Embed Size (px)
Citation preview

XML
(eXtensible Markup Language XM)
XML XMLXML
XML XML
XML(frequent tag data sets) (frequent character
data sets)XML XML
XMLXML 75%
40XML XML
Compressing the Native XML Database via Association Mining
Chin-Feng Lee Chaoyang University of Technology,
Chi-Ming Tang Chaoyang University of Technology

84
Abstract
XML has become a standard so that the transactional processes operate well in enterprise data exchange. However the existing database systems like relational databases provide inadequate facilities to manage the nested and ordered structures in XML documents. Therefore, there exist two important issues about the storage capacity for huge XML documents and the complexity mapping between the relational databases and XML repository. A native XML database is a solution to efficiently retrieve XML documents as basic units without requiring complicated transformation. Moreover, database compression is bound to relief the storage capacities. Hence, we use association mining techniques to compress a native XML database for solving the above problems. The frequent character data sets and frequent tag sets can be explored out and be applied to establish a set of database compression rules. The proposed method also applies dynamically mining techniques to maintain the compression rules without periodically decompressing and exploring the whole database compression again if there are any database updates.
The proposed approach contributes to the native XML database both in extracting hidden information and lossless compression, respectively. The experimental results show that our compression method has powerful compression effectiveness and the static compression can reach the ratio of 75%. When we apply the porposed dynamical mining techniques, we can save 40 seconds in database compression time.
Keywords: XML, Data Mining, Data Compression, Native XML Database
XML(eXtensible Markup Language) W3CXML
DTD(Document Type Definition) XML SchemaXML
(Cannane et al., 2000; Lee et al., 2001; Strobel, 2002; WWW Consortum, 2005)
XMLXML
XML(Bertino et al., 2001; Cannane

Electronic Commerce Studies 85
et al. 2000) XMLXML
(Florescu and Lossmann, 1999; Fong et al., 2003) XML
XMLXML
(Huffman Coding)(Arithmetic Encoding) (Dictionary Coding)
(Knowledge DBcovery in Databases)
XML(Agrawal and Srikant,
1994; Agrawal et al., 1993; Han and Kamber, 2001) XML(frequent tag data sets)
(frequent character data sets)
XML
XML
XML
XML XML

86
XML(eXtensible Markup Language)
XML (tag) (character data)
DTD(Document Type Definition) W3C XML
1 XML “ ” “ ”“ ” “ ” (character data)
“ ” “ ” “ ” “” “ ” “ ” “ ”
“020301” “ 2”
1 XML
(Item)
(Agrawal and Srikant, 1994)
X Y [Support , Confidence] X Y(Support) (Confidence)
Probability(X Y) (X Y)Probability(Y|X) X Y
(Minimum Support)(Minimum Confidence)

Electronic Commerce Studies 87
Class Inheritance Tree(CIT) 2001Apriori (Goh et al. 1998; Lee et al., 2006)
(2001) CIT(Equivalence Class)
CIT CIT
Step1 X={X1, X2, …, Xn} CIT(1) Xi
(Equivalence Class) EC={EC1, EC2, …, ECn} X
(2) CIT ECi
Step2 CIT(Decision
Equivalence Class) DECi
(Condition Equivalence Class) CECi CEC=EC-{DEC1,DEC2, …, DECn } CIT CIT
CECi DECi
Step3(1) Xi Xi = Xi
t (X1, X2, X3, …, Xi-1, , Xi+1, …, Xn ) t’ (X1, X2, X3, …, Xi-1 , Xi+1, …, Xn ) X1, X2, X3, …, Xi-1 , Xi+1, …, Xn
i R*B( ) R Xi =EC B( ) Byte
(2)

88
t (X1, …, Xj1-1, 1, Xj1+1, …, Xj2-1, 2, Xj2+1, …, Xjk-1, k, Xjk+1, …, Xn)
t (X1, …, Xj1-1, Xj1+1, …, Xj2-1 , Xj2+1, …, Xjk-1, Xjk+1, …, Xn)
X1, …, Xj1-1, Xj1+1, …, Xj2-1, Xj2+1, …, Xjk-1 , Xjk+1, …Xn i
ji R*k
1ii)(B R
B( i) i
Byte for i = 1 to k
XML2 XML
XMLXML Collections
Collection DTD (Parse)XML (2001)
XML Collection XML(Frequent Character Data Sets) (Frequent Tag Sets)
XML Collection XMLCollection
XML

