Embed Size (px)
Citation preview

Research Collection
Doctoral Thesis
Presto: Methode und Werkzeug zur Evolution vonDatenbankanwendungen
Author(s): Janes, Peter
Publication Date: 1993
Permanent Link: https://doi.org/10.3929/ethz-a-000897446
Rights / License: In Copyright - Non-Commercial Use Permitted
This page was generated automatically upon download from the ETH Zurich Research Collection. For moreinformation please consult the Terms of use.
ETH Library

Peter Marcel Ronald Janes
Presto: Methode undWerkzeug zurEvolution von Daten-bankanwendungen

Abhandlung zur Erlangung des Titels eines Doktors der TechnischenWissenschaften der Eidgenössischen Technischen Hochschule (ETH)Zürich
Diss. ETH Nr. 10048
Prof. Dr. C.A. Zehnder, ReferentProf. Dr. R. Marti, Korreferent
1993© Verlag der Fachvereinean den schweizerischen Hochschulen und Techniken, Zürich

5
Vorwort
Der Kern dieser Arbeit entstand während meiner mehrjährigen Tätig-keit in der Forschungsgruppe von Herrn Prof. C.A. Zehnder am Institutfür Informationssysteme der Eidgenössischen Technischen Hochschule(ETH) Zürich. Die Konzepte interaktiver Benutzerschnittstellen sindvon einer früheren Tätigkeit bei Herrn Prof. J. Nievergelt beeinflusst.Die praktische Überprüfung und der Abschluss der Arbeit erfolgtenparallel zur Projektarbeit in einem innovativen Informatikprojekt derWinterthur Lebensversicherungsgesellschaft.
Die Forschungsgruppe von Herrn Prof. C.A. Zehnder kann auf einelangjährige Erfahrung beim Entwurf von Datenbanken und daraufbasierenden Informatikanwendungen zurückblicken. Schon früh wurdenDatenbanksysteme und zugehörige Entwurfswerkzeuge entwickelt, undvon Beginn an wurden auch leistungsfähige Arbeitsstationen eingesetzt.In dieser Umgebung entstand das erweiterbare Entwurfssystem Presto I,das als Testbett für den integrierten Entwurf datenbankbasierter An-wendersysteme diente. Um praktische Erfahrungen mit genutzten An-wendungen und der evolutionären Weiterentwicklung zu sammeln, wur-den zwei Anwendersysteme sehr unterschiedlicher Grössen - Delphi undKORA - untersucht; dabei entstand auch das Nachfolgersystem PrestoII. Parallel dazu entstand die vorliegende Arbeit, die das wissenschaft-liche Resultat meiner Tätigkeit als Assistent in der Forschungsgruppevon Herrn Prof. C.A Zehnder und meiner Mitarbeit im Projekt KORAder Winterthur Lebensversicherungsgesellschaft darstellt. Diese gab mirdie Gelegenheit, die theoretischen Erkenntnisse an den Anforderungender Praxis zu messen.
Ich möchte an dieser Stelle all jenen danken, die zum Gelingen dieserArbeit beigetragen haben. Ich erlaube mir, an erster Stelle meine Elternaufzuführen, die mir eine unschätzbare moralische Stütze gewesen sind.Herrn Prof. C.A. Zehnder danke ich für seine wertvollen Hinweise unddafür, dass er die Arbeit ermöglicht hat. Für die interessanten Diskus-sionen und die Übernahme des Korreferats danke ich Herrn Prof. R.Marti. An der ETH verbinden mich viele angeregte und kreative Dis-kussionen mit Fredy Oertly, ebenso mit Peter Leikauf, Andreas Wälchliund Hansbeat Loacker. Die Studenten P. Bloch, D. Schenker und G.Schiller leisteten substantielle Beiträge. Weiter sei gedankt der Biblio-thekarin, Frau H. Sechser, für die gute Zusammenarbeit während derArbeiten an der Fallstudie Delphi, den Herren Dr. W. Heiz, Dr. P.

6
Ursprung, E. Ostertag und H.P. Schwarz bei der Winterthur-Leben fürdie vielen konstruktiven Diskussionen über den Datenbankeinsatz in derPraxis.

Inhalt 7
Inhalt
Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1
Abstract. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 2
1 Einleitung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 31.1 Problemstellung: Ein Vorgehensmodell für die Evolution
datenbankbasierter Anwendersysteme..............................131.2 Zielsetzung ...................................................................151.3 Umfeld.........................................................................161.4 Gliederung der Arbeit ...................................................18
2 Datenbankbasierte Anwendersysteme. . . . . . . . . . . . . . . . . . . . . . . . 1 92.1 Was ist ein datenbankbasiertes Anwendersystem?..............192.2 Beschreibung: Das Anwendungsschema ...........................212.3 Ein datenbankgestütztes Entwurfssystem..........................242.4 Evolution einer Anwendung und ihres Schemas................262.5 Methode und Werkzeug .................................................28
3 Entwicklungsmethoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 13.1 Vorgehensmodelle.........................................................31
3.1.1 Einführung und Begriffe......................................323.1.2 Klassisches Phasenmodell .....................................343.1.3 Prototypenbildung...............................................353.1.4 Pilotprojekt ........................................................373.1.5 Inkrementelle Vervollständigung ..........................383.1.6 Evolutionäre Weiterentwicklung...........................393.1.7 Vergleich ...........................................................39
3.2 Entwurfsmethoden ........................................................413.2.1 Schrittweiser Entwurf..........................................423.2.2 Datenbankentwurf ...............................................433.2.3 Anwendungsentwurf............................................443.2.4 Dialogentwurf.....................................................45
3.3 Versionenbildung ..........................................................47
4 Das Evolutionäre Vorgehensmodell und die integrierteEntwurfsmethode Presto M . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 14.1 Die drei Ebenen des Verfahrens Presto M........................514.2 Versionen und Daten- und Programmgenerationen ...........524.3 Das evolutionäre Vorgehensmodell für Daten und Pro-
gramme (Versionenebene)..............................................564.4 Der Migrationsschritt (Versionenübergang) .....................624.5 Die tieferen Ebenen der Entwurfsmethode Presto M.........65

8 Inhalt
4.6 Teilschemata und Entwurfskomponenten .........................684.7 Konsistenz der Entwurfsdaten ........................................694.8 Bewertung....................................................................73
5 Fallstudien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 75.1 Delphi..........................................................................77
5.1.1 Überblick, Historie..............................................775.1.2 Projektumriss, Konzept, Anforderungen ...............795.1.3 Planung der Evolution.........................................805.1.4 Generation I: Verbesserte Abfragen......................815.1.5 Generation II: Mutationen mit Überprüfungen .......825.1.6 Generation III: Integration und Ablösung ..............845.1.7 Zusammenfassung und Erfahrungen......................85
5.2 KORA .........................................................................885.2.1 Geschichte..........................................................885.2.2 Anforderungen ...................................................895.2.3 Evolutionäre Entwicklung von KORA...................905.2.4 Wegwerfprototyp................................................935.2.5 Generation I: Kernsystem ....................................945.2.6 Generation II: Basissystem ...................................955.2.7 Generation III: KORA 93 ....................................965.2.8 Zusammenfassung und Erfahrungen......................96
5.3 Gegenüberstellung.........................................................975.3.1 Vergleich ...........................................................985.3.2 Bewertung..........................................................99
6 Das erweiterbare Entwurfssystem Presto W. . . . . . . . . . . . . 1036.1 Das Aktualisierungskonzept.......................................... 1036.2 Presto W: Prinzip und Funktionseinheiten ..................... 1076.3 Erweiterbarer Entwurfssystemkern .............................. 1096.4 Entwurfskomponenten................................................. 1126.5 Von der Beschreibung zur Anwendung ......................... 1146.6 Das Entwurfssystem als Datenbankanwendung ............... 1166.7 Die Entwurfswerkzeuge Presto I und Presto II: Vergleich1186.8 Bewertung.................................................................. 121
7 Ergebnisse und Ausblick. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1237.1 Ergebnisse betreffend allgemeines Vorgehen ................. 1237.2 Ergebnisse zu Einzelaspekten ....................................... 125
7.2.1 Bedeutung der ersten Generation ........................ 1257.2.2 Periodische Bereinigung mit Ausrichtung des
Gesamtentwurfs ................................................ 1277.2.3 Kommunikationsbedürfnisse im Projektteam........ 127

Inhalt 9
7.2.4 Werkzeuge .......................................................1287.2.5 Daten ...............................................................1297.2.6 Zusammenfassung .............................................129
7.3 Offene Fragen.............................................................130
Literatur. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .131
Stichwortverzeichnis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .141

10 Inhalt

Zusammenfassung/Abstract 11
Zusammenfassung
Evolution ist die natürlichste Sache der Welt, da unsere Aktivitäten undunser Umfeld einem ständigen Wandel unterworfen sind. Die paralleldazu nötige Evolution der zugehörigen Informatiklösungen bereitetjedoch immer noch beträchtliche Schwierigkeiten, weil viele Vor-gehensmodelle zur Bereitstellung von Informatiklösungen nur eineneinzigen Entwicklungszyklus vorsehen und die später notwendigen An-passungen (an die dennoch vorhandene Evolution der realen Welt) als"Unterhalt" oder als "Nachbesserung" deklarieren. Besser wäre daherein Vorgehen, das von Beginn an auch künftige Anpassungen und Er-gänzungen als Schritte echter Projektarbeit versteht, welche systema-tisch neue Versionen der Informatiklösung bereitstellt.
Die vorliegende Arbeit stellt ein umfassendes, dreistufiges Vorgehens-modell Presto M (M: Methode) vor, das für datenbankbasierte Anwen-dersysteme die Versionenbildung (V-Schritte), die systematische Ände-rungsnachführung innerhalb Teilen einer Version (T-Schritte) undmetakonsistente Anpassungen einzelner Entwurfsobjekte (E-Schritte)unterstützt. Dabei werden die Besonderheiten von Programm- und Da-tengenerationen klar unterschieden.
Die praktische Einsetzbarkeit des Vorgehensmodells Presto M wirdanhand zweier Fallstudien von sehr unterschiedlicher Grössenordnungnachgewiesen. Das Schlusskapitel stellt die Anforderungen an ein er-weiterbares Entwurfswerkzeug Presto W (W: Werkzeug) vor, das dieevolutionäre Weiterentwicklung datenbankbasierter Anwendersystemeinformatisch unterstützt.
Vom Entwurfswerkzeug Presto W wurden zwei Versionen, Presto Iund Presto II, implementiert: Während Presto I als sehr flexibles Test-bett für erste Versuche mit erweiterbaren Enwurfssystemen diente,wurde und wird Presto II in einem Grossprojekt der Versicherungs-branche praktisch eingesetzt und laufend weiterentwickelt.

12 Zusammenfassung/Abstract
Abstract
Evolution is the most natural thing, because our activities and ourenvironment are subject of permanent change. Although current com-puter application systems need the same kind of evolution, most oftoday's life cycle models support only a single development cycle.Changes of application systems are only treated as maintenance. A moresuitable form of a life cycle model should therefore support present andfuture changes as proper follow-up projects which provide new ver-sions of the system as they are needed.
The work presented here introduces a comprehensive life cycle modelPresto M for database applications (M: method), consisting of threelevels: The highest level supports the evolution with versions of thewhole system (V-steps). On the intermediate level, the consistent changemanagement between parts within a single version is enforced (T-steps).The goal of the lowest level are consistent update operations of singledesign objects (E-steps). Special attention is paid to the correct distinc-tion between program and data generations.
The applicability of the presented life cycle model is demonstrated intwo case studies of very different size. The last chapter presents the re-quirements for a corresponding extensible design tool Presto W (W:tool) which supports evolution.
Two versions of the design tool Presto W (Presto I and Presto II) wereimplemented: The main goal of Presto I was to provide a very flexibletest bed for the extensible design system, while Presto II is actually usedin a large software project in the insurance industry and is continuouslyenhanced.

Einleitung 13
1 Einleitung
1.1 Problemstellung: Ein Vorgehensmodell für dieEvolution datenbankbasierter Anwendersysteme
Seit Jahrzehnten haben Informatiker in Forschung und Praxis Methodenerarbeitet und verbessert, mit denen Informatiklösungen zweckge-richtet, qualitätsbewusst und auch rationell bereitgestellt und gewartetwerden können. Begriffe wie Software Engineering, Strukturierung,Projektführung und Datenbanktechnik markieren Stossrichtungen aufdiesem Weg der Professionalisierung der Informatik. Gleichzeitigstiegen aber auch die Ansprüche der Anwender an die Informatik - nachimmer leistungsfähigeren und vielfältigeren Anwendungen - sowie dieDurchdringung der gesamten Industrie- und Dienstleistungsgesellschaftmit Informatikanwendungen.
Diese parallelen und einander gegenseitig beeinflussenden Ent-wicklungen haben inzwischen in der Praxis zu verschiedenen Zielkon-flikten geführt:
• Neue Software-Entwicklungsmethoden (z.B. objektorientierteMethoden und Programmiersprachen) und Software-Ent-wicklungswerkzeuge werden schlecht akzeptiert, da sie riesigevorhandene Programmbibliotheken entwerten können.
• Vorhandene (oft sehr wertvolle) Datenbestände können von er-neuerten Programmen aus nicht immer problemlos verwendetwerden.
• Anpassungswünsche von Anwenderseite belasten Sicherheit undWirtschaftlichkeit bestehender Informatiklösungen.
• Die Grösse und die Komplexität mancher Informatikanwen-dungen in der Praxis widersprechen den Forderungen derTheorie nach einfachen, übersichtlichen und damit qualitativbesseren Lösungen.
• Die Ausbildung junger Informatiker beschränkt sich meist aufisolierte Einzelmethoden, allenfalls Methodengruppen (z.B. Soft-ware Engineering oder Datenbanktechnik), während die Praxisnach Generalisten ruft, welche auch in grossen Problem-bereichen und entsprechenden Projektteams Übersicht undMethodik sicherstellen sollen.

14 Einleitung
Moderne Informatiklösungen vereinigen oft die Aspekte Datenbank, an-spruchsvolle Anwenderprogramme und längerfristige Anpassungen(Evolution). In der vorliegenden Arbeit wird für die soeben aufge-führten Problemkreise eine globale Arbeitsmethode eingeführt, welche
• für verschiedene Programmiertechniken einsetzbar ist,
• die koordinierte Weiterentwicklung von Programmsystemen undDatenbeständen erlaubt,
• jeden Entwicklungsschritt phasenweise aufgliedert (und damitkontrollierbar und verständlich macht),
• den Einsatz moderner Programmierwerkzeuge unterstützt (jageradezu bedingt),
• für Einsteiger (Studierende) wie für Praktiker verständlich undnützlich ist.
Das Schwergewicht der Arbeit liegt dabei auf dem gleichzeitigenAbdecken dieser verschiedenen Zielsetzungen. Dabei können und sollenbereits existierende gute Methoden für Einzelaufgaben konsequent ein-bezogen werden. Sobald aber die Zielsetzungen mehrdimensional wer-den, wird das Methodenangebot dünner. Figur 1.1 zeigt eine derartigeKombination, nämlich die Versionenentwicklung unter Mitberücksichti-gung von Datenbeständen. Während in einem Partnerprojekt der vor-liegenden Arbeit eine Methode für die Versionenbildung von Daten-beständen entwickelt wurde [Oertly 91], liegt das Schwergewicht dieserArbeit auf der methodischen Unterstützung von Entwicklung und Evo-lution aller Komponenten des Gesamtsystems. Beide entwickelten Werk-zeuge basieren bewusst auf demselben Protokollierungsmechanismus fürdie Änderungsbehandlung.

Einleitung 15
Einbezug der System-Evolution
Einbezug von Daten
Evolutionäre Weiterentwicklung
Einmal- Entwurf
Reine Software
Entwicklung
Systementwicklung mit Daten und Datenbanken
Klassischer Software- entwurf
Klassische Datenbank-
technik
klassische Versionen- entwicklung
Versionen- entwicklung mit Daten
Figur 1.1: Kombination von zwei Zielrichtungen
Zusätzlich zu den beiden Zielrichtungen von Figur 1.1 werden in dervorliegenden Arbeit berücksichtigt:
• Mehrere Anwenderbereiche ("Anwenderkomponenten"), die mitder gleichen Datenbank arbeiten, aber allenfalls mit unter-schiedlichem Rhythmus erneuert werden
• Die Unterstützung durch Programmwerkzeuge
In der vorliegenden Arbeit wird ein Vorgehensmodell für die evolu-tionäre Weiterentwicklung datenbankbasierter Anwendersysteme undeine damit verbundene integrierte Entwurfsmethode für alle Bestand-teile eines solchen Anwendersystems vorgestellt und in zwei Fallstudienanhand unterschiedlicher Projekte im praktischen Einsatz erprobt.
1.2 Zielsetzung
Es geht bei der vorliegenden Arbeit um die Bereitstellung einer sy-stematischen Arbeitstechnik für recht anspruchsvolle - realitätsnahe -Informatikaufgaben der Praxis. Das Schwergewicht liegt bei der ein-fachen Formulierung und dem Nachweis der praktikablen Anwendungdes evolutionären Vorgehensmodells und der Entwurfsmethode. Kon-kret heisst das:
• Das Vorgehensmodell für die evolutionäre Weiterentwicklungmuss sowohl die Bildung von Programm- wie auch von Daten-generationen unterstützen.

16 Einleitung
• Mit einer umfassenden Entwurfsmethode sollen alle Teile desAnwendersystems abgedeckt werden (dafür werden übrigenskeine neuen Methoden eingeführt, sondern vielmehr die Kombi-nation existierender und bewährter Methoden in einer einheit-lichen Beschreibungstechnik angestrebt).
Eine sinnvolle hierarchische Gliederung von Vorgehensmodell und Ent-wurfsvorgang soll die Übersicht über den aktuellen Stand der Ent-wicklung verbessern. Dafür werden drei Entwurfsebenen gebildet undauf ihre praktische Anwendbarkeit untersucht:
• Das evolutionäre Vorgehen spiegelt sich in Versionenschrittender Beschreibung (Schema) des Anwendersystems wieder.
• Ausschnitte dieses Schemas werden in Teilschritten verändert.
• Die Entwurfsobjekte der Teilschemata werden in Elementar-schritten verändert.
In den beiden Beispielen (Delphi und KORA) sollen anschliessend nichtnur diese Methoden angewandt und beurteilt werden, sondern es inter-essieren auch die folgenden Fragen:
• Wieviel Flexibilität müssen Vorgehensmodell, Entwurfsmethodeund darauf basierende Werkzeuge für die evolutionäre Weiter-entwicklung bieten?
• Ist die gewählte Aufteilung in Entwurfsebenen in der Praxisdurchführbar, sinnvoll und verständlich?
• Wo ist Werkzeugunterstützung sinnvoll, wo nicht?
• Wie sieht der zeitliche Aspekt aus, d.h. wie lange dauern dieeinzelnen Evolutionsschritte?
• Zwischen welchen Teilen des Schemas bestehen Abhängigkeiten?
1.3 Umfeld
Die vorliegende Arbeit entstand in zwei Phasen: In der Arbeitsgruppevon Prof. C.A. Zehnder im Departement für Informatik der ETH wur-den 1987-1990 im Rahmen des Forschungsprojekts Presto vom Autorzusammen mit Fredy Oertly die theoretischen Grundlagen für ein Vor-gehensmodell der evolutionären Weiterentwicklung datenbankbasierterAnwendersysteme und für eine ganzheitliche Entwurfsmethode bereit-gestellt. Im Rahmen dieser Arbeiten entstand ein erster Prototyp des

Einleitung 17
Entwurfssystems, Presto I, an dem auch Studentinnen und Studenten imRahmen von Semester- und Diplomarbeiten mitwirkten.
Presto I ist ein Softwarewerkzeug (basierend auf der EntwurfsmethodePresto M), gebildet durch Integration mehrerer unabhängiger Ent-wurfssysteme für den Datenbank-, Sicht- und Dialogentwurf, die wäh-rend mehrerer Jahre in der Gruppe von Prof. C.A. Zehnder entwickeltworden sind. Diese Entwicklungen benützten als Arbeitsplattform denArbeitsplatzrechner Lilith [Wirth 81], dessen Nachfolgesystem Ceres[Eberle 87] und den Macintosh [Apple 87]. Alle Rechner verfügten übereine grafische Benutzeroberfläche. Als Programmiersprache wurdeModula-2 [Wirth 83] eingesetzt, für das Datenbankverwaltungssystemdes Datenkatalogs von Presto I kam eine Eigenentwicklung der Gruppe,LIDAS/RDS [Diener 85], zum Einsatz.
Bereits parallel zur Entwicklung von Presto I wurde für die Unter-suchung der praktischen Anwendbarkeit des theoretischen Vorgehens-modells eine erste Fallstudie durchgeführt und das später produktiv ein-gesetzte Informationssystem Delphi für die Informatikbibliothek evolu-tionär entwickelt. Als Programmwerkzeug wurde hier das kommer-zielle Datenbanksystem Oracle [Oracle 86] eingesetzt.
Der zweite Teil der Arbeit entstand ab 1990 am neuen Arbeitsplatz desAutors, in der Informatikabteilung der Winterthur Lebensversiche-rungsgesellschaft, während der Entwicklung des Projekts KORA. Vieleder vorhandenen Konzepte konnten im Projekt nutzbringend eingesetztwerden. Daher wurde für die Bedürfnisse des Datenbankentwurfs einNachfolgesystem von Presto I, das Entwurfssystem Presto II realisiertund schrittweise erweitert. Die Systemumgebung unterschied sich je-doch stark von Presto I: Als Arbeitsplatzrechner für die Entwicklungkamen IBM PS/2 unter dem Betriebssystem OS/2 zum Einsatz (ebenfallsmit grafischer Benutzeroberfläche). Als Programmiersprache wurdewegen seiner weiten Verbreitung C gewählt [Kernighan / Ritchie 88],als Datenbankverwaltungssystem der SQL-basierte IBM Database Mana-ger unter OS/2. Obwohl die Entwicklung auf Arbeitsstationen erfolgte,war die teilweise Portierung auf einen IBM Grossrechner 3090 vonBeginn an eingeplant.
KORA wurde als zweite Fallstudie gewählt, um das evolutionäre Vor-gehensmodell und die Entwurfsmethode in einem wesentlich grösserenProjekt als bei Delphi einsetzen zu können.

18 Einleitung
1.4 Gliederung der Arbeit
Das zweite Kapitel vermittelt eine Übersicht über die zentralen Eigen-schaften datenbankbasierter Anwendersysteme und ihres Entwurfs undstellt die wichtigsten Begriffe vor.
Im dritten Kapitel werden bestehende Entwicklungsmethoden vorge-stellt und verglichen. Eine Einführung in die Versionenbildung rundetdas Kapitel ab.
Im vierten Kapitel wird vorerst das Vorgehensmodell für die evolu-tionäre Weiterentwicklung datenbankbasierter Anwendersysteme einge-führt. Besonderes Gewicht wird auf die Migrationsaspekte gelegt. An-schliessend wird gezeigt, wie bestehende Entwurfsmethoden für Teil-bereiche wie z.B. Datenbank-, Sichten- oder Dialogentwurf zu einereinheitlichen und umfassenden Entwurfsmethode kombiniert werden.
Das fünfte Kapitel ist den beiden Fallstudien Delphi und KORA gewid-met. Nach einer Vorstellung der Projekte wird die praktische Anwen-dung des Vorgehensmodells - insbesondere die Planung der Evolution -demonstriert und es werden die Konsequenzen in der Praxis aufgezeigt.Ein Vergleich und eine Bewertung schliessen das Kapitel ab.
Flexibilität beim Entwurf verlangt nach der Möglichkeit zur Anpassungdes Entwurfssystems. Im sechsten Kapitel werden das erweiterbare Ent-wurfssystem Presto und erste Erfahrungen vorgestellt. Eine Neuerungund Besonderheit ist das Aktualisierungskonzept, das die Erkennungund Verarbeitung von Änderungen während der evolutionären Weiter-entwicklung unterstützt.
Das siebte und letzte Kapitel fasst die Ergebnisse der Arbeit zusammenund bewertet sie. Der Ausblick weist auf mögliche weitere Ent-wicklungsrichtungen hin.

Datenbankbasierte Anwendersysteme 19
2 Datenbankbasierte Anwendersysteme
Informatiklösungen werden in der Praxis in den meisten Fällen für dieVerwaltung und Verarbeitung von Daten eingesetzt. Obwohl die Ent-wicklung solcher Lösungen eine häufig wiederkehrende Aufgabe dar-stellt, ist das Vorgehen vielfach recht unsystematisch und unkoordiniert.Im vorliegenden Kapitel werden die wesentlichen Aspekte in systema-tischer Weise dargestellt und ein dazu passendes Entwurfsvorgehen ge-zeigt.
Ein datenbankbasiertes Anwendersystem besteht aus mehreren Teilen,deren Entwurf in vielen Fällen separat erfolgt. Dieses Kapitel zeigt nacheiner Vorstellung des zu entwerfenden Zielsystems in einem erstenÜberblick, wie der Entwurf in einen grösseren Rahmen gestellt und fürdie spätere Evolution des Anwendersystems erweitert werden muss.
Wegen der nicht einheitlichen Begriffsverwendung auf diesem Gebietwerden die Definitionen aus [Zehnder 89] verwendet. An dieser Stellenoch eine Begriffspräzisierung: Bei Datenbankentwicklungen bestehenzwischen Anwender- und Entwurfsebene grosse Ähnlichkeiten (eineeingehende Diskussion dazu ist in Abschnitt 6.6 zu finden). Weil in denfolgenden Kapiteln diese beiden Ebenen sehr häufig nebeneinander er-scheinen, werden zur eindeutigen Unterscheidung vor die Begriffe diePräzisierungen "Anwender…" und "Entwurfs…" gefügt, bei Abkür-zungen A… und E… Davon betroffen sind Schemata, Daten, Kom-ponenten und Transaktionen.
2.1 Was ist ein datenbankbasiertes Anwendersystem?
Bevor auf das Entwurfsvorgehen eingegangen werden kann, mussKlarheit über das zu entwerfende Anwendersystem bestehen. Diewichtigsten Eigenschaften einer Informatiklösung zur Datenverwaltungsind [Zehnder 89]:
• Zentraler Datenbestand
• Mehrere Dialog- und Verarbeitungsprogramme, welche dieseDaten gemeinsam verwenden
• Verwendung eines Datenbankverwaltungssystems für einheit-lichen Datenzugriff
• Zentrale Konsistenzüberwachung der Daten

20 Datenbankbasierte Anwendersysteme
Ein System mit diesen Eigenschaften wird im folgenden als datenbank-basiertes Anwendersystem, kurz Anwendersystem, bezeichnet. Es dientden Anwendern zur Verwaltung und Verarbeitung ihrer Daten.
Ein datenbankbasiertes Anwendersystem (im folgendenkurz Anwendersystem) ist eine Informatiklösung, in derenZentrum die Verwendung permanent in einer Da-tenbank gespeicherter Daten steht. Es ermöglicht dieManipulation der Daten in benutzergerechter undgesicherter Form.
Die Architektur des Anwendersystems (AS) ist in Figur 2.1 skizziert:Es besteht aus den Anwenderkomponenten (AK) und einer Datenbank(Database Management System, DBMS und Anwenderdaten, AD).
Eine Anwenderkomponente ist ein anwendungsspezi-fischer Teil eines Anwendersystems, welcher einenfachlich zusammengehörigen Ausschnitt eines Anwen-dungsgebiets umfasst.
In der Anwenderdatenbank werden die anwendungs-bezogenen Daten (Anwenderdaten) gespeichert undverwaltet.
AK 1 AK 2 AK 3
DBMS
ADAS
Figur 2.1: Architektur eines Anwendersystems (AS)
Manipulationen der Anwenderdaten sind ausschliesslich via Datenbank-verwaltungssystem möglich; sie werden durch die Anwenderkompo-nenten ausgelöst.
Die Anwenderdaten bilden für die Anwender den eigentlichen Kernihrer Informatiklösung. Die zentrale Datenverwaltung mit Hilfe desDatenbankverwaltungssystem verhindert, dass diese Daten ungewolltoder absichtlich verfälscht oder zerstört werden. Mit dieser zentralen

Datenbankbasierte Anwendersysteme 21
Überprüfung wird auch erreicht, dass die Anwenderdaten wider-spruchsfrei (konsistent) sind und bleiben. Zu diesem Zweck stehen fürDatenmutationen konsistenzerhaltende Operationen, sog. (Anwender-)Transaktionen, zur Verfügung.
Anwendertransaktionen sind Manipulationen an Datenin der Anwenderdatenbank, bei welchen deren Konsi-stenz erhalten bleibt.
2.2 Beschreibung: Das Anwendungsschema
Soll ein Anwendersystem realisiert werden, muss dieses zuerst einmalbeschrieben werden. Analog zu den einzelnen Teilen des Anwendersy-stems setzt sich auch dessen Beschreibung aus mehreren Teilen zusam-men:
AS
FunktionenAK 1
DatenbankSchema
Trans-aktionen
DialogAK 2
DialogAK 1
FunktionenAK 2
Beschreibungen
AK 1 AK 2 AK 3
DBMS
AD
Figur 2.2: Beschreibung der Bestandteile eines Anwendersystems
Die folgende (unvollständige) Liste gibt einen Überblick, welche Teiledes Anwendersystems nacheinander entworfen und beschrieben werdenmüssen:

22 Datenbankbasierte Anwendersysteme
• Datenbank: Das Datenbankschema besteht aus einem konzep-tionellen und einem implementationsnahen Teil. Im ersten wirdvorerst ohne Rücksicht auf das zu verwendende Datenbank-system der gewünschte Realitätsausschnitt in einem bestimmtenDatenmodell (Datenbeschreibungssprache) beschrieben, im zwei-ten werden zusätzlich die in einem konkreten Datenbankverwal-tungssystem für die Datenbankverwaltung benötigten Einzel-angaben festgehalten. Zu diesen Datenbeschreibungen gehörenauch sog. Konsistenzbedingungen, die teilweise direkt im ver-wendeten Datenmodell (modellinhärent), teilweise mit einer zu-sätzlichen Sprache (modellextern) definiert werden.
• Anwendertransaktionen: Der Anwender benötigt für die Be-nützung der Datenbank leistungsfähige Zugriffs- und Mutations-unterstützung in Form von Anwendertransaktionen. Diese sindZusammensetzungen aus minimalen Transaktionen und beziehensich immer auf einen bestimmten Datenausschnitt (Datensicht).Datenausschnitt und Anwendertransaktionen basieren auf demDatenbankschema und sind in einem separaten Teil des Schemasbeschrieben.
• Anwenderkomponenten: Durch Zusammensetzung von Anwen-dertransaktionen werden die Anwenderkomponenten gebildet.Zusätzlich umfassen diese auch Definitionen für Dialog- oderListen- (Report-) gestaltung und Programmlogik; die Trennungzwischen Konsistenzbedingungen und Programm ist in derPraxis nicht immer eindeutig.
In Analogie zur Verwendung des Begriffs Schema bei Datenbankenwird die Beschreibung eines gesamten Anwendersystems als Anwen-dungsschema bezeichnet, die Beschreibungen einzelner Teile des An-wendersystems als Teilschemata.
Das Anwendungsschema ist die Beschreibung eines An-wendersystems. Es besteht aus Daten- und Programm-beschreibungen.
Ein Anwendungsschema setzt sich aus mehreren Teilschemata zusam-men, die je einen Ausschnitt des Anwendersystems beschreiben.

Datenbankbasierte Anwendersysteme 23
Ein Teilschema ist ein genau abgegrenzter Ausschnittdes Anwendungsschemas, der einen bestimmtenAspekt eines Anwendersystems beschreibt. Die ver-schiedenen Teilschemata eines Anwendungsschemassind disjunkt und decken dieses vollständig ab.
Typische Teilschemata sind einerseits die Beschreibung der Anwender-datenbank, andererseits eine Beschreibung einer Anwenderkomponente.
In Figur 2.3 ist die mosaikartige Zusammensetzung des Anwendungs-schemas durch Teilschemata dargestellt (die einzelnen Teilschematawerden im Beispiel in Kapitel 4 noch genauer vorgestellt):
Teilschema
Anwendungsschema
Datenbank(konzeptionell)
Datenbank(technisch)
Anwender- Transaktion
Datensichten Dialoge,Listen
Figur 2.3: Gliederung des Anwendungsschemas in Teilschemata
Datenbank und Anwendertransaktionen werden für das gesamte Anwen-dersystem definiert, beschrieben im allgemeinen Anwendungsschema.Dagegen wird im Anwendungsschema für jede Anwenderkomponenteein separates Teilschema für die Datensicht und zugehörige Darstel-lungsaspekte (Präsentation) eröffnet. Einer Sicht können mehrere unter-schiedliche Präsentationen zugeordnet werden.
Zwischen den Teilschemata bestehen Abhängigkeiten, die dazu führen,dass für das Erstellen und Ändern der Teilschemata eine bestimmteReihenfolge eingehalten werden muss. So können z.B. Transaktionenfür Anwenderdaten erst formuliert werden, wenn die entsprechendenDaten festgelegt sind. Das Anwendersystem kann erstellt werden, wennalle Teilschemata zur Verfügung stehen und auch zusammenpassen, d.h.wenn die sog. Entwurfskonsistenz erreicht ist.

24 Datenbankbasierte Anwendersysteme
Entwurfskonsistenz beschreibt die innere Widerspruchs-freiheit eines Anwendungsschemas.
Die Abhängigkeiten zwischen den Teilschemata werden durch den sog.Abhängigkeitsgraph beschrieben.
Der Abhängigkeitsgraph ist ein gerichteter Graph, derdie gegenseitigen Abhängigkeiten von Teilschematades Anwendungsschemas beschreibt.
Gelegentlich müssen ein Anwendersystem und damit auch dessen An-wendungsschema aktuellen Bedürfnissen angepasst werden und somitgeändert werden. Dies basiert auf dem Abhängigkeitsgraph. Erst mitdessen Hilfe wird eine methodische und widerspruchsfreie Aktuali-sierung aller Änderungen an allen betroffenen Stellen des Anwendungs-schemas überhaupt möglich.
Die Aktualisierung ist ein systematisches und die Ent-wurfskonsistenz erhaltendes Verfahren für die vollstän-dige Beschreibung und Nachführung einer Gruppe vonÄnderungen am Anwendungsschema. Wird ein Anwen-dungsschema, das entwurfskonsistent ist, aktualisiert,bleibt die die Entwurfskonsistenz erhalten.
Entwurfskonsistenz und Aktualisierung werden im sechsten Kapitel imZusammenhang mit dem Entwurfssystem noch detaillierter untersucht.
2.3 Ein datenbankgestütztes Entwurfssystem
Das Anwendungsschema beschreibt das Anwendersystem, d.h. dieDatenstrukturen der Anwenderdatenbank, die Transaktionen, die ver-schiedenen Anwenderkomponenten. Diese Beschreibung besteht selbstwieder aus Daten. Im Gegensatz zu den Anwenderdaten handelt es sichdabei um Entwurfsdaten (ED), wobei das Anwendungsschema durch dieEntwurfsdaten dargestellt wird. Es liegt nun nahe, für die Verwaltungder Entwurfsdaten ein Entwurfssystem (ES) zu verwenden und diezugehörigen Entwurfsdaten in einer Entwurfsdatenbank abzulegen.
In der Entwurfsdatenbank werden die während desEntwurfs eines Anwendersystems entstehenden Entwurfs-daten, namentlich das Anwendungsschema (und all-fällige Versionen davon) abgelegt.

