Embed Size (px)
Citation preview

Running Applications on BlueData EPIC
VERSION 2.1

Running Applications on BlueData EPIC
ii Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.
NoticeBlueData Software, Inc. believes that the information in this publica-
tion is accurate as of its publication date. However, the information is
subject to change without notice. THE INFORMATION IN THIS
PUBLICATION IS PROVIDED “AS IS.” BLUEDATA SOFTWARE,
INC. MAKES NO REPRESENTATIONS OR WARRANTIES OF
ANY KIND WITH RESPECT TO THE INFORMATION IN THIS
PUBLICATION, AND SPECIFICALLY DISCLAIMS IMPLIED WAR-
RANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTIC-
ULAR PURPOSE.
Use, copying, or distribution of any BlueData software described in
this publication requires an applicable software license.
For the most up-to-date regulatory document for your product line,
please refer to your specific agreements or contact BlueData Tech-
nical Support at [email protected].
The information in this document is subject to change. This manual is
believed to be complete and accurate at the time of publication and
no responsibility is assumed for any errors that may appear. In no
event shall BlueData Software, Inc. be liable for incidental or conse-
quential damages in connection with or arising from the use of this
manual and its accompanying related materials.
Copyrights and TrademarksPublished February, 2016. Printed in the United States of America.
Copyright 2016 by BlueData Software, Inc. All rights reserved. This
book or parts thereof may not be reproduced in any form without the
written permission of the publishers.
EPIC, EPIC Lite, and BlueData are trademarks of BlueData Software,
Inc. All other trademarks are the property of their respective own-
ers.
Contact InformationBlueData Software, Inc.
3979 Freedom Circle, Suite 850
Santa Clara, California 95054
Email: [email protected]
Website: www.bluedata.com

Table of Contents
1 - Preface ........................................................................ 11.1 - About This Manual ........................................................... 3
1.1.1 - Formatting Conventions ......................................... 3
1.1.2 - Organization ........................................................... 4
1.2 - Additional Information .................................................... 5
1.2.1 - Related Documentation ......................................... 5
1.2.2 - Contact Information .............................................. 5
1.2.3 - Support .................................................................. 5
1.2.4 - End User License Agreement .............................. 5
2 - Setting up EPIC .......................................................... 72.1 - Downloading the Samples ............................................ 9
2.2 - Creating the Persistent Clusters ................................. 10
2.2.1 - Hadoop Cluster .................................................... 10
2.2.2 - Spark Cluster ....................................................... 11
2.3 - Creating Directories and Uploading Data ....................13
3 - Running Applications ................................................. 153.1 - Hadoop Custom Jar .......................................................17
3.2 - Hadoop Streaming .......................................................20
3.3 - Pig Script ......................................................................22
3.4 - Hive Script ....................................................................24
3.5 - Impala Script ................................................................26
3.6 - Spark - Scala Jar .........................................................29
3.6.1 - About the Spark Context .....................................29
3.6.2 - Running a Spark Scala Jar Job .........................29
3.7 - Spark - Java Jar ...........................................................31
3.8 - Spark - Python Script .................................................. 33
3.9 - Spark - Zeppelin .......................................................... 35
3.10 - SparkR Jobs ............................................................... 37
3.11 - Spark Streaming Jobs ................................................ 38
3.12 - The <Job> Output Popup ........................................... 39
iiiCopyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
This page intentionally left blank.
iv Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

1 - Preface
Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED. 1

Running Applications on BlueData EPIC
Welcome! This manual introduces you to using EPIC or EPIC Lite by
BlueData Software, Inc. by guiding you through some examples of:
• Downloading the sample scripts and data file from BlueData
Software, Inc.
• Uploading the sample data that will be used to run each of the
different job types available in EPIC and EPIC Lite
• Creating two clusters (one each Hadoop and Spark)
• Running one each of the various job types supported by EPIC and
EPIC Lite on the persistent clusters you created
• Viewing the output.
Most of these jobs will count how many times each word in the
sample text file appears in that file. For instance, if the word “EPIC”
appears 50 times, you will see a listing that looks something like
“EPIC 50.” Other scripts will count the number of lines of text that
include the letters “a” and “b” and display a count for each letter. The
Impala script will create data tables, populate those tables, execute
queries on those tables, and then return the results.
This Guide contains the information you need to set up EPIC or EPIC
Lite for the examples contained herein, but does not describe the
interface in any detail. Please see the About EPIC Guide for detailed
information about EPIC, including:
• Key features and benefits
• Hadoop and application support
• Definitions
• Architecture
• Storage
• Users
• System requirements
Note: The instructions in the Guide apply to both the EPIC
(full) and EPIC Lite (evaluation) versions 1.0 and 1.1.
2 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

1 - Preface
1.1 - About This Manual
This section describes the formatting conventions and information
contained in this manual.
1.1.1 - Formatting Conventions
This manual uses several formatting conventions to present
information of special importance.
Lists of items, points to consider, or procedures that do not need to
be performed in a specific order appear in bullet format:
• Item 1
• Item 2
Procedures that must be followed in a specific order appear in
numbered steps:
1. Perform this step first.
2. Perform this step second.
Specific keyboard keys are depicted in square brackets and are
capitalized, for example: [ESC]. If more than one key should be
pressed simultaneously, the notation will appear as [KEY1]+[KEY 2],
for example [ALT]+[F4].
Interface elements such as document titles, fields, windows, tabs,
buttons, commands, options, and icons appear in bold text.
Specific commands appear in standard Courier font. Sequences
of commands appear in the order in which you should execute them
and include horizontal or vertical spaces between commands. The
following additional formatting also applies when discussing
command-line commands:
Plain-text responses from the system appear in bold Courier font.
This manual also contains important safety information and instructions in specially formatted callouts with accompanying graphic symbols. These callouts and their symbols appear as follows throughout the manual:
The Note and Caution icons are blue in the main chapter, and gray in
the appendices.
CAUTION: CAUTIONS ALERT YOU TO THE POSSIBILITY
OF A SERIOUS ERROR, DATA LOSS, OR OTHER
ADVERSE CONDITION.
Note: Notes provide helpful information.
3Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
1.1.2 - Organization
This manual contains the following chapters:
• 1 - Getting Started: Describes how this manual is formatted and
organized.
• 2 - Setting up EPIC: Guides you through setting up the EPIC
environment to run the sample applications that are available for
download from BlueData Software, Inc.
• 3 - Running Applications: Provides step-by-step tutorial
examples of running applications within EPIC.
4 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

1 - Preface
1.2 - Additional Information
This section lists related documentation and provides information on
contacting BlueData, Inc.
1.2.1 - Related Documentation
Please refer to the following documents for additional information:
• About EPIC Guide: This guide explains the EPIC architecture,
features, and benefits. It also contains the End User License
Agreement.
• EPIC Lite Installation Guide: This guide helps you install EPIC
Lite, the free demonstration version of EPIC, on a single host.
• EPIC Installation Guide: This guide contains instructions for
installing the full version of EPIC on your network.
• User/Administrator Guide: This guide describes the EPIC
interface for Site Administrator, Tenant Administrator, and
Member users.
• Deployment Guide: Certain platforms have additional
requirements and/or procedures for installing and running EPIC.
• App Store Image Authoring Guide: Describes how Site
Administrators can author new images and make them available
in their local instance of the EPIC App Store.
1.2.2 - Contact Information
You may contact BlueData Software, Inc. at the following address:
BlueData Software, Inc.