Electronic Commerce Studies 89
2
DTD XML
XML (Hierarchical Structure) XML n-ary
( Document Tree)(Sub-element) (Parent-ChildNodes)
XDB XML (Native XML Database)XDB = {C1, C2, …, Cn} XDB n Colletions
Collection Ci XML X={X1, X2, …, Xm}XML DTD
Collection Ci DTD(Depth-First-Search DFS) XML Xi
Di-Tree (Root Node)(Tag Node) (Character Data Node)
1. XML2. q p p x
q x.yCase 1. q m {r1, r2, …, rm} r1
x.y.z1 r2 x.y.z2 Ym

90
x.y.zmCase 2. x.y
q x.y3(a) DTD XML
3(b) X1 XMLX1 “
” D1-Tree (Content) “” “1” X1 “ ”XML DTD “ ”
“ ” “1” Case 1 “ ”“ ”
“ ” “1.1” “ ”XML DTD “ ”
“ ” “1” Case 1 “ ”“ ”
“1” “ ” “1.1.1” “” “1.1.1”
XML 4 D1-Tree
XML“1”
“ ” “1” “ ”“2”
Collection XMLXML
5
3 (a)DTD
(b) XML

Electronic Commerce Studies 91
XML
XML
= { i1, i2, …, ik} { 1, 2, …, h}{ 1, 2, …, h} XML
EC XML
Definition 1 (Equivalence Class of Character Data)
EC = EC< i1, i2, …, ik> =
{< kiii ...,,,21 >| ji ij XML
for j = 1, 2, …, k}EC< 150> = {<2.2.3, 2.2.4>, <3.2.2,
3.2.3>} “ ” “150” 23 XML “ ” “2.2.3”
“3.2.2” “150” “2.2.4” “3.2.3”
4XML x1
D1-Tree 5

92
Definition 2 k
k (k 2)k
1 (k =1) 11 = < > 2 = < 80>
< > 1 <80> 2
Definition 3 (support)
kEC XML
|EC |
= < 80 >EC =EC< 80 > = {<1.2.2, 1.2.3>, <3.2.1, 3.2.2>}
XML 2|EC< 80 >| =2
Minimum-Support Threshold, min-sup
3.1(min-sup)
CF1 CS1
CF1 Table(1) Content 1(2) List XML
CS1 Table(1) Content 1(2) List
Apriori k (k2) CFk Table CFk Table
(1) Content k(k 2)(2) List
1 k(k 2)
CF1 Table p q p q Content

Electronic Commerce Studies 93
1 2 1 2 11 2 EC 1
EC 2 1 2 XMLEC 1 Most Significant Digit(msd)
EC 1 G1, G2, …, Gm1|Gm1| (say Gj j = 1, 2, …, m1)
msd(say j) 1 j XML EC 2G1’, G2’, …, Gm2’ msd(G1) = msd(G1’)
msd(Gh) = msd(Gh’) …msd(G ) = msd(G ’) h m1 h’ m2|EC< 1, 2>|= min{|G1|, |G1’|} + min{|G2|, |G2’|} + …+ min{|Gh|,
|Gh’|} |EC< 1, 2>| min-sup < 1, 2> 22
k(k 2)1 2min-sup=2
Content 1 2 1 = <bread>, 2 = <coke cola> EC 1 msd G1={1.2.1}, G2={2.2.3},
G3={4.2.2}(m1=3) EC 2 msd G1’={1.2.2}, G2’={2.2.1}(m2=2) Most Significant Digit msd(G1)=1,msd(G2)=2, msd(G3)=4, msd(G1’)=1, msd(G2’)=2 msd(G1)=msd(G1’),msd(G2)=msd(G2’) |EC< 1, 2>|=|EC<bread,coke cola>|= min{|G1|,|G1’|}+min{|G2|, |G2’|}=1+1=2 bread, coke cola
XML XMLmin-sup 2 2
CF2 Table Content “<bread, coke cola>” List “<1.2.1, 1.2.2>, <2.2.3, 2.2.1>”
2
1 CF1 1
Content List
bread 1.2.1, 2.2.3, 4.2.2
coke cola 1.2.2, 2.2.1
cheese 1.2.3, 4.2.1
2 CF2 2
Content List
<bread, coke cola> <1.2.1, 1.2.2>, <2.2.3, 2.2.1>
<bread, cheese> <1.2.1, 1.2.3>, <4.2.2, 4.2.1>