Datenbankbasierte Anwendersysteme 25
Ein Entwurfssystem ist ein Paket von koordinierten Soft-warewerkzeugen und einer Entwurfsdatenbank für denEntwurf eines Anwendersystems.
Das Entwurfssystem hat grundsätzlich die gleiche Architektur wie dasAnwendersystem (Figur 2.4):
EK 1 EK 2 EK 3
DBMS
EDES
Figur 2.4: Architektur des Entwurfssystems (ES)
Ein wesentlicher Unterschied zum Anwendersystem besteht in derUnterteilung der Entwurfsdaten: Sie spiegelt die Gliederung des An-wendungsschemas in Teilschemata wieder. Jedem Teilschema ist genaueine Entwurfskomponente (EK) zugeordnet, welche als einzige an"ihrem" Teilschema Mutationen vornehmen darf. Diese Besonderheitdes Entwurfssystems wird in den folgenden Kapiteln noch detaillierterbetrachtet.
Die kleinste von aussen sichtbare und veränderbare Einheit der Ent-wurfsdaten ist das Entwurfsobjekt (das sind im Fall des konzeptionellenSchemas z.B. Entitätsmengen, Attribute oder Wertebereiche). In jedemTeilschema werden nur einige wenige Typen von Entwurfsobjekten be-nützt, deren Vorkommen (Instanzierungen) mit den Änderungstrans-aktionen (vgl. Abschnitt 6.1) verändert werden.
Das nach Entwurfskomponenten gegliederte und in der Entwurfsdaten-bank gespeicherte Anwendungsschema hat eine doppelte Bedeutung:
• Dokumentation: Umgangssprachliche Beschreibungen dokumen-tieren auf allgemeinverständliche Art die Überlegungen des Ent-wurfs.
• Spezifikation: Die formale Beschreibung ermöglicht die Gene-rierung des Anwendersystems.

26 Datenbankbasierte Anwendersysteme
Entwurfs-system
Anwender-system
Generierung
Figur 2.5: Generierung des Anwendersystems aus den Entwurfsdaten
Das Entwurfssystem steht eine Abstraktionsebene über dem Anwender-system, es bildet die Metaebene des Anwendersystems. Während desEntwurfs sind die Entwurfsdaten variabel. Nach Abschluss des Ent-wurfs wird das Anwendersystem generiert, und die Entwurfsinfor-mationen werden im Anwendersystem fest eingebaut.
2.4 Evolution einer Anwendung und ihres Schemas
Bis hierher wurde fast ausschliesslich ein einmaliger Entwurf desAnwendersystems betrachtet. Bei der Nutzung des fertiggestellten An-wendersystems entsteht aber oft durch neue Anforderungen ein Be-dürfnis nach Änderungen am bestehenden System. Besonders wichtig istdie Möglichkeit von Systemänderungen bei Prototypbildungen. DieseFälle machen es nötig, nebeneinander verschiedene ähnliche Anwender-systeme sowie deren Schemata gleichzeitig verfügbar zu halten. Diesewerden als Schemaversionen bezeichnet, die daraus jeweils generiertenAnwendersysteme als Programmgenerationen (Figur 2.6), oft auchRelease genannt (vgl. Abschnitt 3.3)
Eine Schemaversion ist ein bestimmtes, im Verlauf derEntwicklung entstandenes Anwendungsschema.
V 1 V 2 V 3
Generierung
Schemaversionen
Programmgenerationen von Anwendersystemen
PG 1 PG 2 PG 3
Figur 2.6: Schemaversionen und Programmgenerationen

Datenbankbasierte Anwendersysteme 27
Eine Programmgeneration ist ein betriebsbereites Pro-grammpaket; es entsteht durch die Übersetzung (Kom-pilation) eines Anwendungsschemas oder Teilschemas.
Der Entwicklungsvorgang, wie bestimmte neue Schemaversionen ausbestehenden weiterentwickelt werden, kann in Form eines Versionen-baumes dargestellt werden. In der Praxis ist der Baum oft ziemlich li-near.
Urversion
Weiterentwickelte Versionen
Zweiter Entwicklungsschritt
Figur 2.7: Versionenbaum der Schemaversionen
Die Generierung der Programme eines neuen Anwendersystems erfolgtnach Überarbeitung aller Teilschemata einer neuen Schemaversion.Beim Übergang zu einer neuen Generation des Anwendersystems müs-sen aber auch existierende Anwenderdaten übernommen werden. ImGegensatz zu den aus der entsprechenden Schemaversion neu gene-rierten Programmteilen des Anwendersystems müssen die Daten aus derbisherigen Generation übernommen werden. "Anwendungsgeneratio-nen" müssen daher konsequent nach Daten- und Programmgenerationengegliedert werden. Diese haben nicht den gleichen Ablösungsrhythmus(Figur 2.8).
Datengeneration
Prg-Generation
Figur 2.8: Daten- und Programmgenerationen

28 Datenbankbasierte Anwendersysteme
Eine Datengeneration ist der Inhalt einer Anwender-datenbank, strukturiert und gespeichert nach einer be-stimmten Version des Anwendungsschemas (Schema-version).
Es ist möglich, dass sich mehrere Programmgenerationen auf eine Da-tengeneration beziehen (Figur 2.8), aber nicht umgekehrt. Der ko-ordinierende Zugriff auf die Anwenderdaten erfolgt über ein beson-deres Programmmodul Datenverwaltung (vgl. Abschnitt 4.2).
2.5 Methode und Werkzeug
Softwarewerkzeuge (W) basieren auf Methoden (M) (Figur 2.9, linkerTeil). Bestimmte Methoden können ohne Werkzeuge - manuell - einge-setzt werden, umgekehrt führt jedoch der Einsatz von Werkzeugen ohneKenntnis der Methode nicht zum Erfolg. Oft deckt ein bestimmtesWerkzeug nicht alle Konzepte einer Methode ab, enthält dafür aberTeile, die nicht zu einer bestimmten Methode gehören (Figur 2.9,rechts).
M1 M2
W1 W2 W3
M1
W1
Figur 2.9: Methoden M und Werkzeuge W
In dieser Arbeit werden vorerst verschiedene Entwicklungsmethodenvorgestellt (Kapitel 3), anschliessend Vorgehensmodell und Entwurfs-methode für die evolutionäre Weiterentwicklung datenbankbasierterAnwendersysteme eingeführt (Kapitel 4) und in zwei Fallstudien (Ka-pitel 5) eingesetzt. Danach wird ein auf dieser Methode basierendesWerkzeug vorgestellt (Kapitel 6).
Vorgehensmodell und Entwurfsmethode für die evolutionäre Weiterent-wicklung datenbankbasierter Anwendersysteme decken die folgendenBereiche ab:
• Vorgehensmodell für die evolutionäre Weiterentwicklung.

Datenbankbasierte Anwendersysteme 29
• Entwurfsmethoden für die einzelnen Teile des Anwendersy-stems: Datenbank, Sichten, Funktionen, Dialog- und Listenge-staltung.
• Versionenbildung für Daten und Programme.
Die Entwurfsmethoden für Teile des Anwendersystems sind im einzel-nen bereits gut etabliert, neu ist dagegen die hier vorgestellte Kom-bination zu einem umfassenderen Vorgehen. Eine Besonderheit ist dieZusammensetzbarkeit nach einem Baukastenprinzip, das die Anpassungan unterschiedliche Bedürfnisse erlaubt.


Entwicklungsmethoden 31
3 Entwicklungsmethoden
In einem Informatikprojekt lassen sich mehrere Detaillierungsgradeunterscheiden. Je nach Betrachtung interessiert ganz allgemein die Pro-jektführung, die Art und Methode der Anforderungsbeschreibung oderdie technische Art der Lösung. Die folgende Liste gibt einen Überblicküber diese drei Detaillierungsstufen:
• Vorgehen und Projektführung: Unabhängig vom fachlichen Um-feld gelten für alle Informatikprojekte bestimmte Regeln bezüg-lich der Abläufe, Zeitpläne und Verantwortlichkeiten.
• Anforderungsformulierung: Bereits ausgerichtet auf das ge-wählte Fachgebiet, aber noch ohne technische Details, werdenjetzt die Anforderungen beschrieben und in eine Groblösungumgesetzt.
• Realisierung: Auf dieser detailliertesten Stufe werden die Spezi-fikationen in eine technisch ausführbare Form umgesetzt. Dabeiinteressieren Datenstrukturen, Operationen und Algorithmen.
Vorgehen
Anforderungs- formulierung
Realisierung
Figur 3.1: Detaillierungsstufen in Informatikprojekten
Dieses Kapitel umreisst die wichtigsten Vorgehensmodelle (obersteStufe) und Entwurfsmethoden (mittlere Stufe) und zeigt Besonderheitenbei datenbankbasierten Anwendersystemen auf.
3.1 Vorgehensmodelle
In der Literatur wird eine Vielzahl von Vorgehensmodellen vorgestellt[Lehman 80, Floyd 84, Frühauf et al. 88]. Dieser Abschnitt führt eineeinheitliche Begriffswelt ein und nimmt eine Gliederung in einigewenige Kategorien vor. Am Schluss werden die wichtigsten Unter-schiede aufgezeigt.

32 Entwicklungsmethoden
3.1 .1 Einführung und Begriffe
Ein Vorgehensmodell ist eine bewusste Beschränkung der Aktivitäteninnerhalb einer Projektorganisation auf eine überblickbare Zahl vonStandardschritten, um die Projektabwicklung zu standardisieren, eineeinheitliche "Kultur" bei den Beteiligten zu erreichen und durch diesesgemeinsame Verständnis das Projekt besser, schneller und sichererabzuwickeln.
Ein Vorgehensmodell definiert ein strukturiertes Vor-gehen für die Entwicklung und Nutzung von Informatik-lösungen während der ganzen Lebensdauer.
Allen Vorgehensmodellen gemeinsam ist eine Gliederung des Ablaufs inPhasen. Diese werden in einer vorgegebenen Reihenfolge durchlaufen.Bestandteil des Vorgehensmodells ist die Beschreibung der Voraus-setzungen, die für Abschluss bzw. Eröffnung einer Phase erfüllt seinmüssen.
Im Gegensatz zu konventionellen Projektführungsmethoden enthaltenumfassende Vorgehensmodelle neben den (noch weiter unterteilbaren)Entwicklungsphasen auch die Nutzungsphasen.
Die Entwicklungsphase (kurz Entwicklung) umfasst alle fürdie Erst- oder Weiterentwicklung einer Informatiklösungoder Komponenten davon notwendigen Aktivitäten biszur Inbetriebnahme.
Während der Nutzungsphase (kurz Nutzung) steht dasAnwendersystem den Anwendern uneingeschränkt zurVerfügung. Insbesondere werden keine Veränderungendaran vorgenommen.
Die Vorschrift über die einzuhaltende Phasenreihenfolge und übereventuell zugelassene Phasenwiederholungen führt zu einer für jedesVorgehensmodell charakteristischen Phasenfolgedarstellung. Diesemacht eine Aussage über die zulässigen Phasenübergänge, jedoch nochnicht über die effektive Abfolge aller Phasenschritte in jedem einzelnenProjekt. In der Phasenfolgedarstellung sind die einzelnen Phasen alsRechtecke, die zulässigen Übergänge als Verbindungslinien dargestellt:

Entwicklungsmethoden 33
Entwicklung Nutzung
Entwicklungs- beginn
Inbetrieb- nahme
Figur 3.2: Phasenfolgedarstellung
Erst durch die Ausprägung der Phasenfolge des Vorgehensmodells ineinem konkreten Projekt werden die Phasen sequentiell in ihrer zeit-lichen Abfolge sichtbar (falls Wiederholungen zugelassen sind, mehr-mals). Die Phasenausprägung für ein (Teil-) Projekt führt daher zurZeitsequenzdarstellung. Die Phasen werden in der Zeitsequenzdarstel-lung als pfeilartige Blöcke dargestellt:
Entwicklung Nutzung
Teilprojektdauer NutzungsdauerLebensdauer
Ablösung oder Ausserbetriebnahme
Inbetrieb- nahme
Entwicklungs- beginn
Entwicklung Nutzung
Figur 3.3: Beispiel einer Zeitsequenzdarstellung
In der zeitlichen Dimension nimmt die Dauer einer Phase eine wichtigeBedeutung ein. Dabei lässt sich zwischen der Dauer einzelner Phasen,ausgewählter Gruppen von Phasen (z.B. Entwicklung oder Nutzung)oder der Lebensdauer einzelner Generationen oder des gesamten Sy-stems unterscheiden.
Für die Projektführung sind in erster Linie die Phasen der Entwicklungvon Interesse, denn sie betreffen Veränderungsschritte am System. Beievolutionären Verfahren gewinnt zusätzlich die Phase der Nutzung anBedeutung, denn ein wichtiges Bewertungskriterium ist das Verhältnisvon Entwicklungs- zu Nutzungsdauer. Die Nutzung ist daher in der hierverwendeten Phasenfolge- und Zeitsequenzdastellung hervorgehoben(dick umrandet).

34 Entwicklungsmethoden
Die folgenden Unterabschnitte beschreiben die wichtigsten Eigen-schaften häufig zitierter Vorgehensmodelle. Die Vorgehensmodelle las-sen sich grob folgenden Projektkategorien zuordnen:
• Klassisches Phasenmodell
• Prototypenbildung
• Pilotprojekte
• Inkrementelle Vervollständigung
• Evolutionäre Weiterentwicklung
Im Interesse eines übersichtlichen Vergleichs sind in den folgendenUnterabschnitten für jeden Modelltyp Phasenfolge- und Zeitsequenz-darstellung nebeneinander dargestellt.
3.1 .2 Klassisches Phasenmodell
Das bekannteste Vorgehensmodell ist das klassische Phasenmodell: Esunterscheidet vereinfacht die Phasen Analyse, Entwurf, Realisierung,Systemtest und Wartung [Royce 70].
Analyse Entwurf Realisierung Systemtest Wartung
Planung,Anforderungen
Erweiterungen,Anpassungen,
Fehlerkorr.
Architektur,Details Integration,
Akzeptanz
Programmierung,Komponententest
Figur 3.4: Klassisches Phasenmodell (Wasserfallmodell)
Wegen seiner strikt sequentiellen Phasenabarbeitung wird das klassischePhasenmodell oft auch als "Wasserfallmodell" bezeichnet.
Korrekturen, Anpassungen, Erweiterungen
Figur 3.5: Phasenfolge und Zeitsequenzen des klassischenPhasenmodells
Alle Phasen (mit Ausnahme der Wartung) werden genau einmal durch-laufen. Fehlerbeseitigung, Änderung und Erweiterung sind Teil der

Entwicklungsmethoden 35
"Wartung", wie aus Phasenfolge- und Zeitsequenzdarstellung leicht zuerkennen ist (Figur 3.5). Diese zu wenig präzise Abgrenzung der Erst-entwicklung von den eigentlichen Folgeprojekten für neu hinzugekom-mene Bedürfnisse wird am klassischen Phasenmodell am häufigstenkritisiert: Sie führt zu einem ständig wachsenden Anteil der Wartung imVergleich zum Gesamtaufwand. Aufgrund dieses Mangels wird dasklassische Phasenmodell kaum je in seiner reinen Form eingesetzt. Alsnaheliegende Verbesserung drängt sich eine Wiederholung des gesamtenDurchlaufs auf (Figur 3.6).
Entwicklung erste Generation
Erste Generation
Zweite GenerationKlassisches Phasenmodell
Figur 3.6: Phasenfolge und Zeitsequenzen bei Wiederholungen
Dadurch entstehen anstelle mehrerer Wartungsblöcke mehrere eigent-liche Nutzungsphasen und damit unterschiedliche Programmgenera-tionen. Die folgenden Unterabschnitte führen schrittweise eine differen-ziertere Betrachtung und Verfeinerung der Generationenbildung ein.
3.1 .3 Prototypenbildung
In diesem Rahmen ist nur ein Überblick über das weitläufige Gebiet derPrototypenbildung möglich. Untersuchungen und weiterführende Be-trachtungen sind in [Floyd 84, Riddle 84, Fairley 85, Oertly 91] zufinden.
Ausgangspunkt für Prototypenbildungen ist meist eine unstabile oderunklare Problembeschreibung:
• Tatsächliche und formulierte Anforderungen stimmen nichtüberein
• Das reale Umfeld des Anwendersystems verändert sich
• Der künftige Anwender hat unklare Vorstellungen über dieMöglichkeiten der Informatik
Für unzureichende Anforderungsbeschreibungen existieren verschie-denste Gründe, deren Aufzählung diesen Rahmen sprengen würde. DiePrototypenbildung ist aus der Erkenntnis entstanden, dass es kaum jegelingt, die Anforderungen rein verbal beim ersten Versuch sowohl

36 Entwicklungsmethoden
zweckentsprechend als auch genügend präzise zu formulieren: Um zuverhindern, dass allfällige Missverständnisse erst bei der Betriebs-aufnahme eines grösseren Systems erkannt werden, sieht die Proto-typenbildung bereits in frühen Projektphasen Wiederholungen imPhasenablauf vor.
Prototypenbildung
Figur 3.7: Phasenfolge und Zeitsequenzen der Prototypenbildung
Die Arbeit mit Prototypen soll verhindern, dass sofort ein aufwendiges(weil vollständiges) System erstellt und später geändert werden muss.Dies geschieht, indem unsichere Teilgebiete frühzeitig konkretisiert undder Beurteilung durch den Anwender ausgesetzt werden. [Floyd 84]unterscheidet drei Arten der Prototypenbildung:
• Explorativ: Abgrenzung der Anforderungen, Überprüfung vonAlternativen.
• Experimentell: Bestimmung der Eignung einer getroffenenWahl.
• Evolutionär: Schrittweiser Ausbau; alle Arten der sukzessivenWeiterentwicklung.
Während die Prototypenbildung (Prototyping) den Vorgang bezeichnet,wird das Produkt Prototyp genannt. Es ist ein ausführbarer Ausschnitteiner zukünftigen Anwenderkomponente zur Evaluation ausgesuchterEigenschaften. Der Prototyp ist bezüglich Funktionsumfang, Zuver-lässigkeit, Effizienz oder Wartbarkeit eingeschränkt. Wir unterscheidenhier nun zwei Arten der Prototypenbildung:
• Wegwerfprototyp: Keine Weiterverwendung nach der Evalua-tion.
• Evolutionärer Prototyp: Erweiterbar zur genutzten Anwendung.
Die Wahl der Prototypart muss vor Beginn der Prototypenbildung ge-troffen werden.
Bei der Prototypenbildung interessieren Funktionsauswahl, Konstruk-tion und Evaluation. Während bei der horizontalen Funktionsauswahl

Entwicklungsmethoden 37
viele Funktionen mit geringer Tiefe untersucht werden, basiert dievertikale Funktionsauswahl auf wenigen Funktionen mit grosser Tiefe.
Prototypen unterscheiden sich von definitiven Lösungen durch rascheEntwicklung, tiefe Kosten und sachliche Einschränkungen: Es wirdmöglichst rasch ein einfaches Modell der zukünftigen Anwenderkom-ponente entwickelt. Der Prototyp dient der Kommunikation zwischenEntwerfer und Anwender oder der Klärung technischer Aspekte, z.B.um die Antwortzeiten eines Datenbankverwaltungssystems zu über-prüfen. Der Unterschied zwischen Wegwerfprototyp und weiterverwen-deter Programmgeneration kann verschwimmen, sobald der Prototypnicht mehr manuell erstellt, sondern generiert wird (Rapid Proto-typing).
Eine Abwandlung der Prototypenbildung ist "Advancemanship" [Boehm81], analog einem militärischen "Vorausdetachement": Im militärischenBereich schaffen Vorausdetachemente durch zeitlich vorgezogene Vor-bereitungsarbeiten die Voraussetzungen für eine reibungslose Ab-wicklung des Auftrags. Die Übertragung auf Informatikprojekte betrifftnamentlich zwei Bereiche: Einerseits liefert eine erste, vorwegge-nommene Anwenderdokumentation eine klarere Beschreibung des Pro-dukts in den Begriffen des Anwenders, andererseits beschleunigt diefrühzeitige Bereitstellung von Hilfsmitteln wie Testprogramme und -Daten, Compiler, Konversions- oder Übernahmeprogrammen dieHauptentwicklung.
3.1 .4 Pilotprojekt
Ein Pilotsystem überbrückt mit einer "Zwischenstufe" allzu grosseGrössenunterschiede zwischen "Labormuster" und geplantem End-produkt [Brooks 82, Rzevski 84]. Mit einem Pilotsystem sammeln Ent-wickler und erste, ausgewählte Anwender Erfahrungen. Das Verfahrenwird seit langem z.B. beim Bau komplexer Chemieanlagen oder vor derGrossserienfertigung mit Nullserien angewandt. In der Informatik ist esimmer dann angebracht, wenn viele neue Aspekte zugleich ins Spielkommen, wie z.B. eine neue Entwicklungsumgebung und geänderteTechniken für eine Datenbank oder Benutzerschnittstellen.
Im Gegensatz zum Wegwerfprototyp wird ein Pilotsystem an ausge-wählte Anwender ausgeliefert und muss entsprechend robust sein.[Rzevski 84] verwendet den Begriff des Pilotsystems in der Anwen-dungsentwicklung zur Unterscheidung evolutionär weiterentwickelter

38 Entwicklungsmethoden
und genutzter Anwendungen von Wegwerfprototypen mit ungenügen-der Robustheit: Entwickler und ausgewählte Anwender sollen anhandeines genügend robusten Systems lernen. Anhand des Pilotsystems wirdvor Beginn der definitiven Entwicklung in groben Zügen die Archi-tektur des Gesamtsystems festgelegt.
3.1 .5 Inkrementelle Vervollständigung
Bei inkrementeller (schrittweiser) Vervollständigung wird ein grossesSystem für die Entwicklung in mehrere Teilsysteme zerlegt [Boehm81]. Damit können bereits vor Fertigstellung des Gesamtsystems nutz-bare Zwischenprodukte eingesetzt werden:
• Genutzte Teilprodukte: Jeder fertiggestellte Teil ist ein funktio-nierendes System, das genutzt wird.
• Gesamtentwurf zu Beginn: Die Gesamtarchitektur des Anwen-dersystems wird zu Beginn mit der definitiven Grob-Modulari-sierung festgelegt.
Wesentlich an der inkrementellen Vervollständigung ist, dass die Ge-samtanforderungen bis zur Fertigstellung aller Teilsysteme nicht mehrverändert werden ("eingefroren" sind): Die inkrementelle Vervoll-ständigung ist ein Vorgehensmodell über mehrere genutzte Ausbau-stufen bis zum Erreichen des Vollausbaus.
Figur 3.8: Phasenfolge und Zeitsequenzen der inkrementellenVervollständigung
Nach [Floyd 84] entspricht die inkrementelle Vervollständigung in je-dem Teilschritt weitgehend dem Wasserfallmodell, da die Realisierungaufgeteilt wird, der Vervollständigungsplan sich jedoch nicht ändert.
Obwohl die Grob-Architektur zu Beginn definiert wird, sind kleineKorrekturen noch möglich und Erfahrungen können berücksichtigtwerden. Von der Gesamtplanung wird jedoch nicht abgewichen.

Entwicklungsmethoden 39
3.1 .6 Evolutionäre Weiterentwicklung
Den flexibelsten Ansatz bietet die evolutionäre Weiterentwicklung, in[Fairley 85] auch als "aufeinanderfolgende Versionen" bezeichnet. Ähn-lich wie die inkrementelle Vervollständigung beruht sie auf einer an-fänglichen Gesamtplanung und einer schrittweisen Entwicklung genutz-ter Produkte. Schritte, die noch in weiter Zukunft liegen, werden nichtallzu detailliert geplant, um unnötigen Aufwand zu vermeiden und dieFlexibilität für Änderungen bei noch ungewissen Randbedingungen zuerhalten. Sich ändernde Anforderungen werden bereits im Vorgehens-modell berücksichtigt. Die evolutionäre Weiterentwicklung birgt einenicht zu unterschätzende Gefahr: Durch das Fehlen eines starrenRahmens kann es im Lauf der Zeit zu einem "Strukturverlust" des suk-zessive wachsenden und mehrfach korrigierten Systems kommen[Brooks 82]. Daher ist jeweils nach einigen Evolutionszyklen eineZwischenphase mit einer Bereinigung des Gesamtsystems nötig; diesinnvolle Grösse liegt bei drei bis fünf Generationen.
Bereinigung
Bereinigung
Figur 3.9: Phasenfolge und Zeitsequenzen der evolutionärenWeiterentwicklung
Ein wichtiger Nachteil bei der Festlegung dieses Marschhalts liegt beimmöglicherweise entstehenden Eindruck eines Projektstillstands. OhneBereinigungsphase besteht jedoch das Risiko, dass das System immerunstabiler wird, im schlimmsten Fall bis zur Unbrauchbarkeit bereitsvor der Fertigstellung.
3.1 .7 Vergleich
In diesem Unterabschnitt sollen die vorstehend beschriebenen Vor-gehensmodelle miteinander verglichen werden. Für die schrittweiseVervollständigung des Anwendersystems wird dabei die folgendeDarstellung verwendet:

40 Entwicklungsmethoden
Entwicklung
NutzungA
t1 t2te t3tn
t
Figur 3.10: Notation - Entwicklung und Nutzung
Die Entwicklungsarbeit ist als Dreieck dargestellt: Dieses symbolisiertdie zunehmende Fertigstellung eines Systemteils mit der Zeit. Die Ent-wicklung beginnt zum Zeitpunkt t1, endet bei t2 und dauert te (Ent-wicklungsdauer). Die Höhe A entspricht den im voraus formuliertenAnforderungen. Die Nutzung ist als hervorgehobenes Rechteck darge-stellt, beginnend mit t2 und endend mit t3 (tn: Nutzungsdauer).
Figur 3.11 vergleicht klassisches Phasenmodell, Prototypenbildung, in-krementelle Vervollständigung und evolutionäre Weiterentwicklung be-züglich Phasenzusammensetzung (Anzahl und Dauer der Ent-wicklungen), Planbarkeit und Art der Nutzung.
KlassischesPhasenmodell A
Gut planbar, wenn die Anforde-rungen A genau festgelegt werdenkönnen. In der Praxis schwierig,wenn die benötigten Anforderungennicht genügend präzise schon zuBeginn formulierbar sind.
PilotprojektA
A'
Beginn mit Pilotsystem und Anfor-derungen A'. Verwertung der Er-fahrungen für die Anforderungs-formulierung A für definitives Sy-stem. Gut planbar bei Beschränkungin A' und nicht zu vielen Neue-rungen in A.
InkrementelleVervollständi-gung
AAufteilung der Entwicklung aufmehrere nutzbare Teilsysteme. ZuBeginn formulierte Anforderungen Ableiben unverändert. Gesamtsystemauch bei vorzeitigem Abbruch oderVerzögerung nutzbar: ReduziertesRisiko.
EvolutionäreWeiterent-wicklung A1
A2
Bereinigung
Flexibilität durch Anforderungs-anpassung. Mögliche Gefahr desStrukturverlusts, gebannt durchBereinigung nach einigen Evolu-tionszyklen mit Anpassung der ur-sprünglichen Anforderungen A1.
Figur 3.11: Vergleich der Vorgehensmodelle

Entwicklungsmethoden 41
Die Erweiterung von einem auf mehrere Entwicklungsdurchläufe be-dingt eine Präzisierung des Projektbegriffs: Ist ein Projekt eine einzelneEntwicklung oder eher eine Folge zusammengehöriger Entwicklungen?Für die folgenden Betrachtungen werden all diejenigen Aktivitäteneinem (erfolgreichen) Projekt zugeordnet, die zu einem nutzbarenSystem oder Systemteil führen.
Ein Projekt ist ein zeitlich begrenztes Entwicklungsvor-haben zur Lösung von Problemen innerhalb eines vorge-gebenen Zielsystems. Es umfasst die Gesamtheit der fürdie Problemlösung notwendigen Entwicklungsarbeiten.
So wie das Vorgehen beim Verfassen eines Berichts davon beeinflusstwird, ob er mit Schreibmaschine oder Textsystem erstellt wird, hängtauch die Durchführbarkeit der vorgestellten Vorgehensmodelle von derVerfügbarkeit geeigneter Werkzeuge ab: Während das klassische Pha-senmodell für die manuelle Programmierung entstand, wird die rascheFolge mehrerer Evolutionszyklen erst mit Programmgeneratoren mög-lich. Auch die erstellten Programme und deren Qualität sind je nachVorgehen verschieden [Bersoff / Davis 91, Humphrey et al. 91].
Die Tendenz geht allgemein von Neu- zu Weiterentwicklungen. Dabeimüssen neu Änderungen akzeptiert und systematisch behandelt werden[Skubch 92]. Ebenfalls in diesem Konzept enthalten ist die Übernahmeund Weiterverwendung existierender Systeme, Programme, Entwürfeoder Daten (Re-Engineering) [Biggerstaff / Richter 87, Gibbs et al. 90,Castano et al. 92, Krueger 92, Thoma 92]. Dieser Aspekt wird in dervorliegenden Arbeit jedoch nicht weiter untersucht.
3.2 Entwurfsmethoden
Strukturiertes Vorgehen beim Entwurf basiert auf schrittweiser Ver-feinerung. Nachdem im letzten Abschnitt Vorgehensmodelle für dasAnwendersystem als Ganzes betrachtet wurden, liegt das Schwergewichtdieses Abschnitts beim Entwurf einzelner Teile des Anwendersystems.Dafür werden gebräuchliche Entwurfstechniken für Datenbank-,Sichten- und Darstellungsentwurf verwendet.

42 Entwicklungsmethoden
3.2 .1 Schrittweiser Entwurf
Die Schritte des Entwurfs einer Generation des Anwendersystems lassensich grob in Datenbank-, Sichten- und Anwendungsentwurf gliedern.Darin sind weitere Verfeinerungen möglich, wie Figur 3.12 zeigt. Meistwird jeder dieser Schritte durch eine eigene Entwurfsmethodeabgedeckt.
Eine Entwurfsmethode ist ein planmässiges Verfahren fürdie teilweise oder vollständige Erstellung eines Anwen-dungsschemas.
Figur 3.12 gibt ein Beispiel einer solchen Entwurfsmethode, welchesich primär an den Daten orientiert.
Konzeptioneller Datenbankentwurf
Logischer Datenbankentwurf
Entwurf externer Schemata
Entwurf von Mutationstransaktionen
Dialogentwurf
Entwurf von Abfragen
Entwurf von Verarbeitungen
Listenentwurf
Datenbankentwurf
Anwendungsentwurf
Entwurf von Sichten
Figur 3.12: Schrittweiser Entwurf
Alternativ zu diesem datenzentrierten Vorgehen besteht auch die Mög-lichkeit, den Entwurf auf der Benutzerseite mit Sichten und zuge-hörigen Operationen zu beginnen. Häufig steht jedoch die Datenbe-schreibung im Zentrum. Die folgenden Unterabschnitte geben einenÜberblick über einschlägige Entwurfsmethoden und -umgebungen undzeigen auch deren Schwachstellen auf.
3.2 .2 Datenbankentwurf
Der Datenbankentwurf zeigt konzeptionelle und technische Aspekte. E rumfasst auch die Definition geeigneter Datenausschnitte (Sichten), die

Entwicklungsmethoden 43
den Anwenderkomponenten für Datenzugriffe zur Verfügung stehen.Diese Aufteilung wurde bereits in [ANSI 75] als Drei-Schema-Konzeptvorgestellt:
Abbildung konzeptionell-extern
Abbildung konzeptionell-intern
Konzeptionelles Schema
Externes Schema 1
Externes Schema 2
Internes Schema
Abbildung konzeptionell-extern
Figur 3.13: Drei-Schema Konzept
Ein grundlegender Schritt des Entwurfs datenbankbasierter Anwender-systeme ist der konzeptionelle Datenbankentwurf: Er beschreibt den-jenigen Ausschnitt aus der realen Welt, der durch die Informatiklösungunterstützt werden soll, dokumentiert durch das konzeptionelle Daten-bankschema. Ziel ist die vollständige Beschreibung von Daten und Zu-sammenhängen eines Realitätsausschnitts. Als Arbeitsinstrument dazuexistiert eine Vielzahl von Beschreibungssprachen, auch Datenmodelloder Datenbankmodell bezeichnet. Beispiele:
• Relationenmodell (RM) [Codd 70, Codd 79]
• Entity-Relationship-Model (ERM) [Chen 76]
• Non-First-Normal-Form Model (NF2) [Schek / Scholl 83]
• IFO-Modell [Abiteboul / Hull 87]
• Logical Design Methodology for Relational Databases (LRDM)[Teorey et al. 86]
• Object Modeling Technique (OMT) [Blaha et al. 88]
• Erweitertes Relationenmodell [Thurnherr 80, Zehnder 89]
Weitere Datenmodelle, Zusammenfassungen und Vergleiche sind z.B. in[Ceri 83, Brodie 84, Banerjee et al. 87b, Hull / King 87, Schmidt 87,Vossen 87, Potter / Trueblood 88, Shaw 88, Chen 92] zu finden. ERMund objektorientierte Modelle nähern sich an, indem neben den Datenauch die zugehörigen Funktionen betrachtet werden.

