Embed Size (px)
Citation preview

Information Sciences 179 (2009) 2662–2675
Contents lists available at ScienceDirect
Information Sciences
journal homepage: www.elsevier .com/locate / ins
Scalable multi-feature index structure for music databases q
Yu-Lung Lo *, Chu-Hui Lee, Chun-Hsiung WangDepartment of Information Management, Chaoyang University of Technology, Taichung County 413, Taiwan
a r t i c l e i n f o
Article history:Received 4 July 2008Received in revised form 26 March 2009Accepted 27 March 2009
Keywords:Multimedia databaseMusic databaseSuffix treeMulti-feature indexContent-based retrieval
0020-0255/$ - see front matter � 2009 Elsevier Incdoi:10.1016/j.ins.2009.03.019
q This work was supported by National Science Co* Corresponding author. Tel.: +886 4 23323000x7
E-mail address: [email protected] (Y.-L. Lo).
a b s t r a c t
The management of large collections of music data in a multimedia database has receivedmuch attention in the past few years. In the majority of current work, researchers extractthe features, such as melodies, rhythms, and chords, from the music data and develop indi-ces that will help to retrieve the relevant music quickly. Several reports have pointed outthat these music features can be transformed and represented in forms of music featurestrings or numeric values so that indices can be created for music retrieval. However, thereare only a small number of existing approaches which introduce multi-feature index struc-tures for music queries while most of the others are for developing single feature indices.The existing music multi-feature index structures are memory consuming and have lack ofscalability. In this paper, we will propose a two-tier music index structure which is an effi-cient and scalable approach for multi-feature music indexing. Our experimental resultsshow that this new approach outperforms existing multi-feature index schemes.
� 2009 Elsevier Inc. All rights reserved.
1. Introduction
With the explosive growth of multimedia applications, there is more and more non-alphabet data that now needs to beprocessed. This data, unlike the conventional numeric or character types of data, includes images, voices, films, documentsand so on. Most of the proposed approaches are content-based retrieval systems for manipulating these new data types [1,6–10,13,15,19,21,30,41,42]. Recently, with the rapid progress in digital representations of music data, the methods for effi-ciently managing a music database are receiving more attention. There are more and more increasingly attractive investiga-tions for retrieving music collections such as the Query by Rhythm by Chen et al. [4], Query by Music Segments by Chen et al.[5], Multi-Feature Index Structures by Lee and Chen [18], Non-Trivial Repeating Pattern Discovering by Liu et al. [22], LinearTime for Discovering Non-Trivial Repeating Patterns by Lo and Lee [27], Approximate String Matching Algorithm by Liu et al.[20], Key Melody Extraction and N-note Indexing by Tseng [34], Melodic Matching Techniques by Uitdenbogerd and Zobel[37], Numeric Indexing for Music Data by Lo and Chen [23,24] and more in [1–3,12,17,21,23,26,28,31,35,36].
In studies of music content-based retrieval, many approaches extract the features, such as key melodies, rhythms, andchords, from the music objects and develop indices that will help to retrieve the relevant music efficiently[16,22,24,26,28,32,33,39]. Several reports have also stated that these features of music can be transformed and representedin the form of music feature strings [4,5,12,18,21,28,34] or numeric values [23,25] so that indices can be created for musicretrievals. We can also combine these distinct features to support various types of queries. However, there are only a smallnumber of existing approaches that have introduced multi-feature index structures for music retrievals while most re-searches are for developing single feature indices. The existing music multi-feature string index structures are memory con-suming and have lack of scalability, whereas the numeric indexing approaches for music data are inflexible for varied query
. All rights reserved.
uncil of ROC Grant NSC 95-2221-E-324-039.121; fax: +886 4 23742337.

Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675 2663
lengths and are difficult to support for fault tolerance searching. In this paper, we will address the drawbacks of current mul-ti-feature indices for music data retrieval, proposing a two-tier multi-feature index structure for music query searching. Ourstudy will also show that the proposed index structure is more efficient and more economic in memory need than existingmulti-feature indexing approaches, though it is without query restriction.
The remainder of this paper is organized as follows: in Section 2, we specify the string indexing and numeric indexing formusic data retrieval. The existing music multi-feature indexing schemes are discussed in Section 3. Section 4 introduces ourproposed two-tier multi-feature index structure for music data, and then we show our experimental results in Section 5. Fi-nally, our conclusion is given in the last section.
2. Indexing for music data retrieval
Currently, string indexing and numeric indexing are the two main index approaches for music data retrieval. We willspecify these two indexing schemes in this section.
2.1. String indexing for music data
A suffix tree is a tree-like index structure representing all suffixes of a string which provides solutions for string matchingproblems [29,38,40]. It consists of the following characteristics:
� A suffix tree, constructed from a string with a length of m symbols, consists of m leaf nodes. These leaf nodes can be num-bered from 1 to m.
� Any two branches from a non-leaf node should be labeled with different symbols.� The number of each leaf node points out the start position of the sub-string which consists of the symbols labeled from the
root to this leaf node of the tree.
Recently, suffix trees are also used as indices for music feature strings to help searches within music databases [5,18].Suppose the music data consists of n notes, e.g. Do,Re,Mi, . . . and each note can be represented by a music symbol‘a’, ‘b’, ‘c’, . . ., respectively. Therefore, a melody can be represented as a music feature string by these music symbols. Forexample, if there is a music feature string represented as ‘‘ababc”, the suffix tree constructed from this music string canbe shown in Fig. 1.
