Embed Size (px)
Citation preview

SCALABLE PACKET CLASSIFICATION USING INTERPRETING A CROSS-PLATFORM MULTI-CORE SOLUTION
Author: Haipeng Cheng, Zheng Chen, Bei Hua and Xinan Tang
Publisher/Conf.: ACM/PPoPP '08 (the 13th ACM SIGPLAN Symposium on Principles and practice of parallel programming)
Speaker: Han-Jhen Guo
Date: 2008.10.01

OUTLINE
Developing TIC Algorithm RFC Reduction Tree TIC Algorithm Description Instruction Encoding The Range Interpreter
Architecture-aware Design and Implementation
Simulation and Performance Analysis Relative Speedups for Core 2 Duo Relative Speedups for IXP2800
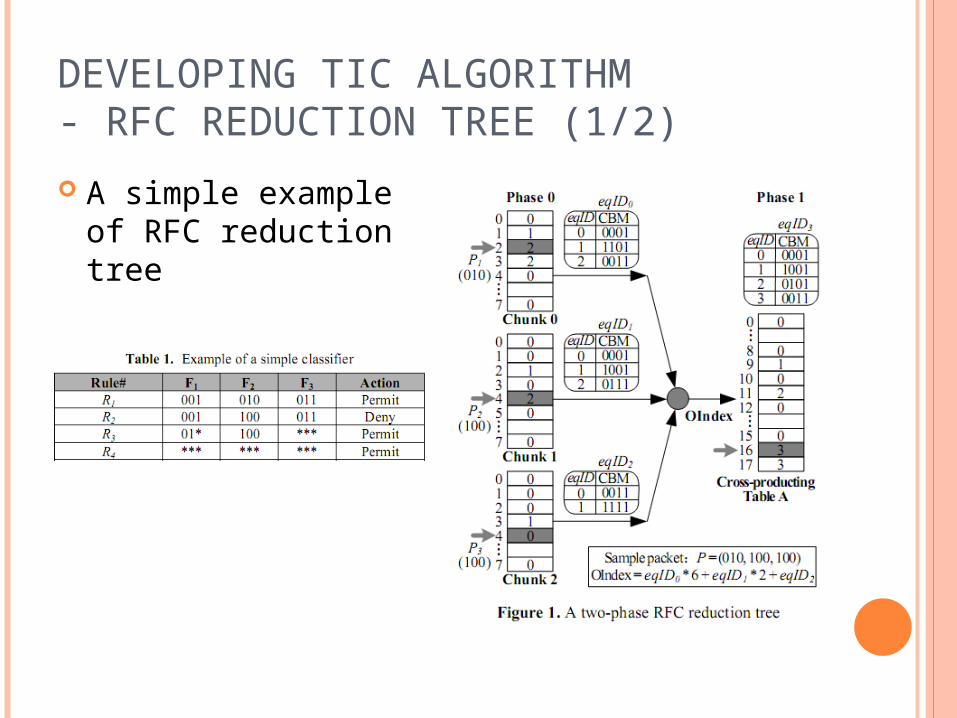
DEVELOPING TIC ALGORITHM- RFC REDUCTION TREE (1/2)
A simple example of RFC reduction tree
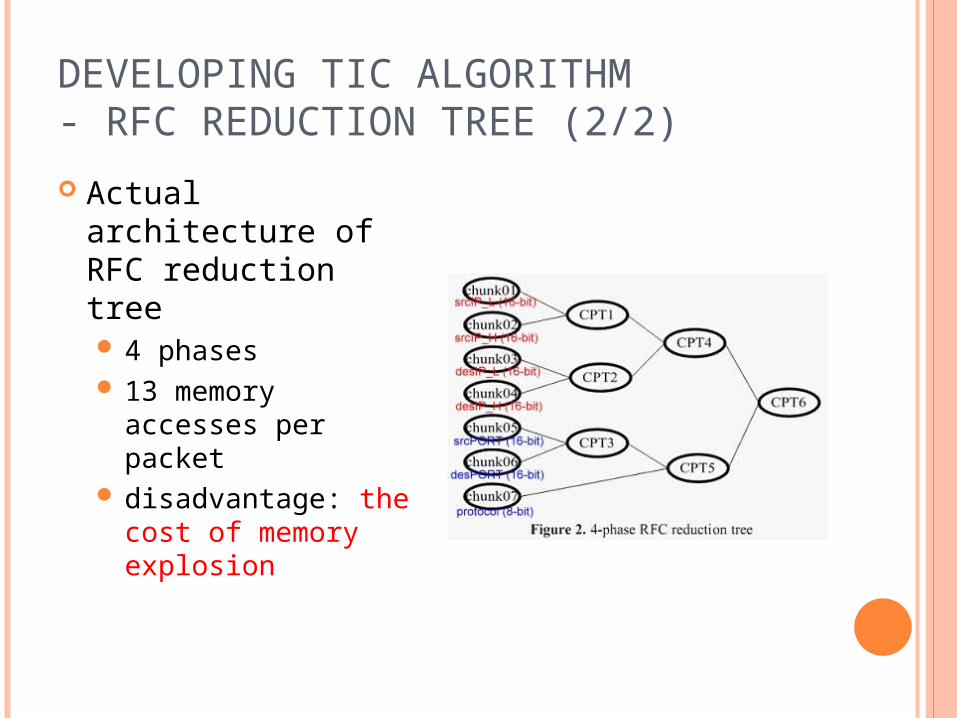