3979 Freedom Circle, Suite 850
Santa Clara, California 95054
Email: [email protected]
Website: www.bluedata.com
1.2.3 - Support
Please see the Installation Guide for information on obtaining
technical support from BlueData Software, Inc.
1.2.4 - End User License Agreement
Your use of EPIC is subject to the terms and conditions described in
the End User License Agreement (EULA).
5Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
This page intentionally left blank.
6 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

2 - Setting up EPIC
Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED. 7

Running Applications on BlueData EPIC
This chapter shows you how to set up the EPIC environment to run
the sample applications that will be presented in “Running
Applications” on page 15.
Setting up the EPIC environment consists of the following steps:
1. Download the sample script and sample data files from http://
support.bluedata.com to your local machine. See “Downloading the
Samples” on page 9.
2. Log into EPIC and create the two persistent clusters (one each
for Hadoop and Spark) that you will use when running the
examples in “Running Applications” on page 15.
3. Create directories within the tenant DataTap to store your job
input data, and then upload the sample text file to the input
directory. See “Creating Directories and Uploading Data” on page 13.
4. Run the jobs described in “Running Applications” on page 15.
Note: These instructions assume that you have just installed
EPIC on your system; however, these instructions and sam-
ples will work with your existing tenants, clusters, file sys-
tems, etc.
8 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

2 - Setting up EPIC
2.1 - Downloading the Samples
To download the sample script and data files from EPIC:
1. Visit the Support page at http://support.bluedata.com.
2. Download the file appsamples.zip to your local device.
3. Extract the .zip file.
The contents of the appsamples.zip file are as follows:
- The sample_text.txt file is a plain text file that you will
use as input data for all of the jobs you will be running,
except Impala.
- The hadoop-custom-jar directory contains the cdh-examples executable .jar file that you will use for the
Hadoop Custom Jar job described in “Hadoop Custom Jar” on
page 17.
- The hadoop-streaming directory contains the
mapper.py and reducer.py scripts that you will use for
the Hadoop Streaming job described in “Hadoop Streaming” on
page 20.
- The pig-script directory contains the
wordcount.pig script that you will use for the Hadoop
Streaming job described in “Hadoop Streaming” on page 20.
- The hive-script directory contains the
wordcount.hql script that you will use for the Pig Script
job described in “Hive Script” on page 24.
- The impala-script directory contains the
impala.script file that you will use for the Impala job
described in “Impala Script” on page 26.
- The spark/spark-scala and spark/spark-java
directories contain the .jar files required to run the sample
Spark Scala and Spark Java applications. See “Spark - Scala
Jar” on page 29 and “Spark - Java Jar” on page 31.
- The spark/spark-python directory contains the script
to run the sample Spark Python application. See “Spark -
Python Script” on page 33.
- The spark/spark-zeppelin directory contains a
sample file for use with the Spark Zeppelin application. See
“Spark - Zeppelin” on page 35.
Note: Do not rename or move the contents of directories
that have multiple files, as each of them is required for the
job to run successfully. You will specify only the executable
file in each such directory, and EPIC will handle the rest.
9Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
2.2 - Creating the Persistent Clusters
You will need to log in to EPIC and create two persistent clusters in
order to run the jobs described in “Running Applications” on page 15.
• If you are logging in as the default Site
Administrator user, click the User button
in the Toolbar and select any tenant in
the list that has a green or yellow icon
next to it. (You cannot create jobs in the
Site Admin tenant.)
• If you are logging in as a Tenant
Administrator or Tenant Member, you
may click the User button in the Toolbar
to switch to any tenant you have access to. You will not be able
to see or access the Site Admin tenant.
2.2.1 - Hadoop Cluster
To create the Hadoop cluster:
1. Ensure that the CDH 5.4.3 with Cloudera Manager image is
installed on the EPIC platform using the App Store. See the
User/Admin Guide for instructions on adding App Store images.
2. Click Clusters in the Main Menu to open the Cluster
Management screen.
3. At the top of the Cluster Management screen, click the blue
Create button to open the Create New Cluster screen.
4. Enter the following information:
- Provide a descriptive name for the cluster in the Cluster
Name field. This manual will use the name
SampleHadoopCluster.
- Select Hadoop using the Select Cluster Type pull-down
menu, if it is not selected already.
- At the bottom of the screen, check the Pig, Hive, Oozie,
Impala & Hue checkbox.
- Leave the rest of the fields as-is; you do not need to modify
them to run the sample applications.
5. Review your selections, which should look like this:
10 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

2 - Setting up EPIC
6. Click the blue Submit button at the bottom of the screen to finish
creating the cluster and return to the Cluster Management
screen.
You will see the newly created cluster with a blue starting bar in
the Status column.
The bar will turn green and say Ready once the cluster is ready
for use.
2.2.2 - Spark Cluster
To create the Spark cluster:
1. Ensure that the Spark 1.5.2 image is installed on the EPIC
platform using the App Store. See the User/Admin Guide for
instructions on adding App Store images.
2. Click Clusters in the Main Menu to open the Cluster
Management screen.
3. At the top of the Cluster Management screen, click the blue
Create button to open the Create New Cluster screen.
4. Enter the following information:
- Provide a descriptive name for the cluster in the Cluster
Name field. This manual will use the name
SampleSparkCluster.
- Select Spark using the Select Cluster Type pull-down
menu, if it is not selected already.
- Leave the rest of the fields as-is; you do not need to modify
them to run the sample applications.
5. Review your selections, which should look like this:
11Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
6. Click the blue Submit button at the bottom of the screen to finish
creating the cluster and return to the Cluster Management
screen. You will see the newly created cluster with a blue
Starting bar in the Status column.
The bar will turn green and say Ready once the cluster is ready for
use.
The SPARK_HOME/bin directory contains all of the binaries
required to Spark jobs (e.g., sparkR, spark-shell, spark-submit, etc.).
The location of the SPARK_HOME directory depends on the version
of Spark being used:
• Spark1.3: /usr/lib/spark/$spark_version (only availavble if the
EPIC platform was upgraded from 2.0 to 2.1)
• Spark1.4: /usr/lib/spark/spark-1.4.0-bin-hadoop2.4
• Spark 1.5: /usr/lib/spark/spark-1.5.2-bin-hadoop2.4
12 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.
2 - Setting up EPIC
2.3 - Creating Directories and Uploading Data
After creating the persistent clusters, the next step is to create
directories to hold your sample data (input) that will be used for
running the sample scripts in “Running Applications” on page 15. You
will do this using the tenant DataTap.
The following example assumes that you are using the default
TenantStorage DataTap that was automatically created by EPIC
when you created the tenant; however, these steps will work for any
DataTap that uses local system storage.
To do this:
1. Click DataTaps in the Main Menu to open the DataTaps screen.
2. In the table on the screen, click the name of the DataTap that you
are going to use in the Name column to open the <DataTap>
Browser screen, where <DataTap> is the name of the DataTap
you are using. In this example, this will be the TenantStorage
Browser screen.
3. At the top of the screen, click the blue Create directory button
(plus sign) to open the Create new directory under screen.
This example assumes that you are creating directories under
the root directory of the DataTap; however, you may create this
directory anywhere you like.
4. Enter a name for the new directory (such as DataInput) and
then click OK. This will be the directory that holds the data being
processed by jobs.