2.2. Numeric indexing for music data
In 2000, Jagadish et al. proposed numeric mapping which maps a string into a real value [14]. Later, a numeric indexingtechnique for music data was proposed by Lo and Chen [23,25]. If the music data can be represented by a numeric value, thenan R-tree and many other numeric index structures can be used to construct an index for music data. For translating musicdata into numeric value, let us assume that the music symbols, ‘a’, ‘b’, ‘c’, . . . , ‘m’, can also map into integer values0,1,2, . . . ,m � 1, respectively. If we pick out a music segment with n continuous notes from a melody feature string, denotedx1; x2; . . . ; xn, the integer value of each note can be represented by PðxiÞ; 1 6 i 6 n. Therefore, this segment of n continuousnotes can be transformed into a numeric value by the conversion function – v(n), as shown below.
vðnÞ ¼Xn
x¼1
PðxÞ �mx�1 ð1Þ
For example, suppose there are 10 kinds of music notes denoted by ‘a’, ‘b’, ‘c’, . . . , ‘j’, and each of them maps into an integervalue of 0,1,2, . . . ,9, respectively. If there is a music segment with four symbols in which music feature string is denotedby ‘bcdb’, then this music feature string can be transformed into numeric value as: vð4Þ ¼ 1� 100 þ 2� 101þ
Fig. 1. An example of suffix tree for music string – ‘‘ababc”.

2664 Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675
3� 102 þ 1� 103 ¼ 1321. Afterwards, this value, 1321, can be inserted into the index, such as an R-tree [11], for music dataretrieval.
3. Existing multi-feature indexing for music data
In current research of indexing for music database retrieval, most of the existing work concentrates on constructing sin-gle-feature index structures for query searching: for instance, in 1999, the Key Melody Extraction and N-note Indexing byTseng [34], Melodic Matching Techniques by Uitdenbogerd and Zobel [37], Approximate String Matching Algorithm byLiu et al. [20]; in 2000, Query by Music Segments by Chen et al. [5]; and in 2002, Numeric Indexing by Lo and Chen [23].There are only a couple of researches that have focused on creating a multi-feature index for music data retrieval. Mostof the recent work is on Multi-Feature Index Structures [18] and Multi-Feature Numeric Indexing [25]. We will briefly dis-cuss these two approaches in the following sections.
3.1. Grid-Twin Suffix Trees
There were four multi-feature index structures for music data retrieval proposed by Lee and Chen [18], which consisted ofCombined Suffix Trees, Independent Suffix Trees, Twin Suffix Trees, and Grid-Twin Suffix Trees. Lee and Chen claimed thatthe structure of Grid-Twin Suffix Trees provided most scalability amongst them. Since the structure of Grid-Twin Suffix Treesis an improved version from Twin Suffix Trees, we will introduce the Twin Suffix Trees first.
There are two music features in Twin Suffix Trees and each feature has its own index structure of an independent suffixtree. There are links between them pointing from each node in one independent suffix tree to the corresponding featurenodes in another independent suffix tree. For example, they use letters, e.g., ‘a’, ‘b’, ‘c’, . . ., and ‘1’, ‘2’, ‘3’, . . ., to represent themelody symbols and rhythm symbols, respectively. They can then be combined into a two-feature music string, such as‘‘a1b2a2b1a2b2c2”. A portion of the Twin Suffix Tree for ‘‘a1b2a2b1a2b2c2” is shown in Fig. 2. There are links between two trees,from nodes ‘a’ and ‘b’ in the 2nd level of the melody suffix tree to corresponding nodes ‘1’ and ‘2’ in the 2nd level of therhythm suffix tree, to represent the melody string ‘‘ab” corresponding to rhythm string ‘‘12”.
Furthermore, Fig. 3 shows an overview of the structure for the Grid-Twin Suffix Tree. They first use a hash function to mapeach suffix of the feature string into a specific bucket of a two-dimensional grid. The hash function uses the first n symbols ofthe suffix to map it into a specific bucket. Considering melody and rhythm only, the hash function is as following,
Pðx; yÞ ¼Xn
i¼1
ðNummÞn
ðNummÞiMi;ðNumrÞn
ðNumrÞiRi
!ð2Þ
where x and y are the row and column coordinates, respectively, and P(x,y) denotes the position of the bucket. The Numm andNumr are the number of symbols for melody and rhythm, respectively. The Mi and Ri are the values of the ith symbols ofmelody and rhythm, respectively. The length of the suffix is denoted by n. Suppose Numm and Numr are both assumed tobe 3 in Fig. 3 and the values that represent melody symbols ‘a’, ‘b’, and ‘c’, and rhythm symbols ‘1’, ‘2’, and ‘3’ are the sameas 0, 1, and 2, respectively. To insert the first two symbols of the music feature string ‘‘a1b2a2c1a3”, said ‘‘a1b2”, it can be com-puted as Pðx; yÞ ¼ ð32=31 � 0;32=31 � 0Þ þ ð32=32 � 1;32=32 � 1Þ ¼ ð0;0Þ þ ð1;1Þ ¼ ð1;1Þ. It can then be mapped into the (1,1)bucket in Fig. 3. After hashing all suffixes, the remaining symbols of the feature string following the suffixes are used to con-struct the Twin Suffix Trees and accompanied under the buckets as shown in Fig. 3.
