Embed Size (px)
Citation preview

Laine CampbellPalominoDB
ScalingMySQL in AWS
Velocity, Santa Clara - June 18th, 2013

Agenda1. Introduction2. Overview of options: RDS and EC2/MySQL3. Web console, CLI, API4. MySQL scaling patterns5. Performance/Availability6. Implementation choices7. Common failure patterns8. Managing cost9. Questions

About usLaine CampbellFounder and CEO, PalominoDB
9 years building the DB team/infrastructure at Travelocity.
7 years at Palomino, supporting 50+ companies, 1000s of databases and way too much coffee.Hiring? Yes. Duh.

Interactivity
Ask away; we've got time. Laine will be glad to try and solve your problems.

MySQL Options:RDS and EC2/MySQL
A love story...

RDS benefits
Relational Database Service
Fully ManagedSimple to DeployEasy to ScaleReliableCost Effective

RDS benefits
Ignore the man behind the curtainBackupsProvisioningPatchingFailoverReplication

RDS benefits
BackupsSnapshot Based - Same as EBS
Snapshots cause spikes in latencyAvoided in Multi-AZ
Snapshots are taken from masterOr the standby in Multi-AZ
Set up automatic schedulesPoint in Time Recovery via binlogsUser executed snapshotsNeed non RDS backups? MySQLDump :(

RDS benefits
Provisioning
Rapid Master LaunchesMaster in a few minutes Standby in a different AZ? Push a button! Call the CLI!
Rapid Replica BuildsNeed more replicas? Push a button! Call the CLI!

RDS ChallengesFully managed
● Log access via API (no binlogs)● No SUPER● No flexible topology (more to discuss)● Reduced visibility into internals
The more experienced a DBA you are, the crankier you will be.

RDS ChallengesLack of Replication Management
● You can skip repl errors (good)● When using sync_binlog=0 and replicas with
Multi-AZ, a multi-AZ failover on a non-flushed binlog strands replicas.○ No "Change Master" access.○ Must rebuild every replica serially.

RDS ChallengesAll of my replicas must be rebuilt!

RDS ChallengesLack of Visibility
● No OS access (Sar, processlist, what's in swap, etc...)
● Lack of access to tcpdump and port listening.
● Log forensics. (binlog, slowlog, general log)○ Must be downloaded, then parsed. ○ Doable but more steps.

RDS improves!Like all AWS properties, RDS features continue to improve all the time. The feature introductions have been impressive to date.
It has proven itself repeatedly. Like anything, you must be prepared.
(Tungsten supports replication into RDS from MySQL).

EC2/MySQL
All the MySQL you've come to love & hate
Multi-Region via replication & WAN tunnel

Why RDS or EC2?
RDS1. You can tolerate ~99% uptime (which many
people can)2. You don't have lots of DBAs and need to
optimize for operational easeEC21. Multi-region availability2. Vertical scaling via SSD3. Complex topologies for perf./downtime
reduction.

Questions?
Any particular scenarios you want to ask us about?

Web Console, CLI, API

Overview
Functionality isn't complete● some things aren't exposed via some
methods● AWS teams always want feedback -
companies like Palomino can get it to them faster

Web Console
Most of the stuff you need for common day-to-day maintenance
Sometimes:● slow● isn't working● needs rage-clicking

CLI setup
RDS CLI
export AWS_RDS_HOMEexport AWS_CREDENTIAL_FILE (AWSAccessKeyId,AWSSecretKey)

CLI pain
It's written in Java right now*. The JVM overhead makes it painfully slow for large-scale automation.
* The future is the Redshift CLI (python, coherent interface)

CLI output
Verbose and clunky
DBINSTANCE,scp01-replica2,2010-05-22T01:53:47.372Z,db.m1.large,mysql,50,(nil),master,available,scp01-replica2.cdysvrlmdirl.us-east-1.rds.amazonaws.com,3306,us-east-1b,(nil),0,(nil),(nil),(nil),(nil),(nil),(nil),(nil),(nil),sun:05:00-sun:09:00,23:00-01:00,(nil),n,5.1.50,n,simcoprod01,general-public-licenseSECGROUP,Name,StatusSECGROUP,default,activePARAMGRP,Group Name,Apply StatusPARAMGRP,default.mysql5.1,in-synch
Combining the worst features of machine- and human-readable text formats.

API
Use Boto! (Mitch works for AWS).
https://github.com/boto/boto

Scaling PatternsMySQL and You
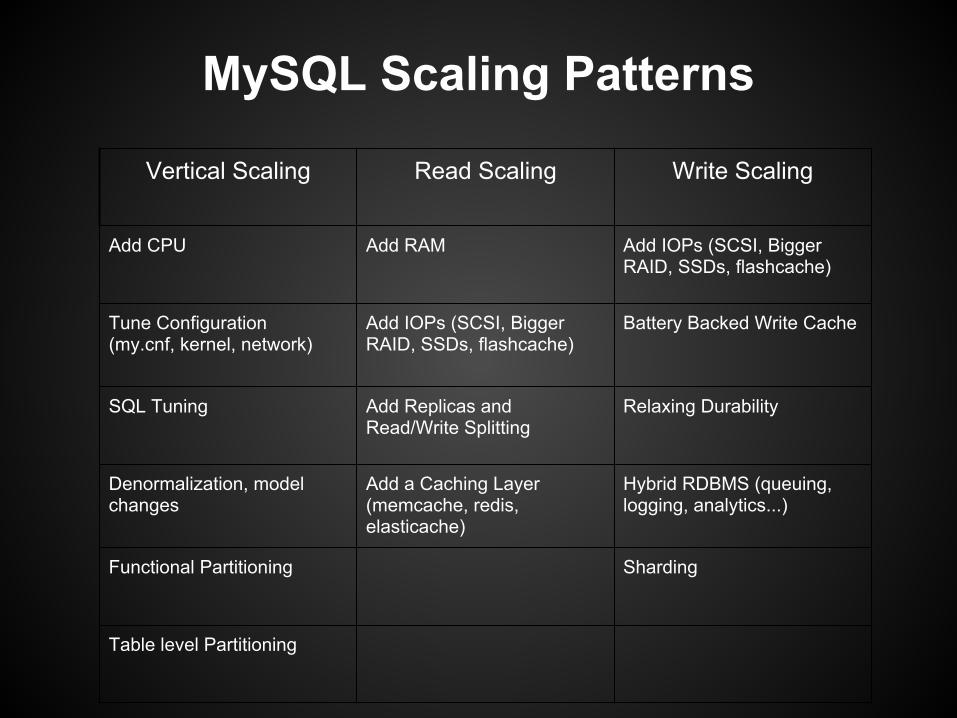
MySQL Scaling Patterns
Vertical Scaling Read Scaling Write Scaling
Add CPU Add RAM Add IOPs (SCSI, Bigger RAID, SSDs, flashcache)
Tune Configuration (my.cnf, kernel, network)
Add IOPs (SCSI, Bigger RAID, SSDs, flashcache)
Battery Backed Write Cache
SQL Tuning Add Replicas and Read/Write Splitting
Relaxing Durability
Denormalization, model changes
Add a Caching Layer (memcache, redis, elasticache)
Hybrid RDBMS (queuing, logging, analytics...)
Functional Partitioning Sharding
Table level Partitioning

MySQL Scaling Patterns
Need more transactions? Scale Vertically.
● Tune your SQL.● Manage your configs.● Add MOAR RAM● Add MOAR DISK● Add MOAR CPU● Need more verticals?