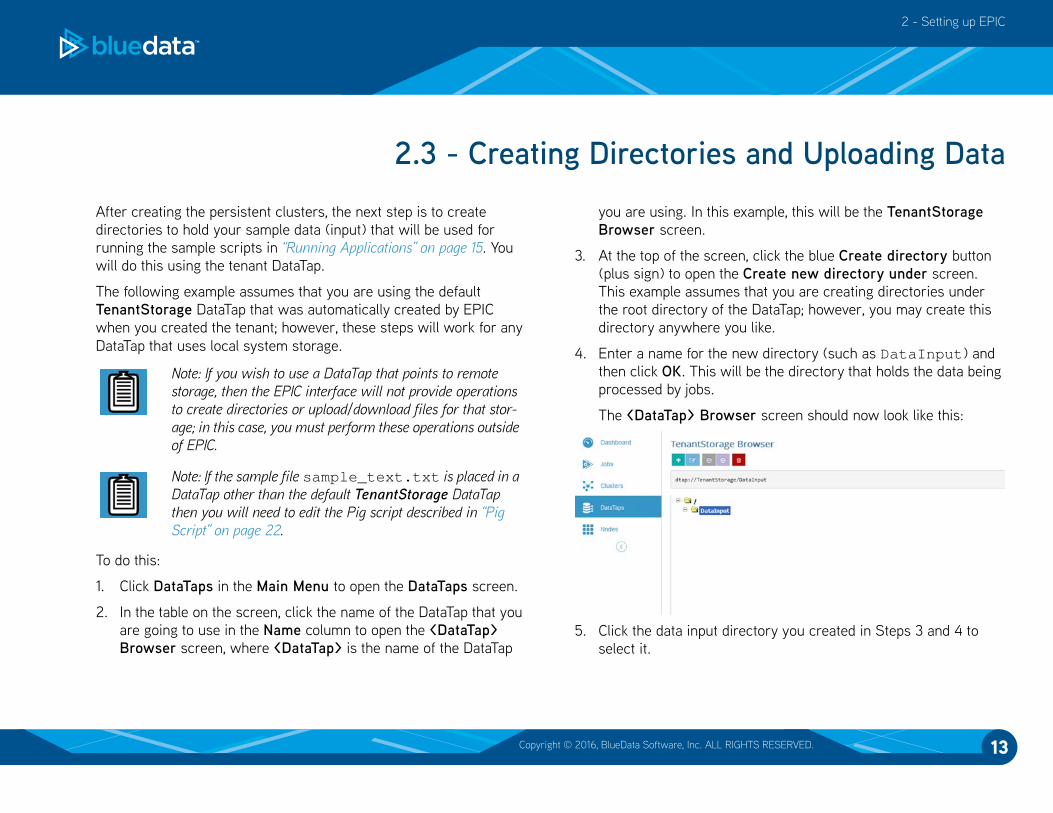
The <DataTap> Browser screen should now look like this:
5. Click the data input directory you created in Steps 3 and 4 to
select it.
Note: If you wish to use a DataTap that points to remote
storage, then the EPIC interface will not provide operations
to create directories or upload/download files for that stor-
age; in this case, you must perform these operations outside
of EPIC.
Note: If the sample file sample_text.txt is placed in a
DataTap other than the default TenantStorage DataTap
then you will need to edit the Pig script described in “Pig
Script” on page 22.
13Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
6. Click the gray File Upload button (up arrow) at the top of the
screen to open a standard File Upload popup.
7. Navigate to the directory containing the sample_text.txt
file and upload it.
The Upload Status popup appears with a progress bar showing
the upload progress. This bar turns green and the word
Completed appears when the upload is complete.
8. Click OK to close the popup.
The <DataTap> Browser screen appears showing the
sample_text.txt file in your data input directory.
Note: Do not create a results (output) directory; this will
occur when creating the jobs. Hadoop jobs will usually
return an error if the output directory exists before the job is
run.
14 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED. 15

Running Applications on BlueData EPIC
This chapter shows you how to run one of each of the job types that
EPIC supports. You will be using the persistent clusters that you
created in “Creating the Persistent Clusters” on page 10.
The jobs you will be running are:
• Hadoop Custom Jar: See “Hadoop Custom Jar” on page 17.
• Hadoop Streaming: See “Hadoop Streaming” on page 20
• Pig Script: See “Pig Script” on page 22.
• Hive Script: See “Hive Script” on page 24.
• Impala Script: See “Impala Script” on page 26.
• Spark - Scala Jar: See “Spark - Scala Jar” on page 29.
• Spark - Java Jar: See “Spark - Java Jar” on page 31.
• Spark - Python Script: See “Spark - Python Script” on page 33.
• Spark - Zeppelin: See “Spark - Zeppelin” on page 35.
Note: These examples assume that you created clusters and
tenants with the same names as those provided in “Setting
up EPIC” on page 7; however, they will also work if you set
up differently-named clusters and directories, so long as
you replace the example names shown with the actual
names you created.
16 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
3.1 - Hadoop Custom Jar
This script will count the number of times each word appears in the
sample test file. To create a new Hadoop Custom Jar job:
1. Click Jobs in the Main Menu to open the Job Management
screen.
2. At the top of the Job Management screen, click the blue Create
button to open the Create New Job screen.
3. Enter a descriptive name for the job (such as
HadoopCustomJar) in the Job Name field.
4. Use the Job Type pull-down menu to select Hadoop Custom
Jar, if it is not selected already.
5. Click the Choose button in the Jar File field to open a standard
File Upload popup.
6. Navigate to the hadoop-custom-jar folder (see “Downloading the
Samples” on page 9) and then select the file cdh-examples.jar to upload.
7. Enter wordcount in the App Name field. This is case sensitive;
do not enter WordCount, WORDCOUNT, or any other variation.
8. Check the Persistent checkbox next to
Cluster Type and make sure that the
correct cluster (SampleHadoopCluster)
is selected in the pull-down menu.
9. Click the Insert button to the right of the
Edit Arguments field to open the
DataTap Browser popup.
10. Navigate to the data input folder that you
created in “Creating Directories and
Uploading Data” on page 13 and then
double click the sample_text.txt entry.
Note: This image shows the Create New Job screen with
the Persistent radio button checked under Cluster Type.
By default, this screen appears with the Transient radio
button selected, which displays some different fields than
those shown here. You will change this setting to Persistent
as you create the job.
17Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
The Edit Arguments field will display dtap://TenantStorage/DataInput/sample_text.txt (or
equivalent, if you are using a tenant and/or directories with
different names).
11. Click the X at the top right of the DataTap Browser window to
close it.
12. In the Edit Arguments field, click just after the text that
appeared in Step 9 and then type dtap://TenantStorage/DataOutput_1.
The Edit Arguments field should now appear as shown below.
13. Review your entries. The Create New Job screen should look
like this:
14. Click the blue Submit button to run the job and return to the Job
Management screen. You will see the newly created cluster with
a blue Running bar in the Job Status column.
The bar will turn green and say Completed once the job is
completed.
Note: You may manually type these entries into the Edit
Arguments field along with any other argument(s) that
you may need to run a job, but this is not necessary to run
this sample job.
18 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
At any time during or after the job run, you may click the name of
the job to open the <Job> Output popup, which displays the
current output for the selected job. See “The <Job> Output Popup”
on page 39.
15. In the Main Menu, click DataTaps to return to the DataTaps
screen.
16. In the table on the screen, click the name of the DataTap that you
used in“Creating Directories and Uploading Data” on page 13 in the
Name column to open the <DataTap> Browser screen, where
<DataTap> is the name of the DataTap you are using. In this
example, this will be the TenantStorage Browser screen.