Fig. 2. Construction of the Twin Suffix Tree.

Fig. 3. An example of the Grid-Twin Suffix Trees.
Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675 2665
3.2. Multi-Feature Numeric Index
The Multi-Feature Numeric Index for music data retrieval was proposed by Lo and Chen [25]. As in Section 3.1, each musicfeature segment can be converted into a numeric value by an Eq. (1) and these values for a music feature segment can beseen as a coordinate for multi-dimensional space. As such, the coordinate can be inserted into a multi-dimensional indextree, such as an R-tree [11], for music retrieval. For example, if we assume there are two music features; melody, with 10distinct melody notes of ‘a’–‘j’ and rhythm, with 10 distinct symbols of ‘0’ to ‘9’, then the symbols of both features can beindividually mapped into integer values of 0–9, respectively. If there is a 2-feature music segment denoted by ‘‘a3b3c3a3”,then the melody string and rhythm string can be extracted as ‘‘abca” and ‘‘3333”, respectively. Consequently, these two fea-ture strings can be transformed into numeric values 210 and 2222 by Eq. (1). Thereafter, the two-dimensional coordinate,(210,2222), of the music segment can be inserted into a two-dimensional index R-tree for music retrieval. It also can be ex-tended for converting three or more features into a high dimensional index tree.
3.3. Discussions
We note that the memory space needed for grid structure of Grid-Twin Suffix Trees can be computed by the following equation:
Mðd; nÞ ¼ ðN1 � N2 � � � � � NdÞn � bucketsize ð3Þ
where d is the number of features, n is the number of symbols of the suffix to map it into a specific bucket, N1;N2; . . . ;Nd arethe number of symbols for each feature, and bucketsize is the size of each bucket in the grid structure. The authors claimedthat Grid-Twin Suffix Trees provided more scalability than the other three index structures in [18]. However, if there aremore features or we use more symbols of suffixes ðn > 2Þ to map into the buckets, a massive memory space is needed forGrid-Twin Suffix Trees to construct buckets of grid structure. For example, suppose there are three features and each featurehas 20 symbols. If the first two symbols of suffix ðn ¼ 2Þ are hashed into buckets, by Eq. (3), there will beð20� 20� 20Þ2 ¼ 64 million buckets in the grid structure of Grid-Twin Suffix Trees. They may need a huge memory spaceand a sparse matrix may occur in the grid structure. We also note that the Twin Suffix Trees accompanied under the gridstructure have to be added for the memory needed of the entire Grid-Twin Suffix Trees. Furthermore, this approach didnot point out the index structure for Twin Suffix Trees if there are three or more music features. Therefore, the scalabilityof Grid-Twin Suffix Trees for a number of music features is unclear.
In addition, since numeric index is created by transforming fixed length, n in Eq. (1), of music segment into numeric value,the main drawback of the Multi-Feature Numeric Index is that the length of example issued by a query (Query By Example,QBE) is inflexible. It had better equal to the length of music segment which the index created. Otherwise, searching time forthe query will be increasingly multiplied. For example, suppose the length is 4 for transforming the music segment into nu-meric value to create an index. If a query is 5 in length, such as ‘‘abcde”, it will be spread into 2 music segments, ‘‘abcd” and‘‘bcde”, thereby doubling the processing time for searching in the index.
4. Two-Tier Multi-Feature Indexing for music data
In this section, we present our proposed Two-Tier Multi-Feature Indexing for music data retrieval, to address the problemof Grid-Twin Suffix Trees for three or more music features, We will use the advantages of Multi-Feature Numeric Index and

2666 Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675
Grid-Twin Suffix Trees to construct our new index structure so that our proposed index structure will require less memoryspace than is currently necessary for Grid-Twin Suffix Trees. In addition, unlike Multi-Feature Numeric Index, our new indexstructure will be without any restrictions on query length. Our approach has not only more scalability than existing schemesbut is also more efficient in query searching.
4.1. Construction of Two-Tier Multi-Feature Index
Similar to a Gird-Twin Suffix Tree, there are two layers in our Two-Tier Multi-Feature Index Structure. Firstly, we use a d-feature tree structure instead of grid structure in Grid-Twin Suffix Trees. Then, the suffix trees with bit arrays are designed toaccompany under the corresponding leaf nodes of the d-feature tree. We organize the construction of Two-Tier Multi-Fea-ture Index Structure in the following two steps:
Step 1. Creating a d-Feature Tree – Suppose that there are d features in music data and, in each music feature string, thefirst n symbols of the suffix will be transformed into a coordinate. We design mapping function (4) for d-featurecoordinate Pðx1; . . . ; xdÞ as follows,
Pðx1; . . . ; xdÞ ¼Xn
i¼1
F1ðiÞ � Nn�i1 ; . . . ; FdðiÞ � Nn�i
d
� �ð4Þ
where F1ðiÞ; . . . ; FdðiÞ and N1; . . . ;Nd represent the values and sizes of alphabet symbols, respectively, for d musicfeatures. We note that a suffix within any music segment, such as ‘‘a1” or ‘‘a1b2”, will have only one correspondingcoordinate. The coordinate, derived from Eq. (4), is then inserted into a d-feature (d-dimensional) tree. The degreeof each non-leaf node in this d-feature tree is 2d. There is also a center point for each non-leaf node. The coordinate,ðx1c; x2c; . . . ; xdcÞ, of the center point is computed by averaging the coordinates inserted under the current node orits descendent nodes. For example, if there are two features and the center point is ðx1c; x2cÞ, the node will be par-titioned into four domains, ðP x1c;P x2cÞ, ð< x1c;P x2cÞ, ðP x1c; < x2cÞ, and ð< x1c; < x2cÞ. To keep the index treebalanced as an R-tree, each non-leaf node in this d-feature tree contains at least 2d�1 not null links (half full).Therefore, to insert a new coordinate into a node, it may cause the center point to be re-computed or may causethe index tree to be reorganized. An example of a 2-feature tree for music data is presented in Fig. 4.