94
2 32
min-sup=2Contetnt 1 2 1=<bread, coke
cola>, 2=<bread, cheese> EC 1 msd G1={<1.2.1, 1.2.2>}, G2={<2.2.3, 2.2.1>}(m1=2) EC 2 msd G1’={<1.2.1,1.2.3>}, G2’={<4.2.2, 4.2.1>} most significant digitmsd(G1)=1, msd(G2)=2, msd(G1’)=1, msd(G2’)=4 msd(G1)=msd (G1’) |EC< 1, 2>|=|EC<bread, coke ke cola, cheese>|=min{|G1|, |G1’|}=1
<bread, coke cola, chees> XML1 min-up
XMLXML
= { i1, i2, …, ik} { 1, 2, …, h}
{ 1, 2, …, h} XML
EC XML
Definition 4 (Equivalence Class of Tag)
EC = EC< i1, i2, …, ik>{< 1i , 2i , …, ki >|
XML }
Definition 5 1
1 (k 2)1
Definition 6 (support)
1 ECXML
|EC |

Electronic Commerce Studies 95
(2001)
Metarule C Metarule T
CFk Table Content k(k 1)
t (P1, …, Pj1-1, 1, Pj1+1, …, Pj2-1, 2, Pj2+1, …, Pjk-1, n, Pjk+1, …, Pn)t (P1, …, Pj1-1, Pj1+1, …, Pj2-1, Pj2+1, …, Pjk-1, Pjk+1, …, Pn) List
P1, …, Pj1-1, Pj1+1, …, Pj2-1, Pj2+1, …Pj k-1, …Pjk+1, Pn DTD
i i
List
|List|*k
i 1
B( i) |CD| i List
B( i) i Byte for i =1, 2, ..., n i
XML
t1 , , , t1’ ,{1.1.1, 1.2.1}, {3.1.1, 3.2.1} “ ” “
” “ ” “ ”“ ” “ ” “ ”
“ ” “ ” “” “ ” “ ” “ ” “ ”
“{1.1.1, 1.2.1}, {3.1.1, 3.2.1}” List
TFk Table Content k (k 1 )
t (P1, …, Pj1-1, 1, Pj1+1, …, Pj2-1, 2, Pj2+1, …, Pjk-1, n, Pjk+1, …, Pn)

96
t (P1, …, Pj1-1, Pj1+1, …, Pj2-1, Pj2+1, …, Pjk-1, Pjk+1, …, Pn) ListP1, …, Pj1-1, Pj1+1, …, Pj2-1, Pj2+1, …Pj k-1, …Pjk+1, Pn DTD
i List
|List|*k
i 1B( i) |List| i
List B( i) i Byte for i =1, 2, ..., n
(Heuristic Compression Method)
Apriori
3“ ” “ ”
“{1.1.1, 1.2.1}, {3.1.1, 3.2.1}”“ ” “ ” CD “{1.1.1, 1.2.2}, {3.1.1, 3.2.3}, {4.1.1, 4.2.1}” 1 3
“ ” “1.1.1” “3.1.1”“RID 1”
“RID 2” “1.1.1” “3.1.1”“RID 2” CD “{4.1.1, 4.2.1}” “RID 2”
3
Compression Rules List
t1
t1’{1.1.1, 1.2.1}, {3.1.1, 3.2.1}
t2
t2’{1.1.1, 1.2.2}, {3.1.1, 3.2.3}, {4.1.1, 4.2.1}
1. (Least Penalty Heuristic Method; LPHM) XML