17. The <DataTap> Browser screen appears, with the Data
Output_1 folder now showing. Clicking the + sign to the left of
this folder expands the folder listing. Your job results are in the
part-r-00000 file.
18. Select the part-r-0000 file by clicking it, and then click the
purple Download File button (down arrow) to open a standard
File Download popup. Save the file to your local device.
19. Open the downloaded file in a text editor to see a complete list of
the words in the sample_text.txt file and how many times
each word appears therein.
This concludes the Hadoop Custom Jar example.
19Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
3.2 - Hadoop Streaming
This script will count the number of times each word appears in the
sample text file. To create a new Hadoop Streaming job:
1. Click Jobs in the Main Menu to open the Job Management
screen.
2. At the top of the Job Management screen, click the blue Create
button to open the Create New Job screen.
3. Enter a descriptive name for the job (such as
HadoopStreaming) in the Job Name field.
4. Use the Job Type pull-down menu to select Hadoop Streaming,
if it is not selected already.
5. Click the Choose button in the Mapper Script field to open a
standard File Upload popup.
6. Navigate to the hadoop-streaming folder (see “Downloading the
Samples” on page 9) and then select the file mapper.py to
upload.
7. Click the Choose button in the Reducer Script field to open a
standard File Upload popup.
8. Navigate to the hadoop-streaming folder (see “Downloading the
Samples” on page 9) and then select the file reducer.py to
upload.Check the Persistent checkbox next to Cluster Type.
9. Check the Persistent checkbox next to Cluster Type and make
sure that the correct cluster (SampleHadoopCluster) is selected
in the pull-down menu.
10. Click the Insert button to the right of the Input Path field to open
the DataTap Browser popup.
11. Navigate to the data input folder that you created in “Creating
Directories and Uploading Data” on page 13 and then double click
the sample_text.txt entry.
12. In the Output Path field, type dtap://TenantStorage/DataOutput_2
13. Review your entries. The Create New Job screen should look
like this:
20 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
14. Click the blue Submit button to run the job and return to the Job
Management screen. You will see the newly created cluster with
a blue Running bar in the Job Status column.
The bar will turn green and say Completed once the job is
completed.
At any time during or after the job run, you may click the name of
the job to open the <Job> Output popup, which displays the
current output for the selected job. See “The <Job> Output Popup”
on page 39.
15. In the Main Menu, click DataTaps to return to the DataTaps
screen.
16. In the table on the screen, click the name of the DataTap that you
used in“Creating Directories and Uploading Data” on page 13 in the
Name column to open the <DataTap> Browser screen, where
<DataTap> is the name of the DataTap you are using. In this
example, this will be the TenantStorage Browser screen.
17. The <DataTap> Browser screen appears, with the Data
Output_2 folder now showing. Clicking the + sign to the left of
this folder expands the folder listing. Your job results are in the
part-00000 file.
18. Select the part-00000 file by clicking it, and then click the
purple Download File button (down arrow) to open a standard
File Download popup. Save the file to your local device.
19. Open the downloaded file in a text editor to see a complete list of
the words in the sample_text.txt file and how many times
each word appears therein. This will look identical to the results
created in “Hadoop Custom Jar” on page 17.
This concludes the Hadoop Streaming example.
21Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
3.3 - Pig Script
This script will count the number of times each word appears in the
sample text file. You may navigate to the pig-script folder and view
the wordcount.pig script in a text editor.
In this script, the line beginning with A = loads the sample text file,
and the next three lines count how many times each word appears in
the sample. To create a new Pig Script job:
1. On your local device, navigate to the pig-script folder (see
“Downloading the Samples” on page 9) and then open the file
wordcount.pig in a text editor.
2. Click Jobs in the Main Menu to open the Job Management
screen.
3. At the top of the Job Management screen, click the blue Create
button to open the Create New Job screen.
4. Enter a descriptive name for the job (such as PigScriptJob)
in the Job Name field.
5. Use the Job Type pull-down menu to select Pig Script, if it is
not selected already.
6. Click the Choose button in the Script Path field to open a
standard File Upload popup.
7. Navigate to the pig-script folder (see “Downloading the Samples”
on page 9) and then select the file wordcount.pig to upload.
8. Check the Persistent checkbox next to Cluster Type and make
sure that the correct cluster (SampleHadoopCluster) is selected
in the pull-down menu.
9. Review your entries. The Create New Job screen should look
like this:
Note: If the sample file sample_text.txt is placed in a
DataTap other than the default TenantStorage DataTap
then you will need to edit the Pig script being used for this
example.
22 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.
3 - Running Applications
10. Click the blue Submit button to run the job and return to the Job
Management screen. You will see the newly created cluster with
a blue Running bar in the Job Status column.
The bar will turn green and say Completed once the job is
completed.
At any time during or after the job run, you may click the name of
the job to open the <Job> Output popup, which displays the
current output for the selected job. See “The <Job> Output Popup”
on page 39.
11. In the Main Menu, click DataTaps to return to the DataTaps
screen.
12. In the table on the screen, click the name of the DataTap that you
used in“Creating Directories and Uploading Data” on page 13 in the
Name column to open the <DataTap> Browser screen, where
<DataTap> is the name of the DataTap you are using. In this
example, this will be the TenantStorage Browser screen.
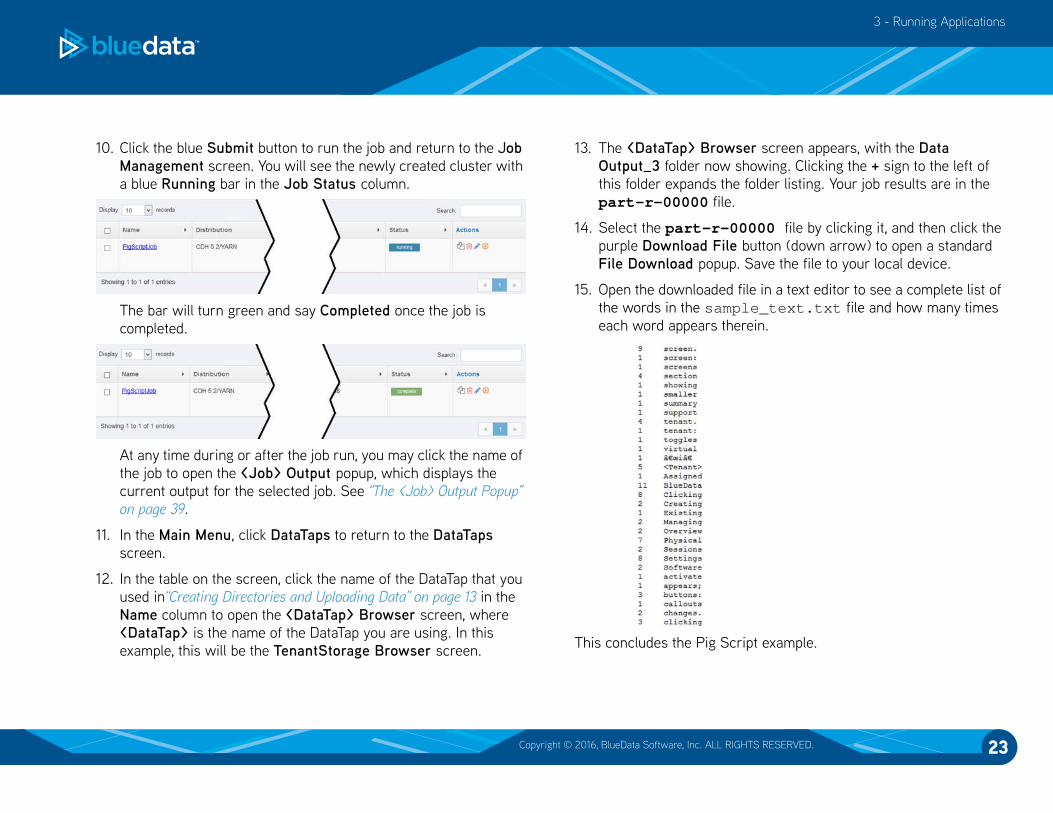
13. The <DataTap> Browser screen appears, with the Data
Output_3 folder now showing. Clicking the + sign to the left of
this folder expands the folder listing. Your job results are in the
part-r-00000 file.