Step 2. Linking of Suffix Tree with bit arrays – The remaining symbols behind the first n symbols of suffix are then used toconstruct the suffix trees accompanied under the d-feature tree structure at Pðx1; . . . ; adÞ. Instead of the linksbetween corresponding feature nodes in a Twin Suffix Tree, we create the bit arrays to indicate the relationshipsbetween each suffix tree. Each non-leaf node of the suffix tree for the first feature consists of d � 1 bit arrays. Thenumber of entries (bits) for each bit array is the number of symbols (m) for each of the corresponding features sothat the bit arrays can record the relationships (or virtual links) of this first feature and each of the other features.Similarly, each non-leaf node in the suffix tree of the second feature consists of d � 2 bit arrays to record the rela-tionships with other d � 2 features. Furthermore, the non-leaf nodes in the suffix trees of third, fourth, and subse-quent features should consist of the bit arrays in the same manner, except the suffix tree of the last feature withouta bit array. The relationship between two suffix trees denotes the occurrence of the symbol combinations of thetwo features. For example, ‘‘a1b2” representing melody ‘a’ and ‘b’ combined with rhythm ‘1’ and ‘2’, respectively,may occur in one part or some of the music. If there is a bit array in each node of the melody suffix tree recordingits relationship with the rhythm suffix tree, the corresponding bits in the bit array of node ‘a’ related to node ‘1’ andnode ‘b’ related to node ‘2’ will be marked as 1. Therefore, the structures of suffix trees with bit arrays for two fea-
Fig. 4. A 2-feature tree for music data.

Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675 2667
tures and three features can be presented in Figs. 5 and 6. In Fig. 5, there is a bit array in each non-leaf node of themelody suffix tree indicating the relationship with the rhythm suffix tree. The first bit in the bit array of ‘a’ marked‘1’ denotes that ‘a1’ occurs in some of the music. Likewise, in Fig. 6, there are two bit arrays in the melody suffix treeindicating the relationships with the rhythm suffix tree and the chord suffix tree. There is also a bit array in eachnon-leaf node of the rhythm suffix tree indicating its relationship with the chord suffix tree. A perspective of Two-Tier Multi-Feature Index for 2-feature music data is shown in Fig. 7.
Moreover, Figs. 8 and 9 represent the sketches of Two-Tier Multi-Feature Index structures for 2-Feature and for 3-Featuremusic data, respectively. We also note that the degrees of each node in d-feature trees for these two indexes are 4 and 8.
4.2. An example for constructing the Two-Tier Multi-Feature Index
In this section, we will provide an example of 2-feature music data to give a clear image for our proposed index scheme.We will assume that melody and rhythm each have three symbols; the values that represent melody symbols ‘a’, ‘b’, and ‘c’,and rhythm symbols ‘1’, ‘2’, and ‘3’ could be 0, 1, and 2, respectively. We will suppose there are five music feature segments,‘‘a2c1a3b2”, ‘‘b2a3b1a3”, ‘‘c1a3b2b2”, ‘‘b2c3b1b2”, and ‘‘a1b2c1b2”, being inserted into the Two-Tier Multi-Feature Index. Whenthe first two symbols of suffixes are transformed into coordinate, the five coordinates can be computed in Table 1.
Since there are two music features, the degrees of each non-leaf node in the 2-feature tree are 4. We insert Pðx1; x2Þ of thefirst four suffixes into the tree and the center point of the root node is (4,3.75) which can be computed by averaging thesefour coordinates. The four Pðx1; x2Þ’s fall into the four different regions of the root node as shown in Fig. 10. The remaining
Fig. 5. Bit array in non-leaf node of 2-feature suffix trees.
Fig. 6. Bit arrays in non-leaf nodes of 3-feature suffix trees.

Fig. 7. A perspective of Two-Tier Multi-Feature Index.
Fig. 8. Two-Tier 2-Feature Index structures.
2668 Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675
symbols behind the first two symbols of suffix are also used to create Suffix Trees with bit arrays accompanied under eachregion as well.
Furthermore, since the fifth coordinate (1,1) has to be inserted into the left-down region of the root node, a new node iscreated. There will be two non-null links in the new node as shown in Fig. 11 and the center point for the new node is (1.5,2).
In addition, we will give an example to illustrate the creation of Suffix Trees with bit arrays. We will use the two musicfeatures as discussed previously (melody and rhythm with three symbols each). Let us suppose there is a music feature seg-ment – ‘‘a1b2a2b1a2b2c2”. Firstly, the rhythm string ‘‘1221222” is used to construct a suffix tree without bit array, as followsin Fig. 12. Then, since the rhythm has three symbols, a bit array that consists of 3 bits is created for each node of suffix tree

Fig. 9. Two-Tier 3-Feature Index structures.