Electronic Commerce Studies 97
2. (Most Penalty Heuristic Method; MPHM) XML
3. (Maximal Compression Spaces Heuristic Method; MaxCSHM)
4. (Minimum Compression Spaces Heuristic Method; MinCSHM)
Java J2SDK 1.4.1Intel P4-2.4G 1.5GB
Microsoft Windows 2000 ProfessionalDTD
6 7 XML RAR ZIP
7 DTD IBM Almaden Research Center (2005) Assoc.gen
IBM 4Assoc.gen
XML XML
RARZIP (LPHM)
(Non-Heuristic Method)
98
4 Assoc.gen
T L_TLEN D NTRANS N L_NITEMS I PATLEN R CORR
6 DTD
7 DTD
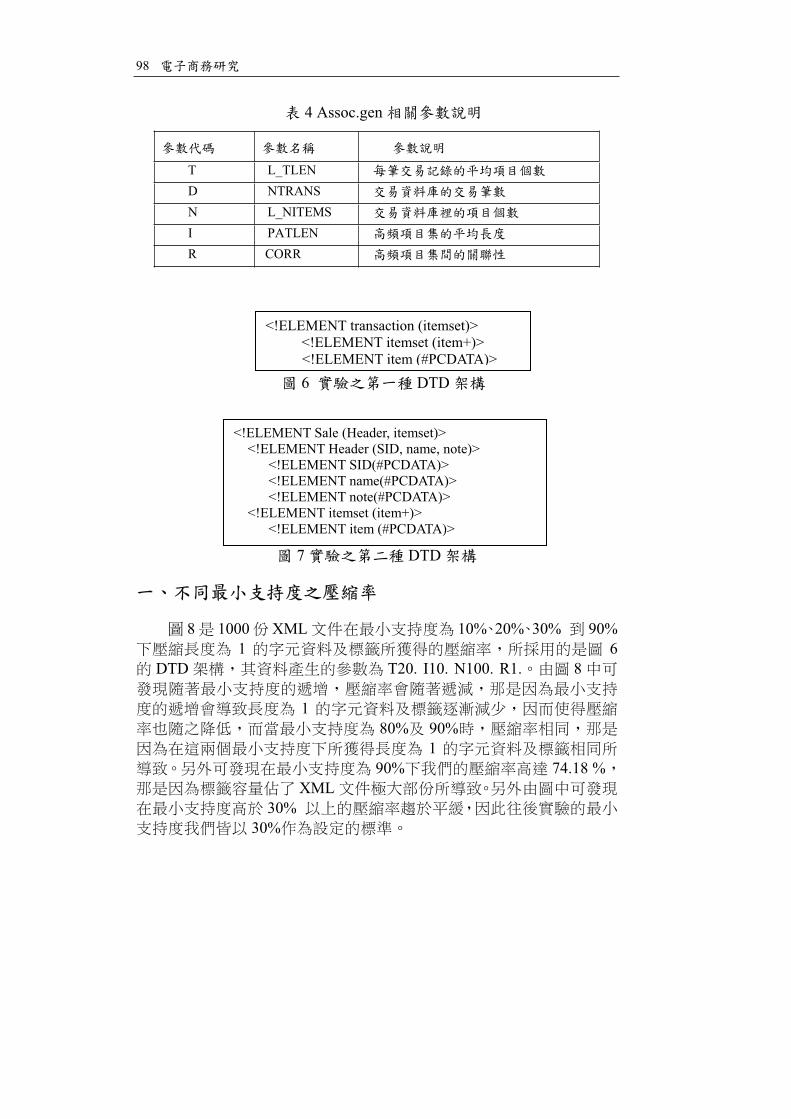
8 1000 XML 10% 20% 30% 90%1 6
DTD T20. I10. N100. R1. 8
180% 90%
190% 74.18 %