44 Entwicklungsmethoden
Während beim konzeptionellen Entwurf die Berücksichtigung und Aus-nützung spezieller Eigenschaften eines zu verwendenden Datenbank-verwaltungssystems vermieden werden, bilden diese das Schwergewichtdes logischen Entwurfs, beschrieben im logischen Datenbankschema (iminternen oder physischen Schema werden noch weiterführende tech-nische Dinge wie z.B. die Belegung des Sekundärspeichers definiert[ANSI 86, Brägger 87, Oertly 91]). Das logische Schema ist eine Ab-bildung auf ein Datenbankverwaltungssystem, wobei je nach verwen-detem Datenbanksystem unterschiedliche Abbildungsregeln angewendetwerden müssen [Schmidt 87], bei relationalen Systemen z.B. die Defi-nition von Beziehungsrelationen und Fremdschlüsseln.
Anwender interessieren sich selten für den vollen Umfang des konzep-tionellen Datenbankschemas, sie wollen lediglich eine bestimmte Sichtihrer Daten entwerfen. Das führt zu verschiedenen externen Schemata[ANSI 86], basierend auf demselben konzeptionellen Datenbankschema,und zwar mit einer oder mehreren Sichten pro Anwender bzw. Anwen-dergruppe. In einer Sicht spielen mehrere Aspekte mit, die z.T. bereitsbis in den Anwendungsentwurf hineinreichen:
• Datenausschnitt
• Datengruppierung
• Zulässige Transaktionen (Abfragen und Mutationen)
• Dialogdarstellung
Eine häufig eingesetzte Methode für die Sichtenmodellierung verwendetdie Beziehungen des konzeptionellen Schemas für die Datenauswahl[Clemons 79, Larson / Wallick 84b, Ursprung 84, Elmasri / Larson 85,Larson 87b]. Dadurch ergibt sich eine (hierarchische) Gruppierung undzulässige Operationen, basierend auf referentieller Integrität und dendaraus resultierenden Fortpflanzungspfaden (propagation paths) [Reb-samen 83, Date 86].
3.2 .3 Anwendungsentwurf
Am schwierigsten zu beschreiben sind jene Eigenschaften eines daten-bankbasierten Anwendersystems, die in den Operationen der Anwen-derkomponenten zum Ausdruck kommen und über Datenentwurf,gemeinsame Konsistenzbedingungen und Dialog hinausgehen, im fol-genden etwas unpräzise als Anwendungslogik bezeichnet. Die Schwie-rigkeit besteht im grossen Spektrum dieser Eigenschaften, das kaum mit

Entwicklungsmethoden 45
einer rein deskriptiven Beschreibungstechnik abgedeckt werden kann.Zusätzliche Programmteile in den Anwenderkomponenten werden be-nötigt, sobald die Anwenderdaten nicht nur gespeichert und dargestellt,sondern auch flexibel verarbeitet werden sollen. Für die Beschreibungder Zusammenhänge zwischen den Daten bestehen namentlich folgendeMöglichkeiten:
• Datenabhängigkeitsfunktionen
• Funktionsblockbildung
Die Verwendung von Datenabhängigkeitsfunktionen ist sinnvoll, wenndie Abhängigkeiten sich durch einfache mathematische Formeln wieMultiplikationen, Summen, Mittelwerte u.ä. beschreiben lassen. Ergän-zend kann dann definiert werden, ob die Werte virtuell oder physischexistent sind, und ob sie bei Veränderung der Eingangsgrössen sofortoder verzögert nachgeführt werden sollen [Gähler 91].
Eine globalere Sicht vermitteln Funktionsblöcke. Sie beschreiben nurnoch Schnittstellen und die Verwendung der Daten. Die Funktions-blöcke sind intern wegen ihrer Komplexität meist prozedural imple-mentiert [Marti 84]. Ein besonderer Vorteil der Verwendung vonFunktionsblöcken besteht in der durch die Schnittstellen bewirkten Mo-dularisierung des Anwendersystems und in der sehr erwünschtenKapselung ("Information Hiding").
3.2 .4 Dialogentwurf
Der Übergang zum Dialogbetrieb, namentlich aber die Verwendunggrafischer Benutzerschnittstellen und der objektorientierten Program-mierung hat eine Vielzahl neuer Methoden, Werkzeuge und Ent-wicklungsumgebungen für den Dialogentwurf hervorgebracht [Gold-berg / Robson 83, Stelovsky 84, Cunningham 85, Nievergelt et al. 86,Burbeck 87, Weinand et al. 88, Apple 89, Linton et al. 89, Myers 89,Myers et al. 90]. Dabei wird meist ein möglichst breites Spektrum desDialogs abgedeckt, die Verbindung zur zugehörigen Anwendung hat da-neben meist untergeordnete Bedeutung.
Im Gegensatz dazu wird bei Dialogen für datenbankbasierte Anwender-systeme für Datenzugriffe nur ein kleiner Ausschnitt aus dem weitge-fächerten Spektrum aller Dialogmöglichkeiten benötigt, und auch dieVerbindung zu den Datensichten basiert auf einigen wenigen Regeln.Wichtig ist aber die konzeptionelle und technische Unterstützung dieser

46 Entwicklungsmethoden
wenigen Konstrukte [Larson / Wallick 84a, ACS 88]. Eine Vielzahlkommerzieller Systeme bietet daher neben dem Zugriff zur Datenbankauch die Möglichkeit zur Dialogdefinition [Oracle 86, Inside Auto-mation 87, Oracle 87, 4th Dimension 87, Knight 89]:
• Oracle (Datenbank, ca. 80 Plattformen)
• Informix (Datenbank, v.a. UNIX-Plattformen)
• Sybase (Datenbank und Benutzerschnittstelle, v.a. UNIX-Platt-formen)
• Uniface (Benutzerschnittstelle, Aufsatz auf bestehende Daten-banken)
• Omnis (Benutzerschnittstelle, v.a. grafische Arbeitsstationen)
• 4th Dimension (Benutzerschnittstelle, Macintosh)
• FileMaker (Benutzerschnittstelle, Macintosh)
Heutige kommerzielle Produkte sind allerdings meist entweder dialog-oder datenbankorientiert, die andere Seite ist dementsprechend schwachausgebildet. Zudem erfolgt die Unterstützung rein technisch, konzep-tionelle Beschreibungsmöglichkeiten oder Entwurfssysteme auf hoherAbstraktionsebene fehlen weitgehend.
Benötigt wird somit eine integrierte Entwurfsmethode mit gleichzei-tiger einheitlicher Behandlung von Datenbank- und Anwendungsent-wurf. Ein durchgängiges Entwurfswerkzeug muss dem Entwerfer mög-lichst viel Information bereits vorhandener Datenbank- oder Sichtdefi-nitionen zur Verfügung stellen, hauptsächlich für Überprüfungen undEingabeerleichterungen während des Entwurfs. Der Entwurf vonSichten wird z.B. durch die Einschränkung auf die Auswahl von Enti-tätsmengen und Attributen des bereits definierten konzeptionellen Sche-mas wesentlich einfacher und sicherer. Die (hierarchischen) Daten-sichten werden dazu in Bildschirmformulare mit Feldern und Wieder-holungsgruppen abgebildet. Der dafür benötigte Programmcode wirdanschliessend durch einen Generator erzeugt.
Listen werden nach denselben Regeln wie Dialoge, d.h. ebenfalls auf-grund hierarchischer Datensichten, entworfen. Weil sie die Anwender-daten nicht verändern, werden dafür nur Abfragen benötigt, welche dieDatenkonsistenz nicht beeinträchtigen.

Entwicklungsmethoden 47
3.3 Versionenbildung
Durch die evolutionäre Weiterentwicklung eines Anwendersystemsentstehen im Verlauf der Zeit verschiedene Schemaversionen. DieserAbschnitt führt dazu die wichtigsten Begriffe ein und stellt Anwen-dungsgebiete und Werkzeuge der Versionenverwaltung vor.
"Ähnliche" Ausprägungen bestimmter "Objekte" führen zu einer Mengevon Versionen (in der Softwareentwicklung gelegentlich auch alsRevisionen bezeichnet). Die Gesamtheit aller Versionen desselbenObjekts wird als abstraktes Objekt bezeichnet, Figur 3.14 links [Petry88]. Synomym zum abstrakten Objekt werden die Begriffe generischesObjekt oder Version Set verwendet [Dittrich et a. 86, Pfefferle et al. 89,Joseph et al. 89]. Jede einzelne Version in dieser Menge ist identifi-zierbar [Tichy 88a]. Zwischen den Versionen bestehen Ableitungsab-hängigkeiten, wenn neue Versionen aus bereits bestehenden gebildetwerden. Diese Abhängigkeiten können je nach Ableitungsregeln linear,baumförmig oder netzwerkartig sein. Am häufigsten ist die baumför-mige Abhängigkeit, als Versionenbaum bezeichnet.
Abstraktes Objekt
Revisionen von x
Alternativen von x
x
x
Figur 3.14: Versionenbaum und Versionsabhängigkeiten
Revision werden jene Versionen genannt, die durch Überarbeitung auseiner bestehenden Version x gebildet werden. Alternativen einer Ver-sion x entstehen parallel durch unterschiedliche Entwicklungspfade.
In der Softwareentwicklung entspricht ein abstraktes Objekt in derRegel der Gesamtheit der im Verlauf der Weiterentwicklung entstande-nen Versionen desselben Moduls. Ein Einzelobjekt repräsentiert somiteine bestimmte Modulversion [Sommerville 85]. Ein Anwendersystembesteht aus einer Zusammensetzung bestimmter Versionen verschiede-ner abstrakter Objekte (Module): Eine Konfiguration [Frühauf et al. 88,Tichy 88a, Tichy 88b] ist eine nutzbare Zusammensetzung bestimmterVersionen verschiedener abstrakter Objekte (Module): Diese beschreibtdie Modulzusammensetzung des Anwendersystems. Ein Release ist die

48 Entwicklungsmethoden
Materialisierung einer Konfiguration: Dies ist ein abgeschlossenesProdukt.
Versionen von Modul 1
Versionen von Modul 2
Versionen von Modul 3
Konfiguration 1.0
Konfiguration 1.1
Figur 3.15: Konfigurationen
Eine Konfiguration kann als Version auf einer höheren Abstraktions-stufe verstanden werden: Beliebige Schachtelungen sind möglich [Katz90].
Mit dem check-out / check-in Konzept wird verhindert, dass mehrereEntwickler gleichzeitig Veränderungen an einer Modulversion vor-nehmen oder dass bei der Zusammenführung unabhängiger Überarbei-tungen an derselben Modulversion Änderungen überschrieben werden:Jede Version muss für Veränderungen aus dem sog. gesicherten Bereichausgetragen werden (check-out) und ist damit bis auf weiteres für Zu-griffe aller anderen Entwickler gesperrt. Nach Abschluss der Än-derungen erfolgt das Eintragen (check-in), wobei eine neue Version ge-bildet wird und Zugriffe wieder freigegeben werden. Dieses check-out /check-in Konzept kann erweitert werden, um weitere Überprüfungenwie Tests und Verifikationen auszulösen: Die Übernahme einer Versionin einen bestimmten gesicherten Bereich ist nur in genau definiertenSchritten möglich (Figur 3.16).
Releasebereich
Entwicklungsbereich
Check-out
Check-in
Kopie v. Version
Testbereich
Verifikation
ungesichert
gesichertgesichert
Figur 3.16: Entwicklung mit ungesicherten und gesicherten Bereichen
Bei grossen Softwareprojekten lässt sich der Überblick nur mit einersystematischen Versionenverwaltung behalten. Gängige Werkzeugedafür sind etwa Make [Feldman 79], SCCS (Source Code Control

Entwicklungsmethoden 49
System) [Rochkind 75] und CCC (Change Control System) [Lobba 85].Universellere Ansätze unterstützen neben der reinen Verwaltung vonProgrammcode auch die Projektführung und -überwachung durchWerkzeuge (IPSE, Integrated Project Support Environment) [Zucker85, Feiler / Smeaton 88, Montes / Haque 88]. Obwohl diese Methodenund Werkzeuge teilweise schon vor längerer Zeit entwickelt wurden,werden sie auch heute noch eingesetzt.
Die genannten Methoden und Werkzeuge sind auf die Verwaltung vonProgrammversionen ausgerichtet. Für die Unterstützung von Anwen-derdatenversionen sind kaum Ansätze vorhanden.
Nur langsam erfolgt mit der Einführung von CASE (Computer AidedSoftware Engineering) -Systemen der Übergang von der Verwaltungvon Files mit Einzelwerkzeugen zu integrierten und aufeinander abge-stimmten Softwarewerkzeugen. CASE-Systeme verwenden oft eine um-fassende Entwurfsdatenbank (Repository) anstelle einer Vielzahl vonFiles für die Verwaltung der Beschreibungsdaten. Vielen heutigenCASE-Umgebungen fehlen jedoch noch methodische Grundlage undIntegration [Forte / Norman 92, Huff 92, Jones 92, Navathe 92].


Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 51
4 Das Evolutionäre Vorgehensmodell und die in-tegrierte Entwurfsmethode Presto M
In diesem Kapitel wird das gesamte Verfahren Presto M (M: Methode)zur evolutionären Weiterentwicklung datenbankbasierter Anwender-systeme vorgestellt. Dazu werden zuerst drei Entwurfsebenen unter-schieden (Abschnitt 4.1) und die Evolutionsschritte über verschiedeneVersionen und Generationen definiert (Abschnitt 4.2). Anschliessendkann einerseits das Vorgehensmodell auf der obersten Ebene (Ver-sionenebene) formuliert werden (Abschnitt 4.3), andererseits dieMechanik der damit verbundenen Versionenübergänge (Abschnitt 4.4).Abschnitt 4.5 verfeinert das Verfahren Presto M anschliessend auf diezweite und dritte Entwurfsebene.
4.1 Die drei Ebenen des Verfahrens Presto M
Presto M ist ein planmässiges Verfahren zur Erreichung eines be-stimmten Ziels.
Dem hier entwickelten planmässigen Vorgehen für Entwurf und Evo-lution datenbankbasierter Anwendersysteme liegt eine dem evolutionä-ren Vorgehen angepasste Unterteilung in drei Entwurfsebenen zu-grunde. Zu jeder Entwurfsebene gehören entsprechend feinere oderumfassendere Entwurfsschritte. Dadurch kann die Aufmerksamkeit desEntwerfers jeweils auf einen Aspekt konzentriert werden.
Figur 4.1: Anwendungsschema, Teilschema und Entwurfsobjekt
• Die Schemaversion ist eine konsistente Beschrei-bung des ganzen Anwendersystems (in einer be-stimmten Version).
• Ein Teilschema gruppiert logisch zusammenge-hörige Teile des Entwurfs (z.B. ein logischesSchema).

52 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
• Ein Entwurfsobjekt ist die kleinste direkt manipu-lierbare Einheit eines Teilschemas (z.B. eine ein-zelne Relation).
Dieser Gliederung entsprechen die drei aufeinander aufbauenden Ent-wurfsebenen. Der Entwurfsprozess umfasst innerhalb einer Ebene je-weils mehrere gleichartige Schritte.
• Ein Versionenschritt (V-Schritt) führt zu einer Schemaversionund besteht aus der Gesamtheit aller für die konsistente Be-schreibung des Anwendersystems durch das Anwendungsschema(Schemaversion) nötigen T-Schritte.
• Ein Teilschritt (T-Schritt) führt zu einem vollständigen und kon-sistenten Teilschema und umfasst alle dafür nötigen E-Schritte.
• Ein Elementarschritt (E-Schritt) ermöglicht das Einfügen,Ändern oder Löschen einzelner Entwurfsobjekte innerhalb einesTeilschemas.
Figur 4.2 zeigt diesen Aufbau:
E
T
V
T
E
Figur 4.2: V-, T- und E-Entwurfsschritte
Jeder Entwurfsschritt auf einer höheren Ebene setzt voraus, dass allezugehörigen Schritte auf der unteren Ebene abgeschlossen sind.
4.2 Versionen und Daten- und Programmgenerationen
Jedes Informatiksystem muss zuerst - im Rahmen eines Entwurfs - be-schrieben werden, nach seiner Realisierung (Programmierung, etc.)lässt es sich nutzen.

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 53
Wir sprechen für die Entwurfsphase von einer Version der Beschrei-bung, für die Nutzungsphase von einer Generation des Anwendersy-stems. Jede Generation des Anwendersystems besteht aus
• den entsprechenden Datendefinitionen und Programmen
• den zugehörigen Anwenderdaten (die in der Verantwortung derAnwender stehen und von diesen nachgeführt werden)
AnwendungsschemaVersion 1
AnwendersystemGeneration 1
Generierung
AnwendungsschemaVersion 2
AnwendersystemGeneration 2
Generierung
t
Figur 4.3: Generationenbildung
Jedes Anwendungsschema enthält genau ein Teilschema für die Daten-beschreibung, aber allenfalls mehrere Teilschemata, welche die Anwen-derkomponenten beschreiben. Bei der Generierung entsteht aus derlogischen Datenbeschreibung ein Programmmodul Datenverwaltung,mit dessen Hilfe die durch den Anwender eingegebenen und mutiertenDaten als zugehörige Datengeneration abgespeichert werden. Datenge-nerationen werden in den folgenden Zeitsequenzdiagrammen grau dar-gestellt.
Die Datenverwaltung gewährleistet zentral, dass alleMutationen der Anwenderdaten einer bestimmten Da-tengeneration konsistenzerhaltend sind. Die Datenver-waltung stellt dafür die benötigten Anwendertrans-aktionen zur Verfügung.
Die Datenverwaltung besteht aus einer Sammlung von datenbankbezo-genen Programmodulen (oft auch als Zugriffsmodule bezeichnet). Siestellen zusammen mit dem Datenbankverwaltungssystem die Einhaltungaller modellinhärenten und modellexternen Konsistenzbedingungensicher.

54 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
Der Programmcode jeder Anwenderkomponente wird direkt aus derentsprechenden Beschreibung generiert und führt zu Programmgene-rationen. Jede einzelne Programmgeneration bleibt während ihrer Le-bensdauer unverändert. Jede Anwenderkomponente muss zu einer ganzbestimmten Datenbeschreibung passen.
• Eine Datengeneration (DG) besteht aus dem generierten Pro-grammmodul Datenverwaltung und den zugehörigen Anwender-daten.
• Eine Programmgeneration (PG) enthält die aus dem ent-sprechenden Teilschema generierte Software der Anwender-komponenten, aber keine eigenen permanenten Daten.
Im einfachsten Fall verlaufen Daten- und Programmgenerationen völligparallel (Figur 4.4), wie die folgende Zeitsequenzdarstellung zeigt.
Datengeneration 1
Programmgeneration 1
Datengeneration 2
Programmgeneration 2
Programmgeneration 1
Programmgeneration 2
AD
AK 1
AK 2
Figur 4.4: Daten- und Programmgenerationen (Idealfall)
Figur 4.4 zeigt noch eine weitere Eigenschaft aller Versions- und Gene-rationswechsel im Informatikbereich: Vor der jeweiligen Nutzung(Pfeile mit dicker Umrandung) ist eine Entwicklungs- und Testphasenotwendig (Pfeile mit dünner Umrandung). Sollen neue Programm-generationen auch auf einer anders strukturierten Datengeneration (undsomit auf einer geänderten Datenverwaltung) basieren, so ist dafür eineTestphase vorzuschalten, während welcher die neuen Testprogrammemit neustrukturierten Testdaten arbeiten können. Erst nach erfolg-reichem Test kann der Übergang von der bisherigen Nutzgeneration aufeine neue Nutzgeneration erfolgen (Migration). In Figur 4.4 wird dabei- etwas idealistisch - angenommen, dass für alle beteiligten Kompo-nenten, d.h. in diesem Fall für die Daten und zwei Anwenderkomponen-ten, der Generationenwechsel völlig synchron erfolgt.

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 55
In der Praxis verlaufen aber die Entwicklungen verschiedener Kompo-nenten oft nicht parallel. Zur Entwicklung neuer Daten- und Pro-grammgenerationen sind häufig mehrere Zwischenversionen und davonabgeleitete Zwischengenerationen nötig. Die nächste Zeitsequenzdar-stellung (Figur 4.5) zeigt solch einen zeitlich gestaffelten Ablauf derEvolution eines Anwendersystems.
DG 1 (V 1b)
PG 1.1
DG 2 (V 2b)
PG 2.1
PG 1.1
PG 2.1
AD
AK 1
AK 2
PG 1.2
V 2a V 2b
V 1a V 1b
PG 1.2
PG 1/3
Figur 4.5: Unterschiedlich lange Daten- und Programmgenerationen
Eine Staffelung von Daten- und Programmgenerationen untersteht aberbestimmten Regeln:
• Jede Programmgeneration bezieht sich auf eine einzige Daten-generation. Auf einer Datengeneration können aber parallelund/oder nacheinander verschiedene Programmgenerationenbasieren.
• Jeder Programmnutzung geht ein Programmtest voraus. Für denProgrammtest einer bestimmten Programmgeneration sind Test-oder Nutzdaten der zugehörigen Datengeneration nötig.
• Weil die Anwender nicht gleichzeitig verschiedene Datenbe-stände nachführen können, ist gleichzeitig immer genau eineDatengeneration die genutzte. Sie enthält zu diesem Zeitpunkt dieNutzdaten.
• Neben der Nutzdatengeneration können gleichzeitig (allenfallsmehrere) Testdatengenerationen existieren.

56 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
• Beim Übergang einer Datengeneration von der Testphase in dieNutzungsphase bleibt häufig die zugehörige Datenverwaltungbestehen, während der Datenbestand (über entsprechende Daten-übernahmeprogramme) aus der abzulösenden Datengenerationübernommen wird (zur Datenübernahme siehe Abschnitt 4.4).
In Figur 4.5 sind mehrere derartige Situationen dargestellt:
• Aus der Anwenderkomponente AK 1 beziehen sich die Pro-grammgenerationen PG 1.1 und PG 1.2, aus AK 2 die Pro-grammgenerationen PG 1.1, PG 1.2 und PG 1.3 auf die Daten-generation DG 1.
• In AK 1 benützt die Programmgeneration PG 1.2 schon in derTestphase die Datengeneration DG 1.
• Die genutzte Datenversion ist schrittweise DG 1, dann DG 2.
• Parallel zur Datengeneration DG 1 wird DG 2 in den VersionenV 2a und V 2b entworfen.
• Die Datengeneration DG 2 hat als zugehörige Testphase dieVersion V 2b. Die Datenverwaltung von DG 2 wurde als Daten-verwaltung von Version V 2b initialisiert und bleibt für DG 2unverändert. Die Daten von DG 2 werden aber (über separateÜbernahmeprogramme) aus DG 1 übernommen bzw. umge-rechnet.
4.3 Das evolutionäre Vorgehensmodell für Daten undProgramme (Versionenebene)
In diesem Abschnitt wird das Modell Presto M auf der obersten Ebene,der Versionenebene, dargestellt. Presto M erlaubt den schrittweisenAufbau und die bedarfsgesteuerte Weiterentwicklung eines grösserendatenbankbasierten Anwendersystems nach den Regeln der evolutio-nären Prototypenbildung. Diese Entwicklung beginnt erstmals miteinem Gesamtentwurf und durchläuft anschliessend iterativ verschie-dene Schritte gemäss Figur 4.6.

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 57
Evolution
NutzungGesamtentwurf Parallelbetrieb
Bereinigung
Entwicklung
Prototypenbildung
Figur 4.6: Phasenfolge
Mit dem Gesamtentwurf wird neben der Umsetzung der Anforderungenin eine Informatiklösung auch die Evolution in Form der nächsten paar(etwa drei) Generationen des Anwendersystems geplant, beschrieben imGenerationenplan.
Der Generationenplan beschreibt die evolutionärenEntwicklungsschritte des Anwendersystems oder vonTeilen davon durch zeitliche und inhaltliche Festlegungmehrerer zukünftiger Generationen.
Da der Generationenplan die künftige Entwicklung des Anwendersy-stems massgeblich beeinflusst, ist dessen Genehmigung durch eine ent-sprechend kompetente Stelle nötig. Dazu ist ein Systemantrag zu formu-lieren.
Der Systemantrag verlangt die offizielle Freigabemehrerer Schritte der evolutionären Entwicklung gemässdem im Rahmen eines Gesamtentwurfs erstelltenGenerationenplans.
Nach Freigabe des Systemantrags werden die einzelnen Generationen alsTeilprojekte entwickelt und benötigen weiterhin noch separate Projekt-anträge. Diese können jedoch wegen des bereits genehmigten System-antrags wesentlich einfacher gehalten werden. Für die Entwicklungeiner Generation (V-Schritt) werden zu Beginn die Anforderungenformuliert und fixiert und dürfen bis zum Abschluss des V-Schrittsnicht mehr geändert werden. Falls sie nicht gehalten werden können, istdas Teilprojekt abzubrechen und eine neue Schemaversion in Angriff zunehmen.
Da der Hauptzyklus "Bereinigung" (siehe Figur 4.6) auch den Schritt"Gesamtentwurf" in die Iteration einbezieht, kann der Gesamtentwurfselber im Laufe der Zeit angepasst werden, verbunden mit einem neuenGenerationenplan und einem neuen Systemantrag. Innerhalb eines Be-reinigungszyklus' sind wiederum verschiedene Evolutionszyklen mög-

58 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
lich; ein Evolutionszyklus fällt mit der Nutzungsdauer einer Daten-oder Programmgeneration zusammen. Durch die in Abschnitt 4.2 vor-gestellten unterschiedlichen Nutzungsdauern von Daten- und Pro-grammgenerationen lassen sich Zeitsequenzen gemäss Figur 4.7 rechtsbilden.
AK 2
AK 1
AD
Bereinigung Evolution
Figur 4.7: Phasenfolge und Zeitsequenzen von Presto M
Der Gesamtverlauf eines grösseren datenbankbasierten Anwendersy-stems (Figur 4.7, rechts) umfasst verschiedenartige charakteristischeSchritte, wie schon in Figur 4.5 gezeigt worden ist. Typische Schritteund Schrittfolgen sind:
A Eine einzige Folge von Nutzdatengenerationen
B Sequenzen von Test- und Nutzdatengenerationenmit gemeinsamem Datenverwaltungssystem
C Testdatengenerationen, die parallel zu Nutzdaten-generationen verlaufen
D Experimentelle Programmgenerationen für Daten-abfragen auf Testdaten oder Nutzdaten
E Experimentelle Programmgenerationen für Daten-mutationen auf Testdaten (gleiche Daten wie fürAbfragen)

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 59
F Genutzte Programmgenerationen für Abfragenund/oder Mutationen auf Nutzdaten
Diese Elemente des Gesamtverlaufs eines Anwendersystems lassen sichverschiedenartig einsetzen und kombinieren. Dabei beziehen sich dieProgrammgenerationen immer auf eine einzige Datengeneration undsind entweder Wegwerfprototypen (kleine weisse Pfeile in Figur 4.7)oder für einen möglichen Nutzeinsatz entwickelte Programme (grosseweisse Pfeile in Figur 4.7). Wir benützen folgende Begriffe:
• Wegwerfprototypen (Typen D und E): Solche Programmgene-rationen werden mit minimalem Aufwand für einen kurzlebigenexperimentellen Einsatz entwickelt, um offene Spezifikations-fragen für eine spätere Nutzgeneration genauer abzuklären.Wegwerfprototypen werden typischerweise im Rahmen vonSpezifikationsarbeiten für andere Projekte entwickelt und nachihrem ersten Einsatz nicht weiter benützt und betreut.
• Evolutionäre Prototypen (Typen D und E): Solche Programm-generationen werden mit einsatztauglichen Qualitätsmassstäbenfür einen reduzierten, aber nutzbaren Einsatz (als Anwender-komponente) entwickelt. Nach dem Testeinsatz als evolutionärerPrototyp wird über eine allfällige praktische Nutzung ent-schieden (Übergang zu Typ F).
• Nutzgenerationen (Typ F): Solche Programmgenerationen wer-den mit einsatztauglichen Qualitätsmassstäben für einen nutz-baren Einsatz (als Anwenderkomponente) entwickelt. Nach demerfolgreichen Test erfolgt der Einsatz. Falls die neue Pro-grammgeneration eine andere Datenstruktur verlangt als dieaktuelle Nutzdatengeneration bereitstellt, verlangt ihre Ein-führung auch einen Generationenwechsel der Nutzdaten mit Da-tenübernahme (Abschnitt 4.4).
In Figur 4.7 sind die verschiedenen Typen von Programmgenerationendeutlich sichtbar.
• Wegwerfprototypen sind provisorische Ent-wicklungen für die Abklärung von Unklarheiten
• Evolutionäre Prototypen sind Programmgenera-tionen in Vorbereitung und Test
• Nutzgenerationen sind nutzbar eingesetzte Pro-grammgenerationen

60 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
Evolutionäre Prototypen können direkt in Nutzgenerationen übergehen.
Im evolutionären Vorgehensmodell genügt es nicht, mit einem einzigenProjektbegriff zu arbeiten, wie er in Abschnitt 3.1 definiert wurde. InGrossprojekten hat sich eine zweistufige Gliederung bewährt [Zehnder91]:
• Ein Superprojekt ist ein aus mehreren normalen Projektenzusammengesetztes Entwicklungsverfahren zur Gesamtlösungeiner Grossaufgabe.
• Ein Teilprojekt ist der Problemlösungsprozess für beschränkteGrössenordnungen.
Für die evolutionäre Entwicklung präzisieren wir das Superprojektentsprechend:
Ein evolutionäres Superprojekt ist ein aus mehrerenProjekten zusammengesetztes Vorgehen zur Gesamt-lösung einer Aufgabe und mit der Möglichkeit für kon-trollierte Wiederholungen. Eine Bereinigung des Ge-samtentwurfs ist jeweils nach einem bzw. einer Folge vonEvolutionsschritten möglich.
Die in dieser Definition bewusst eingeräumte Möglichkeit einer späterenBereinigung des Gesamtentwurfs enthält aber auch Gefahren. LaufendeAnpassungen können nämlich zu einseitigen Korrekturen undSchwerpunktverschiebungen führen, die unerwünschte Differenzenzwischen Anforderungen und deren technischer Realisierung erzeugenkönnen. Um solche Differenzen sichtbar zu machen und bei Not-wendigkeit deren spätere Korrektur einzuleiten, ist nach jeweilsmehreren Evolutionszyklen des Gesamtsystems eine periodische Be-reinigung des Gesamtentwurfs vorzusehen, verbunden mit einem neuenGenerationenplan und zugehörigem Systemantrag.
Wie bei allen Teilprojekten müssen für alle Generationen Pflichten-hefte, Ziele und Zeitpläne definiert und eingehalten werden. Figur 4.8zeigt begriffliche und zeitliche Aspekte der evolutionären Weiterent-wicklung:

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 61
Teilprojekt- dauer
Nutzungsdauer
Generation n
Generation n+1
Nutzung Generation n
Nutzung Generation n+1
Entwicklung Nutzung
Generation:
SuperprojektdauerGenerationsdauer
Lebensdauer
Figur 4.8: Zeitsequenzen und Zeitbegriffe
Die Entwicklung einer Generation (mit oder ohne Änderung der Daten-definition) ist ein Teilprojekt mit entsprechender Teilprojektdauer, ge-folgt von der Nutzung mit ihrer Nutzungsdauer. Die Summe von Teil-projekt- und Nutzungsdauer ist die Generationsdauer. Die Superprojekt-dauer erstreckt sich vom Beginn der ersten bis zum Abschluss derletzten Entwicklung für eine gegebene Menge von Teilprojekten. DieLebensdauer des Anwendersystems reicht darüber hinaus bis zur end-gültigen Ablösung oder Ausserbetriebnahme.
Beim evolutionären Vorgehen sind Anzahl und Dauer der Teilprojekteim voraus schwierig abzuschätzen. Anders als bei klassischen Superpro-jekten kann die Methode der evolutionären Weiterentwicklung mit Teil-projekten auch bei kleineren Vorhaben mit wenigen Beteiligten sinnvolleingesetzt werden, weil die Teilprojekte nicht parallelisiert, sondernsequentialisiert werden.
[Zehnder 91] schlägt für Superprojekte eine frühzeitige gemeinsameDatenbeschreibung als verbindliche Basis vor. Bei der evolutionärenWeiterentwicklung kommt es - besonders bei Neuentwicklungen - häu-fig vor, dass zu Beginn die konzeptionellen Datenbeschreibungen selbstnoch instabil sind. Die für den konzeptionellen Datenentwurf benötigteFlexibilität kann durch die Verwendung externer Datensichten alsKoordinationsbasis zwischen Anwender und Entwickler erreicht wer-den. Diese müssen so lange stabil gehalten werden, bis die zentralenkonzeptionellen Datendefinitionen stehen und ihre Rollen voll über-nehmen können. Voraussetzung für dieses Vorgehen ist die strikteTrennung von konzeptionellem und externem Entwurf.

62 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
4.4 Der Migrationsschritt (Versionenübergang)
Daten- und Programmgenerationen haben nicht die genau gleichenGenerationsübergänge. Beiden Fällen ist jedoch gemeinsam, dass derÜbergang nicht in beliebig kurzer Zeit erfolgen kann, sondern sich übereine bestimmte Migrationsdauer erstreckt.
Zuerst wird der komplexere Fall des Daten-Generationsübergangs vonder Datengeneration n zur Datengeneration n+1 untersucht: WichtigstesKriterium ist, dass zu jedem gegebenen Zeitpunkt immer genau ein Ori-ginal der Daten ("Nutzdaten") existiert, alle anderen Vorkommen sindKopien oder Paralleldaten dieses Originals. Das aktuelle Original ist inder folgenden Zeitsequenzdarstellung durch die dickere Umrandunghervorgehoben. Charakteristisch für die Paralleldaten ist, dass sie mitdem Original in geeigneter Form synchronisiert sind, d.h. ständig oderperiodisch nachgeführt werden. Dadurch entsteht eine "Vorwärts-",allenfalls auch eine "Rückwärtsbrücke".
Nutzdaten Generation n+1
Datenübernahmen für Datensynchronisation
Daten-Generationenwechsel (Generation n zu n+1)
"Vorwärtsbrücke"
Nutzdaten Generation n
"Rückwärtsbrücke"
Testdaten
Datenmigrationsdauer Generationswechsel n zu n+1
Archivdaten
Prototypdaten
Paralleldaten
Paralleldaten
Daten-Parallelbetrieb(Datensynchronisation)
Figur 4.9: Datenmigration
Zum Zeitpunkt des Generationswechsels übernehmen die bisherigenParalleldaten die Rolle des Originals. Die Dauer vom Einrichten derersten Paralleldaten der neuen Generation bis zur Ausserdienstsetzungder Paralleldaten der bisherigen Generation bestimmt die Migrations-dauer des Daten-Generationenwechsels. Als Vorläufer der Paralleldatennach neuer Struktur werden nicht mit dem Original synchronisierte,aber aus diesem abgeleitete Prototyp- und Testdaten verwendet, um inEntwicklung befindliche Anwenderkomponenten zu testen. Analog wer-

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 63
den vielfach nach Migrationsende Paralleldaten der bisherigen Gene-ration in Form nicht mehr synchronisierter Archivdaten aufbewahrt.
Betriebsunterbrüche sowie Varianten und Massnahmen für die Über-führung der Anwenderdaten in konventionellen Datenbanken (Daten-bank-Restrukturierung) wurden in [Oertly 91] untersucht. Noch er-forscht werden Datenbanksysteme, bei denen nach Schemaänderungenkeine Restrukturierung nötig ist [Banerjee et al. 87a, Tresch / Scholl 92,Bratsberg 92].
Die Migration von Programmgenerationen ist zwar einfacher, sie mussaber koordiniert mit der Datenmigration erfolgen. Analog zu den Datenwird der Fall des Programmgenerationswechsels von der Generation nzur Generation n+1 betrachtet. Beim Programmgenerationswechsel sindzwei Fälle zu unterscheiden:
• Gleichzeitig mit dem Programmgenerationswechsel erfolgt auchein Datengenerationswechsel.
• Programmgenerationswechsel ohne Datengenerationswechsel.
Die folgenden Betrachtungen beziehen sich auf die erste, allgemeinereVariante mit Datengenerationswechsel. Parallel zur Nutzung der bis-herigen Generation n wird mit der Entwicklung der neuen Programm-generation, vorerst als Wegwerfprototyp, begonnen. Sobald währendder Entwicklung neuer Programme Datenzugriffe für Tests nötig sind,müssen mindestens Prototypdaten in der neuen Form zur Verfügungstehen. Die versuchsweise Nutzung der neu entwickelten Anwender-komponente als Parallelprogramm (evolutionärer Prototyp) kann erstmit den Paralleldaten der Generation n+1 beginnen; umgekehrt dürfenParalleldaten der bisherigen Generation erst freigegeben werden, wennalle Anwenderkomponenten der Generation n auf die Generation n+1angepasst wurden. Sobald eine Anwenderkomponente der Generation nnicht mehr genutzt wird, kann sie als Archivprogramm behandelt wer-den. Diese ist nur so lange von Nutzen, wie die für seine Ausführungbenötigte Umgebung noch zur Verfügung steht.
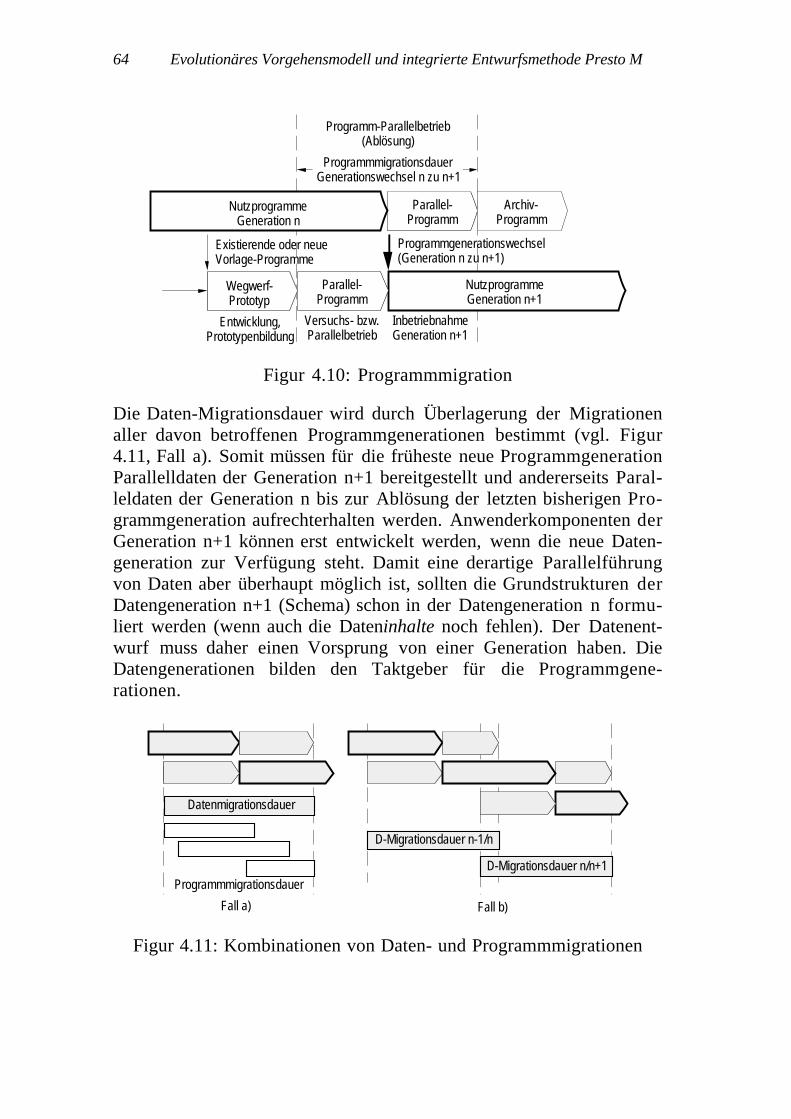
64 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
Nutzprogramme Generation n
Nutzprogramme Generation n+1
Existierende oder neue Vorlage-Programme
Programmgenerationswechsel (Generation n zu n+1)
Entwicklung, Prototypenbildung
Versuchs- bzw. Parallelbetrieb
Parallel- Programm
Parallel- Programm
Wegwerf- Prototyp
Programmmigrationsdauer Generationswechsel n zu n+1
Inbetriebnahme Generation n+1
Archiv- Programm
Programm-Parallelbetrieb(Ablösung)
Figur 4.10: Programmmigration
Die Daten-Migrationsdauer wird durch Überlagerung der Migrationenaller davon betroffenen Programmgenerationen bestimmt (vgl. Figur4.11, Fall a). Somit müssen für die früheste neue ProgrammgenerationParallelldaten der Generation n+1 bereitgestellt und andererseits Paral-leldaten der Generation n bis zur Ablösung der letzten bisherigen Pro-grammgeneration aufrechterhalten werden. Anwenderkomponenten derGeneration n+1 können erst entwickelt werden, wenn die neue Daten-generation zur Verfügung steht. Damit eine derartige Parallelführungvon Daten aber überhaupt möglich ist, sollten die Grundstrukturen derDatengeneration n+1 (Schema) schon in der Datengeneration n formu-liert werden (wenn auch die Dateninhalte noch fehlen). Der Datenent-wurf muss daher einen Vorsprung von einer Generation haben. DieDatengenerationen bilden den Taktgeber für die Programmgene-rationen.
Datenmigrationsdauer
Programmmigrationsdauer
D-Migrationsdauer n-1/n
D-Migrationsdauer n/n+1
Fall a) Fall b)
Figur 4.11: Kombinationen von Daten- und Programmmigrationen

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 65
Wenn die Daten-Migrationsdauer wegen der Überlagerung mehrererProgrammmigrationen sehr lange dauert und die entsprechendeNutzung weniger lang, muss allenfalls ein Parallelbetrieb von mehr alsnur zwei Generationen aufrechterhalten bzw. simuliert werden (Figur4.11, Fall b). Die mittlere Datengeneration muss dabei gleichzeitig eineVorwärts- und eine Rückwärtsbrücke anbieten.
4.5 Die tieferen Ebenen der Entwurfsmethode Presto M
Jeder Versionsentwurf und jede zugehörige Generationsentwicklung be-nötigt selbstverständlich weitere Verfeinerungen. Für die folgenden Er-läuterungen wird eine Aufteilung jedes Anwendungsschemas in fünfTeilschemata und Entwurfskomponenten verwendet. Das VerfahrenPresto M regelt auch die Reihenfolge der Bearbeitung in einem sog.Abhängigkeitsgraph der Teilschemata (Figur 4.12).
Logischer Datenbankentwurf
(L)
Konzeptioneller Datenbankentwurf
(C)
Präsentationsentwurf (P): Layout
Externer Datenbankentwurf
(E)
Entwurf von Anwendertransaktionen
(T)
Figur 4.12: Presto M Abhängigkeitsgraph mit fünfEntwurfskomponenten (Beispiel)
Durch die fünf Teilschemata sind auch fünf T-Schritte definiert. Diedafür verwendeten Entwurfstechniken sind alle aus der Welt desDatenbank- und Anwendungsentwurfs bekannt.
• Konzeptioneller Datenbankentwurf: Fachliche Modellierung undGruppierung der Daten und ihrer Zusammenhänge, ohne bereitsSystem- und Implementationsaspekte zu berücksichtigen. Die imfolgenden verwendete Beschreibungstechnik folgt [Zehnder 89].Typen von Entwurfsobjekten sind Wertebereiche, Entitäts-mengen, Beziehungen, Attribute und Schlüsselkandidaten.