14. Select the part-r-00000 file by clicking it, and then click the
purple Download File button (down arrow) to open a standard
File Download popup. Save the file to your local device.
15. Open the downloaded file in a text editor to see a complete list of
the words in the sample_text.txt file and how many times
each word appears therein.
This concludes the Pig Script example.
23Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
3.4 - Hive Script
This script will count the number of times each word appears in the
sample text file. You may navigate to the hive-script folder and view
the wordcount.hql script in a text editor.
This script creates a table that consists of lines of strings (words, in
this case), loads the sample text file, counts the number of times
each word appears in the sample, and then outputs the results to the
specified folder (/user/hive/DataOutput). To create a new
Hive Script job:
1. On your local device, navigate to the hive-script folder (see
“Downloading the Samples” on page 9) and then open the file
wordcount.hql in a text editor.
2. Click Jobs in the Main Menu to open the Job Management
screen.
3. At the top of the Job Management screen, click the blue Create
button to open the Create New Job screen.
4. Enter a descriptive name for the job (such as
HiveScriptJob) in the Job Name field.
5. Use the Job Type pull-down menu to select Hive Script, if it is
not selected already.
6. Click the Choose button in the Script Path field to open a
standard File Upload popup.
7. Navigate to the hive-script folder (see “Downloading the Samples”
on page 9) and then select the file wordcount.hql to upload.
8. Check the Persistent checkbox next to Cluster Type and make
sure that the correct cluster (SampleHadoopCluster) is selected
in the pull-down menu.
9. Review your entries. The Create New Job screen should look
like this:
24 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
10. Click the blue Submit button to run the job and return to the Job
Management screen. You will see the newly created cluster with
a blue Running bar in the Job Status column.
The bar will turn green and say Completed once the job is
completed.
At any time during or after the job run, you may click the name of
the job to open the <Job> Output popup, which displays the
current output for the selected job. See “The <Job> Output Popup”
on page 39.
11. In the Main Menu, click Clusters to return to the Cluster
Management screen.
12. n the Cluster Details column of the table on the screen, click the
Cluster FS link that corresponds to the SampleHadoopCluster
cluster to open the <Cluster> Cluster FS Browser screen,
where <Cluster> is the name of the persistent cluster you are
using. In this example, this will be the SampleHadoopCluster
Cluster FS Browser screen.
13. In the folder listing, click the + sign next to the / folder and then
click the hive sub-folder, followed by the DataOutput sub-folder.
14. Download the file 000000_0 to your local machine.
15. Open the downloaded file in a text editor to see a complete list of
the words in the sample_text.txt file and how many times
each word appears therein.
This concludes the Hive Script example.
25Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.
Running Applications on BlueData EPIC
3.5 - Impala Script
The sample Impala script does not count words, and you need not
specify any input or output directories, as these are already coded
into the script. Impala essentially functions as a database query
engine; it creates tables, populates them with data, and then runs
queries against that data to produce the desired results. To create a
new Impala Script job:
1. Click Jobs in the Main Menu to open the Job Management
screen.
2. At the top of the Job Management screen, click the blue Create
button to open the Create New Job screen.
3. Enter a descriptive name for the job (such as
ImpalaScriptJob) in the Job Name field.
4. Use the Job Type pull-down menu to select Impala Script, if it
is not selected already.
5. Click the Choose button in the Script Path field to open a
standard File Upload popup.
6. Navigate to the impala-script folder (see “Downloading the
Samples” on page 9) and then select the file impala.script to
upload.
7. Check the Persistent checkbox next to Cluster Type and make
sure that the correct cluster (SampleHadoopCluster) is selected
in the pull-down menu.
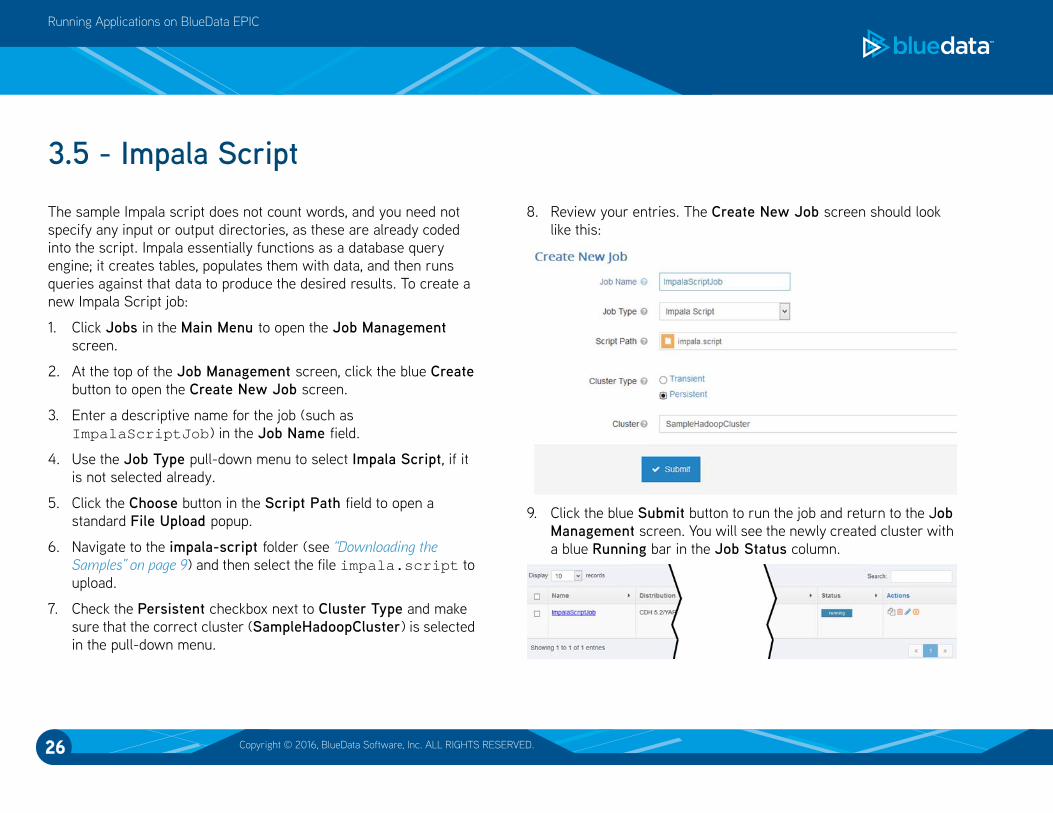
8. Review your entries. The Create New Job screen should look
like this:
9. Click the blue Submit button to run the job and return to the Job
Management screen. You will see the newly created cluster with
a blue Running bar in the Job Status column.