Table 1The coordinates for suffixes.
Music string Computed by Eq. (4) Pðx1; y2Þ
a2c1a3b2 ð0 � 31;1 � 31Þ þ ð2 � 30; 0 � 30Þ (2,3)b2a3b1a3 ð1 � 31;1 � 31Þ þ ð0 � 30;2 � 30Þ (3,5)c1a3b2b2 ð2 � 31; 0 � 31Þ þ ð0 � 30;2 � 30Þ (6,2)b2c3b1b2 ð1 � 31;1 � 31Þ þ ð2 � 30;2 � 30Þ (5,5)a1b2c1b2 ð0 � 31; 0 � 31Þ þ ð1 � 30;1 � 30Þ (1,1)
Fig. 10. An example of constructing Two-Tier 2-Feature Index.
Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675 2669
for melody as shown in Fig. 13. In the bit arrays, each bit represents the relationship to the rhythm symbols ‘1’, ‘2’, and ‘3’from left to right. If some bit is set to 1 in the bit array of a node, it denotes that the melody symbol of the node accompaniesthe bit representing a rhythm symbol occurring in some music segments, such as ‘‘a1” in Fig. 13.
4.3. Searching in Two-Tier Multi-Feature Index
To retrieve the Two-Tier Multi-Feature Index, we first use Eq. (4) to convert the first n symbols of query string into cor-responding coordinate. This coordinate is an entry located in the leaf node of the d-feature tree. We then continue to exam-ine the remaining symbols of query in the feature suffix trees under the entry. To search in the suffix trees, the pointerssimultaneously scan the corresponding suffix trees node by node. If some value in bit array of a node is marked 1, thereshould be a pointer to visit a corresponding node in the relative suffix tree. If not, the search will fail and the target will

Fig. 11. Inserting a new node.
Fig. 12. Construction of the rhythm suffix tree (not all links are shown).
Fig. 13. An example of creating suffix tree with bit array.
2670 Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675
Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675 2671
not be found. For example, if ‘‘a2b1a1b2” is a query string, we initially convert the first two symbols of query string into thecorresponding coordinate, so that ‘‘a2b1” is converted into ð0 � 31;1 � 31Þ þ ð1 � 30;0 � 30Þ ¼ ð1;3Þ. This coordinate (1,3) is ap-plied for searching in the d-feature tree to find the entry in music feature suffix trees. There will be two pointers searchingthe remaining symbols ‘‘a1b2” in the melody suffix tree and rhythm suffix tree (like in Fig. 13). Since the first and second bitsin bit array represent rhythm symbols 1 and 2, respectively, ‘‘a1b2” can be found in the melody (left) tree and ‘‘12” can also befound in the rhythm (right) tree in Fig. 13. The query results will be the music objects synchronously found under the search-ing path of ‘‘ab” and ‘‘12” in the melody suffix tree and the rhythm suffix tree, respectively.
5. Performance study
In order to evaluate the performance of our new approach, a series of experiments are performed in this section. In Sec-tion 3, we discussed that the disadvantages of Multi-Feature Numeric Index [25] were the inflexibility for query length andits limitations in database practice. This will not, therefore, be used for comparison in our study. The Grid-Twin Suffix Trees[18] (GTST) and our Two-Tier Multi-Feature Index (2TiMI) are without any specific limitation for query lengths. Therefore,we need to discover the memory required and how much response time is consumed by comparing 2TiMI with GTST. Ordi-narily, in researches of music database retrieval, music themes or repeating segments are usually stored separately in dat-abases instead of storing entire melodies to save storage [12,20,26,28]. Our experimental database will consist of musicsegments only and the average length of every feature in each segment is 16. We will consider the following four factorsin our experiments and the parameters used are also listed in Table 2:
(a) The effect of the number of symbols for each feature ðNiÞ.(b) The effect of music database size.(c) The effect of query length (l).(d) The effect of the number of music features (d).
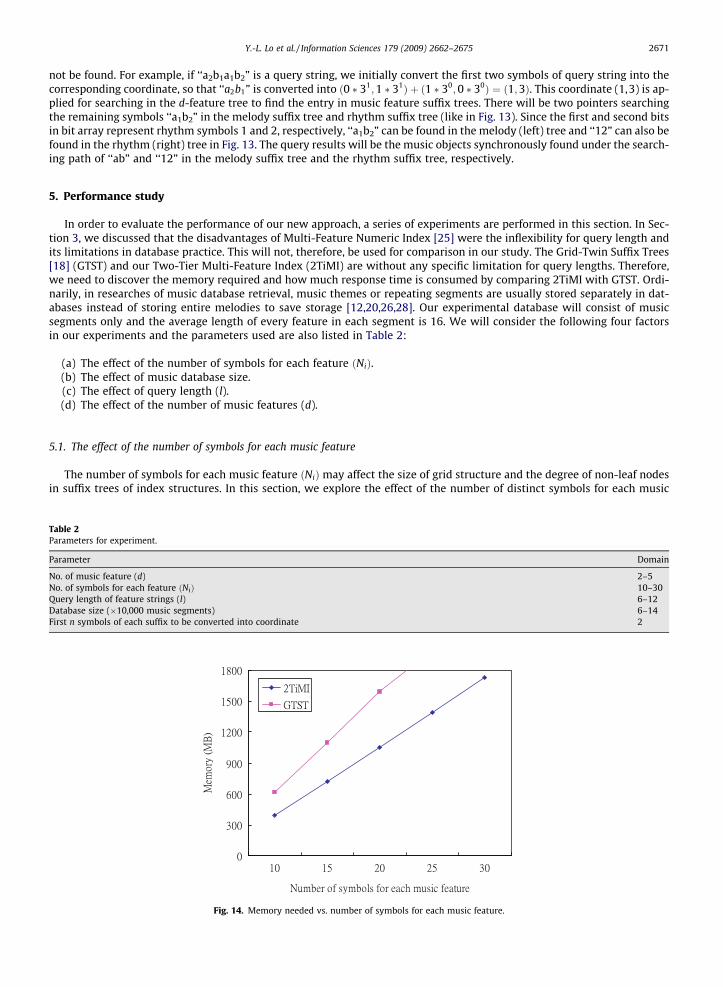
5.1. The effect of the number of symbols for each music feature
The number of symbols for each music feature ðNiÞmay affect the size of grid structure and the degree of non-leaf nodesin suffix trees of index structures. In this section, we explore the effect of the number of distinct symbols for each music
Table 2Parameters for experiment.