66 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
• Logischer Datenbankentwurf: Implementation der Datenbank,d.h. Abbildung des konzeptionellen Datenbank(teil)schemas aufdas verwendete konkrete Datenbanksystem, einschliesslich ersterOptimierungsaspekte [ANSI 86, Mayr et al. 87]. Entwurfsobjektesind (für relationale Datenbanksysteme) Formatdefinitionen,Tabellen, Felder und Indizes. Sie referenzieren Entwurfsobjektedes konzeptionellen Teilschemas und enthalten teilweise re-dundante Information: Das logische Teilschema ist daher vomkonzeptionellen Teilschema abhängig, was im Abhängigkeits-graph durch einen Pfeil von C nach L dargestellt wird.
• Entwurf von Anwendertransaktionen: Datenbankmutationenmüssen modellinhärente und auch zusätzlich definierte Konsi-stenzbedingungen gewährleisten [Gähler 91], sollen aber ande-rerseits möglichst einfach sein. Hilfreich bei der Modellierungvon Anwenderoperationen ist die Analyse der Fortpflanzungs-pfade entlang vorgängig definierter Beziehungen [Rebsamen 83].Entwurfsobjekte des Transaktionsteilschemas sind daher Anwen-dertransaktionen, Ansatzpunkte, Fortpflanzungspfade und Ope-rationsattribute. Sie referenzieren ebenfalls das konzeptionelleTeilschema und sind daher ihrerseits von diesem abhängig (Pfeilvon C nach T).
• Entwurf externer Schemata: Datenausschnitte werden benutzer-nah als hierarchisch strukturierte Sichten entworfen. Die Glie-derung in Hierarchieebenen basiert ebenfalls auf den Be-ziehungen des konzeptionellen Teilschemas, ausgehend von einer(strukturbestimmenden) Entitätsmenge, welche im Hierarchie-baum als Wurzel erscheint [Clemons 79, Ursprung 84, ANSI86]. Hierarchische Sichten können für Mutationen Anwender-transaktionen des Transaktionsteilschemas enthalten, wobei eini-ge Kompatibilitätsregeln einzuhalten sind. Entwurfsobjekte sindSichten (wovon gleichzeitig verschiedene existieren können),Anwendertransaktionen und Sichtattribute. Abhängigkeiten exi-stieren sowohl vom konzeptionellen wie vom Transaktionsteil-schema (Pfeile von C und T nach E).
• Präsentationsentwurf: Erst durch Anordnung und Beschriftungvon Attributen, Hierarchieebenen (Segmenten) und Sichten inBildschirmformularen werden Dialoge und Listen möglich [Lar-son / Wallick 84, Larson 87b, Carlson / Metz 80]. Entwurfs-objekte sind Positionen, Gruppierungen und Darstellungsattri-bute von Objekten auf dem Bildschirm. Das Präsentationsteil-

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 67
schema ist wegen der Hierarchieverwendung vom entsprechen-den externen Teilschema, wegen der Darstellung der Opera-tionen auch vom Operationsteilschema abhängig (Pfeile von Tund E nach P).
In einer nächsten Verfeinerung lässt sich der Entwurfsprozess in sog.Elementarschritte aufgliedern. Figur 4.13 zeigt für sämtliche T-Schrittedie wichtigsten Gruppen von E-Schritten und stellt sie einer klassischenEntwurfsmethode für Datenbanken [Zehnder 89] gegenüber (die Anfor-derungsanalyse ist kein eigentlicher T-Schritt).
Anforderungsanalyse
Konzeptioneller Datenbankentwurf
Logischer Datenbankentwurf
Konsistenzerhaltende Anwendertransaktionen
Externe Datenbankschemata
Präsentationsentwurf
• Abstecken des Problemrahmens
• Bildung von Entitätsmengen• Definition untergeordneter Entitätsmengen: Untermengen• Festlegen von Beziehungen zwischen Entitätsmengen: Assoziationen
• Bestimmung der beschreibenden Eigenschaften: Attribute• Vorschläge für Schlüsselkandidaten aus Attributkombinationen
• Überführung von Entitätsmengen in Tabellen• Abbildung von Assoziationen in Tabellen (globale Normalisierung)• Überführung von Attributen in Kolonnen• Festlegung der Identifikationsschlüssel
• Bestimmung von Anwendertransaktionen• Konsistenzerhaltende Fortpflanzungen (Konsistenzbedingungen)• Anschliessen freiwilliger Fortpflanzungen
• Bestimmung der Hierarchiestruktur• Auswahl strukturverträglicher Anwendertransaktionen
• Ergänzung nicht mutierbarer Entitätsmengen• Weglassen nicht benötigter Sichtattribute
• Zuordnung von Bildschirmformular zu Hierarchie• Gruppenbildung gemäss Hierarchiestruktur• Anordnung und Beschriftung der Formularfelder• Darstellungsparameter von Wiederholungsgruppen
A
B (1)C (1)C (2)
F (1)D (1)
B (2)EF (2)D
GH
• Weglassen nicht benötigter Attribute
Entwurfsschritte nach [Zehnder 89]
Figur 4.13: Verfeinerung des Entwurfsverfahrens: T- und wichtigste E-Schritte

68 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
Wie die Fallstudie KORA in Kapitel 5 zeigt, können Anzahl und Ab-hängigkeiten der Teilschemata bei anderen Bedürfnissen vom Beispielin Figur 4.12 abweichen, was sich in einem etwas anders strukturiertenAbhängigkeitsgraphen manifestiert. Die Methode Presto M ist unab-hängig von Art und Anzahl der Teilschemata, eine sinnvolle Anzahl vonTeilschemata liegt jedoch zwischen 3 und 10.
4.6 Teilschemata und Entwurfskomponenten
Bis zu diesem Punkt wurde erst wenig über Gliederung und Entwurfdes Anwendungsschemas gesagt. Zur Rekapitulation: Das Anwendungs-schema besteht aus Teilschemata, die in T-Schritten mit Hilfe der Ent-wurfskomponenten entworfen werden. Eine Besonderheit der MethodePresto M ist die weitgehende Entkopplung der verschiedenen Teil-schemata. Jedes Teilschema wird durch genau eine Entwurfskompo-nente des Entwurfssystems verwaltet, und umgekehrt ist jeder dieserEntwurfskomponenten genau ein Teilschema zugeordnet. Auf diese Artsind alle Konsistenzbedingungen für ein Teilschema an einem einzigenOrt, in der zugehörigen Entwurfskomponente, konzentriert. Figur 4.14verdeutlicht die 1:1-Zuordnung zwischen Teilschema und Entwurfs-komponente. Die Gesamtheit aller Entwurfsdaten, d.h. das vollständigeAnwendungsschema, ist somit gegliedert nach Teilschemata in der Ent-wurfsdatenbank des Entwurfssystems abgelegt.
EK C EK L
EK T
EK E EK P
Teilschema C Teilschema L
Teilschema T
Teilschema E Teilschema P
Figur 4.14: Entwurfskomponenten und ihre Teilschemata
Da die Teilschemata allerdings nicht vollständig unabhängig voneinan-der sind, muss die Möglichkeit bestehen, als Folge lokaler Änderungenandere Teilschemata nachzuführen. Dies geschieht nicht durch direkten

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 69
Zugriff auf das fremde Teilschema, sondern über die zugehörigenEntwurfskomponenten mit besonderen Aktualisierungsnachrichten. Umdiese Nachrichten korrekt weiterzuleiten, muss dem Entwurfssystembekannt sein, welche Teilschemata welche Informationen anderer Teil-schemata verwenden. Diese Abhängigkeiten sind in Figur 4.14 (wiebereits in Figur 4.12) als dünne Pfeile dargestellt. Sie bilden in ihrerGesamtheit den Abhängigkeitsgraph: Der Abhängigkeitsgraph ist eingerichteter Graph und beschreibt die gegenseitigen Abhängigkeiten derTeilschemata.
4.7 Konsistenz der Entwurfsdaten
Die Generierung eines Anwendersystems ist nur korrekt möglich, wenndessen Anwendungsschema widerspruchsfrei ist, d.h. wenn die Ent-wurfsdaten konsistent sind. Durch die drei Entwurfsebenen ergeben sichauch drei Konsistenzebenen, in Analogie zu den Entwurfsschritten alsV-, T- und E-Konsistenz bezeichnet:
• Die Version eines Anwendungsschemas ist V-kon-sistent, wenn alle Teilschemata T-konsistent sindund zwischen den Teilschemata keine Wider-sprüche bestehen.
• Ein Teilschema ist T-konsistent, wenn seine Ent-wurfsobjekte E-konsistent sind und die Ent-wurfsobjekte untereinander widerspruchsfrei sind.
• Ein Entwurfsobjekt ist E-konsistent, wenn es keineinneren Widersprüche enthält.
Die Definitionen zeigen, dass bei einer Hierarchie von Konsistenzregelnjeweils ein Teil der Konsistenzbedingungen unmittelbar auf E-Stufeoder T-Stufe sichergestellt werden kann, ein anderer Teil erst auf dernächsthöheren Ebene. Dies führt zur Unterscheidung zwischen unmittel-barer und verzögerter Konsistenz:
• Unmittelbare Konsistenz: muss nach jedem Entwurfsschritt(gleichgültig auf welcher Entwurfsebene) eingehalten werden.
• Verzögerte Konsistenz wird nur zu bestimmten Zeitpunktenüberprüft (in der Regel bei der Rückkehr zur nächsthöherenEntwurfsebene).

70 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
Zur Verdeutlichung sollen nun die drei Ebenen V, T und E sowie ihreÜbergänge betrachtet werden:
Beim erstmaligen Entwurf oder für Änderungen an einem bestehendenAnwendungsschema wird eine neue Schemaversion angelegt. Dies ent-spricht einem V-Schritt. Nach der Freigabe der neuen Schemaversionsind T-Schritte möglich. Die Schemaversion kann abgeschlossen wer-den, wenn zwischen den Teilschemata keine Widersprüche mehr be-stehen. Zwischen Freigabe und Abschluss ist die V-Konsistenz temporärverletzt. Sie wird erst für den Abschluss der Schemaversion umfassendüberprüft. Figur 4.15 zeigt diesen Sachverhalt:
freigegebenabgeschlossen
veränderbar(T-Schritte)
gesperrt
Freigabe
Abschluss
vorher:- angelegtnachher:- verändert
V-Konsistenz
Figur 4.15: Freigabe und Abschluss des Anwendungsschemas
Sobald die Freigabe der Schemaversion erfolgt ist, werden nach dem-selben Verfahren T-Schritte ausgeführt. Die korrekte Reihenfolge derT-Schritte wird auf V-Ebene mit Hilfe des Abhängigkeitsgraphen über-wacht. Dabei können je nach Abhängigkeitsgraph einzelne T-Schritteparallel bearbeitet werden (z.B. L und T in Figur 4.17). Um ein Teil-schema zu verändern, muss es erst aus dem gesicherten Bereich aus-getragen werden (check-out). Mit Hilfe der zugehörigen Entwurfskom-ponente werden E-Schritte ausgeführt, bis die neuen Anforderungen imTeilschema erfasst sind. Danach wird es wieder eingetragen (check-in),wobei der verzögerte Teil der T-Konsistenz überprüft wird.
ausgetrageneingetragen
veränderbar(E-Schritte)
gesperrt
check-out
check-in
vorher:- initialisiertnachher:- verändert
T-Konsistenz
Figur 4.16: Aus- und Eintragen von Teilschemata
Mit dem in Figur 4.12 vorgestellten Abhängigkeitsgraphen gliedert sichein V-Schritt in die folgende T- und E-Schritte:

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 71
Freigabe Schemaversion n
Check-out C
Check-in C
Check-out L
Check-in L
Check-out T
Check-in T
Check-out E
Check-in E
Check-out P
Check-in PAbschluss
Schemaversion n
V-Schritte T-Schritte E-Schritte
Anlegen Schemaversion n
Check-out C möglich
Entwurf C
Check-out L, T möglich
Aktualisierungen CEntwurf L
Aktualisierungen CEntwurf T
kein Check-out möglich
Check-out E möglich
Aktualisierungen C, TEntwurf E
Check-out P möglich
Aktualisierungen T, EEntwurf P
V-Konsistenz
T-Konsistenz
T-Konsistenz
T-Konsistenz
T-Konsistenz
T-Konsistenz
Figur 4.17: Abfolge von V-, T- und E-Schritten (vgl. Figur 4.12)
Die Aktualisierungen der Teilschemata werden beim Aktualisierungs-konzept in Abschnitt 6.1 vorgestellt.
Wenn der (gerichtete) Abhängigkeitsgraph zyklenfrei ist, wird währendeines V-Schritts jedes Teilschema nur einmal verändert. In diesem Fallist gewährleistet, dass ein V-Schritt nach einer endlichen Zahl von T-Schritten terminiert. Andernfalls können in einem V-Schritt bestimmteT-Schritte mehrmals ausgeführt werden: Dadurch wird der Zeitauf-wand für den V-Schritt schlecht abschätzbar.
Nach Erreichen von V-Konsistenz kann aus dem Anwendungsschemadas Anwendersystem generiert werden. Dies ist allerdings nicht in allenFällen beabsichtigt und nötig. Die folgende Liste zeigt auch andere, ein-fachere Formen der Schemaverwendung:

72 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
• Sicherungspunkt: Der einfachste Fall. Die Schemaversion wirdlediglich gespeichert, um den Zustand später wieder herstellenzu können. Es finden keine Generierungen statt.
• Wegwerfprototyp: Aus dem Schema wird für Versuche einWegwerfprototyp generiert, der die genutzte Generation nichtbeeinflusst. Er basiert auf Testdaten.
• Generation: Aus dem Schema wird eine echte neue Generationerzeugt, die danach genutzt wird. Je nach Umfang der Ände-rungen handelt es sich dabei um eine Programmgeneration oderum eine Kombination aus Daten- und Programmgeneration (mitDatenbankreorganisation und neuer Datenverwaltung).
Im Versionenbaum sind je nach Verwendungsart unterschiedliche Artenvon Schemaversionen zu finden. Datenbankreorganisationen sind irre-versibel, weil die Datenbestände nach der Reorganisation durch dieAnwender weiter verändert werden. Dadurch entsteht im Versionen-baum ein Hauptentwicklungspfad entlang der Schemaversionen mitneuen Datengenerationen. Zwei Schemaversionen sind ausgezeichnet:Die genutzte (produktiv) und die aktuelle (Weiterentwicklung).
Sicherungs- punkt
Wegwerf- prototyp
Programm- generation
Daten- generation
genutzte Version
aktuelle Version
Hauptent- wicklungspfad
Legende:
Figur 4.18: Typen von Schemaversionen
Im Versionenbaum von Figur 4.18 wird in einem ersten Schritt eineDatengeneration erstellt. In einem nicht weiterverfolgten Ast werdenzwei Sicherungspunkte angelegt und ein Prototyp getestet. Der Haupt-entwicklungspfad führt jedoch über eine Programmgeneration undeinen Sicherungspunkt zur nächsten Datengeneration, der momentangenutzten Generation. Bereits daraus entstanden sind drei weitere

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 73
Schemaversionen; an einer davon, der aktuellen, wird gerade gearbeitet.Der Entscheid, aus welcher der drei Varianten die nächste genutzteVersion hervorgeht, ist zu diesem Zeitpunkt noch nicht gefallen.
4.8 Bewertung
Eine Methode zur evolutionären Weiterentwicklung datenbankbasierterAnwendersysteme muss in der Lage sein, Änderungen im Anwendungs-schema zu verarbeiten und verschiedene Arten von Konsistenz zu er-kennen. In Presto M werden durch die Gliederung in drei Ebenen be-kannte Techniken zu einer solchen Methode kombiniert.
• Für die T-Schritte stehen bewährte Modellierungs- und Be-schreibungstechniken für Datenbank- und Anwendungsentwurfzur Verfügung.
• Die Verknüpfung der T-Schritte im Rahmen eines V-Schritteserfolgt durch die systematische Weiterleitung der Entwurfsdatenentlang der gerichteten Kanten des Abhängigkeitsgraphen.
• Die Zusammenhänge zwischen Daten- und Programmgeneratio-nen verschiedener Anwendungsschemata werden als Versionen-baum gespeichert.
Durch die Kombination etablierter Vorgehensweisen und die Gliede-rung in drei Ebenen mit genau definierten Schritten entsteht eineGesamtmethode, die den zielgerichteten gesamtheitlichen Entwurf undeine ebensolche Weiterentwicklung datenbankbasierter Anwendersy-steme unterstützt.
Selbstverständlich haben auch andere Autoren derartige Methodenentwickelt. Während in den Anfängen Datenbank- und Anwendungs-entwurf separat und unabhängig voneinander erfolgten, zeichnete sichseit Mitte der achtziger Jahre eine Tendenz zum durchgängigen Entwurfab [Marti 84, Blum 85], auch als I-CASE bezeichnet (Integrated CASE).Die Unterstützung von Änderungen mit Versionenbildung undKonfigurationsverwaltung ist in der Softwareentwicklung seit längererZeit weit verbreitet [Rochkind 75, Feldman 79, Lientz / Swanson 80,Shooman 85, Estublier 88, Winkler 88]; beim integrierten Datenbank-und Anwendungsentwurf gehörte sie aber noch lange zur Ausnahme[Blum 85, Dittrich et al. 86, Petry 88].

74 Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M
Hier bringt Presto M mit der systematischen Gliederung in die dreiEntwurfsebenen ein zielgerichtetes Vorgehen. Durch die Kombinationbereits bekannter und bewährter Vorgehensmodelle und Entwurfsme-thoden entsteht dadurch ein systematisches Verfahren für die anspruchs-volle Behandlung von Entwurfsänderungen während der evolutionärenWeiterentwicklung:
• Durch die umfassende und integrierte Systembeschreibung wer-den die potentiellen Auswirkungen einer Änderung an vielen an-deren Stellen erkennbar.
• Die Kadenz der Änderungen ist durch die Evolution tendenziellhoch.
Der Hauptvorteil von Presto M im Vergleich mit anderen Methodenbesteht in der sehr systematischen und mit Werkzeugen automatisier-baren Änderungserkennung und -weiterleitung mit Hilfe des Abhängig-keitsgraphen und des Aktualisierungskonzepts.
Während andere Entwurfssysteme Inkonsistenzen der Entwurfsdatenmit Konsistenzprüfroutinen zu erkennen versuchen, bietet Presto M mitdem Aktualisierungskonzept nicht nur Information über notwendigeNachführungen von Entwurfsobjekten, sondern auch Angaben über dieUrsachen dieser Nachführungen.
Die klare Gliederung in drei Entwurfsebenen erlaubt zudem eine Struk-turierung des Entwurfsvorgangs mit der Konzentration auf den jeweilswichtigen Aspekt. Durch diese Gliederung wird auch eine Arbeitstei-lung in Projekten mit vielen Beteiligten ermöglicht.
Presto M ist vor allem für Datenbankanwendungs-Entwicklungen inneuen Einsatzgebieten mit vielen unbekannten Aspekten (neue Konzepte,Technologien, Hardware, Entwurfswerkzeuge) geeignet, weil es indiesen Fällen wegen der vielen Unbekannten und der fehlenden Infor-mation meist kaum möglich ist, das Gesamtsystem schon zu Beginn voll-ständig und in allen Details zu spezifizieren. Im Rahmen des erstenGesamtentwurfs lässt sich eine allgemeine Richtung vorgeben, die beider evolutionären Weiterentwicklung in jedem Überarbeitungsschritt(Version) nachjustiert werden kann und muss. Andererseits hat jedereinzelne Evolutionsschritt klare Zielvorgaben (Spezifikationen) undwird daher nicht durch dauernde Spezifikationsanpassungen belastet.
Schema-Evolution von Datenbanksystemen mit Beständen von Anwen-derdaten wird v.a. bei objektorientierten Datenbanken untersucht [Ba-

Evolutionäres Vorgehensmodell und integrierte Entwurfsmethode Presto M 75
nerjee et al. 87a, Bertino / Martino 91, Zicari 91, Bratsberg 92, Tresch/ Scholl 92]. Dabei wird anstelle sofortiger Datenbank-Restrukturierung(eager conversion) gewartet, bis anwenderseitig auf die Einträgezugegriffen wird (lazy conversion). Die dabei entstehenden Inkonsisten-zen werden durch das (dafür vorgesehene) Datenbanksystem verwaltet.Im Gegensatz dazu ist Presto auf konventionelle Datenbanksysteme aus-gerichtet, die nicht ohne Datenbankreorganisation auskommen.
Ein ähnliches Gebiet, in dem ebenfalls Ansätze temporärer Inkonsistenzder Entwurfsdaten zu finden sind, ist der CAD-Bereich [Katz 90], ins-besondere der Schaltungsentwurf: Analog zu den Teilschemata des An-wendungsentwurfs existieren Entwurfsphasen für elektrische, geome-trische und physikalische Aspekte der Schaltung, die durch einzelneCAD-Werkzeuge und deren Entwurfsoperationen abgedeckt werden.Diese gewährleisten in ihrem Bereich lokale (T-) Konsistenz. Für dieFertigung der entworfenen Schaltung ist analog zur Generierung desAnwendersystems globale (V-) Konsistenz nötig. Auch zu den Ab-hängigkeiten zwischen Teilschemata existieren Parallelen, müssen dochnach Änderungen an einem Teil eines bestehenden Schaltungsentwurfsnur die betroffenen Teile nachgeführt werden, wobei dies im CAD-Bereich bei Schaltungssimulationen mit hohem Aufwand verbunden ist.


Fallstudien 77
5 Fallstudien
In diesem Kapitel wird die Methode Presto M anhand zweier sehr un-terschiedlicher Informationssysteme - Delphi und KORA - vorgestelltund verglichen. Die anschliessende Bewertung zeigt Stärken undSchwächen der Methode auf.
In der Praxis ist die evolutionäre Weiterentwicklung von Anwender-systemen der Normalfall, obwohl sich die Verantwortlichen dessenselten bewusst sind und dementsprechend eine besondere Methodik da-für fehlt. Im Gegensatz dazu bildete die Methode Presto M zur evolutio-nären Weiterentwicklung in den beiden Fallstudien von Anfang an einenfesten Bestandteil. Sie wurde dabei praktisch erprobt und auchweiterentwickelt.
5.1 Delphi
Delphi ist ein Informationssystem einer Departementsbibliothek. Delphiwurde einfach begonnen und dann evolutionär weiterentwickelt. Diewichtigsten Phasen von Delphi im Überblick:
• Bedürfnisabklärung
• Planung der Evolution
• Rasche Fertigstellung der ersten Generation (Minimallösung)
• Anpassungen und Erweiterungen
• Erweiterung zum nutzbaren System und Ablösung
5.1 .1 Überblick, Historie
Die Bibliothek des Departements Informatik der ETH Zürich ist eineforschungsorientierte Departementsbibliothek: Sie dient als Literatur-sammlung für viele Forschungsgruppen; es existiert kaum eine zentraleBeschaffungspolitik. Ihre Hauptaufgabe besteht in der zentralen admini-strativen Abwicklung von Bestellungen, Katalogisierung und Aufbe-wahrung der von den Departementsmitgliedern benötigten Bücher,Kongressbände und Periodica. Bibliographische und einige adminis-trative Angaben werden erfasst. Sachdeskriptoren werden nur be-schränkt zugeordnet. Die Werke befinden sich über längere Zeiträumehinweg bei den Bestellern bzw. in deren Gruppen. Der Bestand umfasstetwa 6500 Bücher. Katalogisierung und administrative Arbeiten werden

78 Fallstudien
durch eine vollamtliche Bibliothekarin wahrgenommen. Delphi soll sievon den arbeitsintensiven administrativen Aufgaben entlasten, d.h. dieAktualisierung der Bestandesdaten verbessern, um eine optimale Re-cherche zu ermöglichen. In der Vergangenheit wurden seit etwa 1970mehrere Informatiklösungen entwickelt, anfangs als reine Listen-lösungen, ab ca. 1980 als interaktive Systeme. Auch wenn die Program-me oft nicht lange überlebten, konnten doch jedes Mal die Daten über-nommen werden. In deren Erfassung und Pflege steckt der grösste Auf-wand.
Caliban: IR (Lilith); M. Bärtschi, J.F. Jauslin
Textfile (Lilith); P. Schäuble
BibSearch: IR (Lilith); P. Schäuble
DB (Macintosh); J. Ludewig, A. Hörler
Textfile (Macintosh); H. Matheis
Delphi: DB (VAX); F. Oertly, P. Janes
84 85 86 87 88 89
(CDC); B. Thurnherr
83
Figur 5.1: Geschichte der Bibliothekslösung
Im Rahmen des Information Retrieval Forschungsprojektes Calibanwurden anfangs 1984 die Bibliotheksdaten auf der damals sehr fort-schrittlichen, aber speichermässig noch knapp dotierten ArbeitsstationLilith verwaltet und nachgeführt (Figur 5.1). Programme und insbe-sondere Daten wurden für die Lilith bald zu umfangreich. Um dieDaten zu retten, wurden sie in ein Textfile konvertiert und mit demEditor weiterbearbeitet. Dieses File wurde wegen wachsender Datenbe-stände mehrmals aufgeteilt, wobei die gedruckten Kataloge mit Dienst-programmen auf einem Grossrechner erstellt wurden. Für einfache Ab-fragen aus diesen zentral gespeicherten Daten über das lokale Lilithnetzrealisierte P. Schäuble ein kleines Information Retrieval System Bib-Search. Im Jahr 1986 liess Prof. J. Ludewig in einer Diplomarbeit eineDatenbanklösung für den Macintosh entwickeln. Wegen Problemen mitdem verwendeten kommerziellen Datenbankverwaltungssystem konntesich diese Anwendung nie richtig etablieren. Als Sofortmassnahme wur-

Fallstudien 79
den deshalb nach Projektabbruch 1987 nur die Textfiles auf den Mac-intosh übernommen und dort weitergeführt. Weil diese Lösung wegender grossen Anzahl von Textfiles und der Möglichkeit von Fehleingabenimmer aufwendiger wurde, begann 1988 F. Oertly unter Verwendungvon Oracle (auf DEC VAX) mit der Entwicklung der ersten Generationvon Delphi.
Delphi sollte nun nicht direkt als Gesamtlösung entstehen, sondernevolutionär über mehrere Teilprojekte. Als sinnvoller Planungshorizontwurden die drei nächsten Generationen gewählt.
5.1 .2 Projektumriss, Konzept, Anforderungen
Die Analyse des Ist-Zustands sowie das Pflichtenheft sind im folgendenstark komprimiert wiedergegeben: Bestellungen und Nachführung derBestandesdaten verursachen in der bisherigen Lösung den grössten Auf-wand. Bis ein Buch katalogisiert im Regal steht, auffindbar und ausleih-bar ist, sind die folgenden Aktivitäten nötig:
Aktivität Erklärung ➀ ➁ ➂Bestellung Überprüfung des Antrags zur Verhin-
derung von Doppelbeschaffungen:Suche mit Texteditor in Textfiles. Ma-nueller Eintrag in Bestellliste. Zuord-nung einer eindeutigen Eingangsnum-mer beim Eintreffen des Buches.
0.5 400 200
Katalogisierung Manuelle Übertragung der Buchdatenvon Bestellliste in den Eingangskatalog(für Liste der Neuzugänge). Zuordnungder eindeutigen Signatur.
0.25 600 150
Neuzugänge Übersichtliche Anordnung und Forma-tierung der Einträge des Eingangskata-logs (manuell mit Textsystem).
8 12 100
Katalog-Aktualisierung
Verteilung der Daten des Eingangskata-logs auf die Katalogfiles (manuell mitTexteditor).
Kataloge Aufbereitung der Daten mit Hilfspro-gramm. Transfer auf Grossrechner,Sortierung, Zweiter Transfer, Drucken.
4 12 5 0
➀ Aufwand für eine einzelne Aktivität in Stunden pro Aktivität
➁ Anzahl der Aktivitäten pro Jahr
➂ Gesamtaufwand pro Aktivität in Stunden pro Jahr: ➂ = ➀ * ➁

80 Fallstudien
Die Bestandesdaten werden in unterschiedlichen Textfiles verwaltet undperiodisch zu Listen und Katalogen verarbeitet. Die manuell geführteAusleihe verursacht kaum Aufwand. Verwendete Formulare und Listen:
Formular,Liste
Erklärung
Bestellformular Buchbestellung durch Departementsmitglied.Bestellung Auftrag für ein oder mehrere Bücher an die Buchhandlung.Rechnung Kommt meist separat.Bestellliste Kontrolle über bestellte, aber noch nicht eingegangene Bücher.Eingangs-katalog
Eingegangene, aber noch nicht katalogisierte Bücher (Katalogi-sieren ist zeitaufwendig und benötigt vollständige Buchanga-ben).
Liste der Neu-zugänge
Mitteilung an die Bibliotheksbenutzer über Neubeschaffungen.
Katalogfiles Mehrere formatierte Textfiles mit den Bestandesdatensämtlicher Bücher. Grundlage für Kataloge. Bearbeitung mitdem Texteditor; keine Überprüfungen.
Kataloge Ausgedruckte Bestandesdaten, je sortiert nach Signatur, Auto-ren und KWIC-Schlagworten (KWIC: Keyword in Context).
Die zeitintensivsten Tätigkeiten sind umständliches Abfragen und häufi-ges (manuelles und fehleranfälliges) Übertragen von Daten. Das grössteRationalisierungspotential liegt beim Bestellen und Katalogisieren, wenndie Daten nur einmal eingegeben werden müssen und schneller auffind-bar sind. Hauptziel von Delphi ist daher die Teilautomatisierung dieserarbeitsintensivsten Tätigkeiten. Anforderungen:
• Zeiteinsparung, Fehlervermeidung: Ersetzen des Umkopierensdurch schrittweise Vervollständigung der Buchdaten.
• Überprüfung von Bestellungen: Verbesserung der Abfragemög-lichkeiten für die Bibliothekarin, später evtl. auch für Biblio-theksbenutzer.
• Korrekte Datenbestände: Überprüfungen bei Mutationen.
• Benutzerfreundlichkeit: Für die Nutzung dürfen keine vertieftenInformatikkenntnisse vorausgesetzt werden.
5.1 .3 Planung der Evolution
Im Gegensatz zum sequentiellen Arbeits- und Zeitplan bei der klas-sischen Entwicklung wird für die evolutionäre Weiterentwicklung vonDelphi ein Generationenplan erstellt (Figur 5.2). Er umfasst zwei An-wenderkomponenten auf denselben Datenbeständen:

Fallstudien 81
• Anwenderkomponente für die Bibliothekarin, Generation I: Ver-besserung der Bestandesabfragen
• Generation II: Mutationen mit Überprüfungen
• Generation III: Integration
• Anwenderkomponente für Bibliotheksbenutzer, Generation I:Bestandesabfragen für Bibliotheksbenutzer
Generation I: BenutzerabfragenParallelbetriebNutzung
Generation II: Mutationen
Generation I (Minimal)
Generation III: Integration
Daten
AK 1
AK 2
Alte Lösung
Neue Lösung
Ausserbetriebnahme
EntwicklungEP
E P
E P
E P
E P
E
Figur 5.2: Generationenplan von Delphi
Entwurf und Realisierung der ersten Generation eines Anwendersy-stems bieten die grössten Ungewissheiten: Weder Anwendungsgebiet(Bibliothek) noch Werkzeuge (Oracle) sind genau bekannt. Die ersteGeneration soll daher so einfach wie möglich sein! Erweiterungen undVerfeinerungen folgen während der folgenden Generationen. Anstatteines konventionellen Projektantrags wird ein Systemantrag formuliert.
5.1 .4 Generation I: Verbesserte Abfragen
Die Anforderungen der Anwendung können wegen der vielen Unsicher-heiten mit dem ersten Entwurf nur zum Teil erfüllt werden. Trotzdemsoll möglichst rasch ein in Teilen funktionierendes Anwendersystem fürNutzung und erste Erfahrungen zur Verfügung stehen. Die ersteGeneration von Delphi realisiert daher nur die Datenübernahme, dazuwerden die häufigsten Abfragen auf Bücher und Autoren als abrufbareSQL-Befehle zur Verfügung gestellt. Anhand der Erfahrungen wirdspäter über die Details der weiteren Generationen entschieden. Mit demProjektantrag für die Generation I wird für dieses Teilprojekt ein Zeit-und Arbeitsplan erstellt (Figur 5.3). Die Anforderungen sind nach derProjektbewilligung verbindlich und dürfen nur noch präzisiert werden.