XML30%
30%
<!ELEMENT transaction (itemset)> <!ELEMENT itemset (item+)>
<!ELEMENT item (#PCDATA)>
<!ELEMENT Sale (Header, itemset)> <!ELEMENT Header (SID, name, note)> <!ELEMENT SID(#PCDATA)> <!ELEMENT name(#PCDATA)> <!ELEMENT note(#PCDATA)> <!ELEMENT itemset (item+)> <!ELEMENT item (#PCDATA)>
Electronic Commerce Studies 99
(%)
(
%
)
8 1000 XML
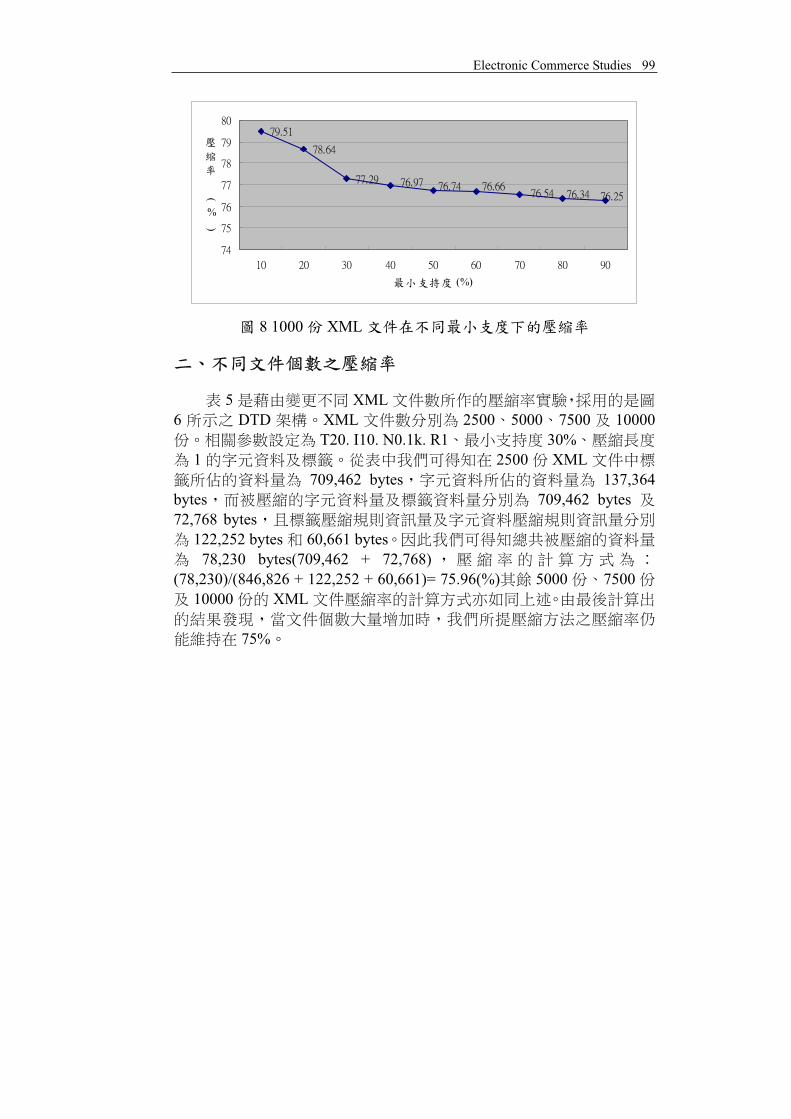
5 XML6 DTD XML 2500 5000 7500 10000
T20. I10. N0.1k. R1 30%1 2500 XML
709,462 bytes 137,364bytes 709,462 bytes72,768 bytes
122,252 bytes 60,661 bytes78,230 bytes(709,462 + 72,768)