MySQL Vertical Scaling
Table Level Partitioning● Break up large tables into physical partitions that appear
logically as one.● Prunes searches to reduce row scans.● Increase DML speed with smaller b-trees.● Rapid data management (drop partition) can save
horsepower for users. (range)

MySQL Vertical Scaling
Functional Partitioning● Split separate workloads into their own logical
groupings.○ Typical breakouts - profiles, content, orders,
inventory, pricing, separate games/apps.○ Let's you scale based on least common denominator
for that functional group.○ Less chance of conflicting workloads, allows for
more focused tuning.○ More horsepower for each app - single tenancy.
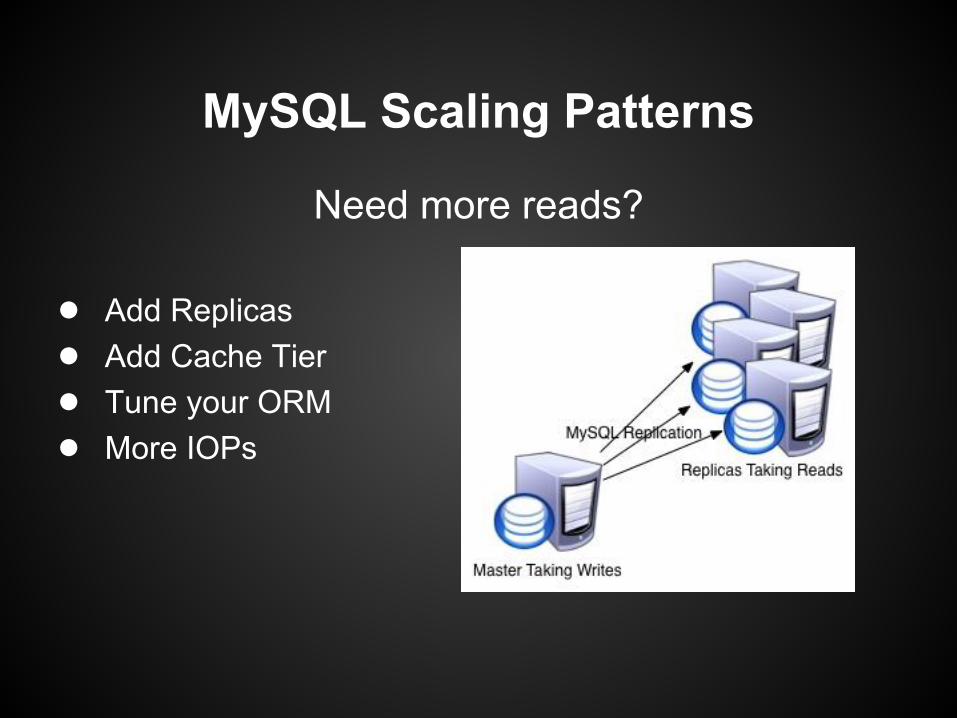
MySQL Scaling Patterns
Need more reads?
● Add Replicas● Add Cache Tier● Tune your ORM● More IOPs

MySQL Scaling Patterns
Replication Lagging?● Functional and table level partitioning if not done
already.● Split database schema into multiple schemas - use
parallel replication. (5.6, or Tungsten)● Stop abusing MySQL! Some workloads don't belong in
a relational database! (logs, queues, massive non-transactional reads)
● Faster disk and CPU (single-threaded repl)● Pre-warm those caches!● Relax durability.

MySQL Scaling Patterns
Need more writes?● Functionally partition if you haven't already.● More IOPs via any means necessary.● Relax your durability. ● Faster Disk seek times.● Hybridize - get those queues, logs and other apps out of
your RDBMS.● Time to shard! Split your data-sets into multiple clusters
and scale linearly.

MySQL Scaling Patterns
Sharding!● It's very easy. RTFM.

MySQL Scaling Patterns
Sharding!● Not really easy! So what is sharding?● Creating subsets of a collection of data.● Partitioning by row, where rows live in their own
instances.○ But not necessarily their own servers.
● Requires new ways of accessing data.● Multiple ways to do this.

MySQL Sharding Methods
Range Based Sharding● Each shard gets a range of rows.
○ BlogID 1-10 shard1○ BlogID 11-20 shard2○ etc...
● Can lead to hot shards depending on the shard key.● Often requires unevenly distributed shards (hot shard
distributed more often, cold shards consolidated)○ Relatively frequent rebalancing.
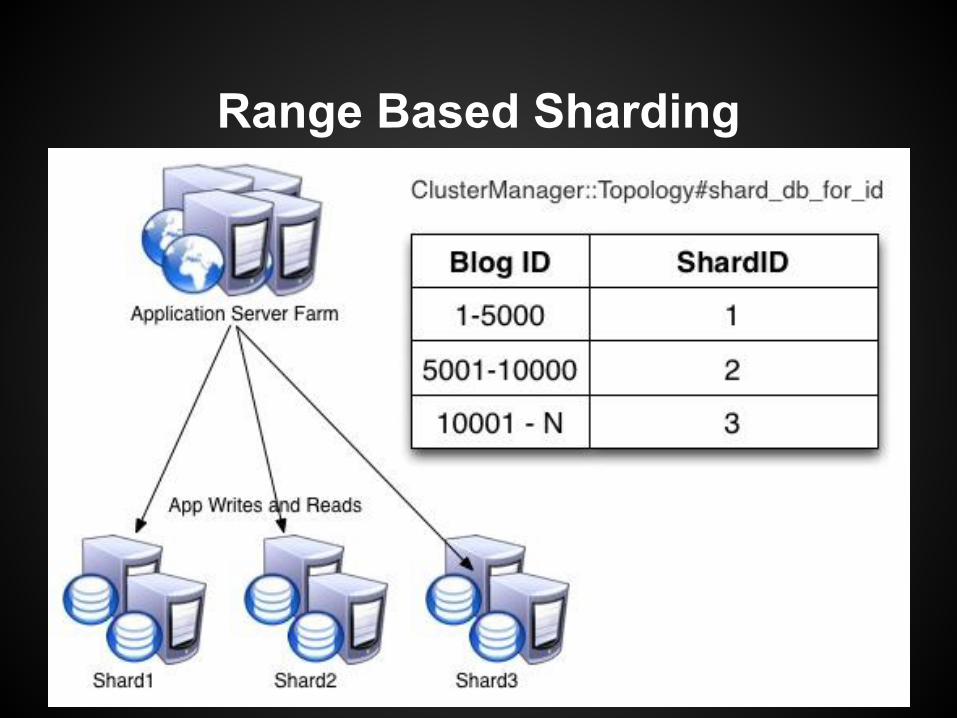
Range Based Sharding