82 Fallstudien
Falls sie geändert werden, muss das Projekt abgebrochen und andersneu gestartet werden.
Januar Februar MärzNovember Dezember
1987 1988
Projektantrag
Entwicklung
Datenbereitstellung
Parallelbetrieb, Dokumentation
Detailkonzept
Nutzung
Daten
AK 1
E
E P
Figur 5.3: Entwicklung von Generation I
Erfahrungen mit der Generation I:
• Die Datenübernahme erweist sich als aufwendiger als angenom-men, weil durch die Datenerfassung mit einem Texteditor Ein-gabefehler nicht abgefangen wurden.
• Abrufbare SQL-Befehle sind für den produktiven Betrieb zuwenig benutzerfreundlich, weil in der Bedienung zu umständ-lich.
• Die Datenmodellierung ist für zielgerichtete Abfragen noch zuungenau.
5.1 .5 Generation II: Mutationen mit Überprüfungen
Mit dem Projektantrag für die zweite Generation werden erkannte Un-zulänglichkeiten aus Generation I beseitigt und geplante Erweiterungenvorgenommen:
• Verwendung von Bildschirmformularen statt SQL-Befehlen fürAbfragen und Mutationen.
• Erhöhung von Benutzerfreundlichkeit und Datenintegrität durchKonsistenz- und Plausibilitätsprüfungen. Kopierfunktionen fürähnliche Eingaben.
• Erweiterung des konzeptionellen Datenbankschemas.

Fallstudien 83
Für die Bildschirmformulare werden mehrere Prototypen erstellt unddurch die Bibliothekarin evaluiert. Figur 5.4 zeigt das Mutationsfor-mular für ein Buch:
DELPHI Operation
Signatur i.O. Eing-Nr
BUCH: Zust. Buch-NrTitel
U'TitelSerieVerlag
Buch eingeben
ISBN
Liefer.Auflage
Ort
Best.Datum Preis
Jahr
Whrg
Autorenname Init. ed. Buchnr
Figur 5.4: Bildschirmformular für Buch mit Autoren
Das neue konzeptionelle Schema (Figur 5.5) erlaubt die Verfolgung desBuchzustandes (bestellt, eingegangen, katalogisiert) und unterstützt dieÜberprüfung von Sachgebieten. Die Bibliotheksdaten werden reorgani-siert und ergänzt.
EingangBestellungAutor
Buch
Katalog
Sachgebiet
mc mc
Figur 5.5: Entitätenblockdiagramm von Delphi
Erfahrungen mit der Generation II:
• Die Bildschirmformulare bewähren sich dank einfacher und ein-heitlicher Bedienung. Für die erstmalige Verwendung ist jedocheine Einarbeitung nötig.

84 Fallstudien
• Der Aufruf der Bildschirmformulare ist noch zu umständlich,weil dafür längere Befehlssequenzen einzugeben sind.
• Mit der Konsolidierung der Datenbestände entsteht das Be-dürfnis, die Daten in benutzernaher Darstellung auszudrucken.
5.1 .6 Generation III: Integration und Ablösung
Mit dem Projektantrag für die dritte Generation wird die Vervollständi-gung, Integration und Abrundung von Delphi in Angriff genommen:
• Listenausgabe für Neuzugänge und bestellte Bücher.
• Druck der Sachgebiet-, Autoren- und KWIC-Kataloge.
• Integration in eine Dialoghierarchie.
• Abschlussarbeiten, Dokumentation, Übergabe.
• Ablösung der bisherigen Lösung.
Alle Funktionen von Delphi werden über eine einheitliche Dialog-oberfläche angesprochen, technische Details bleiben dadurch verborgen:
Buch
KWIC-Suche
ListenBestellt
Neu
Sachgeb.
Autoren
KWIC
Kataloge
Delphi
Stoplisten
Buchaussch.
Lexikon
Bestellt
Neu
Sachgeb. Menu
Bildschirmformular
Liste
Figur 5.6: Dialoghierarchie von Delphi
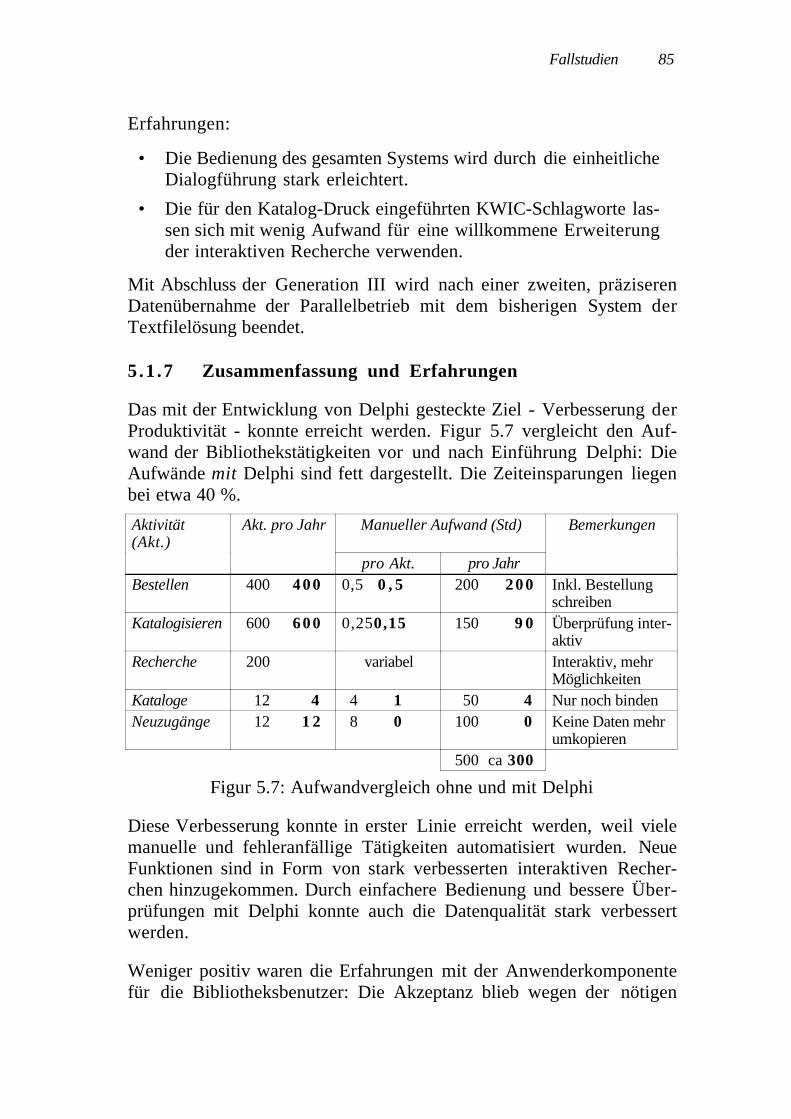
Fallstudien 85
Erfahrungen:
• Die Bedienung des gesamten Systems wird durch die einheitlicheDialogführung stark erleichtert.
• Die für den Katalog-Druck eingeführten KWIC-Schlagworte las-sen sich mit wenig Aufwand für eine willkommene Erweiterungder interaktiven Recherche verwenden.
Mit Abschluss der Generation III wird nach einer zweiten, präziserenDatenübernahme der Parallelbetrieb mit dem bisherigen System derTextfilelösung beendet.
5.1 .7 Zusammenfassung und Erfahrungen
Das mit der Entwicklung von Delphi gesteckte Ziel - Verbesserung derProduktivität - konnte erreicht werden. Figur 5.7 vergleicht den Auf-wand der Bibliothekstätigkeiten vor und nach Einführung Delphi: DieAufwände mit Delphi sind fett dargestellt. Die Zeiteinsparungen liegenbei etwa 40 %.
Aktivität(Akt.)
Akt. pro Jahr Manueller Aufwand (Std) Bemerkungen
pro Akt. pro JahrBestellen 400 400 0,5 0 , 5 200 200 Inkl. Bestellung
schreibenKatalogisieren 600 600 0,250,15 150 9 0 Überprüfung inter-
aktivRecherche 200 variabel Interaktiv, mehr
MöglichkeitenKataloge 12 4 4 1 50 4 Nur noch bindenNeuzugänge 12 1 2 8 0 100 0 Keine Daten mehr
umkopieren500 ca 300
Figur 5.7: Aufwandvergleich ohne und mit Delphi
Diese Verbesserung konnte in erster Linie erreicht werden, weil vielemanuelle und fehleranfällige Tätigkeiten automatisiert wurden. NeueFunktionen sind in Form von stark verbesserten interaktiven Recher-chen hinzugekommen. Durch einfachere Bedienung und bessere Über-prüfungen mit Delphi konnte auch die Datenqualität stark verbessertwerden.
Weniger positiv waren die Erfahrungen mit der Anwenderkomponentefür die Bibliotheksbenutzer: Die Akzeptanz blieb wegen der nötigen

86 Fallstudien
Einarbeitung in die Oracle-Benutzeroberfläche hinter den Erwartungenzurück, es wurden deshalb die ausgedruckten Kataloge verwendet.
Wegen der vielen neuen Aspekte fachlicher und technischer Art wäreeine Planung und Realisierung in einem Projektschritt unmöglich gewe-sen: Sehr viele Neuerungen ergaben sich erst im Verlauf der etwa zweiJahre dauernden Entwicklung.
Jan Mar Mai Jul Sep NovNov
1987 1988 1989
Jan Mar Mai Jul Sep Nov Jan
Minimalgeneration (5 Tage)
Mutationen (16 Tage)
Produktion (29 Tage)
Korrekturen (2 Tage)
Benutzerabfragen (3 Tage)
Portierung (20 Tage)
Daten
AK 1
AK 2
DatenreorganisationAblösung,
Schemaerweiterung
Kopie der Daten
Nutzung
Projektdauer (soll)
Projektdauer (ist)
Figur 5.8: Entwicklung von Delphi - Soll / Ist Vergleich
Stark unterschätzt wurden Datenübernahme und Einarbeitung, was auchder Hauptgrund für die Verzögerungen war. Die folgende Figur zeigtden Anteil der einzelnen Tätigkeiten am Gesamtaufwand der Ent-wicklung:

Fallstudien 87
DatenbereitstellungFormulareDokumentationEinarbeitungListen und KatalogeDetailspezifikationRahmenorganisationBetriebsmittelAusbildungDialogführungPrototypenerprobungDB-DefinitionBeschreibung Ist-ZustandPflichtenheftVerschiedenes
Figur 5.9: Aufwand für Konzeption und Realisierung von Delphi
Bei einer Neuentwicklung wie bei Delphi ist während der Realisierungmit häufigen Änderungen zu rechnen. Deshalb müssen sowohl die ver-wendete Methode - in diesem Fall eine Vorstufe von Presto M - als auchdas Werkzeug in der Lage sein, diese Änderungen zu berücksichtigenund deren Realisierung zu unterstützen.
5.2 KORA
KORA ( Ko llektiv ra tionell) steht noch in Entwicklung und soll alsInformations- und Verwaltungssystem der Winterthur Lebensver-sicherungsgesellschaft zur Abwicklung des Kollektivgeschäfts gemässdem Gesetz über die berufliche Vorsorge (BVG) eingesetzt werden. ImGegensatz zu Delphi ist die Entwicklung von KORA ein sehr grosses"Superprojekt" [Zehnder 91], das mehrere Jahre dauert und etwa 40Beteiligte involviert. Deshalb wurde von Anfang an eine Aufteilung inmehrere Teilprojekte vorgesehen:
• Vorstudie und Fachkonzept
• Pilotsystem: Technische Machbarkeit
• Kernsystem: Minimaler Funktionsumfang
• Basissystem: Wichtige Funktionen
• Vollausbau: Vervollständigung und Datenübernahme

88 Fallstudien
In der vorliegenden Arbeit kommt davon nur ein spezieller Aspekt zurDarstellung. Wir beschränken uns wegen der Komplexität von KORAauf die evolutionäre Gestaltung des Datenbankentwurfs, der in KORAeine sehr zentrale Rolle einnimmt.
5.2 .1 Geschichte
In der Schweiz wird seit 1985 durch das BVG den Arbeitgebern vor-geschrieben, wie sie ihre Arbeitnehmer minimal gegen Invalidität, Alterund Tod zu versichern haben. Die Lebensversicherungsgesellschaftenbieten daher im Rahmen des Kollektivgeschäfts den Arbeitgebern einebreite Palette von obligatorischen und überobligatorischen Leistungenan. Dabei werden einerseits die individuellen Daten der Versicherten -Alter, Geschlecht, Stellung im Betrieb, etc. - verwendet, andererseitsdie in einem Vertrag vereinbarten Versicherungspläne, um dieversicherten Leistungen zu berechnen und die dafür notwendigenPrämien zu erheben. Neben der reinen Verwaltung der Daten sind dazuauch komplexe Berechnungen notwendig. Das Geschäft der Winterthurumfasst zur Zeit etwa 30'000 Kollektivverträge mit Arbeitgebern ver-schiedenster Grössenordnung, in denen ca. 150'000 Arbeitnehmer ver-sichert sind.
Produktive Informatikanwendungen auf Grossrechnern erreichen eineNutzungsdauer zwischen 10 und 20 Jahren. Dies trifft auch für dieKollektivsysteme der Winterthur zu (Figur 5.10): Ab 1965 wurden dieBerechnungen auf einem Univac System vorgenommen, die Daten wur-den auf Lochkarten gespeichert. 1977 erfolgte während einem Parallel-betrieb von weniger als einem Jahr der Übergang zur KOL-Anwen-dung. Bis 1980 wurde der Funktionsumfang der Versicherungspläneausgebaut, später erfolgten Anpassungen für die Tarifrevision und dieBVG-Einführung.
70 80 90
BVGTarif-Revision BVG-RevisionLochkarten (Univac 1050)
KOL: IMS (IBM Host)
KORA: DB2 (IBM Host/PC)
Figur 5.10: Geschichte des Kollektivsystems

Fallstudien 89
5.2 .2 Anforderungen
Bis ein Kollektivvertrag mit dem ganzen Versichertenbestand wirksamwerden kann, dauert es je nach Komplexität der Vertragsbedingungenund Grösse des Versichertenbestandes einige Tage bis über ein Jahr.Am aufwendigsten sind die Erstellung und Überprüfung der Ver-sicherungspläne, besonders bei ausgefallenen Versicherungsplänen: Bis-her wurde dies durch sehr maschinennahe Parametererfassung mitwenigen automatischen Plausibilitätstests gelöst. Die Ergebnisse müssendaher zur Überprüfung für jeden einzelnen Versicherten manuell nach-gerechnet werden, namentlich, weil für eine automatische Überprüfungnicht sämtliche dafür nötigen Daten im System verfügbar sind. Dasgrösste Verbesserungspotential liegt daher in einer flexiblen Ver-sicherungsplandarstellung, einer umfassenderen Überprüfung und einerErweiterung des Datenbankschemas für bisher nicht vorgesehene Fälle.
Aktivitäten, bis ein Kollektivvertrag wirksam werden kann:
Aktivität ErklärungBeratung Besuch eines Unternehmensberaters der Versicherung beim
Kunden (Firma), der seine Arbeitnehmer versichern möchte.Gemeinsame Erarbeitung geeigneter Versicherungsbe-dingungen (mehrere Varianten).
Erstofferte(n) Erfassung von Vertrag (Grunddaten, Versicherungspläne) undVersicherten. Berechnung der Varianten. Präsentation beimKunden.
Ausbau-offerte(n)
Analog zur Erstofferte, jedoch für existierende Verträge:Änderung eines bestehenden Vertrags (Grunddaten, meist je-doch Versicherungspläne).
Abschluss Variantenentscheid durch den Kunden mit Unterstützung desUnternehmensberaters. Erfassung noch fehlender Daten.Erstellung von Listen für den Kunden und persönlichenAusweisen für die Versicherten (Arbeitnehmer). Erstellung desReglements (Versicherungsbedingungen z. Hd. des Kunden).Rechnungsstellung.
Mutation Mitteilung des Kunden über geänderte Daten einzelnerVersicherter (Eintritte, Lohnänderungen, Austritte, etc.).Berechnung neuer Leistungen und Prämien. Erstellung neuerListen und Ausweise.
Rechnungs-stellung
Berechnung der Gesamtprämie aufgrund der versichertenLeistungen (in der Regel Ende Jahr).
Anforderungen und Begründung für den Ersatz des jetzigen Kollektiv-systems:

90 Fallstudien
• Flexible Berechnungsregeln im Hinblick auf die BVG-Revisionvon 1995: Ablösung der bisherigen Parameterlösung durchdurch eine "Versicherungssprache".
• Historienführung: Zugriff auf früher gültige, aber mittlerweile"überschriebene" Daten.
• Neue Anwendungsgebiete: Bedürfnis nach detaillierterer Infor-mation.
• Entlastung des zentralen Rechners durch verteilte Verarbeitung.
• Verbesserung der Bedienung: Beschleunigung der Eingabe undVermeidung von Fehlern durch grafische Benutzeroberfläche.
• Neustrukturierung des bisherigen, über Jahre hinweg organischgewachsenen Systems.
5.2 .3 Evolutionäre Entwicklung von KORA
Das Gesamtsystem KORA wird in Teilprojekten realisiert. Im Gegen-satz zu Delphi bleibt das Datenbankschema wohl während längerer ZeitÄnderungen unterworfen, weil in vielen Bereichen längerdauernde Ab-klärungen zu treffen sind. Bis etwa zur halben Dauer des Superprojektswerden anstelle der (sehr umfangreichen) Datenbestände Testdaten ver-wendet. Im Endausbau wird KORA die Anwenderkomponenten Dialoge(für Vertrag und Versicherte), Berechnung, Dokumentenerstellung undSchnittstellen zu Fremdsystemen umfassen (graue Teile in Figur 5.11sind auszuprogrammieren):
DBMS
ADAS
Dialog Druck Berech-nung
Fremd- systeme
Figur 5.11: Geplante Architektur von KORA
1989 wurde der folgende Generationenplan erstellt (in Klammern dieKORA-Bezeichnungen der Generationen). Innerhalb der Teilprojektewurden in Abständen von drei Monaten Zyklen vorgesehen, in denenneue Datenbankschemata wirksam werden sollen.

Fallstudien 91
• Wegwerfprototyp: Rasche Verifizierung der technischen Mach-barkeit mit der neuen Entwicklungsumgebung.
• Generation I (Kernsystem): Reduziertes Datenbankschema fürraschen Beginn. Einheitliche Datenbankschicht. SchwergewichtDialoge und Berechnung. Technische Integration der Anwender-komponenten bzw. von Teilen davon.
• Generation II (Basissystem): Vollständiges Datenbankschema.Historienführung. Neue Anwenderkomponente Dokumentener-stellung. Ausbau des Funktionsumfangs auf die für die Ge-schäftsabwicklung notwendigen Funktionen. Technisch: VerteilteVerarbeitung.
• Generation III (Ausbausystem): Datenübernahme in Schritten,Migration und Ablösung.
Aufgrund der Erfahrungen wurde 1992 die Planung überarbeitet.Wichtigste Anpassung war die Umstellung auf einen Jahreszyklus, un-terteilt in die Phasen Konzeption, Realisierung, Integration, Evaluationund Neuplanung. Die Generationen wurden nach den Jahren benannt:
• Generation II (KORA 92): Weitgehend fertiggestelltes Daten-bankschema, zentrale Systemsteuerung als Vorstufe der verteil-ten Verarbeitung, Abwicklung fachlich einfacher Normalfällefür Berechnung und Dokumenterstellung. Vorbereitung der Da-tenübernahme.
• Generation III (KORA 93): Historienführung und verteilte Ver-arbeitung. Komplexe Berechnungen und Dokumente. Datenüber-nahme (wo nötig mit Datenerhebungen).
• Generation IV (KORA 94): Ergänzungen und Bereinigung.Fortsetzung der Datenübernahme, Beginn der schrittweisen Ab-lösung.

92 Fallstudien
90 91 92 93 94 95
PT Gen I: Kern Gen II: Basis Gen III: Ausbau
AK 1: Dialog
AK 2: Berechn.
AK 3: Druck
Daten
AlteLösung
Planung 89
Planung 92 KORA 92 KORA 93 KORA 94
Datenüb. Ablösung
Migration
DG 0
DG 1
DG 3DG 4
DG 5
Figur 5.12: Generationenplan (Anwenderkomponenten vereinfacht)
Auch bei KORA erwies sich die erste Generation als die kritischste:Wegen der Vielzahl der Beteiligten mit unterschiedlichsten Voraus-setzungen und Erwartungen galt es, rasch einen Konsens bezüglich ge-meinsamer Begriffe und der einzuschlagenden Marschrichtung zu fin-den. Die Entwicklung dieser gemeinsamen "Kultur" bildete die Basisfür die Entwicklung der nachfolgenden Generationen.
Parallel musste die neue Entwicklungsumgebung (Arbeitsstationen, Be-triebssystem OS/2, grafische Benutzeroberfläche) etabliert werden.Trotz Beschränkung auf ein Minimum entstanden Integrationsprobleme.Mit Bewilligung des Systemantrags von KORA wurde der Startschussfür die evolutionäre Entwicklung des Systems als Gesamtheit gegeben.Das erste Teilprojekt umfasste das Kernsystem.
Die grössten Änderungen am Datenbankschema fanden beim Übergangauf die Generation II statt, denn dieser brachte eine Erweiterung voneiner Teillösung auf das fast vollständige Datenbankschema.
Zur genügenden Vorbereitung der Entwicklung der Anwenderkompo-nenten benötigt der Datenbankentwurf einen Vorsprung von einerGeneration. In den folgenden Unterabschnitten werden das Pilotsystemund die Generationen I und II vorgestellt.
Die Stufen beim Übergang von den bisherigen Datenstrukturen auf dieneuen Definitionen entstehen, weil der Generationenwechsel bei den

Fallstudien 93
Daten gestaffelt erfolgen muss: Eng damit verbunden ist die Datenüber-nahme. Solange die Daten noch nicht auf die neue Generation übernom-men sind, ist die bisherige Datengeneration das "Original", die neueGeneration hat vorerst die Rolle einer "Kopie", verbunden mit Ein-schränkungen bei Mutationen. Nach erfolgreicher Übernahme wechseltdiese Rolle.
5.2 .4 Wegwerfprototyp
Viel stärker als bei Delphi fällt bei KORA die Komplexität desAnwendungsgebiets (Kollektivgeschäft) ins Gewicht: Neben der reinenDatenspeicherung kommt auch der Verarbeitung (Berechnung) grosseBedeutung zu. Verschärft wird diese Problematik noch durch die vielenMitwirkenden: Ein guter Teil des Projektaufwandes ist durch die dafürnötige Kommunikation verursacht. Zudem sind Entwicklungsmethodikund -werkzeuge ungewohnt.
Um Entwicklern, zukünftigen Benutzern und Projektverantwortlicheneine Vorstellung von den neuen Möglichkeiten des zukünftigen Systemszu vermitteln, wird in kurzer Zeit ein Wegwerfprototyp realisiert. Des-sen Architektur entspricht noch nicht dem definitiven Zustand, sondernenthält noch viele Vereinfachungen.
Das Datenbankschema spielt beim Wegwerfprototyp eine untergeord-nete Rolle: Es umfasst das absolute Minimum an Entitätsmengen undAttributen. Anstelle der Anwenderdaten wird eine kleine Menge vonTestdaten verwendet. Die wichtigsten Teile der AnwenderkomponentenDialoge und Berechnung werden realisiert.
Erfahrungen:
• Der Wegwerfprototyp leistet als "Vorzeigemodell" wertvolleDienste für die gegenseitige Kommunikation.
• Die Implementation lässt sich wegen der vielen Vereinfachungennicht weiterverwenden.
• Anhand einer konkreten Aufgabe lernen die Entwickler die neueUmgebung kennen.
5.2 .5 Generation I: Kernsystem
Mit dem Kernsystem werden gemäss Fachkonzept die relevanten Teiledes konzeptionellen Datenbankschemas eingeführt: Die wichtigsten Enti-

94 Fallstudien
tätsmengen sind definiert, hingegen fehlen noch viele Attribute. Aufdieser Grundlage wird mit der Implementation von Datenbank-zugriffen, Dialogen und Berechnungen begonnen. Parallel dazu erfolgtdie Vervollständigung des konzeptionellen Datenbankschemas. Das Enti-tätenblockdiagramm sieht (vereinfacht) folgendermassen aus:
Vertrag
Plan Versicherter
Person
Leist.-Paket
Berechnung
Leistung
m mcm
mc
mc
m
mc
Figur 5.13: Vereinfachtes Entitätenblockdiagramm von KORA
Im Vertrag sind die Vereinbarungen zwischen Versicherer und Ver-sicherungsnehmer (Arbeitgeber) festgehalten, die Berechnungsregelnsind in den Versicherungsplänen zu finden. Die Arbeitnehmer im Ver-trag sind als Versicherte definiert, ihre Personendaten sind separat ge-speichert (dieselbe Person kann in mehreren Verträgen versichert sein).Eine Besonderheit ist das Leistungspaket: Es definiert die Zuordnungvon einem oder mehreren Versicherungsplänen zu den einzelnen Ver-sicherten und enthält individuelle Daten pro Zuordnung. Das Leistungs-paket gruppiert die Berechnungen, welche sich wiederum aus einzelnenLeistungen zusammensetzen (gesamthaft ist mit einer Datenmenge vonetwa 100 Millionen einzelnen Leistungen zu rechnen!).
Erfahrungen:
• Der Start mit einer Teilmenge der Entitätsmengen und Attributeerlaubt den raschen Beginn der Implementationsarbeiten, nochbevor alle Konzepte verabschiedet sind.
• Viele Aussagen des konzeptionellen Datenbankentwurfs müssenzwischen den Beteiligten abgeglichen werden. Eine Vielzahl von(später allenfalls wieder korrigierten) Änderungen ist bis zumKonsens notwendig.

Fallstudien 95
• Die Verwendung eines Datenkatalogs (Presto II) erleichtertStrukturierung, Abgleich und übersichtliche Darstellung allerEntwurfsdaten.
5.2 .6 Generation II: Basissystem
Für das Basissystem werden Entitätsmengen und Attribute vervollstän-digt. Viele Angaben sind zu Beginn noch unpräzise, Attribute nochnicht korrekt zugeordnet. Wichtig ist vielmehr, den "grossen Rahmen"möglichst rasch zu etablieren. Für die Ausarbeitung des Basissystemssind mehrere Überarbeitungsrunden mit je mehrmonatiger Dauer vor-gesehen. Während bei den Entitätsmengen nur noch Ergänzungen er-folgen, gilt die Aufmerksamkeit beim Basissystem der Vervollständi-gung und Beschreibung der Attribute.
Erfahrungen:
• Für ein System der Grössenordnung von KORA ist allein dieMenge der Entwurfsdaten beträchtlich (vgl. Zusammenfassung).
• Für die gegenseitige Kommunikation ist ein möglichst gutdokumentiertes konzeptionelles Datenbankschema unerlässlich.Die Trennung von konzeptioneller Beschreibung und Implemen-tation der Datenbank ist anzustreben.
• Der Konsolidierungsprozess für das konzeptionelle Datenbank-schema hat wegen der vielen Beteiligten Durchlaufzeiten vonWochen bis Monaten.
5.2 .7 Generation III: KORA 93
Einige der für das Basissystem geplanten Teile (Historie, verteilte Ver-arbeitung) mussten während der Neuplanung 92 auf die Generation IIIverschoben werden. Unterschätzt wurden hauptsächlich fachliche undtechnische Einarbeitung und die Durchlaufzeiten für Abklärungen biszum Eintrag in den Datenkatalog.
Vorgezogen wurde in Sinne des Advancemanship die Datenübernahme,weil wegen vieler Spezialfälle ein beträchtlicher Teil der Anwender-daten nicht automatisch übernommen werden kann, sondern manuellbearbeitet und ergänzt werden muss. Die fehlende, im neuen System zu-sätzlich benötigte Information muss zuerst zusammengetragen werden.Teilweise kann dies durch Zugriff auf Dossiers im Hause geschehen, in

96 Fallstudien
Ausnahmefällen müssen die versicherungseigenen Kundenberater dieAngaben beim Kunden erfragen.
5.2 .8 Zusammenfassung und Erfahrungen
Weil der Datenbankentwurf über einen Vorsprung von etwa einer Ge-neration gegenüber den Anwenderkomponenten verfügen muss, ist derwichtigste Teil des konzeptionellen Datenbankschemas zur Halbzeit desBasissystems grösstenteils abgeschlossen. Figur 5.14 zeigt den Zuwachsder Entwurfsobjekte Wertebereich, Aufzählungswert, Entitätsmenge,Beziehung und Attribut im Verlauf der Entwicklung (in Klammern diewährend des V-Schritts veränderten Entwurfsobjekte):
Werteber. Aufzähl'g E-Menge Bezieh'g AttributPrototyp Mai 90 - - 5 4 13Kern März 91 48 146 8 8 96
Mai 91 69 265 11 11 145Basis Sept 91 80 318 11 11 153
Dez 91 117 453 17 22 355KORA 92 März 92 140
(140)533
(123)37
(25)39
(30)440
(273)Juni 92 178
(69)725
(473)37(7)
39(3)
462(239)
Figur 5.14: Mengenmässige Entwicklung der Entwurfsobjekte(konzeptionelles Schema)
Noch ausstehend sind Datenübernahme und Optimierung des logischenDatenbankschemas für optimale Ausführungszeiten.
Eine der schwierigsten Aufgaben in KORA ist der Informationsaus-tausch zwischen den Projektbeteiligten. Besonders wichtig ist, alle be-nötigten Daten und Funktionen (und vor allem Lücken im Entwurf)frühzeitig zu erkennen. Dies ist besonders schwierig, weil das gesamteAnwendungsgebiet nicht von einem einzelnen Projektmitarbeiter inallen Details überblickt werden kann. Zur Verwaltung der umfang-reichen und sich häufig ändernden Entwurfsdaten wird das Dokumen-tations- und Entwurfssystem Presto II entwickelt und eingesetzt, das dierelevanten Entwurfsinformationen in konsolidierter Form enthält:
• Konzeptionelles Datenbankschema
• Logisches Datenbankschema
• Benutzernahe Sichtdefinition

Fallstudien 97
• Datenübernahme (Migration): Verbindungen alt/neu
• Betriebliche Abläufe
Es hat sich als sinnvoll erwiesen, auch erst provisorische Angaben ent-sprechend gekennzeichnet aufzunehmen, um auf offene Probleme hinzu-weisen.
Mit Presto II lässt sich das Anwendungsschema auf die verschiedenstenArten darstellen. Bewährt hat sich je eine Übersichts- und eine detail-lierte Liste. Da die Abbildung vom konzeptionellen Entwurf auf späterverwendete Datenbanktabellen ebenfalls dokumentiert ist, können diefür die Ausführung benötigten Daten direkt aus Presto II generiertwerden.
Presto II wurde während der Phase des Kernsystems für die Bedürf-nisse des Datenbank- und Anwendungsentwurfs entwickelt und aufgrundder Erfahrungen und Bedürfnisse schrittweise erweitert.
5.3 Gegenüberstellung
Trotz vieler Unterschiede zwischen Delphi und KORA existieren auchParallelen. Die folgenden Unterabschnitte stellen Differenzen undGemeinsamkeiten einander gegenüber und bewerten die Erfahrungen.
5.3 .1 Vergleich
Die Entwicklung von Delphi involviert maximal vier Personen unddauert etwas länger als ein Jahr:
• 1 Person auf Führungsebene
• 1 Person als Anwender: Bibliothekar
• 1-2 Personen als Entwickler
Die Anwenderdaten und deren Strukturen sind vorgegeben. Wie dieDaten in den Abläufen verwendet werden, geht aus der Analyse des Ist-Zustands hervor. Die Anwenderdaten werden lediglich gespeichert, esfinden keine Verarbeitungen statt. Das Anwendungsgebiet ist einfachgenug, um von einer einzelnen Person verstanden zu werden.
Bei Verwendung eines Datenbankverwaltungssystems anstelle der Text-files muss wegen der Normalisierung die Struktur der Daten modifi-

98 Fallstudien
ziert werden. Später werden Änderungen der Daten wegen Erweiterungfür neue Möglichkeiten nötig.
Delphi leistete als kleines System wertvolle Dienste zum Erkennen derMechanismen der evolutionären Weiterentwicklung und bei der Reali-sierung von Informatikprojekten. Viele der eigentlichen Probleme derSuperprojektführung traten wegen des geringen Umfangs jedoch nieauf.
Das Gegenteil trifft auf das Grossprojekt KORA zu: Es hat eine Ent-wicklungsdauer von mehreren Jahren und involviert etwa 50 Beteiligte(z.T. in verschiedenen Rollen):
• 10 Personen auf Führungsebene.
• 7 Personen als Vertreter der zukünftigen Anwender (dies wer-den später etwa 400 Personen sein).
• 40 Entwickler.
Die grobe Architektur des Systems und die ungefähre Form der Datenist ebenfalls vorgegeben. Über die Details bestehen z.T. verschiedeneVorstellungen. Mit den Anwenderdaten müssen versicherungstechnischeBerechnungen durchgeführt werden können. Dies führt dazu, dass dasgesamte Anwendersystem mit allen Details kaum von einer einzigenPerson überblickt werden kann. Trotzdem muss verhindert werden,dass im Einzelfall Angaben falsch abgelegt werden oder ein solcher Fallvollständig vergessen wird. Ein weiteres Problem sind die Spezialfälle.Für die technische Lösung gilt es, vorerst den (meist sehr einfachen)Kerngedanken zu extrahieren. Erst beim Besprechen konkreterLösungsvorschläge treten Inkonsistenzen zutage, indem jeder Beteiligteseinen Bereich überprüft. Deshalb bedarf es mehrerer Versionen deskonzeptionellen Datenbankschemas, bis eine akzeptierte Lösung erreichtist.
Weil für KORA eine sehr innovative technische Lösung angestrebtwird, erfreut sich die Entwicklung innerhalb des Unternehmens einesüberdurchschnittlichen Interesses.
Die Gemeinsamkeiten von Delphi und KORA liegen in ihrer Daten-orientierung: Eine Fülle von Anwenderdaten muss gespeichert und aufdem aktuellen Stand gehalten werden. Diese Daten repräsentieren einenenormen Wert.