(78,230)/(846,826 + 122,252 + 60,661)= 75.96(%) 5000 750010000 XML
75%
100
5
2500 5000 7000 10000
XML (bytes) 846,826 1683,026 2,524,412 3,371,170 (bytes) 709,462 1,410,092 2,114,996 2,824,351
(bytes) 137,364 272,934 409,416 546,819 (bytes) 709,462 1,410,092 2,114,996 2,824,351 (bytes) 72,768 140,466 210,612 289,971 (bytes) 782,230 1,550,558 2,325,608 3,114,332 (bytes) 122,252 255,522 383,270 537,114
(bytes) 60,661 122,927 184,305 265,827 (%) 75.96 75.22 75.21 74.61
(%) 75.25
RAR ZIP
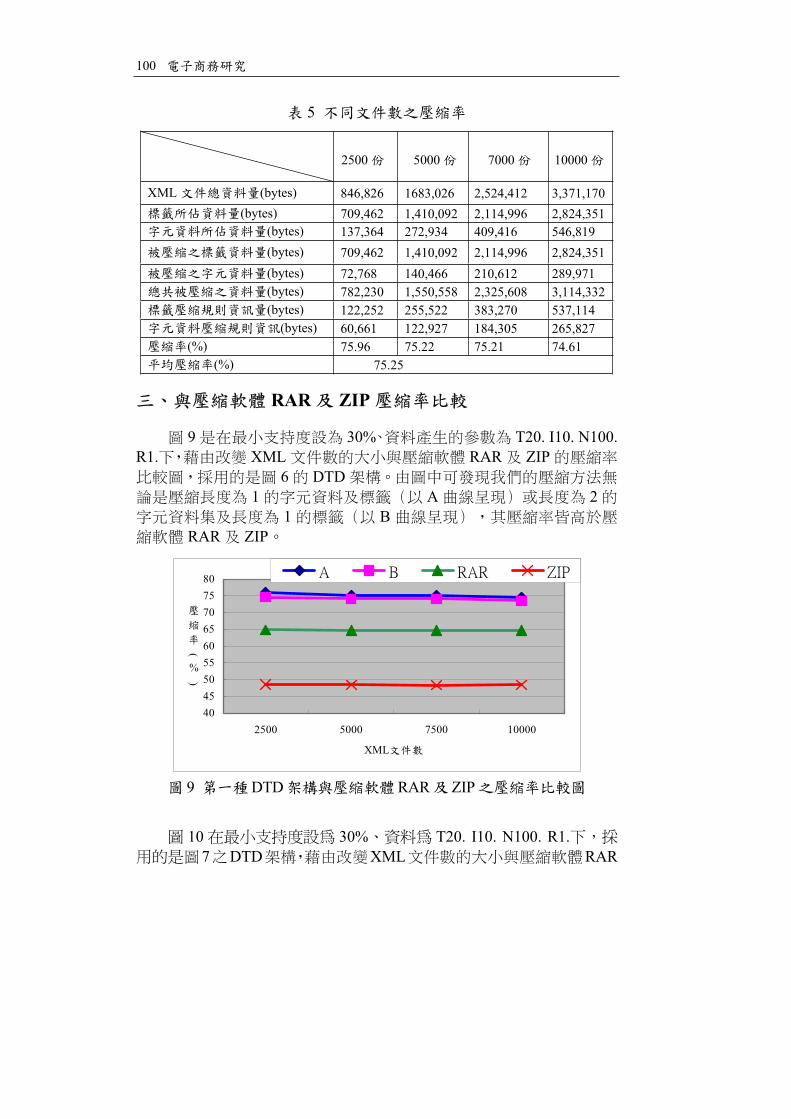
9 30% T20. I10. N100. R1. XML RAR ZIP
6 DTD1 A 2
1 BRAR ZIP