MySQL Sharding Methods
Hash/Modulus Based Sharding● Use a hash on the shard key to determine shard
location● Can reduce likelihood of hot shards with a good key.
Relatively even load means fewer rebalances.○ Which is good since rebalancing is challenging!
● Pre-building a large number of shards that function as many separate, low activity instances on an individual node can help future-proof.
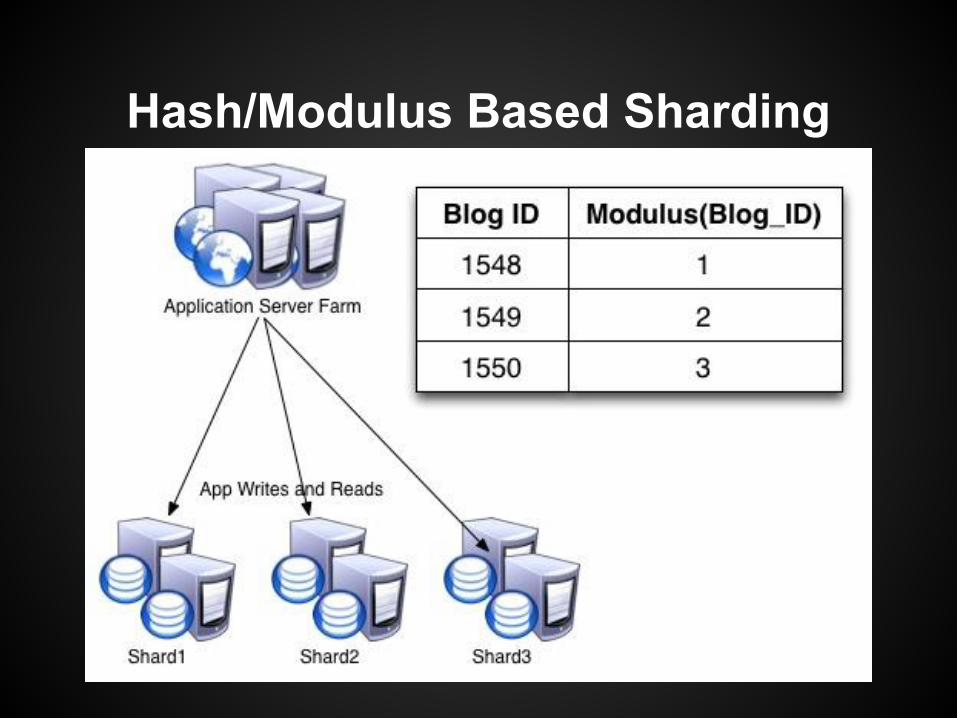
Hash/Modulus Based Sharding

MySQL Sharding Methods
Lookup Table Based Sharding● Store a lookup table in your persistence tier.● Map IDs to Shards.● Micromanaged, allows for easy migration of individual
hot IDs to different shards.● Lookup table is:
○ Another component.○ A concurrency bottleneck.○ Can grow quite large (in rows, not width)
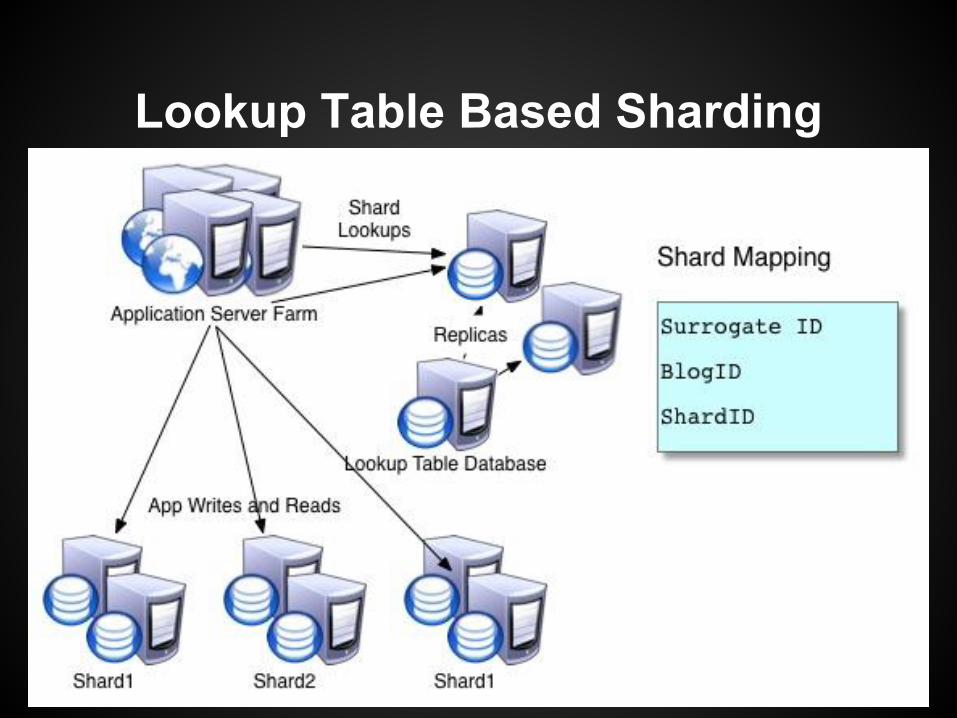
Lookup Table Based Sharding

MySQL Sharding Methods
Choosing a Shard Key● Ideally your key isolates all needed data for the most
called queries into their own shard.○ All posts for a blog. ○ All comments for a post. ○ All users in an org.○ All activity for a user.
● Try to go to the smallest logical grouping to reduce hot shards.○ Post, not blog.○ Ticket, not organization.

MySQL Sharding Methods
Choosing a Shard Key● Think about the long-tail
○ Will you be storing cold data? ○ Can it be consolidated elsewhere to keep your
shards nimble?○ Time based shards can prove quite useful in
conjunction with another shard key. (compound)■ Don't want all of your recent data in one place.■ Want to build time based ascension in keys.■ Usefulness wanes as time waxes.