Fallstudien 99
Ebenfalls gemeinsam ist die Situation, dass zwar ein bekannter Pro-blembereich zu bearbeiten ist, aber mit neuen und daher weitgehendnoch unbekannten technischen Methoden und Werkzeugen. Dadurchwird individuelle Einarbeitung für alle betroffenen Projektbeteiligtennötig; im Fall von Delphi betrifft dies Oracle, in KORA die verteilteVerarbeitung, die Entwicklung auf Arbeitsstationen und die Verwen-dung grafischer Benutzerschnittstellen. Bei beiden Systemen müssen imGegensatz zu gut eingespielten Lösungen (wie z.B. bei Anpassungen anbestehenden Systemen) methodisch und technisch neue, innovative Wegebeschritten werden, was meist zu unerwartet langen Einarbeitungszeitenführt.
Abschliessend einige Unterschiede zwischen der Entwicklung kleinerund grosser Systeme: Bei kleinen Systemen kann das Anwendungsgebietmeist von einer Person überblickt werden, was bei grossen Systemen oftnicht mehr möglich ist. Während Probleme bei kleinen Systemen meistauf die technische Seite beschränkt bleiben, besteht die grössteHerausforderung bei grossen Entwicklungen in der Meisterung der or-ganisatorischen Aspekte.
5.3 .2 Bewertung
Grosse Projekte entwickeln eine besondere Eigendynamik [Brooks 82,Curtis et al. 88, Feiler / Smeaton 88]. Der sequentielle Phasenablauf er-weist sich als problematisch, insbesondere bei innovativen Ansätzen: Esist unmöglich, zu Beginn alle Details zu kennen und zu berücksichtigen.Dazu kommt, dass sich durch den Lernprozess der Beteiligten die Rand-bedingungen und damit häufig auch die Anforderungen während derProjektarbeit ändern. Wie lässt sich unter diesen Umständen ver-hindern, dass mit einem unstabilen Arbeitsziel entwickelt werden muss?
Dies wird durch die evolutionäre Weiterentwicklung erreicht: Durcheine Folge von in sich stabilen Teilprojekten besteht die Möglichkeit fürAnpassungen. Gleichzeitig werden stabile Vorgaben für die Entwick-lung erreicht. Gelegentlich wird die evolutionäre Weiterentwicklung alsMöglichkeit (miss)verstanden, lange keine Entscheide zu treffen: DasGegenteil ist der Fall! Es hat sich eine Technik als geeignet erwiesen, inder Reihenfolge der Prioritäten ein Teilgebiet nach dem andern de-tailliert zu behandeln (und dadurch weniger wichtige Teilgebiete vor-erst beiseite zu lassen).

100 Fallstudien
Die evolutionäre Weiterentwicklung lässt die Möglichkeit offen, bereitsbehandelte Problemkreise nachträglich zu präzisieren. Derartige nach-trägliche Anpassungen sind - weil mit Aufwand verbunden - natürlichunerwünscht. Sie können umso besser vermieden werden, je genauer dieGesamtarchitektur zu einem frühen Zeitpunkt bekannt ist.
Eine zentrale Rolle spielt die rasche Fertigstellung der ersten Gene-ration. Diese erste Generation ist besonders kritisch, denn sie soll einer-seits die wichtigsten Komponenten des zukünftigen Systems enthalten,ansonsten im Sinne einer raschen Fertigstellung aber von sämtlichemBallast befreit werden. Damit wird bei allen Beteiligten frühzeitig einegemeinsame Vorstellung für das Gesamtsystem erreicht, denn bei inno-vativen Ansätzen ist es wichtig, früh die neuen Möglichkeiten zu de-monstrieren. In der Regel tritt nach drei Generationen Stabilität ein.Die Unmöglichkeit, bei innovativen Entwicklungen schon zu Beginn denAufwand klar abzuschätzen, erschwert die Projektführung erheblich.
Parallel dazu wird der Generationenplan erstellt. Er beschreibt, zuwelchen Zeitpunkten welche Ziele erreicht werden sollen (und - meistschwieriger - welche Teile weggelassen werden sollen). Im Genera-tionenplan werden die Teilprojekte der evolutionären Weiterent-wicklung definiert. Innerhalb dieser Teilprojekte sind die Anfor-derungen stabil zu halten.
Im Gegensatz zum sequentiellen Vorgehen ist bei der evolutionärenWeiterentwicklung - insbesondere bei vielen Beteiligten - der Kom-munikation zwischen den Entwicklern und auch mit den Anwenderver-tretern besondere Beachtung zu schenken: Jedermann muss frühzeitigüber Anpassungen informiert werden, am besten mit Angabe derGründe. Zugleich muss bei Änderungen darauf geachtet werden, dasssie nicht im Widerspruch zu anderen Teilen des Entwurfs stehen.Daraus folgt, dass die Entwurfsdaten (hauptsächlich konzeptionellesSchema und Abläufe) zentral geführt und koordiniert werden müssen.Neue Änderungen (seit der letzten Version) sollen erkennbar sein.
In einer ersten Phase von KORA wurden ausschliesslich "bestätigte"Informationen aufgenommen. Es zeigte sich jedoch, dass es sinnvollerist, auch "provisorische" Angaben zu dokumentieren. Somit ist eine An-gabe notwendig, wie "verbindlich" ein bestimmtes Entwurfsobjekt ist.Der Beschluss, welche Angaben als verbindlich zu gelten haben, wirdvon einem Gremium mit Entscheidungsbefugnis gefällt. Im Gegensatz

Fallstudien 101
zu Beschlüssen im kleinen Kreis der Entwickler können sich für solcheEntscheide Durchlaufzeiten im Bereich von Wochen ergeben.
Die evolutionäre Weiterentwicklung erfordert mindestens folgendeArbeitsschritte:
• Erstellen eines Generationenplans: Darin bildet der Datenbank-entwurf den Taktgeber. Um den Entwicklern der Anwender-komponenten die Vorbereitung zu ermöglichen, muss der Daten-bankentwurf eine Generation Vorsprung haben.
• Organisation des Informationsflusses: Der Generationenplankann nur eingehalten werden, wenn alle Projektbeteiligten zumrichtigen Zeitpunkt im Besitz der konsolidierten Entwurfsdatensind. Dazu muss klar definiert werden, wer welche Informationzu welchem Zeitpunkt zur Verfügung stellt (Redaktionsschluss),wie diese Information verarbeitet und wieder verteilt wird. Eingrosser Teil dieser Information besteht aus gemeinsamen Da-tendefinitionen.
• Möglichst rasche Fertigstellung der ersten Generation: Sie mussminimal sein, aber von den wichtigen Aspekten je ein Beispielenthalten. Bei grossen Projekten ist ein Pilotsystem empfehlens-wert.


Das erweiterbare Entwurfssystem Presto W 103
6 Das erweiterbare Entwurfssystem Presto W
Wenn vom Anwendersystem Anpassung an neue Gegebenheiten verlangtwird, sollten auch Methode und Werkzeug vergleichbare Flexibilitätbieten. Diese Überlegung führte zum Konzept des erweiterbarenEntwurfssystems. Es verfolgt zwei Hauptzielsetzungen:
• Gesamtheitlicher Entwurf aller Komponenten datenbankbasierterAnwendersysteme nach einer einheitlichen Methode.
• Unterstützung der Evolution durch Versionenbildung undÄnderungsnachführungen.
Daneben muss das Entwurfssystem an unterschiedliche Bedürfnisse desEntwurfs angepasst werden können. Dieses Kapitel beschreibt, mitwelchen Mitteln dies erreicht wird.
Das Entwurfssystem Presto W (W: Werkzeug) entstand ursprünglichaus den Erfahrungen mit den Komponenten Gambit und DISCUSS desProjekts LIDAS [Rebsamen et al. 83, Brägger et al. 83, Ursprung /Zehnder 83, Ursprung 84, Brägger et al. 85]. Zur besseren Ent-flechtung wurde der Entwurfsvorgang in (T-) Schritte unterteilt. DieseUnterteilung in T-Schritte ermöglicht die Konfiguration des Entwurfs-systems für die unterschiedlichsten Anforderungen, indem neue Phasenunterstützt und nicht benötigte weggelassen werden.
Presto W basiert auf der Methode Presto M. Die ersten Erfahrungenmit der Gliederung des Entwurfs in T-Schritte wurden mit Presto I ge-sammelt, während Presto II im Projekt KORA praktisch eingesetztwird. Dieses Kapitel beschreibt die wichtigsten Eigenschaften desEntwurfssystems, am Schluss werden die beiden Systeme Presto I undPresto II verglichen und die Erfahrungen zusammengefasst.
6.1 Das Aktualisierungskonzept
Das Zusammenspiel von V-, T- und E-Schritten basiert auf demAktualisierungskonzept, einem Mechanismus zur vollständigen Ände-rungsnachführung für die Konsistenzerreichung und -erhaltung derEntwurfsdaten. Das Aktualisierungskonzept bildet auch einen zentralenBestandteil des erweiterbaren Entwurfssystems Presto.

104 Das erweiterbare Entwurfssystem Presto W
Um V-Konsistenz zu erreichen, muss erkennbar sein, ob alle notwendi-gen Nachführungen zwischen den Teilschemata abgeschlossen sind. Weildie Entwurfskomponenten diese Nachführungen oder Aktualisierungennur im eigenen, nicht aber in fremden Teilschemata ausführen, mussüber Entstehung und Nachführung von Änderungen Buch geführtwerden. Das Aktualisierungskonzept wird durch die verzögerteÄnderungsnachführung nötig, d.h. durch die Trennung von Änderungs-erkennung und Änderungsbehandlung. Das Aktualisierungskonzeptbasiert auf dem Zusammenspiel von E- und T-Ebene und stützt sich aufdrei Mechanismen:
• Änderungserkennung: Jede Änderung an einem Entwurfsobjektmacht potentiell eine Änderung an Entwurfsobjekten andererTeilschemata nötig. Deshalb werden alle Änderungen am Ortihrer Entstehung, d.h. als E-Schritte, erfasst oder protokolliert.Dieser Änderungs-Entstehungsort wird als Änderungsquelle be-zeichnet.
• Änderungsverwaltung und -weiterleitung: Alle protokolliertenÄnderungen werden bis zu ihrer Abarbeitung in Änderungslistenaufbewahrt. Weil eine Änderung an mehr als einer StelleNachführungen nach sich ziehen kann, muss sie an all diesenStellen, den Änderungszielen, bekannt gemacht werden. Dies ge-schieht in einer ersten Grobverteilung durch den Abhängigkeits-graphen: Protokollierte E-Schritte werden zur Aktualisierung andie direkt abhängigen Entwurfskomponenten weitergeleitet.
• Änderungsnachführung (Aktualisierung): Jede Entwurfskompo-nente entscheidet bei jedem fremden E-Schritt lokal, ob dieserfür sie von Bedeutung ist und welche lokalen Nachführungen ameigenen Teilschema er nötig macht.
Das Aktualisierungskonzept basiert auf der Identifikation von Ände-rungsquellen und Änderungszielen:
• Jede Veränderung eines Entwurfsobjekts stellt eine Änderungs-quelle dar. Diese Veränderung erfolgt durch eine Änderungs-transaktion während eines E-Schritts (die Änderungstrans-aktionen repräsentieren die Datenverwaltung des Entwurfs-systems).
• Ein Änderungsziel ist ein von einer Veränderung betroffenesEntwurfsobjekt, das aufgrund eines E-Schritts nachgeführt wer-den muss.

Das erweiterbare Entwurfssystem Presto W 105
Die Entwurfsobjekte werden durch die E-Schritte verändert. Für dieAktualisierung werden gleichzeitig die E-Schritte einschliesslich allihrer Parameter in die Änderungslisten protokolliert. ZwischenÄnderungsquelle und Änderungsziel besteht eine 1-m Beziehung: JedeÄnderung kann an mehreren Stellen in anderen Teilschemata Aus-wirkungen haben.
Änderungsquelle Änderungsziel(e)
E-Schritte
Figur 6.1: Verzögerte Änderungsnachführung durch Änderungslisten
Die Änderungslisten sind nach dem first-in/first-out Prinzip organisiert:Die E-Schritte werden in derselben Reihenfolge ausgegeben, in der sieprotokolliert wurden.
Mit dem Aktualisierungskonzept ist jede Entwurfskomponente nebender Durchführung eigener E-Schritte auch in der Lage, aufgrund derprotokollierten E-Schritte anderer Entwurfskomponenten das eigeneTeilschema zu aktualisieren, d.h. wieder mit den Vorgängerteilschematazu synchronisieren. Jede Entwurfskomponente enthält neben dem Ent-wurfsteil auch einen Aktualisierungsteil. Alle Änderungen am eigenenTeilschema werden wieder protokolliert, gleichgültig, ob sie von derAktualisierung oder vom interaktiven Entwurf stammen. In Figur 6.2sind die Aktualisierungsflüsse dargestellt.
Entwerfer
AktualisierungInteraktiver
Entwurf
Fremde Änderungslisten
Eigene Änderungsliste
EK
Figur 6.2: Aktualisierungspfade (Entwurfskomponente)

106 Das erweiterbare Entwurfssystem Presto W
Je nachdem, wie stark das eigene Teilschema von einem fremden E-Schritt betroffen ist, sind während der Aktualisierung für jeden pro-tokollierten E-Schritt unterschiedliche (Aktualisierungs-) Reaktionennötig:
• Keine Reaktion: Die Änderung im geänderten Teilschema be-trifft kein eigenes Entwurfsobjekt, sie kann ignoriert werden.Dieser Fall kann eintreten, weil Änderungen gemäss Abhängig-keitsgraph prinzipiell vollständig an alle abhängigen Teilsche-mata weitergeleitet werden (Grobverteilung).
• Hinweis an den Entwerfer: Aufgrund der mitgeteilten Änderungist eine Anpassung des lokalen Teilschemas möglich, jedoch nichtnötig (häufig bei neuen Entwurfsobjekten in vorhergehendenTeilschemata).
• Automatische Anpassung: Aufgrund der Änderung muss daslokale Teilschema gemäss vorgegebener Regeln nachgeführtwerden (meist bei Löschfortpflanzungen).
• Manuelle Anpassung: Die Angaben der vorzunehmenden Anpas-sung sind mehrdeutig und müssen vom Entwerfer noch präzi-siert werden. Manuelle Anpassungen können mit Vorgaben (De-faults) oder Regeln auf automatische Anpassungen abgebildetwerden.
Prinzipiell ist es möglich, Aktualisierungs- und Entwurfstransaktionenin beliebiger Reihenfolge auszuführen. Es ist jedoch sinnvoller, alleAktualisierungen zu Beginn vorzunehmen und den Entwurf erst aufdem bereits aktualisierten Teilschema zu beginnen.
Um sicherzustellen, dass alle Entwurfskomponenten sämtliche Ände-rungseinträge erhalten, wird jedem Teilschema genau eine Änderungs-liste für die eigenen Änderungen zugeordnet. Alle direkt abhängigenTeilschemata lesen aus dieser Liste, wobei jedes abhängige Teilschemaeine eigene Leseposition verwendet.
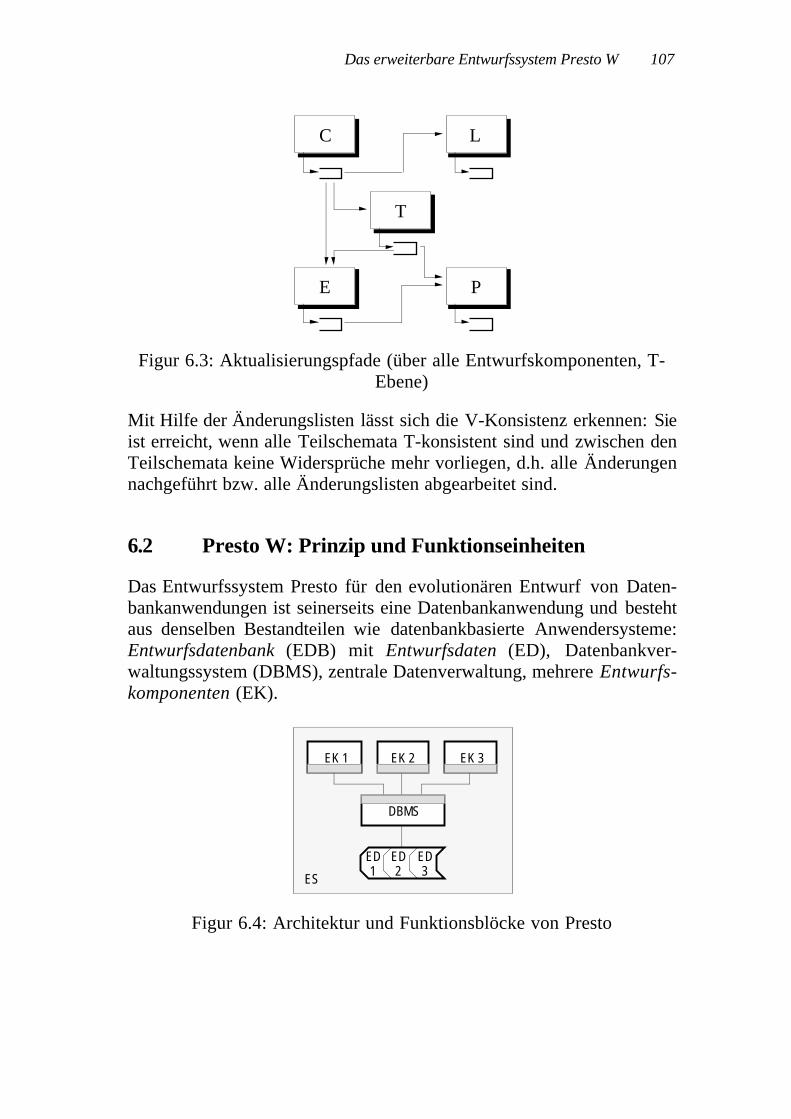
Das erweiterbare Entwurfssystem Presto W 107
C L
T
E P
Figur 6.3: Aktualisierungspfade (über alle Entwurfskomponenten, T-Ebene)
Mit Hilfe der Änderungslisten lässt sich die V-Konsistenz erkennen: Sieist erreicht, wenn alle Teilschemata T-konsistent sind und zwischen denTeilschemata keine Widersprüche mehr vorliegen, d.h. alle Änderungennachgeführt bzw. alle Änderungslisten abgearbeitet sind.
6.2 Presto W: Prinzip und Funktionseinheiten
Das Entwurfssystem Presto für den evolutionären Entwurf von Daten-bankanwendungen ist seinerseits eine Datenbankanwendung und bestehtaus denselben Bestandteilen wie datenbankbasierte Anwendersysteme:Entwurfsdatenbank (EDB) mit Entwurfsdaten (ED), Datenbankver-waltungssystem (DBMS), zentrale Datenverwaltung, mehrere Entwurfs-komponenten (EK).
EK 1 EK 2 EK 3
DBMS
ED 2
ES
ED 3
ED 1
Figur 6.4: Architektur und Funktionsblöcke von Presto

108 Das erweiterbare Entwurfssystem Presto W
Die Besonderheit und Neuerung von Presto liegt im Zusammenspielzwischen Datenbankschicht und Entwurfskomponenten:
• Ein erweiterbarer Entwurfssystemkern enthält die zentralenDienstleistungsfunktionen
• Die Entwurfsdatenbank ist nach Entwurfskomponenten unterteilt
• Die Entwurfskomponenten sind über den Entwurfssystemkernlose gekoppelt
Der Kern übernimmt mit der Ablaufsteuerung als komponentenüber-greifender "Klammer" die Koordination der Entwurfskomponenten undist das Mittel, mit dem Durchgängigkeit und Einheitlichkeit erreichtwird (dieses Konzept lässt sich auch auf Anwendersysteme übertragen).Die Architektur von Presto kann daher folgendermassen präzisiertwerden:
EK 1 EK 2 EK 3
Ablaufsteuerung
Protokollierung
Entwurfs- system-
Kern
Benutzer- schnittstelle,Logik
Änderungs- transaktionen
Entwurfs- daten
System- steuerung
Figur 6.5: Presto - erweiterbarer Kern mit Entwurfskomponenten
Pro Komponente sind zwei vereinheitlichte "Steckverbindungen" nötig(in Figur 6.5 durch die unterschiedlichen oberen und unteren Enden derEntwurfskomponenten symbolisiert): die erste zur Ablaufsteuerung, diezweite zur Entwurfsdatenbank. Dadurch wird ein standardisierter"Toolbus" realisiert.
Die korrekte Aktivierungsreihenfolge der Entwurfskomponenten ge-mäss Abhängigkeitsgraph wird durch die Ablaufsteuerung erreicht. JedeEntwurfskomponente ist in zwei Teile unterteilt: Der erste enthältBenutzerschnittstelle und Logik, der zweite (lokal) konsistenzerhaltendeÄnderungstransaktionen. Dazwischen liegt die Protokollierungsschicht:Sie stellt ohne zusätzlichen Aufwand für die Entwurfskomponenten

Das erweiterbare Entwurfssystem Presto W 109
sicher, dass alle Änderungen an den Entwurfsdaten auch in die Än-derungslisten eingetragen werden. Die Änderungslisten werden durchden Entwurfssystemkern verwaltet. Eine besondere Entwurfskompo-nente (in Figur 6.5 ganz links) dient der Steuerung des Kerns: IhreDaten werden wie die Änderungslisten ebenfalls vom Kern verwaltetund dienen der internen Verwaltung des Entwurfssystems.
Jede Entwurfskomponente realisiert mit Hilfe der Änderungstrans-aktionen in ihrem Teilschema konsistenzerhaltende Mutationen derEntwurfsdaten. Änderungen an anderen Teilschemata werden durchderen Entwurfskomponenten vorgenommen. Eine Entwurfskomponentekann die Entwurfsdaten der anderen Entwurfskomponenten lesen, abernicht verändern.
Zur Erreichung globaler Konsistenz der Entwurfsdaten werden Nach-führungen zwischen den Entwurfskomponenten durch Protokollierungder Änderungstransaktionen in Änderungslisten realisiert. Durch dieProtokollierung ist gewährleistet, dass jede Änderung - sei es beim erst-maligen Entwurf oder im Verlauf der Evolution - an allen betroffenenStellen nachgeführt wird.
Für Erweiterbarkeit muss eine neue Entwurfskomponente beim Ent-wurfssystemkern registriert werden können. Dazu benötigt der Kerndie folgenden Angaben:
• Strukturdefinition der Entwurfsdaten (Datenbeschreibung)
• Änderungstransaktionen mit Parametern (Schnittstellenbeschrei-bung)
• Programme für Änderungstransaktionen und Benutzerschnitt-stelle (Code)
• Abhängigkeiten von anderen Entwurfskomponenten (Einbettung)
Alle übrigen Mechanismen wie Ablaufsteuerung, Versionenbildung,Protokollierung und Änderungslistenverwaltung sind durch den Ent-wurfssystemkern abgedeckt.
6.3 Erweiterbarer Entwurfssystemkern
Der Entwurfssystemkern stellt die von allen Entwurfskomponenten be-nötigten Funktionen zur Verfügung. Er unterstützt V- und T-Schritte:

110 Das erweiterbare Entwurfssystem Presto W
• Anlegen, Freigeben und Abschliessen von Schemaversionen (V-Schritt)
• Aus- und Eintragen der Teilschemata: check-out / check-in (T-Schritt)
• Aufruf und Protokollierung der Änderungstransaktionen
• Abarbeitung der Änderungslisten
• Erkennung von V-Konsistenz: Steuerung von Aktualisierung undVerwaltung der Änderungslisten
Der Entwurfssystemkern hat zwei Schnittstellen zu den Entwurfs-komponenten:
• Ablaufsteuerung der Entwurfskomponenten (Aufruf DoCompo-Op)
• Aufruf und Protokollierung der Änderungstransaktionen (Do-ChangeTA)
Diese beiden Schnittstellen sind für alle Entwurfskomponenten iden-tisch: Sie bilden die genormten "Steckverbindungen" und sind Grund-lage für die Erweiterbarkeit des Entwurfssystems.
Ablaufsteuerung
DoCompoOp
DoChangeTA
EK XBenutzer-
schnittstelle,Logik
EK XÄnderungs-TA
EK XEntwurfsdaten
Protokollierung
EK XÄnderungsliste
Figur 6.6: Einbettung einer Entwurfskomponente
Mit der Ablaufsteuerungsschnittstelle wird der Entwurfskomponente dieKontrolle für Aktualisierung oder Entwurf übergeben, sobald sie durchdie Systemsteuerung für Änderungen ausgetragen wird (vgl. auch Figur

Das erweiterbare Entwurfssystem Presto W 111
6.7): Solange noch Aktualisierungstransaktionen pendent sind, ist nurdie lokale Aktualisierung des eigenen Teilschemas möglich. Erst wennalle Aktualisierungstransaktionen abgearbeitet sind, kann mit demEntwurf begonnen werden. Die Übergabe der Kontrolle an die Ent-wurfskomponente erfolgt mit DoCompoOp:
DoCompoOp (CompoNo, SchemaNo, ChangeMode)
DoCompoOp realisiert die "Steckverbindung" zur Ablaufsteuerung.Bedeutung der Parameter:
• CompoNo: Identifikation der aufgerufenen Entwurfskompo-nente. Nur registrierte Entwurfskomponenten können aufge-rufen werden.
• SchemaNo: Auswahl eines Teilschemas, falls mehrere möglichsind (z.B. bei mehreren externen Schemata). Nur durch den Ent-wurfssystemkern angelegte und eröffnete Teilschemata sindzulässig.
• ChangeMode: Änderungsmodus (Aktualisierung oder Entwurf).
Der Entscheid für Aktualisierung oder Entwurf wird ausserhalb derEntwurfskomponente aufgrund des globalen Systemzustands getroffen.Nach Abschluss der Änderungen wird die Kontrolle durch Trans-aktionsrückkehr an den Entwurfssystemkern zurückgegeben.
Änderungstransaktionen bilden sowohl die Schnittstelle für konsistenz-erhaltende Mutationen der Entwurfsdaten als auch die Einheit derProtokollierung. Sie realisieren die "Steckverbindung" zur Entwurfs-datenbank. Alle Änderungstransaktionen werden einheitlich mit Do-ChangeTA aufgerufen. Da jede Änderungstransaktion eine Änderungs-quelle darstellt, erfolgt gleichzeitig mit der Ausführung der Transaktionauch ihre Protokollierung. Die Änderungstransaktion inklusiv Protokol-lierung ist atomar, d.h. sie wird nur vollständig oder gar nichtausgeführt. Um eine Umgehung dieses Mechanismus zu verhindern,werden alle Änderungstransaktionen sämtlicher Entwurfskomponentensystemweit über einen einzigen Eintrittspunkt aufgerufen:
DoChangeTA (CompoNo, SchemaNo, ChangeTANo, ParmList)

112 Das erweiterbare Entwurfssystem Presto W
Bedeutung der neuen Parameter:
• ChangeTANo: Identifikation der Änderungstransaktion. Es musssich um eine für die betreffende Entwurfskomponente registrier-te Transaktion handeln.
• ParmList: Variable Parameterliste der Änderungstransaktion.Die Bedeutung der Parameter ist von der Transaktion abhängig.
Während Aktualisierung und Entwurf wird im ausgetragenen Zustanddes Teilschemas DoChangeTA so oft wie für die Veränderung der Ent-wurfsdaten nötig aufgerufen. Lesetransaktionen werden direkt aus-geführt, da sie keine Protokollierung benötigen. Durch Aus- und Ein-tragen des Teilschemas (T-Schritt) wird ein Änderungsabschnitt eröff-net und abgeschlossen:
OpenChangeSection ChangeTAA, Parm1, Parm2, Parm3 ChangeTAB, Parm1, Parm2 ChangeTAC, Parm1 ChangeTAB, Parm1, Parm2CloseChangeSection
Die einheitlichen "Steckverbindungen" werden mit dem Do-Konzeptrealisiert: Anstatt für jede einzelne Transaktion einen Aufruf zur Ver-fügung zu stellen, werden alle Anforderungen über dieselbe Schnitt-stelle geleitet, was die Protokollierung vereinfacht. In der Implemen-tation wird anstelle mehrerer Prozeduren nur eine einzige mit demParameter ChangeTANo verwendet. Dadurch ist das System ohne Ver-änderung der Schnittstelle erweiterbar. Stattdessen werden neue gültigeTransaktionen registriert. Der Preis für diese Flexibilität ist die Über-prüfungen auf gültige Transaktionen zur Laufzeit.
6.4 Entwurfskomponenten
Durch Zusammenstellung geeigneter Entwurfskomponenten wird dasEntwurfssystem für ein bestimmtes Anwendungsgebiet konfiguriert,z.B. für reinen Datenbankentwurf oder Datenbankentwurf in Kombina-tion mit Anwendungsentwurf. Wie die Schnittstellen zum Entwurfs-systemkern basiert auch die Architektur der Entwurfskomponenten aufeinem einheitlichen Konzept. Jede Entwurfskomponente enthält diefolgenden Teile (grau in Figur 6.7, von unten nach oben):
• Teilschema der Entwurfsdaten inkl. Referenzierung andererTeilschemata

Das erweiterbare Entwurfssystem Presto W 113
• Änderungstransaktionen für konsistenzerhaltende Entwurfsda-tenmutationen
• Aktualisierung
• Interaktiver Entwurf
• Benutzerschnittstelle
Mit Hilfe dieser Information wird die Entwurfskomponente währendder Konfiguration des Entwurfssystems beim Kern registriert.Zwischen den Änderungstransaktionen und den Entwurfsdaten befindetsich das Datenbankverwaltungssystem (nicht dargestellt).
Aktualisierung Entwurf
Benutzerschnittstelle
Änderungstransaktionen
Entwurfsdaten
Figur 6.7: Architektur einer Entwurfskomponente
Um ausstehende Änderungen aus anderen Entwurfskomponenten nach-zuführen, stehen in den Entwurfskomponenten Aktualisierungstrans-aktionen zur Verfügung, die angestossen werden, sobald bei der Bear-beitung des nächsten Eintrags der Änderungsliste eine lokale auto-matische oder manuelle Anpassung nötig wird. Im Gegensatz dazu wer-den während des Entwurfsprozesses Entwurfstransaktionen verwendet.Sowohl Aktualisierungs- als auch Entwurfstransaktionen sind Ände-rungstransaktionen. Dieselbe Änderungstransaktion kann als Aktuali-sierungs- wie auch als Entwurfstransaktion verwendet werden.
Wegen des zentralen Aufrufs von DoChangeTA für alle Änderungs-transaktionen erfolgt innerhalb des Blocks der Änderungstransaktioneneine Verzweigung auf die einzelnen Transaktionen. Mit Hilfe des Do-

114 Das erweiterbare Entwurfssystem Presto W
Konzepts kann dieselbe Schnittstelle universell für die Übergabe allerÄnderungstransaktionen verwendet werden:
PROCEDURE DoChangeTA (CompoNo, SchemaNo, ChangeTANo,ParmList);BEGIN CASE ChangeTANo OF ChangeTAA: Parm1 := GetParm (ParmList, 1); Parm2 := GetParm (ParmList, 2); Parm3 := GetParm (ParmList, 3); ChangeTAA (SchemaNo, Parm1, Parm2, Parm3); | ChangeTAB: Parm1 := GetParm (ParmList, 1); Parm2 := GetParm (ParmList, 2); ChangeTAB (SchemaNo, Parm1, Parm2); ... ELSE Error (WrongChangeTAErr); END;END DoChangeTA;
Aufgabe der Aktualisierung ist es, aus den Änderungslisten direkterVorgängerkomponenten mit der Funktion GetNextChangeTA desEntwurfssystemkerns solange Änderungstransaktionen zu abzuholen undzu verarbeiten, bis das eigene Teilschema wieder mit den vorange-gangenen Teilschemata synchronisiert ist (verzögerte Änderungsnach-führung). Interaktion mit dem Entwerfer ist dabei nur bei manuellenAnpassungen nötig. Falls diese mit Defaults vermieden werden, kanndie Aktualisierung im Hintergrund durch separate Prozesse erfolgen.
Der nachgeführte Zustand des Teilschemas bildet die Ausgangslage fürden interaktiven Entwurf. Dabei werden eigene Entwurfsdaten und wonötig auch diejenigen von Vorgängerkomponenten für Überprüfungenund grafische Darstellung verwendet.
Je nach Rechnerumgebung kann für die Benutzerschnittstelle einetextuelle Kommandoeingabe oder eine grafische Darstellung gewähltwerden. Um kurze Antwortzeiten zu erreichen, werden die Entwurfs-daten des lokalen Teilschemas im Hauptspeicher gehalten. Dieser Ansatzist für das Entwurfssystem im Gegensatz zu grossen Anwendersystemenwegen der beschränkten Datenmenge der Entwurfsdaten unproble-matisch.
6.5 Von der Beschreibung zur Anwendung
Die Entwurfsdaten bilden - in eine übersichtliche Form gebracht -während der evolutionären Weiterentwicklung die unerlässliche konso-lidierte Dokumentation des aktuellen Wissensstandes über das zu ent-

Das erweiterbare Entwurfssystem Presto W 115
werfende Anwendersystem. Wegen der Koordination einzelner Teil-schemata kommt dem Entwurfssystem die Rolle eines Dokumentations-und Konsolidierungswerkzeugs zu. Bei manueller Programmierungkann diese abgegelichene Beschreibung als detaillierte Vorgabe ver-wendet werden.
Da aufgrund des evolutionären Vorgehens Änderungen häufig vor-kommen, ist neben der Dokumentation auch eine rasche Umsetzung derBeschreibung in ausführbaren Code nötig. Dies wird mit drei unter-schiedlichen Generierungen erreicht:
• Datenbankdefinitionen
• Konsistenzerhaltende Anwendertransaktionen (Datenverwaltung)
• Benutzerschnittstelle
Dies gilt für Anwendersysteme, welche die Anwenderdaten hauptsäch-lich verwalten (z.B. Delphi). Im Fall von Verarbeitungen kommen nochBerechnungen hinzu (z.B. KORA).
Logischer Datenbank-
entwurf
Konzeptioneller Datenbank-
entwurf
Präsentations- entwurf: Layout
Externe Datenbank- schemata
Konsistenz- erhaltende
Anwender-TA
Anforderungs- analyse
Datenbank- definitionen
Benutzer- schnittstelle
Daten- verwaltung
DBMS-abhängig
Analyse Entwurf Generierung
Figur 6.8: Entwurfs- und Generierungsschritte
Aus dem logischen Datenbankschema wird die Strukturbeschreibungder Datenbank, d.h. die Datendefinitionsbefehle für das gewählte Daten-bankverwaltungssystem (DDL, Data Definition Language) erzeugt.
Konsistenzerhaltende Anwendertransaktionen werden in der zentralenDatenverwaltung zusammengefasst. Diese besteht entweder aus gene-riertem Programmcode oder einem Interpreter mit den zugehörigenSteuerdaten. Die Beschreibung der Anwendertransaktionen in der Ent-