DEVELOPING TIC ALGORITHM- RFC REDUCTION TREE (2/2)
Actual architecture of RFC reduction tree 4 phases 13 memory accesses
per packet disadvantage: the
cost of memory explosion
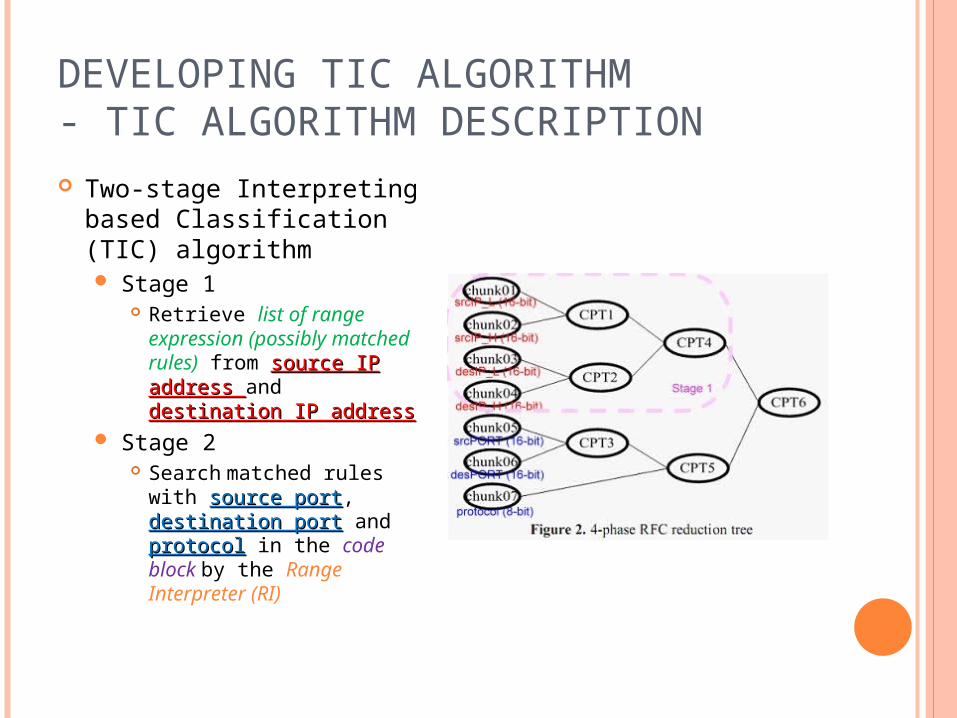
DEVELOPING TIC ALGORITHM- TIC ALGORITHM DESCRIPTION Two-stage Interpreting
based Classification (TIC) algorithm Stage 1
Retrieve list of range expression (possibly matched rules) from source IP address source IP address and destination IP addressdestination IP address
Stage 2 Search matched rules
with source portsource port, destination portdestination port and protocolprotocol in the code block by the Range Interpreter (RI)

DEVELOPING TIC ALGORITHM- INSTRUCTION ENCODING (1/2)
Operator (8-bit) protocol-srcPORT-
desPORT
Operand0 (8-bit) protocol