AvailabilityHow many nines?

Regions and Availability Zones
Overview of AZ and RegionsAmazon Regions equate to data-centers in different geographical regions.
Availability zones are isolated from one another in the same region to minimize impact of failures.
RDS does not interact across regions yet.
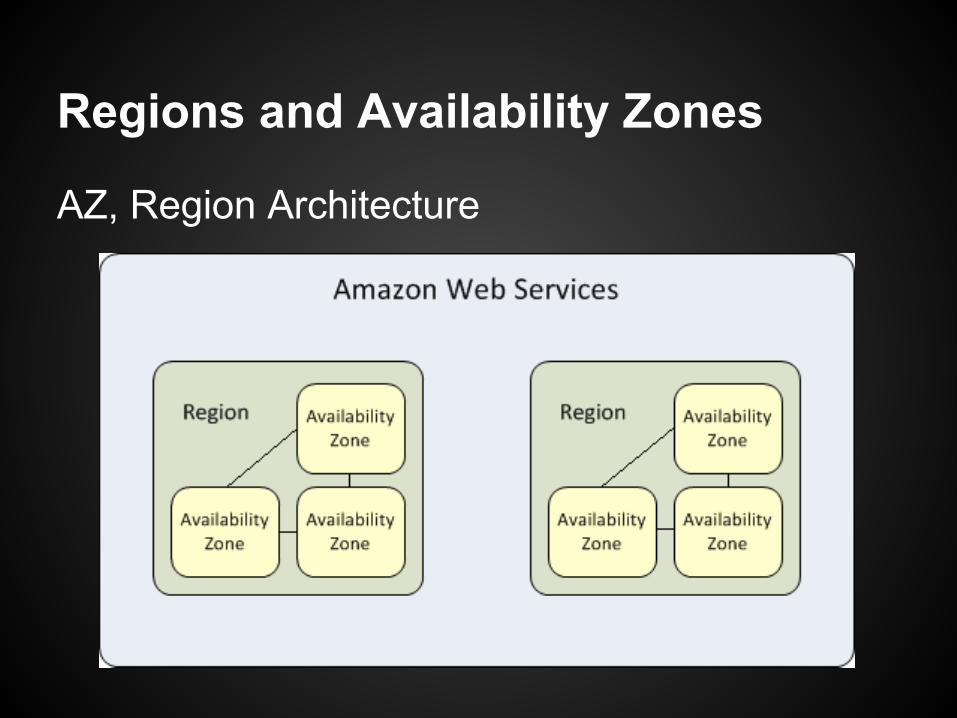
Regions and Availability Zones
AZ, Region Architecture

Regions and Availability Zones
Can multiple AZs save me?Amazon states AZs do not share :
●Cooling●Network●Security●Generators●Facilities

Regions and Availability Zones
Can multiple AZs save me?Apr, 2011 - US East Region EBS Failed
* Incorrect network failover.* Saturated intra-node communications.* Cascading failures impacted EBS in all AZs.
Jul, 2012 - US East Partial Impact* Electrical storms impacted multiple sites.* Failover of metadata DB took too long.* EBS I/O was frozen to minimize corruption.
●

EC2 Region SLA
99.95% SLA“Annual Uptime Percentage” is calculated by subtracting from 100% the percentage of 5 minute periods during the Service Year in which Amazon EC2 was in the state of “Region Unavailable.”
("Region unavailable" == "multiple AZs are toast")
Implies you've got to go multi-region

EC2 Region SLA
~99.2% Reality
The previous definition is very strict; 2 or more regions; can't create instances; blah, blah.
1-2X year multi-AZ degradation (EBS, network, who knows)

Multi-region
It's coming for RDS. Probably before the end of the year.
Until then...

RDS Availability

RDS: Master AvailabilityAlways go Multi-AZ
Minimal downtime for most maintenance
Saves you from most master crashes
{Sometimes, often, frequently} destroys all replicas.

Always go Multi-AZRDS Multi-AZ Magical Failover
Block level replication
Fails over quite often, with up to a few minutes of downtime
You do not get to choose your failover AZ
Typical I/O write impact for block level replication
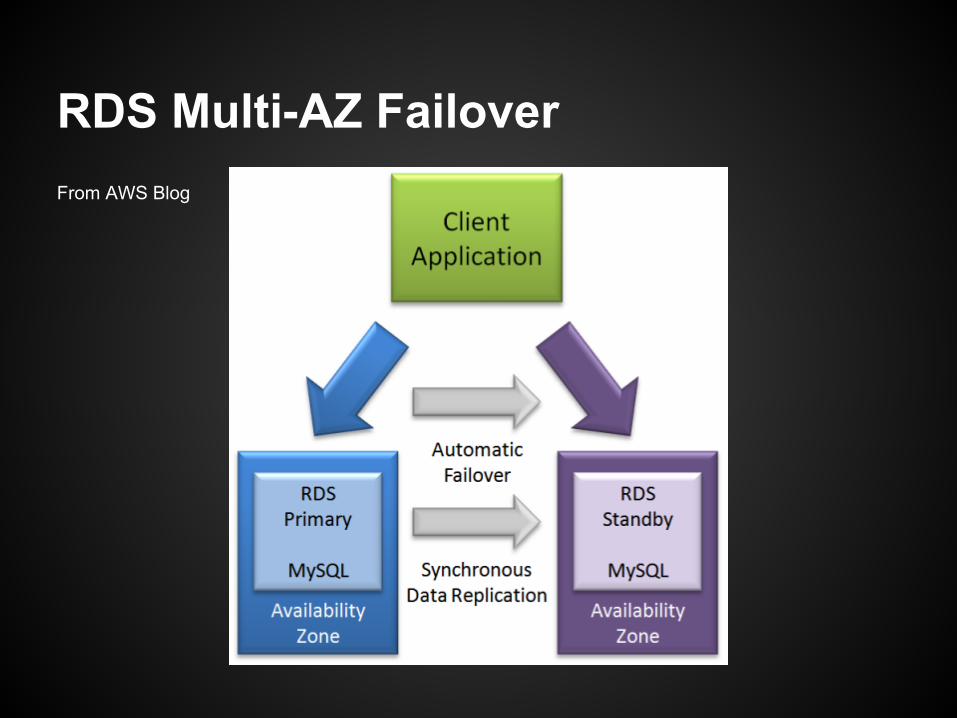
RDS Multi-AZ FailoverFrom AWS Blog