116 Das erweiterbare Entwurfssystem Presto W
wurfsdatenbank wird daher in Programmcode bzw. Interpretersteuer-daten übersetzt.
Die externen Datenbankschemata zusammen mit den Präsentationsbe-schreibungen werden in interaktive Anwenderkomponenten umgesetzt.Strukturbeschreibung, Operationen und Benutzerschnittstelle müssenzusammenpassen: Das ist gewährleistet, wenn die Generierung aus demZustand der V-Konsistenz erfolgt. Ihre Erkennung ist Aufgabe des Ent-wurfssystemkerns.
Das Zusammenspiel der drei generierten Blöcke basiert auf einem Lauf-zeitsystem, d.h. einer Programmbibliothek, welche die benötigtenZugriffs-, Überprüfungs- und Darstellungsalgorithmen implementiert.Die Aufgabe des Entwurfssystems für die Generierung besteht darin,die zur Konfiguration des Laufzeitsystems notwendigen Parameter zusammeln und widerspruchsfrei zu halten.
Im Gegensatz zu ausprogrammierten Lösungen können nur diejenigenFälle von Anwendersystemen automatisch generiert werden, welche imEntwurfssystem vorgesehen und vom Laufzeitsystem unterstützt wer-den. Dadurch entsteht eine Beschränkung auf ein bestimmtes Gebiet vonAnwendersystemen. Diese Beschränkung kann sich aber auch als Vorteilerweisen, weil sie Entwerfern und Anwendern eine einheitliche Ent-wicklungsrichtung vorgibt.
6.6 Das Entwurfssystem als Datenbankanwendung
Ein Vergleich der Architektur datenbankbasierter Anwendersystememit derjenigen des Entwurfssystems zeigt grosse Ähnlichkeiten. SowohlAnwender- wie auch Entwurfssystem basieren auf Datenbeschreibung,konsistenzerhaltenden Mutationsoperationen und Benutzerschnittstelle.In der Tat lassen sich für die Anwendungsentwicklung vorgeseheneMethoden, Techniken und Entwicklungsumgebungen verwenden, umein Entwurfssystem zu realisieren - Presto II ist ein Beispiel dafür. EineDatenbankanwendung, um eine andere Datenbankanwendung zu entwer-fen? Könnte nicht auch diese wieder mit einer dritten Datenbank-anwendung entworfen werden? Wann bricht diese Kette ab? Handelt essich gar um einen Zyklus, d.h. kann das Entwurfssystem mit sich selbstentworfen werden? Figur 6.9 verdeutlicht diese Fragestellungen:

Das erweiterbare Entwurfssystem Presto W 117
AS
ES
KS
?
Figur 6.9: Zusammenspiel von Konfigurations-, Entwurfs- undAnwendersystem
Für die folgenden Erläuterungen ist die Kette der Systeme mitAnwendersystem (AS), Entwurfssystem (ES) und Konfigurationssystem(KS) bezeichnet. ES ist die Metaebene von AS, KS die Metametaebenevon AS, etc. Ein System S (z.B. AS) entsteht, wenn die (variablen)Daten seiner Metaebene (z.B. ES) definitiv festgelegt (fixiert) sind undanschliessend S generiert wird. Diese Information SMeta wird zusätzlichdirekt in die Datenbank von S eingetragen (grauer Teil): Auf diese Artkann S "über sich selbst Auskunft geben" und dieses Wissen auch internverwenden. SMeta kann nicht verändert werden, und ebensowenig dercompilierte Programmcode (aus Effizienzgründen wird nur bei weni-gen Systemen zur Laufzeit SMeta interpretiert). Die Kette der Meta-systeme bricht ab, sobald der Programmcode nicht mehr generiert,sondern von Hand geschrieben und SMeta manuell eingetragen wird. Aufdiese Art entsteht das erste System. Presto als erweiterbares Systemkennt die Ebenen KS, ES und AS. Vorbereitung und Einsatz desEntwurfssystems verlaufen in drei Schritten:
• Bereitstellung des Entwurfssystem-Rahmens: Daten und Pro-gramme des Entwurfssystemkerns (Bootstrap).
• Registrierung der Entwurfskomponenten.
• Entwurf des Anwendersystems.
In einem letzten Schritt wird das Anwendersystem generiert und ge-nutzt.
Sobald ein Entwurfssystem den Entwurf aller Konstrukte unterstützt,die im Entwurfssystem selbst verwendet werden (im Fall von Presto IIz.B. Versionenbildung, Änderungslisten, etc.), lässt es sich mit sichselbst entwerfen. Diese "Bootstrap"-Methode wird im Compilerbauhäufig eingesetzt [Wirth 84, Aho et al. 86]. Compiler werden in derRegel in derjenigen Programmiersprache geschrieben, welche sie auch

118 Das erweiterbare Entwurfssystem Presto W
übersetzen, weil die Sprache alle für den Compilerbau benötigten Kon-strukte unterstützt. Entwurfssysteme werden dagegen selten vollständigauf diesem Weg entworfen:
• Die Anforderungen an Anwender- und Entwurfssystem sind ver-schieden. Entwurfssysteme sind für den Entwurf von Anwender-systemen ausgelegt, die entwurfssystemspezifischen Konstruktewerden nicht primär unterstützt.
• Die universelle Beschreibung aller Konsistenzbedingungen istaufwendig: Von konsistenzerhaltenden Mutationsoperationenwerden daher nur deren Schnittstelle und die gängigen Kon-sistenzbedingungen deskriptiv beschrieben. Spezialfälle werdenprozedural gelöst.
• Während Beschreibung und Generierung von kommando- oderformularorientierten Benutzerschnittstellen noch einigermassenmöglich ist, existieren für die deskriptive Beschreibung grafi-scher Datendarstellung erst wenige Konzepte.
Zusammenfassend kann gesagt werden, dass ein praxisnahes Ent-wurfssystem nicht mit sich selbst entworfen werden kann, da besondereAnforderungen wie spezielle Konstrukte, Konsistenzbedingungen odergrafische Datendarstellung nur mit grossem Aufwand deskriptiv be-schrieben werden können. Daher ist es sinnvoller, für Ausnahmen be-sondere Ausgänge ("User Exits") vorzusehen, die für den Anschlussausgefallener Lösungen vorbereitet sind. Daran werden bei Bedarfeigens implementierte Module angeschlossen.
6.7 Die Entwurfswerkzeuge Presto I und Presto II:Vergleich
Die Konzepte zur Methode Presto M entstanden während der Jahre 85bis 87. Die erste Generation des Werkzeugs Presto W wurde von 88 bis90 realisiert (Presto I), die zweite Generation in den Jahren 91 und 92(Presto II). Weiterentwicklungen sind noch im Gang.
Beide Generationen des Entwurfssystems Presto basieren auf demselbenKonzept, unterscheiden sich technisch jedoch stark: Presto I basiert aufdem Datenbankverwaltungssystem RDS von LIDAS [Rebsamen et al.83], verwendet Modula-2 als Programmiersprache [Wirth 83] und istunter dem Betriebssystem Medos-2 auf den Arbeitsstationen Lilith und

Das erweiterbare Entwurfssystem Presto W 119
Ceres implementiert [Wirth 81, Eberle 87]. Presto I wurde als flexiblesExperimentalsystem realisiert.
Presto II verwendet als Datenbankverwaltungssystem den SQL-basiertenDatabase Manager [Date 89], für Dialoge und Listen den zugehörigenQuery Manager oder die grafische Presentation Manager (PM) Ober-fläche des Betriebssystems OS/2 [Petzold 89]. Als Programmiersprachekommt C zum Einsatz [Kernighan / Ritchie 88].
Presto I Presto IIDatenbanksystem RDS Database Manager (SQL)Dialoge, Listen Ausprogrammiert Query Manager, PMProgrammiersprache Modula-2 CBetriebssystem Medos-2 OS/2Rechner Lilith, Ceres IBM PC, PS/2
Figur 6.10: Vergleich von Presto I und Presto II
Bei Presto I musste ein grosser Teil der Softwarewerkzeuge und Pro-grammbibliotheken von Grund auf neu entwickelt werden. Presto IIkonnte in einem Umfeld mit wesentlich höherer Abstraktion entwickeltwerden, was Prototypenbildung und Entwicklung vereinfachte.
Auch die Anforderungen an die beiden Systeme waren unterschiedlich:Presto I wurde von Grund auf neu konzipiert, um Datenbank- und An-wendungsentwurf in T-Schritten zu unterstützen. Eine Erweiterung derSysteme Gambit oder DISCUSS war wegen deren fehlenden Modulari-sierung nicht möglich: Datenbankzugriffe, Programmlogik und Be-nutzerschnittstelle dieser Systeme sind zu stark ineinander verzahnt.Einen wichtigen Bestandteil von Presto I bildeten die Versuche mit demProtokollierungsmechanismus [Oertly / Schiller 89]. Detaillierung derEntwurfsdaten und Funktionsumfang der Entwurfskomponenten warenvon geringerer Bedeutung.
Presto II musste von Beginn an als Dokumentationssystem für KORAeingesetzt werden. Höchste Priorität hatte daher die detaillierte An-wendungsbeschreibung. Der Beginn erfolgte mit dem konzeptionellenDatenbankschema, später folgten Teilschemata für Datenübernahme(Migration, M), logisches Schema, externe Schemata und System-steuerung (Achtung: Das Teilschema M und die Methode Presto M sindzwei verschiedene Dinge). Um den Dokumentationsanforderungen ge-recht zu werden, enthält jedes Entwurfsobjekt in Presto II mindestensfolgende Information:

120 Das erweiterbare Entwurfssystem Presto W
• Technische Identifikation: Numerisch, automatisch zu vergeben,für interne Verknüpfungen.
• Bezeichner: Eindeutiger Name für Verwendung bei Gene-rierungen.
• Anwender-Bezeichnung: Kurztext mit Klein- und Grossschrei-bung, Verwendung in Dialogen und Listen, Fremdsprachener-weiterung möglich.
• Erklärung: Ausführliche Beschreibung, Verwendung als Hilfe-text, Fremdsprachenerweiterung möglich.
• Anwender-Sortierung.
• Erzeugungs- und Veränderungsdatum.
Im Gegensatz zu Presto I wurde für die praktische Anwendbarkeit einLaufzeitsystem, die Datenbankschicht (Datenverwaltung), benötigt undrealisiert. Die folgende Tabelle fasst die Schwerpunkte der beiden Sy-stem zusammen:
Presto I Presto IISchwergewicht Hohe Flexibilität:
EntwurfssystemkernDetaillierte Dokumentation:
Datendefinitionen TeilschemataHauptaktivität Versuche mit T-Schritten und
ProtokollierungDokumentation von KORA
Anwendungs-generierung
- Datendefinitionen und konsi-stenzerhaltende Operationen
Entwurfskom-ponenten,Teilschemata
C L
T
E P
C L
S
EM
Neue Teilschemata für Migration(M) und Systemsteuerung (S)
Wenigerwichtig
Codegrösse, Effizienz Besondere Konsistenzbe-dingungen, Benutzerschnittstelle
Figur 6.11: Vergleich der Eigenschaften von Presto I und Presto II
Je nach Zielsetzung sind unterschiedliche Kriterien für die Gestaltungdes Entwurfssystems von Bedeutung: Flexibilität, Effizienz und mini-male Codegrösse können nicht gleichzeitig maximiert, sondern müssengegeneinander abgewogen werden. Presto I und Presto II sind in diesemDreieck unterschiedlich positioniert:

Das erweiterbare Entwurfssystem Presto W 121
Effizienz
Flexibilität Kompaktheit
• Presto I• Presto II
Figur 6.12: Positionierung von Presto I und Presto II
6.8 Bewertung
Wie der Vergleich von Presto I und Presto II zeigt, werden je nachEntwurfsbedürfnis unterschiedliche Entwurfskomponenten und Teil-schemata benötigt: Da in KORA Dialoge und Listen ausprogrammiertwerden, sind bei Presto II dafür keine Entwurfskomponenten nötig.Dagegen muss die Datenübernahme vom bisherigen System KOL doku-mentiert werden, insbesondere die dabei anzuwendenden Transforma-tionen. Die Systemsteuerung hat für KORA fast dieselbe Bedeutung wieder Entwurfssystemkern für Presto (vgl. Kapitel 7): Sie dokumentiertdie Anwenderkomponenten Dialog, Berechnung, Druck und Fremd-systemübergänge einschliesslich deren Funktionen.
Zum Schluss sollen Änderungstransaktionen und -listen eingehenderbetrachtet und mit ähnlichen Konzepten verglichen werden. Mit denÄnderungstransaktionen wird eine Entkopplung der konsistenzerhalten-den Datenmutationen von Anwendungslogik und Darstellung erreicht.Dieses Prinzip der Datenkapselung hat grosse Ähnlichkeit mit demMeldungsmechanismus der objektorientierten Programmierung unddem Model-View-Controller Konzept (MVC) [Goldberg / Robson 83,Peterson 87]. Die Technik lässt sich sowohl im Entwurfs- wie im An-wendersystem anwenden. Eine solche Trennung ist auch wichtigeVoraussetzung für die sich immer mehr durchsetzende Client-ServerArchitektur: Ein vertrauenswürdiger Server bietet mit hoher Verfüg-barkeit seine Dienste in Form konsistenzerhaltender Transaktionen(stored procedures) an, welche bei Bedarf von weniger vertrauens-würdigen Clients - in der Regel Arbeitsstationen - angefordert werden,um Daten abzufragen, lokal zu bearbeiten und anschliessend zurückzu-schreiben. Durch die zentrale Überprüfung in den Anwendertrans-aktionen ist die Datenkonsistenz in jedem Fall gewährleistet.

122 Das erweiterbare Entwurfssystem Presto W
Änderungslisten im Zusammenhang mit Datenbanken sind eine beson-dere Form von referentieller Integrität mit verzögerter Nachführung.Sie lassen sich mit den "message queues" ereignisgesteuerter interakti-ver Systeme vergleichen [Goldberg 84, Apple 87, Petzold 89]. Anstelleeiner sofortigen Ausführung der Änderung an allen betroffenen Stellenund mit Abwarten der Funktionsrückkehr (synchrone Ausführung)wird die Änderung mit Hilfe der Änderungsliste in Auftrag gegebenund ihre Ausführung nicht abgewartet (asynchrone Ausführung). Zu-griffe auf noch nicht nachgeführte (d.h. nicht aktualisierte) Datenwerden mit der Ablaufsteuerung gemäss Abhängigkeitsgraph verhin-dert. Durch die Trennung von Nachführungserkennung (Änderungs-quelle) und Nachführungsbearbeitung (Änderungsziel) werden kurzeAntwortzeiten und eine gut modularisierte Systemarchitektur erreicht.Dasselbe Prinzip der Trennung von Annahme und Behandlung wird inzeitkritischen Echtzeitsystemen angewendet. Änderungslisten werdennötig, sobald in einem umfangreichen Schema Schnitte für die Unter-teilung in Teilschemata gelegt werden. Bei Presto I wurde ausschliess-lich die referentielle Integrität über solche Schnitte hinweg mit Än-derungslisten unterstützt. Weil sich viele im Entwurfssystem benötigteKonsistenzbedingungen nicht mit referentieller Integrität lösen lassen,wurde für Presto II das Konzept für beliebige Änderungsoperationenerweitert. Als Nachteil dieser Lösung ist jedoch keine deskriptive Be-schreibung der Konsistenzbedingungen mehr möglich.
Die verzögerte Nachführung kommt immer dann zum Einsatz, wenn dieAktualisierung aufwendig ist und lange Ausführungszeiten zur Folgehat. De facto wird diese Technik häufig eingesetzt, in der Regel ist dieNachführungsverwaltung jedoch ausprogrammiert, über mehrereProgramme verteilt und nicht zentral dokumentiert. Die Neuerung vonPresto ist die vollständige Ausgliederung der Änderungsverwaltung ausden Entwurfskomponenten. Diese Technik ist nicht auf das Entwurfs-system beschränkt, sondern lässt sich auch auf Anwendersysteme über-tragen (z.B. verzögerte Berechnungsläufe in KORA).

Ergebnisse und Ausblick 123
7 Ergebnisse und Ausblick
7.1 Ergebnisse betreffend allgemeines Vorgehen
In dieser Arbeit wird ein systematisches und praktisch anwendbaresVorgehensmodell für die evolutionäre Weiterentwicklung datenbank-basierter Anwendersysteme vorgestellt, das klare Richtlinien für dieGenerationenbildung von Programmen und Daten vorgibt. Der Entwurffür jeden Evolutionsschritt (Generation) ist in weitere Schritte ge-gliedert, die sich aus der Kombination bewährter Entwurfsmethodenfür Datenbank-, Sicht- und Applikationsentwurf ergeben.
Vorgehensmodell, Entwurfsmethode und zugehöriges Entwurfswerk-zeug Presto wurden in zwei Projekten Delphi und KORA unterschied-licher Grössenordnung erfolgreich eingesetzt und weiterentwickelt. AlsBesonderheit enthielten beide Anwendungen technische Neuerungen,während die fachlichen Anforderungen weitgehend vorgegeben waren.Für eine solche Aufgabenstellung erweist sich die evolutionäre Weiter-entwicklung als sehr geeignet, weil besonders in der Anfangsphase desProjekts viele neue Aspekte gleichzeitig berücksichtigt werden müssenund nicht bis ins Detail geplant werden können. Der innovative Charak-ter von Delphi und KORA steht im Gegensatz zur konventionellen Wei-terentwicklung bestehender Anwendersysteme. Diesem Problemkreiswurde in der vorliegenden Arbeit weniger Gewicht beigemessen.
In jedem Projekt kommt klar definierten Rahmenbedingungen in Formvon Vorgehensmodell und Entwurfsmethode eine wichtige Rolle alsgemeinsame Sprache der Projektbeteiligten zu. Vorgehensmodell undMethode können sowohl manuell als auch mit Werkzeugunterstützungangewandt werden.
Der praktische Einsatz des evolutionären Vorgehensmodells führte zueinigen interessanten und z.T. unerwarteten Erkenntnissen:
• Umgang mit vager Information: In der Anfangsphase eines Pro-jekts treten viele Anforderungen und Wünsche auf, die zu die-sem Zeitpunkt weder vollständig formal beschrieben noch prä-zise eingeordnet werden können. Trotzdem müssen sie festge-halten, dokumentiert und wiedergefunden werden. Methode undWerkzeug müssen in der Lage sein, diese vage Information zuverwalten und im geeigneten Moment zu präzisieren.

124 Ergebnisse und Ausblick
• Erkennung von Lücken im Konzept: Während die Erkennungfalscher Information relativ einfach ist, sind fehlende Infor-mationen wesentlich schwieriger zu erkennen. Das geeigneteMittel einer systematischen Aufstellung - z.B. in Matrixform -ist wegen der noch fehlenden Strukturierung allerdings nur be-grenzt anwendbar.
• Durchlaufzeiten: Die Dauer eines Evolutionsschritts wird durchmehrere Faktoren beeinflusst; darunter fallen die Zeiten für dieEntscheidungsfindung und Ausarbeitung, für die Nachführungund Verteilung der Dokumentation und für die technische Reali-sierung. Die Anzahl der Beteiligten spielt ebenfalls eine wichtigeRolle. In einer ersten Planung für KORA wurden für einen Evo-lutionsschritt drei Monate vorgesehen, was sich als zu kurz er-wies: In einem Projekt dieser Grösse dauert ein Zyklus in denfrühen Phasen etwa ein Jahr. Sobald sich die Zahl der Ände-rungen verringert, kann auch die Durchlaufzeit verkürzt wer-den.
• Datenbankschema als Taktgeber: Da die Teilschemata der An-wenderkomponenten vom Datenbankschema abhängig sind, mussfür eine neue Version des gesamten Anwendungsschemas dasDatenbankschema als erstes und frühzeitig fertiggestellt werden,damit für Entwurf und Nachführung der Anwenderkomponentengenügend Zeit zur Verfügung steht. Nötig ist etwa ein halbesJahr, was der halben Dauer eines Evolutionsschritts entspricht.Das Datenbankschema ist von fachlichen Abklärungen abhängig,so dass diese so früh wie möglich eingeleitet werden müssen.
• Migrationspfad und Migrationsdauer: Wenn ein neues Anwen-dersystem gesamthaft neu entwickelt wird, muss es das Umfeld,d.h. bestehende Anwendungen berücksichtigen. Das neue Systemmuss sich gegenüber bestehenden Systemen wie das abzulösendeSystem verhalten, bis alle bisherigen Systeme angepasst sind.Dieser Vorgang dauert meist mehrere Jahre.
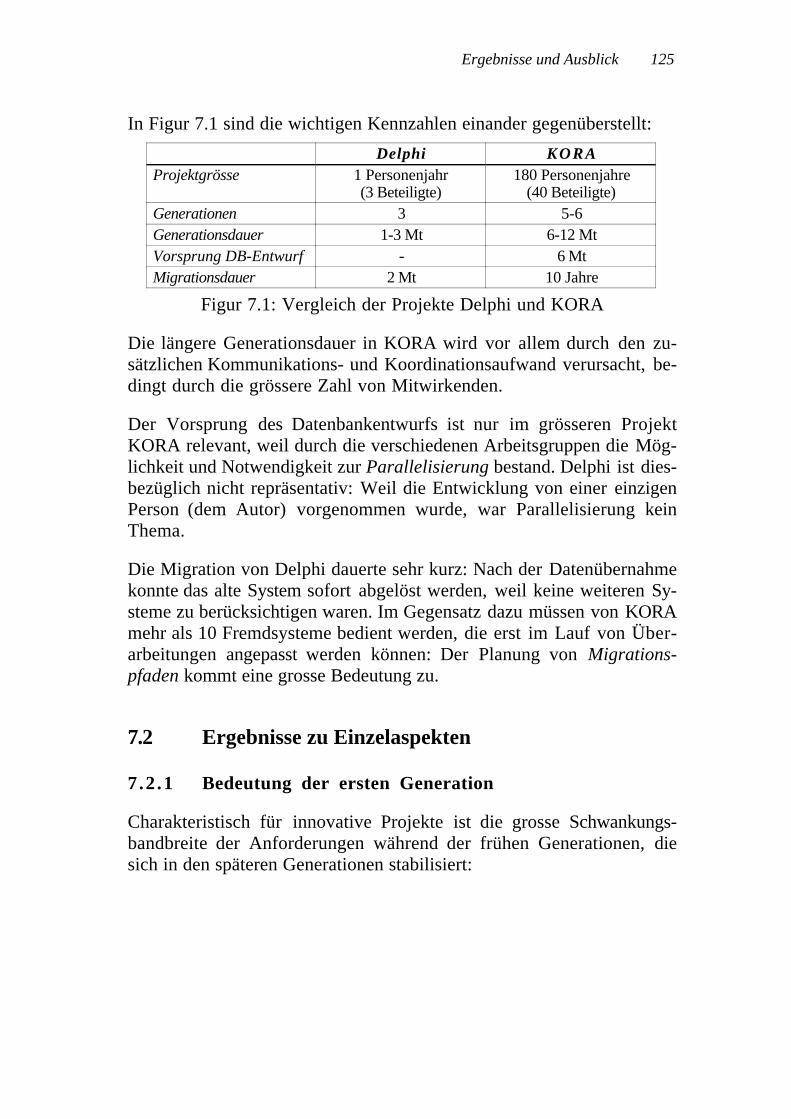
Ergebnisse und Ausblick 125
In Figur 7.1 sind die wichtigen Kennzahlen einander gegenüberstellt:
Delphi KORAProjektgrösse 1 Personenjahr
(3 Beteiligte)180 Personenjahre
(40 Beteiligte)Generationen 3 5-6Generationsdauer 1-3 Mt 6-12 MtVorsprung DB-Entwurf - 6 MtMigrationsdauer 2 Mt 10 Jahre
Figur 7.1: Vergleich der Projekte Delphi und KORA
Die längere Generationsdauer in KORA wird vor allem durch den zu-sätzlichen Kommunikations- und Koordinationsaufwand verursacht, be-dingt durch die grössere Zahl von Mitwirkenden.
Der Vorsprung des Datenbankentwurfs ist nur im grösseren ProjektKORA relevant, weil durch die verschiedenen Arbeitsgruppen die Mög-lichkeit und Notwendigkeit zur Parallelisierung bestand. Delphi ist dies-bezüglich nicht repräsentativ: Weil die Entwicklung von einer einzigenPerson (dem Autor) vorgenommen wurde, war Parallelisierung keinThema.
Die Migration von Delphi dauerte sehr kurz: Nach der Datenübernahmekonnte das alte System sofort abgelöst werden, weil keine weiteren Sy-steme zu berücksichtigen waren. Im Gegensatz dazu müssen von KORAmehr als 10 Fremdsysteme bedient werden, die erst im Lauf von Über-arbeitungen angepasst werden können: Der Planung von Migrations-pfaden kommt eine grosse Bedeutung zu.
7.2 Ergebnisse zu Einzelaspekten
7.2 .1 Bedeutung der ersten Generation
Charakteristisch für innovative Projekte ist die grosse Schwankungs-bandbreite der Anforderungen während der frühen Generationen, diesich in den späteren Generationen stabilisiert:
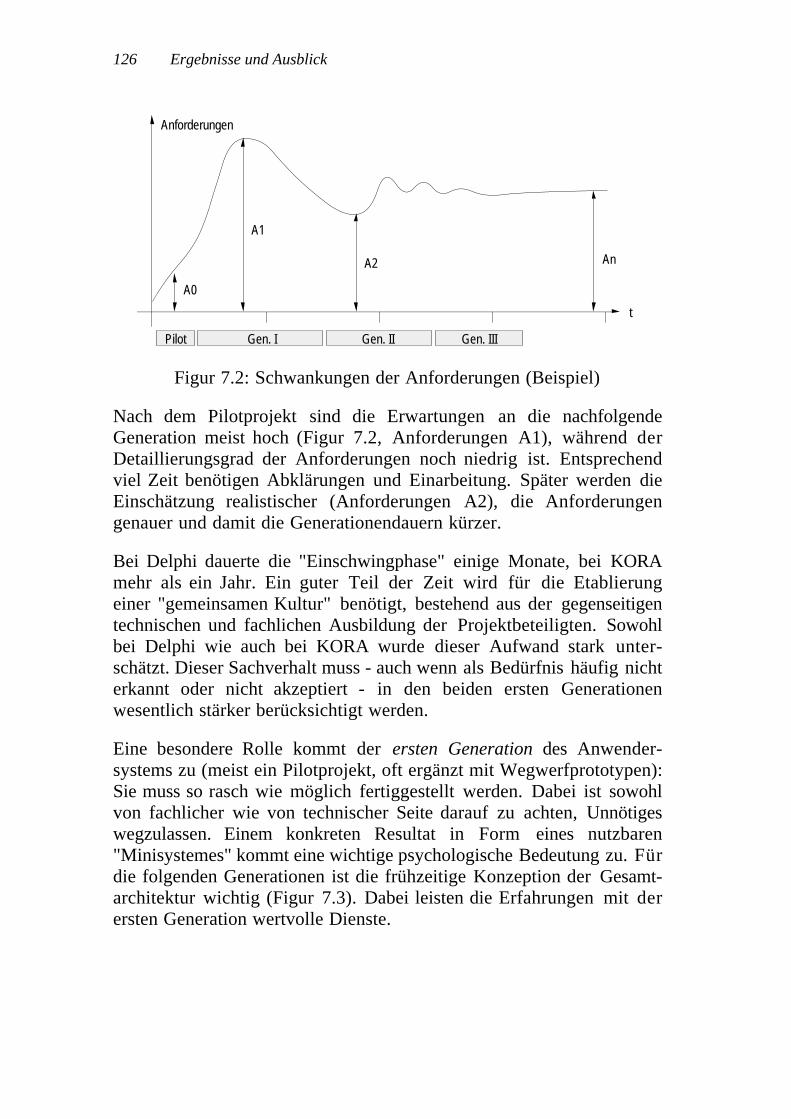
126 Ergebnisse und Ausblick
Pilot Gen. I Gen. II Gen. III
A0
A1
A2 An
Anforderungen
t
Figur 7.2: Schwankungen der Anforderungen (Beispiel)
Nach dem Pilotprojekt sind die Erwartungen an die nachfolgendeGeneration meist hoch (Figur 7.2, Anforderungen A1), während derDetaillierungsgrad der Anforderungen noch niedrig ist. Entsprechendviel Zeit benötigen Abklärungen und Einarbeitung. Später werden dieEinschätzung realistischer (Anforderungen A2), die Anforderungengenauer und damit die Generationendauern kürzer.
Bei Delphi dauerte die "Einschwingphase" einige Monate, bei KORAmehr als ein Jahr. Ein guter Teil der Zeit wird für die Etablierungeiner "gemeinsamen Kultur" benötigt, bestehend aus der gegenseitigentechnischen und fachlichen Ausbildung der Projektbeteiligten. Sowohlbei Delphi wie auch bei KORA wurde dieser Aufwand stark unter-schätzt. Dieser Sachverhalt muss - auch wenn als Bedürfnis häufig nichterkannt oder nicht akzeptiert - in den beiden ersten Generationenwesentlich stärker berücksichtigt werden.
Eine besondere Rolle kommt der ersten Generation des Anwender-systems zu (meist ein Pilotprojekt, oft ergänzt mit Wegwerfprototypen):Sie muss so rasch wie möglich fertiggestellt werden. Dabei ist sowohlvon fachlicher wie von technischer Seite darauf zu achten, Unnötigeswegzulassen. Einem konkreten Resultat in Form eines nutzbaren"Minisystemes" kommt eine wichtige psychologische Bedeutung zu. Fürdie folgenden Generationen ist die frühzeitige Konzeption der Gesamt-architektur wichtig (Figur 7.3). Dabei leisten die Erfahrungen mit derersten Generation wertvolle Dienste.
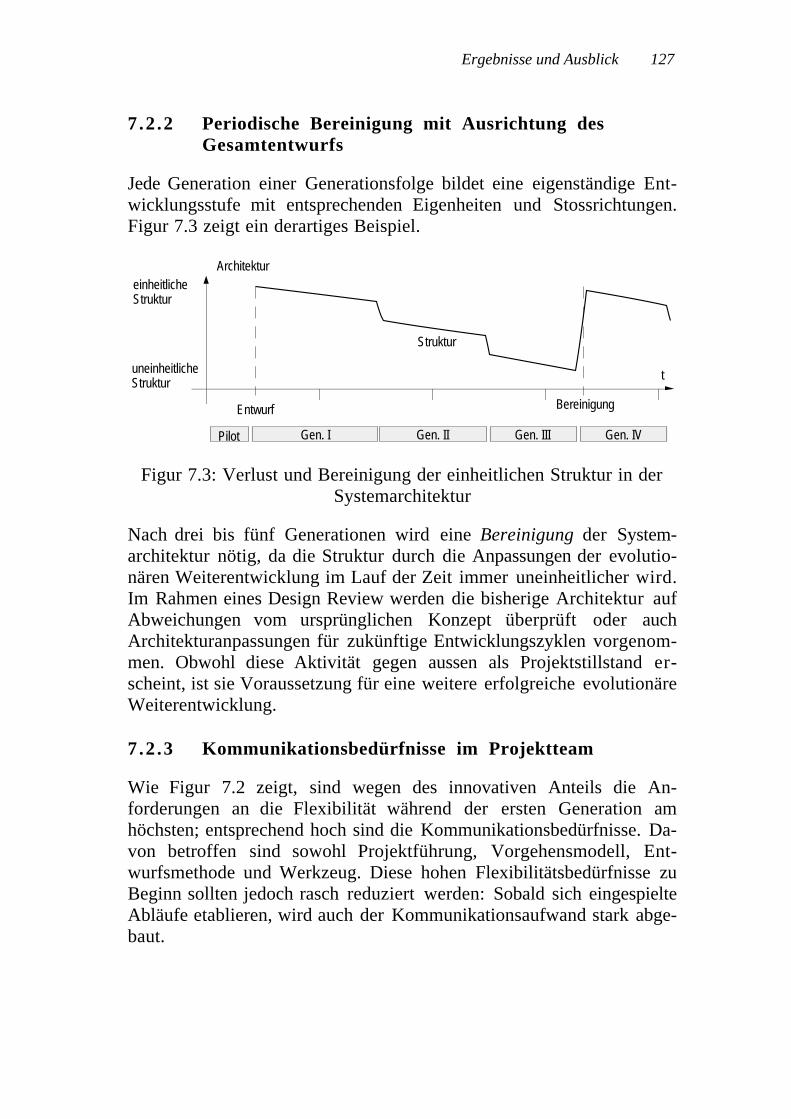
Ergebnisse und Ausblick 127
7.2 .2 Periodische Bereinigung mit Ausrichtung desGesamtentwurfs
Jede Generation einer Generationsfolge bildet eine eigenständige Ent-wicklungsstufe mit entsprechenden Eigenheiten und Stossrichtungen.Figur 7.3 zeigt ein derartiges Beispiel.
t
Architektur
Entwurf Bereinigung
Pilot Gen. I Gen. II Gen. III Gen. IV
Struktur
einheitliche Struktur
uneinheitliche Struktur
Figur 7.3: Verlust und Bereinigung der einheitlichen Struktur in derSystemarchitektur
Nach drei bis fünf Generationen wird eine Bereinigung der System-architektur nötig, da die Struktur durch die Anpassungen der evolutio-nären Weiterentwicklung im Lauf der Zeit immer uneinheitlicher wird.Im Rahmen eines Design Review werden die bisherige Architektur aufAbweichungen vom ursprünglichen Konzept überprüft oder auchArchitekturanpassungen für zukünftige Entwicklungszyklen vorgenom-men. Obwohl diese Aktivität gegen aussen als Projektstillstand er-scheint, ist sie Voraussetzung für eine weitere erfolgreiche evolutionäreWeiterentwicklung.
7.2 .3 Kommunikationsbedürfnisse im Projektteam
Wie Figur 7.2 zeigt, sind wegen des innovativen Anteils die An-forderungen an die Flexibilität während der ersten Generation amhöchsten; entsprechend hoch sind die Kommunikationsbedürfnisse. Da-von betroffen sind sowohl Projektführung, Vorgehensmodell, Ent-wurfsmethode und Werkzeug. Diese hohen Flexibilitätsbedürfnisse zuBeginn sollten jedoch rasch reduziert werden: Sobald sich eingespielteAbläufe etablieren, wird auch der Kommunikationsaufwand stark abge-baut.

128 Ergebnisse und Ausblick
Die hierarchische Gliederung in die drei Entwurfsebenen Versions-,Teil- und Elementarschritte ermöglich durch klare Schnittstellen einestufengerechte Information der Projektmitarbeiter und leistet damiteinen wesentlichen Beitrag zur Reduktion des Kommunikationsauf-wands.
7.2 .4 Werkzeuge
Wie sinnvoll ist Werkzeugunterstützung? Je nach Art des Werkzeugswerden unterschiedliche Bereiche unterstützt:
• Dokumentation: Die Werkzeugunterstützung kann vom einfachenTextsystem über eine geeignet definierte Datenbank bis hin zumdedizierten Entwurfssystem reichen. Je mächtiger das Werkzeug,desto besser die Unterstützung, desto geringer aber auch seineFlexibilität gegenüber nicht vorgesehenen Anforderungen.
• Sicherstellung der Methode: Eine werkzeuggestützte Über-prüfung ist fast nur mit einem eigentlichen, ausprogrammiertenoder regelbasierten Entwurfssystem möglich. Anpassungen derMethode sind aufwendig, weil Programme und Daten des Ent-wurfssystems angepasst werden müssen.
• Generierung: Um aus den Entwurfsdaten ein ausführbares An-wendersystem erzeugen zu können, wird ein Generator und einzugehöriges Laufzeitsystem benötigt. Dieser Teil ist meist derkomplexeste und reicht mit dem Laufzeitsystem bis in dasAnwendersystem hinein.
Ein Werkzeug erleichtert und beschleunigt besonders bei grossenMengen von Entwurfsdaten viele repetitive Arbeiten. Andererseits kannein zu wenig flexibles Werkzeug zu einer Behinderung werden, wennunerwartete Anforderungen abgedeckt werden müssen. Spezialfälle er-schweren den Werkzeugeinsatz ganz erheblich.
Ein Werkzeug kann eine Methode nur unterstützen, nicht ersetzen, undsein Einsatz ist ohne Kenntnis der Methode nicht möglich. Die Bedeu-tung von Werkzeugen wird häufig überschätzt, indem darin der Ersatzfür eine fehlende Methode gesucht wird. Bewährt hat sich ein flexiblerMittelweg zwischen universellen Hilfsmitteln wie z.B. Textsystemen undmethodenspezifisch ausprogrammierten Entwurfssystemen, insbeson-dere während der instabilen Anfangsphase: Das Werkzeug bietet eineKombination aus automatischer und manueller Überprüfung derMethode, kann dafür aber leicht an neue Bedürfnisse angepasst werden.