Parameter Domain
No. of music feature (d) 2–5No. of symbols for each feature ðNiÞ 10–30Query length of feature strings (l) 6–12Database size (�10,000 music segments) 6–14First n symbols of each suffix to be converted into coordinate 2
Fig. 14. Memory needed vs. number of symbols for each music feature.

2672 Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675
feature. In this experiment, we suppose there are melody and rhythm, two music features and a database consisting of100,000 music segments. For simplification, the number of symbols for every feature will be the same and vary from 10to 30. The experimental result is presented in Fig. 14. This clearly demonstrates that 2TiMI always outperforms GTST withapprox. 35% memory saving than GTST in each case. This is due to the size of the grid structure of GTST, which will need toincrease when adding more symbols for each music feature. However, the memory consumption for the 2-feature tree of2TiMI performs in a consistent manner and is not affected by varying the number of symbols for every feature. In addition,adding one symbol will lead to the creation of one more link pointer (normally 4 bytes) for non-leaf nodes of twin suffix treesof GTST. However, there is only one bit added for bit array in non-leaf nodes of suffix trees of 2TiMI.
5.2. The effect of database size
In this section, we will demonstrate the scalability of both index schemes and observe the effect of music database size.Since the structure of Twin Suffix Trees for three or more music features was not pointed out for GTST in [18], we will onlyexamine two music features in this study. In this experiment, we investigate melody and rhythm as the two features of mu-sic. We will suppose that there are 20 notes most frequently used, and that the number of symbols for melody can be set to20. We also suppose that the rhythm consists of 1/8, 1/4, 1/2, 3/8, 3/4, 1, 1 1/4, 1 1/2, 1 3/4, 2, etc., and assume the numbermost frequently used for rhythm is 15 and that, therefore, the number of symbols for rhythm can be 15. The size of the musicdatabase is varied between 60,000 and 140,000 music segments. The experimental result is displayed in Fig. 15. Although thememories required for both index structures grow as the database size increases, the raising of 2TiMI curve is smoother thanGTST. 2TiMI, again, consistently has around 35% improvement compared to GTST. This study demonstrates that 2TiMI hasmore scalability than GTST and is suitable for large databases in practice.
Fig. 15. Memory needed vs. database sizes.
Fig. 16. Average response time vs. query length.

Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675 2673
5.3. The effect of query length
The efficiency of query processing in 2TiMI and GTST is also an important issue to discuss. We would like to demonstratehow well 2TiMI and GTST can perform a variety of query lengths. Again, we suppose there are two music features (20 sym-bols for melody and 15 symbols for rhythm) and the database consists of 100,000 music segments. The query length for eachmusic segment will be the same and vary from 6 to 14. Our experimental computer consists of an AMD Athlon 64 � 2 Dualcore processor 3800+ and 2 GB RAM. We examined 60,000 queries for each query length setting and calculated the averageresponse time for each investigation. The experimental result is shown in Fig. 16. Not surprisingly, average response timesare raised for both 2TiMI and GTST when we increase the query lengths. Nevertheless, the curve of 2TiMI grows at a morerelaxed pace as query length increases, demonstrating that it outperforms GTST, saving from 20% to 30% in average responsetime. This improvement for 2TiMI continues to expand as query length rises. The main reason for the difference is that GTSTspends too much time in examining the links in twin suffix trees whilst 2TiMI simply checks the bit arrays instead.
5.4. The effect of the number of music features
The number of music features will affect the memory required for constructing the index and the response time for querysearching. Since the structure of Twin Suffix Trees for three or more music features was not established for GTST in [18], inthis section we will only determine the scalability for 2TiMI. The number of music features to be examined varies from twoto five. For simplification, the number of symbols for each feature is set to 20. As in the previous experiments, we investi-gated 100,000 music feature segments in our database. Furthermore, 60,000 queries, each of 10 in length are used to exam-ine the average response time for every parameter setting change in the number of music features. Fig. 17 shows thememory consumption for index structure and Fig. 18 presents the average response for query searching for 2TiMI in all mu-
Fig. 17. Memory needed vs. number of music features.
Fig. 18. Average response time vs. number of music features.