RDS Multi-AZ Considerations
To work around replica breakage during a failover:
sync_binlog=1
● This will DESTROY write throughput● MySQL 5.6 drastic improvements
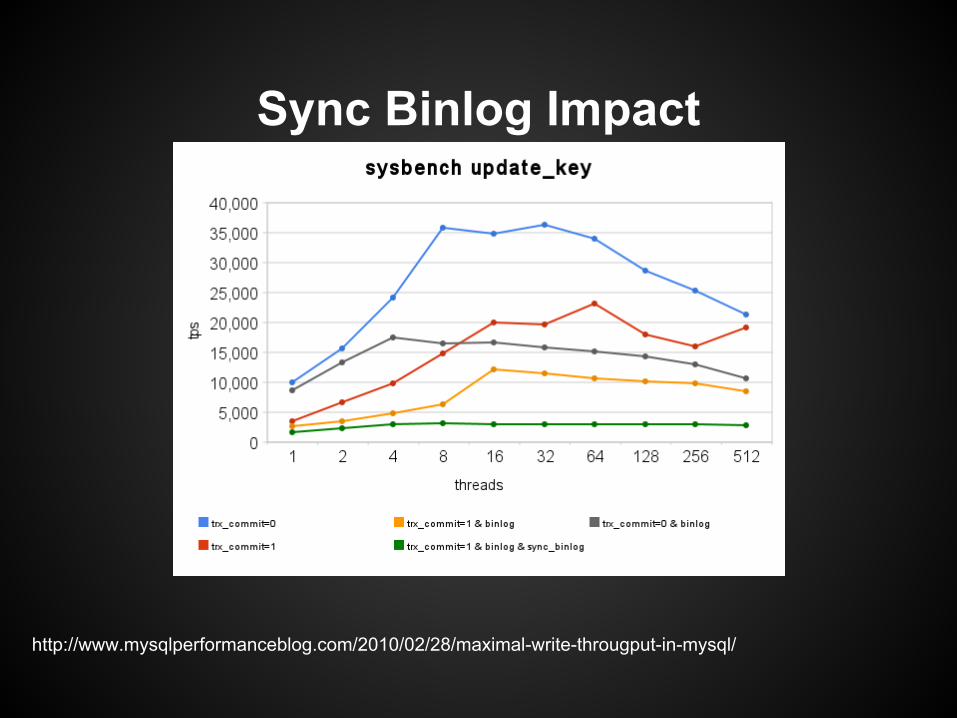
Sync Binlog Impact
http://www.mysqlperformanceblog.com/2010/02/28/maximal-write-througput-in-mysql/

RDS: Replica Availability
● Redundant replicas are good things. N+1 meets most availability needs.
● One or more in each AZ you have app servers in. Cross-AZ latency is a killer. (AWS states low single digit millisecond impact.)
● N+1 per AZ is nice, but you can build more after failover.○ In serial - and thus should be scripted for large
quantities.○ If you lose all replicas due to a replication event, you
might not be able to build them fast enough.

RDS: Multi-AZ Replicas

RDS: Replica AvailabilitySending queries to the replica?
● Set up Route53 cnames - weighted round robin.
● VPC/Route53 does not do a mysql health check.
● HAProxy can be leveraged.
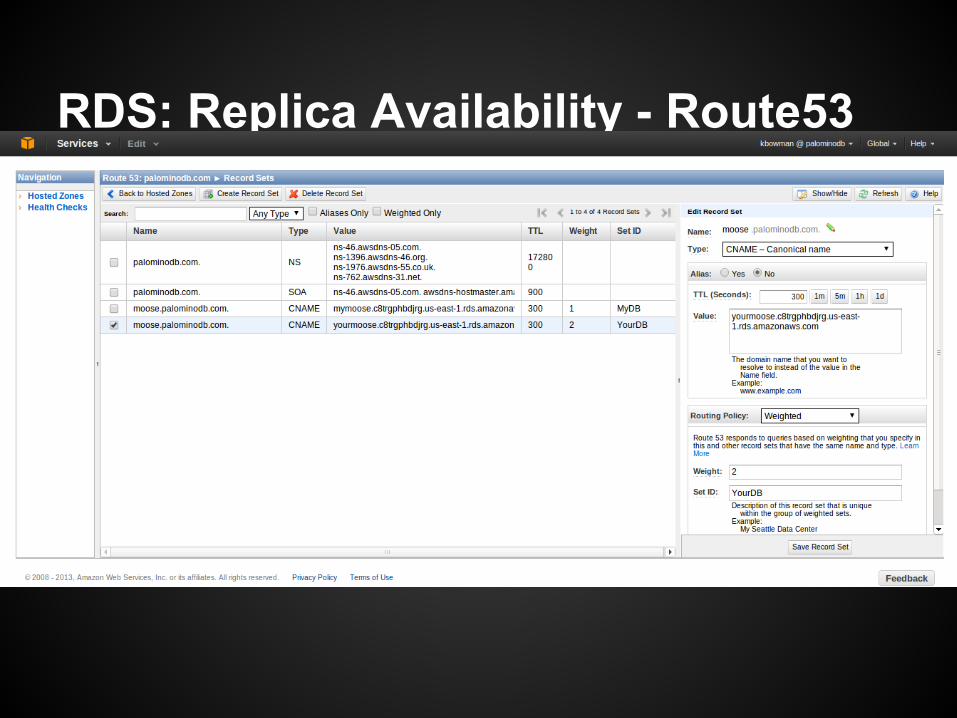
RDS: Replica Availability - Route53

EC2 Availability Patterns
● Master/Replica(s) with native asynchronous replication
● Tungsten, managed replication and clustering
● Galera, synchronous replication
● Multi-Region for DR

Master with Replicas - Overview
MySQL Asynchronous Replication provides simple read scaling.
○ Multiple replicas can provide an easy database layer for distributing concurrency of reads.
○ Advanced topologies can reduce the downtime incurred in impactful changes. (upgrades, significant DDL changes, defragmentation)
○ An easy way to reduce load on a taxed master.
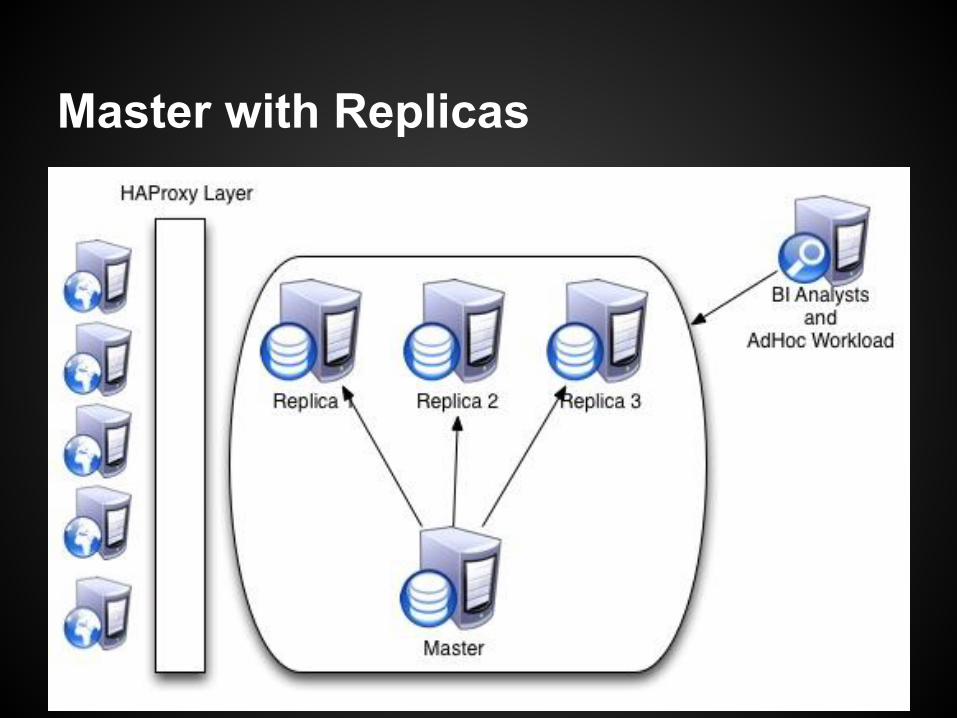
Master with Replicas

