Embed Size (px)
Citation preview

RISC Architecture
RISC vs CISC
Sherwin Chan

Instruction Set Architecture Types of ISA and examples:
RISC -> Playstation CISC -> Intel x86 MISC -> INMOS Transputer ZISC -> ZISC36 SIMD -> many GPUs EPIC -> IA-64 Itanium VLIW -> C6000 (Texas
Instruments)

CISC – Complex Instruction Set Computer
RISC – Reduced Instruction Set Computer
Instruction Set Architecture

Problems of the Past In the past, it was believed that
hardware design was easier than compiler design Most programs were written in
assembly language Hardware concerns of the past:
Limited and slower memory Few registers

The Solution Have instructions do more work,
thereby minimizing the number of instructions called in a program
Allow for variations of each instruction Usually variations in memory access
Minimize the number of memory accesses

CISC Each instruction executes multiple
low level operations Ex. A single instruction can load from
memory, perform an arithmetic operation, and store the result in memory
Smaller program size Less memory calls

The Search for RISC Compilers became more prevalent The majority of CISC instructions
were rarely used Some complex instructions were
slower than a group of simple instructions performing an equivalent task Too many instructions for designers
to optimize each one

Smaller instructions allowed for constants to be stored in the unused bits of the instruction This would mean less memory calls to
registers or memory

RISC Architecture Small, highly optimized set of
instructions Uses a load-store architecture Short execution time Pipelining Many registers

Load/Store Architecture Individual instructions to store/load
data and to perform operations All operations are performed on
operands in registers Main memory is used only to
load/store instructions

RISC vs CISC Less transistors needed in RISC RISC processors have shorter design cycles RISC instructions take less clock cycles
than CISC instructions CISC instructions take up to 3 to 12 times
longer Smaller instructions allowed for constants
to be stored in the unused bits of the instruction This would mean less memory calls to registers
or main memory

MIPS: A RISC example Smaller and simpler instruction set
111 instructions One cycle execution time Pipelining 32 registers
32 bits for each register

MIPS Instruction Set 25 branch/jump instructions 21 arithmetic instructions 15 load instructions 12 comparison instructions 10 store instructions 8 logic instructions 8 bit manipulation instructions 8 move instructions 4 miscellaneous instructions

Pipelining 101 Break instructions into steps Work on instructions like in an
assembly line Allows for more instructions to be
executed in less time A n-stage pipeline is n times faster
than a non pipeline processor (in theory)

MISC/RISC Pipeline Stages Fetch instruction Decode instruction Execute instruction Access operand Write result
Note: Slight variations depending on processor

Without Pipelining Normally, you would peform the
fetch, decode, execute, operate, and write steps of an instruction and then move on to the next instruction
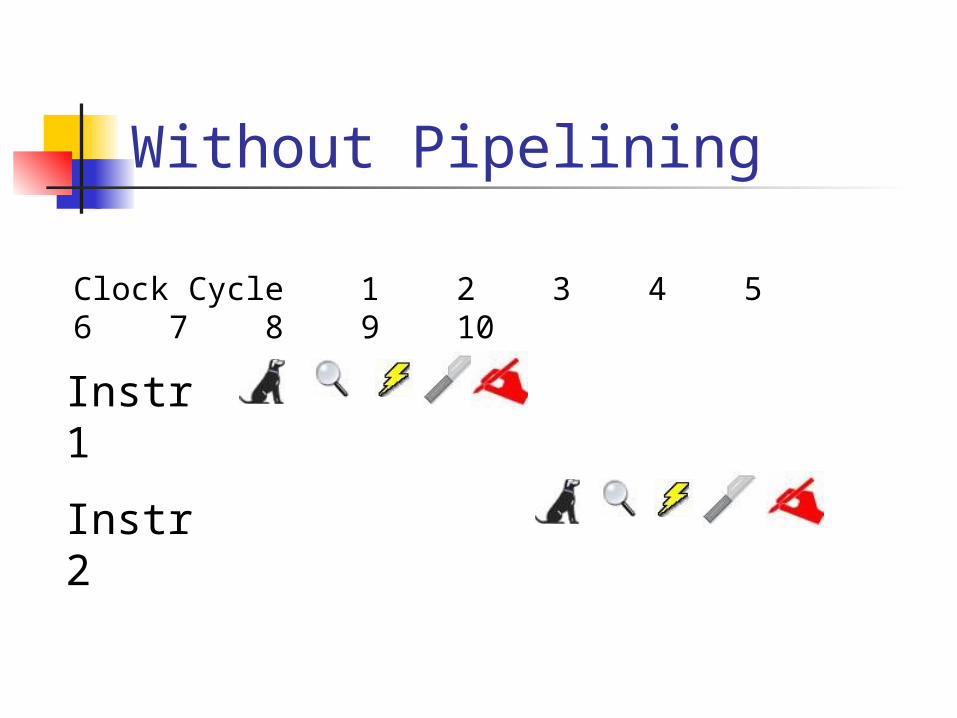
Without Pipelining
Instr 1
Instr 2
Clock Cycle 1 2 3 4 5 6 7 8 9 10

With Pipelining The processor is able to perform
each stage simultaneously. If the processor is decoding an
instruction, it may also fetch another instruction at the same time.

With Pipelining
Clock Cycle 1 2 3 4 5 6 7 8 9
Instr 1
Instr 2
Instr 3
Instr 4
Instr 5

Pipeline (cont.) Length of pipeline depends on the
longest step Thus in RISC, all instructions were
made to be the same length Each stage takes 1 clock cycle In theory, an instruction should be
finished each clock cycle

Pipeline Problem 1 Problem: An instruction may need
to wait for the result of another instruction
Ex: add $r3, $r2, $r1add $r5, $r4, $r3
………

Pipeline Problem 1 (cont) Solution: Compiler may recognize
which instructions are dependent or independent of the current instruction, and rearrange them to run the independent one first

Pipelining Problems 2 Problem: A branch instruction
evaluates the result of another instruction that has not finished yet
Ex: Loop :add $r3, $r2, $r1sub $r6, $r5, $r4beq $r3, $r6, Loop…………

Pipelining Problems 2 (cont) Solution 1: Guess. Begin on
predicted instruction first. If wrong, clear pipeline and begin on correct instruction.
Ex: For a loop statement, assume it will loop back, because the majority of the time it will.
Some processors remember old branches and use that to predict new ones

Pipelining Problems 2 (cont) Solution 2: Begin decoding
instructions from both sides of the branch. After the branch is evaluated, send the correct instructions to the pipeline.

How to make pipelines faster Superpipelining
Divide the stages of pipelining into more stages
Ex: Split “fetch instruction” stage into two stages
SuperduperpipeliningSuperscalarpipelining Run multiple pipelines in parallel

Dynamic pipeline: Uses buffers to hold instruction bits in case a dependent instruction stalls

Why CISC Persists Most Intel and AMD chips are CISC x86 Most PC applications are written for
x86 Intel spent more money improving the
performance of their chips Modern Intel and AMD chips
incorporate elements of pipelining During decoding, x86 instructions are
split into smaller pieces
![RISC, CISC, and Assemblers - Cornell University · RISC, CISC, and Assemblers ... • Complexity: CISC, RISC Assemblers ... –e.g. Mem[segment + reg + reg*scale + offset] 14 RISC](https://img.pdfslide.us/doc/110x75/5c1068af09d3f254228c84fd/risc-cisc-and-assemblers-cornell-risc-cisc-and-assemblers-complexity.jpg)




