26 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
The bar will turn green and say Completed once the job is
completed.
At any time during or after the job run, you may click the name of
the job to open the <Job> Output popup, which displays the
current output for the selected job. See “The <Job> Output Popup”
on page 39.
10. Click the orange Job Output button (down arrow) in the Action
column.
The output appears in a new browser tab. Scroll to the bottom to
see the finished results.
This concludes the Impala Script example; however, if you are
interested, you may see the tables that the script created and queried
by doing the following:
1. Click Clusters to open the Cluster Management screen, and
then click the name of the cluster that you just used to run the
Impala Script job (such as SampleHadoopCluster).
The <Cluster> screen appears, where <Cluster> is the name of
the cluster.
2. In the Process List column, click Hue Console to open the Hue
Login screen in a new browser tab.
3. When logging to Hue for the first time on a virtual cluster, you
will be prompted to create a new user name/password that you
will use for subsequent access. Please refer to your Hue
documentation for additional information.
4. In the blue toolbar at the top of the page, click the Metastore
Manager button.
27Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
5. The Database default screen appears. The tables created and
used by the Impala script are in the Table Name section in the
lower right section of the screen. You may open these tables for
viewing within Hue. Please refer to your Hue documentation for
instructions if needed.
28 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
3.6 - Spark - Scala Jar
This section describes how Spark Scala Jar jobs create a Spark
context and then guides you through running a sample job. In this
example, the script counts the number of times the letters “a” and
“b” appear in the sample text file.
3.6.1 - About the Spark Context
Spark applications typically need to construct a SparkContext as a
first step. The recommended way of constructing this in a Spark
Scala Jar application running on EPIC, is as follows:
val conf = new SparkConf().setAppName(<appName>)val sc = new SparkContext(conf)
In the above example, <appName> is the name of your application
that will show up in the Spark master UI. EPIC automatically
specifies the values for the Spark master host, Spark home, and the
required .jar files from the cluster environment.
3.6.2 - Running a Spark Scala Jar Job
To create a new Spark Scala Jar job:
1. Click Jobs in the Main Menu to open the Job Management
screen.
2. At the top of the Job Management screen, click the blue Create
button to open the Create New Job screen.
3. Enter a descriptive name for the job (such as
SparkScalaJar) in the Job Name field.
4. Use the Job Type pull-down menu to select Spark - Scala Jar,
if it is not selected already.
5. Click the Choose button in the Script Path field to open a
standard File Upload popup.
6. Navigate to the spark-scala-jar folder, which is under the spark
folder (see “Downloading the Samples” on page 9), and then upload
the .jar file.
7. In the App Name field, enter SimpleApp (case sensitive).
8. Check the Persistent checkbox next to Cluster Type and make
sure that the correct cluster (SampleSparkCluster) is selected
in the pull-down menu.
9. Click the Insert button to the right of the Edit Arguments field to
open the DataTap Browser popup.
10. Navigate to the data input folder that you created in “Creating
Directories and Uploading Data” on page 13 and then double click
the sample_text.txt entry.
11. In the Edit Arguments field, type dtap://TenantStorage/DataOutput_4.
29Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
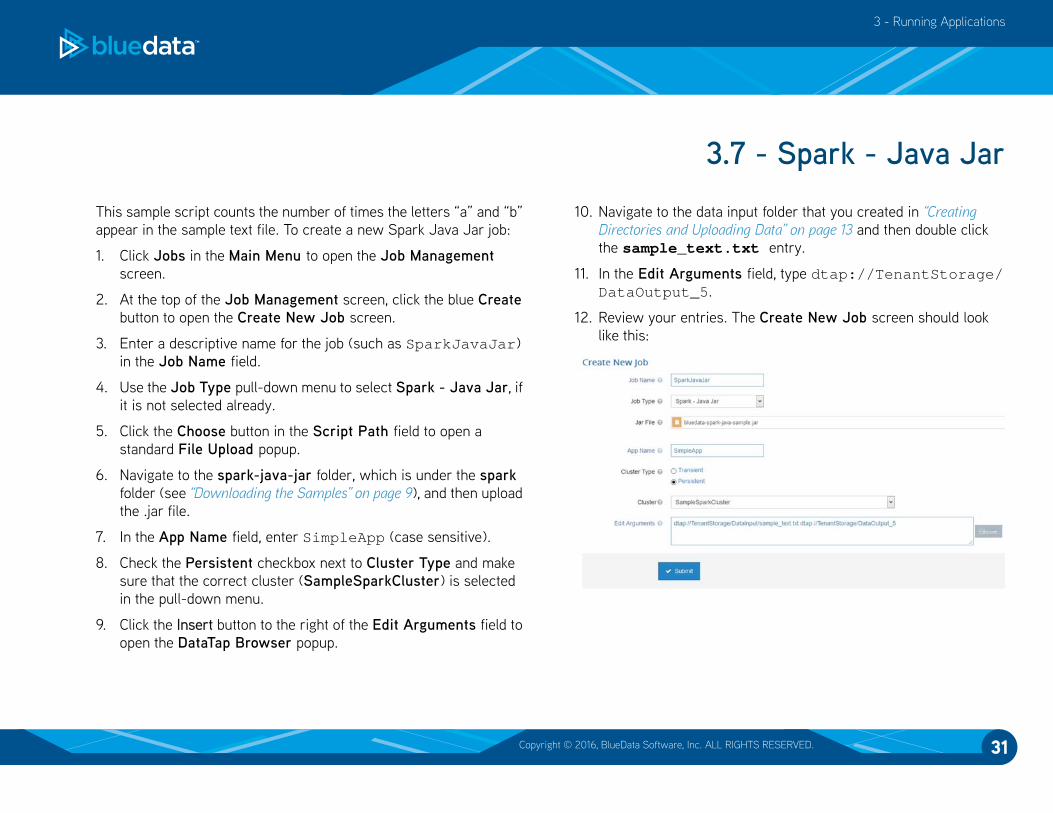
12. Review your entries. The Create New Job screen should look
like this:
13. Click the blue Submit button to run the job and return to the Job
Management screen. You will see the newly created cluster with
a blue Running bar in the Job Status column.
The bar will turn green and say Completed once the job is
completed.
At any time during or after the job run, you may click the name of
the job to open the <Job> Output popup, which displays the
current output for the selected job. See “The <Job> Output Popup”
on page 39.
14. Click the orange Job Output button (down arrow) in the Action
column.
The output appears in a new browser tab. Scroll to the bottom to
see the finished results, which will be the number of lines with
the letters “a” and “b” in them.
This concludes the Spark Scala Jar example.
Note: You can run Spark ML jobs just like any other Spark
Scala jobs via either the EPIC interface as described above
or the command line.
30 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.
3 - Running Applications
3.7 - Spark - Java Jar
This sample script counts the number of times the letters “a” and “b”
appear in the sample text file. To create a new Spark Java Jar job:
1. Click Jobs in the Main Menu to open the Job Management
screen.
2. At the top of the Job Management screen, click the blue Create
button to open the Create New Job screen.
3. Enter a descriptive name for the job (such as SparkJavaJar)
in the Job Name field.
4. Use the Job Type pull-down menu to select Spark - Java Jar, if
it is not selected already.
5. Click the Choose button in the Script Path field to open a
standard File Upload popup.
6. Navigate to the spark-java-jar folder, which is under the spark
folder (see “Downloading the Samples” on page 9), and then upload
the .jar file.