Master with Replicas - Limitations
Asynchronous replication comes with some limitations.
○ With no synchronous commit, replication is not guaranteed. Data drift can occur due to:
● Syncing issues with binary/relay logs.● Non-deterministic SQL.● Unauthorized writes to replicas.
○ Overloaded replicas can create replication latency, impacting the usefulness of the replica in read traffic mitigation.
○ Replication is fragile - you should be able to easily rebuild replicas as needed.

Master with Replicas - Patterns
● High read to write workload ratios.● Moderate dataset (footprint and delta patterns) that
allows for rapid duplication.○ File copies - not ideal.○ EBS snapshots, RDS snapshots
● Small amounts of potential data loss are not catastrophic.○ Asynchronous replication, data drift, unflushed
logs.● Application layer that can manage failover or tolerate
downtime during reconfiguration of connectors.

Master with Replicas - Failover
● When replication breaks manual intervention is required.○ Identify state of replicas compared to each other.○ Selection of a master, reconfiguration of parameters.○ Reslaving replicas to new master.○ Reconfiguration of connectors/proxies.○ Rebuild of previous failed node.○ Reintroduction into replica pool.
● RDS automates this process.

Master with Replicas - Failover
● Automation of the failover process is critical.○ MySQL MHA preferred.
■ Open source software■ http://code.google.com/p/mysql-master-ha■ In use by large sites■ In production 2 years■ Plugin architecture allows external calls for
managing Virtual IPs/ELBs.○ Scripting can be done for a roll-your-on approach.
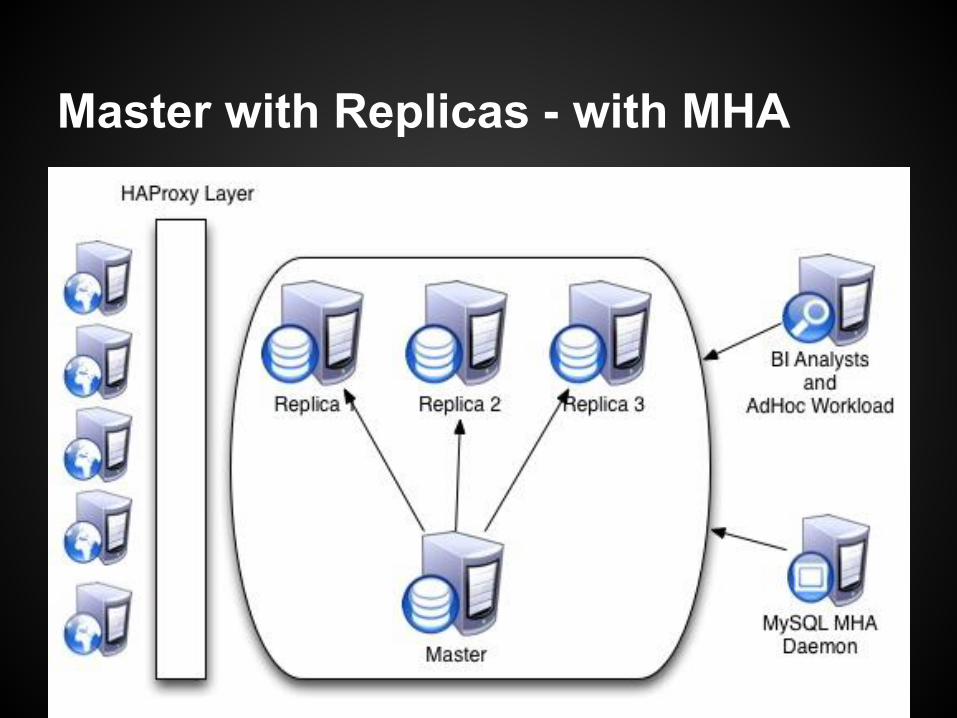
Master with Replicas - with MHA

Master with Replicas - Extending
● Master/Master (active/passive), with Replicas.○ Eliminates some steps in the failover process.○ Does not work with MySQL MHA - must script
● HAProxy for Read/Write Coordination and failovers○ http://palominodb.com/blog/2011/12/01/using-
haproxy-mysql-failovers

Tungsten, Managed Failover
● Replaces MySQL Replication with Tungsten Replicator.
● Tungsten Cluster Manager:○ Manages cluster remastering.○ Sends updated status information to the connectors.
● Tungsten Connector:○ Routes traffic to master and replica as needed.○ Can be used to split reads as well.

