than 2 (bugs) RGR gives themost volatile algorithms This is not surprising because RGRtends to under-explore by focusing too much on bug-yieldingconfigurations that it encounters early on in a campaign Inthe remainder of this section we highlight several importantaspects of our results
Fixed-time algorithms prevail over fixed-run algorithmsIn the majority of Table 2 except for RPM and Densityin the intra-program dataset fixed-time algorithms alwaysproduced more bugs than their fixed-run counterparts In-tuitively different inputs to a program may take differentamounts of time to execute leading to different fuzzingthroughputs A fixed-time algorithm can exploit this factand pick configurations that give higher throughputs ul-timately testing a larger fraction of the input space andpotentially finding more bugs To investigate the above ex-ceptions we have also performed further analysis on theintra-program dataset We found that the performance ofthe fixed-time variants of RPM and Density greatly improvesin longer simulations In particular all fixed-time algorithmsoutperform their fixed-run counterparts after day 11
Along the same line we observe that fixed-time algorithmsyield 16times more bugs on average when compared to theirfixed-run counterparts in the inter-program dataset In con-trast the improvement is only 11times in the intra-programdataset As we have explained above fixed-time algorithmstend to perform more fuzz runs and potentially finding morebugs by taking advantage of faster configurations Thus ifthe runtime distribution of fuzz runs is more biased as in the
case of the inter-program dataset then fixed-time algorithmstend to gain over their fixed-run counterparts
Time-normalization outperforms runs-normalization Inour results EWT always outperforms RPM and Rate alwaysoutperforms Density We believe that this is because EWTand Density do not spend more time on slower programsand slower programs are not necessarily buggier The latterhypothesis seems highly plausible to us if true it wouldimply that time-normalized belief metrics are more desirablethan runs-normalized metrics
Fixed-time Rate works best In both datasets the best-performing algorithms use fixed-time epochs and Rate asbelief (entries shown in boldface in Table 2) Since Ratecan be seen as a time-normalized variant of RGR this givesfurther evidence of the superiority of time normalization Inaddition it also supports the plausibility of the bug prior
65 Speed of Bug FindingBesides the number of bugs found at the end of a fuzzcampaign the speed at which bugs are discovered is alsoan important metric for evaluating scheduling algorithmsWe address two questions in this section First is therea scheduling algorithm that prevails throughout an entirefuzz campaign Second how effective are the algorithmswith respect to our offline algorithm in sect45 To answerthe questions we first show the speed of each algorithm inFigure 5 and Figure 6 by computing the number of bugsfound over time For brevity and readability we picked foreach belief metric the algorithm that produced the greatestaverage number of unique bugs at the end of the 10-daysimulations
Speed We observe that Rate and RGR are in the lead forthe majority of the time during our 10-day simulations Inother words not only do they find more unique bugs atthe end of the simulations but they also outperform otheralgorithms at almost any given time This lends furthercredibility to the bug prior
RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

RPM
DensityRREWT
RGRRate
Offline
0
50
100
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 5 Bug finding speed of different belief-based algo-rithms for the intra-program dataset
Effectiveness We also compare the effectiveness of eachalgorithm by observing how it compares against our offlinealgorithm We have implemented the offline algorithm dis-cussed in sect45 including the post-processing step that dis-counts duplicated bugs and computed the solution for eachdataset The numbers of bugs found by the offline algorithmfor the intra- and the inter-program datasets are 132 and217 respectively (Notice that due to bug overlaps and thediscount heuristic these are lowerbounds on the offline opti-mal) As a comparison Rate found 83 and 77 of bugs inthe intra- and inter-program datasets respectively Basedon these numbers we conclude that Rate-based algorithmsare effective
66 Comparison with CERT BFF
At present the CERT Basic Fuzzing Framework (BFF) [14] isthe closest system that makes use of scheduling algorithms forfuzz campaigns In this section we evaluate the effectivenessof BFFrsquos scheduling algorithm using our simulator