404550556065707580
2500 5000 7500 10000
XML
(
%
)
9 DTD RAR ZIP
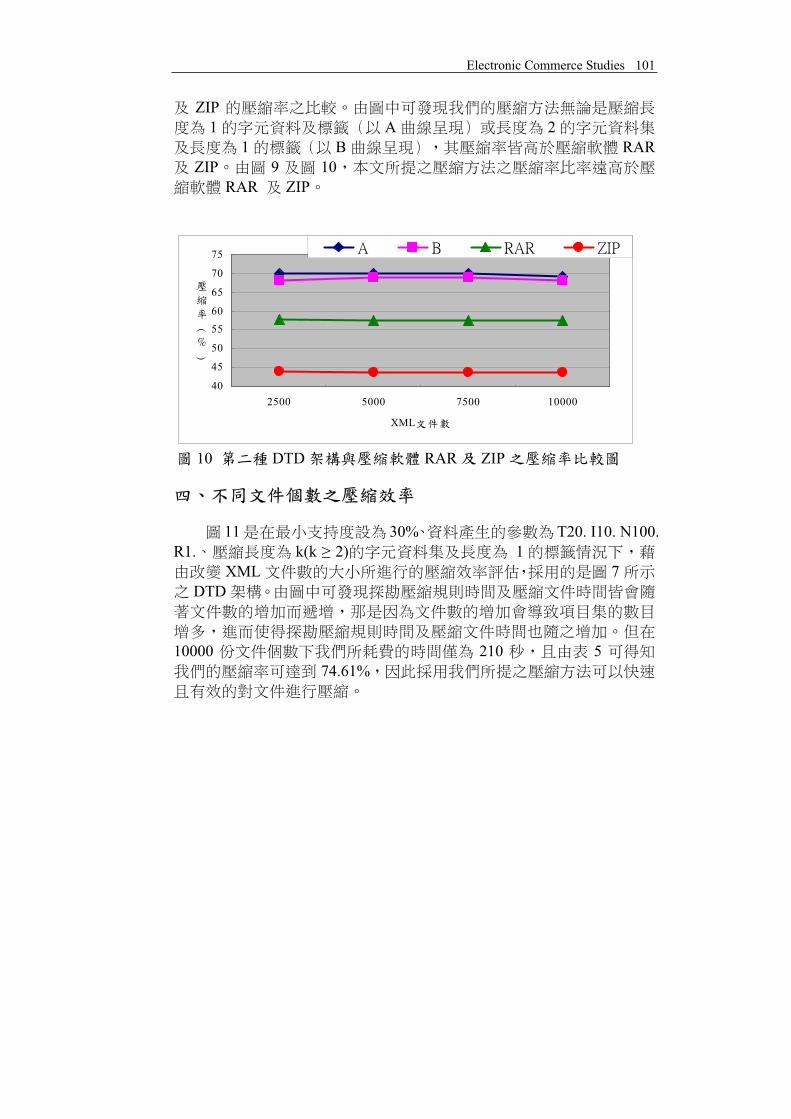
10 30% T20. I10. N100. R1.7 DTD XML RAR
Electronic Commerce Studies 101
ZIP1 A 2
1 B RARZIP 9 10
RAR ZIP
40
45
50
5560
65
70
75
2500 5000 7500 10000
XML
10 DTD RAR ZIP
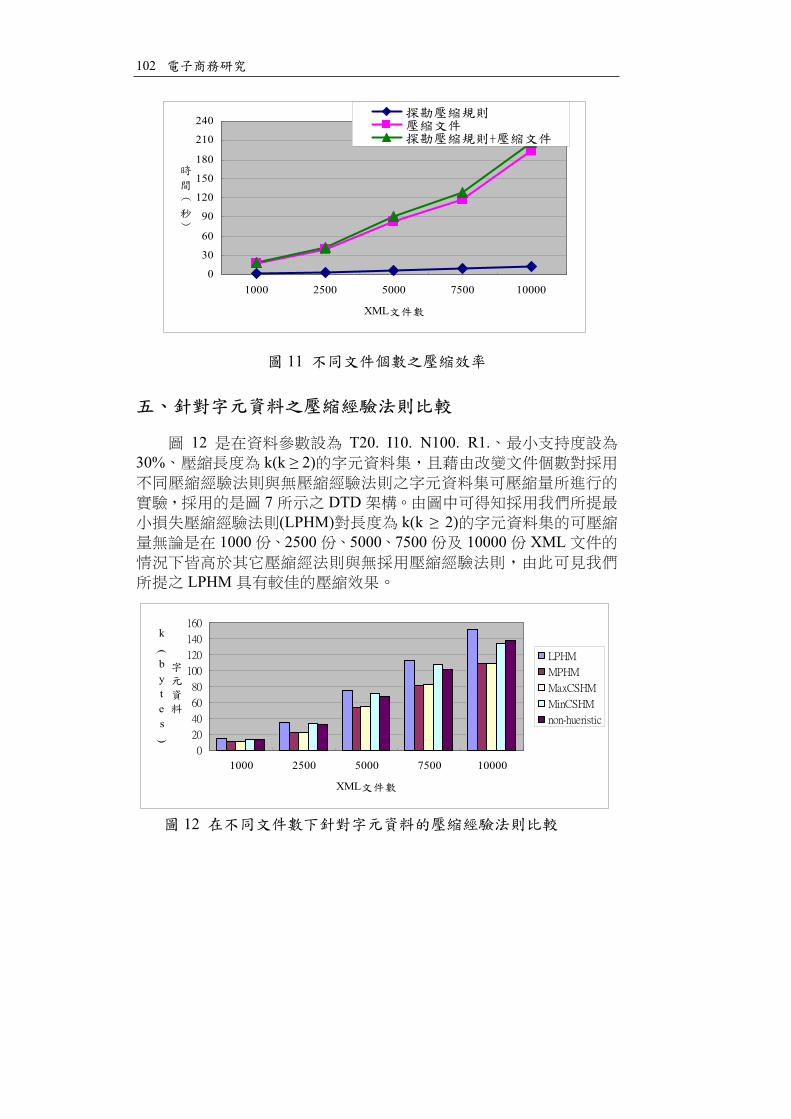
11 30% T20. I10. N100. R1. k(k 2) 1
XML 7DTD
10000 210 574.61%
102
0
30
60
90
120
150
180
210
240
1000 2500 5000 7500 10000
XML
11
12 T20. I10. N100. R1.30% k(k 2)
7 DTD(LPHM) k(k 2)
1000 2500 5000 7500 10000 XML
LPHM
1000 2500 5000 7500 10000
XML
k(
bytes
)
12