Tungsten, Use Cases
● With scripting/config mgmt. wrappers, can perform most of what RDS does in EC2.
● Great for read scaling - still doesn't solve write issues - thus sharding still mandatory for write intensive apps.
● Allows for complex topologies:○ Tiered replication○ Filtering and subsets○ Rolling migrations/implementations.○ Heterogenous types (SSD ephemeral vs. EBS)

Tungsten, Managed Failover
● Pros:○ Visibility to your environment○ Managed failover○ Super access to your DB○ Solid team of developers and good quality software○ Access to complex topologies and patterns
● Cons:○ One more vendor to manage○ Commercial product○ Extra software to learn/train on
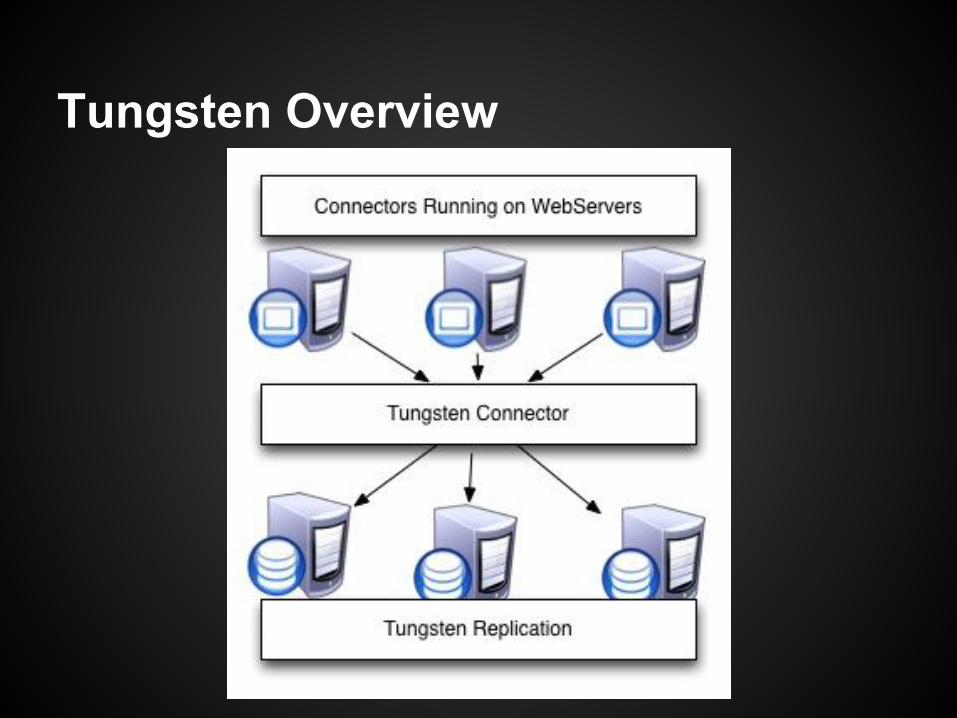
Tungsten Overview

Galera Synchronous Repl
● Synchronous Replication creates a read/write anywhere solution and is available in:○ Galera Binaries○ Percona XtraDB Cluster○ MariaDB
● Eliminates failovers and replication latency.● Uses quorum based cluster partitioning, with a minimum
of three to avoid split brain.● Cluster level conflict management.● Commit groups used for cluster level commit
○ One slow volume can impact all performance

Galera Synchronous Replication
● Pros:○ Read/Write Anywhere○ No failovers○ No replication latency
● Cons:○ Newer tech: Now with more edge cases!○ Least common denominator I/O impact○ More technology to learn (not that much)
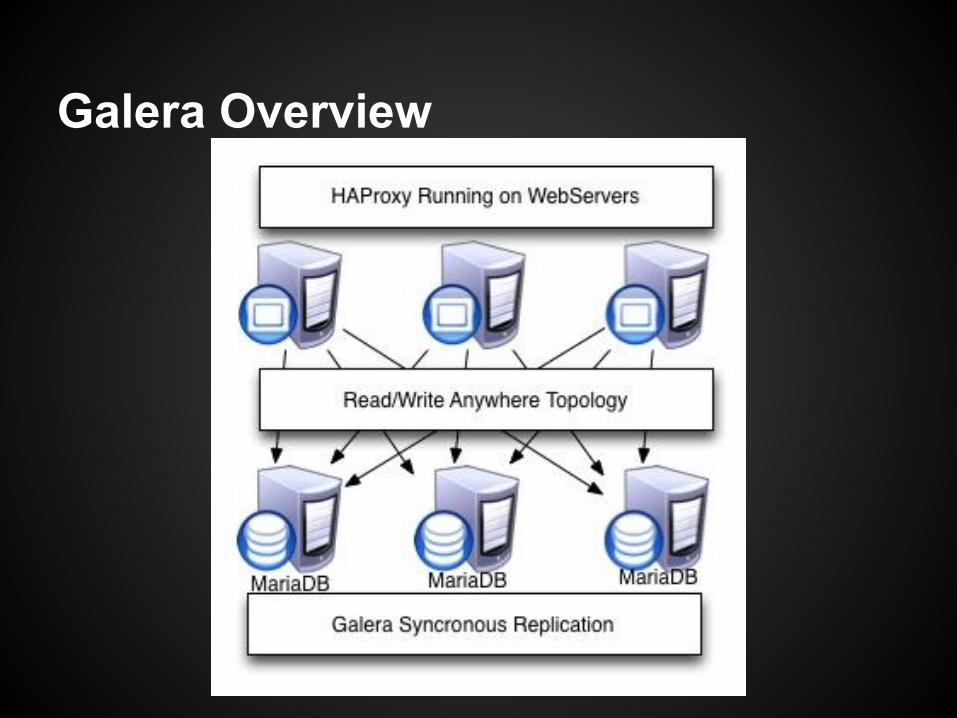
Galera Overview

Performance Considerations

IO and Storage Performance
● Provisioned IOPS allow escape from the nagging concerns about IO throughput in EBS.
● They also eliminate the need to RAID your EBS volumes in EC2. (300 GB size non-piops also stripes in RDS)
● Consider them mandatory for performance sensitive MySQL applications.

IO and Storage Considerations
EC2 allows for SSD ephemeral storage as well.
● 150,000 IOPS of pure amazingness.● Ephemeral, use for power replicas.

RDS Performance Considerations
RDS provides faster guaranteed network performance than EC2.
Multi-AZ block level replication does impact write I/O performance, which is to be expected.
Impacts can also be seen during backups and replica builds and should be benchmarked.

Questions?
Questions about designing for availability?
Questions about performance?

Implementation Choices

Instance Types
General Purpose
Compute Optimized
Memory Optimized - Great multi-purpose DBMS
Storage Optimized - SSD Ephemeral

Instance Options
EBS Optimized - Dedicated throughput
Cluster Networked
Dedicated - Single Tenancy
Storage Optimized - SSD Ephemeral

Storage Options
Ephemeral - Fast, consistent, non-durable
Ephemeral SSD - Faster, SO MUCH SO (150K IOPS)
EBS - Durable, persistent, slower, inconsistent
EBS PIOPS - Faster, more consistent, more expensive, lower failure rate.