2674 Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675
sic feature settings. Both curves in Figs. 17 and 18 tend to ascend. However, they do so in a linear manner (linear scale up) asthe number of music features increases. This demonstrates that 2TiMI has the scalability to deal with increasing the numberof music features in a multi-feature index structure.
6. Conclusion
There are many features in music data, such as melodies, rhythms, chords and the tone differences of adjacent notes. Wecan extract these features to develop the multi-feature index to enhance the speed of query searching and to improve theaccuracy of query results. The investigations on multi-feature indexing for music data are relatively rarer in current researchof music data retrieval. In this paper, we have proposed an index structure, named Two-Tier Multi-Feature Index, for musicdatabase retrieval. Our Two-Tier Multi-Feature Index uses a d-feature tree structure concatenating suffix trees with bit ar-rays instead of grid structure linking twin suffix trees in Grid-Twin Suffix Trees [18]. In our approach, the first couple of sym-bols of suffix are transformed into a coordinate then inserted into a d-feature tree. Thereafter, the remaining symbols behindthe first couple of symbols are then used to construct the bit-array suffix trees accompanied under the d-feature tree. Weexamined our approach by comparison with Grid-Twin Suffix Trees using several variable parameter experiments. As ex-pected, our experimental results show that the memory needed for our proposed Two-Tier Multi-Feature Index is less thanis required for existing index structure. Moreover, the average response time for our Two-Tier Multi-Feature Index also out-performs any existing scheme. We have also demonstrated that our Two-Tier Multi-Feature Index is more scalable to sup-port large music databases. For future work, we expect our approach can not only be used for music databases but also beapplied in all multimedia or related databases.
References
[1] B. Acharya, A.K. Majumdar, J. Mukherjee, Video model for dynamic objects, Information Sciences 176 (17) (2006) 2567–2602.[2] S. Blackburn, D. DeRoure, A tool for content-based navigation of music, in: Proceedings of ACM Multimedia, 1998, pp. 361–368.[3] E. Cambouropoulos, M. Crochemore, C.S. Iliopoulos, M. Mohamed, M.-F. Sagot, All maximal-pairs in step–leap representation of melodic sequence,
Information Sciences 177 (9) (2007) 1954–1962.[4] J.C.C. Chen, Arbee L.P. Chen, Query by rhythm an approach for song retrieval in music databases, in: Proceedings of the International Workshop on
Research Issues in Data Engineering, 1998, pp. 139–146.[5] A.L.P. Chen, M. Chang, J. Chen, J.L. Hsu, C.H. Hsu, Spot Y.S. Hua, Query by music segments: an efficient approach for song retrieval, in: Proceedings of the
IEEE International Conference on Multimedia and Expro, 2000, pp. 873–876.[6] G. Davenport, T.A. Smith, N. Pincever, Cinematic primitives for multimedia, IEEE Computer Graphics & Applications (1991) 67–74.[7] Y.F. Day, S. Pagtas, M. Iino, A. Khokhar, A. Ghafoor, Object-oriented conceptual modeling of video data, in: Proceedings of the IEEE Data Engineering,
1995, pp. 401–408.[8] E.A. El-Kwae, M.R. Kabuka, Efficient content-based indexing of large image databases, ACM Transactions on Information Systems 18 (2) (2000) 171–
210.[9] G. Erozel, N.K. Cicekli, I. Cicekli, Natural language querying for video databases, Information Sciences 178 (12) (2008) 2534–2552.
[10] S.-T. Goh, K.-L. Tan, MOSAIC: a fast multi-feature image retrieval system, Data & Knowledge Engineering, vol. 33 (3), Elsevier Science Publishing Inc.,North-Holland, 2000, pp. 219–239.
[11] A. Guttman, R-Tree a dynamic index structure for spatial search, in: Proceedings of the 1984 ACM SIGMOD International Conference on Management ofData, 1984, pp. 47–57.
[12] J.L. Hsu, C.C. Liu, Arbee L.P. Chen, Efficient repeating pattern finding in music databases, in: Proceedings of ACM International Conference onInformation and Knowledge Management, 1998, pp. 281–288.
[13] K.A. Hua, K. Vu, J.H. Oh, SamMatch: a flexible and efficient sampling-based image retrieval technique for large image databases, in: Proceedings of theACM Multimedia, 1999, pp. 225–234.
[14] H.V. Jagadish, N. Koudas, D. Srivastava, On effective multi-dimensional indexing for strings, in: Proceedings of the ACM SIGMOD, 2000, pp. 403–414.[15] W.-C. Kim, J.-Y. Song, S.-W. Kim, S. Park, Image retrieval model based on weighted visual features determined by relevance feedback, Information
Sciences 178 (22) (2008) 4301–4313.[16] C.L. Krumhansl, Cognitive Foundations of Musical Pitch, Oxford University Press, New York, 2001.[17] S. Kiranyaz, M. Gabbouj Senior Member, Hierarchical cellular tree: an efficient indexing scheme for content-based retrieval on multimedia databases,
IEEE Transactions on Multimedia 9 (1) (2007) 102–119.[18] W. Lee, A.L.P. Chen, Efficient multi-feature index structures for music data retrieval, in: Proceedings of SPIE Conference on Storage and Retrieval for
Image and Video Database, 2000, pp. 177–188.[19] C.C. Liu, Arbee L.P. Chen, 3D-List: a data structure for efficient video query processing, IEEE Transactions on Knowledge and Data Engineering 14 (1)
(2002) 106–122.[20] C.C. Liu, J.L. Hsu, Arbee L.P. Chen, An approximate string matching algorithm for content-based music data retrieval, in: Proceedings of IEEE
International Conference on Multimedia Computing and Systems, 1999, pp. 451–456.[21] C.-H. Lin, A.L.P. Chen, Indexing and matching multiple-attribute strings for efficient multimedia query processing, IEEE Transactions on Multimedia 8
(2) (2006) 408–411.[22] C.C. Liu, J.L. Hsu, A.L.P. Chen, Efficient theme and non-trivial repeating pattern discovering in music databases, in: Proceedings of the IEEE Data
Engineering, 1999, pp. 14–21.[23] Y.-L. Lo, S.-J. Chen, The numeric indexing for music data, in: Proceedings of IEEE 22nd International Conference on Distributed Computing Systems
(ICDCS’2002) Workshops – The Fourth International Workshop on Multimedia Network Systems and Applications (MNSA’2002), Vienna, Austria, July2002, pp. 258–263.