7. In the App Name field, enter SimpleApp (case sensitive).
8. Check the Persistent checkbox next to Cluster Type and make
sure that the correct cluster (SampleSparkCluster) is selected
in the pull-down menu.
9. Click the Insert button to the right of the Edit Arguments field to
open the DataTap Browser popup.
10. Navigate to the data input folder that you created in “Creating
Directories and Uploading Data” on page 13 and then double click
the sample_text.txt entry.
11. In the Edit Arguments field, type dtap://TenantStorage/DataOutput_5.
12. Review your entries. The Create New Job screen should look
like this:
31Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
13. Click the blue Submit button to run the job and return to the Job
Management screen. You will see the newly created cluster with
a blue Running bar in the Job Status column.
The bar will turn green and say Completed once the job is
completed.
At any time during or after the job run, you may click the name of
the job to open the <Job> Output popup, which displays the
current output for the selected job. See “The <Job> Output Popup”
on page 39.
14. Click the orange Job Output button (down arrow) in the Action
column.
The output appears in a new browser tab. Scroll to the bottom to
see the finished results, which will be the number of lines with
the letters “a” and “b” in them.
This concludes the Spark Java Jar example.
32 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.
3 - Running Applications
3.8 - Spark - Python Script
In this example, the script counts the number of times the letters “a”
and “b” appear in the sample text file. To create a new Spark Python
Script job:
1. Click Jobs in the Main Menu to open the Job Management
screen.
2. At the top of the Job Management screen, click the blue Create
button to open the Create New Job screen.
3. Enter a descriptive name for the job (such as
SparkPythonScript) in the Job Name field.
4. Use the Job Type pull-down menu to select Spark - Python
Script, if it is not selected already.
5. Click the Choose button in the Script File field to open a
standard File Upload popup.
6. Navigate to the spark-python folder, which is under either the
spark folder (see “Downloading the Samples” on page 9), and then
upload the Python script.
7. Check the Persistent checkbox next to Cluster Type and make
sure that the correct cluster (SampleSparkCluster) is selected
in the pull-down menu.
8. Click the Insert button to the right of the Input Path field to open
the DataTap Browser popup.
9. Navigate to the data input folder that you created in “Creating
Directories and Uploading Data” on page 13 and then double click
the sample_text.txt entry.
10. In the Edit Arguments field, type dtap://TenantStorage/DataOutput_6.
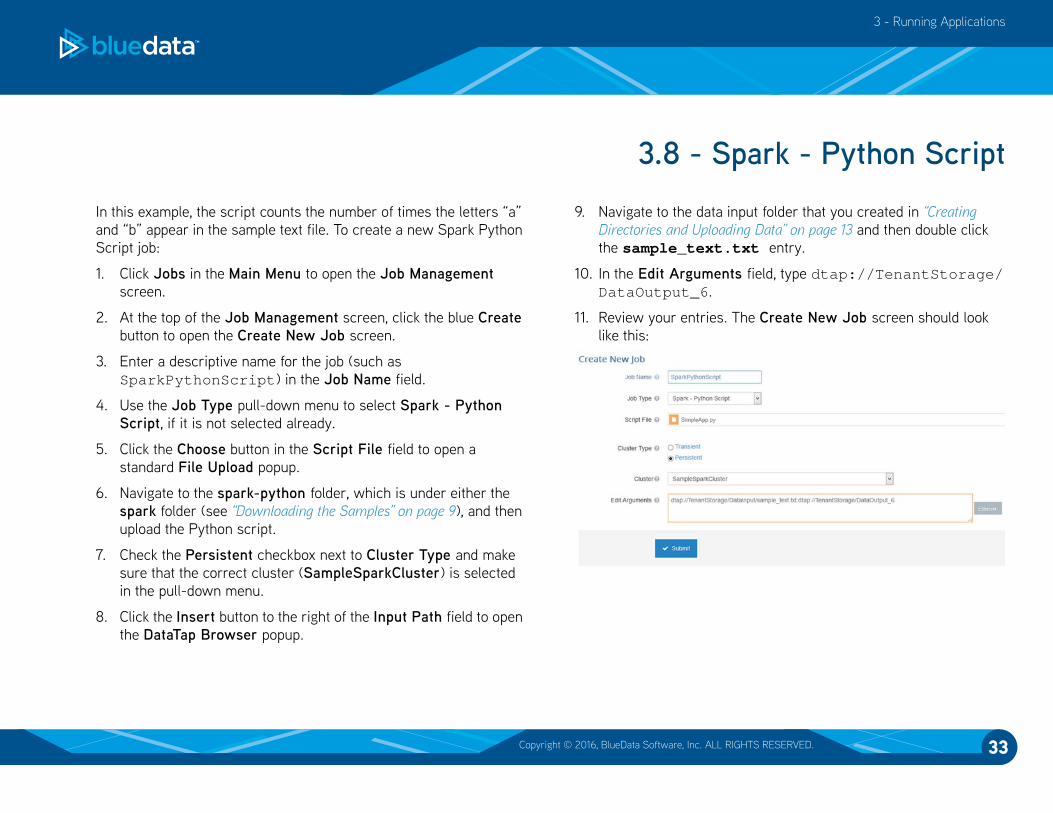
11. Review your entries. The Create New Job screen should look
like this:
33Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.
Running Applications on BlueData EPIC
12. Click the blue Submit button to run the job and return to the Job
Management screen. You will see the newly created cluster with
a blue Running bar in the Job Status column.
The bar will turn green and say Completed once the job is
completed.
At any time during or after the job run, you may click the name of
the job to open the <Job> Output popup, which displays the
current output for the selected job. See “The <Job> Output Popup”
on page 39.
13. Click the orange Job Output button (down arrow) in the Action
column.
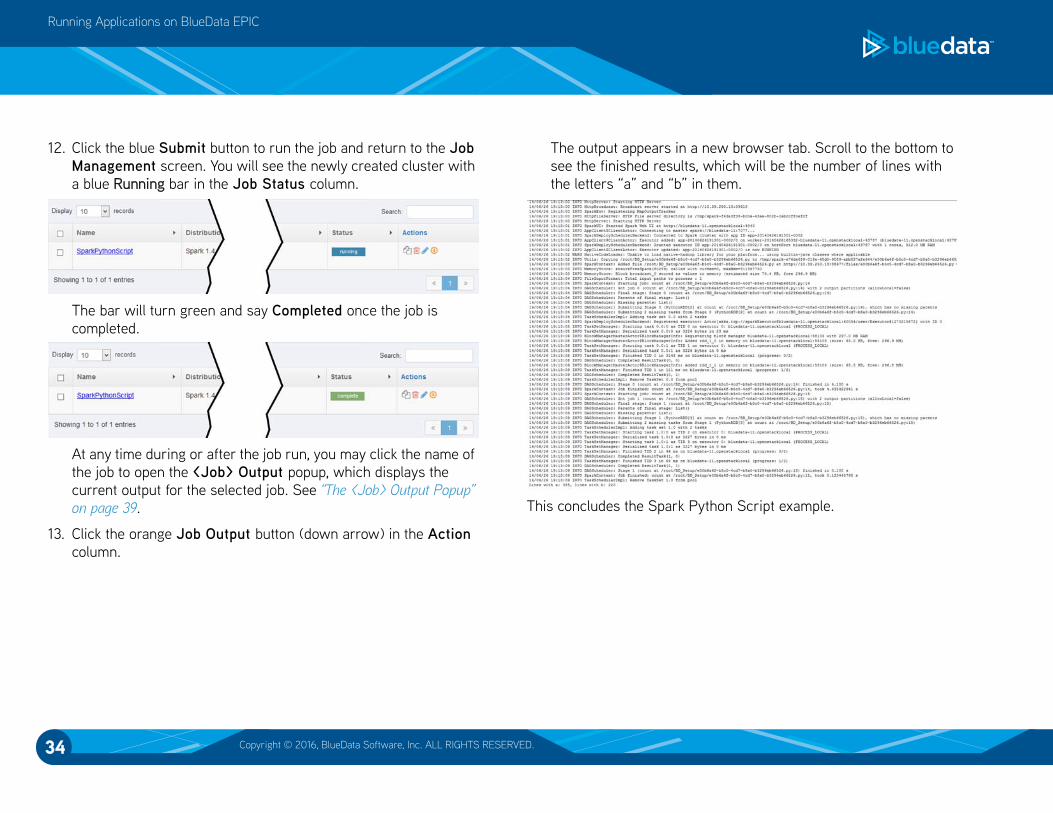
The output appears in a new browser tab. Scroll to the bottom to
see the finished results, which will be the number of lines with
the letters “a” and “b” in them.