Ergebnisse und Ausblick 129
Das vorgestellte Werkzeug Presto W deckt Methodenunterstützung,Dokumentation und Generierung ab. Es zeichnet sich durch einen be-sonders modularen Aufbau aus, der die Erweiterung um neue Ent-wurfskomponenten und damit die Anpassung an neue Bedürfnisse unter-stützt: Die neuen Komponenten werden an einen standardisierten "Tool-bus" angeschlossen.
7.2 .5 Daten
Die Erfahrungen mit der Datenübernahme bereits lange genutzter An-wendersysteme zeigen, dass die Übernahme wenig Automatisierungs-potential bietet: Dies, weil in alle Datenbestände ungewollt und zum Teilauch bewusst Inkonsistenzen aufgenommen wurden, die kaumvollständig mit einem Werkzeug behoben oder kontrolliert werdenkönnen (ein systematischer Umgang mit Inkonsistenzen ist in [Leikauf91] beschrieben). Ein sinnvollerer Ansatz besteht aus mehreren Itera-tionen, in denen alternierend die Annahmen über die Datenstrukturenund die Datenvorkommen angepasst werden.
Die Schema-Evolution war bei den Fallstudien von kleiner Bedeutung,weil während der Entwicklung nur mit kleinen Beständen von Testdatengearbeitet wurde. Dieser Teil war auch nicht Gegenstand der Unter-suchungen (auf die Datenmigration wird in [Oertly 91] eingegangen).
7.2 .6 Zusammenfassung
Richtig eingesetzt führt die evolutionäre Weiterentwicklung in manchenSituationen zu besseren Resultaten als eine kompakte Entwicklung. Dieevolutionäre Entwicklung verlangt aber namentlich:
• Planung der Evolution (Generationenplan)
• Rasche Fertigstellung der ersten Generation
• Etablierung einer gemeinsamen Kommunikationskultur in dernächsten Generation
• Reduktion des Kommunikations- und Koordinationsaufwands:Abläufe, Ausbildung, Arbeitsgruppen
• Vorsprung des Datenbankentwurfs
• Stabilität während einer Generation: Genügend Zeit für die Evo-lutionsschritte

130 Ergebnisse und Ausblick
• Periodische Bereinigung des Gesamtentwurfs nach 3-5 Gene-rationen (Design Review)
• Systematische Planung der Migration beim Generationenüber-gang (Migrationspfad)
7.3 Offene Fragen
Im Rahmen der gewählten Beispiele Delphi und KORA wurden aus-schliesslich Neuentwicklungen untersucht. Zu untersuchen bleibt daherdie Anwendung des Vorgehensmodells Presto M für die Weiterent-wicklung bereits existierender Anwendersysteme. Dieses Reverse undRe-Engineering gewinnt wegen des Erneuerungsbedarfs technologischveralteter Softwaresysteme zunehmend an Bedeutung.
Wie die Projekte gezeigt haben, ist in den frühen Generationen dieFähigkeit zum Umgang mit unpräziser Information nötig, welche fürdie technische Realisierung erst schrittweise formalisiert werden muss.Die Verwaltung solch vager Information muss in Presto M noch starkverbessert werden.
Durch die geforderte Flexibilität muss das Entwurfssystem einfach anneue Bedürfnisse angepasst werden können: In Presto noch nicht enthal-ten sind die Unterstützung für besondere Eigenschaften von Client-Ser-ver Anwendersystemen und objektorientierten Datenbanksystemen.
Komplexere Vorgehensmodelle und Methoden stellen höhere Anfor-derungen an die Ausbildung von Anwendern und Entwicklern. DieseAusbildung muss noch besser und vor allem frühzeitig in der Projektab-lauf integriert werden. Dadurch lässt sich der Kommunikationsaufwandfür die nachfolgenden Generationen reduzieren.

Literatur 131
Literatur
[Abiteboul / Hull 87] 3.2.2Abiteboul, S.F., Hull, R.: IFO: A Formal Semantic Database Model. In: ACMTransactions on Database Systems, Vol. 12, No. 4, December 1987; pp. 525-565.
[Aho et al. 86] 6.6Aho, A.V., Sethi, R., Ullman J.D.: Compilers - Principles, Techniques and Tools.Addison Wesley, Reading MA, 1986.
[ANSI 75] 3.2.2ANSI/X3/SPARC: Interim Report 75-02-08. SIGMOD Record, Vol. 4, No. 7,1975.
[ANSI 86] 3.2.2, 4.5ANSI/X3/SPARC: Reference Model for DBMS Standardization. SIGMOD Record,Vol. 15, No. 1, March 1986.
[Apple 87] 1.3, 6.8Inside Macintosh, Vol. I-V; sixth printing. Addison Wesley, Reading MA, 1987.
[Apple 89] 3.2.4Introduction to MacApp 2.0 and Object-Oriented Programming / MacApp 2.0Tutorial. Apple Computer, Cupertino CA, 1989.
[ASC 88] 3.2.4ASC/X3/SPARC: Reference Model for DBMS User Facility. SIGMOD Record,Vol. 17, No. 2, June 1988; pp. 23-52.
[Banerjee et al. 87a] 4.4, 4.8Banerjee, J. Kim, H.-J., Kim, W., Korth, H.F.: Semantics and Implementation ofSchema Evolution in Object-Oriented Databases. In: Dayal, U., Traiger, I. (eds.):Proceedings of ACM SIGMOD on Management of Data, SIGMOD Record, Vol.16, No. 3, December 1987 (Conference Proceedings, San Francisco, USA, May27-29); pp. 311-322.
[Banerjee et al. 87b] 3.2.2Banerjee, J., Chou, H.-T., Garza, J.F., Kim, H.-J., Kim, W., Woelk, D., Ballou,N.: Data Model Issues for Object-Oriented Applications. In: ACM Transactions onOffice Information Systems, Vol. 5, No. 1, January 1987; pp. 3-26.
[Bersoff / Davis 91] 3.1.7Bersoff, E.H., Davis, A.M.: Impacts of Life Cycle Models on Software. In:Communications of the ACM, Vol. 34, No. 8, August 1991; pp. 104-118.
[Bertino / Martino 91] 4.8Bertino, E., Martino, L.: Object-Oriented Database Managment Systems: Conceptsand Issues. In: IEEE Computer, Vol. 24, No. 4, April 1991; pp. 33-47.
[Biggerstaff / Richter 87] 3.1.7Biggerstaff, T., Richter, C.: Reusability Framework, Assessment, and Directions.In: IEEE Computer, Vol. 20, No. 3, March 1987; pp. 41-49.
[Blaha et al. 88] 3.2.2Blaha, M.R., Premerlani W.J., Rumbaugh, J.E.: Relational Database Design Usingan Object-Oriented Methodology. In: Communications of the ACM, Vol. 31, No. 4,April 1988; pp. 414-427.
[Blum 85] 4.8Blum, B.I.: A Life Cycle Environment for Interactive Information Systems. In:[Shooman 85]; pp. 198-206.

132 Literatur
[Boehm 81] 3.1.3, 3.1.5Boehm, B.W.: Software Engineering Economics. Prentice-Hall, Englewood CliffsNJ, 1981.
[Brägger et al. 83] 6Brägger, R., Dudler, A., Rebsamen, J., Zehnder, C.A.: Gambit: An InteractiveDatabase Design Tool for Data Structures, Integrity Constraints and Transactions.In: [Zehnder 83]; pp. 65-95.
[Brägger et al. 85] 6Brägger, R.P., Dudler, A.M., Rebsamen, J., Zehnder, C.A.: Gambit: AnInteractive Database Design Tool for Data Structures, Integrity Constraints, andTransactions. In: IEEE Transactions on Software Engineering, Vol. 11, No. 7, July1985; pp. 574-583.
[Brägger 87] 3.2.2Brägger, R.: Wissensbasierte Werkzeuge für den Datenbank-Entwurf. Diss. ETH8290. Verlag der Fachvereine - Informatik-Dissertationen ETH Zürich, Nr. 2,Zürich, 1987.
[Bratsberg 92] 4.4, 4.8Bratsberg, S.E.: Unified Class Evolution by Object-Oriented Views. In: [Pernul /Tjoa 92]; pp. 423-439.
[Brodie et al. 84] Zitierter SammelbandBrodie, M.L., Mylopoulos, J., Schmidt, J.W.: On Conceptual Modelling.Springer-Verlag, New York, 1984.
[Brodie 84] 3.2.2Brodie, M.L.: On the Development of Data Models. In: [Brodie et al. 84]; pp. 19-47.
[Brooks 82] 3.1.4, 3.1.6, 5.3.2Brooks, F.P.: The Mythical Man-Month (reprinted with corrections). Addison-Wesley Publishing Company, Reading MA, 1982.
[Budde et al. 84] Zitierter SammelbandBudde, R., Kuhlenkamp, K., Mathiassen, L., Züllighoven, H. (eds.): Approachesto Prototyping. Springer-Verlag, Berlin, 1984.
[Burbeck 87] 3.2.4Burbeck, S.: Applications Programming in Smalltalk-80: How to Use Model-View-Controller (MVC). Preprint of Softsmarts Inc., 1987.
[Carlson / Metz 80] 4.5Carlson, E.D., Metz, W.: Integrating Dialog Management and DatabaseManagement. In: Lavington, S.H. (ed.): Information Processing 80, North HollandPublishing Company, 1980; pp. 463-468.
[Castano et al. 92] 3.1.7Castano, S., De Antonellis, V. Zonta, B.: Classifying and Reusing ConceptualSchemas. In: [Pernul / Tjoa 92]; pp. 121-138.
[Ceri 83] 3.2.2Ceri, S.: Methodology and Tools for Database Design. North-Holland, 1983.
[Chen 76] 3.2.2Chen, P.P.: The Entity-Relationship Model - Toward a Unified View of Data. In:ACM Transactions on Database Systems, Vol. 1, No. 1, 1976; pp. 9-36.
[Chen 92] 3.2.2Chen, P.P.: ER vs. OO (Extended Abstract of Invited Speech). In: [Pernul / Tjoa92]; pp. 1-2.

Literatur 133
[Clemons 79] 3.2.2, 4.5Clemons, E.K.: An External Schema Facility for CODASYL. In: Proceedings of thefifth International Conference on Very Large Databases, Rio de Janeiro, October1979; pp. 119-128.
[Codd 70] 3.2.2Codd, E.F.: A Relational Model of Data for Large Shared Data Banks. In:Communications of the ACM, Vol. 13, No. 6, 1970; pp. 377-387.
[Codd 79] 3.2.2Codd, E.F.: Extending the Database Relational Model to Capture More Meaning. In:ACM Transactions on Database Systems, Vol. 4, No. 4, 1979; pp. 397-434.
[Conradi et al. 86] Zitierter SammelbandConradi, R., Didriksen, T.M., Wanvik, D.H. (eds.): Advanced ProgrammingEnvironments. Springer Verlag, Lecture Notes in Computer Science No. 244,Berlin, 1986 (Proceedings of an International Workshop, Trondheim, Norway,June 16-18).
[Cunningham 85] 3.2.4Cunningham, W.: The Construction of Smalltalk-80 Applications. TektronixResearch Laboratory, Beaverton, Oregon, (Draft Version) November 1985.
[Curtis et al. 88] 5.3.2Curtis, B., Krasner, H., Iscoe, N.: A Field Study of the Software Design Processfor Large Systems. In: Communications of the ACM, Vol. 31, No. 11, 1988; pp.1268-1287.
[Date 86] 3.2.2Date, C.J.: An Introduction to Database Systems, Volume 1; fourth edition.Addison-Wesley Publishing Company, Reading MA, 1986.
[Date 89] 6.7Date, C.J.: A Guide to the SQL Standard; second edition. Addison-WesleyPublishing Company, Reading MA, 1989.
[Diener 85] 1.3Diener, A.R.: Das Datenbanksystem LIDAS. In: [Pomberger 85]; pp 120-166.
[Dittrich et al. 86] 4.8Dittrich, K.R., Gotthard, W., Lockemann, P.C.: DAMOKLES - A DatabaseSystem for Software Engineering Environments. In: [Conradi et al. 86]; pp. 353-371.
[Eberle 87] 1.3, 6.7Eberle, H.: Hardware Description of the Workstation Ceres. ETH Zürich, Berichtedes Instituts für Informatik, Nr. 70, 1987
[Elmasri / Larson 85] 3.2.2Elmasri, R.A., Larson, J.A.: A Graphical Query Facility for ER Databases. In:Proceedings of the 4th International Conference on ER Approach, IEEE, 1985; pp.236-245 (reprinted in [Larson 87a]; pp. 102-111).
[Estublier 88] 4.8Estublier, J.: Configuration Management. In: [Winkler 88]; pp. 38-61.
[Fairley 85] 3.1.3, 3.1.6Fairley, R.E.: Software Engineering Concepts (3rd printing 1987). McGraw-Hill,New York, 1985.
[Feiler / Smeaton 88] 3.3, 5.3.2Feiler, P.H., Smeaton, R.: Managing Development of Very Large Systems:Implications on Integrated Environments. In: [Winkler 88]; pp. 62-82.

134 Literatur
[Feldman 79] 3.3, 4.8Feldman, S.I.: Make - A Program for Maintaining Computer Programs. In:Software - Practice and Experience, Vol. 9, No. 3, 1979; pp. 255-265.
[Floyd 84] 3.1, 3.1.3, 3.1.5Floyd, Ch.: A Systematic Look at Prototyping. In: [Budde et al. 84]; pp. 1-18.
[Forte / Norman 92] 3.3Forte, G., Norman, R.J.: A Self-Asessment by the Software EngineeringCommunity. In: Communications of the ACM, Vol. 35, No. 4, April 1992; pp. 28-32.
[Frühauf et al. 88] 3.1, 3.3Frühauf, K., Ludewig, J., Sandmayr, H.: Software-Projektmanagement und -Qualitätssicherung. Verlag der Fachvereine, Zürich, 1988.
[Gähler 91] 3.2.3, 4.5Gähler, F.: Überwachung von Konsistenzbedingungen. Diss ETH 9325. Verlag derFachvereine - Informatik-Dissertationen ETH Zürich, Nr. 28, Zürich, 1991.
[Gibbs et al. 90] 3.1.7Gibbs, S., Tsichritzis, D., Casais, E.: Class Management for SoftwareCommunities. In: Communications of the ACM, Vol. 33, No. 9, September 1990;pp. 90-103.
[Goldberg / Robson 83] 3.2.4, 6.8Goldberg, A., Robson, D.: Smalltalk-80: The Language an its Implementation.Addison-Wesley, Reading MA, 1983.
[Goldberg 84] 6.8Goldberg, A.: Smalltalk-80: The Interactive Programming Environment. Addison-Wesley, Reading MA, 1984.
[Härder 89] Zitierter SammelbandHärder, T. (Hrsg.): Datenbanksysteme in Büro, Technik und Wissenschaft.Springer Verlag, Informatik-Fachberichte Nr. 204, Berlin, 1989 (Tagungsband derGI/SI-Fachtagung, Zürich, Schweiz, 1.-3. März).
[Huff 92] 3.3Huff, C.C.: Elements of a Realistic CASE Tool Adoption Budget. In:Communications of the ACM, Vol. 35, No. 4, April 1992; pp. 45-54.
[Hull / King 87] 3.2.2Hull, R., King, R.: Semantic Database Modeling: Survey, Applications, andResearch Issues. In: ACM Computing Surveys, Vol. 19, No. 3, 1987; pp. 201-260.
[Humphrey et al. 91] 3.1.7Humphrey, W.S., Snyder, T.R., Willis, R.R.: Software Process Improvement atHughes Aircraft. In: IEEE Software, Vol. 8, No. 4, July 1991; pp. 11-23.
[Inside Automation 87] 3.2.4Inside Automation: The Uniface Information engineering & Design Facility Manual.Amsterdam, 1987.
[Jones 92] 3.3Jones, C.: CASE's missing Elements. In: IEEE Spectrum, June 1992; pp. 38-41.
[Joseph et al. 89] 3.3Joseph, J., Thatte, S., Thompson, C., Wells, D.: Object-Oriented DatabaseWorkshop (Report held in conjunction with the OOPSLA '88 Conference on Object-Oriented Programmings Systems, Languages and Applications, San Diego, CA, 26September). In: SIGMOD Record, Vol. 18, No. 3, September 1989; pp. 78-101.

Literatur 135
[Katz 90] 3.3, 4.8Katz, R.: Toward a Unified Framework for Version Modeling in EngineeringDatabases. In: ACM Computing Surveys, Vol. 22, No. 4, December 1990; pp.375-408.
[Kernighan / Ritchie 88] 1.3, 6.7Kernighan, B.W., Ritchie, D.M.: The C Programming Language; second Edition.Prentice Hall, London, 1988.
[Knight 89] 3.2.4Knight, T.: 4th Dimension - A Complete Guide to Database Development. Scott,Foresman and Company, Glenview, Illinois, 1989.
[Krueger 92] 3.1.7Krueger, C.W.: Software Reuse. In: ACM Computing Surveys, Vol. 24, No. 2,June 1992; pp. 131-183.
[Larson / Wallick 84a] 3.2.4, 4.5Larson, J.A., Wallick, J.B.: Tools for Forms Administrators. In: Proceedings ofthe 1984 IEEE Workshop on Languages for Automation, IEEE, 1984; pp. 221-226(Reprinted in [Larson 87a]; pp. 118-123).
[Larson / Wallick 84b] 3.2.2, 4.5Larson, J.A., Wallick, J.B.: An Interface for Novice and Infrequent DBMS Users.In: AFIPS Conference Proceedings Vol. 53., 1984 National Computer Conference,1984; pp. 523-529 (Reprinted in [Larson 87a]; pp. 112-117).
[Larson 87a] Zitierter SammelbandLarson, J.A. (ed.): Database Managment (Tutorial), IEEE Computer Society Press,Washington DC, 1987.
[Larson 87b] 3.2.2, 4.5Larson, J.A.: User Interfaces to Database Management Systems. In: [Larson 87a];pp. 83-101.
[Lehman 80] 3.1Lehman, M.M.: Programs, Life Cycles and the Laws of Software Evolution. In:Proceedings IEEE, 68 (9), 1980; pp. 1060-1076.
[Leikauf 91] 7.2.5Leikauf, P.: Konsistenzsicherung durch Verwaltung von Inkonsistenzen. DissETH. Verlag der Fachvereine - Informatik-Dissertationen ETH Zürich, Nr. 23,Zürich, 1991.
[Lientz / Swanson 80] 4.8Lientz, B., Swanson, E.: Software Maintenance Management, Addison-Wesley,1980.
[Linton et al. 89] 3.2.4Linton, M.A., Vlissides, J.M., Calder, P.R.: Composing User Interfaces withInterViews. In: IEEE Computer, Vol. 22, No. 2, February 1989; pp. 8-22.
[Lobba 85] 3.3Lobba, A.: Automated Configuration Management. In: [Shooman 85]; pp. 100-103.
[Lockemann / Schmidt 87] Zitierter SammelbandLockemann, P.C., Schmidt, J.W. (Hrsgg.): Datenbank-Handbuch. Springer-Verlag, Berlin, 1987.
[Marti 84] 3.2.3, 4.8Marti, R.: Beschreibung von Datenbanken und Anwendungsprogrammen in einemerweiterten Datenkatalog. Diss. ETH 7567. ETH Zürich, Institut für Informatik,1984.

136 Literatur
[Mayr et al. 87] 4.5Mayr, H.C., Dittrich, K.R., Lockemann, P.C.: Datenbankentwurf. In: [Lockemann/ Schmidt 87]; Kap. 5.
[Montes / Haque 88] 3.3Montes, J., Haque, T.: A Configuration Management System and More! In:[Winkler 88]; pp. 217-227.
[Myers 89] 3.2.4Myers, B.A.: User Interface Tools: Introduction and Survey. In: IEEE Software,Vol. 6, No. 1, January 1989; pp. 15-23.
[Myers et al. 90] 3.2.4Myers, B.A., Guise, D.A., Dannenberg, R.B., Vander Zanden, B., Kosbie, D.S.,Pervin, E., Mickish, A., Marchal, P.: Garnet - Comprehensive Support forGraphical, Highly Interactive User Interfaces. In: IEEE Computer, Vol. 23, No. 11,November 1990; pp. 71-85.
[Navathe 92] 3.3Navathe, S.B.: The Next Ten Years of Modeling, Methodologies and Tools(Extended Abstract of Invited Speech). In: [Pernul / Tjoa 92]; pp. 3-6.
[Nievergelt et al. 86] 3.2.4Nievergelt, J., Ventura, A., Hinterberger, H.: Interactive Computer Programs forEducation - Philosophy, Techniques and Examples. Addison Wesley, Reading MA,1986.
[Oertly / Schiller 89] 6.7Oertly, F., Schiller, G.: Evolutionary Database Design. In: Proceedings of the 5thInternational Conference on Data Engineering, Los Angeles, February 1989, pp.618-624.
[Oertly 91] 1.1, 3.1.3, 3.2.2, 4.4Oertly, F.: Evolutionäre Prototypenbildung für Datenbank-Anwendungs-Komplexe.Diss. ETH 9490. Verlag der Fachvereine - Informatik-Dissertationen ETH Zürich,Nr. 33, Zürich, 1991.
[Oracle 86] 1.3, 3.2.4Oracle Corporation: SQL*Forms Designer's Reference. Belmont, 1986.
[Oracle 87] 3.2.4Oracle Corporation: SQL*Design Dictionary. Richmond, 1987.
[Pernul / Tjoa 92] Zitierter SammelbandPernul, G., Tjoa, A.M. (eds.): 11th International Conference on the EntityRelationship Approach. Springer Verlag, Berlin, 1992 (Conference Proceedings,Karlsruhe, Germany, October 7-9).
[Peterson 87] 6.8Peterson, G.E. (ed.): Object-Oriented Computing (Tutorial). IEEE ComputerSociety Press, Washington DC, 1987.
[Petry 88] 3.3, 4.8Petry, E.: Versionenverwaltung von Objekten durch ein erweitertes relationalesDatenbanksystem. Diss. ETH 8482. Verlag der Fachvereine - Informatik-Dissertationen ETH Zürich, Nr. 9, Zürich, 1988.
[Petzold 89] 6.7, 6.8Petzold, C.: Programming the OS/2 Presentation Manager. Microsoft Press,Redmont WA, 1989.

Literatur 137
[Pfefferle et al. 89] 3.3Pfefferle, H., Härtig, M., Dittrich, K.: Autorisierung und Zugriffsüberwachung instrukturell objekt-orientierten Datenbanksystemen. In: [Härder 89]; pp. 119-134.
[Pomberger 85] Zitierter SammelbandPomberger, G. (Hrsg.): Lilith und Modula-2; Werkzeuge der Softwaretechnik. CarlHanser Verlag, München, 1985.
[Potter / Trueblood 88] 3.2.2Potter, W.D., Trueblood, R.P.: Traditional, Semantic, and Hyper-SemanticApproaches to Data Modeling. In: IEEE Computer, Vol. 21, No. 6, June 1988; pp.53-63.
[Rebsamen 83] 3.2.2, 4.5Rebsamen, J.: Datenbankentwurf im Dialog - Integrierte Beschreibung vonStrukturen, Transaktionen und Konsistenz. Diss. ETH 7325. ETH Zürich, Institutfür Informatik, 1983.
[Rebsamen et al. 83] 6, 6.7Rebsamen, J., Reimer, R., Ursprung, P., Zehnder, C.A., Diener, A.: LIDAS: TheDatabase System for the Personal Computer Lilith. In: [Zehnder 83]; pp. 21-47.
[Riddle 84] 3.1.3Riddle, W.E.: Advancing the State of the Art in Software System Prototyping. In:[Budde et al. 84]; pp. 19-26.
[Rochkind 75] 3.3, 4.8Rochkind, M.J.: The Source Code Control System. In: IEEE Transactions onSoftware Engineering, Vol. 1, No. 4, 1975.
[Royce 70] 3.1.2Royce, W.W.: Managing the Development of Large Software Systems. In:Proceedings, WESCON, 1970.
[Rzevski 84] 3.1.4Rzevski, G.: Prototypes versus Pilot Systems: Strategies for EvolutionaryInformation Systems Development. In: [Budde et al. 84]; pp. 356-367.
[Schek / Scholl 83] 3.2.2Schek, H.J., Scholl, M.H.: Die NF2-Relationenalgebra zur einheitlichenManipulation externer, konzeptueller und interner Datenstrukturen. In: Informatik-Fachberichte, Nr. 72, Springer-Verlag, Berlin, 1983; pp. 113-133.
[Schmidt 87] 3.2.2Schmidt, J.W.: Datenbankmodelle. In: [Lockemann/Schmidt 87]; Kap. 1.
[Shaw 88] 3.2.2Shaw, C.J.: Application and Database Design - Putting it off. In: SIGMOD Record,Vol. 17, No. 2, June 1988; pp. 14-22.
[Shooman 85] Zitierter Sammelband, 4.8Shooman, M. (ed.): Conference on Software Tools. IEEE Computer Society Press,Washington D.C., 1985 (Conference Proceedings, New York, New York, April15-17).
[Skubch 92] 3.1.7Skubch, H.: Informationsmanagement, eine Zwischenbilanz: "Learn to loveChange". In: Computerwoche Extra 1, Februar 1992 (Zusammenfassung einerStudie des Plenum-Instituts).
[Sommerville 85] 3.3Sommerville, I.: Software Engineering; second edition. Addison-Wesley, ReadingMA, 1985.

138 Literatur
[Stelovsky 84] 3.2.4Stelovsky, J.: XS-2: The User Interface of an Interactive System. Diss. ETH 7425.ETH Zürich, Institut für Informatik, 1984.
[Teorey et al. 86] 3.2.2Teorey, T.J., Dongquing, Y., Fry, J.: A Logical Desing Methodology forRelational Databases Using the Extended Entity-Relationship Model. In: ACMComputing Surveys. Vol. 18, No. 2, June 1986; pp. 197-222.
[Thoma 92] 3.1.7Thoma, H.: Zur Integration von Datenbeständen. In: SI-Information, No. 34,Februar 1992; pp. 19-22.
[Thurnherr 80] 3.2.2Thurnherr, B.: Konzepte und Sprachen für den Entwurf konsistenter Datenbanken.Diss. ETH 6526. ETH Zürich, Institut für Informatik, 1980.
[Tichy 88a] 3.3Tichy, W.F.: Tools for Software Configuration Management. In: [Winkler 88]; pp.1-20.
[Tichy 88b] 3.3Tichy, W.F.: Summary of Plenary Diskussion "What is a Configuration?". In:[Winkler 88]; pp. 169-171.
[Tresch / Scholl 92] 4.4, 4.8Tresch, M., Scholl, M.: Meta Object Management and its Application to DatabaseEvolution. In: [Pernul / Tjoa 92]; pp. 299-321.
[Ursprung / Zehnder 83] 6Ursprung, P., Zehnder, C.A.: HIQUEL: An Interactive Query Language to Defineand Use Hierarchies. In: [Zehnder 83]; pp. 97-117.
[Ursprung 84] 3.2.2, 4.5, 6Ursprung, P.: Benutzernahe Sicht von Datenbanken - Entwurf und Manipulationvon Datenhierarchien. Diss. ETH 7566. ETH Zürich, Institut für Informatik, 1984.
[Vossen 87] 3.2.2Vossen, G.: Datenmodelle, Datenbanksprachen und Datenbank-Management-Systeme. Addison-Wesley Publishing Company, Bonn, 1987.
[Weinand et al. 88] 3.2.4Weinand, A., Gamma, E., Marty, R.: ET++ - An Object-Oriented ApplicationFramework in C++. In: OOPSLA '88 Special Issue of SIGPLAN Notices, Vol. 23,No. 11, November 1988 (Conference Proceedings, San Diego, California,September 25-30); pp. 168-182.
[Winkler 88] Zitierter Sammelband, 4.6Winkler, J.F.H. (ed.): Proceedings of the International Workshop on SoftwareVersion and Configuration Control. Teubner Verlag, Berichte des German Chapterof the ACM, Bd. 30, Stuttgart, 1988 (Conference Proceedings, Grassau, Germany,January 27-29).
[Wirth 81] 1.3, 6.7Wirth, N.: The Personal Computer Lilith. ETH Zürich, Berichte des Instituts fürInformatik, Nr. 40, 1981.
[Wirth 83] 1.3, 6.7Wirth, N.: Programming in Modula-2; second Edition. Springer-Verlag, Berlin,1983.

Literatur 139
[Wirth 84] 6.6Wirth, N.: Compilerbau; 4. Auflage. Teubner Verlag, Informatik Studienbücher,Nr. 36, Stuttgart, 1984.
[Zehnder 83] Zitierter SammelbandZehnder, C.A. (ed.): Database Techniques for Professional Workstations. ETHZürich, Berichte des Instituts für Informatik, Nr. 55, 1983.
[Zehnder 89] 2, 2.1, 3.2.2, 4.5Zehnder, C.A.: Informationssysteme und Datenbanken; 5. Auflage. Verlag derFachvereine, Zürich, 1989.
[Zehnder 91] 4.3, 5.2Zehnder, C.A.: Informatik-Projektentwicklung; 2. Auflage. Verlag der Fachvereine,Zürich, 1991.
[Zicari 91] 4.8Zicari, R.: Primitives for Schema Updates in an Object-Oriented Database System: AProposal. In: Computer Standards & Interfaces, Elsevier Science Publishers, 1991;pp. 271-284.
[Zucker / Christian 85] 3.3Zucker, S., Christian, J.B.: Automated Configuration Managment on a DoDSatellite Ground System. In: [Shooman 85]; pp. 92-99.
[4th Dimension 87] 3.2.44th Dimension: User's Guide, Tutorial, Reference. ACI, Paris, 1987.


Stichwortverzeichnis 141
Stichwortverzeichnis
Fett gedruckte Seitenzahlen weisen auf die Definition, gelegentlich auchauf eine ausführliche Erklärung des Begriffs hin.
Abhängigkeitsgraph 24; 65; 69Ablösung 33; 61Advancemanship 37Aktualisierung 24; 69; 103-107Aktualisierungstransaktion 111-114Analyse 34Änderungsabschnitt 112Änderungserkennung 104Änderungsliste 103-110Änderungsnachführung 103; 110-114
verzögert 114Änderungsquelle 104Änderungstransaktion 25; 104; 108-
112Registrierung 112
Änderungsverwaltung 104Änderungsziel 104Anforderung 31; 40; 126
Delphi 79KORA 89
Anwenderdaten 20-23; 53Original 62
Anwenderdatenbank 20Anwenderkomponente 20; 23; 54; 116Anwendersystem 20; 116
datenbankbasiert 19; 20Anwendertransaktion 21; 22; 42; 53;
66; 115Anwendungsentwurf 44; 65Anwendungsschema 22; 53; 68Attribut 65Ausbildung 126; 130Ausserbetriebnahme 33; 61Bereinigung 39-40; 57-58; 60; 127
KORA 91Beziehung 65Bildschirmformular 66
Delphi 82CASE 49; 73Check-Out/Check-In 48; 70
Datenbankentwurf 43; 65Datenbankschema
Delphi 83Evolution 63; 74; 129extern 44; 66konzeptionell 43; 65KORA 94logisch 44; 66physisch 44
Datengeneration 28; 53-59; 62genutzt 55
Datenmigration 62Datenmodell 22; 43Datenübernahme 62; 119; 129
Delphi 81; 85-87KORA 91-93; 96
Datenverwaltung 28; 53; 115Entwurfssystem 104; 107KORA 120
DauerEntwicklung 40Generation 61Migration 62-65Nutzung 33; 40; 61Superprojekt 61Teilprojekt 33; 61
DDL 115Delphi 77-88
Erfahrungen 98Dialogentwurf 45; 66DISCUSS 103; 119Do-Konzept 112Dokumentation 25; 114; 128Drei-Schema-Konzept 43Elementarschritt 52; 67; 71; 104Entitätsmenge 25; 65Entwicklung 32; 33; 57
Dauer 40Entwicklungsphase 32Entwurfsdaten 24; 107-115

142 Stichwortverzeichnis
KORA 96Entwurfsdatenbank 24; 49; 107-114Entwurfsebene 51-52; 69Entwurfskomponente 25; 65; 68; 105;
112-114Architektur 113Registrierung 109; 113
Entwurfskonsistenz 24; 69; 109Entwurfsmethode 42Entwurfsobjekt 25; 52; 65; 119Entwurfssystem 24; 25; 103-122
Ablaufsteuerung 108-112Kern 108; 111
Entwurfstransaktion 106; 113Erste Generation 100; 125
Delphi 81Evolution 39; 57-61
Datenbankschema 63; 74; 129Evolutionäre Weiterentwicklung 39; 40Evolutionäres Superprojekt 60Flexibilität 40; 120; 128Fortpflanzungspfad 44; 66Freigabe
Schemaversion 70Systemantrag 57
Gambit 103; 119Generation 53; 72Generationenplan 57; 60; 101; 129
Delphi 80KORA 91
Generationsdauer 61Generator 41; 46; 115; 128
KORA 97Gesamtentwurf 38; 57Gesicherter Bereich 48; 70Hauptentwicklungspfad 72Historie 90Inkrementelle Vervollständigung 38; 40IPSE 49Klassisches Phasenmodell 34; 40Kommunikation 101; 127; 129Konfiguration 47Konsistenz 46; 69
Entwurfsdaten 69; 103-109Konsistenzbedingung 22; 53; 66
Konsistenzebene 69KORA 88-97
Erfahrungen 98Lebensdauer 33; 61LIDAS 103; 118Methode 28Migration 54; 62-65Migrationspfad 125; 130Nutzdaten 55; 58; 62
KORA 93Nutzung 32; 33; 40; 52; 57; 61
Delphi 81Nutzungsdauer 33; 40; 61
KORA 89Nutzungsphase 32Parallelbetrieb 57Paralleldaten 62Parallelprogramm 63Phase 32Phasenfolgedarstellung 32; 57Pilotprojekt 37; 40Präsentation 23; 66Presto II 97Presto M 51-74Programmgeneration 26; 27; 35; 54-
60; 64Programmmigration 63Projekt 41Projektantrag 57Projektführung 31Protokollierung 104-111Prototyp 36; 59; 63; 72
KORA 93Prototypenbildung 35; 57
Delphi 83Rapid Prototyping 37Re-Engineering 41Registrierung 109; 112Release 47Repository 49Schemaversion 26; 47; 51-53; 69-73;
110aktuell 72Freigabe 70genutzt 72

Stichwortverzeichnis 143
Schlüsselkandidat 65Sicherungspunkt 72Spezifikation 25Strukturverlust 39; 127Superprojekt
evolutionär 60KORA 88
Superprojektdauer 61Systemantrag 57; 60
Delphi 81Freigabe 57KORA 93
Teilprojekt 60KORA 90
Teilprojektdauer 33; 61Teilschema 23; 25; 51; 53; 65; 68; 104-
114Aktualisierung 105
Teilschritt 52; 65-71; 103; 110Testdaten 62Vage Information 123; 130Version 47; 53Versionenbaum 27; 47; 72Versionenebene 56Versionenkonsistenz 69; 107; 116Versionenschritt 52; 57; 71; 110Vorgehensmodell 32Wartung 34Wasserfallmodell 34Werkzeug 28; 41; 103Zeitsequenzdarstellung 33; 61





