Operand1~Operand4 (16-bit) srcPORT (begin|end) desPORT (begin|end)
RuleID (16-bit) # of matched rules
the maximum # of rules in the classifiers is 64K (216)

DEVELOPING TIC ALGORITHM- INSTRUCTION ENCODING (2/2)
Classes of “ClassBench” port range
WC (wildcard) HI ([1024 : 65535]) LO ([0 : 1023]) AR (arbitrary range) EM (exact match)
protocol range WC EM
A small example of instruction encoding EM-WC-WC
use instruction of 4B

DEVELOPING TIC ALGORITHM- THE RANGE INTERPRETER
All instruction blocks are stored in external memory
we get the address of the first code block after the stage 1

ARCHITECTURE-AWARE DESIGN AND IMPLEMENTATION (1/3)
Hardware Intel Core 2 Duo with two levels of cache (multi-
core architecture) 4MB L2 cache size and 64B cache line size
Intel IXP2800 without cache (multi-threaded architecture)
ARCHITECTURE-AWARE DESIGN AND IMPLEMENTATION (2/3)
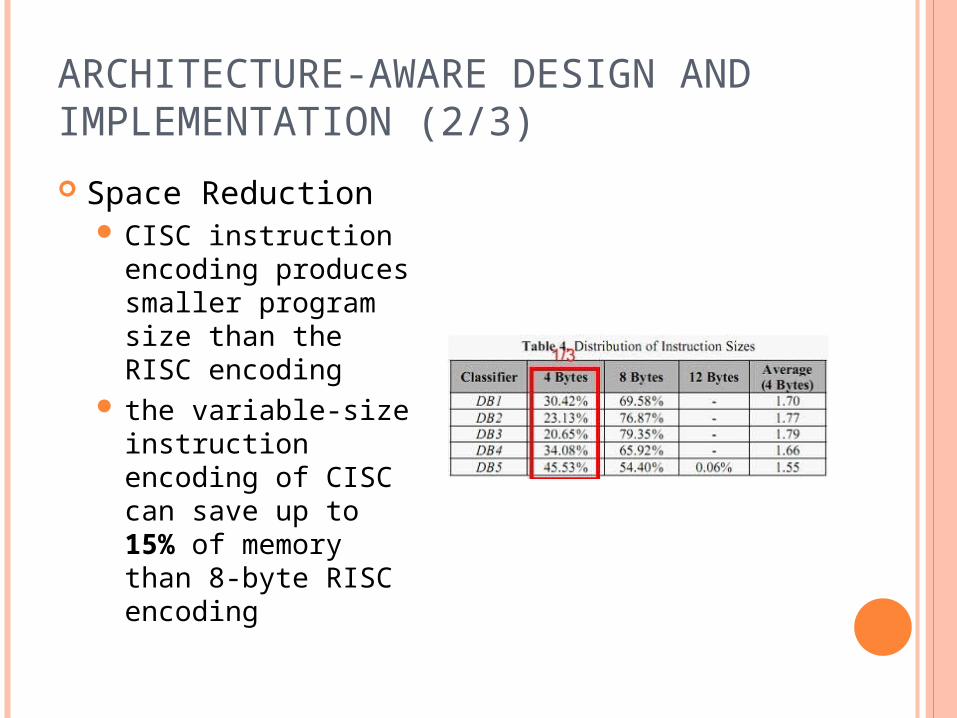
Space Reduction CISC instruction
encoding produces smaller program size than the RISC encoding
the variable-size instruction encoding of CISC can save up to 15% of memory than 8-byte RISC encoding

ARCHITECTURE-AWARE DESIGN AND IMPLEMENTATION (3/3)
Latency hiding of memory access Core 2
one CPU core can be used as a helper thread to warm up L2 cache
the other main thread can be executed faster if the same cache lines are already fetched
IXP28001) issuing outstanding memory requests whenever
possible memory operations in phase 0 at the first stage
can be simultaneously issued2) overlapping the memory access with the ALU
execution their memory address calculation can then be