This concludes the Spark Python Script example.
34 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
3.9 - Spark - Zeppelin
The Apache Zeppelin interpreter concept allows any language or
data-processing backend to plug into Zeppelin. Zeppelin currently
supports many interpreters such as Scala and Python (with Apache
Spark), SparkSQL, Hive, Markdown, and Shell. EPIC supports
Zeppelin with Spark versions 1.4 and higher, and installing Spark
automatically installs Zeppelin as well. This example demonstrates
using the Zeppelin editor to run a job.
1. Click Clusters to open the Cluster Management screen, and
then click the name of the Spark cluster (such as
SampleSparkCluster).
The <Cluster> screen appears, where <Cluster> is the name of
the cluster.
2. In the Process List column, click ZeppelinNotebook.
The Welcome to Zeppelin! page appears in a new browser tab/
window.
3. Click the Zeppelin Tutorial link.
The Zeppelin Tutorial page appears.
4. If you see an Interpreter Binding section with a list of
interpreters (highlighted in blue) and a Save button, then click
Save to accept the defaults.
5. Each section on the page is called a paragraph. You can run a
paragraph by clicking the Run button (arrow) that appears in
each paragraph. Click the Run button in the Prepare Data
paragraph followed by the Run button in the Load Data Into
Table paragraph.
The notation FINISHED next to the Run button changes to
PENDING and then RUNNING while the paragraph runs and
then changes back to FINISHED once the run has completed.
6. In EPIC, click DataTaps in the Main Menu to open the DataTaps
screen.
Note: If you are unable to click the Play button then reload
the page by clicking the browser Refresh button.
35Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
7. In the table on the screen, click the name of the DataTap that you
used in“Creating Directories and Uploading Data” on page 13 in the
Name column to open the <DataTap> Browser screen, where
<DataTap> is the name of the DataTap you are using. In this
example, this will be the TenantStorage Browser screen.
8. Create a folder called data and then create a sub-folder called
page_views.
The <DataTap> Browser screen should now look something like
this:
9. Click the gray File Upload button (up arrow) at the top of the
screen to open a standard File Upload popup.
10. Navigate to the spark-zeppelin folder and upload the
page_views.csv file.
The Upload Status popup appears with a progress bar showing
the upload progress. This bar turns green and the word
Completed appears when the upload is complete.
11. Click OK to close the popup.
12. Return to the Zeppelin Tutorial page and scroll to the bottom,
where you will see a blank paragraph with the notation READY.
13. Type or paste the following text into the blank paragraph and
then click the Run button:
%hiveDROP TABLE IF EXISTS page_views
14. Scroll down to the new blank paragraph at the bottom of the
page, type or paste the following text into that paragraph, and
then click the Run button:
%hiveCREATE EXTERNAL TABLE page_views(viewTime INT, userid BIGINT, page_url STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','STORED AS TEXTFILELOCATION '/data/page_views/'
This process creates a table. You may now run any query on that
table.
36 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
3.10 - SparkR Jobs
To run a SparkR job:
1. Establish an SSH connection to the Spark cluster by opening an
SSH client and pointing it to the IP address of the Spark Master
node and then using your EPIC credentials to log in. If needed,
you can open the <Cluster> screen for the Spark cluster you
want to access, click SparkMaster in the Process List column
to open the Spark Master page and then copy the URL from the
browser address bar.
2. Run the sparkR --master <spark master url> command, where <spark master url> is the URL of the
Spark Master node.
3. If you see permissions warnings, then grant the requested
permissions to the log directories mentioned in the warnings.
A SparkR prompt appears.
4. You may now run the following commands:
- -sqlContext <- sparkRSQL.init(sc) //Create the DataFrame
- df <- createDataFrame(sqlContext, faithful) //Get basic information about the DataFrame df
- //DataFrame[eruptions:double, waiting:double] //Select only the "eruptions" column
- head(select(df, df$eruptions)) // eruptions ##1 3.600 ##2 1.800 ##3 3.333 //You can also pass in column names as strings.
- head(select(df, "eruptions")) //Filter the DataFrame to only retain rows with wait times shorter than 50 mins.
- head(filter(df, df$waiting < 50)) //eruptions waiting ##1 1.750 47 ##2 1.750 47 ##3 1.867 48
- df <- createDataFrame(sqlContext, faithful) //Displays the content of the DataFrame to stdout
- head(df) // eruptions waiting
- //1 3.600 79
- //2 1.800 54
- //3 3.333 74
Note: If you use an SSH+keypair to connect to a virtual node
then the username will be bluedata and not root.
37Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on BlueData EPIC
3.11 - Spark Streaming Jobs
This sample Spark Streaming job performs a word count from a
network stream. To run this job:
1. Open a terminal and start a netcat server at port 9999.
nc -lk 9999
2. Open another terminal and the run the following command:
cd $SPARK_HOMEsudo bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999
3. Return to the terminal you opened in Step 1 and then begin typing
random words separated by spaces. As you type, you should see
the second terminal giving you a continuously running word
count of the stream you are typing.
4. If you are seeing too many extraneous messages in your console
window, you can change your log4j.properties under
$SPARK_HOME/conf as follows:
log4j.rootLogger=INFO,stdout,stderr,file -> log4j.rootLogger=stdout,stderr,file (Remove INFO)
5. Continue typing words in the first terminal window and the word
count will continue updating in the second terminal window.
38 Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

3 - Running Applications
3.12 - The <Job> Output Popup
In the Job Management screen, clicking the name of a running or
complete job in the Job Name column opens the <Job> Output
popup, where <Job> is the name of the selected job. This popup
refreshes every 15 seconds while the job is running and displays the
output of that job.
When you have finished viewing the job output, click the Hide button
to close the popup and return to the Job Management screen.
39Copyright © 2016, BlueData Software, Inc. ALL RIGHTS RESERVED.

Running Applications on EPIC, version 2.1 (02/2016)
This book or parts thereof may not be reproduced in any form with-
out the written permission of the publishers. Printed in the United
States of America. Copyright 2016 by BlueData Software, Inc. All
rights reserved.
Contact Information:
BlueData Software, Inc.
3979 Freedom Circle, Suite 850
Santa Clara, California 95054
Email: [email protected]
Website: www.bluedata.com





