Based on our study of the source code of BFF v26 (thelatest version as of this writing) it uses a fixed-run weighted-random algorithm with Density (bugs
runs) as its belief metric
However a key feature of BFF prevented us from completelyimplementing its algorithm in our simulation framework Inparticular while BFF focuses on fuzzing a single programit considers not only a collection of seeds but also a set ofpredetermined mutation ratios In other words instead ofchoosing program-seed pairs as in our experiments BFFchooses seed-ratio pairs with respect to a single programSince our simulator does not take mutation ratio into ac-count it can only emulate BFFrsquos algorithm in configurationselection using a fixed mutation ratio We note that addingthe capability to vary the mutation ratio is prohibitivelyexpensive for us FuzzSim is an offline simulator and there-fore we need to collect ground-truth data for all possibleconfigurations Adding a new dimension into our currentsystem would directly multiply our data collection cost
Going back to our evaluation let us focus on the Weighted-Random rows in Table 2 Density with fixed-run epochs(BFF) yields 84 and 92 bugs in the two datasets The cor-responding numbers for Rate with fixed-time epochs (ourrecommendation) are 100 and 167 with respective improve-ments of 119times and 182times (average 15times) Based on thesenumbers we believe future versions of BFF may benefit fromswitching over to Rate with fixed-time epochs
Density
RPMRREWTRGRRate
Offline
0
50
100
150
200
0 1 2 3 4 5 6 7 8 9 10
days
bugs
Figure 6 Bug finding speed of different belief-based algo-rithms for the inter-program dataset
7 Related WorkSince its introduction in 1990 by Miller et al [18] fuzzingin its various forms has become the most widely-deployedtechnique for finding bugs There has been extensive work toimprove upon their ground-breaking work A major thrustof this research concerns the generation of test inputs forthe target program and the two main paradigms in use aremutational and generational fuzzing [17]
More recently sophisticated techniques for dynamic testgeneration have been applied in fuzzing [8 11] White-boxfuzzing [7] is grounded in the idea of ldquodata-driven improve-mentrdquo which uses feedback from previous fuzz runs to ldquofocuslimited resources on further research and improve futurerunsrdquo The feedback data used in determining inputs is ob-tained via symbolic execution and constraint solving otherwork in feedback-driven input generation relies on taint anal-ysis and control flow graphs [13 20] Our works bears somesimilarity to feedback-driven or evolutionary fuzzing in thatwe also use data from previous fuzz runs to improve fuzzingeffectiveness However the black-box nature of our approachimplies that feedback is limited to observing crashes Like-wise our focus on mutating inputs means that we do notconstruct brand new inputs and instead rely on selectingamong existing configurations Thus our work can be castas dynamic scheduling of fuzz configurations
Despite its prominence we know of no previous work thathas systematically investigated the effectiveness of differentscheduling algorithms in fuzzing Our approach focuses onallocating resources for black-box mutational fuzzing in orderto maximize the number of unique bugs found in any periodof time The closest related work is the CERT Basic FuzzingFramework (BFF) [14] which considers parameter selectionfor zzuf Like BFF we borrow techniques from Multi-ArmedBandits (MAB) algorithms However unlike BFF whichconsiders repeated fuzz runs as independent Bernoulli trialswe model this process as a Weighted Coupon CollectorrsquosProblem (WCCP) with unknown weights to capture thedecrease in the probability of finding a new bug over thecourse a fuzz campaign
In constructing our model we draw heavily on research insoftware reliability as well as random testing The key insightof viewing random testing as coupon collecting was recentlymade in [1] A key difference between our work and [1] isthat their focus is on the formalization of random testingwhereas our goal is to maximize the number of bugs foundin a fuzz campaign Software reliability refers to the prob-ability of failure-free operation for a specified time period
and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997

and execution environment [6] As a measure of softwarequality software reliability is used within the software engi-neering community to ldquoplan and control resources during thedevelopment processrdquo [12] which is similar to the motivationbehind our work