Electronic Commerce Studies 103
XML
(Lossless Compression)
XML
< > “ ”“ ”
XML75% ZIP RAR
(2001) 2001 —
R. Agrawal, T. Imielinski, and A. Swami(1993), “Mining Association Rules between Sets of Items in Large Databases,” Proceedings of the ACM SIGMOD Conference on Management of Data, Washington, D.C., 207-216.
R. Agrawal and R. Srikant (1994), “Fast Algorithms for Mining Association Rules,” Proceedings of the 20th International Conference on Very Large Data Bases (VLDB’94), 487-499.
E. Bertino and B. Catania (2001), “Integrating XML and Database,” IEEE Internet Computing, 5(4), pp. 84-88.
A. Cannane and H. E. Williams (2000), “A Compression Scheme for Large Databases,” Proceedings of the Australian Database Conference (ADC'2000), 22(2), 6-11.
S.W., Changchien and T.C., Lu (2001)“A New Efficient Association Rules Mining Method Using Class Inheritance Tree (CIT),” Proceedings of the 12th International Conference on Information Management (ICIM 2001), Twaiwn.
D. Florescu and D. Kossmann (1999), “Storing and Querying XML Data Using an RDBMS,” IEEE Data Engineering Bulletin, 22(3), 27-34.

104
J. Fong, H. K. Wong, and Z. Cheng (2003), “Converting Relational Database into XML Documents with DOM,” Information and Software Technology, 45, 335-355.
C. L. Goh, K. M. Aisaka, Tsukamoto, K. Harumoto, and S. Nishio (1998), “Database Compression with Data Mining Methods,” Proceedings of the 5th International Conference on Foundations of Data OrganiPation (FODO'98), 97-106.
J. Han and M. Kamber, (2001), Data Mining: Concepts and Techniques, Morgan Kaufmann.
J. W. Lee, K. Lee, and W. Kim (2001), “Preparations for Semantics-Based XML Mining,” Proceedings of the IEEE International Conference on Data Mining, 345-352.
C. F. Lee, S. W. Changchien, W. T.Wang, and J. J. Shen (2006): “A Data Mining Approach to Database Compression,” Information Systems Frontier (ISF), 8(3), 147-161.
M. Strobel (2002), “An XML Schema Representation for the Communication Design of Electronic Negotiations,” Computer Networks, 39, 661-680.
IBM Almaden Research Center (2005), Quest Synthetic Data Generation, http://www.almaden.ibm.com/software/quest/Resources/dataset/syndata.html.
World Wide Web Consortum (2005), “Extensible Markup Language (XML) Version 1.1,” http://www.w3.org/TR/2004/REC-xml11-20040204/.
s9214612@ cyut.edu.tw


