[24] Y.-L. Lo, S.-J. Chen, Numeric indexing approach for music database retrieval, Journal of Chaoyang University of Technology 2 (2002) 141–163. ISSN:1026-244X.
[25] Y.-L. Lo, S.-J. Chen, Multi-feature indexing for music data, in: Proceedings of IEEE 23nd International Conference on Distributed Computing Systems(ICDCS’2003) Workshops – The Fifth International Workshop on Multimedia Network Systems and Applications (MNSA’2003), Providence, RI, May 19–22, 2003, pp. 654–659.
[26] Y.-L. Lo, H.-C. Yu, M.-C. Fan, Efficient non-trivial repeating pattern discovering in music databases, Tamsui Oxford Journal of Mathematical Sciences 17(2) (2001) 163–187.

Y.-L. Lo et al. / Information Sciences 179 (2009) 2662–2675 2675
[27] Y.-L. Lo, W.-L. Lee, Linear time for discovering non-trivial repeating patterns in music databases, in: Proceedings of 2004 IEEE International Conferenceon Multimedia and Expro (ICME), vol. 1, Taipei, Taiwan, June 27–30, 2004, pp. 293–296.
[28] Y.-L. Lo, W.-L. Lee, L.-H. Chang, True suffix tree approach for discovering non-trivial repeating patterns in a music object, Journal of Multimedia Toolsand Applications 37 (2) (2008) 169–187.
[29] E. McCreight, A space-economical suffix tree construction algorithm, Journal of Association for Computing Machinery (1976) 262–272.[30] J.H. Oh, K.A. Hua, Efficient and cost-effective techniques for browsing and indexing large video databases, in: Proceedings of the ACM DIGMOD, 2000,
pp. 415–426.[31] S. Rein, M. Reisslein, Identifying the classical music composition of an unknown performance with wavelet dispersion vector and neural nets,
Information Sciences 176 (12) (2006) 1629–1655.[32] T. Sonoda, T. Ikenaga, K. Shimizu, Y. Muraoka, The design method of a melody retrieval system on parallelized computers, in: Proceedings of the Second
International Conference on Web Delivering of Music, 2002, pp. 66–73.[33] B. Schuller, G. Rigoll, M. Lang, Multimodal music retrieval for large databases, in: Proceedings of IEEE International Conference on Multimedia and Expo
(ICME), vol. 2, June 2004, pp. 755–758.[34] Y.H. Tseng, Content-based retrieval for music collections, in: Proceedings of the ACM SIGIR’99, 1999, pp. 176–182.[35] M. Tang, Y.C. Lap, B. Kao, Selection of melody lines for music databases, IEEE Multimedia (2000) 243–248.[36] T.-H. Tsai, J.-H. Hung, Content-based retrieval of MP3 songs for one singer using quantization tree indexing and melody-line tracking method, in:
Proceedings of the ICASSP 2006, May 2006, pp. 505–508.[37] A.L. Uitdenbogerd, J. Zobel, Melodic matching techniques for large music databases, in: Proceedings of the ACM Multimedia, 1999, pp. 57–66.[38] E. Ukkonen, On-line construction of suffix tree, Algorithmica 14 (1995) 249–260.[39] Y.-D. Wu, Y. Li, B.-L. Liu, A new method for approximate melody matching, in: Proceedings of the Second International Conference on Machine Learning
and Cybernetics, vol. 3, 2003, pp. 385-388.[40] P. Weiner, Linear pattern matching algorithms, in: Proceedings of IEEE Annual Symposium on Switching and Automata Theory, 1973, pp. 1–11.[41] W.-T. Wong, F.Y. Shih, J. Liu, Shape-based image retrieval using support vector machines – Fourier descriptors and self-organizing maps, Information
Sciences 177 (8) (2007) 1878–1891.[42] R. Yang, M.S. Brown, Music database query with video by synesthesia observation, in: Proceedings of the IEEE International Conference on Multimedia
and Expo (ICME), vol. 1, June 2004, pp. 305–308.


















![[Book] Oracle Enterprise Manager 10g Grid Control - Scalable Management for Databases, Application Servers](https://img.pdfslide.us/doc/110x75/577d2adc1a28ab4e1eaa4cd8/book-oracle-enterprise-manager-10g-grid-control-scalable-management-for.jpg)