Instance sizing
Dynamicity == reduced cost
(Now, in general, $$ isn't why you go to the cloud; it's operational efficiency & reduced friction).
Have a spreadsheet and do capacity analyses frequently.
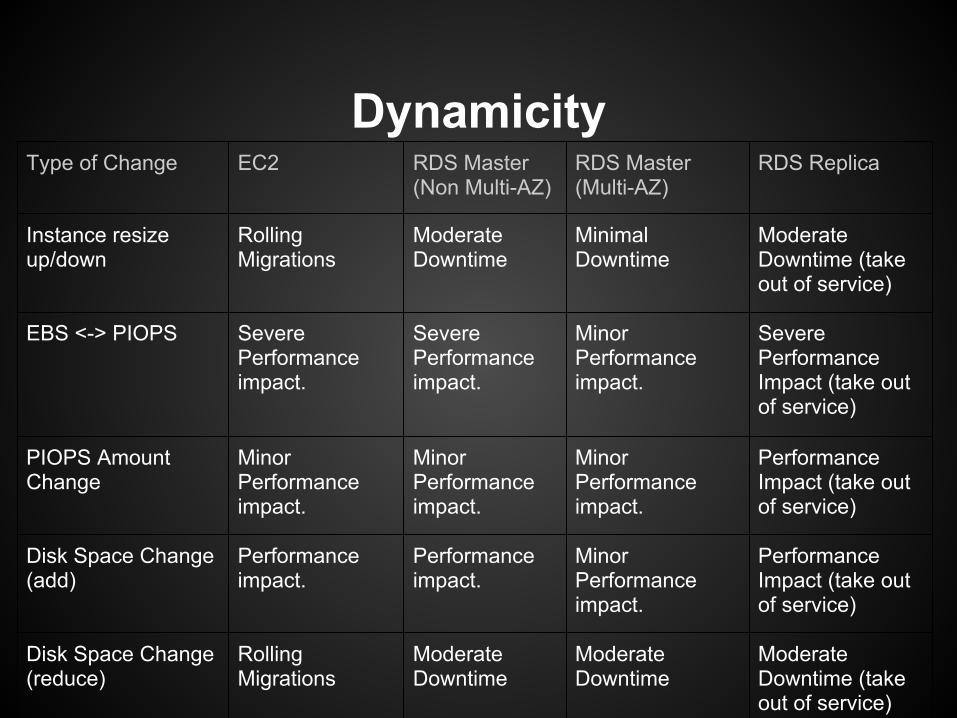
DynamicityType of Change EC2 RDS Master
(Non Multi-AZ)RDS Master(Multi-AZ)
RDS Replica
Instance resize up/down
Rolling Migrations
Moderate Downtime
Minimal Downtime
Moderate Downtime (take out of service)
EBS <-> PIOPS Severe Performance impact.
Severe Performance impact.
Minor Performance impact.
Severe Performance Impact (take out of service)
PIOPS Amount Change
Minor Performance impact.
Minor Performance impact.
Minor Performance impact.
Performance Impact (take out of service)
Disk Space Change (add)
Performance impact.
Performance impact.
Minor Performance impact.
Performance Impact (take out of service)
Disk Space Change (reduce)
Rolling Migrations
Moderate Downtime
Moderate Downtime
Moderate Downtime (take out of service)
Questions?
Questions about your particular setup?

Common failure modes(Should really be called zones and regions)

Operations is about managing change and
mitigating risk.

Local failures
● Database crashes● Human error
○ Misconfigure○ Write to a replica○ Drop a table/database/career
● Localized EBS hang/Corruption● Unacceptable performance

Local failures redux
Local failures should be, at most, annoyances.
Multiple Availability ZonesRunbooks*Game daysMonitoring
* Process is a poor substitute for competence.

How to mitigate?
● In RDS:○ Use Multi-AZ○ Use replicas in multiple AZs○ Frequent backups (practicing restores)
● In EC2:○ Use a failover (Galera, Tungsten, MHA/HAProxy)○ Use multiple AZs and regions○ Frequent Backups (practicing restores)
● Throw away replicas and rebuild○ Monitoring latency to know when to throw away○ Don't waste time on corruption, triage then examine

How to mitigate?
● Poor Performance:○ Have playbooks for upping capacity as needed.○ Instance size, PIOPS, etc...
● Human Error:○ Change control - test changes○ Plan for failure - know how to revert○ Tool and automate as many DB interactions as
possible.

If you can't deal with expected and desired
change, you'll never be able to handle unexpected
and unwanted change.

Managing ChangeQuestions?

Regional failures
A well-designed architecture will save you.
Master/Master?How quickly can your DNS flip? How good is your replication?Do you have a CDN?Is your application going to run?
Not everybody can afford this.

Zones and Regions
A zone is analogous to a data center (for some small number of buildings).
A region is a geographically dispersed collection of zones that is distinct from any other region.

Zones & Regions differ
Different instance typesDifferent featuresDifferent provisioning capacity
OFA had ~40% of the US-East medium instances at one point. Couldn't duplicate that in US-West
Questions?

Cost

Reserved instances
● Substantial savings (how often do you turn off production databases?)
● Secondary market● Must match AZ and instance size

Spot instances
● Bid on spare/unused inventory.● Anytime your bid exceeds the current spot
price, you have access to those instances.● Significant cost savings for:
○ Time flexible operations○ Interrupt tolerant infrastructures
● Much cheaper than on-demand.

You spend money every minute
● Unlike in traditional DCs, hardware isn't paid for once, it is always being paid for.
● Elasticity isn't optional, you must always consider your capacity.
● Build evaluations into your regular checklists.○ Too much CPU? Too many IOPS? Too many
instances?

Watch the $
● Build a budget spreadsheet● Monitor and graph your estimated costs● Keep and review your Inventory
○ Reserved vs. On Demand○ Use spot for non-production
● Load analysis regularly● Cloudability!

Spreadsheets
● Track inventory● Compare options:
○ Reserved, 1 yr, 3 yr?○ Multi-AZ vs. Regular○ PIOPs
● Prepare a monthly budget and track it.

Tools
● http://promptcloud.com/ec2-ondemand-vs-reserved-instance-pricing.php
● http://www.ec2instances.info/● http://www.cloudability.com● http://www.longitudetech.
com/devops/automating-and-monitoring-your-aws-costs/

Monitoring
● Track estimated costs in your graphs● Set up cloudwatch alerts for budget amounts● Monitor for dead instances and remove
them.● Monitor spot instances for termination.

Storage
● Report on aging snapshots● Set TTL in S3 for backups, or else auto
move to glacier.● Don't over allocate storage unless your loads
are unpredictable. You can add more later.

Dynamicity
The only thing you can't do is downsize storage.
Change instance size? Check.Turn PIOPs off? Check.Delete replicas? Check.
Up to meet need. Down to meet budget.
FinAsk away!








![Chasing Chilliwack: recent historical Canadian census aggregate statistics [version 2] A workshop at ACCOLEDS 2008 Laine Ruus Laine Ruus laine.ruus@utoronto.ca](https://img.pdfslide.us/doc/110x75/56649dac5503460f94a9c5c8/chasing-chilliwack-recent-historical-canadian-census-aggregate-statistics.jpg)




