overlapped with other memory operations
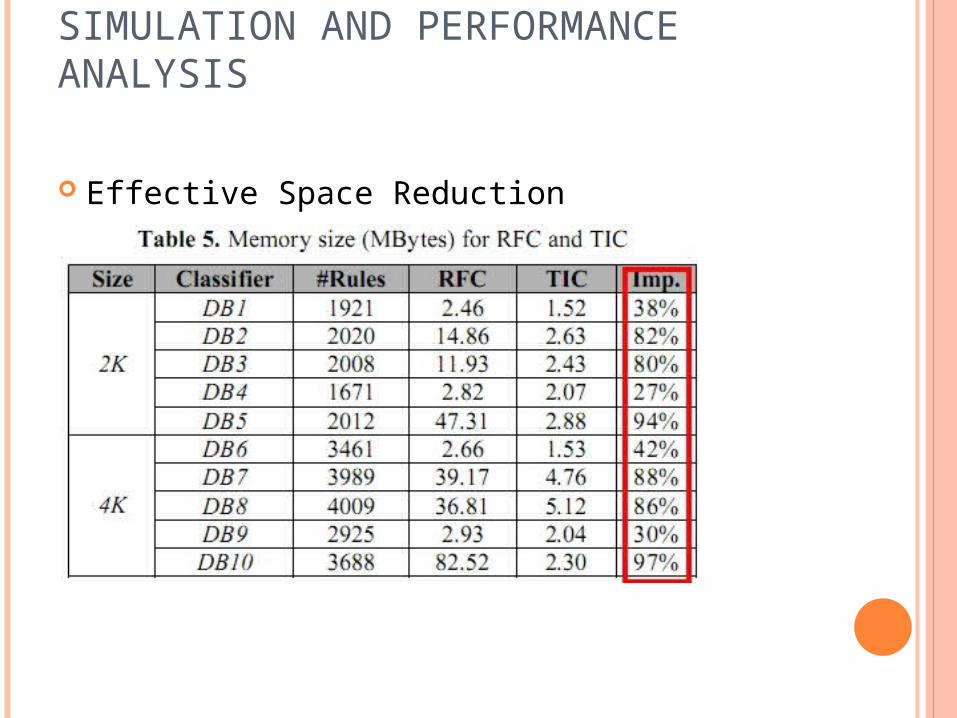
SIMULATION AND PERFORMANCE ANALYSIS
Effective Space Reduction
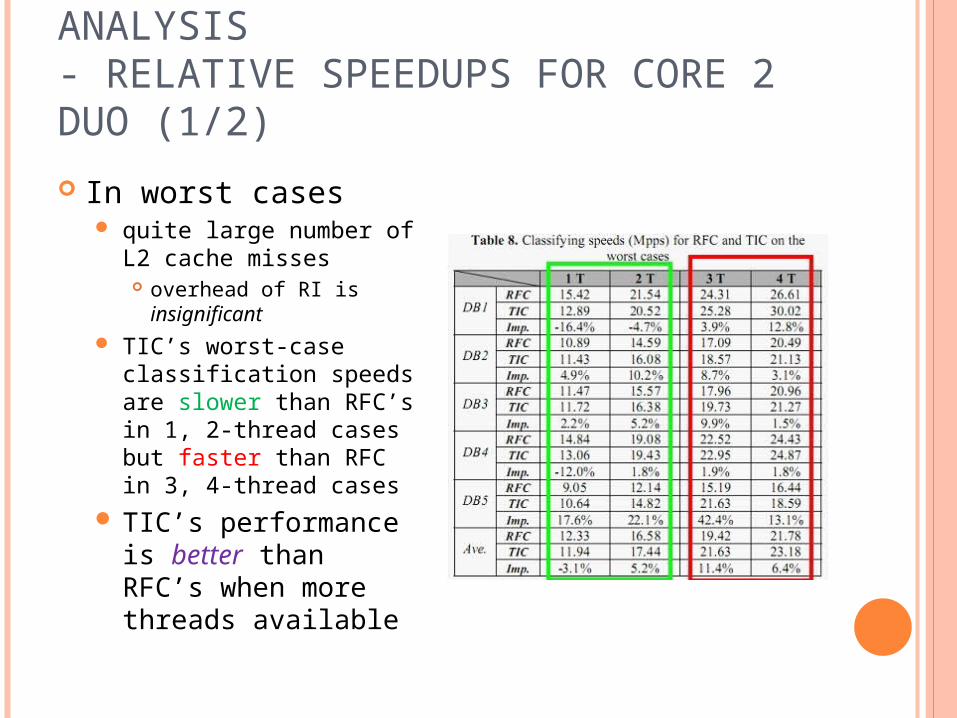
SIMULATION AND PERFORMANCE ANALYSIS- RELATIVE SPEEDUPS FOR CORE 2 DUO (1/2)
In worst cases quite large number of
L2 cache misses overhead of RI is
insignificant TIC’s worst-case
classification speeds are slower than RFC’s in 1, 2-thread cases but faster than RFC in 3, 4-thread cases
TIC’s performance is better than RFC’s when more threads available
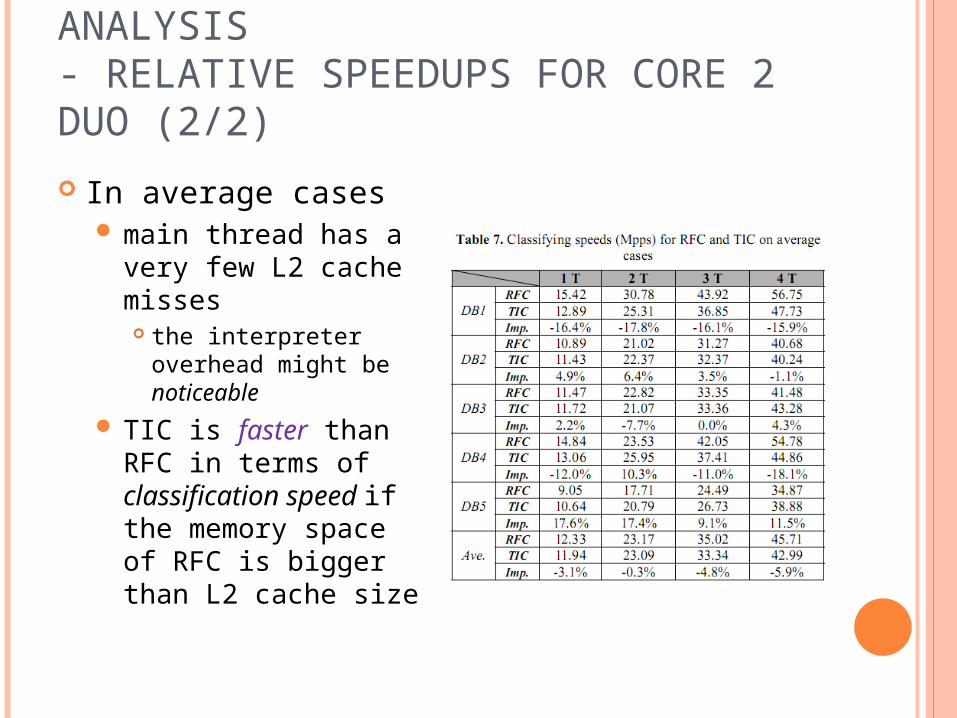
SIMULATION AND PERFORMANCE ANALYSIS- RELATIVE SPEEDUPS FOR CORE 2 DUO (2/2)
In average cases main thread has a
very few L2 cache misses the interpreter
overhead might be noticeable