8 Conclusion and Future WorkIn this paper we studied how to find the greatest number ofunique bugs in a fuzz campaign We modeled black-box muta-tional fuzzing as a WCCP process with unknown weights andused the condition in the No Free Lunch theorem to guide usin designing better online algorithms for our problem In ourevaluation of the 26 algorithms presented in this paper wefound that the fixed-time weighted-random algorithm withthe Rate belief metric shows an average of 15times improvementover its fixed-run Density-based counterpart which is cur-rently used by the CERT Basic Fuzzing Framework (BFF)Since our current project does not investigate the effect ofvarying the mutation ratio a natural follow-up work wouldbe to investigate how to add this capability to our system inan affordable manner
AcknowledgmentThe authors thank Will Dormann Jonathan Foote andAllen Householder of CERT for encouragement and fruitfuldiscussions This material is based upon work funded andsupported by the Department of Defense under Contract NoFA8721-05-C-0003 with Carnegie Mellon University for theoperation of the Software Engineering Institute a federallyfunded research and development center and the NationalScience Foundation This material has been approved forpublic release and unlimited distribution
References[1] A Arcuri M Z Iqbal and L Briand Formal Analysis
of the Effectiveness and Predictability of RandomTesting In International Symposium on SoftwareTesting and Analysis pages 219ndash229 2010
[2] P Auer N Cesa-Bianchi Y Freund and R ESchapire The Nonstochastic Multiarmed BanditProblem Journal on Computing 32(1)48ndash77 2002
[3] P Auer N Cesa-Bianchi and F Paul Finite-timeAnalysis of the Multiarmed Bandit Problem MachineLearning 47(2-3)235ndash256 2002
[4] T Avgerinos S K Cha B T H Lim andD Brumley AEG Automatic Exploit Generation InProceedings of the Network and Distributed SystemsSecurity Symposium 2011
[5] D A Berry and B Fristedt Bandit ProblemsSequential Allocation of Experiments Chapman andHall 1985
[6] A Bertolino Software testing research Achievementschallenges dreams In Future of Software Engineeringpages 85ndash103 2007
[7] E Bounimova P Godefroid and D Molnar Billionsand Billions of Constraints Whitebox Fuzz Testing inProduction In Proceedings of the InternationalConference on Software Engineering pages 122ndash1312013
[8] C Cadar D Dunbar and D Engler KLEEUnassisted and Automatic Generation of High-coverageTests for Complex Systems Programs In Proceedingsof the USENIX Symposium on Operating SystemDesign and Implementation pages 209ndash224 2008
[9] S K Cha T Avgerinos A Rebert and D BrumleyUnleashing Mayhem on Binary Code In Proceedings ofthe IEEE Symposium on Security and Privacy pages380ndash394 2012
[10] D Engler D Chen S Hallem A Chou and B ChelfBugs as Deviant Behavior A General Approach toInferring Errors in Systems Code In Proceedings of theACM Symposium on Operating System Principlespages 57ndash72 2001
[11] P Godefroid M Y Levin and D Molnar SAGEWhitebox Fuzzing for Security Communications of theACM 55(3)40ndash44 2012
[12] A L Goel Software Reliability Models AssumptionsLimitations and Applicability IEEE Transactions onSoftware Engineering 11(12)1411ndash1423 1985
[13] N Gupta A P Mathur and M L Soffa AutomatedTest Data Generation Using An Iterative RelaxationMethod In Proceedings of the ACM SIGSOFTInternational Symposium on Foundations of SoftwareEngineering pages 231ndash244 1998
[14] A D Householder and J M Foote Probability-BasedParameter Selection for Black-Box Fuzz TestingTechnical Report August CERT 2012
[15] B D Jovanovic and P S Levy A Look at the Rule ofThree The American Statistician 51(2)137ndash139 1997
[16] C Labs zzuf multi-purpose fuzzerhttpcacazoyorgwikizzuf
[17] R McNally K Yiu D Grove and D GerhardyFuzzing The State of the Art Technical ReportDSTOndashTNndash1043 Defence Science and TechnologyOrganisation 2012
[18] B P Miller L Fredriksen and B So An EmpiricalStudy of the Reliability of UNIX UtilitiesCommunications of the ACM 33(12)32ndash44 1990
[19] D Molnar X Li and D Wagner Dynamic TestGeneration To Find Integer Bugs in x86 Binary LinuxPrograms In Proceedings of the USENIX SecuritySymposium pages 67ndash82 2009
[20] C Pacheco S K Lahiri M D Ernst and T BallFeedback-Directed Random Test Generation InProceedings of the International Conference onSoftware Engineering pages 75ndash84 2007
[21] D Wagner J S Foster E A Brewer and A Aiken AFirst Step towards Automated Detection of BufferOverrun Vulnerabilities In Proceedings of the Networkand Distributed Systems Security Symposium pages3ndash17 2000
[22] D Wolpert and W Macready No free lunch theoremsfor optimization IEEE Transactions on EvolutionaryComputation 1(1)67ndash82 1997