TIC is faster than RFC in terms of classification speed if the memory space of RFC is bigger than L2 cache size

SIMULATION AND PERFORMANCE ANALYSIS- RELATIVE SPEEDUPS FOR IXP2800 (1/3)
TIC’s performance is worse than RFC’s

SIMULATION AND PERFORMANCE ANALYSIS- RELATIVE SPEEDUPS FOR IXP2800 (2/3)
Factors of poor performance Less memory access
but more long-words access
the FIFO size of TIC is bigger than that of RFC for both average and the worst cases a SRAM operation will
stay in FIFO longer for TIC than for RFC
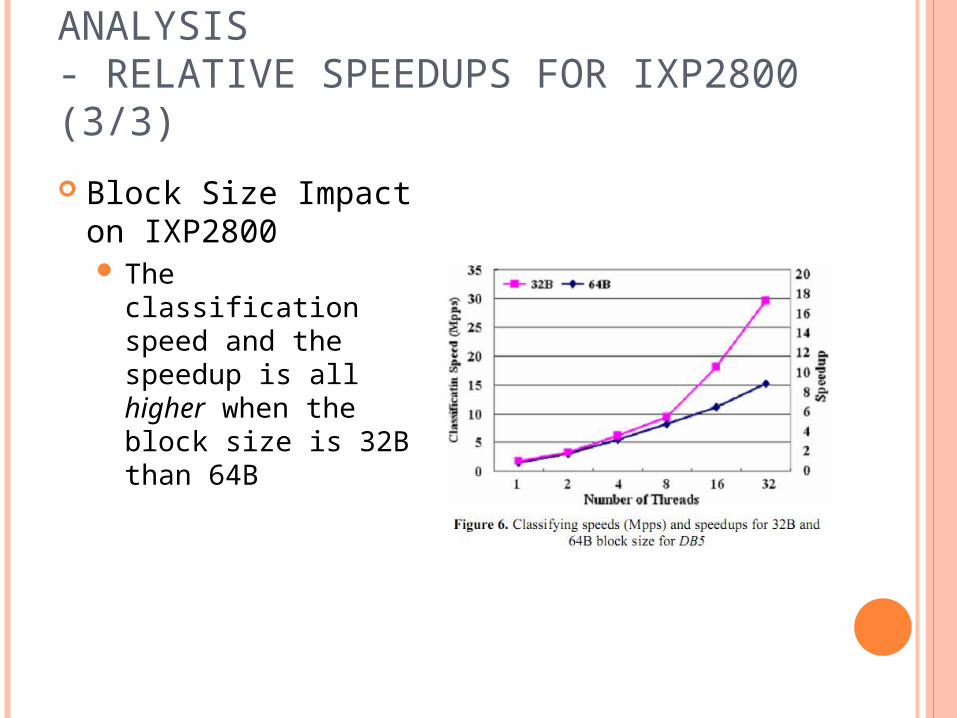
SIMULATION AND PERFORMANCE ANALYSIS- RELATIVE SPEEDUPS FOR IXP2800 (3/3)
Block Size Impact on IXP2800 The classification
speed and the speedup is all higher when the block size is 32B than 64B






























